Over the years, Cloudflare has gained fame for many things, including our technical blog, but also as a tech company securing the Internet using lava lamps, a story that began as a research/science project almost 10 years ago. In March 2025, we added another layer to its legacy: a “wall of entropy” made of 50 wave machines in constant motion at our Lisbon office, the company’s European HQ.
These wave machines are a new source of entropy, joining lava lamps in San Francisco, suspended rainbows in Austin, and double chaotic pendulums in London. The entropy they generate contributes to securing the Internet through LavaRand.
The new waves wall at Cloudflare’s Lisbon office sits beside the Radar Display of global Internet insights, with the 25th of April Bridge overlooking the Tagus River in the background.
It’s exciting to see waves in Portugal now playing a role in keeping the Internet secure, especially given Portugal’s deep maritime history.
The installation honors Portugal’s passion for the sea and exploration of the unknown, famously beginning over 600 years ago, in 1415, with pioneering vessels like caravels and naus/carracks, precursors to galleons and other ships. Portuguese sea exploration was driven by navigation schools and historic voyages “through seas never sailed before” (“Por mares nunca dantes navegados” in Portuguese), as described by Portugal’s famous poet, Luís Vaz de Camões, born 500 years ago (1524).
Anyone familiar with Portugal knows the sea is central to its identity. The small country has 980 km of coastline, where most of its main cities are located. Maritime areas make up 90% of its territory, including the mid-Atlantic Azores. In 1998, Lisbon’s Expo 98 celebrated the oceans and this maritime heritage. Since 2011, the small town of Nazaré also became globally famous among the surfing community for its giant waves.
Nazaré’s waves, famous since Garrett McNamara’s 23.8 m (78 ft) ride in 2011, hold Guinness World Records for the biggest waves ever surfed. Photos: Sam Khawasé & Beatriz Paula, from Cloudflare.
Portugal’s maritime culture also inspired literature and music, including poet Fernando Pessoa, who referenced it in his 1934 book Mensagem, and musician Rui Veloso, who dedicated his 1990s album Auto da Pimenta to Portugal’s historic connection to the sea.
How this chaos came to be
As Cloudflare’s CEO, Matthew Prince, said recently, this new wall of entropy began with an idea back in 2023: “What could we use for randomness that was like our lava lamp wall in San Francisco but represented our team in Portugal?”
The original inspiration came from wave motion machine desk toys, which were popular among some of our team members. Waves and the ocean not only provide a source of movement and randomness, but also align with Portugal’s maritime history and the office’s scenic view.
However, this was easier said than done. It turns out that making a wave machine wall is a real challenge, given that these toys are not as popular as they were in the past, and aren’t being manufactured in the size we needed any more. We scoured eBay and other sources but couldn’t find enough, consistent in style and in working order wave machines. We also discovered that off-the-shelf models weren’t designed to run 24/7, which was a critical requirement for our use.
Artistry to create wave machines
Undaunted, Cloudflare’s Places team, which ensures our offices reflect our values and culture, found a U.S.-based artisan that specializes in ocean wave displays to create the wave machines for us. Since 2009, his one-person business, Hughes Wave Motion Machines, has blended artistry, engineering, and research, following his transition from Lockheed Martin Space Systems, where he designed military and commercial satellites.
Timelapse of the mesmerizing office waves, set to the tune of an AI-generated song.
Collaborating closely, we developed a custom rectangular wave machine (18 inches/45 cm long) that runs nonstop — not an easy task — which required hundreds of hours of testing and many iterations. Featuring rotating wheels, continuous motors, and a unique fluid formula, these machines create realistic ocean-like waves in green, blue, and Cloudflare’s signature orange.
Here’s a quote from the artist himself about these wave machines:
“The machine’s design is a balancing act of matching components and their placement to how the fluid responds in a given configuration. There is a complex yet delicate relationship between viscosity, specific gravity, the size and design of the vessel, and the placement of each mechanical interface. Everything must be precisely aligned, centered around the fluid like a mathematical function. I like to say it’s akin to ’balancing a checkerboard on a beach ball in the wind.’”
The Cloudflare Places Team with Lisbon office architects and contractor testing wave machine placement, shelves, lighting, and mirrors to enhance movement and reflection, March 2024.
Despite delays, the Lisbon wave machines finally debuted on March 10, 2025 — an incredibly exciting moment for the Places team.
Some numbers about our wave-machine entropy wall:
50 wave machines, 50 motion wheels & motors, 50 acrylic containers filled with Hughes Wave Fluid Formula (two immiscible liquids)
3 liquid colors: blue, green, and orange
15 months from concept to completion
14 flips (side-to-side balancing movements) per minute — over 20,000 per day
Over 15 waves per minute
~0.5 liters of liquid per machine
LavaRand origins and walls of entropy
Cloudflare’s servers handle 71 million HTTP requests per second on average, with 100 million HTTP requests per second at peak. Most of these requests are secured via TLS, which relies on secure randomness for cryptographic integrity. A Cryptographically Secure Pseudorandom Number Generator (CSPRNG) ensures unpredictability, but only when seeded with high-quality entropy. Since chaotic movement in the real world is truly random, Cloudflare designed a system to harness it. Our 2024 blog post expands on this topic in a more technical way, but here’s a quick summary.
In 2017, Cloudflare launched LavaRand, inspired by Silicon Graphics’ 1997 concept However, the need for randomness in security was already a hot topic on our blog before that, such as in our discussions of securing systems and cryptography. Originally, LavaRand collected entropy from a wall of lava lamps in our San Francisco office, feeding an internal API that servers periodically query to include in their entropy pools. Over time, we expanded LavaRand beyond lava lamps, incorporating new sources of office chaos while maintaining the same core method.
A camera captures images of dynamic, unpredictable randomness displays. Shadows, lighting changes, and even sensor noise contribute entropy. Each image is then processed into a compact hash, converting it into a sequence of random bytes. These, combined with the previous seed and local system entropy, serve as input for a Key Derivation Function (KDF), which generates a new seed for a CSPRNG — capable of producing virtually unlimited random bytes upon request. The waves in our Lisbon office are now contributing to this pool of randomness.
Cloudflare’s LavaRand API makes this randomness accessible internally, strengthening cryptographic security across our global infrastructure. For example, when you use Math.random() in Cloudflare Workers, part of that randomness comes from LavaRand. Similarly, querying our drand API taps into LavaRand as well. Cloudflare offers this API to enable anyone to generate random numbers and even seed their own systems.
Our new Lisbon office space
Photo of the view from our Lisbon office, featuring ceiling lights arranged in a wave-like pattern.
Entropy also inspired the design ethos of our new Lisbon office, given that the wall of waves and the office are part of the same project. As soon as you enter, you’re greeted not only by the motion of the entropy wall but also by the constant movement of planet Earth on our Cloudflare Radar Display screen that stands next to it. But the waves don’t stop there — more elements throughout the space mimic the dynamic flow of the Internet itself. Unlike ocean tides, however, Internet traffic ebbs and flows with the motion of the Sun, not the Moon.
As you walk through the office, waves are everywhere — in the ceiling lights, the architectural contours, and even the floor plan, thoughtfully designed by our architect to reflect the fluid movement of water. The visual elements create a cohesive experience, reinforcing a sense of motion. Each meeting room embraces this maritime theme, named after famous Portuguese beaches — including, naturally, Nazaré.
We partnered with an incredible group of local Portuguese vendors for this construction project, where all the leads were women — something incredibly rare for the industry. The local teams worked with passion, proudly wore Cloudflare t-shirts, and fostered a warm, family-like atmosphere. They openly expressed pride in the project, sharing how it stood out from anything they had worked on before.
Our amazing third-party team and internal Places team, proudly rocking Cloudflare shirts after bringing this project to life.
Help us select a name for our new wall of entropy
Next, we have several name options for this new wall of entropy. Help us decide the best one, and register your vote using this form.
The Surf Board
Chaos Reef
Waves of Entropy
Wall of Waves
Whirling Wave Wall
Chaotic Wave Wall
Waves of Chaos
If you’re interested in working in Cloudflare’s Lisbon office, we’re hiring! Our career page lists our open roles in Lisbon, as well as our other locations in the U.S., Mexico, Europe and Asia.
Acknowledgements: This project was only possible with the effort, vision and help of John Graham-Cumming, Caroline Quick, Jen Preston, Laura Atwall, Carolina Beja, Hughes Wave Motion Machines, P4 Planning and Project Management, Gensler Europe, Openbook Architecture, and Vector Mais.
Abstract: The wide adoption of deep neural networks (DNNs) raises the question of how can we equip them with a desired cryptographic functionality (e.g, to decrypt an encrypted input, to verify that this input is authorized, or to hide a secure watermark in the output). The problem is that cryptographic primitives are typically designed to run on digital computers that use Boolean gates to map sequences of bits to sequences of bits, whereas DNNs are a special type of analog computer that uses linear mappings and ReLUs to map vectors of real numbers to vectors of real numbers. This discrepancy between the discrete and continuous computational models raises the question of what is the best way to implement standard cryptographic primitives as DNNs, and whether DNN implementations of secure cryptosystems remain secure in the new setting, in which an attacker can ask the DNN to process a message whose “bits” are arbitrary real numbers.
In this paper we lay the foundations of this new theory, defining the meaning of correctness and security for implementations of cryptographic primitives as ReLU-based DNNs. We then show that the natural implementations of block ciphers as DNNs can be broken in linear time by using such nonstandard inputs. We tested our attack in the case of full round AES-128, and had success rate in finding randomly chosen keys. Finally, we develop a new method for implementing any desired cryptographic functionality as a standard ReLU-based DNN in a provably secure and correct way. Our protective technique has very low overhead (a constant number of additional layers and a linear number of additional neurons), and is completely practical.
We’re excited to announce that AWS-LC FIPS 3.0 has been added to the National Institute of Standards and Technology (NIST)Cryptographic Module Validation Program (CMVP)modules in process list. This latest validation of AWS-LC introduces support for Module Lattice-Based Key Encapsulation Mechanisms (ML-KEM), the new FIPS standardized post-quantum cryptographic algorithm. This is a significant step towards enhancing the long-term confidentiality of our most sensitive customer workflows, including U.S. federal government communications.
This validation makes AWS LibCrypto (AWS-LC) the first open source cryptographic module to provide post-quantum algorithm support within the FIPS module. Organizations that require FIPS-validated cryptographic modules—such as those operating under FedRAMP, FISMA, HIPAA, and other federal compliance frameworks—can now use these algorithms within AWS-LC.
This announcement is part of the long-term promise made by AWS-LC of continuous validation to obtain new FIPS 140-3 certificates. AWS-LC obtained its first certificate in October 2023 for AWS-LC-FIPS 1.0. A subsequent version of the library, AWS-LC-FIPS 2.0, was certified in October 2024. In this post, we discuss our FIPS-validation of post-quantum cryptographic algorithm ML-KEM, the performance improvements of existing algorithms in AWS-LC FIPS 2.0 and 3.0, and the new algorithm support added for version 3.0. We also discuss how you can use the new algorithms to implement hybrid post-quantum cipher suites, along with configuration options that you can set up today to help protect against future threats.
FIPS post-quantum cryptography
Large-scale quantum computers pose a threat to the long-term confidentiality of the data that we protect under public-key cryptography today. In what’s known as a record-now, decrypt-later attack, an adversary records internet traffic today, capturing key exchanges and encrypted communication. Then, when a sufficiently powerful quantum computer is available, the adversary can retroactively recover shared secrets and encryption keys by solving the underlying hardness problem.
ML-KEM is one of the new key encapsulation mechanisms that’s being standardized by NIST in an effort to protect the uses of public key cryptography from quantum threats. Much like RSA, Diffie-Hellman (DH), or Elliptic-curve Diffie-Hellman (ECDH) key exchange, it works by establishing a shared secret between two parties. However, unlike RSA or DH, ML-KEM bases the key exchange on an underlying problem that is believed to be hard for quantum computers to solve.
Today, we don’t know how to build such a large-scale quantum computer. Significant scientific research is needed before such a computer can be built. However, you can mitigate the risk of record-now, decrypt-later attacks by introducing post-quantum algorithms such as ML-KEM into your key exchange protocols today. We recommend adopting a hybrid key exchange approach that combines a traditional key exchange method—such as ECDH—with ML-KEM to hedge against current and future adversaries. Later in this post, we show you how you can implement hybrid post-quantum cipher suites today to protect against future threats.
AWS-LC FIPS 3.0 includes the ML-KEM algorithm for all three provided parameter sets, ML-KEM-512, ML-KEM-768, and ML-KEM-1024. The three parameter sets provide differing levels of security strength as specified by NIST (see FIPS 203 [9, Sect. 5.6] or the post-quantum security evaluation criteria). ML-KEM-768 is recommended for general-purpose use cases, ML-KEM-1024 is designed for applications that require a higher security level or adherence to explicit directives such as the Commercial National Security Algorithm Suite (CNSA) 2.0 for National Security System owners and operators.
