Post Syndicated from Matthew Tan original https://aws.amazon.com/blogs/big-data/stream-amazon-emr-on-eks-logs-to-third-party-providers-like-splunk-amazon-opensearch-service-or-other-log-aggregators/
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. You also have flexibility to push logs into an Amazon Simple Storage Service (Amazon S3) bucket or Amazon CloudWatch Logs. In each method, these logs are linked to the specific job in question. The common practice of log management in DevOps culture is to centralize logging through the forwarding of logs to an enterprise log aggregation system like Splunk or Amazon OpenSearch Service (successor to Amazon Elasticsearch Service). This enables you to see all the applicable log data in one place. You can identify key trends, anomalies, and correlated events, and troubleshoot problems faster and notify the appropriate people in a timely fashion.
EMR on EKS Spark logs are generated by Spark and can be accessed via the Kubernetes API and kubectl CLI. Therefore, although it’s possible to install log forwarding agents in the Amazon Elastic Kubernetes Service (Amazon EKS) cluster to forward all Kubernetes logs, which include Spark logs, this can become quite expensive at scale because you get information that may not be important for Spark users about Kubernetes. In addition, from a security point of view, the EKS cluster logs and access to kubectl may not be available to the Spark user.
To solve this problem, this post proposes using pod templates to create a sidecar container alongside the Spark job pods. The sidecar containers are able to access the logs contained in the Spark pods and forward these logs to the log aggregator. This approach allows the logs to be managed separately from the EKS cluster and uses a small amount of resources because the sidecar container is only launched during the lifetime of the Spark job.
Implementing Fluent Bit as a sidecar container
Fluent Bit is a lightweight, highly scalable, and high-speed logging and metrics processor and log forwarder. It collects event data from any source, enriches that data, and sends it to any destination. Its lightweight and efficient design coupled with its many features makes it very attractive to those working in the cloud and in containerized environments. It has been deployed extensively and trusted by many, even in large and complex environments. Fluent Bit has zero dependencies and requires only 650 KB in memory to operate, as compared to FluentD, which needs about 40 MB in memory. Therefore, it’s an ideal option as a log forwarder to forward logs generated from Spark jobs.
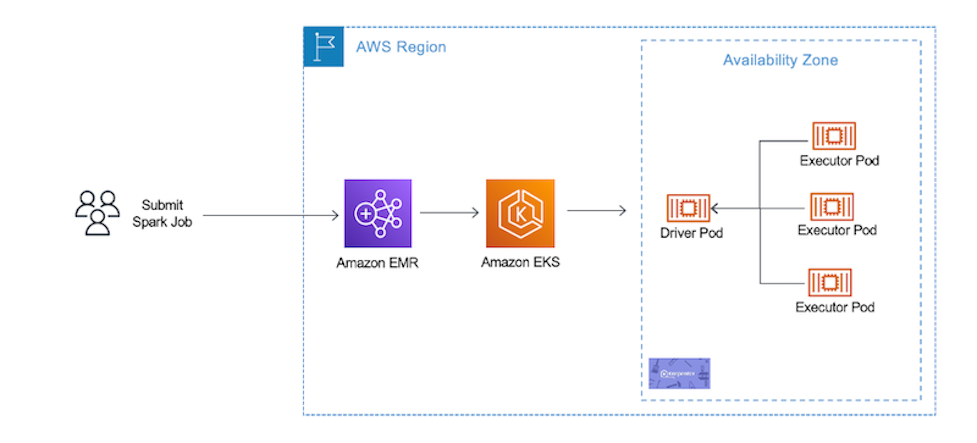
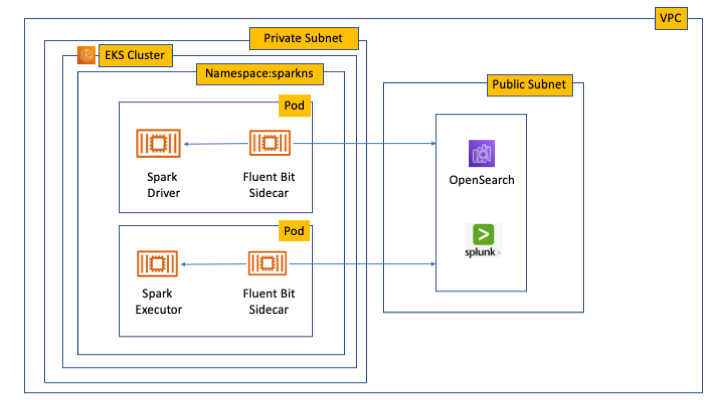
When you submit a job to EMR on EKS, there are at least two Spark containers: the Spark driver and the Spark executor. The number of Spark executor pods depends on your job submission configuration. If you indicate more than one spark.executor.instances, you get the corresponding number of Spark executor pods. What we want to do here is run Fluent Bit as sidecar containers with the Spark driver and executor pods. Diagrammatically, it looks like the following figure. The Fluent Bit sidecar container reads the indicated logs in the Spark driver and executor pods, and forwards these logs to the target log aggregator directly.

