Post Syndicated from sbbusser original https://aws.amazon.com/blogs/compute/managing-and-securing-aws-outposts-instances-using-aws-systems-manager-amazon-inspector-and-amazon-guardduty/
This post is written by Sumeeth Siriyur, Specialist Solutions Architect.
AWS Outposts is a family of fully managed solutions that deliver AWS infrastructure and services to virtually any on-premises or edge location for a truly consistent hybrid experience. Outposts is ideal for workloads that need low latency access to on-premises applications or systems, local data processing, and secure storage of sensitive customer data that must remain anywhere without an AWS region, including inside company-controlled environments or a specific country.
A key feature of Outposts is that it offers the same AWS hardware infrastructure, services, APIs, and tools to build and run your applications on-premises and “in AWS Regions”. Outposts is part of the cloud for a truly consistent hybrid experience. AWS compute, storage, database, and other services run locally on Outposts, and you can access the full range of AWS services available in the Region to build, manage, and scale your on-premises applications using familiar AWS services and tools.
Outposts comes in a variety of form factors, from 1U and 2U servers to 42U Outposts rack. This post focuses on the 42U form factor of Outposts.
This post demonstrates how to use some of the existing AWS services in the Region, such as AWS System Manager (SSM), Amazon Inspector, and Amazon GuardDuty to manage and secure your workload environment on Outposts rack. This is no different from how you use these services for workloads in the AWS Regions.
Solution overview
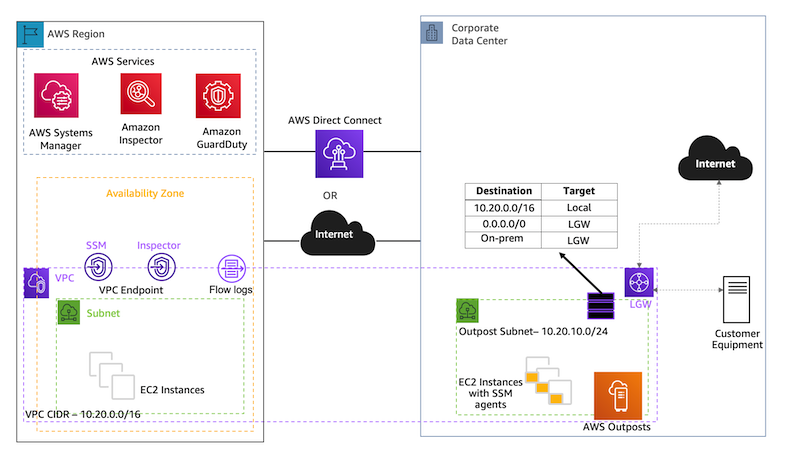
In this scenario, Outposts rack is locally installed in a customer premises. The service link connectivity to the AWS Region can be either via an AWS Direct Connect private virtual interface, a public virtual interface, or the public internet.
The local gateway (LGW) provides connectivity between the Outposts instances and the local on-premises network.
A virtual private cloud (VPC) spans all Availability Zones in its AWS Region. You can extend the VPC in the Region to the Outpost by adding an Outpost subnet. To add an Outpost subnet to a VPC, specify the Amazon Resource Name (ARN) – arn:aws:outposts:region:account-id – of the Outpost when you create the subnet. Outposts rack support multiple subnets. In this scenario, we have extended the VPC from the Region (us-west-2) to the Outpost.
To improve the security posture of the Outposts instance, you can configure AWS SSM to use an interface VPC endpoint in Amazon Virtual Private Cloud (VPC). An interface VPC endpoint lets you connect to services powered by AWS PrivateLink, a technology that lets you privately access AWS SSM APIs by using private IP addresses. See the details in the following AWS SSM section for the VPC endpoints.
Most importantly, to leverage any of the AWS services in the Region, Outposts rack relies on connectivity to the parent AWS Region. Outposts rack is not designed for disconnected operations or environments with limited to no connectivity. We recommend that you have highly-available networking connections back to your AWS Region. For an optimal experience and resiliency, AWS recommends that you use redundant connectivity of at least 500 Mbps (1 Gbps or higher) for the service link connection to the AWS Region.
