Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-happy-lunar-new-year-iac-generator-nfls-digital-athlete-aws-cloud-clubs-and-more-february-12-2024/
 Happy Lunar New Year! Wishing you a year filled with joy, success, and endless opportunities! May the Year of the Dragon bring uninterrupted connections and limitless growth
Happy Lunar New Year! Wishing you a year filled with joy, success, and endless opportunities! May the Year of the Dragon bring uninterrupted connections and limitless growth 

In case you missed it, here’s outstanding news you need to know as you plan your year in early 2024.
AWS was named as a Leader in the 2023 Magic Quadrant for Strategic Cloud Platform Services. AWS is the longest-running Magic Quadrant Leader, with Gartner naming AWS a Leader for the thirteenth consecutive year. See Sebastian’s blog post to learn more. AWS has been named a Leader for the ninth consecutive year in the 2023 Gartner Magic Quadrant for Cloud Database Management Systems, and we have been positioned highest for ability to execute by providing a comprehensive set of services for your data foundation across all workloads, use cases, and data types. See Rahul Pathak’s blog post to learn more.
AWS also has been named a Leader in data clean room technology according to the IDC MarketScape: Worldwide Data Clean Room Technology 2024 Vendor Assessment (January 2024). This report evaluated data clean room technology vendors for use cases across industries. See the AWS for Industries Blog channel post to learn more.
Last Week’s Launches
Here are some launches that got my attention:
A new Local Zone in Houston, Texas – Local Zones are an AWS infrastructure deployment that places compute, storage, database, and other select services closer to large population, industry, and IT centers where no AWS Region exists. AWS Local Zones are available in the US in 15 other metro areas and globally in an additional 17 metros areas, allowing you to deliver low-latency applications to end users worldwide. You can enable the new Local Zone in Houston (us-east-1-iah-2a) from the Zones tab in the Amazon EC2 console settings.

AWS CloudFormation IaC generator – You can generate a template using AWS resources provisioned in your account that are not already managed by CloudFormation. With this launch, you can onboard workloads to Infrastructure as Code (IaC) in minutes, eliminating weeks of manual effort. You can then leverage the IaC benefits of automation, safety, and scalability for the workloads. Use the template to import resources into CloudFormation or replicate resources in a new account or Region. See the user guide and blog post to learn more.

A new look-and-feel of Amazon Bedrock console – Amazon Bedrock now offers an enhanced console experience with updated UI improves usability, responsiveness, and accessibility with more seamless support for dark mode. To get started with the new experience, visit the Amazon Bedrock console.

One-click WAF integration on ALB – Application Load Balancer (ALB) now supports console integration with AWS WAF that allows you to secure your applications behind ALB with a single click. This integration enables AWS WAF protections as a first line of defense against common web threats for your applications that use ALB. You can use this one-click security protection provided by AWS WAF from the integrated services section of the ALB console for both new and existing load balancers.

