Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/amazon-guardduty-enhances-detection-of-ec2-instance-credential-exfiltration/
Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts, workloads, and data stored in Amazon Simple Storage Service (Amazon S3). Informed by a multitude of public and AWS-generated data feeds and powered by machine learning, GuardDuty analyzes billions of events in pursuit of trends, patterns, and anomalies that are recognizable signs that something is amiss. You can enable it with a click and see the first findings within minutes.
Today, we are adding to GuardDuty the ability to detect when your Amazon Elastic Compute Cloud (Amazon EC2) instance credentials are being used from another AWS Account. EC2 instance credentials are the temporary credentials made available through the EC2 metadata service to any applications running on an instance, when an AWS Identity and Access Management (IAM) role is attached to it.
What Are the Risks?
When your workloads deployed on EC2 instances access AWS services, they use an access key, a secret access key, and a session token. The secure mechanism to pass access key credentials to your workloads is to define the permissions required by your workload, create one or several IAM policies with the permissions, attach the policies to an IAM role and, finally, attach the role to the instance.
Any process running on an EC2 instance with a role attached can retrieve the security credentials by calling the EC2 metadata service:
curl 169.254.169.254/latest/meta-data/iam/security-credentials/role_name
{
"Code" : "Success",
"LastUpdated" : "2021-09-05T18:24:45Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "AS...J5",
"SecretAccessKey" : "r1...9m",
"Token" : "IQ...z5Q==",
"Expiration" : "2021-09-06T00:44:06Z"
}These credentials are limited in time and in scope. They are valid for a maximum of six hours. They are limited to the scope of the permissions attached to the IAM role associated with the EC2 instance.
All AWS SDK are able to retrieve and renew such credentials automatically. No additional code is necessary in your application.
Now imagine that your application running on the EC2 instance is compromised and a malicious actor managed to access the instance’s meta data service. The malicious actor would extract the credentials. These credentials have the permissions you defined in the IAM role attached to the instance. Depending on your application, attackers might have the possibility to exfiltrate data from S3 or DynamoDB, to start or terminate EC2 instances, or even to create new IAM users or roles.
Since the launch of GuardDuty, it has detected when such credentials are used from IP addresses outside of AWS. Smart attackers therefore might hide their activity from another AWS account to operate outside of the sight of GuardDuty. Starting today, GuardDuty also detects when the credentials are used from other AWS accounts, inside the AWS network.
What Alerts Are Generated?
There are legitimate reasons why the source IP address communicating with AWS Services APIs might be different than the EC2 instance IP address. Think about complex network topologies that route traffic to one or multiple VPCs; AWS Transit Gateway, or AWS Direct Connect for example. In addition, multi-Region configurations, or not using AWS Organizations, makes it non trivial to detect if the AWS account using the credentials belongs to you or not. Large companies have implemented their own solution to detect such security compromises, but these type of solutions are not easy to build and to maintain. Only a handful of organizations have the resources required to tackle this challenge. When they do so, they distract their engineering efforts from their core business. This is why we decided to address this.
Starting today, GuardDuty generates alerts when it detects a misuse of EC2 instance credentials. When the credentials are used from an affiliated account, the alert is labeled as medium-severity. Otherwise, a high-severity alert is generated. Affiliated accounts are accounts monitored by the same GuardDuty administrator account, also known as GuardDuty member accounts. They might be part of your organization or not.
In Practice
To learn how it’s working, let’s capture and exfiltrate a set of EC2 credentials from one of my EC2 instances. I use SSH to connect to one of my instances, and I use curl to retrieve the credentials, as shown earlier:
curl 169.254.169.254/latest/meta-data/iam/security-credentials/role_name
{
"Code" : "Success",
"LastUpdated" : "2021-09-05T18:24:45Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "AS...J5",
"SecretAccessKey" : "r1...9m",
"Token" : "IQ...z5Q==",
"Expiration" : "2021-09-06T00:44:06Z"
}The instance has an IAM role with permissions allowing to read S3 buckets in this AWS account. I copy and paste the credentials. Then I connect to another EC2 instance running in a different AWS account, not affiliated with the same GuardDuty administrator account. I use SSH to connect to that other instance, and then I configure the AWS CLI with the compromised credentials. I attempt to access a private S3 bucket.
