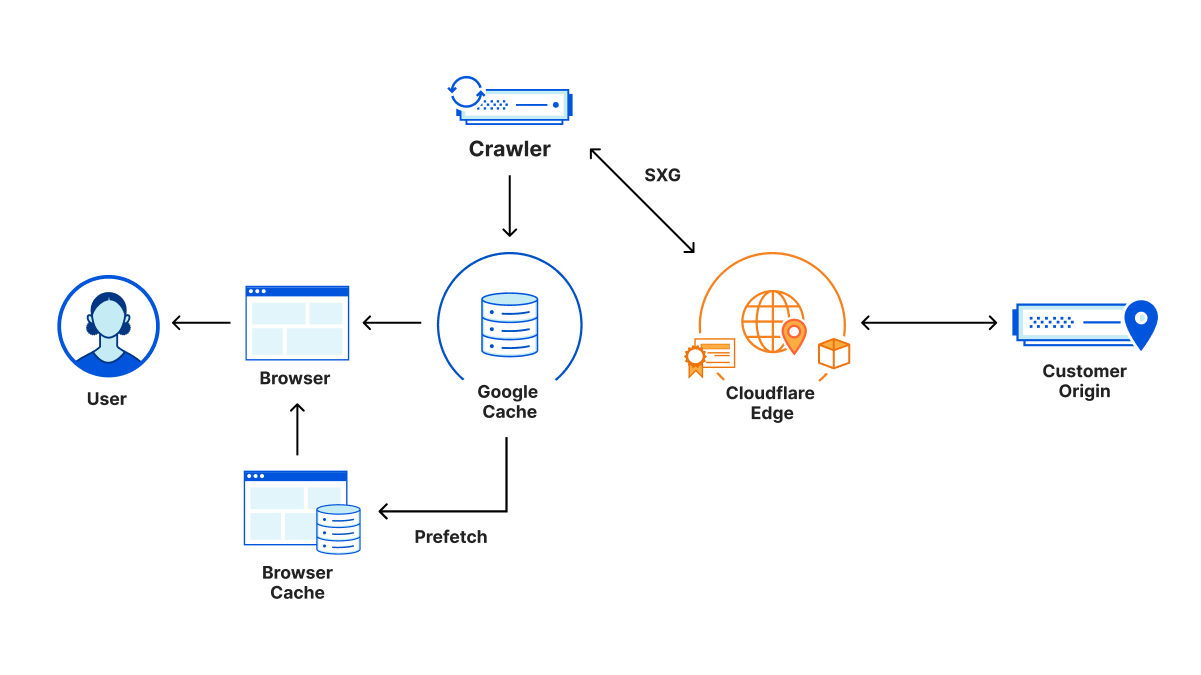
Post Syndicated from John Graham-Cumming original https://blog.cloudflare.com/benchmarking-edge-network-performance/


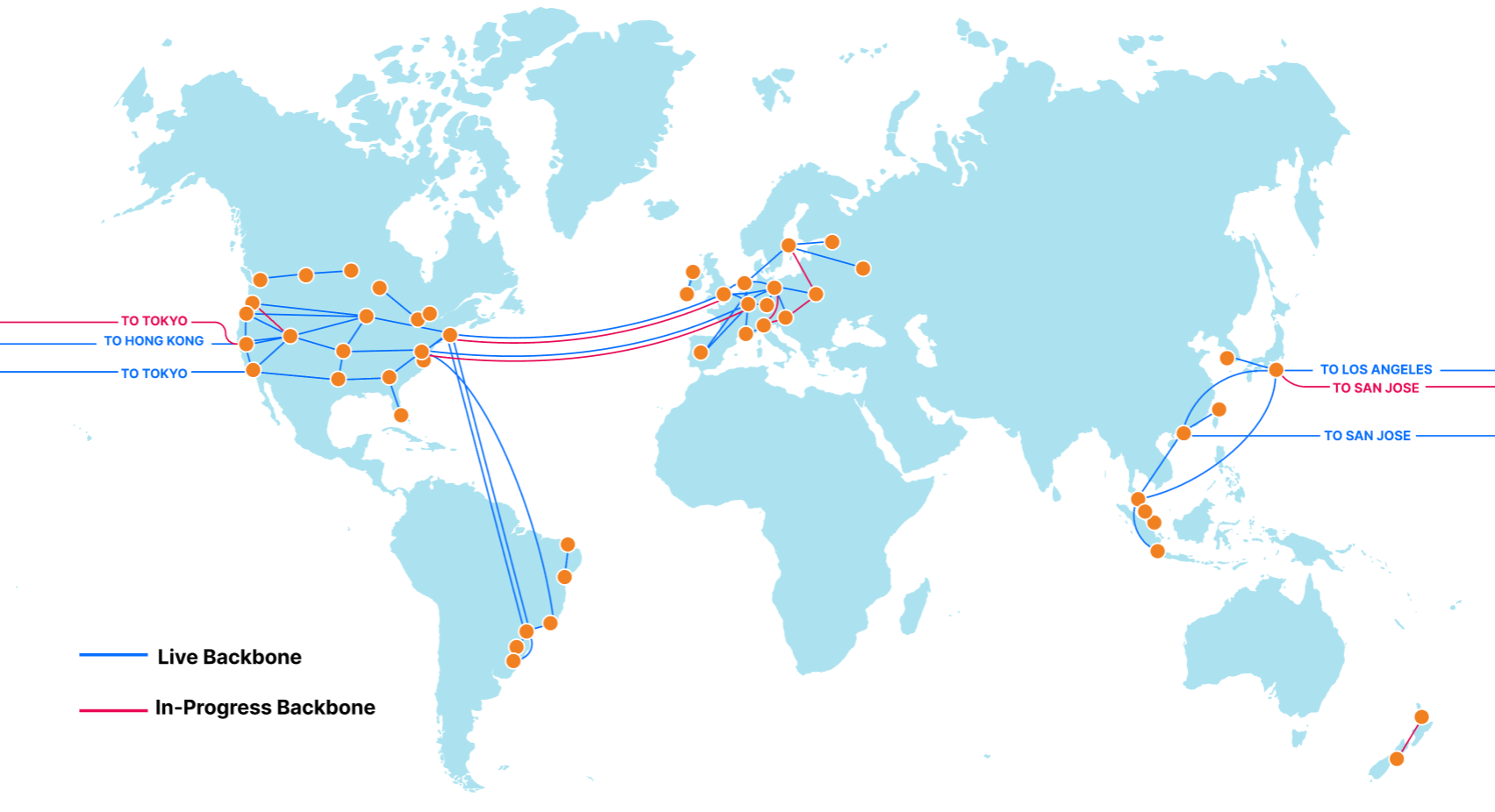
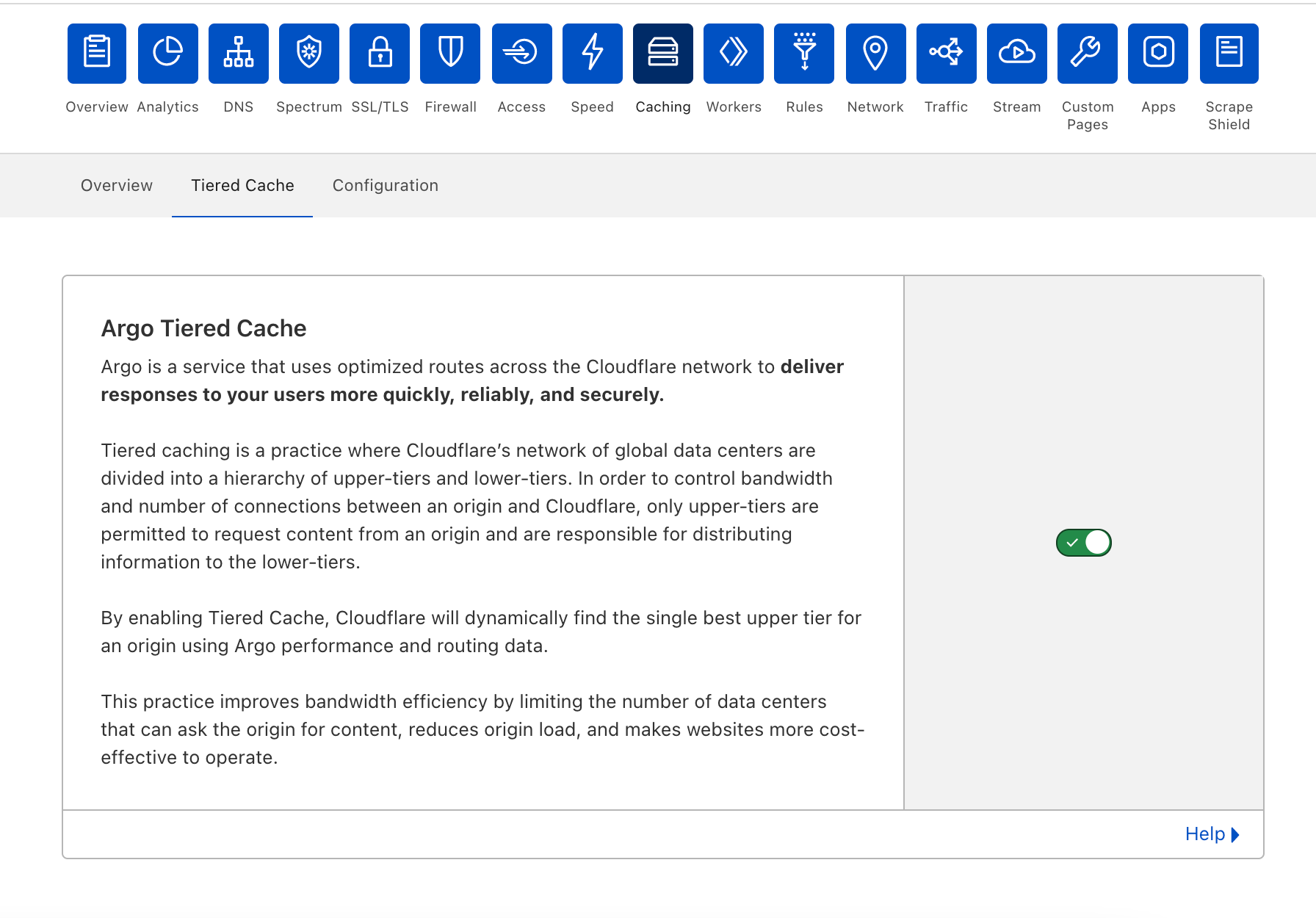
