Post Syndicated from Ross Barich original https://aws.amazon.com/blogs/aws/get-to-know-the-first-aws-heroes-of-2022/
The AWS Heroes program is a worldwide initiative which acknowledges individuals who have truly gone above and beyond to share knowledge in technical communities. AWS Heroes share knowledge by hosting events, Meetups, workshops, and study groups, or by authoring blogs, creating videos, speaking at conferences, or contributing to open source projects. You can see some of the Heroes’ work in the AWS Heroes Content Library.
Today we are excited to introduce the first new Heroes of 2022, including the first Hero based in the Czech Republic:
Albert Suwandhi – Medan, Indonesia
 Community Hero Albert Suwandhi is an academic and IT Professional, and an AWS Champion Authorized Instructor who delivers AWS classroom training courses to AWS users and customers. He strongly believes in the power of community: he joined AWS User Group Indonesia, Medan chapter in 2019 and has since organized and delivered several sharing sessions. He has also been featured in number of tech talks, and his areas of cloud computing interest are cloud architecture and security. He enjoys helping people to realize the true potential of cloud computing and he runs a YouTube channel, which provides tutorials and tips & tricks related to AWS.
Community Hero Albert Suwandhi is an academic and IT Professional, and an AWS Champion Authorized Instructor who delivers AWS classroom training courses to AWS users and customers. He strongly believes in the power of community: he joined AWS User Group Indonesia, Medan chapter in 2019 and has since organized and delivered several sharing sessions. He has also been featured in number of tech talks, and his areas of cloud computing interest are cloud architecture and security. He enjoys helping people to realize the true potential of cloud computing and he runs a YouTube channel, which provides tutorials and tips & tricks related to AWS.
Dipali Kulshrestha – Delhi, India
 Community Hero Dipali Kulshrestha is Vice President of Data Engineering at Natwest Group where she is an AWS trainer & mentor, conducting Cloud Practitioner and Solution Architect workshops every quarter. She is also an AWS Delhi User Group leader, hosts monthly immersive learning sessions on different AWS concepts, and is an active speaker at AWS community events. Dipali released a DevOps with AWS course on LinkedIn Learning, attended by 12000+ learners. She also created an AWS re:Skill series for containers on AWS. Dipali is huge advocate of diversity & inclusion of women in tech, and was recently featured in AWS India’s campaign called Developers of AWS and in a Tech Gig interview about cloud upskilling.
Community Hero Dipali Kulshrestha is Vice President of Data Engineering at Natwest Group where she is an AWS trainer & mentor, conducting Cloud Practitioner and Solution Architect workshops every quarter. She is also an AWS Delhi User Group leader, hosts monthly immersive learning sessions on different AWS concepts, and is an active speaker at AWS community events. Dipali released a DevOps with AWS course on LinkedIn Learning, attended by 12000+ learners. She also created an AWS re:Skill series for containers on AWS. Dipali is huge advocate of diversity & inclusion of women in tech, and was recently featured in AWS India’s campaign called Developers of AWS and in a Tech Gig interview about cloud upskilling.
Faizal Khan – Hyderabad, India
 Community Hero Faizal Khan is a tech entrepreneur, currently Founder & CEO at Ecomm.in and Xite Logic. He is an ardent contributor to the AWS community. As organizer of the AWS Hyderabad User Group, he helps organize AWS hackathons, AWS Meetups, re:Invent recaps, webinars, and AWS certification bootcamps. He is also a speaker at many events covering Networking, IoT, Storage, and Compute. His VPC masterclass on YouTube has garnered about half a million views. He was a core organizing member and host for the AWS Community Day South Asia 2021 Online, which attracted over 24K viewers. In addition, he built an AWS Q&A discussion forum for the community.
Community Hero Faizal Khan is a tech entrepreneur, currently Founder & CEO at Ecomm.in and Xite Logic. He is an ardent contributor to the AWS community. As organizer of the AWS Hyderabad User Group, he helps organize AWS hackathons, AWS Meetups, re:Invent recaps, webinars, and AWS certification bootcamps. He is also a speaker at many events covering Networking, IoT, Storage, and Compute. His VPC masterclass on YouTube has garnered about half a million views. He was a core organizing member and host for the AWS Community Day South Asia 2021 Online, which attracted over 24K viewers. In addition, he built an AWS Q&A discussion forum for the community.
