Post Syndicated from Emma White original https://aws.amazon.com/blogs/compute/insulating-aws-outposts-workloads-from-amazon-ec2-instance-size-family-and-generation-dependencies/
This post is written by Garry Galinsky, Senior Solutions Architect.
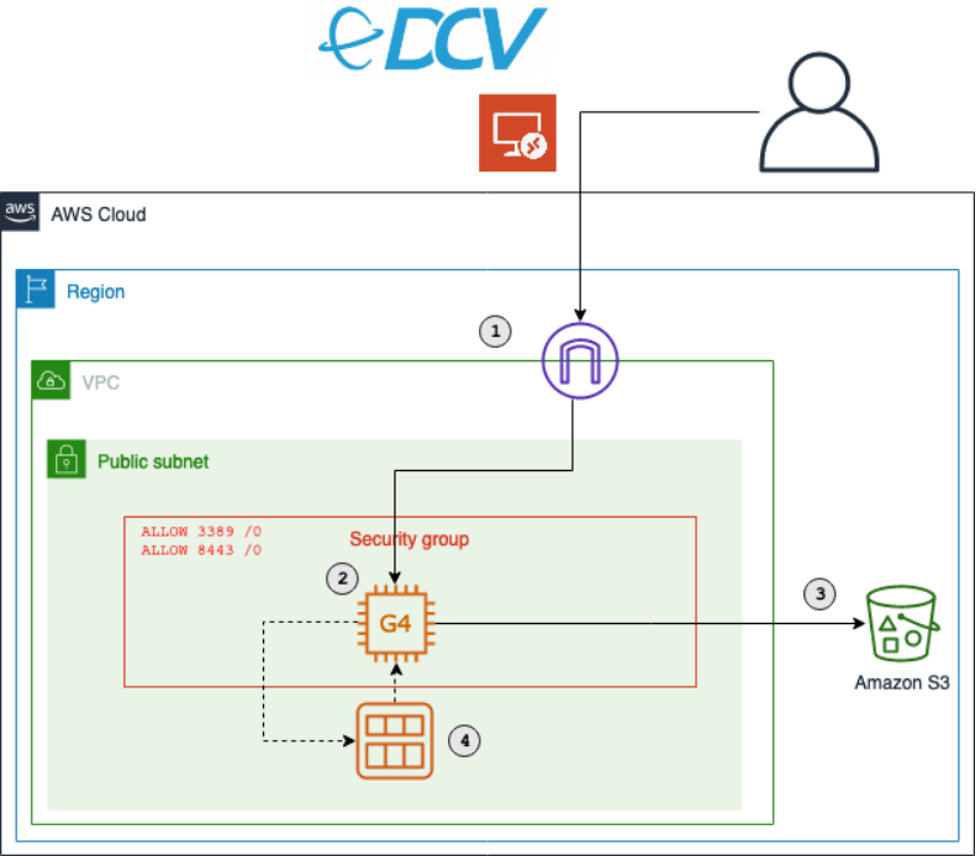
AWS Outposts is a fully managed service that offers the same AWS infrastructure, AWS services, APIs, and tools to virtually any datacenter, co-location space, or on-premises facility for a truly consistent hybrid experience. AWS Outposts is ideal for workloads that require low-latency access to on-premises systems, local data processing, data residency, and application migration with local system interdependencies.
Unlike AWS Regions, which offer near-infinite scale, Outposts are limited by their provisioned capacity, EC2 family and generations, configured instance sizes, and availability of compute capacity that is not already consumed by other workloads. This post explains how Amazon EC2 Fleet can be used to insulate workloads running on Outposts from EC2 instance size, family, and generation dependencies, reducing the likelihood of encountering an error when launching new workloads or scaling existing ones.
Product Overview
Outposts is available as a 42U rack that can scale to create pools of on-premises compute and storage capacity. When you order an Outposts rack, you specify the quantity, family, and generation of Amazon EC2 instances to be provisioned. As of this writing, five EC2 families, each of a single generation, are available on Outposts (m5, c5, r5, g4dn, and i3en). However, in the future, more families and generations may be available, and a given Outposts rack may include a mix of families and generations. EC2 servers on Outposts are partitioned into instances of homogenous or heterogeneous sizes (e.g., large, 2xlarge, 12xlarge) based on your workload requirements.
Workloads deployed through AWS CloudFormation or scaled through Amazon EC2 Auto Scaling generally assume that the required EC2 instance type will be available when the deployment or scaling event occurs. Although in the Region this is a reasonable assumption, the same is not true for Outposts. Whether as a result of competing workloads consuming the capacity, the Outpost having been configured with limited capacity for a given instance size, or an Outpost update resulting in instances being replaced with a newer generation, a deployment or scaling event tied to a specific instance size, family, and generation may encounter an InsufficentInstanceCapacity error (ICE). And this may occur even though sufficient unused capacity of a different size, family, or generation is available.
