Over on the Collabora blog, Tathagata Roy has an update
on the progress of targeting the Coccinelle tool
for matching and transforming source code to Rust. The Coccinelle for Rust
project, which we covered in a 2024
talk by Roy at Kangrejos, is adding
the ability to transform Rust programs and the goal is “to bring
Coccinelle For Rust at par with Coccinelle For C in terms of basic
functionalities“. There is still work to be done to get there, but
progress is being made in various areas.
Computational Tree Logic (CTL) is the heart of Coccinelle, which takes semantic patches and generalizes them over Rust files. Prior to using this engine, CfR used an ad-hoc method for matching patterns of code. This engine is the same as the one used for Coccinelle for C, with a few minor changes. Most of the changes were idiomatic but to the same effect. More information on the engine and its language (CTL-VW) can be found in the POPL Paper. With a standard engine, each step of the matching process can be logged, allowing us to learn and reuse the same design patterns from Coccinelle for C, including critical test cases.
Kernel development and machine learning seem like vastly different areas of
endeavor; there are not, yet, stories circulating about the vibe-coding of
new memory-management algorithms. There may well be places where machine
learning (and large language models — LLMs — in particular) prove to be
helpful on the edges of the kernel project, though. At the 2025
North-American edition of the Open Source Summit, Sasha Levin presented
some of the work he has done putting LLMs to work to make the kernel better
Security updates have been issued by Debian (firefox-esr and libxml2), Fedora (firefox, libtpms, and tigervnc), Mageia (chromium-browser-stable and nss & firefox), Oracle (emacs, iputils, kernel, krb5, libarchive, mod_proxy_cluster, pam, perl-File-Find-Rule, perl-YAML-LibYAML, and qt5-qtbase), Red Hat (opentelemetry-collector, osbuild-composer, and weldr-client), SUSE (clamav, firefox, go1.24-openssl, and helm), and Ubuntu (libarchive, linux-azure, linux-azure-5.4, linux-azure-fips, linux-fips, linux-azure-nvidia, linux-oracle, linux-oracle-6.8, linux-raspi, linux-raspi-realtime, linux-xilinx-zynqmp, and python-urllib3).
Developing a new video conferencing application often begins with a peer-to-peer setup using WebRTC, facilitating direct data exchange between clients. While effective for small demonstrations, this method encounters scalability hurdles with increased participants. The data transmission load for each client escalates significantly in proportion to the number of users, as each client is required to send data to every other client except themselves (n-1).
In the scaling of video conferencing applications, Selective Forwarding Units (SFUs) are essential. Essentially a media stream routing hub, an SFU receives media and data flows from participants and intelligently determines which streams to forward. By strategically distributing media based on network conditions and participant needs, this mechanism minimizes bandwidth usage and greatly enhances scalability. Nearly every video conferencing application today uses SFUs.
In 2024, we announced Cloudflare Realtime (then called Cloudflare Calls), our suite of WebRTC products, and we also released Orange Meets, an open source video chat application built on top of our SFU.
We also realized that use of an SFU often comes with a privacy cost, as there is now a centralized hub that could see and listen to all the media contents, even though its sole job is to forward media bytes between clients as a data plane.
We believe end-to-end encryption should be the industry standard for secure communication and that’s why today we’re excited to share that we’ve implemented and open sourced end-to-end encryption in Orange Meets. Our generic implementation is client-only, so it can be used with any WebRTC infrastructure. Finally, our new designated committer distributed algorithm is verified in a bounded model checker to verify this algorithm handles edge cases gracefully.
End-to-end encryption for video conferencing is different than for text messaging
End-to-end encryption describes a secure communication channel whereby only the intended participants can read, see, or listen to the contents of the conversation, not anybody else. WhatsApp and iMessage, for example, are end-to-end-encrypted, which means that the companies that operate those apps or any other infrastructure can’t see the contents of your messages.
Whereas encrypted group chats are usually long-lived, highly asynchronous, and low bandwidth sessions, video and audio calls are short-lived, highly synchronous, and require high bandwidth. This difference comes with plenty of interesting tradeoffs, which influenced the design of our system.
We had to consider how factors like the ephemeral nature of calls, compared to the persistent nature of group text messages, also influenced the way we designed E2EE for Orange Meets. In chat messages, users must be able to decrypt messages sent to them while they were offline (e.g. while taking a flight). This is not a problem for real-time communication.
The bandwidth limitations around audio/video communication and the use of an SFU prevented us from using some of the E2EE technologies already available for text messages. Apple’s iMessage, for example, encrypts a message N-1 times for an N-user group chat. We can’t encrypt the video for each recipient, as that could saturate the upload capacity of Internet connections as well as slow down the client. Media has to be encrypted once and decrypted by each client while preserving secrecy around only the current participants of the call.
Messaging Layer Security (MLS)
Around the same time we were working on Orange Meets, we saw a lot of excitement around new apps being built with Messaging Layer Security (MLS), an IETF-standardized protocol that describes how you can do a group key exchange in order to establish end-to-end-encryption for group communication.
Previously, the only way to achieve these properties was to essentially run your own fork of the Signal protocol, which itself is more of a living protocol than a solidified standard. Since MLS is standardized, we’ve now seen multiple high-quality implementations appear, and we’re able to use them to achieve Signal-level security with far less effort.
Implementing MLS here wasn’t easy: it required a moderate amount of client modification, and the development and verification of an encrypted room-joining protocol. Nonetheless, we’re excited to be pioneering a standards-based approach that any customer can run on our network, and to share more details about how our implementation works.
We did not have to make any changes to the SFU to get end-to-end encryption working. Cloudflare’s SFU doesn’t care about the contents of the data forwarded on our data plane and whether it’s encrypted or not.
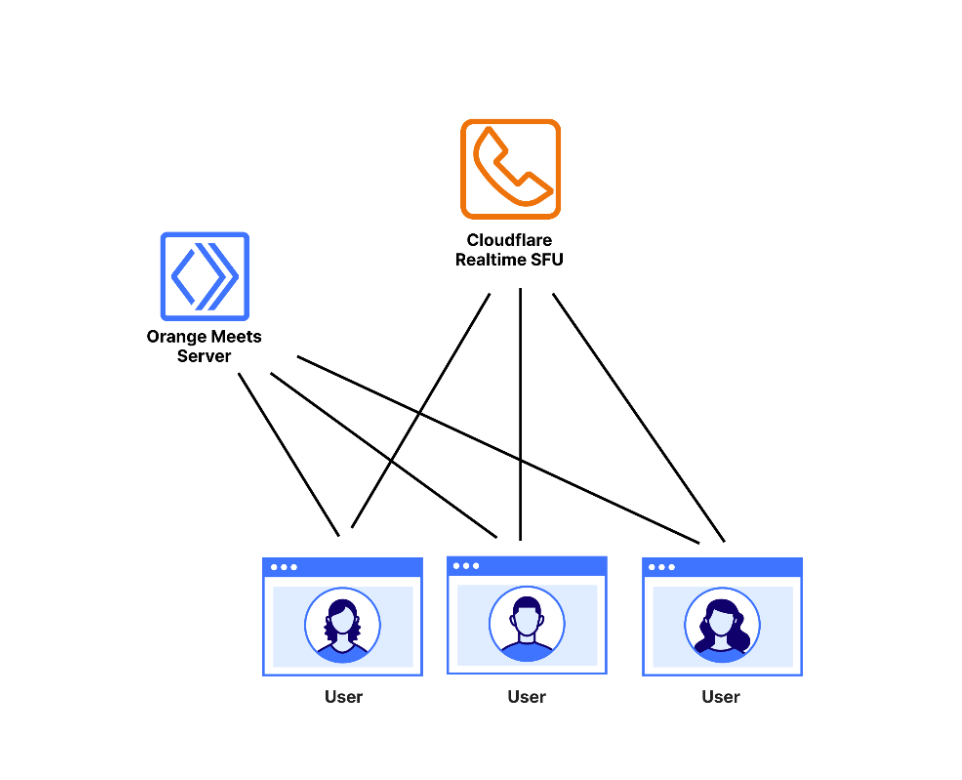
Orange Meets: the basics
Orange Meets is a video calling application built on Cloudflare Workers that uses the Cloudflare Realtime SFU service as the data plane. The roles played by the three main entities in the application are as follows:
The user is a participant in the video call. They connect to the Orange Meets server and SFU, described below.
The Orange Meets Server is a simple service run on a Cloudflare Worker that runs the small-scale coordination logic of Orange Meets, which is concerned with which user is in which video call — called a room — and what the state of the room is. Whenever something in the room changes, like a participant joining or leaving, or someone muting themselves, the app server broadcasts the change to all room participants. You can use any backend server for this component, we just chose Cloudflare Workers for its convenience.
Cloudflare Realtime Selective Forwarding Unit (SFU) is a service that Cloudflare runs, which takes everyone’s audio and video and broadcasts it to everyone else. These connections are potentially lossy, using UDP for transmission. This is done because a dropped video frame from five seconds ago is not very important in the context of a video call, and so should not be re-sent, as it would be in a TCP connection.
The network topology of Orange Meets
Next, we have to define what we mean by end-to-end encryption in the context of video chat.
End-to-end encrypting Orange Meets
The most immediate way to end-to-end encrypt Orange Meets is to simply have the initial users agree on a symmetric encryption/decryption key at the beginning of a call, and just encrypt every video frame using that key. This is sufficient to hide calls from Cloudflare’s SFU. Some source-encrypted video conferencing implementations, such as Jitsi Meet, work this way.
The issue, however, is that kicking a malicious user from a call does not invalidate their key, since the keys are negotiated just once. A joining user learns the key that was used to encrypt video from before they joined. These failures are more formally referred to as failures of post-compromise security and perfect forward secrecy. When a protocol successfully implements these in a group setting, we call the protocol a continuous group key agreement protocol.
Fortunately for us, MLS is a continuous group key agreement protocol that works out of the box, and the nice folks at Phoenix R&D and Cryspen have a well-documented open-source Rust implementation of most of the MLS protocol.
All we needed to do was write an MLS client and compile it to WASM, so we could decrypt video streams in-browser. We’re using WASM since that’s one way of running Rust code in the browser. If you’re running a video conferencing application on a desktop or mobile native environment, there are other MLS implementations in your preferred programming language.
Our setup for encryption is as follows:
Make a web worker for encryption. We wrote a web worker in Rust that accepts a WebRTC video stream, broken into individual frames, and encrypts each frame. This code is quite simple, as it’s just an MLS encryption:
Postprocess outgoing audio/video. We take our normal stream and, using some newer features of the WebRTC API, add a transform step to it. This transform step simply sends the stream to the worker:
Once we do this for both audio and video streams, we’re done.
