Post Syndicated from Zip Zieper original https://aws.amazon.com/blogs/messaging-and-targeting/upgrade-your-email-tech-stack-with-amazon-sesv2-api/
Amazon Simple Email Service (SES) is a cloud-based email sending service that helps businesses and developers send marketing and transactional emails. We introduced the SESv1 API in 2011 to provide developers with basic email sending capabilities through Amazon SES using HTTPS. In 2020, we introduced the redesigned Amazon SESv2 API, with new and updated features that make it easier and more efficient for developers to send email at scale.
This post will compare Amazon SESv1 API and Amazon SESv2 API and explain the advantages of transitioning your application code to the SESv2 API. We’ll also provide examples using the AWS Command-Line Interface (AWS CLI) that show the benefits of transitioning to the SESv2 API.
Amazon SESv1 API
The SESv1 API is a relatively simple API that provides basic functionality for sending and receiving emails. For over a decade, thousands of SES customers have used the SESv1 API to send billions of emails. Our customers’ developers routinely use the SESv1 APIs to verify email addresses, create rules, send emails, and customize bounce and complaint notifications. Our customers’ needs have become more advanced as the global email ecosystem has developed and matured. Unsurprisingly, we’ve received customer feedback requesting enhancements and new functionality within SES. To better support an expanding array of use cases and stay at the forefront of innovation, we developed the SESv2 APIs.
While the SESv1 API will continue to be supported, AWS is focused on advancing functionality through the SESv2 API. As new email sending capabilities are introduced, they will only be available through SESv2 API. Migrating to the SESv2 API provides customers with access to these, and future, optimizations and enhancements. Therefore, we encourage SES customers to consider the information in this blog, review their existing codebase, and migrate to SESv2 API in a timely manner.
Amazon SESv2 API
Released in 2020, the SESv2 API and SDK enable customers to build highly scalable and customized email applications with an expanded set of lightweight and easy to use API actions. Leveraging insights from current SES customers, the SESv2 API includes several new actions related to list and subscription management, the creation and management of dedicated IP pools, and updates to unsubscribe that address recent industry requirements.
One example of new functionality in SESv2 API is programmatic support for the SES Virtual Delivery Manager. Previously only addressable via the AWS console, VDM helps customers improve sending reputation and deliverability. SESv2 API includes vdmAttributes such as VdmEnabled and DashboardAttributes as well as vdmOptions. DashboardOptions and GaurdianOptions.
To improve developer efficiency and make the SESv2 API easier to use, we merged several SESv1 APIs into single commands. For example, in the SESv1 API you must make separate calls for createConfigurationSet, setReputationMetrics, setSendingEnabled, setTrackingOptions, and setDeliveryOption. In the SESv2 API, however, developers make a single call to createConfigurationSet and they can include trackingOptions, reputationOptions, sendingOptions, deliveryOptions. This can result in more concise code (see below).

Another example of SESv2 API command consolidation is the GetIdentity action, which is a composite of SESv1 API’s GetIdentityVerificationAttributes, GetIdentityNotificationAttributes, GetCustomMailFromAttributes, GetDKIMAttributes, and GetIdentityPolicies. See SESv2 documentation for more details.
Why migrate to Amazon SESv2 API?
The SESv2 API offers an enhanced experience compared to the original SESv1 API. Compared to the SESv1 API, the SESv2 API provides a more modern interface and flexible options that make building scalable, high-volume email applications easier and more efficient. SESv2 enables rich email capabilities like template management, list subscription handling, and deliverability reporting. It provides developers with a more powerful and customizable set of tools with improved security measures to build and optimize inbox placement and reputation management. Taken as a whole, the SESv2 APIs provide an even stronger foundation for sending critical communications and campaign email messages effectively at a scale.
Migrating your applications to SESv2 API will benefit your email marketing and communication capabilities with:
- New and Enhanced Features: Amazon SESv2 API includes new actions as well as enhancements that provide better functionality and improved email management. By moving to the latest version, you’ll be able to optimize your email sending process. A few examples include:
- Increase the maximum message size (including attachments) from 10Mb (SESv1) to 40Mb (SESv2) for both sending and receiving.
- Access key actions for the SES Virtual Deliverability Manager (VDM) which provides insights into your sending and delivery data. VDM provides near-realtime advice on how to fix the issues that are negatively affecting your delivery success rate and reputation.