Up to 49% price reduction for AWS Fargate Windows containers on Amazon ECS – Windows containers running on Fargate are now billed per second for infrastructure and Windows Server licenses that their containerized application requests. Along with the infrastructure pricing for on-demand, we are also reducing the minimum billing duration for Windows containers to 5 minutes (from 15 minutes) for any Fargate Windows tasks starting February 1st, 2024 (12:00am UTC). The infrastructure pricing and minimum billing period changes will automatically reflect in your monthly AWS bill. For more information on the specific price reductions, see our pricing page.
Introducing Amazon Data Firehose – We are renaming Amazon Kinesis Data Firehose to Amazon Data Firehose. Amazon Data Firehose is the easiest way to capture, transform, and deliver data streams into Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Splunk, Snowflake, and other 3rd party analytics services. The name change is effective in the AWS Management Console, documentations, and product pages.
AWS Transfer Family integrations with Amazon EventBridge – AWS Transfer Family now enables conditional workflows by publishing SFTP, FTPS, and FTP file transfer events in near real-time, SFTP connectors file transfer event notifications, and Applicability Statement 2 (AS2) transfer operations to Amazon EventBridge. You can orchestrate your file transfer and file-processing workflows in AWS using Amazon EventBridge, or any workflow orchestration service of your choice that integrates with these events.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS News
Some other updates and news that you might have missed:
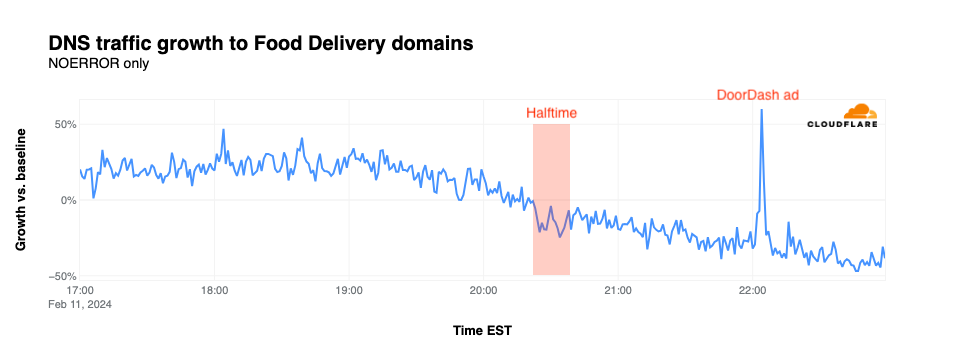
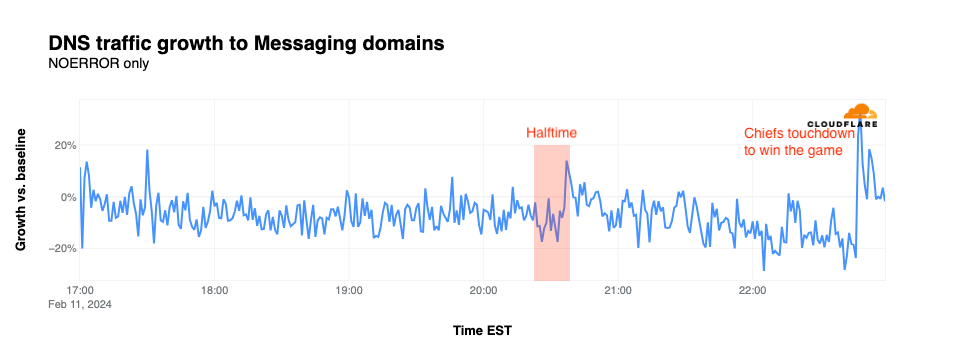
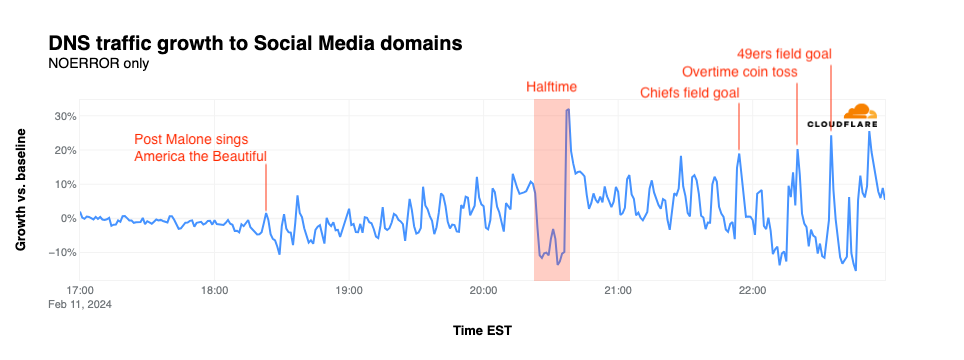
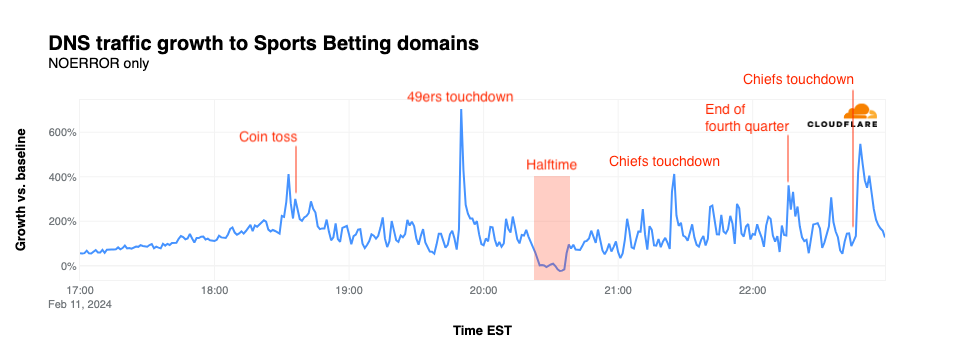
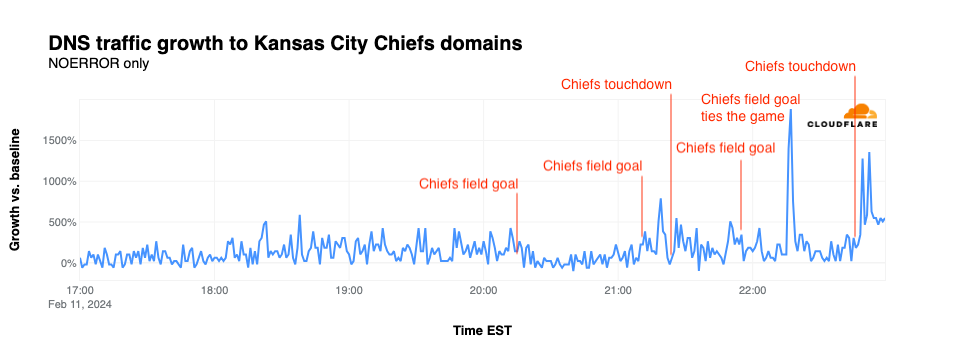
