Prior to 2021, Grab’s search architecture was designed to only support textual matching, which takes in a user query and looks for exact matches within the ecosystem through an inverted index. This legacy system meant that only textual matching results could be fetched.
In the second half of 2021, the Deliveries search team worked on improving this architecture to make it smarter, more scalable and also unlock future growth for different search use cases at Grab. The figure below shows a simplified overview of the legacy architecture.
Legacy architecture
Problem statement
With the legacy system, we noticed several problems.
Search results were textually matched without considering intention and context
If a user types in a query “Roti Prata” (flatbread), he is likely looking for Roti Prata dishes and those matches with the dish name should be prioritised compared with matches with the merchant-partner’s name or matches with other entities.
In the legacy system, all entities whose names partially matched “Roti Prata” were displayed and ranked according to hard coded weights, and matches with merchant-partner names were always prioritised, even if the user intention was clearly to search for the “Roti Prata” dish itself.
This problem was more common in Mart, as users often intended to search for items instead of shops. Besides the lack of intention recognition, the search system was also unable to take context into consideration; users searching the same keyword query at different times and locations could have different objectives. E.g. if users search for “Bread” in the day, they may be likely to look for cafes while searches at night could be for breakfast the next day.
Search results from multiple business verticals were not blended effectively
In Grab’s context, results from multiple verticals were often merged. For example, in Mart searches, Ads and Mart organic search results were displayed together; in Food searches, Ads, Food and Mart organic results were blended together.
In the legacy architecture, multiple business verticals were merged on the Deliveries API layer, which resulted in the leak of abstraction and loss of useful data as data from the search recall stage was also not taken into account during the merge stage.
Inability to quickly scale to new search use cases and difficulty in reusing existing components
The legacy code base was not written in a structured way that could scale to new use cases easily. If new search use cases cannot be built on top of an existing system, it can be rather tedious to keep rebuilding the function every time there is a new search use case.
Solution
In this section, solutions from both architecture and implementation perspectives are presented to address the above problem statements.
Architecture
In the new architecture, the flow is extended from lexical recall only to multi-layer including boosting, multi-recall, and ranking. The addition of boosting enables capabilities like intent recognition and query expansion, while the change from single lexical recall to multi-recall opens up the potential for other recall methods, e.g. embedding based and graph based.
These help address the first problem statement. Furthermore, the multi-recall framework enables fetching results from multiple business verticals, addressing the second problem statement. In the new framework, results from different verticals and different recall methods were grouped and ranked together without any leak of abstraction or loss of useful data from search recall stage in ranking.
Upgraded architecture
Implementation
We believe that the key to a platform’s success is modularisation and flexible assembling of plugins to enable quick product iteration. That is why we implemented a combination of a framework defined by the platform and plugins provided by service teams. In this implementation, plugins are assembled through configurations, which addresses the third problem statement and has two advantages:
Separation of concern. With the main flow abstracted and maintained by the platform, service team developers could focus on the application logic by writing plugins and fitting them into the main flow. In this case, developers without search experience could quickly enable new search flows.
Reusing plugins and economies of scale. With more use cases onboarded, more plugins are written by service teams and these plugins are reusable assets, resulting in scale effect. For example, an Ads recall plugin could be reused in Food keyword or non-keyword searches, Mart keyword or non-keyword searches and universal search flows as all these searches contain non-organic Ads. Similarly, a Mart recall plugin could be reused in Mart keyword or non-keyword searches, universal search and Food keyword search flows, as all these flows contain Mart results. With more plugins accumulated on our platform, developers might be able to ship a new search flow by just reusing and assembling the existing plugins.
Conclusion
Our platform now has a smart search with intent recognition and semantic (embedding-based) search. The process of adding new modules is also more straightforward and adds intention recognition to the boosting step as well as embedding as an additional recall to the multi-recall step. These modules can be easily reused by other use cases.
On top of that, we also have a mixed Ads and an organic framework. This means that data in the recall stage is taken into consideration and Ads can now be ranked together with organic results, e.g. text relevance.
With a modularised design and plugins provided by the platform, it is easier for clients to use our platform with a simple onboarding process. Furthermore, plugins can be reused to cater to new use cases and achieve a scale effect.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The Docs-as-Code concept has been gaining traction in the past few years as more tech companies start implementing this approach. One of the most widely-known examples is Spotify, that uses Docs-as-Code to publish documentation in an internal developer portal.
Since the start of 2021, Grab has also adopted a Docs-as-Code approach to improve our technical documentation. Before we talk about how this is done at Grab, let’s explain what this concept really means.
What is Docs-as-Code?
Docs-as-Code is a mindset of creating and maintaining technical documentation. The goal is to empower engineers to write technical documentation frequently and keep it up to date by integrating with their tools and processes.
This means that technical documentation is placed in the same repository as the code, making it easier for engineers to write and update. Next, we’ll go through the motivations behind this initiative.
Why embark on this journey?
After speaking to Grab engineers, we found that some of their biggest challenges are around finding and writing documentation. Like many other companies on the same journey, Grab is rather big and our engineers are split into many different teams. Within each team, technical documentation can be stored on different platforms and in different formats, e.g. Google drive documents, text files, etc. This makes it hard to find relevant information, especially if you are trying to find another team’s documentation.
On top of that, we realised that the documentation process is disconnected from an engineer’s everyday activities, making technical documentation an awkward afterthought. This means that even if people could find the information, there was a good chance that it would not be up to date.
To address these issues, we need a centralised platform, a single source of truth, so that people can find and discover technical documentation easily. But first, we need to change how we write technical documentation. This is where Docs-as-Code comes in.
How does Docs-as-Code solve the problem?
With Docs-as-Code, technical documentation is:
Written in plaintext.
Editable in a code editor.
Stored in the same repository as the source code so it’s easier to update docs whenever a code change is committed.
Published on a central platform.
The idea is to consolidate all technical documentation on a central platform, making it easier to discover and find content by using an easy-to-navigate information architecture and targeted search.
How is Grab embracing Docs-as-Code?
We’ve developed an internal developer portal that simplifies the process of writing, reviewing and publishing technical documentation.
Here’s a brief overview of the process:
Create a dedicated docs folder in a Git repository.
Push Markdown files into the docs folder.
Configure the developer portal to publish docs from the respective code repository.
The latest version of the documentation will automatically be built and published in the developer portal.
Simplified documentation process
This way, technical documentation is closer to the source code and integrated into the code development process. Writing and updating technical documentation becomes part of writing code, and this encourages engineers to keep documentation updated.
Measuring success
Whenever there’s a change throughout big organisations like Grab, it can be tough to implement. But thankfully, our engineers recognised the importance of improving documentation and making it easier to maintain or update.
We surveyed our users and here’s what some have said about our Docs-as-Code initiative:
“[W]ith the doc and source code in one place, test backend engineers can now make doc changes via standard code review process and re-use the same content for CLI helper message and documentation.” – Kang Yaw Ong, Test Automation – Engineering Manager
“[Docs-as-Code] is a great initiative, as it keeps documentation in line and up-to-date with the development of a project. Managing documentation using a version control system and the same tools to handle merges and conflicts reduces overhead and friction in an engineer’s workflow.” – Eugene Chiang, Foundations – Engineering Manager
Progress and future optimisations
Since we first started the Docs-as-Code initiative in Grab, we’ve made a lot of progress in terms of adoption – approximately 80% of Grab services will have their technical documentation on the internal portal by April 2022.
We’ve also improved overall user experience by enhancing stability and performance, improving navigation and content formatting, and enabling feedback. But it doesn’t stop there; we are continuously improving the internal portal and providing more features for our engineers.
Apart from technical documentation, we are also applying the Docs-as-Code approach to our technical training content. This means moving both self-paced and workshop training content to a centralised repository and providing engineers a single platform for all their learning needs.
Special thanks to the Tech Learning – Documentation team for their contributions to this blog post.
We are hiring!
We are looking for more technical content developers to join the team. If you’re keen on joining our Docs-as-Code journey and improving developer experience, check out our open listings in Singapore and Malaysia.
Join us in driving this initiative forward and making documentation more approachable for everyone!
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
As a leading superapp in Southeast Asia, Grab serves millions of consumers daily. This naturally makes us a target for fraudsters and to enhance our defences, the Integrity team at Grab has launched several hyper-scaled services, such as the Griffin real-time rule engine and Advanced Feature Engineering. These systems enable data scientists and risk analysts to develop real-time scoring, and take fraudsters out of our ecosystems.
Apart from individual fraudsters, we have also observed the fast evolution of the dark side over time. We have had to evolve our defences to deal with professional syndicates that use advanced equipment such as device farms and GPS spoofing apps to perform fraud at scale. These professional fraudsters are able to camouflage themselves as normal users, making it significantly harder to identify them with rule-based detection.
Since 2020, Grab’s Integrity team has been advancing fraud detection with more sophisticated techniques and experimenting with a range of graph network technologies such as graph visualisations, graph neural networks and graph analytics. We’ve seen a lot of progress in this journey and will be sharing some key learnings that might help other teams who are facing similar issues.
What are Graph-based Prediction Platforms?
“You can fool some of the people all of the time, and all of the people some of the time, but you cannot fool all of the people all of the time.” – Abraham Lincoln
A Graph-based Prediction Platform connects multiple entities through one or more common features. When such entities are viewed as a macro graph network, we uncover new patterns that are otherwise unseen to the naked eye. For example, when investigating if two users are sharing IP addresses or devices, we might not be able to tell if they are fraudulent or just family members sharing a device.
However, if we use a graph system and look at all users sharing this device or IP address, it could show us if these two users are part of a much larger syndicate network in a device farming operation. In operations like these, we may see up to hundreds of other fake accounts that were specifically created for promo and payment fraud. With graphs, we can identify fraudulent activity more easily.
Grab’s Graph-based Prediction Platform
Leveraging the power of graphs, the team has primarily built two types of systems:
Graph Database Platform: An ultra-scalable storage system with over one billion nodes that powers:
Graph Visualisation: Risk specialists and data analysts can review user connections real-time and are able to quickly capture new fraud patterns with over 10 dimensions of features (see Fig 1).
Fig 1: Graph visualisation
Network-based feature system: A configurable system for engineers to adjust machine learning features based on network connectivity, e.g. number of hops between two users, numbers of shared devices between two IP addresses.
Graph-based Machine Learning: Unlike traditional fraud detection models, Graph Neural Networks (GNN) are able to utilise the structural correlations on the graph and act as a sustainable foundation to combat many different kinds of fraud. The data science team has built large-scale GNN models for scenarios like anti-money laundering and fraud detection.
Fig 2 shows a Money Laundering Network where hundreds of accounts coordinate the placement of funds, layering the illicit monies through a complex web of transactions making funds hard to trace, and consolidate funds into spending accounts.
Fig 2: Money Laundering Network
What’s next?
In the next article of our Graph Network blog series, we will dive deeper into how we develop the graph infrastructure and database using AWS Neptune. Stay tuned for the next part.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
This article illustrates how the Cauldron Machine Learning (ML) Platform team uses GitLab parent-child pipelines to dynamically generate GitLab CI files to solve several limitations of GitLab for large repositories, namely:
Limitations to the number of includes (100 by default).
Simplifying the GitLab CI file from 1800 lines to 50 lines.
Reducing the need for nested gitlab-ci yml files.
Introduction
Cauldron is the Machine Learning (ML) Platform team at Grab. The Cauldron team provides tools for ML practitioners to manage the end to end lifecycle of ML models, from training to deployment. GitLab and its tooling are an integral part of our stack, for continuous delivery of machine learning.
One of our core products is MerLin Pipelines. Each team has a dedicated repo to maintain the code for their ML pipelines. Each pipeline has its own subfolder. We rely heavily on GitLab rules to detect specific changes to trigger deployments for the different stages of different pipelines (for example, model serving with Catwalk, and so on).
Background
Approach 1: Nested child files
Our initial approach was to rely heavily on static code generation to generate the child gitlab-ci.yml files in individual stages. See Figure 1 for an example directory structure. These nested yml files are pre-generated by our cli and committed to the repository.
Figure 1: Example directory structure with nested gitlab-ci.yml files.
Child gitlab-ci.yml files are added by using the include keyword.
Figure 2: Example root .gitlab-ci.yml file, and include clauses.
Figure 3: Example child `.gitlab-ci.yml` file for a given stage (Deploy Model) in a pipeline (pipeline 1).
As teams add more pipelines and stages, we soon hit a limitation in this approach:
There was a soft limit in the number of includes that could be in the base .gitlab-ci.yml file.
It became evident that this approach would not scale to our use-cases.
Approach 2: Dynamically generating a big CI file
Our next attempt to solve this problem was to try to inject and inline the nested child gitlab-ci.yml contents into the root gitlab-ci.yml file, so that we no longer needed to rely on the in-built GitLab “include” clause.
To achieve it, we wrote a utility that parsed a raw gitlab-ci file, walked the tree to retrieve all “included” child gitlab-ci files, and to replace the includes to generate a final big gitlab-ci.yml file.
Figure 4 illustrates the resulting file is generated from Figure 3.
Figure 4: “Fat” YAML file generated through this approach, assumes the original raw file of Figure 3.
This approach solved our issues temporarily. Unfortunately, we ended up with GitLab files that were up to 1800 lines long. There is also a soft limit to the size of gitlab-ci.yml files. It became evident that we would eventually hit the limits of this approach.
Solution
Our initial attempt at using static code generation put us partially there. We were able to pre-generate and infer the stage and pipeline names from the information available to us. Code generation was definitely needed, but upfront generation of code had some key limitations, as shown above. We needed a way to improve on this, to somehow generate GitLab stages on the fly. After some research, we stumbled upon Dynamic Child Pipelines.
Quoting the official website:
Instead of running a child pipeline from a static YAML file, you can define a job that runs your own script to generate a YAML file, which is then used to trigger a child pipeline.
This technique can be very powerful in generating pipelines targeting content that changed or to build a matrix of targets and architectures.
We were already on the right track. We just needed to combine code generation with child pipelines, to dynamically generate the necessary stages on the fly.
Architecture details
Figure 5: Flow diagram of how we use dynamic yaml generation. The user raises a merge request in a branch, and subsequently merges the branch to master.
Implementation
The user Git flow can be seen in Figure 5, where the user modifies or adds some files in their respective Git team repo. As a refresher, a typical repo structure consists of pipelines and stages (see Figure 1). We would need to extract the information necessary from the branch environment in Figure 5, and have a stage to programmatically generate the proper stages (for example, Figure 3).
In short, our requirements can be summarized as:
Detecting the files being changed in the Git branch.
Extracting the information needed from the files that have changed.
Passing this to be templated into the necessary stages.
Let’s take a very simple example, where a user is modifying a file in stage_1 in pipeline_1 in Figure 1. Our desired output would be:
Figure 6: Desired output that should be dynamically generated.
Our template would be in the form of:
Figure 7: Example template, and information needed. Let’s call it template_file.yml.
First, we need to detect the files being modified in the branch. We achieve this with native git diff commands, checking against the base of the branch to track what files are being modified in the merge request. The output (let’s call it diff.txt) would be in the form of:
M pipelines/pipeline_1/stage_1/modelserving.yaml
Figure 8: Example diff.txt generated from git diff.
We must extract the yellow and green information from the line, corresponding to pipeline_name and stage_name.
Figure 9: Information that needs to be extracted from the file.
We take a very simple approach here, by introducing a concept called stop patterns.
Stop patterns are defined as a comma separated list of variable names, and the words to stop at. The colon (:) denotes how many levels before the stop word to stop.
For example, the stop pattern:
pipeline_name:pipelines
tells the parser to look for the folder pipelines and stop before that, extracting pipeline_1 from the example above tagged to the variable name pipeline_name.
The stop pattern with two colons (::):
stage_name::pipelines
tells the parser to stop two levels before the folder pipelines, and extract stage_1 as stage_name.
Our cli tool allows the stop patterns to be comma separated, so the final command would be:
We elected to write the util in Rust due to its high performance, and its rich templating libraries (for example, Tera) and decent cli libraries (clap).
Combining all these together, we are able to extract the information needed from git diff, and use stop patterns to extract the necessary information to be passed into the template. Stop patterns are flexible enough to support different types of folder structures.
Figure 10: Example Rust code snippet for parsing the Git diff file.
When triggering pipelines in the master branch (see right side of Figure 5), the flow is the same, with a small caveat that we must retrieve the same diff.txt file from the source branch. We achieve this by using the rich GitLab API, retrieving the pipeline artifacts and using the same util above to generate the necessary GitLab steps dynamically.
Impact
After implementing this change, our biggest success was reducing one of the biggest ML pipeline Git repositories from 1800 lines to 50 lines. This approach keeps the size of the .gitlab-ci.yaml file constant at 50 lines, and ensures that it scales with however many pipelines are added.
Our users, the machine learning practitioners, also find it more productive as they no longer need to worry about GitLab yaml files.
Learnings and conclusion
With some creativity, and the flexibility of GitLab Child Pipelines, we were able to invest some engineering effort into making the configuration re-usable, adhering to DRY principles.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
To build a NoOps managed streaming platform in Grab, the Coban team has:
Engineered an ecosystem on top of Apache Kafka.
Successfully adopted it to production for both transactional and analytical use cases.
Made it a battle-tested industrial-standard platform.
In 2021, the Coban team embarked on a new journey (Kafka Connect) that enables and empowers Grabbers to move data in and out of Apache Kafka seamlessly and conveniently.
Kafka Connect stack in Grab
This is what Coban’s Kafka Connect stack looks like today. Multiple data sources and data sinks, such as MySQL, S3 and Azure Data Explorer, have already been supported and productionised.
The Coban team has been using Protobuf as the serialisation-deserialisation (SerDes) format in Kafka. Therefore, the role of Confluent schema registry (shown at the top of the figure) is crucial to the Kafka Connect ecosystem, as it serves as the building block for conversions such as Protobuf-to-Avro, Protobuf-to-JSON and Protobuf-to-Parquet.
What problems are we trying to solve?
Problem 1: Change Data Capture (CDC)
In a big organisation like Grab, we handle large volumes of data and changes across many services on a daily basis, so it is important for these changes to be reflected in real time.
In addition, there are other technical challenges to be addressed:
As shown in the figure below, data is written twice in the code base – once into the database (DB) and once as a message into Kafka. In order for the data in the DB and Kafka to be consistent, the two writes have to be atomic in a two-phase commit protocol (or other atomic commitment protocols), which is non-trivial and impacts availability.
Some use cases require data both before and after a change.
Problem 2: Message mirroring for disaster recovery
The Coban team has done some research on Kafka MirrorMaker, an open-source solution. While it can ensure better data consistency, it takes significant effort to adopt it onto existing Kubernetes infrastructure hosted by the Coban team and achieve high availability.
Another major challenge that the Coban team faces is offset mirroring and translation, which is a known challenge in Kafka communities. In order for Kafka consumers to seamlessly resume their work with a backup Kafka after a disaster, we need to cater for offset translation.
Data ingestion into Azure Event Hubs
Azure Event Hubs has a Kafka-compatible interface and natively supports JSON and Avro schema. The Coban team uses Protobuf as the SerDes framework, which is not supported by Azure Event Hubs. It means that conversions have to be done for message ingestion into Azure Event Hubs.
Solution
To tackle these problems, the Coban team has picked Kafka Connect because:
It is an open-source framework with a relatively big community that we can consult if we run into issues.
It has the ability to plug in transformations and custom conversion logic.
Let us see how Kafka Connect can be used to resolve the previously mentioned problems.
Kafka Connect with Debezium connectors
Debezium is a framework built for capturing data changes on top of Apache Kafka and the Kafka Connect framework. It provides a series of connectors for various databases, such as MySQL, MongoDB and Cassandra.
Here are the benefits of MySQL binlog streams:
They not only provide changes on data, but also give snapshots of data before and after a specific change.
Some producers no longer have to push a message to Kafka after writing a row to a MySQL database. With Debezium connectors, services can choose not to deal with Kafka and only handle MySQL data stores.
Architecture
In case of DB upgrades and outages
DB Data Definition Language (DDL) changes, migrations, splits and outages are common in database operations, and each operation type has a systematic resolution.
The Debezium connector has built-in features to handle DDL changes made by DB migration tools, such as pt-online-schema-change, which is used by the Grab DB Ops team.
To deal with MySQL instance changes and database splits, the Coban team leverages on the Kafka Connect framework’s ability to change the offsets of connectors. By changing the offsets, Debezium connectors can properly function after DB migrations and resume binlog synchronisation from any position in any binlog file on a MySQL instance.
The CDC project on MySQL via Debezium connectors has been greatly successful in Grab. One of the biggest examples is its adoption in the Elasticsearch optimisation carried out by GrabFood, which has been published in another blog.
MirrorMaker2 with offset translation
Kafka MirrorMaker2 (MM2), developed in and shipped together with the Apache Kafka project, is a utility to mirror messages and consumer offsets. However, in the Coban team, the MM2 stack is deployed on the Kafka Connect framework per connector because:
A few Kafka Connect clusters have already been provisioned.
Compared to launching three connectors bundled in MM2, Coban can have finer controls on MirrorSourceConnector and MirrorCheckpointConnector, and manage both of them in an infrastructure-as-code way via Hashicorp Terraform.
Success stories
Ensuring business continuity is a key priority for Grab and this includes the ability to recover from incidents quickly. In 2021H2, there was a campaign that ran across many teams to examine the readiness and robustness of various services and middlewares. Coban’s Kafka is one of these services that proved to be robust after rounds of chaos engineering. With MM2 on Kafka Connect to mirror both messages and consumer offsets, critical services and pipelines could safely be replicated and launched across AWS regions if outages occur.
Because the Coban team has proven itself as the battle-tested Kafka service provider in Grab, other teams have also requested to migrate streams from self-managed Kafka clusters to ones managed by Coban. MM2 has been used in such migrations and brought zero downtime to the streams’ producers and consumers.
Mirror to Azure Event Hubs with an in-house converter
The Analytics team runs some real time ingestion and analytics projects on Azure. To support this cross-cloud use case, the Coban team has adopted MM2 for message mirroring to Azure Event Hubs.
Typically, Event Hubs only accept JSON and Avro bytes, which is incompatible with the existing SerDes framework. The Coban team has developed a custom converter that converts bytes serialised in Protobuf to JSON bytes at runtime.
These steps explain how the converter works:
Deserialise bytes in Kafka to a Protobuf DynamicMessage according to a schema retrieved from the Confluent™ schema registry.
Perform a recursive post-order depth-first-search on each field descriptor in the DynamicMessage.
Convert every Protobuf field descriptor to a JSON node.
Serialise the root JSON node to bytes.
The converter has not been open sourced yet.
Deployment
Docker containers are the Coban team’s preferred infrastructure, especially since some production Kafka clusters are already deployed on Kubernetes. The long-term goal is to provide Kafka in a software-as-a-service (SaaS) model, which is why Kubernetes was picked. The diagram below illustrates how Kafka Connect clusters are built and deployed.
What’s next?
The Coban team is iterating on a unified control plane to manage resources like Kafka topics, clusters and Kafka Connect. In the foreseeable future, internal users should be able to provision Kafka Connect connectors via RESTful APIs and a graphical user interface (GUI).
At the same time, the Coban team is closely working with the Data Engineering team to make Kafka Connect the preferred tool in Grab for moving data in and out of external storages (S3 and Apache Hudi).
Coban is hiring!
The Coban (Real-time Data Platform) team at Grab in Singapore is hiring software and site reliability engineers at all levels as we double down on growing our platform capabilities.
Join us in building state-of-the-art, mission critical, TB/hour scale data platforms that enable thousands of engineers, data scientists, and analysts to serve millions of consumers, businesses, and partners across Southeast Asia!
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
At Grab, we run large marketing campaigns every day. A typical campaign may require executing multiple actions for millions of users all at once. The actions may include sending rewards, awarding points, and sending messages. Here is what a campaign may look like: On 1st Jan 2022, send two ride rewards to all the users in the “heavy users” segment. Then, send them a congratulatory message informing them about the reward.
Years ago, Grab’s marketing team used to stay awake at midnight to manually trigger such campaigns. They would upload a file at 12 am and then wait for a long time for the campaign execution to complete. To solve this pain point and support more capabilities down this line, we developed a “batch job” service, which is part of our in-house real-time automation engine, Trident.
The following are some services we use to support Grab’s marketing teams:
Rewards: responsible for managing rewards.
Messaging: responsible for sending messages to users. For example, push notifications.
Segmentation: responsible for storing and retrieving segments of users based on certain criteria.
For simplicity, only the services above will be referenced for this article. The “batch job” service we built uses rewards and messaging services for executing actions, and uses the segmentation service for fetching users in a segment.
System requirements
Functional requirements
Apply a sequence of actions targeting a large segment of users at a scheduled time, display progress to the campaign manager and provide a final report.
For each user, the actions must be executed in sequence; the latter action can only be executed if the preceding action is successful.
Non-functional requirements
Quick execution and high turnover rate.
Definition of turnover rate: the number of scheduled jobs completed per unit time.
Maximise resource utilisation and balance server load.
For the sake of brevity, we will not cover the scheduling logic, nor the generation of the report. We will focus specifically on executing actions.
Naive approach
Let’s start thinking from the most naive solution, and improve from there to reach an optimised solution.
Here is the pseudocode of a naive action executor.
def executeActionOnSegment(segment, actions):
for user in fetchUsersInSegment(segment):
for action in actions:
success := doAction(user, action)
if not success:
break
recordActionResult(user, action)
def doAction(user, action):
if action.type == "awardReward":
rewardService.awardReward(user, action.meta)
elif action.type == "sendMessage":
messagingService.sendMessage(user, action.meta)
else:
# other action types ...
One may be able to quickly tell that the naive solution does not satisfy our non-functional requirements for the following reasons:
Execution is slow:
The programme is single-threaded.
Actions are executed for users one by one in sequence.
Each call to the rewards and messaging services will incur network trip time, which impacts time cost.
Resource utilisation is low: The actions will only be executed on one server. When we have a cluster of servers, the other servers will sit idle.
Here are our alternatives for fixing the above issues:
Actions for different users should be executed in parallel.
API calls to other services should be minimised.
Distribute the work of executing actions evenly among different servers.
Note: Actions for the same user have to be executed in sequence. For example, if a sequence of required actions are (1) award a reward, (2) send a message informing the user to use the reward, then we can only execute action (2) after action (1) is successfully done for logical reasons and to avoid user confusion.
Our approach
A message queue is a well-suited solution to distribute work among multiple servers. We selected Kafka, among numerous message services, due to its following characteristics:
High throughput: Kafka can accept reads and writes at a very high speed.
Robustness: Events in Kafka are distributedly stored with redundancy, without a need to worry about data loss.
Pull-based consumption: Consumers can consume events at their own speed. This helps to avoid overloading our servers.
When a scheduled campaign is triggered, we retrieve the users from the segment in batches; each batch comprises around 100 users. We write the batches into a Kafka stream, and all our servers consume from the stream to execute the actions for the batches. The following diagram illustrates the overall flow.
Data in Kafka is stored in partitions. The partition configuration is important to ensure that the batches are evenly distributed among servers:
Number of partitions: Ensure that the number of stream partitions is greater than or equal to the max number of servers we will have in our cluster. This is because one Kafka partition can only be consumed by one consumer. If we have more consumers than partitions, some consumers will not receive any data.
Partition key: For each batch, assign a hash value as the partition key to randomly allocate batches into different partitions.
Now that work is distributed among servers in batches, we can consider how to process each batch faster. If we follow the naive logic, for each user in the batch, we need to call the rewards or messaging service to execute the actions. This will create very high QPS (queries per second) to those services, and incur significant network round trip time.
To solve this issue, we decided to build batch endpoints in rewards and messaging services. Each batch endpoint takes in a list of user IDs and action metadata as input parameters, and returns the action result for each user, regardless of success or failure. With that, our batch processing logic looks like the following:
In the implementation of batch endpoints, we also made optimisations to reduce latency. For example, when awarding rewards, we need to write the records of a reward being given to a user in multiple database tables. If we make separate DB queries for each user in the batch, it will cause high QPS to DB and incur high network time cost. Therefore, we grouped all the users in the batch into one DB query for each table update instead.
Benchmark tests show that using the batch DB query reduced API latency by up to 85%.
Further optimisations
As more campaigns started running in the system, we came across various bottlenecks. Here are the optimisations we implemented for some major examples.
Shard stream by action type
Two widely used actions are awarding rewards and sending messages to users. We came across situations where the sending of messages was blocked because a different campaign of awarding rewards had already started. If millions of users were targeted for rewards, this could result in significant waiting time before messages are sent, ultimately leading them to become irrelevant.
We found out the API latency of awarding rewards is significantly higher than sending messages. Hence, to make sure messages are not blocked by long-running awarding jobs, we created a dedicated Kafka topic for messages. By having different Kafka topics based on the action type, we were able to run different types of campaigns in parallel.
Shard stream by country
Grab operates in multiple countries. We came across situations where a campaign of awarding rewards to a small segment of users in one country was delayed by another campaign that targeted a huge segment of users in another country. The campaigns targeting a small set of users are usually more time-sensitive.
Similar to the above solution, we added different Kafka topics for each country to enable the processing of campaigns in different countries in parallel.
Remove unnecessary waiting
We observed that in the case of chained actions, messaging actions are generally the last action in the action list. For example, after awarding a reward, a congratulatory message would be sent to the user.
We realised that it was not necessary to wait for a sending message action to complete before processing the next batch of users. Moreover, the latency of the sending messages API is lower than awarding rewards. Hence, we adjusted the sending messages API to be asynchronous, so that the task of awarding rewards to the next batch of users can start while messages are being sent to the previous batch.
Conclusion
We have architected our batch jobs system in such a way so that it can be enhanced and optimised without redoing its work. For example, although we currently obtain the list of targeted users from a segmentation service, in the future, we may obtain this list from a different source, for example, all Grab Platinum tier members.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Telematics is a collection of sensor data such as accelerometer data, gyroscope data, and GPS data that a driver’s mobile phone provides, and we collect, during the ride. With this information, we apply data science logic to detect traffic events such as harsh braking, acceleration, cornering, and unsafe lane changes, in order to help improve our consumers’ ride experience.
Introduction
As Grab grows to meet our consumers’ needs, the number of driver-partners has also grown. This requires us to ensure that our consumers’ safety continues to remain the highest priority as we scale. We developed an in-house telematics engine which uses mobile phone sensors to determine, evaluate, and quantify the driving behaviour of our driver-partners. This telemetry data is then evaluated and gives us better insights into our driver-partners’ driving patterns.
Through our data, we hope to improve our driver-partners’ driving habits and reduce the likelihood of driving-related incidents on our platform. This telemetry data also helps us determine optimal insurance premiums for driver-partners with risky driving patterns and reward driver-partners who have better driving habits.
In addition, we also merge telematics data with spatial data to further identify areas where dangerous driving manoeuvres happen frequently. This data is used to inform our driver-partners to be alert and drive more safely in such areas.
Background
With more consumers using the Grab app, we realised that purely relying on passenger feedback is not enough; we had no definitive way to tell which driver-partners were actually driving safely, when they deviated from their routes or even if they had been involved in an accident.
To help address these issues, we developed an in-house telematics engine that analyses telemetry data, identifies driver-partners’ driving behaviour and habits, and provides safety reports for them.
Architecture details
As shown in the diagram, our telematics SDK receives raw sensor data from our driver-partners’ devices and processes it in two ways:
On-device processing for crash detection: Used to determine situations such as if the driver-partner has been in an accident.
Raising traffic events and generating safety reports after each job: Useful for detecting events like speeding and harsh braking.
Note: Safety reports are generated by our backend service using sensor data that is only uploaded as a text file after each ride.
Implementation
Our telematics framework relies on accelerometer, gyroscope and GPS sensors within the mobile device to infer the vehicle’s driving parameters. Both accelerometer and gyroscope are triaxial sensors, and their respective measurements are in the mobile device’s frame of reference.
That being said, the data collected from these sensors have no fixed sample rate, so we need to implement sensor data time synchronisation. For example, there will be temporal misalignment between gyroscope and accelerometer data if they do not share the same timestamp. The sample rate that comes from the accelerometer and gyroscope also varies independently. Therefore, we need to uniformly sample the sensor data to be at the same frequency rate.
This synchronisation process is done in two steps:
Interpolation to uniform time grid at a reasonably higher frequency.
Decimation from the higher frequency to the output data rate for accelerometer and gyroscope data.
We then use the Fourier Transform to transform a signal from time domain to frequency domain for compression. These components are then written to a text file on the mobile device, compressed, and uploaded after the end of each ride.
Learnings/Conclusion
There are a few takeaways that we learned from this project:
Sensor data frequency: There are many device manufacturers out there for Android and each one of them has a different sensor chipset. The frequency of the sensor data may vary from device to device.
Four-wheel (4W) vs two-wheel (2W): The behaviour is different for a driver-partner on 2W vs 4W, so we need different rules for each.
