Post Syndicated from turnoff.us original http://turnoff.us/geek/dev-interviews/

Post Syndicated from turnoff.us original http://turnoff.us/geek/dev-interviews/
Post Syndicated from jzb original https://lwn.net/Articles/1005007/
The Mastodon project has announced
that founder Eugen Rochko will be transferring “key Mastodon
” to a new non-profit organization:
ecosystem and platform components (including name and copyrights,
among other assets)
Practically Mastodon will remain headquartered in and operate from
Europe primarily. We will continue day-to-day operations through the
Mastodon GmbH for-profit entity, which will become wholly owned by the
new European not-for-profit entity. The Mastodon GmbH entity
automatically became a for-profit as a result of its charitable status
being stripped
away in Germany. The existing US-based non-profit entity, the
501(c)(3), will continue to function as a fundraising hub.[…] We are in the process of a phased transition. First we are
establishing a new legal home for Mastodon and transferring ownership
and stewardship. We are taking the time to select the appropriate
jurisdiction and structure in Europe. Then we will determine which
other (subsidiary) legal structures are needed to support operations
and sustainability.
Rochko has, naturally, also posted
about the transition on Mastodon.social.
Post Syndicated from jzb original https://lwn.net/Articles/1004988/
TuxFamily is a
French free-software-hosting service that has been in operation since
1999. It is a non-profit that accepts “any project
“, whether that is a software license
released under a free license
or a free-content license, such as CC-BY-SA. It is also,
unfortunately, slowly dying due to hardware failures and lack of
interest. For example, the site’s download servers are currently
offline with no plan to restore them.
Post Syndicated from Ishan Gupta original https://aws.amazon.com/blogs/big-data/juicebox-recruits-amazon-opensearch-service-for-improved-talent-search/
This post is cowritten by Ishan Gupta, Co-Founder and Chief Technology Officer, Juicebox.
Juicebox is an AI-powered talent sourcing search engine, using advanced natural language models to help recruiters identify the best candidates from a vast dataset of over 800 million profiles. At the core of this functionality is Amazon OpenSearch Service, which provides the backbone for Juicebox’s powerful search infrastructure, enabling a seamless combination of traditional full-text search methods with modern, cutting-edge semantic search capabilities.
In this post, we share how Juicebox uses OpenSearch Service for improved search.
Recruiting search engines traditionally rely on simple Boolean or keyword-based searches. These methods aren’t effective in capturing the nuance and intent behind complex queries, often leading to large volumes of irrelevant results. Recruiters spend unnecessary time filtering through these results, a process that is both time-consuming and inefficient.
In addition, recruiting search engines often struggle to scale with large datasets, creating latency issues and performance bottlenecks as more data is indexed. At Juicebox, with a database growing to more than 1 billion documents and millions of profiles being searched per minute, we needed a solution that could not only handle massive-scale data ingestion and querying, but also support contextual understanding of complex queries.
The following diagram illustrates the solution architecture.

OpenSearch Service securely unlocks real-time search, monitoring, and analysis of business and operational data for use cases like application monitoring, log analytics, observability, and website search. You send search documents to OpenSearch Service and retrieve them with search queries that match text and vector embeddings for fast, relevant results.
At Juicebox, we solved five challenges with Amazon OpenSearch Service, which we discuss in the following sections.
Initially, we faced significant delays in returning search results due to the scale of our dataset, especially for complex semantic queries that require deep contextual understanding. Other full-text search engines couldn’t meet our requirements for speed or relevance when it came to understanding recruiter intent behind each search.
The OpenSearch Service BM25 algorithm quickly proved invaluable by allowing Juicebox to optimize full-text search performance while maintaining accuracy. Through keyword relevance scoring, BM25 helps rank profiles based on the likelihood that they match the recruiter’s query. This optimization reduced our average query latency from around 700 milliseconds to 250 milliseconds, allowing recruiters to retrieve relevant profiles much faster than our previous search implementation.
With BM25, we observed a nearly threefold reduction in latency for keyword-based searches, improving the overall search experience for our users.
In recruiting, exact keyword matching can often lead to missing out on qualified candidates. A recruiter looking for “data scientists with NLP experience” might miss candidates with “machine learning” in their profiles, even though they have the right expertise.
To address this, Juicebox uses k-nearest neighbor (k-NN) vector search. Vector embeddings allow the system to understand the context behind recruiter queries and match candidates based on semantic meaning, not just keyword matches. We maintain a billion-scale vector search index that is capable of performing low-latency k-NN search, thanks to OpenSearch Service optimizations like product quantization capabilities. The neural search capability allowed us to build a Retrieval Augmented Generation (RAG) pipeline for embedding natural language queries before searching. OpenSearch Service allows us to optimize algorithm hyperparameters for Hidden Navigable Small Worlds (HNSW) like m, ef_search, and ef_construction. This enabled us to achieve our target latency, recall, and cost goals.
Semantic search, powered by k-NN, allowed us to surface 35% more relevant candidates compared to keyword-only searches for complex queries. The speed of these searches was still fast and accurate, with vectorized queries achieving a 0.9+ recall.
There are several key performance indicators (KPIs) that measure the success of your search. When you use vector embeddings, you have a number of choices to make when selecting the model, fine-tuning the model, and choosing the hyperparameters to use. You need to benchmark your solution to make sure that you’re getting the right latency, cost, and especially accuracy. Benchmarking machine learning (ML) models for recall and performance is challenging due to the vast number of fast-evolving models available (such as MTEB leaderboard on Hugging Face). We faced difficulties in selecting and measuring models accurately while making sure we performed well across large-scale datasets.
Juicebox used exact k-NN with scoring script features to address these challenges. This feature allows for precise benchmarking by executing brute-force nearest neighbor searches and applying filters to a subset of vectors, making sure that recall metrics are accurate. Model testing was streamlined using the wide range of pre-trained models and ML connectors (integrated with Amazon Bedrock and Amazon SageMaker) provided by OpenSearch Service. The flexibility of applying filtering and custom scoring scripts helped us evaluate multiple models across high-dimensional datasets with confidence.
Juicebox was able to measure model performance with fine-grained control, achieving 0.9+ recall. The use of exact k-NN allowed Juicebox to benchmark faster and reliably, even on billion-scale data, providing the confidence needed for model selection.
Recruiters need to not only find candidates, but also gain insights into broader talent industry trends. Analyzing hundreds of millions of profiles to identify trends in skills, geographies, and industries was computationally intensive. Most other search engines that support full-text search or k-NN search didn’t support aggregations.
The powerful aggregation features of OpenSearch Service allowed us to build Talent Insights, a feature that provides recruiters with actionable insights from aggregated data. By performing large-scale aggregations across millions of profiles, we identified key skills and hiring trends, and helped clients adjust their sourcing strategies.
Aggregation queries now run on over 100 million profiles and return results in under 800 milliseconds, allowing recruiters to generate insights instantly.
Juicebox ingests data continuously from multiple sources across the web, reaching terabytes of new data per month. We needed a robust data pipeline to ingest, index, and query this data at scale without performance degradation.
Using Amazon OpenSearch Ingestion, we implemented scalable pipelines. This allowed us to efficiently process and index hundreds of millions of profiles every month without worrying about pipeline failures or system bottlenecks. We used AWS Glue to preprocess data from multiple sources, chunk it for optimal processing, and feed it into our indexing pipeline.
In this post, we shared how Juicebox uses OpenSearch Service for improved search. We can now index hundreds of millions of profiles per month, keeping our data fresh and up to date, while maintaining real-time availability for searches.
 Ishan Gupta is the Co-Founder and CTO of Juicebox, an AI-powered recruiting software startup backed by top Silicon Valley investors including Y Combinator, Nat Friedman, and Daniel Gross. He has built search products used by thousands of customers to recruit talent for their teams.
Ishan Gupta is the Co-Founder and CTO of Juicebox, an AI-powered recruiting software startup backed by top Silicon Valley investors including Y Combinator, Nat Friedman, and Daniel Gross. He has built search products used by thousands of customers to recruit talent for their teams.
 Jon Handler is the Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is the Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
Post Syndicated from corbet original https://lwn.net/Articles/1004455/
The ptrace()
system call allows a suitably privileged process to modify another in a
large number of ways. Among other things, ptrace() can intercept
system calls and make changes to them, but such operations can be fiddly
and architecture-dependent. This patch series from
Dmitry Levin seeks to improve that situation by adding a new
ptrace() operation to make changes to another process’s system
calls in an architecture-independent manner.
Post Syndicated from Kari Rivas original https://www.backblaze.com/blog/disaster-recovery-101-hot-vs-warm-vs-cold-dr-sites/

It goes without saying (but I will say it anyway) that having a disaster recovery (DR) site is essential to protecting business continuity (BC) in the face of disasters both big and small. However, even for large enterprises, building and maintaining a separate physical facility to store data copies can be cost prohibitive, and it may not make sense operationally.
DR sites differ according to the availability of data for retrieval and by type of ownership (e.g., fully owned or colocated). In recent years, public cloud has also emerged as a viable DR “site”—meaning that backups, production data, and/or virtualized infrastructure can be effectively housed in the cloud.
In this blog, I’ll examine the primary differences and pros and cons between various types of DR sites, and I’ll outline the most important criteria for deciding on the right DR setup for your business.
If your business is able to fully invest in owning a DR site, the obvious upsides are greater control over security and infrastructure. But owning and operating your own site may still not be the most ideal option, given the staffing and expertise required. For many businesses, it doesn’t make sense to invest in owning and operating a data center when that’s not your area of expertise.
That’s why many businesses opt for colocation. It can be a great option for adhering to your DR strategy and your expense limits. However, you must be careful to thoroughly vet the location and provider. Here are a few important points to consider:
In order to satisfy cyber insurance policy requirements, AcenTek’s backups needed to be off-site and geographically distant from their own data centers. Backblaze offered a critical feature—immutability and certification as a Veeam Ready Object partner—as well as geographic distance from AcenTek’s own data centers to meet the requirements and protect AcenTek’s business.

