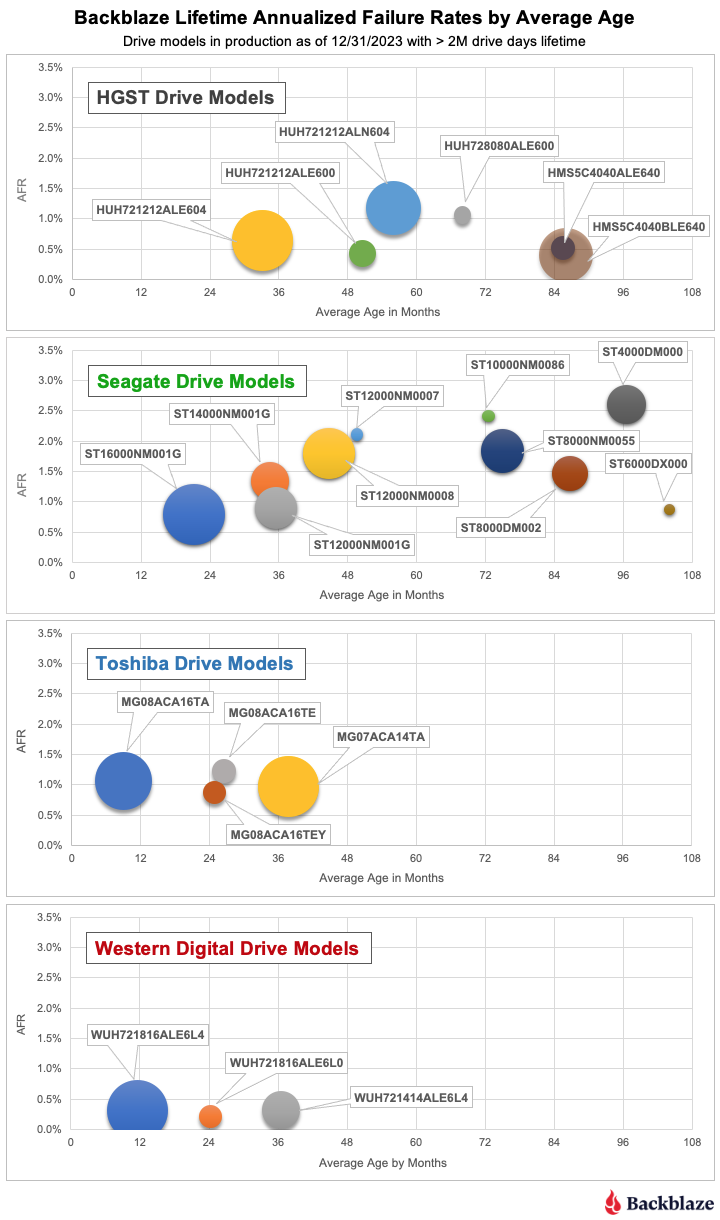
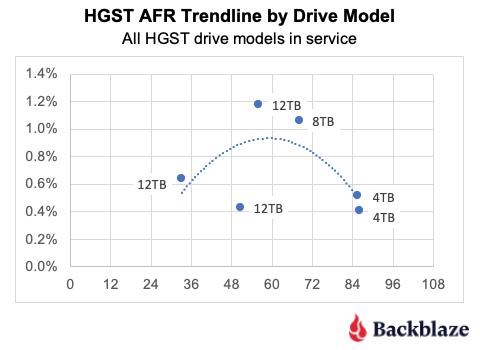
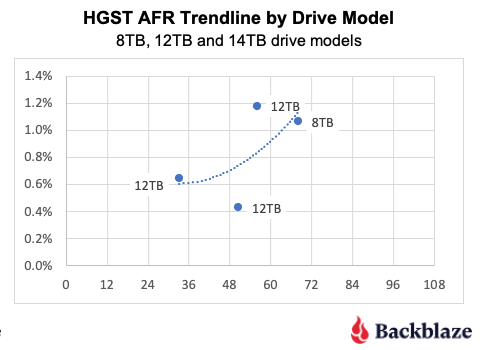
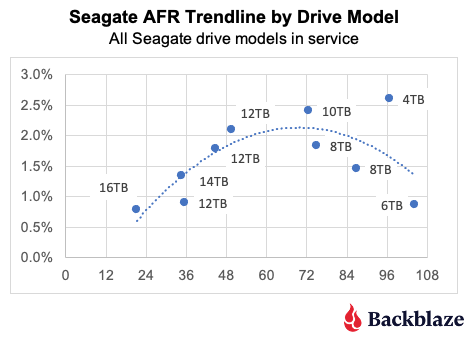
Post Syndicated from Noritaka Sekiyama original https://aws.amazon.com/blogs/big-data/part-2-enhance-monitoring-and-debugging-for-aws-glue-jobs-using-new-job-observability-metrics/
Monitoring data pipelines in real time is critical for catching issues early and minimizing disruptions. AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics, which provide valuable insights into your data integration pipelines built on AWS Glue. However, you might need to track key performance indicators across multiple jobs. In this case, a dashboard that can visualize the same metrics with the ability to drill down into individual issues is an effective solution to monitor at scale.
This post, walks through how to integrate AWS Glue job observability metrics with Grafana using Amazon Managed Grafana. We discuss the types of metrics and charts available to surface key insights along with two use cases on monitoring error classes and throughput of your AWS Glue jobs.
Solution overview
Grafana is an open source visualization tool that allows you to query, visualize, alert on, and understand your metrics no matter where they are stored. With Grafana, you can create, explore, and share visually rich, data-driven dashboards. The new AWS Glue job observability metrics can be effortlessly integrated with Grafana for real-time monitoring purpose. Metrics like worker utilization, skewness, I/O rate, and errors are captured and visualized in easy-to-read Grafana dashboards. The integration with Grafana provides a flexible way to build custom views of pipeline health tailored to your needs. Observability metrics open up monitoring capabilities that weren’t possible before for AWS Glue. Companies relying on AWS Glue for critical data integration pipelines can have greater confidence that their pipelines are running efficiently.
AWS Glue job observability metrics are emitted as Amazon CloudWatch metrics. You can provision and manage Amazon Managed Grafana, and configure the CloudWatch plugin for the given metrics. The following diagram illustrates the solution architecture.