Hardware axis-bias: The device may not be aligned with the vehicle during the ride. It cannot be assumed that the phone will remain in a fixed orientation throughout the trip, so the mobile device sensors might not accurately measure the acceleration/braking or sharp turning of the vehicle.
Sensor noise: There are artifacts in sensor readings, which are basically a single outlier event that represents an error and is not a valid sensor reading.
Time-synchronisation: GPS, accelerometer, and gyroscope events are captured independently by three different sensors and have different time formats. These events will need to be transformed into the same time grid in order to work together. For example, the GPS location from 30 seconds prior to the gyroscope event will not work as they are out of sync.
Data compression and network consumption: Longer rides will contain more telematics data. It will result in a bigger upload size and increase in time for file compression.
What’s next?
There are a few milestones that we want to accomplish with our telematics framework in the future. However, our number one goal is to extend telematics to all bookings across Grab verticals. We are also planning to add more on-device rules and data processing for event detections to further eliminate future delays from backend communication for crash detection.
With the data from our telematics framework, we can improve our passengers’ experience and improve safety for both passengers and driver-partners.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Typically, modern applications use various database engines for their service needs; within Grab, these would be MySQL, Aurora and DynamoDB. Lately, the Caspian team has observed an increasing need to consume real-time data for many service teams. These real-time changes in database records help to support online and offline business decisions for hundreds of teams.
Because of that, we have invested time into synchronising data from MySQL, Aurora and Dynamodb to the message queue, i.e. Kafka. In this blog, we share how real-time data ingestion has helped since it was launched.
Introduction
Over the last few years, service teams had to write all transactional data twice: once into Kafka and once into the database. This helped to solve the inter-service communication challenges and obtain audit trail logs. However, if the transactions fail, data integrity becomes a prominent issue. Moreover, it is a daunting task for developers to maintain the schema of data written into Kafka.
With real-time ingestion, there is a notably better schema evolution and guaranteed data consistency; service teams no longer need to write data twice.
You might be wondering, why don’t we have a single transaction that spans the services’ databases and Kafka, to make data consistent? This would not work as Kafka does not support being enlisted in distributed transactions. In some situations, we might end up having new data persisting into the services’ databases, but not having the corresponding message sent to Kafka topics.
Instead of registering or modifying the mapped table schema in Golang writer into Kafka beforehand, service teams tend to avoid such schema maintenance tasks entirely. In such cases, real-time ingestion can be adopted where data exchange among the heterogeneous databases or replication between source and replica nodes is required.
While reviewing the key challenges around real-time data ingestion, we realised that there were many potential user requirements to include. To build a standardised solution, we identified several points that we felt were high priority:
Make transactional data readily available in real time to drive business decisions at scale.
Capture audit trails of any given database.
Get rid of the burst read on databases caused by SQL-based query ingestion.
To empower Grabbers with real-time data to drive their business decisions, we decided to take a scalable event-driven approach, which is being facilitated with a bunch of internal products, and designed a solution for real-time ingestion.
Anatomy of architecture
The solution for real-time ingestion has several key components:
Stream data storage
Event producer
Message queue
Stream processor
Figure 1. Real time ingestion architecture
Stream storage
Stream storage acts as a repository that stores the data transactions in order with exactly-once guarantee. However, the level of order in stream storage differs with regards to different databases.
For MySQL or Aurora, transaction data is stored in binlog files in sequence and rotated, thus ensuring global order. Data with global order assures that all MySQL records are ordered and reflects the real life situation. For example, when transaction logs are replayed or consumed by downstream consumers, consumer A’s Grab food order at 12:01:44 pm will always appear before consumer B’s order at 12:01:45 pm.
However, this does not necessarily hold true for DynamoDB stream storage as DynamoDB streams are partitioned. Audit trails of a given record show that they go into the same partition in the same order, ensuring consistent partitioned order. Thus when replay happens, consumer B’s order might appear before consumer A’s.
Moreover, there are multiple formats to choose from for both MySQL binlog and DynamoDB stream records. We eventually set ROW for binlog formats and NEW_AND_OLD_IMAGES for DynamoDB stream records. This depicts the detailed information before and after modifying any given table record. The binlog and DynamoDB stream main fields are tabulated in Figures 2 and 3 respectively.
Figure 2. Binlog record schema
Figure 3. DynamoDB stream record schema
Event producer
Event producers take in binlog messages or stream records and output to the message queue. We evaluated several technologies for the different database engines.
For MySQL or Aurora, three solutions were evaluated: Debezium, Maxwell, and Canal. We chose to onboard Debezium as it is deeply integrated with the Kafka Connect framework. Also, we see the potential of extending solutions among other external systems whenever moving large collections of data in and out of the Kafka cluster.
One such example is the open source project that attempts to build a custom DynamoDB connector extending the Kafka Connect (KC) framework. It self manages checkpointing via an additional DynamoDB table and can be deployed on KC smoothly.
However, the DynamoDB connector fails to exploit the fundamental nature of storage DynamoDB streams: dynamic partitioning and auto-scaling based on the traffic. Instead, it spawns only a single thread task to process all shards of a given DynamoDB table. As a result, downstream services suffer from data latency the most when write traffic surges.
In light of this, the lambda function becomes the most suitable candidate as the event producer. Not only does the concurrency of lambda functions scale in and out based on actual traffic, but the trigger frequency is also adjustable at your discretion.
Kafka
This is the distributed data store optimised for ingesting and processing data in real time. It is widely adopted due to its high scalability, fault-tolerance, and parallelism. The messages in Kafka are abstracted and encoded into Protobuf.
Stream processor
The stream processor consumes messages in Kafka and writes into S3 every minute. There are a number of options readily available in the market; Spark and Flink are the most common choices. Within Grab, we deploy a Golang library to deal with the traffic.
Use cases
Now that we’ve covered how real-time data ingestion is done in Grab, let’s look at some of the situations that could benefit from real-time data ingestion.
1. Data pipelines
We have thousands of pipelines running hourly in Grab. Some tables have significant growth and generate workload beyond what a SQL-based query can handle. An hourly data pipeline would incur a read spike on the production database shared among various services, draining CPU and memory resources. This deteriorates other services’ performance and could even block them from reading. With real-time ingestion, the query from data pipelines would be incremental and span over a period of time.
Another scenario where we switch to real-time ingestion is when a missing index is detected on the table. To speed up the query, SQL-based query ingestion requires indexing on columns such as created_at, updated_at and id. Without indexing, SQL based query ingestion would either result in high CPU and memory usage, or fail entirely.
Although adding indexes for these columns would resolve this issue, it comes with a cost, i.e. a copy of the indexed column and primary key is created on disk and the index is kept in memory. Creating and maintaining an index on a huge table is much costlier than for small tables. With performance consideration in mind, it is not recommended to add indexes to an existing huge table.
Instead, real-time ingestion overshadows SQL-based ingestion. We can spawn a new connector, archiver (Coban team’s Golang library that dumps data from Kafka at minutes-level frequency) and compaction job to bubble up the table record from binlog to the destination table in the Grab data lake.
Figure 4. Using real-time ingestion for data pipelines
2. Drive business decisions
A key use case of enabling real-time ingestion is driving business decisions at scale without even touching the source services. Saga pattern is commonly adopted in the microservice world. Each service has its own database, splitting an overarching database transaction into a series of multiple database transactions. Communication is established among services via message queue i.e. Kafka.
In an earlier tech blog published by the Grab Search team, we talked about how real-time ingestion with Debezium optimised and boosted search capabilities. Each MySQL table is mapped to a Kafka topic and one or multiple topics build up a search index within Elasticsearch.
With this new approach, there is no data loss, i.e. changes via MySQL command line tool or other DB management tools can be captured. Schema evolution is also naturally supported; the new schema defined within a MySQL table is inherited and stored in Kafka. No producer code change is required to make the schema consistent with that in MySQL. Moreover, the database read has been reduced by 90 percent including the efforts of the Data Synchronisation Platform.
Figure 5. Grab Search team use case
The GrabFood team exemplifies mostly similar advantages in the DynamoDB area. The only differences compared to MySQL are that the frequency of the lambda functions is adjustable and parallelism is auto-scaled based on the traffic. By auto-scaling, we mean that more lambda functions will be auto-deployed to cater to a sudden spike in traffic, or destroyed as the traffic falls.
Figure 6. Grab Food team use case
3. Database replication
Another use case we did not originally have in mind is incremental data replication for disaster recovery. Within Grab, we enable DynamoDB streams for tier 0 and critical DynamoDB tables. Any insert, delete, modify operations would be propagated to the disaster recovery table in another availability zone.
When migrating or replicating databases, we use the strangler fig pattern, which offers an incremental, reliable process for migrating databases. This is a method whereby a new system slowly grows on top of an old system and is gradually adopted until the old system is “strangled” and can simply be removed. Figure 7 depicts how DynamoDB streams drive real-time synchronisation between tables in different regions.
Figure 7. Data replication among DynamoDB tables across different regions in DBOps team
4. Deliver audit trails
Reasons for maintaining data audit trails are manifold in Grab: regulatory requirements might mandate businesses to keep complete historical information of a consumer or to apply machine learning techniques to detect fraudulent transactions made by consumers. Figure 8 demonstrates how we deliver audit trails in Grab.
Figure 8. Deliver audit trails in Grab
Summary
Real time ingestion is playing a pivotal role in Grab’s ecosystem. It:
boosts data pipelines with less read pressure imposed on databases shared among various services;
empowers real-time business decisions with assured resource efficiency;
provides data replication among tables residing in various regions; and
delivers audit trails that either keep complete history or help unearth fraudulent operations.
Since this project launched, we have made crucial enhancements to facilitate daily operations with several in-house products that are used for data onboarding, quality checking, maintaining freshness, etc.
We will continuously improve our platform to provide users with a seamless experience in data ingestion, starting with unifying our internal tools. Apart from providing a unified platform, we will also contribute more ideas to the ingestion, extending it to Azure and GCP, supporting multi-catalogue and offering multi-tenancy.
In our next blog, we will drill down to other interesting features of real-time ingestion, such as how ordering is achieved in different cases and custom partitioning in real-time ingestion. Stay tuned!
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Earlier in 2021 we published an article on Trident, Grab’s in-house real-time if this, then that (IFTTT) engine which manages campaigns for the Grab Loyalty Programme. The Grab Loyalty Programme encourages consumers to make Grab transactions by rewarding points when transactions are made. Grab rewards two types of points namely OVOPoints and GrabRewards Points (GRP). OVOPoints are issued for transactions made in Indonesia and GRP are for the transactions that are made in all other markets. In this article, the term GRP will be used to refer to both OVOPoints and GrabRewards Points.
Rewarding GRP is one of the main components of the Grab Loyalty Programme. By rewarding GRP, our consumers are incentivised to transact within the Grab ecosystem. Consumers can then redeem their GRP for a range of exciting items on the GrabRewards catalogue or to offset the cost of their spendings.
As we continue to grow our consumer base and our product offerings, a more robust platform is needed to ensure successful points transactions. In this post, we will share the challenges in rewarding GRP and how Abacus, our Point Issuance platform helps to overcome these challenges while managing various use cases.
Challenges
Growing number of products
The number of Grab’s product offerings has grown as part of Grab’s goal in becoming a superapp. The demand for rewarding GRP increased as each product team looked for ways to retain consumer loyalty. For this, we needed a platform which could support the different requirements from each product team.
External partnerships
Grab’s external partnerships consist of both one- and two-way point exchanges. With selected partners, Grab users are able to convert their GRP for the partner’s loyalty programme points, and the other way around.
Use cases
Besides the need to cater for the growing number of products and external partnerships, Grab needed a centralised points management system which could cater to various use cases of points rewarding. Let’s take a look at the use cases.
Any product, any points
There are many products in Grab and each product should be able to reward different GRP for different scenarios. Each product rewards GRP based on the goal they are trying to achieve.
The following examples illustrate the different scenarios:
GrabCar: Reward 100 GRP for when a driver cancels a booking as a form of compensation or to reward GRP for every ride a consumer makes.
GrabFood: Reward consumers for each meal order.
GrabPay: Reward consumers three times the number of GRP for using GrabPay instead of cash as the mode of payment.
More points for loyal consumers
Another use case is to reward loyal consumers with more points. This incentivises consumers to transact within the Grab ecosystem. One example are membership tiers granted based on the number of GRP a consumer has accumulated. There are four membership tiers: Member, Silver, Gold and Platinum.
Point multiplier
There are different points multipliers for different membership tiers. For example, a Gold member would earn 2.25 GRP for every dollar spent while a Silver member earns only 1.5 GRP for the same amount spent. A consumer can view their membership tier and GRP information from the account page on the Grab app.
GrabRewards Points and membership tier information
Growing number of transactions
Teams within Grab and external partners use GRP in their business. There is a need for a platform that can process millions of transactions every day with high availability rates. Errors can easily impact the issuance of points which may affect our consumers’ trust.
Our solution – Abacus
To overcome the challenges and cater for various use cases, we developed a Points Management System known as Abacus. It offers an interface for external partners with the capability to handle millions of daily transactions without significant downtime.
Points rewarding
There are seven main components of Abacus as shown in the following architectural diagram. Details of each component are explained in this section.
Abacus architecture
Transaction input source
The points rewarding process begins when a transaction is complete. Abacus listens to streams for completed transactions on the Grab platform. Each transaction that abacus receives in the stream carries the data required to calculate the GRP to be rewarded such as country ID, product ID, and payment ID etc.
Apart from computing the number of GRP to be rewarded for a transaction and then rewarding the points, Abacus also allows clients from within the Grab platform and outside of the Grab platform to make an API call to reward GRP to consumers. The client who wants to reward their consumers with GRP will call Abacus with either a specific point value (for example 100 points) or will provide the necessary details like transaction amount and the relevant multipliers for Abacus to compute the points and then reward them.
Point Calculation module
The Point Calculation module calculates the GRP using the data and multipliers that are unique to each transaction.
Point Calculation dependencies for internal services
Point Calculation dependencies are the multipliers needed to calculate the number of points. The Point Calculation module fetches the correct point multipliers for each transaction. The multipliers are configured by specific country teams when the product is launched. They may vary by country to allow country teams the flexibility to achieve their growth and retention targets. There are different types of multipliers.
Vertical multiplier: The multiplier for each vertical. A vertical is a service or product offered by Grab. Examples of verticals are GrabCar and GrabFood. The multiplier can be different for each vertical.
EPPF multiplier: The effective price per fare multiplier. EPPF is the reference conversion rate per point. For example:
EPPF = 1.0; if you are issuing X points per SGD1
EPPF = 0.1; if you are issuing X points per THB10
EPPF = 0.0001; if you are issuing X points per IDR10,000
Payment Type multiplier: The multiplier for different modes of payments.
Tier multiplier: The multiplier for each tier.
Point Calculation formula for internal clients
The Point Calculation module uses a formula to calculate GRP. The formula is the product of all the multipliers and the transaction amount.
Example of multipliers for payment options and tiers
Point Calculation dependencies for external clients
External partners supply the Point Calculation dependencies which are then configured in our backend at the time of integration. These external partners can set their own multipliers instead of using the above mentioned multipliers which are specific to Grab. This document details the APIs which are used to award points for external clients.
Simple Queue Service
Abacus uses Amazon Simple Queue Service (SQS) to ensure that the points system process is robust and fault tolerant.
Point Awarding SQS
If there are no errors during the Point Calculation process, the Point Calculation module will send a message containing the points to be awarded to the Point Awarding SQS.
Retry SQS
The Point Calculation module may not receive the required data when there is a downtime in the Point Calculation dependencies. If this occurs, an error is triggered and the Point Calculation module will send a message to Retry SQS. Messages sent to the Retry SQS will be re-processed by the Point Calculation module. This ensures that the points are properly calculated despite having outages on dependencies. Every message that we push to either the Point Awarding SQS or Retry SQS will have a field called Idempotency key which is used to ensure that we reward the points only once to a particular transaction.
Point Awarding module
The successful calculation of GRP triggers a message to the Point Awarding module via the Point SQS. The Point Awarding module tries to reward GRP to the consumer’s account. Upon successful completion, an ACK is sent back to the Point SQS signalling that the message was successfully processed and triggers deletion of the message. If Point SQS does not receive an ACK, the message is redelivered after an interval. This process ensures that the points system is robust and fault tolerant.
Ledger
GRP is rewarded to the consumer once it is updated in the Ledger. The Ledger tracks how many GRP a consumer has accumulated, what they were earned for, and the running total number of GRP.
Notification service
Once the Ledger is updated, the Notification service sends the consumer a message about the GRP they receive.
Point Kafka stream
For all successful GRP transactions, Abacus sends a message to the Point Kafka stream. Downstream services listen to this stream to identify the consumer’s behaviour and take the appropriate actions. Services of this stream can listen to events they are interested in and execute their business logic accordingly. For example, a service can use the information from the Point Kafka stream to determine a consumer’s membership tier.
Points expiry
Further addition to Abacus is the handling of points expiry. The Expiry Extension module enables activity-based points expiry. This enables GRP to not expire as long as the consumer makes one Grab transaction within the next three or six months from their last transaction.
The Expiry Extension module updates the point expiry date to the database after successfully rewarding GRP to the consumer. At the end of each month, a process loads all consumers whose points will expire in that particular month and sends it to the Point Expiry SQS. The Point Expiry Consumer will then expire all the points for the consumers and this data is updated in the Ledger. This process repeats on a monthly basis.
Expiry Extension module
Points expiry date is always the last day of the third or sixth month. For example, Adam makes a transaction on 10 January. His points expiry date is 31 July which is six months from the month of his last transaction. Adam then makes a transaction on 28 February. His points expiry period is shifted by one month to 31 August.
Points expiry
Conclusion
The Abacus platform enables us to perform millions of GRP transactions on a daily basis. Being able to curate rewards for consumers increases the value proposition of our products and consumer retention. If you have any comments or questions about Abacus, feel free to leave a comment below.
Special thanks to Arianto Wibowo and Vaughn Friesen.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In large organisations, it is a common practice to isolate the cloud resources of different verticals. Amazon Web Services (AWS) Virtual Private Cloud (VPC) is a convenient way of doing so. At Grab, while our core AWS services reside in a main VPC, a number of Grab Tech Families (TFs) have their own dedicated VPC. One such example is GrabKios. Previously known as “Kudo”, GrabKios was acquired by Grab in 2017 and has always been residing in its own AWS account and dedicated VPC.
In this article, we explore how we exposed an Apache Kafka cluster across multiple Availability Zones (AZs) in Grab’s main VPC, to producers and consumers residing in the GrabKios VPC, via a VPC Endpoint Service. This design is part of Coban unified stream processing platform at Grab.
There are several ways of enabling communication between applications across distinct VPCs; VPC peering is the most straightforward and affordable option. However, it potentially exposes the entire VPC networks to each other, needlessly increasing the attack surface.
Security has always been one of Grab’s top concerns and with Grab’s increasing growth, there is a need to deprecate VPC peering and shift to a method of only exposing services that require remote access. The AWS VPC Endpoint Service allows us to do exactly that for TCP/IPv4 communications within a single AWS region.
Setting up a VPC Endpoint Service compared to VPC peering is already relatively complex. On top of that, we need to expose an Apache Kafka cluster via such an endpoint, which comes with an extra challenge. Apache Kafka requires clients, called producers and consumers, to be able to deterministically establish a TCP connection to all brokers forming the cluster, not just any one of them.
Last but not least, we need a design that optimises performance and cost by limiting data transfer across AZs.
Note: All variable names, port numbers and other details used in this article are only used as examples.
Architecture overview
As shown in this diagram, the Kafka cluster resides in the service provider VPC (Grab’s main VPC) while local Kafka producers and consumers reside in the service consumer VPC (GrabKios VPC).
In Grab’s main VPC, we created a Network Load Balancer (NLB) and set it up across all three AZs, enabling cross-zone load balancing. We then created a VPC Endpoint Service associated with that NLB.
Next, we created a VPC Endpoint Network Interface in the GrabKios VPC, also set up across all three AZs, and attached it to the remote VPC endpoint service in Grab’s main VPC. Apart from this, we also created a Route 53 Private Hosted Zone .grab and a CNAME record kafka.grab that points to the VPC Endpoint Network Interface hostname.
Lastly, we configured producers and consumers to use kafka.grab:10000 as their Kafka bootstrap server endpoint, 10000/tcp being an arbitrary port of our choosing. We will explain the significance of these in later sections.
Network Load Balancer setup
On the NLB in Grab’s main VPC, we set up the corresponding bootstrap listener on port 10000/tcp, associated with a target group containing all of the Kafka brokers forming the cluster. But this listener alone is not enough.
As mentioned earlier, Apache Kafka requires producers and consumers to be able to deterministically establish a TCP connection to all brokers. That’s why we created one listener for every broker in the cluster, incrementing the TCP port number for each new listener, so each broker endpoint would have the same name but with different port numbers, e.g. kafka.grab:10001 and kafka.grab:10002.
We then associated each listener with a dedicated target group containing only the targeted Kafka broker, so that remote producers and consumers could differentiate between the brokers by their TCP port number.
The following listeners and associated target groups were set up on the NLB:
In the Kafka brokers’ Security Group (SG), we added an ingress SG rule allowing 9094/tcp traffic from each of the three private IP addresses of the NLB. As mentioned earlier, the NLB was set up across all three AZs, with each having its own private IP address.
On the GrabKios VPC (consumer side), we created a new SG and attached it to the VPC Endpoint Network Interface. We also added ingress rules to allow all producers and consumers to connect to tcp/10000-10003.
Kafka setup
Kafka brokers typically come with a listener on port 9092/tcp, advertising the brokers by their private IP addresses. We kept that default listener so that local producers and consumers in Grab’s main VPC could still connect directly.
$ kcat -L -b 10.0.0.1:9092
3 brokers:
broker 101 at 10.0.0.1:9092 (controller)
broker 201 at 10.0.0.2:9092
broker 301 at 10.0.0.3:9092
... truncated output ...
We also configured all brokers with an additional listener on port 9094/tcp that advertises the brokers by:
Their shared private name kafka.grab.
Their distinct TCP ports previously set up on the NLB’s dedicated listeners.
$ kcat -L -b 10.0.0.1:9094
3 brokers:
broker 101 at kafka.grab:10001 (controller)
broker 201 at kafka.grab:10002
broker 301 at kafka.grab:10003
... truncated output ...
Note that there is a difference in how the broker’s endpoints are advertised in the two outputs above. The latter enables connection to any particular broker from the GrabKios VPC via the VPC Endpoint Service.
It would definitely be possible to advertise the brokers directly with the remote VPC Endpoint Interface hostname instead of kafka.grab, but relying on such a private name presents at least two advantages.
First, it decouples the Kafka deployment in the service provider VPC from the infrastructure deployment in the service consumer VPC. Second, it makes the Kafka cluster easier to expose to other remote VPCs, should we need it in the future.
Limiting data transfer across Availability Zones
At this stage of the setup, our Kafka cluster is fully reachable from producers and consumers in the GrabKios VPC. Yet, the design is not optimal.
When a producer or a consumer in the GrabKios VPC needs to connect to a particular broker, it uses its individual endpoint made up of the shared name kafka.grab and the broker’s dedicated TCP port.
The shared name arbitrarily resolves into one of the three IP addresses of the VPC Endpoint Network Interface, one for each AZ.
Hence, there is a fair chance that the obtained IP address is neither in the client’s AZ nor in that of the target Kafka broker. The probability of this happening can be as high as 2/3 when both client and broker reside in the same AZ and 1/3 when they do not.
While that is of little concern for the initial bootstrap connection, it becomes a serious drawback for actual data transfer, impacting the performance and incurring unnecessary data transfer cost.
For this reason, we created three additional CNAME records in the Private Hosted Zone in the GrabKios VPC, one for each AZ, with each pointing to the VPC Endpoint Network Interface zonal hostname in the corresponding AZ:
kafka-az1.grab
kafka-az2.grab
kafka-az3.grab
Note that we used az1, az2, az3 instead of the typical AWS 1a, 1b, 1c suffixes, because the latter’s mapping is not consistent across AWS accounts.
We also reconfigured each Kafka broker in Grab’s main VPC by setting their 9094/tcp listener to advertise brokers by their new zonal private names.
$ kcat -L -b 10.0.0.1:9094
3 brokers:
broker 101 at kafka-az1.grab:10001 (controller)
broker 201 at kafka-az2.grab:10002
broker 301 at kafka-az3.grab:10003
... truncated output ...
Our private zonal names are shared by all brokers in the same AZ while TCP ports remain distinct for each broker. However, this is not clearly shown in the output above because our cluster only counts three brokers, one in each AZ.
The previous common name kafka.grab remains in the GrabKios VPC’s Private Hosted Zone and allows connections to any broker via an arbitrary, likely non-optimal route. GrabKios VPC producers and consumers still use that highly-available endpoint to initiate bootstrap connections to the cluster.
Future improvements
For this setup, scalability is our main challenge. If we add a new broker to this Kafka cluster, we would need to:
Assign a new TCP port number to it.
Set up a new dedicated listener on that TCP port on the NLB.
Configure the newly spun up Kafka broker to advertise its service with the same TCP port number and the private zonal name corresponding to its AZ.
Add the new broker to the target group of the bootstrap listener on the NLB.
Update the network SG rules on the service consumer side to allow connections to the newly allocated TCP port.
We rely on Terraform to dynamically deploy all AWS infrastructure and on Jenkins and Ansible to deploy and configure Apache Kafka. There is limited overhead but there are still a few manual actions due to a lack of integration. These include transferring newly allocated TCP ports and their corresponding EC2 instances’ IP addresses to our Ansible inventory, commit them to our codebase and trigger a Jenkins job deploying the new Kafka broker.
Another concern of this setup is that it is only applicable for AWS. As we are aiming to be multi-cloud, we may need to port it to Microsoft Azure and leverage the Azure Private Link service.
In both cases, running Kafka on Kubernetes with the Strimzi operator would be helpful in addressing the scalability challenge and reducing our adherence to one particular cloud provider. We will explain how this solution has helped us address these challenges in a future article.
Special thanks to David Virgil Naranjo whose blog post inspired this work.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
GrabAds is a service that provides businesses with an opportunity to market their products to Grab’s consumer base. During the pandemic, as the demand for food delivery grew, we realised that ads could be a service we offer to our small restaurant merchant-partners to expand their reach. This would allow them to not only mitigate the loss of in-person traffic but also grow by attracting more customers.
Many of these small merchant-partners had no experience with digital advertising and we provided an easy-to-use, scalable option that could match their business size. On the other side of the equation, our large network of merchant-partners provided consumers with more choices. For hungry consumers stuck at home, personalised ads and promotions helped them satisfy their cravings, thus fulfilling their intent of opening the Grab app in the first place!
Why build our own ad server?
Building an ad server is an ambitious undertaking and one might rightfully ask why we should invest the time and effort to build a technically complex distributed system when there are several reasonable off-the-shelf solutions available.
The answer is we didn’t, at least not at first. We used one of these off-the-shelf solutions to move fast and build a minimally viable product (MVP). The result of this experiment was a resounding success; we were providing clear value to our merchant-partners, our consumers and Grab’s overall business.
However, to take things to the next level meant scaling the ads business up exponentially. Apart from being one of the few companies with the user engagement to support an ads business at scale, we also have an ecosystem that combines our network of merchant-partners, an understanding of our consumers’ interactions across multiple services in the Grab superapp, and a payments solution, GrabPay, to close the loop. Furthermore, given the hyperlocal nature of our business, the in-app user experience is highly customised by location. In order to integrate seamlessly with this ecosystem, scale as Grab’s overall business grows and handle personalisation using machine learning (ML), we needed an in-house solution.
What we built
We designed and built a set of microservices, streams and pipelines which orchestrated the core ad serving functionality, as shown below.
Targeting – This is the first step in the ad serving flow. We fetch a set of candidate ads specifically targeted to the request based on keywords the user searched for, the user’s location, the time of day, and the data we have about the user’s preferences or other characteristics. We chose ElasticSearch as the data store for our ads repository as it allows us to query based on a disparate set of targeting criteria.
Capping – In this step, we filter out candidate ads which have exceeded various caps. This includes cases where an advertising campaign has already reached its budget goal, as well as custom requirements about the frequency an ad is allowed to be shown to the same user. In order to make this decision, we need to know how much budget has already been spent and how many times an ad has already been shown. We chose ScyllaDB to store these “stats”, which is scalable, low-cost and can handle the large read and write requirements of this process (more on how this data gets written to ScyllaDB in the Tracking step).
Pacing – In this step, we alter the probability that a matching ad candidate can be served, based on a specific campaign goal. For example, in some cases, it is desirable for an ad to be shown evenly throughout the day instead of exhausting the entire ad budget as soon as possible. Similar to Capping, we require access to information on how many times an ad has already been served and use the same ScyllaDB stats store for this.
Scoring – In this step, we score each ad. There are a number of factors that can be used to calculate this score including predicted clickthrough rate (pCTR), predicted conversion rate (pCVR) and other heuristics that represent how relevant an ad is for a given user.
Ranking – This is where we compare the scored candidate ads with each other and make the final decision on which candidate ads should be served. This can be done in several ways such as running a lottery or performing an auction. Having our own ad server allows us to customise the ranking algorithm in countless ways, including incorporating ML predictions for user behaviour. The team has a ton of exciting ideas on how to optimise this step and now that we have our own stack, we’re ready to execute on those ideas.
Pricing – After choosing the winning ads, the final step before actually returning those ads in the API response is to determine what price we will charge the advertiser. In an auction, this is called the clearing price and can be thought of as the minimum bid price required to outbid all the other candidate ads. Depending on how the ad campaign is set up, the advertiser will pay this price if the ad is seen (i.e. an impression occurs), if the ad is clicked, or if the ad results in a purchase.
Tracking – Here, we close the feedback loop and track what users do when they are shown an ad. This can include viewing an ad and ignoring it, watching a video ad, clicking on an ad, and more. The best outcome is for the ad to trigger a purchase on the Grab app. For example, placing a GrabFood order with a merchant-partner; providing that merchant-partner with a new consumer. We track these events using a series of API calls, Kafka streams and data pipelines. The data ultimately ends up in our ScyllaDB stats store and can then be used by the Capping and Pacing steps above.
Principles
In addition to all the usual distributed systems best practices, there are a few key principles that we focused on when building our system.
Latency – Latency is important for ads. If the user scrolls faster than an ad can load, the ad won’t be seen. The longer an ad remains on the screen, the more likely the user will notice it, have their interest piqued and click on it. As such, we set strict limits on the latency of the ad serving flow. We spent a large amount of effort tuning ElasticSearch so that it could return targeted ads in the shortest amount of time possible. We parallelised parts of the serving flow wherever possible and we made sure to A/B test all changes both for business impact and to ensure they did not increase our API latency.
Graceful fallbacks – We need user-specific information to make personalised decisions about which ads to show to a given user. This data could come in the form of segmentation of our users, attributes of a single user or scores derived from ML models. All of these require the ad server to make dependency calls that could add latency to the serving flow. We followed the principle of setting strict timeouts and having graceful fallbacks when we can’t fetch the data needed to return the most optimal result. This could be due to network failures or dependencies operating slower than usual. It’s often better to return a non-personalised result than no result at all.
Global optimisation – Predicting supply (the amount of users viewing the app) and demand (the amount of advertisers wanting to show ads to those users) is difficult. As a superapp, we support multiple types of ads on various screens. For example, we have image ads, video ads, search ads, and rewarded ads. These ads could be shown on the home screen, when booking a ride, or when searching for food delivery. We intentionally decided to have a single ad server supporting all of these scenarios. This allows us to optimise across all users and app locations. This also ensures that engineering improvements we make in one place translate everywhere where ads or promoted content are shown.
What’s next?
Grab’s ads business is just getting started. As the number of users and use cases grow, ads will become a more important part of the mix. We can help our merchant-partners grow their own businesses while giving our users more options and a better experience.
Some of the big challenges ahead are:
Optimising our real-time ad decisions, including exciting work on using ML for more personalised results. There are many factors that can be considered in ad personalisation such as past purchase history, the user’s location and in-app browsing behaviour. Another area of optimisation is improving our auction strategy to ensure we have the most efficient ad marketplace possible.
Expanding the types of ads we support, including experimenting with new types of content, finding the best way to add value as Grab expands its breadth of services.
Scaling our services so that we can match Grab’s velocity and handle growth while maintaining low latency and high reliability.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In recent years, Identity and Access Management has gained importance within technology industries as attackers continue to target large corporations in order to gain access to private data and services. To address this issue, the Grab Identity team has been using a 6-digit PIN to authenticate a user during a sensitive transaction such as accessing a GrabPay Wallet. We also use SMS one-time passwords (OTPs) to log a user into the application.
We look at existing mechanisms that Grab uses to authenticate its users and how biometric authentication helps strengthen application security and save costs. We also look at the various technical decisions taken to ensure the robustness of this feature as well as some key learnings.
Introduction
The mechanisms we use to authenticate our users have evolved as the Grab Identity team consistently refines our approach. Over the years, we have observed several things:
OTP and Personal Identification Number (PIN) are susceptible to hacking and social engineering.