Handling different codec behaviors
The streams are now encrypted before sending and decrypted before rendering, but the browser doesn’t know this. To the browser, the stream is still an ordinary video or audio stream. This can cause errors to occur in the browser’s depacketizing logic, which expects to see certain bytes in certain places, depending on the codec. This results in some extremely cypherpunk artifacts every dozen seconds or so:
Fortunately, this exact issue was discovered by engineers at Discord, who handily documented it in their DAVE E2EE videocalling protocol. For the VP8 codec, which we use by default, the solution is simple: split off the first 1–10 bytes of each packet, and send them unencrypted:
fn split_vp8_header(frame: &[u8]) -> Option<(&[u8], &[u8])> {
// If this is a keyframe, keep 10 bytes unencrypted. Otherwise, 1 is enough
let is_keyframe = frame[0] >> 7 == 0;
let unencrypted_prefix_size = if is_keyframe { 10 } else { 1 };
frame.split_at_checked(unencrypted_prefix_size)
}
These bytes are not particularly important to encrypt, since they only contain versioning info, whether or not this frame is a keyframe, some constants, and the width and height of the video.
And that’s truly it for the stream encryption part! The only thing remaining is to figure out how we will let new users join a room.
“Join my Orange Meet”
Usually, the only way to join the call is to click a link. And since the protocol is encrypted, a joining user needs to have some cryptographic information in order to decrypt any messages. How do they receive this information, though? There are a few options.
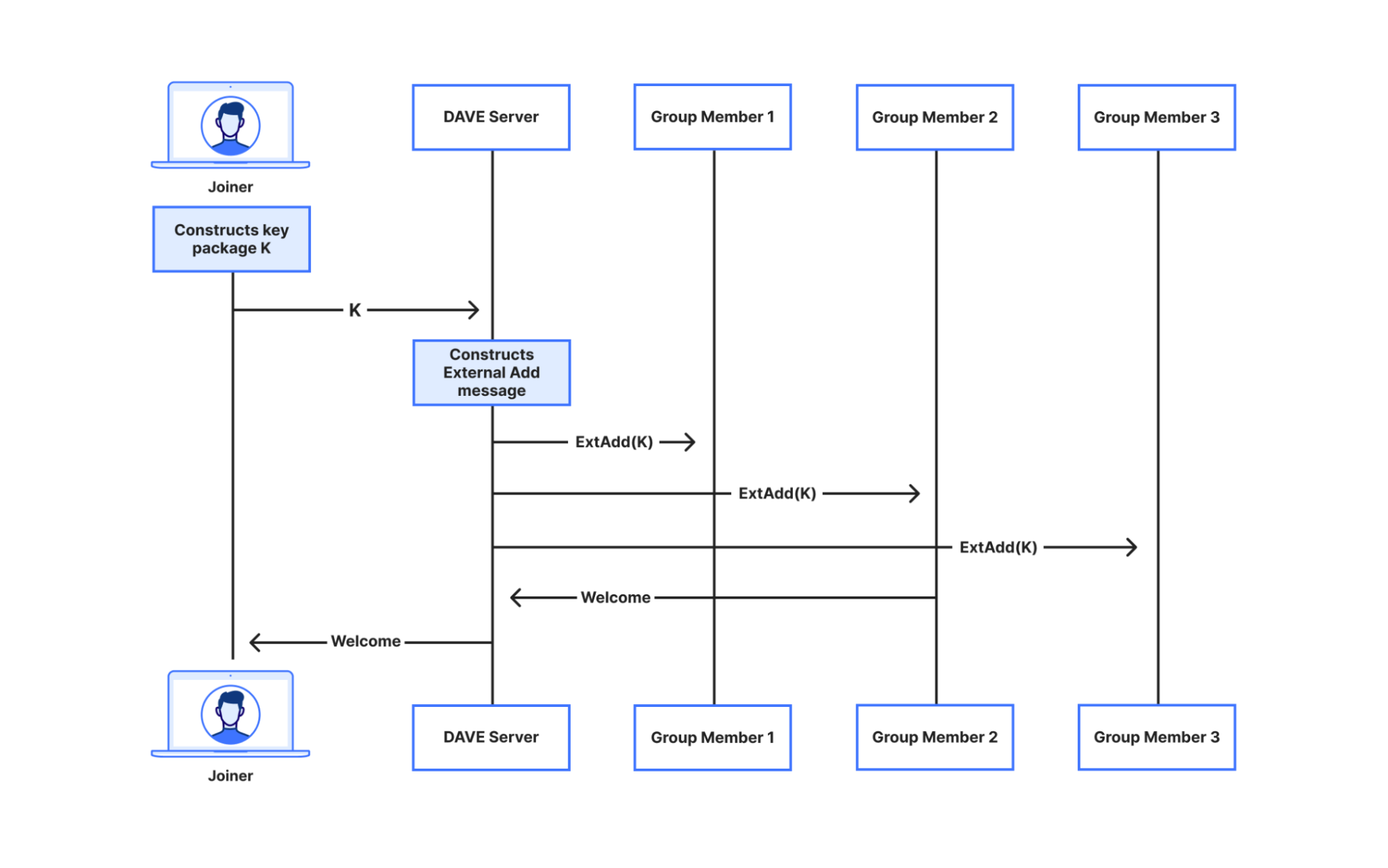
DAVE does it by using an MLS feature called external proposals. In short, the Discord server registers itself as an external sender, i.e., a party that can send administrative messages to the group, but cannot receive any. When a user wants to join a room, they provide their own cryptographic material, called a key package, and the server constructs and sends an MLS External Add message to the group to let them know about the new user joining. Eventually, a group member will commit this External Add, sending the joiner a Welcome message containing all information necessary to send and receive video.
A user joining a group via MLS external proposals. Recall the Orange Meets app server functions as a broadcast channel for the whole group. We consider a group of 3 members. We write member #2 as the one committing to the proposal, but this can be done by any member. Member #2 also sends a Commit message to the other members, but we omit this for space.
This is a perfectly viable way to implement room joining, but implementing it would require us to extend the Orange Meets server logic to have some concept of MLS. Since part of our goal is to keep things as simple as possible, we would like to do all our cryptography client-side.
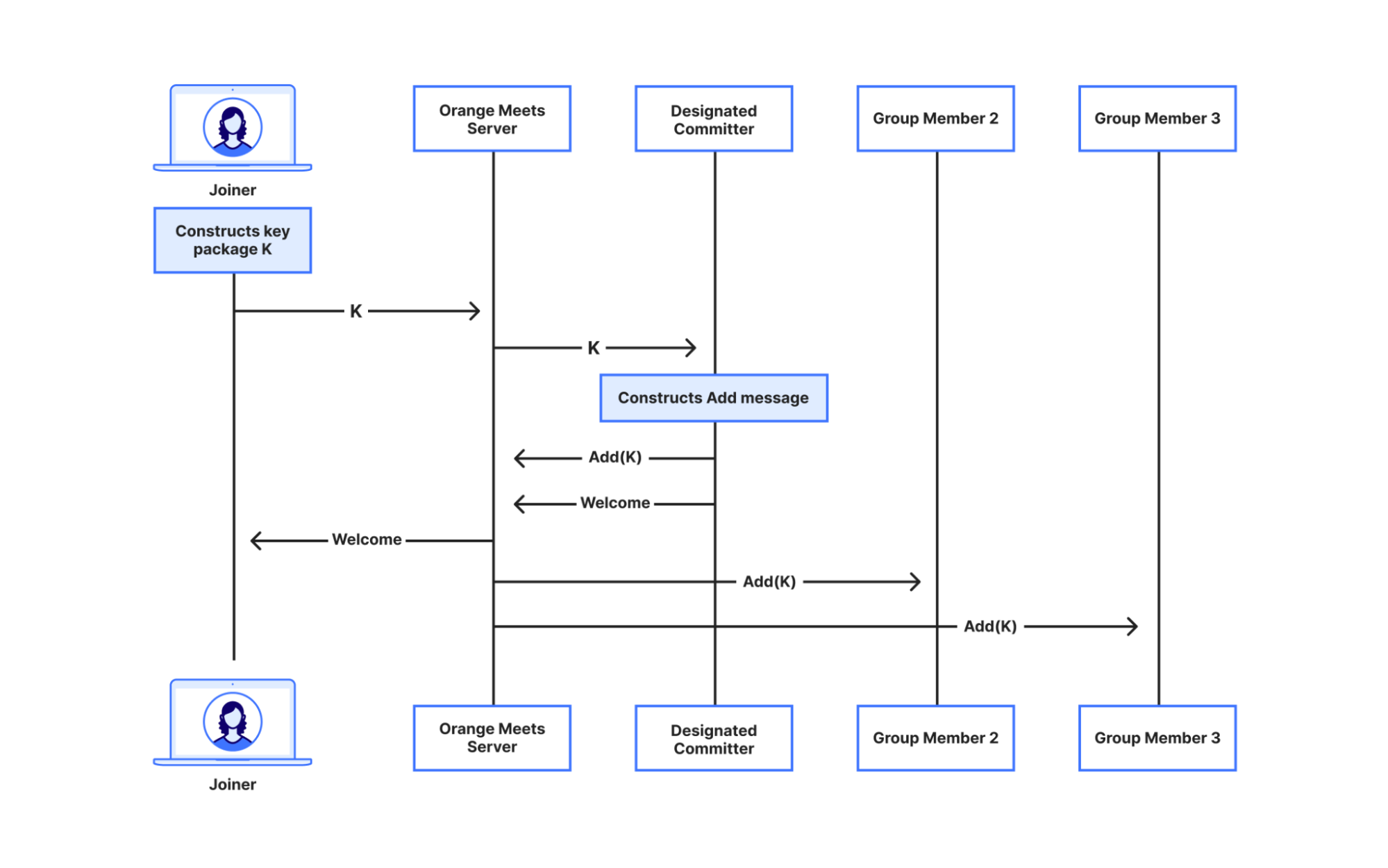
So instead we do what we call the designated committer algorithm. When a user joins a group, they send their cryptographic material to one group member, the designated committer, who then constructs and sends the Add message to the rest of the group. Similarly, when notified of a user’s exit, the designated committer constructs and sends a Remove message to the rest of the group. With this setup, the server’s job remains nothing more than broadcasting messages! It’s quite simple too—the full implementation of the designated committer state machine comes out to 300 lines of Rust, including the MLS boilerplate, and it’s about as efficient.
A user joining a group via the designated committer algorithm.
One cool property of the designated committer algorithm is that something like this isn’t possible in a text group chat setting, since any given user (in particular, the designated committer) may be offline for an arbitrary period of time. Our method works because it leverages the fact that video calls are an inherently synchronous medium.
Verifying the Designated Committer Algorithm with TLA+
The designated committer algorithm is a pretty neat simplification, but it comes with some non-trivial edge cases that we need to make sure we handle, such as:
How do we make sure there is only one designated committer at a time? The designated committer is the alive user with the smallest index in the MLS group state, which all users share.