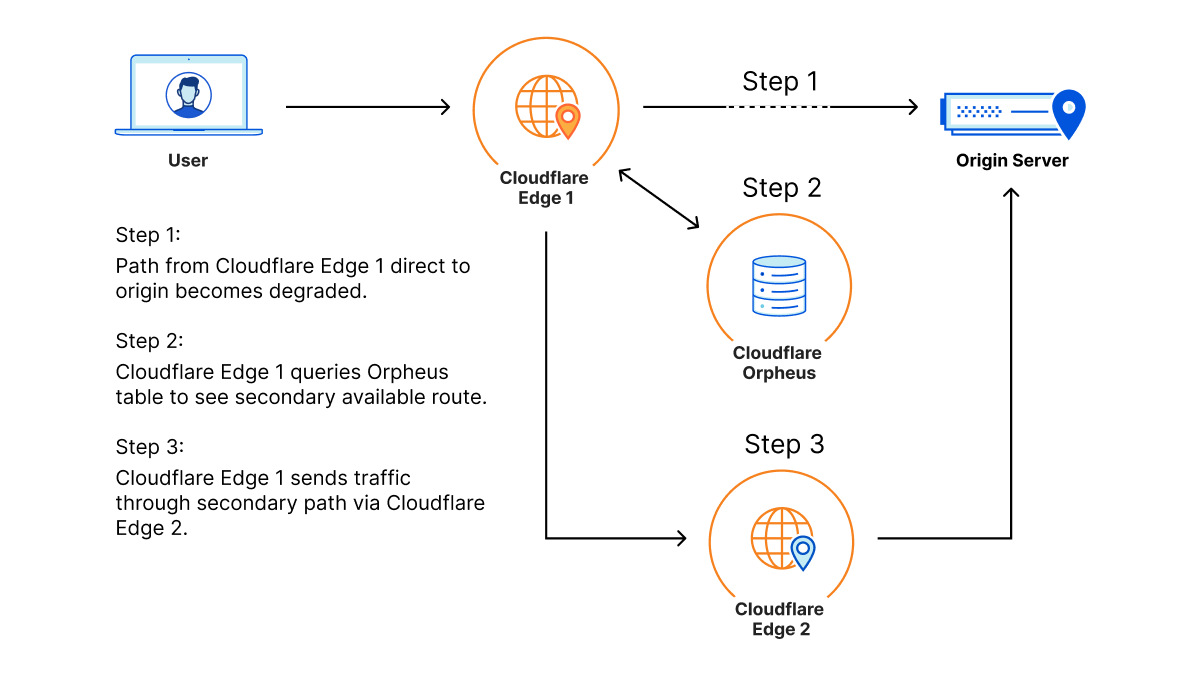
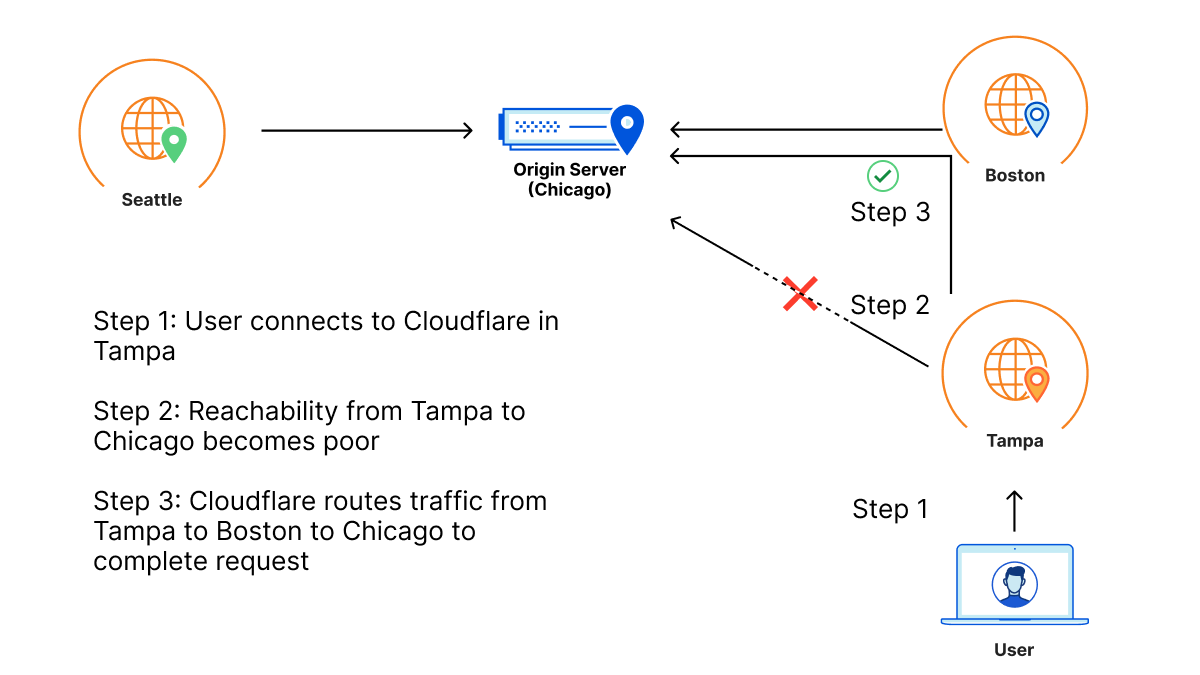
During Speed Week we’ve talked a lot about services that make the web faster. Argo 2.0 for better routing around bad Internet weather, Orpheus to ensure that origins are reachable from anywhere, image optimization to send just the right bits to the client, Tiered Cache to maximize cache hit rates and get the most out of Cloudflare’s new 25% bigger network, our expanded fiber backbone and more.
