Post Syndicated from Rostislav Markov original https://aws.amazon.com/blogs/devops/balance-deployment-speed-and-stability-with-dora-metrics/
Development teams adopt DevOps practices to increase the speed and quality of their software delivery. The DevOps Research and Assessment (DORA) metrics provide a popular method to measure progress towards that outcome. Using four key metrics, senior leaders can assess the current state of team maturity and address areas of optimization.
This blog post shows you how to make use of DORA metrics for your Amazon Web Services (AWS) environments. We share a sample solution which allows you to bootstrap automatic metric collection in your AWS accounts.
Benefits of collecting DORA metrics
DORA metrics offer insights into your development teams’ performance and capacity by measuring qualitative aspects of deployment speed and stability. They also indicate the teams’ ability to adapt by measuring the average time to recover from failure. This helps product owners in defining work priorities, establishing transparency on team maturity, and developing a realistic workload schedule. The metrics are appropriate for communication with senior leadership. They help commit leadership support to resolve systemic issues inhibiting team satisfaction and user experience.
Use case
This solution is applicable to the following use case:
- Development teams have a multi-account AWS setup including a tooling account where the CI/CD tools are hosted, and an operations account for log aggregation and visualization.
- Developers use GitHub code repositories and AWS CodePipeline to promote code changes across application environment accounts.
- Tooling, operations, and application environment accounts are member accounts in AWS Control Tower or workload accounts in the Landing Zone Accelerator on AWS solution.
- Service impairment resulting from system change is logged as OpsItem in AWS Systems Manager OpsCenter.
Overview of solution
The four key DORA metrics
The ‘four keys’ measure team performance and ability to react to problems:
- Deployment Frequency measures the frequency of successful change releases in your production environment.
- Lead Time For Changes measures the average time for committed code to reach production.
- Change Failure Rate measures how often changes in production lead to service incidents/failures, and is complementary to Mean Time Between Failure.
- Mean Time To Recovery measures the average time from service interruption to full recovery.
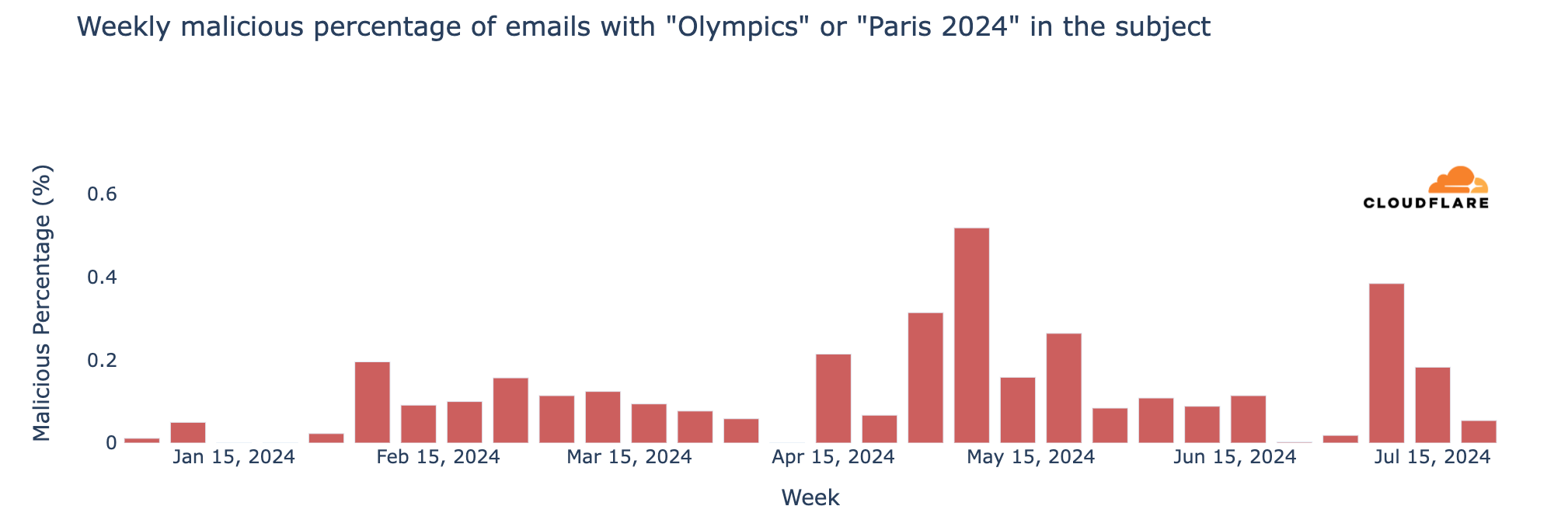
The first two metrics focus on deployment speed, while the other two indicate deployment stability (Figure 1). We recommend organizations to set their own goals (that is, DORA metric targets) based on service criticality and customer needs. For a discussion of prior DORA benchmark data and what it reveals about the performance of development teams, consult How DORA Metrics Can Measure and Improve Performance.