What happens if the designated committer exits? Then the next user will take its place. Every user keeps track of pending Adds and Removes, so it can continue where the previous designated committer left off.
If a user has not caught up to all messages, could they think they’re the designated committer? No, they have to believe first that all prior eligible designated committers are disconnected.
To make extra sure that this algorithm was correct, we formally modeled it and put it through the TLA+ model checker. To our surprise, it caught some low-level bugs! In particular, it found that, if the designated committer dies while adding a user, the protocol does not recover. We fixed these by breaking up MLS operations and enforcing a strict ordering on messages locally (e.g., a Welcome is always sent before its corresponding Add).
You can find an explainer, lessons learned, and the full PlusCal program (a high-level language that compiles to TLA+) here. The caveat, as with any use of a bounded model checker, is that the checking is, well, bounded. We verified that no invalid protocol states are possible in a group of up to five users. We think this is good evidence that the protocol is correct for an arbitrary number of users. Because there are only two distinct roles in the protocol (designated committer and other group member), any weird behavior ought to be reproducible with two or three users, max.
Preventing Man-in-the-Middle attacks
One important concern to address in any end-to-end encryption setup is how to prevent the service provider from replacing users’ key packages with their own. If the Orange Meets app server did this, and colluded with a malicious SFU to decrypt and re-encrypt video frames on the fly, then the SFU could see all the video sent through the network, and nobody would know.
To resolve this, like DAVE, we include a safety number in the corner of the screen for all calls. This number uniquely represents the cryptographic state of the group. If you check out-of-band (e.g., in a Signal group chat) that everyone agrees on the safety number, then you can be sure nobody’s key material has been secretly replaced.
In fact, you could also read the safety number aloud in the video call itself, but doing this is not provably secure. Reading a safety number aloud is an in-band verification mechanism, i.e., one where a party authenticates a channel within that channel. If a malicious app server colluding with a malicious SFU were able to construct believable video and audio of the user reading the safety number aloud, it could bypass this safety mechanism. So if your threat model includes adversaries that are able to break into a Worker and Cloudflare’s SFU, and simultaneously generate real-time deep-fakes, you should use out-of-band verification 😄.
Future work
There are some areas we could improve on:
There is another attack vector for a malicious app server: it is possible to simply serve users malicious Javascript. This problem, more generally called the Javascript Cryptography Problem, affects any in-browser application where the client wants to hide data from the server. Fortunately, we are working on a standard to address this, called Web Application Manifest Consistency, Integrity, and Transparency. In short, like our Code Verify solution for WhatsApp, this would allow every website to commit to the Javascript it serves, and have a third party create an auditable log of the code. With transparency, malicious Javascript can still be distributed, but at least now there is a log that records the code.
We can make out-of-band authentication easier by placing trust in an identity provider. Using OpenPubkey, it would be possible for a user to get the identity provider to sign their cryptographic material, and then present that. Then all the users would check the signature before using the material. Transparency would also help here to ensure no signatures were made in secret.
Conclusion
We built end-to-end encryption into the Orange Meets video chat app without a lot of engineering time, and by modifying just the client code. To do so, we built a WASM (compiled from Rust) service worker that sets up an MLS group and does stream encryption and decryption, and designed a new joining protocol for groups, called the designated committer algorithm, and formally modeled it in TLA+. We made comments for all kinds of optimizations that are left to do, so please send us a PR if you’re so inclined!
Програмата „Вояджър“ е най-продължителната мисия на NASA. Далечните сонди все още изпращат информация и ни вълнуват с премеждията си в дълбокия Космос. Макар и да е впечатляващо колко добре се държат двата апарата предвид възрастта си, за съжаление, с напредване на времето състоянието им се влошава и все по-често се налагат намеси от екипа инженери, който работи с тях. В последните няколко месеца към пътешествениците бяха изпратени редица команди, за да осигурят още интригуващи новини.
Апаратите се захранват от специални модули, които превръщат в електрическа енергия топлината, отделена при разпада на радиоактивни елементи (в случая плутоний). Въпреки че мощността им не е особено голяма, те са предпочитани за подобен тип мисии, тъй като са надеждни поради сравнително простата си конструкция. Годишно източникът губи около 4 вата, което не е пречка за основната им мисия, приключваща в края на 1989 г. Но удължаването ѝ налага постепенно изключване на различни научни инструменти поради намаляването на енергийните ресурси – миналата година това стана с уреда, измерващ количеството и посоката на заредени частици (плазма) на „Вояджър 2“.
В началото на март бяха изключени още два инструмента – измерващият космически лъчи на „Вояджър 1“ и засичащият заредени частици с ниска енергия на „Вояджър 2“. И двата са поставени на платформи, които се въртят, така че да осигуряват пълно измервателно поле. Задвижващите ги мотори са изпитани да издържат 500 000 стъпки – достатъчно, за да осигурят нормална работа на инструментите до прелитането на „Вояджър 2“ покрай Сатурн през август 1980 г. Към момента на изключването си те вече са направили над 8,5 млн. стъпки – 17 пъти повече от предвиденото.
Тъй като данните, които събират апаратите, са уникални, екипът на NASA се опитва да отложи изключването на научните инструменти, но за съжаление, това е неизбежно. През идната година всеки от двата апарата ще загуби по още един инструмент, което би трябвало да им даде възможност да функционират с поне по един аналитичен уред и след 2030 г.
Моменти от изграждането на апаратите „Вояджър“. Снимки: NASA
От дълбокия Космос пристигат и добри новини. Сондите са оборудвани с няколко набора двигатели, които променят ориентацията им в пространството. Освен за изпълняване на преките задачи на апаратите това е важно и за точното им позициониране и комуникация със Земята. Два от наборите двигатели позволяват завъртането им, така че сондите да могат да държат навигационните си инструменти насочени към конкретно избрани звезди. Поради проблем с нагревателните им елементи основните двигатели на „Вояджър 1“ спират да работят през 2004 г., но специалистите не го отчитат като особен проблем, защото резервните функционират нормално и навигационните маневри могат да се поверят на тях.
Това от своя страна води до други проблеми, които тогава може би са преценени като прекалено далечни. С времето по тръбите, провеждащи гориво до двигателите, се натрупват остатъци, които стесняват диаметъра им и могат да доведат до пълно запушване. За забавяне на процеса екипът на NASA започва да използва и другите двигатели на апарата – те нямат възможност за завъртане на апарата около оста му, но поне могат да правят малките корекции, нужни за насочване на антената към Земята. С едно от последните обновявания на софтуера беше разредено и времето между включването на двигателите.
Все пак рискът „Вояджър 1“ да остане без завъртането си кара инженерите да направят нов анализ на проблема с нагревателите на основния двигател. Оказва се, че най-вероятно ситуацията е тривиална – някой от ключовете, които контролират захранването на двигателите, е в грешна позиция.
Но проверяването на хипотезата не е толкова лесно. За целта двигателите трябва да бъдат активирани, след което да започне работата по проучване и евентуално по възстановяване на нагревателите. Това крие известен риск – ако сондата се отклони значително, автоматичната система за навигация ще включи двигателите, което би довело до малка експлозия, в случай че нагревателите не функционират. Ситуацията се усложнява и заради планов ремонт на голямата антена в Австралия, с помощта на която се осъществява комуникацията с апарата. Тя почти няма да работи до май 2026 г. Поради това инженерите искат основните двигатели да са активни за краткия прозорец през август, когато ще получат данни от „Вояджър 1“ и ще могат да изпратят нови инструкции до апарата.
Така в края на март специалистите активират основния двигател и изпращат командите, които би трябвало да включат нагревателите. Два дни по-късно (сондата е на почти един светлинен ден от Земята) получават телеметрични данни, които показват повишаване на температурата в нагревателите.
Това е поредният случай на почти невероятно спасяване на някоя от системите на дълголетните апарати и показва изключителното ниво на инженерите, които са ги проектирали навремето, както и на тези, които работят с тях в момента. Може да се надяваме, че въпреки зачестяващите премеждия двете сонди ще продължат да носят вести от дълбокия Космос. Към момента се предполага, че радиоактивната батерия на „Вояджър 1“ ще издържи още около 10 години, но ако съдим по досегашния си опит с „Вояджър“, е много вероятно да ни очакват изненади.
Футуристични влакна
Паяжините са впечатляващи творения, които освен насекоми пленяват и нашето въображение със своята изящност. Те са продукт на сложен биологичен процес, започващ със синтеза на специализирани протеини в жлезите на паяците. От тези протеини после се предат влакна със специфични свойства – здрави и еластични за основата на мрежата; леки – използвани за парашут; и лепкави – за улавяне на плячка. Поради изключителната си якост, по-висока от тази на стоманата, някои от нишките имат огромен потенциал за приложение в редица индустрии. Плат, изработен от тях, би могъл да бъде използван за най-различни бронезащитни изделия; въжета, изплетени от тях, ще са по-леки и по-здрави от стоманените. Медицината също е поле, което би имало полза от подобен материал – от нишките може да се направят конци, сухожилия или специални марли и бинтове.
Пречка за разгръщане на този потенциал е липсата на масово производство на паяжина. Паяците са изключително трудни за отглеждане, а събраната паяжина е в малки количества. За справяне с това през годините са предлагани различни решения, като може би най-куриозното беше генетично модифицирани кози, които експресират в млякото си протеините, изграждащи паяжините. Тъй като отделянето на протеините е сложен процес, а и обществената реакция беше доста критична, този подход не се наложи. Интересен вариант е представен в публикация от 2023 г. – създаване на копринени буби, които отделят чисти паяжинови нишки, готови за употреба.
Изненадващото е, че доскоро нямаше разработена процедура за генетична манипулация на паяци. Най-вероятно това се дължи на по-трудното им отглеждане и манипулиране. Наскоро германски учени публикуваха статия за първите генно редактирани паяци. Подходът, на който са се спрели, е инжектирането на конструкта, носещ CRISPR/Cas9, в хемолимфата на неоплодени женски паяци. По този начин той се разпространява в тялото им, достига ооцитите (развиващите се женски полови клетки) и редактира техния геном. След чифтосване с мъжки паяк част от потомството на женската би трябвало да носи редактираните гени.
За да изпита работата на системата, екипът първо се спира на по-лесната модификация – нарушаване на функционирането на добре известен ген. Избран е sine oculis – ген, регулиращ развитието на очите на паяците, тъй като загубата му не е летална за животните, а полученият фенотип (промяната във външния вид) е лесно забележима. След извършване на процедурата в потомството на редактираните майки се наблюдават различни степени на проблеми с развитието на очите – от грешна форма до пълната им липса. С това учените доказват, че sine oculis наистина е регулатор на генната каскада, отговорна за формирането на очите. Интересното е, че при всички редактирани паяци лещата на очите присъства, което означава, че тя е под контрола на друг регулаторен ген. Промените показват също, че системата за редакция работи и може да се приложи и за други намеси в генома на паяците. След като доказват това, учените започват по-вълнуващата част от работата си – вмъкването на нов ген.