Those things are all great.
But it’s vital that we also measure the performance of our network and benchmark ourselves against industry players large and small to make sure we are providing the best, fastest service.
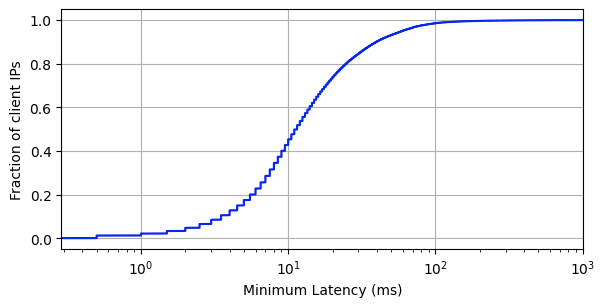
We recently ran a measurement experiment where we used Real User Measurement (RUM) data from the standard browser API to test the performance of Cloudflare and others in real-world conditions across the globe. We wanted to use third-party tests for this, but they didn’t have the granularity we wanted. We want to drill down to every single ISP in the world to make sure we optimize everywhere. We knew that in some places the answers we got wouldn’t be good, and we’d need to do work to improve our performance. But without detailed analysis across the entire globe we couldn’t know we were really the fastest or where we needed to improve.
In this blog post I’ll describe how that measurement worked and what the results are. But the short version is: Cloudflare is #1 in almost all cases whether you look at all the networks on the globe, or the top 1,000 largest, or the top 1,000 most active, and whether you look at mean timings or 95th percentile, and you measure how quickly a connection can be established, how long it takes for the first byte to arrive in a user’s web browser, or how long the complete download takes. And we’re not resting here, we’re committed to working network by network globally to ensure that we are always #1.
Why we measured