Pod templates in EMR on EKS
A Kubernetes pod is a group of one or more containers with shared storage, network resources, and a specification for how to run the containers. Pod templates are specifications for creating pods. It’s part of the desired state of the workload resources used to run the application. Pod template files can define the driver or executor pod configurations that aren’t supported in standard Spark configuration. That being said, Spark is opinionated about certain pod configurations and some values in the pod template are always overwritten by Spark. Using a pod template only allows Spark to start with a template pod and not an empty pod during the pod building process. Pod templates are enabled in EMR on EKS when you configure the Spark properties spark.kubernetes.driver.podTemplateFile and spark.kubernetes.executor.podTemplateFile. Spark downloads these pod templates to construct the driver and executor pods.
Forward logs generated by Spark jobs in EMR on EKS
A log aggregating system like Amazon OpenSearch Service or Splunk should always be available that can accept the logs forwarded by the Fluent Bit sidecar containers. If not, we provide the following scripts in this post to help you launch a log aggregating system like Amazon OpenSearch Service or Splunk installed on an Amazon Elastic Compute Cloud (Amazon EC2) instance.
We use several services to create and configure EMR on EKS. We use an AWS Cloud9 workspace to run all the scripts and to configure the EKS cluster. To prepare to run a job script that requires certain Python libraries absent from the generic EMR images, we use Amazon Elastic Container Registry (Amazon ECR) to store the customized EMR container image.
Create an AWS Cloud9 workspace
The first step is to launch and configure the AWS Cloud9 workspace by following the instructions in Create a Workspace in the EKS Workshop. After you create the workspace, we create AWS Identity and Access Management (IAM) resources. Create an IAM role for the workspace, attach the role to the workspace, and update the workspace IAM settings.
Prepare the AWS Cloud9 workspace
Clone the following GitHub repository and run the following script to prepare the AWS Cloud9 workspace to be ready to install and configure Amazon EKS and EMR on EKS. The shell script prepare_cloud9.sh installs all the necessary components for the AWS Cloud9 workspace to build and manage the EKS cluster. These include the kubectl command line tool, eksctl CLI tool, jq, and to update the AWS Command Line Interface (AWS CLI).
$ sudo yum -y install git
$ cd ~
$ git clone https://github.com/aws-samples/aws-emr-eks-log-forwarding.git
$ cd aws-emr-eks-log-forwarding
$ cd emreks
$ bash prepare_cloud9.sh
All the necessary scripts and configuration to run this solution are found in the cloned GitHub repository.
Create a key pair
As part of this particular deployment, you need an EC2 key pair to create an EKS cluster. If you already have an existing EC2 key pair, you may use that key pair. Otherwise, you can create a key pair.
Install Amazon EKS and EMR on EKS
After you configure the AWS Cloud9 workspace, in the same folder (emreks), run the following deployment script:
$ bash deploy_eks_cluster_bash.sh
Deployment Script -- EMR on EKS
-----------------------------------------------
Please provide the following information before deployment:
1. Region (If your Cloud9 desktop is in the same region as your deployment, you can leave this blank)
2. Account ID (If your Cloud9 desktop is running in the same Account ID as where your deployment will be, you can leave this blank)
3. Name of the S3 bucket to be created for the EMR S3 storage location
Region: [xx-xxxx-x]: < Press enter for default or enter region >
Account ID [xxxxxxxxxxxx]: < Press enter for default or enter account # >
EC2 Public Key name: < Provide your key pair name here >
Default S3 bucket name for EMR on EKS (do not add s3://): < bucket name >
Bucket created: XXXXXXXXXXX ...
Deploying CloudFormation stack with the following parameters...
Region: xx-xxxx-x | Account ID: xxxxxxxxxxxx | S3 Bucket: XXXXXXXXXXX
...
EKS Cluster and Virtual EMR Cluster have been installed.
The last line indicates that installation was successful.
Log aggregation options
There are several log aggregation and management tools on the market. This post suggests two of the more popular ones in the industry: Splunk and Amazon OpenSearch Service.
Option 1: Install Splunk Enterprise
To manually install Splunk on an EC2 instance, complete the following steps:
- Launch an EC2 instance.
- Install Splunk.
- Configure the EC2 instance security group to permit access to ports 22, 8000, and 8088.
This post, however, provides an automated way to install Spunk on an EC2 instance:
- Download the RPM install file and upload it to an accessible Amazon S3 location.
- Upload the following YAML script into AWS CloudFormation.
- Provide the necessary parameters, as shown in the screenshots below.
- Choose Next and complete the steps to create your stack.