Algorithm
NIST security category
Public key (B)
Private key (B)
Ciphertext (B)
ML-KEM-512
1
800
1632
768
ML-KEM-768
3
1184
2400
1088
ML-KEM-1024
5
1568
3168
1568
Table 1. Security strength category, public key, private key, and ciphertext sizes in bytes for the three parameter sets of ML-KEM
Integration with s2n-tls
ML-KEM is now available in our open source TLS implementation, s2n-tls, through hybrid key exchange for TLS 1.3 (draft-ietf-tls-hybrid-design). We’ve also added support for hybrid ECDHE-ML-KEM key agreement for TLS 1.3 (draft-kwiatkowski-tls-ecdhe-mlkem), along with new key share identifiers for Curve x25519 and ML-KEM-768.
For hybrid key establishment in FIPS 140-approved mode, one component algorithm must be a NIST-approved mechanism (detailed in NIST post-quantum FAQs). With ML-KEM added to the list of NIST-approved algorithms, you can now include non-FIPS standardized algorithms like Curve x25519 in hybrid cipher suites. By configuring your TLS cipher suite to use ML-KEM-768 and x25519 (draft-kwiatkowski-tls-ecdhe-mlkem), you can use x25519 within a FIPS-validated cryptographic module for the first time. This can facilitate more efficient key exchange through the highly optimized and functionally verified Curve x25519 implementation provided by AWS-LC.
New algorithms and new implementations
Two integral parts of our commitment to continuous validation of AWS-LC FIPS are to include new algorithms as approved cryptographic services and new implementations of existing algorithms that provide performance improvements and functional correctness.
New algorithms
We’re committed to continually validating new algorithms so that builders can adopt FIPS-validated cryptography by including the latest revisions of approved cryptographic algorithms and supporting new primitives. Validating new algorithms in their latest standardized revision helps ensure that our cryptographic tool-kit is providing high-assurance implementations that achieve compliance with globally recognized standards.
In AWS-LC FIPS 3.0 we’ve added the latest member of the Secure Hash Algorithm standard SHA-3 to the module. The SHA-3 family is a cryptographic primitive used to support a variety of algorithms. In AWS-LC FIPS 3.0, we’ve integrated ECDSA and RSA signature generation and verification with SHA-3 and within the post-quantum algorithm ML-KEM. In AWS-LC, ML-KEM calls into our FIPS-validated SHA-3 functions, which provide optimized implementations of SHA-3 and SHAKE hashing procedures. This means that as we continually refine and optimize our AWS-LC SHA-3 implementation, we’ll continue to see performance increases across algorithms that use the primitive, such as ML-KEM.
EdDSA is a digital signature algorithm based on elliptic curves using the curve Ed25519. It was added to NIST’s updated Digital Signature Standard (DSS), FIPS 186-5. This signature algorithm is now offered as part of the AWS-LC 3.0 FIPS module. For key agreement, the Single-step Key Derivation Function (SSKDF) used to derive keys from a shared secret (SP 800-56Cr2) is available both in the digest-based and HMAC-based specifications. It can be used, for example, to derive a key from a shared secret produced by KMS when using ECDH. Further keys can be derived from that original key using a Key-based Key Derivation Function (KBKDF)—SP 800-108r1—which is available using a counter-mode based on HMAC.
Performance improvements
We focused on increasing the performance of public-key cryptography algorithms widely used in transport protocols such as the TLS protocol. For example, RSA signatures on Graviton2 are 81 percent faster for bit-length 2048, 33 percent for 3072, and 94 percent for 4096, with added formal verification of functional correctness of the main operation. Using Intel’s AVX512 Integer Fused Multiply Add (IFMA) instructions—available starting from 3rd Gen Intel Xeon—Intel developers contributed an RSA implementation that employs these instruction and the wide AVX512 registers, which are twice as fast as the existing implementation.
We increased throughput for EdDSA signing by an average of 108 percent and for verifying by 37 percent. This average is taken over three environments: Graviton2, Graviton3, and Intel Ice Lake (Intel Xeon Platinum 8375C CPU). This boost in performance is achieved by integrating assembly implementations of the core operation for each target from the s2n-bignum library. That, in addition to the careful constant-time implementation of the core operations, is how each one has been proven to be functionally correct.
In Figure 1 that follows, we highlight the percentage of performance improvements compared to AWS-LC FIPS 1.0 in versions 2.0 and 3.0. The improvements achieved in 2.0 are maintained in 3.0 and are not repeated in the graph. The graph also includes symmetric-key improvements. In AES-256-GCM, which is widely used in TLS to encrypt the communication after the session has been established, the increase is on average 115 percent across Intel Ice Lake and Graviton4 to encrypt a 16 KB message. In AES-256-XTS, which is used in disk storage, encrypting a 256 B input is 360 percent faster on Intel Ice Lake and 90 percent faster on Graviton4.
Figure 1: Graph of performance improvements in versions 2.0 and 3.0 of AWS-LC FIPS
How to use ML-KEM today
You can configure both s2n-tls and AWS-LC TLS libraries to enable hybrid post-quantum security with ML-KEM today by enabling X25519MLKEM768 and SecP256r1MLKEM768 for key exchange. We’ve integrated support for both of these hybrid algorithms in AWS-LC libssl and s2n-tls using each library’s exisiting TLS configuration APIs. To negotiate a TLS connection, use one of the following commands:
# S2N-tls Client CLI Example
./s2n/build/bin/s2nc -c default_pq -i <hostname><port>
Conclusion
In this post, we described the ongoing development, optimization, and validation of the cryptography that we provide to our customers and products through our open source cryptographic library, AWS-LC. We introduced the addition of FIPS-validated post-quantum algorithms and provided configuration options to begin using these algorithms today to protect against future threats.
AWS-LC-FIPS 3.0 is part of our commitment to continually validate new versions of AWS-LC as we add new algorithms within the FIPS boundary as they become specified, and as we raise the performance and formal verification bar on existing algorithms. Through this commitment, we continue to support the wider developer community of Rust, Java and Python developers by providing integrations into the AWS Libcrypto for Rust (aws-lc-rs) and ACCP 2.0 libraries. We facilitate integration into CPython so that you can build against AWS-LC and use it for all cryptography in the Python standard library. We enabled rustls to provide FIPS support.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) is migrating to post-quantum cryptography (PQC). Like other security and compliance features in AWS, we will deliver PQC as part of our shared responsibility model. This means that some PQC features will be transparently enabled for all customers while others will be options that customers can choose to implement to help meet their requirements. This transition will happen in phases, starting with systems that communicate over untrusted networks such as the internet.
The threat of a large-scale quantum computer, sometimes referred to as a cryptographically relevant quantum computer, is its potential to break the public-key cryptographic algorithms in use today. These algorithms are used in most communication protocols and digital signature schemes. For the past eight years, AWS—along with other industry leaders, government agencies, and academia—has been advocating, researching, and proposing new public-key cryptographic algorithms that are resistant to quantum computing. Because customers rely on cryptography performed by AWS to secure their data, we engaged in this work early on to minimize the effort and the impact of the eventual migration to PQC. While there is no evidence that a quantum computer powerful enough to break the public key cryptography in use throughout AWS exists today, we are not waiting. We would rather put protections in place now to protect the security of our customers’ data into the future.
This post summarizes where AWS is today in the journey of migrating to PQC and outlines our path forward.
For the past five years we’ve deployed early versions of PQC algorithms under evaluation by the U.S. National Institute of Standards and Technology (NIST) in both our open-source libraries and security-critical services to allow customers to test the performance impact of moving to PQC. For example, our open-source library for algorithm implementations (AWS-LC), our implementation of TLS (s2n) and core security services like AWS Key Management Service (AWS KMS), AWS Secrets Manager and AWS Certificate Manager (ACM) have had implementations of NIST PQC proposed algorithms for key encapsulation as far back as 2019.
Now that the first round of PQC algorithms has been standardized, we can start to implement them for long-term support. Here’s our approach to implementing PQC to provide a seamless transition for our customers who rely on our services and open-source tools to handle cryptographic operations on their behalf.
AWS will take a multi-layered approach to migrating to PQC over the coming years. We define the simultaneous workstreams as:
Workstream 1: Inventory of existing systems, identification and development of new standards, testing, and migration planning. While the first set of algorithm standards has been published, there are additional standards to come that will define how PQC should be integrated in specific applications and protocols to ensure interoperability.
Workstream 2: Integration of PQC algorithms on public AWS endpoints to provide long-lived confidentiality of customer data transmitted to AWS.
Workstream 3: Integration of PQC signing algorithms into AWS cryptographic services to enable customers to deploy new post-quantum long-lived roots of trust to be used for functions such as software, firmware, and document signing.
Workstream 4: Integration of PQC signing algorithms into AWS services to enable the use of post-quantum signatures for session-based authentication such as server and client certificate validation.
Workstream 1
We view the work here as an ongoing aspect of our migration plan. It has already informed our overall strategy and prioritized our migration based on our customers’ needs.
Similar to our customers, we had to look across all of the places where we use cryptography to determine which implementations needed migration and at which priority. One of the important decisions we made was to focus more on encryption in transit and less on encryption at rest. Public key (asymmetric) cryptography is the foundation of encryption in transit because it enables two parties to negotiate a shared secret across an untrusted network—it’s today’s traditional public key algorithms that are at risk of being compromised by a cryptographically relevant quantum computer. Based on the current consensus across the industry, the risk of a cryptographically relevant quantum computer to the 256-bit symmetric key cryptography isn’t something that needs to be mitigated. Because data at rest in AWS is encrypted using 256-bit symmetric cryptography, we believe that we don’t need to re-encrypt existing customer data or change the symmetric algorithms and keys that we use to encrypt future data.
While the security of symmetric encryption keys and algorithms isn’t impacted by a cryptographically relevant quantum computer, there are cases where public key algorithms are used to negotiate a shared symmetric key, thereby creating risk that the symmetric key could be compromised. The first use of public key cryptography in AWS that we will migrate to PQC is exactly this case—where we negotiate a shared symmetric key between our customers and the public endpoints of AWS services. The networks that customers use to communicate with AWS services are often outside the control of either AWS or the customer, and therefore susceptible to a bad actor capturing data now and then brute-force decrypting it in the future using a cryptographically relevant quantum computer. Workstream 2 discusses this plan in more detail.
The next use of public key cryptography in AWS that we will migrate to PQC is where we offer the ability to create a key pair that acts as a long-term root of trust, typically used to apply a digital signature to software, firmware, or documents. These types of key pairs might need to be valid for digital signing years into the future because they can’t easily be updated. Think of the firmware on satellites, gaming consoles, and other IoT devices where replacing the public key pairs and the signing algorithm code might not be possible over the life of the device. Workstream 3 describes this plan in more detail.
The final area of public key cryptography in AWS that we will migrate to PQC is where we offer the ability to create a key pair that acts as a shorter-term root of trust, typically used to apply a digital signature to a single transaction, a web session, or some other ephemeral message. The most common example of this use case is the way that digital certificates are used to authenticate the server or client in a TLS session. You might assume that workstreams 2 and 3 handle the risks to session key negotiation and digital signatures in a TLS session, so what’s left to protect? It turns out that the way that public key cryptography is used to mutually authenticate two parties using digital certificates to exchange a message is heavily dependent on standards and interoperability across a large set of internet infrastructure. Getting the industry to agree on those standards and testing interoperability will take time before this workstream is finished. Workstream 4 describes this plan in more detail.
We’ve talked about how AWS has done its cryptographic inventory and our plan to migrate to PQC. If you don’t delegate all your cryptographic operations to AWS, what should you be doing to prepare? While no single approach will be right for all applications and industries, here are some resources with more context on recommendations that we contributed to or used as part of our work:
While doing an inventory of cryptography across your organization to prioritize PQC migration might be a multi-year effort for you, we have a couple of tactical recommendations to consider in the short-term. First, work to make sure that you have agility in your abilities to distribute updated versions of software. This is a critical capability for any organization in the context of vulnerability management and software lifecycle maintenance. This ability will be required to adopt new PQ versions of the AWS Command Line Interface (AWS CLI) and AWS SDKs when we publish them. You might also need to update third-party software components that use TLS or other cryptographic implementations used to communicate with AWS services to make sure that you can take advantage of the PQC we offer.
Second, we strongly encourage you to begin a comprehensive program to adopt TLS 1.3 across your entire organization. This and later versions of TLS not only offer security and performance improvements using classical public key cryptography, but they are strictly mandated to be able to use PQC at all. Even if you recently updated to TLS 1.2 in your clients and servers, you still have work to do to prepare your systems for a PQC future.
Workstream 2
Customers communicate with cloud services using protocols based on public key cryptography. These protocols (such as TLS) help ensure that customers’ communications are confidential and cannot be altered in transit. To protect our customers’ long-term need for confidentiality, we pioneered a mechanism known as hybrid post-quantum key agreement. Hybrid post-quantum key agreement combines Elliptic-Curve Diffie-Hellman (ECDH), a classic key exchange algorithm, with a post-quantum key encapsulation method, such as the newly standardized ML-KEM algorithm. The resulting two keys are combined to establish session communication keys that encrypt the network traffic. An adversary would need to break both of these public-key primitives (ECDH and ML-KEM) to break the confidentiality property provided by the hybrid key agreement.