- Meet Google & Yahoo’s June 2024 unsubscribe requirements with the SES v2
SendEmail action. For more information, see the “What’s New blog”
- Future-proof Your Application: Avoid potential compatibility issues and disruptions by keeping your application up-to-date with the latest version of the Amazon SESv2 API via the AWS SDK.
- Improve Usability and Developer Experience: Amazon SESv2 API is designed to be more user-friendly and consistent with other AWS services. It is a more intuitive API with better error handling, making it easier to develop, maintain, and troubleshoot your email sending applications.
Migrating to the latest SESv2 API and SDK positions customers for success in creating reliable and scalable email services for their businesses.
What does migration to the SESv2 API entail?
While SESv2 API builds on the v1 API, the v2 API actions don’t universally map exactly to the v1 API actions. Current SES customers that intend to migrate to SESv2 API will need to identify the SESv1 API actions in their code and plan to refactor for v2. When planning the migration, it is essential to consider several important considerations:
- Customers with applications that receive email using SESv1 API’s
CreateReceiptFilter, CreateReceiptRule or CreateReceiptRuleSet actions must continue using the SESv1 API client for these actions. SESv1 and SESv2 can be used in the same application, where needed.
- We recommend all customers follow the security best practice of “least privilege” with their IAM policies. As such, customers may need to review and update their policies to include the new and modified API actions introduced in SESv2 before migrating. Taking the time to properly configure permissions ensures a seamless transition while maintaining a securely optimized level of access. See documentation.
Below is an example of an IAM policy with a user with limited allow privileges related to several SESv1 Identity actions only:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ses:VerifyEmailIdentity",
"ses:Deleteldentity",
"ses:VerifyDomainDkim",
"ses:ListIdentities",
"ses:VerifyDomainIdentity"
],
"Resource": "*"
}
]
}
When updating to SESv2, you need to update this user’s permissions with the SESv2 actions shown below:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ses:CreateEmailIdentity",
"ses:DeleteEmailIdentity",
"ses:GetEmailIdentity",
"ses:ListEmailIdentities"
],
"Resource": "*"
}
]
}
Examples of SESv1 vs. SESv2 APIs
Let’s look at a three examples that compare the SESv1 API with the SESv2 API.
LIST APIs
When listing identities in SESv1 list API, you need to specify type which requires multiple calls to API to list all resources:
aws ses list-identities --identity-type Domain
{
"Identities": [
"example.com"
]
}
aws ses list-identities --identity-type EmailAddress
{
"Identities": [
"[email protected]",
"[email protected]",
"[email protected]"
]
}
With SESv2, you can simply call a single API. Additionally, SESv2 also provides extended feedback:
aws sesv2 list-email-identities
{
"EmailIdentities": [
{
"IdentityType": "DOMAIN",
"IdentityName": "example.com",
"SendingEnabled": false,
"VerificationStatus": "FAILED"
},
{
"IdentityType": "EMAIL_ADDRESS",
"IdentityName": "[email protected]",
"SendingEnabled": true,
"VerificationStatus": "SUCCESS"
},
{
"IdentityType": "EMAIL_ADDRESS",
"IdentityName": "[email protected]",
"SendingEnabled": false,
"VerificationStatus": "FAILED"
},
{
"IdentityType": "EMAIL_ADDRESS",
"IdentityName": "[email protected]",
"SendingEnabled": true,
"VerificationStatus": "SUCCESS"
}
]
}
CREATE APIs
With SESv1, creating email addresses or domains requires calling two different APIs:
aws ses verify-email-identity --email-address [email protected]
aws ses verify-domain-dkim --domain example.com
{
"DkimTokens": [
"mwmzhwhcebfh5kvwv7zahdatahimucqi",
"dmlozjwrdbrjfwothoh26x6izvyts7qx",
"le5fy6pintdkbxg6gdoetgbrdvyp664v"
]
}
With SESv2, we build an abstraction so you can call a single API. Additionally, SESv2 provides more detailed responses and feedback:
aws sesv2 create-email-identity --email-identity [email protected]
{
"IdentityType": "EMAIL_ADDRESS",
"VerifiedForSendingStatus": false
}
aws sesv2 create-email-identity --email-identity example.com
{
"IdentityType": "DOMAIN",
"VerifiedForSendingStatus": false,
"DkimAttributes": {
"SigningEnabled": true,
"Status": "NOT_STARTED",
"Tokens": [
"mwmzhwhcebfh5kvwv7zahdatahimucqi",
"dmlozjwrdbrjfwothoh26x6izvyts7qx",
"le5fy6pintdkbxg6gdoetgbrdvyp664v"
],
"SigningAttributesOrigin": "AWS_SES",
"NextSigningKeyLength": "RSA_2048_BIT",
"CurrentSigningKeyLength": "RSA_2048_BIT",
"LastKeyGenerationTimestamp": "2024-02-23T15:01:53.849000+00:00"
}
}
DELETE APIs
When calling delete- with SESv1, SES returns 200 (or no response), even if the identity was previously deleted or doesn’t exist:
aws ses delete-identity --identity example.com
SESv2 provides better error handling and responses when calling the delete API:
aws sesv2 delete-email-identity --email-identity example.com
An error occurred (NotFoundException) when calling the DeleteEmailIdentity operation: Email identity example.com does not exist.
