Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/announcing-fully-managed-rstudio-on-amazon-sagemaker-for-data-scientists/
Two years ago, we introduced Amazon SageMaker Studio, the industry’s first fully integrated development environment (IDE) for machine learning (ML). Amazon SageMaker Studio provides a single, web-based visual interface where you can perform all ML development steps, improving data science team productivity by up to 10 times
Many data scientists love the R project, an open-source ecosystem with more than 18,000 packages that is not just a programming language but is also an interactive environment for doing data science. RStudio is one of the most popular IDE among R developers for ML and data science projects. RStudio provides open-source tools for R and enterprise-ready professional software for data science teams to develop and share their work in the organization. But, building, securing, scaling and maintaining RStudio yourself is tedious and cumbersome.
Today, in collaboration with RStudio PBC, we are excited to announce the general availability of RStudio on Amazon SageMaker, the industry’s first fully managed RStudio Workbench IDE in the cloud. You can now bring your current RStudio license to easily migrate your self-managed RStudio environments to Amazon SageMaker in just a few simple steps. If you’d like to read more about this exciting collaboration, check out this blog from RStudio PBC.
With RStudio on Amazon SageMaker, administrators can have a simple experience to migrate their RStudio environments to integrate into Amazon SageMaker and bring existing RStudio licenses to manage through AWS License Manager. They can onboard both R and Python developers to the same Amazon SageMaker domain using AWS Single Sign-On (SSO) or AWS Identity and Access Management (IAM) and take it as a centralized place to configure both RStudio and Amzon SageMaker Studio.
