Post Syndicated from Explosm.net original https://explosm.net/comics/fight-or-flight
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/fight-or-flight
New Cyanide and Happiness Comic
Post Syndicated from xkcd.com original https://xkcd.com/2945/

Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=-FKxV9YoG_s
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/announcing-systemd-v256.html
Yesterday evening we released systemd v256 into the wild. While other projects,
such as Firefox
are just about to leave the 7bit world and enter 8bit territory, we already
entered 9bit version territory! For details about the release, see our
announcement
mail.
In the weeks leading up to this release I have posted a series of serieses of
posts to Mastodon about key new features in this release. Mastodon has its
goods and its bads. Among the latter is probably that it isn’t that great for
posting listings of serieses of posts. Hence let me provide you with a list of
the relevant first post in the series of posts here:
v./ DirectoriesX_SYSTEMD_UNIT_ACTIVE= sd_notify() MessagesProtectSystem=run0 As sudo Replacementsystemd-nspawnssh into systemd-homed Accountssystemd-vmspawnsystemd-sysextsystemctl sleepsystemd-ssh-generatorsystemd-cryptenroll without device argumentdlopen() ELF MetadataCapsulesI intend to do a similar series of serieses of posts for the next systemd
release (v257), hence if you haven’t left tech Twitter for Mastodon yet, now is
the opportunity.
And while I have you: note that the All Systems Go 2024 Conference
(Berlin) Call for Papers ends 😲 THIS WEEK 🤯!
Hence, HURRY, and get your submissions in
now, for the best
low-level Linux userspace conference around!
Post Syndicated from corbet original https://lwn.net/Articles/978007/
The extensible scheduler class
(“sched_ext”) framework allows the writing of CPU schedulers as a set of
BPF programs. It has been somewhat
controversial, and its merging into the kernel has been blocked despite
a clear level of interest from users.
Linus Torvalds has now let
it be known that he has made a decision and, overriding the scheduler
maintainer, will merge sched_ext for the 6.11 release.
I honestly see no reason to delay this any more. This whole
patchset was the major (private) discussion at last year’s kernel
maintainer summit, and I don’t find any value in having the same
discussion (whether off-list or as an actual event) at the upcoming
maintainer summit one year later, so to make any kind of sane
progress, my current plan is to merge this for 6.11.
Post Syndicated from Adam Barnett original https://blog.rapid7.com/2024/06/11/patch-tuesday-june-2024/