Recovery sites are often referred to by temperature (hot, warm, cold) to describe the speed and importance of applications and data in those protected sites. The ideal DR site temperature depends on your organization’s budget, risk tolerance, and RTOs. Businesses with critical systems requiring near-instantaneous recovery might opt for a hot site. Others might find a warm site or even a cold site a more cost-effective option for less time-sensitive systems.
| Hot site | Warm site | Cold site | |
|---|---|---|---|
| Description | A fully functional replica of your primary production resources, constantly maintained and ready for immediate failover in the cloud or to a secondary on-premises site. | A pre-configured cloud recovery site or hybrid recovery with hardware and software infrastructure. Requires some manual intervention (e.g., software installation) before becoming operational. | A basic physical facility with essential infrastructure (power, cooling, and network connectivity) requiring significant configuration and installation before use. May also include cold cloud storage. |
| Pros | Fastest recovery times due to the site’s constant readiness. | A balance between cost and recovery time. Faster than cold sites, but slower than hot sites. | Most cost-effective option, requiring minimal ongoing maintenance. |
| Cons | This is the most expensive option due to the need for complete infrastructure replication. | Still requires some manual setup, potentially delaying recovery time. | Longest recovery times due to the extensive configuration and installation needed. Or, in the case of cold cloud storage—the time required to retrieve your data. |
| Example RTO goal times | RTO <15 minutes | RTO <24 hours | RTO >24 hours |
Traditionally, DR for large enterprises would involve building a physical site to support RTO objectives. It’s important to note that building or buying a dedicated DR site might not be the most cost-effective option for all backups. Instead, cloud storage offers a compelling solution specifically for backups, even if you have your own physical DR site.
Cloud storage from a specialized provider like Backblaze is generally more affordable and scalable than on-premises storage solutions or off-site DR facilities, making it a great fit for this purpose. Backblaze offers always hot storage with 3x free egress, meaning data can be immediately recovered when needed without surprise egress bills. In this way, Backblaze B2 Cloud Storage constitutes a virtualized hot DR site.

While some consider cold cloud storage to be the most cost-effective solution, the cost savings of cold storage are often entirely negated by its long retrieval time and egress charges—so much so that it no longer becomes a viable disaster recovery option.
In a way, you can consider the public cloud very similarly to a colocated DR site. All the same questions apply when choosing between cloud storage providers (CSPs):
Ultimately, you must carefully balance business requirements for RTO and RPO with DR investment costs. Businesses located in likely disaster areas like tornado alley, earthquake-prone zones, or coastal areas are well served by the additional investment in DR infrastructure. But even if your company has its own DR site, public cloud can be a beneficial supplement to your own DR infrastructure.
The post Disaster Recovery 101: Hot vs. Warm vs. Cold DR Sites appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/01/upcoming-speaking-engagements-42.html
This is a current list of where and when I am scheduled to speak:
The list is maintained on this page.
Post Syndicated from Anshu Bathla original https://aws.amazon.com/blogs/security/how-to-implement-iam-policy-checks-with-visual-studio-code-and-iam-access-analyzer/
In a previous blog post, we introduced the IAM Access Analyzer custom policy check feature, which allows you to validate your policies against custom rules. Now we’re taking a step further and bringing these policy checks directly into your development environment with the AWS Toolkit for Visual Studio Code (VS Code).
In this blog post, we show how you can integrate IAM Access Analyzer custom policy check capability into VS Code, so you can identify overly permissive IAM policies and fine-tune access controls early in the development process. This proactive approach to security and compliance helps to ensure that your IAM policies are validated before they are deployed, reducing the risk of introducing misconfigurations or granting unintended access. It also saves developer time by providing fast feedback to developers when they write a policy that does not meet organizational standards.
Although security teams oversee an organization’s overall security posture, developers create applications that require specific permissions. To enable developers to work efficiently while maintaining high security standards, organizations often seek ways to safely delegate the authoring of AWS Identity and Access Management (IAM) policies to developers. Many AWS customers manually review developer-authored IAM policies before deploying them to production environments to help prevent granting excessive or unintended permissions. However, depending on the volume and complexity of policies, these manual reviews can be time-consuming, leading to development delays and potential bottlenecks in the deployment of applications and services. Organizations need to balance secure access management with the agility required for rapid application development and deployment.
Custom policy checks are a feature in IAM Access Analyzer that are designed to help security teams proactively identify and analyze critical permissions within their IAM policies. In this section, we provide step-by-step instructions for using custom policy checks directly in VS Code.
To complete the examples in our walkthrough, you first need to do the following:

Figure 1: Search for the AWS: Open IAM Policy Checks option
By using the IAM policy checks option in VS Code, you can perform four types of checks:
We’ll walk through examples of each of these checks in the sections that follow.
In this example, we use the ValidatePolicy option provided by the IAM policy check plugin to validate IAM policies against IAM policy grammar and AWS best practices. When you run this check, you can view policy validation check findings that include security warnings, errors, general warnings, and suggestions for your policy. These actionable recommendations help you author policies that are aligned with AWS best practices.
To run the ValidatePolicy check
* (a wildcard) is being used in the first statement, which indicates that the iam:PassRole action is allowed for all resources.

Figure 2: IAM Access Analyzer ValidatePolicy check results
You can see that Access Analyzer has detected an issue, which is shown in the PROBLEMS pane.

Figure 3: Problems pane with finding details for the ValidatePolicy check
The security warning shown in Figure 3 states that the iam:PassRole action with a wildcard (*) in the resource can be overly permissive because it allows the ability to pass any IAM role in that account.
*) with a specific role Amazon Resource Name (ARN).
ValidatePolicy check to make sure that it doesn’t generate findings after you updated the IAM policy.
Figure 4: Results of the ValidatePolicy check after IAM policy correction
With the CheckNoPublicAccess option, you can verify whether your resource policy grants public access for supported resource types.
To run the CheckNoPublicAccess check
WARNING: This sample bucket policy should not be used in production. Using a wildcard in the principal element of a bucket policy would allow any IAM principal to view the contents of the bucket.
CheckNoPublicAccess check.

Figure 5: IAM Access Analyzer CheckNoPublicAccess check results
The policy check returns a failed result because this bucket does allow public access.

Figure 6: Problems pane finding details for CheckNoPublicAccess check
CheckNoPublicAccess check. The resource policy no longer grants public access and the status of the policy check is PASS.The CheckAccessNotGranted option allows you to check whether a policy allows access to a list of IAM actions and resource ARNs. You can use this check to give developers fast feedback that certain permissions or access to certain resources are not allowed.
To run the CheckAccessNotGranted check
In the VS Code editor, under Custom Policy Checks, choose the check type CheckAccessNotGranted. Using a comma-separated list, create a list of actions and resource ARNs that you don’t want to allow in your IAM policy. You can also create a JSON file with your actions and resources by using the syntax shown in Figure 7. For this example, set the s3:PutBucketPolicy and dynamodb:DeleteTable IAM actions to “not allowed” in the IAM policy.

Figure 7: Configure the CheckAccessNotGranted check
s3:PutBucketPolicy and dynamodb:DeleteTable, which you marked as actions that you don’t want developers to grant access to. Remove the restricted actions from the policy and run the check again to see a PASS result for the policy check.The CheckNoNewAccess option is a custom policy check that verifies whether your policy grants new access compared to a reference policy.
You use a reference policy to check whether a candidate policy allows more access than the reference policy does. In other words, the check passes if the candidate policy is a subset of the reference policy. A reference policy typically starts by allowing all access. You then add a statement or statements that deny the access that you want the reference policy to check for. For more details and examples of reference policies, see the iam-access-analyzer-custom-policy-check-samples repository on GitHub.
The ability to use a reference policy provides you with the flexibility to look for almost anything in an IAM policy. This is useful when you have custom requirements for your organization that may not be met with some of the other custom policy checks.
To run the CheckNoNewAccess check
The following reference policy checks that an IAM role trust policy only grants access to an allowlisted set of AWS services. This enables you to allow builders to create roles, but constrain the use of those roles to the set of AWS services specified.
In this reference policy, only the specified AWS service principals ec2.amazonaws.com, lambda.amazonaws.com, and ecs-tasks.amazonaws.com are allowed to assume the role.