So, data scientists have a freedom of choice between programming languages and coding interfaces to switch between RStudio and Amazon SageMaker Studio notebooks. All of their work, including code, datasets, repositories, and other artifacts are synchronized between the two environments through the underlying Amazon EFS storage.
Getting Started with RStudio on SageMaker
You now can launch the familiar RStudio Workbench with a simple click from Amazon SageMaker. Before getting started, your administrator needs to buy an appropriate license from RStudio PBC for end-users, set up your granted licenses in AWS License Manager, and create an Amazon SageMaker domain and user profile to launch RStudio on Amazon SageMaker. To learn all the administrator jobs, including managing licenses and monitoring usages, see a blog post of the setting up process, or Manage RStudio on Amazon SageMaker in the AWS documentation.
Once the required setup process is completed, you can open the RStudio Workbench from the new Launch app drop-down list in the created user list and select RStudio.
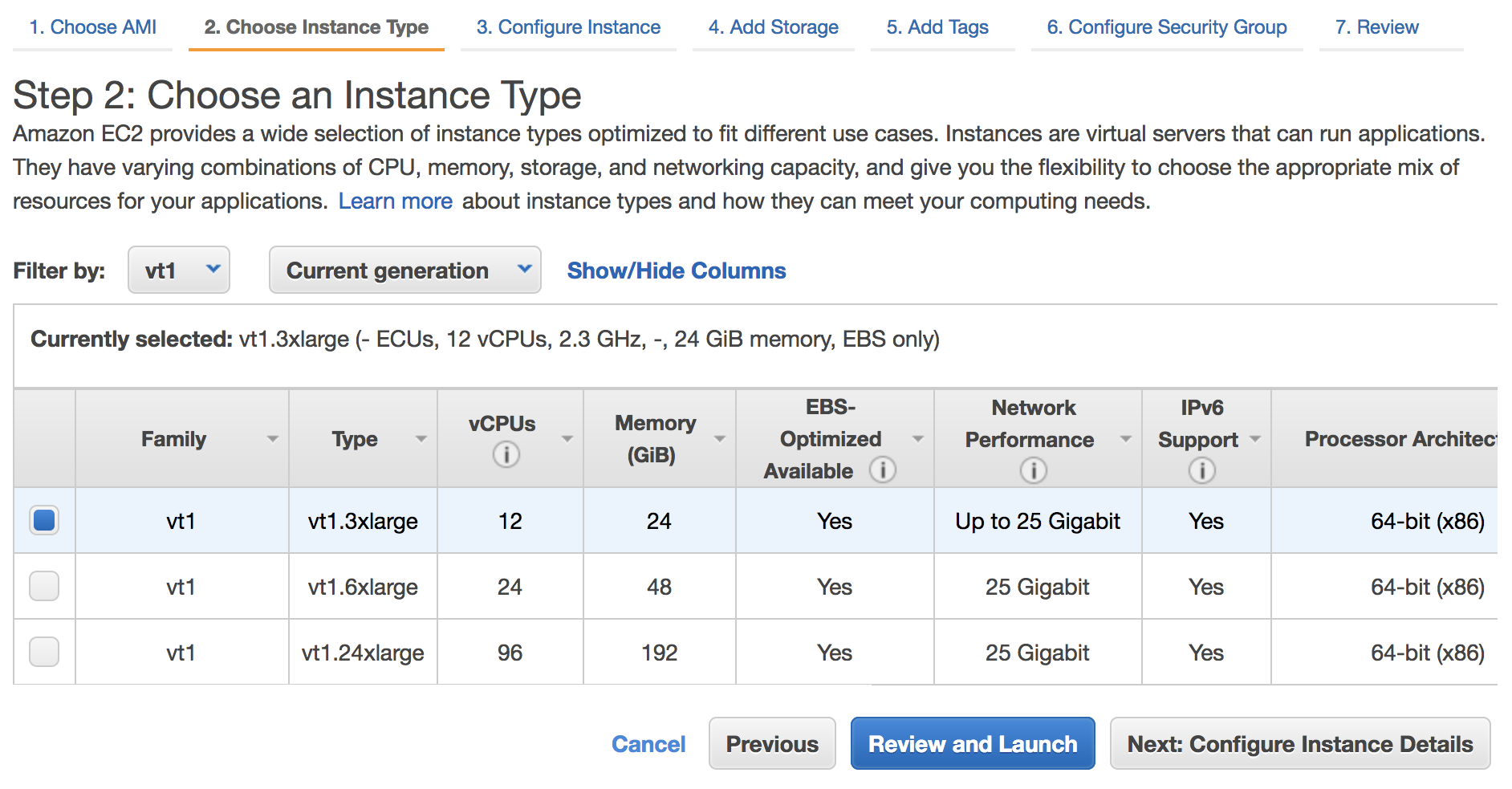
You will immediately see the RStudio Workbench home page and a list of sessions, projects, and published content on the home page. To create a new session, select the New Session button on the page, select a desired instance in the Instance Type dropdown list, and choose Start Session.

When you choose a compute instance type for a lightweight analysis that can be powered by two vCPU and four GiB memory, you can use a default ml.t3.medium instance. For a complex and large-scale ML modeling, you can choose a large instance with desired compute and memory from a wide array of ML instances available on Amazon SageMaker.