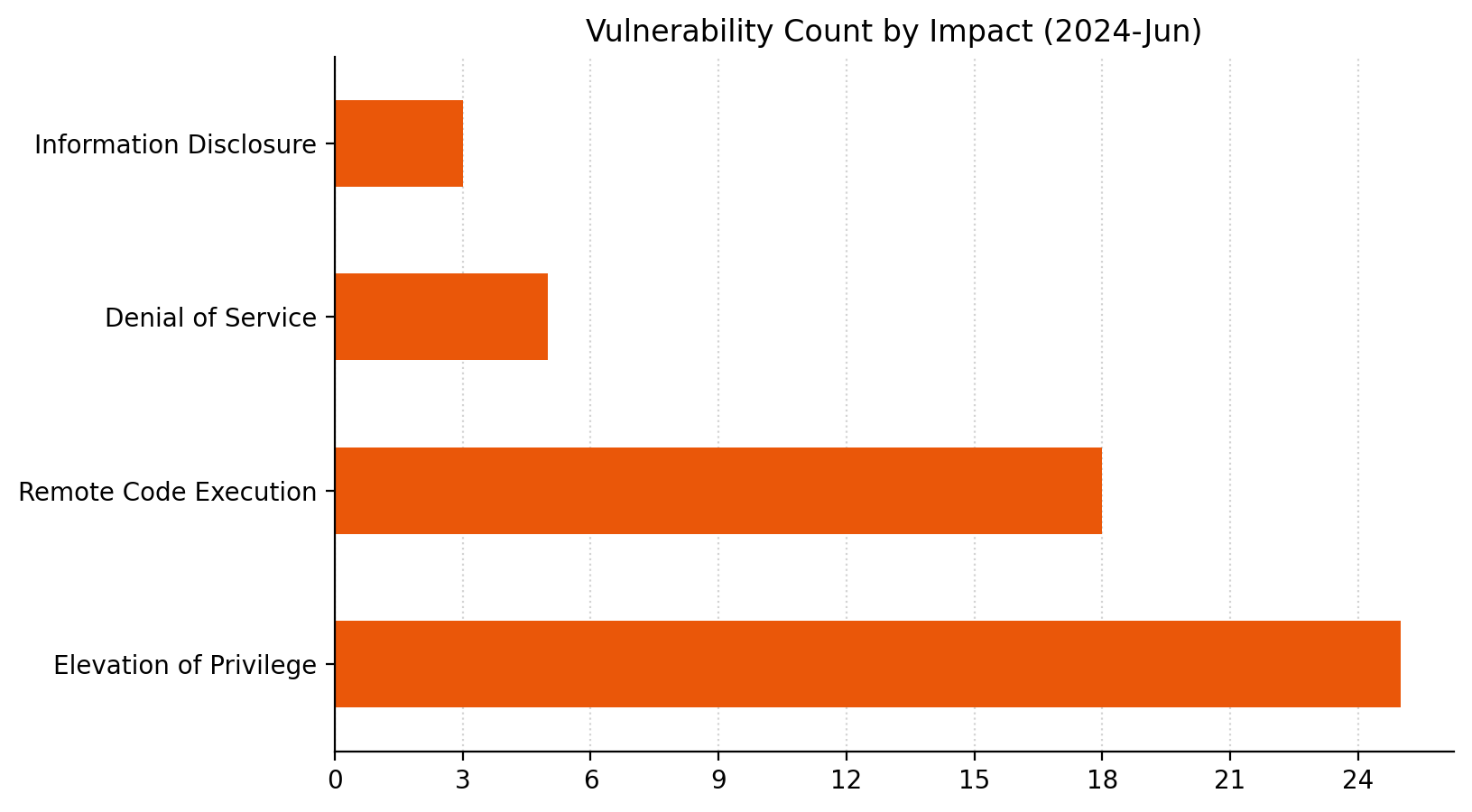
It’s June 2024 Patch Tuesday. Microsoft is addressing 51 vulnerabilities today, and has evidence of public disclosure for just a single one of those. At time of writing, none of the vulnerabilities published today are listed on CISA KEV, although this is always subject to change. Microsoft is patching a single critical remote code execution (RCE) vulnerability today. Seven browser vulnerabilities were published separately this month, and are not included in the total.
The sole critical RCE patched today is CVE-2024-30080 for all current versions of Windows. Exploitation requires that an attacker send a specially crafted malicious packet to an MSMQ server, which Patch Tuesday watchers will know as a perennial source of vulnerabilities. As usual, Microsoft points out that the Windows message queuing service is not enabled by default; as usual, Rapid7 notes that a number of applications – including Microsoft Exchange – quietly introduce MSMQ as part of their own installation routine. As is typical of MSMQ RCE vulnerabilities, CVE-2024-30080 receives a high CVSSv3 base score due to the network attack vector, low attack complexity, and lack of required privileges. Code execution is presumably in a SYSTEM context, although the advisory does not specify.
Microsoft Office receives patches for a pair of RCE-via-malicious-file vulnerabilities. CVE-2024-30101 is a vulnerability in Outlook; although the Preview Pane is a vector, the user must subsequently perform unspecified specific actions to trigger the vulnerability and the attacker must win a race condition. On the other hand, CVE-2024-30104 does not have the Preview Pane as a vector, but nevertheless ends up with a slightly higher CVSS base score of 7.8, since exploitation relies solely on the user opening a malicious file.
This month also brings a patch for SharePoint RCE CVE-2024-30100. The advisory is sparing on details, and the context of code exploitation is not clear. The weakness is described as CWE-426: Untrusted Search Path; many (but not all) vulnerabilities associated with CWE-426 lead to elevation of privilege.
And now for something completely different: CVE-2023-50868, which describes a denial of service vulnerability in DNSSEC. This vulnerability is present in the DNSSEC spec itself, and the CVE was assigned by MITRE on behalf of DNSSEC. Microsoft’s implementation of DNSSEC is thus subject to the same attack as other implementations. An attacker can exhaust CPU resources on a DNSSEC-validating DNS resolver by demanding responses from a DNSSEC-signed zone, if the resolver uses NSEC3 to respond to the request. NSEC3 is designed to provide a safe way for a DNSSEC-validating DNS resolver to indicate that a requested resource does not exist. Under certain circumstances, the DNS resolver must perform thousands of iterations of a hash function to calculate an NSEC3 response, and this is the foundation on which this DoS exploit rests. All current versions of Windows Server receive a patch today.
Typically, when Microsoft publishes a security advisory and describes the vulnerability as publicly disclosed, that public disclosure will have been recent. However, in the case of CVE-2023-50868, the flaw in DNSSEC was first publicly disclosed on 2024-02-13. The advisory acknowledges four academics from the German National Research Centre for Applied Cybersecurity (ATHENE), which is perhaps of interest since these same researchers are authors on a March 2024 academic paper that downplays the DoS potential of CVE-2024-50868. Those same researchers published another DNSSEC flaw CVE-2023-50387 (also known as KeyTrap) in January 2024, which they describe as having potentially serious implications; Microsoft patched that one at the next scheduled opportunity in February. The CVE-2023-50868 advisory published today does not provide further insight as to why this vulnerability wasn’t patched sooner; a reasonable assumption might be that Microsoft assesses CVE-2023-50868 as less urgent/critical than CVE-2023-50387, although both receive a rating of Important on Microsoft’s proprietary severity ranking scale. It’s also possible that Microsoft does not wish to be the only major server OS vendor without a patch.
There are no significant changes to the lifecycle phase of Microsoft products this month. In July, Microsoft SQL Server 2014 will move past the end of extended support. From August onwards, Microsoft only guarantees to provide SQL Server 2014 security updates to customers who choose to participate in the paid Extended Security Updates program.
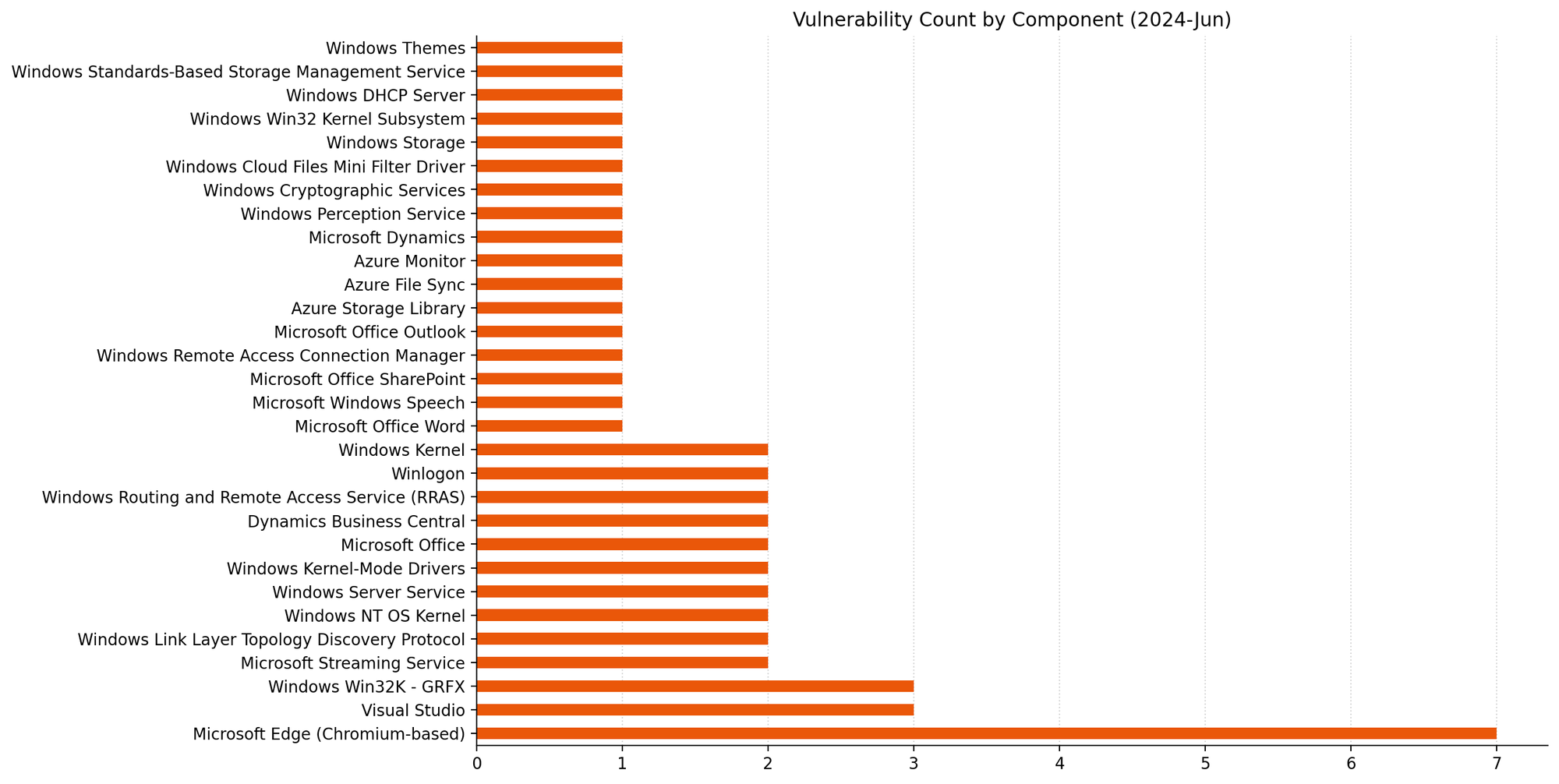
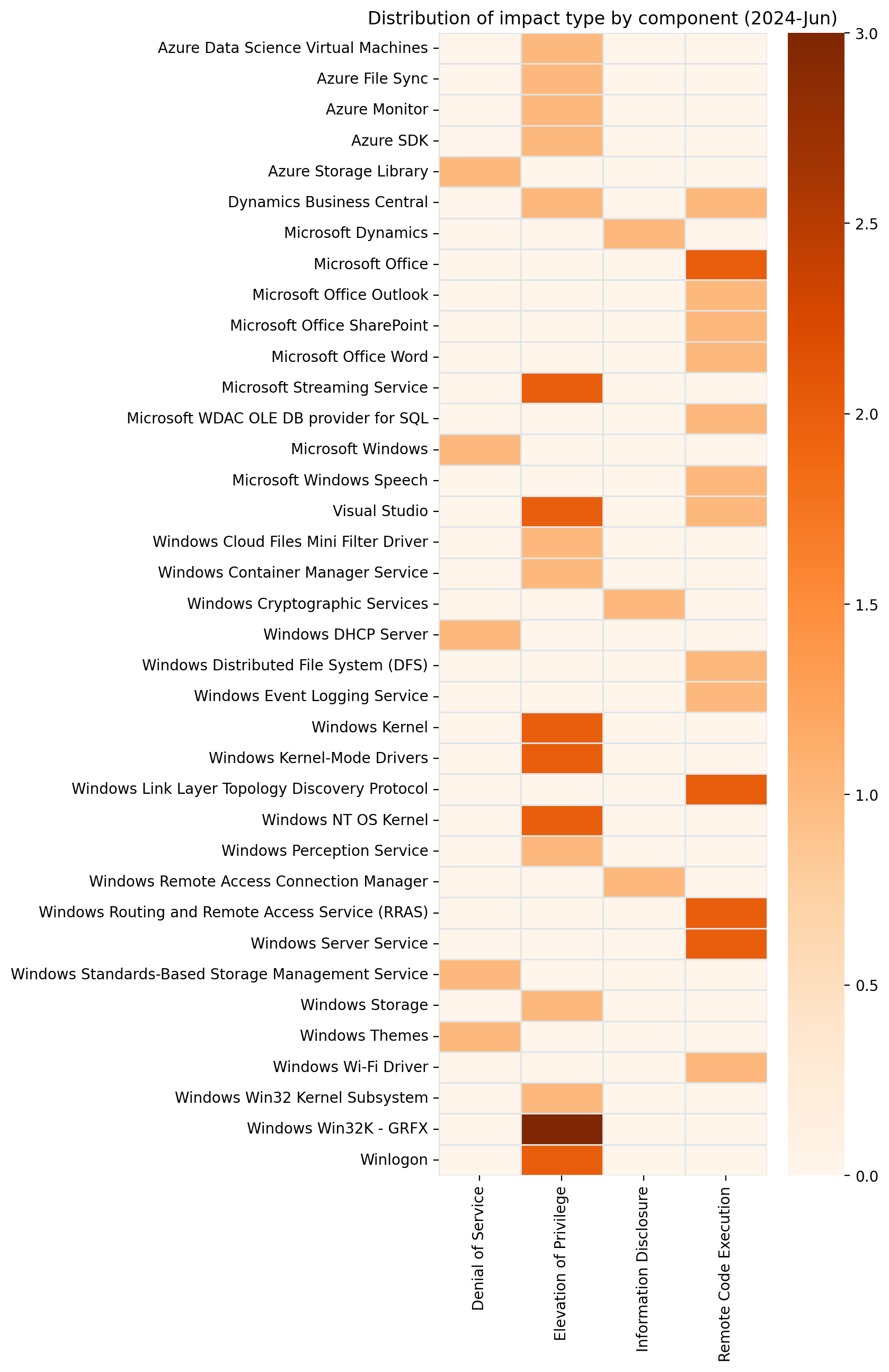
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-37325 | Azure Science Virtual Machine (DSVM) Elevation of Privilege Vulnerability | No | No | 8.1 |
| CVE-2024-35252 | Azure Storage Movement Client Library Denial of Service Vulnerability | No | No | 7.5 |
| CVE-2024-35254 | Azure Monitor Agent Elevation of Privilege Vulnerability | No | No | 7.1 |
| CVE-2024-35255 | Azure Identity Libraries and Microsoft Authentication Library Elevation of Privilege Vulnerability | No | No | 5.5 |
| CVE-2024-35253 | Microsoft Azure File Sync Elevation of Privilege Vulnerability | No | No | 4.4 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-5499 | Chromium: CVE-2024-5499 Out of bounds write in Streams API | No | No | N/A |
| CVE-2024-5498 | Chromium: CVE-2024-5498 Use after free in Presentation API | No | No | N/A |
| CVE-2024-5497 | Chromium: CVE-2024-5497 Out of bounds memory access in Keyboard Inputs | No | No | N/A |
| CVE-2024-5496 | Chromium: CVE-2024-5496 Use after free in Media Session | No | No | N/A |
| CVE-2024-5495 | Chromium: CVE-2024-5495 Use after free in Dawn | No | No | N/A |
| CVE-2024-5494 | Chromium: CVE-2024-5494 Use after free in Dawn | No | No | N/A |
| CVE-2024-5493 | Chromium: CVE-2024-5493 Heap buffer overflow in WebRTC | No | No | N/A |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-29187 | GitHub: CVE-2024-29187 WiX Burn-based bundles are vulnerable to binary hijack when run as SYSTEM | No | No | 7.3 |
| CVE-2024-29060 | Visual Studio Elevation of Privilege Vulnerability | No | No | 6.7 |
| CVE-2024-30052 | Visual Studio Remote Code Execution Vulnerability | No | No | 4.7 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30074 | Windows Link Layer Topology Discovery Protocol Remote Code Execution Vulnerability | No | No | 8 |
| CVE-2024-30075 | Windows Link Layer Topology Discovery Protocol Remote Code Execution Vulnerability | No | No | 8 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-35249 | Microsoft Dynamics 365 Business Central Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-35248 | Microsoft Dynamics 365 Business Central Elevation of Privilege Vulnerability | No | No | 7.3 |
| CVE-2024-35263 | Microsoft Dynamics 365 (On-Premises) Information Disclosure Vulnerability | No | No | 5.7 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30103 | Microsoft Outlook Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30100 | Microsoft SharePoint Server Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-30104 | Microsoft Office Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-30101 | Microsoft Office Remote Code Execution Vulnerability | No | No | 7.5 |
| CVE-2024-30102 | Microsoft Office Remote Code Execution Vulnerability | No | No | 7.3 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30064 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2024-30068 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2024-30097 | Microsoft Speech Application Programming Interface (SAPI) Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30085 | Windows Cloud Files Mini Filter Driver Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30089 | Microsoft Streaming Service Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30072 | Microsoft Event Trace Log File Parsing Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-35265 | Windows Perception Service Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2024-30088 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2024-30099 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2024-30076 | Windows Container Manager Service Elevation of Privilege Vulnerability | No | No | 6.8 |
| CVE-2024-30096 | Windows Cryptographic Services Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2024-30069 | Windows Remote Access Connection Manager Information Disclosure Vulnerability | No | No | 4.7 |
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2024-30080 | Microsoft Message Queuing (MSMQ) Remote Code Execution Vulnerability | No | No | 9.8 |
| CVE-2024-30078 | Windows Wi-Fi Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2024-30077 | Windows OLE Remote Code Execution Vulnerability | No | No | 8 |
| CVE-2024-30086 | Windows Win32 Kernel Subsystem Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30062 | Windows Standards-Based Storage Management Service Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-30094 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-30095 | Windows Routing and Remote Access Service (RRAS) Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2024-35250 | Windows Kernel-Mode Driver Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30082 | Win32k Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30087 | Win32k Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30091 | Win32k Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2024-30083 | Windows Standards-Based Storage Management Service Denial of Service Vulnerability | No | No | 7.5 |
| CVE-2023-50868 | MITRE: CVE-2023-50868 NSEC3 closest encloser proof can exhaust CPU | No | Yes | 7.5 |
| CVE-2024-30070 | DHCP Server Service Denial of Service Vulnerability | No | No | 7.5 |
| CVE-2024-30093 | Windows Storage Elevation of Privilege Vulnerability | No | No | 7.3 |
| CVE-2024-30084 | Windows Kernel-Mode Driver Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2024-30090 | Microsoft Streaming Service Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2024-30063 | Windows Distributed File System (DFS) Remote Code Execution Vulnerability | No | No | 6.7 |
| CVE-2024-30066 | Winlogon Elevation of Privilege Vulnerability | No | No | 5.5 |
| CVE-2024-30067 | Winlogon Elevation of Privilege Vulnerability | No | No | 5.5 |
| CVE-2024-30065 | Windows Themes Denial of Service Vulnerability | No | No | 5.5 |
Post Syndicated from Vishal Pabari original https://aws.amazon.com/blogs/security/aws-completes-police-assured-secure-facilities-pasf-audit-in-the-europe-london-region/
We’re excited to announce that our Europe (London) Region has renewed our accreditation for United Kingdom (UK) Police-Assured Secure Facilities (PASF) for Official-Sensitive data. Since 2017, the Amazon Web Services (AWS) Europe (London) Region has been assured under the PASF program. This demonstrates our continuous commitment to adhere to the heightened expectations of customers with UK law enforcement workloads. Our UK law enforcement customers who require PASF can continue to run their applications in the PASF-assured Europe (London) Region in confidence.
The PASF is a long-established assurance process, used by UK law enforcement, as a method for assuring the security of facilities such as data centers or other locations that house critical business applications that process or hold police data. PASF consists of a control set of security requirements, an on-site inspection, and an audit interview with representatives of the facility.
The Police Digital Service (PDS) confirmed the renewal for AWS on May 24, 2024. A letter confirming PASF status from the Police Digital Service (PDS) can be found on AWS Artifact. The UK police force and law enforcement organizations can also obtain confirmation of the compliance status of AWS through the Police Digital Service.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
Please reach out to your AWS account team if you have questions or feedback about PASF compliance.
If you have feedback about this post, submit comments in the Comments section below.
Post Syndicated from daroc original https://lwn.net/Articles/977394/
BPF is in a unique position in terms of security. It runs in a privileged
context, within the kernel, and can have access to many sensitive details of the
kernel’s operation. At the same time, unlike kernel modules, BPF programs aren’t signed.
Additionally, the mechanisms behind BPF present challenges to implementing
signing or other security features. Three nearly back-to-back sessions at the
2024
Linux Storage,
Filesystem, Memory Management, and BPF Summit
addressed some of the potential security problems.
Post Syndicated from Josh Moss original https://aws.amazon.com/blogs/security/implementing-a-compliance-and-reporting-strategy-for-nist-sp-800-53-rev-5/
Amazon Web Services (AWS) provides tools that simplify automation and monitoring for compliance with security standards, such as the NIST SP 800-53 Rev. 5 Operational Best Practices. Organizations can set preventative and proactive controls to help ensure that noncompliant resources aren’t deployed. Detective and responsive controls notify stakeholders of misconfigurations immediately and automate fixes, thus minimizing the time to resolution (TTR).
By layering the solutions outlined in this blog post, you can increase the probability that your deployments stay continuously compliant with the National Institute of Standards and Technology (NIST) SP 800-53 security standard, and you can simplify reporting on that compliance. In this post, we walk you through the following tools to get started on your continuous compliance journey:
Detective
Preventative
Proactive
Responsive
Reporting
This post covers quite a few solutions, and these solutions operate in different parts of the security pillar of the AWS Well-Architected Framework. It might take some iterations to get your desired results, but we encourage you to start small, find your focus areas, and implement layered iterative changes to address them.
For example, if your organization has experienced events involving public Amazon Simple Storage Service (Amazon S3) buckets that can lead to data exposure, focus your efforts across the different control types to address that issue first. Then move on to other areas. Those steps might look similar to the following:
Implement your detective controls first. Use them to identify misconfigurations and your priority areas to address. Detective controls are security controls that are designed to detect, log, and alert after an event has occurred. Detective controls are a foundational part of governance frameworks. These guardrails are a second line of defense, notifying you of security issues that bypassed the preventative controls.
Security Hub consumes, aggregates, and analyzes security findings from various supported AWS and third-party products. It functions as a dashboard for security and compliance in your AWS environment. Security Hub also generates its own findings by running automated and continuous security checks against rules. The rules are represented by security controls. The controls might, in turn, be enabled in one or more security standards. The controls help you determine whether the requirements in a standard are being met. Security Hub provides controls that support specific NIST SP 800-53 requirements. Unlike other frameworks, NIST SP 800-53 isn’t prescriptive about how its requirements should be evaluated. Instead, the framework provides guidelines, and the Security Hub NIST SP 800-53 controls represent the service’s understanding of them.
Using this step-by-step guide, enable Security Hub for your organization in AWS Organizations. Configure the NIST SP 800-53 security standard for all accounts, in all AWS Regions that are required to be monitored for compliance, in your organization by using the new centralized configuration feature; or if your organization uses AWS GovCloud (US), by using this multi-account script. Use the findings from the NIST SP 800-53 security standard in your delegated administrator account to monitor NIST SP 800-53 compliance across your entire organization, or a list of specific accounts.
Figure 1 shows the Security Standard console page, where users of the Security Hub Security Standard feature can see an overview of their security score against a selected security standard.