Figure 8: Enter the reference policy for the CheckNoNewAccess check
lambda.amazonaws.com and glue.amazonaws.com to assume the sample-application-role IAM role.

Figure 9: Problems pane finding details for the CheckNoNewAccess check
The issue is that glue.amazonaws.com was not listed as a service principal that was allowed to assume a role in your reference policy. You can remove glue.amazonaws.com from the CloudFormation template and re-run the check to receive a PASS result.
In this post, we explored how you can use the integration of VS Code with IAM Access Analyzer in your development workflow to make sure that your IAM policies align with best practices and adhere to your organization’s security requirements. The four critical checks provided by IAM Access Analyzer can be summarized as follows:
ValidatePolicy check provides actionable recommendations that help you author policies that are aligned with AWS best practices.CheckNoPublicAccess check helps protect resources from being exposed publicly and mitigates the risk of unauthorized public access.CheckAccesNotGranted check looks for specific IAM actions and resource ARNs to help enforce access restrictions and help prevent unauthorized access to critical data or services.CheckNoNewAccess check validates that the permissions granted in your IAM policies remain within the intended scope, as defined by your organization’s requirements.Install or update the AWS Toolkit for VS Code today, and make sure that you have the CloudFormation Policy Validator or Terraform Policy Validator, to take advantage of these features.
If you have feedback about this post, submit comments in the Comments section below.
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=uAShJl-wH9Q
Post Syndicated from corbet original https://lwn.net/Articles/1005076/
Security updates have been issued by AlmaLinux (kernel, NetworkManager, and thunderbird), Fedora (golang-github-aws-sdk-2, golang-github-aws-smithy, golang-github-ncw-swift-2, rclone, and thunderbird), Mageia (ceph, firefox, and thunderbird), Oracle (kernel, NetworkManager, and thunderbird), Red Hat (fence-agents and raptor2), SUSE (dpdk, firefox, frr, grafana, operator-sdk, perl-Module-ScanDeps, proftpd, python311-mistune, redis, thunderbird, valkey, and yq), and Ubuntu (hplip and webkit2gtk).
Post Syndicated from jzb original https://lwn.net/Articles/1005031/
Hans de Goede has posted an
update about his work to support IPU6 cameras on Fedora and
submitting fixes upstream.
The initial IPU6 camera support landed in Fedora 41 only works on a
limited set of laptops. The reason for this is that with MIPI cameras
every different sensor and glue-chip like IO-expanders needs to be
supported separately.I have been working on making the camera work on more laptop
models. After receiving and sending many emails and blog post comments
about this I have started filing Fedora bugzilla issues on a per
sensor and/or laptop-model basis to be able to properly keep track of
all the work.
LWN covered the lack
of IPU6 drivers in 2022.
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=2yX6_l0a0AM
Post Syndicated from Xipu Li original https://aws.amazon.com/blogs/devops/effortlessly-execute-aws-cli-commands-using-natural-language-with-amazon-q-developer/
Command-line tools are meant to simplify infrastructure and DevOps workflows, but the reality is often the opposite. Instead of speeding things up, the vast array of commands, flags, and syntax turns the CLI into a puzzle. Tools meant to enhance productivity have developers endlessly tab-switching between searches, forums, and docs just to find basic commands.
Much like learning a new language, mastering the CLI involves navigating intricate and unfamiliar syntax. In the real world, we have translators to help bridge communication gaps—and now, there’s Amazon Q Developer to do the same for your CLI.
In this post, we’ll guide you through setting up Amazon Q Developer on your command line and demonstrate how it simplifies complex tasks.
Make sure you have AWS CLI installed and configured to have a smooth experience as you go through this post.
To use Amazon Q Developer in your CLI, start by installing Amazon Q. Currently, Amazon Q’s CLI capability is only available for macOS and Linux users, so make sure you are on the right platform.
Using Amazon Q Developer requires you to have an AWS Builder ID or be part of an organization with an AWS IAM Identity Center instance set up.
We will be interacting with Amazon S3 and Amazon CloudFront, check that your AWS account has the necessary permissions:
Once you have these prerequisites in place, you’re ready to see how Amazon Q Developer can simplify your CLI workflow. Let’s get started.
Open a new terminal window, and type q translate, followed by a natural language prompt to execute a complex command. Amazon Q Developer will take your input and process it through a Large Language Model (LLM), generating the corresponding bash command.
Let’s start with something simple and fun: count down from 10 second by second in your terminal:
q translate “Count down from 10 second by second”When you execute the command, you’ll see Amazon Q suggest an executable shell command with a few action items:

For now, we can just execute the command and see it in action:

Now that we’ve covered the basics, let’s get our hands dirty with something practical. In this tutorial, we’ll walk through creating a static website hosted on AWS, entirely using the command line.
Amazon S3 is great for static website hosting. First, we need to create an S3 bucket to store our website files. We can simply instruct Amazon Q Developer to “create an S3 bucket called ‘ai-generated-bucket’ on us-west-2”:

Note: that if you already have a bucket with the same name, feel free to change it to something else.
We can see that Amazon Q Developer has correctly generated the command:
aws s3 mb s3://ai-generated-bucket —region us-west-2If you see something that’s not quite right, you can try to “Edit command” or “Regenerate answer”. For now, we can just execute that generated command and verify in the AWS S3 console that the S3 bucket has indeed been created.
Now, we need to upload a basic HTML file to the bucket. Instead of manually writing it, we can let Amazon Q Developer guide us. Prompt:
q translate "Create a simple index.html file with 'Hello World' message"
Amazon Q Developer is suggesting echo '<h1>Hello World</h1>' > index.html, which looks good. We can go ahead execute that command.
Now, we’ll upload the index.html file to the S3 bucket:
q translate "Upload index.html to the 'ai-generated-bucket' S3 bucket"
After executing the command, we can check on the Amazon S3 console to see we have successfully uploaded the index.html file to our bucket.

By default, Amazon S3 blocks public access to your account and buckets. We recommend keeping Block Public Access enabled for production use cases and securely serve your site through Amazon CloudFront, a global Content Delivery Network (CDN) that securely delivers your content with low latency and high transfer speeds, making it ideal for hosting static websites.
Use Amazon Q Developer to create a CloudFront distribution for your S3 bucket:
q translate "Create a CloudFront distribution for my S3 bucket 'ai-generated-bucket'"
Hmm, that doesn’t look right. Amazon Q Developer is trying to supply —distribution-config with an unspecified configuration file. To fix this, you can either manually provide the CloudFront distribution configuration or we can push the limit of what Amazon Q Developer can do.
Let’s try to refine our prompt so that we don’t use the --distribution-config flag:
q translate "Create a CloudFront distribution for my S3 bucket 'ai-generated-bucket' without using the ‘—distribution-config' flag"
Much better! Looks like we need to replace the ‘X’s with an actual origin domain name. In our case, the S3 bucket origin uses the following format:
bucket-name.s3.amazonaws.com
Navigate to and toggle the Edit command option on your CLI, and replace the ‘X’s. In our case, the replacement value would be ai-generated-bucket.s3.amazonaws.com. Execute the command, and upon success, you should be able to see the CloudFront configuration printed on the console:

Copy the “Id” from the output, we will need it for the next step.
We want to set index.html as our default root object for the CloudFront distribution we just created, this will ensure that when users access your website’s root URL, CloudFront automatically serves the index.html file without requiring the user to explicitly specify it in the URL.
q translate "Update my CloudFront distribution CLOUDFRONT_ID to have 'index.html' as default root object without using the --distribution-config flag"
Don’t forget to replace CLOUDFRONT_ID with the Id you retrieved from the previous step. Once you execute that command, you should see the CloudFront configuration printed on the console like the step above.
Now, to securely serve our HTML file to the public, we need to perform the following:
Let’s have Amazon Q generate an OAC for us:
q translate "Create an OAC named 'ai-generated-oac' for my CloudFront distribution CLOUDFRONT_ID"
When we execute the command, we get an error saying:
An error occurred (MalformedXML) when calling the CreateOriginAccessControl operation: 1 validation error detected: Value 'origin-access-identity' at 'originAccessControlConfig.originAccessControlOriginType' failed to satisfy constraint: Member must satisfy enum value set: [s3, lambda, mediastore, mediapackagev2]
It might be difficult to debug this error message without consulting the internet. Luckily, Amazon Q Developer offers another powerful capability, q chat, which is like a chatbot in your terminal. Let’s try it out to troubleshoot:
q chat "@history An error occurred (MalformedXML) when calling the CreateOriginAccessControl operation: 1 validation error detected: Value 'origin-access-identity' at 'originAccessControlConfig.originAccessControlOriginType' failed to satisfy constraint: Member must satisfy enum value set: [s3, lambda, mediastore, mediapackagev2]. Help me resolve this error"Note that I included @history in the prompt to pass our shell history to Amazon Q so it can respond based on the context provided.