These methods have high user friction (e.g. delay or failure to receive SMS, need to launch Facebook/Google).
Shared/rented driver accounts cause safety concerns for passengers and increases potential for fraud.
High OTP costs at $0.03/SMS.
Social engineering efforts have gotten more advanced – attackers could pretend to be your friends and ask for your OTP or even post phishing advertisements that prompt for your personal information.
With more sophisticated social engineering attacks on the rise, we need solutions that can continue to protect our users and Grab in the long run.
Background
When we looked into developing solutions for these problems, which was mainly about cost and security, we went back to basics and looked at what a secure system meant.
Knowledge Factor: Something that you know (password, PIN, some other data)
Possession Factor: Something physical that you have (device, keycards)
Inherent Factor: Something that you are (face ID, fingerprint, voice)
We then compared the various authentication mechanisms that the Grab app currently uses, as shown in the following table:
Authentication factor
1. Something that you know
2. Something physical that you have
3. Something that you are
OTP
✔️
✔️
Social
✔️
PIN
✔️
Biometrics
✔️
✔️
With methods based on the knowledge and possession factors, it is still possible for attackers to get users to reveal sensitive account information. On the other hand, biometrics are something you are born with and that makes it more complex to mimic. Hence, we have added biometrics as an additional layer to enhance Grab’s existing authentication methods and build a more secure platform for our users.
Solution
Biometric authentication powered by device biometrics provides a robust platform to enhance trust. This is because modern phones provide a few key features that allow client server trust to be established:
Biometric sensor (fingerprint or face ID).
Advent of devices with secure enclaves.
A secure enclave, being a part of the device, is separate from the main operating system (OS) at the kernel level. The enclave is used to store private keys that can be unlocked only by the biometrics on the device.
Any changes to device security such as changing a PIN or adding another fingerprint will invalidate all prior access to this secure enclave. This means that when we enroll a user in biometrics this way, we can be sure that any payload from said device that matches the public part of said private key is authorised by the user that created it.
Architecture details
The important part of the approach lies in the enrollment flow. The process is quite simple and can be described in the following steps:
Create an elevated public/private key pair that requires users authentication.
Ask users to authenticate in order to prove they are the device holders.
Sign payload with confirmed unlocked private key and send public key to finish enrolling.
Store returned reference id in the encrypted shared preferences/keychain.
Implementation
The key implementation details is as follows:
Grab’s HellfireSDK confirms if the device is not rooted.
Uses SHA512withECDSA for hashing algorithm.
Encrypted shared preferences/keychain to store data.
Secure enclave to store private keys.
These key technologies allow us to create trust between devices and services. The raw biometric data stays within the device and instead sends an encrypted signature of biometry data to Grab for verification purposes.
Impact
Biometric login aims to resolve the many problems highlighted earlier in this article such as reducing user friction and saving SMS OTP costs.
We are still experimenting with this feature so we do not have insights on business impact yet. However, from early experiment runs, we estimate over 90% adoption rate and a success rate of nearly 90% for biometric logins.
Learnings/Conclusion
As methods of executing identity theft or social engineering get more creative, simply using passwords and PINs is not enough. Grab, and many other organisations, are realising that it’s important to augment existing security measures with methods that are inherent and unique to users.
By using biometrics as an added layer of security in a multi-factor authentication strategy, we can keep our users safe and decrease the probability of successful attacks. Not only do we ensure that the user is a legitimate entity, we also ensure that we protect their privacy by ensuring that the biometric data remains on the user’s device.
What’s next?
IdentitySDK – this feature will be moved into an SDK so other teams integrate it via plug and play.
Standalone biometrics – biometric authentication is currently tightly coupled with PIN i.e. biometric authentication happens in place of PIN if biometric authentication is set up. Therefore, users would never see both PIN and biometric in the same session, which limits our robustness in terms of multi-factor authentication.
Integration with DAX and beyond – We plan to enable this feature for all teams who need to use biometric authentication.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
A research publication authored by Tenindra Abeywickrama (Grab), Victor Liang (Grab) and Kian-Lee Tan (NUS) based on their work, which was awarded the Best Scalable Data Science Paper Award for 2021.
Matching the right passengers to the right driver-partners is a critically important task in ride-hailing services. Doing this suboptimally can lead to passengers taking longer to reach their destinations and drivers losing revenue. Perhaps, the most challenging of all is that this is a continuous process with a constant stream of new ride requests and new driver-partners becoming available. This makes computing matchings a very computationally expensive task requiring high throughput.
We discovered that one component of the typically used algorithm to find matchings has a significant impact on efficiency that has hitherto gone unnoticed. However, we also discovered a useful property of real-world optimal matchings that allows us to improve the algorithm, in an interesting scenario of practice informing theory.
A real-world example
Let us consider a simple matching algorithm as depicted in Figure 1, where passengers and driver-partners are matched by travel time. In the figure, we have three driver-partners (D1, D2, and D3) and three passengers (P1, P2, and P3).
Finding the travel time involves computing the fastest route from each driver-partner to each passenger, for example the dotted routes from D1 to P1, P2 and P3 respectively. Finding the assignment of driver-partners to passengers that minimise the overall travel time involves representing the problem in a more abstract way as a bipartite graph shown below.
In the bipartite graph, the set of passengers and the set of driver-partners form the two bipartite sets, respectively. The edges connecting them represent the travel time of the fastest routes, and their costs are shown in the cost matrix on the right.
Figure 1. Example driver-to-passenger matching scenario
Finding the optimal assignment is known as solving the minimum weight bipartite matching problem (also known as the assignment problem). This problem is often solved using a technique called the Kuhn-Munkres (KM) algorithm1 (also known as the Hungarian Method).
If we were to run the algorithm on the scenario shown in Figure 1, we would find the optimal matching highlighted in red on the cost matrix shown in the figure. However, there is an important step that we have not paid great attention to so far, and that is the computation of the cost matrix. As it turns out, this step has quite a significant impact on performance in real-world settings.
Impact of the cost matrix
Past work that solves the assignment problem assumes the cost matrix is given as input, but we observe that the time taken to compute the cost matrix is not always trivial. This is especially true in our real-world scenario. Firstly, matching driver-partners and passengers is a continuous process, as we mentioned earlier. Costs are not fixed; they change over time as driver-partners move and new passenger requests are received.
This means the matrix must be recomputed each time we attempt a matching (for example every X seconds). Not only is finding the shortest path between a single passenger and driver-partner computationally expensive, we must do this for all pairs of passengers and driver-partners. In fact, in the real world, the time taken to compute the matrix is longer than the time taken to compute the optimal assignment! A simple consideration of time complexity suggests that this is true.
If m is the number of driver-partners/passengers we are trying to match, the KM algorithm typically runs in O(m^3). If n is the number of nodes in the road network, then computing the cost matrix runs in O(m x n log n) using Dijkstra’s algorithm2.
We know that n is around 400,000 for Singapore’s road network (and much larger for bigger cities), thus we can reasonably expect O(m x n log n) to dominate O(m^3) for m < 1500, which is the kind of value for m we expect in the real-world. We ran experiments on Singapore’s road network to verify this, as shown in Figure 2.
Figure 2. Proportion of time to compute the matrix vs. assignment for varying m on the Singapore road network
In Figure 2a, we can see that m must be greater than 2500, before the assignment time overtakes the matrix computation time. Even if we use a modern and advanced technique like Contraction Hierarchies3 to compute the fastest path, the observation holds, as shown in Figure 2b. This shows we can significantly improve overall matching performance if we can reduce the matrix computation time.
A redeeming intuition: Spatial locality of matching
While studying real-world locations of passengers and driver-partners, we observed an interesting property, which we dubbed “spatial locality of matching”. We find that the passenger assigned to each driver-partner in an optimal matching is one of the nearest passengers to the driver-partner (it might not be the nearest). This makes intuitive sense as passengers and driver-partners will be distributed throughout a city and it’s unlikely that the best match for a particular driver-partner is on the other side of the city.
In Figure 3, we see an example scenario exhibiting spatial locality of matching. While this is an idealised case to demonstrate the principle, it is not a significant departure from the real-world. From the cost matrix shown, it is very easy to see which assignment will give the lowest total travel time.
Figure 3. Example driver-partner to passenger matching scenario exhibiting spatial locality of matching
Now, it begs the question, do we even need to compute the other costs to find the optimal matching? For example, can we avoid computing the cost from D3 to P1, which are very far apart and unlikely to be matched?
Incremental Kuhn-Munkres
As it turns out, there is a way to take advantage of spatial locality of matching to reduce cost computation time. We propose an Incremental KM algorithm that computes costs only when they are required, and (hopefully) avoids computing all of them. Our modified KM algorithm incorporates an inexpensive lower-bounding technique to achieve this without adding significant overhead, as we will elaborate in the next section.
Figure 4. System overview of Incremental Kuhn-Munkres implementation
Retrieving objects nearest to a query point by their fastest route is a very well studied problem (commonly referred to as k-Nearest Neighbour search)4. We employ this concept to implement a priority queue Qi for each driver ui, as displayed in Figure 4. These priority queues allow retrieving the nearest passengers by a lower-bound on the travel time. The top of a priority queue implies a lower-bound on the travel time for all passengers that have not been retrieved yet. We can then use this minimum lower-bound as a lower-bound edge cost for all bipartite edges associated with that driver-partner for which we have not computed the exact cost so far.
Now, the KM algorithm can proceed as usual, using the virtual edge cost implied by the relevant priority queue, to avoid computing the exact edge cost. Of course, there may be circumstances where the virtual edge cost is insufficiently accurate for KM to compute the optimal matching. To solve this, we propose refinement rules that detect when a virtual edge cost is insufficient.
If a rule is triggered, we refine the queue by retrieving the top element and computing its exact edges; this is where the “incremental” part comes from. In almost all cases, this will also increase the minimum key (lower-bound) in the priority queue.
If you’re interested in finding out more, you can delve deeper into the pruning rules, inner workings of the algorithm and mathematical proofs of correctness by reading our research paper5.
For now, it suffices to say that the Incremental KM algorithm produces the exact same result as the original KM algorithm. It just does so in an optimistic incremental way, hoping that we can find the result without computing all possible costs. This is perfectly suited to take advantage of spatial locality of matching. Moreover, not only do we save time by avoiding computing exact costs, we avoid computing longer fastest paths/travel times to further away passengers that are more computationally expensive than those for nearby passengers.
Experimental investigation
Competition
We conducted a thorough experimental investigation to verify the practical performance of the proposed techniques. We implemented two variants of our Incremental KM technique, differing in the implementation of the priority queue and the shortest path technique used.
IKM-DIJK: Uses Dijkstra’s algorithm to compute shortest paths. Priority queues are simply the priority queue of the Dijkstra’s search from each driver-partner. This adds no overhead over the regular KM algorithm, so any speedup comes for free.
IKM-GAC: Uses state-of-the-art lower-bound technique COLT6 to implement the priority queues and G-tree4, a fast technique to compute shortest paths. The COLT index must be built for each assignment, and this overhead is included in all running times.
We compared our proposed variants against the regular KM algorithm using Dijkstra and G-tree, respectively, to compute the entire cost matrix up front. Thus, we can make an apples-to-apples comparison to see how effective our techniques are.
Datasets
We ran experiments using the real-world road network for Singapore. For the Singapore dataset, we also use a real production workload consisting of Grab bookings over a 7-day period from December 2018.
Performance evaluation
To test our technique on the Singapore workload, we created an assignment problem by first choosing the window size W in seconds. Then, we batched all the bookings in a randomly selected window of that size and used the passenger and driver-partner locations from these bookings to create the bipartite sets. Next, we found an optimal matching using each technique and reported the results averaged over several randomly selected windows for several metrics.
Figure 5. Average percentage of the cost matrix computed by each technique vs. batching window size
In Figure 5, we verify that our proposed techniques are indeed computing fewer exact costs compared to their counterparts. Naturally, the original KM variants compute 100% of the matrix.
Figure 6. Average running time to find an optimal assignment by each technique vs. batching window size
In Figure 6, we can see the running times of each technique. The results in the figure confirm that the reduced computation of exact costs translates to a significant reduction of running time by over an order of magnitude. This verifies that the time saved is greater than any overhead added. Remember, the improvement of IKM-DIJK comes essentially for free! On the other hand, using IKM-GAC can achieve very low running times.
Figure 7. Maximum throughput supported by each technique vs. batching window size
In Figure 7, we report a slightly different metric. We measure m, the maximum number of passengers/driver-partners that can be batched within the time window W. This can be considered as the maximum throughput of each technique. Our technique supports significantly higher throughput.
Note that the improvement is smaller than in other cases because real-world values of m rarely reach these levels, where the assignment time starts to take up a greater proportion of the overall computation time.
Conclusion
In summary, computing assignment costs do indeed have a significant impact on the running time of finding optimal assignments. However, we show that by utilising the spatial locality of matching inherent in real-world assignment problems, we can avoid computing exact costs, unless absolutely necessary, by modifying the KM algorithm to work incrementally.
We presented an interesting case where practice informs the theory, with our novel modifications to the classical KM algorithm. Moreover, our technique can be potentially applied beyond driver-partner and passenger matching in ride-hailing services.
For example, the Route Inspection algorithm also uses shortest path edge costs to find a minimum-weight bipartite matching, and our technique could be a drop-in replacement. It would also be interesting to see if these principles can be generalised and applied to other domains where the assignment problem is used.
Acknowledgements
This research was jointly conducted between Grab and the Grab-NUS AI Lab within the Institute of Data Science at the National University of Singapore (NUS). Tenindra Abeywickrama was previously a postdoctoral fellow at the lab and now a data scientist with Grab.
Special thanks to Kian-Lee Tan from NUS for co-authoring this paper.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
References
H. W. Kuhn. 1955. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly 2, 1-2 (1955), 83–97 ↩
Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1, 269–271 (1959) ↩
Robert Geisberger, Peter Sanders, Dominik Schultes, and Daniel Delling. 2008. Contraction Hierarchies: Faster and Simpler Hierarchical Routing in Road Networks. In WEA. 319–333 ↩
Ruicheng Zhong, Guoliang Li, Kian-Lee Tan, Lizhu Zhou, and Zhiguo Gong. 2015. G-Tree: An Efficient and Scalable Index for Spatial Search on Road Networks. IEEE Trans. Knowl. Data Eng. 27, 8 (2015), 2175–2189 ↩↩2
Tenindra Abeywickrama, Victor Liang, and Kian-Lee Tan. 2021. Optimizing bipartite matching in real-world applications by incremental cost computation. Proc. VLDB Endow. 14, 7 (March 2021), 1150–1158 ↩
Tenindra Abeywickrama, Muhammad Aamir Cheema, and Sabine Storandt. 2020. Hierarchical Graph Traversal for Aggregate k Nearest Neighbors Search in Road Networks. In ICAPS. 2–10 ↩
In 2016, Clayton Christensen, a Harvard Business School professor, wrote a book called Competing Against Luck. In his book, he talked about the kind of jobs that exist in our everyday life and how we can uncover hidden jobs through the act of non-consumption. Non-consumption is the inability for a consumer to fulfil an important Job to be Done (JTBD).
JTBD is a framework; it is a different way of looking at consumer goals and is based on the notion that people buy products and services to get a job done. In this article, we will walk through what the JTBD framework is, look at an example of a popular JTBD, and look at how we use the JTBD framework in one of Grab’s services.
JTBD framework
In his book, Clayton Christensen gives the example of the milkshake, as a JTBD example. In the mid-90s, a fast food chain was trying to understand how to improve the milkshakes they were selling and how they could sell more milkshakes. To sell more, they needed to improve the product. To understand the job of the milkshake, they interviewed their customers. They asked their customers why they were buying the milkshakes, and what progress the milkshake would help them make.
Job 1: To fill their stomachs
One of the key insights was the first job, the customers wanted something that could fill their stomachs during their early morning commute to the office. Usually, these car drives would take one to two hours, so they needed something to keep them awake and to keep themselves full.
In this scenario, the competition could be a banana, but think about the properties of a banana. A banana could fill your stomach but your hands get dirty and sticky after peeling it. Bananas cannot do a good job here. Another competitor could be a Snickers bar, but it is rather unhealthy, and depending on how many bites you take, you could finish it in one minute.
By understanding the job the milkshake was performing, the restaurant now had a specific way of improving the product. The milkshake could be made milkier so it takes time to drink through a straw. The customer can then enjoy the milkshake throughout the journey; the milkshake is optimised for the job.
Milkshake
Job 2: To make children happy
As part of the study, they also interviewed parents who came to buy milkshakes in the afternoon, around 3:00 PM. They found out that the parents were buying the milkshakes to make their children happy.
By knowing this, they were able to optimise the job by offering a smaller version of the milkshake which came in different flavours like strawberry and chocolate. From this milkshake example, we learn that multiple jobs can exist for one product. From that, we can make changes to a product to meet those different jobs.
JTBD at GrabFood
A team at GrabFood wanted to prioritise which features or products to build, and performed a prioritisation exercise. However, there was a lack of fundamental understanding of why our consumers were using GrabFood or any other food delivery services. To gain deeper insights on this, we conducted a JTBD study.
We applied the JTBD framework in our research investigation. We used the force diagram framework to find out what job a consumer wanted to achieve and the corresponding push and pull factors driving the consumer’s decision. A job here is defined as the progress that the consumer is trying to make in a particular context.
Force diagram
There were four key points in the force diagram:
What jobs are people using GrabFood for?
What did people use prior to GrabFood to get the jobs done?
What pushed them to seek a new solution? What is attractive about this new solution?
What are the things that will make them go back to the old product? What are the anxieties of the new product?
By applying this framework, we progressively asked these questions in our interview sessions:
Can you remind us of the last time you used GrabFood? — This was to uncover the situation or the circumstances.
Why did you order this food? — This was to get down to the core of the need.
Can you tell us, before GrabFood, what did you use to get the same job done?
From the interview sessions, we were able to uncover a number of JTBDs, one example was working parents buying food for their families. Before GrabFood, most of them were buying from food vendors directly, but that is a time consuming activity and it adds additional friction to an already busy day. This led them in search of a new solution and GrabFood provided that solution.
Let’s look at this JTBD in more depth. One anxiety that parents had when ordering GrabFood was the sheer number of choices they had to make in order to check out their order:
Force diagram – inertia, anxiety
There was already a solution for this problem: bundles! Food bundles is a well-known concept from the food and beverage industry; items that complement each other are bundled together for a more efficient checkout experience.
Force diagram – pull, push
However, not all GrabFood merchants created bundles to solve this problem for their consumers. This was an untapped opportunity for the merchants to solve a critical problem for their consumers. Eureka! We knew that we needed to help merchants create bundles in an efficient way to solve for the consumer’s JTBD.
We decided to add a functionality to the GrabMerchant app that allowed merchants to create bundles. We built an algorithm that matched complementary items and automatically suggested these bundles to merchants. The merchant only had to tap a button to create a bundle instantly.
Bundle
The feature was released and thousands of restaurants started adding bundles to their menu. Our JTBD analysis proved to be correct: food and beverage entrepreneurs were now equipped with an essential tool to drive growth and we removed an obstacle for parents to choose GrabFood to solve for their JTBD.
Conclusion
At Grab, we understand the importance of research. We educate designers and other non-researcher employees to conduct research studies. We also encourage the sharing of research findings, and we ensure that research insights are consumable. By using the JTBD framework and asking questions specifically to understand the job of our consumers and partners, we are able to gain fundamental understanding of why our consumers are using our products and services. This helps us improve our products and services, and optimise it for the jobs that need to be done throughout Southeast Asia.
This article was written based on an episode of the Grab Design Podcast – a conversation with Grab Lead Researcher Soon Hau Chua. Want to listen to the Grab Design Podcast? Join the team, we’re hiring!
Special thanks to Amira Khazali and Irene from Tech Learning.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Modern applications commonly utilise various database engines, with each serving a specific need. At Grab Deliveries, MySQL database (DB) is utilised to store canonical forms of data, and ElasticSearch (ES) to provide advanced search capabilities. MySQL serves as the primary data storage for raw data, and ES as the derived storage.
Search data flow
Efforts have been made to synchronise data between MySQL and ES. In this post, a series of techniques will be introduced on how to optimise incremental search data indexing.
Background
The synchronisation of data from the primary data storage to the derived data storage is handled by Food-Puxian, a Data Synchronisation Platform (DSP). In a search service context, it is the synchronisation of data between MySQL and ES.
The data synchronisation process is triggered on every real-time data update to MySQL, which will streamline the updated data to Kafka. DSP consumes the list of Kafka streams and incrementally updates the respective search indexes in ES. This process is also known as Incremental Sync.
Kafka to DSP
DSP uses Kafka streams to implement Incremental Sync. A stream represents an unbounded, continuously updating data set. A stream is ordered, replayable and is a fault-tolerant sequence of immutable.
Data synchronisation process using Kafka
The above diagram depicts the process of data synchronisation using Kafka. The Data Producer creates a Kafka stream for every operation done on MySQL and sends it to Kafka in real-time. DSP creates a stream consumer for each Kafka stream and the consumer reads data updates from respective Kafka streams and synchronises them to ES.
MySQL to ES
Indexes in ES correspond to tables in MySQL. MySQL data is stored in tables, while ES data is stored in indexes. Multiple MySQL tables are joined to form an ES index. The below snippet shows the Entity-Relationship mapping in MySQL and ES. Entity A has a one-to-many relationship with entity B. Entity A has multiple associated tables in MySQL, table A1 and A2, and they are joined into a single ES index A.
ER mapping in MySQL and ES
Sometimes a search index contains both entity A and entity B. In a keyword search query on this index, e.g. “Burger”, objects from both entity A and entity B whose name contains “Burger” are returned in the search response.
Original Incremental Sync
Original Kafka streams
The Data Producers create a Kafka stream for every MySQL table in the ER diagram above. Every time there is an insert/update/delete operation on the MySQL tables, a copy of the data after the operation executes is sent to its Kafka stream. DSP creates different stream consumers for every Kafka stream since their data structures are different.
Stream Consumer infrastructure
Stream Consumer consists of 3 components.
Event Dispatcher: Listens and fetches events from the Kafka stream, pushes them to the Event Buffer and starts a goroutine to run Event Handler for every event whose ID does not exist in the Event Buffer
Event Buffer: Caches events in memory by the primary key (aID, bID, etc). An event is cached in the Buffer until it is picked by a goroutine or replaced when a new event with the same primary key is pushed into the Buffer.
Event Handler: Reads an event from the Event Buffer and the goroutine started by the Event Dispatcher handles it.
Stream consumer infrastructure
Event Buffer procedure
Event Buffer consists of many sub buffers, each with a unique ID which is the primary key of the event cached in it. The maximum size of a sub buffer is 1. This allows Event Buffer to deduplicate events having the same ID in the buffer.
The below diagram shows the procedure of pushing an event to Event Buffer. When a new event is pushed to the buffer, the old event sharing the same ID will be replaced. The replaced event is therefore not handled.
Pushing an event to the Event Buffer
Event Handler procedure
The below flowchart shows the procedures executed by the Event Handler. It consists of the common handler flow (in white), and additional procedures for object B events (in green). After creating a new ES document by data loaded from the database, it will get the original document from ES to compare if any field is changed and decide whether it is necessary to send the new document to ES.
When object B event is being handled, on top of the common handler flow, it also cascades the update to the related object A in the ES index. We name this kind of operation Cascade Update.
Procedures executed by the Event Handler
Issues in the original infrastructure
Data in an ES index can come from multiple MySQL tables as shown below.
Data in an ES index
The original infrastructure came with a few issues.
Heavy DB load: Consumers read from Kafka streams, treat stream events as notifications then use IDs to load data from the DB to create a new ES document. Data in the stream events are not well utilised. Loading data from the DB every time to create a new ES document results in heavy traffic to the DB. The DB becomes a bottleneck.
Data loss: Producers send data copies to Kafka in application code. Data changes made via MySQL command-line tool (CLT) or other DB management tools are lost.
Tight coupling with MySQL table structure: If producers add a new column to an existing table in MySQL and this column needs to be synchronised to ES, DSP is not able to capture the data changes of this column until the producers make the code change and add the column to the related Kafka Stream.
Redundant ES updates: ES data is a subset of MySQL data. Producers publish data to Kafka streams even if changes are made on fields that are not relevant to ES. These stream events that are irrelevant to ES would still be picked up.
Duplicate cascade updates: Consider a case where the search index contains both object A and object B. A large number of updates to object B are created within a short span of time. All the updates will be cascaded to the index containing both objects A and B. This will bring heavy traffic to the DB.
Optimised Incremental Sync
MySQL Binlog
MySQL binary log (Binlog) is a set of log files that contain information about data modifications made to a MySQL server instance. It contains all statements that update data. There are two types of binary logging:
Statement-based logging: Events contain SQL statements that produce data changes (inserts, updates, deletes).
Row-based logging: Events describe changes to individual rows.
The Grab Caspian team (Data Tech) has built a Change Data Capture (CDC) system based on MySQL row-based Binlog. It captures all the data modifications made to MySQL tables.
Current Kafka streams
The Binlog stream event definition is a common data structure with three main fields: Operation, PayloadBefore and PayloadAfter. The Operation enums are Create, Delete, and Update. Payloads are the data in JSON string format. All Binlog streams follow the same stream event definition. Leveraging PayloadBefore and PayloadAfter in the Binlog event, optimisations of incremental sync on DSP becomes possible.
Binlog stream event main fields
Stream Consumer optimisations
Event Handler optimisations
Optimisation 1
Remember that there was a redundant ES updates issue mentioned above where the ES data is a subset of the MySQL data. The first optimisation is to filter out irrelevant stream events by checking if the fields that are different between PayloadBefore and PayloadAfter are in the ES data subset.
Since the payloads in the Binlog event are JSON strings, a data structure only with fields that are present in ES data is defined to parse PayloadBefore and PayloadAfter. By comparing the parsed payloads, it is easy to know whether the change is relevant to ES.
The below diagram shows the optimised Event Handler flows. As shown in the blue flow, when an event is handled, PayloadBefore and PayloadAfter are compared first. An event will be processed only if there is a difference between PayloadBefore and PayloadAfter. Since the irrelevant events are filtered, it is unnecessary to get the original document from ES.
Event Handler optimisation 1
Achievements
No data loss: changes made via MySQL CLT or other DB manage tools can be captured.
No dependency on MySQL table definition: All the data is in JSON string format.
No redundant ES updates and DB reads.
ES reads traffic reduced by 90%: Not a need to get the original document from ES to compare with the newly created document anymore.
55% irrelevant stream events filtered out
DB load reduced by 55%
ES event updates for optimisation 1
Optimisation 2
The PayloadAfter in the event provides updated data. This makes us think about whether a completely new ES document is needed each time, with its data read from several MySQL tables. The second optimisation is to change to a partial update using data differences from the Binlog event.
The below diagram shows the Event Handler procedure flow with a partial update. As shown in the red flow, instead of creating a new ES document for each event, a check on whether the document exists will be performed first. If the document exists, which happens for the majority of the time, the data is changed in this event, provided the comparison between PayloadBefore and PayloadAfter is updated to the existing ES document.
Event Handler optimisation 2
Achievements
Change most ES relevant events to partial update: Use data in stream events to update ES.
ES load reduced: Only fields that have been changed will be sent to ES.
DB load reduced: DB load reduced by 80% based on Optimisation 1.
ES event updates for optimisation 2
Event Buffer optimisation
Instead of replacing the old event, we merge the new event with the old event when the new event is pushed to the Event Buffer.
The size of each sub buffer in Event Buffer is 1. In this optimisation, the stream event is not treated as a notification anymore. We use the Payloads in the event to perform Partial Updates. The old procedure of replacing old events is no longer suitable for the Binlog stream.
When the Event Dispatcher pushes a new event to a non-empty sub buffer in the Event Buffer, it will merge event A in the sub buffer and the new event B into a new Binlog event C, whose PayloadBefore is from Event A and PayloadAfter is from Event B.
Merge operation for Event Buffer optimisation
Cascade Update optimisation
Optimisation
Use a new stream to handle cascade update events.
When the producer sends data to the Kafka stream, data sharing the same ID will be stored at the same partition. Every DSP service instance has only one stream consumer. When Kafka streams are consumed by consumers, one partition will be consumed by only one consumer. So the Cascade Update events sharing the same ID will be consumed by one stream consumer on the same EC2 instance. With this special mechanism, the in-memory Event Buffer is able to deduplicate most of the Cascade Update events sharing the same ID.
The flowchart below shows the optimised Event Handler procedure. Highlighted in green is the original flow while purple highlights the current flow with Cascade Update events.
When handling an object B event, instead of cascading update the related object A directly, the Event Handler will send a Cascade Update event to the new stream. The consumer of the new stream will handle the Cascade Update event and synchronise the data of object A to the ES.
Event Handler with Cascade Update events
Achievements
Cascade Update events deduplicated by 80%
DB load introduced by cascade update reduced
Cascade Update events
Summary
In this article four different DSP optimisations are explained. After switching to MySQL Binlog streams provided by the Coban team and optimising Stream Consumer, DSP has saved about 91% DB reads and 90% ES reads, and the average queries per second (QPS) of stream traffic processed by Stream Consumer increased from 200 to 800. The max QPS at peak hours could go up to 1000+. With a higher QPS, the duration of processing data and the latency of synchronising data from MySQL to ES was reduced. The data synchronisation ability of DSP has greatly improved after optimisation.
Special thanks to Jun Ying Lim and Amira Khazali for proofreading this article.
Join Us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
A/B testing is an experiment where a random e-commerce platform user is given two versions of a variable: a control group and a treatment group, to discover the optimal version that maximizes conversion. When running A/B testing, you can take the Multi-Armed Bandit optimisation approach to minimise the loss of conversion due to low performance.
In the traditional software development process, Multi-Armed Bandit (MAB) testing and rolling out a new feature are usually separate processes. The novel Multi-Armed Bandit System for Recommendation solution, hereafter the Multi-Armed Bandit Optimiser, proposes automating the Multi-Armed Bandit testing simultaneously while rolling out the new feature.
Advantages
Automates the MAB testing process during new feature rollouts.
Selects the optimal parameters based on predefined metrics of each use case, which results in an end-to-end solution without the need for user intervention.
Uses the Batched Multi-Armed Bandit and Monte Carlo Simulation, which enables it to process large-scale business scenarios.
Uses a feedback loop to automatically collect recommendation metrics from user event logs and to feed them to the Multi-Armed Bandit Optimiser.
Uses an adaptive rollout method to automatically roll out the best model to the maximum distribution capacity according to the feedback metrics.
Architecture
The following diagram illustrates the system architecture.
System architecture
The novel Multi-Armed Bandit System for Recommendation solution contains three building blocks.
Stream processing framework
A lightweight system that performs basic operations on Kafka Streams, such as aggregation, filtering, and mapping. The proposed solution relies on this framework to pre-process raw events published by mobile apps and backend processes into the proper format that can be fed into the feedback loop.
Feedback loop
A system that calculates the goal metrics and optimises the model traffic distribution. It runs a metrics server which pulls the data from Stalker, which is a time series database that stores the processed events in the last one hour. The metrics server invokes a Spark Job periodically to run the SQL queries that computes the pre-defined goal metrics: the Clickthrough Rate, Conversion Rate and so on, provided by users. The output of the job is dumped into an S3 bucket, and is picked up by optimiser runtime. It runs the Multi-Armed Bandit Optimiser to optimise the model traffic distribution based on the latest goal metrics.
Dynamic value receiver, or the GrabX variable
Multi-Armed Bandit Optimiser modules
The Multi-Armed Bandit Optimiser consists of the following modules:
Reward Update
Batched Multi-Armed Bandit Agent
Monte-Carlo Simulation
Adaptive Rollout
Multi-Armed Bandit Optimiser modules
The goal of the Multi-Armed Bandit Optimisation is to find the optimal Arm that results in the best predefined metrics, and then allocate the maximum traffic to that Arm.
The solution can be illustrated in the following problem. For K Arm, in which the action space A={1,2,…,K}, the Multi-Arm-Bandit Optimiser goal is to solve the one-shot optimisation problem of .
Reward Update module
The Reward Update module collects a batch of the metrics. It calculates the Success and Failure counts, then updates the Beta distribution of each Arm with the Batched Multi-Armed Bandit algorithm.
Multi-Armed Bandit Agent module
In the Multi-Armed Bandit Agent module, each Arm’s metrics are modelled as a Beta distribution which is sampled with Thompson Sampling. The Beta distribution formula is: .
The Batched Multi-Armed Bandit algorithm updates the Beta distribution with the batch metrics. The optimisation algorithm can be described in the following method.
Batched Multi-Armed Bandit algorithm
Monte-Carlo Simulation module
The Monte-Carlo Simulation module runs the simulation for N repeated times to find the best Arm over a configurable simulation window. Then, it applies the simulated results as each Arm’s distribution percentage for the next round.
To handle different scenarios, we designed two strategies.
Max strategy: We count each Arm’s Success count’s result in Monte-Carlo Simulation, and then compute the next round distribution according to the success rate.