Figure 1: Security Hub security standard console
On this console page, you can select each control that is checked by a Security Hub Security Standard, such as the NIST 800-53 Rev. 5 standard, to find detailed information about the check and which NIST controls it maps to, as shown in Figure 2.

Figure 2: Security standard check detail
After you enable Security Hub with the NIST SP 800-53 security standard, you can link responsive controls such as the Automated Security Response (ASR), which is covered later in this blog post, to Amazon EventBridge rules to listen for Security Hub findings as they come in.
Prowler is an open source security tool that you can use to perform assessments against AWS Cloud security recommendations, along with audits, incident response, continuous monitoring, hardening, and forensics readiness. The tool is a Python script that you can run anywhere that an up-to-date Python installation is located—this could be a workstation, an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Fargate or another container, AWS CodeBuild, AWS CloudShell, AWS Cloud9, or another compute option.
Figure 3 shows Prowler being used to perform a scan.

Figure 3: Prowler CLI in action
Prowler works well as a complement to the Security Hub NIST SP 800-53 Rev. 5 security standard. The tool has a native Security Hub integration and can send its findings to your Security Hub findings dashboard. You can also use Prowler as a standalone compliance scanning tool in partitions where Security Hub or the security standards aren’t yet available.
At the time of writing, Prowler has over 300 checks across 64 AWS services.
In addition to integrations with Security Hub and computer-based outputs, Prowler can produce fully interactive HTML reports that you can use to sort, filter, and dive deeper into findings. You can then share these compliance status reports with compliance personnel. Some organizations run automatically recurring Prowler reports and use Amazon Simple Notification Service (Amazon SNS) to email the results directly to their compliance personnel.
Get started with Prowler by reviewing the Prowler Open Source documentation that contains tutorials for specific providers and commands that you can copy and paste.
Preventative controls are security controls that are designed to prevent an event from occurring in the first place. These guardrails are a first line of defense to help prevent unauthorized access or unwanted changes to your network. Service control policies (SCPs) and IAM controls are the best way to help prevent principals in your AWS environment (whether they are human or nonhuman) from creating noncompliant or misconfigured resources.
In the ideal environment, principals (both human and nonhuman) have the least amount of privilege that they need to reach operational objectives. Ideally, humans would at the most only have read-only access to production environments. AWS resources would be created through IaC that runs through a DevSecOps pipeline where policy-as-code checks review resources for compliance against your policies before deployment. DevSecOps pipeline roles should have IAM policies that prevent the deployment of resources that don’t conform to your organization’s compliance strategy. Use IAM conditions wherever possible to help ensure that only requests that match specific, predefined parameters are allowed.
The following policy is a simple example of a Deny policy that uses Amazon Relational Database Service (Amazon RDS) condition keys to help prevent the creation of unencrypted RDS instances and clusters. Most AWS services support condition keys that allow for evaluating the presence of specific service settings. Use these condition keys to help ensure that key security features, such as encryption, are set during a resource creation call.
You can use an SCP to specify the maximum permissions for member accounts in your organization. You can restrict which AWS services, resources, and individual API actions the users and roles in each member account can access. You can also define conditions for when to restrict access to AWS services, resources, and API actions. If you haven’t used SCPs before and want to learn more, see How to use service control policies to set permission guardrails across accounts in your AWS Organization.
Use SCPs to help prevent common misconfigurations mapped to NIST SP 800-53 controls, such as the following:
Although SCPs aren’t the optimal choice for preventing every misconfiguration, they can help prevent many of them. As a feature of AWS Organizations, SCPs provide inheritable controls to member accounts of the OUs that they are applied to. For deployments in Regions where AWS Organizations isn’t available, you can use IAM policies and permissions boundaries to achieve preventative functionality that is similar to what SCPs provide.
The following is an example of policy mapping statements to NIST controls or control families. Note the placeholder values, which you will need to replace with your own information before use. Note that the SIDs map to Security Hub NIST 800-53 Security Standard control numbers or NIST control families.
For a collection of SCP examples that are ready for your testing, modification, and adoption, see the service-control-policy-examples GitHub repository, which includes examples of Region and service restrictions.
For a deeper dive on SCP best practices, see Achieving operational excellence with design considerations for AWS Organizations SCPs.
You should thoroughly test SCPs against development OUs and accounts before you deploy them against production OUs and accounts.
Proactive controls are security controls that are designed to prevent the creation of noncompliant resources. These controls can reduce the number of security events that responsive and detective controls handle. These controls help ensure that deployed resources are compliant before they are deployed; therefore, there is no detection event that requires response or remediation.
CloudFormation Guard (cfn-guard) is an open source, general-purpose, policy-as-code evaluation tool. Use cfn-guard to scan Information as Code (IaC) against a collection of policies, defined as JSON, before deployment of resources into an environment.
Cfn-guard can scan CloudFormation templates, Terraform plans, Kubernetes configurations, and AWS Cloud Development Kit (AWS CDK) output. Cfn-guard is fully extensible, so your teams can choose the rules that they want to enforce, and even write their own declarative rules in a YAML-based format. Ideally, the resources deployed into a production environment on AWS flow through a DevSecOps pipeline. Use cfn_guard in your pipeline to define what is and is not acceptable for deployment, and help prevent misconfigured resources from deploying. Developers can also use cfn_guard on their local command line, or as a pre-commit hook to move the feedback timeline even further “left” in the development cycle.
Use policy as code to help prevent the deployment of noncompliant resources. When you implement policy as code in the DevOps cycle, you can help shorten the development and feedback cycle and reduce the burden on security teams. The CloudFormation team maintains a GitHub repo of cfn-guard rules and mappings, ready for rapid testing and adoption by your teams.
Figure 4 shows how you can use Guard with the NIST 800-53 cfn_guard Rule Mapping to scan infrastructure as code against NIST 800-53 mapped rules.