The Internet Engineering Task Force (IETF) is currently finalizing the TLS protocol standard incorporating post-quantum cryptography. Upon completion of this standard, AWS will update s2n-tls to align with these new specifications. After we have the ML-KEM implementation from AWS-LC integrated with a version of s2n based on IETF standards, we will begin deployment of this s2n version across all AWS public endpoints that offer HTTPS-based interfaces. This represents most AWS services, typically accessed through the AWS SDK or AWS CLI. AWS services that offer public endpoints with other interfaces such as SFTP, IPsec, or SSH will get ML-KEM support as standards bodies such as the IETF publish implementation guidance for those protocols.
As a part of migrating AWS managed service endpoints to PQC over TLS, we’ll also be enabling services that provide server-side TLS termination for your workloads, including Elastic Load Balancing (ELB), Amazon API Gateway, and Amazon CloudFront. This will allow you to use the same digital certificates that you’ve been using with these services and let them negotiate the server-side TLS session using ML-KEM on your behalf. This will provide the long-term confidentiality of your TLS sessions without you having to upgrade the underlying certificates themselves to some as-yet-undefined PQC standard.
Many of our customers manufacture systems with firmware, operating systems, and pre-installed third-party applications. These components are cryptographically signed using a public-key-based root of trust to maintain the security and authenticity of systems as they deliver services to end users. Some of these systems, such as smart TVs connected to set-top boxes, might operate without internet connectivity for a decade or longer until they’re installed.
Additionally, certain customers must embed long-lived roots of trust directly into their hardware during manufacturing—a process that cannot be reversed or updated. For devices designed to operate for 10+ years, the security of these initial roots of trust must remain robust even when cryptographically relevant quantum computers become available.
To address this need for long-lived roots of trust for code and document signing, AWS will adopt ML-DSA, a new digital signature algorithm that is believed to be secure against adversaries in possession of a cryptographically relevant quantum computer. We will first offer ML-DSA as a feature within AWS Key Management Service (AWS KMS), enabling customers to generate and use PQC keys as roots of trust for signing operations within the FIPS-140-3 Level 3 validated hardware security modules (HSMs) used in AWS KMS. This integration represents a crucial milestone in our PQC roadmap, providing customers with the capability to establish secure, quantum-resistant roots of trust and authentication for their long-term security needs.
This long-term perspective underscores the importance of implementing PQC early, helping to ensure that systems will remain secure throughout their entire operational lifetime, even if they are disconnected for a prolonged period. While Amazon will use this capability from AWS KMS to protect our own roots of trust, we encourage you to consider ways in which this capability might help you do the same.
Workstream 4
In workstream 2 we discussed how PQC can be deployed to protect against risks to the confidentiality of data shared across a communication channel. To complete the story, there still needs to be a way to protect the authenticity of server and client identities over a communication channel in a post-quantum world.
Digital signatures are used today for end-entity authentication in networking protocols such as TLS and SSH. Customers use certificates from a trusted certificate authority (CA) that binds a public key to an identity using a digital signature to authenticate service and client endpoints. While some of the PQC standards available today (e.g. ML-DSA) could be implemented with certificates to address the post-quantum risk, the work cannot begin without further standardization and interoperability testing between certificate authorities and the systems that use digital certificates. The primary reason for this delay has to do with how publicly trusted certificates are validated today by recipients of a signed message. In the TLS protocol, for example, the client connecting to a server that presents a chain of digital certificates would need to validate all PQC signatures embedded in each certificate to determine if the server is authentic. The format of those signatures and the processes by which the certificates are issued and managed is governed by the Certificate Authority (CA) Browser Forum. The internet browser manufacturers and certificate issuer members of the CA Browser Forum need to determine how PQC will work for certificate issuance and validation before anyone can safely use them for publicly trusted certificates in TLS sessions. Amazon Trust Services is a certificate issuer and member of the CA Browser Forum; we are engaged to help drive these standards to expedite interoperability testing.
While the PQC story is being finalized for publicly trusted certificates, the AWS Private CA service isn’t necessarily blocked for the same reasons from issuing privately trusted certificates using PQC algorithms like ML-DSA. We would be able to do this because privately trusted certificates aren’t strictly beholden to the rules published by the CA Browser Forum. Customers using privately trusted certificates have the freedom to implement both the client and server portions of a PQC authentication scheme when they control the software on both ends. When workstream 3 is finished and ML-DSA is available for use from AWS KMS for signing operations, AWS Private CA will consider offering PQC as a part of certificate issuance for those customers who are ready to adopt it for their private networking channels. Our open-source AWS-LC and s2n solutions will be available for our customers to implement the PQC certificate validation functions on their clients and servers if need be.
Conclusion
In this post, we covered how AWS will migrate to PQC as part of our shared responsibility model. We also provided guidance to you on how to start your PQC migration strategy, and what part of that strategy you can expect AWS to provide. The road ahead will present new challenges and new opportunities as the industry performs the migration to new cryptographic algorithms. For additional information, blog posts, and periodic updates on our PQC migration, keep watching the AWS Post-Quantum Cryptography page.
On October 24, 2024, the National Institute of Standards and Technology (NIST) announced that they’re advancing fourteen post-quantum signature schemes to the second round of the “signatures on ramp” competition. “Post-quantum” means that these algorithms are designed to resist the attack of quantum computers. NIST already standardized four post-quantum signature schemes (ML-DSA, SLH-DSA, XMSS, and LHS) and they are drafting a standard for a fifth (Falcon). Why do we need even more, you might ask? We’ll get to that.
A regular reader of the blog will know that this is not the first time we’ve taken measure of post-quantum signatures. In 2021 we took a first hard look, and reported on the performance impact we expect from large-scale measurements. Since then, dozens of new post-quantum algorithms have been proposed. Many of them have been submitted to this new NIST competition. We discussed some of the more promising ones in our early 2024 blog post.
In this blog post, we will go over the fourteen schemes advanced to the second round of the on ramp and discuss their feasibility for use in TLS — the protocol that secures browsing the Internet. The defining feature of practically all of them, is that they require much more bytes on the wire. Back in 2021 we shared experimental results on the impact of these extra bytes. Today, we will share some surprising statistics on how TLS is used in practice. One is that today already almost half the data sent over more than half the QUIC connections are just for the certificates.
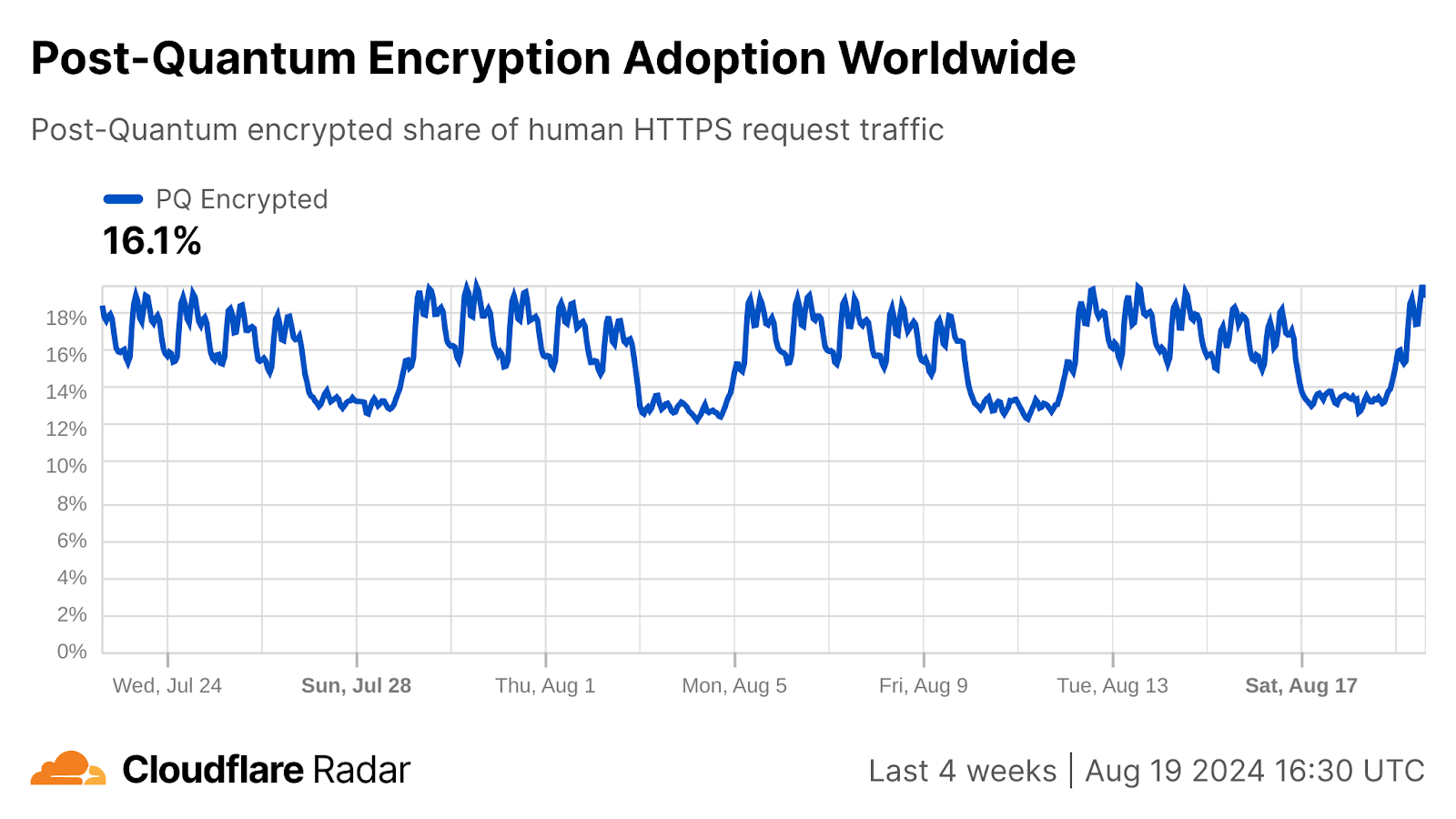
For a broader context and introduction to the post-quantum migration, check out our early 2024 blog post. One take-away to mention here: there will be two migrations for TLS. First, we urgently need to migrate key agreement to post-quantum cryptography to protect against attackers that store encrypted communication today in order to decrypt it in the future when a quantum computer is available. The industry is making good progress here: 18% of human requests to websites using Cloudflare are secured using post-quantum key agreement. The second migration, to post-quantum signatures (certificates), is not as urgent: we will need to have this sorted by the time the quantum computer arrives. However, it will be a bigger challenge.
The signatures in TLS
Before we have a look at the long list of post-quantum signature algorithms and their performance characteristics, let’s go through the signatures involved when browsing the Internet and their particular constraints.
When you visit a website, the browser establishes a TLS connection with the server for that website. The connection starts with a cryptographic handshake. During this handshake, to authenticate the connection, the server signs the transcript so far, and presents the browser with a TLS leaf certificate to prove that it’s allowed to serve the website. This leaf certificate is signed by a certification authority (CA). Typically, it’s not signed by the CA’s root certificate, but by an intermediate CA certificate, which in turn is signed by the root CA, or another intermediate. That’s not all: a leaf certificate has to include at least two signed certificate timestamps (SCTs). These SCTs are signatures created by certificate transparency (CT) logs to attest they’ve been publicly logged. Certificate Transparency is what enables you to look up a certificate on websites such crt.sh and merklemap. In the future three or more SCTs might be required. Finally, servers may also send an OCSP staple to demonstrate a certificate hasn’t been revoked.
Thus, we’re looking at a minimum of five signatures (not counting the OCSP staple) and two public keys transmitted across the network to establish a new TLS connection.
Tailoring
Only the handshake transcript signature is created online; the other signatures are “offline”. That is, they are created ahead of time. For these offline signatures, fast verification is much more important than fast signing. On the other hand, for the handshake signature, we want to minimize the sum of signing and verification time.
Only the public keys of the leaf and intermediate certificates are transmitted on the wire during the handshake, and for those we want to minimize the combined size of the signature and the public key. For the other signatures, the public key is not transmitted during the handshake, and thus a scheme with larger public keys would be tolerable, and preferable if it trades larger public keys for smaller signatures.
The algorithms
Now that we’re up to speed, let’s have a look at the candidates that progressed (marked by 🤔 below), compared to the classical algorithms vulnerable to quantum attack (marked by ❌), and the post-quantum algorithms that are already standardized (✅) or soon will be (📝). Each submission proposes several variants. We list the most relevant variants to TLS from each submission. To explore all variants, check out Thom Wigger’s signatures zoo.