We get a detailed AI generated response on our terminal with step by step instructions and citations! By using the @history tag, Amazon Q Developer knows to relate the error message to the correct shell command we executed (we can see that it knows we want to create an OAC with name ai-generated-oac without us explicitly telling it so).
Let’s try executing the revised bash command:
aws cloudfront create-origin-access-control \
--origin-access-control-config \
Name=ai-generated-oac,\
OriginAccessControlOriginType=s3,\
SigningBehavior=always,\
SigningProtocol=sigv4This time, it succeeded:
Take a note of the Id field, we will need it later.
We can now ask q chat about how to attach the generated OAC to our CloudFront distribution:
q chat "@history Update my CloudFront distribution CLOUDFRONT_ID with the OAC we just generated, be specific"
Notice how @history even helps Amazon Q fill in CLOUDFRONT_ID for me!
We just need to follow the instruction and once we completed the last step, we should see an updated CloudFront distribution in our console output:

It shows a “Status” of “InProgress”. To proceed to the next step, we will need to wait for CloudFront to finish deployment. Let’s ask Amazon Q Developer how to get the latest status:
q translate "Get the status of my CloudFront distribution with CLOUDFRONT_ID on us-west-2"
Replace $CLOUDFRONT_ID with your own and execute the command to get the latest status. It might take a few minutes, it’s time to grab a coffee or go for a short walk!
Once the status is Deployed, we can go ahead and update our S3 bucket policy to give public read access to our CloudFront distribution:

You can see we are using a very vague prompt but @history made sure that Amazon Q has enough context to generate helpful responses.
Simply follow the instruction and we’re ready to access the site!

Let’s get the public URL of our CloudFront distribution.

Once you get the URL, you can open it in a browser, and it should show “Hello World”!

In this post, we’ve successfully:
All of these steps were accomplished on our terminal using Amazon Q Developer on the CLI.
You’ve seen how effortlessly complex CLI commands can be translated into natural language, making AWS more accessible than ever. But this is just the start. As your needs grow, Amazon Q scales with you, delivering faster deployments, enhanced productivity, and seamless access to the full AWS ecosystem.
We encourage you to explore AWS services you haven’t yet tried, with Amazon Q Developer simplifying the process every step of the way. Let it streamline your workflow and unlock new opportunities to innovate and grow.
Post Syndicated from Elizabeth Fuentes original https://aws.amazon.com/blogs/aws/now-open-aws-mexico-central-region/
In February 2024, we announced plans to expand Amazon Web Services (AWS) infrastructure in Mexico. Today, I’m excited to announce the general availability of the AWS Mexico (Central) Region with three Availability Zones and API code mx-central-1. This new AWS Region is the first AWS infrastructure Region in Mexico and adds to our growing presence in Latin America.
The AWS Region in Mexico represents a significant commitment to the country’s digital future. AWS is planning to invest more than $5 billion in Mexico over 15 years. This AWS Region will provide customers with advanced and secure cloud technologies, including cutting-edge artificial intelligence (AI) and machine learning (ML) capabilities with purpose-built processors, while supporting Mexico’s growing digital economy. With this effort, AWS will support an average of more than 7,000 full-time equivalent jobs annually in Mexico, adding more than $10 billion to Mexico’s gross domestic product (GDP). AWS has also launched a $300,000 AWS InCommunities Fund in Queretaro to help local groups, schools, and organizations initiate new community projects.

Palacio de Bellas Artes, Mexico City
The AWS Mexico (Central) Region provides organizations in Mexico with a new option to run their workloads and store data locally. Organizations that need data residency capabilities, enhanced performance with lower latency, or robust security standards can now use infrastructure located in Mexico.
AWS in Mexico
AWS has operated infrastructure in Mexico since 2020. The infrastructure includes seven Amazon CloudFront edge locations, AWS Outposts, and strategic offerings such as AWS Local Zones in Queretaro and AWS Direct Connect. These infrastructure offerings help customers run low-latency applications while maintaining secure connectivity.
Performance and Innovation
The AWS Mexico (Central) Region brings AWS infrastructure and services closer to local customers. With this new Region, AWS provides lower latency for customers in Mexico compared to using other AWS Regions. Customers will also be able to use our innovation in purpose-built processors, notably AWS Graviton, that delivers up to 40% better price performance compared to x86-based Amazon EC2 instances across diverse workloads.
This technological advantage extends to our cutting-edge AI and ML capabilities, including:
Security and Compliance
AWS provides comprehensive security capabilities with support for 143 security standards and compliance certifications, including PCI-DSS, HIPAA/HITECH, FedRAMP, GDPR, FIPS 140-2, and NIST 800-171. All AWS customers own their data, choose where to store it, and decide if/when to move it. This means customers storing content in the AWS Mexico (Central) Region have the assurance that their content will not leave Mexico, unless they chose to move it.
AWS Customers in Mexico
Leading Mexican organizations are already achieving significant results with AWS. Companies such as Aeroméxico, Banco Santander Mexico, Cinépolis, Grupo Salinas, Kavak, Palace Resorts, and Vector Casa de Bolsa are running mission-critical workloads on AWS. Here are key examples:
BBVA, a leading multinational financial services company, is using AWS to accelerate its data-driven transformation. Using Amazon SageMaker and Amazon Bedrock, BBVA is empowering over 1,000 data scientists to build, train, and deploy machine learning models efficiently. This technology enables BBVA to explore advanced technologies and create innovative financial solutions, supporting their goal of becoming a true data and AI-driven digital organization.
Grupo Multimedios, a leading Mexican media group, is pioneering the use of generative AI, by implementing Amazon Bedrock for their media asset manager (MAM), reducing content research time by 88%, decreasing news generation time by 40%, and increasing content production by 70% (250 additional news items daily). As the fastest-growing media group embracing technological leadership, their AI implementation demonstrates a commitment to innovation while streamlining operations.
Bowhead Health, a digital healthcare company, is revolutionizing cancer research by using Amazon Bedrock to accelerate the research pipeline. The company has built a vast, de-identified dataset that’s ready for analysis without traditional recruitment barriers. Bowhead Health also delivers robust, real-world insights to drive faster breakthroughs in oncology drug development.
SkyAlert, an innovative technology company protecting millions in earthquake-prone areas, transformed its alert system by migrating to AWS in 2018. Before AWS, their system required 20 virtual machines and experienced significant delays during critical moments. Using AWS Lambda, AWS Fargate, and Amazon Pinpoint, they can now scale automatically and deliver messages to users quickly. With the opening of the AWS Mexico (Central) Region, SkyAlert anticipates further improvements to their services with local AWS infrastructure. As Santiago Cantú, Co-Founder of SkyAlert, explains, “The opening of the AWS Region in Mexico is an extremely important event for SkyAlert and for the security of those who trust us. Having local AWS infrastructure will improve our ability to deliver critical alerts, which potentially save lives, even faster and more reliably. This perfectly aligns with our mission to provide the most robust and advanced earthquake early warning system available. The new Region will allow us to take even greater advantage of AWS services, ensuring that we continue to be at the forefront of innovation in disaster preparedness.”
Building Skills Together
AWS has made significant investments in upskilling initiatives in Mexico including:
AWS Commitment to Sustainability
Amazon is committed to reaching net-zero carbon across its business by 2040. A recent Accenture study shows that running workloads on AWS is up to 4.1 times more energy-efficient than on-premises environments. When workloads are optimized on AWS, the associated carbon footprint can be lowered by up to 99%. The AWS Mexico (Central) Region incorporates sustainable design practices, using air-cooling technology that eliminates the need for cooling water in operations. With this new Region, customers will also benefit from AWS sustainability efforts across its infrastructure. To learn more about sustainability at AWS, visit the AWS Cloud sustainability page.
Things to know
AWS Community in Mexico – The AWS Community in Mexico is one of the most vibrant in Latin America, with 26+ AWS Community Builders and 15 AWS User Groups. These groups are located in Jalisco, Puebla, Monterrey, Mérida, Mexico City, Mexicali, Cancún, León, Querétaro, San Luis Potosí, Ensenada, Saltillo, Tijuana, and Villahermosa, plus a specialized User Group called Embajadoras cloud (Cloud ambassadors) focused on women’s professional development. Together, these groups comprise 9,000+ total members.