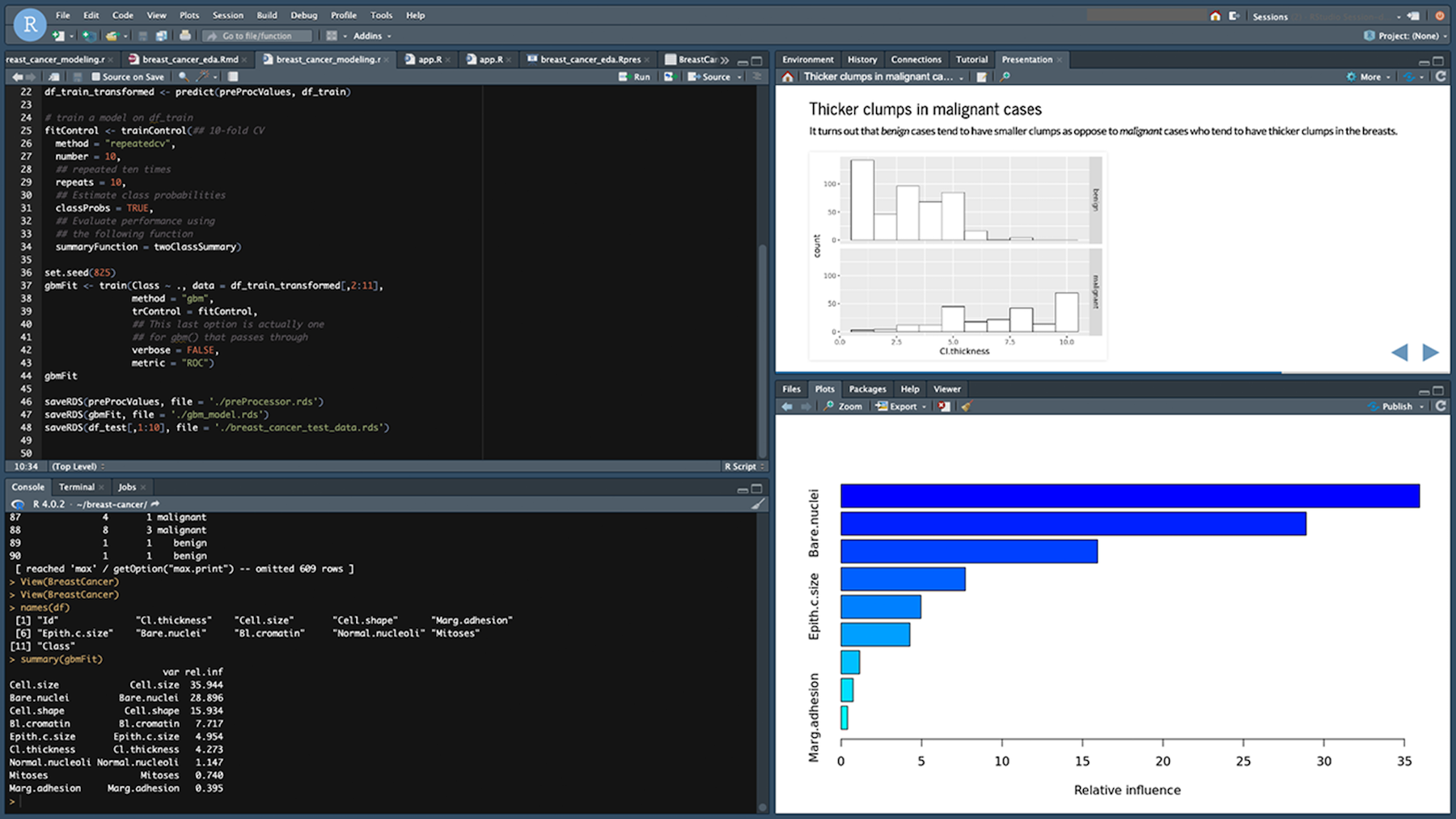
In a few minutes, your session will be ready for development in RStudio Workbench. When you launch your RStudio session, the Base R image serves as the basis of your instance. This Docker image includes R v4.0, AWS tools such as awscli, sagemaker, boto3 Python packages, and reticulate package for the interoperability between Python and R.
