Post Syndicated from Suresh Patnam original https://aws.amazon.com/blogs/big-data/part-1-migrate-a-large-data-warehouse-from-greenplum-to-amazon-redshift-using-aws-sct/
A data warehouse collects and consolidates data from various sources within your organization. It’s used as a centralized data repository for analytics and business intelligence.
When working with on-premises legacy data warehouses, scaling the size of your data warehouse or improving performance can mean purchasing new hardware or adding more powerful hardware. This is often expensive and time-consuming. Running your own on-premises data warehouse also requires hiring database managers, administrators to deal with outages, upgrades, and data access requests. As companies become more data-driven, reliable access to centralized data is increasingly important. As a result, there is a strong demand for data warehouses that are fast, accessible, and able to scale elastically with business needs. Cloud data warehouses like Amazon Redshift address these needs while eliminating the cost and risk of purchasing new hardware.
This multi-part series explains how to migrate an on-premises Greenplum data warehouse to Amazon Redshift using AWS Schema Conversion Tool (AWS SCT). In this first post, we describe how to plan, run, and validate the large-scale data warehouse migration. It covers the solution overview, migration assessment, and guidance on technical and business validation. In the second post, we share best practices for choosing the optimal Amazon Redshift cluster, data architecture, converting stored procedures, compatible functions and queries widely used for SQL conversions, and recommendations for optimizing the length of data types for table columns.
Solution overview
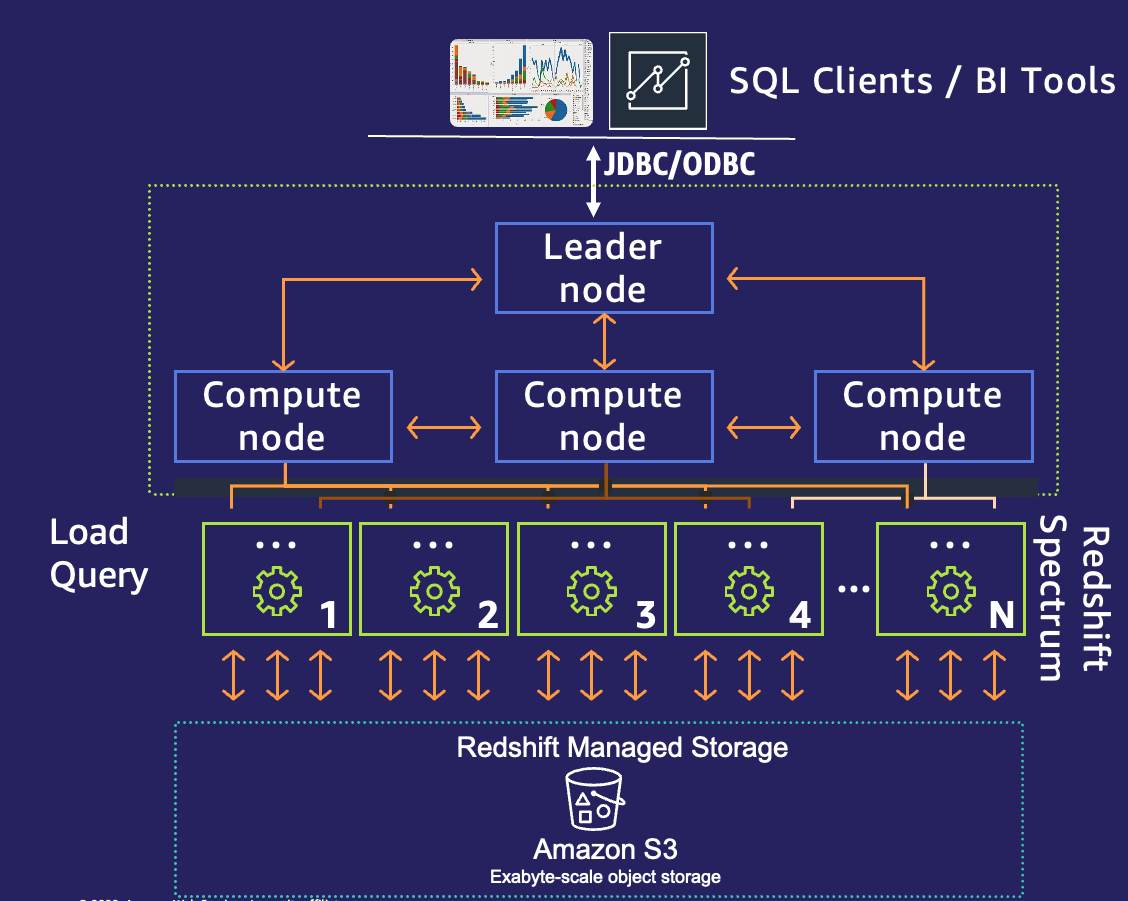
Amazon Redshift is an industry-leading cloud data warehouse. Amazon Redshift uses Structured Query Language (SQL) to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes using AWS-designed hardware and machine learning to deliver the best price-performance at any scale.