AWS Global footprint – With this launch, AWS now spans 114 Availability Zones within 36 geographic Regions.
Available now – The new AWS Mexico (Central) Region is ready to support your business, and you can find a detailed list of the services available in this Region on the AWS Services by Region page.
To start building in mx-central-1, visit the AWS Global Infrastructure page.
Thanks to David Victoria for the AWS Community México 2024 photo.
— Eli
Post Syndicated from Sri Pulla original https://blog.cloudflare.com/cisa-pledge-commitment-reducing-vulnerability/
In today’s rapidly evolving digital landscape, securing software systems has never been more critical. Cyber threats continue to exploit systemic vulnerabilities in widely used technologies, leading to widespread damage and disruption. That said, the United States Cybersecurity and Infrastructure Agency (CISA) helped shape best practices for the technology industry with their Secure-by-Design pledge. Cloudflare signed this pledge on May 8, 2024, reinforcing our commitment to creating resilient systems where security is not just a feature, but a foundational principle.
We’re excited to share an update aligned with one of CISA’s goals in the pledge: To reduce entire classes of vulnerabilities. This goal aligns with the Cloudflare Product Security program’s initiatives to continuously automate proactive detection and vigorously prevent vulnerabilities at scale.
Cloudflare’s commitment to the CISA pledge reflects our dedication to transparency and accountability to our customers. This blog post outlines why we prioritized certain vulnerability classes, the steps we took to further eliminate vulnerabilities, and the measurable outcomes of our work.
Cloudflare’s core security philosophy is to prevent security vulnerabilities from entering production environments. One of the goals for Cloudflare’s Product Security team is to champion this philosophy and ensure secure-by-design approaches are part of product and platform development. Over the last six months, the Product Security team aggressively added both new and customized rulesets aimed at completely eliminating secrets and injection code vulnerabilities. These efforts have enhanced detection precision, reducing false positives, while enabling the proactive detection and blocking of these two vulnerability classes. Cloudflare’s security practice to block vulnerabilities before they are introduced into code at merge or code changes serves to maintain a high security posture and aligns with CISA’s pledge around proactive security measures.
Injection vulnerabilities are a critical vulnerability class, irrespective of the product or platform. These occur when code and data are improperly mixed due to lack of clear boundaries as a result of inadequate validation, unsafe functions, and/or improper sanitization. Injection vulnerabilities are considered high impact as they lead to compromise of confidentiality, integrity, and availability of the systems involved. Some of the ways Cloudflare continuously detects and prevents these risks is through security reviews, secure code scanning, and vulnerability testing. Additionally, ongoing efforts to institute improved precision serve to reduce false positives and aggressively detect and block these vulnerabilities at the source if engineers accidentally introduce these into code.
Secrets in code is another vulnerability class of high impact, as it presents significant risk related to confidential information leaks, potentially leading to unauthorized access and insider threat challenges. In 2023, Cloudflare prioritized tuning our security tools and systems to further improve the detection and reduction of secrets within code. Through audits and usage patterns analysis across all Cloudflare repositories, we further decreased the probability of the reintroduction of these vulnerabilities into new code by writing and enabling enhanced secrets detection rules.
Cloudflare is committed to elimination of these vulnerability classes regardless of their criticality. By addressing these vulnerabilities at their source, Cloudflare has significantly reduced the attack surface and the potential for exploitation in production environments. This approach established secure defaults by enabling developers to rely on frameworks and tools that inherently separate data or secrets from code, minimizing the need for reactive fixes. Additionally, resolving these vulnerabilities at the code level “future-proofs” applications, ensuring they remain resilient as the threat landscape evolves.
To address both injection and embedded secrets vulnerabilities, Cloudflare focused on building secure defaults, leveraging automation, and empowering developers. To establish secure default configurations, Cloudflare uses frameworks designed to inherently separate data from code. We also increased reliance on secure storage systems and secret management tools, integrating them seamlessly into the development pipeline.
Continuous automation played a critical role in our strategy. Static analysis tools integration with DevOps process were enhanced with customized rule sets to block issues based on observed patterns and trends. Additionally, along with security scans running on every pull and merge request, software quality assurance measures of “build break” and “stop the code” were enforced. This prevented risks from entering production when true positive vulnerabilities were detected across all Cloudflare development activities, irrespective of criticality and impacted product. This proactive approach has further reduced the likelihood of these vulnerabilities reaching production environments.
Developer enablement was another key pillar. Priority was placed on bolstering existing continuous education and training for engineering teams by providing additional guidance and best practices on preventing security vulnerabilities, and leveraging our centralized secrets platform in an automated way. Embedding these principles into daily workflows has fostered a culture of shared responsibility for security across the organization.
To operationalize the more aggressive detection and blocking capabilities, Cloudflare’s Product Security team wrote new detection rulesets for its static application security testing (SAST) tool integrated in CI/CD workflows and hardened the security criteria for code releases to production. Using the SAST tooling with both default and custom rulesets allows the security team to perform comprehensive scans for secure code, secrets, and software supply chain vulnerabilities, virtually eliminating injection vulnerabilities and secrets from source code. It also enables the security team to identify and address issues early while systematically enforcing security policies.
Cloudflare’s expansion of the security tool suite played a critical role in the company’s secure product strategy. Initially, rules were enabled in “monitoring only” mode to understand trends and potential false positives. Then rules were fine-tuned to enforce and adjust priorities without disrupting development workflows. Leveraging internal threat models, the team writes custom rules tailored to Cloudflare’s infrastructure. Every pull request (PR) and merge request (MR) was scanned against these specific rule sets, including those targeting injection and secrets. The fine-tuned rules, optimized for high precision, are then activated in blocking mode, which leads to breaking the build when detected. This process provides vulnerability remediation at the PR/MR stage.
Hardening these security checks directly into the CI/CD pipeline enforces a proactive security assurance strategy in the development lifecycle. This approach ensures vulnerabilities are detected and addressed early in the development process before reaching production. The detection and blocking of these issues early reduces remediation efforts, minimizes risk, and strengthens the overall security of our products and systems.
Cloudflare continues to follow a culture of transparency as it provides increased visibility into the root cause of an issue and consequently allowing us to improve the process/product at scale. As a result, these efforts have yielded tangible results and continue to strengthen the security posture of all Cloudflare products.
In the second half of 2024, the team aggressively added new rulesets that helped detect and remove new secrets introduced into code repositories. This led to a 79% reduction of secrets in code over the previous quarter, underscoring Cloudflare’s commitment to safeguarding the company’s codebase and protecting sensitive information. Following a similar approach, the team also introduced new rulesets in blocking mode, irrespective of the criticality level for all injection vulnerabilities. These improvements led to an additional 44% reduction of potential SQL injection and code injection vulnerabilities.
While security tools may produce false positives, customized rulesets with high-confidence true positives remain a key step in order to methodically evaluate and address the findings. These reductions reflect the effectiveness of proactive security measures in reducing entire vulnerability classes at scale.
Cloudflare will continue to mature the current practices and enforce secure-by-design principles. Some other security practices we will continue to mature include: providing secure frameworks, threat modeling at scale, integration of automated security tooling in every stage of the software development lifecycle (SDLC), and ongoing role based developer training on leading edge security standards. All of these strategies help reduce, or eliminate, entire classes of vulnerabilities.
Irrespective of the industry, if your organization builds software, we encourage you to familiarize yourself with CISA’s ‘Secure by Design’ principles and create a plan to implement them in your company. The commitment is built around seven security goals, prioritizing the security of customers.
The CISA Secure by Design pledge challenges organizations to think differently about security. By addressing vulnerabilities at their source, Cloudflare has demonstrated measurable progress in reducing systemic risks.
Cloudflare’s continued focus on addressing vulnerability classes through prevention mechanisms outlined above serves as a critical foundation. These efforts ensure the security of Cloudflare systems, employees, and customers. Cloudflare is invested in continuous innovation and building a safe digital world.
You can also find more updates on our blog as we build our roadmap to meet all seven CISA Secure by Design pledge goals by May 2025, such as our post about reaching Goal #5 of the pledge.
As a cybersecurity company, Cloudflare considers product security an integral part of its DNA. We strongly believe in CISA’s principles issued in the Secure by Design pledge, and will continue to uphold these principles in the work we do.
Post Syndicated from original https://www.toest.bg/arhitekturata-na-obrazovanieto-urotsi-ot-istoriyata-na-detskite-gradini-v-bulgaria/