Implement the solution
Complete following steps to set up the solution:
- Set up an Amazon Managed Grafana workspace.
- Sign in to your workspace.
- Choose Administration.
- Choose Add new data source.
- Choose CloudWatch.
- For Default Region, select your preferred AWS Region.
- For Namespaces of Custom Metrics, enter Glue.
- Choose Save & test.
Now the CloudWatch data source has been registered.
- Copy the data source ID from the URL
https://g-XXXXXXXXXX.grafana-workspace.<region>.amazonaws.com/datasources/edit/<data-source-ID>/.
The next step is to prepare the JSON template file.
- Download the Grafana template.
- Replace
<data-source-id>in the JSON file with your Grafana data source ID.
Lastly, configure the dashboard.
- On the Grafana console, choose Dashboards.
- Choose Import on the New menu.
- Upload your JSON file, and choose Import.
The Grafana dashboard visualizes AWS Glue observability metrics, as shown in the following screenshots.



The sample dashboard has the following charts:
- [Reliability] Job Run Errors Breakdown
- [Throughput] Bytes Read & Write
- [Throughput] Records Read & Write
- [Resource Utilization] Worker Utilization
- [Job Performance] Skewness
- [Resource Utilization] Disk Used (%)
- [Resource Utilization] Disk Available (GB)
- [Executor OOM] OOM Error Count
- [Executor OOM] Heap Memory Used (%)
- [Driver OOM] OOM Error Count
- [Driver OOM] Heap Memory Used (%)
Analyze the causes of job failures
Let’s try analyzing the causes of job run failures of the job iot_data_processing.
First, look at the pie chart [Reliability] Job Run Errors Breakdown. This pie chart quickly identifies which errors are most common.

Then filter with the job name iot_data_processing to see the common errors for this job.

We can observe that the majority (75%) of failures were due to glue.error.DISK_NO_SPACE_ERROR.
Next, look at the line chart [Resource Utilization] Disk Used (%) to understand the driver’s used disk space during the job runs. For this job, the green line shows the driver’s disk usage, and the yellow line shows the average of the executors’ disk usage.

We can observe that there were three times when 100% of disk was used in executors.
Next, look at the line chart [Throughput] Records Read & Write to see whether the data volume was changed and whether it impacted disk usage.

The chart shows that around four billion records were read at the beginning of this range; however, around 63 billion records were read at the peak. This means that the incoming data volume has significantly increased, and caused local disk space shortage in the worker nodes. For such cases, you can increase the number of workers, enable auto scaling, or choose larger worker types.
After implementing those suggestions, we can see lower disk usage and a successful job run.