Figure 4: CloudFormation Guard scan results
You should implement policy as code as pre-commit checks so that developers get prompt feedback, and in DevSecOps pipelines to help prevent deployment of noncompliant resources. These checks typically run as Bash scripts in a continuous integration and continuous delivery (CI/CD) pipeline such as AWS CodeBuild or GitLab CI. To learn more, see Integrating AWS CloudFormation Guard into CI/CD pipelines.
To get started, see the CloudFormation Guard User Guide. You can also view the GitHub repos for CloudFormation Guard and the AWS Guard Rules Registry.
Many other third-party policy-as-code tools are available and include NIST SP 800-53 compliance policies. If cfn-guard doesn’t meet your needs, or if you are looking for a more native integration with the AWS CDK, for example, see the NIST-800-53 rev 5 rules pack in cdk-nag.
Responsive controls are designed to drive remediation of adverse events or deviations from your security baseline. Examples of technical responsive controls include setting more stringent security group rules after a security group is created, setting a public access block on a bucket automatically if it’s removed, patching a system, quarantining a resource exhibiting anomalous behavior, shutting down a process, or rebooting a system.
The Automated Security Response on AWS (ASR) is an add-on that works with Security Hub and provides predefined response and remediation actions based on industry compliance standards and current recommendations for security threats. This AWS solution creates playbooks so you can choose what you want to deploy in your Security Hub administrator account (which is typically your Security Tooling account, in our recommended multi-account architecture). Each playbook contains the necessary actions to start the remediation workflow within the account holding the affected resource. Using ASR, you can resolve common security findings and improve your security posture on AWS. Rather than having to review findings and search for noncompliant resources across many accounts, security teams can view and mitigate findings from the Security Hub console of the delegated administrator.
The architecture diagram in Figure 5 shows the different portions of the solution, deployed into both the Administrator account and member accounts.

Figure 5: ASR architecture diagram
The high-level process flow for the solution components deployed with the AWS CloudFormation template is as follows:
The NIST SP 800-53 Playbook contains 52 remediations to help security and compliance teams respond to misconfigured resources. Security teams have a choice between launching these remediations manually, or enabling the associated EventBridge rules to allow the automations to bring resources back into a compliant state until further action can be taken on them. When a resource doesn’t align with the Security Hub NIST SP 800-53 security standard automated checks and the finding appears in Security Hub, you can use ASR to move the resource back into a compliant state. Remediations are available for 17 of the common core services for most AWS workloads.
Figure 6 shows how you can remediate a finding with ASR by selecting the finding in Security Hub and sending it to the created custom action.

Figure 6: ASR Security Hub custom action
Findings generated from the Security Hub NIST SP 800-53 security standard are displayed in the Security Hub findings or security standard dashboards. Security teams can review the findings and choose which ones to send to ASR for remediation. The general architecture of ASR consists of EventBridge rules to listen for the Security Hub custom action, an AWS Step Functions workflow to control the process and implementation, and several AWS Systems Manager documents (SSM documents) and AWS Lambda functions to perform the remediation. This serverless, step-based approach is a non-brittle, low-maintenance way to keep persistent remediation resources in an account, and to pay for their use only as needed. Although you can choose to fork and customize ASR, it’s a fully developed AWS solution that receives regular bug fixes and feature updates.
To get started, see the ASR Implementation Guide, which will walk you through configuration and deployment.
You can also view the code on GitHub at the Automated Security Response on AWS GitHub repo.
Several options are available to concisely gather results into digestible reports that compliance professionals can use as artifacts during the Risk Management Framework (RMF) process when seeking an Authorization to Operate (ATO). By automating reporting and delegating least-privilege access to compliance personnel, security teams may be able to reduce time spent reporting compliance status to auditors or oversight personnel.
Remove some of the burden of reporting from your security engineers, and give compliance teams read-only access to your Security Hub dashboard in your Security Tooling account. Enabling compliance teams with read-only access through AWS IAM Identity Center (or another sign-on solution) simplifies governance while still maintaining the principle of least privilege. By adding compliance personnel to the AWSSecurityAudit managed permission set in IAM Identity Center, or granting this policy to IAM principals, these users gain visibility into operational accounts without the ability to make configuration changes. Compliance teams can self-serve the security posture details and audit trails that they need for reporting purposes.
Meanwhile, administrative teams are freed from regularly gathering and preparing security reports, so they can focus on operating compliant workloads across their organization. The AWSSecurityAudit permission set grants read-only access to security services such as Security Hub, AWS Config, Amazon GuardDuty, and AWS IAM Access Analyzer. This provides compliance teams with wide observability into policies, configuration history, threat detection, and access patterns—without the privilege to impact resources or alter configurations. This ultimately helps to strengthen your overall security posture.
For more information about AWS managed policies, such as the AWSSecurityAudit managed policy, see the AWS managed policies.
To learn more about permission sets in IAM Identity Center, see Permission sets.
AWS Audit Manager helps you continually audit your AWS usage to simplify how you manage risk and compliance with regulations and industry standards. Audit Manager automates evidence collection so you can more easily assess whether your policies, procedures, and activities—also known as controls—are operating effectively. When it’s time for an audit, Audit Manager helps you manage stakeholder reviews of your controls. This means that you can build audit-ready reports with much less manual effort.
Audit Manager provides prebuilt frameworks that structure and automate assessments for a given compliance standard or regulation, including NIST 800-53 Rev. 5. Frameworks include a prebuilt collection of controls with descriptions and testing procedures. These controls are grouped according to the requirements of the specified compliance standard or regulation. You can also customize frameworks and controls to support internal audits according to your specific requirements.
For more information about using Audit Manager to generate automated compliance reports, see the AWS Audit Manager User Guide.
Security Hub is the premier security information aggregating tool on AWS, offering automated security checks that align with NIST SP 800-53 Rev. 5. This alignment is particularly critical for organizations that use the Security Hub NIST SP 800-53 Rev. 5 framework. Each control within this framework is pivotal for documenting the compliance status of cloud environments, focusing on key aspects such as:
Such comprehensive information is crucial in the accreditation and continuous monitoring of cloud environments.
To further augment the utility of this data for customers seeking to compile artifacts and articulate compliance status, the AWS ProServe team has introduced the Security Hub Compliance Analyzer (SHCA).
SHCA is engineered to streamline the RMF process. It reduces manual effort, delivers extensive reports for informed decision making, and helps assure continuous adherence to NIST SP 800-53 standards. This is achieved through a four-step methodology:
The diagram in Figure 7 shows the SHCA steps in action.

Figure 7: SHCA steps
By integrating these steps, SHCA simplifies compliance management and helps enhance the overall security posture of AWS environments, aligning with the rigorous standards set by NIST SP 800-53 Rev. 5.
The following is a list of the artifacts that SHCA provides:
As shown in Figure 8, the Security Hub NIST 800-53 Analysis Summary adopts an OpenSCAP-style format akin to Security Technical Implementation Guides (STIGs), which are grounded in the Department of Defense’s (DoD) policy and security protocols.

Figure 8: SHCA Summary Report
You can also view the code on GitHub at Security Hub Compliance Analyzer.
Organizations can use AWS security and compliance services to help maintain compliance with the NIST SP 800-53 standard. By implementing preventative IAM and SCP policies, organizations can restrict users from creating noncompliant resources. Detective controls such as Security Hub and Prowler can help identify misconfigurations, while proactive tools such as CloudFormation Guard can scan IaC to help prevent deployment of noncompliant resources. Finally, the Automated Security Response on AWS can automatically remediate findings to help resolve issues quickly. With this layered security approach across the organization, companies can verify that AWS deployments align to the NIST framework, simplify compliance reporting, and enable security teams to focus on critical issues. Get started on your continuous compliance journey today. Using AWS solutions, you can align deployments with the NIST 800-53 standard. Implement the tips in this post to help maintain continuous compliance.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, & Compliance re:Post or contact AWS Support.
Post Syndicated from Will Haltom original https://github.blog/engineering/architecture-optimization/how-we-improved-push-processing-on-github/
What happens when you push to GitHub? The answer, “My repository gets my changes” or maybe, “The refs on my remote get updated” is pretty much right—and that is a really important thing that happens, but there’s a whole lot more that goes on after that. To name a few examples:
Those are some pretty important things, and this is just a sample of what goes on for every push. In fact, in the GitHub monolith, there are over 60 different pieces of logic owned by 20 different services that run in direct response to a push. That’s actually really cool—we should be doing a bunch of interesting things when code gets pushed to GitHub. In some sense, that’s a big part of what GitHub is, the place you push code1 and then cool stuff happens.
What’s not so cool is that, up until recently, all of these things were the responsibility of a single, enormous background job. Whenever GitHub’s Ruby on Rails monolith was notified of a push, it enqueued a massive job called the RepositoryPushJob. This job was the home for all push processing logic, and its size and complexity led to many problems. The job triggered one thing after another in a long, sequential series of steps, kind of like this:

There are a few things wrong with this picture. Let’s highlight some of them:
RepositoryPushJob made it very difficult for different push processing tasks to be retried correctly. On a retry, all the logic of the job is repeated from the beginning, which is not always appropriate for individual tasks. For example:
Push records to the database can be retried liberally on errors and reattempted any amount of time after the push, and will gracefully handle duplicate data. RepositoryPushJob being avoided in most cases. To prevent one step from killing the entire job, however, much of the push handling logic was wrapped in code catching any and all errors. This lack of retries led to issues where crucial pieces of push processing never occurred.Pushes MySQL cluster occurred in the beginning of the RepositoryPushJob. This meant that everything occurring after that had an implicit dependency on this cluster. This structure led to incidents where errors from this database cluster meant that user pull requests were not synchronized, even though pull requests have no explicit need to connect to this cluster.At a high level, we took this very long sequential process and decoupled it into many isolated, parallel processes. We used the following approach:
We had to make investments in several areas to support this architecture, including:
Now, things look like this:

A push triggers a Kafka event, which is fanned out via independent consumers to many isolated jobs that can process the event without worrying about any other consumers.
Pushes MySQL cluster and now have no such dependency, simply as a product of being moved into isolated processes. 
Improved observability.
RepositoryPushJob system fully processed about 99.897% of pushes.Pushing code to GitHub is one of the most fundamental interactions that developers have with GitHub every day. It’s important that our system handles everyone’s pushes reliably and efficiently, and over the past several months we have significantly improved the ability of our monolith to correctly and fully process pushes from our users. Through platform level investments like this one, we strive to make GitHub the home for all developers (and their many pushes!) far into the future.
The post How we improved push processing on GitHub appeared first on The GitHub Blog.
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/06/11/enhancing-velociraptor-with-the-cado-security-platform/

By: Nicholas Handy, Director of Technical Alliances & Partnerships at Cado Security
Velociraptor is a robust open-source tool designed for collecting and querying forensic and incident response artifacts across various endpoints. This powerful tool allows incident responders to effortlessly gather data from remote systems, regardless of their location.
The Cado Security platform is a complementary technology that enables analysis and process of captured data at scale and from multiple sources. In conjunction with Velociraptor data, Cado analyzes data captured from cloud VMs, container-based, serverless, and SaaS environments. The platform automatically scales up and down to provide fast, parallel data processing. This means that it can process hundreds of systems simultaneously.
The Cado Security Platform integrates seamlessly with Velociraptor, creating a comprehensive suite for end-to-end data capture and analysis. In fact, Cado’s existing customers routinely analyze data collected by Velociraptor during investigations using this platform, making the most of its powerful capabilities
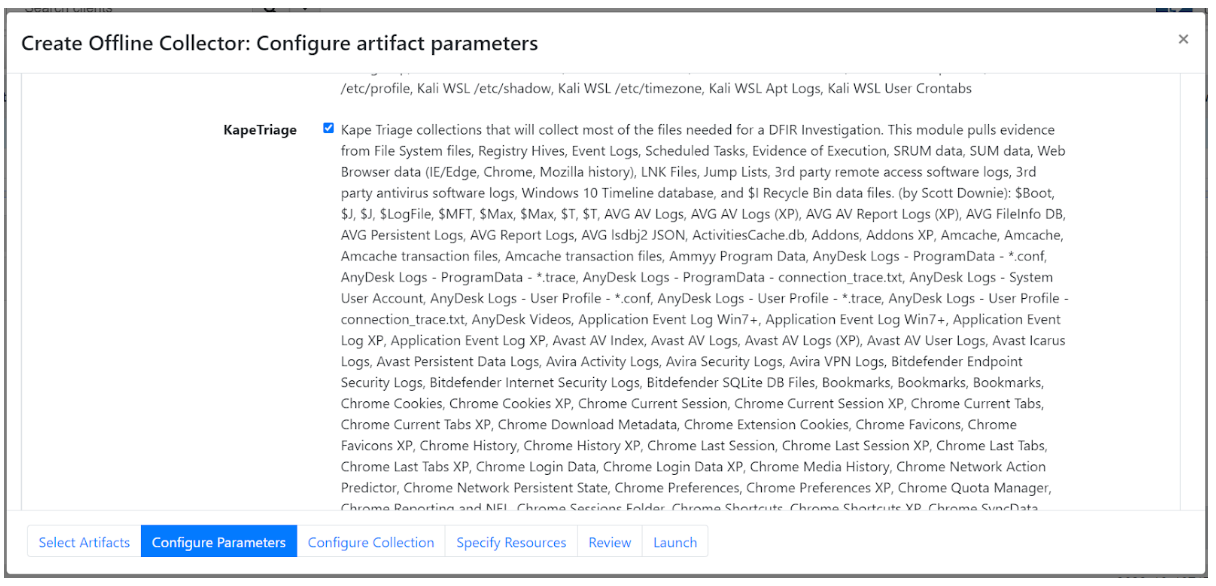
A common use case involves users performing offline triage to create an agent to collect Windows.KapeFiles from endpoints, to then upload these to cloud storage where Cado can import, process, and analyze them. This capability leverages Cado’s cloud-based parallel processing to quickly normalize collected artifacts. Cado creates a timeline of what happened on the systems, runs analysis against the files and enables an analyst to search and browse the captured data.
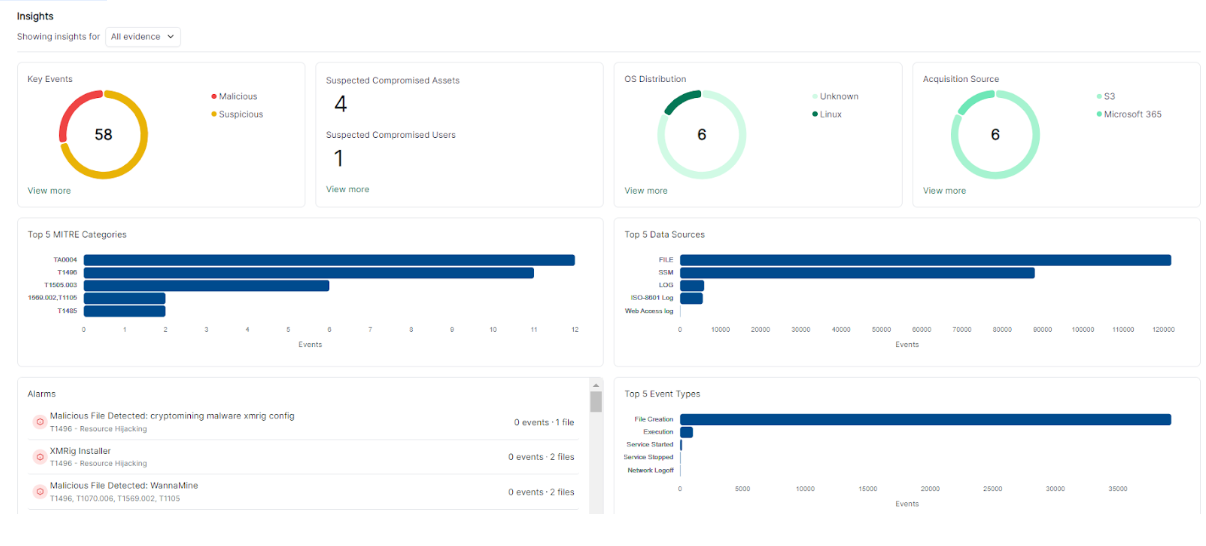
The Cado Security Platform creates detailed timelines of system events, conducts thorough file analysis, and enables analysts to search and browse captured data efficiently. This detailed insight is invaluable for understanding the full impact of threats.
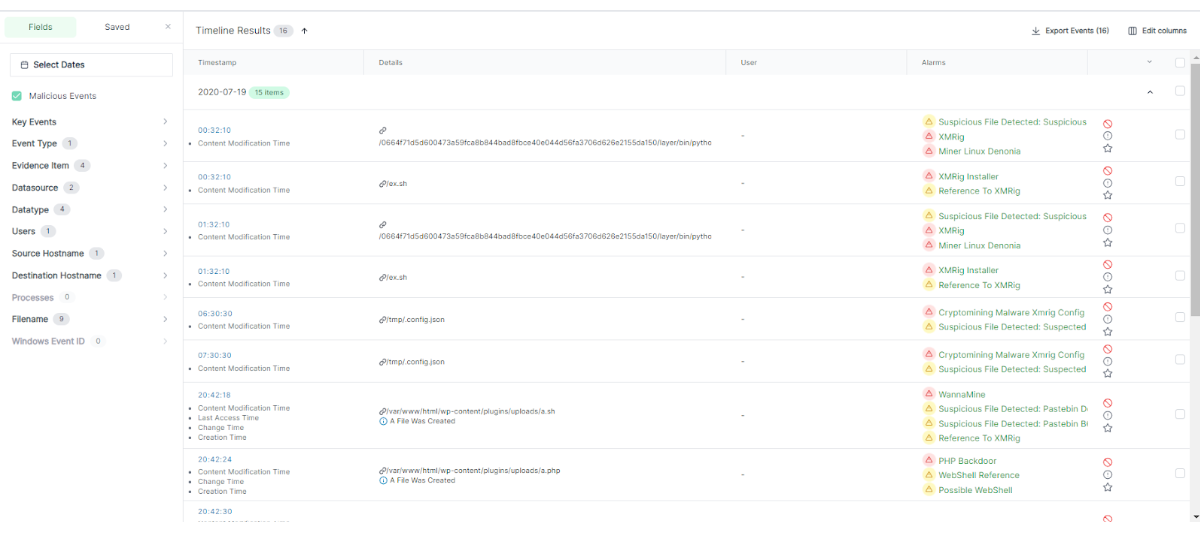
With Velociraptor and The Cado Security Platform working together, incident response teams can achieve a better understanding of the impact of threats with complete visibility across their entire ecosystem, enhancing the overall efficiency of forensic investigations and incident response.
Post Syndicated from corbet original https://lwn.net/Articles/977973/
Version
127.0 of the Firefox browser is out. Changes include support for DNS
prefetching and the ability to close duplicate tabs in a window. The
browser will now try to upgrade images and videos with HTTP URLs that are
found in an HTTPS page to HTTPS as well; if that fails, the non-HTTPS
resources will simply fail to load.
Update: this
Mozilla Secuirty Blog post describes the HTTPS-related changes in
detail.
Post Syndicated from Yev original https://backblaze.com/blog/2024-state-of-the-backup-security-incidents-and-data-loss-on-the-rise/