EC2 Fleet
Amazon EC2 Fleet simplifies the provisioning of Amazon EC2 capacity across different Amazon EC2 instance types and Availability Zones, as well as across On-Demand, Amazon EC2 Reserved Instances (RI), and Amazon EC2 Spot purchase models. A single API call lets you provision capacity across EC2 instance types and purchase models in order to achieve the desired scale, performance, and cost.
An EC2 Fleet contains a configuration to launch a fleet, or group, of EC2 instances. The LaunchTemplateConfigs parameter lets multiple instance size, family, and generation combinations be specified in a priority order.
This feature is commonly used in AWS Regions to optimize fleet costs and allocations across multiple deployment strategies (reserved, on-demand, and spot), while on Outposts it can be used to eliminate the tight coupling of a workload to specific EC2 instances by specifying multiple instance families, generations, and sizes.
Launch Template Overrides
The EC2 Fleet LaunchTemplateConfigs definition describes the EC2 instances required for the fleet. A specific parameter of this definition, the Overrides, can include prioritized and/or weighted options of EC2 instances that can be launched to satisfy the workload. Let’s investigate how you can use Overrides to decouple the EC2 size, family, and generation dependencies.
Overriding EC2 Instance Size
Let’s assume our Outpost was provisioned with an m5 server. The server is the equivalent of an m5.24xlarge, which can be configured into multiple instances. For example, the server can be homogeneously provisioned into 12 x m5.2xlarge, or heterogeneously into 1 x m5.8xlarge, 3 x m5.2xlarge, 8 x m5.xlarge, and 4 x m5.large. Let’s assume the heterogeneous configuration has been applied.
Our workload requires compute capacity equivalent to an m5.4xlarge (16 vCPUs, 64 GiB memory), but that instance size is not available on the Outpost. Attempting to launch this instance would result in an InsufficentInstanceCapacity error. Instead, the following LaunchTemplateConfigs override could be used:
"Overrides": [
{
"InstanceType": "m5.4xlarge",
"WeightedCapacity": 1.0,
"Priority": 1.0
},
{
"InstanceType": "m5.2xlarge",
"WeightedCapacity": 0.5,
"Priority": 2.0
},
{
"InstanceType": "m5.8xlarge",
"WeightedCapacity": 2.0,
"Priority": 3.0
}
]
The Priority describes our order of preference. Ideally, we launch a single m5.4xlarge instance, but that’s not an option. Therefore, in this case, the EC2 Fleet would move to the next priority option, an m5.2xlarge. Given that an m5.2xlarge (8 vCPUs, 32 GiB memory) offers only half of the resource of the m5.4xlarge, the override includes the WeightedCapacity parameter of 0.5, resulting in two m5.2xlarge instances launching instead of one.
Our overrides include a third, over-provisioned and less preferable option, should the Outpost lack two m5.2xlarge capacity: launch one m5.8xlarge. Operating within finite resources requires tradeoffs, and priority lets us optimize them. Note that had the launch required 2 x m5.4xlarge, only one instance of m5.8xlarge would have been launched.
Overriding EC2 Instance Family
Let’s assume our Outpost was provisioned with an m5 and a c5 server, homogeneously partitioned into 12 x m5.2xlarge and 12 x c5.2xlarge instances. Our workload requires compute capacity equivalent to a c5.2xlarge instance (8 vCPUs, 16 GiB memory). As our workload scales, more instances must be launched to meet demand. If we couple our workload to c5.2xlarge, then our scaling will be blocked as soon as all 12 instances are consumed. Instead, we use the following LaunchTemplateConfigs override:
"Overrides": [
{
"InstanceType": "c5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 1.0
},
{
"InstanceType": "m5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 2.0
}
]
The Priority describes our order of preference. Ideally, we scale more c5.2xlarge instances, but when those are not an option EC2 Fleet would launch the next priority option, an m5.2xlarge. Here again the outcome may result in over-provisioned memory capacity (32 vs 16 GiB memory), but it’s a reasonable tradeoff in a finite resource environment.
Overriding EC2 Instance Generation
Let’s assume our Outpost was provisioned two years ago with an m5 server. Since then, m6 servers have become available, and there’s an expectation that m7 servers will be available soon. Our single-generation Outpost may unexpectedly become multi-generation if the Outpost is expanded, or if a hardware failure results in a newer generation replacement.