Паяк от вида Parasteatoda tepidariorum (обикновен домашен паяк), който е във фокуса на изследването и произвежда флуоресцираща червена светлина нишка, след като е бил генно редактиран с CRISPR-Cas9. Изображение: University of Bayreuth
Съставът на нишката, която служи за изграждане на опорните и радиалните нишки на паяжината, е добре проучен. Главните компоненти са два протеина – единият с високо, а другият с ниско съдържание на аминокиселината пролин, като първият придава еластичност, а вторият – здравина. И двата протеина в краищата си имат участъци, които нямат участие във функцията на нишките, а служат за определяне на тяхната структура по време на съхранението и изплитането им. Именно там е подходящо да се вмъкне парче ДНК, което не нарушава тази функция, но добавя белтъчна структура, способна да флуоресцира в червен цвят.
След третиране на женските паяци и получаване на потомство учените виждат, че експериментът им е успешен – нишките, които изплитат паяците, са белязани с добавеното багрило. При дисекция на паяците флуоресценцията се наблюдава и в самите жлези, отговорни за произвеждането на този тип нишки. Още повече, редакцията е стабилна и присъства и в потомството на модифицираните паяци, което също носи червения протеин.
Положителните резултати означават, че вече има ясен протокол за генетични редакции на паяци, което отваря възможности както за фундаментални, така и за по-практично насочени проучвания. Например промяната на свойствата на паяжината може да бъде основа за нови материали или технологии. Въпреки че звучи леко фантастично, сходно приложение е вмъкването на багрила в нишките на копринените буби, за да се премахне нуждата от допълнително оцветяване на платовете, което често се прави с токсични химикали и голямо количество вода. Стъпка към това е проект, започнал в началото на месеца. Целта е да се създаде термостабилен син хромопротеин, базиран на хромопротеина от корала обикновена актиния, който може да се използва за багрене на тъкани.
Тайните на аксолотлите
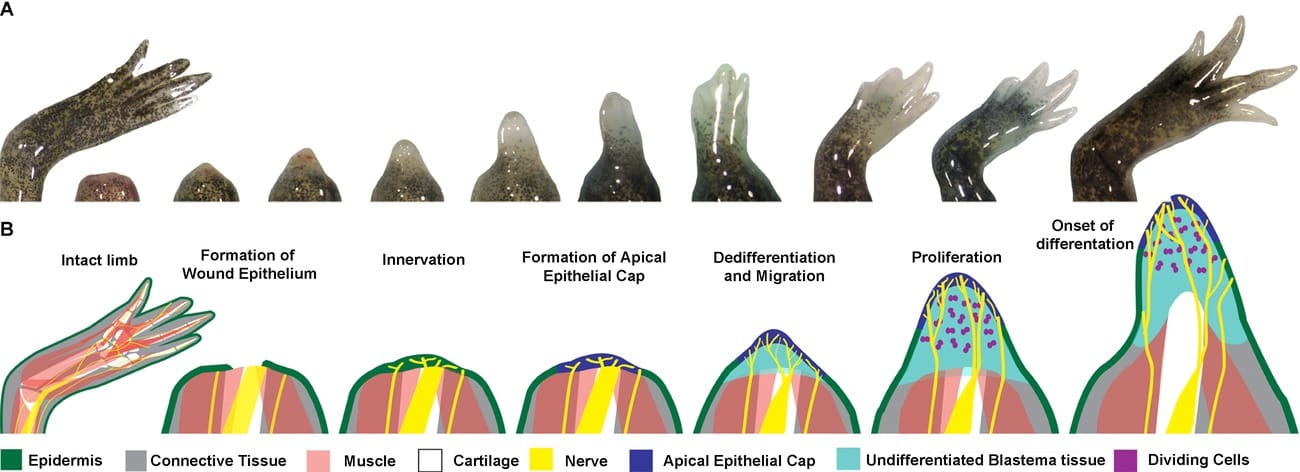
Способността на саламандъра аксолотъл за възстановяване на наранени органи е впечатляваща – симпатичните животни могат да регенерират сложни части от тялото си, например опашка и крайници. За процеса вече се знае много – първо се образува т.нар. бластема от дедиференцирани клетки (клетки, които се връщат към състояние на стволови и могат да се развият като всеки вид тъкан). След това от бластемата се формира „пъпка“, от която започва да израства крайникът, като за това е важно участъкът да има запазена нервна тъкан. А за координацията на тези стъпки отговаря молекула, производна на витамин А (ретиноева киселина).
Но как бластемата „разбира“ точно коя част от крайника трябва да пресъздаде? На този въпрос отговаря ново изследване, публикувано в журнала Nature Communications.
Текущата хипотеза е, че в различните участъци на крайниците се произвеждат различни количества ретиноева киселина, което насочва клетките на бластемата към това коя част от крайника липсва. Оказва се, че предположението е донякъде вярно – концентрацията на киселината наистина определя развитието на конкретни части, но това става не чрез промени в синтезираното количество, а с разграждането ѝ в различна степен.
Клетките в крайната част на регенерирания орган (например китката) произвеждат много голямо количество от ензим (CYP26B1), който има способността да разгражда ретиноевата киселина. Обратно – в раменния пояс ензимът почти не се произвежда. Така чрез разрушаването на киселината се създава градиент на концентрацията ѝ от рамото към китката, който помага на стволовите клетки да „се ориентират“ в пространството.
Изображение, показващо развитието на бластемата на аксолотъл в крайник. Публикувано е в изследване от 2015 г. Източник: Wiley Online Library
За да потвърдят откритието си, учените провеждат прост експеримент. След ампутация на крайника на саламандъра при китката, участъкът се третира с медикамента таларозол, който има свойството да нарушава работата на ензима CYP26B1. Така ретиноевата киселина не се разгражда и може да се натрупа в големи количества. И наистина, животните регенерират от китката си цял крайник, сякаш са го загубили от рамото си. Това ясно доказва, че действието на ензима и количеството ретиноева киселина ръководят процеса на възстановяване.
Опитвайки се да вникнат по-дълбоко в молекулярните механизми на регулация на процеса, учените разглеждат нивата на експресия на различни гени в крайника на земноводните и установяват, че с покачване на нивата на ретиноева киселина се повишава и активността на гена SHOX (short-stature homeobox gene). Той се среща и при човека и също отговаря за регулацията на крайниците, като при нарушения на функцията му се уврежда развитието им. Това се наблюдава и при аксолотли, в които генът е изключен с помощта на CRISPR. „Дланите“ се развива нормално, но горната част на крайника е скъсена. Интересното е, че присъствието на гена не е нужно за изграждането на нов крайник.
Откритието е важна стъпка към разплитането на мистерията как протича и как се регулира процесът на регенерация, въпреки че остават много отворени въпроси. Например от това изследване не става ясно какъв е механизмът за засичане на по-ниска концентрация на ретиноева киселина – SHOX се експресира предимно в основата на крайниците.
Към момента основната спънка пред регенерацията на органи при хора е създаването на бластема. Но ако учените успеят да открият начин да го направят възможно, познаването на процесите, които протичат след това, ще бъде безценно. Ето защо всеки пробив в опознаването на сигналните пътища, които ги регулират, е окуражаващ.
България разбуни духовете в Комисията за външни отношения на Европейския парламент на 4 юни и стана причина за отлагането на гласуването на проектодоклада за напредъка на Северна Македония. Български евродепутати и австрийският докладчик Томас Вайц си размениха гневни погледи и нападателни реплики, докато парламентаристи от различни политически групи изразиха възмущението си от целенасочената (българска) кампания срещу Вайц. Докладът все пак беше гласуван 3 седмици по-късно, но българските предложения (засега) отпаднаха от текста.
Как се изготвят докладите за страните кандидатки за членство в ЕС и какво точно причини бурята между София и Скопие в Брюксел?
Ежегодните доклади на Европейския парламент за напредъка на страните кандидатки за членство в ЕС са политически оценки, които евродепутатите изготвят въз основа на докладите на Европейската комисия. В тях се коментират теми като състоянието на демокрацията и институциите, съдебната система и борбата с корупцията, икономическите и социалните реформи, правата на малцинствата и отношенията със съседните държави. Въпреки че докладите на Парламента не са правно обвързващи, те дават политически сигнал на Европейската комисия и Съвета, както и на самата страна кандидат дали и как ще продължи процесът на присъединяване.
За да бъде подготвен въпросният доклад, един евродепутат се посочва за докладчик за дадената страна кандидатка, а всяка политическа група избира докладчици в сянка, чиято задача е да участват в обсъжданията на бъдещия текст и да преговарят за постигането на добър компромис. Идеята е да има представители на всички политически групи в обсъждането, за да може да се стигне до максимално широк консенсус. След като тези преговори приключат, всички депутати могат все още да предлагат текстови изменения, които после се гласуват едно по едно веднъж в парламентарната комисия и втори път в пленарната зала.
Финалната версия на текста, одобрена от мнозинството евродепутати, става официална позиция на Европарламента. Целият процес продължава няколко месеца и е съставен от многобройни закрити работни срещи, посещения в страната кандидатка, обсъждания и дискусии с главна цел да се постигне съгласие, което да обедини най-голямо мнозинство. Ако работата е добре свършена от всички засегнати страни, голяма част от конфликтните въпроси се разрешават още преди текстът да бъде подложен на гласуване или в най-лошия случай по време на самото гласуване чрез предложения за компромисни изменения, които вече са предоговорени и подкрепени от мнозинството евродепутати.
Как се разигра този иначе доста консенсусен сценарий в случая с доклада за напредъка на Северна Македония и кога гърнето се счупи?
Томас Вайц – австрийски евродепутат от Групата на Зелените/Европейски свободен алианс, е посочен за докладчик за Северна Македония през ноември 2024 г. Това е третият му мандат като евродепутат. В настоящия Парламент той е председател на делегацията в Парламентарния комитет по стабилизиране и асоцииране ЕС – Черна гора, а по време на предишните мандати е бил член на същите делегации за ЕС – Албания и ЕС – Босна и Херцеговина и Косово. Именно познанията и опитът му с различни балкански държави са фактор да бъде посочен за докладчик за Северна Македония.
Докладът му от 7 страници беше определен като балансиран и конструктивен от повечето евродепутати при първото обсъждане на текста в Комисията за външни отношения на 18 март 2025 г. България се споменава само два пъти: във връзка с Договора за приятелство, добросъседство и сътрудничество и в контекста на т.нар. френско предложение, според което Северна Македония трябва да впише българите в преамбюла на конституцията си. След първото изслушване евродепутатите имаха срок от 10 дни да внесат предложения за изменения на текста. Докладът получи огромния брой 313 предложения за промени, сред които почти една трета са на български евродепутати. Българските предложения засягат необходимостта от конституционни промени, спазването на вече договорените ангажименти от страна на Северна Македония и случаите на дискриминация и насилие срещу българи и български организации. Фактът, че тези най-важни за България теми са засегнати едва в предложенията за изменения, а не в първоначалния текст на доклада, сам по себе си е тревожен сигнал. Каква е ролята на българските евродепутати в този процес?