Alternatively, run an AWS CLI script like the following:
aws cloudformation create-stack \
--stack-name "splunk" \
--template-body file://splunk_cf.yaml \
--parameters ParameterKey=KeyName,ParameterValue="< Name of EC2 Key Pair >" \
ParameterKey=InstanceType,ParameterValue="t3.medium" \
ParameterKey=LatestAmiId,ParameterValue="/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2" \
ParameterKey=VPCID,ParameterValue="vpc-XXXXXXXXXXX" \
ParameterKey=PublicSubnet0,ParameterValue="subnet-XXXXXXXXX" \
ParameterKey=SSHLocation,ParameterValue="< CIDR Range for SSH access >" \
ParameterKey=VpcCidrRange,ParameterValue="172.20.0.0/16" \
ParameterKey=RootVolumeSize,ParameterValue="100" \
ParameterKey=S3BucketName,ParameterValue="< S3 Bucket Name >" \
ParameterKey=S3Prefix,ParameterValue="splunk/splunk-8.2.5-77015bc7a462-linux-2.6-x86_64.rpm" \
ParameterKey=S3DownloadLocation,ParameterValue="/tmp" \
--region < region > \
--capabilities CAPABILITY_IAM
- After you build the stack, navigate to the stack’s Outputs tab on the AWS CloudFormation console and note the internal and external DNS for the Splunk instance.
You use these later to configure the Splunk instance and log forwarding.

- To configure Splunk, go to the Resources tab for the CloudFormation stack and locate the physical ID of
EC2Instance.
- Choose that link to go to the specific EC2 instance.
- Select the instance and choose Connect.

- On the Session Manager tab, choose Connect.

You’re redirected to the instance’s shell.
- Install and configure Splunk as follows:
$ sudo /opt/splunk/bin/splunk start --accept-license
…
Please enter an administrator username: admin
Password must contain at least:
* 8 total printable ASCII character(s).
Please enter a new password:
Please confirm new password:
…
Done
[ OK ]
Waiting for web server at http://127.0.0.1:8000 to be available......... Done
The Splunk web interface is at http://ip-xx-xxx-xxx-x.us-east-2.compute.internal:8000
- Enter the Splunk site using the
SplunkPublicDns value from the stack outputs (for example, http://ec2-xx-xxx-xxx-x.us-east-2.compute.amazonaws.com:8000). Note the port number of 8000.
- Log in with the user name and password you provided.

Configure HTTP Event Collector
To configure Splunk to be able to receive logs from Fluent Bit, configure the HTTP Event Collector data input:
- Go to Settings and choose Data input.
- Choose HTTP Event Collector.
- Choose Global Settings.
- Select Enabled, keep port number 8088, then choose Save.
- Choose New Token.
- For Name, enter a name (for example,
emreksdemo).
- Choose Next.
- For Available item(s) for Indexes, add at least the main index.
- Choose Review and then Submit.
- In the list of HTTP Event Collect tokens, copy the token value for
emreksdemo.
You use it when configuring the Fluent Bit output.

Option 2: Set up Amazon OpenSearch Service
Your other log aggregation option is to use Amazon OpenSearch Service.
Provision an OpenSearch Service domain
Provisioning an OpenSearch Service domain is very straightforward. In this post, we provide a simple script and configuration to provision a basic domain. To do it yourself, refer to Creating and managing Amazon OpenSearch Service domains.
Before you start, get the ARN of the IAM role that you use to run the Spark jobs. If you created the EKS cluster with the provided script, go to the CloudFormation stack emr-eks-iam-stack. On the Outputs tab, locate the IAMRoleArn output and copy this ARN. We also modify the IAM role later on, after we create the OpenSearch Service domain.

