A new paper presents a polynomial-time quantum algorithm for solving certain hard lattice problems. This could be a big deal for post-quantum cryptographic algorithms, since many of them base their security on hard lattice problems.
A few things to note. One, this paper has not yet been peer reviewed. As this comment points out: “We had already some cases where efficient quantum algorithms for lattice problems were discovered, but they turned out not being correct or only worked for simple special cases.” I expect we’ll learn more about this particular algorithm with time. And, like many of these algorithms, there will be improvements down the road.
Two, this is a quantum algorithm, which means that it has not been tested. There is a wide gulf between quantum algorithms in theory and in practice. And until we can actually code and test these algorithms, we should be suspicious of their speed and complexity claims.
And three, I am not surprised at all. We don’t have nearly enough analysis of lattice-based cryptosystems to be confident in their security.
EDITED TO ADD (4/20): The paper had a significant error, and has basically been retracted. From the new abstract:
Note: Update on April 18: Step 9 of the algorithm contains a bug, which I don’t know how to fix. See Section 3.5.9 (Page 37) for details. I sincerely thank Hongxun Wu and (independently) Thomas Vidick for finding the bug today. Now the claim of showing a polynomial time quantum algorithm for solving LWE with polynomial modulus-noise ratios does not hold. I leave the rest of the paper as it is (added a clarification of an operation in Step 8) as a hope that ideas like Complex Gaussian and windowed QFT may find other applications in quantum computation, or tackle LWE in other ways.
I can’t remember when I first met Ross. Of course it was before 2008, when we created the Security and Human Behavior workshop. It was well before 2001, when we created the Workshop on Economics and Information Security. (Okay, he created both—I helped.) It was before 1998, when we wrote about the problems with key escrow systems. I was one of the people he brought to the Newton Institute, at Cambridge University, for the six-month cryptography residency program he ran (I mistakenly didn’t stay the whole time)—that was in 1996.
I know I was at the first Fast Software Encryption workshop in December 1993, another conference he created. There I presented the Blowfish encryption algorithm. Pulling an old first-edition of Applied Cryptography (the one with the blue cover) down from the shelf, I see his name in the acknowledgments. Which means that sometime in early 1993—probably at Eurocrypt in Lofthus, Norway—I, as an unpublished book author who had only written a couple of crypto articles for Dr. Dobb’s Journal, asked him to read and comment on my book manuscript. And he said yes. Which means I mailed him a paper copy. And he read it. And mailed his handwritten comments back to me. In an envelope with stamps. Because that’s how we did it back then.
I have known Ross for over thirty years, as both a colleague and a friend. He was enthusiastic, brilliant, opinionated, articulate, curmudgeonly, and kind. Pick up any of his academic papers—there are many—and odds are that you will find a least one unexpected insight. He was a cryptographer and security engineer, but also very much a generalist. He published on block cipher cryptanalysis in the 1990s, and the security of large-language models last year. He started conferences like nobody’s business. His masterwork book, Security Engineering—now in its third edition—is as comprehensive a tome on cybersecurity and related topics as you could imagine. (Also note his fifteen-lecture video series on that same page. If you have never heard Ross lecture, you’re in for a treat.) He was the first person to understand that security problems are often actually economic problems. He was the first person to make a lot of those sorts of connections. He fought against surveillance and backdoors, and for academic freedom. He didn’t suffer fools in either government or the corporate world.
He’s listed in the acknowledgments as a reader of every one of my books from Beyond Fear on. Recently, we’d see each other a couple of times a year: at this or that workshop or event. The last time I saw him was last June, at SHB 2023, in Pittsburgh. We were having dinner on Alessandro Acquisti‘s rooftop patio, celebrating another successful workshop. He was going to attend my Workshop on Reimagining Democracy in December, but he had to cancel at the last minute. (He sent me the talk he was going to give. I will see about posting it.) The day before he died, we were discussing how to accommodate everyone who registered for this year’s SHB workshop. I learned something from him every single time we talked. And I am not the only one.
My heart goes out to his wife Shireen and his family. We lost him much too soon.
EDITED TO ADD (4/10): I wrote a longer version for Communications of the ACM.
The winner of the Best Paper Award at Crypto this year was a significant improvement to lattice-based cryptanalysis.
This is important, because a bunch of NIST’s post-quantumoptions base their security on lattice problems.
I worry about standardizing on post-quantum algorithms too quickly. We are still learning a lot about the security of these systems, and this paper is an example of that learning.
AWS re:Invent drew 52,000 attendees from across the globe to Las Vegas, Nevada, November 27 to December 1, 2023.
Now in its 12th year, the conference featured 5 keynotes, 17 innovation talks, and over 2,250 sessions and hands-on labs offering immersive learning and networking opportunities.
With dozens of service and feature announcements—and innumerable best practices shared by AWS executives, customers, and partners—the air of excitement was palpable. We were on site to experience all of the innovations and insights, but summarizing highlights isn’t easy. This post details three key security themes that caught our attention.
Security culture
When we think about cybersecurity, it’s natural to focus on technical security measures that help protect the business. But organizations are made up of people—not technology. The best way to protect ourselves is to foster a proactive, resilient culture of cybersecurity that supports effective risk mitigation, incident detection and response, and continuous collaboration.
In Sustainable security culture: Empower builders for success, AWS Global Services Security Vice President Hart Rossman and AWS Global Services Security Organizational Excellence Leader Sarah Currey presented practical strategies for building a sustainable security culture.
Rossman noted that many customers who meet with AWS about security challenges are attempting to manage security as a project, a program, or a side workstream. To strengthen your security posture, he said, you have to embed security into your business.
“You’ve got to understand early on that security can’t be effective if you’re running it like a project or a program. You really have to run it as an operational imperative—a core function of the business. That’s when magic can happen.” — Hart Rossman, Global Services Security Vice President at AWS
Three best practices can help:
Be consistently persistent. Routinely and emphatically thank employees for raising security issues. It might feel repetitive, but treating security events and escalations as learning opportunities helps create a positive culture—and it’s a practice that can spread to other teams. An empathetic leadership approach encourages your employees to see security as everyone’s responsibility, share their experiences, and feel like collaborators.
Brief the board. Engage executive leadership in regular, business-focused meetings. By providing operational metrics that tie your security culture to the impact that it has on customers, crisply connecting data to business outcomes, and providing an opportunity to ask questions, you can help build the support of executive leadership, and advance your efforts to establish a sustainable proactive security posture.
Have a mental model for creating a good security culture. Rossman presented a diagram (Figure 1) that highlights three elements of security culture he has observed at AWS: a student, a steward, and a builder. If you want to be a good steward of security culture, you should be a student who is constantly learning, experimenting, and passing along best practices. As your stewardship grows, you can become a builder, and progress the culture in new directions.
Figure 1: Sample mental model for building security culture
Thoughtful investment in the principles of inclusivity, empathy, and psychological safety can help your team members to confidently speak up, take risks, and express ideas or concerns. This supports an escalation-friendly culture that can reduce employee burnout, and empower your teams to champion security at scale.
Rodgers highlighted three pillars of progression (Figure 2)—aware, bolted-on, and embedded—that are based on meetings with more than 800 customers. As organizations mature from a reactive security posture to a proactive, security-first approach, he noted, security culture becomes a true business enabler.
“When organizations have a strong security culture and everyone sees security as their responsibility, they can move faster and achieve quicker and more secure product and service releases.” — Clarke Rodgers, Director of Enterprise Strategy at AWS
Figure 2: Shipping with a security-first mindset
Human-centric AI
CISOs and security stakeholders are increasingly pivoting to a human-centric focus to establish effective cybersecurity, and ease the burden on employees.
According to Gartner, by 2027, 50% of large enterprise CISOs will have adopted human-centric security design practices to minimize cybersecurity-induced friction and maximize control adoption.
As Amazon CSO Stephen Schmidt noted in Move fast, stay secure: Strategies for the future of security, focusing on technology first is fundamentally wrong. Security is a people challenge for threat actors, and for defenders. To keep up with evolving changes and securely support the businesses we serve, we need to focus on dynamic problems that software can’t solve.
Maintaining that focus means providing security and development teams with the tools they need to automate and scale some of their work.
“People are our most constrained and most valuable resource. They have an impact on every layer of security. It’s important that we provide the tools and the processes to help our people be as effective as possible.” — Stephen Schmidt, CSO at Amazon
Organizations can use artificial intelligence (AI) to impact all layers of security—but AI doesn’t replace skilled engineers. When used in coordination with other tools, and with appropriate human review, it can help make your security controls more effective.
