Post Syndicated from Tyler Holmes original https://aws.amazon.com/blogs/messaging-and-targeting/how-to-build-resilient-sms-delivery-with-aws-end-user-messaging/
Reliable SMS delivery is a critical requirement for many businesses. However, SMS communications can be impacted by factors outside your direct control, such as carrier availability and delivery challenges.
In this post, we explore strategies for building resilient SMS architectures using AWS End User Messaging. We discuss how to architect your SMS communications at the originator, account, and Regional levels to support high availability and seamless failover, even in the face of disruptions. This includes implementing best practices like using phone pools, dedicated originators, and multi-Region redundancy.
By understanding these strategies, you can create a resilient messaging system that keeps your mission-critical SMS flowing reliably to your customers and stakeholders, regardless of external service interruptions or carrier-specific issues.
How SMS delivery works
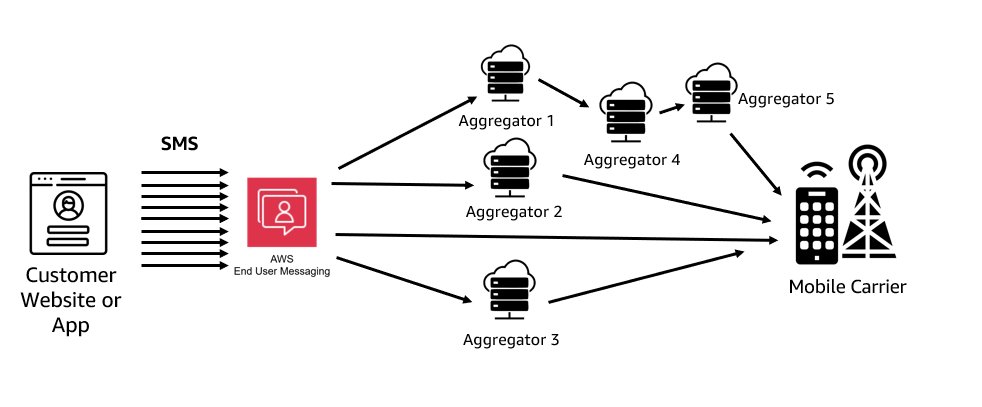
The process of delivering an SMS message involves a complex chain of interconnected systems. The message needs to be routed to the appropriate mobile network operator (carrier) based on the recipient’s phone number, and there are many paths the message could take. When a user sends an SMS through AWS End User Messaging, the message is routed appropriately based on the country, carrier, and originator type being used.
The inherent complexity of SMS delivery means there are numerous potential service degradation points, such as issues with an aggregator, carrier configurations, and filtering. The general availability of a mobile device can also be a factor, because it’s dependent on the current health of the network the device uses. Things as simple as weather changes or location (such as parking garages) can impact the delivery of messages and illustrates why alternate channels should be provided.
Understanding this underlying architecture is crucial for building resilient SMS systems that can withstand disruptions at different stages of the process. The following diagram shows a simplified version of how an SMS is delivered to a handset.

The need for SMS resiliency
Given the complex dependencies and potential points of degradation in the SMS delivery chain, it’s critical to architect your SMS communications for resilience. This helps make sure your messages can be delivered reliably, even when facing Regional service disruptions, carrier challenges, or other potential communication barriers.
Levels of resiliency for SMS
The following are the three levels of resiliency to consider for SMS and some potential reasons for disruption:
- Originator-level resiliency – Carriers and other downstream entities can sometimes block or filter specific origination numbers, causing delivery issues. Originators must be configured with these downstream entities, so downstream misconfigurations might occur.
- Account resiliency – Your primary AWS account might experience a disruption, preventing you from sending messages through that account. Account-level issues, such as reaching an account SMS spending limit or throughput, might limit your ability to send from a specific account.
- AWS Region resiliency – Regions can experience degradation of service, and originators are tied to an account and Region when they are configured and can’t be moved.
