Around the world, organizations are evaluating and embracing artificial intelligence (AI) and machine learning (ML) to drive innovation and efficiency. From accelerating research and enhancing customer experiences to optimizing business processes, improving patient outcomes, and enriching public services, the transformative potential of AI is being realized across sectors. Although using emerging technologies helps drive positive outcomes, leaders worldwide must balance these benefits with the need to maintain security, compliance, and resilience. Many organizations, including those in the public sector and regulated industries, are investing in generative AI applications powered by large language models (LLMs) and other foundation models (FMs) because these applications can transform and scale their work and provide better experiences for customers. Beyond computing power, unlocking this AI potential resides in the AI applications that organizations can create based on a variety of AI/ML development services, models, and data sources. Organizations must navigate the complexity of building AI applications in light of existing and emerging regulatory regimes while verifying that their AI applications and related data are secure, protected, and resilient to risks and threats.
AWS offers a wide range of AI/ML services and capabilities, built on our sovereign-by-design foundation, that are making it simpler for our customers to meet their digital sovereignty needs while getting the security, control, compliance, and resilience that they need. For example, Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, and Stability AI through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon SageMaker provides tools and infrastructure to build, train, and deploy ML models at scale while supporting responsible AI with governance controls and access to pretrained models.
Innovating securely across the AI lifecycle
Security is and always has been our top priority at AWS. AWS customers benefit from our ongoing investment in data centers, networks, custom hardware, and secure software services, built to satisfy the requirements of the most security-sensitive organizations, including the government, healthcare, and financial services. We have always believed that it is essential that customers have control over their data and its location. That’s why we architected the AWS Cloud to be secure and sovereign-by-design from day one. We remain committed to giving our customers more control and choice so that they can use the full power of AWS while meeting their unique digital sovereignty needs.
As organizations develop and implement generative AI, they want to make sure that their data and applications are secured across the AI lifecycle, including data preparation, training, and inferencing. To help ensure the confidentiality and integrity of customer data, all of our Nitro-based Amazon Elastic Compute Cloud (Amazon EC2) instances that run ML accelerators such as AWS Inferentia and AWS Trainium, and graphics processing units (GPUs) such as P4, P5, G5, and G6, are backed by the industry-leading security capabilities of the AWS Nitro System. By design, there is no mechanism for anyone at AWS to access Nitro EC2 instances that customers use to run their workloads. The NCC Group, an independent cybersecurity firm, has validated the design of the Nitro System.
We take a secure approach to generative AI and make it practical for our customers to secure their generative AI workloads across the generative AI stack so that they can focus on building and scaling. All AWS services—including generative AI services—support encryption, and we continue to innovate and invest in controls and encryption features that allow our customers to encrypt everything everywhere.
For example, Amazon Bedrock uses encryption to protect data in transit and at rest, and data remains in the AWS Region where Amazon Bedrock is being used. Customer data, such as prompts, completions, custom models, and data used for fine-tuning or continued pre-training, is not used for Amazon Bedrock service improvement and is never shared with third-party model providers. When customers fine-tune a model in Amazon Bedrock, the data is never exposed to the public internet, never leaves the AWS network, is securely transferred through a customer’s virtual private cloud (VPN), and is encrypted in transit and at rest.
SageMaker protects ML model artifacts and other system artifacts by encrypting data in transit and at rest. Amazon Bedrock and SageMaker integrate with AWS Key Management Service (AWS KMS) so that customers can securely manage cryptographic keys. AWS KMS is designed so that no one—not even AWS employees—can retrieve plaintext keys from the service.
Developing responsibly
The responsible development and use of AI is a priority for AWS. We believe that AI should take a people-centric approach that makes AI safe, fair, secure, and robust. We are committed to supporting customers with responsible AI and helping them build fairer and more transparent AI applications to foster trust, meet regulatory requirements, and use AI to benefit their business and stakeholders. AWS is the first major cloud service provider to announce ISO/IEC 42001 accredited certification for AI services, covering Amazon Bedrock, Amazon Q Business, Amazon Textract, and Amazon Transcribe. ISO/IEC 42001 is an international management system standard that outlines requirements and controls for organizations to promote the responsible development and use of AI systems.
We take responsible AI from theory into practice by providing the necessary tools, guidance, and resources, including Amazon Bedrock Guardrails to help implement safeguards tailored to customer generative AI applications and aligned with their responsible AI policies, or Model Evaluation on Amazon Bedrock to evaluate, compare, and select the best FMs for specific use cases based on custom metrics, such as accuracy, robustness, and toxicity. Additionally, Amazon SageMaker Model Monitor automatically detects and alerts customers of inaccurate predictions from deployed models. We continue to publish AI Service Cards to enhance transparency by providing a single place to find information on the intended use cases and limitations, responsible AI design choices, and performance optimization best practices for our AI services and models.
Building resilience
Resilience plays a pivotal role in the development of any workload, and AI/ML workloads are no different. Customers need to know that their workloads in the cloud will continue to operate in the face of natural disasters, network disruptions, or disruptions due to geopolitical crises. AWS delivers the highest network availability of any cloud provider and is the only cloud provider to offer three or more Availability Zones (AZs) in all Regions, providing more redundancy. Understanding and prioritizing resilience is crucial for generative AI workloads to meet organizational availability and business continuity requirements. We have published guidance on designing generative AI workloads for resilience. To enable higher throughput and enhanced resilience during periods of peak demands in Amazon Bedrock, customers can use cross-region inference to distribute traffic across multiple Regions. For customers with specific European Union data sovereignty requirements, we are launching the AWS European Sovereign Cloud in 2025 to offer an additional layer of control and resilience.
Supporting choice and flexibility
It’s important that customers have access to diverse AI technologies, while having the freedom to choose the right solutions to meet their needs. AWS provides more diversity, choice, and flexibility so that customers can select the AI solution that best aligns with their specific requirements, whether that’s using open-source models, proprietary solutions, or their own custom AI models. For example, we understand the importance of open-source AI in fostering transparency, collaboration, and rapid innovation. Open-source models enable scrutiny of vulnerabilities, drive security improvements, and support research on AI safety. Amazon SageMaker JumpStart provides pretrained, open-source models for a wide range of common use cases. To provide practitioners and developers with the guidance and tools that they need to create secure-by-design AI systems, we are a founding member of the open-source initiative Coalition for Secure AI (CoSAI).
Also, our commitment to portability and interoperability helps ensure that customers can move easily between environments. For customers changing IT providers, we’ve taken concrete steps to lower costs, and AWS is actively engaged in efforts to facilitate switching between cloud providers, including through our support of the Cloud Infrastructure Service Providers in Europe (CISPE)Cloud Switching Framework, which lays out guidance to assist providers and customers in the switching process. This gives organizations the flexibility to adapt their cloud and AI strategies as their needs evolve.
We remain committed to providing customers with a choice of diverse AI technologies, along with secure and compliant ways to build their AI applications throughout the development lifecycle. Through this approach, customers can enhance the security, compliance, and resilience of their systems.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
This post is co-written with Dr. Geoff Ryder, Manager, at SmugMug.
Introduction
SmugMug operates two very large online photo platforms: SmugMug and Flickr. These platforms enable more than 100 million customers to safely store, search, share, and sell tens of billions of photos every day. However, the data science and engineering team at SmugMug and Flickr often faces complex data modeling challenges that require significant time to resolve.
These challenges arise due to several factors. First, the team has to contend with diverse datasets from different sources. Additionally, the database schema and tables are highly complex, and the team needs to quickly understand application (PHP) code and database table structures in order to generate the necessary complex database queries. Specifically, SmugMug uses Amazon Redshift as its cloud data warehouse to analyze patterns in petabyte-scale data stored in Amazon S3, as well as transactional data in Amazon Aurora and Amazon DynamoDB. This allows them to generate dozens of business reports daily.
However, the complexity increases further as many database tables also need to be imported from third-party organizations into Amazon Redshift, where they are joined with SmugMug and Flickr’s internal tables. In extreme cases, properly modeling all these database tables and handling issues like granularity, cardinality, timestamps and missing data could take years – an impractical timeline for the business. We are excited to walk through SmugMug’s data modeling use cases and how SmugMug uses Amazon Q Developer to improve the data science and engineering team’s productivity.
Discovering Amazon Q Developer
SmugMug was one of the first customers to pilot Amazon Q Developer (previously Amazon CodeWhisperer), the most capable AI-powered assistant for software development that re-imagines the experience across the entire software development lifecycle, making it easier and faster to build, secure, manage, optimize, operate, and transform applications on AWS. There are multiple Amazon Q Developer use cases at SmugMug and Flickr, such as using Amazon Q Developer agent (/dev) for software development (i.e. generating implementation plans and the accompanying code), generating inline code suggestions, asking Amazon Q Developer in chat about AWS services and best practices, and analyzing AWS usage and costs for Cloud Financial Management (CFM) needs. For the data science and engineering team specifically, the key feature is chatting with Amazon Q Developer in integrated development environments (IDEs) like Intellij DataGrip. The data analysts and data scientists at SmugMug and Flickr ask questions in Amazon Q Developer chat to analyze database schemas, generate data model diagrams from DDL (Data Definition Language) statements, convert queries between languages, automatically generate complex database queries for data analysis, generate code to validate table contents, and predict trends using ML (Machine Learning).
Implementing Amazon Q Developer
To solve the data modeling challenges SmugMug faced, the team collaborated closely with their AWS Account Team, AWS Professional Services, and the Amazon Q Developer service team to create and test a data modeling assistant solution using Amazon Q Developer.
As a first step, the data modeler needs to bring the right metadata to bear. For simpler cases, the commands “show view myschema.v” or “show table myschema.t“ retrieve DDL schema information about the specified view or table from Amazon Redshift into the IDE console.
Here’s an example using simulated data for a hypothetical company. For this typical company that handles orders for products, the result of typing “show table sample.orderinfo” and “show table sample.skuinfo”might be:
This DDL text is now in the open tab. By selecting the text to highlight it, that DDL text becomes part of the context that Amazon Q Developer sees. The modeler can start asking questions about them in the Amazon Q Developer chat window in the IDE.
In complex scenarios, establishing the correct modeling context requires a combination of schema information, legacy SQL, application source code in various programming languages, sample values, and natural language documentation. Amazon Q Developer addresses this by creating a local index of relevant files and content. When a question is asked using @workspace, this index is consulted to identify and include pertinent sections of code and information in the request. (See this article for additional details on workspace). The prompt plays a crucial role in measuring similarity, so providing comprehensive context within it is essential. To optimize this process, the IDE settings feature a tunable workspace index function, allowing for enhanced performance in identifying and incorporating relevant context.
Workspace Index Settings
By adopting Amazon Q Developer as a team, we are able to jointly develop and share proprietary prompt text to address the four steps in our modeling process, as follows.
Step 1. Define the goal for the data modeling project
From prior knowledge, sketch a high-level goal for a data model. Gather the data for it manually, or by e.g. querying a vector database and adding its documents to the project.
For this example, we choose as the goal to compute aggregated metrics from a new table or view composed of two existing tables, sample.orderinfo and sample.skuinfo. These contain simulated data about product sales that are common to many companies. The order table is in the style of a fact table that logs customer orders, and the stock keeping unit (SKU) table is a dimension table that provides additional data points of interest about each order. The order and SKU information need to be combined by a join operation before we can compute the metrics. We would like Amazon Q Developer to tell us how to write that SQL join statement.
Step 2. Conduct an exploratory analysis and generate candidates
Next, prompt Amazon Q Developer for candidate foreign keys to join the tables, and for SQL code to execute those joins. Generate an entity-relationship diagram (ERD) as a visual aid. Prompts do not have to be complicated. For example:
@workspace What columns of database tables sample.orderinfo and sample.skuinfo
would be best to join the two tables? Provide SQL code for the join. Draw an
entity relationship diagram that shows the joins between the two tables, and
includes only the fields involved in the join. Add a crow's foot cardinality
marker to indicate a 1:many relationship, and add it next to the high
cardinality table.
Each time tables are joined together, new aggregated metrics become available to drive business insights. Now, for instance, we can find the top selling SKUs in October thanks to our results:
Sometimes we need to look at code written in languages other than SQL to complete the data model. For example, the names of some vendors this company works with happen to appear in application PHP code as human readable strings, but are saved in the application database as numbers. The analytics data staged in Redshift only contain the numbers. So, we pull a copy of the PHP text file into @workspace, and ask Amazon Q Developer to translate the relevant string-integer mappings into a SQL case statement.
PHP Switch statement showing the mapping of Vendor Ids to String Names.
I am a Redshift database administrator and I am working on a data modeling
problem. I would like to write SQL statements to join tables sample.orderinfo
and sample.skuinfo. Please write that SQL to join the two tables. Also, I
would like to write a SQL case statement to recover all string values defined
in PHP that are represented as integer values in the database table.
The output of that prompt is shown below.
Amazon Q Developer automatically detected the PHP switch case statement, converted to SQL, and added it to the final query. Many other programming languages are supported, and modelers should try this technique with other kinds of source code. Note that data scientists and analysts may not know where to look in complex application code for these details, so this discovery-plus-code translation step is a net new benefit to our company that is only possible thanks to Amazon Q Developer.
Step 3. Create code to test the analysis
Now we request SQL source code for a battery of small test queries. These can return cardinality, grain, arithmetic, and null count results.
Please write a short SQL test to compute counts of the key fields that are used
in the joins, which will verify the cardinality assignments indicated in the
entity relationship diagram above. The SQL test should compare distinct counts
to total counts and null counts when it verifies the cardinality.
Step 4. Validate the results of the analysis
Run the test queries to see if the candidate solution from step 2 meets our goals. The “Insert at cursor” button at the bottom of the response is handy for this. The data modeler can easily spot an error in the join logic and ERD from inspecting the output of the test query. (Or, if it’s hard to interpret the results, keep making the test queries simpler.) If errors arise from the AI misinterpreting or miscalculating a result, or from a vaguely worded prompt, simply adjust the prompt in step 2 to fix the known errors, and repeat steps 2 – 4.
After a few iterations, taking from seconds to at most tens of minutes each, the modeling errors have been worked out and we arrive at a valid production query.
Key Benefits and Results
With this Amazon Q Developer powered solution and iterative approach, SmugMug has achieved highly accurate data modeling results across numerous database tables. Once the correct modeling configuration is established, various useful outputs may become available.
We already described production SQL, unit tests, and ERDs for documentation. By the end of the process, because Amazon Q Developer has a good understanding of the data it just modeled in its chat history, it will also generate useful Python machine learning programs to predict business trends. Here is a prompt for that, and a partial screenshot of the Python output:
Please write Python code to implement a linear regression that predicts the
quantity_ordered value based on other fields in the data set. Choose predictor
variables that are less likely to cause multi-collinearity problems.
This only shows the model training step, but the full response included all library imports, a Redshift query, feature engineering steps, ML performance metrics, and code for plotting the metrics. And the AI can produce other types of predictive models. For example, you can try:
Please write Python code to implement an XGBoost model that predicts the
quantity_ordered value based on other fields in the data set.
Ultimately, the solution has improved team productivity for both existing and new team members, while maintaining legacy knowledge needed to onboard new team members more efficiently. Key benefits include:
Reducing SmugMug data analyst and scientist’s time spent on data modeling tasks from days to hours, allowing them to reallocate this time to other high-priority projects.
Automating the generation of BI documentation and predictive ML, also saving crucial time.
Providing net new value by translating application code constant definitions into SQL. Due to organizational boundaries, we would not have achieved this without an assist from the AI.
Future Plans and Expansion
SmugMug conducted the initial data modeling use case testing with over a dozen data science team members and analysts. We are moving on to analyze more complex tables and data schemas, and generating Python code in Amazon SageMaker for ML tasks like data preparation, training, inference, and MLOps. From our experience, Amazon Q Developer has become a preferred internal tool for development that has a data modeling component, and its use continues to expand to different groups around the company.