Училищата и детските градини ни казват много както за развитието на обществото и неговите ценности, така и за настоящето му. Същевременно те илюстрират и множество настоящи проблеми.
Предисторията и основите на съвременното българско предучилищно образование може да се открият в колективните грижи и социалната отговорност за възпитанието и отглеждането на децата през XIX в. Този подход е отражение на тогавашната реалност, когато семейството, включително баби, дядовци и по-големите деца, е играло водеща роля в грижите за подрастващите. Общността също е заемала важно място, демонстрирайки силна подкрепа и чувство за принадлежност, насочени към развитието на „новия живот“. Традициите и обичаите са били основният метод за предаване на културни и морални ценности, докато процесът по модернизация не е наложил необходимостта от образователни институции.
С модернизирането на обществото все повече родители започват да работят извън дома и така в края на XIX век възниква потребността от предучилищно образование. Още през 1882 г. Никола Живков и жена му откриват първата детска градина в Свищов, която нарекли „Детинска мъдрост“. Живков впрочем е участник в Руско-турската война и автор на първия български химн – „Шуми Марица“.
Принос към развитието на детските градини има и Анастасия Тошева, която поставя основите на философията на ранното образование в България. В съответствие с нейните възгледи и с нейното съдействие са положени основите на осигуряването на грижи и начално обучение преди постъпване в училище. През 1905 г. по инициатива на Софийската община се открива първата детска градина в столицата, разположена в къща на ул. „Сердика“. Създаването ѝ е вдъхновено от модерните тогава европейски модели и идеите на германския педагог Фридрих Фрьобел.
През първата половина на XX в. австрийската архитектка Маргарете Шюте-Лихоцки оставя значителен отпечатък върху архитектурата на детските градини в България. Вдъхновена от германската архитектурна школа „Баухаус“, тя въвежда модернистични идеи, залагайки на функционалност, естествена светлина, достъпни материали и връзка с природата. Нейните проекти се отличават с рационален дизайн, осигуряващ комфорт и икономическа ефективност. Сред реализираните ѝ проекти е днешната 199-та детска градина „Сарагоса“ в столичния квартал „Банишора“, както и Детска градина №1 на ул. „Брегалница“ №48. За съжаление, архитектурното състояние и намесите в тези сгради през годините силно са подменили автентичния им образ.
По времето на социализма става задължително всички да работят, включително жените. Така възниква необходимостта от масови детски градини. Децата са в тях в делничните дни и прекарват вкъщи само почивните. Детските градини стават широко достъпни, включително в селските райони. Откриването на ясли за деца до 3-годишна възраст допълнително разширява обхвата на предучилищното образование. Яслите и градините предоставят цялостни грижи, включително храна, медицинска помощ и обучение. Всичко това върви в комплект с идеологическо индоктриниране на децата. Основните му акценти са върху колективизма, трудовото възпитание и лоялността към социалистическата идеология.
С края на социализма този модел губи популярност, тъй като дългият престой на децата в институции започва да се възприема като недостатък за тяхното развитие. Все повече деца се отглеждат от бабите и дядовците си или се „самоотглеждат“ – като малкия Митко от филма „Куче в чекмедже“.
До 1989 г. детските градини се планират с цялостни устройствени планове, които включват т.нар. баланс на територията, тоест търсене на оптимално съотношение между броя на новозаселващите се домакинства и капацитета на градините. Типичен пример са изградените по времето на социализма столични квартали, например „Люлин“, „Младост“, „Дружба“ и „Надежда“, в които сградите и терените на детските градини са унифицирани, но съобразени с демографското натоварване, съпровождащо заселването в новопостроените жилища. Детските градини се планират така, че до тях да може да се стигне за около 5 минути път пеша, което е видно от пространствените анализи на тези квартали. В тях мрежата от детски заведения е гъста, а сградите са с просторни дворове.
След 1989 г. предучилищното образование става – поне на теория – по-свободно и фокусирано върху индивидуалното развитие. Въпреки това развитието на системата се забавя, изоставайки от световните тенденции, според които в образованието се поставя акцент върху съзряването, развитието на духовност, социална принадлежност и емоционална интелигентност. Детските градини и училищата често не отговарят на съвременните тенденции, а липсата на иновации в предучилищното и училищното образование поставя децата в България в неконкурентна среда и липса на равен старт спрямо техни връстници от други държави.
През 90-те години на ХХ век България попада в поредица от икономически кризи. След падането на тоталитарния режим вече е позволено да се пътува в чужбина и над милион българи емигрират. До 1997 г. раждаемостта бележи спад. Тези процеси водят до затваряне на голяма част от детските заведения или до промяна на тяхната функция. В същото време новоразвиващите се квартали, особено в южната част на София („Манастирски ливади“, „Кръстова вада“, „Малинова долина“, „Витоша“ и др.), се изграждат на базата на т.нар. частични изменения на устройствените планове. По този начин се дава зелена светлина на достигането на максималните параметри на застрояване от Общия устройствен план на София. Така се нарушава балансът на територията, а значението на социалната инфраструктура (пътища, обществен транспорт, училища, детски градини и т.н.) се маргинализира (вж. анализите на „Софияплан“ на „Южен Лозенец“ за кварталите „Кръстова вада“ и „Витоша“, както и анализа на „Манастирски ливади – изток“).
Пример за подобно маргинализиране е кв. „Манастирски ливади – запад“. Първоначално той е планиран като добре балансиран, зелен и с гледка към Витоша, със средно към ниско застрояване, зелени площи и социална инфраструктура. С годините обаче се превръща в силно застроено „бетонно гето“, лишено от основни обществени услуги. Това е един от изводите от анализите на „Софияплан“ на подробните устройствени планове.
Реституцията в реални граници след 1989 г. допълнително усложнява планирането. Процесът изисква дълги и трудни процедури по отчуждаване, което забавя изграждането на публичната инфраструктура – като улици, детски градини, паркове и училища. В началото на XXI в. строителният бум на жилищни и бизнес сгради задълбочава още повече пропастта между частните и общинските инвестиции. Темпото на изграждане на жилища изпреварва значително развитието на инфраструктурата.
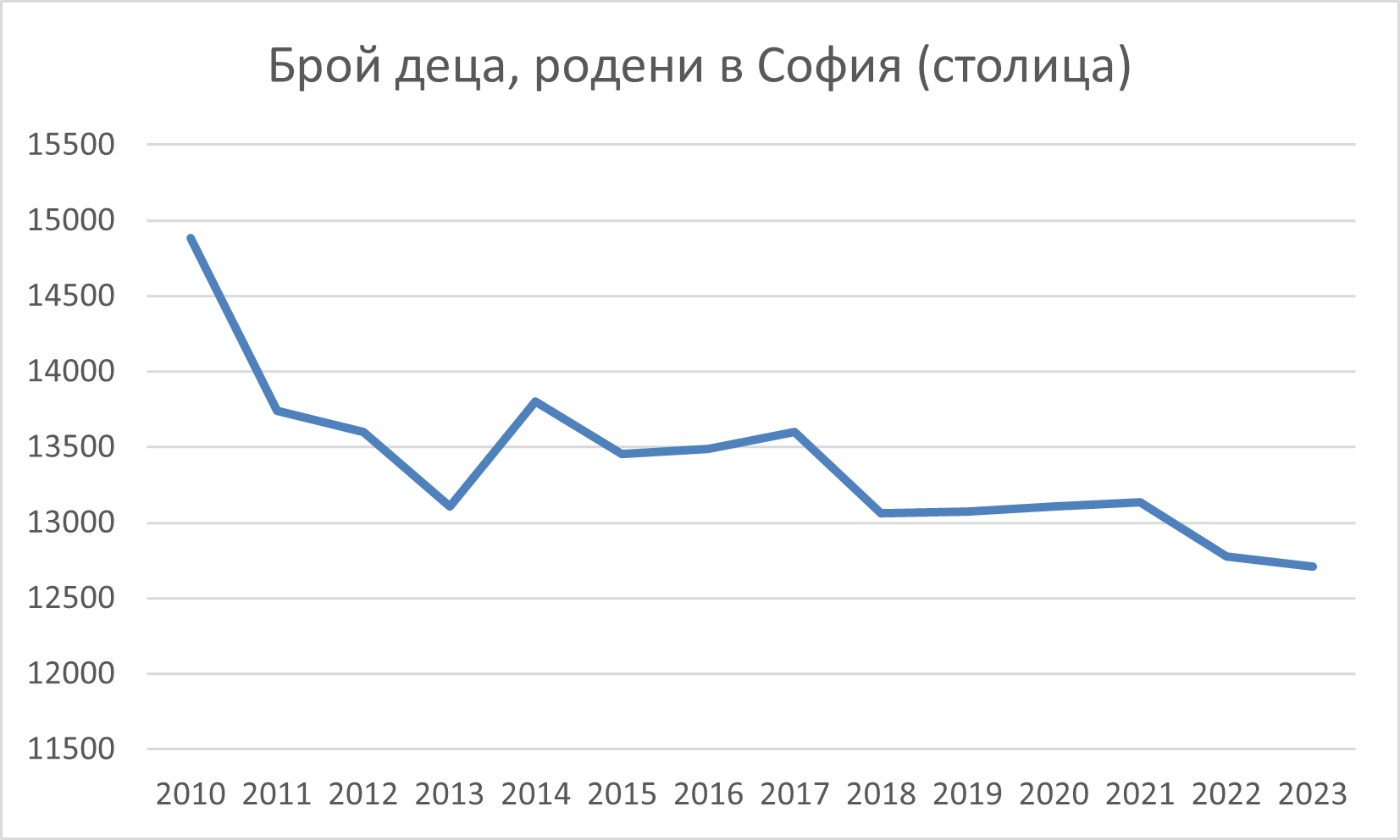
След отмяната на социалистическото жителство (задължението хората да живеят в точно определено населено място) се увеличава притокът на население към София. Същевременно след 1997 г., като се изключи периодът на въздействието на глобалната икономическа криза в България, коефициентът на плодовитост в страната бележи ръст (в София тенденцията е по-различна). Тези процеси водят до допълнително задълбочаване на проблема и недостиг на места в детските градини. Любопитен факт обаче е, че въпреки намаляващата раждаемост в София след 2010 г., дефицитът на места в детските градини достига около 10 000 деца през последните години.
Последиците от този дефицит не са само неприети деца, нито се свежда до увеличената социална тежест, която се прехвърля върху семействата под формата на финансово и времево бреме. Той се отразява на цялото функциониране на града – усилията на родителите да осигурят място за децата си често водят до промяна на адресната регистрация и „паразитен“ трафик. Както показва анализът на „Софияплан“ на „Манастирски ливади – запад“, новите квартали без социална инфраструктура натоварват и добре планираните (поне преди презастрояването им) стари квартали, нарушавайки баланса на територията и капацитета на обществените услуги.
В търсенето на решения за недостига на места в детските градини са разработени редица стратегии и програми – като дългосрочната „Визия за София“ и краткосрочната Програма за строителство на детски градини 2021–2023. Въпреки усилията проблемът често се крие в липсата на яснота и систематичност при вземането на решения, които невинаги са аргументирани, рационални и базирани на данни. Действията се предприемат хаотично, без да се отчита съществуващата демографска картина на София, а концентрацията на децата в различни райони остава неясна.
Не се отчита и информацията за броя на родителите, които изобщо не кандидатстват за места в детски градини или ясли, водени от убеждението, че шансовете им са нищожни. Скорошен и все още непубликуван анализ, направен от „Софияплан“, разглежда капацитета на всички детски градини спрямо нормативните изисквания, като определя потенциала за тяхното разширяване на базата на съществуващото застрояване и устройствени параметри, а също така картира наличните имоти, предвидени за детски градини. В него се включва и информация за статута на собственост на терените на тези имоти и фазата на реализацията на проектите за градините. Подходът предоставя ясна представа за ресурсите, с които разполага общината, и показва какви интервенции могат да бъдат извършени извън изграждането на нови сгради върху неусвоени терени.
Често пренебрегван е и един ключов аспект на проблема – пространственото разпределение на детските градини. Понастоящем все по-ясно се откроява дисбалансът между местоположението на съществуващите детски заведения, от една страна, и демографската динамика и реалното търсене, от друга. Един систематичен подход би означавал да се вземат предвид данни за демографската структура на отделните квартали, дългосрочните демографски прогнози, устройствените планове, издадените визи за проектиране и разрешителните за строеж. Това би позволило да се идентифицират зоните с най-голямо натоварване и най-голяма нужда от нови или разширени обекти.
На основата на такива данни вече е възможно да се търсят конкретни, индивидуални решения за всеки район, вместо да се прилага универсален подход за целия град. Един от примерите е Програмата за строителство на детски градини 2021–2023 г., която успя частично да намали дефицита, но не реши проблема изцяло. Общият брой места в детските градини и ясли може да съответства на броя на децата в София, но това само по себе си не е достатъчно. От ключово значение е също местоположението на детската градина спрямо местоживеенето на детето. С други думи, ако вниманието се насочи само към количествени показатели, без да се отчитат качествените и пространствените характеристики, проблемът ще остане трайно нерешен.
Планирането и детайлното проектиране на детски градини изисква внимателно вникване и в редица въпроси, например: Дали да строим нови, или да адаптираме съществуващи сгради? Какво преживяване осигуряваме на децата в градинския двор? Как интегрираме архитектура, интериор, мебелен и графичен дизайн? Отговор на тези въпроси ще потърсим в следващата ни статия по темата.
В настоящата ни съвместна поредица с „Екипът на София“ обсъждаме планирането, озеленяването, архитектурата, инфраструктурата, мобилността и още много други градски теми, описваме добрите примери и търсим възможните решения за подобряването на качеството на живот в нашите градове.
Post Syndicated from original https://www.toest.bg/literaturata-vinagi-sushtestvuva-nasred-protivorechiya-2/