Sizes (bytes)
CPU time (lower is better)
Family
Name variant
Public key
Signature
Signing
Verification
Elliptic curves
Ed25519
❌
32
64
0.15
1.3
Factoring
RSA 2048
❌
272
256
80
0.4
Lattices
ML-DSA 44
✅
1,312
2,420
1 (baseline)
1 (baseline)
Symmetric
SLH-DSA 128s
✅
32
7,856
14,000
40
SLH-DSA 128f
✅
32
17,088
720
110
LMS M4_H20_W8
✅
48
1,112
2.9 ⚠️
8.4
Lattices
Falcon 512
📝
897
666
3 ⚠️
0.7
Codebased
CROSS R-SDP(G)1 small
🤔
38
7,956
20
35
LESS 1s
🤔
97,484
5,120
620
1800
MPC in the head
Mirath Mirith Ia fast
🤔
129
7,877
25
60
MQOM L1-gf251-fast
🤔
59
7,850
35
85
PERK I-fast5
🤔
240
8,030
20
40
RYDE 128F
🤔
86
7,446
15
40
SDitH gf251-L1-hyp
🤔
132
8,496
30
80
VOLE in the head
FAEST EM-128f
🤔
32
5,696
6
18
Lattices
HAWK 512
🤔
1,024
555
0.25
1.2
Isogeny
SQISign I
🤔
64
177
17,000
900
Multivariate
MAYO one
🤔
1,168
321
1.4
1.4
MAYO two
🤔
5,488
180
1.7
0.8
QR-UOV I-(31,165,60,3)
🤔
23,657
157
75
125
SNOVA (24,5,4)
🤔
1,016
248
0.9
1.4
SNOVA (25,8,3)
🤔
2,320
165
0.9
1.8
SNOVA (37,17,2)
🤔
9,842
106
1
1.2
UOV Is-pkc
🤔
66,576
96
0.3
2.3
UOV Ip-pkc
🤔
43,576
128
0.3
0.8
Some notes about the table. It compares selected variants of the submissions progressed to the second round of the NIST PQC signature on ramp with earlier existing traditional and post-quantum schemes at the security level of AES-128. CPU times are taken from the signatures zoo, which collected them from the submission documents and some later advances. CPU performance varies significantly by platform and implementation, and should only be taken as a rough indication. We are early in the competition, and the on-ramp schemes will evolve: some will improve drastically (both in compute and size), whereas others will regress to counter new attacks. Check out the zoo for the latest numbers. We marked Falcon signing with a ⚠️, as Falcon signing is hard to implement in a fast and timing side-channel secure manner. LMS signing has a ⚠️, as secure LMS signing requires keeping a state and the listed signing time assumes a 32MB cache. This will be discussed later on.
These are a lot of algorithms, and we didn’t even list all variants. One thing is clear: none of them perform as well as classical elliptic curve signatures across the board. Let’s start with NIST’s 2022 picks.
ML-DSA, SLH-DSA, and Falcon
The most viable general purpose post-quantum signature scheme standardized today is the lattice-based ML-DSA (FIPS 204), which started its life as Dilithium. It’s light on the CPU and reasonably straightforward to implement. The big downside is that its signatures and public keys are large: 2.4kB and 1.3kB respectively. Here and for the balance of the blog post, we will only consider the variants at the AES-128 security level unless stated otherwise. Adding ML-DSA, adds 14.7kB to the TLS handshake (two 1312-byte public keys plus five 2420-byte signatures).
SLH-DSA (FIPS 205, née SPHINCS+) looks strictly worse, adding 39kB and significant computational overhead for both signing and verification. The advantage of SLH-DSA, being solely based on hashes, is that its security is much better understood than ML-DSA. The lowest security level of SLH-DSA is generally more trusted than the highest security levels of many other schemes.
Falcon (to be renamed FN-DSA) seems much better than SLH-DSA and ML-DSA if you look only at the numbers in the table. There is a catch though. For fast signing, Falcon requires fast floating-point arithmetic, which turns out to be difficult to implement securely. Signing can be performed securely with emulated floating-point arithmetic, but that makes it roughly twenty times slower. This makes Falcon ill-suited for online signatures. Furthermore, the signing procedure of Falcon is complicated to implement. On the other hand, Falcon verification is simple and doesn’t require floating-point arithmetic.
Leaning into Falcon’s strength, by using ML-DSA for the handshake signature, and Falcon for the rest, we’re only adding 7.3kB (at security level of AES-128).
There is one more difficulty with Falcon worth mentioning: it’s missing a middle security level. That means that if Falcon-512 (which we considered so far) turns out to be weaker than expected, then the next one up is Falcon-1024, which has double signature and public key size. That amounts to adding about 11kB.
Stateful hash-based signatures
The very first post-quantum signature algorithms standardized are the stateful hash-based XMSS(MT) and LMS/HSS. These are hash-based signatures, similar to SLH-DSA, and so we have a lot of trust in their security. They come with a big drawback: when creating a keypair you prepare a finite number of signature slots. For the variant listed in the table, there are about one million slots. Each slot can only be used once. If by accident a slot is used twice, then anyone can (probably) use those two signatures to forge any new signature from that slot and break into the connection the certificate is supposed to protect. Remembering which slots have been used, is the state in stateful hash-based signature. Certificate authorities might be able to keep the state, but for general use, Adam Langley calls keeping the state a huge foot-cannon.
There are more quirks to keep in mind for stateful hash-based signatures. To start, during key generation, each slot needs to be prepared. Preparing each slot takes approximately the same amount of time as verifying a signature. Preparing all million takes a couple of hours on a single core. For intermediate certificates of a popular certificate authority, a million slots are not enough. Indeed, Let’s Encrypt issues more than four million certificates per day. Instead of increasing the number of slots directly, we can use an extra intermediate. This is what XMSSMT and HSS do internally. A final quirk of stateful hash-based signatures is that their security is bottlenecked on non-repudiation: the listed LMS instance has 192 bits of security against forgery, but only 96 bits against the signer themselves creating a single signature that verifies two different messages.
Even when stateful hash-based signatures or Falcon can be used, we are still adding a lot of bytes on the wire. From earlier experiments we know that that will impact performance significantly. We summarize those findings later in this blog post, and share some new data. The short of it: it would be nice to have a post-quantum signature scheme that outperforms Falcon, or at least outperforms ML-DSA and is easier to deploy. This is one of the reasons NIST is running the second competition.
With that in mind, let’s have a look at the candidates.
Structured lattice alternatives
With only performance in mind, it is surprising that half of the candidates do worse than ML-DSA. There is a good reason for it: NIST is worried that we’re putting all our eggs in the structured lattices basket. SLH-DSA is an alternative to lattices today, but it doesn’t perform well enough for many applications. As such, NIST would primarily like to standardize another general purpose signature algorithm that is not based on structured lattices, and that outperforms SLH-DSA. We will briefly touch upon these schemes here.
Code-based
CROSS and LESS are two code-based signature schemes. CROSS is based on a variant of the traditional syndrome decoding problem. Its signatures are about as large as SLH-DSA, but its edge over SLH-DSA is the much better signing times. LESS is based on the novel linear equivalence problem. It only outperforms SLH-DSA on signature size, requiring larger public keys in return. For use in TLS, the high verification times of LESS are especially problematic. Given that LESS is based on a new approach, it will be interesting to see how much it can improve going forward.
Multi-party computation in the head
Five of the submissions (Mirath, MQOM, PERK, RYDE, SDitH) use the Multi-Party Computation in the Head (MPCitH) paradigm.
It has been exciting to see the developments in this field. To explain a bit about it, let’s go back to Picnic. Picnic was an MPCitH submission to the previous NIST PQC competition. In essence, its private key is a random key x, and its public key is the hash H(x). A signature is a zero-knowledge proof demonstrating that the signer knows x. So far, it’s pretty similar in shape to other signature schemes that use zero knowledge proofs. The difference is in how that proof is created. We have to talk about multi-party computation (MPC) first. MPC starts with splitting the key x into shares, using Shamir secret sharing for instance, and giving each party one share. No single party knows the value of x itself, but they can recover it by recombining. The insight of MPC is that these parties (with some communication) can perform arbitrary computation on the data they shared. In particular, they can compute a secret share of H(x). Now, we can use that to make a zero-knowledge proof as follows. The signer simulates all parties in the multi-party protocol to compute and recombine H(x). The signer then reveals part of the intermediate values of the computation using Fiat–Shamir: enough so that none of the parties could have cheated on any of the steps, but not enough that it allows the verifier to figure out x themselves.
For H, Picnic uses LowMC, a block cipher for which it’s easy to do the multi-party computation. The initial submission of Picnic performed poorly compared to SLH-DSA with 32kB signatures. For the second round, Picnic was improved considerably, boasting 12kB signatures. SLH-DSA won out with smaller signatures, and more conservative security assumptions: Picnic relies on LowMC which didn’t receive as much study as the hashes on which SLH-DSA is based.
Back to the MPCitH candidates that progressed. All of them have variants (listed in the table) with similar or better signature sizes as SLH-DSA, while outperforming SLH-DSA considerably in signing time. There are variants with even smaller signatures, but their verification performance is significantly higher. The difference between the MPCitH candidates is the underlying trapdoor they use. In Picnic the trapdoor was LowMC. For both RYDE and SDiTH, the trapdoors used are based on variants of syndrome decoding, and could be classified as code-based cryptography.
Over the years, MPCitH schemes have seen remarkable improvements in performance, and we don’t seem to have reached the end of it yet. There is still some way to go before these schemes would be competitive in TLS: signature size needs to be reduced without sacrificing the currently borderline acceptable verification performance. On top of that, not all underlying trapdoors of the various schemes have seen enough scrutiny.
FAEST
FAEST is a peek into the future. It’s similar to the MPCitH candidates in that its security reduces to an underlying trapdoor. It is quite different from those in that FAEST’s underlying trapdoor is AES. That means that, given the security analysis of FAEST is correct, it’s on the same footing as SLH-DSA. Despite the conservative trapdoor, FAEST beats the MPCitH candidates in performance. It also beats SLH-DSA on all metrics.
At the AES-128 security level, FAEST’s signatures are larger than ML-DSA. For those that want to hedge against improvements in lattice attacks, and would only consider higher security levels of ML-DSA, FAEST becomes an attractive alternative. ML-DSA-65 has a combined public key and signature size of 5.2kB, which is similar to FAEST EM-128f. ML-DSA-65 still has a slight edge in performance.
FAEST is based on the 2023 VOLE in the Head paradigm. These are new ideas, and it seems likely their full potential has not been realized yet. It is likely that FAEST will see improvements.
The VOLE in the Head techniques can and probably will be adopted by some of the MPCitH submissions. It will be interesting to see how far VOLEitH can be pushed when applied to less conservative trapdoors. Surpassing ML-DSA seems in reach, but Falcon? We will see.
Now, let’s move on to the submissions that surpass ML-DSA today.
HAWK
HAWK is similar to Falcon, but improves upon it in a few key ways. Most importantly, it doesn’t rely on floating point arithmetic. Furthermore, its signing procedure is simpler and much faster. This makes HAWK suitable for online signatures. Using HAWK adds 4.8kB. Apart from size and speed, it’s beneficial to rely on only a single scheme: using multiple schemes increases the attack surface for algorithmic weaknesses and implementation mistakes.
Similar to Falcon, HAWK is missing a middle security level. Using HAWK-1024 doubles sizes (9.6kB).
There is one downside to HAWK over Falcon: HAWK relies on a new security assumption, the lattice isomorphism problem.
SQISign
SQISign is based on isogenies. Famously, SIKE, another isogeny-based scheme in the previous competition, got broken badly late into the competition. SQISign is based on a different problem, though. SQISign is remarkable for having very small signatures and public keys: it even beats RSA-2048. The glaring downside is that it is computationally very expensive to compute and verify a signature. Isogeny-based signature schemes is a very active area of research with many advances over the years.
It seems unlikely that any future SQISign variant will sign fast enough for the TLS handshake signature. Furthermore, SQISign signing seems to be hard to implement in a timing side-channel secure manner. What about the other signatures of TLS? The bottleneck is verification time. It would be acceptable for SQISign to have larger signatures, if that allows it to have faster verification time.
UOV
UOV (unbalanced oil and vinegar) is an old multivariate scheme with large public keys (67kB), but small signatures (96 bytes). Furthermore, it has excellent signing and verification performance. These interesting size tradeoffs make it quite suited for use cases where the public key is known in advance.
If we use UOV in TLS for the SCTs and root CA, whose public keys are not transmitted when setting up the connection, together with ML-DSA for the others, we’re looking at 7.2kB. That’s a clear improvement over using ML-DSA everywhere, and a tad better than combining ML-DSA with Falcon.
When combining UOV with HAWK instead of ML-DSA, we’re looking at adding only 3.4kB. That’s better again, but only a marginal improvement over using HAWK everywhere (4.8kB). The relative advantage of UOV improves if the certificate transparency ecosystem moves towards requiring more SCTs.