For SmugMug’s data modeling projects, we continue to enhance the four-step process described above. In order to gather the most relevant context to solve a problem, we build vector database collections to pull from schemas, older SQL code, application source code, BI tool content, and curated documentation. The vector search operation surfaces the right content, and spares data modelers from manually searching in different code archives. We use ChromaDB to do the searches, and bring the results from ChromaDB into the workspace as additional files.
Conclusion
Using Amazon Q Developer for data modeling use cases, SmugMug has managed to increase data science and engineering team productivity by up to 100% when compared to prior workflows. To explore how Amazon Q Developer can benefit your organization, get started here. If you have questions or suggestions, please leave a comment below.
At Amazon Web Services (AWS), we’ve built our services with secure by design principles from day one, including features that set a high bar for our customers’ default security posture. Strong authentication is a foundational component in overall account security, and the use of multi-factor authentication (MFA) is one of the simplest and most effective ways to help prevent unauthorized individuals from gaining access to systems or data. We have found that enabling MFA prevents greater than 99% of password-related attacks. Today, we’re sharing progress from the past year since we first announced that we would require customers to improve their default security posture by requiring the use of MFA for root users in the AWS Management Console.
In recent years, the typical workplace has evolved significantly. With an increase in practices like hybrid work and bring-your-own-device (BYOD) policies, defining security boundaries became much more complex. Most organizations have adjusted their security perimeters to emphasize identity-based controls, which often made user passwords the new weakest link in the perimeter. Users sometimes choose low-complexity passwords for ease of use, or reuse complex passwords across multiple websites, which substantially increases risk when a website experiences a data breach.
We take many steps to improve our customers’ resilience against these types of risks. For example, we monitor online sources for compromised credentials and block customers from using these in AWS. We also guard against setting weak passwords, never suggest default passwords for users to use, and when we detect unusual sign-in activity for customers who haven’t yet enabled MFA, we validate the sign-in with one-time PIN challenges to their primary email address. Despite these measures, passwords alone remain inherently risky.
We recognized two key opportunities to improve the situation. The first is to accelerate our customers’ MFA adoption, raising the bar for default security posture at AWS by requiring MFA for highly privileged users. In May 2024, we began requiring MFA for AWS Organizations management account root users, starting with users in larger environments. Then, in June, we launched support for FIDO2 passkeys as an MFA method, to offer customers an additional highly secure but also user-friendly way to align with their security requirements. At the same time, we announced that our MFA requirements expanded to include root users in standalone accounts. After AWS Identity and Access Management (IAM) launched FIDO2 passkey support in June 2024, customer registration rates for phishing-resistant MFA increased by over 100%. Between April and October 2024, more than 750,000 AWS root users enabled MFA.
The second opportunity we recognized is to eliminate unnecessary passwords altogether. On top of the security issues with passwords, attempting to secure password-based authentication introduces operational overhead for customers, especially those operating at scale and those with regulatory requirements to rotate passwords periodically. Today, we are launching a new capability to centrally manage root access for accounts managed in AWS Organizations. This capability enables customers to greatly reduce the number of passwords they have to manage while still maintaining strong controls over the use of root principals. Customers can now enable centralized root access with a simple configuration change through the IAM console or the AWS CLI, a process which is described further in this post. Then, customers can remove the long-term credentials (including passwords or long-term access keys) of member account root users in their organizations. This will improve the security posture of our customers while simultaneously reducing their operational effort.
We strongly recommend that Organizations customers get started enabling our centralized root access feature today to experience these benefits. However, in cases where customers continue to maintain root users, it’s essential to make sure that these highly privileged credentials are well-protected. With enhanced support for our customers operating at scale, as well as additional features like passkeys, we’re expanding our MFA requirements to member accounts in AWS Organizations. Beginning in the Spring of 2025, customers who have not enabled central management of root access will be required to register MFA for their AWS Organizations member account root users in order to access the AWS Management Console. As with our previous expansions to management and standalone accounts, we will roll this change out gradually and notify individual customers who are required to take action in advance, to help customers adhere to the new requirements while minimizing impact to their day-to-day operations.
You can learn more about our new feature to centrally manage root access in the IAM User Guide, and more about using MFA at AWS in the AWS MFA in IAM User Guide.
If you have feedback about this post, submit comments in the Comments section below.
AWS re:Invent 2024, which takes place December 2–6 in Las Vegas, will be packed with invaluable sessions for security professionals, cloud architects, and compliance leaders who are eager to learn about the latest security innovations. This year’s event puts best practices for zero trust, generative AI–driven security, identity and access management (IAM), DevSecOps, network and infrastructure security, data protection, and threat detection and incident response at the forefront. The event will provide invaluable learning and networking opportunities for professionals focused on cloud security.
To help you navigate the extensive list of sessions and maximize your learning, we’ve curated a list of must-attend security sessions at re:Invent 2024. To join us, register today, and we’ll see you in Vegas!
Keynotes and innovation talks
The re:Invent 2024 keynote and innovation talks offer the opportunity to gain direct, transformative insights from senior AWS leaders. Delve into the latest breakthroughs in generative AI, cloud security, and cutting-edge architectural innovations that are redefining the future of application development and the AWS Cloud.
KEY002 – CEO Keynote with Matt Garman. Discover how AWS is innovating across the cloud, from reinventing core services to creating new experiences, empowering customers and partners to build a secure and better future.
SEC203-INT – Security insights and innovation from AWS with Chris Betz. Discover how groundbreaking security innovations and generative AI empower your organization to accelerate innovation securely, as AWS CISO Chris Betz reveals transformative strategies to integrate and automate security, freeing your team to focus on high-value initiatives.
Check out the full list of innovation talks. Not attending live this year? The keynote and innovation talks will be live streamed.
Sessions
To add sessions to your re:Invent 2024 agenda and find time and location information, choose the session title link.
Accelerating least privilege with advanced access analysis
Explore identity management and access control best practices to minimize your attack surface and enable a zero-trust architecture.
SEC337| Chalk talk | Scaling IAM: advanced administration and delegation patterns: Discover innovative strategies for effective access management, balancing security and agility as your organization expands. Learn from real-world scenarios, best practices, and cutting-edge techniques to optimize your IAM infrastructure for scalability, performance, and future growth.
SEC232 |Breakout session | Secure by design: Enhancing the posture of root with central control: This session explores how to manage root access securely across your AWS environment, while maintaining centralized control and governance. Additionally, discover the latest tools and initiatives AWS offers to enforce multi-factor authentication (MFA), align with industry initiatives, and help your environment to remain secure.
Fortifying your security posture with threat detection and incident response
Use AWS security services to help you enhance your security posture and streamline security operations by continuously identifying and prioritizing security risks.
SEC321 | Breakout session | Innovations in AWS detection and response: This session focuses on practical use cases, such as threat detection, workload and data protection, automated and continual vulnerability management, centralized monitoring, continuous cloud security posture management, unified security data management, investigation and response, and generative AI. Gain a deeper understanding of how you can seamlessly integrate AWS detection and response services to help protect your workloads at scale, enhance your security posture, and streamline security operations across your entire AWS environment.
SEC332 | Chalk talk | Anatomy of a ransomware event targeting data within AWS: In this chalk talk, learn the anatomy of a ransomware event that targets data within AWS, including detection, response, and recovery. Leave with a deeper understanding of the AWS services and features you can use to protect against ransomware events in your environment and the knowledge to investigate possible ransomware events if they occur.
SEC301 | Workshop | Threat detection and response using AWS security services: This workshop simulates several security events across different resources and behaviors. Get hands-on in a provided sandbox environment to review and respond to findings from the simulated events. You must bring your laptop to participate.
SEC219 | Breakout session |Uncovering sophisticated cloud threats with Amazon GuardDuty: Learn how Amazon GuardDuty offers fully managed threat detection that gives you end-to-end visibility across your AWS environment. The unique detection capabilities of GuardDuty are guided by AWS visibility into the cloud threat landscape and can help responders address issues faster, minimizing the mean time to repair (MTTR) and optimizing security resources—so your teams can spend more time innovating and less time chasing down security risks.
SEC343 | Chalk talk | Identify a prioritization strategy for security response & remediation: Join this chalk talk to learn about a framework for automating your response and remediation to security findings for your accounts. With AWS Security Hub as the foundation, explore the decision-making process regarding which findings could be auto-remediated, the implications of an auto-remediation approach, and how to achieve a quick and thorough response.
SEC401 | Code talk| Inspect and secure your application with generative AI: Explore how to use generative AI to improve the security of your applications. Learn how AI-powered tools can help rapidly identify and then recommend remediations for security issues. Learn about how Amazon Inspector detects software and code vulnerabilities in your applications, and discover how to scan for issues and remediate them using generative AI in your integrated development environment (IDE).
Securing the edge against evolving risks with confidence
Use AWS edge security services to help protect against distributed denial of service (DDoS) and exploits directed against applications and achieve a more consistent security posture.
SEC344 | Chalk talk | Lessons learned from DDoS mitigation: Insights from AWS Shield Response Team (AWS SRT) escalations: In this chalk talk, dive into past DDoS events and find out how the AWS SRT helped to mitigate security escalations. Gain insights into this type of intrusion and how you can apply mitigation strategies to make your application more DDoS-resilient.
SEC327| Chalk talk | Building secure network designs for generative AI applications: In this chalk talk, learn how to build layered network security controls to protect, detect, and respond to issues faster and to accelerate your generative AI applications securely on AWS. Discover key considerations, best practices, and reference architectures to achieve your defense-in-depth network design objectives.
SEC317 | Breakout session | How Amazon threat intelligence helps protect your infrastructure: Explore AWS threat intelligence capabilities and learn how they power managed firewall rules and security findings in security services such as AWS WAF, AWS Network Firewall, and Amazon Route 53 Resolver DNS Firewall. Learn about the threat intelligence AWS uses to protect AWS infrastructure, build new security features, and empower customers to enhance their application protection on AWS.
Safeguarding sensitive data in the age of generative AI
Discover advanced techniques and AWS services to help you protect the confidentiality and privacy of your data when you implement emerging AI technologies.
SEC323 | Breakout session | The AWS approach to secure generative AI: Join this session to learn how AWS thinks about security across the three layers of our generative AI stack, from the bottom infrastructure layer to the middle layer (which provides access to the models and tools customers need to build and scale generative AI applications) to the top layer (which includes applications that make use of large language models (LLMs) and other foundation models (FMs) to make work easier).
SEC310 | Workshop | Persona-based access to data for generative AI applications: In this workshop, manage document access in a chatbot application tailored to various user roles within an organization. Learn how to address challenges around secure information distribution, enhancing efficiency and compliance by aligning access rights with job functions. You must bring your laptop to participate.
SEC217 | Breakout session | Building a resilient and effective culture of security: This talk offers guidance on cultivating a resilient, empowered culture of security, including gaining leadership support, distributing security ownership, and embedding psychological safety to build trust, transparency, and a proactive security-first mindset.
SEC218 | Breakout session | Emotionally intelligent security leadership to drive business impact: Elevate your leadership and learn to align security needs with strategic business outcomes, spearhead impactful transformations, and cultivate a sustainable security culture. Get an inside look how AWS and its customers lead security with empathy, translate security purpose into results, inspire innovation, and foster connections to improve positive escalation culture. Become empowered to lead with precision, acquire the art of connecting security objectives to meaningful business impact, and steer your organization toward a future where security is a catalyst for success and resilience.
SEC314 | Code talk | Accelerate your DevOps pipeline and remain secure with policy as code: In this code talk, learn how to define compliance rules for your AWS infrastructure and evaluate them using AWS CloudFormation Guard, which is an open source, general-purpose, policy-as-code evaluation tool. Explore how to seamlessly integrate automated policy validation into your existing deployment pipeline, empowering DevOps engineers to build policy assessment steps into their CI/CD pipelines. Security assessors will experience streamlined review processes while maintaining a robust security posture.
SEC302 | | Breakout session | Better together: Protecting data through culture and technology: This session examines the full range of data protection capabilities that are available with AWS and how best practices and culture can complement these capabilities to improve security outcomes. Learn more about the defense-in-depth perspective, which details how organizations can protect their data and bolster their security culture by consistently building security into every layer.
Expo
Want to talk directly with an AWS expert on cloud security? Then don’t miss this opportunity to have one-on-one conversations with leading AWS security experts in the Security Activation area of the expo floor to help you take your organization’s security posture to new heights.
Delve into key security domains such as:
Detection and response: Explore techniques for detecting and responding to security risks to help protect your workloads at scale.
Network and infrastructure security: Learn how to build and manage a secure global network with AWS services.
Application security: Discover strategies to ship secure software and address the challenges of application security.
Identity and access management: Adopt modern cloud-native identity solutions and apply least-privilege access controls.
Digital sovereignty and data protection: Maintain control over your data and choose how to secure and manage it in the AWS Cloud.
Still time for fun!
After an inspiring week of transformative insights and deep learning, join us for the world renowned re:Play party—the ultimate re:Invent sendoff! Immerse yourself in live entertainment from headlining musical artists, scrumptious cuisine, and flowing refreshments as we come together to unwind, connect, and toast to a future of limitless possibilities.
Register today
It’s going to be an amazing event, and we can’t wait to see you at re:Invent 2024! Register now to secure your spot.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Education is critical to effective security. As organizations migrate, modernize, and build with Amazon Web Services (AWS), engineering and development teams need specific skills and knowledge to embed security into workloads. Lack of support for these skills can increase the likelihood of security incidents.
AWS has partnered with SANS Institute to create SEC480: AWS Secure Builder—a new training course that can help you confidently build and deploy secure workloads in the AWS Cloud.
The training, authored and delivered by the experts at SANS Institute, is designed to equip architects, engineers, and developers with the ability to implement and enhance security controls, and strengthen your security posture with a secure by design approach to product development.
What you’ll learn
The course features eight comprehensive modules that focus on different aspects of AWS security. Each is accompanied by a hands-on lab to provide practical experience and boost confidence in building secure AWS environments.
Responsibility to, for, and of security: Understand the shared responsibility model, the difference between cloud and on-premises security, AWS security architecture, compliance requirements, and how to apply effective security controls.
Identification and authorization: Implement best practices for AWS Identity and Access Management (IAM), explore workforce identity management, address common authentication failures, and apply secure access controls.
Continuous integration and delivery (CI/CD): Learn how to configure and use CI/CD pipelines, automate code deployment with AWS CodePipeline, integrate security tools, and help prevent misconfigurations through hands-on labs and real-world demos.
Security monitoring: Implement comprehensive security monitoring with logging at all levels, use monitoring tools, enhance alerting with artificial AI, and set up early warning systems.
Exposure and attack vectors: Identify and mitigate exposure and attack vectors through open source intelligence (OSINT), understand the anatomy of exploitations, and minimize threat surfaces using threat modeling and compliance tools.
Incident response: Master the six-step incident response process, implement best practices with roles, playbooks, and technology, and prepare with tools and exercises.
Trust, control, and the supply chain: Evaluate vendor reliance and onboarding processes, implement Zero Trust principles, and defend against supply chain attacks to ensure secure vendor interactions.
Anyone technical who will be building in, operating in, configuring, or managing AWS cloud environments can benefit from the training, including AWS customers and partners. The training is offered online, and learnings are validated by an associated GIAC exam.
Arming your teams with the insight provided by this training can help your organization design, build, and maintain applications in the cloud with a security-first mindset, increase product development velocity, and enhance business agility through secure cloud practices.
This course will be offered online. SANS provides in-person training only for private, high-volume trainings.
GIAC is providing a micro-credential for the AWS Secure Builder certification. It will be the first course to have this designation by GIAC. Micro-certifications are short, competency-based courses that demonstrate mastery in a particular area.
If you have feedback about this post, submit comments in the Comments section below.
AWS re:Invent 2024, a learning conference hosted by Amazon Web Services (AWS) for the global cloud computing community, will take place December 2–6, 2024, in Las Vegas, Nevada, across multiple venues. At re:Invent, you can join cloud enthusiasts from around the world to hear the latest cloud industry innovations, meet with AWS experts, and build connections. Whether you want to build deep technical expertise, understand how to prioritize your investments, learn more about the infrastructure offerings of the sovereign-by-design AWS Cloud, or see how the AWS Nitro System enables enhanced security for your workloads, re:Invent is a great opportunity to explore our digital sovereignty solutions.