AWS SCT makes heterogeneous database migrations predictable by automatically converting the source database schema and most of the database code objects, SQL scripts, views, stored procedures, and functions to a format compatible with the target database. AWS SCT helps you modernize your applications simultaneously during database migration. When schema conversion is complete, AWS SCT can help migrate data from various data warehouses to Amazon Redshift using data extraction agents.
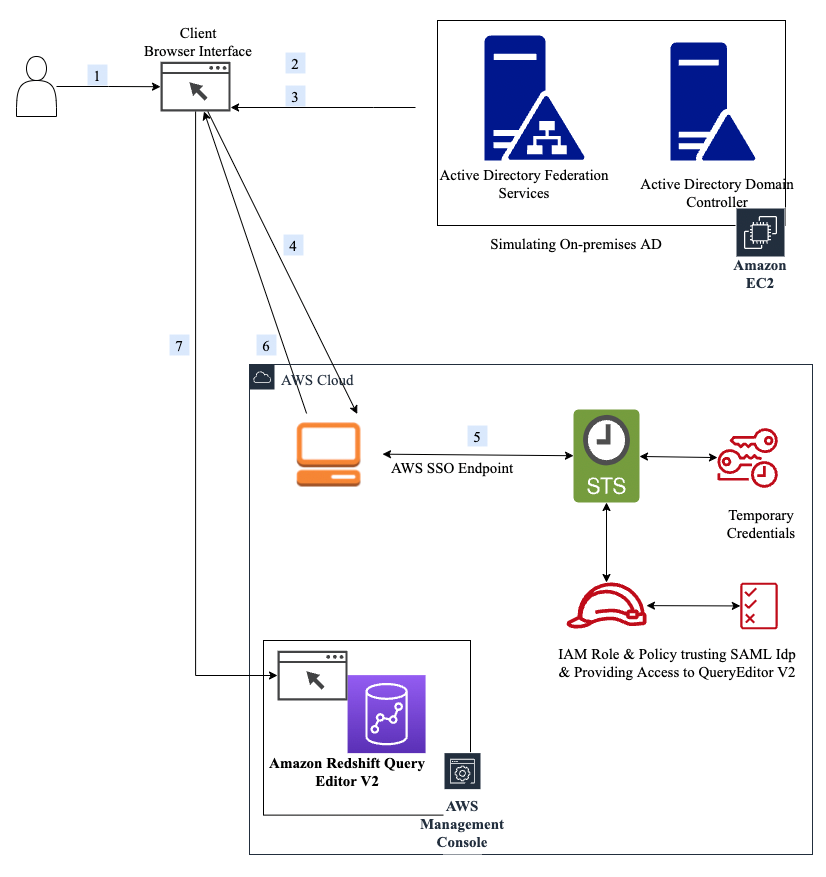
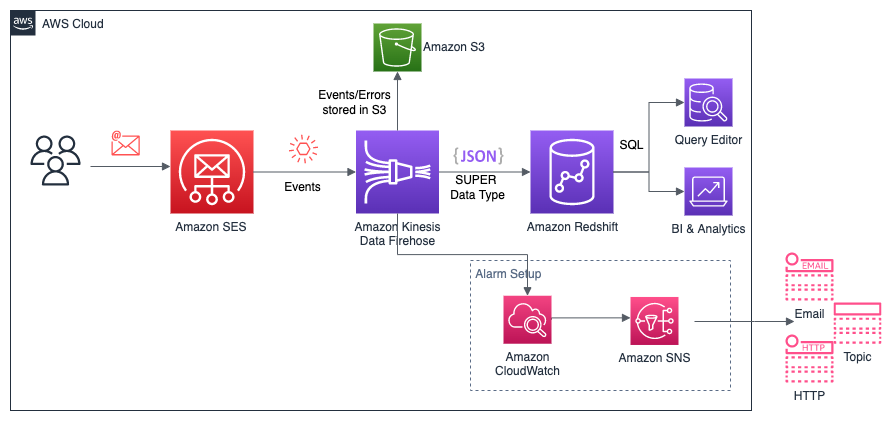
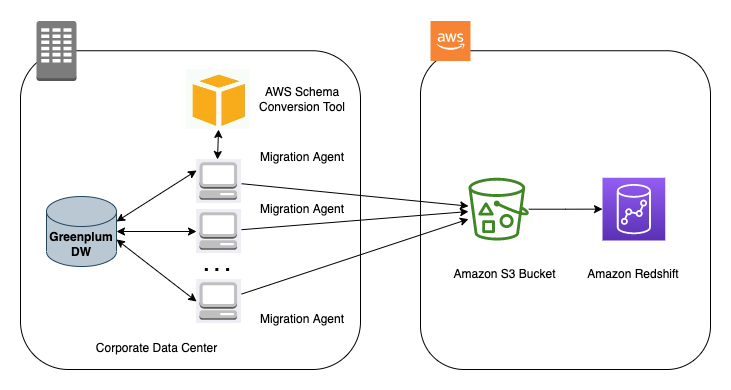
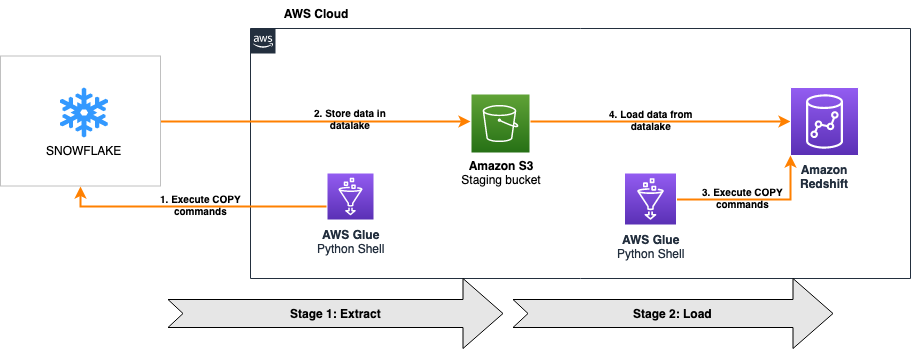
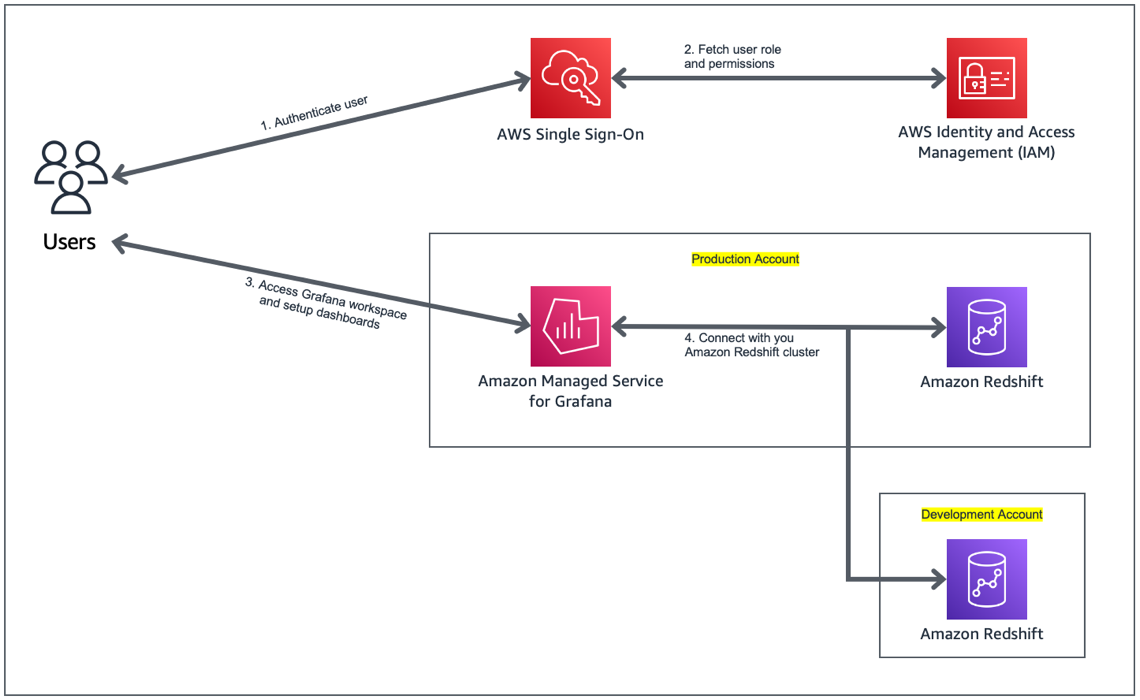
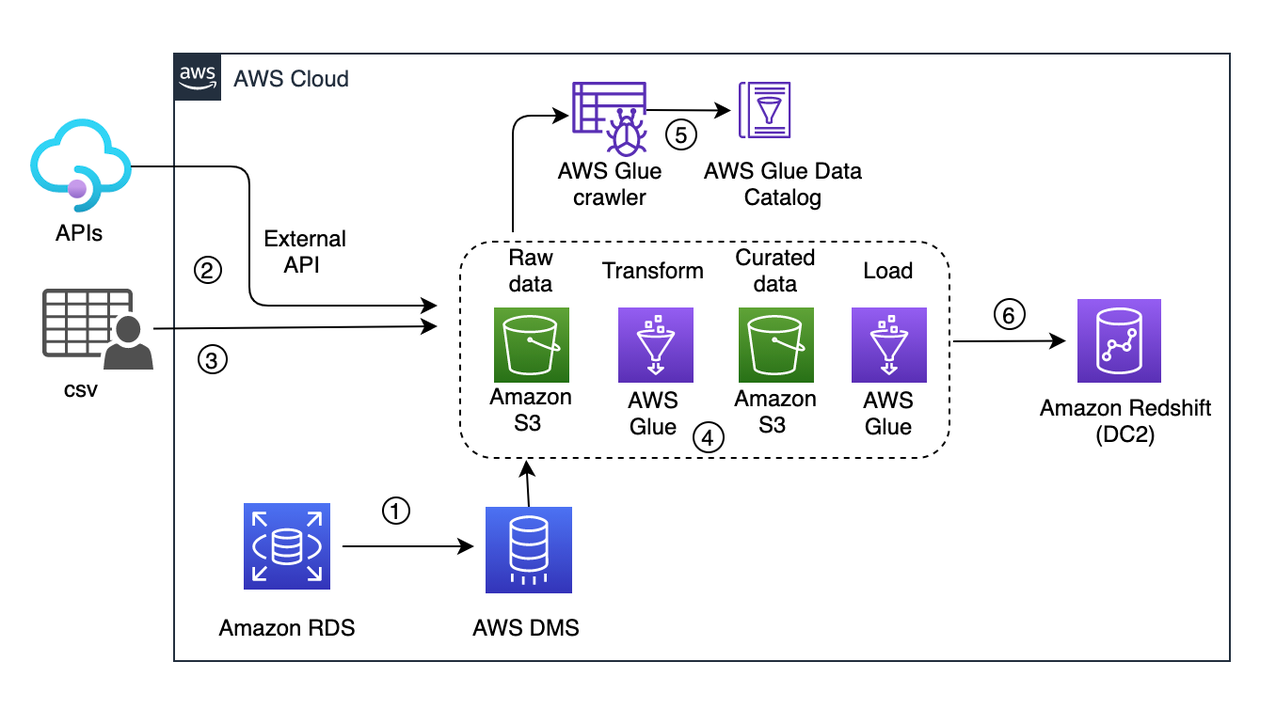
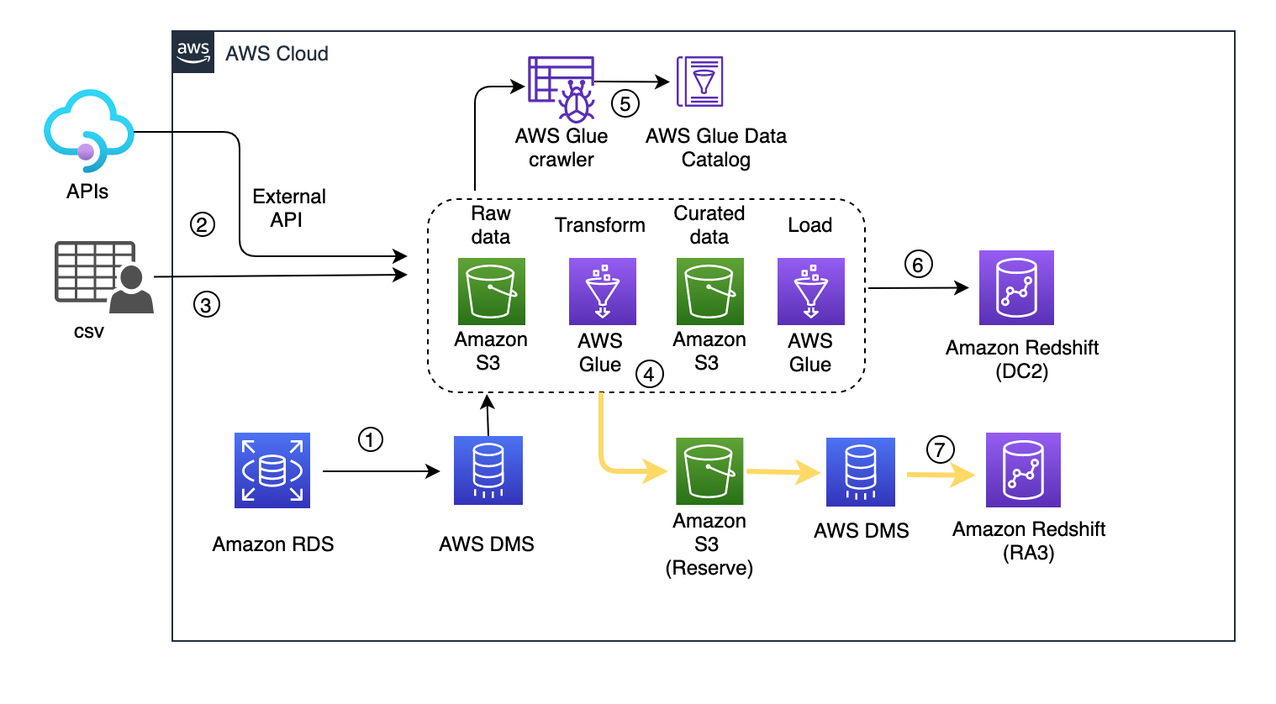
The following diagram illustrates our architecture for migrating data from Greenplum to Amazon Redshift using AWS SCT data extraction agents.
Perform a migration assessment
The initial data migration is the first milestone of the project. The main requirements for this phase are to minimize the impact on the data source and transfer the data as fast as possible. To do this, AWS offers several options, depending on the size of the database, network performance (AWS Direct Connect or AWS Snowball), and whether the migration is heterogeneous or not (AWS Database Migration Service (AWS DMS) or AWS SCT).
AWS provides a portfolio of cloud data migration services to provide the right solution for any data migration project. The level of connectivity is a significant factor in data migration, and AWS has offerings that can address your hybrid cloud storage, online data transfer, and offline data transfer needs.
Additionally, the AWS Snow Family makes it simple to get your data into and out of AWS via offline methods. Based on the size of the data, you can use AWS Snowmobile or AWS Snowball if you have petabytes to exabytes of data. To decide which transfer method is better for your use case, refer to Performance for AWS Snowball.
Perform schema conversion with AWS SCT
To convert your schema using AWS SCT, you must start a new AWS SCT project and connect your databases. Complete the following steps:
- Install AWS SCT.
- Open and initiate a new project.
- For Source database engine, choose Greenplum.
- For Target database engine, choose Amazon Redshift.
- Choose OK.