For SCTs, the size of UOV public keys seems acceptable, as there are not that many certificate transparency logs at the moment. Shipping a UOV public key for hundreds of root CAs is more painful, but within reason. Even with intermediate suppression, using UOV in each of the thousands of intermediate certificates does not make sense.
Structured multivariate
Since the original UOV, over the decades, many attempts have been made to add additional structure UOV, to get a better balance between the size of the signature and public key. Unfortunately many of these structured multivariate schemes, which include GeMMS and Rainbow, have been broken.
Let’s have a look at the multivariate candidates. The most interesting variant of QR-UOV for TLS has 24kB public keys and 157 byte signatures. The current verification times are unacceptably high, but there seems to be plenty of room for an improved implementation. There is also a variant with a 12kB public key, but its verification time needs to come down even further. In any case, the combined size QR-UOV’s public key and signatures remain large enough that it’s not a competitor of ML-DSA or Falcon. Instead, QR-UOV competes with UOV, where UOV’s public keys are unwieldy. Although QR-UOV hasn’t seen a direct attack yet, a similar scheme has recently been weakened and another broken.
Finally, we get toSNOVA and MAYO. Although they’re based on a different technique, they have a lot of properties in common. To start, they have the useful property that they allow for a granular tradeoff between public key and signature size. This allows us to use a different variant optimized for whether we’re transmitting the public in the connection or not. Using MAYOone for the leaf and intermediate, and MAYOtwo for the others, adds 3.5kB. Similarly with SNOVA, we add 2.8kB. On top of that, both schemes have excellent signing and verification performance.
The elephant in the room is the security. During the end of the first round, a new generic attack on underdefined multivariate systems prompted the MAYO team to tweak their parameters slightly. SNOVA has been hit a bit harder by three attacks (1, 2, 3), but so far it seems that SNOVA’s parameters can be adjusted to compensate.
Ok, we had a look at all the candidates. What did we learn? There are some very promising algorithms that will reduce the number of bytes required on the wire compared to ML-DSA and Falcon. None of the practical ones will prevent us from adding any extra bytes to TLS. So, given that we must add some bytes: how many extra bytes are too many?
How many added bytes are too many for TLS?
On average, around 15 million TLS connections are established with Cloudflare per second. Upgrading each to ML-DSA, would take 1.8Tbps, which is 0.6% of our current total network capacity. No problem so far. The question is how these extra bytes affect performance.
Back in 2021, we ran a large-scale experiment to measure the impact of big post-quantum certificate chains on connections to Cloudflare’s network over the open Internet. There were two important results. First, we saw a steep increase in the rate of client and middlebox failures when we added more than 10kB to existing certificate chains. Secondly, when adding less than 9kB, the slowdown in TLS handshake time would be approximately 15%. We felt the latter is workable, but far from ideal: such a slowdown is noticeable and people might hold off deploying post-quantum certificates before it’s too late.
Chrome is more cautious and set 10% as their target for maximum TLS handshake time regression. They report that deploying post-quantum key agreement has already incurred a 4% slowdown in TLS handshake time, for the extra 1.1kB from server-to-client and 1.2kB from client-to-server. That slowdown is proportionally larger than the 15% we found for 9kB, but that could be explained by slower upload speeds than download speeds.
There has been pushback against the focus on TLS handshake times. One argument is that session resumption alleviates the need for sending the certificates again. A second argument is that the data required to visit a typical website dwarfs the additional bytes for post-quantum certificates. One example is this 2024 publication, where Amazon researchers have simulated the impact of large post-quantum certificates on data-heavy TLS connections. They argue that typical connections transfer multiple requests and hundreds of kilobytes, and for those the TLS handshake slowdown disappears in the margin.
Are session resumption and hundreds of kilobytes over a connection typical though? We’d like to share what we see. We focus on QUIC connections, which are likely initiated by browsers or browser-like clients. Of all QUIC connections with Cloudflare that carry at least one HTTP request, 37% are resumptions, meaning that key material from a previous TLS connection is reused, avoiding the need to transmit certificates. The median number of bytes transferred from server-to-client over a resumed QUIC connection is 4.4kB, while the average is 395kB. For non-resumptions the median is 7.8kB and average is 551kB. This vast difference between median and average indicates that a small fraction of data-heavy connections skew the average. In fact, only 15.8% of all QUIC connections transfer more than 100kB.
The median certificate chain today (with compression) is 3.2kB. That means that almost 40% of all data transferred from server to client on more than half of the non-resumed QUIC connections are just for the certificates, and this only gets worse with post-quantum algorithms. For the majority of QUIC connections, using ML-DSA as a drop-in replacement for classical signatures would more than double the number of transmitted bytes over the lifetime of the connection.
It sounds quite bad if the vast majority of data transferred for a typical connection is just for the post-quantum certificates. It’s still only a proxy for what is actually important: the effect on metrics relevant to the end-user, such as the browsing experience (e.g. largest contentful paint) and the amount of data those certificates take from a user’s monthly data cap. We will continue to investigate and get a better understanding of the impact.
Zooming out
That was a lot — let’s step back.
It’s great to see how much better the post-quantum signature algorithms are today in almost every family than they were in 2021. The improvements haven’t slowed down either. Many of the algorithms that do not improve over ML-DSA for TLS today could still do so in the third round. Looking back, we are also cautioned: several algorithms considered in 2021 have since been broken.
From an implementation and performance perspective for TLS today, HAWK, SNOVA, and MAYO are all clear improvements over ML-DSA and Falcon. They are also very new, and presently we cannot depend on them without a plan B. UOV has been around a lot longer. Due to its large public key, it will not work on its own, but be a very useful complement to another general purpose signature scheme.
Even with the best performers out of the competition, the way we see TLS connections used today, suggest that drop-in post-quantum certificates will have a big impact on at least half of them.
In the meantime, we can also make plan B our plan A: there are several ways in which we can reduce the number of signatures used in TLS. We can leave out intermediate certificates (1, 2, 3). Another is to use a KEM instead of a signature for handshake authentication. We can even get rid of all the offline signatures with a more ambitious redesign for the vast majority of visits: a post-quantum Internet with fewer bytes on the wire! We’ve discussed these ideas at more length in a previous blog post.
So what does this mean for the coming years? We will continue to work with browsers to understand the end user impact of large drop-in post-quantum certificates. When certificate authorities support them (our guess: 2026), we will add support for ML-DSA certificates for free. This will be opt-in until cryptographically relevant quantum computers are imminent, to prevent undue performance regression. In the meantime, we will continue to pursue larger changes to the WebPKI, so that we can bring full post-quantum security to the Internet without performance compromise.
We’ve talked a lot about certificates, but what we need to care about today is encryption. Along with many across industry, including the major browsers, we have deployed the post-quantum key agreement X25519MLKEM768 across the board, and you can make sure your connections with Cloudflare are already secured against harvest-now/decrypt-later. Visit pq.cloudflareresearch.com to learn how.
Consider the case of basic public key cryptography, in which a person’s public and private key are created together in a single operation. These two keys are entangled, not with quantum physics, but with math.
When I create a virtual machine server in the Amazon cloud, I am prompted for an RSA public key that will be used to control access to the machine. Typically, I create the public and private keypair on my laptop and upload the public key to Amazon, which bakes my public key into the server’s administrator account. My laptop and that remove server are thus entangled, in that the only way to log into the server is using the key on my laptop. And because that administrator account can do anything to that server—read the sensitivity data, hack the web server to install malware on people who visit its web pages, or anything else I might care to do—the private key on my laptop represents a security risk for that server.
Here’s why it’s impossible to evaluate a server and know if it is secure: as long that private key exists on my laptop, that server has a vulnerability. But if I delete that private key, the vulnerability goes away. By deleting the data, I have removed a security risk from the server and its security has increased. This is true entanglement! And it is spooky: not a single bit has changed on the server, yet it is more secure.
Researchers at Google havedeveloped a watermark for LLM-generated text. The basics are pretty obvious: the LLM chooses between tokens partly based on a cryptographic key, and someone with knowledge of the key can detect those choices. What makes this hard is (1) how much text is required for the watermark to work, and (2) how robust the watermark is to post-generation editing. Google’s version looks pretty good: it’s detectable in text as small as 200 tokens.
Amazon Web Services (AWS) prioritizes the security, privacy, and performance of its services. AWS is responsible for the security of the cloud and the services it offers, and customers own the security of the hosts, applications, and services they deploy in the cloud. AWS has also been introducing quantum-resistant key exchange in common transport protocols used by our customers in order to provide long-term confidentiality. In this blog post, we elaborate how customer compliance and security configuration responsibility will operate in the post-quantum migration of secure connections to the cloud. We explain how customers are responsible for enabling quantum-resistant algorithms or having these algorithms enabled by default in their applications that connect to AWS. We also discuss how AWS will honor and choose these algorithms (if they are supported on the server side) even if that means the introduction of a small delay to the connection.
Secure connectivity
Security and compliance is a shared responsibility between AWS and the customer. This Shared Responsibility Model can help relieve the customer’s operational burden as AWS operates, manages, and controls the components from the host operating system and virtualization layer down to the physical security of the facilities in which the service operates. The customer assumes responsibility and management of the guest operating system and other associated application software, as well as the configuration of the AWS provided security group firewall. AWS has released Customer Compliance Guides (CCGs) to support customers, partners, and auditors in their understanding of how compliance requirements from leading frameworks map to AWS service security recommendations.
In the context of secure connectivity, AWS makes available secure algorithms in encryption protocols (for example, TLS, SSH, and VPN) for customers that connect to its services. That way AWS is responsible for enabling and prioritizing modern cryptography in connections to the AWS Cloud. Customers, on the other hand, use clients that enable such algorithms and negotiate cryptographic ciphers when connecting to AWS. It is the responsibility of the customer to configure or use clients that only negotiate the algorithms the customer prefers and trusts when connecting.
Prioritizing quantum-resistance or performance?
AWS has been in the process of migrating to post-quantum cryptography in network connections to AWS services. New cryptographic algorithms are designed to protect against a future cryptanalytically relevant quantum computer (CRQC) which could threaten the algorithms we use today. Post-quantum cryptography involves introducing post-quantum (PQ) hybrid key exchanges in protocols like TLS 1.3 or SSH/SFTP. Because both classical and PQ-hybrid exchanges need to be supported for backwards compatibility, AWS will prioritize PQ-hybrid exchanges for clients that support it and classical for clients that have not been upgraded yet. We don’t want to switch a client to classical if it advertises support for PQ.
PQ-hybrid key establishment leverages quantum-resistant key encapsulation mechanisms (KEMs) used in conjunction with classical key exchange. The client and server still do an ECDH key exchange, which gets combined with the KEM shared secret when deriving the symmetric key. For example, clients could perform an ECDH key exchange with curve P256 and post-quantum Kyber-768 from NIST’s PQC Project Round 3 (TLS group identifier X25519Kyber768Draft00) when connecting to AWS Certificate Manager (ACM), AWS Key Management Service (AWS KMS), and AWS Secrets Manager. This strategy combines the high assurance of a classical key exchange with the quantum-resistance of the proposed post-quantum key exchanges, to help ensure that the handshakes are protected as long as the ECDH or the post-quantum shared secret cannot be broken. The introduction of the ML-KEM algorithm adds more data (2.3 KB) to be transferred and slightly more processing overhead. The processing overhead is comparable to the existing ECDH algorithm, which has been used in most TLS connections for years. As shown in the following table, the total overhead of hybrid key exchanges has been shown to be immaterial in typical handshakes over the Internet. (Sources: Blog posts How to tune TLS for hybrid post-quantum cryptography with Kyber and The state of the post-quantum Internet)
Data transferred (bytes)
CPU processing (thousand ops/sec)
Client
Server
ECDH with P256
128
17
17
X25519
64
31
31
ML-KEM-768
2,272
13
25
The new key exchanges introduce some unique conceptual choices that we didn’t have before, which could lead to the peers negotiating classical-only algorithms. In the past, our cryptographic protocol configurations involved algorithms that were widely trusted to be secure. The client and server configured a priority for their algorithms of choice and they picked the more appropriate ones from their negotiated prioritized order. Now, the industry has two families of algorithms, the “trusted classical” and the “trusted post-quantum” algorithms. Given that a CRQC is not available, both classical and post-quantum algorithms are considered secure. Thus, there is a paradigm shift that calls for a decision in the priority vendors should enforce on the client and server configurations regarding the “secure classical” or “secure post-quantum” algorithms.
Figure 1 shows a typical PQ-hybrid key exchange in TLS.