Mean strategy: We average each Arm’s Beta distribution probabilities’s result in Monte-Carlo Simulation, and then compute the next round distribution according to the averaged probabilities of each Arm.
Adaptive Rollout module
The Adaptive Rollout module rolls out the sampled distribution of each Multi-Armed Bandit Arm, in the form of Multi-Armed Bandit Arm Model ID and distribution, to the experimentation platform’s configuration variable. The resulting variable is then read from the online service. The process repeats as it collects feedback from the Adaptive Rollout metrics’ results in the feedback loop.
Multi-Armed Bandit for Recommendation Solution
In the GrabFood Recommended for You widget, there are several food recommendation models that categorise lists of merchants. The choice of the model is controlled through experiments at rollout, and the results of the experiments are analysed offline. After the analysis, data scientists and product managers rectify the model choice based on the experiment results.
The Multi-Armed Bandit System for Recommendation solution improves the process by speeding up the feedback loop with the Multi-Armed Bandit system. Instead of depending on offline data which comes out at T+N, the solution responds to minute-level metrics, and adjusts the model faster.
This results in an optimal solution faster. The proposed Multi-Armed Bandit for Recommendation solution workflow is illustrated in the following diagram.
Multi-Armed Bandit for Recommendation solution workflow
Optimisation metrics
The GrabFood recommendation uses the Effective Conversion Rate metrics as the optimisation objective. The Effective Conversion Rate is defined as the total number of checkouts through the Recommended for You widget, divided by the total widget viewed and multiplied by the coverage rate.
The events of views, clicks, and checkouts are collected over a 30-minute aggregation window and the coverage. A request with a checkout is considered as a success event, while a non-converted request is considered as a failure event.
Multi-Armed Bandit strategy
With the Multi-Armed Bandit Optimiser, the Beta distribution is selected to model the Effective Conversion Rate. The use of the mean strategy in the Monte-Carlo Simulation results in a more stable distribution.
Rollout policy
The Multi-Armed Bandit Optimiser uses the eater ID as the unique entity, applies a policy and assigns different percentages of eaters to each model, based on computed distribution at the beginning of each loop.
Fallback logic
The Multi-Armed Bandit Optimiser first runs model validation to ensure all candidates are suitable for rolling out. If the scheduled MAB job fails, it falls back to a default distribution that is set to 50-50% for each model.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
Every week, GrabFood.com’s cloud infrastructure serves over >1TB network egress and 175 million requests, which increased our costs. To minimise cloud costs, we had to look at optimising (and reducing) GrabFood.com’s bundle size.
Any reduction in bundle size helps with:
Faster site loads! (especially for locations with lower mobile broadband speeds)
Cost savings for users: Less data required for each site load
Cost savings for Grab: Less network egress required to serve users
Faster build times: Fewer dependencies -> less code for webpack to bundle -> faster builds
Smaller builds: Fewer dependencies -> less code -> smaller builds
After applying the 7 webpack bundle optimisations, we were able to yield the following improvements:
7% faster page load time from 2600ms to 2400ms
66% faster JS static asset load time from 180ms to 60ms
3x smaller JS static assets from 750KB to 250KB
1.5x less network egress from 1800GB to 1200GB
20% less for CloudFront costs from $1750 to $1400
1.4x smaller bundle from 40MB to 27MB
3.6x faster build time from ~2000s to ~550s
Solution
One of the biggest factors influencing bundle size is dependencies. As mentioned earlier, fewer dependencies mean fewer lines of code to compile, which result in a smaller bundle size. Thus, to optimise GrabFood.com’s bundle size, we had to look into our dependencies.
In this step, we need to ask ourselves ‘what are our largest dependencies?’. We used the webpack-bundle-analyzer to inspect GrabFood.com’s bundles. This gave us an overview of all our dependencies and we could easily see which bundle assets were the largest.
There are two broad approaches that can be used to identify how our dependencies are used:
I: Top-down approach: “Where does our project use dependency X?”
Conceptually identify which feature(s) requires the use of dependency X.
E.g. Given that we have ‘jwt-simple’ as a dependency, which set of features in my project requires JWT encoding/decoding?
II: Bottom-up approach: “How did dependency X get used in my project?”
Trace dependencies by manually tracing import() and require() statements
Alternatively, use dependency visualisation tools such as dependency-cruiser to identify file interdependencies. Note that output can quickly get noisy for any non-trivial project, so use it for inspecting small groups of files (e.g. single domains).
Our recommendation is to use a mix of both Top-down and Bottom-up approaches to identify and isolate dependencies.
Dos:
Be methodical when tracing dependencies: Use a document to track your progress as you manually trace inter-file dependencies.
Use dependency visualisation tools like dependency-cruiser to quickly view a given file’s dependencies.
Note: These strategies have been listed in ascending order of difficulty – focus on the easy wins first 🙂
1. Lazy Load Large Dependencies and Less-used Dependencies
“When a file adds +2MB worth of dependencies”, Image source
Similar to how lazy loading is used to break down large React pages to improve page performance, we can also lazy load libraries that are rarely used, or are not immediately used until prior to certain user actions.
Scenario: Use of Anti-abuse library prior to sensitive API calls
Action: Instead of bundling the anti-abuse library together with the main page asset, we opted to lazy load the library only when we needed to use it (i.e. load the library just before making certain sensitive API calls).
Results: Saved 400KB on the main page asset.
Notes:
Any form of lazy loading will incur some latency on the user, since the asset must be loaded with XMLHttpRequest.
Scenario: Duplicate ‘grab-maps’ dependencies in bundle
Action: We observed that we were bundling the same ‘grab-maps’ dependency in 4 different assets so we refactored the application to use a single entrypoint, ensuring that we only bundled one instance of ‘grab-maps’.
Results: Saved 2MB on total bundle size.
Notes:
Alternative approach: Manually define a new cacheGroup to target a specific module (see more) with ‘enforce:true’, in order to force webpack to always create a separate chunk for the module. Useful for cases where the single dependency is very large (i.e. >100KB), or when asynchronously loading a module isn’t an option.
Certain libraries that appear in multiple assets (e.g. antd) should not be mistaken as identical dependencies. You can verify this by inspecting each module with one another. If the contents are different, then webpack has already done its job of tree-shaking the dependency and only importing code used by our code.
Webpack relies on the import() statement to identify that a given module is to be explicitly bundled as a separate chunk (see more).
3. Use Libraries that are Exported in ES Modules Format
Action: Instead of using the standard ‘lodash’ library, you can swap it out with ‘lodash-es’, which is bundled using ES Modules and is functionally equivalent.
Results: Saved 0KB – We were already directly importing individual Lodash functions (e.g. ‘lodash/get’), therefore importing only the code we need. Still, ES Modules is a more convenient way to go about this 👍.
Notes:
Alternative approach: Use babel plugins (e.g. ‘babel-plugin-transform-imports’) to transform your import statements at build time to selectively import specific code for a given library.
4. Replace Libraries whose Features are Already Available on the Browser Web API
If you are relying on libraries for functionality that is available on the Web API, you should revise your implementation to leverage on the Web API, allowing you to skip certain libraries when bundling, thus saving on bundle size.
Use Case: Replacing axios with fetch() in the anti-abuse library
Action: We observed that our anti-abuse library was relying on axios to make web requests. Since our web app is only targeting modern browsers – most of which support fetch() (with the notable exception of IE) – we refactored the library’s code to use fetch() exclusively.
Results: Saved 15KB on anti-abuse library size.
5. Avoid Large Dependencies by Changing your Technical Approach
Action: As we needed to store certain user preferences in the user’s browser, we previously opted to use JWT encoding; this involved signing JWTs on the client side, which has a hard dependency on ‘crypto’. We revised the implementation to use plain JSON encoding instead, removing the need for ‘crypto’.
Results: Saved 250KB per page asset, 13MB in total bundle size.
6. Avoid Using Node Dependencies or Libraries that Require Node Dependencies
“When someone does require(‘crypto’)”, Image source
You should not need to use node-related dependencies, unless your application relies on a node dependency directly or indirectly.
Examples of node dependencies: ‘Buffer’, ‘crypto’, ‘https’ (see more)
Action: In terms of JWT usage on the client side, we only need to decode JWTs – we do not need any logic related to encoding JWTs. Therefore, we can opt to use libraries that perform just decoding (e.g. ‘jwt-decode’) instead of libraries (e.g. ‘jsonwebtoken’) that performs the full suite of JWT-related operations (e.g. signing, verifying).
Results: Same as in Point 5: Example. (i.e. no need to decode JWTs anymore, since we aren’t using JWT encoding for browser cookie persistence)
7. Optimise your External Dependencies
“Team: Can you reduce the bundle size further? You: (nervous grin)“, Image source
We can do a deep-dive into our dependencies to identify possible size optimisations by applying all the aforementioned techniques. If your size optimisation changes get accepted, regardless of whether it’s publicly (e.g. GitHub) or privately hosted (own company library), it’s a win-win for everybody! 🥳
Example:
Scenario: Creating custom ‘node-forge’ builds for our Anti-abuse library
Action: Our Anti-abuse library only uses certain features of ‘node-forge’. Thankfully, the ‘node-forge’ maintainers have provided an easy way to make custom builds that only bundle selective features (see more).
Results: Saved 85KB in Anti-abuse library size and reduced bundle size for all other dependent projects.
Step D: Verify that You have Modified the Dependencies
So, you’ve found some opportunities for major bundle size savings, that’s great!
But as always, it’s best to be methodical to measure the impact of your changes, and to make sure no features have been broken.
Perform your code changes
Build the project again and open the bundle analysis report
Verify the state of a given dependency
Deleted dependency – you should not be able to find the dependency
Lazy-loaded dependency – you should see the dependency bundled as a separate chunk
Non-duplicated dependency – you should only see a single chunk for the non-duplicated dependency
Run tests to make sure you didn’t break anything (i.e. unit tests, manual tests)
Other Considerations
Preventive Measures
Periodically monitor your bundle size to identify increases in bundle size
Periodically monitor your site load times to identify increases in site load times
Webpack Configuration Options
Disable bundling node modules with ‘node: false’
Only if your project doesn’t already include libraries that rely on node modules.
Allows for fast detection when someone tries to use a library that requires node modules, as the build will fail
Experiment with ‘cacheGroups’
Most default configurations of webpack do a pretty good job of identifying and bundling the most commonly used dependencies into a single chunk (usually called vendor.js)
You can experiment with webpack optimisation options to see if you get better results
Experiment with import() ‘Magic Comments’
You may experiment with import() magic comments to modify the behaviour of specific import() statements, although the default setting will do just fine for most cases.
If you can’t remove the dependency:
For all dependencies that must be used, it’s probably best to lazy load all of them so you won’t block the page’s initial rendering (see more).
To summarise, here’s how you can go about this business of reducing your bundle size.
Namely…
Identify Your Dependencies
Investigate the Usage of Your Dependencies
Reduce Your Dependencies
Verify that You have Modified the Dependencies
And by using these 7 strategies…
Lazy load large dependencies and less-used dependencies
Unify instance of duplicate modules
Use libraries that are exported in ES Modules format
Replace libraries whose features are already available on the Browser Web API
Avoid large dependencies by changing your technical approach
Avoid using node dependencies
Optimise your external dependencies
You can have…
Faster page load time (smaller individual pages)
Smaller bundle (fewer dependencies)
Lower network egress costs (smaller assets)
Faster builds (fewer dependencies to handle)
Now armed with this information, may your eyes be keen, your bundles be lean, your sites be fast, and your cloud costs be low! 🚀 ✌️
Special thanks to Han Wu, Melvin Lee, Yanye Li, and Shujuan Cheong for proofreading this article. 🙂
Join Us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Starting a few years ago, we realised the strong demand to better understand the streets where our drivers and clients go, with the purpose to better fulfil their needs and also to be able to quickly adapt ourselves to the rapidly changing environment in the Southeast Asia cities.
One way to fulfil that demand was to create an image collection platform named KartaView which is Grab Geo’s platform for geotagged imagery. It empowers collection, indexing, storage, retrieval of imagery, and map data extraction.
KartaView is a public, partially open-sourced product, used both internally and externally by the OpenStreetMap community and other users. As of 2021, KartaView has public imagery in over 100 countries with various coverage degrees, and 60+ cities of Southeast Asia. Check it out at www.kartaview.com.
Figure 1 – KartaView platform
Why Image Blurring is Important
Many incidental people and licence plates are in the collected images, whose privacy is a serious concern. We deeply respect all of them and consequently, we are using image obfuscation as the most effective anonymisation method for ensuring privacy protection.
Because manually annotating the regions in the picture where faces and licence plates are located is impractical, this problem should be solved using machine learning and engineering techniques. Hence we detect and blur all faces and licence plates which could be considered as personal data.
Figure 2 – Sample blurred picture
In our case, we have a wide range of picture types: regular planar, very wide and 360 pictures in equirectangular format collected with 360 cameras. Also, because we are collecting imagery globally, the vehicle types, licence plates, and human environments are quite diverse in appearance, and are not handled well by off-the-shelf blurring software. So we built our own custom blurring solution which yielded higher accuracy and better cost-efficiency overall with respect to blurring of personal data.
Figure 3 – Example of equirectangular image where personal data has to be blurred
Behind the scenes, in KartaView, there are a set of cool services which are able to derive useful information from the pictures like image quality, traffic signs, roads, etc. A big part of them are using deep learning algorithms which potentially can be negatively affected by running them over blurred pictures. In fact, based on the assessment we have done so far, the impact is extremely low, similar to the one reported in a well known study of face obfuscation in ImageNet [9].
Outline of Grab’s Blurring Process
Roughly, the processing steps are the following:
Transform each picture into a set of planar images. In this way, we further process all pictures, whatever the format they had, in the same way.
Use an object detector able to detect all faces and licence plates in a planar image having a standard field of view.
Transform the coordinates of the detected regions into original coordinates and blur those regions.
Figure 4 – Picture’s processing steps [8]
In the following section, we are going to describe in detail the interesting aspects of the second step, sharing the challenges and how we were solving them. Let’s start with the first and most important part, the dataset.
Dataset
Our current dataset consists of images from a wide range of cameras, including normal perspective cameras from mobile phones, wide field of view cameras and also 360 degree cameras.
It is the result of a series of data collections contributed by Grab’s data tagging teams, which may contain 2 classes of dataset that are of interest for us: FACE and LICENSE_PLATE.
The data was collected using Grab internal tools, stored in queryable databases, making it a system that gives the possibility to revisit the data and correct it if necessary, but also making it possible for data engineers to select and filter the data of interest.
Dataset Evolution
Each iteration of the dataset was made to address certain issues discovered while having models used in a production environment and observing situations where the model lacked in performance.
Dataset v1
Dataset v2
Dataset v3
Nr. images
15226
17636
30538
Nr. of labels
64119
86676
242534
If the first version was basic, containing a rough tagging strategy we quickly noticed that it was not detecting some special situations that appeared due to the pandemic situation: people wearing masks.
This led to another round of data annotation to include those scenarios.
The third iteration addressed a broader range of issues:
Small regions of interest (objects far away from the camera)
Objects in very dark backgrounds
Rotated objects or even upside down
Variation of the licence plate design due to images from different countries and regions
People wearing masks
Faces in the mirror – see below the mirror of the motorcycle
But the main reason was because of a scenario where the recording, at the start or end (but not only), had close-ups of the operator who was checking the camera. This led to images with large regions of interest containing the camera operator’s face – too large to be detected by the model.
An investigation in the dataset structure, by splitting the data into bins based on the bbox sizes (in pixels), made something clear: the dataset was unbalanced.
We made bins for tag sizes with a stride of 100 pixels and went up to the max present in the dataset which accounted for 1 sample of size 2000 pixels. The majority of the labels were small in size and the higher we would go with the size, the less tags we would have. This made it clear that we would need more targeted annotations for our dataset to try to balance it.
All these scenarios required the tagging team to revisit the data multiple times and also change the tagging strategy by including more tags that were considered at a certain limit. It also required them to pay more attention to small details that may have been missed in a previous iteration.
Data Splitting
To better understand the strategy chosen for splitting the data we need to also understand the source of the data. The images come from different devices that are used in different geo locations (different countries) and are from a continuous trip recording. The annotation team used an internal tool to visualise the trips image by image and mark the faces and licence plates present in them. We would then have access to all those images and their respective metadata.
The chosen ratios for splitting are:
Train 70%
Validation 10%
Test 20%
Number of train images
12733
Number of validation images
1682
Number of test images
3221
Number of labeled classes in train set
60630
Number of labeled classes in validation set
7658
Number of of labeled classes in test set
18388
The split is not so trivial as we have some requirements and need to complete some conditions:
An image can have multiple tags from one or both classes but must belong to just one subset.
The tags should be split as close as possible to the desired ratios.
As different images can belong to the same trip in a close geographical relation we need to force them in the same subset, thus avoiding similar tags in train and test subsets, resulting in incorrect evaluations.
Data Augmentation
The application of data augmentation plays a crucial role while training the machine learning model. There are mainly three ways in which data augmentation techniques can be applied. They are:
Offline data augmentation – enriching a dataset by physically multiplying some of its images and applying modifications to them.
Online data augmentation – on the fly modifications of the image during train time with configurable probability for each modification.
Combination of both offline and online data augmentation.
In our case, we are using the third option which is the combination of both.
The first method that contributes to offline augmentation is a method called image view splitting. This is necessary for us due to different image types: perspective camera images, wide field of view images, 360 degree images in equirectangular format. All these formats and field of views with their respective distortions would complicate the data and make it hard for the model to generalise it and also handle different image types that could be added in the future.
For this we defined the concept of image views which are an extracted portion (view) of an image with some predefined properties. For example, the perspective projection of 75 by 75 degrees field of view patches from the original image.
Here we can see a perspective camera image and the image views generated from it:
Figure 5 – Original image
Figure 6 – Two image views generated
The important thing here is that each generated view is an image on its own with the associated tags. They also have an overlapping area so we have a possibility to contain the same tag in two views but from different perspectives. This brings us to an indirect outcome of the first offline augmentation.
The second method for offline augmentation is the oversampling of some of the images (views). As mentioned above, we faced the problem of an unbalanced dataset, specifically we were missing tags that occupied high regions of the image, and even though our tagging teams tried to annotate as many as they could find, these were still scarce.
As our object detection model is an anchor-based detector, we did not even have enough of them to generate the anchor boxes correctly. This could be clearly seen in the accuracy of the previous trained models, as they were performing poorly on bins of big sizes.
By randomly oversampling images that contained big tags, up to a minimum required number, we managed to have better anchors and increase the recall for those scenarios. As described below, the chosen object detector for blurring was YOLOv4 which offers a large variety of online augmentations. The online augmentations used are saturation, exposure, hue, flip and mosaic.
Model
As of summer of 2021, the “to go” solution for object detection in images are convolutional neural networks (CNN), being a mature solution able to fulfil the needs efficiently.
Architecture
Most CNN based object detectors have three main parts: Backbone, Neck and (Dense or Sparse Prediction) Heads. From the input image, the backbone extracts features which can be combined in the neck part to be used by the prediction heads to predict object bounding-boxes and their labels.
Figure 7 – Anatomy of one and two-stage object detectors [1]
The backbone is usually a CNN classification network pretrained on some dataset, like ImageNet-1K. The neck combines features from different layers in order to produce rich representations for both large and small objects. Since the objects to be detected have varying sizes, the topmost features are too coarse to represent smaller objects, so the first CNN based object detectors were fairly weak in detecting small sized objects. The multi-scale, pyramid hierarchy is inherent to CNNs so [2] introduced the Feature Pyramid Network which at marginal costs combines features from multiple scales and makes predictions on them. This or improved variants of this technique is used by most detectors nowadays. The head part does the predictions for bounding boxes and their labels.
YOLO is part of the anchor-based one-stage object detectors family being developed originally in Darknet, an open source neural network framework written in C and CUDA. Back in 2015 it was the first end-to-end differentiable network of this kind that offered a joint learning of object bounding boxes and their labels.
One reason for the big success of newer YOLO versions is that the authors carefully merged new ideas into one architecture, the overall speed of the model being always the north star.
YOLOv4 introduces several changes to its v3 predecessor:
Backbone – CSPDarknet53: YOLOv3 Darknet53 backbone was modified to use Cross Stage Partial Network (CSPNet [5]) strategy, which aims to achieve richer gradient combinations by letting the gradient flow propagate through different network paths.
Multiple configurable augmentation and loss function types, so called “Bag of freebies”, which by changing the training strategy can yield higher accuracy without impacting the inference time.
Configurable necks and different activation functions, they call “Bag of specials”.
Insights
For this task, we found that YOLOv4 gave a good compromise between speed and accuracy as it has doubled the speed of a more accurate two-stage detector while maintaining a very good overall precision/recall. For blurring, the main metric for model selection was the overall recall, while precision and intersection over union (IoU) of the predicted box comes second as we want to catch all personal data even if some are wrong. Having a multitude of possibilities to configure the detector architecture and train it on our own dataset we conducted several experiments with different configurations for backbones, necks, augmentations and loss functions to come up with our current solution.
We faced challenges in training a good model as the dataset posed a large object/box-level scale imbalance, small objects being over-represented in the dataset. As described in [3] and [4], this affects the scales of the estimated regions and the overall detection performance. In [3] several solutions are proposed for this out of which the SPP [6] blocks and PANet [7] neck used in YOLOv4 together with heavy offline data augmentation increased the performance of the actual model in comparison to the former ones.
As we have evaluated the model; it still has some issues:
Occlusion of the object, either by the camera view, head accessories or other elements:
These cases would need extra annotation in the dataset, just like the faces or licence plates that are really close to the camera and occupy a large region of interest in the image.
As we have a limited number of annotations of close objects to the camera view, the model has incorrectly learnt this, sometimes producing false positives in these situations:
Again, one solution for this would be to include more of these scenarios in the dataset.
What’s Next?
Grab spends a lot of effort ensuring privacy protection for its users so we are always looking for ways to further improve our related models and processes.
As far as efficiency is concerned, there are multiple directions to consider for both the dataset and the model. There are two main factors that drive the costs and the quality: further development of the dataset for additional edge cases (e.g. more training data of people wearing masks) and the operational costs of the model.
As the vast majority of current models require a fully labelled dataset, this puts a large work effort on the Data Entry team before creating a new model. Our dataset increased 4x for it’s third version, still there is room for improvement as described in the Dataset section.
As Grab extends its operation in more cities, new data is collected that has to be processed, this puts an increased focus on running detection models more efficiently.
Directions to pursue to increase our efficiency could be the following:
As plenty of unlabelled data is available from imagery collection, a natural direction to explore is self-supervised visual representation learning techniques to derive a general vision backbone with superior transferring performance for our subsequent tasks as detection, classification.
Experiment with optimisation techniques like pruning and quantisation to get a faster model without sacrificing too much on accuracy.
Explore new architectures: YOLOv5, EfficientDet or Swin-Transformer for Object Detection.
Introduce semi-supervised learning techniques to improve our model performance on the long tail of the data.
References
Alexey Bochkovskiy et al.. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv:2004.10934v1
Tsung-Yi Lin et al. Feature Pyramid Networks for Object Detection. arXiv:1612.03144v2
Kemal Oksuz et al.. Imbalance Problems in Object Detection: A Review. arXiv:1909.00169v3
Bharat Singh, Larry S. Davis. An Analysis of Scale Invariance in Object Detection – SNIP. arXiv:1711.08189v2
Chien-Yao Wang et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv:1911.11929v1
Kaiming He et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. arXiv:1406.4729v4
Shu Liu et al. Path Aggregation Network for Instance Segmentation. arXiv:1803.01534v4
Zhenda Xie et al. Self-Supervised Learning with Swin Transformers. arXiv:2105.04553v2
Join Us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
At Grab, the Lending team is focused towards building products that help finance various segments of users, such as Passengers, Drivers, or Merchants, based on their needs. The team builds products that enable users to avail funds in a seamless and hassle-free way. In order to achieve this, multiple lending microservices continuously interact with each other. Each microservice handles different responsibilities, such as providing offers, storing user information, disbursing availed amounts to a user’s account, and many more.
In this tech blog, we will discuss what Data and Extract, Transform and Load (ETL) pipelines are and how they are used for processing multiple tasks in the Lending Team at Grab. We will also discuss Ratchet, which is a Go library, that helps us in building data pipelines and handling ETL tasks. Let’s start by covering the basis of Data and ETL pipelines.
What is a Data Pipeline?
A Data pipeline is used to describe a system or a process that moves data from one platform to another. In between platforms, data passes through multiple steps based on defined requirements, where it may be subjected to some kind of modification. All the steps in a Data pipeline are automated, and the output from one step acts as an input for the next step.
An ETL pipeline is a type of Data pipeline that consists of 3 major steps, namely extraction of data from a source, transformation of that data into the desired format, and finally loading the transformed data to the destination. The destination is also known as the sink.
The combination of steps in an ETL pipeline provides functions to assure that the business requirements of the application are achieved.
Let’s briefly look at each of the steps involved in the ETL pipeline.
Data Extraction
Data extraction is used to fetch data from one or multiple sources with ease. The source of data can vary based on the requirement. Some of the commonly used data sources are:
Database
Web-based storage (S3, Google cloud, etc)
Files
User Feeds, CRM, etc.
The data format can also vary from one use case to another. Some of the most commonly used data formats are:
SQL
CSV
JSON
XML
Once data is extracted in the desired format, it is ready to be fed to the transformation step.
Data Transformation
Data transformation involves applying a set of rules and techniques to convert the extracted data into a more meaningful and structured format for use. The extracted data may not always be ready to use. In order to transform the data, one of the following techniques may be used:
Filtering out unnecessary data.
Preprocessing and cleaning of data.
Performing validations on data.
Deriving a new set of data from the existing one.
Aggregating data from multiple sources into a single uniformly structured format.
Data Loading
The final step of an ETL pipeline involves moving the transformed data to a sink where it can be accessed for its use. Based on requirements, a sink can be one of the following:
Database
File
Web-based storage (S3, Google cloud, etc)
An ETL pipeline may or may not have a loadstep based on its requirements. When the transformed data needs to be stored for further use, the loadstep is used to move the transformed data to the storage of choice. However, in some cases, the transformed data may not be needed for any further use and thus, the loadstep can be skipped.
Now that you understand the basics, let’s go over how we, in the Grab Lending team, use an ETL pipeline.
Why Use Ratchet?
At Grab, we use Golang for most of our backend services. Due to Golang’s simplicity, execution speed, and concurrency support, it is a great choice for building data pipeline systems to perform custom ETL tasks.
Given that Ratchet is also written in Go, it allows us to easily build custom data pipelines.
Go channels are connecting each stage of processing, so the syntax for sending data is intuitive for anyone familiar with Go. All data being sent and received is in JSON, providing a nice balance of flexibility and consistency.
Utilising Ratchet for ETL Tasks
We use Ratchet for multiple ETL tasks like batch processing, restructuring and rescheduling of loans, creating user profiles, and so on. One of the backend services, named Azkaban, is responsible for handling various ETL tasks.
Ratchet uses Data Processors for building a pipeline consisting of multiple stages. Data Processors each run in their own goroutine so all of the data is processed concurrently. Data Processors are organised into stages, and those stages are run within a pipeline. For building an ETL pipeline, each of the three steps (Extract, Transform and Load) use a Data Processor for implementation. Ratchet provides a set of built-in, useful Data Processors, while also providing an interface to implement your own. Usually, the transform stage uses a Custom Data Processor.
Let’s take a look at one of these tasks to understand how we utilise Ratchet for processing an ETL task.
Whitelisting Merchants Through ETL Pipelines
Whitelisting essentially means making the product available to the user by mapping an offer to the user ID. If a merchant in Thailand receives an option to opt for Cash Loan, it is done by whitelisting that merchant. In order to whitelist our merchants, our Operations team uses an internal portal to upload a CSV file with the user IDs of the merchants and other required information. This CSV file is generated by our internal Data and Risk team and handed over to the Operations team. Once the CSV file is uploaded, the user IDs present in the file are whitelisted within minutes. However, a lot of work goes in the background to make this possible.
Data Extraction
Once the Operations team uploads the CSV containing a list of merchant users to be whitelisted, the file is stored in S3 and an entry is created on the Azkaban service with the document ID of the uploaded file.
File upload by Operations team
The data extraction step makes use of a Custom CSV Data Processor that uses the document ID to first create a PreSignedUrl and then uses it to fetch the data from S3. The data extracted is in bytes and we use commas as the delimiter to format the CSV data.
Data Transformation
In order to transform the data, we define a Custom Data Processor that we call a Transformer for each ETL pipeline. Transformers are responsible for applying all necessary transformations to the data before it is ready for loading. The transformations applied in the merchant whitelisting transformers are:
Convert data from bytes to struct.
Check for presence of all mandatory fields in the received data.
Perform validation on the data received.
Make API calls to external microservices for whitelisting the merchant.
As mentioned earlier, the CSV file is uploaded manually by the Operations team. Since this is a manual process, it is prone to human errors. Validation of data in the data transformation step helps avoid these errors and not propagate them further up the pipeline. Since CSV data consists of multiple rows, each row passes through all the steps mentioned above.
Data Loading
Whenever the merchants are whitelisted, we don’t need to store the transformed data. As a result, we don’t have a loadstep for this ETL task, so we just use an Empty Data Processor. However, this is just one of many use cases that we have. In cases where the transformed data needs to be stored for further use, the loadstep will have a Custom Data Processor, which will be responsible for storing the data.
Connecting All Stages
After defining our Data Processors for each of the steps in the ETL pipeline, the final piece is to connect all the stages together. As stated earlier, the ETL tasks have different ETL pipelines and each ETL pipeline consists of 3 stages defined by their Data Processors.
In order to connect these 3 stages, we define a Job Processor for each ETL pipeline. A Job Processor represents the entire ETL pipeline and encompasses Data Processors for each of the 3 stages. Each Job Processor implements the following methods:
SetSource: Assigns the Data Processor for the Extraction stage.
SetTransformer: Assigns the Data Processor for the Transformation stage.
SetDestination: Assigns the Data Processor for the Load stage.
Execute: Runs the ETL pipeline.
Job processors containing Data Processor for each stage in ETL
When the Azkaban service is initialised, we run the SetSource(), SetTransformer() and SetDestination() methods for each of the Job Processors defined. When an ETL task is triggered, the Execute() method of the corresponding Job Processor is run. This triggers the ETL pipeline and gradually runs the 3 stages of ETL pipeline. For each stage, the Data Processor assigned during initialisation is executed.
Conclusion
ETL pipelines help us in streamlining various tasks in our team. As showcased through the example in the above section, an ETL pipeline breaks a task into multiple stages and divides the responsibilities across these stages.
In cases where a task fails in the middle of the process, ETL pipelines help us determine the cause of the failure quickly and accurately. With ETL pipelines, we have reduced the manual effort required for validating data at each step and avoiding propagation of errors towards the end of the pipeline.
Through the use of ETL pipelines and schedulers, we at Lending have been able to automate the entire pipeline for many tasks to run at scheduled intervals without any manual effort involved at all. This has helped us tremendously in reducing human errors, increasing the throughput of the system and making the backend flow more reliable. As we continue to automate more and more of our tasks that have tightly defined stages, we foresee a growth in our ETL pipelines usage.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Wanna know how we improved our app’s build time performance and developer experience at Grab? Continue reading…
Where it all began
Imagine you are working on an app that grows continuously as more and more features are added to it, it becomes challenging to manage the code at some point. Code conflicts increase due to coupling, development slows down, releases take longer to ship, collaboration becomes difficult, and so on.
Grab superapp is one such app that offers many services like booking taxis, ordering food, payments using an e-wallet, transferring money to friends/families, paying at merchants, and many more, across Southeast Asia.
Grab app followed a monolithic architecture initially where the entire code was held in a single module containing all the UI and business logic for almost all of its features. But as the app grew, new developers were hired, and more features were built, it became difficult to work on the codebase. We had to think of better ways to maintain the codebase, and that’s when the team decided to modularise the app to solve the issues faced.
What is Modularisation?
Breaking the monolithic app module into smaller, independent, and interchangeable modules to segregate functionality so that every module is responsible for executing a specific functionality and will contain everything necessary to execute that functionality.
Modularising the Grab app was not an easy task as it brought many challenges along with it because of its complicated structure due to the high amount of code coupling.
Approach and Design
We divided the task into the following sub-tasks to ensure that only one out of many functionalities in the app was impacted at a time.
Setting up the infrastructure by creating Base/Core modules for Networking, Analytics, Experimentation, Storage, Config, and so on.
Building Shared Library modules for Styling, Common-UI, Utils, etc.
Incrementally building Feature modules for user-facing features like Payments Home, Wallet Top Up, Peer-to-Merchant (P2M) Payments, GrabCard and many others.
Creating Kit modules for the feature to feature module communication. This step helped us in building the feature modules in parallel.
Finally, the App module is used as a hub to connect all the other modules together using dependency injection (Dagger).
