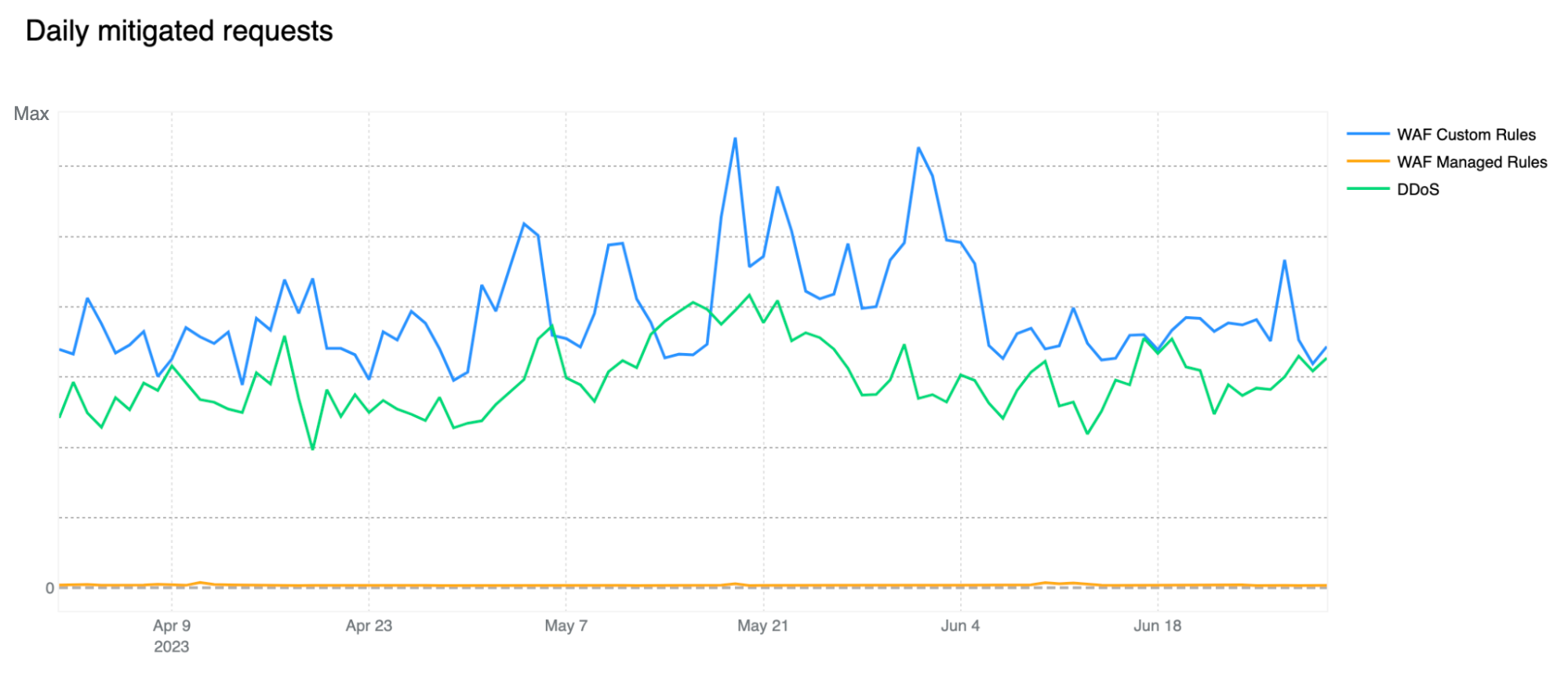
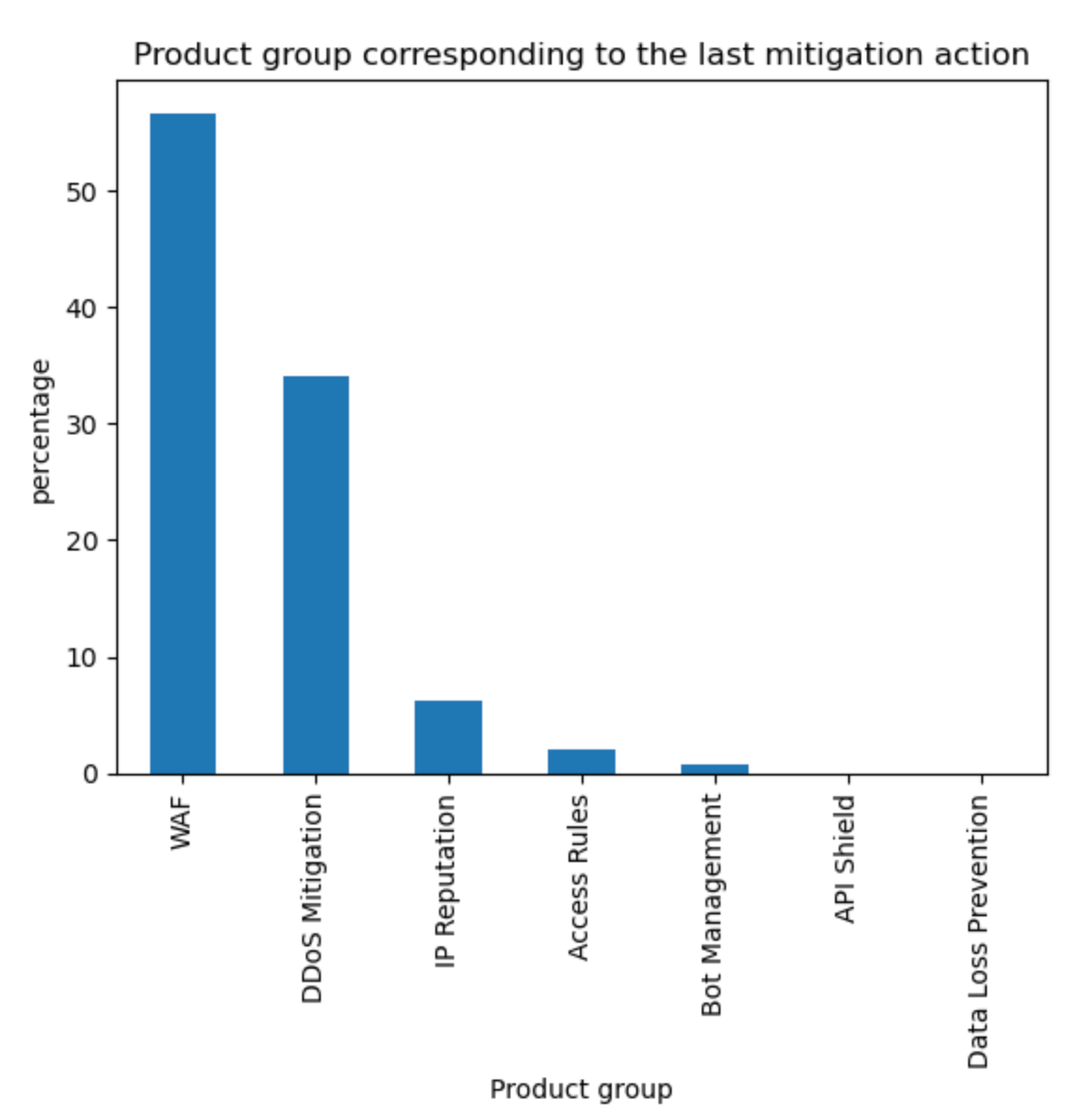
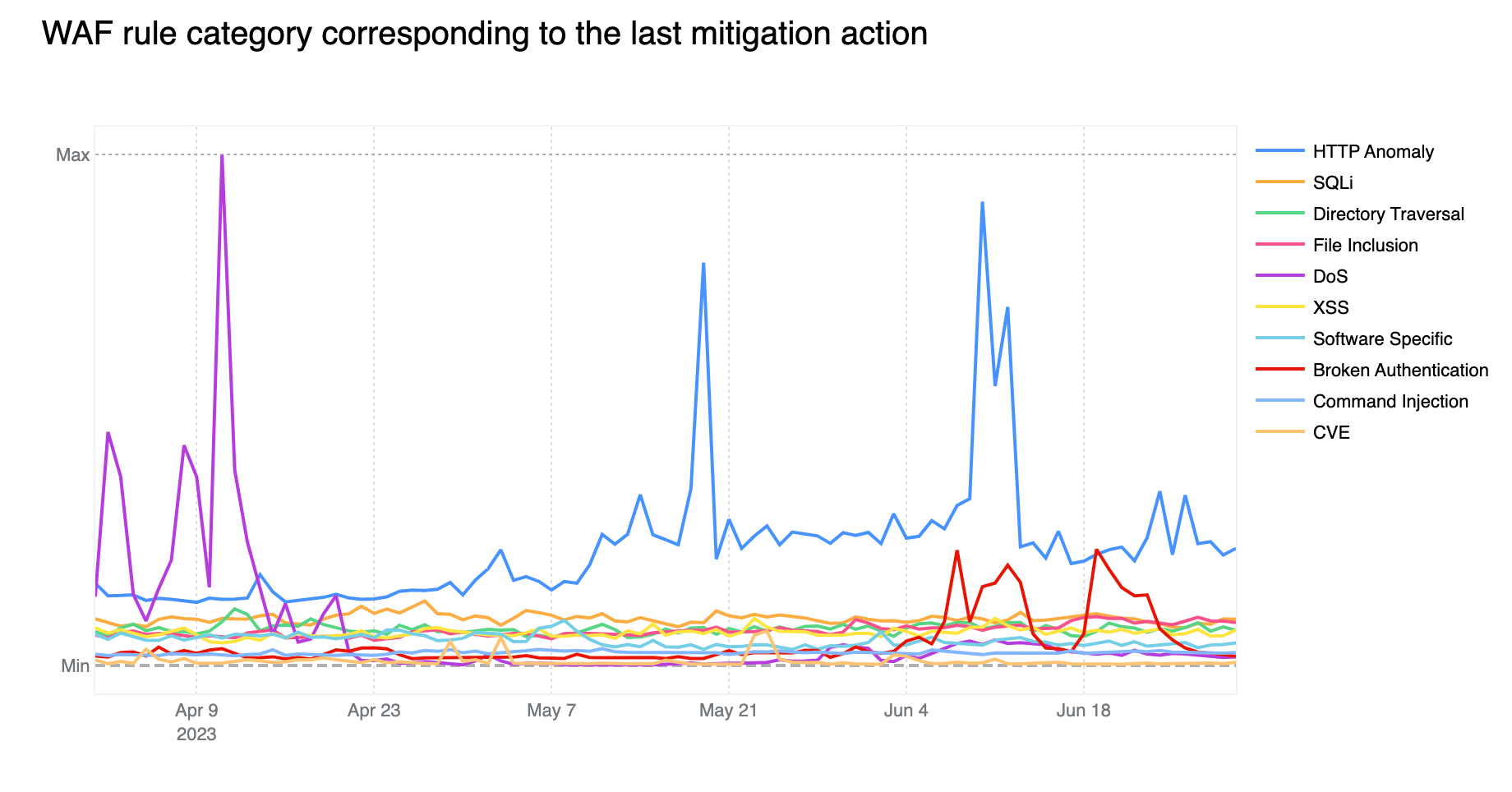
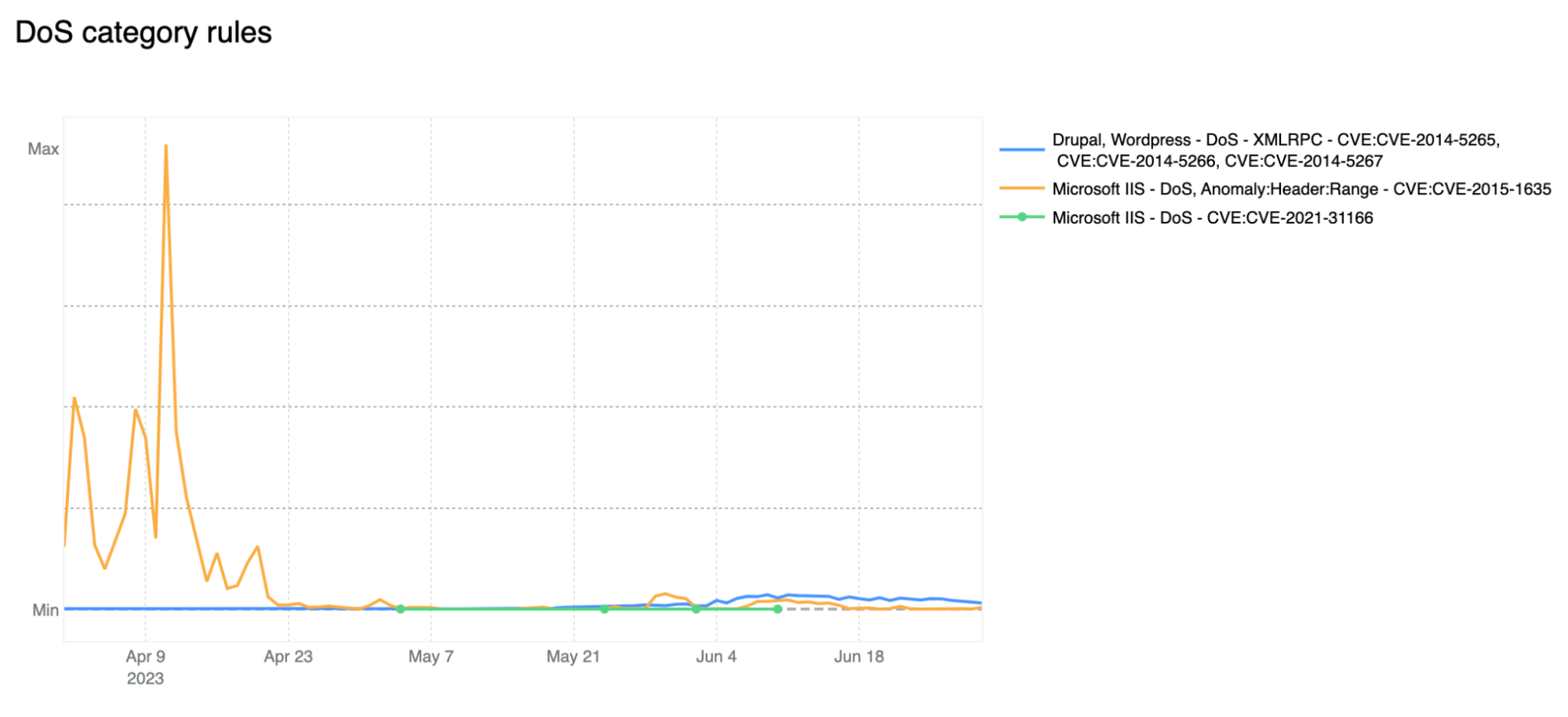
Post Syndicated from Oliver Payne original https://blog.cloudflare.com/turnstile-ephemeral-ids-for-fraud-detection
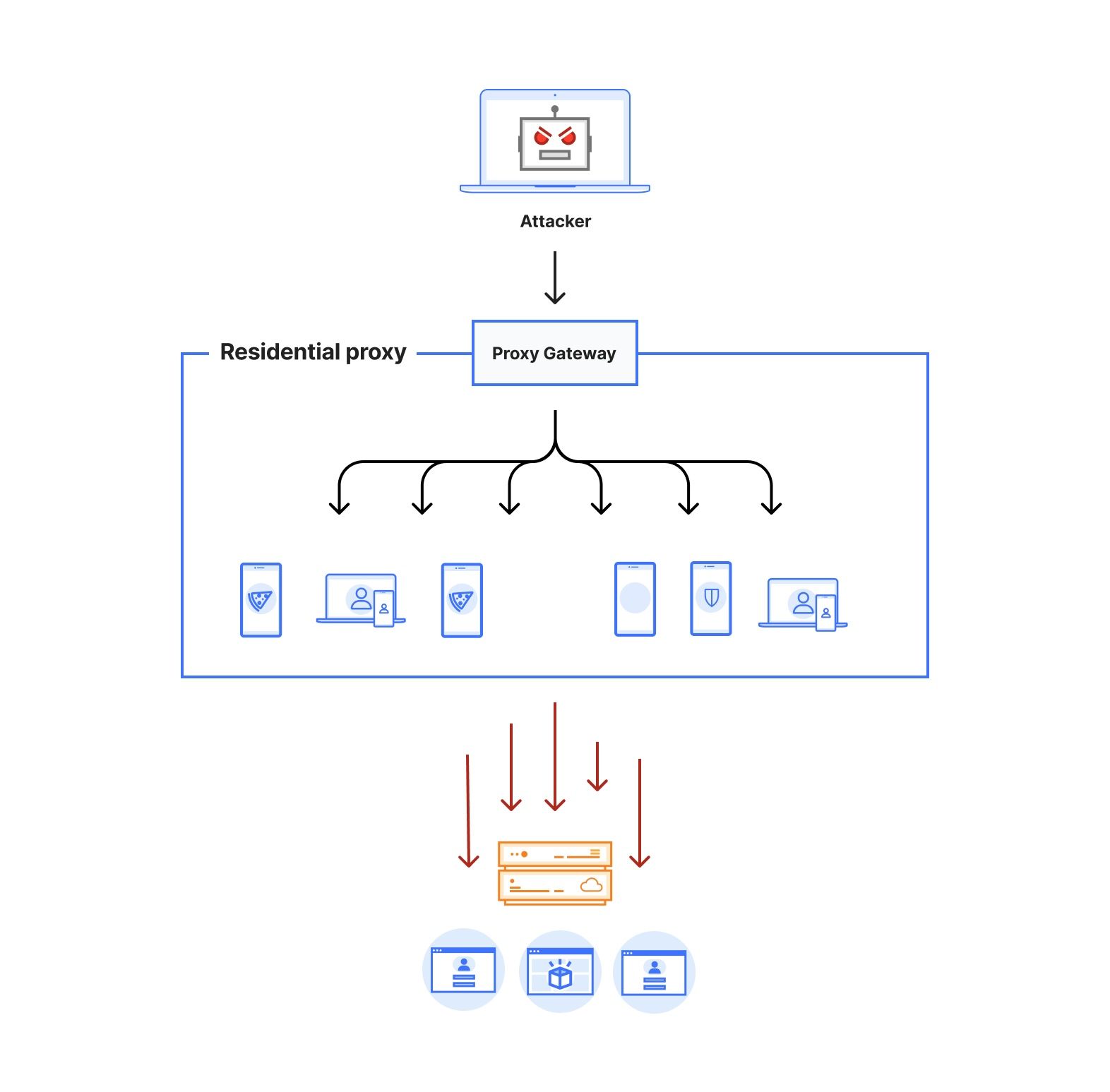
In the early days of the Internet, a single IP address was a reliable indicator of a single user. However, today’s Internet is more complex. Shared IP addresses are now common, with users connecting via mobile IP address pools, VPNs, or behind CGNAT (Carrier Grade Network Address Translation). This makes relying on IP addresses alone a weak method to combat modern threats like automated attacks and fraudulent activity. Additionally, many Internet users have no option but to use an IP address which they don’t have sole control over, and as such, should not be penalized for that.