If you’re using the provided opensearch.sh installer, before you run it, modify the file.
From the root folder of the GitHub repository, cd to opensearch and modify opensearch.sh (you can also use your preferred editor):
[../aws-emr-eks-log-forwarding] $ cd opensearch
[../aws-emr-eks-log-forwarding/opensearch] $ vi opensearch.sh
Configure opensearch.sh to fit your environment, for example:
# name of our Amazon OpenSearch cluster
export ES_DOMAIN_NAME="emreksdemo"
# Elasticsearch version
export ES_VERSION="OpenSearch_1.0"
# Instance Type
export INSTANCE_TYPE="t3.small.search"
# OpenSearch Dashboards admin user
export ES_DOMAIN_USER="emreks"
# OpenSearch Dashboards admin password
export ES_DOMAIN_PASSWORD='< ADD YOUR PASSWORD >'
# Region
export REGION='us-east-1'
Run the script:
[../aws-emr-eks-log-forwarding/opensearch] $ bash opensearch.sh
Configure your OpenSearch Service domain
After you set up your OpenSearch service domain and it’s active, make the following configuration changes to allow logs to be ingested into Amazon OpenSearch Service:
- On the Amazon OpenSearch Service console, on the Domains page, choose your domain.

- On the Security configuration tab, choose Edit.

- For Access Policy, select Only use fine-grained access control.
- Choose Save changes.
The access policy should look like the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:xx-xxxx-x:xxxxxxxxxxxx:domain/emreksdemo/*"
}
]
}
- When the domain is active again, copy the domain ARN.
We use it to configure the Amazon EMR job IAM role we mentioned earlier.
- Choose the link for OpenSearch Dashboards URL to enter Amazon OpenSearch Service Dashboards.

- In Amazon OpenSearch Service Dashboards, use the user name and password that you configured earlier in the opensearch.sh file.
- Choose the options icon and choose Security under OpenSearch Plugins.

- Choose Roles.
- Choose Create role.

- Enter the new role’s name, cluster permissions, and index permissions. For this post, name the role
fluentbit_role and give cluster permissions to the following:
indices:admin/createindices:admin/template/getindices:admin/template/putcluster:admin/ingest/pipeline/getcluster:admin/ingest/pipeline/putindices:data/write/bulkindices:data/write/bulk*create_index

- In the Index permissions section, give write permission to the index
fluent-*.
- On the Mapped users tab, choose Manage mapping.
- For Backend roles, enter the Amazon EMR job execution IAM role ARN to be mapped to the
fluentbit_role role.
- Choose Map.