Schmidt highlighted the internal use of AI at Amazon to accelerate our software development process, as well as new generative AI-powered Amazon Inspector, Amazon Detective, AWS Config, and Amazon CodeWhisperer features that complement the human skillset by helping people make better security decisions, using a broader collection of knowledge. This pattern of combining sophisticated tooling with skilled engineers is highly effective, because it positions people to make the nuanced decisions required for effective security that AI can’t make on its own.
In How security teams can strengthen security using generative AI, AWS Senior Security Specialist Solutions Architects Anna McAbee and Marshall Jones, and Principal Consultant Fritz Kunstler featured a virtual security assistant (chatbot) that can address common security questions and use cases based on your internal knowledge bases, and trusted public sources.
The generative AI-powered solution depicted in Figure 3—which includes Retrieval Augmented Generation (RAG) with Amazon Kendra, Amazon Security Lake, and Amazon Bedrock—can help you automate mundane tasks, expedite security decisions, and increase your focus on novel security problems.
It’s available on Github with ready-to-use code, so you can start experimenting with a variety of large and multimodal language models, settings, and prompts in your own AWS account.
Secure collaboration
Collaboration is key to cybersecurity success, but evolving threats, flexible work models, and a growing patchwork of data protection and privacy regulations have made maintaining secure and compliant messaging a challenge.
An estimated 3.09 billion mobile phone users access messaging apps to communicate, and this figure is projected to grow to 3.51 billion users in 2025.
The use of consumer messaging apps for business-related communications makes it more difficult for organizations to verify that data is being adequately protected and retained. This can lead to increased risk, particularly in industries with unique recordkeeping requirements.
In How the U.S. Army uses AWS Wickr to deliver lifesaving telemedicine, Matt Quinn, Senior Director at The U.S. Army Telemedicine & Advanced Technology Research Center (TATRC), Laura Baker, Senior Manager at Deloitte, and Arvind Muthukrishnan, AWS Wickr Head of Product highlighted how The TATRC National Emergency Tele-Critical Care Network (NETCCN) was integrated with AWS Wickr—a HIPAA-eligible secure messaging and collaboration service—and AWS Private 5G, a managed service for deploying and scaling private cellular networks.
During the session, Quinn, Baker, and Muthukrishnan described how TATRC achieved a low-resource, cloud-enabled, virtual health solution that facilitates secure collaboration between onsite and remote medical teams for real-time patient care in austere environments. Using Wickr, medics on the ground were able to treat injuries that exceeded their previous training (Figure 4) with the help of end-to-end encrypted video calls, messaging, and file sharing with medical professionals, and securely retain communications in accordance with organizational requirements.
“Incorporating Wickr into Military Emergency Tele-Critical Care Platform (METTC-P) not only provides the security and privacy of end-to-end encrypted communications, it gives combat medics and other frontline caregivers the ability to gain instant insight from medical experts around the world—capabilities that will be needed to address the simultaneous challenges of prolonged care, and the care of large numbers of casualties on the multi-domain operations (MDO) battlefield.” — Matt Quinn, Senior Director at TATRC
Figure 4: Telemedicine workflows using AWS Wickr
In a separate Chalk Talk titled Bolstering Incident Response with AWS Wickr and Amazon EventBridge, Senior AWS Wickr Solutions Architects Wes Wood and Charles Chowdhury-Hanscombe demonstrated how to integrate Wickr with Amazon EventBridge and Amazon GuardDuty to strengthen incident response capabilities with an integrated workflow (Figure 5) that connects your AWS resources to Wickr bots. Using this approach, you can quickly alert appropriate stakeholders to critical findings through a secure communication channel, even on a potentially compromised network.
Figure 5: AWS Wickr integration for incident response communications
Security is our top priority
AWS re:Invent featured many more highlights on a variety of topics, including adaptive access control with Zero Trust, AWS cyber insurance partners, Amazon CTO Dr. Werner Vogels’ popular keynote, and the security partnerships showcased on the Expo floor. It was a whirlwind experience, but one thing is clear: AWS is working hard to help you build a security-first mindset, so that you can meaningfully improve both technical and business outcomes.
We don’t have a useful quantum computer yet, but we do have quantum algorithms. Shor’s algorithm has the potential to factor large numbers faster than otherwise possible, which—if the run times are actually feasible—could break both the RSA and Diffie-Hellman public-key algorithms.
Now, computer scientist Oded Regev has a significant speed-up to Shor’s algorithm, at the cost of more storage.
The improvement was profound. The number of elementary logical steps in the quantum part of Regev’s algorithm is proportional to n1.5 when factoring an n-bit number, rather than n2 as in Shor’s algorithm. The algorithm repeats that quantum part a few dozen times and combines the results to map out a high-dimensional lattice, from which it can deduce the period and factor the number. So the algorithm as a whole may not run faster, but speeding up the quantum part by reducing the number of required steps could make it easier to put it into practice.
Of course, the time it takes to run a quantum algorithm is just one of several considerations. Equally important is the number of qubits required, which is analogous to the memory required to store intermediate values during an ordinary classical computation. The number of qubits that Shor’s algorithm requires to factor an n-bit number is proportional to n, while Regev’s algorithm in its original form requires a number of qubits proportional to n1.5—a big difference for 2,048-bit numbers.
Again, this is all still theoretical. But now it’s theoretically faster.
I’ve been at AWS for more than four years, and I’ve enjoyed every minute of it! I started as a consultant in Professional Services, and I’ve been a Security Solutions Architect for around three years.
How do you explain your job to your non-tech friends?
Well, my mother doesn’t totally understand my role, and she’s been known to tell her friends that I’m the cable company technician that installs your internet modem and router. I usually tell my non-tech friends that I help AWS customers protect their sensitive data. If I mention cryptography, I typically only get asked questions about cryptocurrency—which I’m not qualified to answer. If someone asks what cryptography is, I usually say it’s protecting data by using mathematics.
How did you get started in data protection and cryptography? What about it piqued your interest?
I originally went to school to become a network engineer, but I discovered that moving data packets from point A to point B wasn’t as interesting to me as securing those data packets. Early in my career, I was an intern at an insurance company, and I had a mentor who set up ethnical hacking lessons for me—for example, I’d come into the office and he’d have a compromised workstation preconfigured. He’d ask me to do an investigation and determine how the workstation was compromised and what could be done to isolate it and collect evidence. Other times, I’d come in and find my desk cabinets were locked with a padlock, and he wanted me to pick the lock. Security is particularly interesting because it’s an ever-evolving field, and I enjoy learning new things.
What’s been the most dramatic change you’ve seen in the data protection landscape?
One of the changes that I’ve been excited to see is an emphasis on encrypting everything. When I started my career, we’d often have discussions about encryption in the context of tradeoffs. If we needed to encrypt sensitive data, we’d have a conversation with application teams about the potential performance impact of encryption and decryption operations on their systems (for example, their databases), when to schedule downtime for the application to encrypt the data or rotate the encryption keys protecting the data, how to ensure the durability of their keys and make sure they didn’t lose data, and so on.
When I talk to customers about encryption on AWS today—of course, it’s still useful to talk about potential performance impact—but the conversation has largely shifted from “Should I encrypt this data?” to “How should I encrypt this data?” This is due to services such as AWS Key Management Service (AWS KMS) making it simpler for customers to manage encryption keys and encrypt and decrypt data in their applications with minimal performance impact or application downtime. AWS KMS has also made it simple to enable encryption of sensitive data—with over 120 AWS services integrated with AWS KMS, and services such as Amazon Simple Storage Service (Amazon S3) encrypting new S3 objects by default.
You are a frequent contributor to the AWS Security Blog. What were some of your recent posts about?
You are speaking in a couple of sessions at AWS re:Invent; what will your sessions focus on? What do you hope attendees will take away from your session?
I’m delivering two sessions at re:Invent this year. The first is a chalk talk, Centrally manage application secrets with AWS Secrets Manager (SEC221), that I’m delivering with Ritesh Desai, who is the General Manager of Secrets Manager. We’re discussing how you can securely store and manage secrets in your workloads inside and outside of AWS. We will highlight some recommended practices for managing secrets, and answer your questions about how Secrets Manager integrates with services such as AWS KMS to help protect application secrets.