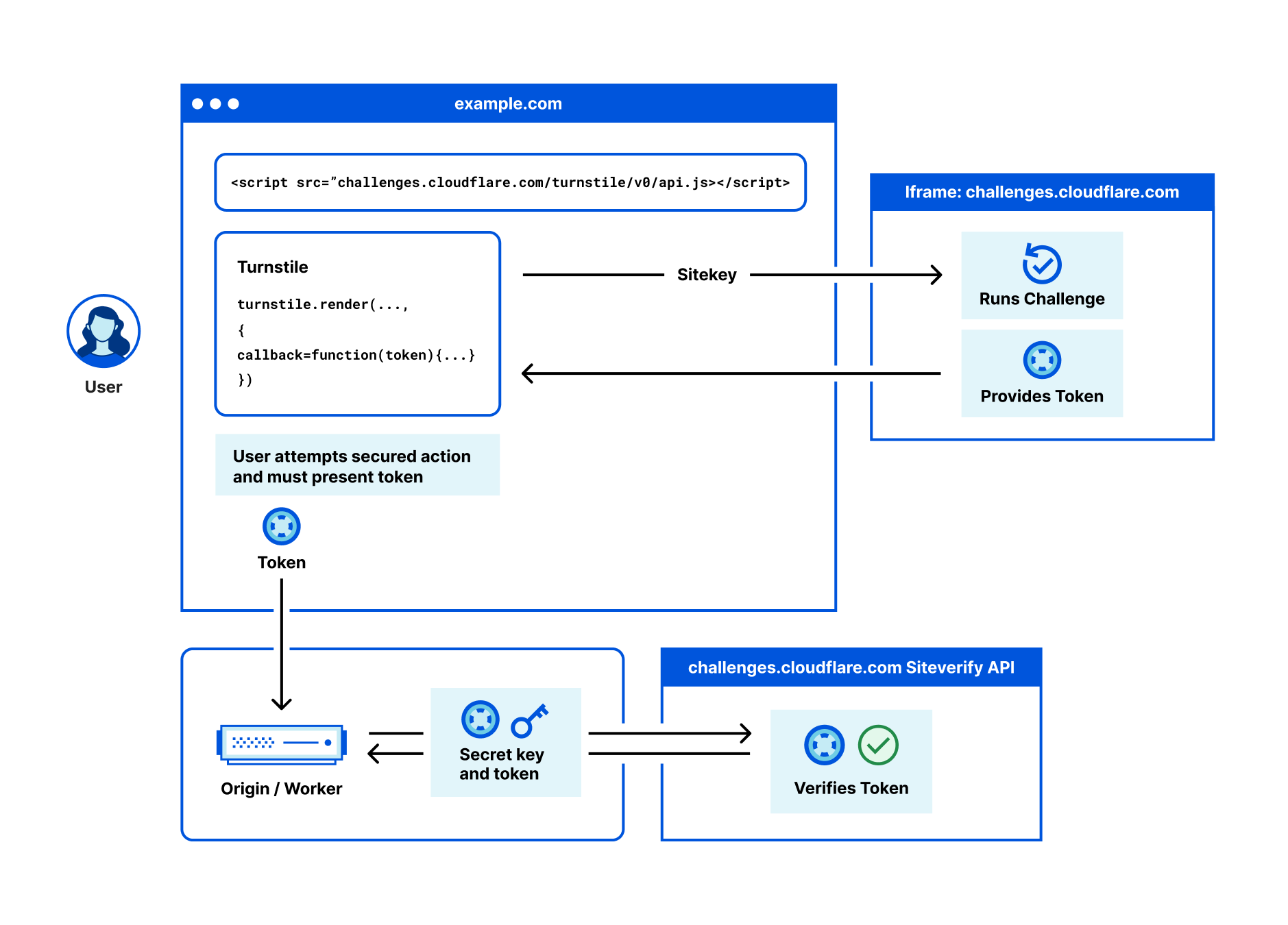
At Cloudflare, we are solving this complexity with Turnstile, our CAPTCHA alternative. And now, we’re taking the next step in advancing security with Ephemeral IDs, a new feature that generates a unique short-lived ID, without relying on any network-level information.
When a website visitor interacts with Turnstile, we now calculate an Ephemeral ID that can link behavior to a specific client instead of an IP address. This means that even when attackers rotate through large pools of IP addresses, we can still identify and block malicious actions. For example, in attacks like credential stuffing or account signups, where fraudsters attempt to disguise themselves using different IP addresses, Ephemeral IDs allow us to detect abuse patterns more accurately beyond just determining whether the visitor is a human or a bot. Multiple fraudulent actions from the same client are grouped together, improving our detection rate while reducing false positives.
How Ephemeral IDs work
Turnstile detects bots by analyzing browser attributes and signals. Using these aggregated client-side signals, we generate a short-lived Ephemeral ID without setting any cookies or using similar client-side storage. These IDs are intentionally not 100% unique and have a brief lifespan, making them highly effective in identifying patterns of fraud and abuse, without compromising user privacy.
When the same visitor interacts with Turnstile widgets from different Cloudflare customers, they receive different Ephemeral IDs for each one. Additionally, because these IDs change frequently, they cannot be used to track a single visitor over multiple days.