- To complete the security configuration, go to the IAM console and add the following inline policy to the EMR on EKS IAM role entered in the backend role. Replace the resource ARN with the ARN of your OpenSearch Service domain.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"es:ESHttp*"
],
"Resource": "arn:aws:es:us-east-2:XXXXXXXXXXXX:domain/emreksdemo"
}
]
}
The configuration of Amazon OpenSearch Service is complete and ready for ingestion of logs from the Fluent Bit sidecar container.
Configure the Fluent Bit sidecar container
We need to write two configuration files to configure a Fluent Bit sidecar container. The first is the Fluent Bit configuration itself, and the second is the Fluent Bit sidecar subprocess configuration that makes sure that the sidecar operation ends when the main Spark job ends. The suggested configuration provided in this post is for Splunk and Amazon OpenSearch Service. However, you can configure Fluent Bit with other third-party log aggregators. For more information about configuring outputs, refer to Outputs.
Fluent Bit ConfigMap
The following sample ConfigMap is from the GitHub repo:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-sidecar-config
namespace: sparkns
labels:
app.kubernetes.io/name: fluent-bit
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-application.conf
@INCLUDE input-event-logs.conf
@INCLUDE output-splunk.conf
@INCLUDE output-opensearch.conf
input-application.conf: |
[INPUT]
Name tail
Path /var/log/spark/user/*/*
Path_Key filename
Buffer_Chunk_Size 1M
Buffer_Max_Size 5M
Skip_Long_Lines On
Skip_Empty_Lines On
input-event-logs.conf: |
[INPUT]
Name tail
Path /var/log/spark/apps/*
Path_Key filename
Buffer_Chunk_Size 1M
Buffer_Max_Size 5M
Skip_Long_Lines On
Skip_Empty_Lines On
output-splunk.conf: |
[OUTPUT]
Name splunk
Match *
Host < INTERNAL DNS of Splunk EC2 Instance >
Port 8088
TLS On
TLS.Verify Off
Splunk_Token < Token as provided by the HTTP Event Collector in Splunk >
output-opensearch.conf: |
[OUTPUT]
Name es
Match *
Host < HOST NAME of the OpenSearch Domain | No HTTP protocol >
Port 443
TLS On
AWS_Auth On
AWS_Region < Region >
Retry_Limit 6
In your AWS Cloud9 workspace, modify the ConfigMap accordingly. Provide the values for the placeholder text by running the following commands to enter the VI editor mode. If preferred, you can use PICO or a different editor:
[../aws-emr-eks-log-forwarding] $ cd kube/configmaps
[../aws-emr-eks-log-forwarding/kube/configmaps] $ vi emr_configmap.yaml
# Modify the emr_configmap.yaml as above
# Save the file once it is completed
Complete either the Splunk output configuration or the Amazon OpenSearch Service output configuration.
Next, run the following commands to add the two Fluent Bit sidecar and subprocess ConfigMaps:
[../aws-emr-eks-log-forwarding/kube/configmaps] $ kubectl apply -f emr_configmap.yaml
[../aws-emr-eks-log-forwarding/kube/configmaps] $ kubectl apply -f emr_entrypoint_configmap.yaml
You don’t need to modify the second ConfigMap because it’s the subprocess script that runs inside the Fluent Bit sidecar container. To verify that the ConfigMaps have been installed, run the following command:
$ kubectl get cm -n sparkns
NAME DATA AGE
fluent-bit-sidecar-config 6 15s
fluent-bit-sidecar-wrapper 2 15s
Set up a customized EMR container image
To run the sample PySpark script, the script requires the Boto3 package that’s not available in the standard EMR container images. If you want to run your own script and it doesn’t require a customized EMR container image, you may skip this step.
Run the following script:
[../aws-emr-eks-log-forwarding] $ cd ecr
[../aws-emr-eks-log-forwarding/ecr] $ bash create_custom_image.sh <region> <EMR container image account number>
The EMR container image account number can be obtained from How to select a base image URI. This documentation also provides the appropriate ECR registry account number. For example, the registry account number for us-east-1 is 755674844232.
To verify the repository and image, run the following commands:
$ aws ecr describe-repositories --region < region > | grep emr-6.5.0-custom
"repositoryArn": "arn:aws:ecr:xx-xxxx-x:xxxxxxxxxxxx:repository/emr-6.5.0-custom",
"repositoryName": "emr-6.5.0-custom",
"repositoryUri": " xxxxxxxxxxxx.dkr.ecr.xx-xxxx-x.amazonaws.com/emr-6.5.0-custom",
$ aws ecr describe-images --region < region > --repository-name emr-6.5.0-custom | jq .imageDetails[0].imageTags
[
"latest"
]