Българските докладчици в сянка
За да бъдат докладчици в сянка и да участват в изготвянето на доклада, евродепутатите трябва да бъдат членове или зам.-членове на съответната парламентарна комисия. В случая това е Комисията за външни отношения и в нея членуват петима български евродепутати: Андрей Ковачев (ГЕРБ, ЕНП), Станислав Стоянов („Възраждане“, ЕСН), Илхан Кючюк (ДПС, „Обнови Европа“), Ивайло Вълчев (ИТН, ЕКР) и Петър Волгин („Възраждане“, ЕСН). За доклада за Северна Македония и Вълчев, и Стоянов са докладчици в сянка. Тоест те са били поканени на всички вътрешни работни срещи на докладчиците. Това е първото място, на което могат да изразят българската позиция и да преговарят за българските национални интереси. Останалите български евродепутати също имат възможност да го направят чрез срещи със съответния докладчик в сянка от своята политическа група, който ще участва в преговорите. Така може да се даде гласност на единна българска позиция, която да отекне на всички нива.
Такава единна българска позиция отекна, но предизвиквайки скандал, когато всички 17 български евродепутати изпратиха писмо, уличаващо докладчика Вайц в изтичане на информация и липса на безпристрастност.
Тези подозрения се появиха, след като македонският премиер Християн Мицкоски направи медийни изказвания, от които се разбра, че той познава съдържанието на някои предложения за изменения, преди да са станали публични. Въпросните проблемни изменения, внесени от докладчика Вайц и от други депутати от Европейската народна партия и от Групата на Социалистите и демократите, включват „признаване и зачитане на македонския език и идентичност“. За да добави сол в раната, премиерът Християн Мицкоски каза, че по този начин Европа признава „вековната“ македонска идентичност и македонски език – прилагателно, което не присъства нито в доклада, нито в измененията.
Минавайки в контраатака, българските евродепутати поискаха да внесат ново изменение за „съвременната“ македонска идентичност и език, но крайният срок за поправки вече беше изтекъл. Междувременно на 30 май българският парламент единодушно прие като извънредна точка в дневния си ред по искане на ИТН решение за напредъка на Северна Македония в процеса на присъединяване към ЕС, в което се подчертава, че:
България остава напълно ангажирана с европейския консенсус от юли 2022 г. и призовава властите в Република Северна Македония (РСМ) също да изпълняват стриктно поетите от тях договорености.
Решението беше наложено от лошото предчувствие, че македонската страна ще се опита да заобиколи поетите по-рано ангажименти към България и да наложи своята гледна точка на европейската сцена.
След изпратеното от българските евродепутати писмо, в което се съобщава за нередности по изготвянето на доклада, и сигналите, подадени към председателя на Европарламента Роберта Мецола, гласуването на доклада в Комисията за външни отношения беше отложено за 24 юни, а в пленарната зала – за юли.
От българска страна обвиниха докладчика, че поддържа прекалено близки отношения с властите в държавата, която оценява, и че изпълнява нейните инструкции. Вайц пък се оплака, че телефонният му номер е бил публикуван в социалните мрежи в профилите на български крайнодесни групи и е получил множество заплахи и закани.
В публичния регистър на Европарламента Вайц, както и докладчиците в сянка са длъжни да регистрират всички външни срещи, свързани с доклада. От списъка се вижда, че Вайц се е срещал с много македонски институции и организации, както и с изследователи от Съвместната комисия за България и Северна Македония и с дипломати от Постоянното представителство на България към ЕС. Българските докладчици в сянка, от друга страна, нямат нито една регистрирана среща. В отговор на коментара на Вайц по този въпрос Вълчев каза, че няма какво да регистрира, защото той не провежда срещи с лобисти. Срещите на Вайц с представители на македонската страна не нарушават правилника на Европейския парламент, тъй като са част от работата му по доклада за Северна Македония. Лобизмът присъства в работната среда в Европейския парламент и срещите с държавни представители и организации, записани в Регистъра за прозрачност на европейските институции, са част от ежедневието на евродепутатите.
Въпросът, който можем да си зададем, ако допуснем, че докладчикът наистина е бил едностранно повлиян от македонските си партньори, е
как една страна кандидатка успява да бъде по-видима, влиятелна и гласовита от страна членка като България, която разполага с много повече механизми за влияние, участие и защита на гледната си точка само поради простия факт, че вече членува в Европейския съюз?
Положени ли са били необходимите усилия от страна на българските евродепутати и българските организации в България и в Северна Македония, така че тяхната гледна точка също да бъде чута, обяснена, разбрана и застъпена? Не бихме ли постигнали по-добри резултати, ако вместо нападателна и негативна кампания в последния момент, каквато изглеждаше българската реакция в европейското (и македонското) публично пространство, бяхме провели навременна, градивна и обяснителна комуникационна кампания, с която да защитим позициите си на европейската сцена?
Това може да бъде направено по много и различни начини в Европейския парламент – чрез активно участие в работните срещи на докладчиците в сянка и лобиране във всяка политическа група, но също и чрез организиране на конференции, публични дискусии и културни събития, чрез неформални срещи и търсене на пресечни точки и общи интереси по въпроса с други държави… Важно е и как се представят проблемите спрямо публиката, на която се говори. Както подчертава журналистът Бойко Василев в лекцията си „София, Скопие и Брюксел в лодката, като не се забравя и Белград“ в Македонския научен институт в София на 12 юни, различните европейски публики са склонни да разбират различни наративи.
Според Василев германците разбират разкази за нарушени човешки права, докато французите и испанците разбират разкази за история. По принцип историческите теми невинаги са добре посрещнати в европейски контекст заради разминаванията в интерпретациите, за разлика от проблемите с човешките права и правата на малцинствата, които се вземат под внимание и получават необходимото сериозно отношение. С други думи, ако историческата призма на отношенията между България и Северна Македония е трудна за предаване в политически контекст, то темата за правата на българите в Северна Македония днес е подходяща и съвсем европейска тема, която би могла да спечели подкрепата на различни евродепутати и политически групи, ако се представи по подходящ начин. Да адаптираш разказа си спрямо публиката и контекста, в който го представяш, е от ключово значение, за да бъдеш чут и разбран. Това са усилия, които се полагат в дългосрочен план и изискват координация, инвестиции и визия за бъдещето.
Заслужава да се отбележи, че българските евродепутати в Брюксел, както и народните представители в София успяха да застанат единодушно зад позицията си по отношение на Северна Македония, което рядко се случва по който и да било друг въпрос.
Остава сега и да намерят подходящия тон и подобаващия начин своевременно да изразят позициите си на европейско ниво. Един от тези начини е да се спечели навреме подкрепата на големите политически групи. Именно този далеч по-удачен подход беше приложен на 24 юни при повторното гласуване на доклада в Комисията за външни отношения. В началото на събранието групите на Европейската народна партия, Социалистите и демократите, „Обнови Европа“ и Зелените предложиха устна поправка, предвиждаща преди думите „македонски език и идентичност“ да се добави „съвременен“. Това по същество е българска поправка, съвпадаща с българските национални интереси, но координирана предварително с останалите евродепутати, така че да събере максимално широка подкрепа и да бъде внесена не на национално или индивидуално, а на политическо ниво. Такава подготовка очевидно липсваше в месеците, през които докладът се е изготвял.
Въпреки правилния подход, приложен в последния момент, въпросната устна поправка в крайна сметка не беше подложена на гласуване, тъй като шестима евродепутати от Групата на „Патриоти за Европа“ (половината от които от унгарската партия на Виктор Орбан) се обявиха против внасянето ѝ. Това не е първият опит на Унгария да се намеси в отношенията между България и Северна Македония, за да засили позициите на националистическото правителство в Скопие, в чието лице вижда свой верен съюзник.
Изходът не е фатален, тъй като докладът отново ще бъде гласуван в пленарната зала и тогава поправката ще бъде внесена писмено и вероятно приета, тъй като четирите политически групи, които я внесоха днес, ще разполагат с мнозинство. Освен ако Северна Македония не измисли друг неочакван ход, който отново да завари София неподготвена като след първи паднал сняг – всяка зима знаем, че ще дойде, и все сме изненадани!
Изразеното мнение е лично и не представлява позицията на Европейския парламент.
Reuters is reporting that the White House has banned WhatsApp on all employee devices:
The notice said the “Office of Cybersecurity has deemed WhatsApp a high risk to users due to the lack of transparency in how it protects user data, absence of stored data encryption, and potential security risks involved with its use.”
В сърцето ми има стихотворение,в главата ми има бомби, в енергоспестяващ режим съм, изпитвам тежък криндж, гледам театър в кавички, в очите на актрисата има почуда, когато ме вижда в публиката на поклона.
Лежа в хотелска стая в Шумен след расистко представление, което ми проби дупка в стомаха. В „Захарна фабрика“ бутат ромски квартали, в Хасково правят расистки спектакли, в Украйна и Газа убиват цивилни.
Две баби седят в кафенето до театъра, събота е. Люта тъмница е, да те обеси някой, няма да те видят – говори за вечерите в Шумен едната. То стана модерно да вдигаш кръвно – казва другата.
В очите ми има стихотворение, в ушите ми има картечници, под ръцете ми има клавиатура.
училището в руини половината клас е умрял 15 септември в Газа
бащата и синът оставят карамфили на майката 8 март в Украйна
Аз съм, общо взето, добре, мога да умра… Не, няма нищо конкретно, просто имам такова усещане – казва ми един приятел. Защитните ми механизми ги няма. Трябва да се импрегнирам наново – казва ми една приятелка.
Сядам на пейка в Братислава, изведнъж се оказва, че два часа съм чел новини и информация за Газа и палестинците, за да пиша коментари във Фейсбук. Влизам в списък с врагове антисемити, Слагам си ангелски криле от празни блистери от лекарства на словашка изложба.
Нормалността на човечеството ме плаши.