The second session is also a chalk talk, Securely modernize payment applications with AWS (SEC326). I’m delivering this talk with Mark Cline, who is the Senior Product Manager of AWS Payment Cryptography. We will walk through an example scenario on creating a new payment processing application. We will discuss how to use AWS Payment Cryptography, as well as other services such as AWS Lambda, to build a simple architecture to help process and secure credit card payment data. We will also include common payment industry use cases such as tokenization of sensitive data, and how to include basic anti-fraud detection, in our example app.
What are you currently working on that you’re excited about?
My re:Invent sessions are definitely something that I’m excited about. Otherwise, I spend most of my time talking to customers about AWS Cryptography services such as AWS KMS, AWS Secrets Manager, and AWS Private Certificate Authority. I also lead a program at AWS that enables our subject matter experts to create and publish videos to demonstrate new features of AWS Security Services. I like helping people create videos, and I hope that our videos provide another mechanism for viewers who prefer information in a video format. Visual media can be more inclusive for customers with certain disabilities or for neurodiverse customers who find it challenging to focus on written text. Plus, you can consume videos differently than a blog post or text documentation. If you don’t have the time or desire to read a blog post or AWS public doc, you can listen to an instructional video while you work on other tasks, eat lunch, or take a break. I invite folks to check out the AWS Security Services Features Demo YouTube video playlist.
Is there something you wish customers would ask you about more often?
I always appreciate when customers provide candid feedback on our services. AWS is a customer-obsessed company, and we build our service roadmaps based on what our customers tell us they need. You should feel comfortable letting AWS know when something could be easier, more efficient, or less expensive. Many customers I’ve worked with have provided actionable feedback on our services and influenced service roadmaps, just by speaking up and sharing their experiences.
How about outside of work, any hobbies?
I have two toddlers that keep me pretty busy, so most of my hobbies are what they like to do. So I tend to spend a lot of time building elaborate toy train tracks, pushing my kids on the swings, and pretending to eat wooden toy food that they “cook” for me. Outside of that, I read a lot of fiction and indulge in binge-worthy TV.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
For the first time, researchers have demonstrated that a large portion of cryptographic keys used to protect data in computer-to-server SSH traffic are vulnerable to complete compromise when naturally occurring computational errors occur while the connection is being established.
[…]
The vulnerability occurs when there are errors during the signature generation that takes place when a client and server are establishing a connection. It affects only keys using the RSA cryptographic algorithm, which the researchers found in roughly a third of the SSH signatures they examined. That translates to roughly 1 billion signatures out of the 3.2 billion signatures examined. Of the roughly 1 billion RSA signatures, about one in a million exposed the private key of the host.
Abstract: We demonstrate that a passive network attacker can opportunistically obtain private RSA host keys from an SSH server that experiences a naturally arising fault during signature computation. In prior work, this was not believed to be possible for the SSH protocol because the signature included information like the shared Diffie-Hellman secret that would not be available to a passive network observer. We show that for the signature parameters commonly in use for SSH, there is an efficient lattice attack to recover the private key in case of a signature fault. We provide a security analysis of the SSH, IKEv1, and IKEv2 protocols in this scenario, and use our attack to discover hundreds of compromised keys in the wild from several independently vulnerable implementations.
The NIST elliptic curves that power much of modern cryptography were generated in the late ’90s by hashing seeds provided by the NSA. How were the seeds generated? Rumor has it that they are in turn hashes of English sentences, but the person who picked them, Dr. Jerry Solinas, passed away in early 2023 leaving behind a cryptographic mystery, some conspiracy theories, and an historical password cracking challenge.
So there’s a $12K prize to recover the hash seeds.
Some of the backstory here (it’s the funniest fucking backstory ever): it’s lately been circulating—though I think this may have been somewhat common knowledge among practitioners, though definitely not to me—that the “random” seeds for the NIST P-curves, generated in the 1990s by Jerry Solinas at NSA, were simply SHA1 hashes of some variation of the string “Give Jerry a raise”.
At the time, the “pass a string through SHA1” thing was meant to increase confidence in the curve seeds; the idea was that SHA1 would destroy any possible structure in the seed, so NSA couldn’t have selected a deliberately weak seed. Of course, NIST/NSA then set about destroying its reputation in the 2000’s, and this explanation wasn’t nearly enough to quell conspiracy theories.
But when Jerry Solinas went back to reconstruct the seeds, so NIST could demonstrate that the seeds really were benign, he found that he’d forgotten the string he used!
If you’re a true conspiracist, you’re certain nobody is going to find a string that generates any of these seeds. On the flip side, if anyone does find them, that’ll be a pretty devastating blow to the theory that the NIST P-curves were maliciously generated—even for people totally unfamiliar with basic curve math.
Note that this is not the constants used in the Dual_EC_PRNG random-number generator that the NSA backdoored. This is something different.
AWS Cryptography is pleased to announce that today, the National Institute for Standards and Technology (NIST) awarded AWS-LC its validation certificate as a Federal Information Processing Standards (FIPS) 140-3, level 1, cryptographic module. This important milestone enables AWS customers that require FIPS-validated cryptography to leverage AWS-LC as a fully owned AWS implementation.
AWS-LC is an open source cryptographic library that is a fork from Google’s BoringSSL. It is tailored by the AWS Cryptography team to meet the needs of AWS services, which can require a combination of FIPS-validated cryptography, speed of certain algorithms on the target environments, and formal verification of the correctness of implementation of multiple algorithms. FIPS 140 is the technical standard for cryptographic modules for the U.S. and Canadian Federal governments. FIPS 140-3 is the most recent version of the standard, which introduced new and more stringent requirements over its predecessor, FIPS 140-2. The AWS-LC FIPS module underwent extensive code review and testing by a NIST-accredited lab before we submitted the results to NIST, where the module was further reviewed by the Cryptographic Module Validation Program (CMVP).
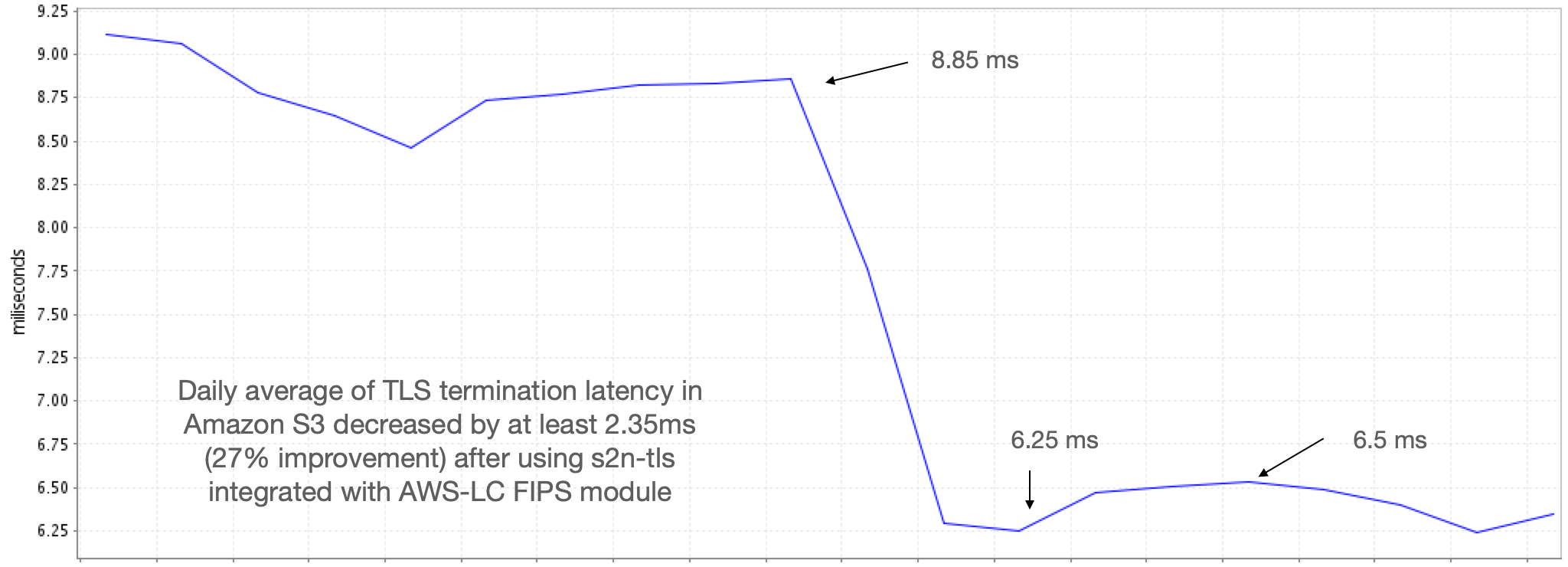
Our goal in designing the AWS-LC FIPS module was to create a validated library without compromising on our standards for both security and performance. AWS-LC is validated on AWS Graviton2 (c6g, 64-bit AWS custom Arm processor based on Neoverse N1) and Intel Xeon Platinum 8275CL (c5, x86_64) running Amazon Linux 2 or Ubuntu 20.04. Specifically, it includes low-level implementations that target 64-bit Arm and x86 processors, which are essential to meeting—and even exceeding—the performance that customers expect of AWS services. For example, in the integration of the AWS-LC FIPS module with AWS s2n-tls for TLS termination, we observed a 27% decrease in handshake latency in Amazon Simple Storage Service (Amazon S3), as shown in Figure 1.