This year, there will be many ways that you can learn about our advanced sovereignty controls, security features, and infrastructure options that can help meet your unique digital sovereignty needs, including sessions and hands-on activities with AWS hybrid and edge services including AWS Local Zones, AWS Dedicated Local Zones, and AWS Outposts. In the Expo, you can visit the Digital Sovereignty & Data Protection kiosk in the AWS Village to watch demos, learn about the upcoming AWS European Sovereign Cloud, and get your questions answered by AWS team members. To see AWS designed chips and Outposts devices, check out the AWS Next Gen Infrastructure Hub in the AWS Village. You can also visit the AWS Partner Network (APN) booth to connect with AWS Digital Sovereignty Partners to learn about the benefits of partner programs.
Breakout sessions and lightning talks
To add sessions to your AWS re:Invent agenda and find time and location information, choose the session title link.
SEC229 | Breakout | Digital sovereignty: overcome complexity and enable future-readiness Max Peterson, VP, Sovereign Cloud, AWS Organizations are facing increasing complexity in an evolving sovereignty landscape. Building a strong digital foundation can help simplify efforts to meet requirements today and prepare your organization for the future, without slowing innovation. Join this session to learn how AWS sovereign cloud offerings, ranging from encryption services to the announced AWS European Sovereign Cloud, provides more control and choice to help meet your unique needs. Discover how customers are keeping critical workloads secure and protected when leveraging new technologies on AWS, including generative AI, and learn about new digital sovereignty solutions offered by AWS Partners.
HYB201 | Breakout | AWS wherever you need it: From the cloud to the edge Jan Hofmeyr, VP, EC2 Networking and Hybrid Edge, AWS, and Jeff Feist, Executive Director – Hosting Solutions, Merck & Co., Inc. While most workloads can be migrated to the cloud, some remain on premises or at the edge due to low latency, local data processing, or digital sovereignty needs. In this session, learn how AWS services like AWS Outposts, AWS Local Zones, AWS Dedicated Local Zones, and AWS IoT Core support hybrid cloud and edge computing workloads such as multiplayer gaming, high-frequency trading, medical imaging, smart manufacturing, and generative AI applications with data residency requirements.
HYB309 | Breakout | Well-architected for data residency with hybrid cloud services Sherry Lin, Principal Product Manager, AWS; Lakshmi VP, Specialist SA – Hybrid Edge, AWS; and Kevin Ng, Senior Director, Core Engineering Products, GovTech With concerns over data privacy, security, and digital sovereignty, many countries across the world are strengthening data residency laws to keep personal and sensitive data within their borders. For organizations operating across multiple geographies, it can be challenging to meet the evolving data residency laws. In this session, following the AWS Well-Architected Framework, explore the best practices around data residency when using hybrid cloud services, including AWS Local Zones, AWS Dedicated Local Zones, and AWS Outposts.
IOT202 | Breakout | AWS IoT for edge LLM deployment and execution Nikit Pednekar, Principal Product Manager, AWS, and Stefano Marzani, WW Tech Leader, SDX, AWS With the advent of generative AI and large language models (LLMs), you must be wondering, how can these technologies be applied at the IoT edge? After all, there are many benefits of running LLMs at the edge—from network bandwidth efficiencies, offline processing, lower latency, and data sovereignty to cost savings, security, and differentiation. In this session, learn how using AWS IoT services and LLMs at the edge can uplift your solutions with actionable outcomes and innovative capabilities, such as gesture recognition, natural language processing for voice control, real-time predictive maintenance, energy optimization, anomaly detection, and more.
KUB310 | Breakout | Amazon EKS for edge and hybrid use cases Chris Splinter, Product Manager, AWS, and Gokul Chandra Purnachandra Reddy, Senior Solutions Architect, AWS There are some workloads that may need to run on-premises, at the edge, or in a hybrid scenario due to low-latency, data dependencies, data sovereignty, or other regulatory reasons, especially in industries such as manufacturing, healthcare, telco, and financial services. Data dependent workloads may have to wait for the data to be on AWS services before fully migrating. In this session, we will share production-ready architectures leveraging services like Amazon EKS Anywhere to run container workloads on-premises and support modernizing VMware-based workloads. Also learn best practices on migration of on-premises Kubernetes deployments to AWS Cloud.
PEX110 | Lightening Talk | Supercharge your growth and capabilities with partner programs Mike Cannady, Director, Partner Core Public Sector, AWS Discover the latest AWS Partner program updates that propel your public sector business forward. Join this lightning talk to explore innovations tailored to partners: generative AI programs, digital sovereignty, solution building, and managed services. Whether you’re starting out or seasoned, glean insights and use cases to elevate your journey. Don’t miss this opportunity to supercharge your development and stay ahead in this ever-evolving landscape.
Interactive sessions (chalk talks and workshops)
HYB304 | Workshop | Implement RAG without compromising on digital sovereignty Aditya Lolla, Senior Solutions Architect, Hybrid Edge, AWS, and Robert Belson, Senior Developer Advocate, AWS As governments and standards bodies develop data protection and privacy regulations, organizations increasingly need to combine the use of generative AI tooling in the cloud with regulated data that need to remain on premises to meet data sovereignty requirements. In this workshop, learn how to extend Agents for Amazon Bedrock to hybrid and edge services like AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes. Get hands-on with Amazon Bedrock, AWS Lambda, and AWS hybrid and edge services, and build Amazon Simple Storage Service (Amazon S3) compliant workflows using a hybrid S3 compatible solution. You must bring your laptop to participate.
WPS207 | Chalk Talk | How AWS can help you meet your digital sovereignty requirements Mehmet Bakkaloglu, Principal Solutions Architect, AWS, and Addy Upreti, Principal Technical Product Manager – Digital Sovereignty, AWS Customers in the public sector and regulated industries such as healthcare, financial services and telecom have shared how they face digital sovereignty concerns in their cloud journey. In this talk, you can learn about how AWS is sovereign-by-design and the range of capabilities that can enable you to meet your digital sovereignty needs. Plus, discover how the AWS European Sovereign Cloud is being built to provide further choice to meet these needs. We’ll talk through how AWS can help accelerate your cloud journey while meeting your requirements.
HYB310 | Chalk Talk | Addressing data residency requirements with hybrid and edge services Sedji Gaouaou, Senior Solutions Architect, AWS, and Fabio Rodriguez, Head of Hybrid Cloud Solutions Architect, AWS Data residency is a critical consideration for organizations that collect and store sensitive information, including personal identifiable information (PII), financial data, healthcare data, or information pertaining to national security. To help organizations operating across multiple geographies drive innovation while meeting data residency requirements, AWS offers multiple global infrastructure offerings like AWS Regions, AWS Dedicated Local Zones, AWS Local Zones, and AWS Outposts. In this interactive chalk talk, learn how these infrastructure offerings can help you accelerate digital transformation while meeting data residency needs.
For a full view of digital sovereignty content, including sessions with partners, explore the AWS re:Invent catalog and filter on the Digital Sovereignty area of interest. Not able to attend in-person? Register for free for the virtual-only pass to livestream keynotes and innovation talks, and access on-demand breakout sessions today. See you in Las Vegas or on the livestream!
If you have feedback about this post, submit comments in the Comments section below.
Amazon Web Services (AWS) is excited to announce that 170 AWS services have achieved HITRUST certification for the 2024 assessment cycle, including the following 12 services that were certified for the first time:
The full list of AWS services, which a third-party assessor audited and certified under the HITRUST CSF, is now available on our Services in Scope by Compliance Program page. Customers can view and download our 2024 HITRUST certification on demand through AWS Artifact.
AWS HITRUST certification is available for customer inheritance
As an added benefit to our customers, organizations no longer have to assess inherited controls for their HITRUST validated assessment because AWS already has. You can deploy business solutions to the AWS Cloud and inherit our HITRUST certification, provided that you use only in-scope services and properly apply the controls detailed on the HITRUST website according to the AWS Shared Responsibility Model.
Our HITRUST certification is based on the version 11.2 control framework, so you can inherit the latest controls and related scoring, knowing that AWS has attested to the latest framework standards available. Leading organizations in a variety of industries have adopted HITRUST CSF as part of their approach to security and privacy. For more information, see the HITRUST website.
As always, we value your feedback and questions and are committed to helping you achieve and maintain the highest standard of security and compliance. Feel free to contact the team through AWS Compliance Support. If you have feedback about this post, submit comments in the Comments section below.
Multiple popular browsers have announced that they will no longer trust public certificates issued by Entrust later this year. Certificates that are issued by Entrust on dates up to and including October 31, 2024 will continue to be trusted until they expire, according to current information from browser makers. Certificates issued by Entrust after that date will not be trusted.
If you’ve imported Entrust certificates into AWS Certificate Manager (ACM) for use with integrated services such as Amazon CloudFront or Elastic Load Balancing, consider reissuing these certificates through Entrust before October 31, 2024, and re-importing them. This will provide you with a longer timeline to evaluate your alternatives. In this blog post, we discuss how you can determine whether certificates you imported to ACM will be affected, and suggest potential alternatives, including public certificates issued by Amazon Trust Services.
How to tell if you’ve imported Entrust certificates to ACM
If you’re unsure whether you’ve imported certificates to ACM, there are a few different ways to verify. You can use the ACM console to view your certificates for that AWS account. Certificates that are imported to ACM have the type Imported, as shown in Figure 1.
Figure 1: Viewing certificates in AWS Certificate Manager
You can also list the certificates in your AWS account by using the AWS CLI or APIs. You can use the list-certificates command with the AWS CLI:
aws acm list-certificates
You can then filter the response to only show the certificate ARN of certificates that are imported into ACM by using the following command:
After you’ve identified the ARNs of imported certificates, you can use the describe-certificate CLI command to get more information about each of the imported certificates. One of the returned fields is Issuer—this field indicates who originally issued the certificate in question. See the following example command and output, where in this case the issuer is Amazon:
You can use one of these methods to determine whether you’ve imported certificates to ACM, and use the Issuer field of the DescribeCertificate response to check whether any of your imported certificates were issued by Entrust and will be affected by the coming changes in popular browsers.
Lastly, you can also use this sample code from our GitHub repository to discover imported certificates that were issued by a certain CA or issuer. The project evaluates the ACM certificates for a given AWS account, flagging certificates with an Issuer value that matches against a specific, customizable list of CAs. This can be run as a Python script, an AWS Configquery, or a custom rule in AWS Config.
Consider replacing Entrust certificates with public certificates issued through ACM
If you’re using Extended Validation (EV) or Organization Validation (OV) certificates, we recommend that you use Domain Validated (DV) certificates from ACM instead. Popular browsers do not differentiate between EV/OV and DV certificates when indicating whether a site is trusted. Additionally, EV/OV certificate issuance and renewals cannot be automated and require manual effort, unlike DV certificates.
Evaluate use of private certificates for internal-facing use cases
We also recommend that you re-evaluate your use of certificates to reconsider whether you need private or public certificates for your use cases. For internal-facing workloads, you should consider using private certificates. This will allow you to control the certificate parameters, such as the certificate type or the validity period, to align with your specific TLS requirements. For example, ACM issued public certificates are valid for 395 days, but you might have use cases in which certificates with a longer validity period make more sense, and in such cases you can issue private certificates from AWS Private Certificate Authority (AWS Private CA).
Conclusion
In summary, if you are importing Entrust-issued certificates to ACM, evaluate whether you need public or private certificates, especially for internal-facing workloads—for which private certificates are typically better suited. For public certificates, take this opportunity to re-evaluate your usage of EV and OV certificates, and whether they could be replaced with DV certificates. If you want to use public certificates with services such as Amazon CloudFront, Elastic Load Balancing, or Amazon API Gateway, issue the certificates directly from ACM. Lastly, if you need more time to evaluate your options before making a decision, consider re-issuing and re-importing your certificates from Entrust before October 31, 2024. Popular browsers stated their intention to trust certificates issued by Entrust prior to October 31, 2024 until these certificates expire, giving you until the next certificate renewal to make an informed decision. You can learn more about ACM by reviewing the AWS documentation, and get started issuing certificates from ACM in the AWS Management Console.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Attention all developers, architects, and IT professionals! We’re thrilled to announce the launch of the official Amazon OpenSearch Service YouTube channel—a comprehensive resource for anyone looking to master Amazon OpenSearch Service. Whether you’re just getting started with searches , vectors, analytics, or you’re looking to optimize large-scale implementations, our channel can be your go-to resource to help you unlock the full potential of OpenSearch Service.
OpenSearch is a distributed search and analytics suite that is open source, community-driven, Apache License v2 licensed, and governed by the OpenSearch Software Foundation, under the Linux Foundation.
Amazon OpenSearch Service is a managed service that makes it straightforward to deploy, operate, and scale OpenSearch domains in AWS. OpenSearch Service offers a robust set of features that can transform the way you handle log analytics, real-time monitoring, vector search, and advanced search workloads. But to truly unlock its full potential, you need more than just the basics. That’s where our new YouTube channel comes in.
Dive into a world of practical expertise
We’ve carefully curated a collection of videos that are designed to provide you with the tools, techniques, and insights you need to navigate OpenSearch Service with confidence. The channel also offers a direct line of communication between you and the AWS team. By leaving comments on our videos, you can share your feedback, ideas, and pain points. We’ll be closely monitoring these comments and using them to shape the content we create and influence the future roadmap of OpenSearch Service.
Here’s what sets our channel apart:
Bite-sized learning – Our videos are short and concise—each one packed with practical information that you can consume in under 15 minutes. Whether you’re looking for a quick tutorial or a deep-dive into advanced features, we make it effortless for you to learn on the go.
Curated content – We hand-pick the most important topics around OpenSearch Service and break them down into simple-to-follow, informative videos. From configuring clusters to scaling for petabyte-scale analytics, we cover the most relevant use cases to help you build, manage, and optimize your OpenSearch environment.
Organized playlists – The channel is organized into playlists based on workloads and features of OpenSearch Service such as log analytics, observability, lexical search, vector search, generative AI, and more.
Influence the AWS team – You can leave comments on our videos, and your feedback will be reviewed by the AWS team. This input allows us to work backward from your feedback to influence the content we create and feed into the product roadmap.
What you’ll learn
On the OpenSearch Service YouTube channel, you can expect new content regularly, including:
Log Analytics and Observability
Learn how to ingest, search, and visualize logs at scale with OpenSearch, making log analytics efficient and powerful for enterprises of all sizes. Gain deep insights into using OpenSearch Service for observability, including infrastructure monitoring, application performance management (APM), and more.
Lexical and Semantic Search
Discover the key differences between lexical and semantic search, and learn how to implement both in OpenSearch Service. We’ll cover optimizing search relevancy, handling complex queries, using machine learning models for semantic understanding and much more.
Vector Database & GenAI
Explore OpenSearch Service’s vector database capabilities to power advanced semantic search and AI-driven applications. Learn how generative AI models can enhance your search solutions.
Operational Best Practices
Learn the best practices for running OpenSearch Service in production, covering everything from security and scaling to performance tuning and cost management.
And More
Expect a wide array of content, including deep dives into new features, architecture best practices, how to demo videos, use case showcases, and interviews with industry experts.
Subscribe to stay ahead
Whether you’re a beginner looking to get started or an experienced professional seeking to optimize your workflows, make sure to subscribe to the OpenSearch Service YouTube channel so you don’t miss out on the latest tutorials, insights, and updates. Get ready to elevate your search and analytics skills and be part of shaping the future of this channel and powerful service.
About the Authors
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He has over 14 years of experience helping organizations derive insights from their data.
Wendy Neu is a Senior Manager at AWS focused on leading the NoSQL Specialist Solutions Architecture team worldwide. She is passionate about Data Services and leverages her extensive expertise to help customers optimize their data storage, management, and analytics strategies, enabling them to drive innovation and achieve their business goals.