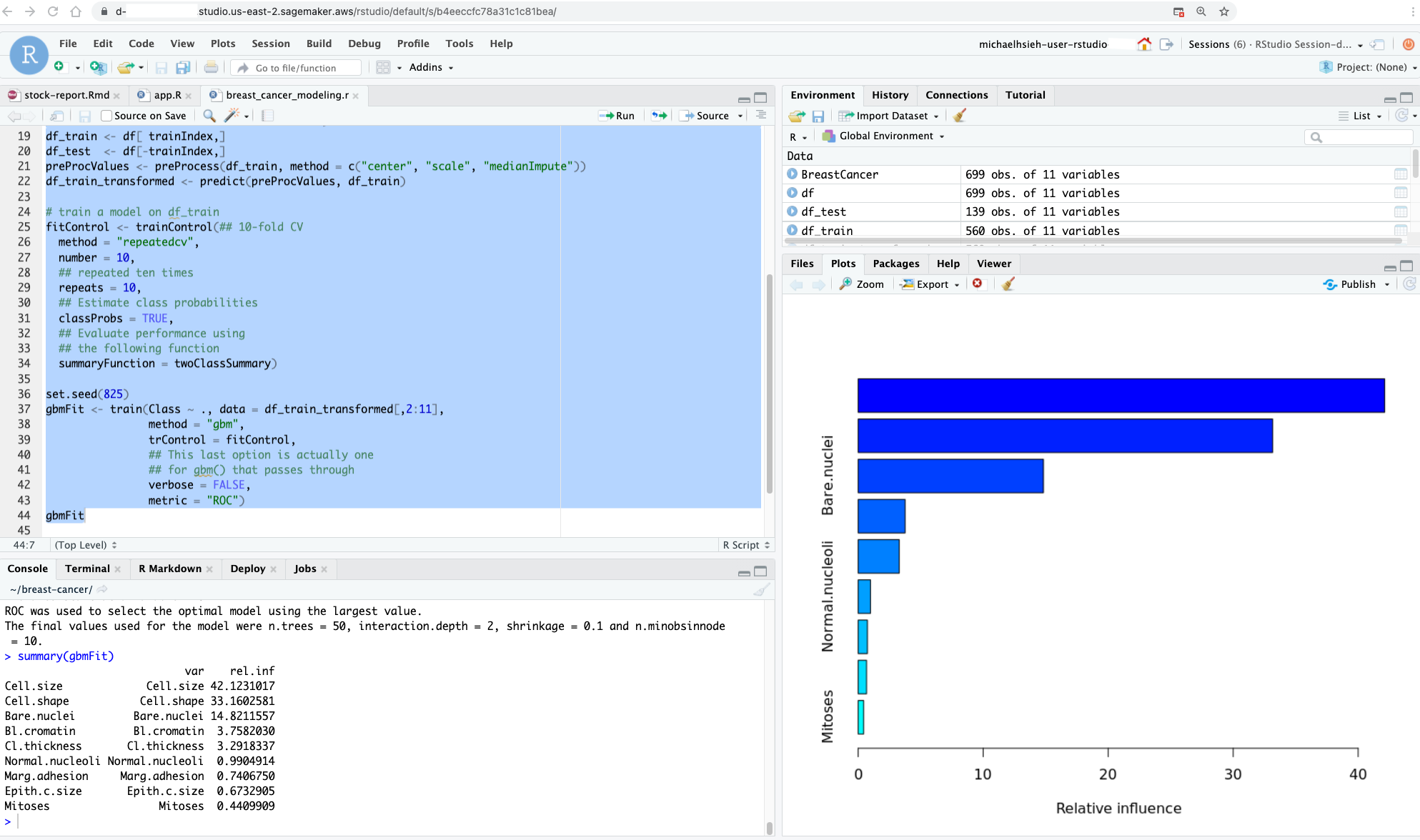
Managing R Packages and Publishing your Analysis
Along with the RStudio Workbench, RStudio Connect and RStudio Package Manager are the most used products of RStudio.
RStudio Connect is designed to allow data scientists to publish insights and dashboard and web applications from RStudio Workbench easily. RStudio Package Manager centrally manages the package repository for your organization so that data scientists can securely install packages faster while ensuring project reproducibility and repeatability.
Your administrator, for example, can create a repository and subscribe it to the built-in source named cran in RStudio Package Manager.
$ rspm sync --wait # Initiate a sync
$ rspm create repo --name=prod-cran --description='Access CRAN packages' # Create a repository:
$ rspm subscribe --repo=prod-cran --source=cran # Subscribe the repository to the cran sourceWhen these steps are completed, you can use the prod-cran repository in the web interface of RStudio Package Manager.