„Път сред пътеките“ – спомням си тези думи на Рьоне Шар, посягайки отново и отново към „Китай в десет думи“ на Ю Хуа. Книгата излезе през миналата година във великолепния превод на Стефан Русинов. Пътят е Китай, разбира се, безкраен и безграничен, какъвто си е във времето и пространството, а пътеките, сред които лъкатуши, са смехът и ужасът, въображението и истината, преживяваното и невъзможното за преживяване, Културната революция, Бандата на четиримата и котката на Дън Сяопин, ментосването на дребно и едро и болезненият стремеж към истината. Пътят се вие дълъг, а по него се нижат и думите: „народ“, „революция“, „писане“, „неравенство“ и т.н. Ето го цял Китай, Китай като минало и настояще, събран в точно десет думи – само десет, но какви… Вярно е, че понякога думата дупка не прави, но думите на Ю Хуа са от друг порядък: те измислят, и то измислят истината. Не е за учудване тогава, че това е единствената негова книга, която все още чака да бъде издадена в родината му.
Следващият кратък разговор с автора е покана към читателя да се потопи в света на тези десет думи, откривайки за себе си един свой път през пътеките.
Тъй като Вашата книга е посветена на думите, позволете ми да започна с въпрос, свързан с езика. Какво е китайският език за Вас като автор? По какъв начин „магията“ му е свързана с истината? A с лъжата?
Китайският език се състои от едносрични думи, в китайската прозодия ритъмът изпъква повече от мелодията, затова, когато искаме да кажем, че някоя творба е написана добре, често използваме фрази от рода на „звънти в устата“ – значи, че се чете плавно и звънко. Магията на литературния език идва от въображението на писателя – въображението без проницателност най-често е нещо празнословно, а проницателността без въображение винаги е нещо приковано – като войник, който марширува на място. А лъжите, стига само да се повтарят, да се повтарят непрекъснато, ден след ден, година след година, се превръщат в истини.
В едно интервю казвате, че Кафка Ви е научил на един особен тип свобода – призоваването и отзоваването на нещата посредством езика. Смятате ли, че литературата трябва да поддържа света, или е призвана да го поставя под въпрос? Ако мога да използвам съзнателно две клишета – еволюционна или революционна трябва да бъде тя?
Ако един писател не се съмнява в света, той не би имал мотив да пише, така че усъмняването в нашия свят е мотивът ни да не спираме да пишем. Писането тръгва от съмнението и поддържа един измислен свят – трябва да се уточни, че поддържаният от литературата свят е измислен, но между него и действителния има определени съответствия. Читателят, изхождайки от собствената си гледна точка, влиза в творбата, където открива собствените си съответствия с действителността. В този смисъл литературата е едновременно еволюционна и революционна – понеже читателите се променят поколение след поколение, променят се и техните отношения със света, понякога по еволюционен начин, друг път – по революционен.
В една от главите в „Китай в десет думи“, посветена на писането, Вие се спирате на факта, че в ранните Ви разкази доминират насилието и смъртта, и обяснявате как те са свързани с преживяванията Ви по време на Културната революция. Говорите още и за тогавашните си сънища, както и за това, че денем сте убивал в творчеството си, а пък вечер са убивали Вас насън. Какви са сънищата Ви днес – начало или край за Вас?
Аз вече не сънувам нито хубави, нито лоши сънища. Сигурно защото всяка вечер преди лягане вземам приспивателни – пия две таблетки естазолам, лекарство за удължаване на съня, всъщност то не удължава кой знае колко съня, но пък спя, без да сънувам, пия го вече от няколко години. Литературата понякога е сънуване, друг път е събуждане, различните писатели пишат различни творби, различните читатели избират да четат различни творби. Литературата винаги съществува насред противоречия, в нея има усмивки и сълзи, благословии и проклятия и пр.
В разказите и романите Ви абсурдът и гротеската постоянно се вплитат в тъканта на най-баналното всекидневие, а преживяванията на героите в него изглеждат едновременно познати и непознати, близки и далечни. Същото се вижда на много места и в „Китай в десет думи“: аналитични и исторически наблюдения изведнъж пропадат в бездната на спомените Ви, възкресяващи живота в Китай през 70-те и 80-те, наситен с чудати персонажи и абсурдни ситуации. Човек се опитва да мисли с Вас за Китай, но мисълта му редовно бива поставяна на изпитание – или от смях, или от ужас. Има ли все пак някаква точка на равновесие между двете?
Когато пиша разкази и романи, се стремя да не анализирам, искам нещата в разума да бъдат изразени с похватите на чувствата. Думите и действията на персонажите, детайлите, напредването на сюжета – всички проблеми на разказването да се разрешават с похватите на разказването. „Китай в десет думи“ е друго, това е документална книга, нещата в разума могат да бъдат изразени с похватите на разума, тоест нямам нужда от разказвателни увъртания, за да изразя мислите си, мога направо да ги изкажа, като аз не изказвам гледища, това всеки го може, то не е важно, важното е какво е предизвикало гледището, затова трябва да привеждам примери, примери от реалността и историята, разбира се, собствените ми изживявания са още по-живи и интересни, затова и по-силни. Така написах тази книга. Точката на равновесие, за която говорите, е много важна, трябва да се омесят в едно собствените разсъждения, познания и реалност с историческите факти и личните изживявания, трябва на всеки кръстопът на разказването да се намери мястото на равновесие и оттам да се пише за всички тези неща. На това са ме научили дългите години писане – способен съм да намеря повечето точки на равновесие. Но се случва и да не мога и това са моментите, в които писането няма как да продължи.
А какво е мястото на Красотатa в писането Ви? Изкушен съм да цитирам една мисъл на танския философ и поет Лиу Дзунюен, която по някакъв начин е останала в ума ми още от времето, когато бях ученик: „Красотата не проявява сама себе си, а бива разкрита от човека“, след което Лиу продължава, че ако Уан Сиджъ не беше описал Павилиона на орхидеите, неговата красота щеше да изчезне в бездната на планината, без никога да бъде позната. Съгласен ли сте с Лиу?
Много съм изненадан, че сте чели Лиу Дзунюен като ученик. Тази негова мисъл чудесно изразява отношението между съществуването и откриването на красотата. Красотата е навсякъде, а ние откриваме само малка част от нея. Примерът с Павилиона на орхидеите показва как се придобива усетът за красота – Лиу Дзунюен набляга върху важността на субекта при усещането на красотата. Преди десет години посетих Павилиона на орхидеите и сега с голямо съжаление ви казвам, че като естетически обект той вече не съществува. Казано направо, красотата я няма, поне не онази красота на Уан Сиджъ – профанизацията, извършена от туристическата индустрия, е унищожила красотата на Павилиона на орхидеите.
На много места в книгата се връщате настойчиво към Културната революция, нейните езици, символи и практики. От друга страна, неведнъж е било отбелязвано значението ѝ за литературата в Китай: първо на спирачка, а през 80-те и 90-те – на двигател на нейното развитие. Какво е значението на Културната революция за днешен Китай?
Днес в Китай Културната революция е нещо много далечно. Нашето поколение, което е изживяло тази епоха, при това е израснало в нея, няма да я забрави, макар че споменът неизбежно ще избледнява – времето е безмилостно, то е гумичка, минаваща през спомените ни. А по-младите поколения в Китай не знаят какво е Културната революция, за тях това е просто название. За мое голямо съжаление има и такива млади хора, които преиначават тази епоха, те не знаят какви бедствия е донесла тя на страната ни и сега някои техни действия и думи все повече бият на културнореволюционност. Затова и ще продължавам да пиша за истинските изживявания по време на тази епоха. Надеждата ми е, че посредством литературата истинската Културна революция ще остане в четенето на хората – колкото, толкова.
Прави впечатление, че отделните есета в книгата могат да се обединят в своеобразни блокове. Вие пишете за историята на Китай през ХХ век, за нейните превратности и жестокост („народ“, „лидер“, „революция“), както и за ефектите от тях през ХХI век („неравенство“, „низовци“, „менте“, „баламосване“). И сякаш единствената утеха и единственият начин за противодействие – макар и вероятно обречен – се оказват словото и изкуството („четене“, „писане“, „Лу Сюн“). Дали литературата трябва да доближава предела, или да го отдалечава?
Харесва ми това разделение на три части, освен това сте изказали напрегнатите отношения между тях, страхотен анализ, много интересен. Аз съм преживял две крайни епохи – Културната революция през 60-те и 70-те и реформите и отварянето през 80-те. Книгата ми „Братя“ е написана чрез приближаване на всички крайни неща възможно най-близо до мен, а в „Живи“ се опитах да опиша крайностите, но едва след като ги отдалечих от себе си.
Петнайсет години ни делят от първото издание на „Китай в десет думи“. И до днес обаче книгата не е публикувана в Китай. Ако сега трябва да я пренапишете, изкушен ли сте да замените някои от десетте думи в светлината на днешното време?
Да, старите думи вече са заменени от нови. Тази година написах една статия за The Economist за това как младите хора в днешен Китай дават мило и драго да се домогнат до държавна служба. За тях най-важната дума е „служба“, тоест да имат стабилна работа в държавния апарат и да няма опасност да ги съкратят – това, което в миналото наричахме „желязна паница“.
Превод от китайски Стефан Русинов
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/01/the-first-password-on-the-internet.html
It was created in 1973 by Peter Kirstein:
So from the beginning I put password protection on my gateway. This had been done in such a way that even if UK users telephoned directly into the communications computer provided by Darpa in UCL, they would require a password.
In fact this was the first password on Arpanet. It proved invaluable in satisfying authorities on both sides of the Atlantic for the 15 years I ran the service during which no security breach occurred over my link. I also put in place a system of governance that any UK users had to be approved by a committee which I chaired but which also had UK government and British Post Office representation.
I wish he’d told us what that password was.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=wMEBbRHBosk
Post Syndicated from Lizzie Jackson original https://www.raspberrypi.org/blog/entry-is-open-for-coolest-projects-2025/
Coolest Projects is our global technology showcase for young people aged up to 18. Coolest Projects gives young creators the incredible opportunity to share the cool stuff they’ve made using digital technology with a global audience. Everyone who takes part will also receive certificates and rewards to celebrate their achievements.