Figure 1. Overview of DORA metrics
Consult the GitHub code repository Balance deployment speed and stability with DORA metrics for a detailed description of the metric calculation logic. Any modifications to this logic should be made carefully.
For example, the Change Failure Rate focuses on changes that impair the production system. Limiting the calculation to tags (such as hotfixes) on pull requests would exclude issues related to the build process. It’s important to match system change records that lead to actual impairments in production. Limiting the calculation to the number of failed deployments from the deployment pipeline only considers deployments that didn’t reach production. We use AWS Systems Manager OpsCenter as the system of records for change-related outages, rather than relying solely on data from CI/CD tools.
Similarly, Mean Time To Recovery measures the duration from a service impairment in production to a successful pipeline run. We encourage teams to track both pipeline status and recovery time, as frequent pipeline failure can indicate insufficient local testing and potential pipeline engineering issues.
Gathering DORA events
Our metric calculation process runs in four steps:
- In the tooling account, we send events from CodePipeline to the default event bus of Amazon EventBridge.
- Events are forwarded to custom event buses which process them according to the defined metrics and any filters we may have set up.
- The custom event buses call AWS Lambda functions which forward metric data to Amazon CloudWatch. CloudWatch gives us an aggregated view of each of the metrics. From Amazon CloudWatch, you can send the metrics to another designated dashboard like Amazon Managed Grafana.
- As part of the data collection, the Lambda function will also query GitHub for the relevant commit to calculate the lead time for changes metric. It will query AWS Systems Manager for OpsItem data for change failure rate and mean time to recovery metrics. You can create OpsItems manually as part of your change management process or configure CloudWatch alarms to create OpsItems automatically.
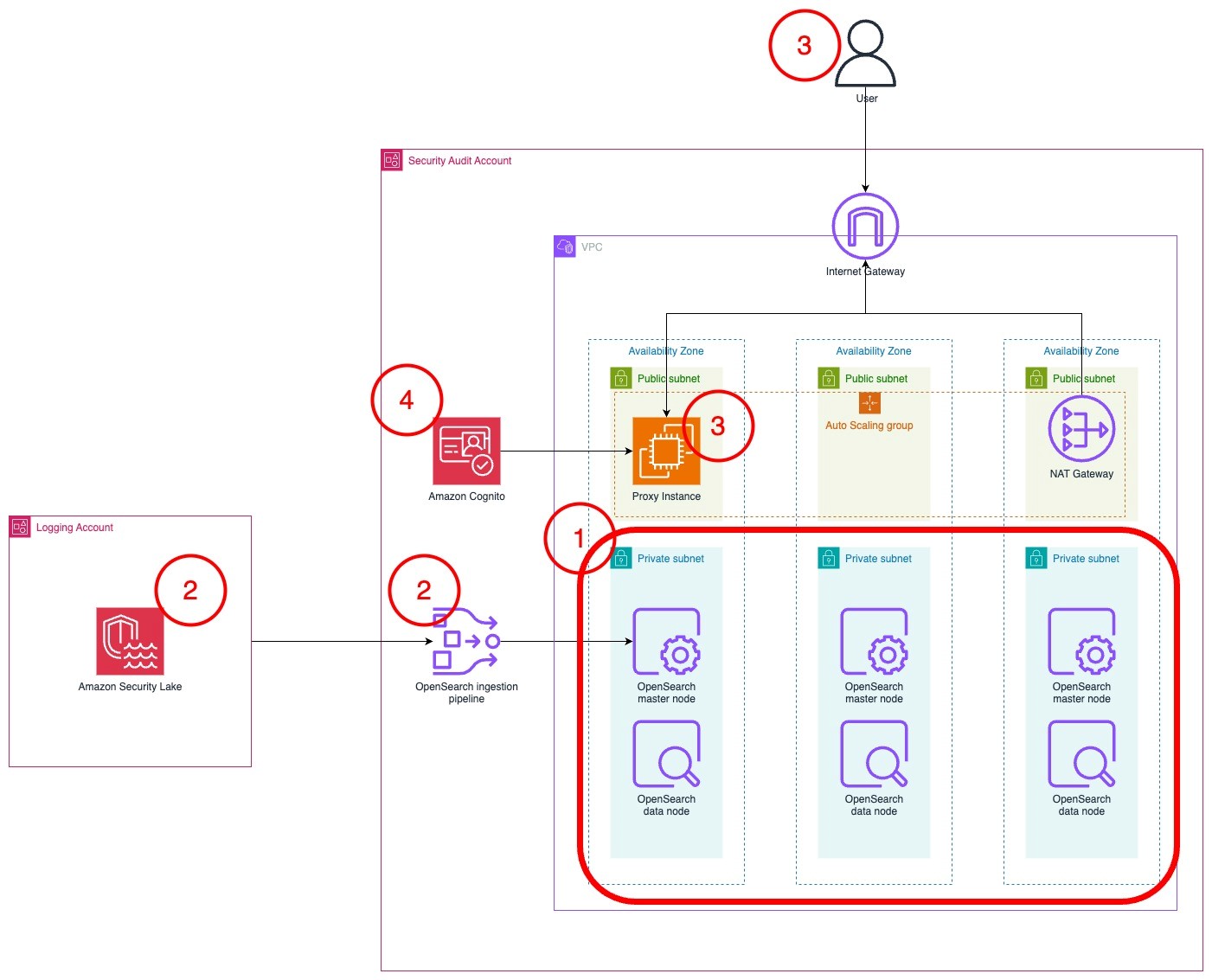
Figure 2 visualizes these steps. This setup can be replicated to a group of accounts of one or multiple teams.