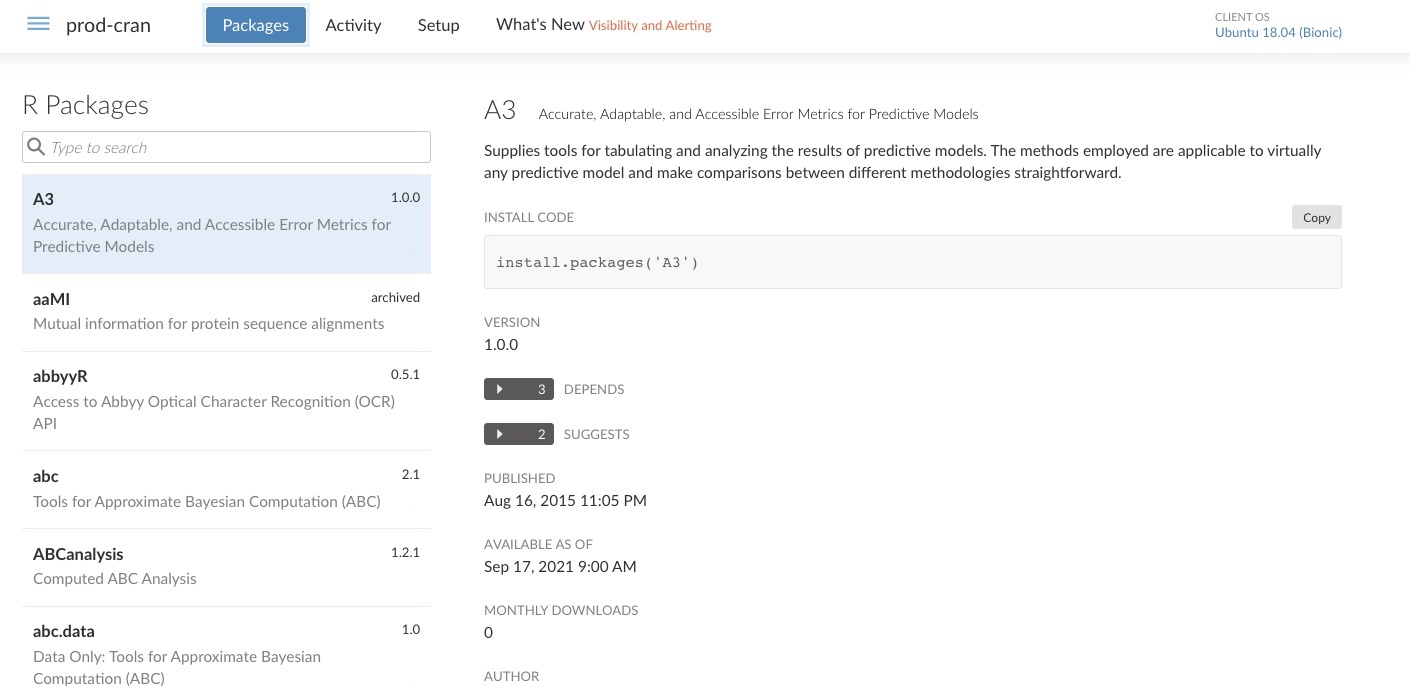
Now, you can configure this repository to install and manage your packages in RStudio Workbench. You can also configure RStudio Connect to publish insights, dashboard and web applications from RStudio Workbench via RStudio Connect so that your collaborators can easily consume your work.