The Coolest Projects online showcase is open to young people worldwide. Young creators can enter their projects to share them with the world in our online project gallery and join our extra special livestream event to celebrate what they have made with the global Coolest Projects community.
By taking part in Coolest Projects, young people can join an international community of young makers, represent their country, receive feedback on their projects, and get certificates to recognise their achievements.
Coolest Projects is completely free to take part in, and we welcome all digital technology projects, from young people’s very first projects to advanced builds. The projects also don’t have to be completed before they can be submitted.

Projects can be submitted to one of seven categories: Scratch, games, web, mobile apps, hardware, advanced programming, and AI (new for 2025).
We know Coolest Projects has a big impact on young people all over the world, and we can’t wait to see your creations for 2025. You can find out more about the incredible creativity and collaboration from mentors and makers worldwide in our 2024 impact report.

Taking part in Coolest Projects is simple:
Mentors — entering more than one project? Sign up for a group code, and your young people can link their projects to your account.
Submit your coolest projects. Every young person who uses your group code will have their project linked to your account. You can review and edit their projects in your group dashboard and submit them from there. There is no limit to the number of young people who can submit entries using your group code.
For a more detailed run-through of how to use group codes, please see our ‘how-to’ video.
As well as the global online showcase, Coolest Projects in-person events are held for young people locally in certain countries. We encourage creators to take part in both the online showcase and their local in-person event. In 2025, creators can attend the following in-person events, run by the Raspberry Pi Foundation and partner organisations around the world:

More events are on the way, so sign up for the Coolest Projects newsletter to be sure you hear about any in-person events in your country. And if there isn’t an event near you, don’t worry, as the online showcase is open to any young person anywhere in the world.
Coolest Projects welcomes all digital tech projects, from beginner to advanced, and there are loads of great resources available to help you help the young people in your community to take part. If you’re searching for inspiration, take a look at the 2024 showcase gallery, where you can explore the incredible projects submitted by participants last year.
You’ll find everything you need to know about all seven Coolest Projects categories on our category pages, including our brand new AI category. Our projects site is also a great place for participants to begin — there are hundreds of free step-by-step project guides to help young people create their own projects, whether they’re experienced tech creators or just getting started.

We will also be running a series of online webinars for mentors and young people to help participants develop their creations for each Coolest Projects category. Sign up for the sessions here. All sessions will be recorded, so you can watch them back if you can’t join live.
Be sure to check out the Coolest Projects guidance page for resources to help you support young people throughout their Coolest Projects journey, including a mentor guide and session plans.
There’s lots more exciting news to come, from the announcement of our VIP judges to details about this year’s swag, so sign up for updates to be the first to know.
Whether your coders have already made something that they want to share, or they’re inspired to make something new, Coolest Projects is the place for them. We can’t wait to see what they create!
The post Entry is open for Coolest Projects 2025 appeared first on Raspberry Pi Foundation.