# first verify I do not have access
[ec2-user@ip-1-1-0-79 ~]$ aws s3 ls s3://my-private-bucket
An error occurred (AccessDenied) when calling the ListObjectsV2 operation: Access Denied
# then I configure the CLI using the compromised credentials
[ec2-user@ip-1-1-0-79 ~]$ aws configure
AWS Access Key ID [None]: AS...J5
AWS Secret Access Key [None]: r1...9m
Default region name [None]: us-east-1
Default output format [None]:
[ec2-user@ip-1-1-0-79 ~]$ aws configure set aws_session_token IQ...z5Q==
# Finally, I attempt to access S3 again
[ec2-user@ip-1-1-0-79 ~]$ aws s3 ls s3://my-private-bucket
PRE folder1/
PRE folder2/
PRE folder3/
2021-01-22 16:37:48 6148 .DS_Store
Shortly after, I use the AWS Management Console to access GuardDuty in the AWS account where I stole the credentials. I can verify a high-severity alert was generated.
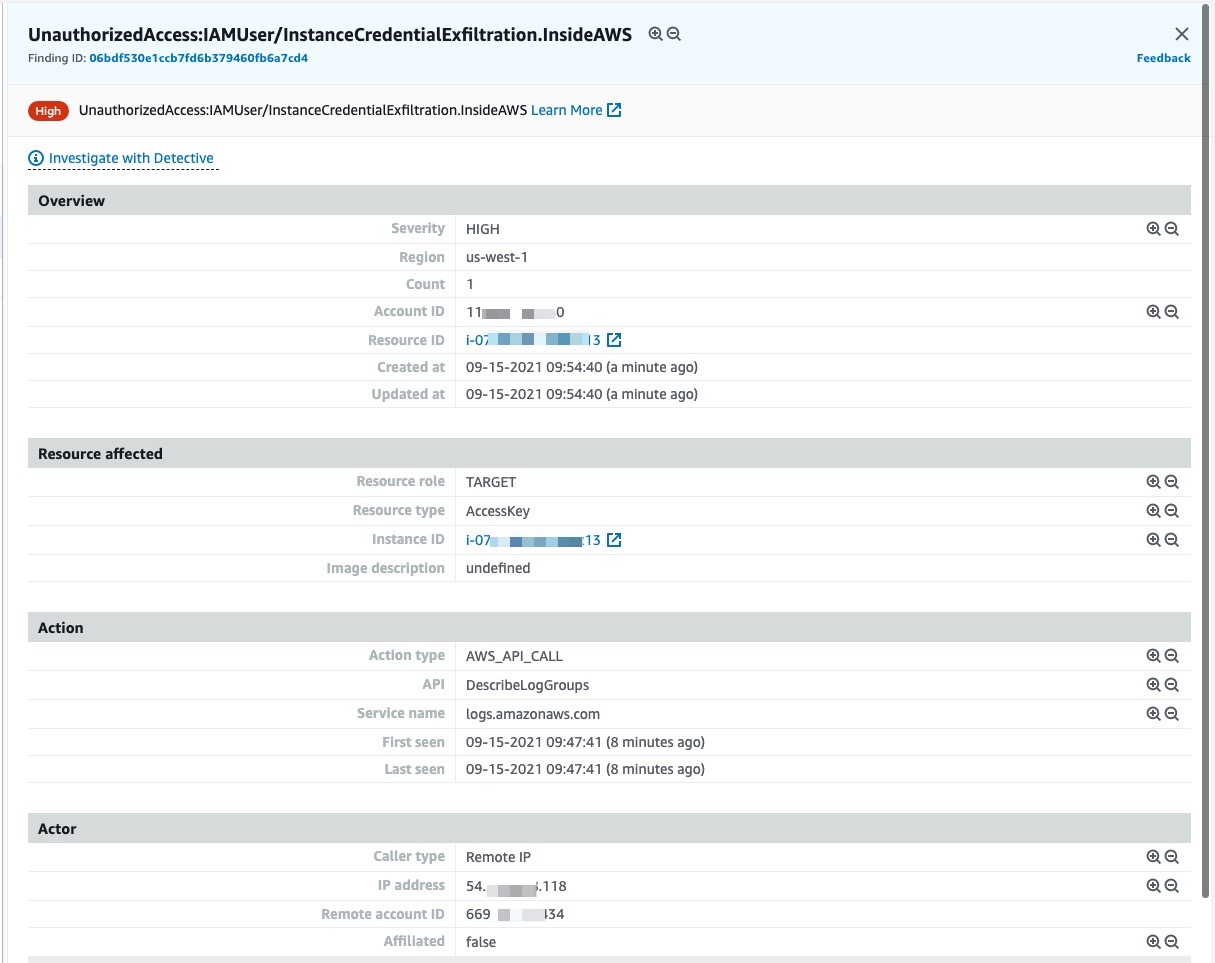
And So What?