Figure 1: A typical TLS 1.3 handshake
In the example in Figure 1, the client advertises support for PQ-hybrid algorithms with ECDH curve P256 and quantum-resistant ML-KEM-768, ECDH curve P256 and quantum-resistant Kyber-512 Round 3, and classical ECDH with P256. The client also sends a Keyshare value for classical ECDH with P256 and for PQ-hybrid P256+MLKEM768. The Keyshare values include the client’s public keys. The client does not include a Keyshare for P256+Kyber512, because that would increase the size of the ClientHello unnecessarily and because ML-KEM-768 is the ratified version of Kyber Round 3, and so the client chose to only generate and send a P256+MLKEM768 public key. Now let’s say that the server supports ECDH curve P256 and PQ-hybrid P256+Kyber512, but not P256+MLKEM768. Given the groups and the Keyshare values the client included in the ClientHello, the server has the following two options:
Use the client P256 Keyshare to negotiate a classical key exchange, as shown in Figure 1. Although one might assume that the P256+Kyber512 Keyshare could have been used for a quantum-resistant key exchange, the server can pick to negotiate only classical ECDH key exchange with P256, which is not resistant to a CRQC.
Send a Hello Retry Request (HRR) to tell the client to send a PQ-hybrid Keyshare for P256+Kyber512 in a new ClientHello (Figure 2). This introduces a round trip, but it also forces the peers to negotiate a quantum-resistant symmetric key.
Note: A round-trip could take 30-50 ms in typical Internet connections.
Previously, some servers were using the Keyshare value to pick the key exchange algorithm (option 1 above). This generally allowed for faster TLS 1.3 handshakes that did not require an extra round-trip (HRR), but in the post-quantum scenario described earlier, it would mean the server does not negotiate a quantum-resistant algorithm even though both peers support it.
Such scenarios could arise in cases where the client and server don’t deploy the same version of a new algorithm at the same time. In the example in Figure 1, the server could have been an early adopter of the post-quantum algorithm and added support for P256+Kyber512 Round 3. The client could subsequently have upgraded to the ratified post-quantum algorithm with ML-KEM (P256+MLKEM768). AWS doesn’t always control both the client and the server. Some AWS services have adopted the earlier versions of Kyber and others will deploy ML-KEM-768 from the start. Thus, such scenarios could arise while AWS is in the post-quantum migration phase.
Note: In these cases, there won’t be a connection failure; the side-effect is that the connection will use classical-only algorithms although it could have negotiated PQ-hybrid.
These intricacies are not specific to AWS. Other industry peers have been thinking about these issues, and they have been a topic of discussion in the Internet Engineering Task Force (IETF) TLS Working Group. The issue of potentially negotiating a classical key exchange although the client and server support quantum-resistant ones is discussed in the Security Considerations of the TLS Key Share Prediction draft (draft-davidben-tls-key-share-prediction). To address some of these concerns, the Transport Layer Security (TLS) Protocol Version 1.3 draft (draft-ietf-tls-rfc8446bis), which is the draft update of TLS 1.3 (RFC 8446), introduces text about client and server behavior when choosing key exchange groups and the use of Keyshare values in Section 4.2.8. The TLS Key Share Prediction draft also tries to address the issue by providing DNS as a mechanism for the client to use a proper Keyshare that the server supports.
Prioritizing quantum resistance
In a typical TLS 1.3 handshake, the ClientHello includes the client’s key exchange algorithm order of preferences. Upon receiving the ClientHello, the server responds by picking the algorithms based on its preferences.
Figure 2 shows how a server can send a HelloRetryRequest (HRR) to the client in the previous scenario (Figure 1) in order to request the negotiation of quantum-resistant keys by using P256+Kyber512. This approach introduces an extra round trip to the handshake.
Figure 2: An HRR from the server to request the negotiation of mutually supported quantum-resistant keys with the client
AWS services that terminate TLS 1.3 connections will take this approach. They will prioritize quantum resistance for clients that advertise support for it. If the AWS service has added quantum-resistant algorithms, it will honor a client-supported post-quantum key exchange even if that means that the handshake will take an extra round trip and the PQ-hybrid key exchange will include minor processing overhead (ML-KEM is almost performant as ECDH). A typical round trip in regionalized TLS connections today is usually under 50 ms and won’t have material impact to the connection performance. In the post-quantum transition, we consider clients that advertise support for quantum-resistant key exchange to be clients that take the CRQC risk seriously. Thus, the AWS server will honor that preference if the server supports the algorithm.
Pull Request 4526 introduces this behavior in s2n-tls, the AWS open source, efficient TLS library built over other crypto libraries like OpenSSL libcrypto or AWS libcrypto (AWS-LC). When built with s2n-tls, s2n-quic handshakes will also inherit the same behavior. s2n-quic is the AWS open source Rust implementation of the QUIC protocol.
What AWS customers can do to verify post-quantum key exchanges
AWS services that have already adopted the behavior described in this post include AWS KMS, ACM, and Secrets Manager TLS endpoints, which have been supporting post-quantum hybrid key exchange for a few years already. Other endpoints that will deploy quantum-resistant algorithms will inherit the same behavior.
AWS customers that want to take advantage of new quantum-resistant algorithms introduced in AWS services are expected to enable them on the client side or the server side of a customer-managed endpoint. For example, if you are using the AWS Common Runtime (CRT) HTTP client in the AWS SDK for Java v2, you would need to enable post-quantum hybrid TLS key exchanges with the following.
The AWS KMS and Secrets Manager documentation includes more details for using the AWS SDK to make HTTP API calls over quantum-resistant connections to AWS endpoints that support post-quantum TLS.
To confirm that a server endpoint properly prioritizes and enforces the PQ algorithms, you can use an “old” client that sends a PQ-hybrid Keyshare value that the PQ-enabled server does not support. For example, you could use s2n-tls built with AWS-LC (which supports the quantum-resistant KEMs). You could use a client TLS policy (PQ-TLS-1-3-2023-06-01) that is newer than the server’s policy (PQ-TLS-1-0-2021-05-24). That will lead the server to request the client by means of an HRR to send a new ClientHello that includes P256+MLKEM768, as shown following.
The hrr-capture.pcap packet capture will show the negotiation and the HRR from the server.
To confirm that a server endpoint properly implements the post-quantum hybrid key exchanges, you can use a modern client that supports the key exchange and connect against the endpoint. For example, using the s2n-tls client built with AWS-LC (which supports the quantum-resistant KEMs), you could try connecting to a Secrets Manager endpoint by using a post-quantum TLS policy (for example, PQ-TLS-1-2-2023-12-15) and observe the PQ hybrid key exchange used in the output, as shown following.
./bin/s2nc -c PQ-TLS-1-2-2023-12-15 secretsmanager.us-east-1.amazonaws.com 443
CONNECTED:
Handshake: NEGOTIATED|FULL_HANDSHAKE|MIDDLEBOX_COMPAT
Client hello version: 33
Client protocol version: 34
Server protocol version: 34
Actual protocol version: 34
Server name: secretsmanager.us-east-1.amazonaws.com
Curve: NONE
KEM: NONE
KEM Group: SecP256r1Kyber768Draft00
Cipher negotiated: TLS_AES_128_GCM_SHA256
Server signature negotiated: RSA-PSS-RSAE+SHA256
Early Data status: NOT REQUESTED
Wire bytes in: 6699
Wire bytes out: 1674
s2n is ready
Connected to secretsmanager.us-east-1.amazonaws.com:443
Cryptographic migrations can introduce intricacies to cryptographic negotiations between clients and servers. During the migration phase, AWS services will mitigate the risks of these intricacies by prioritizing post-quantum algorithms for customers that advertise support for these algorithms—even if that means a small slowdown in the initial negotiation phase. While in the post-quantum migration phase, customers who choose to enable quantum resistance have made a choice which shows that they consider the CRQC risk as important. To mitigate this risk, AWS will honor the customer’s choice, assuming that quantum resistance is supported on the server side.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, & Compliance re:Post or contact AWS Support. For more details regarding AWS PQC efforts, refer to our PQC page.
On August 20, 2024, we announced the general availability of the new AWS CloudHSMhardware security module (HSM) instance typehsm2m.medium, referred to in this post as hsm2. This new type comes with additional features compared to the previous CloudHSM instance type hsm1.medium (hsm1). The new features include the following:
Support for Federal Information Processing Standard (FIPS) 140-3 Level 3
The ability to run CloudHSM clusters in non-FIPS mode
In this blog post, I walk you through the steps to securely migrate Triple Data Encryption Algorithm (Triple DES or 3DES) keys from your hsm1 CloudHSM cluster to a new hsm2 cluster running in non-FIPS mode, without using backups.
CloudHSM and 3DES keys
On January 1, 2024, the National Institute of Standards and Technology (NIST) withdrew Special Publication 800-67 Revision 2. This means that 3DES is no longer a FIPS-approved block cipher for applying cryptographic protection (that is, encryption, key wrapping, and generation of Message Authentication Codes (MACs)).
For customers that use 3DES keys in their workloads for applying cryptographic protection, AWS recommends that you do the following:
Migrate your 3DES workloads to Advanced Encryption Standard (AES), which is a FIPS-approved, modern symmetric block cipher
If you use 3DES for payment processing, consider migrating your workloads to the AWS Payment Cryptography service
However, if migrating to a different encryption algorithm or cryptography service isn’t feasible and you intend to continue to use 3DES, you can use an hsm2 cluster running in non-FIPS mode to manage your 3DES keys and take advantage of the new hsm2 benefits.
Note that moving to a non-FIPS CloudHSM cluster might change your compliance posture. If a regulatory standard or certification requires you to run FIPS-compliant cryptographic modules, this move might impact you. When you create a non-FIPS cluster, the underlying FIPS-certified HSM will be configured to run in non-FIPS mode. Give careful consideration to these issues before you move to a non-FIPS CloudHSM cluster. For details on what certification and compliance requirements apply to hsm1 and hsm2, see AWS CloudHSM cluster modes and HSM types.
Normally you can migrate keys from an existing CloudHSM cluster to a new one by creating the new cluster from an existing backup. But you cannot migrate keys to a non-FIPS hsm2 cluster by using an hsm1 cluster backup. This is because CloudHSM doesn’t allow you to change compliance modes from FIPS to non-FIPS. However, there is an alternate way to migrate keys between CloudHSM clusters without using backups. In the following solution guidance, I show you how to use an RSA-AES wrap mechanism to migrate keys without exposing the key material in plaintext outside the CloudHSM boundaries. The RSA-AES mechanism provides the benefit of migrating large-sized keys while avoiding the payload size limitation typically associated with asymmetric RSA key pairs.
Solution overview
The solution uses CloudHSM CLI to run the key migration commands against the source and target CloudHSM clusters. Figure 1 provides a summary of the steps involved in the solution.
Figure 1: Solution overview
The workflow is as follows:
Generate the RSA wrapping key pair on CloudHSM hsm2.
Export the RSA public key to the hsm2 CloudHSM client instance.
Move the RSA public key to the CloudHSM hsm1 client instance.
Import the RSA public key into CloudHSM hsm1.
Wrap the designated key using the imported RSA public key.
Move the wrapped key to the CloudHSM hsm2 client instance.
Unwrap the key into CloudHSM hsm2 with the RSA private key.
Although the steps in this post are specific to CloudHSM CLI, the same procedure can be used with other CloudHSM SDKs such as the Java Cryptographic Extension (JCE) and the PKCS #11 library. With JCE, the RSAWrappingRunner example code demonstrates how to wrap and unwrap keys by using the RSA-AES mechanism. Similarly, with PKCS #11, the rsa_wrapping.c example code demonstrates how to wrap and unwrap keys by using RSA-AES.
Important considerations
There are a few important things that you need to keep in mind when migrating cryptographic keys:
Exportable keys – This solution only works for exportable keys (keys with the attribute extractable set to “true”). If non-extractable keys need to be migrated, you must rotate them: Generate a new key on the CloudHSM hsm2 cluster, use the old key from hsm1 to decrypt the data, and then use the new key in hsm2 to re-encrypt the data. If possible, use advanced keys like AES for re-encryption.
Key ownership – When a key is migrated to a new cluster, the crypto user who unwraps the key becomes the key owner. You need to have a plan to make sure the appropriate crypto users are migrating keys and the applications that rely on those keys are updated with the right crypto user credentials. You can also share the unwrapped keys with the appropriate crypto users after migration. This helps to prevent the availability of your applications from being impacted due to the key migration. You can use one of the following strategies to manage key ownership during migration:
The recommended strategy is to first create the required crypto users in the hsm2 cluster by using CloudHSM CLI and then use each user to migrate the required keys they currently own in hsm1. You can either create separate wrapping key pairs per crypto user or have one wrapping key pair that is shared with required crypto users to migrate their keys.
Another strategy is to employ one crypto user to migrate the required keys and then share the migrated keys with the appropriate crypto users after migration. Note that shared keys have limitations such that the recipient crypto user cannot modify or share the key.
Key attributes – When a key is migrated, only the attributes that are specified during the unwrap operation are set on the key. Make sure to identify the key attributes from hsm1 and set them on the key when unwrapping to hsm2. Note that some attributes like extractable can only be set while the key is being created or unwrapped, but that others can be set after creation by using the key set-attribute See Key attributes for CloudHSM CLI for a list of attributes and when can they be set. You can use the CloudHSM CLI key list command with the verbose argument to list keys owned by a crypto user, along with the attributes of those keys. Additionally, you can use unwrap templates to specify attributes that must be set while unwrapping. Note that this feature is only supported by the PKCS #11 SDK.