General best practices for SMS resiliency
A phone pool, also known as a pool, is a collection of originators that share the same settings. When you send messages through a phone pool, it selects an appropriate origination identity to use for sending the message based on the country code. In general, pools will select the highest throughput originator in the pool for the country being sent to. This means that the order from first to last will be short codes, long codes, sender ID, toll-free, and finally shared routes. If one of the origination identities in the phone pool is unable to send the message, the phone pool will automatically fail over to another origination identity, which is part of the same phone pool, for that same country if there is one available.
Having a dedicated originator for each country you send to improves deliverability and allows for two-way communication if the originator supports it. Pools have a setting for shared routes in some countries, which is a pool of shared origination identities that AWS maintains. When you activate shared routes on a pool and don’t have a dedicated originator, AWS End User Messaging SMS attempts to deliver your message using one of the shared identities. The origination identity could be a sender ID, long code, or short code, and could vary within each country. These shared routes are not capable of two-way communication so they are not eligible for any use cases that require it. Deliverability on these shared routes also varies; it’s always a best practice to use a shared route as a last resort option. Using at least one dedicated originator for each destination and use case you support will improve your deliverability and the experience of your end-users. Refer to How to Manage Global Sending of SMS with AWS End User Messaging for more details on getting ready to send SMS. The post includes a template for organizing use cases and selecting originators.
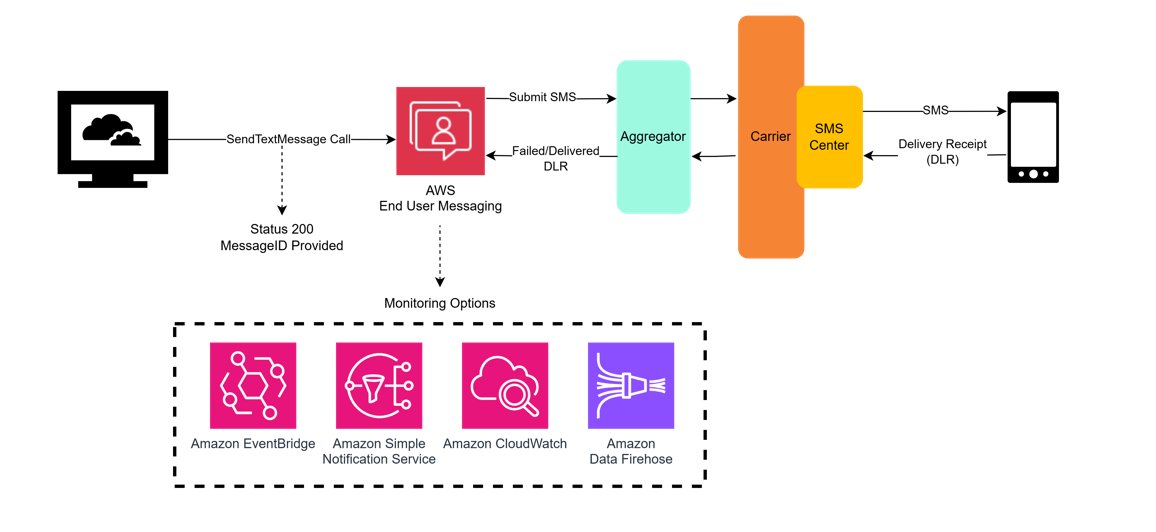
AWS End User Messaging provides several options for sending Delivery Receipts (DLRs), as shown in the following diagram, including Amazon Simple Notification Service (Amazon SNS), Amazon CloudWatch Logs, and Amazon Data Firehose. If you are using a multi-Region or multi-account architecture, it’s important to centralize this data. The following GitHub repo provides a solution as a deployable starter project that builds on top of an Amazon S3 storage location and combines channel engagement and conversational data into a centralized data store. You can also optionally deploy an Amazon QuickSight dashboard to visualize the engagement data.

Using the message feedback feature of AWS End User Messaging also allows for more visible and finite message statuses. You can use signals from customers to determine if they have received the message and set the message feedback status record as delivered. Using message feedback means you don’t have to wait for the DLR to be returned and you can set your message as received and update your message metrics. Message feedback can be used for typical user actions, such as completing a workflow, clicking a link, verifying a one-time password.