Outposts offers a consistent experience with the same hardware infrastructure, services, APIs, management, and operations on-premises as in the AWS Regions. Unlike other hybrid solutions that require different APIs, manual software updates, and purchase of third-party hardware and support, Outposts enables developers and IT operations teams to achieve the same pace of innovation across different environments.
In the first section, let’s see how we can use AWS SSM services for managing and operating Outposts instances.
Managing Outposts instances using AWS SSM
The Amazon Systems Manager Agent (SSM Agent) is installed and running on the Outposts instances.
SSM Agent is installed by default on Amazon Linux, Amazon Linux 2, Ubuntu Server16.04 and Ubuntu Server 18.04 LTS based Amazon Elastic Compute Cloud (EC2) AMIs. If SSM Agent isn’t preinstalled, then you must manually install the agent. Agent communication with SSM is via TCP port 443.
Linux: Manually install SSM Agent on EC2 instances for Linux
Windows: Manually install SSM Agent on EC2 instances for Windows Server
- Create an IAM instance profile for SSM
By default, SSM doesn’t have permission to perform actions on your instances. Grant access by using an AWS Identity and Access Management (IAM) instance profile. An instance profile is a container that passes IAM role information to an Amazon EC2 instance at launch. You can create an instance profile for SSM by attaching one or more IAM policies that define the necessary permissions to a new role or to a role that you already created. Make sure that you follow AWS best practices by having a least-privileges policy created.