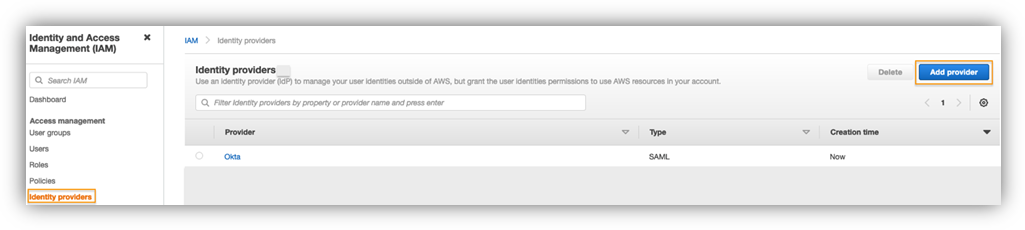
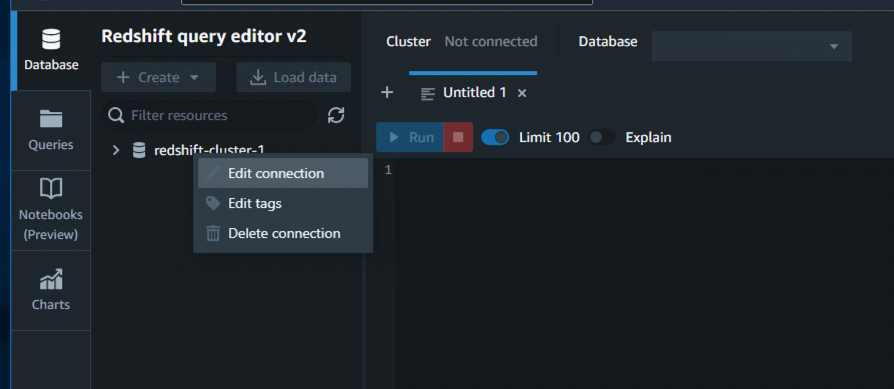
- Open your project and choose Connect to Greenplum.