When choosing a repository for your DLRs, make sure to consider your data requirements related to data consistency, tolerance for latency, performance requirements, and your unique access patterns.
Strategies for resiliency at each level
Each level at which SMS operates provides layered resiliency. You don’t need to implement all the layers; this will depend on your comfort level for complexity and increased cost. In this section, we review the resiliency strategies at each level.
Originator-level resiliency
AWS recommends provisioning a minimum of two origination number types per country in each Region you are using to provide redundancy. Different originator types often use different paths to send, so if one sending is degraded on one path, you can switch to the other. The implementation itself will depend on the countries you are sending to and the level of complexity and cost you are willing to incur, because some originators have costs associated with owning them.If you decide to have multiple originators, we recommend communicating with your end-users about the methods by which you might communicate with them. This reduces the chance of spam complaints if you need to deliver SMS with an unfamiliar originator.
Let’s explore an example of designing originator-level resiliency for the US (the general pattern is the same across different countries).The US options for originators, in order of highest to lowest throughput, are short codes, 10DLC, and toll-free numbers (TFNs). Each requires registration to be completed. Depending on your throughput needs, there are a few things we recommend when implementing resiliency in the US.
If you’re using 10DLC, we recommend getting at least one other 10DLC number that you don’t use. If you encounter a filtering or blocking event by US carriers, you can use this number to swap into your pool to continue to be able to send while you solve the problem on the blocked or filtered number. This might give you more time to fix an issue while still maintaining your ability to send. The other option, and another layer of redundancy, is to register a TFN that you could swap into your pool. Although TFNs have lower throughput, this can help you continue some level of sending while solving for the blocking issue.
If you’re using a short code, you have an added layer of redundancy because carriers don’t generally block those codes without warning. You will receive an audit and be given a chance to fix whatever issue the carriers have found with your sending. Having a second short code or using a lower throughput backup such as a 10DLC or TFN is also an option.
Account-level resiliency
There is always the chance that your primary account could be degraded in some way. Issues such as an inaccessible account or hitting a spending limit can take time to mitigate. For example, Artificially Inflated Traffic (AIT), also known as SMS pumping fraud, can cause your spending limit to be hit, shutting off your ability to send from that account. To learn more, refer to Defending Against SMS Pumping: New AWS Features to Help Combat Artificially Inflated Traffic.
You can mitigate these issues by having a secondary account in the same Region that you share your originators, pools, and opt-out lists with by using AWS Resource Access Manager (AWS RAM) to enable resource sharing. You can use AWS RAM to share some AWS End User Messaging SMS resources with other AWS accounts or through AWS Organizations. The accounts being shared to must be in the same Region as the account that owns the resources. Configuring this sharing makes it possible to send from a secondary account using the same resources in the primary account. Billing on the volume is attributed to the sending account, whereas charges for the originators are billed to the account that owns them.
Region-level resiliency
There is always the possibility of a Regional degradation of services or a downstream misconfiguration for a particular originator or Region. The only way to protect your sending against this is to configure origination numbers in at least one other Region. This way, you can fail over to a secondary Region if the primary Region experiences a degradation of service. When implementing this approach, keep the following considerations in mind:
- If a country requires registration for SMS sending, you must complete that registration separately in each Region where you plan to use an originator for that country. You can submit the same registration for each Region, or for some originators you can specify multiple Regions at the time of registration, rather than applying twice.
- Many countries support sender IDs, and as long as they don’t require a registration, the same sender ID can be configured in multiple Regions. This simplifies the multi-Region setup. If you need to configure many sender IDs, refer to Automating Sender ID Configuration for SMS with AWS End User Messaging APIs to learn how to automate the process of configuring sender IDs across Regions.
- Carrier availability can also be a point of failure, so it’s important to have multiple origination numbers provisioned in each Region to avoid a single point of failure.
Although this post focuses specifically on SMS resiliency, as a general best practice for your messaging system, you should also enable alternative channels as failover or primary channels. Channels such as WhatsApp, push, voice, or email offer increased resiliency in the event of a degradation of SMS service.