Prepare pod templates for Spark jobs
Upload the two Spark driver and Spark executor pod templates to an S3 bucket and prefix. The two pod templates can be found in the GitHub repository:
- emr_driver_template.yaml – Spark driver pod template
- emr_executor_template.yaml – Spark executor pod template
The pod templates provided here should not be modified.
Submitting a Spark job with a Fluent Bit sidecar container
This Spark job example uses the bostonproperty.py script. To use this script, upload it to an accessible S3 bucket and prefix and complete the preceding steps to use an EMR customized container image. You also need to upload the CSV file from the GitHub repo, which you need to download and unzip. Upload the unzipped file to the following location: s3://<your chosen bucket>/<first level folder>/data/boston-property-assessment-2021.csv.
The following commands assume that you launched your EKS cluster and virtual EMR cluster with the parameters indicated in the GitHub repo.
| Variable |
Where to Find the Information or the Value Required |
| EMR_EKS_CLUSTER_ID |
Amazon EMR console virtual cluster page |
| EMR_EKS_EXECUTION_ARN |
IAM role ARN |
| EMR_RELEASE |
emr-6.5.0-latest |
| S3_BUCKET |
The bucket you create in Amazon S3 |
| S3_FOLDER |
The preferred prefix you want to use in Amazon S3 |
| CONTAINER_IMAGE |
The URI in Amazon ECR where your container image is |
| SCRIPT_NAME |
emreksdemo-script or a name you prefer |
Alternatively, use the provided script to run the job. Change the directory to the scripts folder in emreks and run the script as follows:
[../aws-emr-eks-log-forwarding] cd emreks/scripts
[../aws-emr-eks-log-forwarding/emreks/scripts] bash run_emr_script.sh < S3 bucket name > < ECR container image > < script path>
Example: bash run_emr_script.sh emreksdemo-123456 12345678990.dkr.ecr.us-east-2.amazonaws.com/emr-6.5.0-custom s3://emreksdemo-123456/scripts/scriptname.py
After you submit the Spark job successfully, you get a return JSON response like the following:
{
"id": "0000000305e814v0bpt",
"name": "emreksdemo-job",
"arn": "arn:aws:emr-containers:xx-xxxx-x:XXXXXXXXXXX:/virtualclusters/upobc00wgff5XXXXXXXXXXX/jobruns/0000000305e814v0bpt",
"virtualClusterId": "upobc00wgff5XXXXXXXXXXX"
}
What happens when you submit a Spark job with a sidecar container
After you submit a Spark job, you can see what is happening by viewing the pods that are generated and the corresponding logs. First, using kubectl, get a list of the pods generated in the namespace where the EMR virtual cluster runs. In this case, it’s sparkns. The first pod in the following code is the job controller for this particular Spark job. The second pod is the Spark executor; there can be more than one pod depending on how many executor instances are asked for in the Spark job setting—we asked for one here. The third pod is the Spark driver pod.
$ kubectl get pods -n sparkns
NAME READY STATUS RESTARTS AGE
0000000305e814v0bpt-hvwjs 3/3 Running 0 25s
emreksdemo-script-1247bf80ae40b089-exec-1 0/3 Pending 0 0s
spark-0000000305e814v0bpt-driver 3/3 Running 0 11s
To view what happens in the sidecar container, follow the logs in the Spark driver pod and refer to the sidecar. The sidecar container launches with the Spark pods and persists until the file /var/log/fluentd/main-container-terminated is no longer available. For more information about how Amazon EMR controls the pod lifecycle, refer to Using pod templates. The subprocess script ties the sidecar container to this same lifecycle and deletes itself upon the EMR controlled pod lifecycle process.
$ kubectl logs spark-0000000305e814v0bpt-driver -n sparkns -c custom-side-car-container --follow=true
Waiting for file /var/log/fluentd/main-container-terminated to appear...
AWS for Fluent Bit Container Image Version 2.24.0Start wait: 1652190909
Elapsed Wait: 0
Not found count: 0
Waiting...
Fluent Bit v1.9.3
* Copyright (C) 2015-2022 The Fluent Bit Authors
* Fluent Bit is a CNCF sub-project under the umbrella of Fluentd
* https://fluentbit.io
[2022/05/10 13:55:09] [ info] [fluent bit] version=1.9.3, commit=9eb4996b7d, pid=11
[2022/05/10 13:55:09] [ info] [storage] version=1.2.0, type=memory-only, sync=normal, checksum=disabled, max_chunks_up=128
[2022/05/10 13:55:09] [ info] [cmetrics] version=0.3.1
[2022/05/10 13:55:09] [ info] [output:splunk:splunk.0] worker #0 started
[2022/05/10 13:55:09] [ info] [output:splunk:splunk.0] worker #1 started