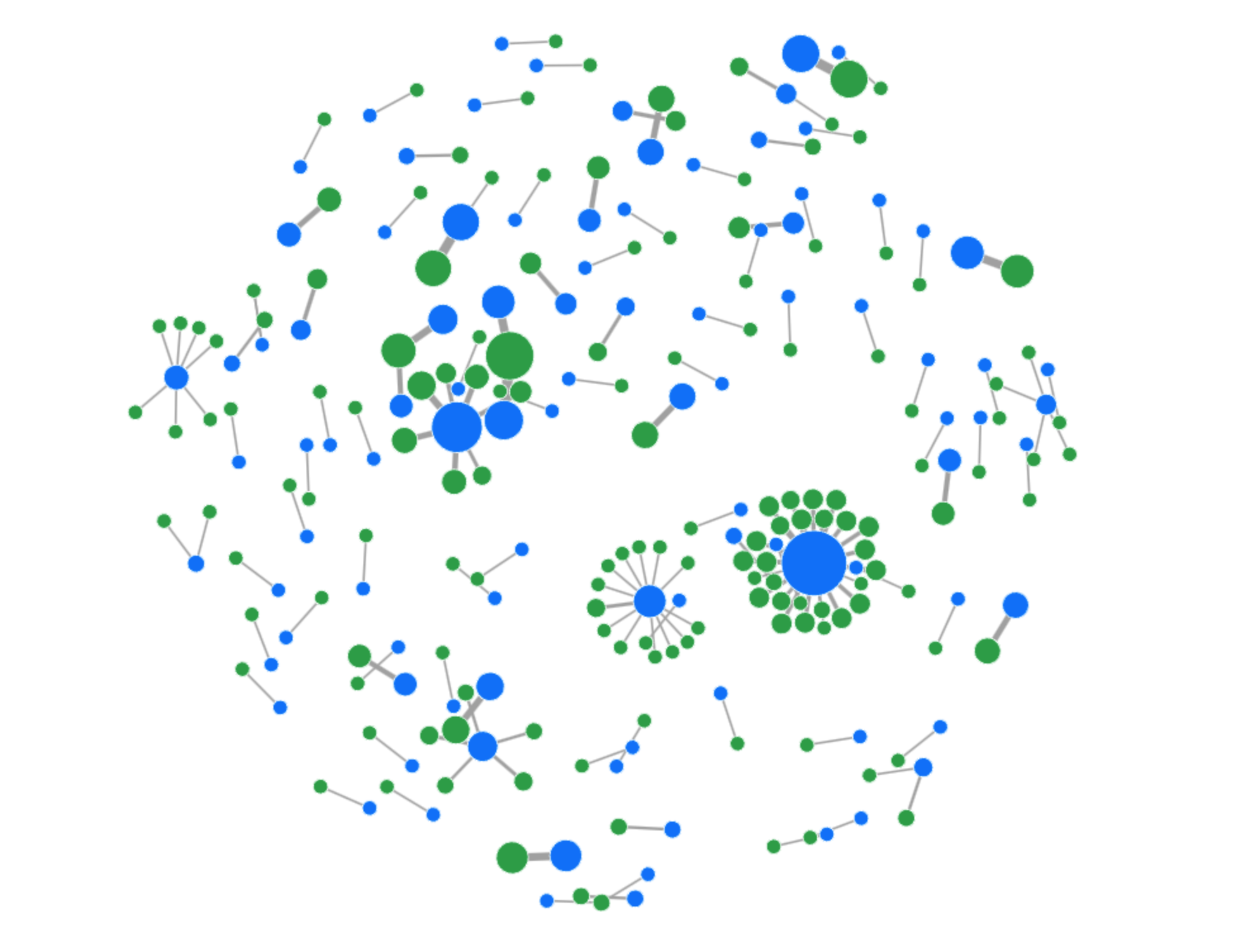
Blue: A single IP address | Green: A single Ephemeral ID
The bigger the node, the more frequently seen that ID or IP address was in our dataset.
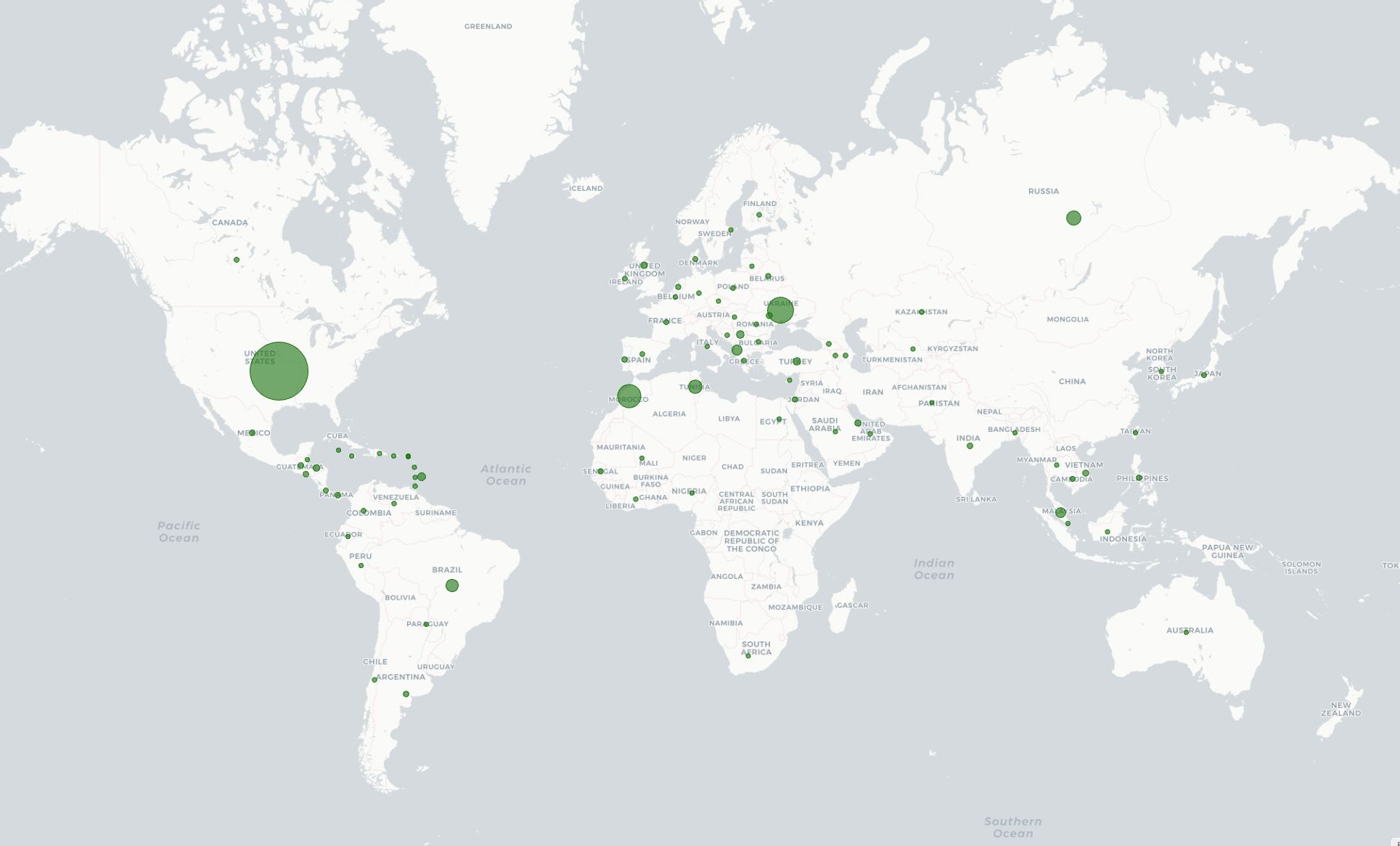
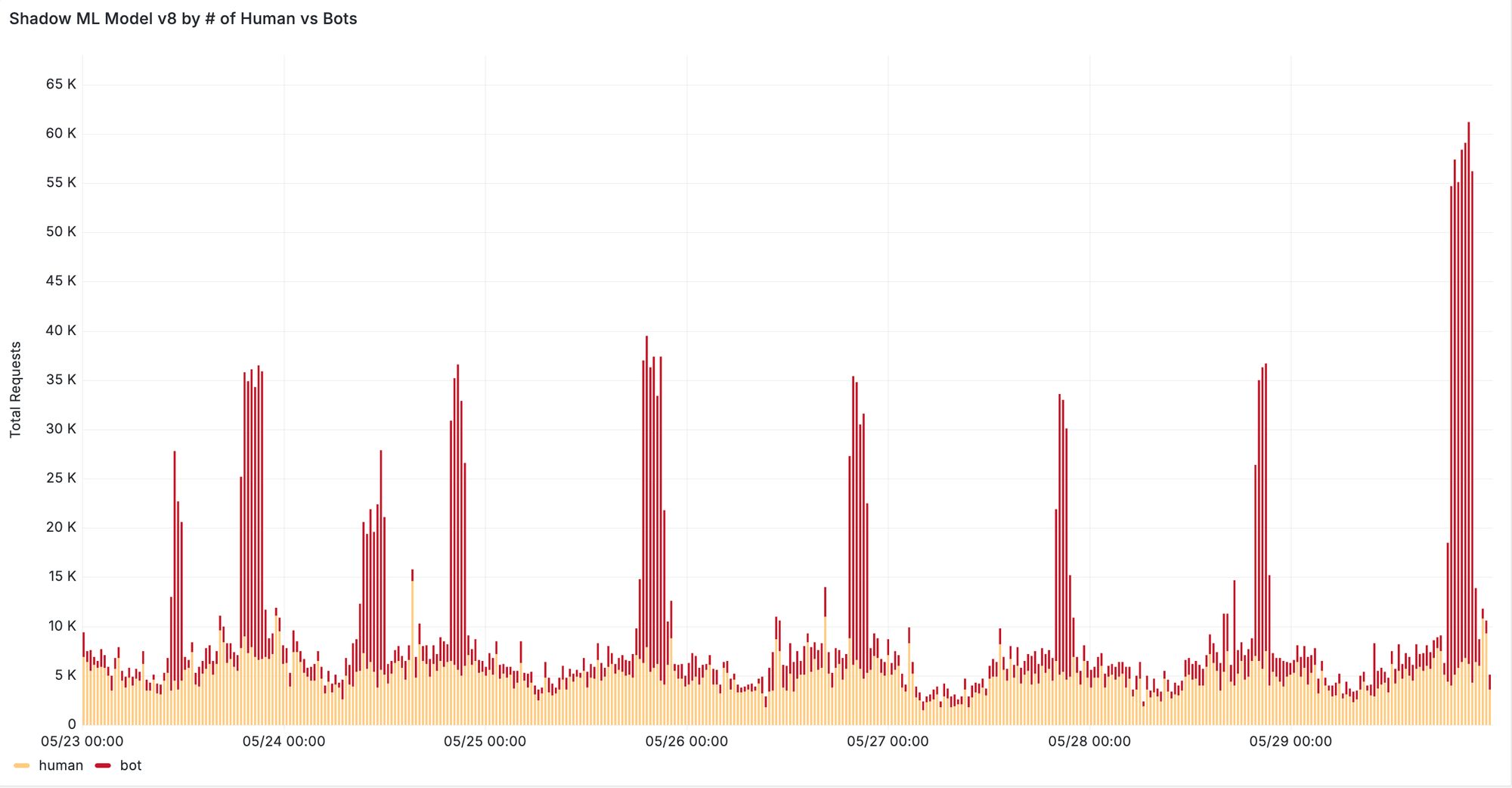
The graphic above illustrates the complex reality of the modern Internet, where the relationship between clients and IP addresses is far from a simple one-to-one mapping. While some straightforward mappings still exist, they are no longer the norm.