Figure 2. DORA metric setup for AWS CodePipeline deployments
Walkthrough
Follow these steps to deploy the solution in your AWS accounts.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- AWS accounts for tooling, operations, and application environments
- Install Python version 3.9 or later
- AWS Cloud Development Kit (AWS CDK) v2 installed
- Set up an AWS CDK pipeline
- Access to AWS CodePipeline, AWS Systems Manager OpsCenter and GitHub
Deploying the solution
Clone the GitHub code repository Balance deployment speed and stability with DORA metrics.
Before you start deploying or working with this code base, there are a few configurations you need to complete in the constants.py file in the cdk/ directory. Open the file in your IDE and update the following constants:
TOOLING_ACCOUNT_ID&TOOLING_ACCOUNT_REGION: These represent the AWS account ID and AWS region for AWS CodePipeline (that is, your tooling account).OPS_ACCOUNT_ID&OPS_ACCOUNT_REGION: These are for your operations account (used for centralized log aggregation and dashboard).TOOLING_CROSS_ACCOUNT_LAMBDA_ROLE: The IAM Role for cross-account access that allows AWS Lambda to post metrics from your tooling account to your operations account/Amazon CloudWatch dashboard.DEFAULT_MAIN_BRANCH: This is the default branch in your code repository that’s used to deploy to your production application environment. It is set to “main” by default, as we assumed feature-driven development (GitFlow) on the main branch; update if you use a different naming convention.APP_PROD_STAGE_NAME: This is the name of your production stage and set to “DeployPROD” by default. It’s reserved for teams with trunk-based development.
Setting up the environment
To set up your environment on MacOS and Linux:
- Create a virtual environment:
$ python3 -m venv .venv - Activate the virtual environment: On MacOS and Linux:
$ source .venv/bin/activate
Alternatively, to set up your environment on Windows:
- Create a virtual environment:
% .venv\Scripts\activate.bat - Install the required Python packages:
$ pip install -r requirements.txt
To configure the AWS Command Line Interface (AWS CLI):
- Follow the configuration steps in the AWS CLI User Guide.