[2022/05/10 13:55:09] [ info] [output:es:es.1] worker #0 started
[2022/05/10 13:55:09] [ info] [output:es:es.1] worker #1 started
[2022/05/10 13:55:09] [ info] [http_server] listen iface=0.0.0.0 tcp_port=2020
[2022/05/10 13:55:09] [ info] [sp] stream processor started
Waiting for file /var/log/fluentd/main-container-terminated to appear...
Last heartbeat: 1652190914
Elapsed Time since after heartbeat: 0
Found count: 0
list files:
-rw-r--r-- 1 saslauth 65534 0 May 10 13:55 /var/log/fluentd/main-container-terminated
Last heartbeat: 1652190918
…
[2022/05/10 13:56:09] [ info] [input:tail:tail.0] inotify_fs_add(): inode=58834691 watch_fd=6 name=/var/log/spark/user/spark-0000000305e814v0bpt-driver/stdout-s3-container-log-in-tail.pos
[2022/05/10 13:56:09] [ info] [input:tail:tail.1] inotify_fs_add(): inode=54644346 watch_fd=1 name=/var/log/spark/apps/spark-0000000305e814v0bpt
Outside of loop, main-container-terminated file no longer exists
ls: cannot access /var/log/fluentd/main-container-terminated: No such file or directory
The file /var/log/fluentd/main-container-terminated doesn't exist anymore;
TERMINATED PROCESS
Fluent-Bit pid: 11
Killing process after sleeping for 15 seconds
root 11 8 0 13:55 ? 00:00:00 /fluent-bit/bin/fluent-bit -e /fluent-bit/firehose.so -e /fluent-bit/cloudwatch.so -e /fluent-bit/kinesis.so -c /fluent-bit/etc/fluent-bit.conf
root 114 7 0 13:56 ? 00:00:00 grep fluent
Killing process 11
[2022/05/10 13:56:24] [engine] caught signal (SIGTERM)
[2022/05/10 13:56:24] [ info] [input] pausing tail.0
[2022/05/10 13:56:24] [ info] [input] pausing tail.1
[2022/05/10 13:56:24] [ warn] [engine] service will shutdown in max 5 seconds
[2022/05/10 13:56:25] [ info] [engine] service has stopped (0 pending tasks)
[2022/05/10 13:56:25] [ info] [input:tail:tail.1] inotify_fs_remove(): inode=54644346 watch_fd=1
[2022/05/10 13:56:25] [ info] [input:tail:tail.0] inotify_fs_remove(): inode=60917120 watch_fd=1
[2022/05/10 13:56:25] [ info] [input:tail:tail.0] inotify_fs_remove(): inode=60917121 watch_fd=2
[2022/05/10 13:56:25] [ info] [input:tail:tail.0] inotify_fs_remove(): inode=58834690 watch_fd=3
[2022/05/10 13:56:25] [ info] [input:tail:tail.0] inotify_fs_remove(): inode=58834692 watch_fd=4
[2022/05/10 13:56:25] [ info] [input:tail:tail.0] inotify_fs_remove(): inode=58834689 watch_fd=5
[2022/05/10 13:56:25] [ info] [input:tail:tail.0] inotify_fs_remove(): inode=58834691 watch_fd=6
[2022/05/10 13:56:25] [ info] [output:splunk:splunk.0] thread worker #0 stopping...
[2022/05/10 13:56:25] [ info] [output:splunk:splunk.0] thread worker #0 stopped
[2022/05/10 13:56:25] [ info] [output:splunk:splunk.0] thread worker #1 stopping...
[2022/05/10 13:56:25] [ info] [output:splunk:splunk.0] thread worker #1 stopped
[2022/05/10 13:56:25] [ info] [output:es:es.1] thread worker #0 stopping...
[2022/05/10 13:56:25] [ info] [output:es:es.1] thread worker #0 stopped
[2022/05/10 13:56:25] [ info] [output:es:es.1] thread worker #1 stopping...
[2022/05/10 13:56:25] [ info] [output:es:es.1] thread worker #1 stopped
View the forwarded logs in Splunk or Amazon OpenSearch Service
To view the forwarded logs, do a search in Splunk or on the Amazon OpenSearch Service console. If you’re using a shared log aggregator, you may have to filter the results. In this configuration, the logs tailed by Fluent Bit are in the /var/log/spark/*. The following screenshots show the logs generated specifically by the Kubernetes Spark driver stdout that were forwarded to the log aggregators. You can compare the results with the logs provided using kubectl:
kubectl logs < Spark Driver Pod > -n < namespace > -c spark-kubernetes-driver --follow=true
…
root
|-- PID: string (nullable = true)
|-- CM_ID: string (nullable = true)
|-- GIS_ID: string (nullable = true)
|-- ST_NUM: string (nullable = true)
|-- ST_NAME: string (nullable = true)
|-- UNIT_NUM: string (nullable = true)
|-- CITY: string (nullable = true)
|-- ZIPCODE: string (nullable = true)
|-- BLDG_SEQ: string (nullable = true)
|-- NUM_BLDGS: string (nullable = true)
|-- LUC: string (nullable = true)
…
|02108|RETAIL CONDO |361450.0 |63800.0 |5977500.0 |
|02108|RETAIL STORE DETACH |2295050.0 |988200.0 |3601900.0 |
|02108|SCHOOL |1.20858E7 |1.20858E7 |1.20858E7 |
|02108|SINGLE FAM DWELLING |5267156.561085973 |1153400.0 |1.57334E7 |
+-----+-----------------------+--------------------+---------------+---------------+
only showing top 50 rows
The following screenshot shows the Splunk logs.