- Enter the Greenplum database information.
- Choose Test connection.

- Choose OK after a successful connection test.
- Choose OK to complete the connection.

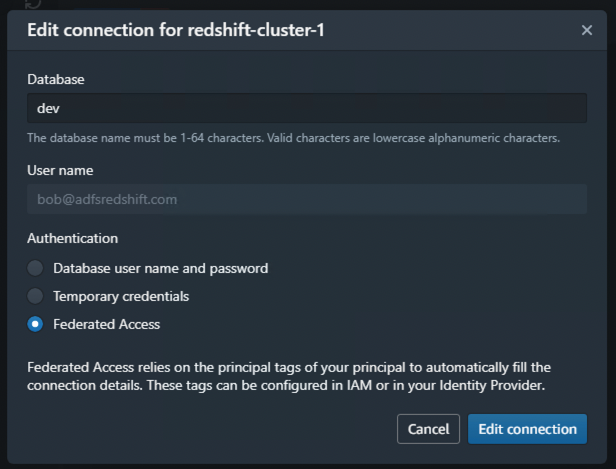
- Repeat similar steps to establish a connection to your Amazon Redshift cluster.

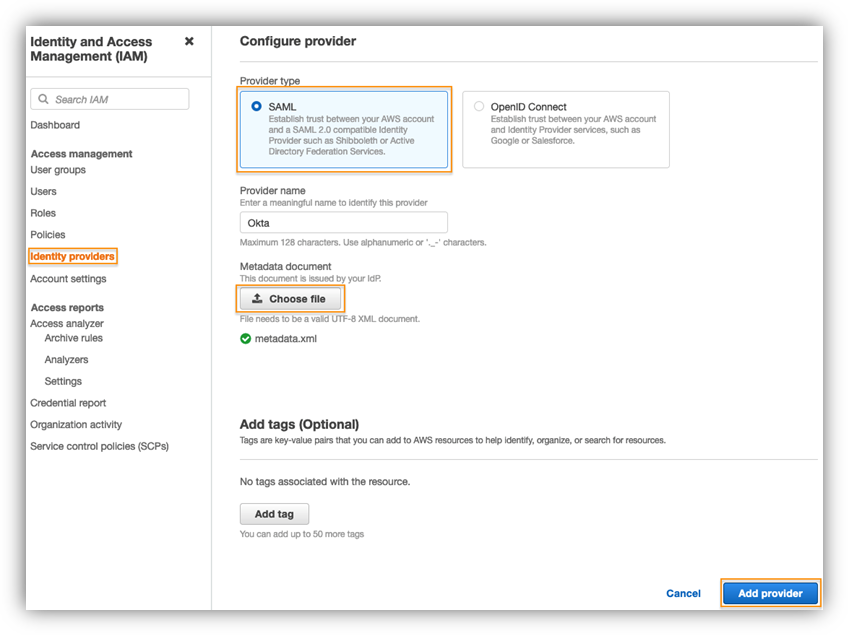
By default, AWS SCT uses AWS Glue as the extract, transform, and load (ETL) solution for the migration. Before you continue, you must disable this setting. - On the Settings menu, choose Project settings.

- Deselect Use AWS Glue.
- Choose OK.

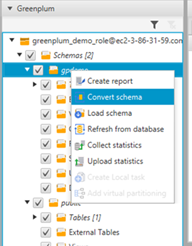
- In the left pane, choose your schema (right-click) and choose Convert schema.

- When asked to replace objects, choose Yes.

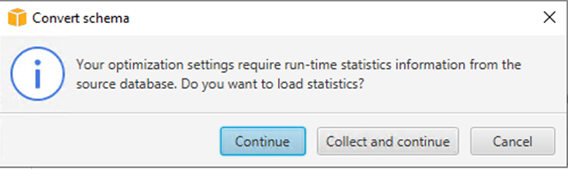
- When asked to load statistics, choose Continue.

By the end of this step, all Greenplum objects should be migrated to Amazon Redshift syntax. Some objects may be shown in red, meaning that AWS SCT couldn’t fully migrate these objects. You can view an assessment summary of the migration for more information. - On the View menu, choose Assessment report view.

In the bottom pane, you can see Greenplum DDL and Amazon Redshift DDL of the selected objects side by side for comparison.