Attackers may extract credentials when they have remote code execution (RCE), local presence on the instance, or by exploiting application-level vulnerabilities like Server Side Request Forgery (SSRF) and XML External Entity (XXE) injection. There are multiple methods to mitigate RCE or local access, including rebuilding the instances from a secured and patched AMI to eliminate remote access, rotate access credentials, and so on. When the vulnerability is at the application level, you or the application vendor are required to patch the application code to eliminate the vulnerability.
When you receive an alert indicating a risk of compromised credentials, the first thing to do is to verify the account ID. Is it one of your company accounts or not? During the analysis, when the business case allows, you may terminate the compromised instances or shut down the application. This prevents the attacker from extracting renewed instance credentials upon expiration. When in doubt, contact the AWS Trust & Safety team using the Report Amazon AWS abuse form or by contacting [email protected]. Provide all the necessary information, including the suspicious AWS account ID, logs in plaintext, and so on, when you submit your request.
Availability
This new ability is available in all AWS Regions at no additional cost. It is enabled by default when GuardDuty is already enabled on your AWS account.
Otherwise, enable GuardDuty now, and start the 30-day trial period.

 processor (Milan) cores with 384 GB RAM, and offers up to 65 percent better price-performance over comparable x86-based compute-optimized instances.
processor (Milan) cores with 384 GB RAM, and offers up to 65 percent better price-performance over comparable x86-based compute-optimized instances.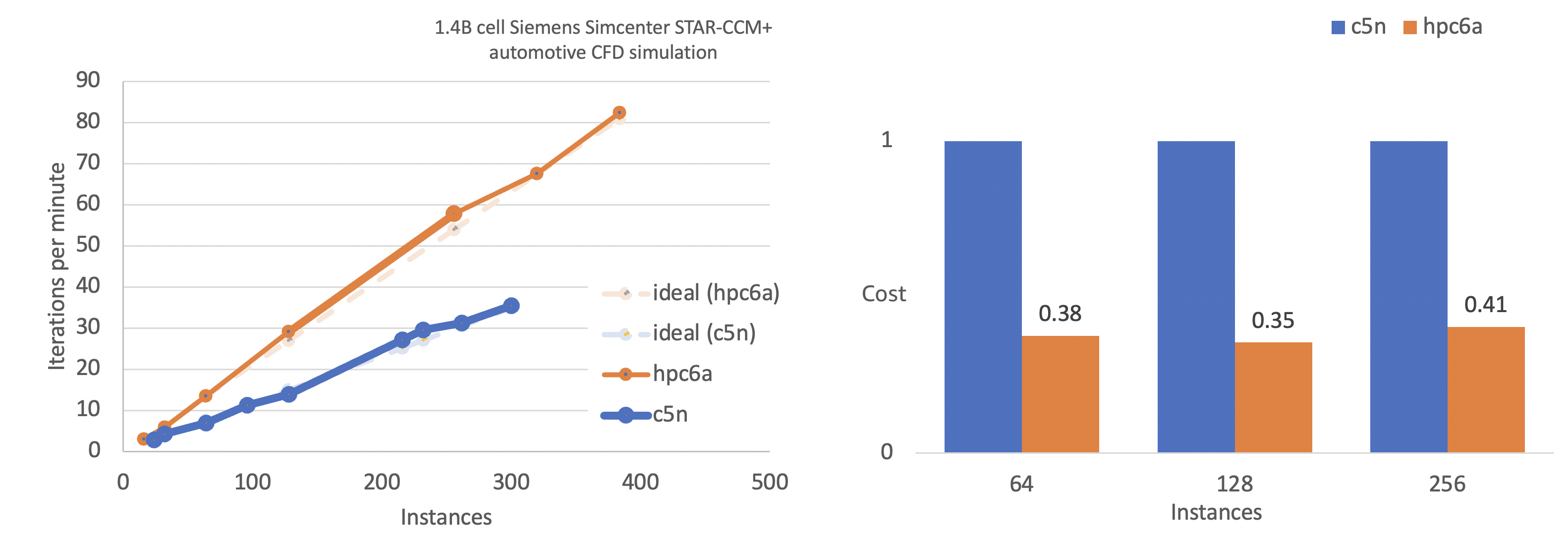


 Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.
Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.
















 Available, I navigate to the Data repository tab, and then select Create data repository association.
Available, I navigate to the Data repository tab, and then select Create data repository association.