- Create VPC endpoints for SSM.
a. amazonaws.us-west-2.ssm: The endpoint for the Systems Manager service.
b. amazonaws.us-west-2.ec2messages: Systems Manager uses this endpoint to make calls from the SSM Agent to the Systems Manager service.
c. amazonaws.us-west-2.ec2: If you’re using Systems Manager to create VSS-enabled snapshots, then you must make sure that you have an endpoint to the EC2 service. Without the EC2 endpoint defined, a call to enumerate attached Amazon Elastic Block Storage (EBS) volumes fails, which causes the Systems Manager command to fail.
d. amazonaws.us-west-2.ssmmessages: This endpoint is for connecting to your instances with a secure data channel using Session Manager.
e. amazonaws.us-west-2.s3: Systems Manager uses this endpoint to update SSM agent, perform patch operation, and for uploading logs into Amazon Simple Storage Service (S3) buckets.
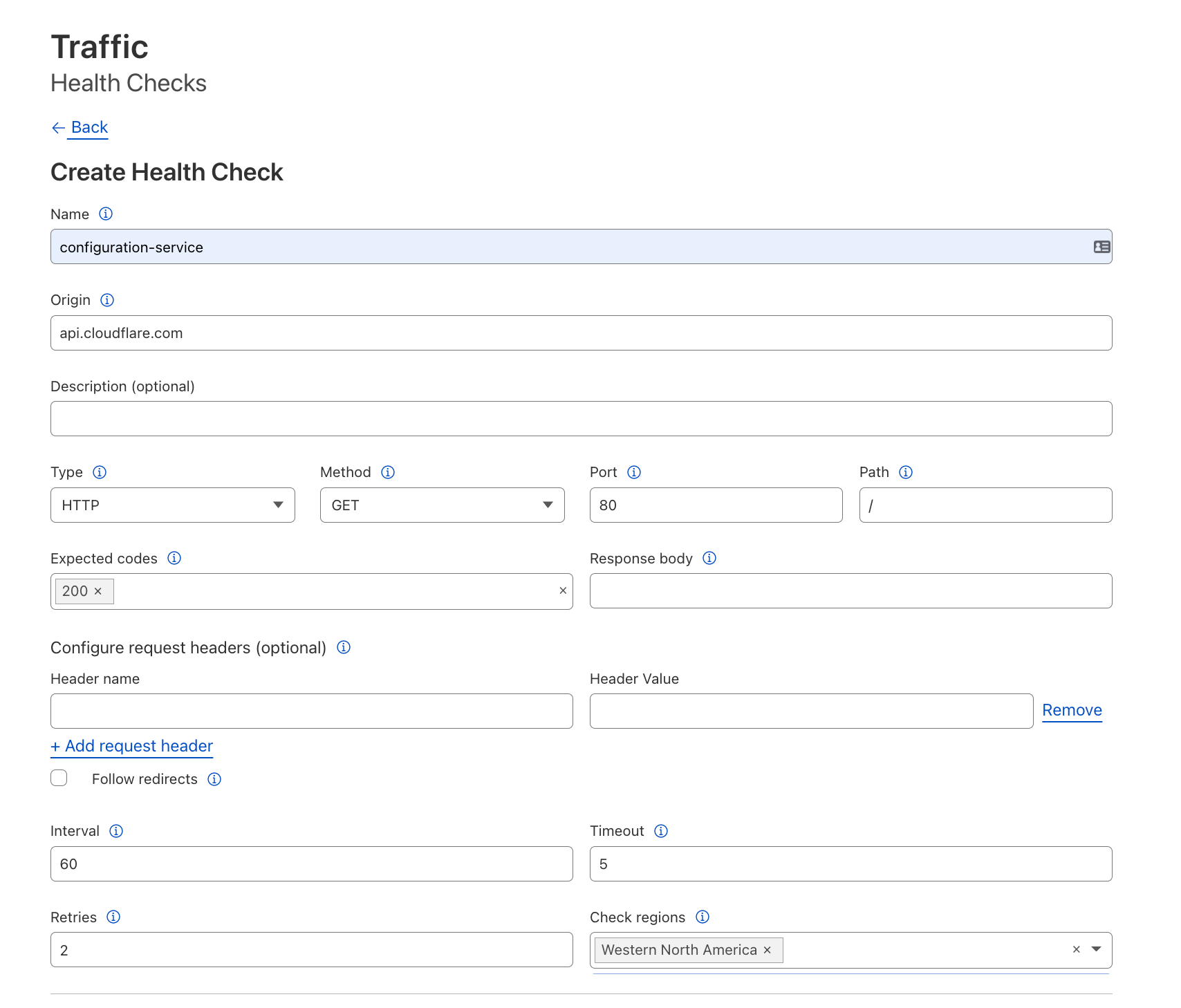
- Once the SSM agent has been installed and the necessary permission has been provided for the Systems Manager, log in to Systems Manager Console and navigate to Fleet Manager to discover the Outposts instances as shown in the following image.
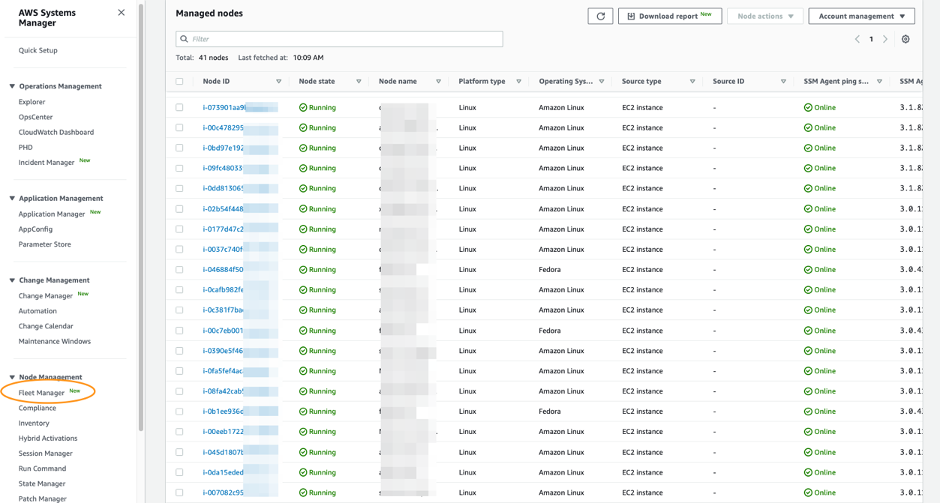
4. You can use compliance to scan the Outposts instances for patch compliance and configuration inconsistencies.
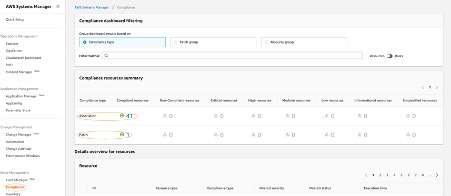
5. AWS Systems Manager Inventory provides visibility into your Outposts computing environment. You can use this inventory to collect metadata about the instances.