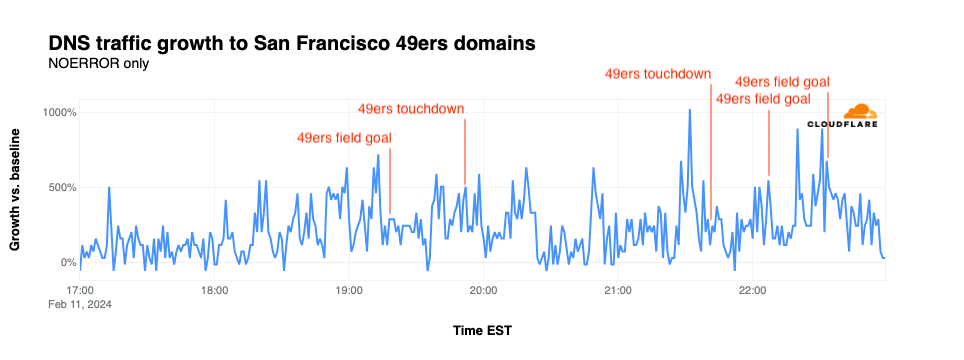
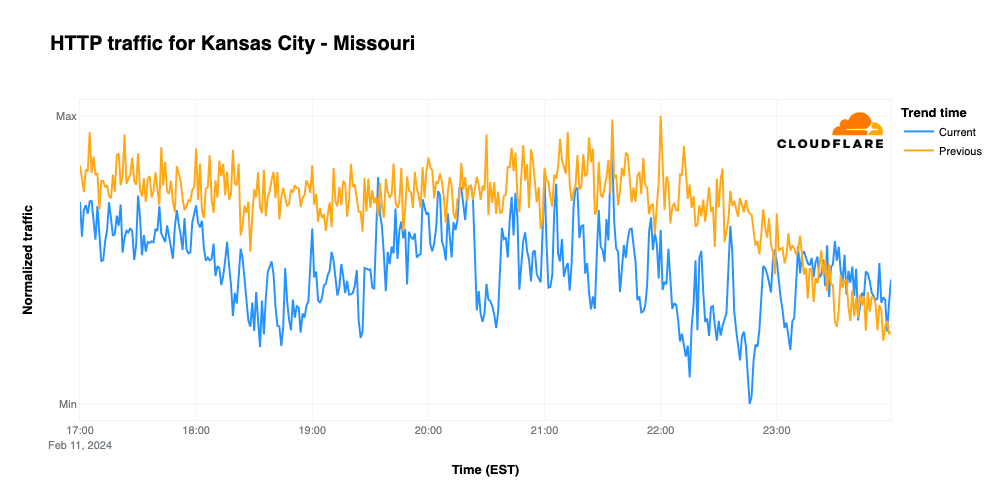
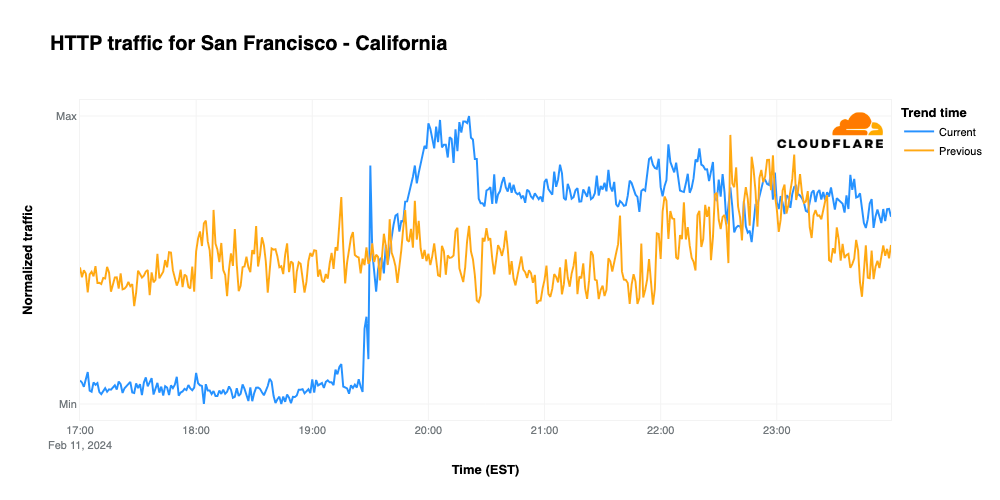
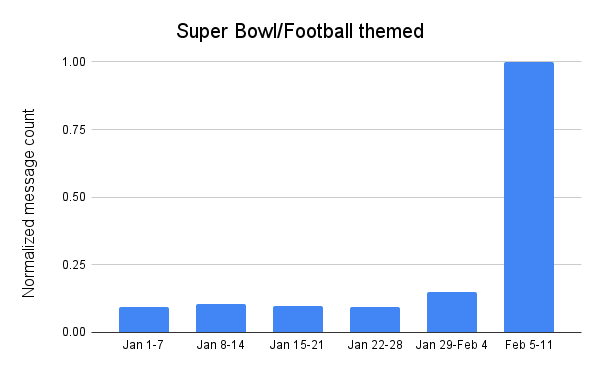
NFL’s digital athlete in the Super Bowl – AWS is working with the National Football League (NFL) to take player health and safety to the next level. Using AI and machine learning, they are creating a precise picture of each player in training, practice, and games. You could see this technology in action, especially with the Super Bowl on the last Sunday!
Amazon’s commiting the responsible AI – On February 7, Amazon joined the U.S. Artificial Intelligence Safety Institute Consortium, established by the National Institute of Standards of Technology (NIST), to further our government and industry collaboration to advance safe and secure artificial intelligence (AI). Amazon will contribute compute credits to help develop tools to evaluate AI safety and help the institute set an interoperable and trusted foundation for responsible AI development and use.
Compliance updates in South Korea – AWS has completed the 2023 South Korea Cloud Service Providers (CSP) Safety Assessment Program, also known as the Regulation on Supervision on Electronic Financial Transactions (RSEFT) Audit Program. AWS is committed to helping our customers adhere to applicable regulations and guidelines, and we help ensure that our financial customers have a hassle-free experience using the cloud. Also, AWS has successfully renewed certification under the Korea Information Security Management System (K-ISMS) standard (effective from December 16, 2023, to December 15, 2026).
Join AWS Cloud Clubs Captains – AWS Cloud Clubs are student-led user groups for post-secondary level students and independent learners. Interested in founding or co-founding a Cloud Club in your university or region? We are accepting applications from February 5-18, 2024.