The following screenshots show the Amazon OpenSearch Service logs.

Optional: Include a buffer between Fluent Bit and the log aggregators
If you expect to generate a lot of logs because of high concurrent Spark jobs creating multiple individual connects that may overwhelm your Amazon OpenSearch Service or Splunk log aggregation clusters, consider employing a buffer between the Fluent Bit sidecars and your log aggregator. One option is to use Amazon Kinesis Data Firehose as the buffering service.
Kinesis Data Firehose has built-in delivery to both Amazon OpenSearch Service and Splunk. If using Amazon OpenSearch Service, refer to Loading streaming data from Amazon Kinesis Data Firehose. If using Splunk, refer to Configure Amazon Kinesis Firehose to send data to the Splunk platform and Choose Splunk for Your Destination.
To configure Fluent Bit to Kinesis Data Firehose, add the following to your ConfigMap output. Refer to the GitHub ConfigMap example and add the @INCLUDE under the [SERVICE] section:
@INCLUDE output-kinesisfirehose.conf
…
output-kinesisfirehose.conf: |
[OUTPUT]
Name kinesis_firehose
Match *
region < region >
delivery_stream < Kinesis Firehose Stream Name >
Optional: Use data streams for Amazon OpenSearch Service
If you’re in a scenario where the number of documents grows rapidly and you don’t need to update older documents, you need to manage the OpenSearch Service cluster. This involves steps like creating a rollover index alias, defining a write index, and defining common mappings and settings for the backing indexes. Consider using data streams to simplify this process and enforce a setup that best suits your time series data. For instructions on implementing data streams, refer to Data streams.
Clean up
To avoid incurring future charges, delete the resources by deleting the CloudFormation stacks that were created with this script. This removes the EKS cluster. However, before you do that, remove the EMR virtual cluster first by running the delete-virtual-cluster command. Then delete all the CloudFormation stacks generated by the deployment script.
If you launched an OpenSearch Service domain, you can delete the domain from the OpenSearch Service domain. If you used the script to launch a Splunk instance, you can go to the CloudFormation stack that launched the Splunk instance and delete the CloudFormation stack. This removes remove the Splunk instance and associated resources.
You can also use the following scripts to clean up resources:
Conclusion
EMR on EKS facilitates running Spark jobs on Kubernetes to achieve very fast and cost-efficient Spark operations. This is made possible through scheduling transient pods that are launched and then deleted the jobs are complete. To log all these operations in the same lifecycle of the Spark jobs, this post provides a solution using pod templates and Fluent Bit that is lightweight and powerful. This approach offers a decoupled way of log forwarding based at the Spark application level and not at the Kubernetes cluster level. It also avoids routing through intermediaries like CloudWatch, reducing cost and complexity. In this way, you can address security concerns and DevOps and system administration ease of management while providing Spark users with insights into their Spark jobs in a cost-efficient and functional way.
If you have questions or suggestions, please leave a comment.
About the Author
 Matthew Tan is a Senior Analytics Solutions Architect at Amazon Web Services and provides guidance to customers developing solutions with AWS Analytics services on their analytics workloads.
Matthew Tan is a Senior Analytics Solutions Architect at Amazon Web Services and provides guidance to customers developing solutions with AWS Analytics services on their analytics workloads.

 Peter Dalbhanjan is a Solutions Architect for AWS based in Herndon, VA. Peter is passionate about evangelizing and solving complex business problems using combination of AWS services and open source solutions. At AWS, Peter helps with designing and architecting variety of customer workloads.
Peter Dalbhanjan is a Solutions Architect for AWS based in Herndon, VA. Peter is passionate about evangelizing and solving complex business problems using combination of AWS services and open source solutions. At AWS, Peter helps with designing and architecting variety of customer workloads. Amine Hilaly is a Software Development Engineer at Amazon Web Services working on the Kubernetes and Open source related projects for about two years. Amine is a Go, open-source, and Kubernetes fanatic.
Amine Hilaly is a Software Development Engineer at Amazon Web Services working on the Kubernetes and Open source related projects for about two years. Amine is a Go, open-source, and Kubernetes fanatic.









































 One-year anniversary of CloudFront Functions – I can’t believe it’s been
One-year anniversary of CloudFront Functions – I can’t believe it’s been