Modularised app structure
In the above diagram, payments-home, wallet top-up, and grabcard are different features provided by the Grab app. top-up-kit and grabcard-kit are bridges that expose functionalities from topup and grabcard modules to the payments-home module, respectively.
In the process of modularising the Grab app, we ensured that a feature module did not directly depend on other feature modules so that they could be built in parallel using the available CPU cores of the machine, hence reducing the overall build time of the app.
With the Kit module approach, we separated our code into independent layers by depending only on abstractions instead of concrete implementation.
Modularisation Benefits
Faster build times and hence faster CI: Gradle build system compiles only the changed modules and uses the binaries of all the non-affected modules from its cache. So the compilation becomes faster. Moreover, independent modules are run in parallel on different threads.
Fine dependency graph: Dependencies of a module are well defined.
Reusability across other apps: Modules can be used across different apps by converting them into an AAR SDK.
Scale and maintainability: Teams can work independently on the modules owned by them without blocking each other.
Well-defined code ownership: Clear responsibility on who owns which code.
Limitations
Requires more effort and time to modularise an app.
Separate configuration files to be maintained for each module.
Gradle sync time starts to grow.
IDE becomes very slow and its memory usage goes up a lot.
Parallel execution of the module depends on the machine’s capabilities.
Where we are now
There are more than 1,000 modules in the Grab app and are still counting.
At Grab, we have many sub-teams which take care of different features available in the app. Grab Financial Group (GFG) is one such sub-team that handles everything related to payments in the app. For example: P2P & P2M money transfers, e-Wallet activation, KYC, and so on.
We started modularising payments further in July 2020 as it was already bombarded with too many features and it was difficult for the team to work on the single payments module. The result of payments modularisation is shown in the following chart.
Build time graph of payments module
As of today, we have about 200+ modules in GFG and more than 95% of the modules take less than 15s to build.
Conclusion
Modularisation has helped us a lot in reducing the overall build time of the app and also, in improving the developer experience by breaking dependencies and allowing us to define code ownership. Having said that, modularisation is not an easy or a small task, especially for large projects with legacy code. However, with careful planning and the right design, modularisation can help in forming a well-structured and maintainable project.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
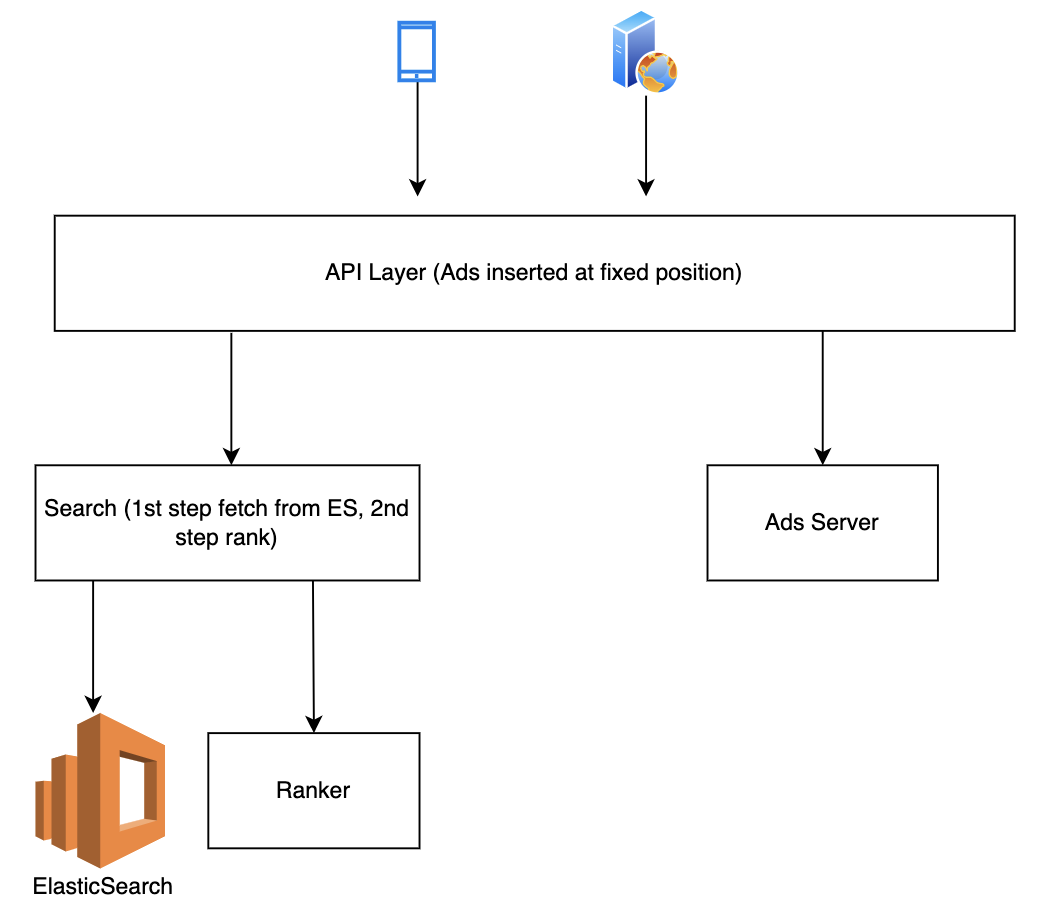