Commercial Internet measurement services (such as Cedexis, Catchpoint, Pingdom, ThousandEyes) already exist and perform the sorts of RUM measurements that Cloudflare used for this test. And we wanted to ensure that our test was as fair as possible and allowed each network to put its best foot forward.
We subscribe to the third party monitoring services already. And, when we looked at their data we weren’t satisfied.
First, we worried that the way they sampled wasn’t globally representative and was often skewed by measuring from the server, rather than the eyeball, side of the network. Or, even if operating from the eyeball side, could be skewed as artificial or tainted by bots and other automated traffic.
Second, it wasn’t granular enough. It showed our performance by country or region, but didn’t dive into individual networks and therefore obscured the details and outliers behind averages. While we looked good in third party tests, we didn’t trust them to be as thorough and accurate as we wanted. The goal isn’t to pick a test where we looked good. The goal was to be accurate and see where we weren’t good enough yet, so we could focus on those areas and improve. That’s why we had to build this ourselves.
We benchmark against others because it’s useful to know what’s possible. If someone else is faster than we are somewhere then it proves it’s possible. We won’t be satisfied until we’re at least as good as everyone else everywhere. Now we have the granular data to ensure that’ll happen. We plan our next update during Birthday Week when our target is to take 10% of networks where we’re not the fastest and become the fastest.
How we measured