During a recent visit to the Defense Advanced Research Projects Agency (DARPA), I mentioned a trend that piqued their interest: Over the last 10 years of applying automated reasoning at Amazon Web Services (AWS), we’ve found that formally verified code is often more performant than the unverified code it replaces.
The reason is that the bug fixes we make during the process of formal verification often positively impact the code’s runtime. Automated reasoning also gives our builders confidence to explore additional optimizations that improve system performance even further. We’ve found that formally verified code is easier to update, modify, and operate, leading to fewer late-night log analysis and debugging sessions. In this post, I’ll share three examples that came up during my discussions with DARPA.
Automated reasoning: The basics
At AWS, we strive to build services that are simple and intuitive for our customers. Underneath that simplicity lie vast, complex distributed systems that process billions of requests every second. Verifying the correctness of these complex systems is a significant challenge. Our production services are in a constant state of evolution as we introduce new features, redesign components, enhance security, and optimize performance. Many of these changes are complex themselves, and must be made without impacting the security or resilience of AWS or our customers.
Design reviews, code audits, stress testing, and fault injection are all invaluable tools we use regularly, and always will. However, we’ve found that we need to supplement these techniques in order to confirm correctness in many cases. Subtle bugs can still escape detection, particularly in large-scale, fault-tolerant architectures. And some issues might even be rooted in the original system design, rather than implementation flaws. As our services have grown in scale and complexity, we’ve had to supplement traditional testing approaches with more powerful techniques based on math and logic. This is where the branch of artificial intelligence (AI) called automated reasoning comes into play.
While traditional testing focuses on validating system behavior under specific scenarios, automated reasoning aims to use logic to verify system behavior under any possible scenario. In even a moderately complex system, it would take an intractably large amount of time to reproduce every combination of possible states and parameters that may occur. With automated reasoning, it’s possible to achieve the same effect quickly and efficiently by computing a logical proof of the correctness of the system.
Using automated reasoning requires our builders to have a different mindset. Instead of trying to think about all possible input scenarios and how they might go wrong, we define how the system should work and identify the conditions that must be met in order for it to behave correctly. Then we can verify that those conditions are true by using mathematical proof. In other words, we can verify that the system is correct.
Automated reasoning views a system’s specification and implementation in mathematics, then applies algorithmic approaches to verify that the mathematical representation of the system satisfies the specification. By encoding our systems as mathematical systems and reasoning about them using formal logic, automated reasoning allows us to efficiently and authoritatively answer critical questions about the systems’ future behavior. What can the system do? What will it do? What can it never do? Automated reasoning can help answer these questions for even the most complex, large-scale, and potentially unbounded systems—scenarios that are impossible to exhaustively validate through traditional testing alone.
Does automated reasoning allow us to achieve perfection? No, because it still depends on certain assumptions about the correct behavior of the components of a system and the relationship between the system and the model of its environment. For example, the model of a system might incorrectly assume that underlying components such as compilers and processors don’t have any bugs (although it is possible to formally verify those components as well). That said, automated reasoning allows us to achieve higher confidence in correctness than is possible by using traditional software development and testing methods.
Faster development
Automated reasoning is not just for mathematicians and scientists. Our Amazon Simple Storage Service (Amazon S3) engineers use automated reasoning every day to prevent bugs. Behind the simple interface of S3 is one of the world’s largest and most complex distributed systems, holding 400 trillion objects, exabytes of data, and regularly processing over 150 million requests per second. S3 is composed of many subsystems that are distributed systems in their own right, many consisting of tens of thousands of machines. New features are being added all the time, while S3 is under heavy use by our customers.
A key component of S3 is the S3 index subsystem, an object metadata store that enables fast data lookups. This component contains a very large, complex data structure and intricate, optimized algorithms. Because the algorithms are difficult for humans to get right at S3 scale, and because we can’t afford errors in S3 lookups, we made new improvements on a cadence of about once per quarter, due to the extreme care and extensive testing required to confidently make a change.
S3 is a well-built and well-tested system built on 15 years of experience. However, there was a bug in the S3 index subsystem for which we couldn’t determine the root cause for some time. The system was able to automatically recover from the exception, so its presence didn’t impact the behavior of the system. Still, we were not satisfied.
Why was this bug around so long? Distributed systems like S3 have a large number of components, each with their own corner cases, and a number of corner cases happen at the same time. In the case of S3, which has over 300 microservices, the number of potential combinations of these corner cases is enormous. It’s not possible for developers to think through each of these corner cases, even when they have evidence the bug exists and ideas about its root cause—never mind all of the possible combinations of corner cases.
This complexity drove us to look at how we could use automated reasoning to explore the possible states and errors that might be hidden in those states. By building a formal specification of the system, we were able to find the bug and prove the absence of further bugs of its type. Using automated reasoning also gave us the confidence to ship updates and improvements every one to two months rather than just three to four times a year.
Faster code
The correctness of the AWS Identity and Access Management (IAM) service is foundational to the security of our customers’ workloads. Across millions of customers, thousands of resource types, and hundreds of AWS services, every API call—every single request to AWS—is processed by the IAM authorization engine. That’s over 1.2 billion requests per second. This is some of the most security-critical and highly scaled software in AWS.
Before any change at AWS goes into production, we need an extremely high degree of confidence that the system remains secure and correct. Using automated reasoning, we can prove that our systems adhere to specific security properties, under an exhaustive number of circumstances. We call this provable security. Not only has automated reasoning enabled us to provide provable security assurance to our customers, it gives us the ability to deliver functionality, security, and optimization at scale.
Like S3, IAM has evolved over 15 years into a time-tested and trusted system. But we wanted to raise the bar further. We built a formal specification that captures the behavior of the existing IAM authorization engine, codified its policy evaluation principles into provable theorems, and used automated reasoning to build a new and more efficient implementation. Earlier this year, we deployed the new proved-correct authorization engine —and no one noticed. Automated reasoning allowed us to seamlessly replace one of the most critical pieces of AWS infrastructure, the authorization engine, with a proved-correct equivalent.
With the specification and proofs in place, we could safely and aggressively optimize the code with a high degree of confidence. At the massive scale of IAM, every microsecond of performance improvement translates into a better customer experience and better cost optimization for AWS. We optimized string matching, removed unnecessary memory allocation and redundant computations, strengthened security, and improved scalability. After every change, we re-ran our proofs to confirm that the system was still operating correctly.
The optimized IAM authorization engine is now 50% faster than its predecessor. We simply would not have been able to make these types of impactful optimizations with such confidence if we didn’t use automated reasoning. For a deeper look at how we did this, see this AWS re:Inforce session.
Faster deployment (of faster code)
Most secure online transactions are protected by encryption. For example, the RSA encryption algorithm protects data by generating two keys: one to encrypt the data, and one to decrypt it. These keys enable secure data transmission as well as secure digital signatures. In the context of encryption, correctness and performance are both essential—a bug in an encryption algorithm can be disastrous.
As AWS customers move their workloads to AWS Graviton, the benefits of optimizing cryptography for the ARM instruction set increase. But optimizing encryption for better performance is complex, which makes it difficult to verify that modified encryption algorithms are behaving properly. Before we started to use automated reasoning, optimizations to cryptography libraries often required months-long reviews to achieve confidence for release into production.
Over the last decade, we’ve increasingly applied automated reasoning techniques within AWS to prove the correctness of our cloud infrastructure and services. We routinely use these methods not only to verify correctness, but also to enhance security and reliability and minimize design flaws. Automated reasoning can be used to create a precise, testable model of a system, which we can use to quickly verify that changes are safe—or learn they are unsafe without causing harm in production.
We can answer critical questions about our infrastructure to detect misconfigurations that might expose data. We can help stop subtle but serious bugs from reaching production that we would not have found with other techniques. We can make bold performance optimizations that we would not have dared attempt without model checking. Automated reasoning provides rigorous mathematical assurance that critical systems behave as expected.
AWS is the first and only cloud provider to use automated reasoning at this scale. As adoption of automated reasoning tools increases, it becomes easier for us to justify ever-larger investments into improving the usability and scalability of automated reasoning tools. The easier it is to use the automated reasoning tools and the more powerful they become, the more adoption we’ve observed. The more we’re able to prove correctness of our cloud infrastructure, the more compelling the cloud is to security-obsessed customers. And, as the examples in this post illustrate, not only are we able to increase security assurance, we are delivering higher performant code to customers faster, translating into cost savings that we can eventually pass on to customers.
My prediction is that we’re in the beginning of an era in which critical properties like security, compliance, availability, durability, and safety can be proved automatically for large-scale cloud architectures. From preventing potential issues with AI hallucinations to analyzing hypervisors, cryptography, and distributed systems, having sound mathematical reasoning at our foundations and continuously analyzing what we build sets Amazon apart.
Generative AI is transforming industries in new and exciting ways every single day. At Amazon Web Services (AWS), security is our top priority, and we see security as a foundational enabler for organizations looking to innovate. As you prepare for AWS re:Invent 2024, make sure that these essential sessions are on your schedule to learn how security can help your organization innovate with generative AI solutions quickly and securely. Leading experts will provide deep insights into how you can secure generative AI workloads in order to protect data and navigate governance, risk, and compliance.
In this post, we’ve highlighted some of our must-attend sessions and favorite activities for security leaders and practitioners, technical decision-makers, and artificial intelligence and machine learning (AI/ML) builders. To join in on the fun, register here, and we’ll see you in Vegas!
Keynotes and innovation talks
The AWS re:Invent 2024 keynote and innovation talks offer the opportunity to gain direct, transformative insights from senior AWS leaders. Delve into the latest breakthroughs in generative AI, cloud security, and cutting-edge architectural innovations that are redefining the future of application development and the AWS Cloud.
KEY002 – CEO Keynote with Matt Garman. Discover how AWS is innovating across the cloud, from reinventing core services to creating new experiences, empowering customers and partners to build a secure and better future.
SEC203-INT – Security insights and innovation from AWS with Chris Betz. Discover how groundbreaking security innovations and generative AI empower your organization to accelerate innovation securely, as AWS CISO Chris Betz reveals transformative strategies to integrate and automate security, freeing your team to focus on high-value initiatives.
ARC203-INT – Architectural methods & breakthroughs in innovative apps in the cloud with Shaown Nandi and Ben Cabanas. This talk showcases how generative AI and cutting-edge architectural advancements are transforming application design, empowering AWS customers to modernize their systems, develop robust data strategies, and securely navigate the evolving cloud landscape.
Check out the full list of innovation talks. Not attending live this year? The keynote and all innovation talks will be live streamed.
Sessions
Discover a range of learning opportunities designed to deepen your expertise in securing generative AI. This year’s sessions put a strong focus on providing customers with impactful real-world, practical prescriptions for securing your AI workloads and the data that powers them. Whether you prefer lecture-style breakout sessions, interactive chalk talks, hands-on workshops, or code-driven discussions, there’s a session tailored to help meet your needs. Explore the following options and reserve your spot to enhance your understanding and practical skills in this rapidly evolving field.
You can find more details and descriptions for session levels (100–400) and session types on the re:Invent website.
Breakout sessions
Breakout sessions are lecture-style, 1-hour sessions delivered by AWS experts, customers, and partners—perfect for deepening your knowledge on important topics, gaining actionable insights, and connecting with industry leaders.
SEC214 –Elevating client experiences with secure AI: Rocket Mortgage’s approach. Discover how Rocket Mortgage implemented AWS generative AI services to enhance customer experiences while navigating security challenges. Register for this session
SEC315 – Bring your workforce identities to AWS for generative AI and analytics. This session will demonstrate the power of integrating your workforce identity provider to gain easier access to generative AI applications and tools. AWS and NVIDIA will demonstrate a full end-to-end identity-aware experience. Register for this session
SEC323 –The AWS approach to secure generative AI. Learn how AWS secures generative AI across the infrastructure, model, and application layers, giving customers control over their data with built-in security features. Register for this session
SEC403 –Generative AI for security in the real world. Explore practical generative AI applications for security teams, including incident response, red team/blue team enablement, and security operations center (SOC) use cases, to boost your security operations. Register for this session
Chalk talks
Chalk talks are 1-hour long, highly interactive sessions with a small audience. This format is ideal for diving deep into specific topics, engaging directly with AWS experts, and getting your questions answered in real time.
SEC303 – Protecting data within your generative AI architectures. Mitigate risks when training large language models (LLMs) on sensitive data. Explore techniques like sanitization, anonymization, and differential privacy. Register for this talk
SEC327 – Building secure network designs for gen AI applications. Optimize your cloud network design to power transformative generative AI applications more securely, as we share proven best practices, proactive controls, and reference architectures to build resilient, defense-in-depth architectures and accelerate innovation on AWS. Register for this talk
SEC335 –Harness generative AI for business growth amidst the regulatory landscape. Explore how AWS AI/ML solutions can drive business growth while helping you align to responsible practices. Learn from your peers about their strategies to navigate evolving regulatory landscapes, from the European Union’s General Data Protection Regulation (GDPR) to industry-specific mandates. Register for this talk
SEC336 –Security and compliance considerations using Amazon Q Business. Discover best practices for securing your Amazon Q Business application, focusing on access control, data protection, and compliance considerations, so that you can keep your AI assistant secure and compliant. Register for this talk
SEC338 –Safeguard your generative AI apps from prompt injections. Learn to protect your generative AI applications from prompt injection attacks by understanding input validation, secure prompt engineering, and content moderation. Register for this talk
PEX308 – Securing generative AI on AWS. Explore generative AI security considerations through a partner lens, including how partners can enhance data security and the value-adds that partners bring to a customer’s generative AI workloads. Register for this talk
AIM344 – Understanding the deep security controls within Amazon Q Business. Learn about the security-related capabilities and controls within Amazon Q that allow you to confidently use your business data safely. Register for this talk
AIM407 – Understand the deep security controls within Amazon Bedrock. Dive deep into the security nuances of Amazon Bedrock, as we unpack the architectures, data flows, and lifecycle management of complex features like Guardrails, Agents, and Knowledge Bases, empowering you to use this generative AI service with uncompromising data privacy and control. Register for this talk
DEV323 – OWASP Top 10 for LLMs. Strengthen your skills in securing generative AI applications by exploring real-world vulnerabilities and proven mitigation strategies against the OWASP Top 10 risks for large language models (LLMs), through interactive demos and hands-on exercises. Register for this talk
Code talks
Code talks are similar to our popular chalk talk format, but with a focus on live coding or code samples rather than whiteboarding. These sessions look into the actual code used to build a solution, allowing attendees to understand the “why” behind the approach and witness the development process, including any errors that may arise. Participants are encouraged to ask questions and follow along for a deeper, hands-on learning experience.
SEC401 – Inspect and secure your application with generative AI. Harness the power of generative AI to bolster your application security, as we unveil how AI-driven tools can rapidly detect vulnerabilities and recommend remediation strategies, empowering you to build more secure software with ease. Register for this talk
SEC405 – Consolidated data protection insights with generative AI. Discover how to secure your AWS KMS keys across your accounts by using Amazon Q in QuickSight for quick, actionable insights. Register for this talk
Builders’ sessions
Interact with small groups, led by an AWS expert providing interactive learning about how to build on AWS. Each builders’ session begins with a short explanation or demonstration of what attendees are building, then it’s your turn to build! The expert will guide you end-to-end through this hands-on experience.
Note: You must bring your own laptop to participate in these sessions.
DOP302 – Creating secure code with Amazon Q Developer. Supercharge your coding prowess with Amazon Q Developer, as you gain hands-on experience using its AI-powered capabilities to write more secure, optimized code, detect vulnerabilities, and implement instant remediations—transforming your development workflow. Register for this session
SMB302 – Empower your business with defense-in-depth architecture. Empower your small-to-medium business to innovate more securely with generative AI by exploring practical, cost-effective defense-in-depth strategies, layered security architectures, and AI-specific safeguards to build resilient, trusted AI-powered solutions in the AWS Cloud. Register for this session
Workshops
Workshops are 2-hour interactive sessions where you collaborate in teams or work individually to solve real-world challenges by using AWS services, making them perfect for hands-on learning. Each workshop begins with a brief lecture, followed by dedicated time to work through the problem.