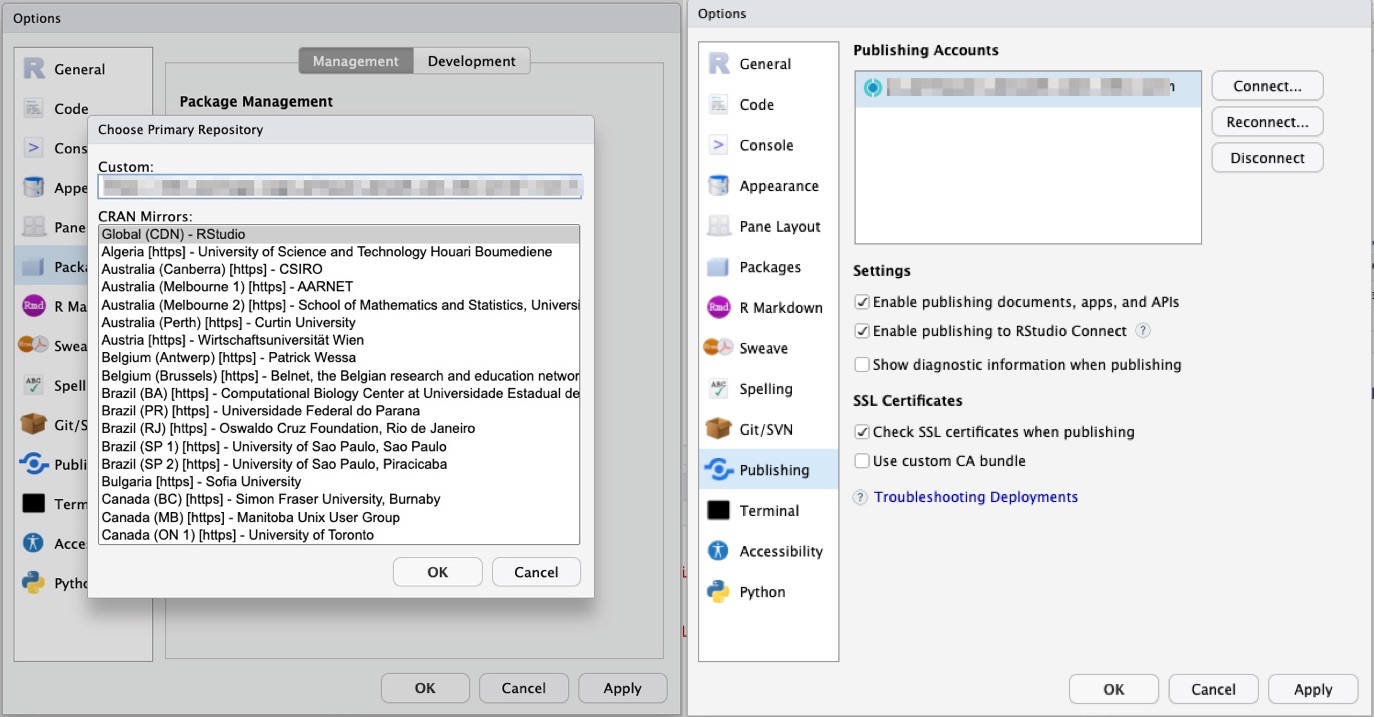
For example, you run the analysis inline to create an R Markdown that can be published to your collaborators. You can preview the slides while writing codes with the Preview button and publish it with the Publish icon in your RStudio session.
You can also publish Shiny application easy to create interactive web interfaces, or Python-based content such as Streamlit to the RStudio Connect instance.
To learn more, see Host RStudio Connect and Package Manager for ML development in RStudio on Amazon SageMaker written by my colleagues, Michael Hsieh, Chayan Panda, and Farooq Sabir on the AWS Machine Learning Blog.
Integrating training jobs with Amazon SageMaker
One of the benefits of using RStudio on Amazon SageMaker is the integration of Amazon SageMaker features. Your RStudio and Jupyter Notebook instances of Amazon SageMaker allow you to share the same Amazon EFS file system. You can import R codes written in Jupyter Notebook or use the same files in both Jupyter Notebook and RStudio without having to move your files between the two.
For example, you can run an R sample code including importing libraries, creating an Amazon SageMaker session, getting the IAM role, and importing and visualizing sample data. And then, it stores data on the S3 bucket, and triggers a training task with an XGBoost model by specifying the training container and defining an Amazon SageMaker Estimator. To learn more, see R sample codes in Amazon SageMaker.