Upcoming AWS Events
Check your calendars and sign up for upcoming AWS events:
AWS Innovate AI/ML and Data Edition – Join our free online conference to learn how you and your organization can leverage the latest advances in generative AI. You can register upcoming AWS Innovate Online event that fits your timezone in Asia Pacific & Japan (February 22), EMEA (February 29), and Americas (March 14).
AWS Public Sector events – Join us at the AWS Public Sector Symposium Brussels (March 12) to discover how the AWS Cloud can help you improve resiliency, develop sustainable solutions, and achieve your mission. AWS Public Sector Day London (March 19) gathers professionals from government, healthcare, and education sectors to tackle pressing challenges in United Kingdom public services.
Kicking off AWS Global Summits – AWS Summits are a series of free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Below is a list of available AWS Summit events taking place in April:
- AWS Summit Paris (April 3, 2024)
- AWS Summit Amsterdam (April 9, 2024)
- AWS Summit Sydney (April 10-11, 2024)
- AWS Summit London (April 24, 2024)
You can browse all upcoming AWS-led in-person and virtual events, and developer-focused events such as AWS DevDay.
That’s all for this week. Check back next Monday for another Week in Review!
— Channy



 Shabi Abbas Sayed is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with the customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud.
Shabi Abbas Sayed is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with the customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud. Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.
Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.






 Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS. Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.