June is Backup Awareness Month, and every year, we work with the Harris Poll to survey the state of computer backups in the U.S. It’s our 16th year running, and this year, we expanded our lens and created a new survey focused on analyzing the state of backups among businesses, providing critical insights into organizational backup strategies and challenges.
And as in previous years, our consumer backup survey provides a comprehensive summary which reflects trends and changes over nearly two decades. The combination of these two audience surveys provides a more complete picture for the state of backups in the U.S. Let’s start with our new survey data.
Our inaugural Business Backup Survey included 300 IT decision makers across the U.S. Part of what we wanted to learn was:
With all of the different ways IT professionals have to protect their user’s data, how are they choosing to back up and are backup solutions even working?
We can infer the answers to those questions by looking at the tools organizations use to back up their data, the frequency of data recoveries, and how successful or not those recoveries were.
One of the most striking findings from the poll is that a significant majority (84%) of IT decision makers say their organizations utilize cloud drive services, which rely on syncing data to the cloud, for off-site data backup. You may have heard us say this before—sync is not backup.
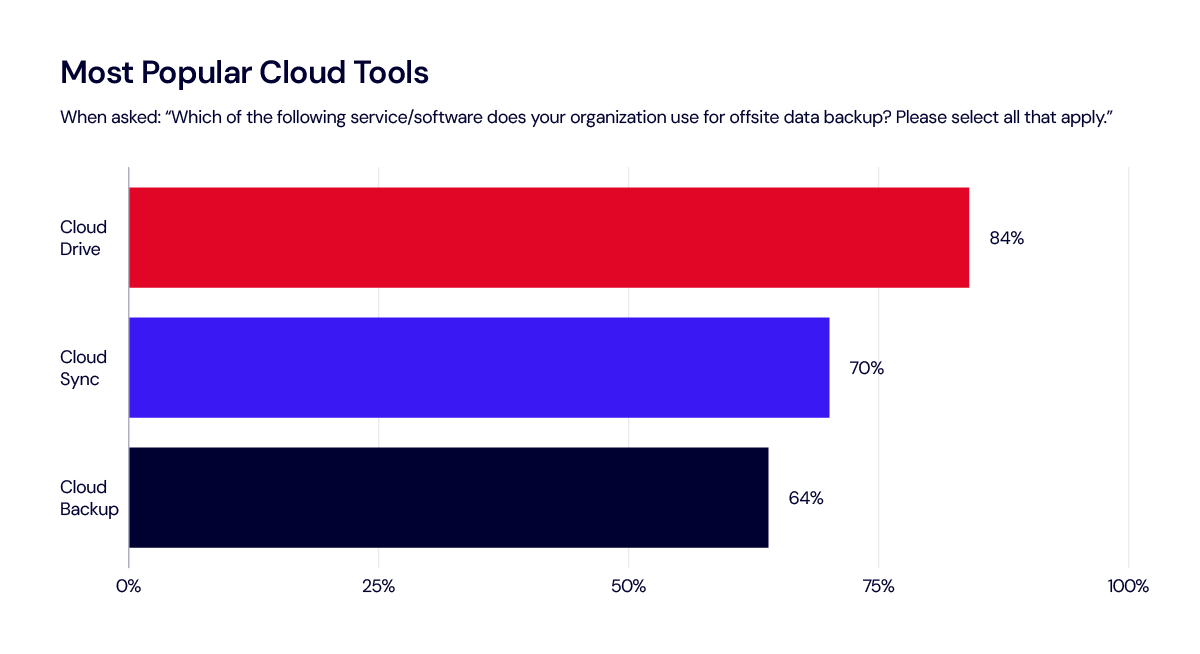


Cloud drives allow for file storage and sharing but may not protect against file corruption or accidental deletion. Sync services automatically update files across multiple devices, meaning that any changes or deletions are replicated everywhere, which can lead to unintended data loss. While some cloud drives have added minimal backup capabilities (i.e., 30 days of version history or similar), they are often lacking in key areas that are necessary for business continuity or compliance standards.
Cloud backup solutions, on the other hand, are designed to systematically and securely back up data, offering robust protection against loss, corruption, and security breaches. This makes cloud backup a better choice, particularly for addressing security concerns and ensuring the integrity and availability of critical data.
39% of IT decision-makers report that their organizations need to restore data from backups at least once a month, with special requests for archived or deleted data (62%), backup software failure (54%), hard drive failure (52%), and cyber attacks (49%) reported as some of the top reasons. This frequent need for data recovery underscores the persistent vulnerabilities IT professionals face.
Not only do many organizations need to restore on a regular basis, but the survey also shows that among those that experienced data loss, only 42% were able to recover all of their data when they perform a restore. That leaves 58% with some amount of unrecovered data.
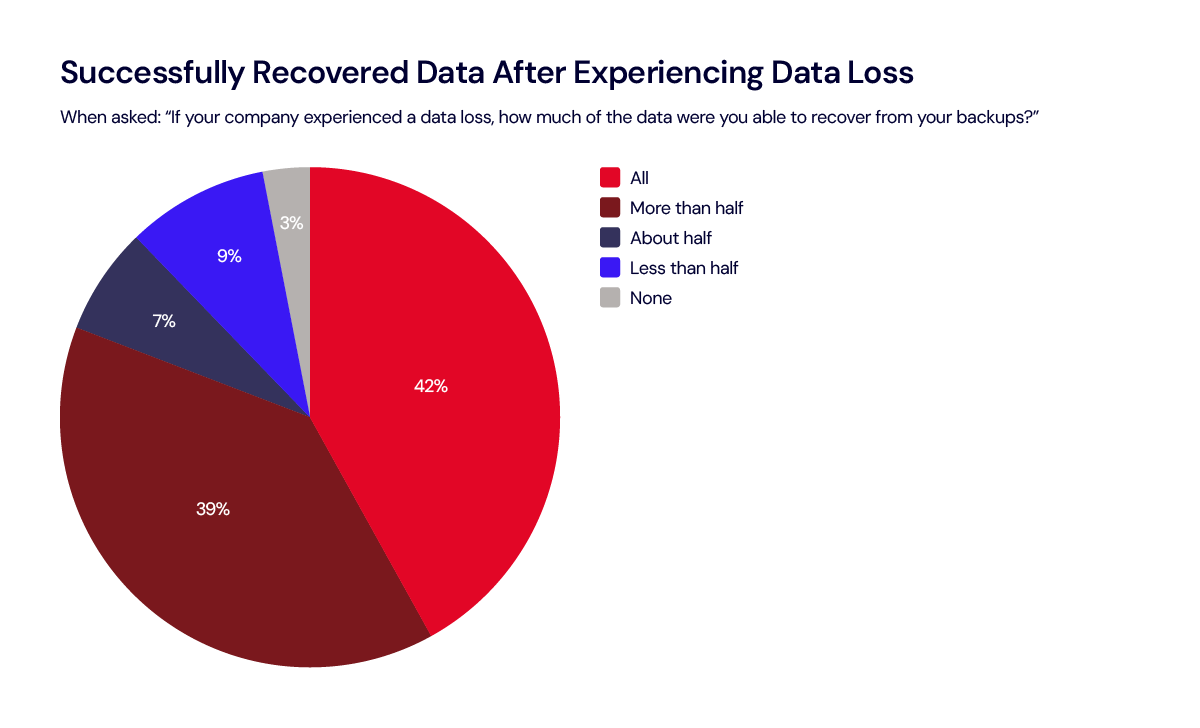
The data shows a sizable gap between the use of backup services and the effectiveness of data restoration. Although a significant percentage of organizations indicate they’re using what they would consider a cloud backup solution (the shortcomings of cloud drives and cloud sync services aside), only 42% of those that experienced data loss were able to restore all their data. This discrepancy highlights the risks associated with inadequate backup measures and the potential for data loss, which can have serious repercussions for businesses.
Only 42% of organizations that experienced data loss were able to restore all their data.
There are all sorts of ways businesses need to slice their data management strategy in order to make sure all data is backed up. This includes data type (e.g., files vs. system information), frequency with which the data is updated or changed, retention requirements for compliance, and more. There are often reasons that businesses will employ different backup frequency or strategies for different file types—file-based versus block-level incremental backups, for example. However, incomplete backups can lead to situations where only parts of the data can be restored, disrupting business operations and resulting in downtime as efforts are made to recover or reconstruct lost data.
The importance of creating an end-to-end data backup plan, as well as choosing the right tools that provide comprehensive coverage, may be highlighted only at the moment of failure. As it stands, the Harris Poll data suggests that the limitations of cloud sync and cloud drive tools are leaving gaps in data protection and disaster recovery strategies.
This is further validated by the features IT decision makers report as being absolutely essential/very important in selecting backup tools, including security (97%), bandwidth and memory capacity (87%), a variety of features (79%), ease of operations and customizable elements (83% each). These rigorous requirements suggest that many existing solutions may fall short of meeting the comprehensive needs of modern businesses, and/or that the complex mix of tools may be contributing to blind spots in an overall data management strategy, only exposed at the point of recovery.
These insights underscore the need for innovative and robust backup solutions that address evolving business requirements. As the volume of data continues to grow and cyber threats become increasingly sophisticated, the demand for reliable, secure, and user-friendly backup systems will only heighten. Given the challenges many businesses face in fully recovering their data, there’s an opportunity to promote education and awareness regarding the importance of refreshing backup strategies and utilizing suitable backup tools.
The consumer portion of the 2024 Backup Awareness Survey seeks to understand a simple question we’ve asked year after year: How often do you back up all of the data on your computer? We also look at who backs up the most and the reasons people cite for needing to restore data, and we compare those trends over time. Let’s dig in to the results.
This year’s survey reveals that fewer than 1 in 5 Americans (15%) feel absolutely certain that their most important files are securely backed up. This is despite 84% of Americans who own a computer stating that they’ve backed up all their data and 45% performing backups at least once a month.
The survey also highlights the predominance of cloud solutions among backup methods. 63% of individuals who back up their data use a cloud-based system as their primary method. However, only 11% utilize dedicated cloud backup services, indicating a preference towards cloud drives (39%) and sync services (13%). As we noted above, cloud drives and sync services are fundamentally different from cloud backup solutions and can create gaps in a robust 3-2-1 backup strategy.
Every year, we highlight which demographic is the best at backing up their data, and in 2024, men (73% vs. 66% of women) and younger adults ages 18–54 (76% vs. just 61% of those ages 55+) take the lead backing up at least once a year.
The survey also found that 74% of Americans who own a computer have accidentally deleted important data (a 5.7% increase from 2023), and 57% have experienced a security incident on their computer.
For those interested in the data over time, let’s travel back and see how this year’s data compares to previous years. The first graph is one of our favorites. Since 2023, daily backups have dipped by 1%, while weekly and monthly backups have remained steady, which is encouraging. Additionally, there is a slight, but not statistically significant, increase of 1% in yearly and more-than-yearly backups. Notably, the percentage of people who have never backed up their data has decreased by 2%.
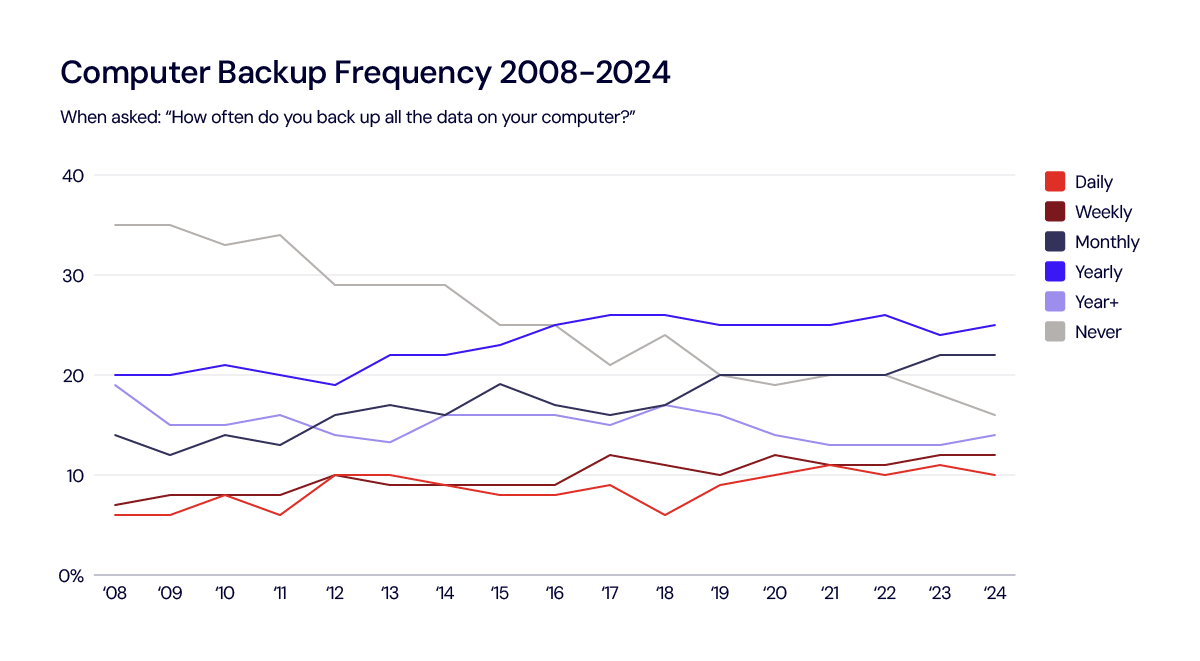
For all the table enthusiasts, you’ll appreciate this detailed view showcasing how 2024 compares with previous years. We love to see Never down to an all-time low, although Daily took a slight dip.