Coupling our workload to a specific generation could result in future scaling challenges. Instead, we use the following LaunchTemplateConfigs override:
"Overrides": [
{
"InstanceType": "m6.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 1.0
},
{
"InstanceType": "m5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 2.0
},
{
"InstanceType": "m7.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 3.0
}
]
Note the Priority here, our preference is for the current generation m6, even though it’s not yet provisioned in our Outpost. The m5 is what would be launched now, given that it’s the only provisioned generation. However, we’ve also future-proofed our workload by including the yet unreleased m7.
Deploying an EC2 Fleet
To deploy an EC2 Fleet, you must:
- Create a launch template, which streamlines and standardizes EC2 instance provisioning by simplifying permission policies and enforcing best practices across your organization.
- Create a fleet configuration, where you set the number of instances required and specify the prioritized instance family/generation combinations.
- Launch your fleet (or a single EC2 instance).
These steps can be codified through AWS CloudFormation or executed through AWS Command Line Interface (CLI) commands. However, fleet definitions cannot be implemented by using the AWS Console. This example will use CLI commands to conduct these steps.
Prerequisites
To follow along with this tutorial, you should have the following prerequisites:
- An AWS account.
- AWS Command Line Interface (CLI) version 1.17.0 or later installed and configured on your workstation.
- An operational AWS Outposts associated with your AWS account.
- Existing VPC, Subnet, and Route Table associated with your AWS Outposts deployment.
- Your AWS Outpost’s anchor Availability Zone.
Create a Launch Template
Launch templates let you store launch parameters so that you do not have to specify them every time you launch an EC2 instance. A launch template can contain the Amazon Machine Images (AMI) ID, instance type, and network settings that you typically use to launch instances. For more details about launch templates, reference Launch an instance from a launch template .
For this example, we will focus on these specifications:
- AMI image
ImageId - Subnet (the
SubnetIdassociated with your Outpost) - Availability zone (the
AvailabilityZoneassociated with your Outpost) - Tags
Create a launch template configuration (launch-template.json) with the following content:
{
"ImageId": "<YOUR-AMI>",
"NetworkInterfaces": [
{
"DeviceIndex": 0,
"SubnetId": "<YOUR-OUTPOST-SUBNET>"
}
],
"Placement": {
"AvailabilityZone": "<YOUR-OUTPOST-AZ>"
},
"TagSpecifications": [
{
"ResourceType": "instance",
"Tags": [
{
"Key": "<YOUR-TAG-KEY>",
"Value": "<YOUR-TAG-VALUE>"
}
]
}
]
}
Create your launch template using the following CLI command:
aws ec2 create-launch-template \
--launch-template-name <YOUR-LAUNCH-TEMPLATE-NAME> \
--launch-template-data file://launch-template.json
You should see a response like this:
{
"LaunchTemplate": {
"LaunchTemplateId": "lt-010654c96462292e8",
"LaunchTemplateName": "<YOUR-LAUNCH-TEMPLATE-NAME>",
"CreateTime": "2021-07-12T15:55:00+00:00",
"CreatedBy": "arn:aws:sts::<YOUR-AWS-ACCOUNT>:assumed-role/<YOUR-AWS-ROLE>",
"DefaultVersionNumber": 1,
"LatestVersionNumber": 1
}
}
The value for LaunchTemplateId is the identifier for your newly created launch template. You will need this value lt-010654c96462292e8 in the subsequent step.
Create a Fleet Configuration
Refer to Generate an EC2 Fleet JSON configuration file for full documentation on the EC2 Fleet configuration.
For this example, we will use this configuration to override a mix of instance size, family, and generation. The override includes three EC2 instance types:
- m5.large, the instance family and generation currently available on the Outpost.
- m6.large, a forthcoming family and generation not yet available for Outposts.
- m7.large, a potential future family and generation.