Hands-on with SESv1 API vs. SESv2 API
Below are a few examples you can use to explore the differences between SESv1 API and the SESv2 API. To complete these exercises, you’ll need:
- AWS Account (setup) with enough permission to interact with the SES service via the CLI
- Upgrade to the latest version of the AWS CLI (aws-cli/2.15.27 or greater)
- SES enabled, configured and properly sending emails
- A recipient email address with which you can check inbound messages (if you’re in the SES Sandbox, this email must be verified email identity). In the following examples, replace
[email protected] with the verified email identity.
- Your preferred IDE with AWS credentials and necessary permissions (you can also use AWS CloudShell)
Open the AWS CLI (or AWS CloudShell) and:
- Create a test directory called v1-v2-test.
- Create the following (8) files in the v1-v2-test directory:
destination.json (replace [email protected] with the verified email identity):
{
"ToAddresses": ["[email protected]"]
}
ses-v1-message.json
{
"Subject": {
"Data": "SESv1 API email sent using the AWS CLI",
"Charset": "UTF-8"
},
"Body": {
"Text": {
"Data": "This is the message body from SESv1 API in text format.",
"Charset": "UTF-8"
},
"Html": {
"Data": "This message body from SESv1 API, it contains HTML formatting. For example - you can include links: <a class=\"ulink\" href=\"http://docs.aws.amazon.com/ses/latest/DeveloperGuide\" target=\"_blank\">Amazon SES Developer Guide</a>.",
"Charset": "UTF-8"
}
}
}
ses-v1-raw-message.json (replace [email protected] with the verified email identity):
{
"Data": "From: [email protected]\nTo: [email protected]\nSubject: Test email sent using the SESv1 API and the AWS CLI \nMIME-Version: 1.0\nContent-Type: text/plain\n\nThis is the message body from the SESv1 API SendRawEmail.\n\n"
}
ses-v1-template.json (replace [email protected] with the verified email identity):
{
"Source":"SES Developer<[email protected]>",
"Template": "my-template",
"Destination": {
"ToAddresses": [ "[email protected]"
]
},
"TemplateData": "{ \"name\":\"SESv1 Developer\", \"favoriteanimal\": \"alligator\" }"
}
my-template.json (replace [email protected] with the verified email identity):
{
"Template": {
"TemplateName": "my-template",
"SubjectPart": "Greetings SES Developer, {{name}}!",
"HtmlPart": "<h1>Hello {{name}},</h1><p>Your favorite animal is {{favoriteanimal}}.</p>",
"TextPart": "Dear {{name}},\r\nYour favorite animal is {{favoriteanimal}}."