- Choose the schema with a red icon, which indicates that it needs manual conversion.You’re presented with specific actions regarding the tables, constraints, or views that can’t be migrated to Amazon Redshift. You must investigate these issues and fix the errors manually with the required changes. Some examples are binary data in BLOB format, which AWS SCT automatically converts to character varying data type, but this may be highlighted as an issue. Additionally, some vendor-supplied procedures and functions couldn’t be converted, so AWS SCT can error out.
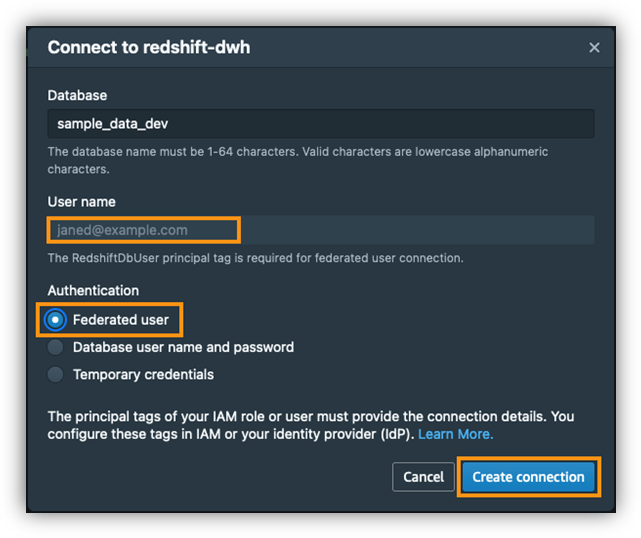
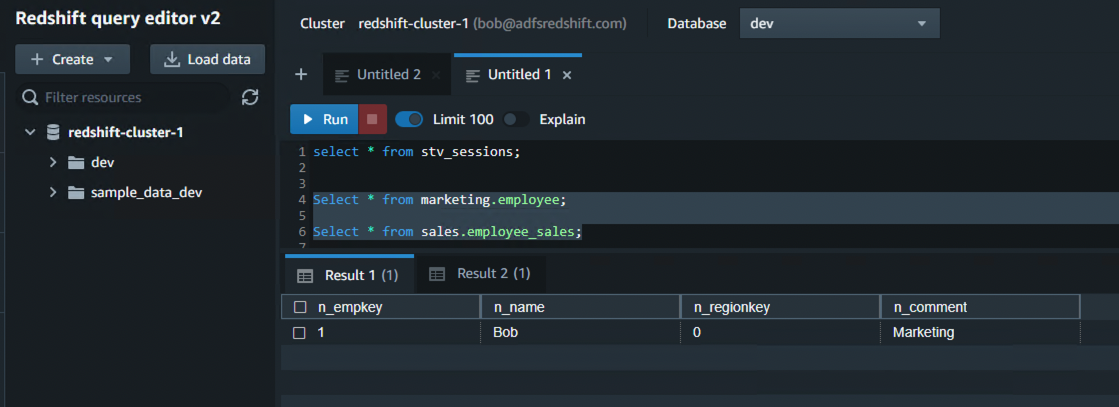
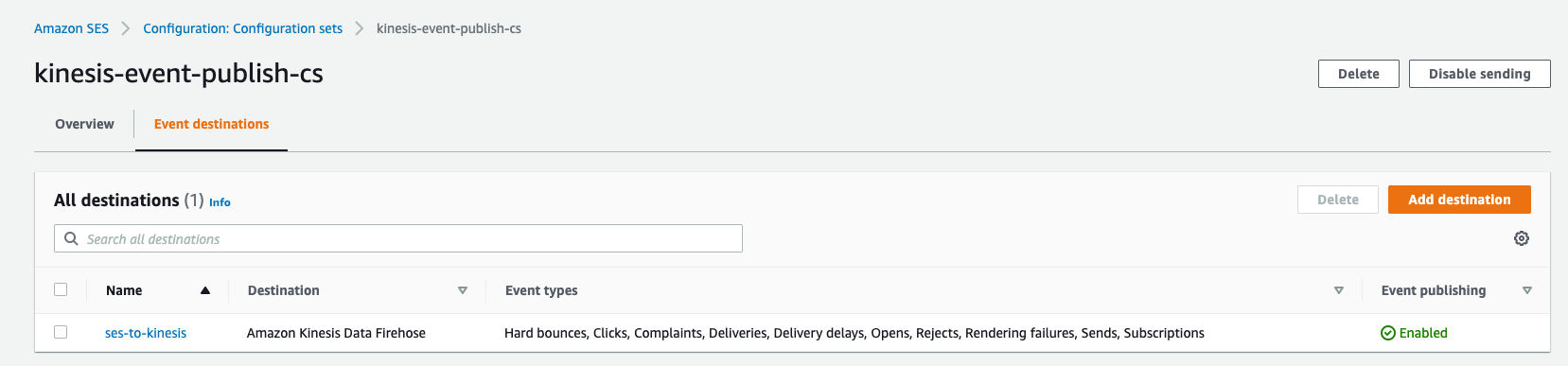
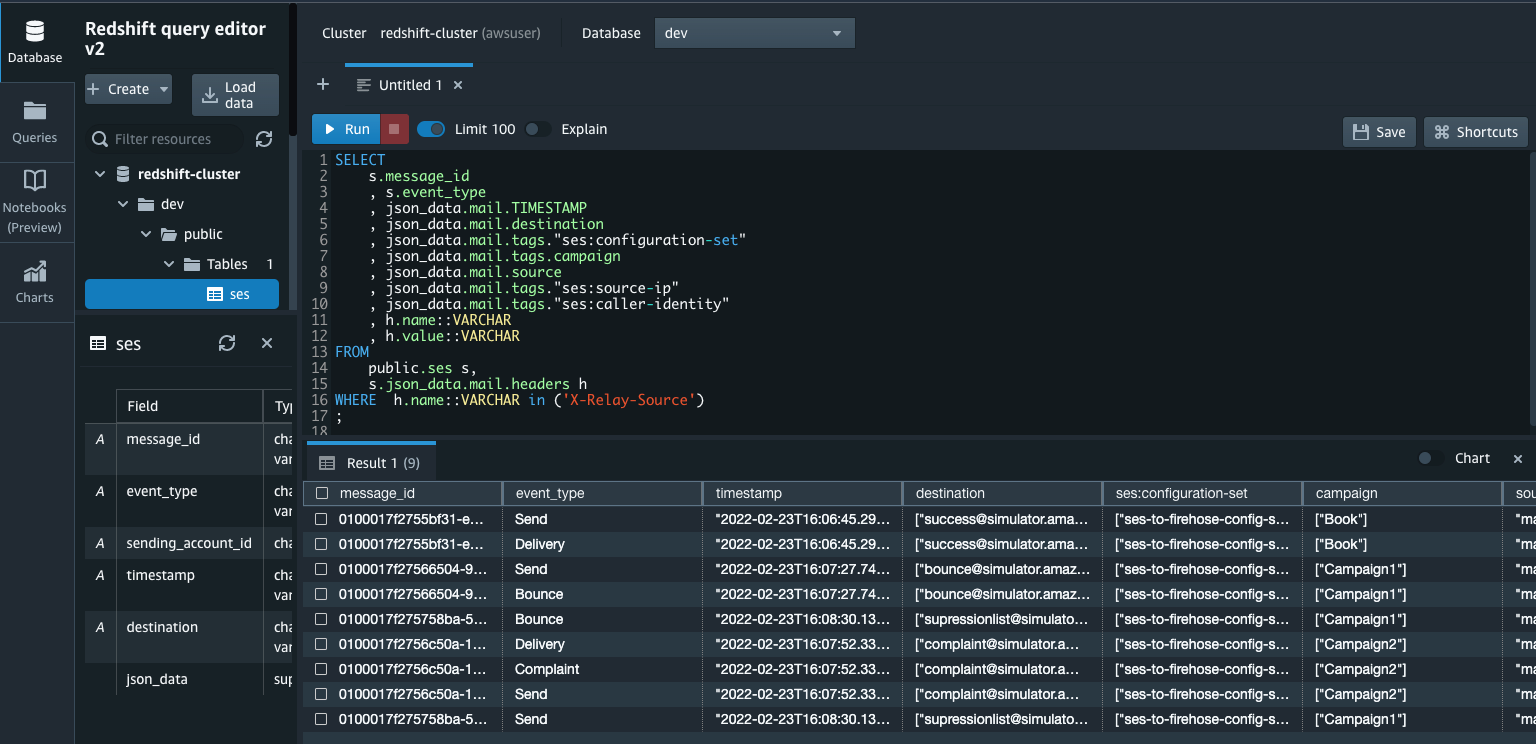
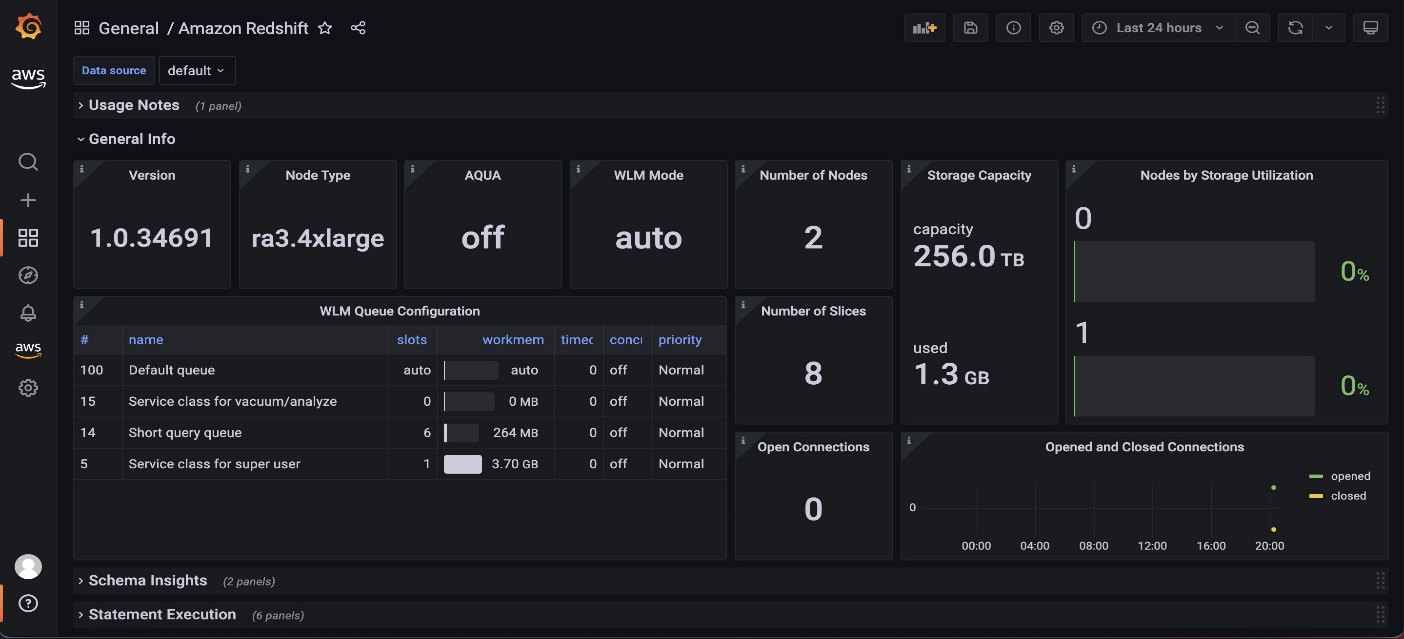
As a final step, you can validate that the tables exist in Amazon Redshift. - Connect using the Amazon Redshift query editor v2 or another third-party tool or utility of your choice and check for all the tables with the following code:










Migrate the data
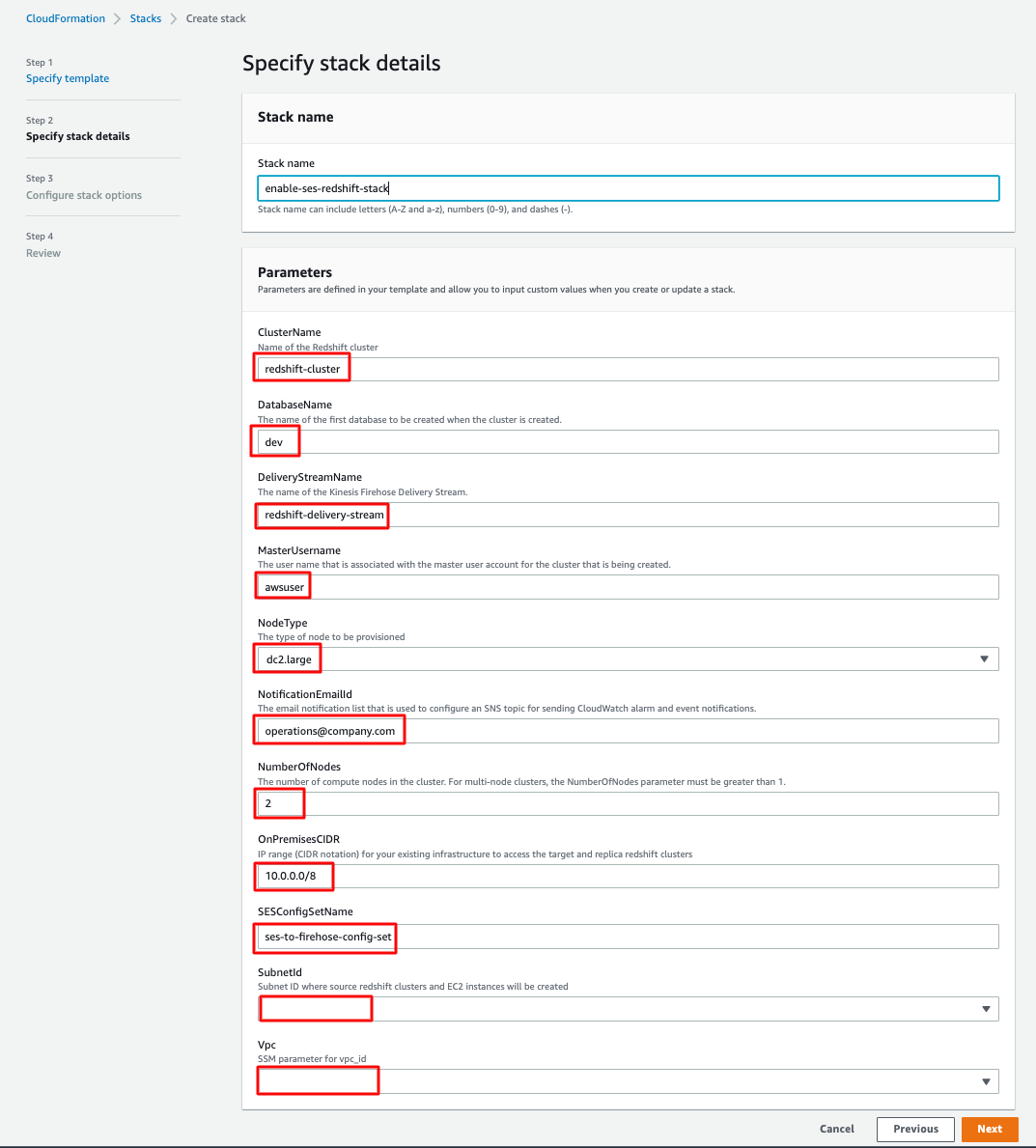
To start your data migration using AWS SCT data extraction agents, complete the following steps:
- Configure the AWS SCT extractor properties file with corresponding Greenplum properties:
Now you configure the AWS SCT extractor to perform a one-time data move. You can use multiple extractors when dealing with a large volume of data.
- To register the extractor, on the View menu, choose Data migration view.