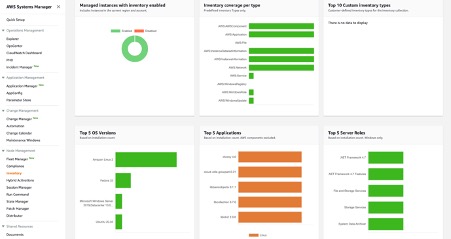
6. With Session Manager, you can log into your Outposts instances. You can use either an interactive one-click browser-based shell, or the AWS Command Line Interface (CLI) for Linux based EC2 instances. For Windows instances, you can connect using Remote Desktop Protocol (RDP). For better SEO, suggest replacing this with “Check out”, attach the link to “how to connect to Windows instances from the Fleet Manager console”, and delete can be found here. here.
Note that accessing the Outposts EC2 instances through SSH or RDP via the Region based Session Manager will have more latency via service link than accessing via the LGW.
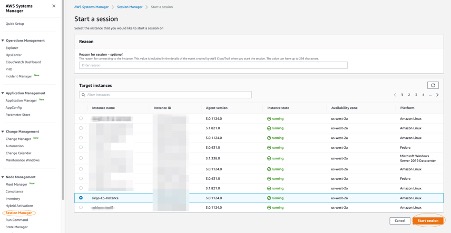
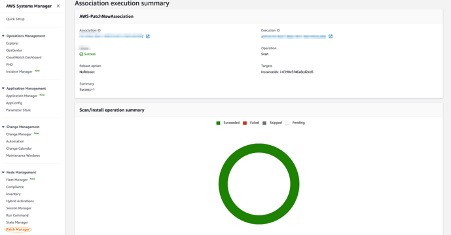
7. Patch Manager automated the process of patching the Outposts instances with both security-related and other types of updates. In the following you can see that one of the Outposts instances is scanned and updated with an operational update.
Security at AWS is the highest priority. Security is a shared responsibility between AWS and customers. We offer the security tools and procedures to secure the Outposts instances as in the AWS region. By using AWS services, you can enhance your security posture on Outposts rack in these areas.
- Data Protection
- IAM
- Infrastructure Security
- Resiliency
- Compliance Validation
- Find out more about these individual aspects of security in AWS Outposts.
In the second section, let’s see how we can use Amazon Inspector running in the AWS Region to scan for vulnerabilities within the Outposts environment. Amazon Inspector uses the widely deployed SSM Agent to automatically scan for vulnerabilities on Outposts instances.
Scan Outposts instances for vulnerabilities using Amazon Inspector
Amazon Inspector is an automated vulnerability management service that continually scans AWS workloads for software vulnerabilities and unintended network exposure. Amazon Inspector automatically discovers all of the Outposts EC2 instances (installed with SSM Agent) and container images residing in Amazon Elastic Container Registry (ECR) that are identified for scanning. Then, it immediately starts scanning them for software vulnerabilities and unintended network exposure.
All workloads are continually rescanned when a new Common Vulnerabilities And Exposures (CVE) is published, or when there are changes in the workloads, such as installation of new software in an Outposts EC2 instance.
Amazon Inspector uses the widely deployed SSM Agent (deployed in the previous scenario) to collect the software inventory and configurations from your Outposts EC2 instances. Use the VPC interface endpoint – com.amazonaws.us-west-2.inspector2 – to privately access Amazon Inspector. The collected application inventory and configurations are used to assess workloads for vulnerabilities.
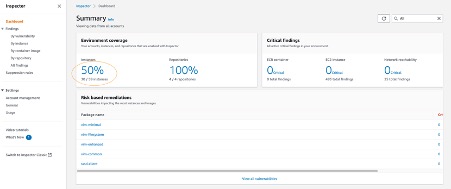
- The following Summary Dashboard provides information on how many Outposts EC2 instances and the container repositories are scanned and discovered.