During a period where a site or service is under attack, we observe a “nest” of highly correlated Ephemeral IDs. In the example below, the correlation is based on both Ephemeral ID and IP address.
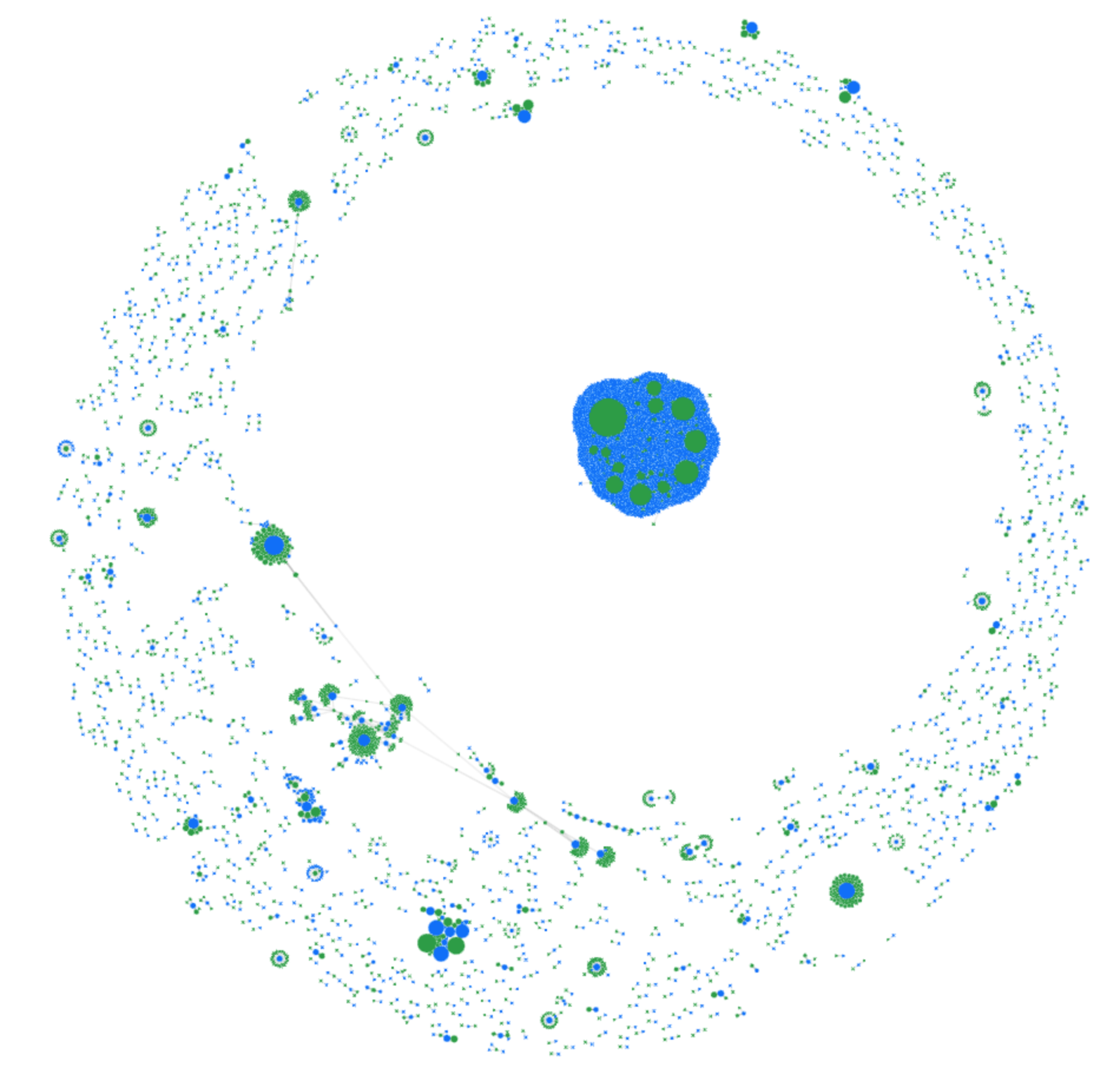
Nest in the center of the diagram visualizes thousands of IP addresses (blue) which are correlated by the commonly identified Ephemeral IDs (green). The bigger the node, the more frequently seen that ID or IP address was in our dataset.
This is real-world data showing fraudulent activity on one of Cloudflare’s public-facing forms. Even with access to a broad range of IP addresses, attackers struggle to completely disguise their requests because Ephemeral IDs are generated based on patterns beyond IP addresses. This means that even if they rotate addresses, the underlying client characteristics are still detected, making it harder for them to evade our security measures. This makes it easier for us to group these requests and apply appropriate business logic, whether that means discarding the requests, requiring further validation, enforcing multi-factor authentication (MFA), or other actions.
This new client identification technology seamlessly integrates into the broader advancements we’ve made to Turnstile over the past year. Whether you’re protecting login forms, signup pages, or high value transactions, you’ll immediately benefit from this extra layer of abuse detection without needing to change a single line of code. We’ll take care of all the heavy lifting and analysis behind the scenes, and our system will continue to improve its accuracy and effectiveness over time.
What does this mean for you? Starting today, Turnstile will go beyond just identifying bots. All websites protected by Turnstile will automatically benefit from the integration of Ephemeral IDs into our detection logic. This means we can more effectively identify and penalize offending clients without impacting other users on the same network, or IP address, improving security and user experience for everyone.
Ephemeral IDs in action
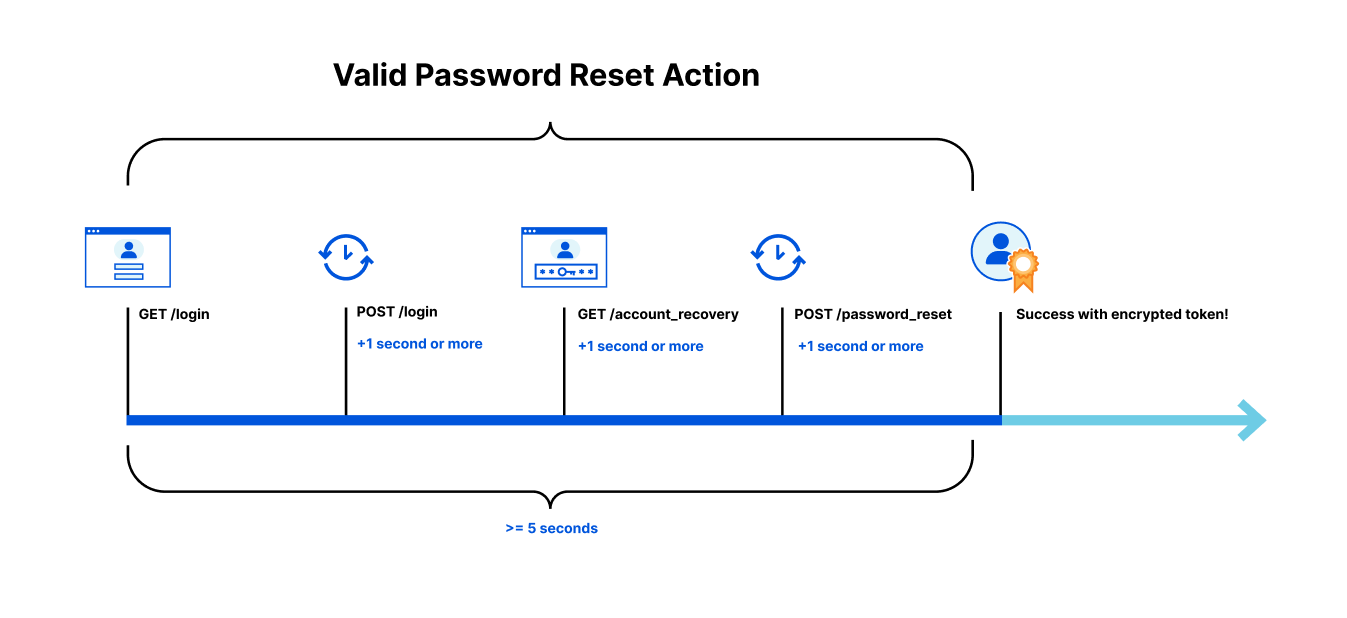
Everyone benefits from the addition of Ephemeral IDs to the Challenge Platform, but for those who want to use it beyond that, the Ephemeral ID is available through the Turnstile siteverify response. A practical use case for Ephemeral IDs is preventing fraudulent account signups. Imagine a bad actor, a real person using a real device, creating hundreds of fake accounts while rotating IP addresses to avoid detection. By ingesting Ephemeral IDs and logging them alongside your account creation logs, you can set up alerts based on account creation thresholds in real-time or retroactively investigate suspicious activity. Even though Ephemeral IDs are short-lived and may have changed by the time an investigation begins, they still provide valuable insights through aggregate analysis, and provide an extra dimension to identify fraud and abuse.