Figure 1: Amazon S3 TLS termination time after using AWS-LC
AWS-LC integrates CPU-Jitter as the source of entropy, which works on widely available modern processors with high-resolution timers by measuring the tiny time variations of CPU instructions. Users of AWS-LC FIPS can have confidence that the keys it generates adhere to the required security strength. As a result, the library can be run with no uncertainty about the impact of a different processor on the entropy claims.
AWS-LC is a high-performance cryptographic library that provides an API for direct integration with C and C++ applications. To support a wider developer community, we’re providing integrations of a future version of the AWS-LC FIPS module, v2.0, into the AWS Libcrypto for Rust (aws-lc-rs) and ACCP 2.0 libraries . aws-lc-rs is API-compatible with the popular Rust library named ring, with additional performance enhancements and support for FIPS. Amazon Corretto Crypto Provider 2.0 (ACCP) is an open source OpenJDK implementation interfacing with low-level cryptographic algorithms that equips Java developers with fast cryptographic services. AWS-LC FIPS module v2.0 is currently submitted to an accredited lab for FIPS validation testing, and upon completion will be submitted to NIST for certification.
Today’s AWS-LC FIPS 140-3 certificate is an important milestone for AWS-LC, as a performant and verified library. It’s just the beginning; AWS is committed to adding more features, supporting more operating environments, and continually validating and maintaining new versions of the AWS-LC FIPS module as it grows.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Jake Appelbaum’s PhD thesis contains several newrevelations from the classified NSA documents provided to journalists by Edward Snowden. Nothing major, but a few more tidbits.
Kind of amazing that that all happened ten years ago. At this point, those documents are more historical than anything else.
And it’s unclear who has those archives anymore. According to Appelbaum, The Intercept destroyed their copy.
I recently published an essay about my experiences ten years ago.
Effective collaboration is central to business success, and employees today depend heavily on messaging tools. An estimated 3.09 billion mobile phone users access messaging applications (apps) to communicate, and this figure is projected to grow to 3.51 billion users in 2025.
This post highlights the risks associated with messaging apps and describes how you can use enterprise solutions — such as AWS Wickr — that combine end-to-end encryption with data retention to drive positive security and business outcomes.
The business risks of messaging apps
Evolving threats, flexible work models, and a growing patchwork of data protection and privacy regulations have made maintaining secure and compliant enterprise messaging a challenge.
The use of third-party apps for business-related messages on both corporate and personal devices can make it more difficult to verify that data is being adequately protected and retained. This can lead to business risk, particularly in industries with unique record-keeping requirements. Organizations in the financial services industry, for example, are subject to rules that include Securities and Exchange Commission (SEC) Rule 17a-4 and Financial Industry Regulatory Authority (FINRA) Rule 3120, which require them to preserve all pertinent electronic communications.
A recent Gartner report on the viability of mobile bring-your-own-device (BYOD) programs noted, “It is now logical to assume that most financial services organizations with mobile BYOD programs for regulated employees could be fined due to a lack of compliance with electronic communications regulations.”
In the public sector, U.S. government agencies are subject to records requests under the Freedom of Information Act (FOIA) and various state sunshine statutes. For these organizations, effectively retaining business messages is about more than supporting security and compliance—it’s about maintaining public trust.
Securing enterprise messaging
Enterprise-grade messaging apps can help you protect communications from unauthorized access and facilitate desired business outcomes.
Security — Critical security protocols protect messages and files that contain sensitive and proprietary data — such as personally identifiable information, protected health information, financial records, and intellectual property — in transit and at rest to decrease the likelihood of a security incident.
Control — Administrative controls allow you to add, remove, and invite users, and organize them into security groups with restricted access to features and content at their level. Passwords can be reset and profiles can be deleted remotely, helping you reduce the risk of data exposure stemming from a lost or stolen device.
Compliance — Information can be preserved in a customer-controlled data store to help meet requirements such as those that fall under the Federal Records Act (FRA) and National Archives and Records Administration (NARA), as well as SEC Rule 17a-4 and Sarbanes-Oxley (SOX).
Marrying encryption with data retention
Enterprise solutions bring end-to-end encryption and data retention together in support of a comprehensive approach to secure messaging that balances people, process, and technology.
End-to-end encryption
Many messaging apps offer some form of encryption, but not all of them use end-to-end encryption. End-to-end encryption is a secure communication method that protects data from unauthorized access, interception, or tampering as it travels from one endpoint to another.
In end-to-end encryption, encryption and decryption take place locally, on the device. Every call, message, and file is encrypted with unique keys and remains indecipherable in transit. Unauthorized parties cannot access communication content because they don’t have the keys required to decrypt the data.
Encryption in transit compared to end-to-end encryption
Encryption in transit encrypts data over a network from one point to another (typically between one client and one server); data might remain stored in plaintext at the source and destination storage systems. End-to-end encryption combines encryption in transit and encryption at rest to secure data at all times, from being generated and leaving the sender’s device, to arriving at the recipient’s device and being decrypted.
“Messaging is a critical tool for any organization, and end-to-end encryption is the security technology that provides organizations with the confidence they need to rely on it.” — CJ Moses, CISO and VP of Security Engineering at AWS
Data retention
While data retention is often thought of as being incompatible with end-to-end encryption, leading enterprise-grade messaging apps offer both, giving you the option to configure a data store of your choice to retain conversations without exposing them to outside parties. No one other than the intended recipients and your organization has access to the message content, giving you full control over your data.
How AWS can help
AWS Wickr is an end-to-end encrypted messaging and collaboration service that was built from the ground up with features designed to help you keep internal and external communications secure, private, and compliant. Wickr protects one-to-one and group messaging, voice and video calling, file sharing, screen sharing, and location sharing with 256-bit Advanced Encryption Standard (AES) encryption, and provides data retention capabilities.
Figure 1: How Wickr works
With Wickr, each message gets a unique AES private encryption key, and a unique Elliptic-curve Diffie–Hellman (ECDH) public key to negotiate the key exchange with recipients. Message content — including text, files, audio, or video — is encrypted on the sending device (your iPhone, for example) using the message-specific AES key. This key is then exchanged via the ECDH key exchange mechanism, so that only intended recipients can decrypt the message.
“As former employees of federal law enforcement, the intelligence community, and the military, Qintel understands the need for enterprise-federated, secure communication messaging capabilities. When searching for our company’s messaging application we evaluated the market thoroughly and while there are some excellent capabilities available, none of them offer the enterprise security and administrative flexibility that Wickr does.” — Bill Schambura, CEO at Qintel
Wickr network administrators can configure and apply data retention to both internal and external communications in a Wickr network. This includes conversations with guest users, external teams, and other partner networks, so you can retain messages and files sent to and from the organization to help meet internal, legal, and regulatory requirements.
Figure 2: Data retention process
Data retention is implemented as an always-on recipient that is added to conversations, not unlike the blind carbon copy (BCC) feature in email. The data-retention process participates in the key exchange, allowing it to decrypt messages. The process can run anywhere: on-premises, on an Amazon Elastic Compute Cloud (Amazon EC2) instance, or at a location of your choice.
Wickr networks can be created through the AWS Management Console, and workflows can be automated with Wickr bots. Wickr is currently available in the AWS US East (Northern Virginia), AWS GovCloud (US-West), AWS Canada (Central), and AWS Europe (London) Regions.
