Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/new-aws-marketplace-for-containers-anywhere-to-deploy-your-kubernetes-cluster-in-any-environment/
More than 300,000 customers use AWS Marketplace today to find, subscribe to, and deploy third-party software packaged as Amazon Machine Images (AMIs), software-as-a-service (SaaS), and containers. Customers can find and subscribe containerized third-party applications from AWS Marketplace and deploy them in Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS).
Many customers that run Kubernetes applications on AWS want to deploy them on-premises due to constraints, such as latency and data governance requirements. Also, once they have deployed the Kubernetes application, they need additional tools to govern the application through license tracking, billing, and upgrades.
Today, we announce AWS Marketplace for Containers Anywhere, a set of capabilities that allows AWS customers to find, subscribe to, and deploy third-party Kubernetes applications from AWS Marketplace on any Kubernetes cluster in any environment. This capability makes the AWS Marketplace more useful for customers who run containerized workloads.
With this launch, you can deploy third party Kubernetes applications to on-premises environments using Amazon EKS Anywhere or any customer self-managed Kubernetes cluster in on-premises environments or in Amazon Elastic Compute Cloud (Amazon EC2), enabling you to use a single catalog to find container images regardless of where they eventually plan to deploy.
With AWS Marketplace for Containers Anywhere, you can get the same benefits as any other products in AWS Marketplace, including consolidated billing, flexible payment options, and lower pricing for long-term contracts. You can find vetted, security-scanned, third-party Kubernetes applications, manage upgrades with a few clicks, and track all licenses and bills. You can migrate applications between any environment without purchasing duplicate licenses. After you have subscribed to an application using this feature, you can migrate your Kubernetes applications to AWS by deploying the independent software vendor (ISV) provided Helm charts onto their Kubernetes clusters on AWS without changing their licenses.
Getting Started with AWS Marketplace for Containers Anywhere
You can get started by visiting AWS Marketplace. Easily search in Delivery methods in all products, then filter Helm Chart in the catalog to find Kubernetes-based applications that they can deploy on AWS and on premises.

If you chose to subscribe to your favorite product, you would select Continue to Subscribe.
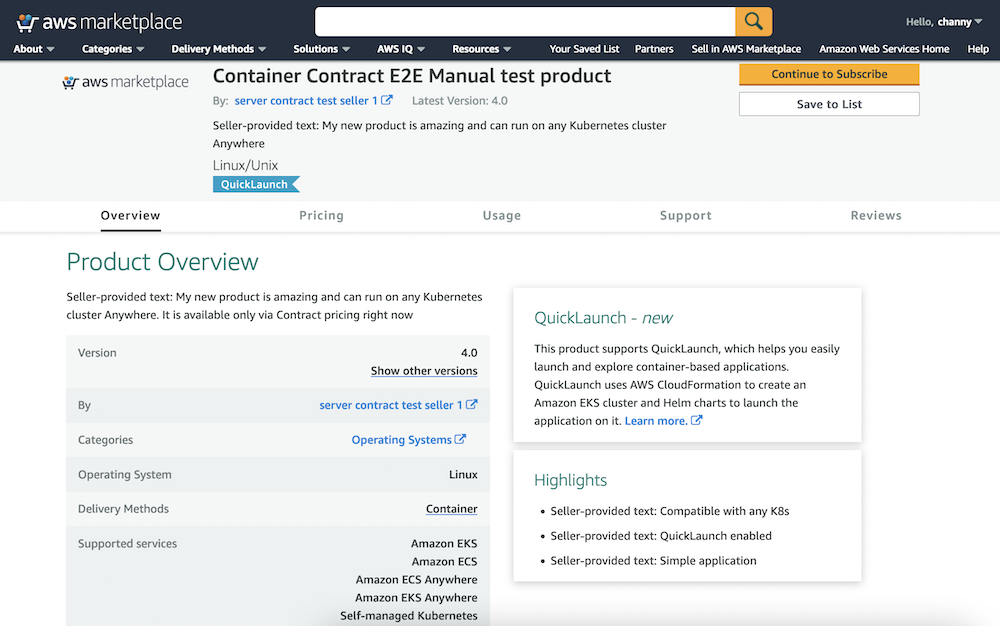
Once you accept the seller’s end user license agreement (EULA), select Create Contract and Continue to Configuration.