To measure performance we did two things. We created a small internal team to do the measurements separate from the team that manages and optimizes our network. The goal was to show the team where we need to improve.
And to ensure that the other CDNs were tested using their most representative assets we used the very same endpoints that commercial measurement services use on the assumption that our competitors will have already ensured that those endpoints are optimized to show their networks’ best performance.
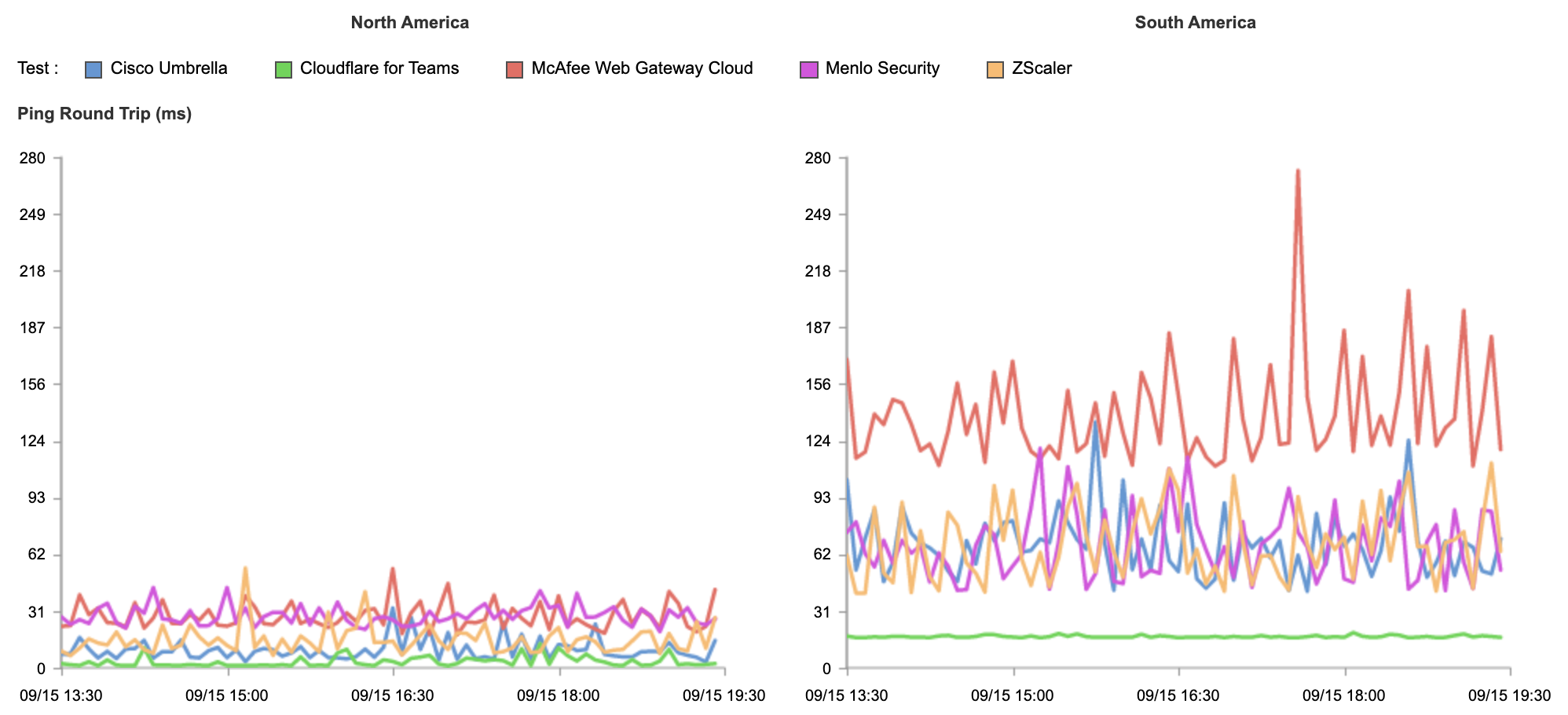
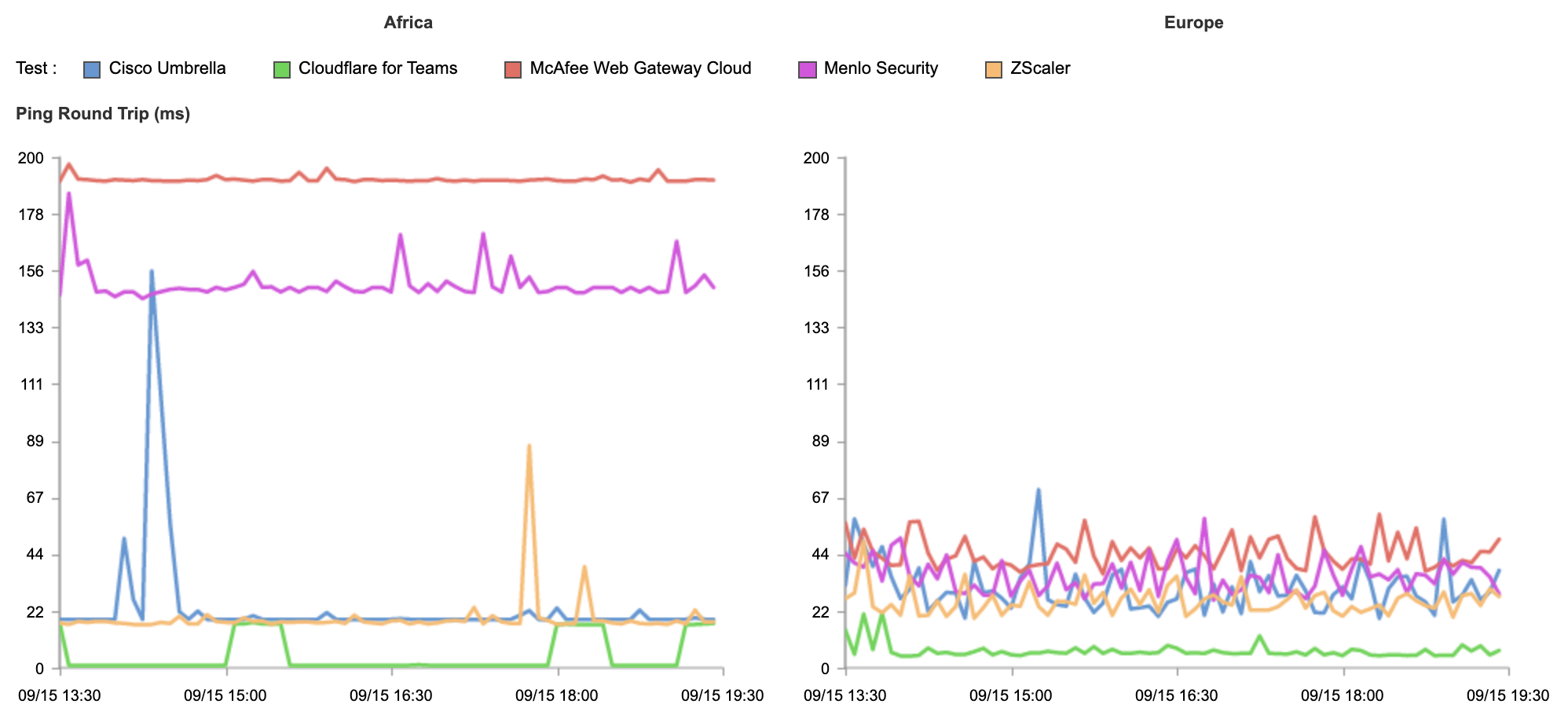
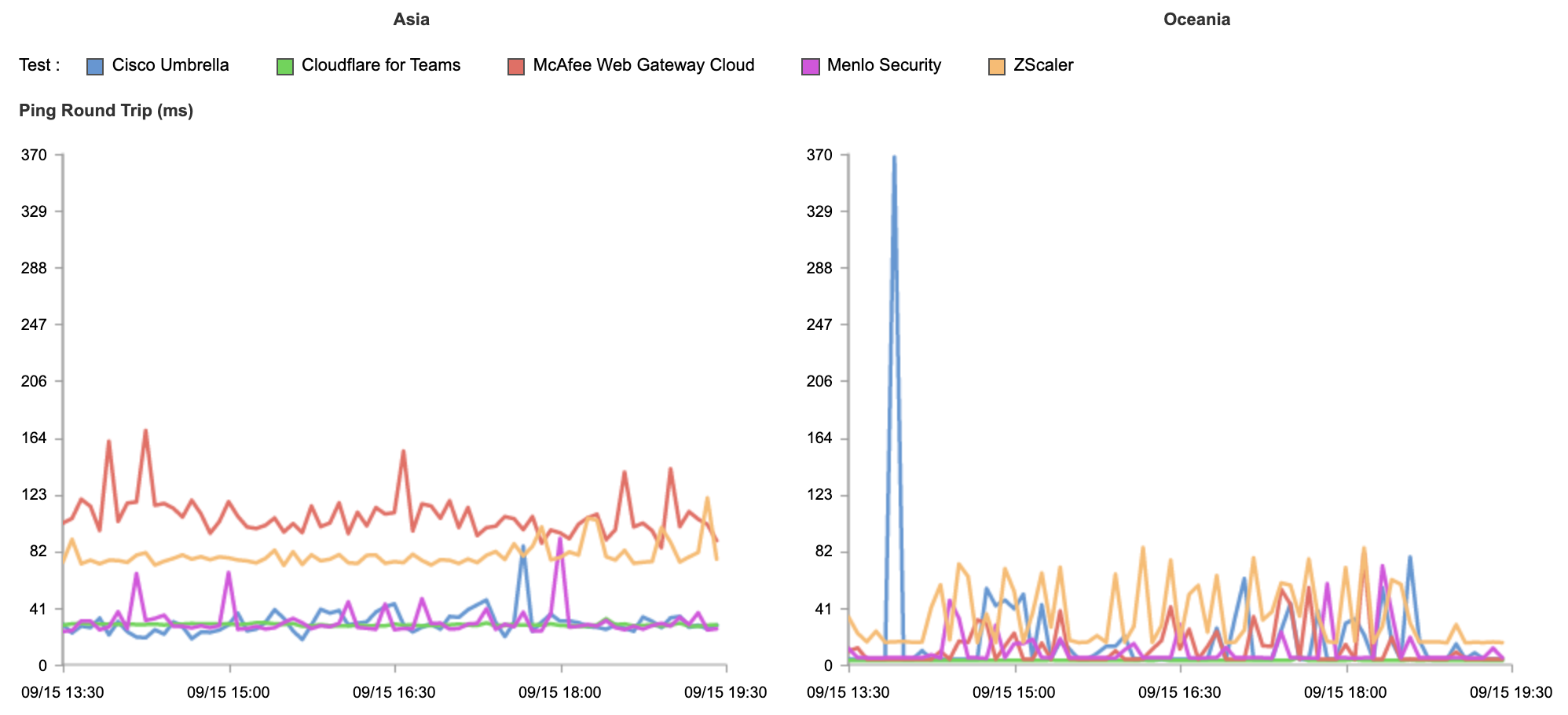
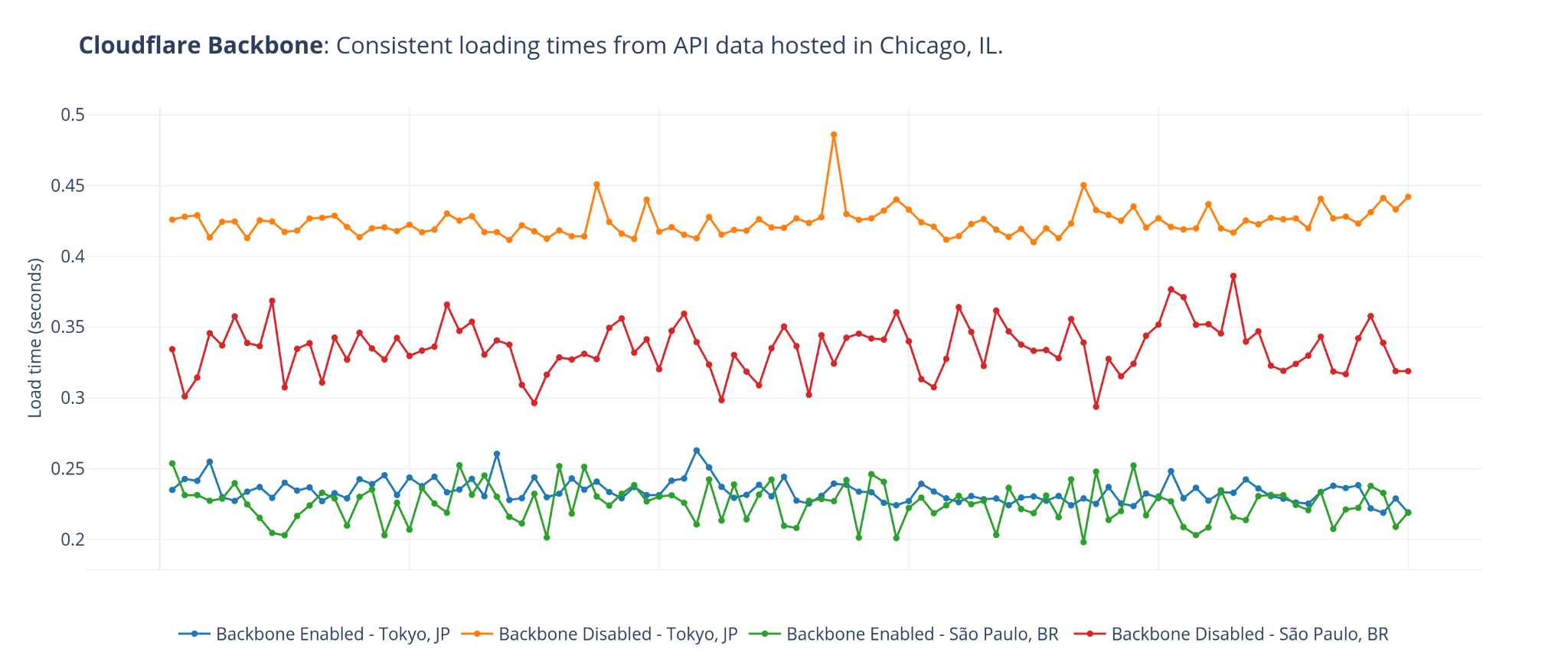
The measurements in this blog post are based on four days just before Speed Week began (2021-09-10 12:25:02 UTC to 2021-09-13 16:21:10 UTC). We took measurements of downloading exactly the same 100KB PNG file. We categorized them by the network the measurement was taken from. It’s identified by its ASN and a name. We’re not done with these measurements and will continue measuring and optimizing.
A 100KB file is a common test measurement used in the industry and allows us to measure network characteristics like the connection time, but also the total download time.
Before we get into results let’s talk a little about how the Internet fits together. The Internet is a network of networks that cooperate to form the global network that we all use. These networks are identified by a strangely named “autonomous system number” or ASN. The idea is that large networks (like ISPs, or cloud providers, or universities, or mobile phone companies) operate autonomously and then join the global Internet through a protocol called BGP (which we’ve written about in the past).