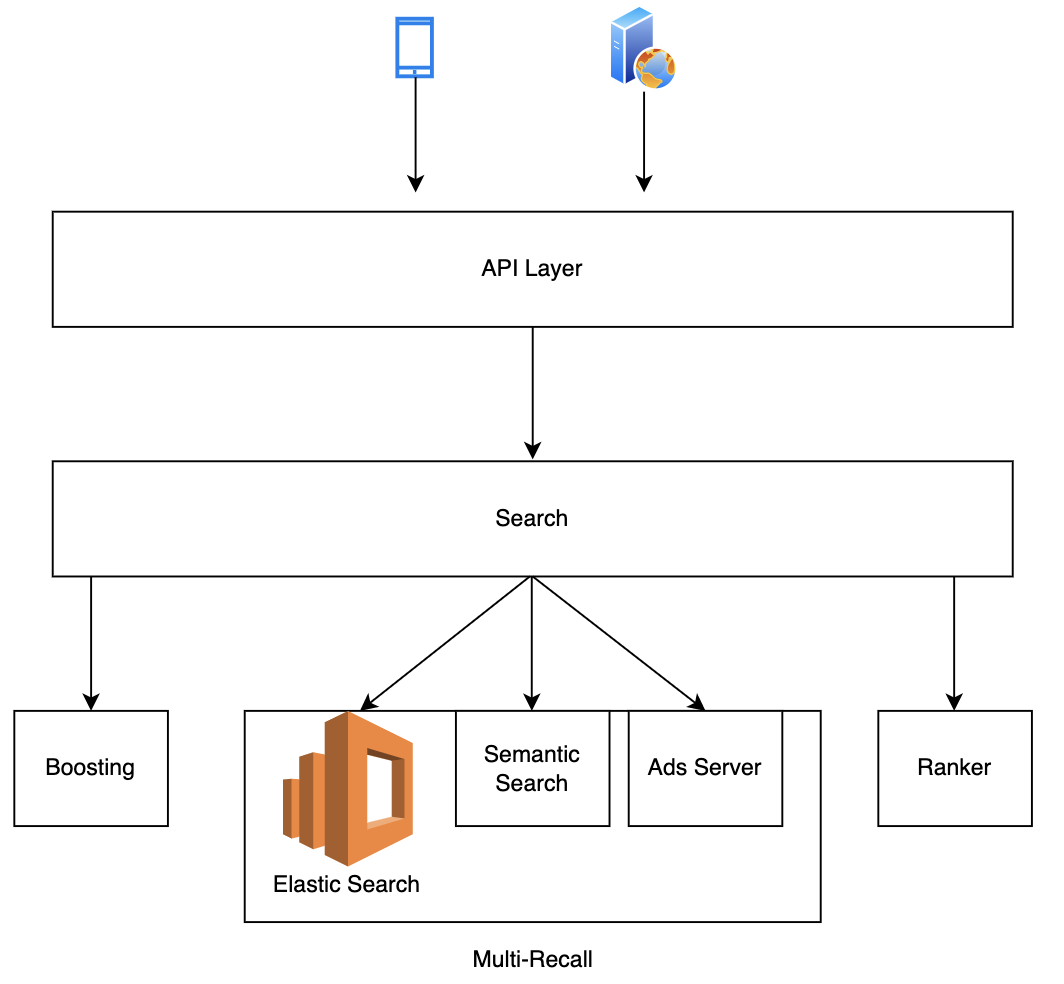
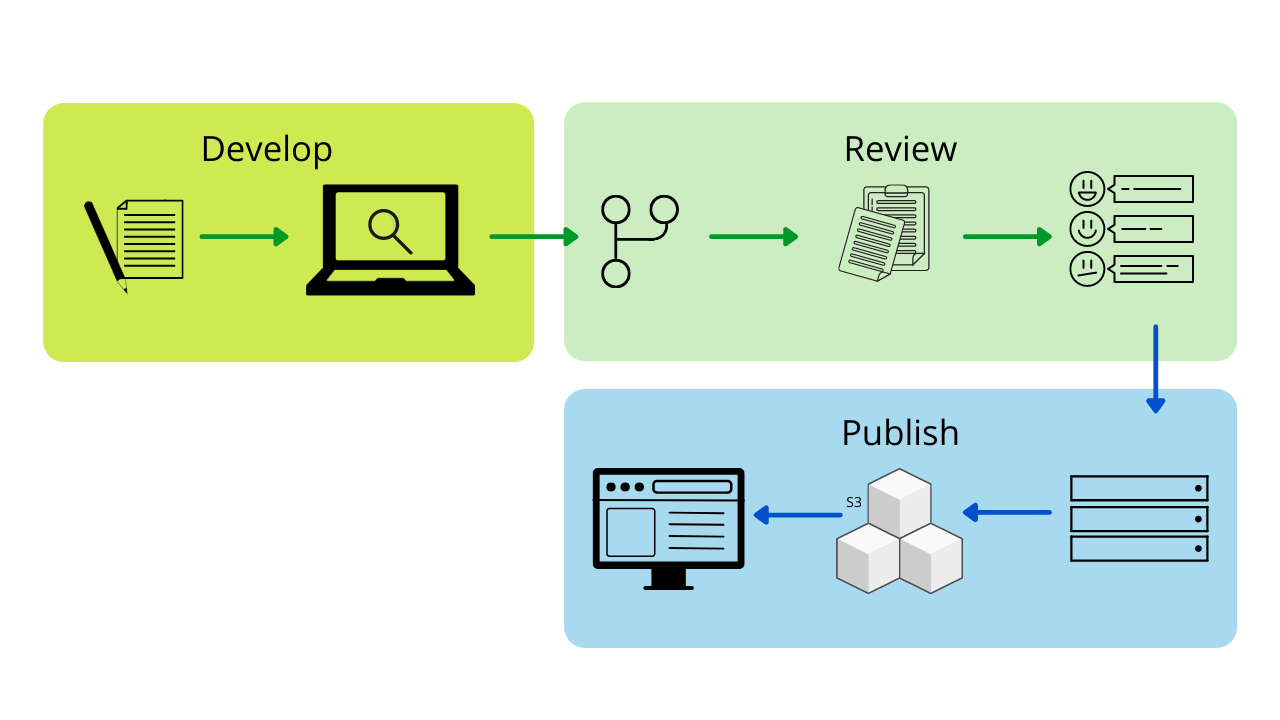

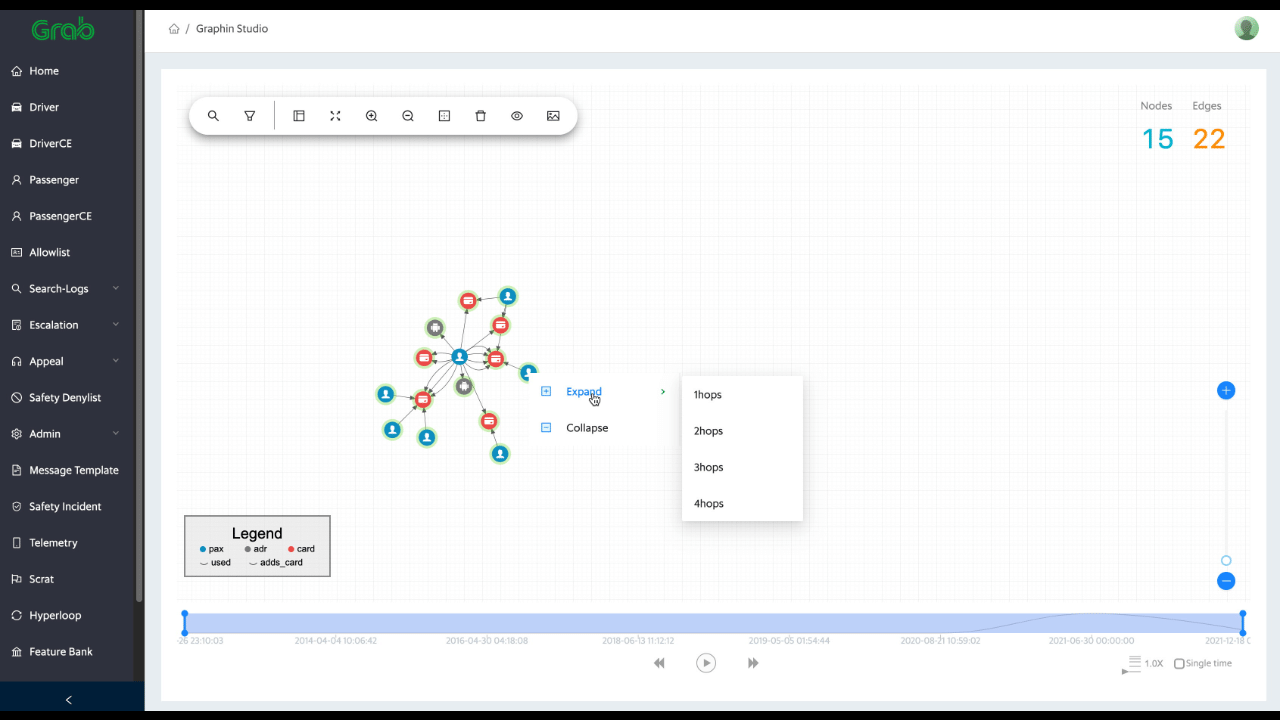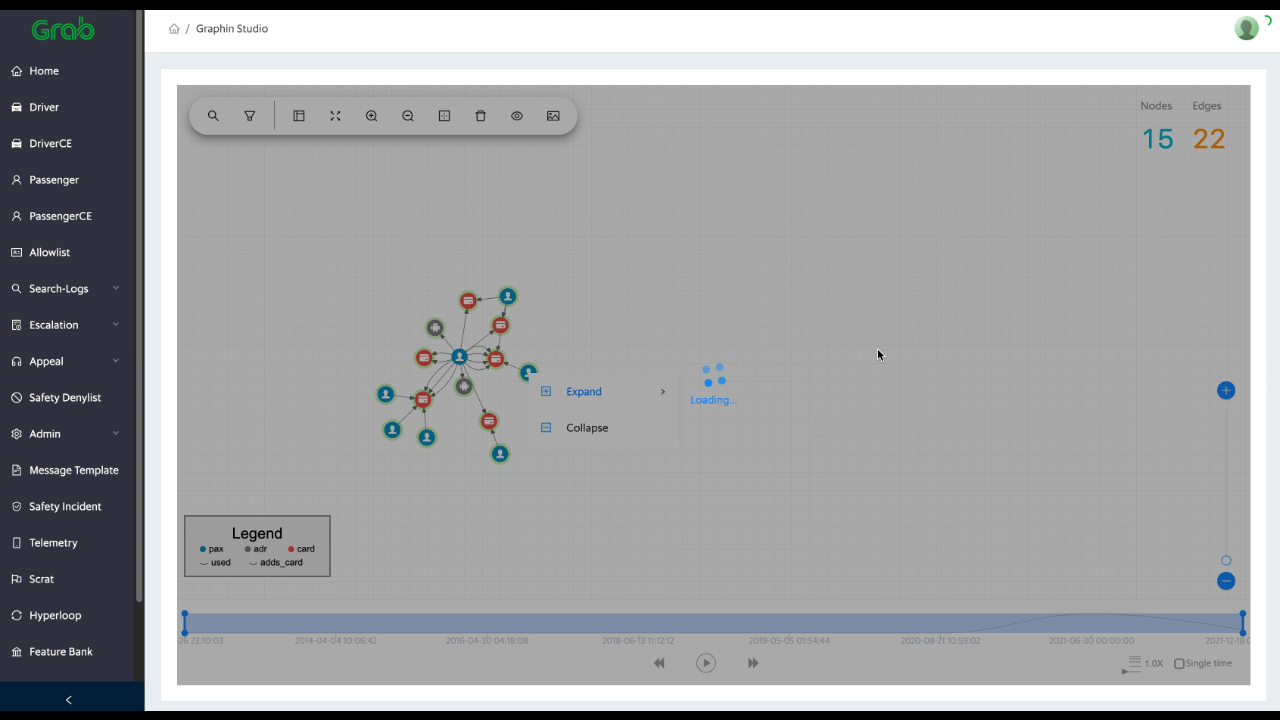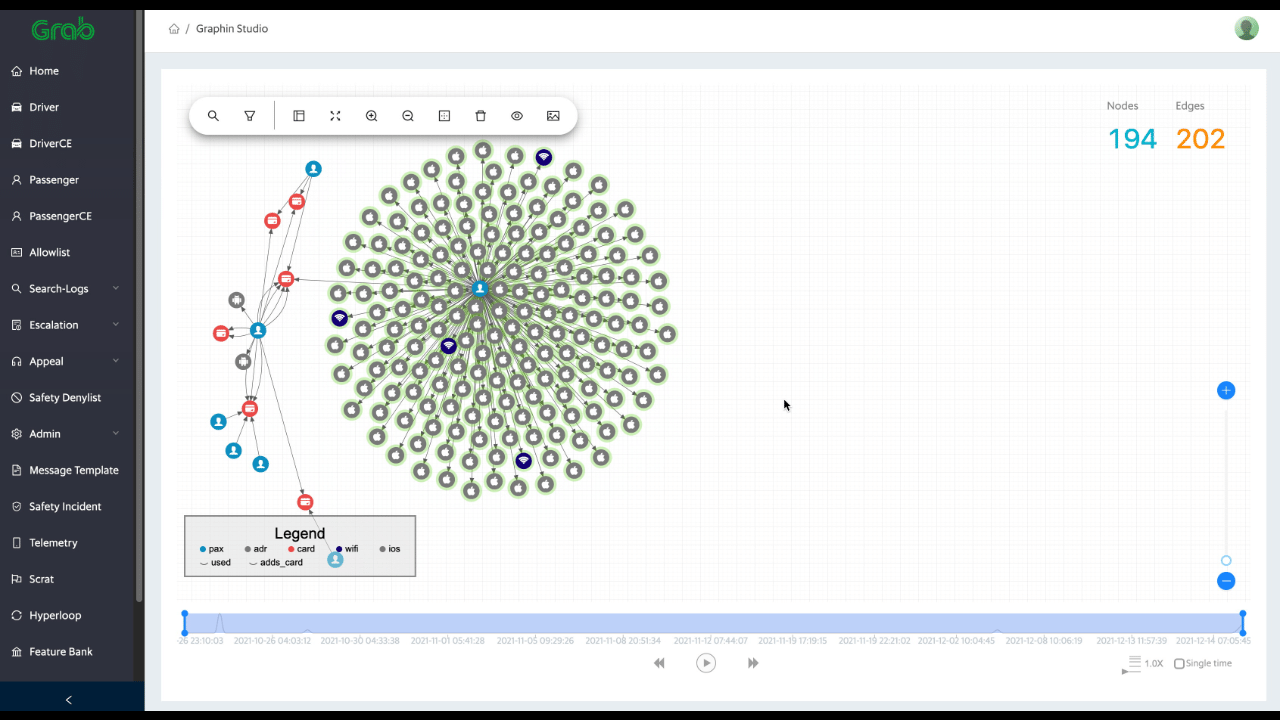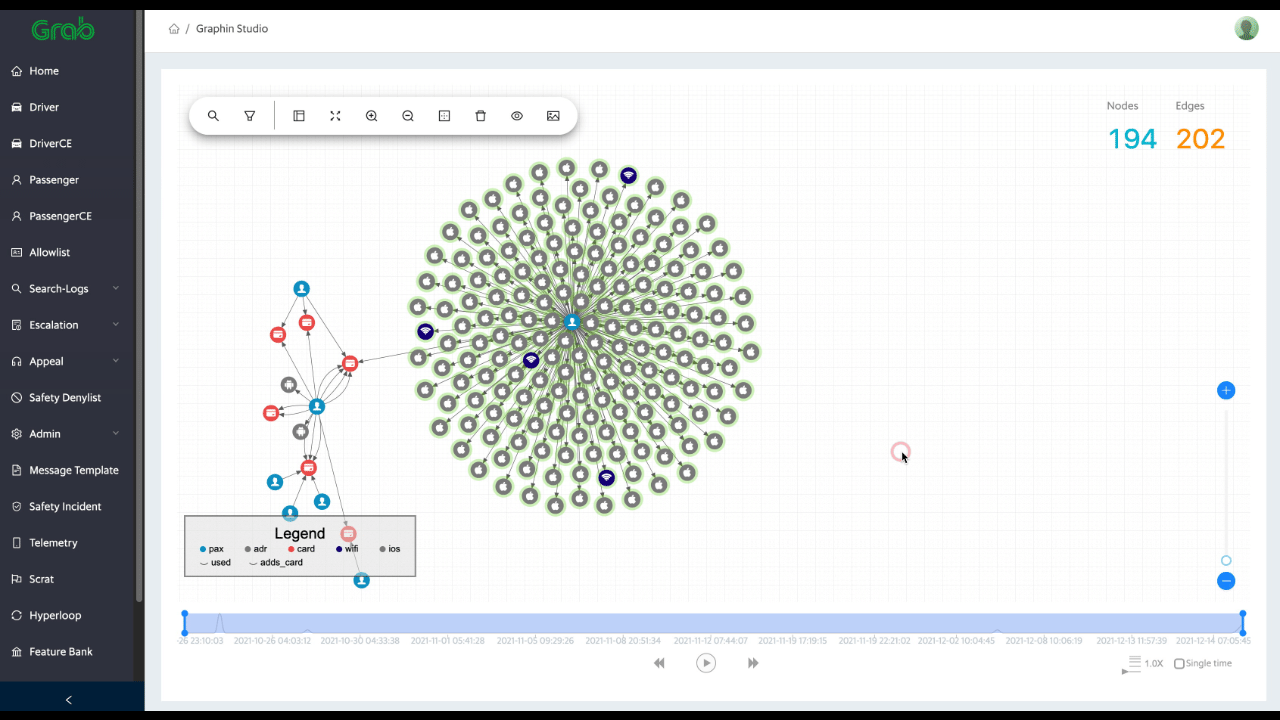

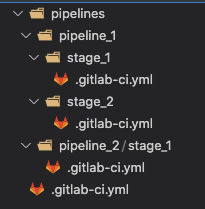
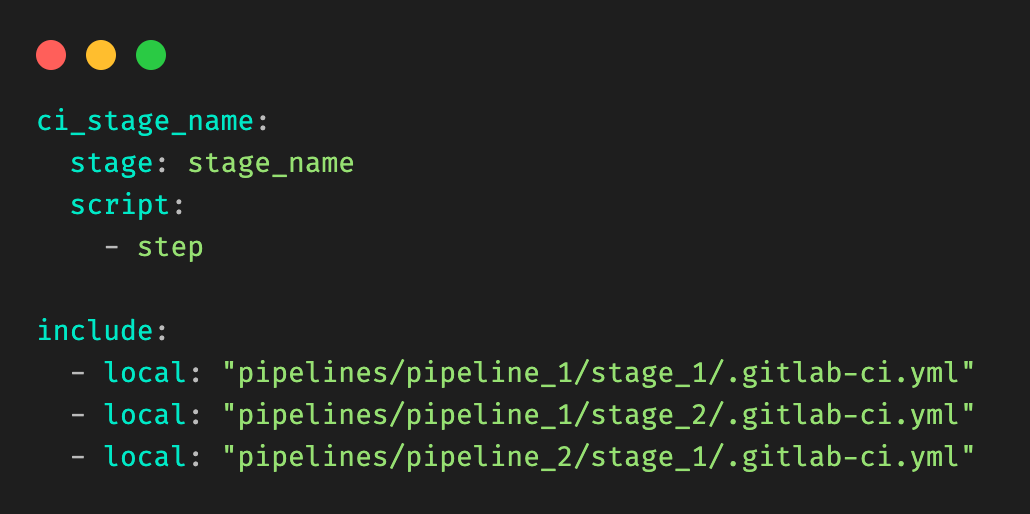

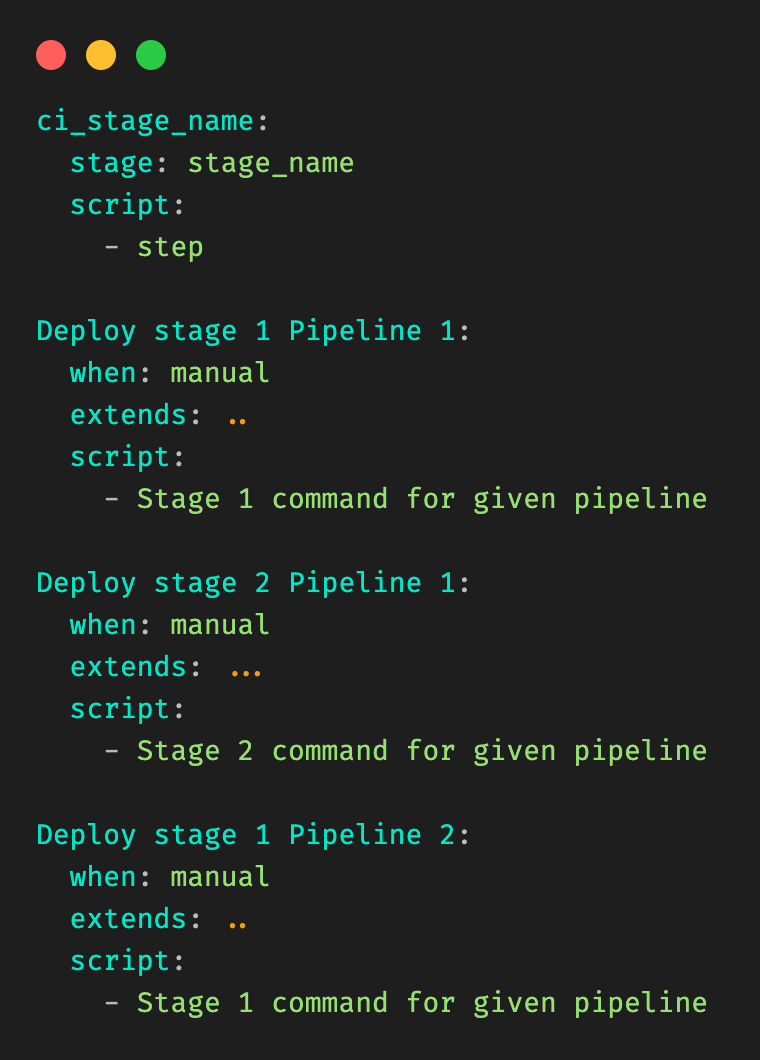
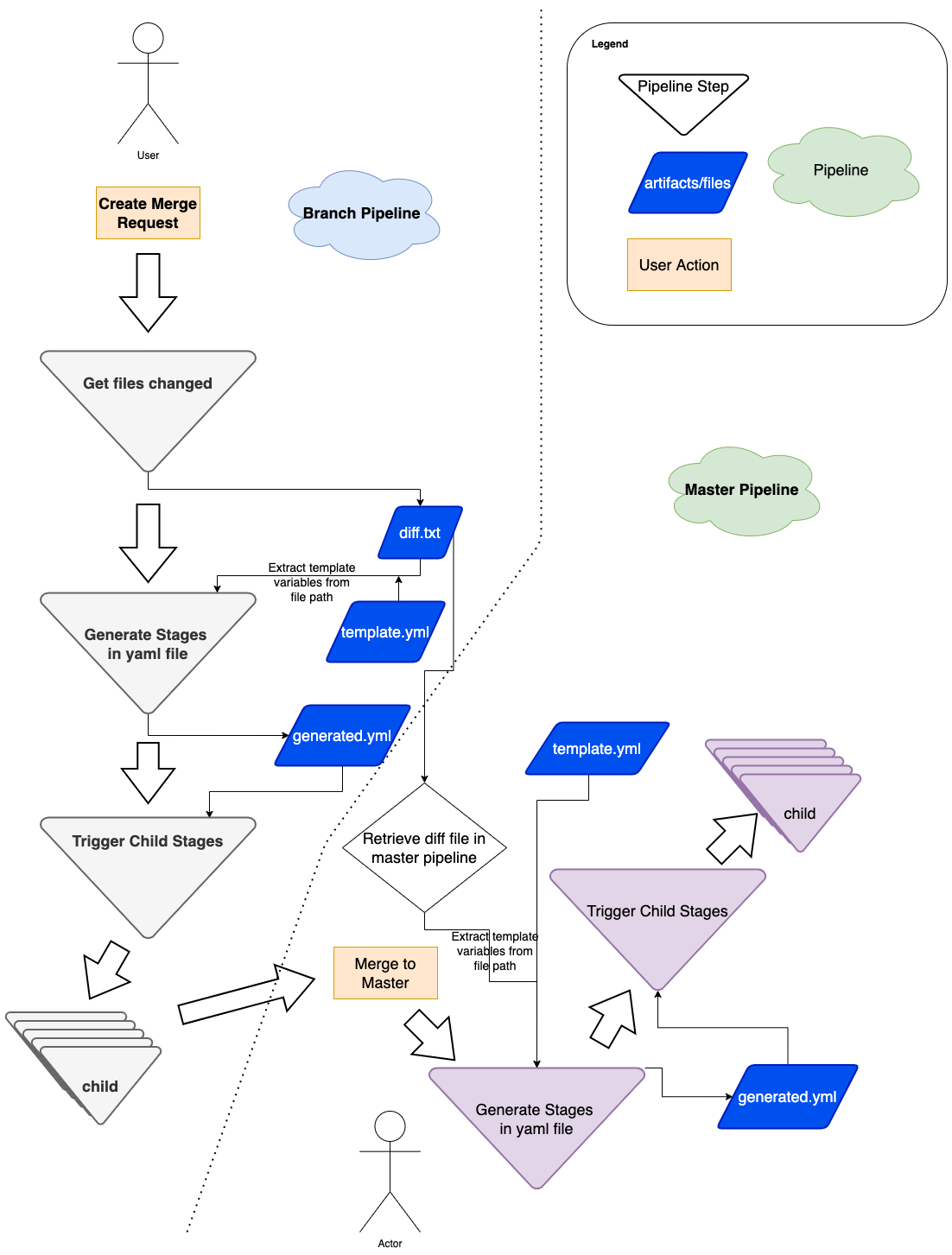
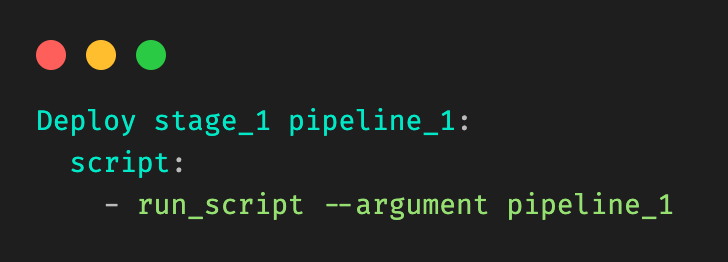
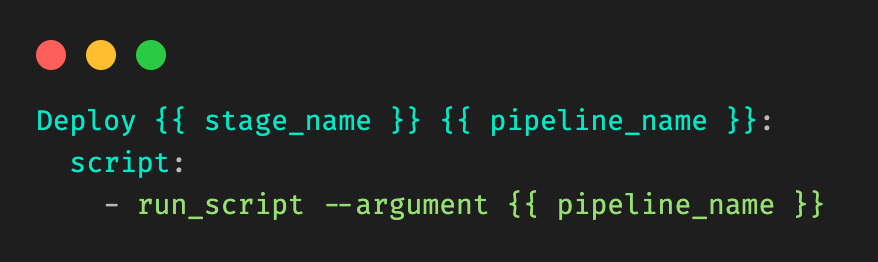

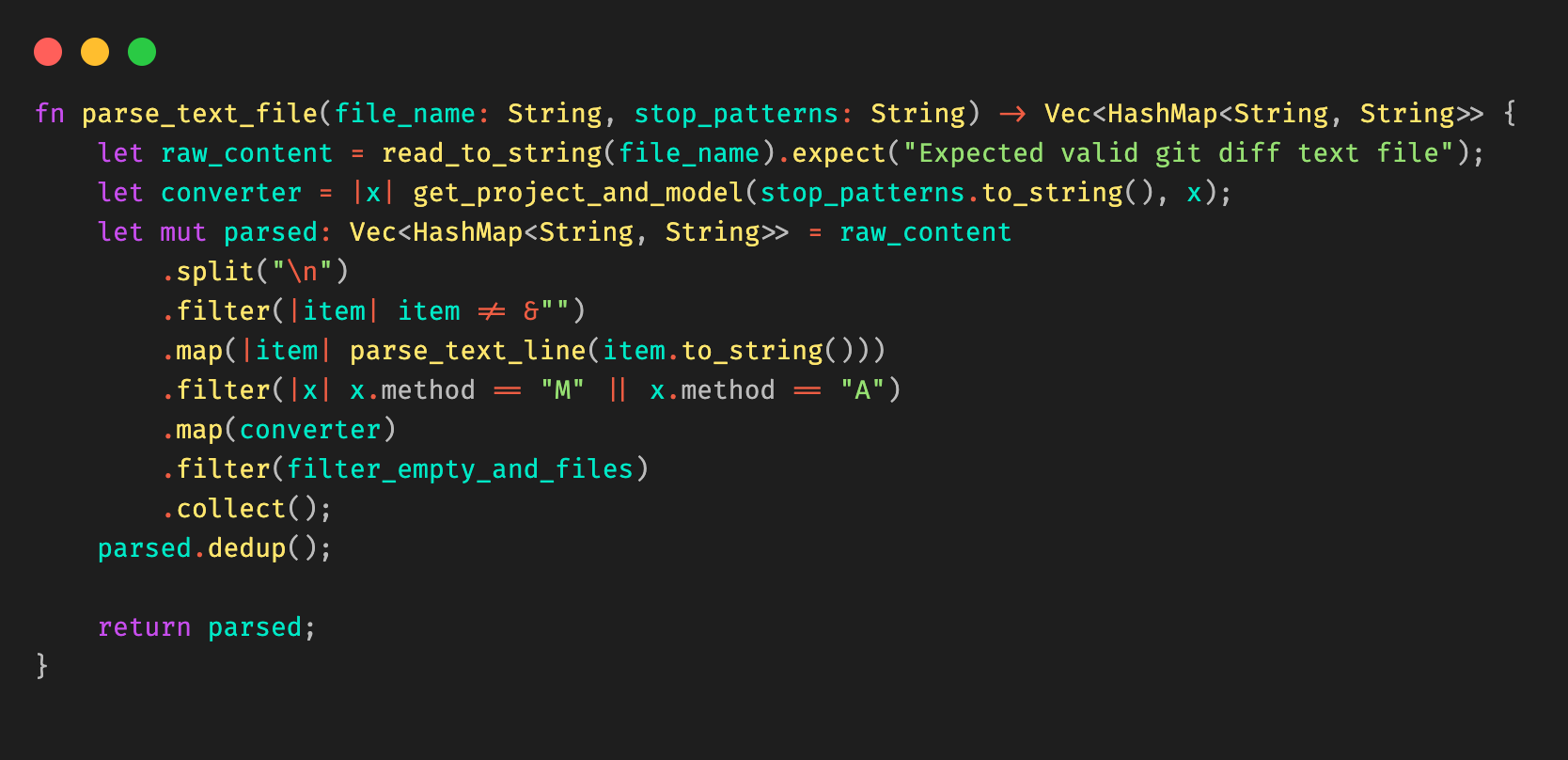
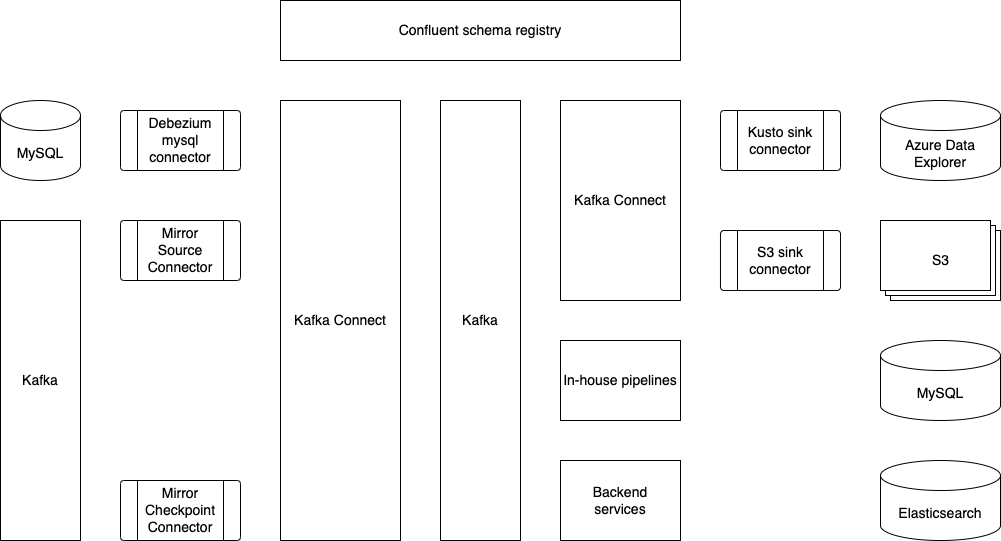
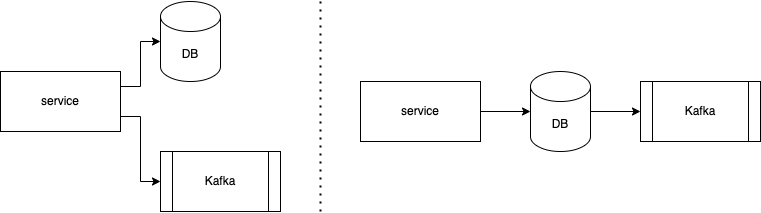
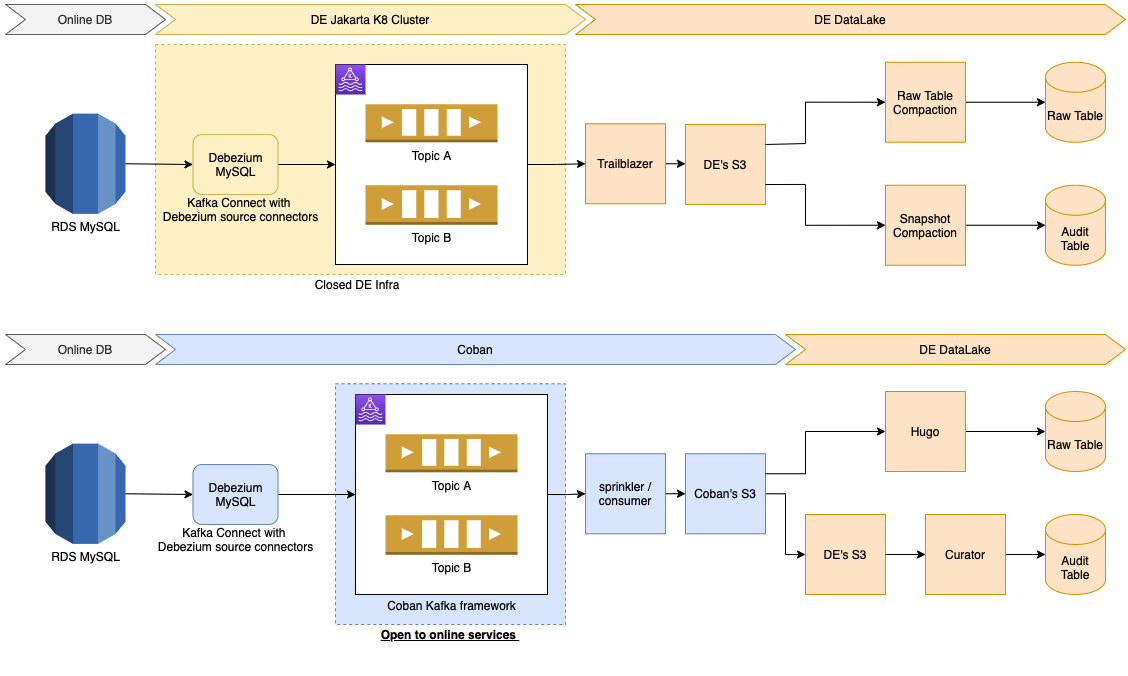
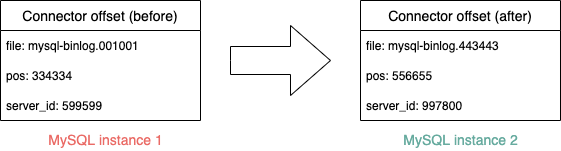
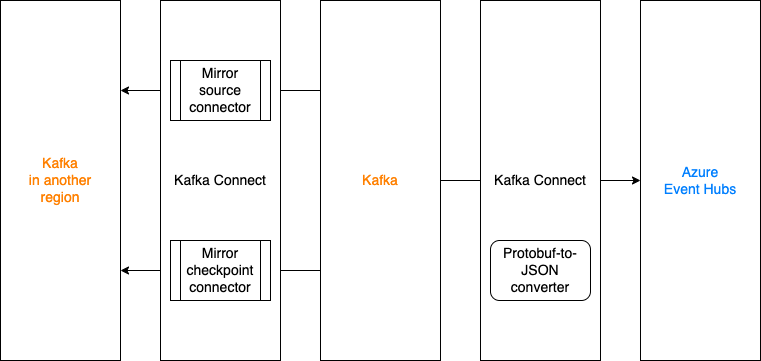

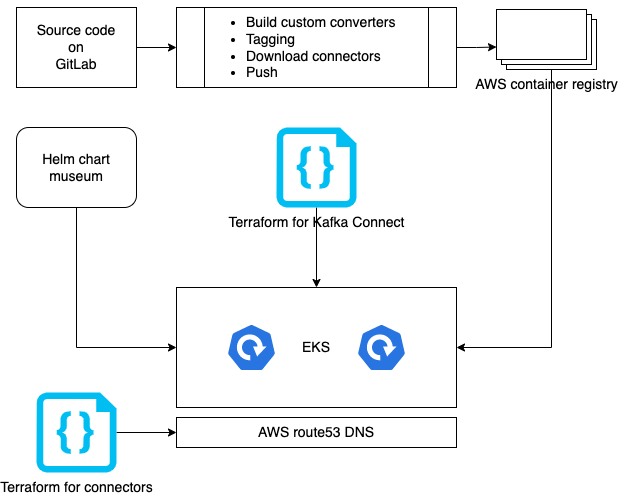
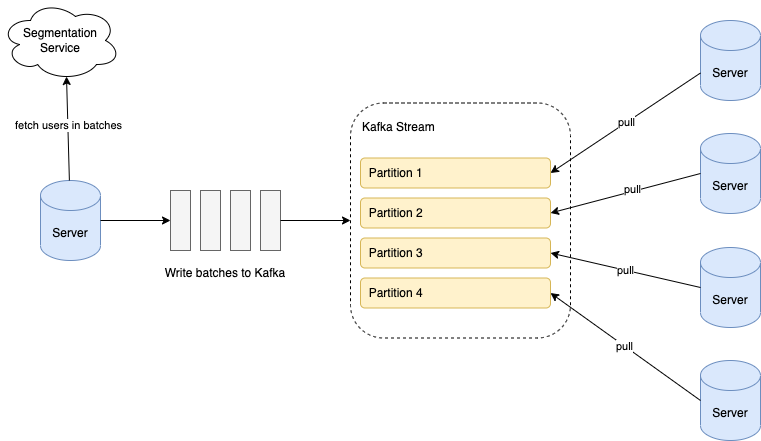
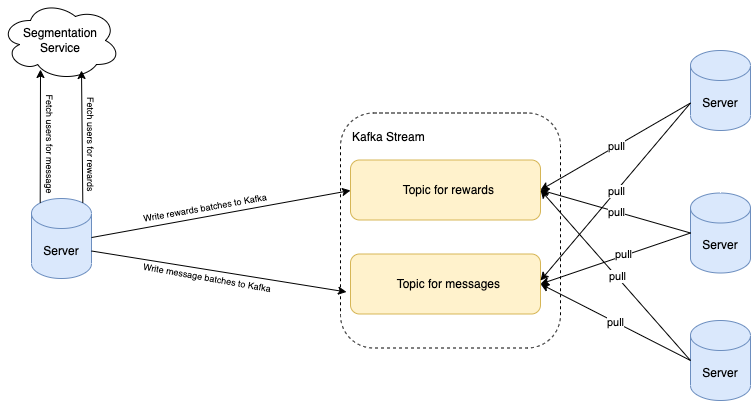
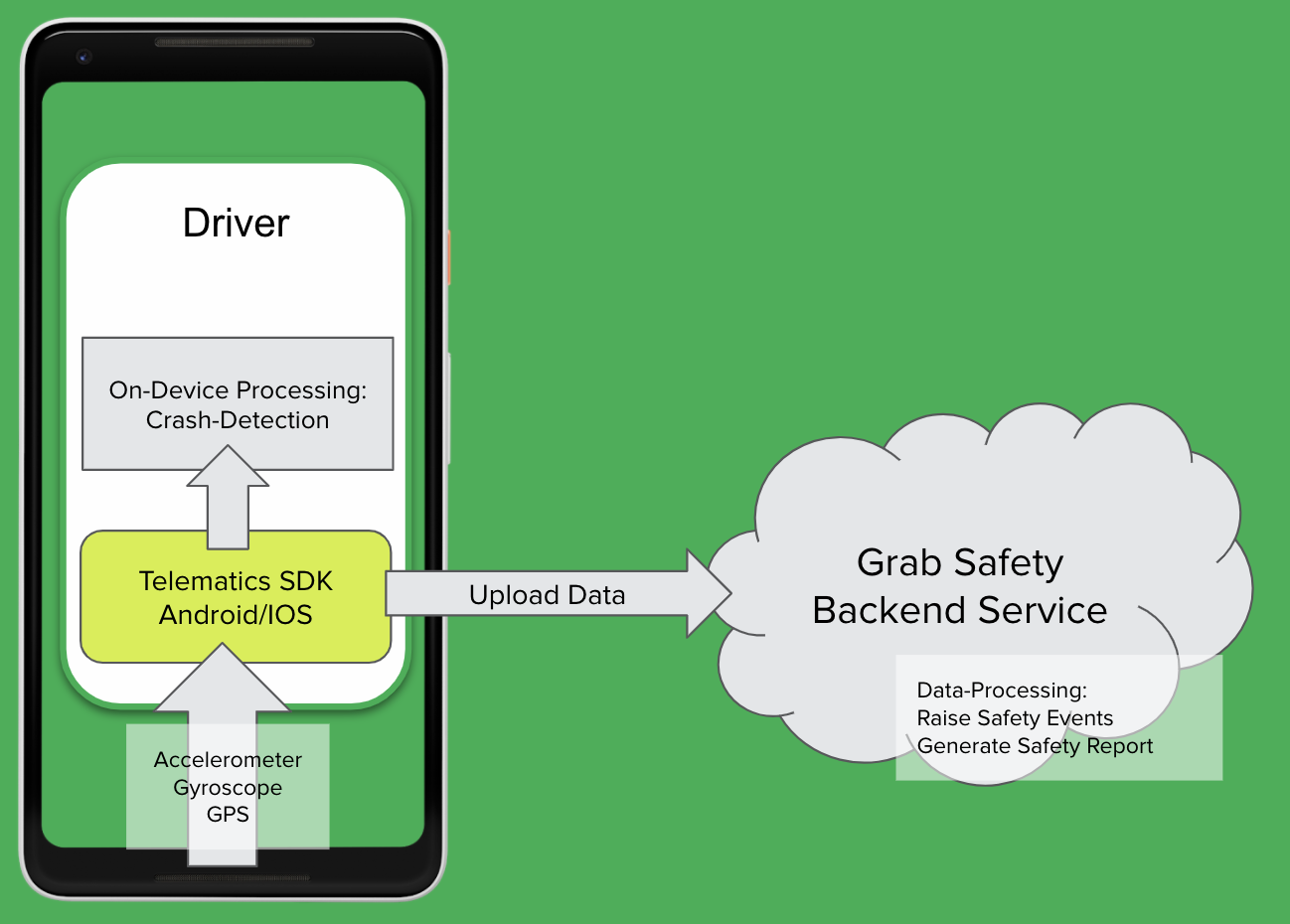
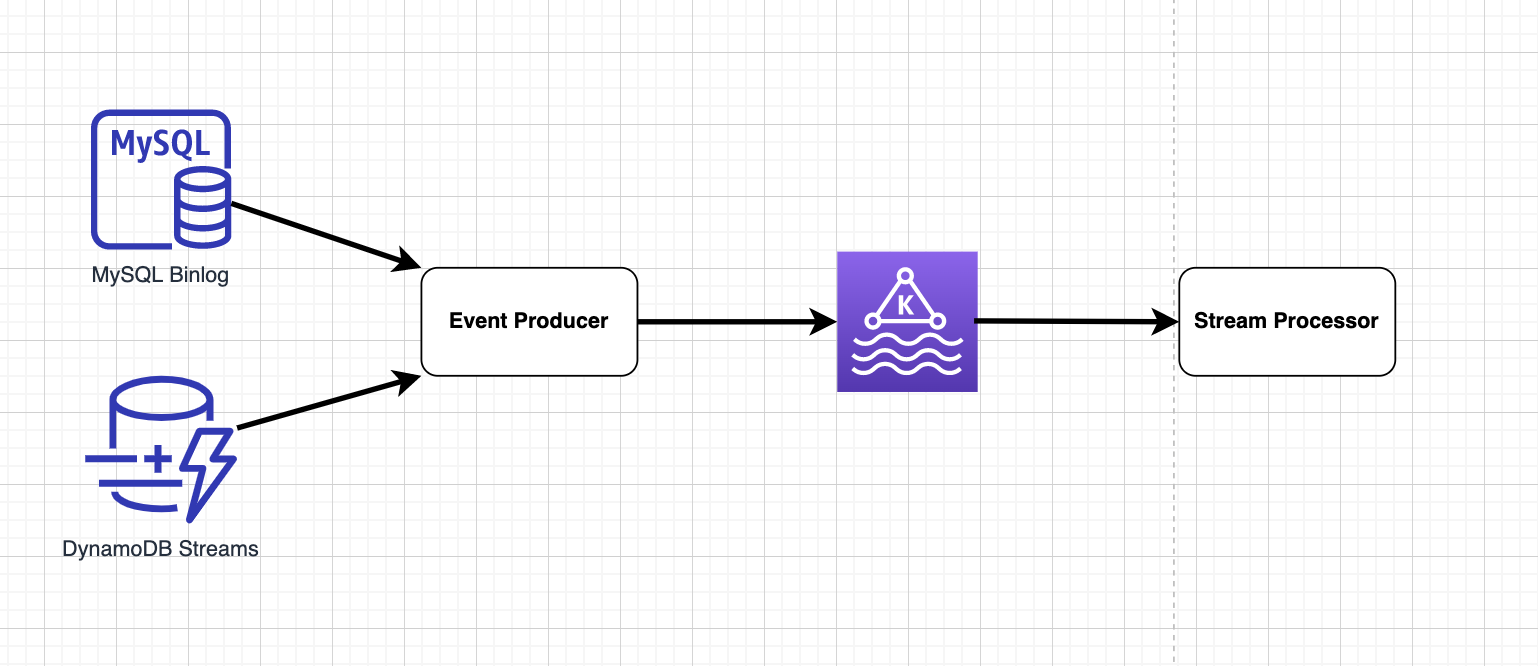



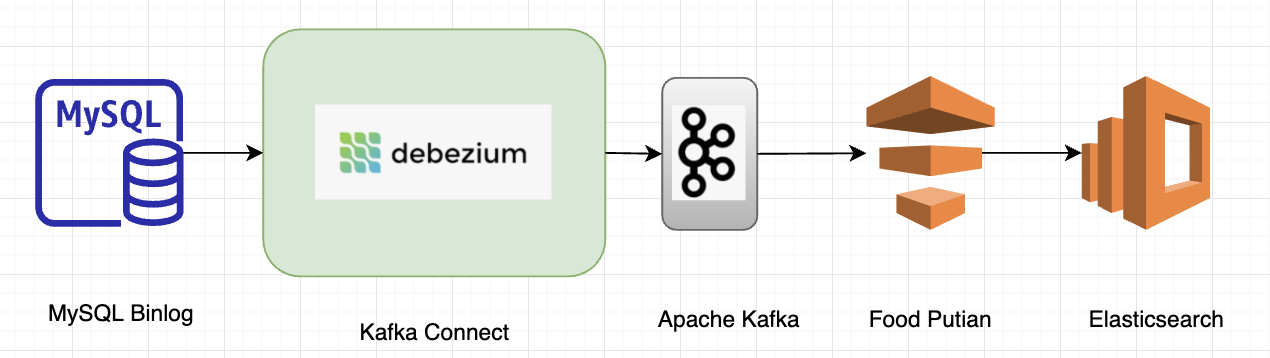
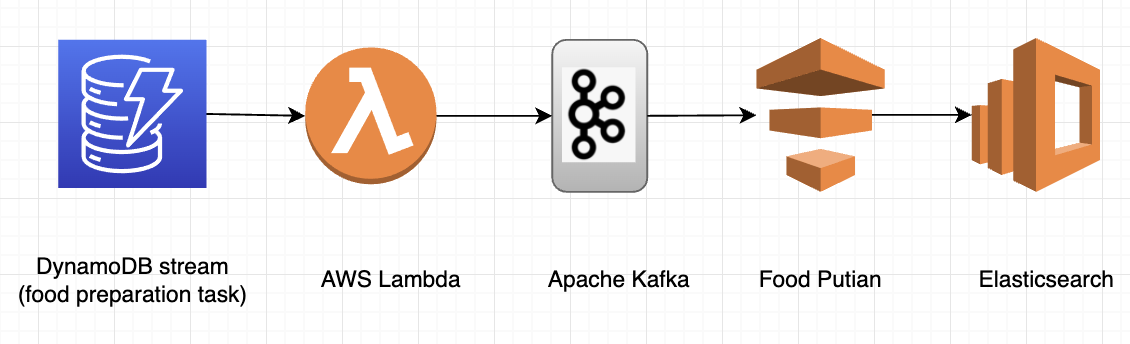
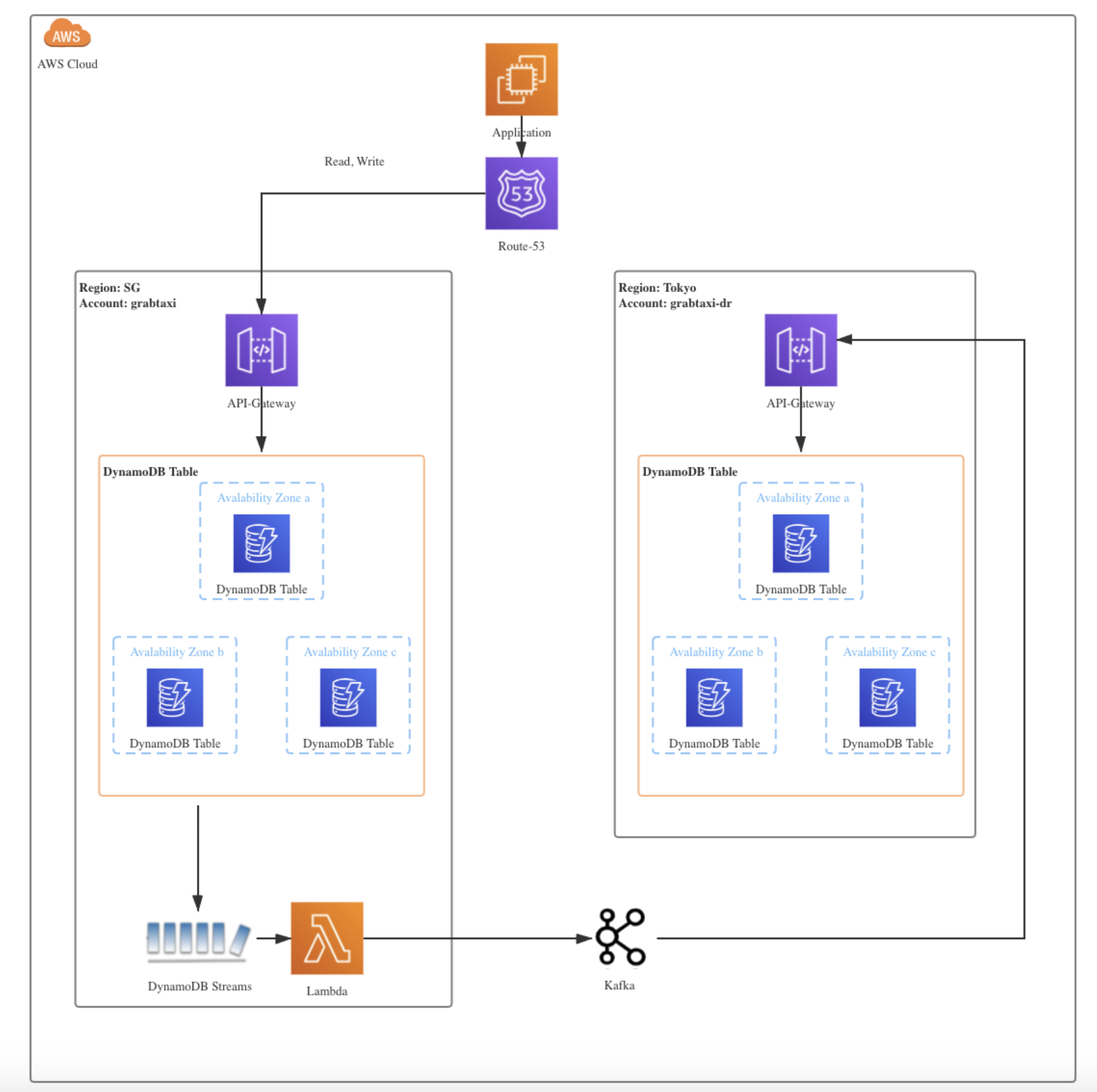
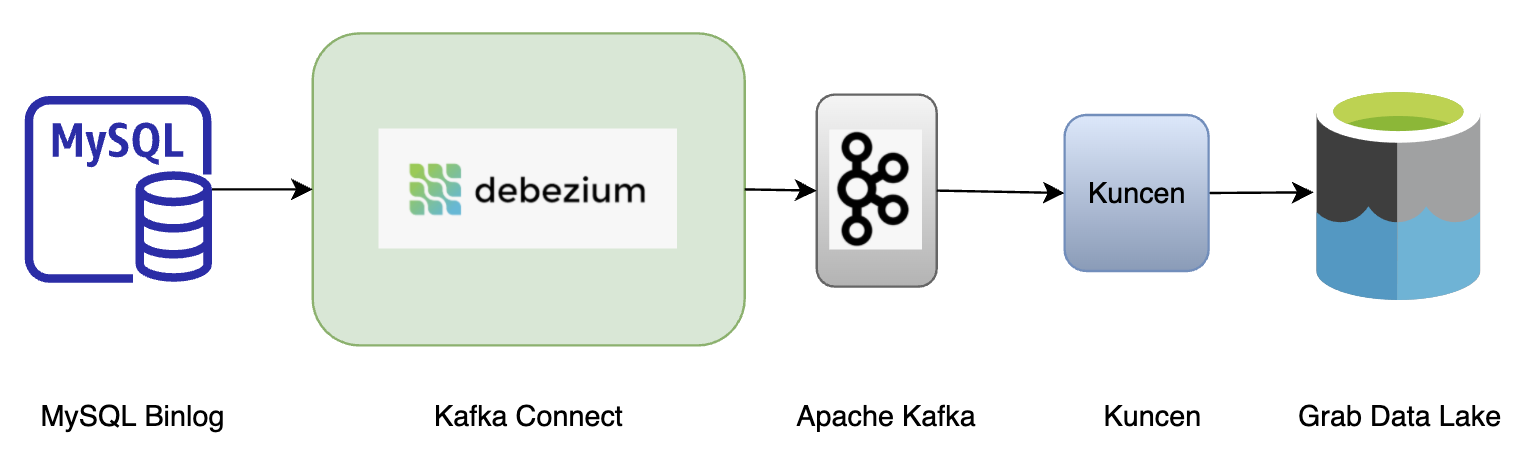
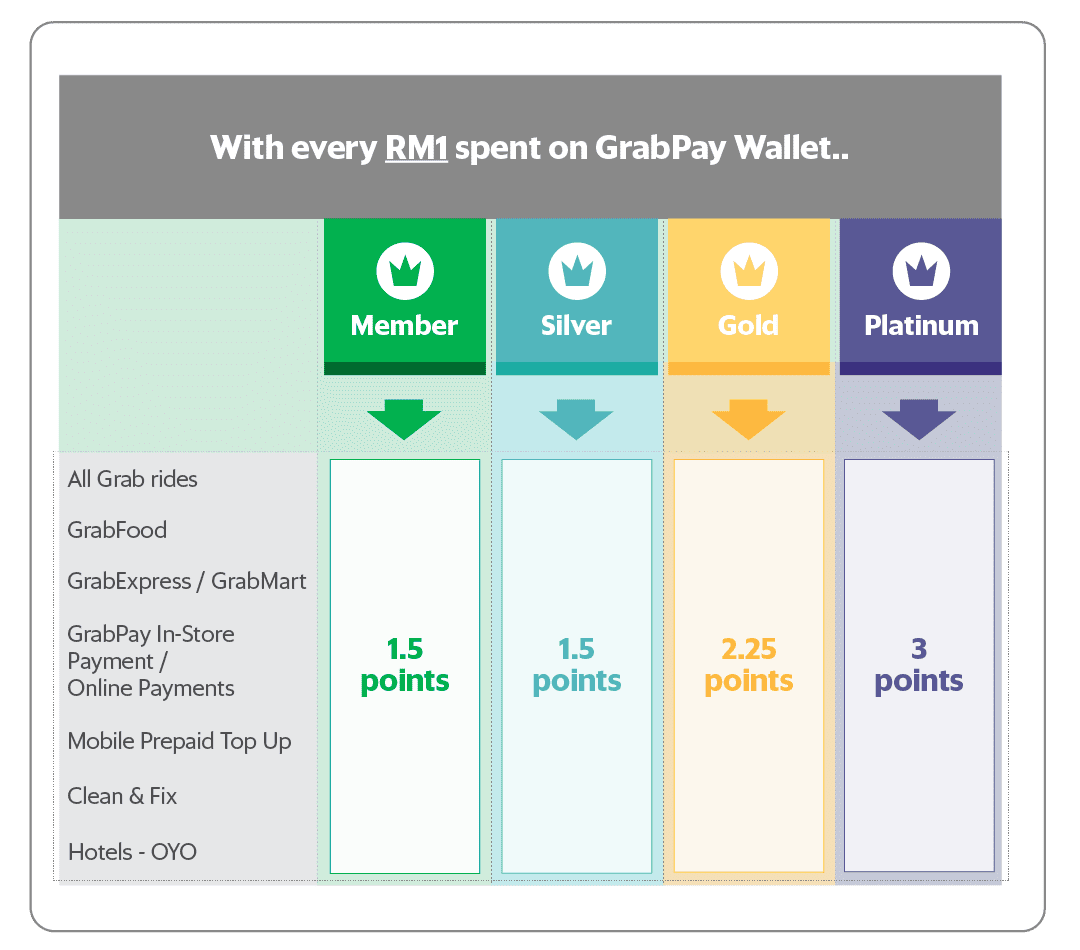
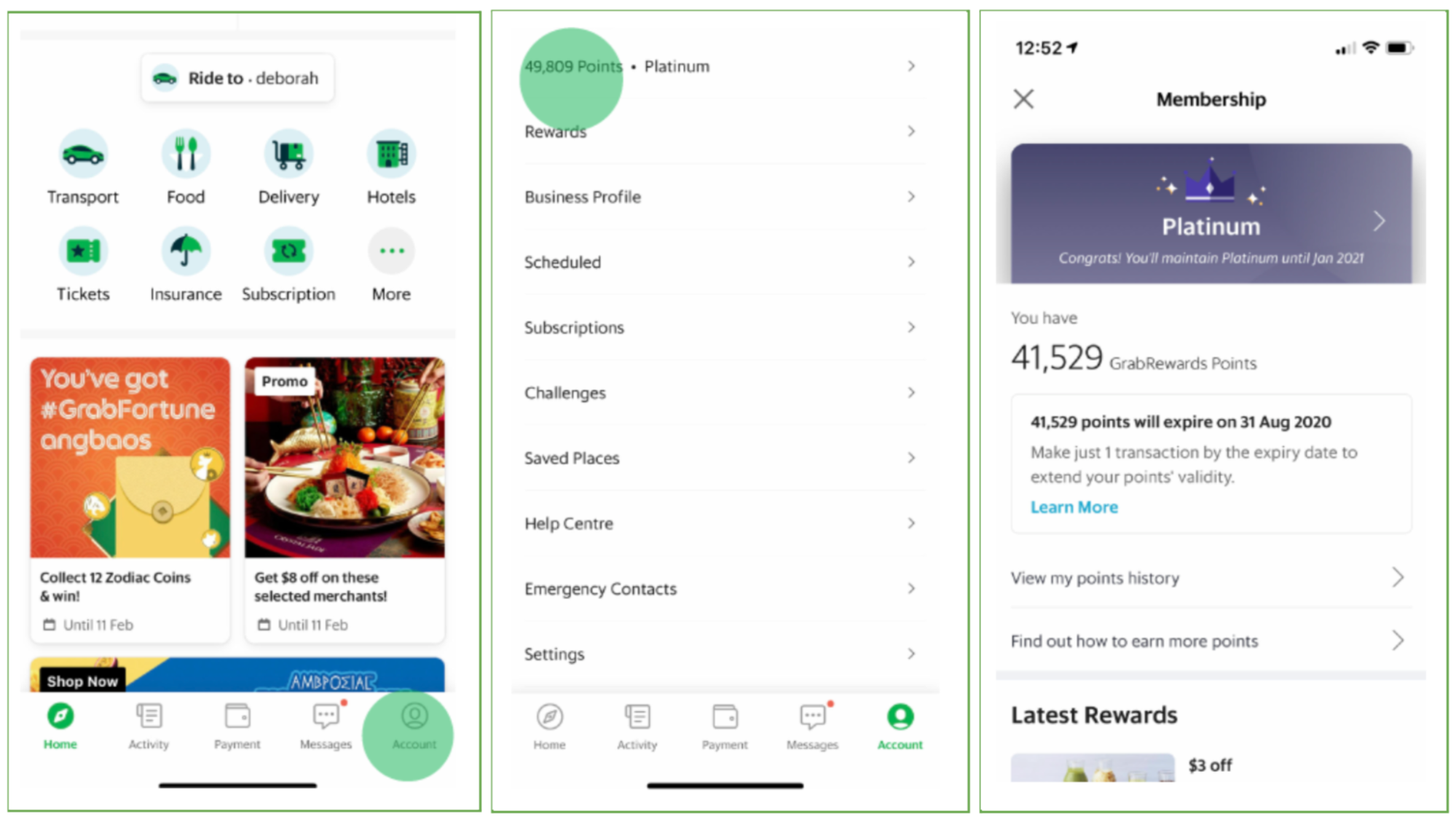
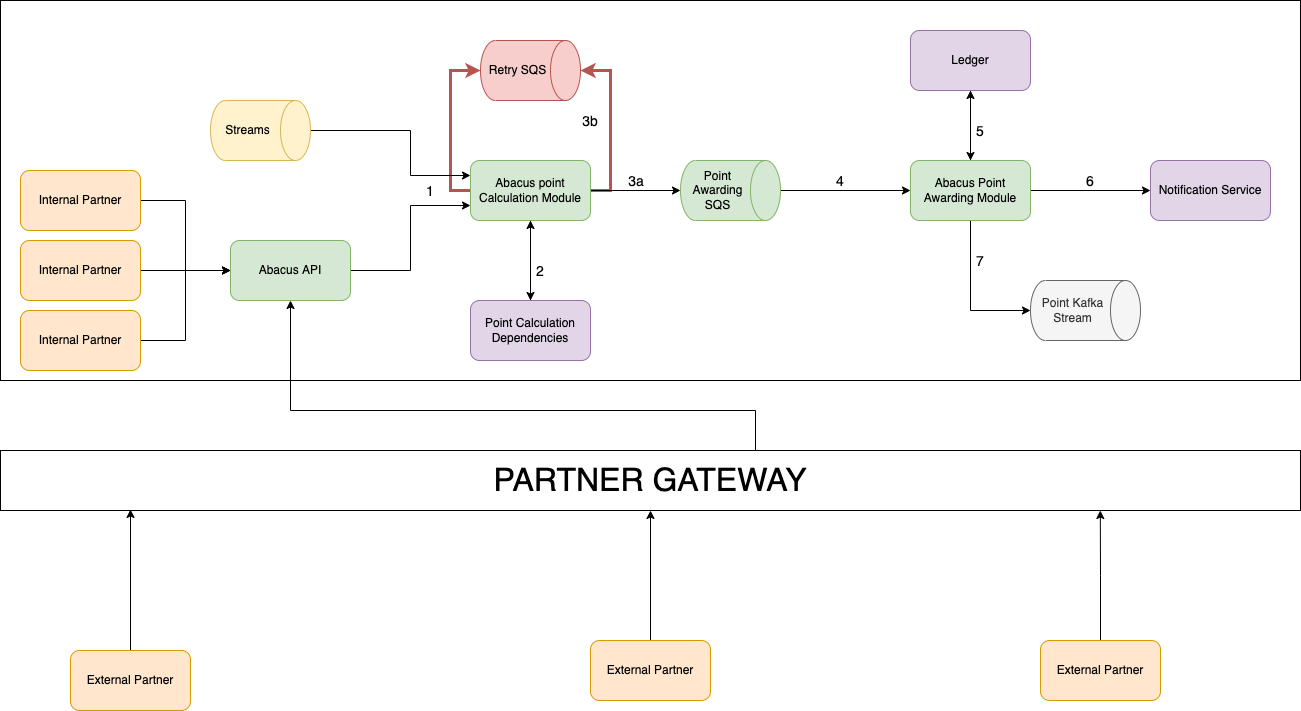
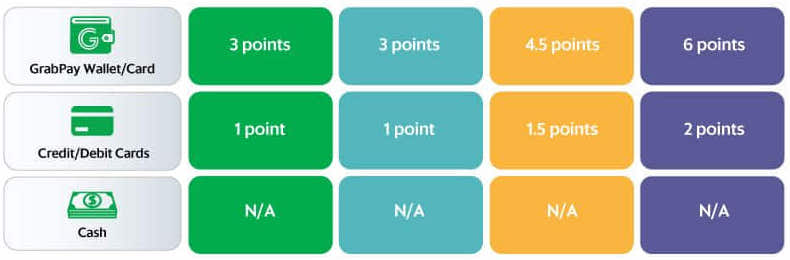
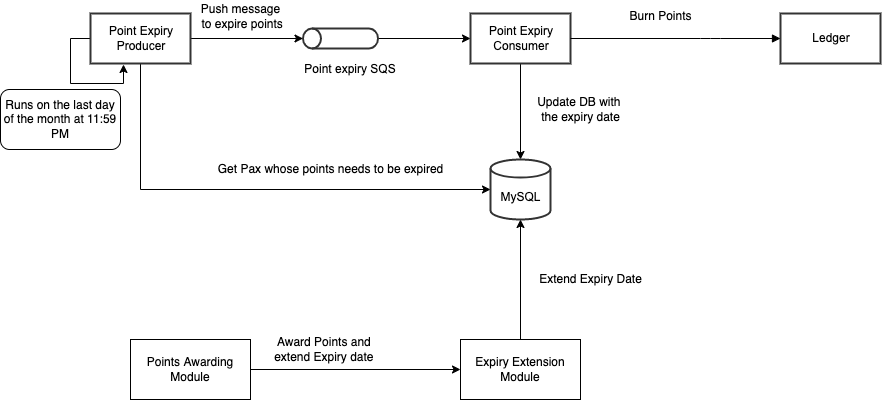

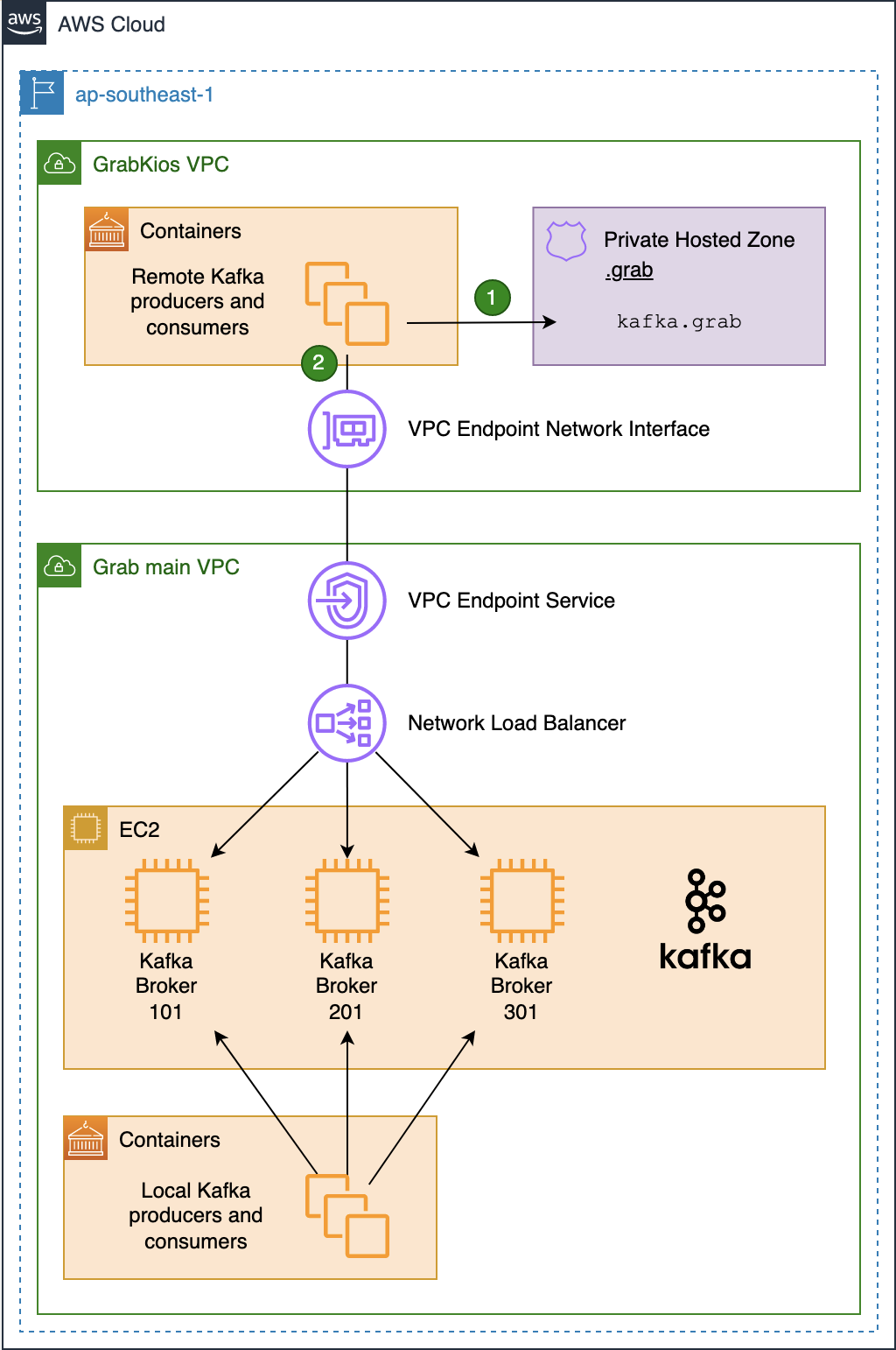
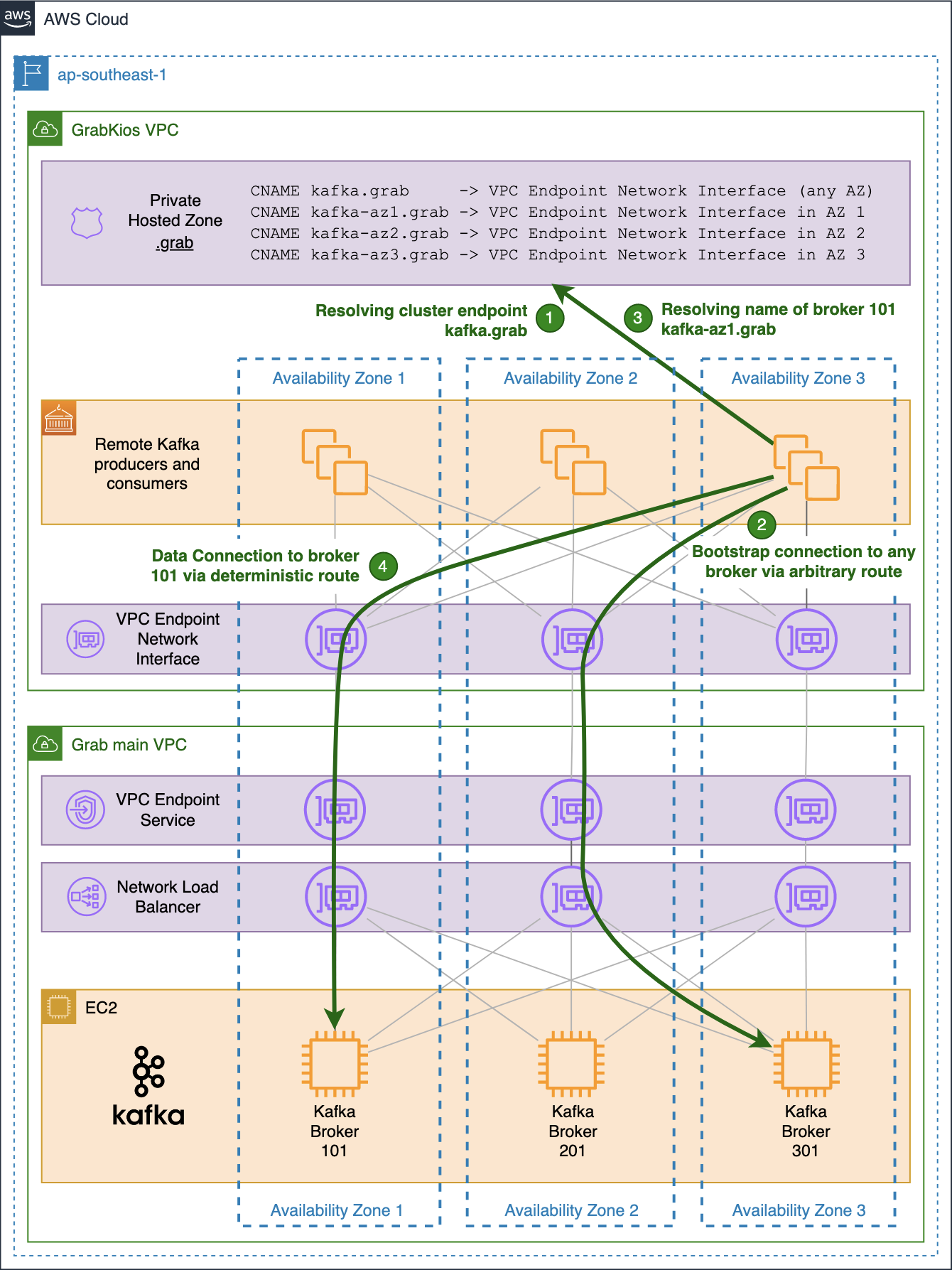
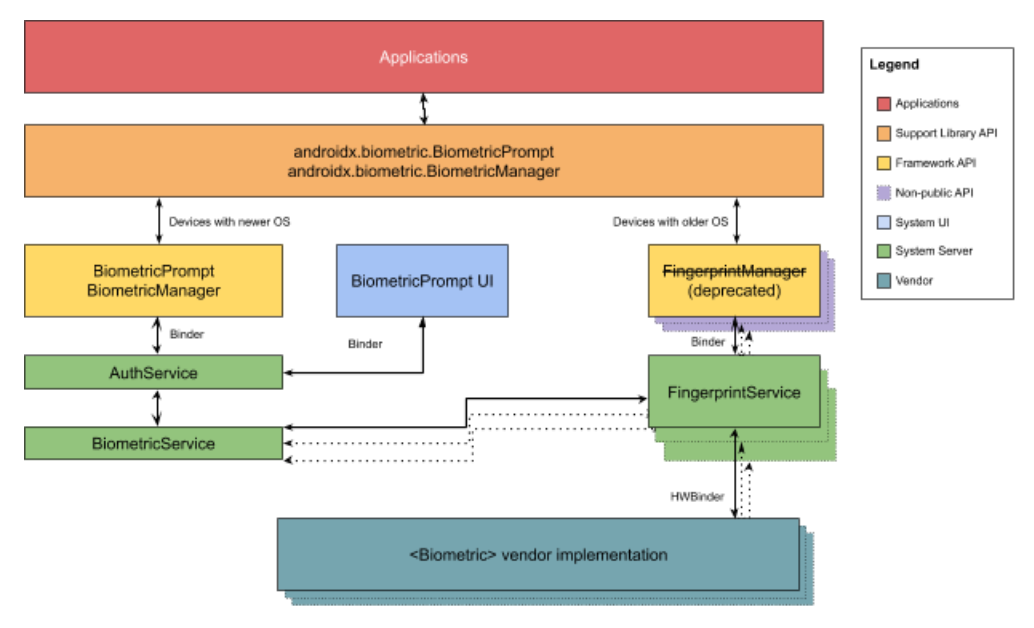
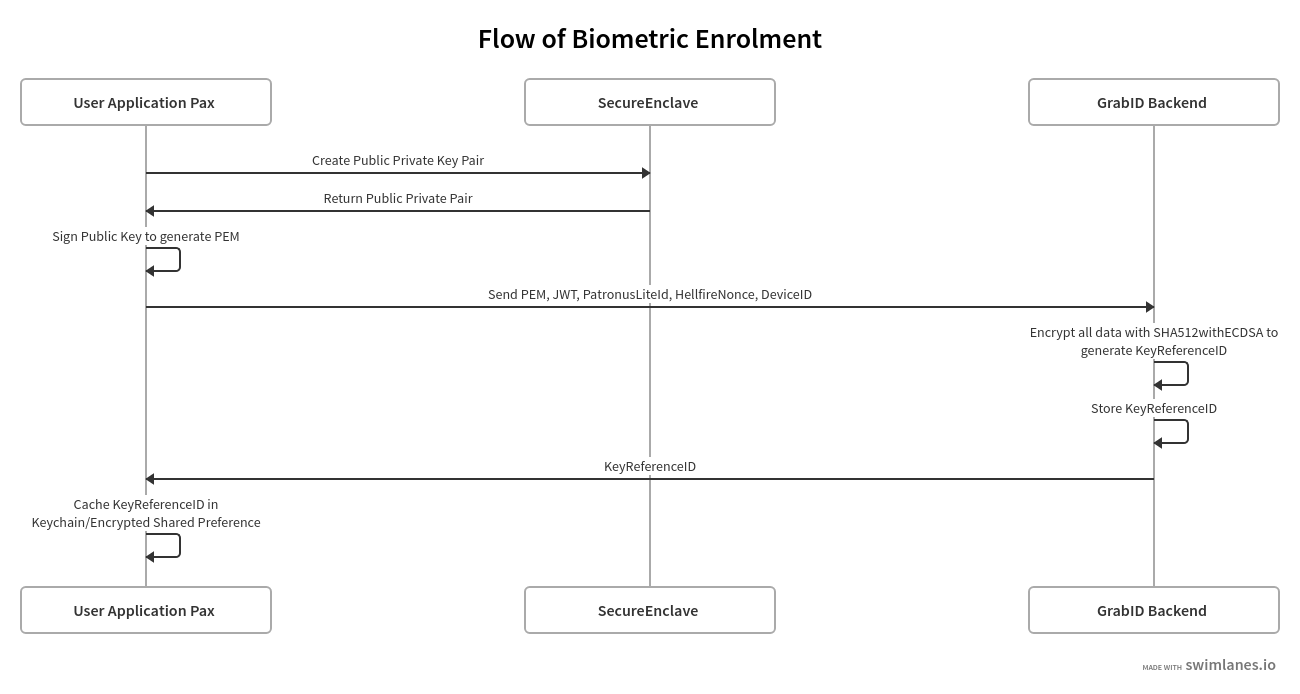