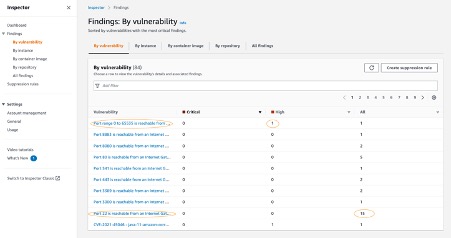
2. The findings by Vulnerability tab help to identify the most vulnerable Outposts EC2 instances in your environment. In the following, you can see Outposts instances with the following vulnerability highlighted.
a. Port range 0 to 65535 is reachable from an Internet Gateway
b. Port 22 is reachable from an Internet Gateway
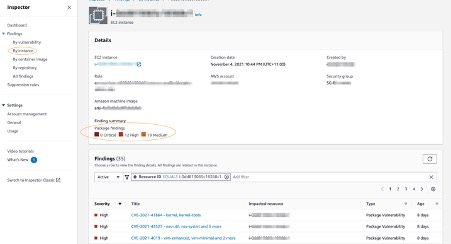
3. The findings by instance tab shows you all of the active findings for a Single Outposts instance in your environment. In the following, you can see that for this instance there are a total of 12 high and 19 medium findings based on the rules in the Common Vulnerabilities And Exposures (CVE) package.
In the last section, let’s see how we can use GuardDuty to detect any threats within the Outposts environment.
Threat Detection service for your AWS accounts and Outposts workloads using Amazon GuardDuty
GuardDuty is a threat detection service that continuously monitors your AWS accounts and workloads for malicious activities and delivers detailed security findings for visibility and remediation.
GuardDuty continuously monitors and analyses the Outposts instances and reports suspicious activities using the GuardDuty console. It gets this information from CloudTrail Management Events, VPC Flow Logs, and DNS logs.
In this scenario, GuardDuty has detected an SSH brute force attack against an Outposts instance.
Costs associated with the scenario
- Systems Manager: With AWS Systems Manager, you pay only for what you use on the priced feature. In this scenario, we have used the following features.
- Inventory – No additional charges
- Session Manager – No additional charges
- Patch Manager – No additional charges
*Note that there will be charges for the VPC endpoint created.
- Amazon Inspector: Costs for Amazon Inspector are based on container images scanned to ECR and the EC2 instances being scanned.
- The average number of EC2 instances scanned per month in US-WEST-2 region is $1.258 per instance. In the above scenario, there are three instances within the Outposts at $1.258 = $3.774
- Amazon GuardDuty: VPC Flow logs and CloudWatch logs are used for GuardDuty analysis. In this scenario, Only VPC Flow logs are considered.
- VPC Flow log is charged per GB/month. In US-WEST-2 region – the First 500 GB/month is $1 per GB. In the above scenario, there are three instances within the Outposts that would generate approximately 80 MB of data, which is still within the 500 GB limit.
- Understand more about AWS Outposts rack pricing on our website.
Cleaning up
Please delete example resources if they are no longer needed to avoid incurring future costs.
- Amazon Inspector: Disable Amazon Inspector from the Amazon Inspector Console.
- Amazon GuardDuty: You can use the GuardDuty console to suspend or disable GuardDuty. You are not charged for using GuardDuty when the service is suspended.
- Delete unused IAM policies
Conclusion
On-premises data centers traditionally use a variety of infrastructure, tools, and APIs. This disparate assortment of hardware and software solutions results in complexity. In turn, this leads to greater management costs, inability of staff to translate skills from one setting to another, and limits in innovation and knowledge-sharing between environments.
Using a common set of tools, services in the AWS Regions and on Outposts on premises allows you to have a consistent operation environment, thereby delivering a true hybrid cloud experience. Equally, by using the same tools to deploy and manage workloads in both environments, you can reduce operational overhead.
To get started with Outposts, see AWS Outposts Family. For more information about Outposts availability, see the Outposts rack FAQ.










 list of fastest-growing private companies and best places to work, and as a leader on G2 and Gartner for call tracking and marketing attribution software.
list of fastest-growing private companies and best places to work, and as a leader on G2 and Gartner for call tracking and marketing attribution software.