Note: Don’t forget to bring your laptop to build alongside AWS experts.
SEC305 – Generative AI-based code remediations and patch management at scale. Experience hands-on how to use generative AI to assist in automating vulnerability detection and remediation across AWS Lambda, containers, and Amazon Elastic Compute Cloud (Amazon EC2) at scale, empowering your team to proactively secure your applications. Register for this workshop
SEC306 – Securing your generative AI applications on AWS. Gain hands-on experience securing generative AI applications by using AWS services and features. Deploy a vulnerable sample AI app, then implement layered security controls to protect, detect, and respond to issues. Use these best practices to secure your own AI apps when you return home! Register for this workshop
SEC309 – AWS IAM Identity Center: Secure access to generative AI applications. You’ll learn how to build an identity-aware chat experience, train it on a sample dataset, and connect it to an external workforce identity provider by using native integration between Amazon Q Business and AWS Identity and Access Management (IAM) Identity Center. Register for this workshop
SEC310 – Persona-based access to enterprise data for generative AI applications. Learn how to secure document access in generative AI applications by using retrieval augmented generation (RAG), metadata filtering, and Amazon Cognito in this interactive workshop. Register for this workshop
Expo
Want to talk directly with an AWS security expert on generative AI security, or a variety of other security topics? Then don’t miss this opportunity to have one-on-one conversations with leading AWS security experts in the Security Activation area of the expo floor to help you take your organization’s security posture to new heights.
Delve into key security domains such as:
Detection and Response: Explore techniques for detecting and responding to security risks to help protect your workloads at scale.
Network and Infrastructure Security: Learn how to build and manage a secure global network with AWS services.
Application Security: Discover strategies to ship secure software and address the challenges of application security.
Identity and Access Management: Adopt modern cloud-native identity solutions and apply least-privilege access controls.
Digital Sovereignty & Data Protection: Maintain control over your data and choose how to secure and manage it in the AWS Cloud.
Still time for fun!
After an inspiring week of transformative insights and deep learning, join us for the world renowned re:Play party—the ultimate re:Invent sendoff! Immerse yourself in live entertainment from headlining musical artists, scrumptious cuisine, and flowing refreshments as we come together to unwind, connect, and toast to a future of limitless possibilities.
Register today
It’s going to be an amazing event, and we can’t wait to see you at re:Invent 2024! Register now to secure your spot.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AWS is deeply committed to earning and maintaining the trust of customers who rely on us to run their workloads. Security has always been our top priority, which includes designing our own services with security in mind at the outset, and taking proactive measures to mitigate potential threats so that customers can focus on their businesses with confidence. We continuously innovate and invest in advancing our security capabilities.
To help prevent security incidents from disrupting our customers’ businesses, we need to stay ahead of potential threats, and protect customers quickly when we become aware of activities that could be potentially harmful to them. We’ve previously shared details about our sophisticated global honeypot system MadPot and our massive internal neural network graph model Mithra. These are two examples of internal threat intelligence tools that we use to take proactive, real-time action to help prevent a potential threat from becoming a real security issue for our customers.
I mentioned another internal threat intelligence tool called Sonaris in my recent re:Inforce keynote. Sonaris is an active defense tool that analyzes potentially harmful network traffic so that we can quickly and automatically restrict threat actors who are hunting for exploitable vulnerabilities. With MadPot, Mithra, and Sonaris in the hands of our world-class security teams, AWS is equipped with powerful, actionable threat intelligence on a scale that is only possible with AWS. This blog post covers why and how we use Sonaris behind the scenes to help protect customers, and how we know our threat intelligence is having measurable results.
AWS security innovation tackles threats with measurable results for customers at global scale
As organizations have migrated to the cloud over the last decade, threat actors have evolved their tactics to exploit environments that aren’t properly secured. In 2017, our security teams observed an increasing number of unauthorized attempts to scan (systematic examination through digital means and tools) and probe AWS customer accounts—activities conducted by threat actors who were hunting for Amazon Simple Storage Service (Amazon S3) buckets that customers unintentionally configured with public access. To help address this security issue on behalf of our customers, AWS security teams developed active defense capabilities to help detect these kinds of suspicious scanning behaviors and then restrict the actions that malicious actors might take to further improperly access a customer’s S3 bucket.
This novel approach to a new cloud-era security challenge evolved to become the threat intelligence tool we now call Sonaris, which today identifies and automatically restricts unauthorized scanning and S3 bucket discovery within minutes at global scale. Sonaris applies security rules and algorithms to identify anomalies from over two hundred billion events each minute. Preventing opportunistic attempts from threat actors to discover and exploit misconfigurations or out-of-date software represents a significant leap forward in our security capabilities at AWS.
How do we know that the network mitigations performed by Sonaris are actually making a difference for our customers? We can compare threat activity between MadPot sensors, with and without Sonaris protections. To do this, we use MadPot to construct two separate large-scale fleets of honeypot testing groups to compare statistics for each security configuration. One group is protected by our perimeter security controls fed by Sonaris analytics, and a separate fleet receives no protection. This allows us to measure the protective coverage of hosts within the AWS network perimeter.
Findings from these split testing groups underscore the sheer volume of potential threats that Sonaris manages to thwart, and the ongoing work behind the scenes to enhance the security of AWS infrastructure. For example, across the hundreds of different types of malicious interactions that MadPot classified, Sonaris observed an 83% reduction in abuse attempts in September 2024. In the past 12 months, Sonaris denied more than 27 billion attempts to find unintentionally public S3 buckets, and prevented nearly 2.7 trillion attempts to discover vulnerable services on Amazon Elastic Compute Cloud (Amazon EC2). This protection drastically reduces risk for AWS customers.
How Sonaris detects and restricts abusive scanning and exploitation attempts
Sonaris plays a critical role in helping to secure AWS and our customers by detecting and then restricting certain suspicious behavior aimed at AWS infrastructure and services. Its capabilities are built on the integration of both network telemetry sources across AWS, plus our threat intelligence data. What sets Sonaris apart is its integration of AWS network telemetry with Amazon threat intelligence to provide safe and effective threat mitigation to reduce indiscriminate scanning activity.
Sonaris applies heuristic, statistical, and machine learning algorithms to vast amounts of the summarized metadata and service health telemetry that we use to operate our services. One threat intelligence source that Sonaris uses is MadPot, which receives traffic on tens of thousands of IP addresses every day. MadPot emulates hundreds of different services and mimics customer accounts, and then classifies these interactions into known Common Vulnerabilities and Exposures (CVEs) and other vulnerabilities. Through MadPot, Sonaris can also integrate additional high-fidelity signals that help identify activities of threat actors with enhanced precision. First-party threat intelligence collected from MadPot increases Sonaris confidence and accuracy for automatically restricting known malicious vulnerability enumeration attacks so that customers are protected automatically.
When Sonaris identifies malicious attempts to scan an AWS IP address or customer account, it triggers automated protections in AWS Shield, Amazon Virtual Private Cloud (Amazon VPC), Amazon S3, and AWS WAF, automatically protecting customer resources from unauthorized activity in real time. Sonaris is judicious about what activities it restricts, only intervening when there is a sufficiently high assurance that the interactions are malicious. For example, to help ensure that legitimate customer interactions are not restricted, we developed dynamic guardrail models to identify what normal behavior looks like in AWS services so that only suspicious activities are detected and acted on. We update and refresh these guardrail models constantly with our latest observations to help avoid taking action on legitimate customer activities.
Sonaris is having real-world impact at scale against dynamic threats that exist today
Throughout 2023 and 2024, a large active botnet known as Dota3 has been scanning the internet for vulnerable hosts and devices to install cryptominer malware (malicious software designed to secretly use a victim’s computer or device resources). Sonaris has been effectively protecting customers from this botnet, even as the botnet’s operators try new ways to evade defenses. In Q3 2024, we observed this botnet’s scanning behavior change as it began using different payloads, rates, and endpoints, as shown in the following figure. Thanks to the layered detection methods of Sonaris, this botnet was unable to avoid our automatic detection. Sonaris automatically protected customers from more than 16,000 malicious scanning endpoints each hour.
Figure 1: Dota3 botnet activity suddenly changes in September 2024
AWS is committed to making the internet a safer place
Although Sonaris reduces risk, it does not eliminate it entirely, and our work is far from over. As we continue to evolve and strengthen our security measures, AWS remains committed to making the internet a safer place so that customers can thrive in an increasingly complex digital landscape while maintaining a strong security posture. Through the creation of active security tools such as Sonaris, and our customers’ diligent application of security best practices, we can collectively create a more secure cloud environment for all.
Your feedback is crucial to us and we encourage you to leave comments, reach out to our customer support teams, or engage with us through your preferred channels. Together, we can shape the future of cloud security and stay ahead of emerging threats.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
At Amazon Web Services (AWS), we continue to listen to our customers, regulators, and stakeholders to understand their needs regarding audit, assurance, certification, and attestation programs. We are pleased to announce that the AWS System and Organization Controls (SOC) 1 report is now available in Japanese, Korean, and Spanish. This translated report will help drive greater engagement and alignment with customer and regulatory requirements across Japan, Korea, Latin America, and Spain.
The Japanese, Korean, and Spanish language versions of the report do not contain the independent opinion issued by the auditors, but you can find this information in the English language version. Stakeholders should use the English version as a complement to the Japanese, Korean, or Spanish versions.
Going forward, the following reports in each quarter will be translated. Spring and Fall SOC 1 controls are included in the Spring and Fall SOC 2 reports, so this translation schedule will provide year-round coverage of the English versions.
The Summer 2024 SOC 1 report includes a total of 177 services in scope. For up-to-date information, including when additional services are added, see the AWS Services in Scope by Compliance Program webpage and choose SOC.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about SOC compliance.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
Japanese version
Summer 2024 SOC 1 レポートの日本語、韓国語、スペイン語版の提供を開始
当社はお客様、規制当局、利害関係者の声に継続的に傾聴し、Amazon Web Services (AWS) における監査、保証、認定、認証プログラムに関するそれぞれのニーズを理解に努めています。この度、AWS System and Organization Controls (SOC) 1 レポートが、日本語、韓国語、スペイン語で利用可能になりました。この翻訳版のレポートは、日本、韓国、ラテンアメリカ、スペインのお客様および規制要件との連携と協力体制を強化するためのものです。
Amazon은 고객, 규제 기관 및 이해관계자의 의견을 지속적으로 경청하여 Amazon Web Services (AWS)의 감사, 보증, 인증 및 증명 프로그램과 관련된 요구사항을 파악하고 있습니다. AWS System and Organization Controls(SOC) 1 보고서가 이제 한국어, 일본어, 스페인어로 제공됨을 알려 드립니다. 이 번역된 보고서는 일본, 한국, 중남미, 스페인 전역의 고객의 참여도를 높이고 규제 요건을 준수하는 데 도움이 될 것입니다.
보고서의 일본어, 한국어, 스페인어 버전에는 감사인의 독립적인 의견이 포함되어 있지 않지만, 영어 버전에서는 해당 정보를 확인할 수 있습니다. 이해관계자는 일본어, 한국어 또는 스페인어 버전을 보완하기 위해 영어 버전을 사용해야 합니다.
앞으로 분기마다 다음 보고서가 번역본으로 제공됩니다. SOC 1 통제 조치는 춘계 및 추계 SOC 2 보고서에 포함되어 있으므로, 이 일정은 영어 버전과 함께 모든 번역된 언어로 연중 내내 제공됩니다.
AWS는 고객이 아키텍처 및 규제 요구사항을 충족할 수 있도록 지속적으로 서비스를 규정 준수 프로그램의 범위에 포함시키기 위해 노력하고 있습니다. SOC 규정 준수에 대한 질문이나 피드백이 있는 경우 AWS Account 팀에 문의하시기 바랍니다.
규정 준수 및 보안 프로그램에 대한 자세한 내용은 AWS 규정 준수 프로그램을 참조하세요. 언제나 그렇듯이 AWS는 여러분의 피드백과 질문을 소중히 여깁니다. 문의하기 페이지를 통해 AWS 규정 준수 팀에 문의하시기 바랍니다.
Spanish version
El informe SOC 1 verano 2024 se encuentra disponible actualmente en japonés, coreano y español
Seguimos escuchando a nuestros clientes, reguladores y partes interesadas para comprender sus necesidades en relación con los programas de auditoría, garantía, certificación y acreditación en Amazon Web Services (AWS). Nos enorgullece anunciar que el informe de controles de sistema y organización (SOC) 1 de AWS se encuentra disponible en japonés, coreano y español. Estos informes traducidos ayudarán a impulsar un mayor compromiso y alineación con los requisitos normativos y de los clientes en Japón, Corea, Latinoamérica y España.
Estas versiones del informe en japonés, coreano y español no contienen la opinión independiente emitida por los auditores, pero se puede acceder a esta información en la versión en inglés del documento. Las partes interesadas deben usar la versión en inglés como complemento de las versiones en japonés, coreano y español.
De aquí en adelante, los siguientes informes trimestrales estarán traducidos. Dado que los controles SOC 1 se incluyen en los informes de primavera y otoño de SOC 2, esta programación brinda una cobertura anual para todos los idiomas traducidos cuando se la combina con las versiones en inglés.
de AWS IAM
Período cubierto
SOC 2 primavera
Del 1 de abril al 31 de marzo
SOC 1 verano
Del 1 de julio al 30 de junio
SOC 2 otoño
Del 1 de octubre al 30 de septiembre
SOC 1 invierno
Del 1 de enero al 31 de diciembre
Los clientes pueden descargar los informes SOC 1 verano 2024 traducidos al japonés, coreano y español a través de AWS Artifact, un portal de autoservicio para el acceso bajo demanda a los informes de conformidad de AWS. Inicie sesión en AWS Artifact mediante la Consola de administración de AWS u obtenga más información en Introducción a AWS Artifact.
El informe SOC 1 verano 2024 incluye un total de 177 servicios que se encuentran dentro del alcance. Para acceder a información actualizada, que incluye novedades sobre cuándo se agregan nuevos servicios, consulte los Servicios de AWS en el ámbito del programa de conformidad y seleccione SOC.
AWS se esfuerza de manera continua por añadir servicios dentro del alcance de sus programas de conformidad para ayudarlo a cumplir con sus necesidades de arquitectura y regulación. Si tiene alguna pregunta o sugerencia sobre la conformidad de los SOC, no dude en comunicarse con su equipo de cuenta de AWS.
Para obtener más información sobre los programas de conformidad y seguridad, consulte los Programas de conformidad de AWS. Como siempre, valoramos sus comentarios y preguntas; de modo que no dude en comunicarse con el equipo de conformidad de AWS a través de la página Contacte con nosotros.
Amazon Web Services (AWS) customers of various sizes across different industries are pursuing initiatives to better classify and protect the data they store in Amazon Simple Storage Service (Amazon S3). Amazon Macie helps customers identify, discover, monitor, and protect sensitive data stored in Amazon S3. However, it’s important that customers evaluate and test the capabilities of Macie to verify that they can meet their specific data identification and protection goals. In this post, we show you how to define and run a proof of concept (POC) to validate using Macie and automated discovery to enhance your current data protection strategies. The POC steps demonstrate how you can use Macie to detect and alert you to sensitive data discovered in your AWS environment and help you determine the value of using Macie to enhance your current data protection strategies.
Note: This POC uses some features that offer a 30-day free trial and other features that will incur minimal charges during the POC phase. We highlight and summarize these throughout this post.
Data security business challenges
Data security is a broad concept that revolves around protecting digital information from unauthorized access, corruption, theft, and other forms of malicious activity throughout its lifecycle. There’s an exponential growth of digital data and organizations are grappling with not only managing it but also determining where their sensitive data exists. Additionally, many organizations have compliance requirements from government regulators and industry standards, such as PCI DSS or HIPAA. Organizations want to move fast, which means giving developers the tools to build quickly to stay ahead, while making sure that the correct data classification policies are defined and enforced.