}
}
ses-v2-simple.json (replace [email protected] with the verified email identity):
{
"FromEmailAddress": "[email protected]",
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"Content": {
"Simple": {
"Subject": {
"Data": "SESv2 API email sent using the AWS CLI",
"Charset": "utf-8"
},
"Body": {
"Text": {
"Data": "SESv2 API email sent using the AWS CLI",
"Charset": "utf-8"
}
},
"Headers": [
{
"Name": "List-Unsubscribe",
"Value": "insert-list-unsubscribe-here"
},
{
"Name": "List-Unsubscribe-Post",
"Value": "List-Unsubscribe=One-Click"
}
]
}
}
}
ses-v2-raw.json (replace [email protected] with the verified email identity):
{
"FromEmailAddress": "[email protected]",
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"Content": {
"Raw": {
"Data": "Subject: Test email sent using SESv2 API via the AWS CLI \nMIME-Version: 1.0\nContent-Type: text/plain\n\nThis is the message body from SendEmail Raw Content SESv2.\n\n"
}
}
}
ses-v2-tempate.json (replace [email protected] with the verified email identity):
{
"FromEmailAddress": "[email protected]",
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"Content": {
"Template": {
"TemplateName": "my-template",
"TemplateData": "{ \"name\":\"SESv2 Developer\",\"favoriteanimal\":\"Dog\" }",
"Headers": [
{
"Name": "List-Unsubscribe",
"Value": "insert-list-unsubscribe-here"
},
{
"Name": "List-Unsubscribe-Post",
"Value": "List-Unsubscribe=One-Click"
}
]
}
}
}
Perform the following commands using the SESv1 API:
send-email (simple):
aws ses send-email --from [email protected] --destination file://destination.json --message file://ses-v1-message.json
- The response will return a valid MessageID (signaling the action was successful). An email will be received by
the verified email identity.
{
"MessageId": "0100018dc7649400-Xx1x0000x-bcec-483a-b97c-123a4567890d-xxxxx"
}
send-raw-email:
aws ses send-raw-email --cli-binary-format raw-in-base64-out --raw-message file://ses-v1-raw-message.json
- The response will return a valid MessageID (signaling the action was successful). An email will be received by
the verified email identity.
{
"MessageId": "0200018dc7649400-Xx1x1234x-bcec-483a-b97c-123a4567890d-
}
send templated mail:
- In the CLI, run the following to create the template:
aws ses create-template --cli-input-json file://my-template.json
aws ses send-templated-email --cli-input-json file://ses-v1-template.json
- The response will return a valid MessageID (signaling the action was successful). An email will be received by
the verified email identity.
{
"MessageId": "0000018dc7649400-Xx1x1234x-bcec-483a-b97c-123a4567890d-xxxxx"
}
Perform similar commands using the SESv2 API:
As mentioned above, customers who are using least privilege permissions with SESv1 API must first update their IAM policies before running the SESv2 API examples below. See documentation for more info.
As you can see from the .json files we created for SES v2 API (above), you can modify or remove sections from the .json files, based on the type of email content (simple, raw or templated) you want to send.
Please ensure you are using the latest version of the AWS CLI (aws-cli/2.15.27 or greater).
Send simple email
aws sesv2 send-email --cli-input-json file://ses-v2-simple.json
- The response will return a valid MessageID (signaling the action was successful). An email will be received by
the verified email identity
{
"MessageId": "0100018dc83ba7e0-7b3149d7-3616-49c2-92b6-00e7d574f567-000000"
}
Send raw email (note – if the only reason is to set custom headers, you don’t need to send raw email)
aws sesv2 send-email --cli-binary-format raw-in-base64-out --cli-input-json file://ses-v2-raw.json
- The response will return a valid MessageID (signaling the action was successful). An email will be received by
the verified email identity.
{
"MessageId": "0100018dc877bde5-fdff0df3-838e-4f51-8582-a05237daecc7-000000"
}
Send templated email
aws sesv2 send-email --cli-input-json file://ses-v2-tempate.json
- The response will return a valid MessageID (signaling the action was successful). An email will be received by
the verified email identity.
{
"MessageId": "0100018dc87fe72c-f2c547a1-2325-4be4-bf78-b91d6648cd12-000000"
}
Migrating your application code to SESv2 API
As you can see from the examples above, SESv2 API shares much of its syntax and actions with the SESv1 API. As a result, most customers have found they can readily evaluate, identify and migrate their application code base in a relatively short period of time. However, it’s important to note that while the process is generally straightforward, there may be some nuances and differences to consider depending on your specific use case and programming language.
Regardless of the language, you’ll need anywhere from a few hours to a few weeks to:
- Update your code to use SESv2 Client and change API signature and request parameters
- Update permissions / policies to reflect SESv2 API requirements
- Test your migrated code to ensure that it functions correctly with the SESv2 API
- Stage, test
- Deploy
Summary
As we’ve described in this post, Amazon SES customers that migrate to the SESv2 API will benefit from updated capabilities, a more user-friendly and intuitive API, better error handling and improved deliverability controls. The SESv2 API also provide for compliance with the industry’s upcoming unsubscribe header requirements, more flexible subscription-list management, and support for larger attachments. Taken collectively, these improvements make it even easier for customers to develop, maintain, and troubleshoot their email sending applications with Amazon Simple Email Service. For these, and future reasons, we recommend SES customers migrate their existing applications to the SESv2 API immediately.