If you’re a visual person who appreciates vibrant pie charts for easier data digestion, here are pie charts comparing data from 2008 to 2024:

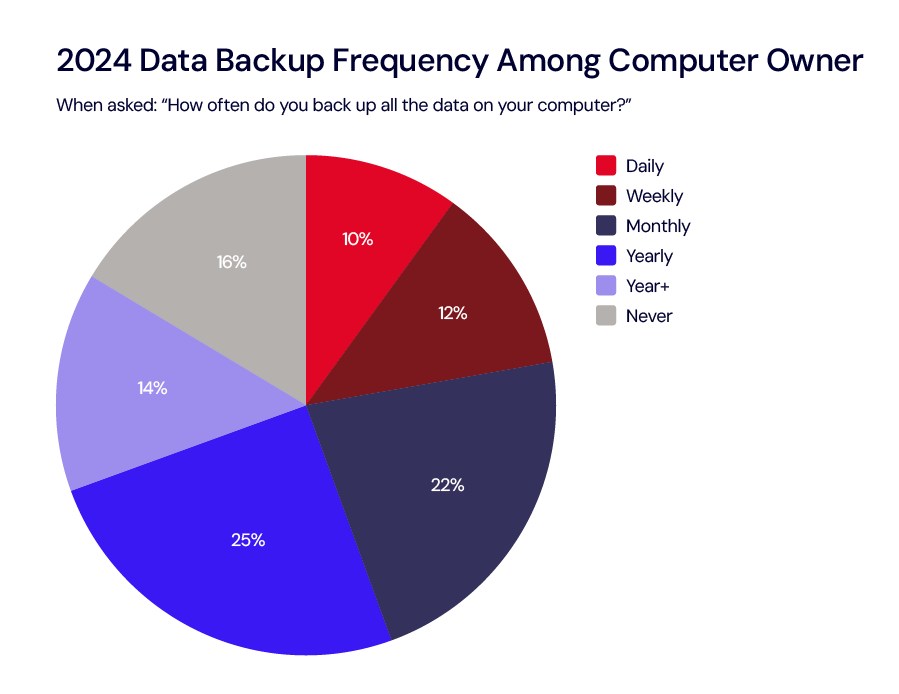
Within each population (business and consumer), the most striking data points are around the differences between backup and sync. Both consumers and businesses are leveraging cloud drive and sync services for ease of use, but that has not translated to successful data recoveries. With ransomware attacks on the rise, now more than ever, it’s essential to have a strong backup strategy.
Still, we’ve come a long way since 2008, and the consumer data shows positive change over time around backup awareness and tool adoption. Going forward, we’ll be interested to see how the business audience data changes over time. See below for our full testing methodology, and, as always, drop us a line in the comment section if you have any questions or insights.
This survey was conducted online within the United States by The Harris Poll on behalf of Backblaze from April 25-29, 2024, among 2,058 adults ages 18 and older, among whom 1,877 own a computer. The sampling precision of Harris online polls is measured by using a Bayesian credible interval. For this study, the sample data is accurate to within +/- 2.5 percentage points using a 95% confidence level.
Prior year’s surveys were conducted online by The Harris Poll on behalf of Backblaze among U.S. adults ages 18+ who own a computer in April 25–27, 2023 (n=1,857) May 19–23, 2022 (n=1,861); May 12–14, 2021 (n=1,870); June 1–3, 2020 (n=1,913); June 6–10, 2019 (n=1,858); June 5–7, 2018 (n=1,871); May 19–23, 2017 (n=1,954); May 13–17, 2016 (n=1,920); May 15–19, 2015 (n=2,009); June 2-4, 2014 (n=1,991); June 13–17, 2013 (n=1,952); May 31–June 4, 2012 (n=2,176); June 28–30, 2011 (n=2,209); June 3–7, 2010 (n=2,051); May 13–14, 2009 (n=2,154); and May 27–29, 2008 (n=2,723).
Business Backup Survey Method:
This survey was conducted online within the United States by The Harris Poll on behalf of Backblaze from April 30 – May 8, 2024, among 300 IT Decision Makers. The sampling precision of Harris online polls is measured by using a Bayesian credible interval. For this study, the sample data is accurate to within +/- 5.7 percentage points using a 95% confidence level.
For complete survey methodologies, including weighting variables and subgroup sample sizes, please contact Backblaze.
The post 2024 State of the Backup: Survey Says Security Incidents and Data Loss on the Rise appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from Technology Connextras original https://www.youtube.com/watch?v=0Kp3bjm55xw
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=xezOx64nLhA
Post Syndicated from Sarthak Aggarwal original https://aws.amazon.com/blogs/big-data/optimize-storage-costs-in-amazon-opensearch-service-using-zstandard-compression/
This post is co-written with Praveen Nischal and Mulugeta Mammo from Intel.
Amazon OpenSearch Service is a managed service that makes it straightforward to secure, deploy, and operate OpenSearch clusters at scale in the AWS Cloud. In an OpenSearch Service domain, the data is managed in the form of indexes. Based on the usage pattern, an OpenSearch cluster may have one or more indexes, and their shards are spread across the data nodes in the cluster. Each data node has a fixed disk size and the disk usage is dependent on the number of index shards stored on the node. Each index shard may occupy different sizes based on its number of documents. In addition to the number of documents, one of the important factors that determine the size of the index shard is the compression strategy used for an index.
As part of an indexing operation, the ingested documents are stored as immutable segments. Each segment is a collection of various data structures, such as inverted index, block K dimensional tree (BKD), term dictionary, or stored fields, and these data structures are responsible for retrieving the document faster during the search operation. Out of these data structures, stored fields, which are largest fields in the segment, are compressed when stored on the disk and based on the compression strategy used, the compression speed and the index storage size will vary.
In this post, we discuss the performance of the Zstandard algorithm, which was introduced in OpenSearch v2.9, amongst other available compression algorithms in OpenSearch.
Compression plays a crucial role in OpenSearch, because it significantly impacts the performance, storage efficiency and overall usability of the platform. The following are some key reasons highlighting the importance of compression in OpenSearch:
When configuring OpenSearch, it’s essential to consider compression settings carefully to strike the right balance between storage efficiency and query performance, depending on your specific use case and resource constraints.
Before diving into various compression algorithms that OpenSearch offers, let’s look into three standard metrics that are often used while comparing compression algorithms:
OpenSearch provides support for codecs that can be used for compressing the stored fields. Until OpenSearch 2.7, OpenSearch provided two codecs or compression strategies: LZ4 and Zlib. LZ4 is analogous to best_speed because it provides faster compression but a lesser compression ratio (consumes more disk space) when compared to Zlib. LZ4 is used as the default compression algorithm if no explicit codec is specified during index creation and is preferred by most because it provides faster indexing and search speeds though it consumes relatively more space than Zlib. Zlib is analogous to best_compression because it provides a better compression ratio (consumes less disk space) when compared to LZ4, but it takes more time to compress and decompress, and therefore has higher latencies for indexing and search operations. Both LZ4 and Zlib codecs are part of the Lucene core codecs.
The Zstandard codec was introduced in OpenSearch as an experimental feature in version 2.7, and it provides Zstandard-based compression and decompression APIs. The Zstandard codec is based on JNI binding to the Zstd native library.
Zstandard is a fast, lossless compression algorithm aimed at providing a compression ratio comparable to Zlib but with faster compression and decompression speed comparable to LZ4. The Zstandard compression algorithm is available in two different modes in OpenSearch: zstd and zstd_no_dict. For more details, see Index codecs.
Both codec modes aim to balance compression ratio, index, and search throughput. The zstd_no_dict option excludes a dictionary for compression at the expense of slightly larger index sizes.
With the recent OpenSearch 2.9 release, the Zstandard codec has been promoted from experimental to mainline, making it suitable for production use cases.
You can use the index.codec during index creation to create an index with the Zstd codec. The following is an example using the curl command (this command requires the user to have necessary privileges to create an index):
With Zstandard codecs, you can optionally specify a compression level using the index.codec.compression_level setting, as shown in the following code. This setting takes integers in the [1, 6] range. A higher compression level results in a higher compression ratio (smaller storage size) with a trade-off in speed (slower compression and decompression speeds lead to higher indexing and search latencies). For more details, see Choosing a codec.
You can update the index.codec and index.codec.compression_level settings any time after the index is created. For the new configuration to take effect, the index needs to be closed and reopened.
You can update the setting of an index using a PUT request. The following is an example using curl commands.
Close the index:
Update the index settings:
Reopen the index:
Changing the index codec settings doesn’t immediately affect the size of existing segments. Only new segments created after the update will reflect the new codec setting. To have consistent segment sizes and compression ratios, it may be necessary to perform a reindexing or other indexing processes like merges.
To understand the performance benefits of Zstandard codecs, we carried out a benchmark exercise.
The server setup was as follows:
cluster_manager node.cluster_manager node was r5.xlarge, both backed by an Amazon Elastic Block Store (Amazon EBS) volume of type GP3 and size 100GB.Benchmarking was set up as follows:
The index setup was as follows:
From the experiments, zstd provides a better compression ratio compared to Zlib (best_compression) with a slight gain in write throughput and with similar read latency as LZ4 (best_speed). zstd_no_dict provides 14% better write throughput than LZ4 (best_speed) and a slightly lower compression ratio than Zlib (best_compression).
The following table summarizes the benchmark results.