Macie features
Amazon Macie is a data security service that discovers sensitive data using machine learning and pattern matching, provides visibility into data security risks, and enables automated protection against those risks. The following is a summary of the key features of Macie, many of which will be used in this POC. The core capabilities of Macie are focused on the security of your S3 buckets and helping to identify sensitive data including financial data, personal data, and credentials as well as sensitive data that’s unique to your organization, such as intellectual property.
S3 bucket security
Customers use Amazon S3 for a variety of use cases and store various types of data in S3 buckets, including sensitive data. Continuously monitoring these buckets for the presence of sensitive data is a vital part of a data protection strategy. Macie gives you visibility into your S3 bucket inventory and the security and access controls associated with your buckets. This visibility includes if the bucket is publicly accessible, the encryption level of the bucket, and if the bucket is shared with other accounts. Whenever the security posture of one of your buckets is reduced, Macie generates a finding about the change, enabling you to respond. These findings are consumable through the AWS Management Console for Macie, through Macie APIs, as Amazon EventBridge messages, or through AWS Security Hub.
Sensitive data discovery jobs
Sensitive data discovery jobs provide a way to target a specific S3 bucket or group of buckets to do a deep analysis of the objects in those buckets and identify if sensitive data is present in the objects and if so, the type of data. These jobs can run on a daily, weekly, or monthly basis for new or changed data or once for on-demand analysis.
Automated data discovery
Macie offers an automated data discovery feature that can continually discover sensitive data within your S3 buckets. This feature is intended to help customers who have large amounts of S3 buckets and data better understand where sensitive data might be stored without having to scan all their data. By using automated data discovery, you can focus your resources on deeper investigations of the security of buckets identified to have sensitive data. Macie selects samples of the objects within S3 buckets and inspects them for the presence of sensitive data daily, providing insight into where sensitive data might reside in your overall Amazon S3 data estate.
POC overview
This POC is intended to help you gain an understanding of what Macie is capable of and how you can use it to achieve your data discovery goals. The POC in this post includes the following tasks in Macie:
Reviewing managed data identifiers
Defining custom data identifiers
Staging POC data
Running a sensitive data discovery job
Reviewing the output of the discovery job
Enabling and reviewing the output of automated data discovery
Note: The amount of time required for each task depends on your preparation and analysis for each stage. Note that, in the automated data discovery phase, it will take 24–48 hours for Macie to perform the first scan after the feature is enabled.
Enable Macie
Macie must be enabled before you can proceed with the POC. If you haven’t yet enabled Macie, see Enable Macie for instructions.
Note: When you enable Macie and the 30-day free trial for S3, monitoring S3 bucket security and privacy is automatically enabled. There’s also a 30-day free trial for automated data discovery, which is covered later in this post. There is no free trial for running targeted data discovery jobs. Review the Macie pricing page for details.
Review managed data identifiers
A successful POC of Macie includes understanding what data Macie can detect. Macie comes with over 150 managed data identifiers that are designed to identify sensitive data in your S3 objects. It’s important to first understand the available managed data identifiers and which ones align with the use cases you want to address. Examples of Macie managed data identifiers include credit card numbers, AWS secret access keys, and national identification numbers. Macie offers a default collection of recommend managed data identifiers to use for detecting general categories and types of sensitive data while optimizing data discovery results and reducing noise.
Keywords are an important component for Macie to be able to detect sensitive data. Many managed data identifiers require keywords to be in proximity of the data for Macie to be able to detect findings. Understanding the keywords that are used as part of sensitive data detection is important when it comes to building test data for a POC.
Prior to beginning your POC, review the list of managed data identifiers and determine which ones you feel will be necessary to use for your data discovery requirements. Additionally, identify which managed data identifiers, which are applicable to your POC, fall outside of the default list of identifiers.
Define custom data identifiers
Macie covers a wide number of use cases with its managed data identifiers, but some use cases need custom data identifiers for data types that aren’t included in the managed data identifiers. For example, customers might need to identify sensitive data that’s specific to their company, such as an employee ID or project number. Other customers might operate in industries that have data types unique to that industry, such as a known traveler number in the airline industry. If your requirements for identifying sensitive data include detecting sensitive data that isn’t part of the current list of managed data identifiers, then you can create custom data identifiers for those data types. For a POC, you might not want to create a custom data identifier for every additional detection. Instead, you can create a few to help confirm that you can use custom data identifiers for sensitive data detection and that Macie can support your data discovery goals. Building custom data identifiers has a thorough explanation of how to define a custom data identifier. Similar to managed data identifiers, custom data identifiers have keyword requirements. Defining detection criteria for custom data identifiers provides details for the types of data that require keywords.
Stage POC data
After reviewing the managed data identifiers provided by Macie and creating the custom data identifiers needed for your POC, it’s time to stage data sets that will help demonstrate the capabilities of these identifiers and better understand how Macie identifies sensitive data. We recommend that you stage data sets that contain sensitive data as well as data sets that do not to gain a full understanding of how Macie detects and reports on each of these situations. You can stage a variety of data sets to use for your POC using just a few GB of data to help keep your initial POC scans’ cost low. Staged data must be in file formats that Macie supports.
When preparing data to stage, keep in mind the keyword requirements for many of the Macie managed data identifiers. To determine which managed data identifiers have keyword requirements, see Managed data identifiers by type. When you’re staging your data, reference the keywords that are supported for the managed data identifiers you are using to help ensure that the data can be identified in your POC tests.
We recommend staging the data in one S3 bucket that’s dedicated to the POC and to use S3 server-side encryption on the bucket. If you want to use a customer managed AWS KMS key to encrypt the S3 data at rest, follow the instructions in Allowing Macie to use a customer managed AWS KMS key to give Macie access to decrypt the data in the bucket. You should also follow best practices for the S3 bucket related to not allowing public access and implementing least privilege access.
You can use one or more of the following approaches to identify and stage data for your POC:
Stage data files created by synthetic data generator tools with sensitive data included. There are many tools available for generating sensitive data. The following are two that you can use to generate test data.
Stage data files from public data repositories. There are various repositories staged with information that could be used for sensitive data detection. These repositories are often comprised of publicly available data sets or were created to help with testing machine learning models or sensitive data detection.
Stage data files of your own data with sensitive information. Because the goal is to use Macie to identify sensitive information in your S3 buckets, including examples of your own data that contains sensitive information can be helpful to test the capabilities of Macie.
Stage data files that don’t contain sensitive information. This can help you understand how Macie handles data that you believe doesn’t contain sensitive information. With the managed data identifiers that Macie offers, you should stage data files that you believe don’t contain information that aligns to the managed data identifiers. The staged data files could be log files, documents, or data sets that meet the criteria of this step.
Stage data that contains information that’s representative of data that you would want to detect using custom data identifiers.
Run a data classification job
Now that you’ve reviewed the managed data identifiers, defined custom data identifiers, and staged sample data, it’s time to run a sensitive data discovery job. When configuring the job scope, we recommend the following:
A specific S3 bucket where the POC data is staged.
The scope is set to be a one-time job.
Leave the sampling depth at 100 percent. Most customers leave this value at 100 percent, but some will lower it if they want a smaller random sample scan of their data. Most customers use automated data discovery to get sample scans instead of adjusting the sampling depth for individual jobs.
Select the recommended managed data identifiers. If your testing requires that Macie identify additional sensitive data types that are offered as managed data identifiers but aren’t part of the recommended list, choose the Custom option and select the managed data identifiers that you need. Make sure that the recommended managed data identifiers are part of the custom list that you construct.
Choose the custom data identifiers that you want to be used in the job.
After you configure your job, give it a name, review the final configuration, and then submit the job to run. A job that uses a data set of a few GB should complete within 30 minutes.
Review the findings from your job
After the job completes, it’s time to review what Macie found in the data. Objects that Macie found with sensitive data will be presented as Findings in the Macie console. From the Jobs screen, choose the job you submitted. In the right-hand window, you will see the overview information for the job. From the overview window you can choose Show results menu and then select Show findings to view a list of the findings that were generated by the job.
Figure 1: Viewing Macie job findings
Each object where Macie found sensitive data will be listed as a single finding. If there were multiple types of sensitive data found in the object, each type of sensitive data and a count will be included in the details. Choose each of the findings that was produced and review the details to confirm what sensitive data was identified and if the sensitive data was discovered as you expected. Additionally, confirm that you don’t have findings for objects that you staged that were not supposed to have sensitive data so that you can confirm how Macie handles these types of objects. If you created custom data identifiers, review findings for the objects that included the custom data that you detect to confirm that the data was detected.
Enable automated discovery
Now that you understand how to use Macie to discover sensitive data, the next step in the POC is to enable automated discovery and use Macie to discover sensitive data across a larger collection of your existing S3 data.
You will be enabling automated discovery in Macie as a 30-day free trial. For the free trial, the scope of total data storage to be evaluated will be 150 GB. Use the following steps to guide your setup of the automated discovery feature:
After your delegated administrator account is configured, enable automated discovery. As part of enabling automated discovery, pay extra attention to the following items:
Set managed data identifiers. Ideally, choose the recommended data identifiers to help reduce noise. If there are specific managed data identifiers that you really want to see, then choose Custom to choose the ones you want.
Include custom data identifiers that you want to be used to evaluate your sensitive data.
Exclude buckets that you don’t want included in the scope for identifying sensitive data.
Include or exclude specific accounts that should be part of the POC. Step 5 of Enable automated discovery covers how to enable it for specific accounts.
You will see the first set of results 24 to 48 hours after you enable automated discovery. After that, you will see updates to the automated discovery results every 24 hours.
After automated discovery starts producing results, you will start seeing data in the Automated Discovery section of the Macie summary page in the console. The summary includes metrics for the total number of buckets eligible for discovery, counts for the number of buckets where sensitive data was or was not found, and how many of these buckets are public.
Figure 2: Example automated discovery summary metrics
Choosing a link for one of the counts will take you to the S3 buckets view with the appropriate filters applied.
After reviewing the summary screen, choose S3 buckets from the navigation pane to see a heatmap that shows each account and the buckets within each account.
Figure 3: S3 bucket heatmap view in Macie
The heatmap provides point-in-time insights into the data that Macie has scanned, and in which buckets sensitive data has been identified or no sensitive data has been found.
Over time, this heatmap might change as automated data discovery continues sampling the data in each bucket. The heatmap view provides information on each organizational member account and insight about sensitive data within each bucket in the account.
The console displays the results as a set of colored squares for each account. Each square represents a bucket in that account and the color of the square indicates whether sensitive data was discovered in that bucket. Red indicates that some type of sensitive data has been found in the bucket, while blue indicates no sensitive data has been identified. If a bucket is blue, that means only that automated data discovery hasn’t identified sensitive data up to the point in time of the last scan, not that there is no sensitive data in the bucket.
Hover over each bucket to see a summary of the sensitivity score of the bucket along with statistics about the data in the bucket. Choosing a bucket in the heatmap will open a window that provides more information about the bucket. This information includes the sensitivity score of the bucket, a summary of the types of sensitive data found in the bucket, which objects within the bucket have been sampled, statistics related to the data that has been scanned and data that is still to be scanned, and other information about the bucket.
Figure 4: S3 bucket sensitivity information in Macie
As part of your POC, it’s recommended that you investigate buckets that are reported to contain sensitive data. For your investigation, validate if the data identified is sensitive based on your organization’s data classification policy. Each Macie finding contains not only the details on the types of sensitive data identified, but also the location within the file where the sensitive data is located so that you can confirm the identified data is sensitive. The following is an example of a Macie finding in an Excel file where bank account numbers were found. This example shows the row and column where the sensitive data was found.
Investigating sensitive data with findings has detailed guidance around locating sensitive data from Macie findings, retrieving the sensitive data, and the schema for sensitive data locations. If the findings are true positives, make sure that the bucket has the right level of security configurations and permissions based on the data stored in the bucket.
In addition to reviewing the bucket level statistics that are generated by automated discovery, you can view the individual findings that were generated for each S3 object that was identified as having sensitive data. You can view the findings through the Findings tab in Macie or by choosing the sensitive data type when looking at the summary detections for a bucket.
Next steps
With the preceding POC, you should now have a more complete understanding of how Macie identifies sensitive data and how you can use the information that Macie provides about that data identified. As you complete your POC, there are a few next steps that other customers have taken after completing their POC with Macie.
Operationalize Macie output
In the POC steps, we outlined how to view the findings and the insights that the automated discovery provides. Before you proceed with Macie, you should have a plan for how you will operationalize the Macie output. This will help ensure that the remediation steps for identified sensitive data are directed to the correct parties.
Depending on what operational tools you have in place, the steps that you take to operationalize the output of Macie will vary. Many customers implement operational processes that cover the following areas:
The privacy or security team that’s responsible for Macie does an initial triage on the findings to confirm if there are true positives.
The privacy or security team defines their operational processes related to the summary dashboard and bucket sensitivity information that’s provided by automated discovery.
The team that owns the bucket where the sensitive data is located is provided the information needed to investigate the identified data and provide a response. Responses will vary but could include removal of the data, correcting the application that is writing the data, or applying additional security to the bucket.
A key part of operationalizing Macie output is also how you are getting and reviewing the signals related to Macie findings. As outlined in this post, you can view and investigate findings in the Macie console. At a steady state, customers find it beneficial to consume Macie findings using Amazon EventBridge, through Macie APIs, or through the integration of Macie with AWS Security Hub. These options can be used to incorporate the findings that are reported by Macie into the operational workflows and tools that work best for your organization and allow you to consume and address findings at scale. Monitoring and processing findings provides more insight into these integration approaches.
Store and retain sensitive data discovery results
As you move forward with Macie, it’s important to enable logging for each of the S3 objects that Macie has scanned. Macie creates an analysis record for each S3 object that’s in scope for a data discovery job or an automated discovery scan. These records are an audit of every object that Macie attempted to scan, including objects that didn’t contain sensitive data. Data discovery results are written to an S3 bucket that you own and where you control the data retention. These data discovery results can assist with analysis of records over time or to get a broader sense of what data Macie has scanned and which objects had sensitive data and which did not.
The data discovery scan results are stored as JSON Lines files. You can use multiple approaches to analyze and query these log files. The Amazon Macie Results Analytics GitHub repository provides instructions on how to configure Amazon Athena with tables that allow you to query the results of Macie discovery scan files.
Define the scope for Macie use
After a POC with Macie, you can set the scope of how you will use Macie in production by deciding which buckets don’t need to be evaluated and so can be excluded, such as buckets used for AWS logs and buckets deemed not in scope for sensitive data identification.
You can also refine the managed data identifiers that are required for detecting sensitive data. Based on what they learned from the POC. You can create custom data identifiers to help meet your data detection needs if necessary.
As you identify the sensitive data discovery jobs to run as part of your production use of Macie, keep in mind that these jobs are immutable. To edit an existing scheduled job, you must create a copy of the job with the updated configuration and cancel the original job for changes to take effect. Depending on the updated criteria for your job, you must do one of the following to help avoid re-scanning objects that were covered by the previous job:
Clear include existing objects when setting the scope. This will cause the new job to schedule only objects that were created between when it was first created and when it was run for the first time.
When setting the job scope, set the object attributes so that the object last modified date is the date of the last time the previous job ran. This helps ensure that when the new scheduled job runs, it evaluates only objects that weren’t covered by the previous job.
Clean up
To avoid incurring additional charges, disable Macie while you evaluate the value of the additional data protection provided. If S3 buckets were created for this POC, those should also be deleted.
Call to action
After the POC is complete, evaluate the results to determine how much using Macie can strengthen your organization’s data protection program. Based on that evaluation, you can identify how and where to use Macie for maximum effectiveness. Also consider how the information provided can be factored into operational workflows to get additional value from Macie.
Conclusion
This post outlined how you can use a POC to better understand how Amazon Macie can help meet your data discovery and classification needs. A well thought-out and implemented POC can provide valuable early insights and help you develop a more thorough understanding of what your data discovery and classification strategy should be. Planning your POC using the guidance in this post can help you determine more quickly if Macie is a fit for your company.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The new IRAP report includes an additional seven AWS services that are now assessed at the PROTECTED level under IRAP. This brings the total number of services assessed at the PROTECTED level to 158.