For our Turnstile Enterprise and Bot Management Enterprise customers, you now have the option to access Ephemeral IDs directly through the Turnstile siteverify response. Get in touch with your Account Executive to enable it on your account.
Below is an example of siteverify response for those who have enabled Ephemeral IDs.
curl 'https://challenges.cloudflare.com/turnstile/v0/siteverify' --data 'secret=verysecret&response=<RESPONSE>'{
"success": true,
"error-codes": [],
"challenge_ts": "2024-09-10T17:29:00.463Z",
"hostname": "example.com",
"metadata": {
"ephemeral_id": "x:9f78e0ed210960d7693b167e"
}
}
What’s next for Turnstile?
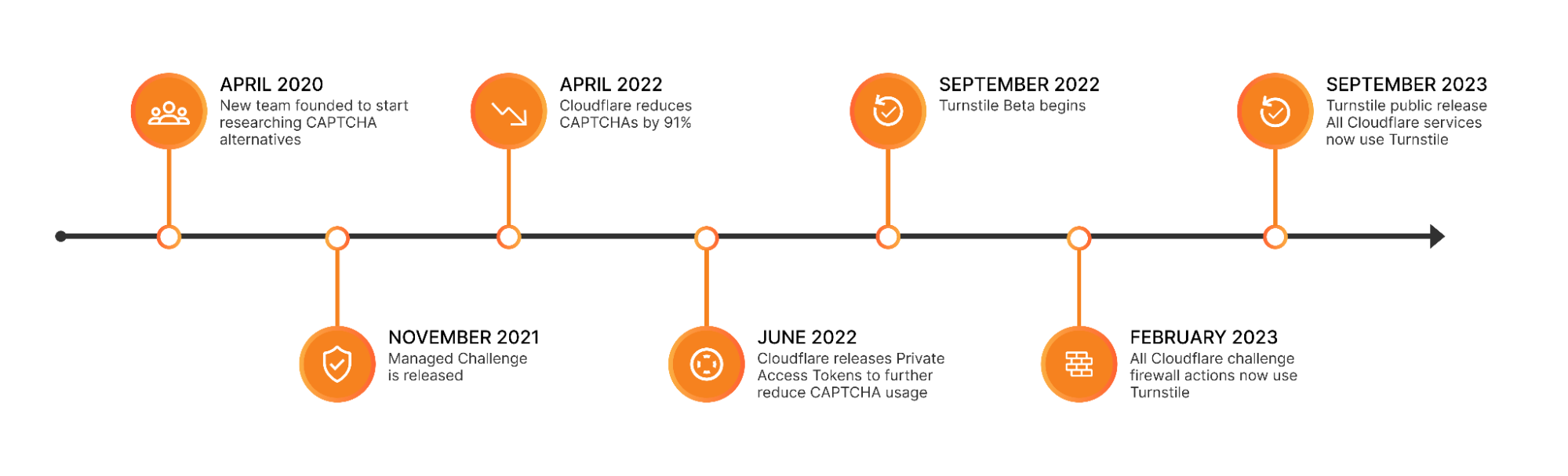
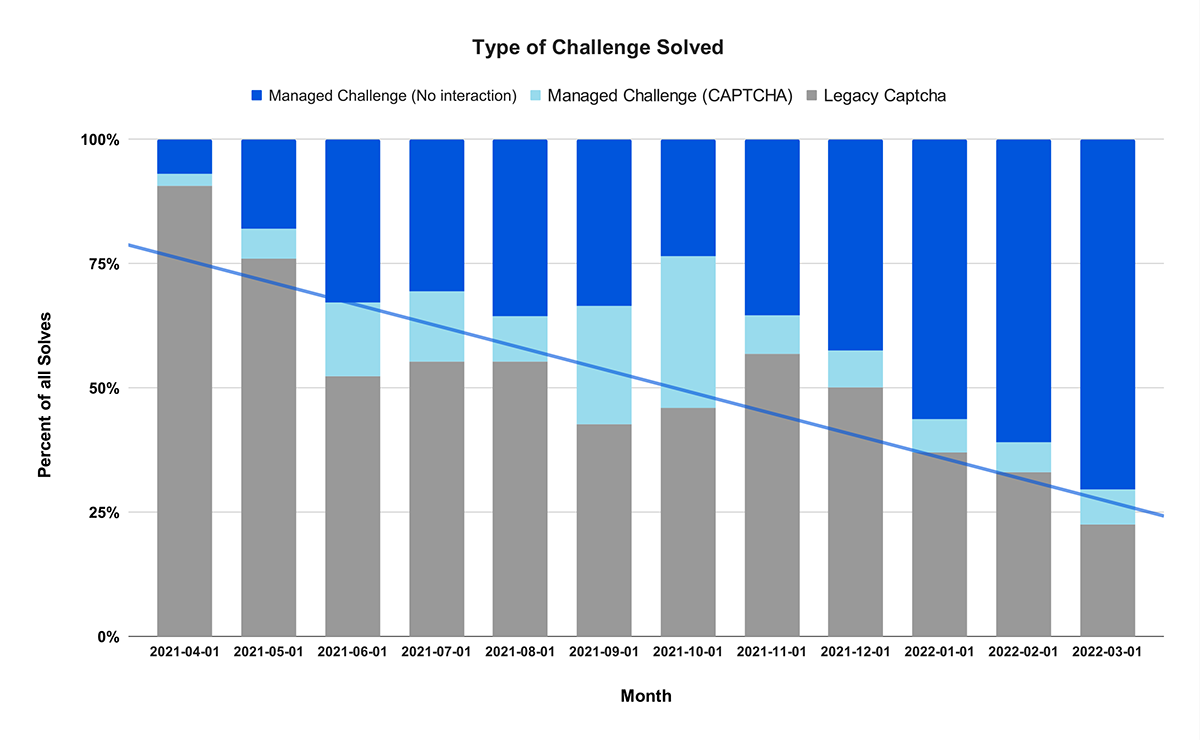
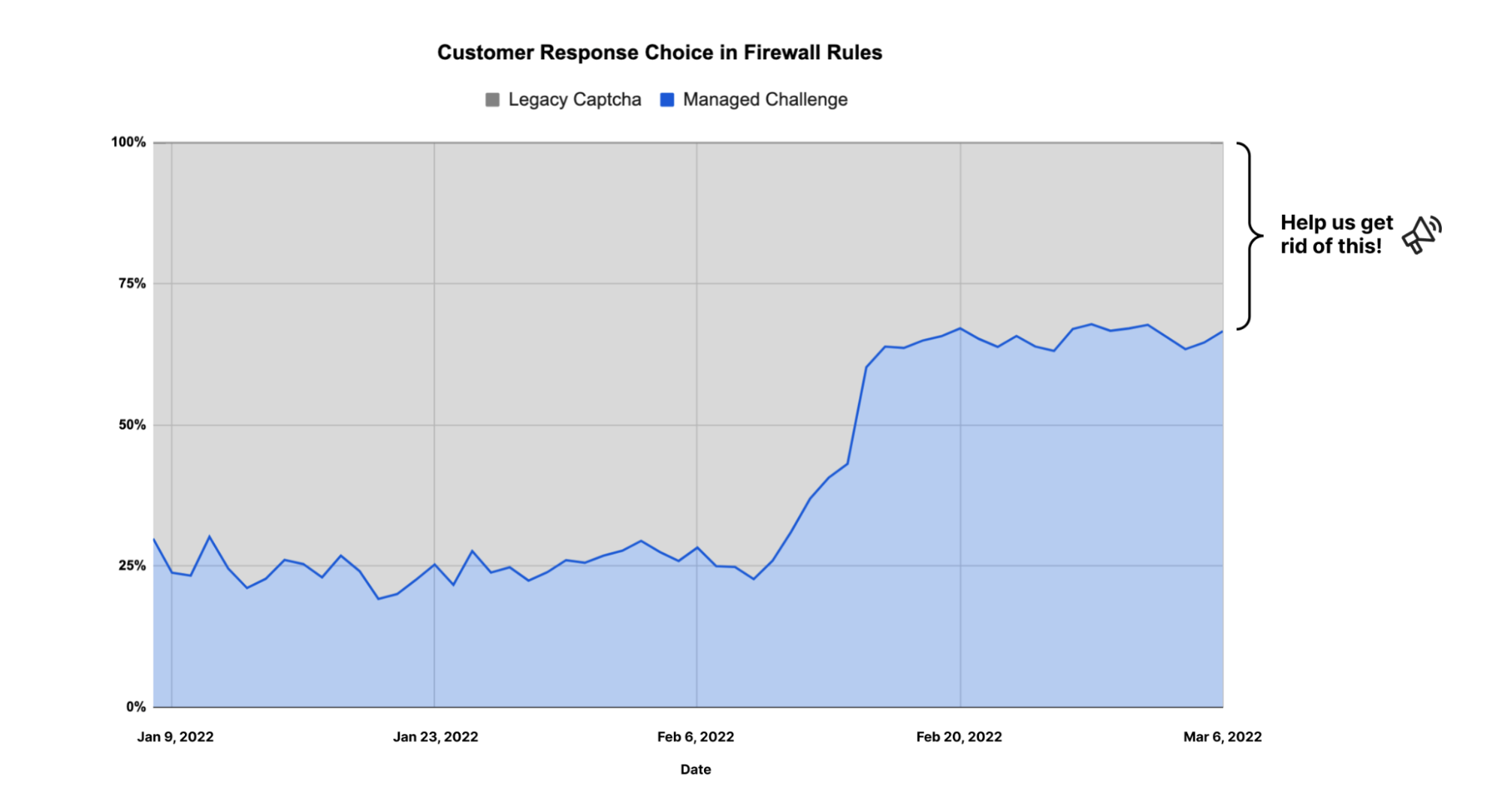
We launched Turnstile with a bold mission: to redefine CAPTCHAs with a frictionless, privacy-first solution that eliminates the annoyance of picking puzzles, selecting