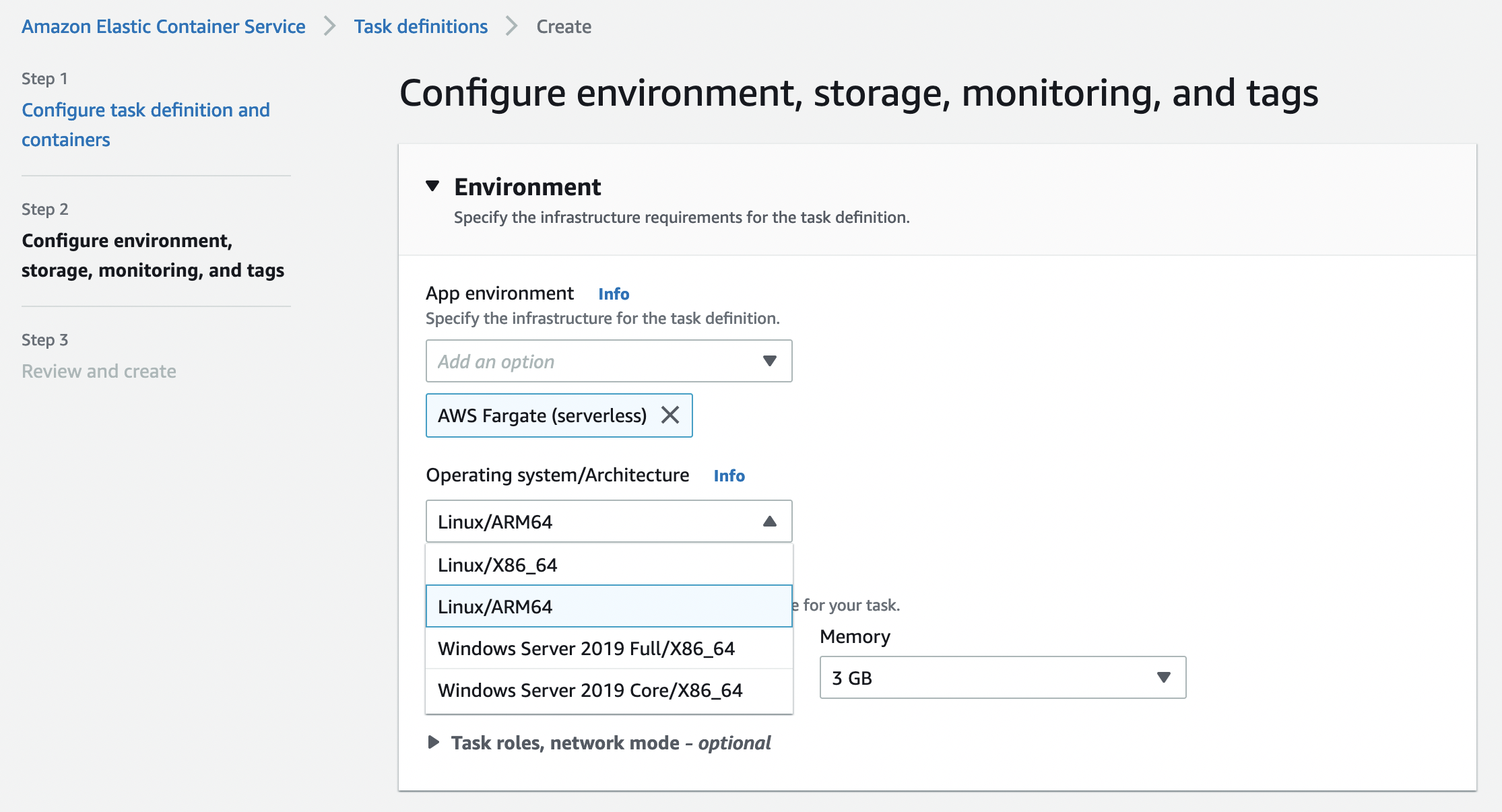
You can configure the software deployment using the dropdowns. Once Fulfillment option and Software Version are selected, choose Continue to Launch.

To deploy on Amazon EKS, you have the option to deploy the application on a new EKS cluster or copy and paste commands into existing clusters. You can also deploy into self-managed Kubernetes in EC2 by clicking on the self-managed Kubernetes option in the supported services.

To deploy on-premises or in EC2, you can select EKS Anywhere and then take an additional step to request a license token on the AWS Marketplace launch page. You will then use commands provided by AWS Marketplace to download container images, Helm charts from the AWS Marketplace Elastic Container Registry (ECR), the service account creation, and the token to apply IAM Roles for Service Accounts on your EKS cluster.