The following are the seven newly assessed services:
Many Australian customers are looking to experiment with how generative AI applications can help them better serve the Australian public. Customers can use two of the newly assessed services—Amazon Bedrock and Amazon DataZone—to help align with their governance, sovereignty, and security requirements up to the PROTECTED level:
Amazon Bedrock is a fully managed service that offers a choice of high-performing large language models (LLMs) and other foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, as well as Amazon through a single API. Amazon Bedrock also provides a broad set of capabilities customers need to build generative AI applications with security, privacy, and responsible AI.
Amazon DataZone is a data management service that makes it faster and simpler for customers to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources.
AWS has developed an IRAP documentation pack to help Australian customers and their partners to plan, architect, and assess risk for their workloads when they use AWS Cloud services.
The IRAP pack on AWS Artifact also includes newly updated versions of the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud.
Reach out to your AWS representatives to let us know which additional services you would like to see in scope for upcoming IRAP assessments. We strive to bring more services into scope at the PROTECTED level under IRAP to support your requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) announces that it has successfully renewed the Portuguese GNS (Gabinete Nacional de Segurança, National Security Cabinet) certification in the AWS Regions and edge locations in the European Union. This accreditation confirms that AWS cloud infrastructure, security controls, and operational processes adhere to the stringent requirements set forth by the Portuguese government for handling classified information at the National Reservado level (equivalent to the NATO Restricted level).
The GNS certification is based on the NIST SP800-53 Rev. 5 and CSA CCM v4 frameworks. It demonstrates the AWS commitment to providing the most secure cloud services to public-sector customers, particularly those with the most demanding security and compliance needs. By achieving this certification, AWS has demonstrated its ability to safeguard classified data up to the Reservado (Restricted) level, in accordance with the Portuguese government’s rigorous security standards.
AWS was evaluated by an authorized and independent third-party auditor, Adyta Lda, and by the Portuguese GNS itself. With the GNS certification, AWS customers in Portugal, including public sector organizations and defense contractors, can now use the full extent of AWS cloud services to handle national restricted information. This enables these customers to take advantage of AWS scalability, reliability, and cost-effectiveness, while safeguarding data in alignment with GNS standards.
The Australian Prudential Regulation Authority (APRA) has established the CPS 230 Operational Risk Management standard to verify that regulated entities are resilient to operational risks and disruptions. CPS 230 requires regulated financial entities to effectively manage their operational risks, maintain critical operations during disruptions, and manage the risks associated with service providers.
Amazon Web Services (AWS) is excited to announce the launch of the AWS Workbook for the APRA CPS 230 standard to support AWS customers as they work to meet applicable CPS 230 requirements. The workbook describes operational resilience, AWS and the Shared Responsibility Model, AWS compliance programs, and relevant AWS services and whitepapers that relate to regulatory requirements.
As the regulatory environment continues to evolve, we’ll provide further updates regarding AWS offerings in this area on the AWS Security Blog and the AWS Compliance page. The AWS Workbook for the APRA CPS 230 adds to the resources AWS provides about financial services regulation across the world. You can find more information on cloud-related regulatory compliance at the AWS Compliance Center. You can also reach out to your AWS account manager for help finding the resources you need.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Developing strategies to navigate the evolving digital sovereignty landscape is a top priority for organizations operating across industries and in the public sector. With data privacy, security, and compliance requirements becoming increasingly complex, organizations are seeking cloud solutions that provide sovereign controls and flexibility. Recently, Max Peterson, Amazon Web Services (AWS) Vice President of Sovereign Cloud, sat down with Daniel Newman, CEO of The Futurum Group and co-founder of Six Five Media, to explore how customers are meeting their unique digital sovereignty needs with AWS. Their thought-provoking conversation delves into the factors that are driving digital sovereignty strategies, the key considerations for customers, and AWS offerings that are designed to deliver control, choice, security, and resilience in the cloud. The podcast includes a discussion of AWS innovations, including the AWS Nitro System, AWS Dedicated Local Zones, AWS Key Management Service External Key Store, and the upcoming AWS European Sovereign Cloud. Check out the episode to gain valuable insights that can help you effectively navigate the digital sovereignty landscape while unlocking the full potential of cloud computing.
Developing secure products and services is imperative for organizations that are looking to strengthen operational resilience and build customer trust. However, system design often prioritizes performance, functionality, and user experience over security. This approach can lead to vulnerabilities across the supply chain.
As security threats continue to evolve, the concept of Secure by Design (SbD) is gaining importance in the effort to mitigate vulnerabilities early, minimize risks, and recognize security as a core business requirement. We’re excited to share a whitepaper we recently authored with SANS Institute called Building Security from the Ground up with Secure by Design, which addresses SbD strategy and explores the effects of SbD implementations.
The whitepaper contains context and analysis that can help you take a proactive approach to product development that facilitates foundational security. Key considerations include the following:
Integrating SbD into the software development lifecycle (SDLC)
Supporting SbD with automation
Reinforcing defense-in-depth
Applying SbD to artificial intelligence (AI)
Identifying threats in the design phase with threat modeling
Using SbD to simplify compliance with requirements and standards
Planning for the short and long term
Establishing a culture of security
While the journey to a Secure by Design approach is an iterative process that is different for every organization, the whitepaper details five key action items that can help set you on the right path. We encourage you to download the whitepaper and gain insight into how you can build secure products with a multi-layered strategy that meaningfully improves your technical and business outcomes. We look forward to your feedback and to continuing the journey together.
Amazon Redshift, a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. Whether your data resides in operational databases, data lakes, on-premises systems, Amazon Elastic Compute Cloud (Amazon EC2), or other AWS services, Amazon Redshift provides multiple ingestion methods to meet your specific needs. The currently available choices include:
The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR, Amazon DynamoDB, or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables. Further, the auto-copy feature simplifies and automates data loading from Amazon S3 into Amazon Redshift.
This post explores each option (as illustrated in the following figure), determines which are suitable for different use cases, and discusses how and why to select a specific Amazon Redshift tool or feature for data ingestion.
Amazon Redshift COPY command
The Redshift COPY command, a simple low-code data ingestion tool, loads data into Amazon Redshift from Amazon S3, DynamoDB, Amazon EMR, and remote hosts over SSH. It’s a fast and efficient way to load large datasets into Amazon Redshift. It uses massively parallel processing (MPP) architecture in Amazon Redshift to read and load large amounts of data in parallel from files or data from supported data sources. This allows you to utilize parallel processing by splitting data into multiple files, especially when the files are compressed.
Recommended use cases for the COPY command include loading large datasets and data from supported data sources. COPY automatically splits large uncompressed delimited text files into smaller scan ranges to utilize the parallelism of Amazon Redshift provisioned clusters and serverless workgroups. With auto-copy, automation enhances the COPY command by adding jobs for automatic ingestion of data.
COPY command advantages:
Performance – Efficiently loads large datasets from Amazon S3 or other sources in parallel with optimized throughput
Simplicity – Straightforward and user-friendly, requiring minimal setup
Cost-optimized – Uses Amazon Redshift MPP at a lower cost by reducing data transfer time
Flexibility – Supports file formats such as CSV, JSON, Parquet, ORC, and AVRO
Amazon Redshift federated queries
Amazon Redshift federated queries allow you to incorporate live data from Amazon RDS or Aurora operational databases as part of business intelligence (BI) and reporting applications.
Federated queries are useful for use cases where organizations want to combine data from their operational systems with data stored in Amazon Redshift. Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines. If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported. In scenarios where data transformation is required, you can use Redshift stored procedures to modify data in Redshift tables.
Federated queries key features:
Real-time access – Enables querying of live data across discrete sources, such as Amazon RDS and Aurora, without the need to move the data
Unified data view – Provides a single view of data across multiple databases, simplifying data analysis and reporting
Cost savings – Eliminates the need for ETL processes to move data into Amazon Redshift, saving on storage and compute costs
Flexibility – Supports Amazon RDS and Aurora data sources, offering flexibility in accessing and analyzing distributed data
Amazon Redshift Zero-ETL integration
Aurora zero-ETL integration with Amazon Redshift allows access to operational data from Amazon Aurora MySQL-Compatible (and Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL in preview), and DynamoDB from Amazon Redshift without the need for ETL in near real time. You can use zero-ETL to simplify ingestion pipelines for performing change data capture (CDC) from an Aurora database to Amazon Redshift. Built on the integration of Amazon Redshift and Aurora storage layers, zero-ETL boasts simple setup, data filtering, automated observability, auto-recovery, and integration with either Amazon Redshift provisioned clusters or Amazon Redshift Serverless workgroups.
Zero-ETL integration benefits:
Seamless integration – Automatically integrates and synchronizes data between operational databases and Amazon Redshift without the need for custom ETL processes
Near real-time insights – Provides near real-time data updates, so the most current data is available for analysis
Ease of use – Simplifies data architecture by eliminating the need for separate ETL tools and processes
Efficiency – Minimizes data latency and provides data consistency across systems, enhancing overall data accuracy and reliability
Amazon Redshift integration for Apache Spark
The Amazon Redshift integration for Apache Spark, automatically included through Amazon EMR or AWS Glue, provides performance and security optimizations when compared to the community-provided connector. The integration enhances and simplifies security with AWS Identity and Access Management (IAM) authentication support. AWS Glue 4.0 provides a visual ETL tool for authoring jobs to read from and write to Amazon Redshift, using the Redshift Spark connector for connectivity. This simplifies the process of building ETL pipelines to Amazon Redshift. The Spark connector allows use of Spark applications to process and transform data before loading into Amazon Redshift. The integration minimizes the manual process of setting up a Spark connector and shortens the time needed to prepare for analytics and machine learning (ML) tasks. It allows you to specify the connection to a data warehouse and start working with Amazon Redshift data from your Apache Spark-based applications within minutes.
The integration provides pushdown capabilities for sort, aggregate, limit, join, and scalar function operations to optimize performance by moving only the relevant data from Amazon Redshift to the consuming Apache Spark application. Spark jobs are suitable for data processing pipelines and when you need to use Spark’s advanced data transformation capabilities.
With the Amazon Redshift integration for Apache Spark, you can simplify the building of ETL pipelines with data transformation requirements. It offers the following benefits:
High performance – Uses the distributed computing power of Apache Spark for large-scale data processing and analysis
Scalability – Effortlessly scales to handle massive datasets by distributing computation across multiple nodes
Flexibility – Supports a wide range of data sources and formats, providing versatility in data processing tasks
Interoperability – Seamlessly integrates with Amazon Redshift for efficient data transfer and queries
Amazon Redshift streaming ingestion
The key benefit of Amazon Redshift streaming ingestion is the ability to ingest hundreds of megabytes of data per second directly from streaming sources into Amazon Redshift with very low latency, supporting real-time analytics and insights. Supporting streams from Kinesis Data Streams, Amazon MSK, and Data Firehose, streaming ingestion requires no data staging, supports flexible schemas, and is configured with SQL. Streaming ingestion powers real-time dashboards and operational analytics by directly ingesting data into Amazon Redshift materialized views.
Amazon Redshift streaming ingestion unlocks near real-time streaming analytics with:
Low latency – Ingests streaming data in near real time, making streaming ingestion ideal for time-sensitive applications such as Internet of Things (IoT), financial transactions, and clickstream analysis
Scalability – Manages high throughput and large volumes of streaming data from sources such as Kinesis Data Streams, Amazon MSK, and Data Firehose
Integration – Integrates with other AWS services to build end-to-end streaming data pipelines
Continuous updates – Keeps data in Amazon Redshift continuously updated with the latest information from the data streams
Amazon Redshift ingestion use cases and examples
In this section, we discuss the details of different Amazon Redshift ingestion use cases and provide examples.
Redshift COPY use case: Application log data ingestion and analysis
Ingesting application log data stored in Amazon S3 is a common use case for the Redshift COPY command. Data engineers in an organization need to analyze application log data to gain insights into user behavior, identify potential issues, and optimize a platform’s performance. To achieve this, data engineers ingest log data in parallel from multiple files stored in S3 buckets into Redshift tables. This parallelization uses the Amazon Redshift MPP architecture, allowing for faster data ingestion compared to other ingestion methods.
The following code is an example of the COPY command loading data from a set of CSV files in an S3 bucket into a Redshift table:
COPY myschema.mytable
FROM 's3://my-bucket/data/files/'
IAM_ROLE ‘arn:aws:iam::1234567891011:role/MyRedshiftRole’
FORMAT AS CSV;
This code uses the following parameters:
mytable is the target Redshift table for data load
‘s3://my-bucket/data/files/‘ is the S3 path where the CSV files are located
IAM_ROLE specifies the IAM role required to access the S3 bucket
FORMAT AS CSV specifies that the data files are in CSV format
In addition to Amazon S3, the COPY command loads data from other sources, such as DynamoDB, Amazon EMR, remote hosts through SSH, or other Redshift databases. The COPY command provides options to specify data formats, delimiters, compression, and other parameters to handle different data sources and formats.
Federated queries use case: Integrated reporting and analytics for a retail company
For this use case, a retail company has an operational database running on Amazon RDS for PostgreSQL, which stores real-time sales transactions, inventory levels, and customer information data. Additionally, a data warehouse runs on Amazon Redshift storing historical data for reporting and analytics purposes. To create an integrated reporting solution that combines real-time operational data with historical data in the data warehouse, without the need for multi-step ETL processes, complete the following steps:
Set up network connectivity. Make sure your Redshift cluster and RDS for PostgreSQL instance are in the same virtual private cloud (VPC) or have network connectivity established through VPC peering, AWS PrivateLink, or AWS Transit Gateway.
Create a secret and IAM role for federated queries:
In AWS Secrets Manager, create a new secret to store the credentials (user name and password) for your Amazon RDS for PostgreSQL instance.
Create an IAM role with permissions to access the Secrets Manager secret and the Amazon RDS for PostgreSQL instance.
Associate the IAM role with your Amazon Redshift cluster.
Create an external schema in Amazon Redshift:
Connect to your Redshift cluster using a SQL client or the query editor v2 on the Amazon Redshift console.
Create an external schema that references your Amazon RDS for PostgreSQL instance:
CREATE EXTERNAL SCHEMA postgres_schema
FROM POSTGRES
DATABASE 'mydatabase'
SCHEMA 'public'
URI 'endpoint-for-your-rds-instance.aws-region.rds.amazonaws.com:5432'
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftRoleForRDS'
SECRET_ARN 'arn:aws:secretsmanager:aws-region:123456789012:secret:my-rds-secret-abc123';
Query tables in your Amazon RDS for PostgreSQL instance directly from Amazon Redshift using federated queries:
SELECT
r.order_id,
r.order_date,
r.customer_name,
r.total_amount,
h.product_name,
h.category
FROM
postgres_schema.orders r
JOIN redshift_schema.product_history h ON r.product_id = h.product_id
WHERE
r.order_date >= '2024-01-01';
Create views or materialized views in Amazon Redshift that combine the operational data from federated queries with the historical data in Amazon Redshift for reporting purposes:
CREATE MATERIALIZED VIEW sales_report AS
SELECT
r.order_id,
r.order_date,
r.customer_name,
r.total_amount,
h.product_name,
h.category,
h.historical_sales
FROM
(
SELECT
order_id,
order_date,
customer_name,
total_amount,
product_id
FROM
postgres_schema.orders
) r
JOIN redshift_schema.product_history h ON r.product_id = h.product_id;
With this implementation, federated queries in Amazon Redshift integrate real-time operational data from Amazon RDS for PostgreSQL instances with historical data in a Redshift data warehouse. This approach eliminates the need for multi-step ETL processes and enables you to create comprehensive reports and analytics that combine data from multiple sources.