stoplights, and clicking crosswalks to prove our humanity. It’s incredible to think that Turnstile has been generally available for a whole year now! During this time, it has blocked over one trillion bots, and is actively protecting more than 350,000 domains worldwide.
As we celebrate Turnstile’s second birthday, we’re proud of the progress we’ve made and thrilled to introduce our latest innovations. While Ephemeral IDs represent the newest evolution of Turnstile, they’re part of our ongoing commitment to continuous improvement. Over the past year, we’ve also introduced a Cloudflare Pages Plugin and partnered with Google Firebase, ensuring that developers have easy access to Turnstile.
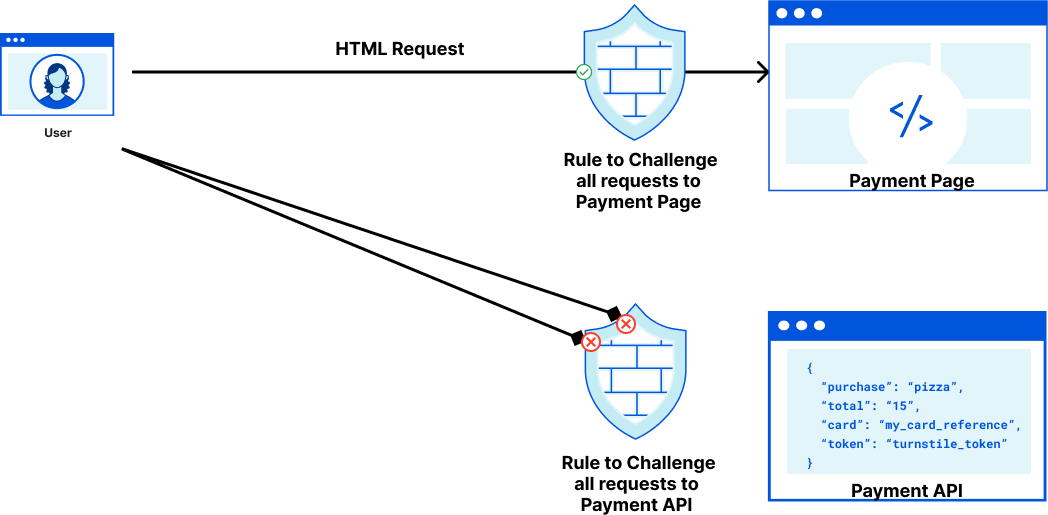
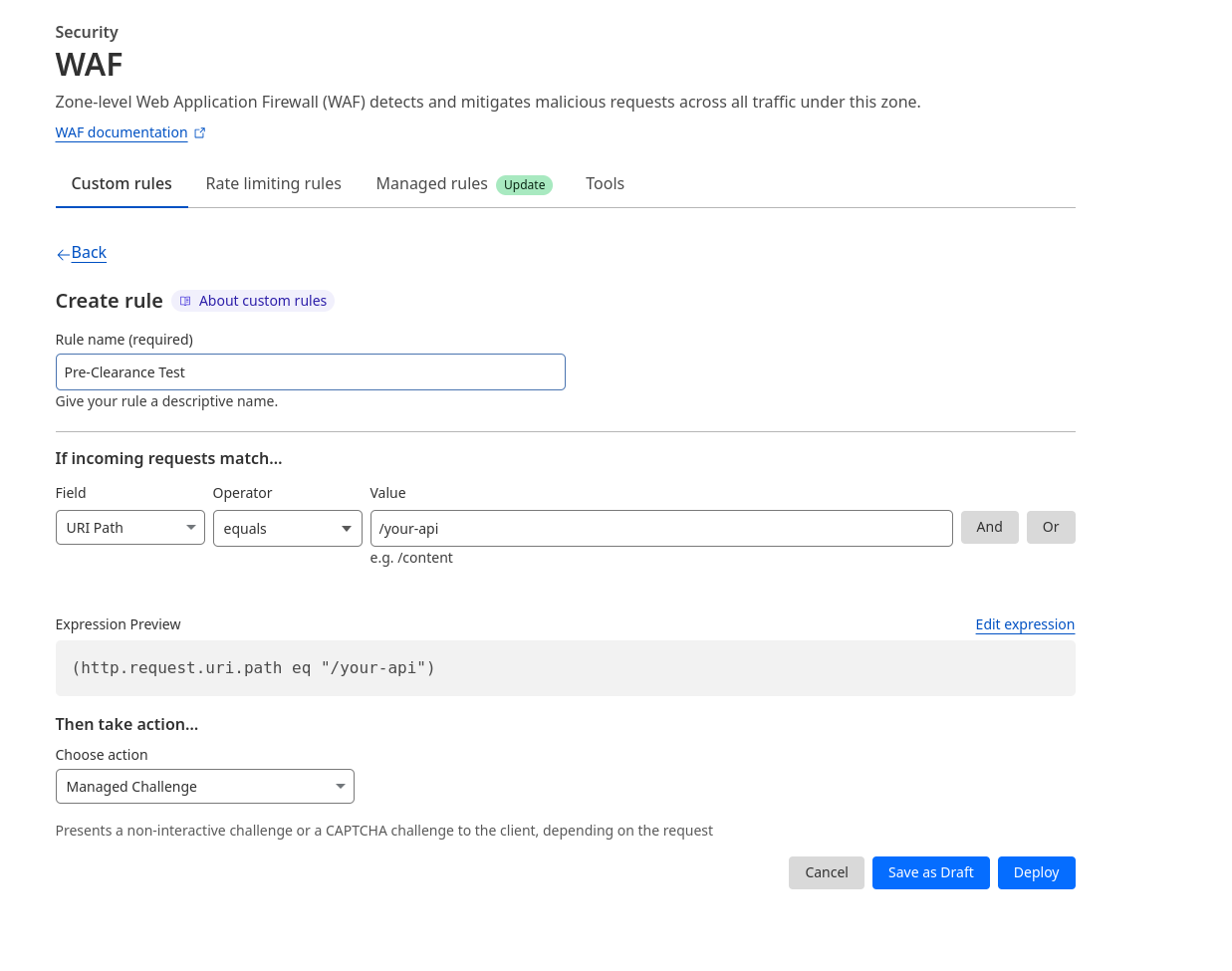
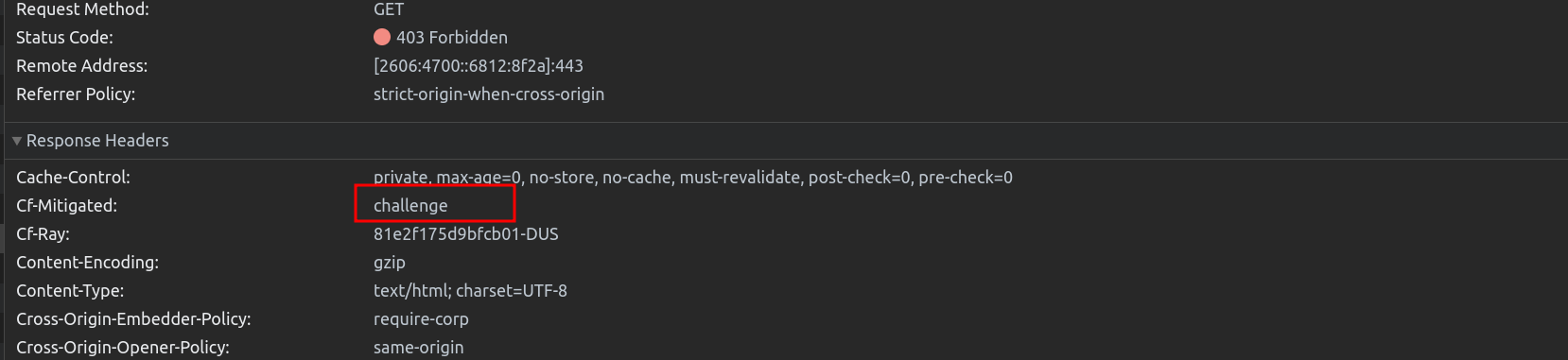
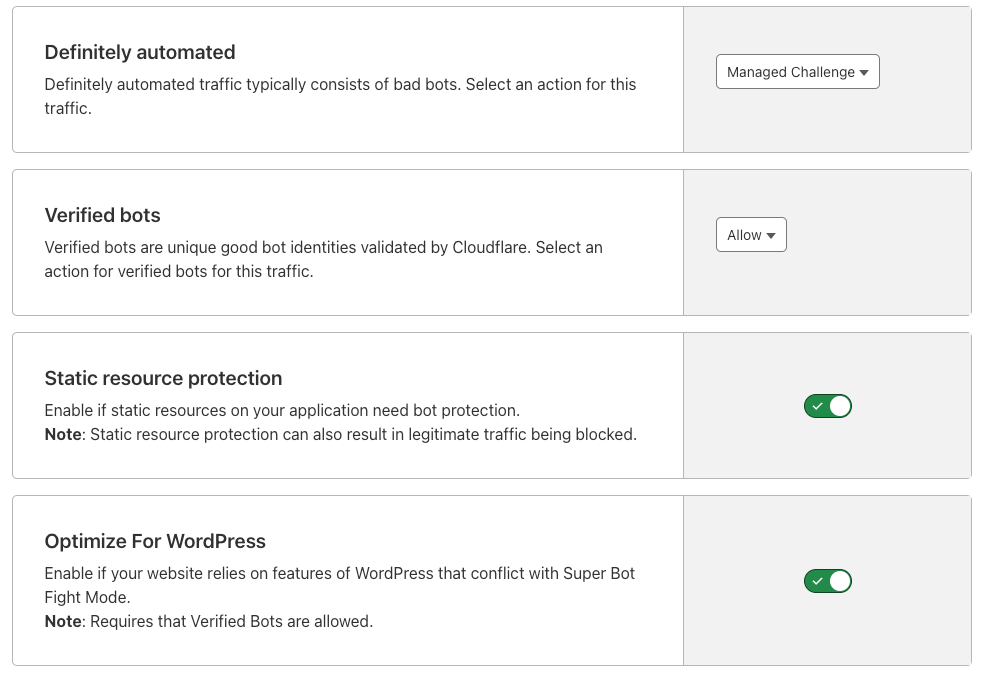
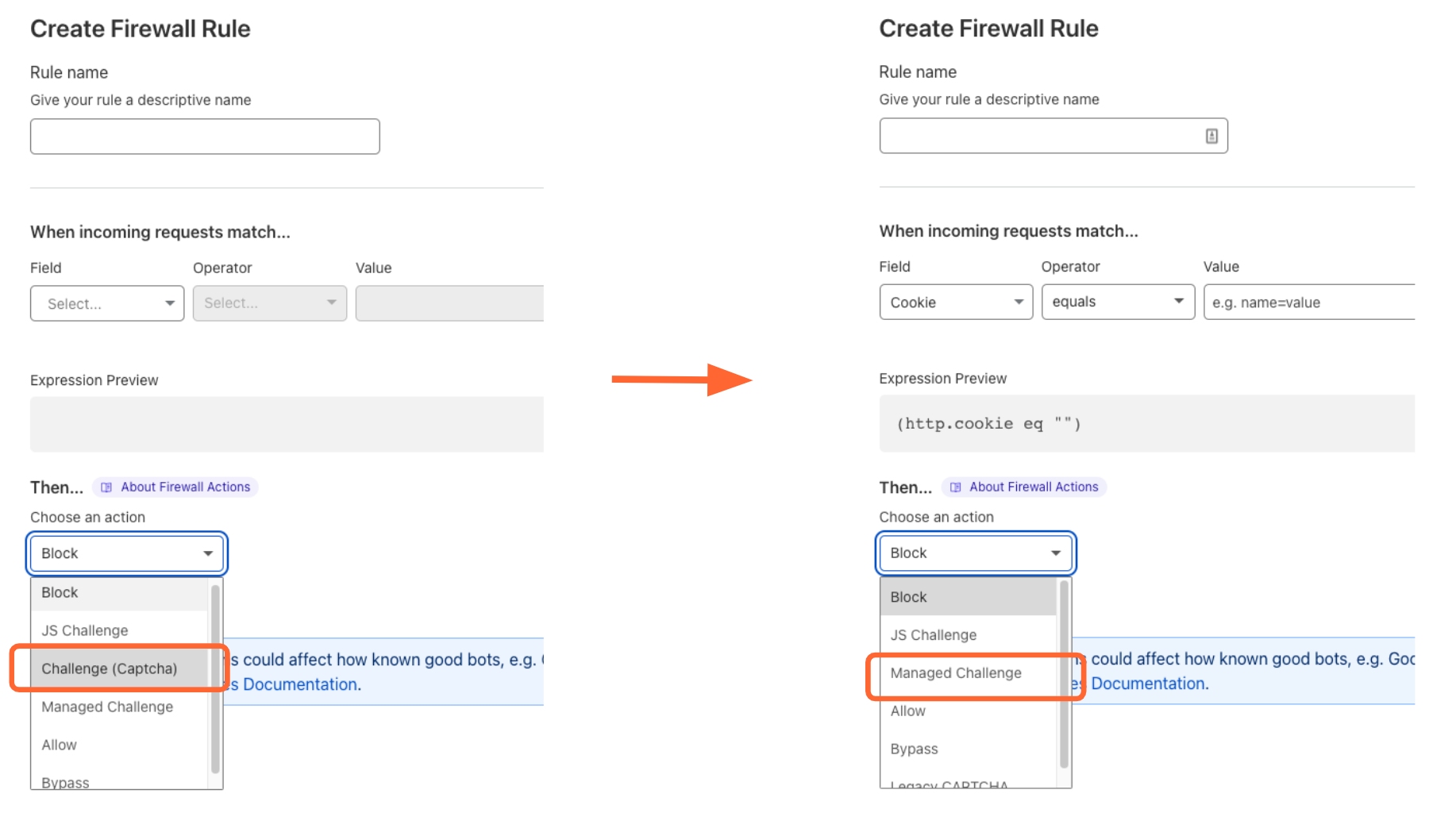
Earlier this year, we also launched Pre-Clearance for Turnstile, integrating it with Cloudflare WAF’s Challenge action, making it easier for customers to use Cloudflare’s Application Security products together. If you want to learn more about how to use Turnstile with Cloudflare’s Bot Management and WAF in more detail, check it out here!
We’re incredibly excited about what’s ahead. The introduction of Ephemeral IDs is just one of many innovations on the horizon. We’re committed to making the Internet a safer, more private place for everyone, eliminating the need for frustrating CAPTCHA puzzles while keeping security our top priority. And with our free tier remaining open and unlimited for all, there’s no barrier to getting started with Turnstile today.
Join us in revolutionizing online security – get started with Turnstile now or dive straight into our how-to guides. Let’s help make the Internet a better place, together!