To upgrade or renew your existing software licenses, you can go to the AWS Marketplace website for a self-service upgrade or renewal experience. You can also negotiate a private offer directly with ISVs to upgrade and renew the application. After you subscribe to the new offer, the license is automatically updated in AWS License Manager. You can view all the licenses you have purchased from AWS Marketplace using AWS License Manager, including the application capabilities you’re entitled to and the expiration date.
Launch Partners of AWS Marketplace for Containers Anywhere
Here is the list of our launch partners to support an on-premises deployment option. Try them out today!
- D2iQ delivers the leading independent platform for enterprise-grade Kubernetes implementations at scale and across environments, including cloud, hybrid, edge, and air-gapped.
- HAProxy Technologies offers widely used software load balancers to deliver websites and applications with the utmost performance, observability, and security at any scale and in any environment.
- Isovalent builds open-source software and enterprise solutions such as Cilium and eBPF solving networking, security, and observability needs for modern cloud-native infrastructure.
- JFrog‘s “liquid software” mission is to power the world’s software updates through the seamless, secure flow of binaries from developers to the edge.
- Kasten by Veeam provides Kasten K10, a data management platform purpose-built for Kubernetes, an easy-to-use, scalable, and secure system for backup and recovery, disaster recovery, and application mobility.
- Nirmata, the creator of Kyverno, provides open source and enterprise solutions for policy-based security and automation of production Kubernetes workloads and clusters.
- Palo Alto Networks, the global cybersecurity leader, is shaping the cloud-centric future with technology that is transforming the way people and organizations operate.
- Prosimo‘s SaaS combines cloud networking, performance, security, AI powered observability and cost management to reduce enterprise cloud deployment complexity and risk.
- Solodev is an enterprise CMS and digital ecosystem for building custom cloud apps, from content to crypto. Get access to DevOps, training, and 24/7 support—powered by AWS.
- Trilio, a leader in cloud-native data protection for Kubernetes, OpenStack, and Red Hat Virtualization environments, offers solutions for backup and recovery, migration, and application mobility.
If you are interested in offering your Kubernetes application on AWS Marketplace, register and modify your product to integrate with AWS License Manager APIs using the provided AWS SDK. Integrating with AWS License Manager will allow the application to check licenses procured through AWS Marketplace.
Next, you would create a new container product on AWS Marketplace with a contract offer by submitting details of the listing, including the product information, license options, and pricing. The details would be reviewed, approved, and published by AWS Marketplace Technical Account Managers. You would then submit the new container image to AWS Marketplace ECR and add it to a newly created container product through the self-service Marketplace Management Portal. All container images are scanned for Common Vulnerabilities and Exposures (CVEs).
Finally, the product listing and container images would be published and accessible by customers on AWS Marketplace’s customer website. To learn more details about creating container products on AWS Marketplace, visit Getting started as a seller and Container-based products in the AWS documentation.
Available Now
The feature of AWS Marketplace for Containers Anywhere is available now in all Regions that support AWS Marketplace. You can start using the feature directly from the product of launch partners.
Give it a try, and please send us feedback either in the AWS forum for AWS Marketplace or through your usual AWS support contacts.
– Channy