В сърцето ми има стихотворение, в белите ми дробове има изтребители, във фонтана пред Карлскирхе във Виена има съп с момче и момиче, момчето е сложило на ръцете си детски плавници, момичето потапя във водата гребло, в разговора ни има смях без бомби, в раницата ми има тефтер, в който съм написал:
в цялата писана история на човечеството за около 3400 години периодите на пълен мир са не повече от 268 години 8 процента мир 92 процента война това е човечеството 8 процента мир 92 процента война това е човекът Украйна Русия Израел Ивицата Газа всички човешки същества са равни и тези управлявани от силни лидери и тези управлявани от диктатори и тези управлявани от ислямофоби расисти и тези управлявани от терористи човечеството е човек 8 процента мир 92 процента война Джон Ленън пее за свят без войни и светът отговаря с войни Боб Марли пее за свят с равни човешки права независимо от расата и един сатрап в бункер казва че няма украински народ и решава да го заличи и едно правителство се държи сякаш всички палестинци в Газа са терористи и светът отговаря че човекът сам решава кой е човек и кой не е човек 8 процента мир 92 процента война
В трахеите ми има стихотворение, в гърлото ми има мини, в ръката на възрастната жена в театралната зала в Смолян има оранжева неразцъфнала роза, жената ми връчва розата, аз ѝ разписвам книгата, търся си думите, с думите е като с такситата – винаги са там, когато не ти трябват, аз подарявам розата на Б. На сутринта жълтата роза е разцъфнала като слънце в хотелската стая, Б. разправя как вчера жената отишла до нея и ѝ казала, че по-късно ще ѝ подаря роза, и наистина съм ѝ подарил роза, и отивам на репетиции в театъра на спектакъл по поезията на Борис Христов, БОМ, БОМ, БОМ, думкат актьорите с палки по варели, БИ, БИ, БИ, отговаря съзнанието ми, БОМ, БОМ, БИ, БИ, БОМ, БОМ, БОМ, БОМ, усъвършенстват ритъма актьорите. БИ, БИ, БИ, БИ, отговаря умът ми.
В съзнанието ми има бомби, в корема ми има стихотворение. Завалява. Б. се стряска толкова силно от две от гръмотевиците, че буквално подскача, БОМ, БОМ, трещи небето, БУМ, БУМ, отговаря съзнанието ми,
от месеци някаква част от мен винаги е в Газа, от месеци някаква част от мен винаги е в Украйна.
В гръбначния ми стълб има стихотворение, в корема ми има бомби, в месеца ми имаше четири града. Шумен, Братислава, Виена, Смолян. Тъкмо се отпускам в един, втори, трети, четвърти град. Тъкмо се разпилявам на един, втори, трети, четвърти площад. Тъкмо потъвам в един, втори, трети, четвърти парк. Тъкмо се вдълбавам в една, втора, трета, четвърта галерия. Тъкмо си казвам, в сърцето ми има стихотворение, така че ще напиша стихотворение. Тъкмо си казвам, в главата ми има бомба, но сега ще заглуша бомбата. Ще заглуша бомбата, за да напиша стихотворение.
БОМ, БОМ, трещи небето, БУМ, БУМ, отговаря съзнанието ми. После, мокри, се прибираме в хотелската стая в Смолян, Б. заспива над дисертация, аз нахвърлям бележки за стихотворение.
Не питай кога е време да се пречистим времето е сега Не питай кога е време да се смирим времето е сега Не питай кога е време времето е сега Не питай време Не сега
Всичко зависи от нас Всичко зависи от нас Всичко зави
Б. спи изгрява слънце аз пиша слънцето залязва Бум Бум
Шшшт. Тихо. Стихотворението неуверено подава главичка от съзнанието ми и плашливо пристъпва по аортата ми.
И БУМ в главата ми го на-БУМ обратно в сърцето.
Иван Димитров
Иван Димитров е автор на седем книги с проза, драматургия и поезия. Носител е на няколко награди за произведенията си – „София: Поетики“ (2013), наградата „Яна Язова“ за разказ и наградата „Чудомир“ за хумористичен разказ. През 2012 г. пиесата му „Очите на другите“ e селектирана на фестивала HotInk at the LARK в Ню Йорк и през същата година е поставена в New Ohio Theatre. Последната му книга е сборникът „Разкази от пандемията, или как се сприятелих с един комар“. Негови произведения са превеждани на английски, френски, унгарски, сръбски, румънски, руски, македонски и гръцки. В интернет може да бъде открит тук.
Стихотворението „8 процента“ е написано специално за рубриката „Стихотворение на месеца“ на „Тоест“.
Според Екатерина Йосифова „четящият стихотворение сутрин… добре понася другите часове“ от деня. Убедени, че поезията държи умовете ни будни, а сърцата – отворени, в края на всеки месец ви предлагаме по едно стихотворение. Защото и в най-смутни времена доброто стихотворение е добра новина.
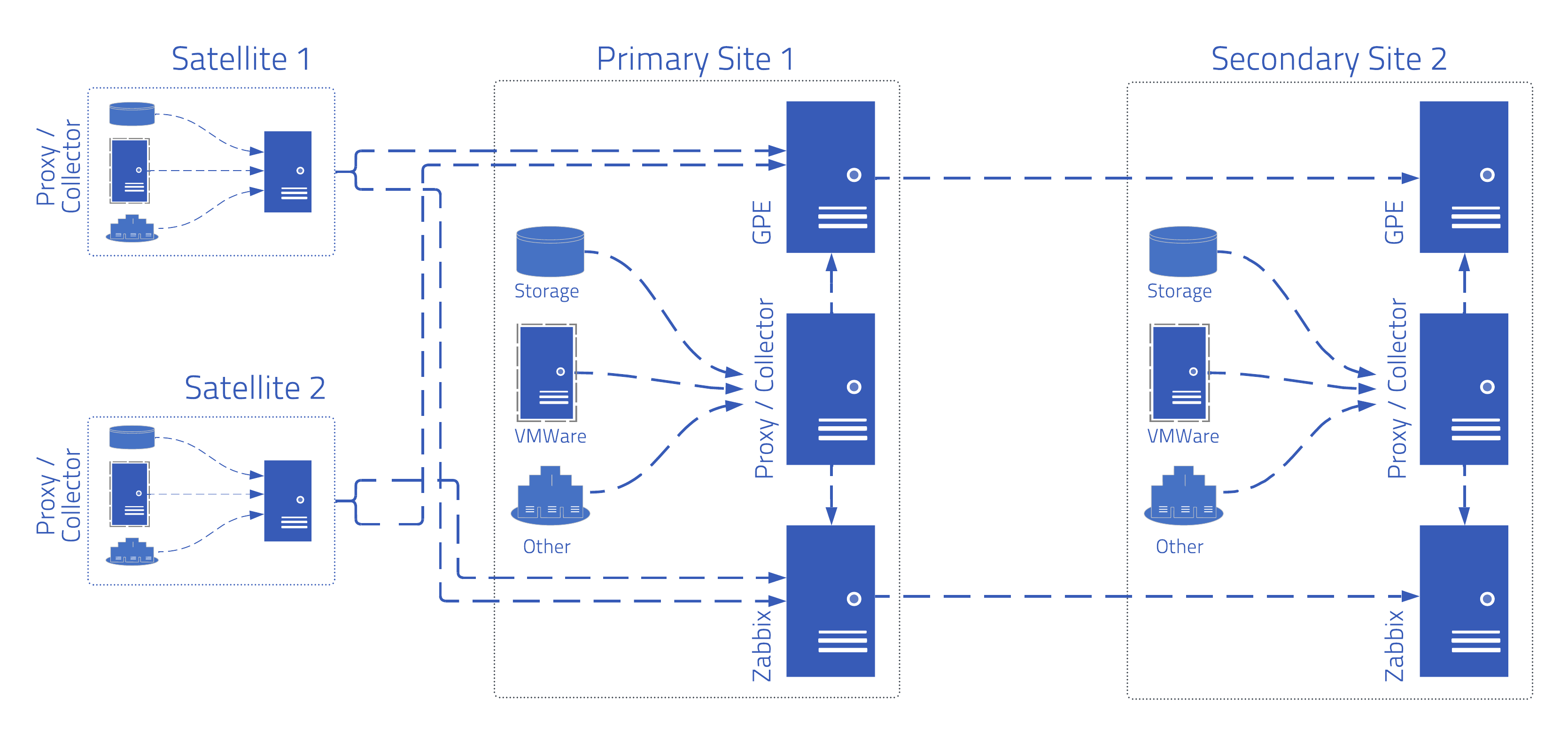
Our Premium Partners at the ATS Group work with a large federal government agency in the United States. They primarily provide storage and compute-as-a-service for the agency, which relies on them to stay up and running at all times.
The challenge
The agency’s primary goal was to simplify their capacity and performance monitoring without extra costs. They had very strict regulatory and SLO oversight requirements that had to be met, especially when it came to capacity and performance.
There was no commercially available software that could accomplish everything they needed directly out of the box, but they still required a solution that was powerful and flexible enough to monitor almost anything.
The solution
Because the agency has several different data centers of different sizes, they use a distributed proxy set up, intense SLA reporting, a ServiceNow integration, a variety of internal integrations, and a monitoring solution provided by Zabbix that includes a predictive alerting setup.
The agency has plenty of software in the mix, but it primarily relies on storage, VMWare, and Kubernetes. They also have multiple satellite offices and data centers, so that in the event of a data center failure, another can come online with minimal downtime in between.
On top of that, they have over 30 metrics and more than a trillion data points across 10 major technologies that they need to measure, primarily from a regulatory perspective. Thousands of granular metrics needed to have solutions and reporting designed for them in Zabbix, including (for example) CPU cores and frequency, processor-to-core usage metrics, and virtualization ratios from hosts to virtual machines.