Keep your messages safe
Employees will continue to use messaging apps to chat with friends and family, and boost productivity at work. While many of these apps can introduce risks if not used properly in business settings, Wickr combines end-to-end encryption with data-retention capabilities to help you achieve security and compliance goals. Incorporating Wickr into a comprehensive approach to secure enterprise messaging that includes clear policies and security awareness training can help you to accelerate collaboration, while protecting your organization’s data.
Earlier this year, Amazon Web Services (AWS)released Amazon Corretto Crypto Provider (ACCP) 2, a cryptography provider built by AWS for Java virtual machine (JVM) applications. ACCP 2 delivers comprehensive performance enhancements, with some algorithms (such as elliptic curve key generation) seeing a greater than 13-fold improvement over ACCP 1. The new release also brings official support for the AWS Graviton family of processors. In this post, I’ll discuss a use case for ACCP, then review performance benchmarks to illustrate the performance gains. Finally, I’ll show you how to get started using ACCP 2 in applications today.
This release changes the backing cryptography library for ACCP from OpenSSL (used in ACCP 1) to the AWS open source cryptography library, AWS libcrypto (AWS-LC). AWS-LC has extensive formal verification, as well as traditional testing, to assure the correctness of cryptography that it provides. While AWS-LC and OpenSSL are largely compatible, there are some behavioral differences that required the ACCP major version increment to 2.
The move to AWS-LC also allows ACCP to leverage performance optimizations in AWS-LC for modern processors. I’ll illustrate the ACCP 2 performance enhancements through the use case of establishing a secure communications channel with Transport Layer Security version 1.3 (TLS 1.3). Specifically, I’ll examine cryptographic components of the connection’s initial phase, known as the handshake. TLS handshake latency particularly matters for large web service providers, but reducing the time it takes to perform various cryptographic operations is an operational win for any cryptography-intensive workload.
TLS 1.3 requires ephemeral key agreement, which means that a new key pair is generated and exchanged for every connection. During the TLS handshake, each party generates an ephemeral elliptic curve key pair, exchanges public keys using Elliptic Curve Diffie-Hellman (ECDH), and agrees on a shared secret. Finally, the client authenticates the server by verifying the Elliptic Curve Digital Signature Algorithm (ECDSA) signature in the certificate presented by the server after key exchange. All of this needs to happen before you can send data securely over the connection, so these operations directly impact handshake latency and must be fast.
Figure 1 shows benchmarks for the three elliptic curve algorithms that implement the TLS 1.3 handshake: elliptic curve key generation (up to 1,298% latency improvement in ACCP 2.0 over ACCP 1.6), ECDH key agreement (up to 858% latency improvement), and ECDSA digital signature verification (up to 260% latency improvement). These algorithms were benchmarked over three common elliptic curves with different key sizes on both ACCP 1 and ACCP 2. The choice of elliptic curve determines the size of the key used or generated by the algorithm, and key size correlates to performance. The following benchmarks were measured under the Amazon Corretto 11 JDK on a c7g.large instance running Amazon Linux with a Graviton 3 processor.
Figure 1: Percentage improvement of ACCP 2.0 over 1.6 performance benchmarks on c7g.large Amazon Linux Graviton 3
The performance improvements due to the optimization of secp384r1 in AWS-LC are particularly noteworthy.
Getting started
Whether you’re introducing ACCP to your project or upgrading from ACCP 1, start the onboarding process for ACCP 2 by updating your dependency manager configuration in your development or testing environment. The Maven and Gradle examples below assume that you’re using linux on an ARM64 processor. If you’re using an x86 processor, substitute linux-x86_64 for linux-aarch64. After you’ve performed this update, sync your application’s dependencies and install ACCP in your JVM process. ACCP can be installed either by specifying our recommended security.properties file in your JVM invocation or programmatically at runtime. The following sections provide more details about all of these steps.
After ACCP has been installed, the Java Cryptography Architecture (JCA) will look for cryptographic implementations in ACCP first before moving on to other providers. So, as long as your application and dependencies obtain algorithms supported by ACCP from the JCA, your application should gain the benefits of ACCP 2 without further configuration or code changes.
Maven
If you’re using Maven to manage dependencies, add or update the following dependency configuration in your pom.xml file.
After updating your dependency manager, you’ll need to install ACCP. You can install ACCP using security properties as described in our GitHub repository. This installation method is a good option for users who have control over their JVM invocation.
Install programmatically
If you don’t have control over your JVM invocation, you can install ACCP programmatically. For Java applications, add the following code to your application’s initialization logic (optionally performing a health check).
Although the migration path to version 2 is straightforward for most ACCP 1 users, ACCP 2 ends support for some outdated algorithms: a finite field Diffie-Hellman key agreement, finite field DSA signatures, and a National Institute of Standards and Technology (NIST)-specified random number generator. The removal of these algorithms is not backwards compatible, so you’ll need to check your code for their usage and, if you do find usage, either migrate to more modern algorithms provided by ACCP 2 or obtain implementations from a different provider, such as one of the default providers that ships with the JDK.
Check your code
Search for unsupported algorithms in your application code by their JCA names:
DH: Finite-field Diffie-Hellman key agreement
DSA: Finite-field Digital Signature Algorithm
NIST800-90A/AES-CTR-256: NIST-specified random number generator
Use ACCP 2 supported algorithms
Where possible, use these supported algorithms in your application code:
ECDH for key agreement instead of DH
ECDSA or RSA for signatures instead of DSA
Default SecureRandom instead of NIST800-90A/AES-CTR-256
If your use case requires the now-unsupported algorithms, check whether any of those algorithms are explicitly requested from ACCP.
If ACCP is not explicitly named as the provider, then you should be able to transparently fall back to another provider without a code change.
If ACCP is explicitly named as the provider, then remove that provider specification and register a different provider that offers the algorithm. This will allow the JCA to obtain an implementation from another registered provider without breaking backwards compatibility in your application.
Test your code
Some behavioral differences exist between ACCP 2 and other providers, including ACCP 1 (backed by OpenSSL). After onboarding or migrating, it’s important that you test your application code thoroughly to identify potential incompatibilities between cryptography providers.
Conclusion
Integrate ACCP 2 into your application today to benefit from AWS-LC’s security assurance and performance improvements. For a full list of changes, see the ACCP CHANGELOG on GitHub. Linux builds of ACCP 2 are now available on Maven Central for aarch64 and x86-64 processor architectures. If you encounter any issues with your integration, or have any feature suggestions, please reach out to us on GitHub by filing an issue.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
I just read an article complaining that NIST is taking too long in finalizing its post-quantum-computing cryptography standards.
This process has been going on since 2016, and since that time there has been a huge increase in quantum technology and an equally large increase in quantum understanding and interest. Yet seven years later, we have only four algorithms, although last week NIST announced that a number of other candidates are under consideration, a process that is expected to take “several years.
The delay in developing quantum-resistant algorithms is especially troubling given the time it will take to get those products to market. It generally takes four to six years with a new standard for a vendor to develop an ASIC to implement the standard, and it then takes time for the vendor to get the product validated, which seems to be taking a troubling amount of time.
Yes, the process will take several years, and you really don’t want to rush it. I wrote this last year:
Ian Cassels, British mathematician and World War II cryptanalyst, once said that “cryptography is a mixture of mathematics and muddle, and without the muddle the mathematics can be used against you.” This mixture is particularly difficult to achieve with public-key algorithms, which rely on the mathematics for their security in a way that symmetric algorithms do not. We got lucky with RSA and related algorithms: their mathematics hinge on the problem of factoring, which turned out to be robustly difficult. Post-quantum algorithms rely on other mathematical disciplines and problems—code-based cryptography, hash-based cryptography, lattice-based cryptography, multivariate cryptography, and so on—whose mathematics are both more complicated and less well-understood. We’re seeing these breaks because those core mathematical problems aren’t nearly as well-studied as factoring is.
[…]
As the new cryptanalytic results demonstrate, we’re still learning a lot about how to turn hard mathematical problems into public-key cryptosystems. We have too much math and an inability to add more muddle, and that results in algorithms that are vulnerable to advances in mathematics. More cryptanalytic results are coming, and more algorithms are going to be broken.
As to the long time it takes to get new encryption products to market, work on shortening it:
The moral is the need for cryptographic agility. It’s not enough to implement a single standard; it’s vital that our systems be able to easily swap in new algorithms when required.
Whatever NIST comes up with, expect that it will get broken sooner than we all want. It’s the nature of these trap-door functions we’re using for public-key cryptography.