Filip Pyrek – Brno, Czech Republic
 Serverless Hero Filip Pyrek is Serverless Architect at Purple Technology. At the age of 23 Filip is one of the youngest AWS Heroes. He started his serverless journey back in 2016 when he was 17 years old. He is helping grow the serverless community in Czech Republic and Slovakia by organizing Serverless Brno meetups, contributing to local podcasts, writing serverless blog posts in Czech language, and doing other evangelization activities. He is in touch with a community of maintainers and developers of serverless tooling projects and provides them with feedback, feature requests, and open-source contributions in order to continuously improve the serverless ecosystem.
Serverless Hero Filip Pyrek is Serverless Architect at Purple Technology. At the age of 23 Filip is one of the youngest AWS Heroes. He started his serverless journey back in 2016 when he was 17 years old. He is helping grow the serverless community in Czech Republic and Slovakia by organizing Serverless Brno meetups, contributing to local podcasts, writing serverless blog posts in Czech language, and doing other evangelization activities. He is in touch with a community of maintainers and developers of serverless tooling projects and provides them with feedback, feature requests, and open-source contributions in order to continuously improve the serverless ecosystem.
Karolina Boboli – Warsaw, Poland
 Community Hero Karolina Boboli works as an AWS Cloud Architect and Consultant. She has experience in cloud security, cloud governance, cost management, landing zones, serverless, and IoT. She created an online course “AWS in practice – your first project” about infrastructure as code. In 2019 she founded a vibrant cloud community – swiatchmury.pl – a Slack for cloud professionals focused on AWS – which she runs on a daily basis. The goal of the community is to have a friendly place to ask questions, inspire each other, and simply be together. From time to time she gives talks in AWS UG Poland and organizes her own webinars.
Community Hero Karolina Boboli works as an AWS Cloud Architect and Consultant. She has experience in cloud security, cloud governance, cost management, landing zones, serverless, and IoT. She created an online course “AWS in practice – your first project” about infrastructure as code. In 2019 she founded a vibrant cloud community – swiatchmury.pl – a Slack for cloud professionals focused on AWS – which she runs on a daily basis. The goal of the community is to have a friendly place to ask questions, inspire each other, and simply be together. From time to time she gives talks in AWS UG Poland and organizes her own webinars.
Masaya Arai – Kanagawa, Japan
 Container Hero Masaya Arai is an 11x certified Tech Lead working for Nomura Research Institute (NRI). He is the central organizer of the JAWS-UG Container chapter (about 3000 registered members), an AWS user group in Japan, and he regularly contributes to activities in the AWS user community. Masaya wrote a commercial magazine called “AWS Container Guide + Hands-on”, which became a best-selling cloud-related book on amazon.co.jp, and published more than 10,000 copies. He focuses on promoting development of AWS container technologies through a wide variety of activities such as blogs, public presentations, contributing to magazines, and writing books. He truly enjoys sharing his knowledge and experience with others.
Container Hero Masaya Arai is an 11x certified Tech Lead working for Nomura Research Institute (NRI). He is the central organizer of the JAWS-UG Container chapter (about 3000 registered members), an AWS user group in Japan, and he regularly contributes to activities in the AWS user community. Masaya wrote a commercial magazine called “AWS Container Guide + Hands-on”, which became a best-selling cloud-related book on amazon.co.jp, and published more than 10,000 copies. He focuses on promoting development of AWS container technologies through a wide variety of activities such as blogs, public presentations, contributing to magazines, and writing books. He truly enjoys sharing his knowledge and experience with others.
Mayank Pandey – Bengaluru, India
 Community Hero Mayank Pandey is a cloud architect & teacher, helping both small and large organizations in their cloud adoption journey. He holds Professional & Specialty AWS Certifications and handles assignments including security & cost optimization on AWS, and cloud-native applications. Mayank is passionate about teaching and has done several classroom and online trainings. He is an active member of AWS community and contributes with hands-on demos and video tutorials to the YouTube channel – KnowledgeIndia. The YouTube channel has 65,000 subscribers and 150+ videos on various AWS topics.