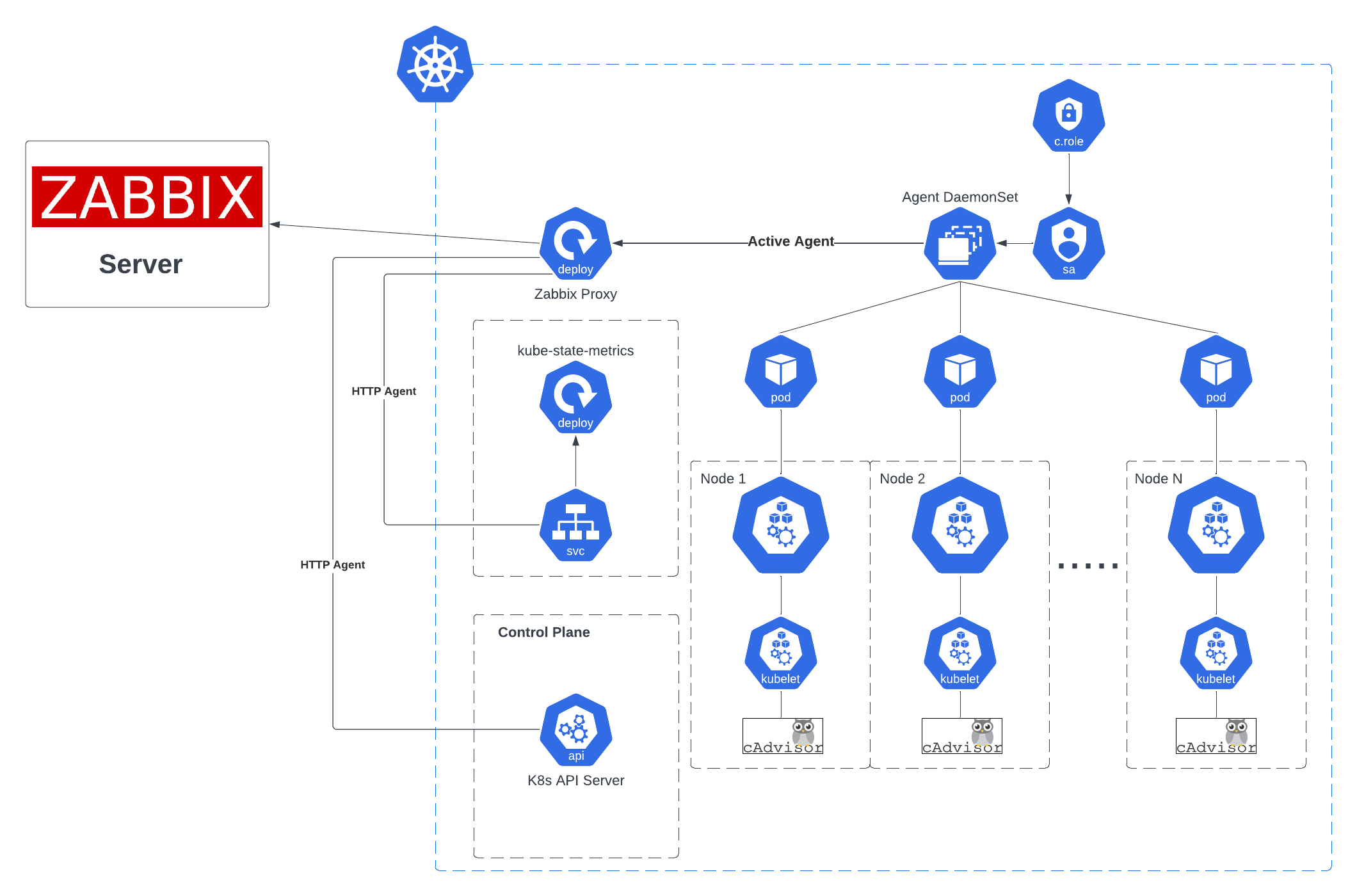
Their Kubernetes-based Openshift environment also needs to be monitored to exact specifications. Deployment took place via Helm Chart, with Zabbix components being installed as Kubernetes resources, node-level resources, and applications being monitored, while data was aggregated and sent to the Zabbix server.
Metrics are collected via the Kubernetes API and kube-state metrics, and the solution uses Prometheus-exported metrics or direct HTTP endpoint calls. When it comes to configuration, proxies and hosts are created in Zabbix to represent Kubernetes nodes and clusters, while templates and macros are configured to point to the Kubernetes API and kube-state-metrics endpoints.
The results
Thanks to Zabbix, the federal government agency in question has a solution that provides centralized monitoring of Kubernetes alongside other IT resources, supports application-specific metrics without requiring Prometheus endpoints, and offers plenty of flexibility to customize and scale.
In addition, Zabbix’s predictive alerting capabilities identify abnormalities in operational data and predictively alert the agency about anything that could potentially impact an application or service, which lets them meet SLAs, optimize user experience, and increase productivity.
In conclusion
Zabbix’s flexibility and ease of customization make it ideal for customers who need a single source of truth that can be relied on in even the most stringent regulatory environments.
To learn more about what Zabbix can do for customers in the public sector, visit us here.
Since its inception, Let’s Encrypt has been sending expiration notification emails to subscribers that have provided an email address to us via the ACME API. This service ended on June 4, 2025. The decision to end the service is the result of the following factors:
Over the past 10 years more and more of our subscribers have been able to put reliable automation into place for certificate renewal.
Providing expiration notification emails means that we have to retain millions of email addresses connected to issuance records. As an organization that values privacy, removing this requirement is important to us.
Providing expiration notifications costs Let’s Encrypt tens of thousands of dollars per year, money that we believe can be better spent on other aspects of our infrastructure.
Providing expiration notifications adds complexity to our infrastructure, which takes time and attention to manage and increases the likelihood of mistakes being made. Over the long term, particularly as we add support for new service components, we need to manage overall complexity by phasing out system components that can no longer be justified.
For those who would like to continue receiving expiration notifications, we recommend using a third party service such as Red Sift Certificates Lite (formerly Hardenize). Red Sift’s monitoring service providing expiration emails is free of charge for up to 250 certificates. More monitoring options can be found here.
We have deleted the email addresses provided to Let’s Encrypt via the ACME API that were stored in our CA database in association with issuance data. This doesn’t affect addresses signed up to mailing lists and other systems. They are managed in a separate ISRG system unassociated with issuance data.
Going forward, if an email address is provided to Let’s Encrypt via the ACME API, Let’s Encrypt will not store the address but will instead forward it to the general ISRG mailing list system unassociated with any account data. If the email address has not been seen before, that system may send an onboarding email with information about how to subscribe to various sources of updates.
If you’d like to stay informed about technical updates and other news about Let’s Encrypt and our parent nonprofit, ISRG, based on the preferences you choose, you can sign up for our email lists below:
Since its inception, Let’s Encrypt has been sending expiration notification emails to subscribers that have provided an email address to us via the ACME API. This service ended on June 4, 2025. The decision to end the service is the result of the following factors:
Over the past 10 years more and more of our subscribers have been able to put reliable automation into place for certificate renewal.
Providing expiration notification emails means that we have to retain millions of email addresses connected to issuance records. As an organization that values privacy, removing this requirement is important to us.
Providing expiration notifications costs Let’s Encrypt tens of thousands of dollars per year, money that we believe can be better spent on other aspects of our infrastructure.
Providing expiration notifications adds complexity to our infrastructure, which takes time and attention to manage and increases the likelihood of mistakes being made. Over the long term, particularly as we add support for new service components, we need to manage overall complexity by phasing out system components that can no longer be justified.
For those who would like to continue receiving expiration notifications, we recommend using a third party service such as Red Sift Certificates Lite (formerly Hardenize). Red Sift’s monitoring service providing expiration emails is free of charge for up to 250 certificates. More monitoring options can be found here.
We have deleted the email addresses provided to Let’s Encrypt via the ACME API that were stored in our CA database in association with issuance data. This doesn’t affect addresses signed up to mailing lists and other systems. They are managed in a separate ISRG system unassociated with issuance data.
Going forward, if an email address is provided to Let’s Encrypt via the ACME API, Let’s Encrypt will not store the address but will instead forward it to the general ISRG mailing list system unassociated with any account data. If the email address has not been seen before, that system may send an onboarding email with information about how to subscribe to various sources of updates.
If you’d like to stay informed about technical updates and other news about Let’s Encrypt and our parent nonprofit, ISRG, based on the preferences you choose, you can sign up for our email lists below:
Organizations store hundreds of exabytes of file data on premises and want to move this data to AWS for greater agility, reliability, security, scalability, and reduced costs. Once their file data is in AWS, organizations often want to do even more with it. For example, they want to use their enterprise data to augment generative AI applications and build and train machine learning models with the broad spectrum of AWS generative AI and machine learning services. They also want the flexibility to use their file data with new AWS applications. However, many AWS data analytics services and applications are built to work with data stored in Amazon S3 as data lakes. After migration, they can use tools that work with Amazon S3 as their data source. Previously, this required data pipelines to copy data between Amazon FSx for OpenZFS file systems and Amazon S3 buckets.
Amazon S3 Access Points attached to FSx for OpenZFS file systems remove data movement and copying requirements by maintaining unified access through both file protocols and Amazon S3 API operations. You can read and write file data using S3 object operations including GetObject, PutObject, and ListObjectsV2. You can attach hundreds of access points to a file system, with each S3 access point configured with application-specific permissions. These access points support the same granular permissions controls as S3 access points that attach to S3 buckets, including AWS Identity and Access Management (IAM)access point policies, Block Public Access, and network origin controls such as restricting access to your Virtual Private Cloud (VPC). Because your data continues to reside in your FSx for OpenZFS file system, you continue to access your data using Network File System (NFS) and benefit from existing data management capabilities.
To start, you can follow the steps in the Amazon FSx for OpenZFS file system documentation page to create the file system, then, using the Amazon FSx console, go to Actions and select Create S3 access point. Leave the standard configuration and then create.
To monitor the creation progress, you can go to the Amazon FSx console.
Once available, choose the name of the new S3 access point and review the access point summary. This summary includes an automatically generated alias that works anywhere you would normally use S3 bucket names.
Using the bucket-style alias, you can access the FSx data directly through S3 API operations.
To create the Amazon Bedrock Knowledge Base, I followed the connection steps in Connect to Amazon S3 for your knowledge base user guide. I chose Amazon S3 as the data source, entered my S3 access point alias as the S3 source, then configured and created the knowledge base.
Once the knowledge base is synchronized, I can see all documents and the Document source as S3.
Finally, I ran queries against the knowledge base and verified that it successfully used the file data from my Amazon FSx for OpenZFS file system to provide contextual answers, demonstrating seamless integration without data movement.
Things to know Integration and access control – Amazon S3 Access Points for Amazon FSx for OpenZFS file systems support standard S3 API operations (such as GetObject, ListObjectsV2, PutObject) through the S3 endpoint, with granular access controls through AWS Identity and Access Management (IAM) permissions and file system user authentication. Your S3 Access Point includes an automatically generated access point alias for data access using S3 bucket names, and public access is blocked by default for Amazon FSx resources.
Data management – Your data stays in your Amazon FSx for OpenZFS file system while becoming accessible as if it were in Amazon S3, eliminating the need for data movement or copies, with file data remaining accessible through NFS file protocols.
Performance – Amazon S3 Access Points for Amazon FSx for OpenZFS file systems deliver first-byte latency in the tens of milliseconds range, consistent with S3 bucket access. Performance scales with your Amazon FSx file system’s provisioned throughput, with maximum throughput determined by your underlying FSx file system configuration.
Pricing – You’re billed by Amazon S3 for the requests and data transfer costs through your S3 Access Point, in addition to your standard Amazon FSx charges. Learn more on the Amazon FSx for OpenZFS pricing page.
You can get started today using the Amazon FSx console, AWS CLI, or AWS SDK to attach Amazon S3 Access Points to your Amazon FSx for OpenZFS file systems. The feature is available in the following AWS Regions: US East (N. Virginia, Ohio), US West (Oregon), Europe (Frankfurt, Ireland, Stockholm), and Asia Pacific (Hong Kong, Singapore, Sydney, Tokyo).
Free and open source technologies, open standards, open hardware and
open data help to strengthen the open web and the open internet. The
projects selected by NLnet all contribute in their own way to this
important goal, and will empower end users and the community at large
on different layers of the stack. For example, there are people
working a browser controlled ad hoc cellular network (Wsdr) which can be used to
create small mobile networks where they are needed. The open hardware
security key Nitrokey is
aiming for formal certification of their implementation of the FIDO2
standard, and will be adding encrypted storage
capabilities. There are also more applied technologies: the high
end open hardware microscope OpenFlexure will
enable among others e-health use cases such as telepathology, allowing
medical professionals to work together to help people in more remote
areas.