$ aws configure sso - Configure your user profile (for example, Ops for operations account, Tooling for tooling account). You can check user profile names in the credentials file.
Deploying the CloudFormation stacks
- Switch directory
$ cd cdk - Bootstrap CDK
$ cdk bootstrap –-profile Ops - Synthesize the AWS CloudFormation template for this project:
$ cdk synth - To deploy a specific stack (see Figure 3 for an overview), specify the stack name and AWS account number(s) in the following command:
$ cdk deploy <Stack-Name> --profile {Tooling, Ops}To launch the DoraToolingEventBridgeStack stack in the Tooling account:
$ cdk deploy DoraToolingEventBridgeStack --profile ToolingTo launch the other stacks in the Operations account (including DoraOpsGitHubLogsStack, DoraOpsDeploymentFrequencyStack, DoraOpsLeadTimeForChangeStack, DoraOpsChangeFailureRateStack, DoraOpsMeanTimeToRestoreStack, DoraOpsMetricsDashboardStack):
$ cdk deploy DoraOps* --profile Ops
The following figure shows the resources you’ll launch with each CloudFormation stack. This includes six AWS CloudFormation stacks in operations account. The first stack sets up log integration for GitHub commit activity. Four stacks contain a Lambda function which creates one of the DORA metrics. The sixth stack creates the consolidated dashboard in Amazon CloudWatch.

Figure 3. Resources provisioned with this solution
Testing the deployment
To run the provided tests:
$ pytestUnderstanding what you’ve built
Deployed resources in tooling account
The DoraToolingEventBridgeStack includes Amazon EventBridge rules with a target of the central event bus in the operations account, plus an AWS IAM role with cross-account access to put events in the operations account. The event pattern for invoking our EventBridge rules listens for deployment state changes in AWS CodePipeline:
{
"detail-type": ["CodePipeline Pipeline Execution State Change"],
"source": ["aws.codepipeline"]
}Deployed resources in operations account
- The Lambda function for Deployment Frequency tracks the number of successful deployments to production, and posts the metric data to Amazon CloudWatch. You can add a dimension with the repository name in Amazon CloudWatch to filter on particular repositories/teams.
- The Lambda function for the Lead Time For Change metric calculates the duration from the first commit to successful deployment in production. This covers all factors contributing to lead time for changes, including code reviews, build, test, as well as the deployment itself.
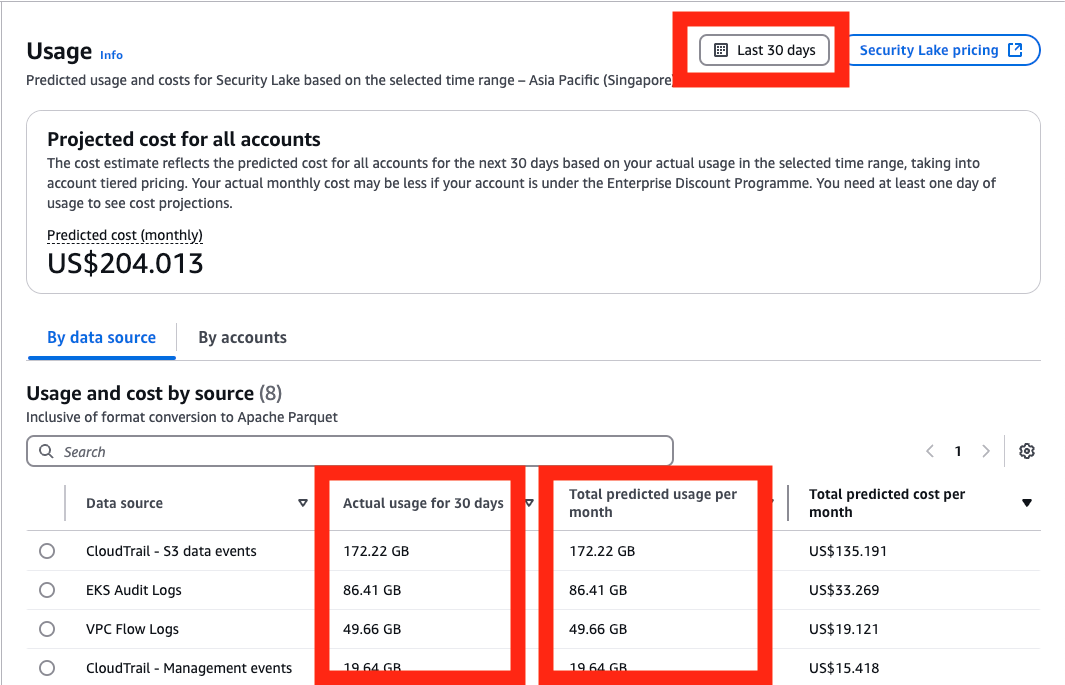
- The Lambda function for Change Failure Rate keeps track of the count of successful deployments and the count of system impairment records (OpsItems) in production. It publishes both as metrics to Amazon CloudWatch and the latter calculates the ratio, as shown in below example.