Community Hero Mayank Pandey is a cloud architect & teacher, helping both small and large organizations in their cloud adoption journey. He holds Professional & Specialty AWS Certifications and handles assignments including security & cost optimization on AWS, and cloud-native applications. Mayank is passionate about teaching and has done several classroom and online trainings. He is an active member of AWS community and contributes with hands-on demos and video tutorials to the YouTube channel – KnowledgeIndia. The YouTube channel has 65,000 subscribers and 150+ videos on various AWS topics.
Niv Yungelson – Tel Aviv, Israel
 Community Hero Niv Yungelson works at Melio as the DevOps Team Lead. She is co-leader of the AWS Israel User Group, one of the biggest AWS User Groups in the world. As a community leader, she organizes Meetups and ensures they include underrepresented groups in the technology industry. She achieves this by both collaborating with other User Groups and experimenting with new initiatives. Niv also volunteers as an instructor in OpsSchool, which is a non-profit program meant to gather industry leaders to contribute together, train new DevOps engineers, and help the community continue the cycle of good deeds. She is active in tech user groups, forums, and Meetups, and is committed to sharing her knowledge and experience at any given opportunity.
Community Hero Niv Yungelson works at Melio as the DevOps Team Lead. She is co-leader of the AWS Israel User Group, one of the biggest AWS User Groups in the world. As a community leader, she organizes Meetups and ensures they include