(Optional) Configure cross-account setup
We can optionally configure a cross-account setup. Cross-account metrics depend on CloudWatch cross-account observability. In this setup, we expect the following environment:
- AWS accounts are not managed in AWS Organizations
- You have two accounts: one account is used as the monitoring account where Grafana is located, another account is used as the source account where the AWS Glue-based data integration pipeline is located
To configure a cross-account setup for this environment, complete the following steps for each account.
Monitoring account
Complete the following steps to configure your monitoring account:
- Sign in to the AWS Management Console using the account you will use for monitoring.
- On the CloudWatch console, choose Settings in the navigation pane.
- Under Monitoring account configuration, choose Configure.
- For Select data, choose Metrics.
- For List source accounts, enter the AWS account ID of the source account that this monitoring account will view.
- For Define a label to identify your source account, choose Account name.
- Choose Configure.
Now the account is successfully configured as a monitoring account.
- Under Monitoring account configuration, choose Resources to link accounts.
- Choose Any account to get a URL for setting up individual accounts as source accounts.
- Choose Copy URL.
You will use the copied URL from the source account in the next steps.
Source account
Complete the following steps to configure your source account:
- Sign in to the console using your source account.
- Enter the URL that you copied from the monitoring account.
You can see the CloudWatch settings page, with some information filled in.
- For Select data, choose Metrics.
- Do not change the ARN in Enter monitoring account configuration ARN.
- The Define a label to identify your source account section is pre-filled with the label choice from the monitoring account. Optionally, choose Edit to change it.
- Choose Link.
- Enter
Confirmin the box and choose Confirm.
Now your source account has been configured to link to the monitoring account. The metrics emitted in the source account will show on the Grafana dashboard in the monitoring account.
To learn more, see CloudWatch cross-account observability.
Considerations
The following are some considerations when using this solution:
- Grafana integration is defined for real-time monitoring. If you have a basic understanding of your jobs, it will be straightforward for you to monitor performance, errors, and more on the Grafana dashboard.
- Amazon Managed Grafana depends on AWS IAM Identify Center. This means you need to manage single sign-on (SSO) users separately, not just AWS Identity and Access Management (IAM) users and roles. It also requires another sign-in step from the AWS console. The Amazon Managed Grafana pricing model depends on an active user license per workspace. More users can cause more charges.
- Graph lines are visualized per job. If you want to see the lines across all the jobs, you can choose ALL in the control.
Conclusion
AWS Glue job observability metrics offer a powerful new capability for monitoring data pipeline performance in real time. By streaming key metrics to CloudWatch and visualizing them in Grafana, you gain more fine-grained visibility that wasn’t possible before. This post showed how straightforward it is to enable observability metrics and integrate the data with Grafana using Amazon Managed Grafana. We explored the different metrics available and how to build customized Grafana dashboards to surface actionable insights.
Observability is now an essential part of robust data orchestration on AWS. With the ability to monitor data integration trends in real time, you can optimize costs, performance, and reliability.
About the Authors
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
 Xiaoxi Liu is a Software Development Engineer on the AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on the cloud, and her concentrations are distributed system, big data, and cloud computing.
Xiaoxi Liu is a Software Development Engineer on the AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on the cloud, and her concentrations are distributed system, big data, and cloud computing.
 Akira Ajisaka is a Senior Software Development Engineer on the AWS Glue team. He likes open source software and distributed systems. In his spare time, he enjoys playing arcade games.
Akira Ajisaka is a Senior Software Development Engineer on the AWS Glue team. He likes open source software and distributed systems. In his spare time, he enjoys playing arcade games.
 Shenoda Guirguis is a Senior Software Development Engineer on the AWS Glue team. His passion is in building scalable and distributed data infrastructure and processing systems. When he gets a chance, Shenoda enjoys reading and playing soccer.
Shenoda Guirguis is a Senior Software Development Engineer on the AWS Glue team. His passion is in building scalable and distributed data infrastructure and processing systems. When he gets a chance, Shenoda enjoys reading and playing soccer.
 Sean Ma is a Principal Product Manager on the AWS Glue team. He has an 18-year track record of innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Sean enjoys scuba diving and college football.
Sean Ma is a Principal Product Manager on the AWS Glue team. He has an 18-year track record of innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Sean enjoys scuba diving and college football.
 Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team focuses on building distributed systems to enable customers with interactive and simple to use interfaces to efficiently manage and transform petabytes of data seamlessly across data lakes on Amazon S3, databases and data-warehouses on cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team focuses on building distributed systems to enable customers with interactive and simple to use interfaces to efficiently manage and transform petabytes of data seamlessly across data lakes on Amazon S3, databases and data-warehouses on cloud.



 Tamer Soliman is a Senior Solutions Architect at AWS. He helps Independent Software Vendor (ISV) customers innovate, build, and scale on AWS. He has over two decades of industry experience, and is an inventor with three granted patents. His experience spans multiple technology domains including telecom, networking, application integration, data analytics, AI/ML, and cloud deployments. He specializes in AWS Networking and has a profound passion for machine leaning, AI, and Generative AI.
Tamer Soliman is a Senior Solutions Architect at AWS. He helps Independent Software Vendor (ISV) customers innovate, build, and scale on AWS. He has over two decades of industry experience, and is an inventor with three granted patents. His experience spans multiple technology domains including telecom, networking, application integration, data analytics, AI/ML, and cloud deployments. He specializes in AWS Networking and has a profound passion for machine leaning, AI, and Generative AI.