- Choose Register.

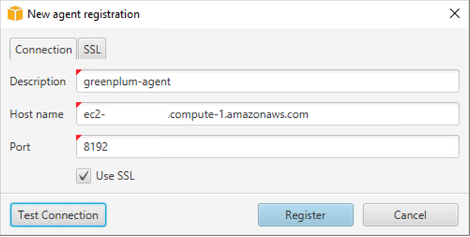
- Enter the information for your new agent.
- Test the connection and choose Register.

Now you create a task for the extractor to extract data into the tables created on Amazon Redshift. - Under your schema in the left pane, choose Tables (right-click) and choose Create Local task.

- For Task name, enter a name.

- Test the connection and choose OK.

- Choose Create.
- Run your task and monitor its progress.


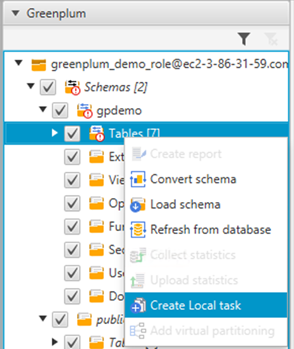



You can choose each task to get a detailed breakdown of its activity. Make sure to examine errors during the extract, upload, and copy process.

You can monitor the status of the tasks, the percentage completed, and the tables that were loaded successfully. You must also verify the count of records loaded into the Amazon Redshift database.