Seems that there is a deliberate backdoor in the twenty-year-old TErrestrial Trunked RAdio (TETRA) standard used by police forces around the world.
The European Telecommunications Standards Institute (ETSI), an organization that standardizes technologies across the industry, first created TETRA in 1995. Since then, TETRA has been used in products, including radios, sold by Motorola, Airbus, and more. Crucially, TETRA is not open-source. Instead, it relies on what the researchers describe in their presentation slides as “secret, proprietary cryptography,” meaning it is typically difficult for outside experts to verify how secure the standard really is.
The researchers said they worked around this limitation by purchasing a TETRA-powered radio from eBay. In order to then access the cryptographic component of the radio itself, Wetzels said the team found a vulnerability in an interface of the radio.
[…]
Most interestingly is the researchers’ findings of what they describe as the backdoor in TEA1. Ordinarily, radios using TEA1 used a key of 80-bits. But Wetzels said the team found a “secret reduction step” which dramatically lowers the amount of entropy the initial key offered. An attacker who followed this step would then be able to decrypt intercepted traffic with consumer-level hardware and a cheap software defined radio dongle.
Looks like the encryption algorithm was intentionally weakened by intelligence agencies to facilitate easy eavesdropping.
Specifically on the researchers’ claims of a backdoor in TEA1, Boyer added “At this time, we would like to point out that the research findings do not relate to any backdoors. The TETRA security standards have been specified together with national security agencies and are designed for and subject to export control regulations which determine the strength of the encryption.”
And I would like to point out that that’s the very definition of a backdoor.
Why aren’t we done with secret, proprietary cryptography? It’s just not a good idea.
The threat detection and incident response track showcased how AWS customers can get the visibility they need to help improve their security posture, identify issues before they impact business, and investigate and respond quickly to security incidents across their environment.
With dozens of service and feature announcements—and innumerable best practices shared by AWS experts, customers, and partners—distilling highlights is a challenge. From an incident response perspective, three key themes emerged.
Proactively detect, contextualize, and visualize security events
When it comes to effectively responding to security events, rapid detection is key. Among the launches announced during the keynote was the expansion of Amazon Detective finding groups to include Amazon Inspector findings in addition to Amazon GuardDuty findings.
Detective, GuardDuty, and Inspector are part of a broad set of fully managed AWS security services that help you identify potential security risks, so that you can respond quickly and confidently.
Using machine learning, Detective finding groups can help you conduct faster investigations, identify the root cause of events, and map to the MITRE ATT&CK framework to quickly run security issues to ground. The finding group visualization panel shown in the following figure displays findings and entities involved in a finding group. This interactive visualization can help you analyze, understand, and triage the impact of finding groups.
Figure 1: Detective finding groups visualization panel
With the expanded threat and vulnerability findings announced at re:Inforce, you can prioritize where to focus your time by answering questions such as “was this EC2 instance compromised because of a software vulnerability?” or “did this GuardDuty finding occur because of unintended network exposure?”
In the session Streamline security analysis with Amazon Detective, AWS Principal Product Manager Rich Vorwaller, AWS Senior Security Engineer Rima Tanash, and AWS Program Manager Jordan Kramer demonstrated how to use graph analysis techniques and machine learning in Detective to identify related findings and resources, and investigate them together to accelerate incident analysis.
In addition to Detective, you can also use Amazon Security Lake to contextualize and visualize security events. Security Lake became generally available on May 30, 2023, and several re:Inforce sessions focused on how you can use this new service to assist with investigations and incident response.
As detailed in the following figure, Security Lake automatically centralizes security data from AWS environments, SaaS providers, on-premises environments, and cloud sources into a purpose-built data lake stored in your account. Security Lake makes it simpler to analyze security data, gain a more comprehensive understanding of security across an entire organization, and improve the protection of workloads, applications, and data. Security Lake automates the collection and management of security data from multiple accounts and AWS Regions, so you can use your preferred analytics tools while retaining complete control and ownership over your security data. Security Lake has adopted the Open Cybersecurity Schema Framework (OCSF), an open standard. With OCSF support, the service normalizes and combines security data from AWS and a broad range of enterprise security data sources.
Figure 2: How Security Lake works
To date, 57 AWS security partners have announced integrations with Security Lake, and we now have more than 70 third-party sources, 16 analytics subscribers, and 13 service partners.
In Gaining insights from Amazon Security Lake, AWS Principal Solutions Architect Mark Keating and AWS Security Engineering Manager Keith Gilbert detailed how to get the most out of Security Lake. Addressing questions such as, “How do I get access to the data?” and “What tools can I use?,” they demonstrated how analytics services and security information and event management (SIEM) solutions can connect to and use data stored within Security Lake to investigate security events and identify trends across an organization. They emphasized how bringing together logs in multiple formats and normalizing them into a single format empowers security teams to gain valuable context from security data, and more effectively respond to events. Data can be queried with Amazon Athena, or pulled by Amazon OpenSearch Service or your SIEM system directly from Security Lake.
Build your security data lake with Amazon Security Lake featured AWS Product Manager Jonathan Garzon, AWS Product Solutions Architect Ross Warren, and Global CISO of Interpublic Group (IPG) Troy Wilkinson demonstrating how Security Lake helps address common challenges associated with analyzing enterprise security data, and detailing how IPG is using the service. Wilkinson noted that IPG’s objective is to bring security data together in one place, improve searches, and gain insights from their data that they haven’t been able to before.
“With Security Lake, we found that it was super simple to bring data in. Not just the third-party data and Amazon data, but also our on-premises data from custom apps that we built.” — Troy Wilkinson, global CISO, Interpublic Group
Use automation and machine learning to reduce mean time to response
Incident response automation can help free security analysts from repetitive tasks, so they can spend their time identifying and addressing high-priority security issues.
LLA operates in over 20 countries across Latin America and the Caribbean. After completing multiple acquisitions, LLA needed a centralized security operations team to handle incidents and notify the teams responsible for each AWS account. They used GuardDuty, Security Hub, and Systems Manager Incident Manager to automate and streamline detection and response, and they configured the services to initiate alerts whenever there was an issue requiring attention.
Speaking alongside AWS Principal Solutions Architect Jesus Federico and AWS Principal Product Manager Sarah Holberg, LLA Senior Manager of Cloud Services Joaquin Cameselle noted that when GuardDuty identifies a critical issue, it generates a new finding in Security Hub. This finding is then forwarded to Systems Manager Incident Manager through an Amazon EventBridge rule. This configuration helps ensure the involvement of the appropriate individuals associated with each account.
“We have deployed a security framework in Liberty Latin America to identify security issues and streamline incident response across over 180 AWS accounts. The framework that leverages AWS Systems Manager Incident Manager, Amazon GuardDuty, and AWS Security Hub enabled us to detect and respond to incidents with greater efficiency. As a result, we have reduced our reaction time by 90%, ensuring prompt engagement of the appropriate teams for each AWS account and facilitating visibility of issues for the central security team.” — Joaquin Cameselle, senior manager, cloud services, Liberty Latin America
After describing the four phases of the incident response process — preparation and prevention; detection and analysis; containment, eradication, and recovery; and post-incident activity—AWS ProServe Global Financial Services Senior Engagement Manager Harikumar Subramonion noted that, to fully benefit from the cloud, you need to embrace automation. Automation benefits the third phase of the incident response process by speeding up containment, and reducing mean time to response.
Citibank Head of Cloud Security Operations Elvis Velez and Vice President of Cloud Security Damien Burks described how Citi built the Cloud Containment Automation Framework (CCAF) from the ground up by using AWS Step Functions and AWS Lambda, enabling them to respond to events 24/7 without human error, and reduce the time it takes to contain resources from 4 hours to 15 minutes. Velez described how Citi uses adversary emulation exercises that use the MITRE ATT&CK Cloud Matrix to simulate realistic attacks on AWS environments, and continuously validate their ability to effectively contain incidents.
Innovate and do more with less
Security operations teams are often understaffed, making it difficult to keep up with alerts. According to data from CyberSeek, there are currently 69 workers available for every 100 cybersecurity job openings.