For more information regarding the SESv2 APIs, comment on this post, reach out to your AWS account team, or consult the AWS SESv2 API documentation:
About the Authors
Zip
Zip is an Amazon Pinpoint and Amazon Simple Email Service Sr. Specialist Solutions Architect at AWS. Outside of work he enjoys time with his family, cooking, mountain biking and plogging.
Vinay Ujjini
Vinay is an Amazon Pinpoint and Amazon Simple Email Service Worldwide Principal Specialist Solutions Architect at AWS. He has been solving customer’s omni-channel challenges for over 15 years. He is an avid sports enthusiast and in his spare time, enjoys playing tennis and cricket.
Dmitrijs Lobanovskis
Dmitrijs is a Software Engineer for Amazon Simple Email service. When not working, he enjoys traveling, hiking and going to the gym.






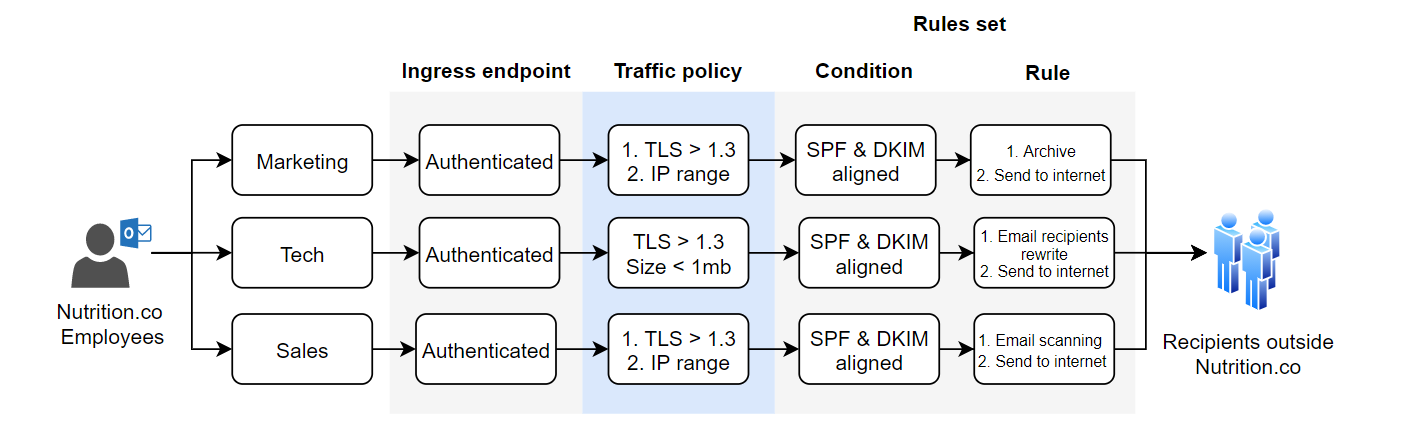
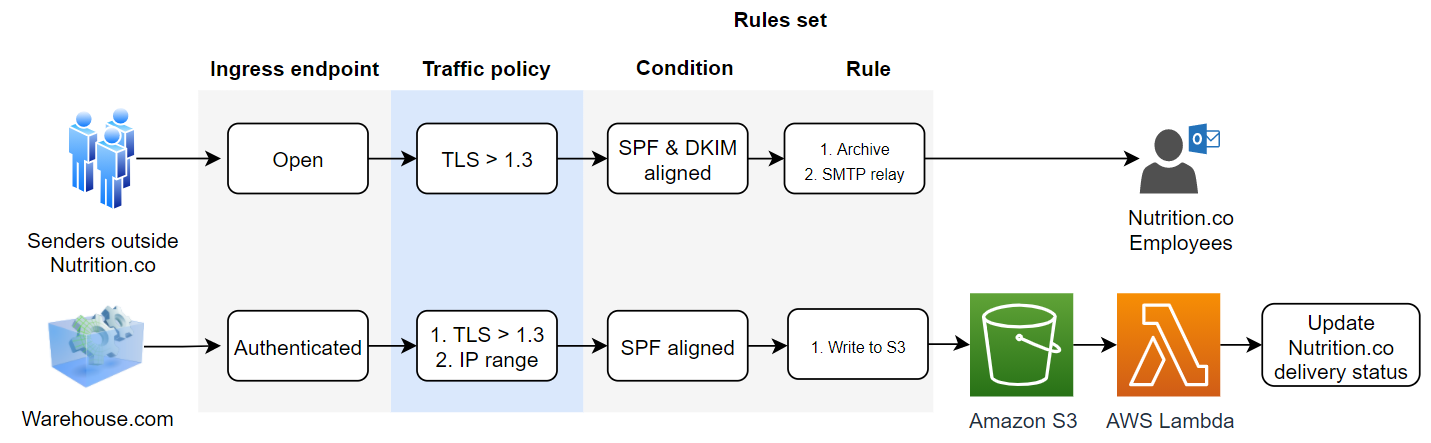
 Navigate to Amazon SES > Mail Manager > Ingress endpoint, select the ingress endpoint named Archiving and copy the ARecord, which looks like this <unique-id>.fips.wmjb.mail-manager-smtp.amazonaws.com – see screenshot below. Add this value to your MX record.
Navigate to Amazon SES > Mail Manager > Ingress endpoint, select the ingress endpoint named Archiving and copy the ARecord, which looks like this <unique-id>.fips.wmjb.mail-manager-smtp.amazonaws.com – see screenshot below. Add this value to your MX record.



 ” width=”1252″ height=”889″>
” width=”1252″ height=”889″>
 ” width=”1280″ height=”720″>
” width=”1280″ height=”720″>
 ” width=”863″ height=”521″>
” width=”863″ height=”521″> ” width=”865″ height=”582″>
” width=”865″ height=”582″> ” width=”1497″ height=”1173″>
” width=”1497″ height=”1173″> ” width=”1336″ height=”1313″>
” width=”1336″ height=”1313″> ” width=”1333″ height=”1364″>
” width=”1333″ height=”1364″> ” width=”1611″ height=”680″>
” width=”1611″ height=”680″>
 ” width=”964″ height=”732″>
” width=”964″ height=”732″>
 ” width=”661″ height=”341″>
” width=”661″ height=”341″>
 ” width=”1800″ height=”563″>