See the announcement for the full list of selected projects and the current projects
page for other projects recently funded by NLnet.
Organizations today face the challenge of managing and deriving insights from an ever-expanding universe of data in real time. Industrial Internet of Things (IoT) sensors stream millions of temperature, pressure, and performance metrics from field equipment every second. Ecommerce platforms need to surface relevant products from vast catalogs instantly. Security teams must analyze system logs in real time to detect threats. As data volumes grow, organizations increasingly struggle with fragmented monitoring tools that create critical visibility gaps and slow incident response times. The cost of commercial observability solutions becomes prohibitive, forcing teams to manage multiple separate tools and increasing both operational overhead and troubleshooting complexity. Across these diverse scenarios, the ability to efficiently search, analyze, and visualize data in real time has become crucial for business success.
Amazon OpenSearch Service addresses these challenges by providing a fully managed search and analytics service. This managed service configures, manages, and scales OpenSearch clusters so you can focus on your search workloads and end customers. Amazon OpenSearch Serverless further makes it straightforward to run search and log analytics workloads by automatically scaling compute and storage resources up and down to match your application’s demands—with no infrastructure to manage. Whether you’re processing continuous streams of IoT telemetry, enabling product discovery, or performing security analytics, OpenSearch Service scales to meet your needs.
In this post, we walk you through a search application building process using Amazon OpenSearch Service. Whether you’re a developer new to search or looking to understand OpenSearch fundamentals, this hands-on post shows you how to build a search application from scratch—starting with the initial setup; diving into core components such as indexing, querying, result presentation; and culminating in the execution of your first search query.
Components of OpenSearch Service
Before building your first search application, it’s important to understand some key architectural components in OpenSearch. The fundamental unit of information in OpenSearch is a document stored in JSON format. These documents are organized into indices—collections of related documents that function similar to database tables. When you search for information, OpenSearch queries these indices to find matching documents.
OpenSearch operates on a distributed architecture where multiple servers, called nodes, work together in a cluster or domain. Each cluster can utilize dedicated master nodes that focus solely on cluster management tasks, such as maintaining cluster state, managing indices, and orchestrating shard allocation. These specialized nodes enhance cluster stability by offloading cluster management duties from data nodes. Data nodes, on the other hand, handle the storage, indexing, and querying of data—essentially performing the heavy lifting of data operations. Together, they provide scalability, availability, and efficient data processing in the cluster. Configure dedicated coordinator nodes that specialize in routing and distributing search and indexing requests across the cluster. These nodes reduce the load on data nodes, which allows them to focus on data storage, indexing, and search operations.
Coordinator nodes in OpenSearch are most beneficial in the following scenarios:
Large cluster deployments – When managing substantial data volumes across many nodes.
Query-intensive workloads – For environments handling frequent search queries or aggregations, especially those with complex date histograms or multiple aggregations, benefit from faster query processing.
Heavy dashboard utilization – OpenSearch Dashboards can be resource-intensive. Offloading this responsibility to dedicated coordinator nodes reduces the strain on data nodes.
To manage large datasets efficiently, OpenSearch splits indices into smaller pieces called shards. Each shard is distributed across the cluster, with a recommended size of 10–50 GB for optimal performance. For reliability and high availability, OpenSearch maintains replica copies of these shards on different nodes, which means that your data remains accessible even if some nodes fail.
Search operations in OpenSearch are powered by inverted indices, a data structure that maps terms to the documents containing them. The BM25 ranking algorithm helps make sure that search results are relevant to users’ queries. Although searches happen in near real time, with configurable refresh intervals, individual document retrievals are immediate.
This architecture provides the foundation for handling high-volume IoT data streams, complex full-text search operations, and real-time analytics, all while maintaining fault tolerance. Understanding these components will help you make informed decisions as you build your search application.OpenSearch Dashboards is a visualization and analytics tool for exploring, analyzing, and visualizing data in real time. It provides an intuitive interface for querying, monitoring, and reporting on OpenSearch data using visualizations such as charts, graphs, and maps. Key features include interactive dashboards, alerting, anomaly detection, security monitoring, and trace analytics.
Sample Amazon OpenSearch Service tutorial application overview
The following architecture diagram demonstrates how to build and deploy a scalable, fully managed search application on Amazon Web Services (AWS). The architecture uses Amazon OpenSearch Service for indexing and searching data. The UI application is deployed on AWS App Runner and interacts with Amazon OpenSearch Service through secure serverless Amazon API Gateway and AWS Lambda.
Here is the end-to-end workflow for our application detailing how user requests are handled from initial access through to data retrieval or indexing:
Users access the application through AWS App Runner, which hosts the frontend interface.
Amazon Cognito handles user authentication and authorization for secure access to the application.
When users interact with the application, their requests are sent to API Gateway. API Gateway communicates with Amazon Cognito to verify user authentication status. It serves as the primary entry point for all API operations and routes the requests appropriately. It forwards requests to Lambda functions within the virtual private cloud (VPC).
Lambda functions process the requests, performing either:
Data indexing operations into OpenSearch Service
Search queries against the OpenSearch Service cluster
The OpenSearch Service cluster resides within a private subnet in a VPC for enhanced security.
Prerequisites
Before you deploy the solution, review the prerequisites.
Install the sample app
The entire infrastructure is deployed using AWS Cloud Development Kit (AWS CDK), with cluster configurations customizable through the cdk.json file on GitHub. This deployment approach provides consistent and repeatable infrastructure creation while maintaining security best practices. The steps to deploy this infrastructure are available in this README file. After deployment, you’ll access a comprehensive search application built with Cloudscape React components that includes:
Interactive search functionality – Test various OpenSearch query methods including prefix match keyword searches, phrase matching, fuzzy searches, and field-specific queries against the sample product dataset
Document management tools – Bulk index the product catalog with a single click or delete and recreate the index as needed for testing purposes
Educational resources – Access embedded guides explaining OpenSearch concepts, query syntax, and best practices
Index the documents
After you’ve deployed this search application, the first step is to index some documents into OpenSearch Service. Sign in to the search application UI and follow these steps:
To trigger a bulk index process, under Index Documents in the navigation pane, choose Bulk Index Product Catalog.
Choose Index Product catalog, as shown in the following screenshot.
The Lambda function indexes a comprehensive ecommerce product catalog into your newly created OpenSearch Service cluster. This sample dataset includes detailed fashion and lifestyle products spanning multiple categories. Each product record contains rich metadata, including title, detailed description, category, color, and price.
Keyword searches
OpenSearch Service offers multiple search features. For an exhaustive list, refer to Search features. We focus on a few keyword search types to help you get started with OpenSearch.
With the product catalog in OpenSearch, you can perform prefix searches through the search application’s intuitive interface. To better understand the search functionality, expand the Guide section at the top of the interface. This interactive guide explains how various kinds of searches work, complete with a practical example in context of the product catalog dataset. The guide includes best practices and a link to the detailed documentation to help you make the most of OpenSearch’s powerful query capabilities.
You can do a prefix search on any of the three key search fields: Title, Description, or Color.
You can use this query pattern to find documents where specific fields begin with your search term, offering an intuitive “starts with” search experience.
The following image illustrates a practical example of the Prefix Match search. Entering “Ru” in the title field matches products with titles such as “Running”, “Runners” and “Ruby.” Prefix Match search is particularly useful when users only remember the beginning of a product name or are searching across multiple variations or simply exploring product categories.
Multi Match search enables searching across multiple fields simultaneously. For example, you can search for “Coral” across product title, description, and color fields simultaneously. The search query can be customized using field boosting in which matches in certain fields carry more weight than others.
You can explore Wildcard Match, Range Filter, and other search features through the search application. For developers and administrators managing this search infrastructure, OpenSearch Dashboards is a native, developer-friendly interface for indexing, searching, and managing your data. It serves as a comprehensive control center where you can interact directly with your indices, test queries, and monitor performance in real time. The following screenshot shows OpenSearch Dashboards which provides an interactive UI to explore, analyze and visualize search and log data.
While our example demonstrates lexical search functionality on a sample product catalog, OpenSearch Service is equally powerful for observability usecases. When handling time-series data from logs, metrics, or traces, OpenSearch excels at real-time analytics and visualization. For instance, DevOps teams can index application logs and system telemetry data, then use date histograms and statistical aggregations to identify performance bottlenecks or security anomalies as they occur. This real-time search allows IT teams to detect and respond to incidents with minimal delay. Using OpenSearch Dashboards, teams can create live operational dashboards that update automatically as new data streams in. For IoT applications monitoring thousands of sensors, this means temperature anomalies or equipment failures can trigger immediate alerts through OpenSearch’s alerting capabilities. These observability workloads benefit from the same distributed architecture that powers our product search example, with the added advantage of time-series optimized indices and retention policies for managing high-volume streaming data efficiently.
Beyond search management, you can configure alerts for specific conditions, set up notification channels for operational events, and enable data discovery features. If you want to experiment with the same search queries we implemented in our application, you can launch OpenSearch Dashboards and use relevant index and search APIs from the Dev Tools section, which is an ideal environment for developing and testing before implementing in your production application. Because our OpenSearch Service cluster resides within a private subnet, you need to create a Secure Shell (SSH) tunnel to access the dashboard. For more information and steps to do this, refer to How do I use an SSH tunnel to access OpenSearch Dashboards with Amazon Cognito authentication from outside a VPC? in the Knowledge Center. So far, we’ve explored OpenSearch’s query domain-specific language (DSL). However, for those coming in from a traditional database background, OpenSearch also offers SQL and Piped Processing Language (PPL) functionality, making the transition smoother. You can explore more on this at SQL and PPL in the OpenSearch documentation.
You can now build sample search applications by following the steps outlined in this post and the implementation details available at sample-for-amazon-opensearch-service-tutorials-101 on GitHub. By using the distributed architecture of Amazon OpenSearch Service, an AWS managed service, you get fast, scalable search capabilities that grow with your business, built-in security and compliance controls, and automated cluster management—all with pay-only-for-what-you-use pricing flexibility.
We hope this detailed guide and accompanying code will help you get started. Try it out, let us know your thoughts in the comments section, and feel free to reach out to us for questions!
About the authors
Sriharsha Subramanya Begolli works as a Senior Solutions Architect with Amazon Web Services (AWS), based in Bengaluru, India. His primary focus is assisting large enterprise customers in modernizing their applications and developing cloud-based systems to meet their business objectives. His expertise lies in the domains of data and analytics.
Fraser Sequeira is a Startups Solutions Architect with Amazon Web Services (AWS) based in Melbourne, Australia. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS. He enjoys staying on top of the latest technology innovations from AWS and sharing his learnings with customers. He spends his free time tinkering with new open source technologies.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.