 processors in 2018 such as
processors in 2018 such as 





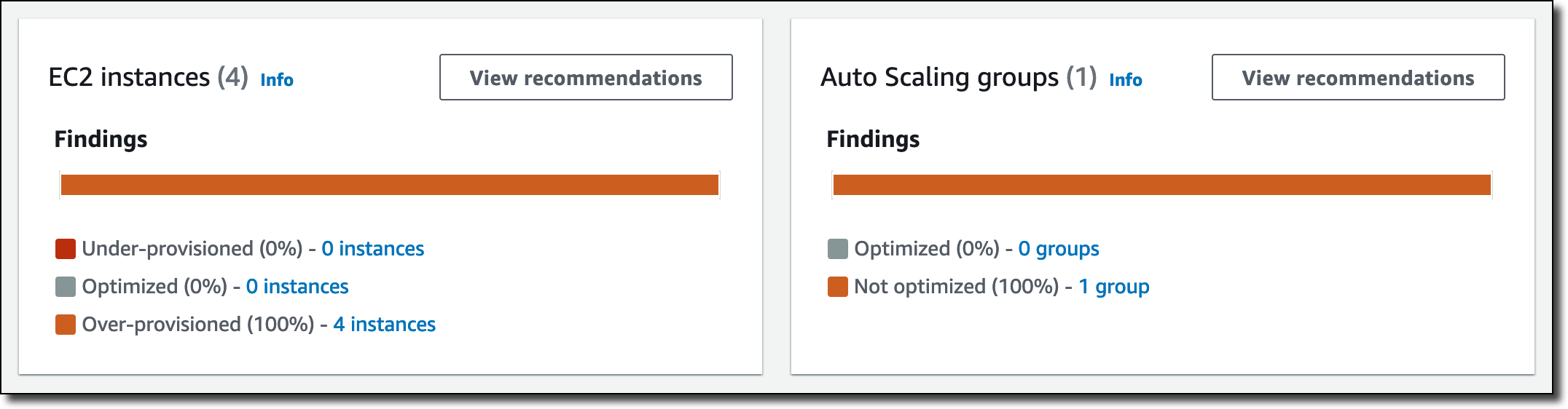


 Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to:
Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to: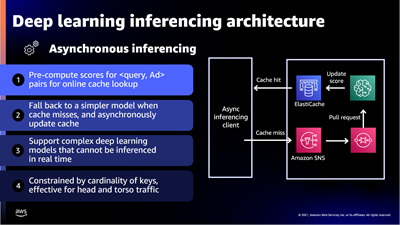 The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
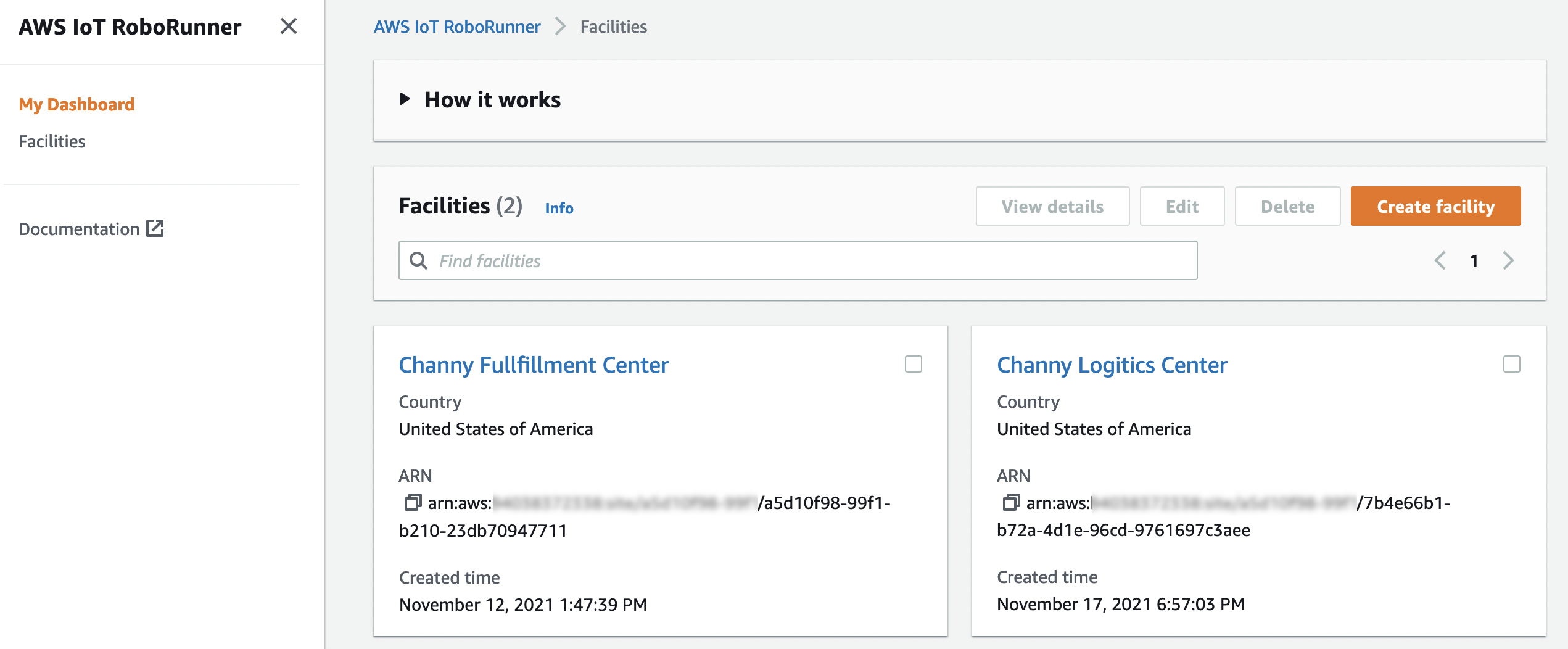

 The
The