Automating failover
AWS End User Messaging provides DLR data for your sent messages, which is a key piece of information you can use to automate retries and handle failures. As a protocol, SMS doesn’t guarantee delivery. Depending on the country being sent to, DLRs might take up to 72 hours to be returned or in some cases might not be returned at all. For this reason, relying on DLRs alone is not enough. You might also want to monitor the health of your Region or the AWS End User Messaging service, which can be done through the AWS Health Dashboard.
For a deep dive on managing SMS deliverability, refer to A Guide to Optimizing SMS Delivery and Best Practices, which goes into more detail on the complexities of SMS delivery and how to effectively monitor your message performance.
When it comes to automating your failover process, the DLR data provided by AWS End User Messaging can be a powerful tool. By analyzing the delivery statuses and error codes, you can build logic to automatically retry messages that fail on the first attempt. The key is to build in this automation proactively, rather than relying on manual intervention. Building your failover logic ahead of time can provide for a seamless recovery when delivery issues occur, minimizing disruption to your users.
It’s also important to remember that DLRs are fallible and might take up to 72 hours to arrive. The message feedback feature will give you more insight into message status, and you don’t have to wait for the DLR to be returned. You can set your message as received and update your message metrics based on expected user actions.
The goal is to create a resilient messaging architecture that can withstand the inevitable complexities of SMS delivery. Automating your failover process is a crucial component of that strategy.
Pros and cons of multi-Region SMS redundancy
Although implementing multi-Region redundancy can increase the reliability and resilience of your SMS communications, there are both advantages and trade-offs to consider. Evaluating the specific needs of your use cases against the added complexity and costs is important in determining the optimal approach.
The following are key benefits of having a resilient SMS architecture:
- Increased reliability and availability of SMS communications – Having redundant originators and routing across multiple Regions strengthens your ability to withstand Regional disruptions or carrier-specific issues, so you can continue sending SMS reliably.
- Seamless failover during outages – The ability to automatically fail over to a secondary Region when issues occur in the primary Region minimizes disruptions and keeps your SMS flowing.
- Reduced impact of carrier-specific problems – By diversifying your origination numbers across AWS accounts and Regions, you can avoid being heavily impacted by a problem with a single carrier or originator.
However, consider the following important trade-offs:
- Increased complexity in configuration and management – Maintaining redundant resources (originators, phone pools, opt-out lists, and so on) across multiple Regions adds complexity to your SMS architecture. A multi-Region setup requires additional configuration and ongoing maintenance.
- Additional costs – Provisioning origination numbers, short codes, and so on in multiple Regions can incur additional costs compared to a single-Region setup. There might also be costs for cross-Region data transfers if centralizing delivery logs and event data. Centralizing DLR data from multiple Regions likely requires additional storage and processing costs.
- Potential reputation and deliverability challenges – When failing over to a different Region, your SMS messages might come from new originators. If customers aren’t prepared for this change, they might mistake legitimate messages for spam. These spam reports can harm your overall SMS deliverability rates.
Overall, the pros of increased reliability and resilience must be weighed against the cons of higher complexity and costs. The optimal approach will depend on the criticality of the SMS use cases and your organization’s risk tolerance.
Conclusion
By implementing the layered resiliency strategies outlined in this post, you can significantly improve the reliability of your critical SMS communications. Whether you start with originator-level redundancy using phone pools or build a fully Regional-resilient architecture, proactively investing in your setup helps your messages reach your customers, even in the face of unexpected challenges.
To get started, consider the following next steps:
- Evaluate your current SMS workloads and determine what level of resiliency is right for your business needs and risk tolerance.
- As a first step, implement phone pools in your primary Region to protect against single-originator filtering or blocking.
- For critical applications, set up a secondary account and use AWS RAM to share your primary originators, providing a robust layer of account-level redundancy.
To learn more, explore the AWS End User Messaging documentation and the AWS RAM User Guide. For personalized guidance, work with your AWS account team to design the optimal SMS architecture for your business.
About the author



 David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner.
David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.