# Import reticulate, readr and sagemaker libraries
library(reticulate)
library(readr)
sagemaker <- import('sagemaker')
# Create a sagemaker session
session <- sagemaker$Session()
# Get execution role
role_arn <- sagemaker$get_execution_role()
# Read a csv file from UCI public repository
data_file <- 'http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data'
# Copy data to a dataframe, rename columns, and show dataframe head
data_csv <- read_csv(file = data_file, col_names = FALSE, col_types = cols())
names(data_csv) <- c('sex', 'length', 'diameter', 'height', 'whole_weight', 'shucked_weight', 'viscera_weight', 'shell_weight', 'rings')
head(data_csv)
# Visualize data have height equal to 0
library(ggplot2)
options(repr.plot.width = 5, repr.plot.height = 4)
ggplot(abalone, aes(x = height, y = rings, color = sex, alpha=0.5)) + geom_point() + geom_jitter()
# Upload data to Amazon S3 bucket
s3_train <- session$upload_data(path = data_csv,
bucket = my_s3_bucket,
key_prefix = 'r_hello_world_demo/data')
s3_path = paste('s3://',bucket,'/r_hello_world_demo/data/abalone.csv',sep = '')
# Train a XGBoost model, specify the training containers, and define an Amazon SageMaker Estimator
container <- sagemaker$image_uris$retrieve(framework='xgboost',
region= session$boto_region_name,
version='latest')
estimator <- sagemaker$estimator$Estimator(image_uri = container,
role = role_arn,
train_instance_count = 1L,
train_instance_type = 'ml.m5.4xlarge',
train_volume_size = 30L,
train_max_run = 3600L,
input_mode = 'File',
output_path = s3_path)Now Available
RStudio on Amazon SageMaker is available in all AWS Regions where both Amazon SageMaker Studio and AWS License Manager are available. You can bring your own license of RStudio on Amazon SageMaker and pay for the underlying compute and storage resources within Amazon SageMaker or other AWS services, based on your usage.
To get started with RStudio on Amazon SageMaker, you can use AWS Free Tier. You can use 250 hours of ml.t3.medium instance on Amazon SageMaker Studio per month for the first two months. To learn more, see Amazon SageMaker Pricing page.
Give it a try, and please send us feedback either in the AWS forum for Amazon SageMaker or through your usual AWS support contacts.
– Channy


















































 To recap, Q is a natural language query tool for the Enterprise Edition of
To recap, Q is a natural language query tool for the Enterprise Edition of 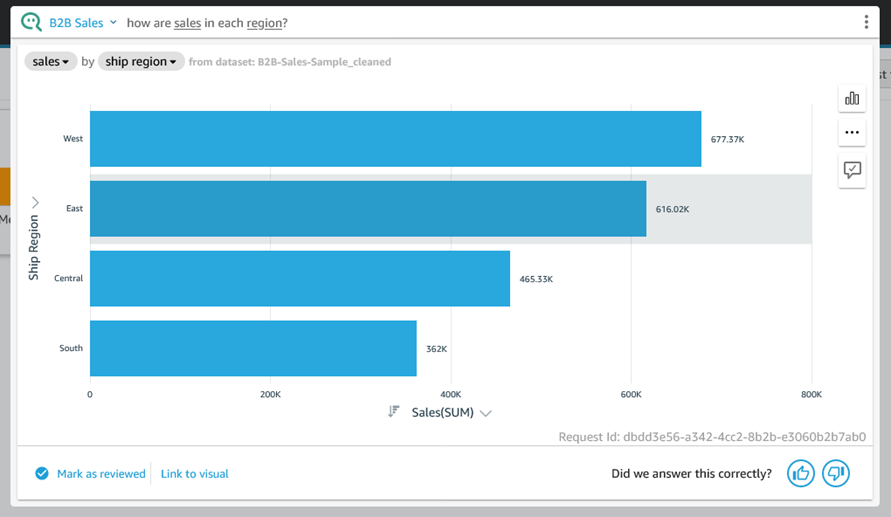








 U30 media accelerator transcoding cards
U30 media accelerator transcoding cards