Effectively evaluating security and compliance posture is critical, despite resource constraints. In Centralizing security at scale with Security Hub and Intuit’s experience, AWS Senior Solutions Architect Craig Simon, AWS Senior Security Hub Product Manager Dora Karali, and Intuit Principal Software Engineer Matt Gravlin discussed how to ease security management with Security Hub. Fortune 500 financial software provider Intuit has approximately 2,000 AWS accounts, 10 million AWS resources, and receives 20 million findings a day from AWS services through Security Hub. Gravlin detailed Intuit’s Automated Compliance Platform (ACP), which combines Security Hub and AWS Config with an internal compliance solution to help Intuit reduce audit timelines, effectively manage remediation, and make compliance more consistent.
“By using Security Hub, we leveraged AWS expertise with their regulatory controls and best practice controls. It helped us keep up to date as new controls are released on a regular basis. We like Security Hub’s aggregation features that consolidate findings from other AWS services and third-party providers. I personally call it the super aggregator. A key component is the Security Hub to Amazon EventBridge integration. This allowed us to stream millions of findings on a daily basis to be inserted into our ACP database.” — Matt Gravlin, principal software engineer, Intuit
At AWS re:Inforce, we launched a new Security Hub capability for automating actions to update findings. You can now use rules to automatically update various fields in findings that match defined criteria. This allows you to automatically suppress findings, update the severity of findings according to organizational policies, change the workflow status of findings, and add notes. With automation rules, Security Hub provides you a simplified way to build automations directly from the Security Hub console and API. This reduces repetitive work for cloud security and DevOps engineers and can reduce mean time to response.
In Continuous innovation in AWS detection and response services, AWS Worldwide Security Specialist Senior Manager Himanshu Verma and GuardDuty Senior Manager Ryan Holland highlighted new features that can help you gain actionable insights that you can use to enhance your overall security posture. After mapping AWS security capabilities to the core functions of the NIST Cybersecurity Framework, Verma and Holland provided an overview of AWS threat detection and response services that included a technical demonstration.
Bolstering incident response with AWS Wickr enterprise integrations highlighted how incident responders can collaborate securely during a security event, even on a compromised network. AWS Senior Security Specialist Solutions Architect Wes Wood demonstrated an innovative approach to incident response communications by detailing how you can integrate the end-to-end encrypted collaboration service AWS Wickr Enterprise with GuardDuty and AWS WAF. Using Wickr Bots, you can build integrated workflows that incorporate GuardDuty and third-party findings into a more secure, out-of-band communication channel for dedicated teams.
The first attack uses an Internet-connected surveillance camera to take a high-speed video of the power LED on a smart card reader—or of an attached peripheral device—during cryptographic operations. This technique allowed the researchers to pull a 256-bit ECDSA key off the same government-approved smart card used in Minerva. The other allowed the researchers to recover the private SIKE key of a Samsung Galaxy S8 phone by training the camera of an iPhone 13 on the power LED of a USB speaker connected to the handset, in a similar way to how Hertzbleed pulled SIKE keys off Intel and AMD CPUs.
There are lots of limitations:
When the camera is 60 feet away, the room lights must be turned off, but they can be turned on if the surveillance camera is at a distance of about 6 feet. (An attacker can also use an iPhone to record the smart card reader power LED.) The video must be captured for 65 minutes, during which the reader must constantly perform the operation.
[…]
The attack assumes there is an existing side channel that leaks power consumption, timing, or other physical manifestations of the device as it performs a cryptographic operation.
So don’t expect this attack to be recovering keys in the real world anytime soon. But, still, really nice work.
Amazon Web Services (AWS) prioritizes security, privacy, and performance. Encryption is a vital part of privacy. To help provide long-term protection of encrypted data, AWS has been introducing quantum-resistant key exchange in common transport protocols used by AWS customers. In this blog post, we introduce post-quantum hybrid key exchange with Kyber, the National Institute of Standards and Technology’s chosen quantum-resistant key encapsulation algorithm, in the Secure Shell (SSH) protocol. We explain why it’s important and show you how to use it with Secure File Transfer Protocol (SFTP) file transfers in AWS Transfer Family, the AWS file transfer service.
Why use PQ-hybrid key establishment in SSH
Although not available today, a cryptanalytically relevant quantum computer (CRQC) could theoretically break the standard public key algorithms currently in use. Today’s network traffic could be recorded now and then decrypted in the future with a CRQC. This is known as harvest-now-decrypt-later.
With such concerns in mind, the U.S. Congress recently signed the Quantum Computing Cybersecurity Preparedness Act, and the White House issued National Security Memoranda (NSM-8, NSM-10) to prepare for a timely and equitable transition to quantum-resistant cryptography. The National Security Agency (NSA) also announced its quantum-resistant algorithm requirements and timelines in its CNSA 2.0 release. Many other governments like Canada, Germany, and France and organizations like ISO/IEC and IEEE have also been prioritizing preparations and experiments with quantum-resistant cryptography technologies.
SSH is a protocol widely used by AWS customers for various tasks ranging from moving files between machines to managing Amazon Elastic Compute Cloud (Amazon EC2) instances. Considering the importance of the SSH protocol, its ubiquitous use, and the data it transfers, we introduced PQ-hybrid key exchange with Kyber in it.
How PQ-hybrid key exchange works in Transfer Family SFTP
AWS just announced support for post-quantum key exchange in SFTP file transfers in AWS Transfer Family. Transfer Family securely scales business-to-business file transfers to AWS Storage services using SFTP and other protocols. SFTP is a secure version of the File Transfer Protocol (FTP) that runs over SSH. The post-quantum key exchange support of Transfer Family raises the security bar for data transfers over SFTP.
PQ-hybrid key establishment in SSH introduces post-quantum KEMs used in conjunction with classical key exchange. The client and server still do an ECDH key exchange. Additionally, the server encapsulates a post-quantum shared secret to the client’s post-quantum KEM public key, which is advertised in the client’s SSH key exchange message. This strategy combines the high assurance of a classical key exchange with the security of the proposed post-quantum key exchanges, to help ensure that the handshakes are protected as long as the ECDH or the post-quantum shared secret cannot be broken.
AWS is committed to supporting standardized interoperable algorithms, so we wanted to introduce Kyber to SSH. Kyber was chosen for standardization by NIST’s Post-Quantum Cryptography (PQC) project. Some standards bodies are already integrating Kyber in various protocols.
We also wanted to encourage interoperability by adopting, making available, and submitting for standardization, a draft that combines Kyber with NIST-approved curves like P256 for SSH. To help enhance security for our customers, the AWS implementation of the PQ key exchange in SFTP and SSH follows that draft.
Is PQ-hybrid SSH key exchange aligned with cryptographic requirements like FIPS 140?
For customers that require FIPS compliance, Transfer Family provides FIPS cryptography in SSH by using the AWS-LC, open-source cryptographic library. The PQ-hybrid key exchange methods supported in the TransferSecurityPolicy-PQ-SSH-FIPS-Experimental-2023-04 policy in Transfer Family continue to meet FIPS requirements as described in SP 800-56Cr2 (section 2). BSI Germany and ANSSI France also recommend such PQ-hybrid key exchange methods.
How to test PQ SFTP with Transfer Family
To enable PQ-hybrid SFTP in Transfer Family, you need to enable one of the two security policies that support PQ-hybrid key exchange in your SFTP-enabled endpoint. You can choose the security policy when you create a new SFTP server endpoint in Transfer Family, as explained in the documentation; or by editing the Cryptographic algorithm options in an existing SFTP endpoint. The following figure shows an example of the AWS Management Console where you update the security policy.
Figure 1: Use the console to set the PQ-hybrid security policy in the Transfer Family endpoint
The security policy names that support PQ key exchange in Transfer Family are TransferSecurityPolicy-PQ-SSH-Experimental-2023-04 and TransferSecurityPolicy-PQ-SSH-FIPS-Experimental-2023-04. For more details on Transfer Family policies, see Security policies for AWS Transfer Family.
After you choose the right PQ security policy in your SFTP Transfer Family endpoint, you can experiment with post-quantum SFTP in Transfer Family with an SFTP client that supports PQ-hybrid key exchange by following the guidance in the aforementioned draft specification. AWS tested and confirmed interoperability between the Transfer Family PQ-hybrid key exchange in SFTP and the SSH implementations of our collaborators on the NIST NCCOE Post-Quantum Migration project, namely OQS OpenSSH and wolfSSH.
OQS OpenSSH client
OQS OpenSSH is an open-source fork of OpenSSH that adds quantum-resistant cryptography to SSH by using liboqs. liboqs is an open-source C library that implements quantum-resistant cryptographic algorithms. OQS OpenSSH and liboqs are part of the Open Quantum Safe (OQS) project.