HSM backup – It is recommended to keep a backup of hsm1 until you have confirmed that all the required keys have been migrated to hsm2. You can configure a CloudHSM backup retention policy to manage backups. Note that CloudHSM doesn’t delete a cluster’s last backup. See Configuring AWS CloudHSM backup retention policy for more information. You can also share the CloudHSM backups with other AWS accounts as described in Working with shared backups.
Prerequisites
You need to have the following prerequisites in place to implement the solution:
An active CloudHSM hsm1 cluster with at least one active HSM.
The credentials of crypto users in hsm1 who are the owners of the keys that need to be migrated.
An active CloudHSM hsm2 cluster with at least one active HSM and a valid crypto user As I mentioned in the Key ownership notes, make sure to create crypto users in hsm2 who will own the migrated keys.
A second EC2 instance with CloudHSM CLI installed and configured to connect to the hsm2 cluster. For instructions on how to configure and connect the client instance, see Getting started with AWS CloudHSM.
A list of exportable keys with their attributes that you want to migrate from hsm1. You can use the key list command with the verbose argument to list the keys owned by a crypto user. The output will contain the key attributes, including label, extractable, and key-type. You can also pass the filter argument to the command to list specific keys based on label or key-type, such as 3des. The CloudHSM CLI command to list 3DES keys with their attributes is as follows:
key list --filter attr.key-type=3des --verbose
As I mentioned in the Key attributes note, some attributes like extractable can only be set while the key is being created or unwrapped, but others can be set after creation using the key set-attribute command.
Note the following:
You can configure CloudHSM CLI to connect to multiple clusters. You can use a single EC2 instance with CloudHSM CLI to migrate keys from one cluster to another, provided that you can set up a network path to both clusters from the client instance.
You can run CloudHSM CLI commands using a bash script or similar by running the commands in interactive mode.
Step 1: Generate the RSA wrapping key pair on hsm2
The first step in the solution is to create a wrapping key pair on your new CloudHSM hsm2 cluster by using CloudHSM CLI. The public key from the key pair will be used to wrap and the private key to unwrap. Label the key pair accordingly and note down the labels.
Note: As mentioned in the Key ownership notes, choose an appropriate strategy to migrate the keys. The crypto user who generates the wrapping key pair in this step or with whom this key pair is shared will be required to unwrap the key in the final step.
Run the following key generate-asymmetric-pair rsa command to create an RSA key pair. Make sure to replace <rsa_wrapping_key_label> and <rsa_unwrapping_key_label> with your own labels for the public and private key that are being generated. Note down the public and private key labels because this data is required in the following steps.
Step 2: Export the RSA public key to the hsm2 client instance
In this step, you export the RSA public key from hsm2 to the EC2 instance file system.
To export the RSA public key to the hsm2 client instance:
Run the following key generate-file command to export the RSA public key you created in the previous step. Make sure to replace <file_path> and <rsa_wrapping_key_label> with your own data. You noted down the public key label in the previous step. The exported RSA public key bytes are written in PEM format into the <file_path> you provide.
Step 3: Move the RSA public key to the hsm1 client instance
Now you need to copy the exported public key PEM file from the hsm2 client instance to the hsm1 client instance. You can use your enterprise file transfer solution or secure copy protocol (SCP). However, if you’ve configured CloudHSM CLI to connect to both hsm1 and hsm2 clusters by using the connect to multiple clusters feature, you can skip this step.
Step 4: Import the RSA public key to hsm1
In this step, you import the RSA public key that was copied to the hsm1 client instance into the hsm1 cluster.
On the hsm1 client instance, sign in to CloudHSM CLI as a crypto user. Run the following key import pem command to import the public key. Replace the <file_path> and <rsa_wrapping_key_label> with your own values for the public key PEM file path and label, respectively.
Step 5: Wrap the key using the imported RSA public key
In this step, you wrap the key that you have identified as part of the prerequisites from hsm1. Note that only the crypto user who owns the key can wrap it out. Therefore, you need to sign in to CloudHSM CLI on hsm1 as that crypto user.
Run the following key wrap rsa-aes command to wrap the key out. Make sure to replace <exportable_key_label> and <rsa_wrapping_key_label> with your own values for the label of the key being wrapped out and the wrapping RSA public key, respectively.
The wrapped key data, in binary format, is saved on the file system at the file path specified in the --path argument. Note down the key type of the wrapped key. This value will be required in step 7 while unwrapping.
Step 6: Move the wrapped key to the hsm2 client instance
Copy the wrapped binary key from the hsm1 client instance to the hsm2 client instance using the same method that you used in Step 3. Note down the file path to the copied file.
Step 7: Unwrap the wrapped key to the hsm2 cluster using the RSA private key
In this step, you unwrap the wrapped key into hsm2 using the RSA private key associated with the RSA public key that was used to wrap the key. You noted down the RSA private key label in Step 1 and the key type in Step 5. There are some important points to keep in mind before unwrapping:
The crypto user who created the wrapping key pair in step 1, or with whom the wrapping key pair is shared, must sign in to CloudHSM CLI to run the unwrap command.
As mentioned in the prerequisites section, some of the key attributes can only be set during creation. Make sure you have a list of attributes that you want to set on the key.
Run the following key unwrap rsa-aes command to unwrap the key into hsm2. Make sure to replace these command arguments with your own values:
<key_type_of_wrapped_key>: The key type of the wrapped key, for example, AES, 3DES.
<label_of_unwrapped_key>: The label for the new unwrapped key. Choose an appropriate label to identify the key.
<rsa_unwrapping_key_label>: The RSA private key label from step 1.
<path_to_the_wrapped_binary_file>: The path to the wrapped key binary file from Step 6.
<list_of_attributes_for_unwrapped>: A space-separated list of key attributes in the form KEY_ATTRIBUTE_NAME=KEY_ATTRIBUTE_VALUE for the unwrapped key. This is optional.
(Optional) Step 8: Update the attributes of the unwrapped key
If you didn’t set all the required attributes while unwrapping the key, you can update the key attributes key now by using the key set-attribute command.
Test whether your 3DES key was migrated successfully
In symmetric cryptography, the same key is used for encryption and decryption. 3DES is a symmetric key algorithm. To verify that your migrated 3DES key functions the same in hsm2, you can do the following test:
Encrypt a simple message by using the 3DES key in hsm1 to create ciphertext
Decrypt the ciphertext by using the migrated 3DES key in hsm2 to obtain plaintext
The decrypted plaintext should match the original message.
You can use the CloudHSM JCE or PKCS #11 SDKs to run the test. With JCE, the DESedeECBEncryptDecryptRunner example code demonstrates how to encrypt and decrypt using a 3DES key. Similarly, for PKCS #11, the des_ecb.c example code demonstrates how to encrypt and decrypt using a 3DES key.
Conclusion
In this blog post, you learned how to migrate cryptographic keys from a CloudHSM hsm1 cluster to an hsm2 cluster by using CloudHSM CLI. We recommend that you migrate keys using a backup whenever possible, but you can use the approach described in this post in cases where using a backup isn’t possible.
Although this post focused on migrating keys between CloudHSM hsm1 and hsm2, you can use the same methodology to migrate keys between many AWS CloudHSM cluster pairs. The methodology can also be extended to other CloudHSM SDKs, like JCE and PKCS #11, to automate the migration process.
To migrate keys from on-premises or other non AWS HSMs to AWS CloudHSM, you can also apply the same principle of wrap and unwrap.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Microsoft is updating SymCrypt, its core cryptographic library, with new quantum-secure algorithms. Microsoft’s details are here. From a news article:
The first new algorithm Microsoft added to SymCrypt is called ML-KEM. Previously known as CRYSTALS-Kyber, ML-KEM is one of three post-quantum standards formalized last month by the National Institute of Standards and Technology (NIST). The KEM in the new name is short for key encapsulation. KEMs can be used by two parties to negotiate a shared secret over a public channel. Shared secrets generated by a KEM can then be used with symmetric-key cryptographic operations, which aren’t vulnerable to Shor’s algorithm when the keys are of a sufficient size.
The ML in the ML-KEM name refers to Module Learning with Errors, a problem that can’t be cracked with Shor’s algorithm. As explained here, this problem is based on a “core computational assumption of lattice-based cryptography which offers an interesting trade-off between guaranteed security and concrete efficiency.”
ML-KEM, which is formally known as FIPS 203, specifies three parameter sets of varying security strength denoted as ML-KEM-512, ML-KEM-768, and ML-KEM-1024. The stronger the parameter, the more computational resources are required.
The other algorithm added to SymCrypt is the NIST-recommended XMSS. Short for eXtended Merkle Signature Scheme, it’s based on “stateful hash-based signature schemes.” These algorithms are useful in very specific contexts such as firmware signing, but are not suitable for more general uses.
On August 13th, 2024, the US National Institute of Standards and Technology (NIST) published the first three cryptographic standards designed to resist an attack from quantum computers: ML-KEM, ML-DSA, and SLH-DSA. This announcement marks a significant milestone for ensuring that today’s communications remain secure in a future world where large-scale quantum computers are a reality.
In this blog post, we briefly discuss the significance of NIST’s recent announcement, how we expect the ecosystem to evolve given these new standards, and the next steps we are taking. For a deeper dive, see our March 2024 blog post.
Why are quantum computers a threat?
Cryptography is a fundamental aspect of modern technology, securing everything from online communications to financial transactions. For instance, when visiting this blog, your web browser used cryptography to establish a secure communication channel to Cloudflare’s server to ensure that you’re really talking to Cloudflare (and not an impersonator), and that the conversation remains private from eavesdroppers.
Much of the cryptography in widespread use today is based on mathematical puzzles (like factoring very large numbers) which are computationally out of reach for classical (non-quantum) computers. We could likely continue to use traditional cryptography for decades to come if not for the advent of quantum computers, devices that use properties of quantum mechanics to perform certain specialized calculations much more efficiently than traditional computers. Unfortunately, those specialized calculations include solving the mathematical puzzles upon which most widely deployed cryptography depends.
As of today, no quantum computers exist that are large and stable enough to break today’s cryptography, but experts predict that it’s only a matter of time until such a cryptographically-relevant quantum computer (CRQC) exists. For instance, more than a quarter of interviewed experts in a 2023 survey expect that a CRQC is more likely than not to appear in the next decade.
What is being done about the quantum threat?
In recognition of the quantum threat, the US National Institute of Standards and Technology (NIST) launched a public competition in 2016 to solicit, evaluate, and standardize new “post-quantum” cryptographic schemes that are designed to be resistant to attacks from quantum computers. On August 13, 2024, NIST published the final standards for the first three post-quantum algorithms to come out of the competition: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. A fourth standard based on FALCON is planned for release in late 2024 and will be dubbed FN-DSA, short for FFT (fast-Fourier transform) over NTRU-Lattice-Based Digital Signature Algorithm.
The publication of the final standards marks a significant milestone in an eight-year global community effort managed by NIST to prepare for the arrival of quantum computers. Teams of cryptographers from around the world jointly submitted 82 algorithms to the first round of the competition in 2017. After years of evaluation and cryptanalysis from the global cryptography community, NIST winnowed the algorithms under consideration down through several rounds until they decided upon the first four algorithms to standardize, which they announced in 2022.
This has been a monumental effort, and we would like to extend our gratitude to NIST and all the cryptographers and engineers across academia and industry that participated.
Security was a primary concern in the selection process, but algorithms also need to be performant enough to be deployed in real-world systems. Cloudflare’s involvement in the NIST competition began in 2019 when we performed experiments with industry partners to evaluate how algorithms under consideration performed when deployed on the open Internet. Gaining practical experience with the new algorithms was a crucial part of the evaluation process, and helped to identify and remove obstacles for deploying the final standards.
Having standardized algorithms is a significant step, but migrating systems to use these new algorithms is going to require a multi-year effort. To understand the effort involved, let’s look at two classes of traditional cryptography that are susceptible to quantum attacks: key agreement and digital signatures.
Key agreement allows two parties that have never communicated before to establish a shared secret over an insecure communication channel (like the Internet). The parties can then use this shared secret to encrypt future communications between them. An adversary may be able to observe the encrypted communication going over the network, but without access to the shared secret they cannot decrypt and “see inside” the encrypted packets.
However, in what is known as the “harvest now, decrypt later” threat model, an adversary can store encrypted data until some point in the future when they gain access to a sufficiently large quantum computer, and then can decrypt at their leisure. Thus, today’s communication is already at risk from a future quantum adversary, and it is urgent that we upgrade systems to use post-quantum key agreement as soon as possible.
In 2022, soon after NIST announced the first set of algorithms to be standardized, Cloudflare worked with industry partners to deploy a preliminary version of ML-KEM to protect traffic arriving at Cloudflare’s servers (and our internal systems), both to pave the way for adoption of the final standard and to start protecting traffic as soon as possible. As of mid-August 2024, over 16% of human-generated requests to Cloudflare’s servers are already protected with post-quantum key agreement.