Create an EC2 fleet configuration (ec2-fleet.json) with the following content (note that the LaunchTemplateId was the value returned in the prior step):
{
"TargetCapacitySpecification": {
"TotalTargetCapacity": 1,
"OnDemandTargetCapacity": 1,
"SpotTargetCapacity": 0,
"DefaultTargetCapacityType": "on-demand"
},
"OnDemandOptions": {
"AllocationStrategy": "prioritized",
"SingleInstanceType": true,
"SingleAvailabilityZone": true,
"MinTargetCapacity": 1
},
"LaunchTemplateConfigs": [
{
"LaunchTemplateSpecification": {
"LaunchTemplateId": "lt-010654c96462292e8",
"Version": "1"
},
"Overrides": [
{
"InstanceType": "m6.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 1.0
},
{
"InstanceType": "c5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 2.0
},
{
"InstanceType": "m5.large",
"WeightedCapacity": 0.25,
"Priority": 3.0
},
{
"InstanceType": "m5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 4.0
},
{
"InstanceType": "r5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 5.0
}
]
}
],
"Type": "instant"
}
Launch the Single Instance Fleet
To launch the fleet, execute the following CLI command (this will launch a single instance, but a similar process can be used to launch multiple):
aws ec2 create-fleet \
--cli-input-json file://ec2-fleet.json
You should see a response like this:
{
"FleetId": "fleet-dc630649-5d77-60b3-2c30-09808ef8aa90",
"Errors": [
{
"LaunchTemplateAndOverrides": {
"LaunchTemplateSpecification": {
"LaunchTemplateId": "lt-010654c96462292e8",
"Version": "1"
},
"Overrides": {
"InstanceType": "m6.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 1.0
}
},
"Lifecycle": "on-demand",
"ErrorCode": "InvalidParameterValue",
"ErrorMessage": "The instance type 'm6.2xlarge' is not supported in Outpost 'arn:aws:outposts:us-west-2:111111111111:outpost/op-0000ffff0000fffff'."
},
{
"LaunchTemplateAndOverrides": {
"LaunchTemplateSpecification": {
"LaunchTemplateId": "lt-010654c96462292e8",
"Version": "1"
},
"Overrides": {
"InstanceType": "c5.2xlarge",
"WeightedCapacity": 1.0,
"Priority": 2.0
}
},
"Lifecycle": "on-demand",
"ErrorCode": "InsufficientCapacityOnOutpost",
"ErrorMessage": "There is not enough capacity on the Outpost to launch or start the instance."
}
],
"Instances": [
{
"LaunchTemplateAndOverrides": {
"LaunchTemplateSpecification": {
"LaunchTemplateId": "lt-010654c96462292e8",
"Version": "1"
},
"Overrides": {
"InstanceType": "m5.large",
"WeightedCapacity": 0.25,
"Priority": 3.0
}
},
"Lifecycle": "on-demand",
"InstanceIds": [
"i-03d6323c8a1df8008",
"i-0f62593c8d228dba5",
"i-0ae25baae1f621c15",
"i-0af7e688d0460a60a"
],
"InstanceType": "m5.large"
}
]
}
Results
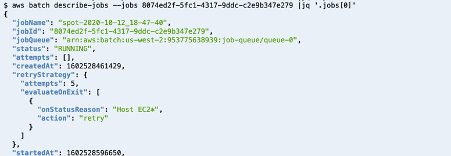
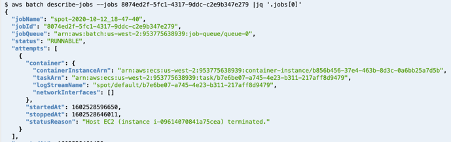
Navigate to the EC2 Console where you will find new instances running on your Outpost. An example is shown in the following screenshot:

Although multiple instance size, family, and generation combinations were included in the Overrides, only the c5.large was available on the Outpost. Instead of launching one m6.2xlarge, four c5.large were launched in order to compensate for their lower WeightedCapacity. From the fleet-create response, the overrides were clearly evaluated in priority order with the error messages explaining why the top two overrides were ignored.
Clean up
AWS CLI EC2 commands can be used to create fleets but can also be used to delete them.
To clean up the resources created in this tutorial:
-
- Note the
FleetIdvalues returned in the create-fleet command. - Run the following command for each fleet created:
- Note the
aws ec2 delete-fleets \
--fleet-ids \
--terminate-instances
- Note the
launch-template-nameused in thecreate-launch-templatecommand. - Run the following command for each fleet created:
{
"SuccessfulFleetDeletions": [
{
"CurrentFleetState": "deleted_terminating",
"PreviousFleetState": "active",
"FleetId": "fleet-dc630649-5d77-60b3-2c30-09808ef8aa90"
}
],
"UnsuccessfulFleetDeletions": []
}
- Clean up any resources you created for the prerequisites.
Conclusion
This post discussed how EC2 Fleet can be used to decouple the availability of specific EC2 instance sizes, families, and generation from the ability to launch or scale workloads. On an Outpost provisioned with multiple families of EC2 instances (say m5 and c5) and different sizes (say m5.large and m5.2xlarge), EC2 Fleet can be used to satisfy a workload launch request even if the capacity of the preferred instance size, family, or generation is unavailable.
To learn more about AWS Outposts, check out the Outposts product page. To see a full list of pre-defined Outposts configurations, visit the Outposts pricing page