To test PQ-hybrid key exchange in Transfer Family SFTP with OQS OpenSSH, you first need to build OQS OpenSSH, as explained in the project’s README. Then you can run the example SFTP client to connect to your AWS SFTP endpoint (for example, s-9999999999999999999.server.transfer.us-west-2.amazonaws.com) by using the PQ-hybrid key exchange methods, as shown in the following command. Make sure to replace <user_priv_key_PEM_file> with the SFTP user private key PEM-encoded file used for user authentication, and <username> with the username, and update the SFTP-enabled endpoint with the one that you created in Transfer Family.
To test PQ-hybrid key exchange in Transfer Family SFTP with wolfSSH, you first need to build wolfSSH. When built with liboqs, the open-source library that implements post-quantum algorithms, wolfSSH automatically negotiates [email protected]. Run the example SFTP client to connect to your AWS SFTP server endpoint, as shown in the following command. Make sure to replace <user_priv_key_DER_file> with the SFTP user private key DER-encoded file used for user authentication, <user_public_key_PEM_file> with the corresponding SSH user public key PEM-formatted file, and <username> with the username. Also replace the s-9999999999999999999.server.transfer.us-west-2.amazonaws.com SFTP endpoint with the one that you created in Transfer Family.
As we migrate to a quantum-resistant future, we expect that more SFTP and SSH clients will add support for PQ-hybrid key exchanges that are standardized for SSH.
How to confirm PQ-hybrid key exchange in SFTP
To confirm that PQ-hybrid key exchange was used in an SSH connection for SFTP to Transfer Family, check the client output and optionally use packet captures.
OQS OpenSSH client
The client output (omitting irrelevant information for brevity) should look similar to the following:
$./sftp -S ./ssh -v -o KexAlgorithms=ecdh-nistp384-kyber-768r3-sha384-d00@openquantumsafe.org -i panos_priv_key_PEM_file panos@s-9999999999999999999.server.transfer.us-west-2.amazonaws.com
OpenSSH_8.9-2022-01_p1, Open Quantum Safe 2022-08, OpenSSL 3.0.2 15 Mar 2022
debug1: Reading configuration data /home/lab/openssh/oqs-test/tmp/ssh_config
debug1: Authenticator provider $SSH_SK_PROVIDER did not resolve; disabling
debug1: Connecting to s-9999999999999999999.server.transfer.us-west-2.amazonaws.com [xx.yy.zz..12] port 22.
debug1: Connection established.
[...]
debug1: Local version string SSH-2.0-OpenSSH_8.9-2022-01_
debug1: Remote protocol version 2.0, remote software version AWS_SFTP_1.1
debug1: compat_banner: no match: AWS_SFTP_1.1
debug1: Authenticating to s-9999999999999999999.server.transfer.us-west-2.amazonaws.com:22 as 'panos'
debug1: load_hostkeys: fopen /home/lab/.ssh/known_hosts2: No such file or directory
[...]
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: algorithm: [email protected]
debug1: kex: host key algorithm: ssh-ed25519
debug1: kex: server->client cipher: aes192-ctr MAC: [email protected] compression: none
debug1: kex: client->server cipher: aes192-ctr MAC: [email protected] compression: none
debug1: expecting SSH2_MSG_KEX_ECDH_REPLY
debug1: SSH2_MSG_KEX_ECDH_REPLY received
debug1: Server host key: ssh-ed25519 SHA256:BY3gNMHwTfjd4n2VuT4pTyLOk82zWZj4KEYEu7y4r/0
[...]
debug1: rekey out after 4294967296 blocks
debug1: SSH2_MSG_NEWKEYS sent
debug1: expecting SSH2_MSG_NEWKEYS
debug1: SSH2_MSG_NEWKEYS received
debug1: rekey in after 4294967296 blocks
[...]
Authenticated to AWS.Tranfer.PQ.SFTP.test-endpoint.aws.com ([xx.yy.zz..12]:22) using "publickey".s
debug1: channel 0: new [client-session]
[...]
Connected to s-9999999999999999999.server.transfer.us-west-2.amazonaws.com. sftp>
The output shows that client negotiation occurred using the PQ-hybrid [email protected] method and successfully established an SFTP session.
To view the negotiated PQ-hybrid key, you can use a packet capture in Wireshark or a similar network traffic analyzer. The key exchange method negotiation offered by the client should look similar to the following:
Figure 2: View the client proposed PQ-hybrid key exchange method in Wireshark
Figure 2 shows that the client is offering the PQ-hybrid key exchange method [email protected]. The Transfer Family SFTP server negotiates the same method, and the client offers a PQ-hybrid public key.
Figure 3: View the client P384 ECDH and Kyber-768 public keys
As shown in Figure 3, the client sent 1281 bytes for the PQ-hybrid public key. These are the ECDH P384 92-byte public key, the 1184-byte Kyber-768 public key, and 5 bytes of padding. The server response is of similar size and includes the 92-byte P384 public key and the 1088 Kyber-768 ciphertext.
wolfSSH client
The client output (omitting irrelevant information for brevity) should look similar to the following:
$ ./examples/sftpclient/wolfsftp -p 22 -u panos -i panos_priv_key_DER_file -j panos_public_key_PEM_file -h s-9999999999999999999.server.transfer.us-west-2.amazonaws.com
[...]
2023-05-25 17:37:24 [DEBUG] SSH-2.0-wolfSSHv1.4.12
[...]
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = [email protected]
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = unknown
2023-05-25 17:37:24 [DEBUG] DNL: name ID = diffie-hellman-group-exchange-sha256
[...]
2023-05-25 17:37:24 [DEBUG] connect state: SERVER_KEXINIT_DONE
[...]
2023-05-25 17:37:24 [DEBUG] connect state: CLIENT_KEXDH_INIT_SENT
[...]
2023-05-25 17:37:24 [DEBUG] Decoding MSGID_KEXDH_REPLY
2023-05-25 17:37:24 [DEBUG] Entering DoKexDhReply()
2023-05-25 17:37:24 [DEBUG] DKDR: Calling the public key check callback
Sample public key check callback
public key = 0x24d011a
public key size = 104
ctx = s-9999999999999999999.server.transfer.us-west-2.amazonaws.com
2023-05-25 17:37:24 [DEBUG] DKDR: public key accepted
[...]
2023-05-25 17:37:26 [DEBUG] Entering wolfSSH_get_error()
2023-05-25 17:37:26 [DEBUG] Entering wolfSSH_get_error()
wolfSSH sftp>
The output shows that the client negotiated the PQ-hybrid [email protected] method and successfully established a quantum- resistant SFTP session. A packet capture of this session would be very similar to the previous one.
Conclusion
In this blog post, we introduced the importance of both migrating to post-quantum cryptography and adopting standardized algorithms and protocols. We also shared our approach for bringing PQ-hybrid key exchanges to SSH, and how to use this today using SFTP with Transfer Family. Additionally, AWS employees are collaborating with other cryptography experts on a draft for PQ-hybrid SSH key exchange, which is the draft specification that Transfer Family follows.
If you have questions about how to use Transfer Family PQ key exchange, start a new thread in the Transfer Family for SFTP forum. If you want to learn more about post-quantum cryptography with AWS, contact the post-quantum cryptography team.
New research suggests that AIs can produce perfectly secure steganographic images:
Abstract: Steganography is the practice of encoding secret information into innocuous content in such a manner that an adversarial third party would not realize that there is hidden meaning. While this problem has classically been studied in security literature, recent advances in generative models have led to a shared interest among security and machine learning researchers in developing scalable steganography techniques. In this work, we show that a steganography procedure is perfectly secure under Cachin (1998)’s information theoretic-model of steganography if and only if it is induced by a coupling. Furthermore, we show that, among perfectly secure procedures, a procedure is maximally efficient if and only if it is induced by a minimum entropy coupling. These insights yield what are, to the best of our knowledge, the first steganography algorithms to achieve perfect security guarantees with non-trivial efficiency; additionally, these algorithms are highly scalable. To provide empirical validation, we compare a minimum entropy coupling-based approach to three modern baselines—arithmetic coding, Meteor, and adaptive dynamic grouping—using GPT-2, WaveRNN, and Image Transformer as communication channels. We find that the minimum entropy coupling-based approach achieves superior encoding efficiency, despite its stronger security constraints. In aggregate, these results suggest that it may be natural to view information-theoretic steganography through the lens of minimum entropy coupling.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.