- The Lambda function for Mean Time To Recovery keeps track of all deployments with status
SUCCEEDEDin production and whose repository branch name references an existing OpsItem ID. For every matching event, the function gets the creation time of the OpsItem record and posts the duration between OpsItem creation and successful re-deployment to the CloudWatch dashboard.

All Lambda functions publish metric data to Amazon CloudWatch using the PutMetricData API. The final calculation of the four keys is performed on the CloudWatch dashboard. The solution includes a simple CloudWatch dashboard so you can validate the end-to-end data flow and confirm that it has deployed successfully:

Cleaning up
Remember to delete example resources if you no longer need them to avoid incurring future costs.
You can do this via the CDK CLI:
$ cdk destroy <Stack-Name> --profile {Tooling, Ops}Alternatively, go to the CloudFormation console in each AWS account, select the stacks related to DORA and click on Delete. Confirm that the status of all DORA stacks is DELETE_COMPLETE.
Conclusion
DORA metrics provide a popular method to measure the speed and stability of your deployments. The solution in this blog post helps you bootstrap automatic metric collection in your AWS accounts. The four keys help you gain consensus on team performance and provide data points to back improvement suggestions. We recommend using the solution to gain leadership support for systemic issues inhibiting team satisfaction and user experience. To learn more about developer productivity research, we encourage you to also review alternative frameworks including DevEx and SPACE.
Further resources
If you enjoyed this post, you may also like:
- DevOps Monitoring Dashboard on AWS
- How to automate capture and analysis of CI/CD metrics using AWS DevOps Monitoring Dashboard solution
































 Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography.
Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography. Vijay Velpula is a Data Lake Architect with AWS Professional Services. He assists customers in building modern data platforms by implementing big data and analytics solutions. Outside of his professional responsibilities, Velpula enjoys spending quality time with his family, as well as indulging in travel, hiking, and biking activities.
Vijay Velpula is a Data Lake Architect with AWS Professional Services. He assists customers in building modern data platforms by implementing big data and analytics solutions. Outside of his professional responsibilities, Velpula enjoys spending quality time with his family, as well as indulging in travel, hiking, and biking activities.





































 Carlos Gallegos is a Senior Analytics Specialist Solutions Architect at AWS. Based in Austin, TX, US. He’s an experienced and motivated professional with a proven track record of delivering results worldwide. He specializes in architecture, design, migrations, and modernization strategies for complex data and analytics solutions, both on-premises and on the AWS Cloud. Carlos helps customers accelerate their data journey by providing expertise in these areas. Connect with him on
Carlos Gallegos is a Senior Analytics Specialist Solutions Architect at AWS. Based in Austin, TX, US. He’s an experienced and motivated professional with a proven track record of delivering results worldwide. He specializes in architecture, design, migrations, and modernization strategies for complex data and analytics solutions, both on-premises and on the AWS Cloud. Carlos helps customers accelerate their data journey by providing expertise in these areas. Connect with him on  Jose Romero is a Senior Solutions Architect for Startups at AWS. Based in Austin, TX, US. He’s passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on
Jose Romero is a Senior Solutions Architect for Startups at AWS. Based in Austin, TX, US. He’s passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on  Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed and uses the working backwards process to build modern architectures to help customers solve their unique challenges. Connect with him on
Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed and uses the working backwards process to build modern architectures to help customers solve their unique challenges. Connect with him on