underrepresented groups in the technology industry. She achieves this by both collaborating with other User Groups and experimenting with new initiatives. Niv also volunteers as an instructor in OpsSchool, which is a non-profit program meant to gather industry leaders to contribute together, train new DevOps engineers, and help the community continue the cycle of good deeds. She is active in tech user groups, forums, and Meetups, and is committed to sharing her knowledge and experience at any given opportunity.
If you’d like to learn more about the new Heroes, or connect with a Hero near you, please visit the AWS Heroes website or browse the AWS Heroes Content Library.
— Ross;
 We launched
We launched 
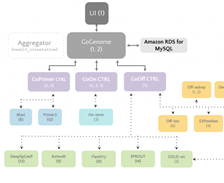 This team came together to build a best-in-class gene-editing prediction platform. CRISPR (
This team came together to build a best-in-class gene-editing prediction platform. CRISPR (
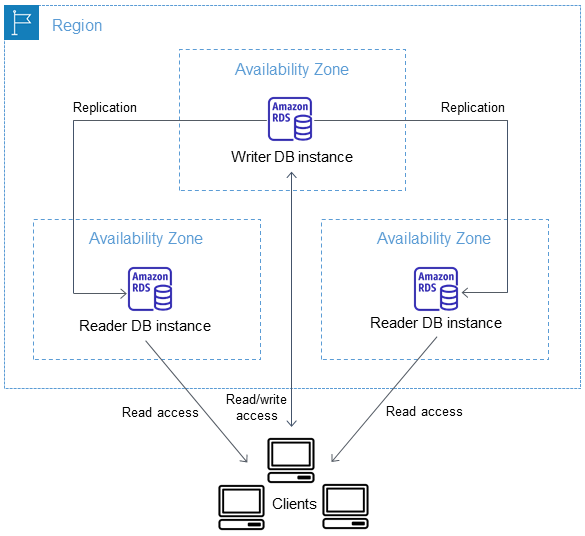

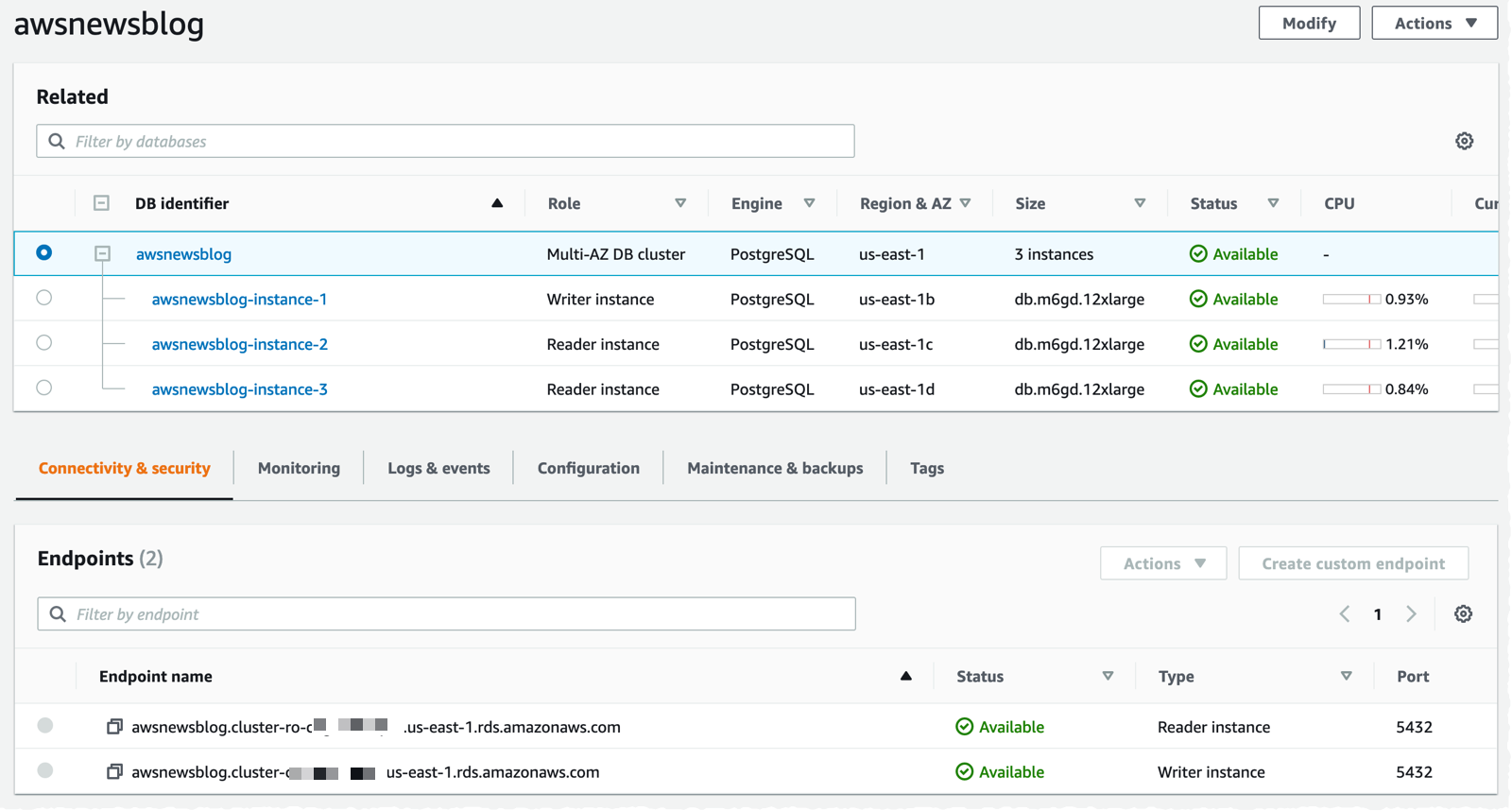









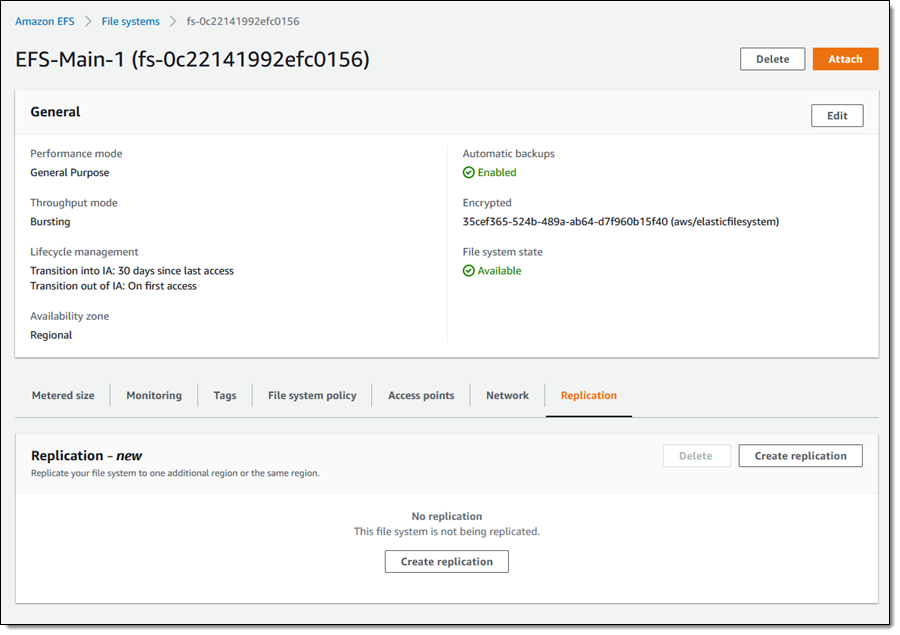
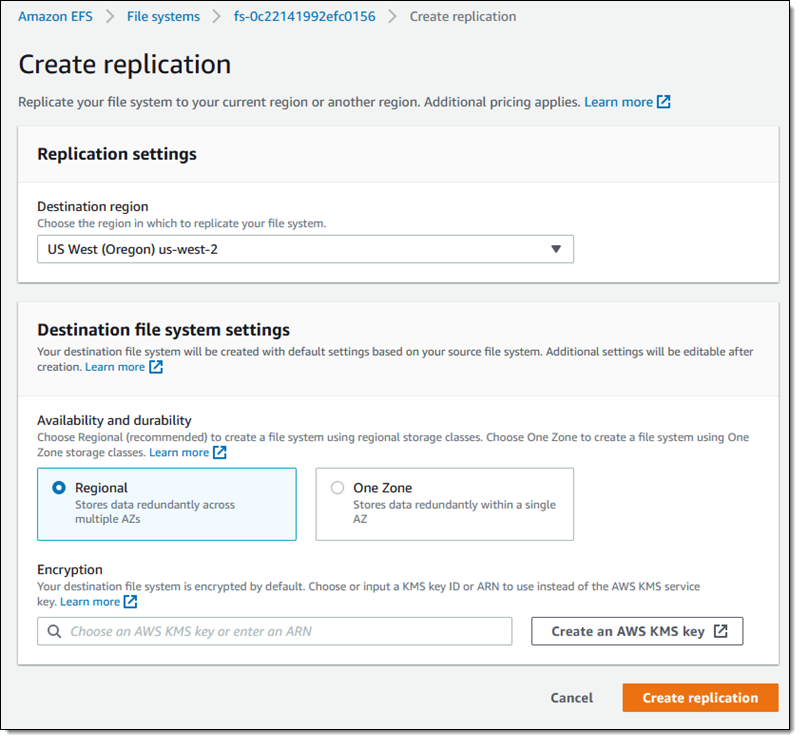
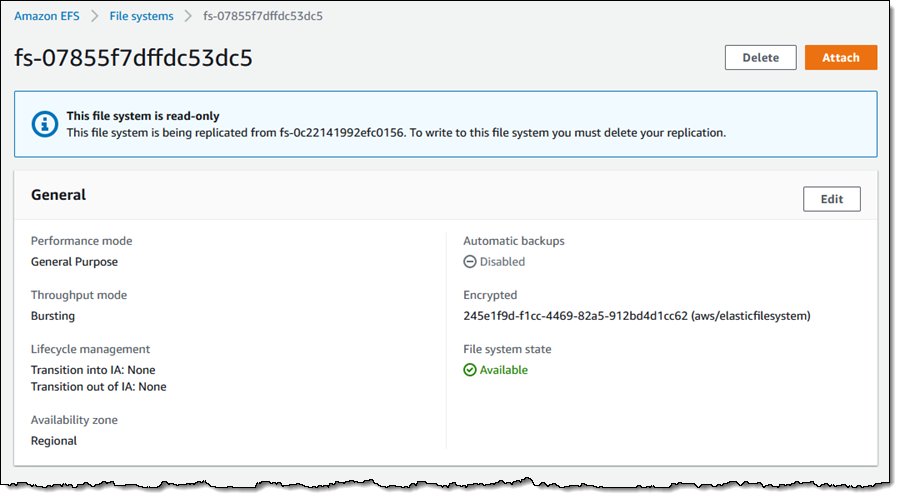
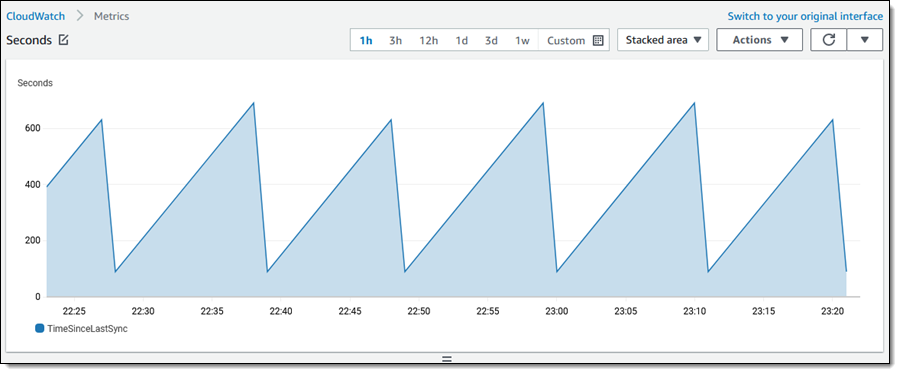
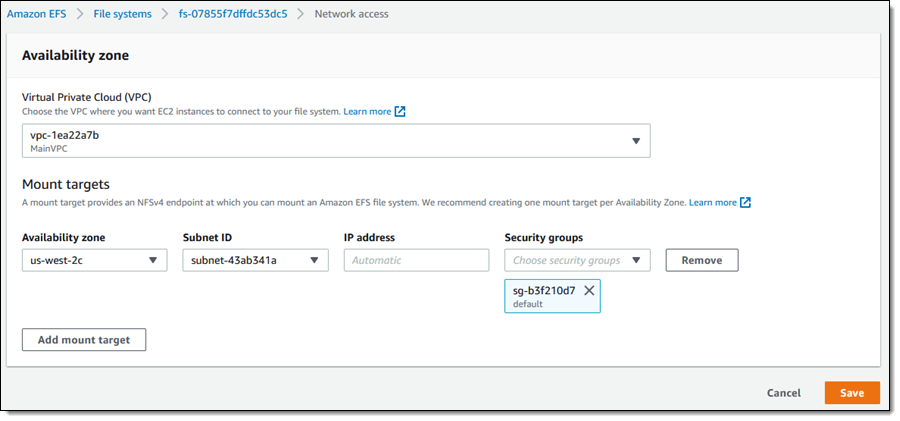
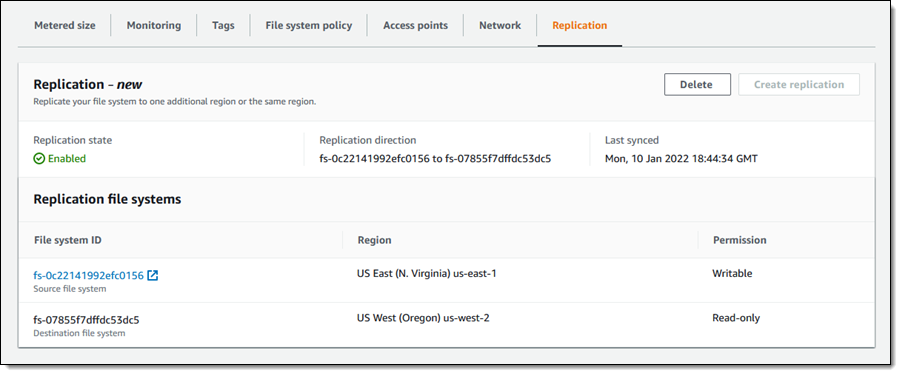
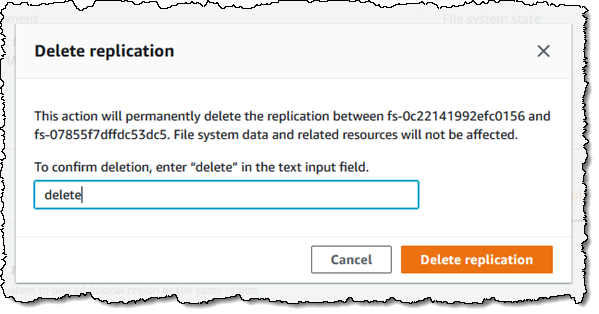
 Faster is always better, and today I am thrilled to be able to tell you that your latency-sensitive EFS workloads can now run about twice as fast as before!
Faster is always better, and today I am thrilled to be able to tell you that your latency-sensitive EFS workloads can now run about twice as fast as before!