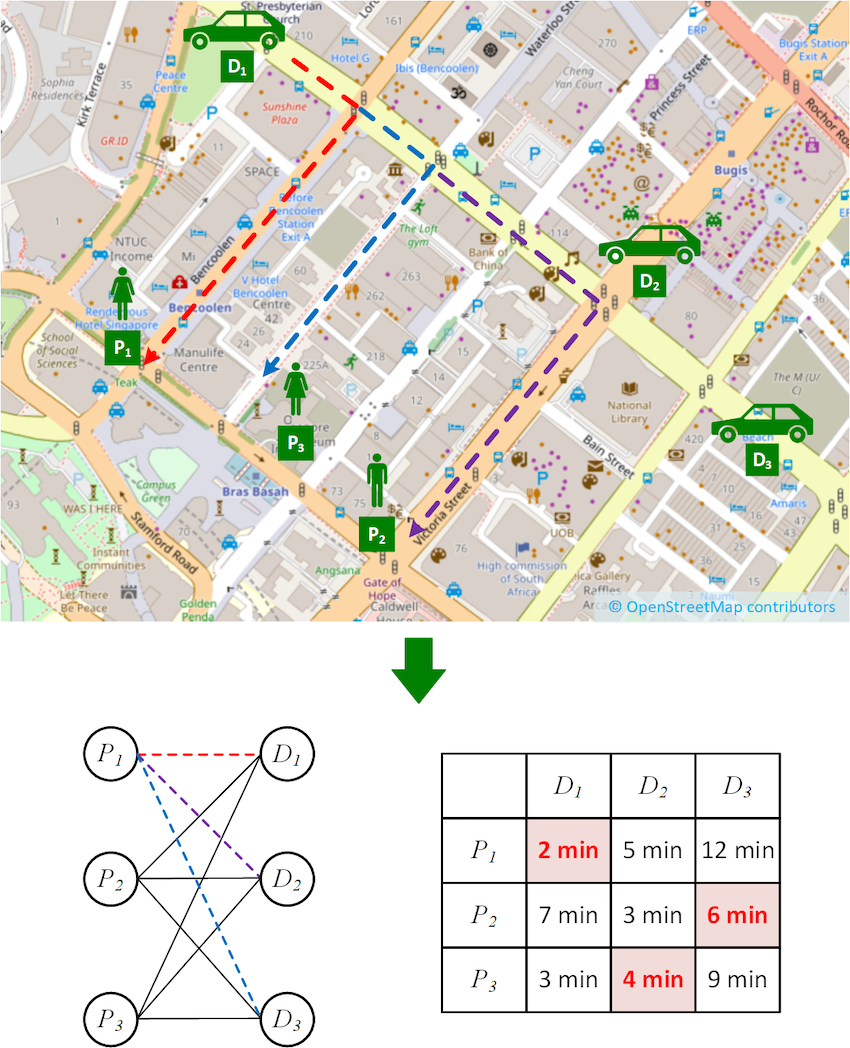
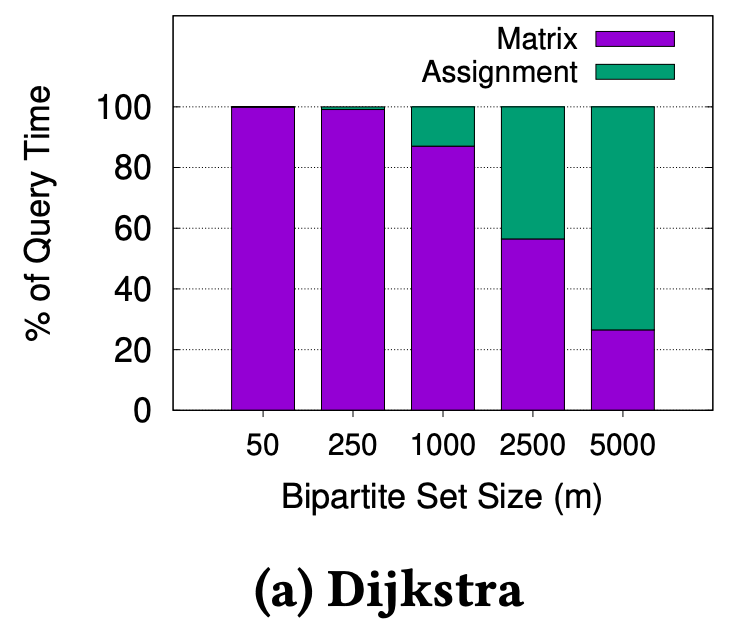
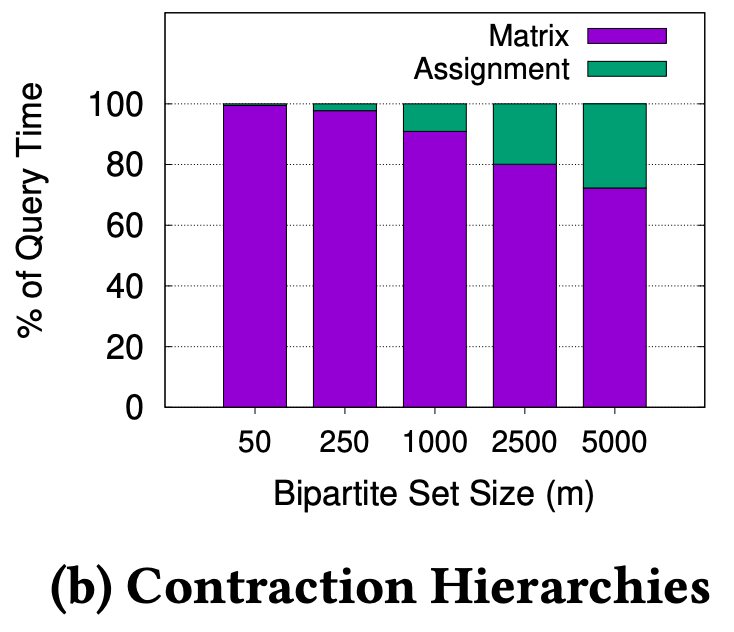
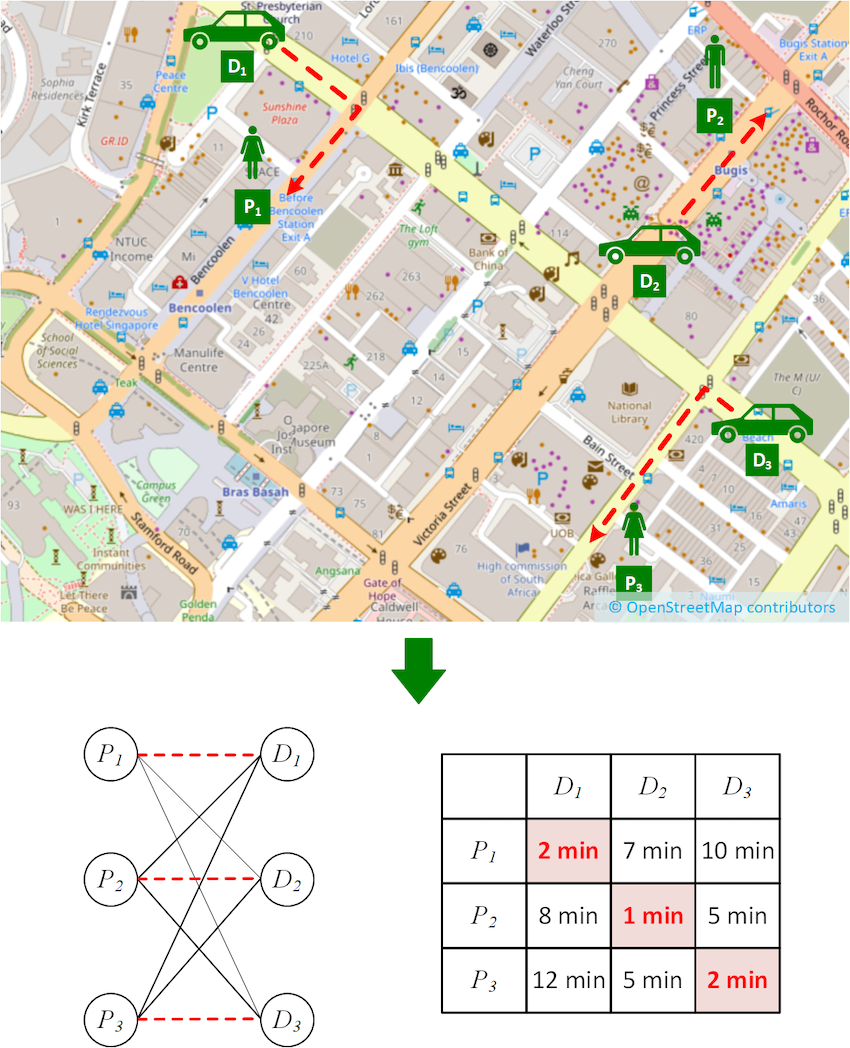
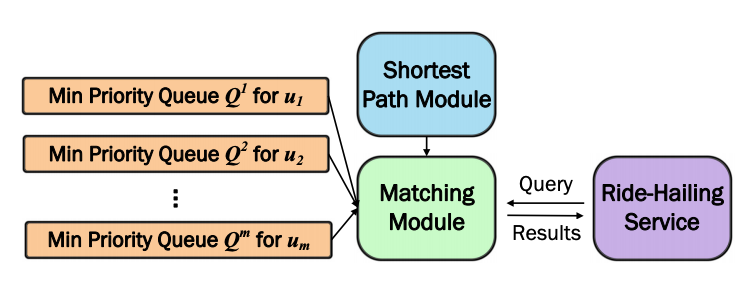
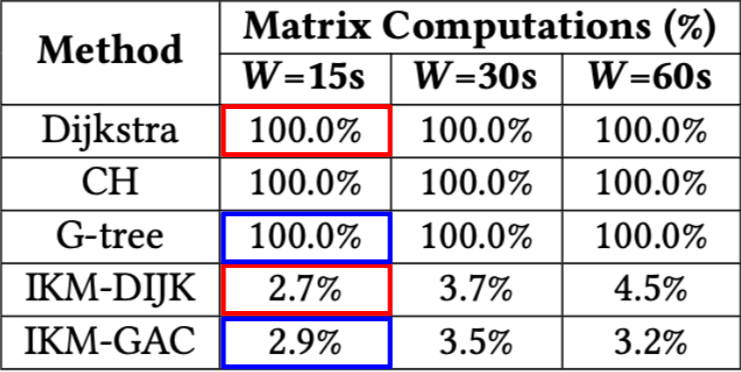
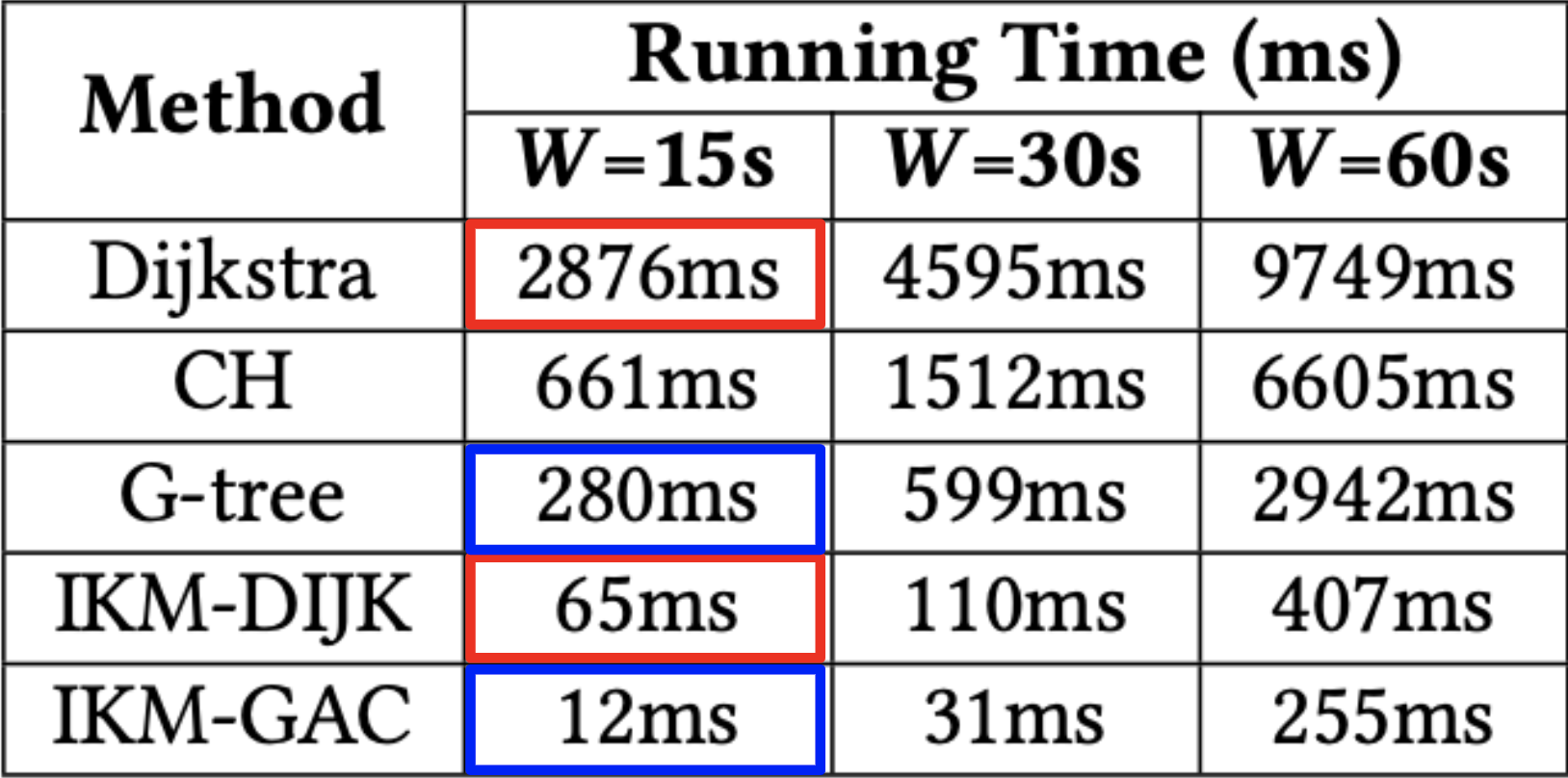
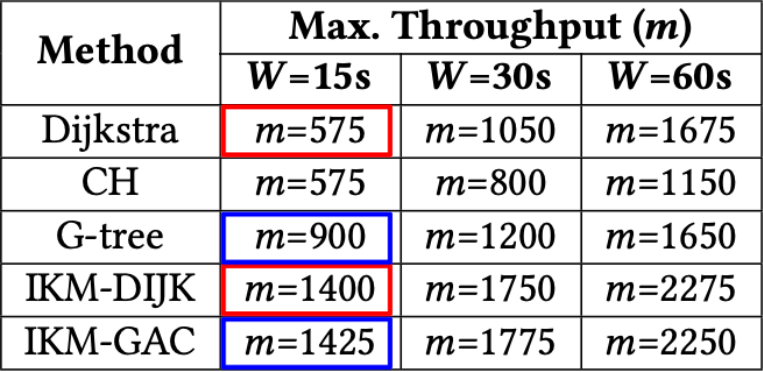

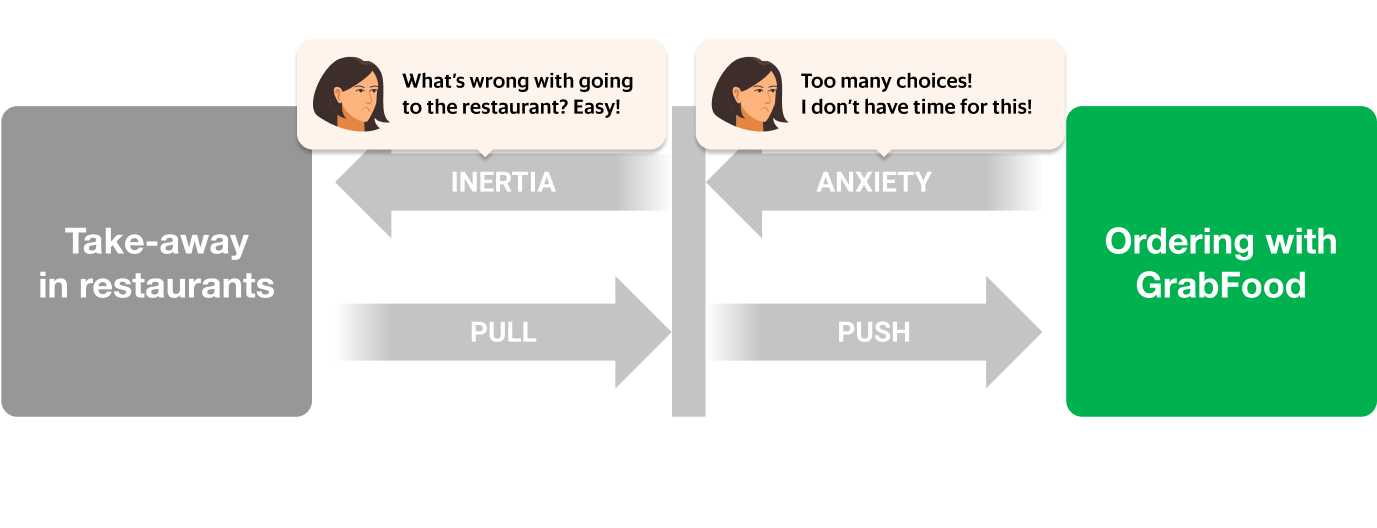
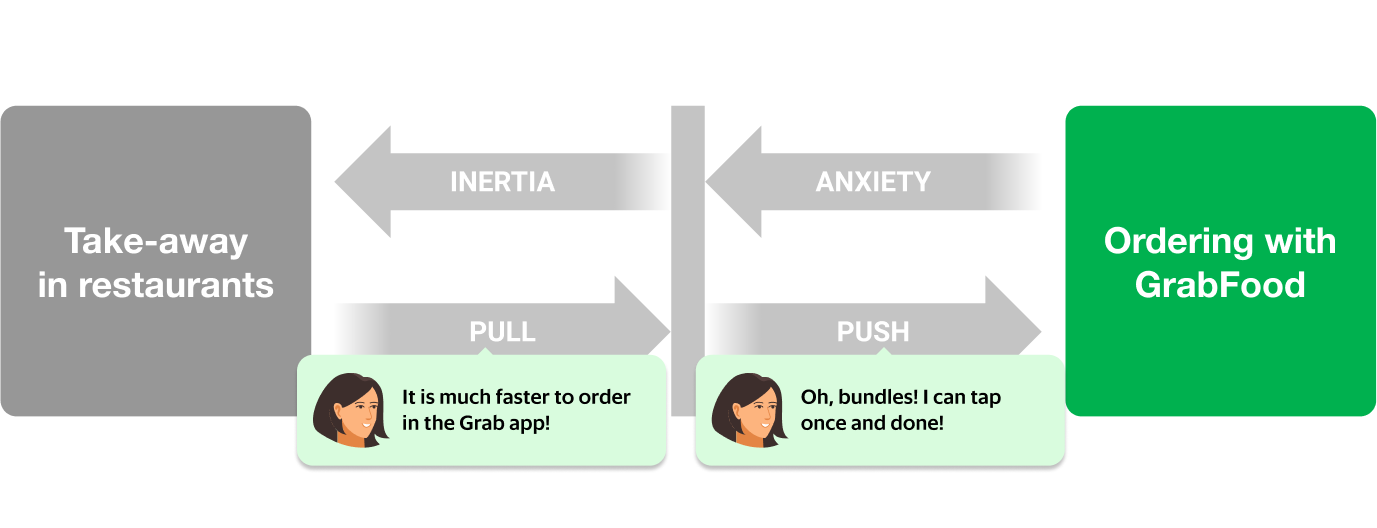
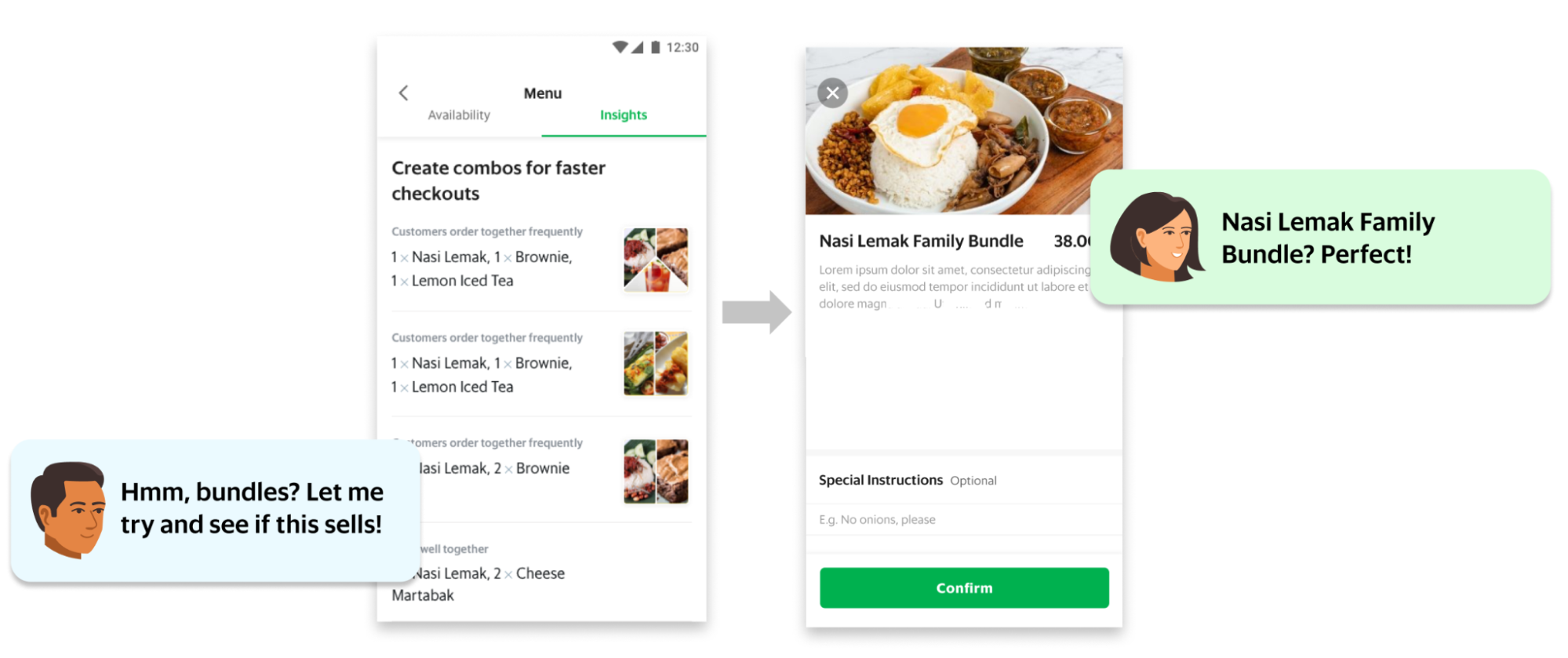


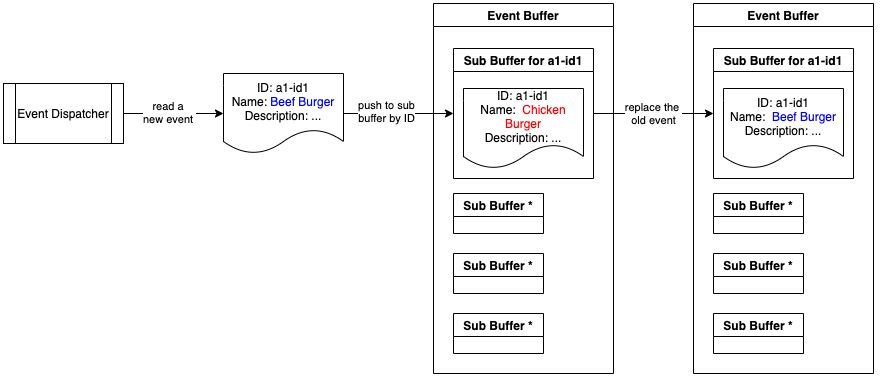
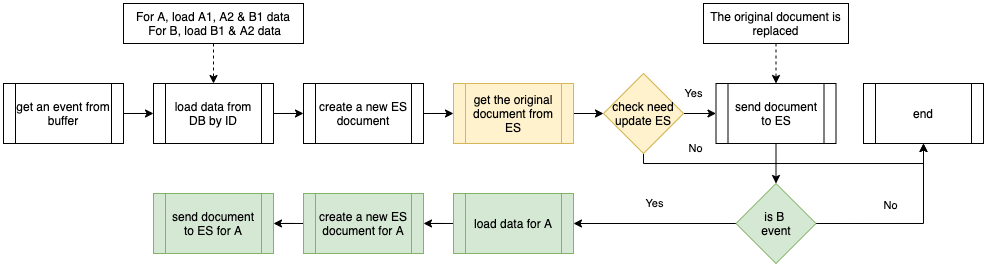
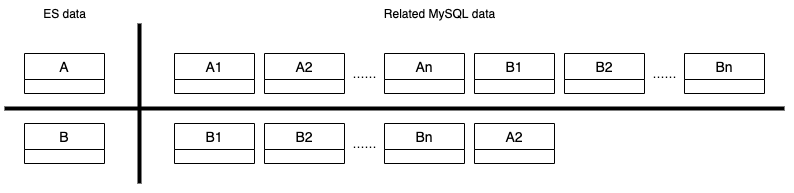

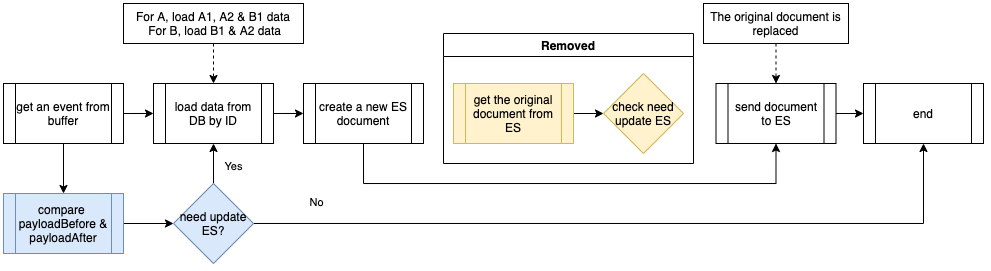
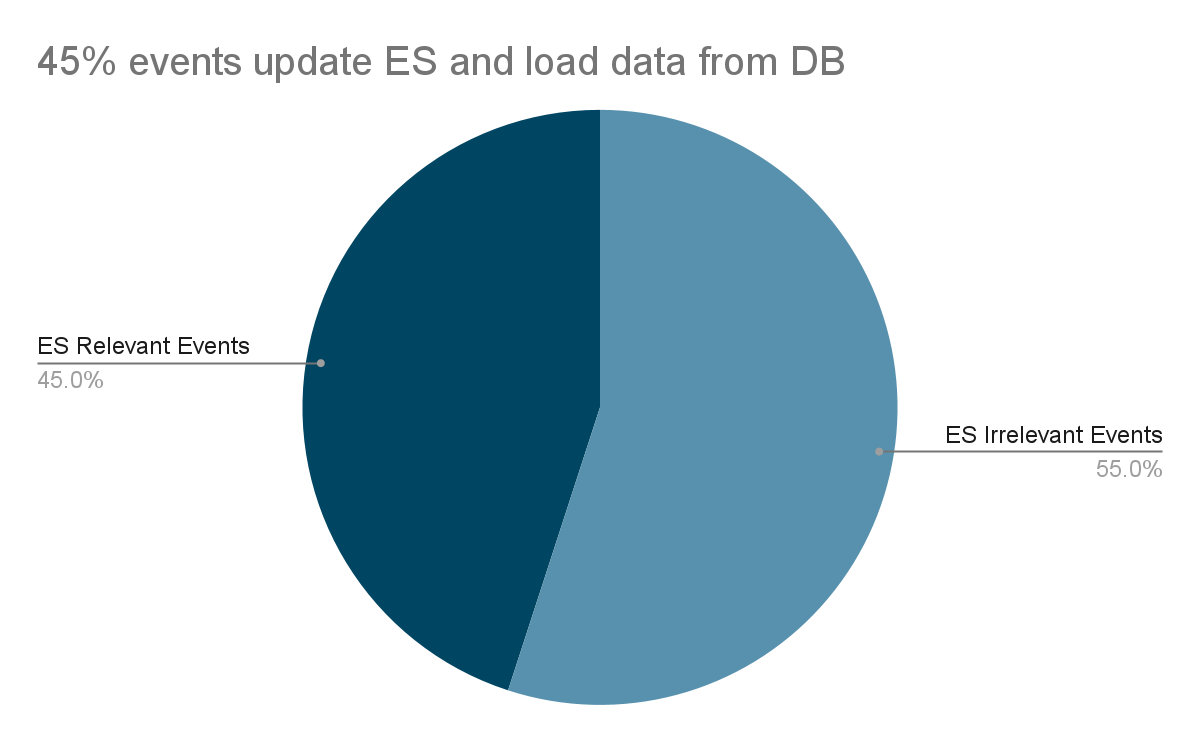
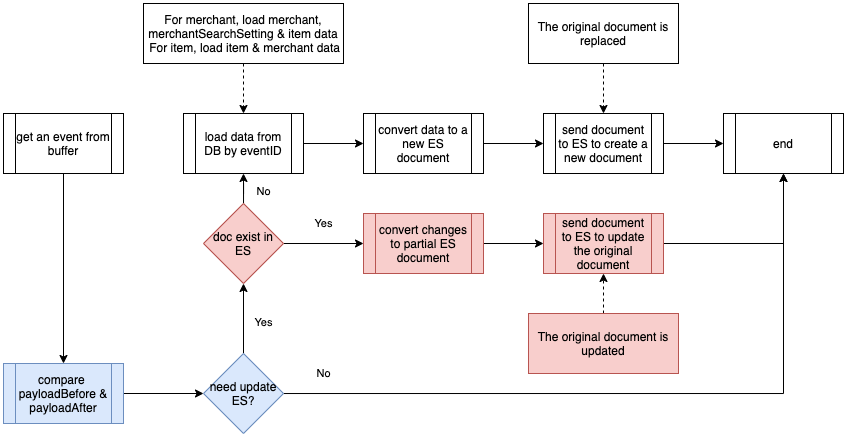
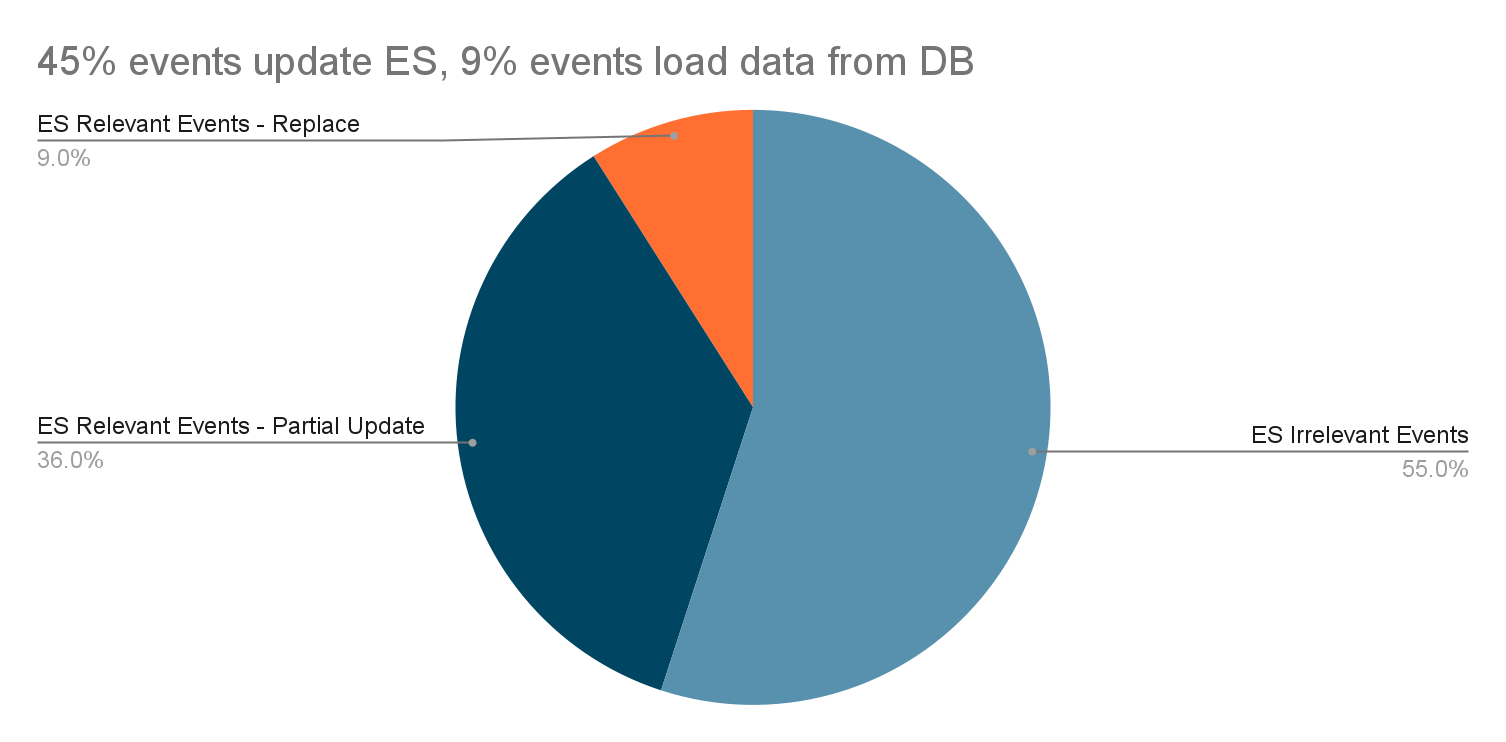
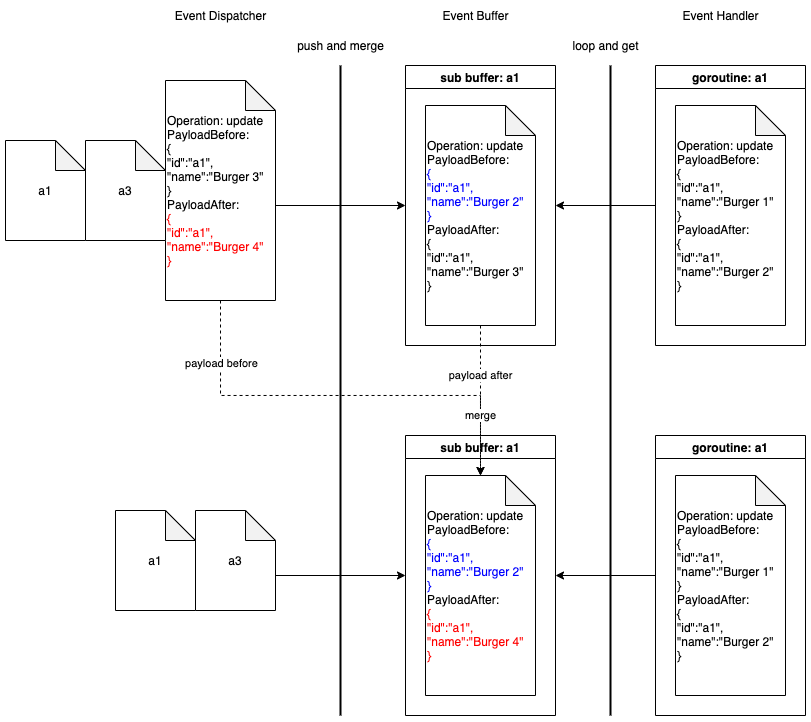
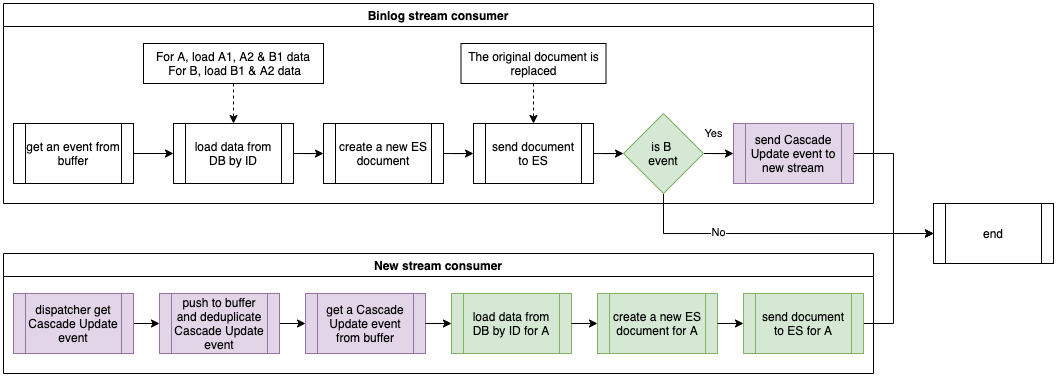
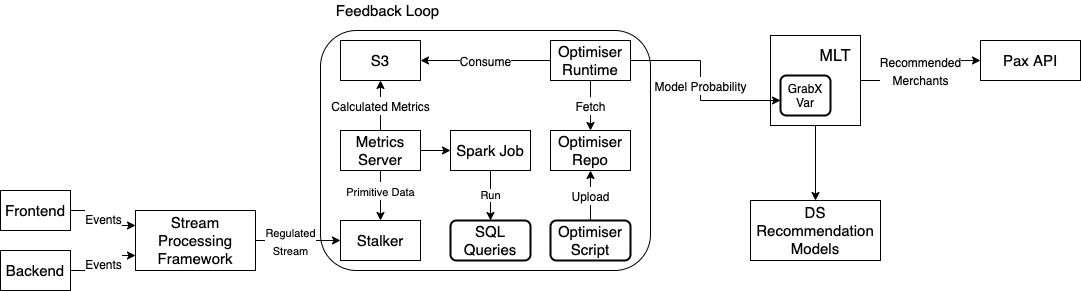

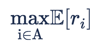 .
. .
.
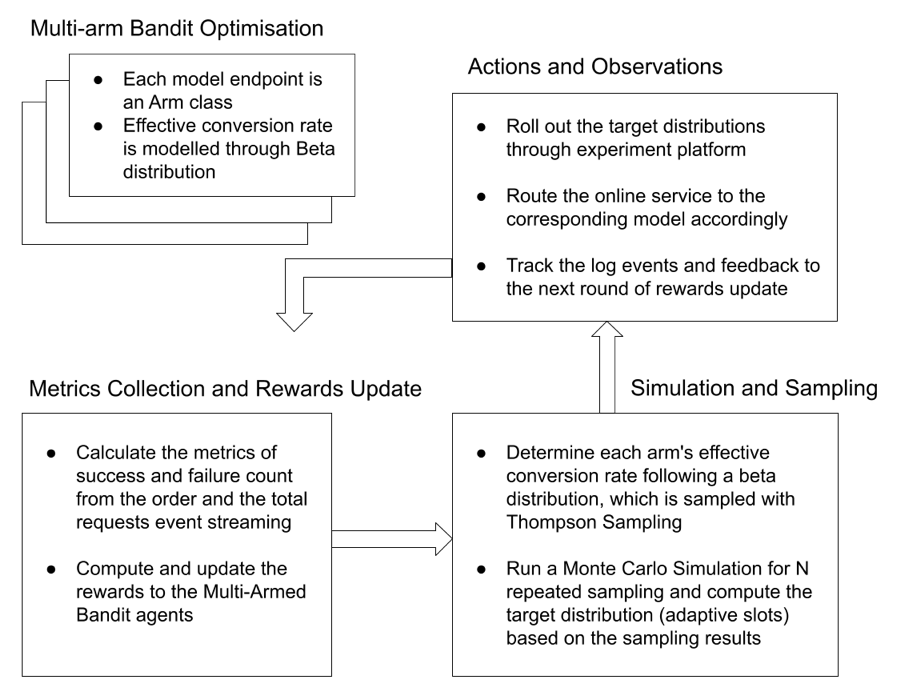














![Figure 4 - Picture’s processing steps [8]](https://engineering.grab.com/img/protecting-personal-data-in-grabs-imagery/figure-4-picture-processing-steps.png)









![Figure 7 - Anatomy of one and two-stage object detectors [1]](https://engineering.grab.com/img/protecting-personal-data-in-grabs-imagery/figure-7-anatomy-of-object-detectors.png)



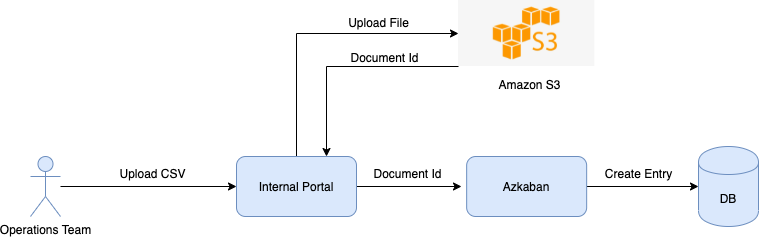
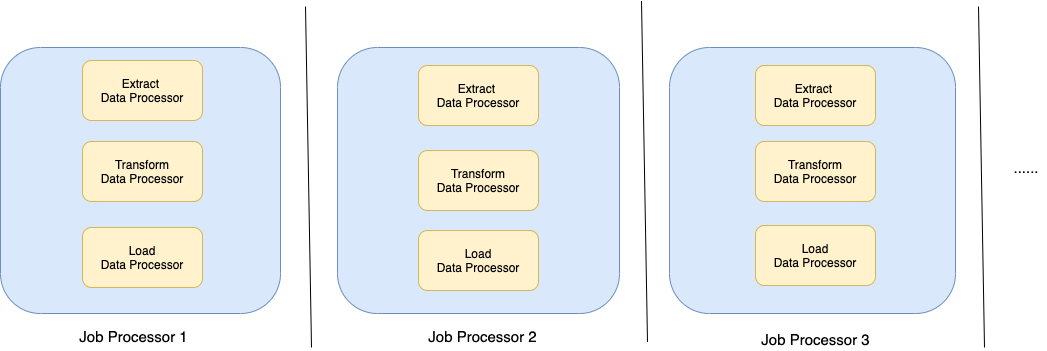
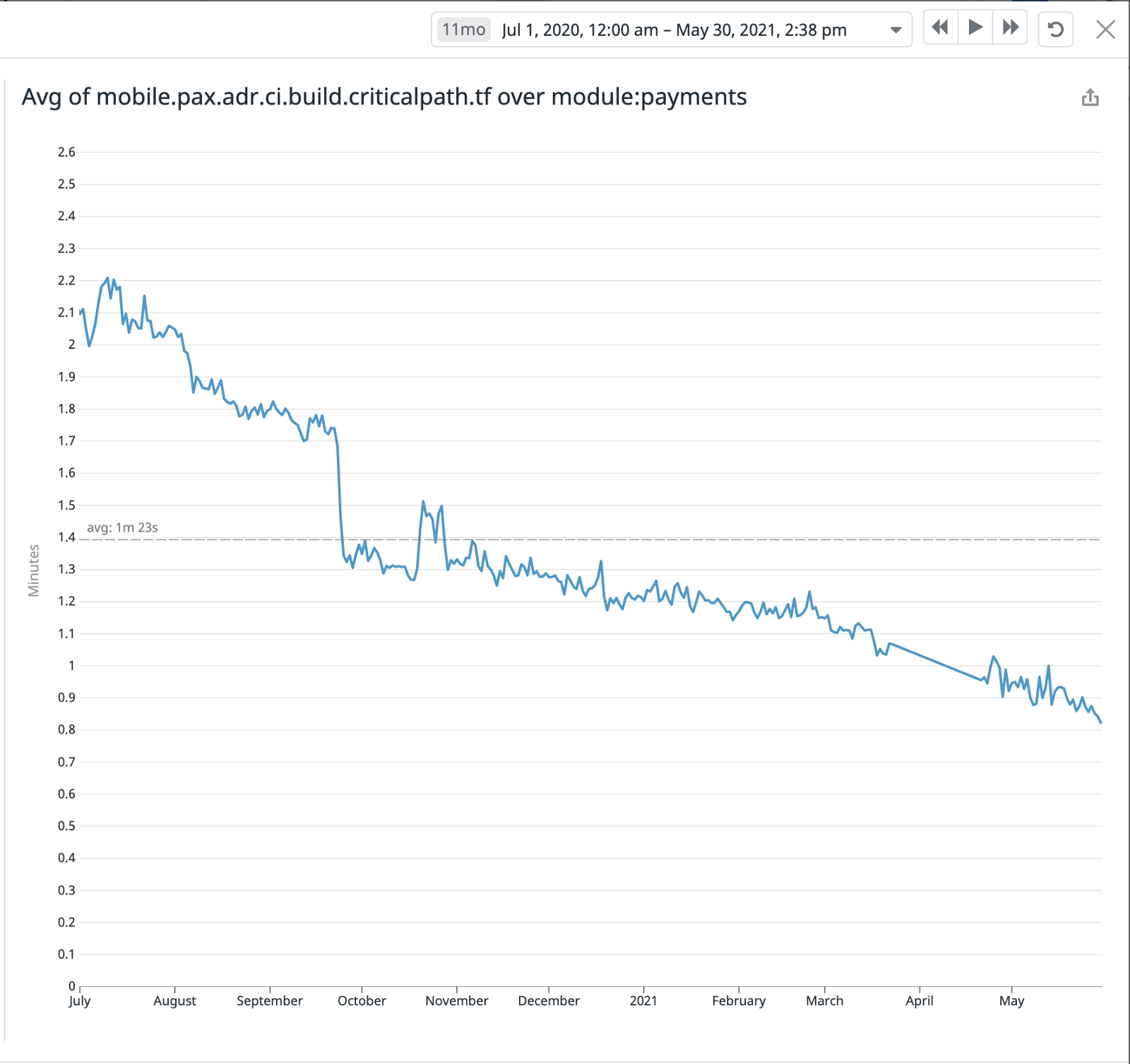
{kind=link}