Percentage of human traffic to Cloudflare protected by X25519Kyber, a preliminary version of ML-KEM as shown on Cloudflare Radar.
Other players in the tech industry have deployed post-quantum key agreement as well, including Google, Apple, Meta, and Signal.
Signatures are crucial to ensure that you’re communicating with who you think you are communicating. In the web public key infrastructure (WebPKI), signatures are used in certificates to prove that a website operator is the rightful owner of a domain. The threat model for signatures is different than for key agreement. An adversary capable of forging a digital signature could carry out an active attack to impersonate a web server to a client, but today’s communication is not yet at risk.
While the migration to post-quantum signatures is less urgent than the migration for key agreement (since traffic is only at risk once CRQCs exist), it is much more challenging. Consider, for instance, the number of parties involved. In key agreement, only two parties need to support a new key agreement protocol: the client and the server. In the WebPKI, there are many more parties involved, from library developers, to browsers, to server operators, to certificate authorities, to hardware manufacturers. Furthermore, post-quantum signatures are much larger than we’re used to from traditional signatures. For more details on the tradeoffs between the different signature algorithms, deployment challenges, and out-of-the-box solutions see our previous blog post.
Reaching consensus on the right approach for migrating to post-quantum signatures is going to require extensive effort and coordination among stakeholders. However, that work is already well underway. For instance, in 2021 we ran large scale experiments to understand the feasibility of post-quantum signatures in the WebPKI, and we have more studies planned.
What’s next?
Now that NIST has published the first set of standards for post-quantum cryptography, what comes next?
In 2022, Cloudflare deployed a preliminary version of the ML-KEM key agreement algorithm, Kyber, which is now used to protect double-digit percentages of requests to Cloudflare’s network. We use a hybrid with X25519, to hedge against future advances in cryptanalysis and implementation vulnerabilities. In coordination with industry partners at the NIST NCCoE and IETF, we will upgrade our systems to support the final ML-KEM standard, again using a hybrid. We will slowly phase out support for the pre-standard version X25519Kyber768 after clients have moved to the ML-KEM-768 hybrid, and will quickly phase out X25519Kyber512, which hasn’t seen real-world usage.
Now that the final standards are available, we expect to see widespread adoption of ML-KEM industry-wide as support is added in software and hardware, and post-quantum becomes the new default for key agreement. Organizations should look into upgrading their systems to use post-quantum key agreement as soon as possible to protect their data from future quantum-capable adversaries. Check if your browser already supports post-quantum key agreement by visiting pq.cloudflareresearch.com, and if you’re a Cloudflare customer, see how you can enable post-quantum key agreement support to your origin today.
Adoption of the newly-standardized post-quantum signatures ML-DSA and SLH-DSA will take longer as stakeholders work to reach consensus on the migration path. We expect the first post-quantum certificates to be available in 2026, but not to be enabled by default. Organizations should prepare for a future flip-the-switch migration to post-quantum signatures, but there is no need to flip the switch just yet.
After three rounds of evaluation and analysis, NIST selected four algorithms it will standardize as a result of the PQC Standardization Process. The public-key encapsulation mechanism selected was CRYSTALS-KYBER, along with three digital signature schemes: CRYSTALS-Dilithium, FALCON, and SPHINCS+.
These algorithms are part of three NIST standards that have been finalized:
One – ML-KEM [PDF] (based on CRYSTALS-Kyber) – is intended for general encryption, which protects data as it moves across public networks. The other two –- ML-DSA [PDF] (originally known as CRYSTALS-Dilithium) and SLH-DSA [PDF] (initially submitted as Sphincs+)—secure digital signatures, which are used to authenticate online identity.
A fourth algorithm – FN-DSA [PDF] (originally called FALCON) – is slated for finalization later this year and is also designed for digital signatures.
NIST continued to evaluate two other sets of algorithms that could potentially serve as backup standards in the future.
One of the sets includes three algorithms designed for general encryption – but the technology is based on a different type of math problem than the ML-KEM general-purpose algorithm in today’s finalized standards.
NIST plans to select one or two of these algorithms by the end of 2024.
On Thursday, researchers from security firm Binarly revealed that Secure Boot is completely compromised on more than 200 device models sold by Acer, Dell, Gigabyte, Intel, and Supermicro. The cause: a cryptographic key underpinning Secure Boot on those models that was compromised in 2022. In a public GitHub repository committed in December of that year, someone working for multiple US-based device manufacturers published what’s known as a platform key, the cryptographic key that forms the root-of-trust anchor between the hardware device and the firmware that runs on it. The repository was located at https://github.com/raywu-aaeon/Ryzen2000_4000.git, and it’s not clear when it was taken down.
The repository included the private portion of the platform key in encrypted form. The encrypted file, however, was protected by a four-character password, a decision that made it trivial for Binarly, and anyone else with even a passing curiosity, to crack the passcode and retrieve the corresponding plain text. The disclosure of the key went largely unnoticed until January 2023, when Binarly researchers found it while investigating a supply-chain incident. Now that the leak has come to light, security experts say it effectively torpedoes the security assurances offered by Secure Boot.
[…]
These keys were created by AMI, one of the three main providers of software developer kits that device makers use to customize their UEFI firmware so it will run on their specific hardware configurations. As the strings suggest, the keys were never intended to be used in production systems. Instead, AMI provided them to customers or prospective customers for testing. For reasons that aren’t clear, the test keys made their way into devices from a nearly inexhaustive roster of makers. In addition to the five makers mentioned earlier, they include Aopen, Foremelife, Fujitsu, HP, Lenovo, and Supermicro.
A new paper, “Polynomial Time Cryptanalytic Extraction of Neural Network Models,” by Adi Shamir and others, uses ideas from differential cryptanalysis to extract the weights inside a neural network using specific queries and their results. This is much more theoretical than practical, but it’s a really interesting result.
Abstract:
Billions of dollars and countless GPU hours are currently spent on training Deep Neural Networks (DNNs) for a variety of tasks. Thus, it is essential to determine the difficulty of extracting all the parameters of such neural networks when given access to their black-box implementations. Many versions of this problem have been studied over the last 30 years, and the best current attack on ReLU-based deep neural networks was presented at Crypto’20 by Carlini, Jagielski, and Mironov. It resembles a differential chosen plaintext attack on a cryptosystem, which has a secret key embedded in its black-box implementation and requires a polynomial number of queries but an exponential amount of time (as a function of the number of neurons). In this paper, we improve this attack by developing several new techniques that enable us to extract with arbitrarily high precision all the real-valued parameters of a ReLU-based DNN using a polynomial number of queries and a polynomial amount of time. We demonstrate its practical efficiency by applying it to a full-sized neural network for classifying the CIFAR10 dataset, which has 3072 inputs, 8 hidden layers with 256 neurons each, and about 1.2 million neuronal parameters. An attack following the approach by Carlini et al. requires an exhaustive search over 2^256 possibilities. Our attack replaces this with our new techniques, which require only 30 minutes on a 256-core computer.
A group of cryptographers have analyzed the eiDAS 2.0 regulation (electronic identification and trust services) that defines the new EU Digital Identity Wallet.
Quantum computers are probably coming, though we don’t know when—and when they arrive, they will, most likely, be able to break our standard public-key cryptography algorithms. In anticipation of this possibility, cryptographers have been working on quantum-resistant public-key algorithms. The National Institute for Standards and Technology (NIST) has been hosting a competition since 2017, and there already are several proposed standards. Most of these are based on lattice problems.
The mathematics of lattice cryptography revolve around combining sets of vectors—that’s the lattice—in a multi-dimensional space. These lattices are filled with multi-dimensional periodicities. The hard problem that’s used in cryptography is to find the shortest periodicity in a large, random-looking lattice. This can be turned into a public-key cryptosystem in a variety of different ways. Research has been ongoing since 1996, and there has been some really great work since then—including many practical public-key algorithms.
On April 10, Yilei Chen from Tsinghua University in Beijing posted a paper describing a new quantum attack on that shortest-path lattice problem. It’s a very dense mathematical paper—63 pages long—and my guess is that only a few cryptographers are able to understand all of its details. (I was not one of them.) But the conclusion was pretty devastating, breaking essentially all of the lattice-based fully homomorphic encryption schemes and coming significantly closer to attacks against the recently proposed (and NIST-approved) lattice key-exchange and signature schemes.
However, there was a small but critical mistake in the paper, on the bottom of page 37. It was independently discovered by Hongxun Wu from Berkeley and Thomas Vidick from the Weizmann Institute in Israel eight days later. The attack algorithm in its current form doesn’t work.
This was discussed last week at the Cryptographers’ Panel at the RSA Conference. Adi Shamir, the “S” in RSA and a 2002 recipient of ACM’s A.M. Turing award, described the result as psychologically significant because it shows that there is still a lot to be discovered about quantum cryptanalysis of lattice-based algorithms. Craig Gentry—inventor of the first fully homomorphic encryption scheme using lattices—was less impressed, basically saying that a nonworking attack doesn’t change anything.
I tend to agree with Shamir. There have been decades of unsuccessful research into breaking lattice-based systems with classical computers; there has been much less research into quantum cryptanalysis. While Chen’s work doesn’t provide a new security bound, it illustrates that there are significant, unexplored research areas in the construction of efficient quantum attacks on lattice-based cryptosystems. These lattices are periodic structures with some hidden periodicities. Finding a different (one-dimensional) hidden periodicity is exactly what enabled Peter Shor to break the RSA algorithm in polynomial time on a quantum computer. There are certainly more results to be discovered. This is the kind of paper that galvanizes research, and I am excited to see what the next couple of years of research will bring.
To be fair, there are lots of difficulties in making any quantum attack work—even in theory.
Breaking lattice-based cryptography with a quantum computer seems to require orders of magnitude more qubits than breaking RSA, because the key size is much larger and processing it requires more quantum storage. Consequently, testing an algorithm like Chen’s is completely infeasible with current technology. However, the error was mathematical in nature and did not require any experimentation. Chen’s algorithm consisted of nine different steps; the first eight prepared a particular quantum state, and the ninth step was supposed to exploit it. The mistake was in step nine; Chen believed that his wave function was periodic when in fact it was not.
Should NIST be doing anything differently now in its post–quantum cryptography standardization process? The answer is no. They are doing a great job in selecting new algorithms and should not delay anything because of this new research. And users of cryptography should not delay in implementing the new NIST algorithms.
But imagine how different this essay would be were that mistake not yet discovered? If anything, this work emphasizes the need for systems to be crypto-agile: to be able to easily swap algorithms in and out as research continues. And for using hybrid cryptography—multiple algorithms where the security rests on the strongest—where possible, as in TLS.
And—one last point—hooray for peer review. A researcher proposed a new result, and reviewers quickly found a fatal flaw in the work. Efforts to repair the flaw are ongoing. We complain about peer review a lot, but here it worked exactly the way it was supposed to.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




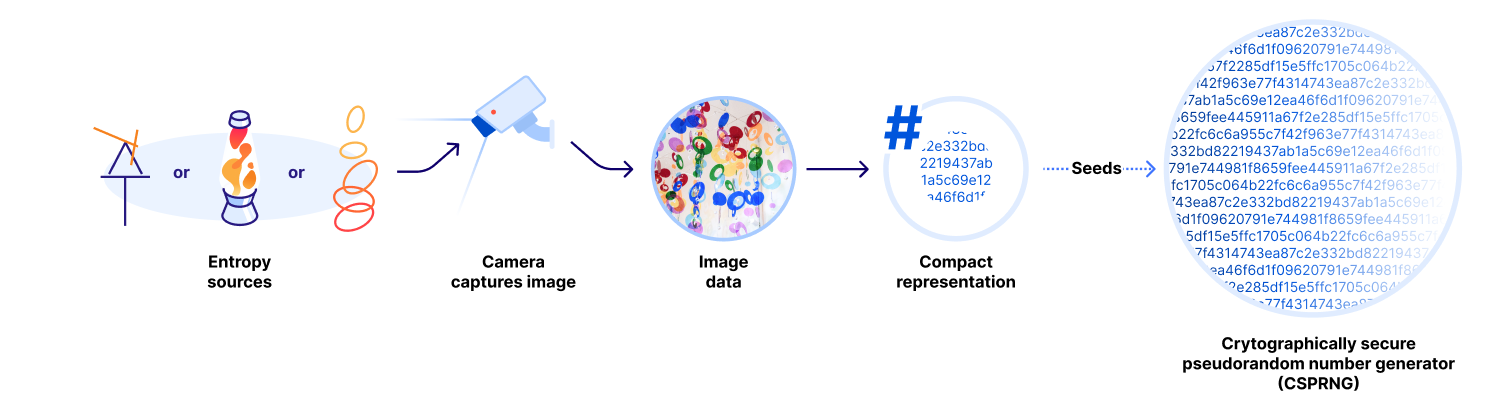


 We’re excited to announce that
We’re excited to announce that