In a way the Internet is these ASNs and because the Internet is made of them we want to measure our performance for each ASN. Why? Because one part of improving performance is improving our connectivity to each ASN and knowing how we’re doing on a per-network basis helps enormously.
There are roughly 70,000 ASNs in the global Internet and during the measurement period we saw traffic from about 21,000 (exact number: 20,728) of them. This makes sense since not all networks are “external” (as in the source of traffic to websites); many ASNs are intermediaries moving traffic around the Internet.
For the rest of this blog we simply say “network” instead of “ASN”.
What we measured
Getting real user measurement data used to be hard but has been made easy for HTTP endpoints thanks to the Resource Timing API, supported by most modern browsers. This API allows a page to measure network timing data of fetched resources using high-resolution timestamps, accurate to 5 µs (microseconds).
The point of this API is to get timing information that shows how a real end-user experiences the Internet (and not a synthetic test that might measure a single component of all the things that happen when a user browses the web).
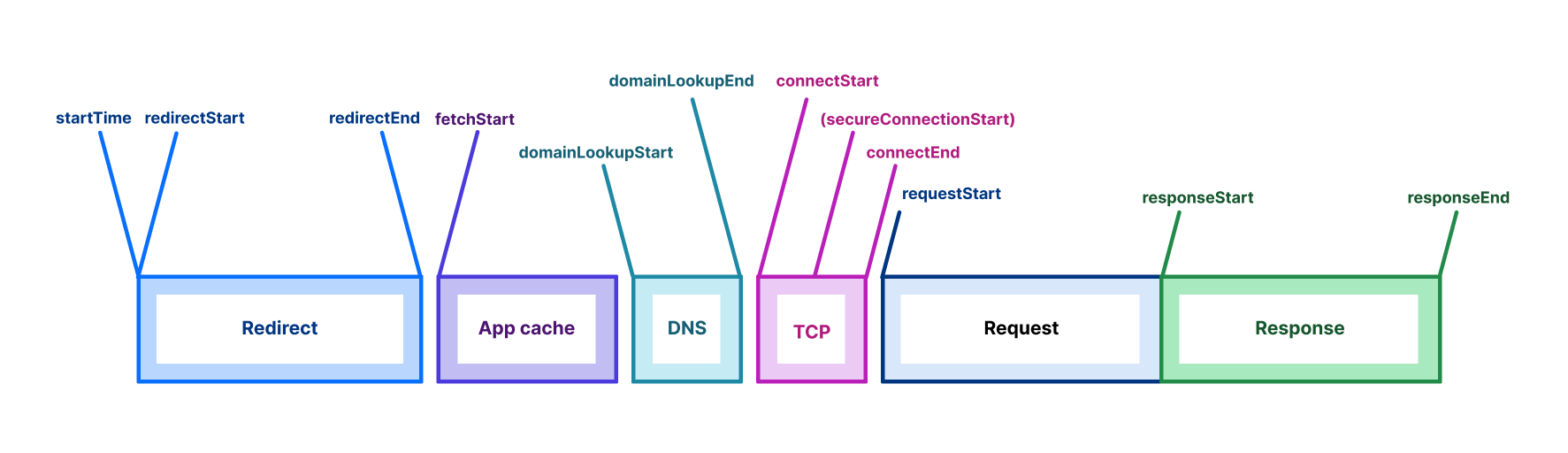
The Resource Timing API is supported by pretty much every browser enabling measurement on everything from old versions of Internet Explorer, to mobile browsers on iOS and Android to the latest version of Chrome. Using this API gives us a view of real world use on real world browsers.