Technical validation
After the initial extracted data is loaded to Amazon Redshift, you must perform data validation tests in parallel. The goal at this stage is to validate production workloads, comparing Greenplum and Amazon Redshift outputs from the same inputs.
Typical activities covered during this phase include the following:
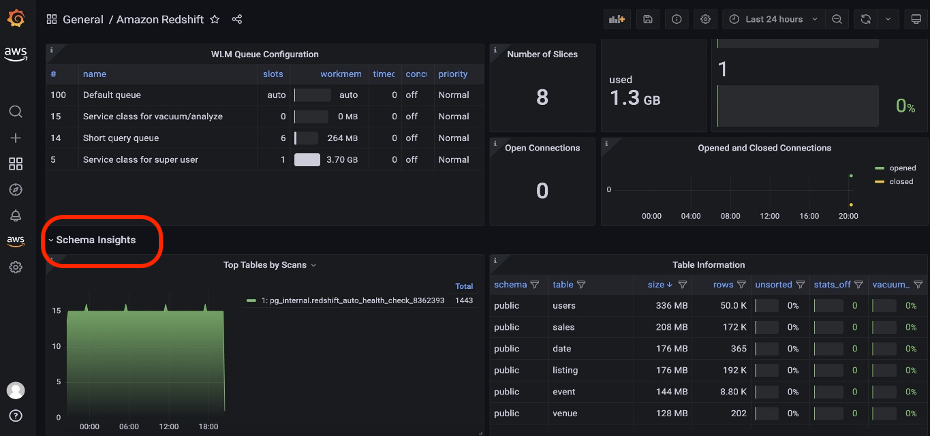
- Count the number of objects and rows on each table.
- Compare the same random subset of data in both Greenplum and Amazon Redshift for all migrated tables, validating that the data is exactly the same row by row.
- Check for incorrect column encodings.
- Identify skewed table data.
- Annotate queries not benefiting from sort keys.
- Identify inappropriate join cardinality.
- Identify with tables with large VARCHAR columns.
- Confirm that processes don’t crash when connected with the target environment.
- Validate daily batch jobs (job duration, number of rows processed). To find the right techniques to perform most of those activities, refer to Top 10 Performance Tuning Techniques for Amazon Redshift
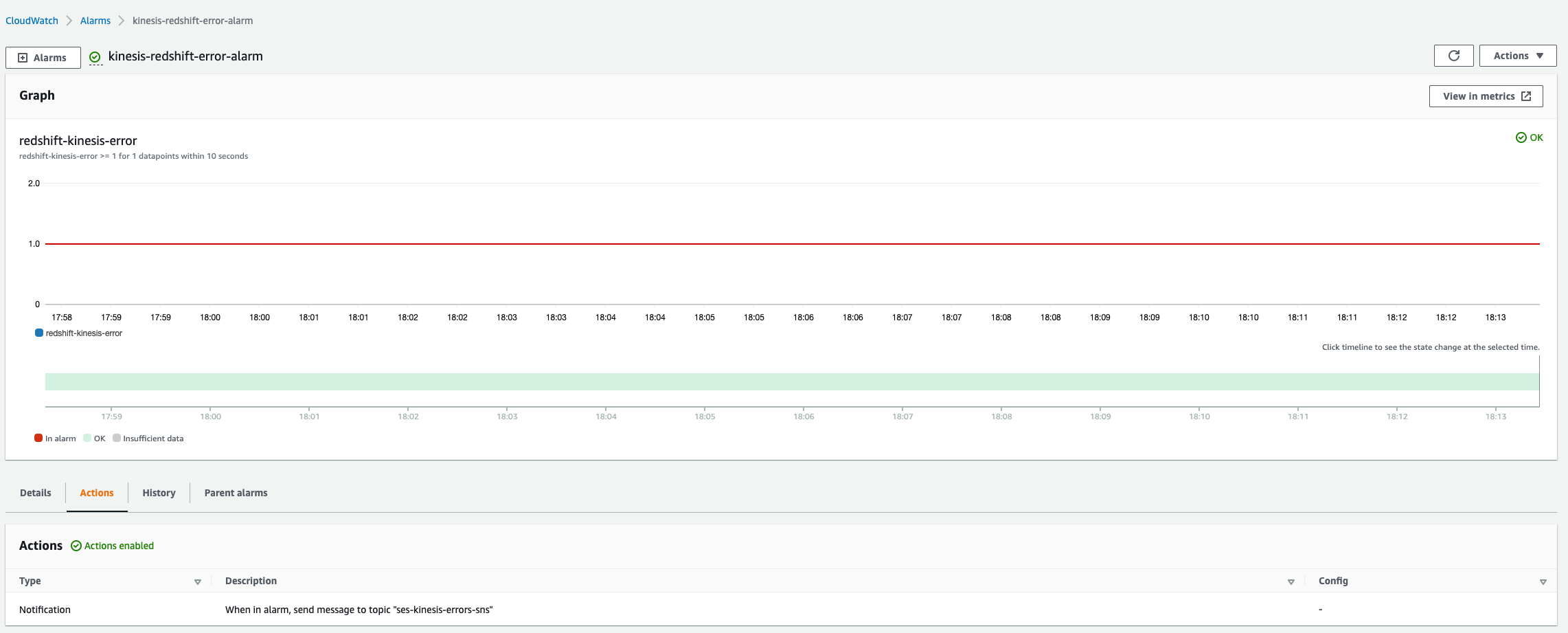
- Set up Amazon Redshift automated alerts with Amazon Redshift Advisor.
Business validation
After you successfully migrate the data and validate the data movement, the last remaining task is to involve the data warehouse users in the validation process. These users from different business units across the company access the data warehouse using various tools and methods: JDBC/ODBC clients, Python scripts, custom applications, and more. It’s central to the migration to make sure that every end-user has verified and adapted this process to work seamlessly with Amazon Redshift before the final cutover.
This phase can consist of several tasks:
- Adapt business users’ tools, applications, and scripts to connect to Amazon Redshift endpoints.
- Modify users’ data load and dump procedures, replacing data movement to and from shared storage via ODBC/JDBC with COPY and UNLOAD operations from and to Amazon Simple Storage Service (Amazon S3).
- Modify any incompatible queries, taking into account any implementation nuances between Amazon Redshift and PostgreSQL.
- Run business processes against Greenplum and Amazon Redshift, and compare results and runtimes. Make sure to notify any issue or unexpected result to the team in charge of the migration, so the case can be analyzed in detail.
- Tune query performance, taking into account table distribution and sort keys, and make extensive use of the EXPLAIN command in order to understand how Amazon Redshift plans and runs queries. For advanced table design concepts, refer to Amazon Redshift Engineering’s Advanced Table Design Playbook: Preamble, Prerequisites, and Prioritization.
This business validation phase is key so all end-users are aligned and ready for the final cutover. Following Amazon Redshift best practices enables end-users to fully take advantage of the capabilities of their new data warehouse. After you perform all the migration validation tasks, connect and test every ETL job, business process, external system, and user tool against Amazon Redshift, you can disconnect every process from the old data warehouse, which you can now safely power off and decommission.
Conclusion
In this post, we provided detailed steps to migrate from Greenplum to Amazon Redshift using AWS SCT. Although this post describes modernizing and moving to a cloud warehouse, you should be augmenting this transformation process towards a full-fledged modern data architecture. The AWS Cloud enables you to be more data-driven by supporting multiple use cases. For a modern data architecture, you should use purposeful data stores like Amazon S3, Amazon Redshift, Amazon Timestream, and other data stores based on your use case.
Check out the second post in this series, where we cover prescriptive guidance around data types, functions, and stored procedures.
About the Authors
 Suresh Patnam is a Principal Solutions Architect at AWS. He is passionate about helping businesses of all sizes transforming into fast-moving digital organizations focusing on big data, data lakes, and AI/ML. Suresh holds a MBA degree from Duke University- Fuqua School of Business and MS in CIS from Missouri State University. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Suresh Patnam is a Principal Solutions Architect at AWS. He is passionate about helping businesses of all sizes transforming into fast-moving digital organizations focusing on big data, data lakes, and AI/ML. Suresh holds a MBA degree from Duke University- Fuqua School of Business and MS in CIS from Missouri State University. In his spare time, Suresh enjoys playing tennis and spending time with his family.
 Arunabha Datta is a Sr. Data Architect at Amazon Web Services (AWS). He collaborates with customers and partners to architect and implement modern data architecture using AWS Analytics services. In his spare time, Arunabha enjoys photography and spending time with his family.
Arunabha Datta is a Sr. Data Architect at Amazon Web Services (AWS). He collaborates with customers and partners to architect and implement modern data architecture using AWS Analytics services. In his spare time, Arunabha enjoys photography and spending time with his family.










 Rahul Chaturvedi is an Analytics Specialist Solutions Architect at AWS. Prior to this role, he was a Data Engineer at Amazon Advertising and Prime Video, where he helped build petabyte-scale data lakes for self-serve analytics.
Rahul Chaturvedi is an Analytics Specialist Solutions Architect at AWS. Prior to this role, he was a Data Engineer at Amazon Advertising and Prime Video, where he helped build petabyte-scale data lakes for self-serve analytics.
























































































 Dipayan Sarkar is a Specialist Solutions Architect for Analytics at AWS, where he helps customers to modernise their data platform using AWS Analytics services. He works with customer to design and build analytics solutions enabling business to make data-driven decisions.
Dipayan Sarkar is a Specialist Solutions Architect for Analytics at AWS, where he helps customers to modernise their data platform using AWS Analytics services. He works with customer to design and build analytics solutions enabling business to make data-driven decisions.















 Jiayuan Chen is a Senior Software Development Engineer at AWS. He is passionate about designing and building data-intensive applications, and has been working in the areas of data lake, query engine, ingestion, and analytics. He keeps up with latest technologies and innovates things that spark joy.
Jiayuan Chen is a Senior Software Development Engineer at AWS. He is passionate about designing and building data-intensive applications, and has been working in the areas of data lake, query engine, ingestion, and analytics. He keeps up with latest technologies and innovates things that spark joy.