Zero-ETL integration use case: Near real-time analytics for an ecommerce application
Suppose an ecommerce application built on Aurora MySQL-Compatible manages online orders, customer data, and product catalogs. To perform near real-time analytics with data filtering on transactional data to gain insights into customer behavior, sales trends, and inventory management without the overhead of building and maintaining multi-step ETL pipelines, you can use zero-ETL integrations for Amazon Redshift. Complete the following steps:
Set up an Aurora MySQL cluster (must be running Aurora MySQL version 3.05-compatible with MySQL 8.0.32 or higher):
Create an Aurora MySQL cluster in your desired AWS Region.
Configure the cluster settings, such as the instance type, storage, and backup options.
Create a zero-ETL integration with Amazon Redshift:
On the Amazon RDS console, navigate to the Zero-ETL integrations
Choose Create integration and select your Aurora MySQL cluster as the source.
Choose an existing Redshift cluster or create a new cluster as the target.
Provide a name for the integration and review the settings.
Choose Create integration to initiate the zero-ETL integration process.
Verify the integration status:
After the integration is created, monitor the status on the Amazon RDS console or by querying the SVV_INTEGRATION and SYS_INTEGRATION_ACTIVITY system views in Amazon Redshift.
Wait for the integration to reach the Active state, indicating that data is being replicated from Aurora to Amazon Redshift.
Create analytics views:
Connect to your Redshift cluster using a SQL client or the query editor v2 on the Amazon Redshift console.
Create views or materialized views that combine and transform the replicated data from Aurora for your analytics use cases:
CREATE MATERIALIZED VIEW orders_summary AS
SELECT
o.order_id,
o.customer_id,
SUM(oi.quantity * oi.price) AS total_revenue,
MAX(o.order_date) AS latest_order_date
FROM
aurora_schema.orders o
JOIN aurora_schema.order_items oi ON o.order_id = oi.order_id
GROUP BY
o.order_id,
o.customer_id;
Query the views or materialized views in Amazon Redshift to perform near real-time analytics on the transactional data from your Aurora MySQL cluster:
SELECT
customer_id,
SUM(total_revenue) AS total_customer_revenue,
MAX(latest_order_date) AS most_recent_order
FROM
orders_summary
GROUP BY
customer_id
ORDER BY
total_customer_revenue DESC;
This implementation achieves near real-time analytics for an ecommerce application’s transactional data using the zero-ETL integration between Aurora MySQL-Compatible and Amazon Redshift. The data automatically replicates from Aurora to Amazon Redshift, eliminating the need for multi-step ETL pipelines and supporting insights from the latest data quickly.
Integration for Apache Spark use case: Gaming player events written to Amazon S3
Consider a large volume of gaming player events stored in Amazon S3. The events require data transformation, cleansing, and preprocessing to extract insights, generate reports, or build ML models. In this case, you can use the scalability and processing power of Amazon EMR to perform the required data changes using Apache Spark. After it’s processed, the transformed data must be loaded into Amazon Redshift for further analysis, reporting, and integration with BI tools.
In this scenario, you can use the Amazon Redshift integration for Apache Spark to perform the necessary data transformations and load the processed data into Amazon Redshift. The following implementation example assumes gaming player events in Parquet format are stored in Amazon S3 (s3://<bucket_name>/player_events/).
Launch an Amazon EMR (emr-6.9.0) cluster with Apache Spark (Spark 3.3.0) with Amazon Redshift integration with Apache Spark support.
Configure the necessary IAM role for accessing Amazon S3 and Amazon Redshift.
Add security group rules to Amazon Redshift to allow access to the provisioned cluster or serverless workgroup.
Create a Spark job that sets up a connection to Amazon Redshift, reads data from Amazon S3, performs transformations, and writes resulting data to Amazon Redshift. See the following code:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
import os
def main():
# Create a SparkSession
spark = SparkSession.builder \
.appName("RedshiftSparkJob") \
.getOrCreate()
# Set Amazon Redshift connection properties
Redshift_jdbc_url = "jdbc:redshift://<redshift-endpoint>:<port>/<database>"
redshift_table = "<schema>.<table_name>"
temp_s3_bucket = "s3://<bucket_name>/temp/"
iam_role_arn = "<iam_role_arn>"
# Read data from Amazon S3
s3_data = spark.read.format("parquet") \
.load("s3://<bucket_name>/player_events/")
# Perform transformations
transformed_data = s3_data.withColumn("transformed_column", lit("transformed_value"))
# Write the transformed data to Amazon Redshift
transformed_data.write \
.format("io.github.spark_redshift_community.spark.redshift") \
.option("url", redshift_jdbc_url) \
.option("dbtable", redshift_table) \
.option("tempdir", temp_s3_bucket) \
.option("aws_iam_role", iam_role_arn) \
.mode("overwrite") \
.save()
if __name__ == "__main__":
main()
In this example, you first import the necessary modules and create a SparkSession. Set the connection properties for Amazon Redshift, including the endpoint, port, database, schema, table name, temporary S3 bucket path, and the IAM role ARN for authentication. Read data from Amazon S3 in Parquet format using the spark.read.format("parquet").load() method. Perform a transformation on the Amazon S3 data by adding a new column transformed_column with a constant value using the withColumn method and the lit function. Write the transformed data to Amazon Redshift using the write method and the io.github.spark_redshift_community.spark.redshift format. Set the necessary options for the Redshift connection URL, table name, temporary S3 bucket path, and IAM role ARN. Use the mode("overwrite") option to overwrite the existing data in the Amazon Redshift table with the transformed data.
Streaming ingestion use case: IoT telemetry near real-time analysis
Imagine a fleet of IoT devices (sensors and industrial equipment) that generate a continuous stream of telemetry data such as temperature readings, pressure measurements, or operational metrics. Ingesting this data in real time to perform analytics to monitor the devices, detect anomalies, and make data-driven decisions requires a streaming solution integrated with a Redshift data warehouse.
In this example, we use Amazon MSK as the streaming source for IoT telemetry data.
Create an external schema in Amazon Redshift:
Connect to an Amazon Redshift cluster using a SQL client or the query editor v2 on the Amazon Redshift console.
Create an external schema that references the MSK cluster:
CREATE EXTERNAL SCHEMA kafka_schema
FROM KAFKA
BROKER 'broker-1.example.com:9092,broker-2.example.com:9092'
TOPIC 'iot-telemetry-topic'
REGION 'us-east-1'
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftRoleForMSK';
Create a materialized view in Amazon Redshift:
Define a materialized view that maps the Kafka topic data to Amazon Redshift table columns.
CAST the streaming message payload data type to the Amazon Redshift SUPER type.
Set the materialized view to auto refresh.
CREATE MATERIALIZED VIEW iot_telemetry_view
AUTO REFRESH YES
AS SELECT
kafka_partition,
kafka_offset,
kafka_timestamp_type,
kafka_timestamp,
CAST(kafka_value AS SUPER) payload
FROM kafka_schema.iot-telemetry-topic;
Query the iot_telemetry_view materialized view to access the real-time IoT telemetry data ingested from the Kafka topic. The materialized view will automatically refresh as new data arrives in the Kafka topic.
SELECT
kafka_timestamp,
payload:device_id,
payload:temperature,
payload:pressure
FROM iot_telemetry_view;
With this implementation, you can achieve near real-time analytics on IoT device telemetry data using Amazon Redshift streaming ingestion. As telemetry data is received by an MSK topic, Amazon Redshift automatically ingests and reflects the data in a materialized view, supporting query and analysis of the data in near real time.
This post detailed the options available for Amazon Redshift data ingestion. The choice of data ingestion method depends on factors such as the size and structure of data, the need for real-time access or transformations, data sources, existing infrastructure, ease of use, and user skill-sets. Zero-ETL integrations and federated queries are suitable for simple data ingestion tasks or joining data between operational databases and Amazon Redshift analytics data. Large-scale data ingestion with transformation and orchestration benefit from Amazon Redshift integration with Apache Spark with Amazon EMR and AWS Glue. Bulk loading of data into Amazon Redshift regardless of dataset size fits perfectly with the capabilities of the Redshift COPY command. Utilizing streaming sources such as Kinesis Data Streams, Amazon MSK, or Data Firehose are ideal scenarios for utilizing AWS streaming services integration for data ingestion.
Evaluate the features and guidance provided for your data ingestion workloads and let us know your feedback in the comments.
About the Authors
Steve Phillips is a senior technical account manager at AWS in the North America region. Steve has worked with games customers for eight years and currently focuses on data warehouse architectural design, data lakes, data ingestion pipelines, and cloud distributed architectures.
Sudipta Bagchi is a Sr. Specialist Solutions Architect at Amazon Web Services. He has over 14 years of experience in data and analytics, and helps customers design and build scalable and high-performant analytics solutions. Outside of work, he loves running, traveling, and playing cricket.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.














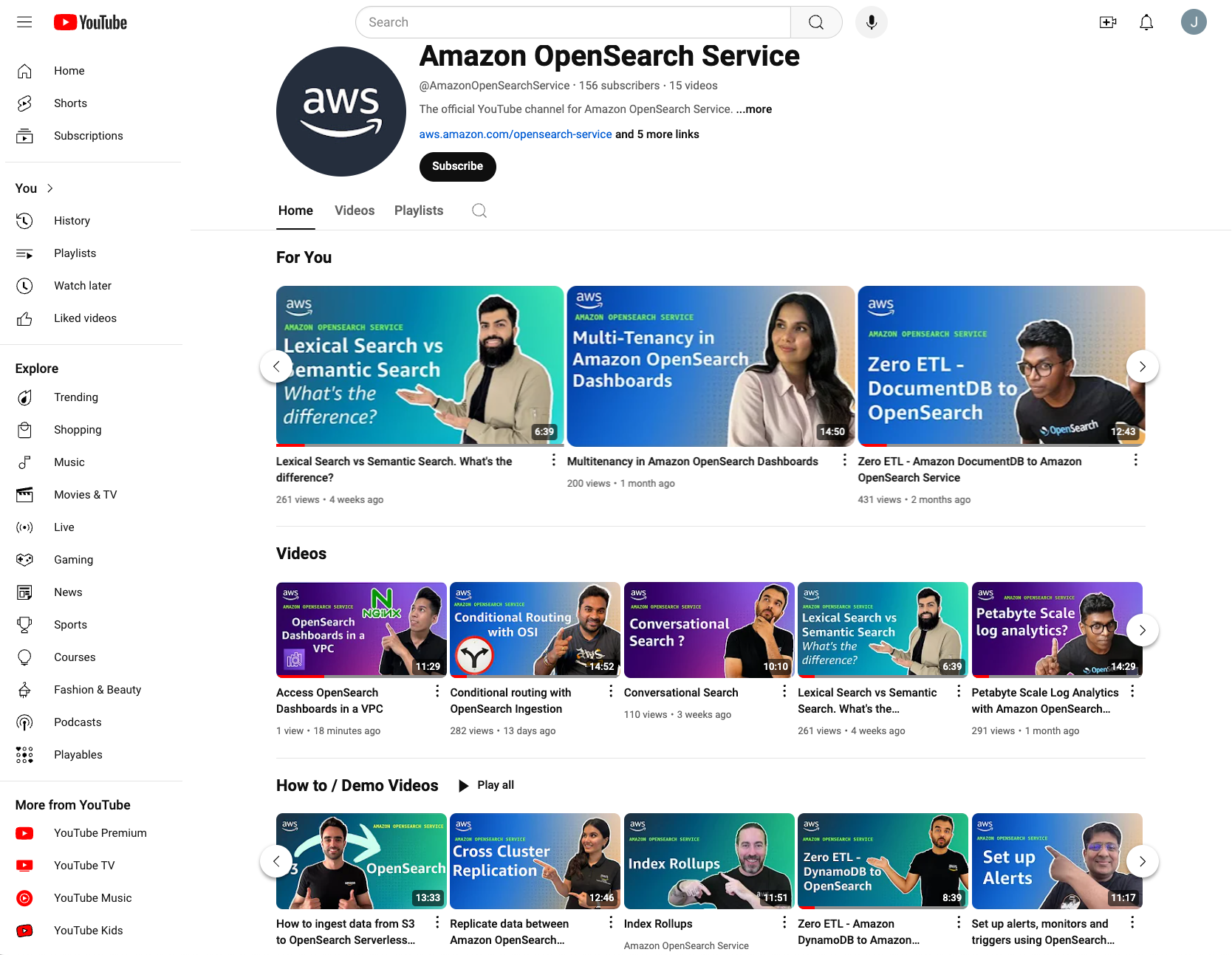
 Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS. Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He has over 14 years of experience helping organizations derive insights from their data.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He has over 14 years of experience helping organizations derive insights from their data. Wendy Neu is a Senior Manager at AWS focused on leading the NoSQL Specialist Solutions Architecture team worldwide. She is passionate about Data Services and leverages her extensive expertise to help customers optimize their data storage, management, and analytics strategies, enabling them to drive innovation and achieve their business goals.
Wendy Neu is a Senior Manager at AWS focused on leading the NoSQL Specialist Solutions Architecture team worldwide. She is passionate about Data Services and leverages her extensive expertise to help customers optimize their data storage, management, and analytics strategies, enabling them to drive innovation and achieve their business goals.

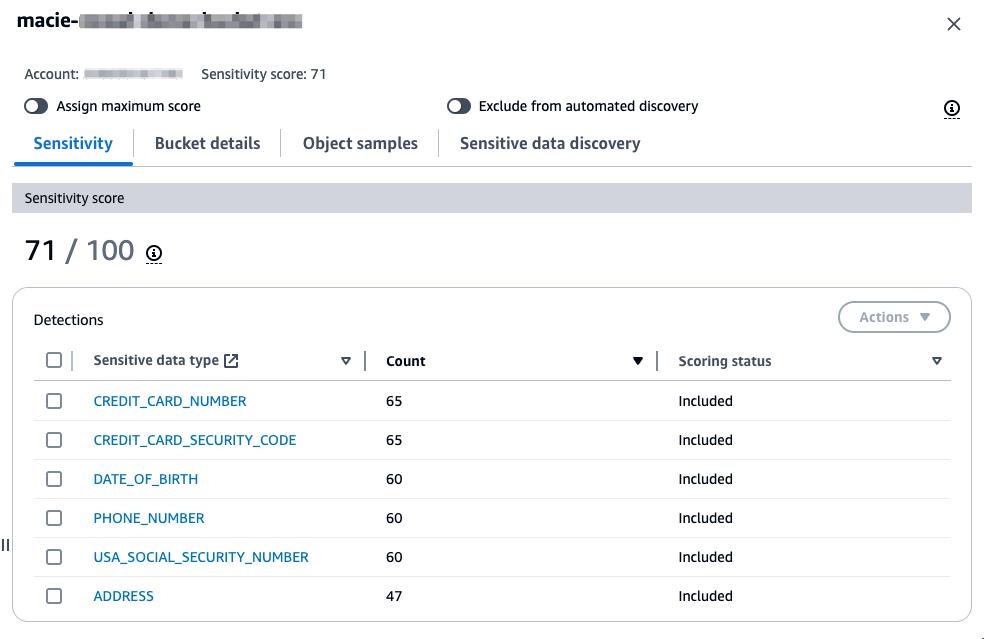

 Steve Phillips is a senior technical account manager at AWS in the North America region. Steve has worked with games customers for eight years and currently focuses on data warehouse architectural design, data lakes, data ingestion pipelines, and cloud distributed architectures.
Steve Phillips is a senior technical account manager at AWS in the North America region. Steve has worked with games customers for eight years and currently focuses on data warehouse architectural design, data lakes, data ingestion pipelines, and cloud distributed architectures. Sudipta Bagchi is a Sr. Specialist Solutions Architect at Amazon Web Services. He has over 14 years of experience in data and analytics, and helps customers design and build scalable and high-performant analytics solutions. Outside of work, he loves running, traveling, and playing cricket.
Sudipta Bagchi is a Sr. Specialist Solutions Architect at Amazon Web Services. He has over 14 years of experience in data and analytics, and helps customers design and build scalable and high-performant analytics solutions. Outside of work, he loves running, traveling, and playing cricket.