Although Zstd provides the best of both worlds (compression ratio and compression speed), it has the following limitations:
zstd and zstd_no_dict compression codecs for k-NN or Security Analytics indexes.Zstandard compression provides a good balance between storage size and compression speed, and is able to tune the level of compression based on the use case. Intel and the OpenSearch Service team collaborated on adding Zstandard as one of the compression algorithms in OpenSearch. Intel contributed by designing and implementing the initial version of compression plugin in open-source which was released in OpenSearch v2.7 as experimental feature. OpenSearch Service team worked on further improvements, validated the performance results and integrated it into the OpenSearch server codebase where it was released in OpenSearch v2.9 as a generally available feature.
If you would want to contribute to OpenSearch, create a GitHub issue and share your ideas with us. We would also be interested in learning about your experience with Zstandard in OpenSearch Service. Please feel free to ask more questions in the comments section.
 Praveen Nischal is a Cloud Software Engineer, and leads the cloud workload performance framework at Intel.
Praveen Nischal is a Cloud Software Engineer, and leads the cloud workload performance framework at Intel.
 Mulugeta Mammo is a Senior Software Engineer, and currently leads the OpenSearch Optimization team at Intel.
Mulugeta Mammo is a Senior Software Engineer, and currently leads the OpenSearch Optimization team at Intel.
 Akash Shankaran is a Software Architect and Tech Lead in the Xeon software team at Intel. He works on pathfinding opportunities, and enabling optimizations for data services such as OpenSearch.
Akash Shankaran is a Software Architect and Tech Lead in the Xeon software team at Intel. He works on pathfinding opportunities, and enabling optimizations for data services such as OpenSearch.
 Sarthak Aggarwal is a Software Engineer at Amazon OpenSearch Service. He has been contributing towards open-source development with indexing and storage performance as a primary area of interest.
Sarthak Aggarwal is a Software Engineer at Amazon OpenSearch Service. He has been contributing towards open-source development with indexing and storage performance as a primary area of interest.
 Prabhakar Sithanandam is a Principal Engineer with Amazon OpenSearch Service. He primarily works on the scalability and performance aspects of OpenSearch.
Prabhakar Sithanandam is a Principal Engineer with Amazon OpenSearch Service. He primarily works on the scalability and performance aspects of OpenSearch.
Post Syndicated from Arynn Crow original https://aws.amazon.com/blogs/security/passkeys-enhance-security-and-usability-as-aws-expands-mfa-requirements/
Amazon Web Services (AWS) is designed to be the most secure place for customers to run their workloads. From day one, we pioneered secure by design and secure by default practices in the cloud. Today, we’re taking another step to enhance our customers’ options for strong authentication by launching support for FIDO2 passkeys as a method for multi-factor authentication (MFA) as we expand our MFA capabilities. Passkeys deliver a highly secure, user-friendly option to enable MFA for many of our customers.
In October 2023, we first announced we would begin requiring MFA for the most privileged users in an AWS account, beginning with AWS Organizations management account root users before expanding to other use cases. Beginning in July 2024, root users of standalone accounts (those that aren’t managed with AWS Organizations) will be required to use MFA when signing in to the AWS Management Console. Just as with management accounts, this change will start with a small number of customers and increase gradually over a period of months. Customers will have a grace period to enable MFA, which is displayed as a reminder at sign-in. This change does not apply to the root users of member accounts in AWS Organizations. We will share more information about MFA requirements for remaining root user use cases, such as member accounts, later in 2024 as we prepare to launch additional features to help our customers manage MFA for larger numbers of users at scale.
As we prepare to expand this program over the coming months, today we are launching support for FIDO2 passkeys as an MFA method to help customers align with their MFA requirements and enhance their default security posture. Customers already use passkeys on billions of computers and mobile devices across the globe, using only a security mechanism such as a fingerprint, facial scan, or PIN built in to their device. For example, you could configure Apple Touch ID on your iPhone or Windows Hello on your laptop as your authenticator, then use that same passkey as your MFA method as you sign in to the AWS console across multiple other devices you own.
There has been a lot of discussion about passkeys in the industry over the past year, so in this blog post, I’ll address some common questions about passkeys and share reflections about how they can fit into your security strategy.
Passkeys are a new name for a familiar technology: Passkeys are FIDO2 credentials, which use public key cryptography to provide strong, phishing-resistant authentication. Syncable passkeys are an evolution of FIDO2 implementation by credential providers—such as Apple, 1Password, Google, Dashlane, Microsoft, and others—that enable FIDO keys to be backed up and synced across devices and operating systems rather than being stored on physical devices like a USB-based key.
These changes are substantial enhancements for customers who prioritize usability and account recovery, but the changes required no modifications to the specifications that make up FIDO2. Passkeys possess the same fundamental cryptographically secure, phishing-resistant properties FIDO2 has had from the start. As a member company of the FIDO Alliance, we continue to work with FIDO to support the evolution and growth of strong authentication technologies, and are excited to enable this new experience for FIDO technology that provides a good balance between usability and strong security.
Before describing who should use passkeys, I want to emphasize that any type of MFA is better than no MFA at all. MFA is one of the simplest but most effective security controls you can apply to your account, and everyone should be using some form of MFA. Still, it’s useful to understand some of the key differences between types of MFA when making a decision about what to use personally or to deploy at your company.
We recommend phishing-resistant forms of MFA, such as passkeys and other FIDO2 authenticators. In recent years, as credential-based exploits increased, so did phishing and social engineering exploits that target users who utilize one-time PINs (OTPs) for MFA. As an example, a user of an OTP device must read the PIN from the device and enter it manually, so bad actors could attempt to get unsuspecting users to read the OTP to them instead, thereby bypassing the value of MFA. Although passkeys are a clear improvement above password-only authentication, like any kind of MFA, in many cases passkeys are both more user friendly and also more secure than OTP-based MFA. This is why passkeys are such an important tool in the Secure by Design strategy: Usable security is essential to effective security. For this reason, passkeys are a great option to balance user experience and security for most people. It’s not always easy to find security mechanisms that are both more secure and yet easier to use, but compared to OTP-based MFA, passkeys are one of those nice exceptions.
If you’re already using another form of MFA like a non-syncable FIDO2 hardware security key or authenticator app, the question of whether or not you should migrate to syncable passkeys is dependent on your or your organizations’ uses and requirements. Because their credentials are bound only to the device that created them, FIDO2 security keys provide the highest level of security assurance for customers whose regulatory or security requirements demand the strongest forms of authentication, such as FIPS-certified devices. It’s also important to understand that the passkey providers’ security model, such as what requirements the provider places for accessing or recovering access to the key vault, are now important considerations in your overall security model when you decide what kinds of MFA to deploy or to use going forward.
At the RSA Conference last month, we made the decision to sign on to the Cybersecurity and Infrastructure Security Agency’s (CISA’s) Secure by Design pledge, a voluntary pledge for enterprise software products and services, in line with CISA’s Secure by Design principles. One key element of the pledge is to increase the use of MFA, one of the simplest and most effective ways to enhance account security.
When used as MFA, passkeys provide enhanced security for human authentication in a user-friendly manner. You can register and use passkeys today to enhance the security of your AWS console access. This will help you to adhere to AWS default MFA security requirements as those roll out to a larger group of customers starting in July. We’ll cover more about our status and progress regarding other elements of the Secure by Design pledge in subsequent communications. Meanwhile, we strongly encourage you adopt some form of MFA anywhere you’re signing in today, and especially phishing-resistant MFA, which we’re excited to enhance with FIDO2 passkeys.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Post Syndicated from jake original https://lwn.net/Articles/977486/
VFS maintainer Christian Brauner led a discussion about the possibility of
selectively dropping the contents of the page cache for a filesystem in a
session at the
2024 Linux Storage,
Filesystem, Memory Management, and BPF Summit. As he described in his
topic
proposal, the use case that started him down this path comes from
GNOME, which wants to be able to safely suspend access to an encrypted home
directory. While it is known to kernel
developers, it is surprising to others that reads from encrypted
filesystems that have been suspended will succeed if the data to be read
still exists in the
page cache.
Post Syndicated from Stephen Fewer original https://blog.rapid7.com/2024/06/11/etr-cve-2024-28995-trivially-exploitable-information-disclosure-vulnerability-in-solarwinds-serv-u/

On June 5, 2024, SolarWinds disclosed CVE-2024-28995, a high-severity directory traversal vulnerability affecting their Serv-U file transfer server, which comes in two editions (Serv-U FTP and Serv-U MFT). Successful exploitation of the vulnerability allows unauthenticated attackers to read sensitive files on the target server. Rapid7’s vulnerability research team has reproduced the vulnerability and confirmed that it’s trivially exploitable and allows an external unauthenticated attacker to read any file on disk, including binary files, so long as they know the path and the file is not locked (i.e., opened exclusively by something else).
CVE-2024-28995 is not known to be exploited in the wild as of 9 AM ET on June 11. We expect this to change; Rapid7 recommends installing the vendor-provided hotfix (Serv-U 15.4.2 HF 2) immediately, without waiting for a regular patch cycle to occur.
High-severity information disclosure issues like CVE-2024-28995 can be used in smash-and-grab attacks where adversaries gain access to and attempt to quickly exfiltrate data from file transfer solutions with the goal of extorting victims. File transfer products have been targeted by a wide range of adversaries the past several years, including ransomware groups.
Internet exposure estimates for SolarWinds Serv-U vary substantially based on the query used. For example (note that exposed does not automatically mean vulnerable):
SolarWinds Serv-U 15.4.2 HF 1 and previous versions are vulnerable to CVE-2024-28995, per the vendor advisory. The vulnerability is fixed in SolarWinds Serv-U 15.4.2 HF 2. SolarWinds Serv-U customers should apply the vendor-provided hotfix immediately.
InsightVM and Nexpose customers can assess their exposure to CVE-2024-28995 with an unauthenticated vulnerability check available as of the Monday, June 10 content release.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=eNSD5pKHfhA