” width=”1800″ height=”563″>


















 Check out this exclusive sneak peek video.“
Check out this exclusive sneak peek video.“ Here’s a fun photo from our recent in-store event. Thanks for stopping by!”
Here’s a fun photo from our recent in-store event. Thanks for stopping by!” Explore our latest makeup collection with this handy lookbook.”
Explore our latest makeup collection with this handy lookbook.”

























































Response:
3) Send test message
Response:
Response – (ConflictException):
Conclusion
As SMS messaging continues to play a crucial role in customer engagement and authentication, protecting your communications from AIT is more important than ever. Amazon Pinpoint Protect provides a powerful and user-friendly solution to help you mitigate the impact of SMS pumping, ensuring the integrity of your SMS channels and preserving your business’ reputation and resources. Whether you’re a small business or a large enterprise, Pinpoint Protect is a valuable tool to have in your arsenal as you navigate the evolving landscape of SMS messaging.
To get started with Pinpoint SMS Protect, visit the Amazon Pinpoint SMS documentation or reach out to your AWS account team. And don’t forget to let us know in the comments how Protect configurations has helped you combat AIT and strengthen your SMS communications.
A few resources to help you plan for your SMS program:
About the Author
Brett Ezell is your friendly neighborhood Solutions Architect at AWS, where he specializes in helping customers optimize their SMS and email campaigns using Amazon Pinpoint and Amazon Simple Email Service. As a former US Navy veteran, Brett brings a unique perspective to his work, ensuring customers receive tailored solutions to meet their needs. In his free time, Brett enjoys live music, collecting vinyl, and the challenges of a good workout. And, as a self-proclaimed comic book aficionado, he can often be found combing through his local shop for new books to add to his collection.