We don’t just instruct the browser to download an image too. To make sure that we’re fair and replicate the real-life end-user experience, we make sure that no local caching was involved in the request, check if the object has been compressed by the server or not, take the HTTP headers size into account, and record if the connection has been pre-warmed or not, to name a few technical details.
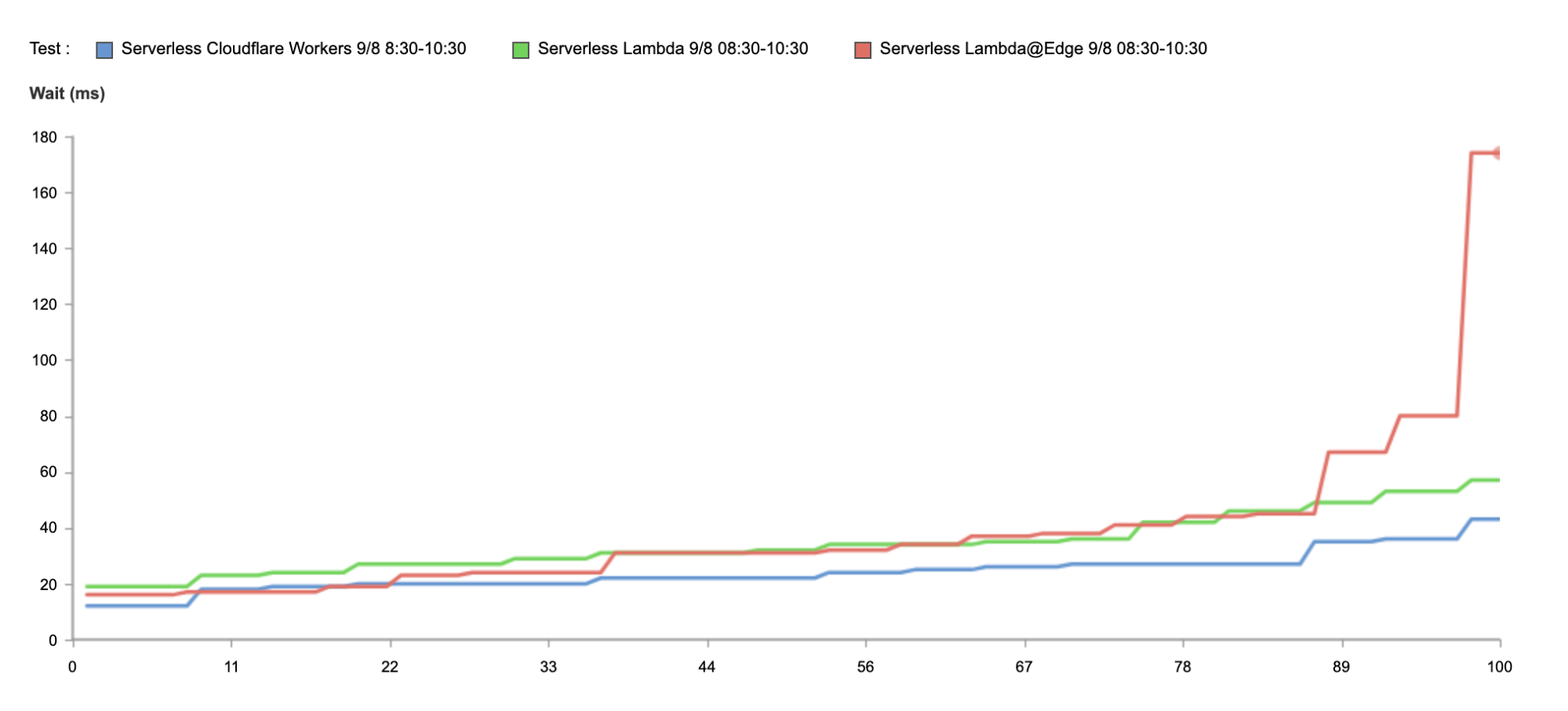
Here’s a high-level example on how this works:
await fetch("https://example.com/100KB.png?r=7562574954", {
mode: "cors",
cache: "no-cache",
credentials: "omit",
method: "GET",
})
performance.getEntriesByType("resource");
{
connectEnd: 1400.3999999761581
connectStart: 1400.3999999761581
decodedBodySize: 102400
domainLookupEnd: 1400.3999999761581
domainLookupStart: 1400.3999999761581
duration: 51.60000002384186
encodedBodySize: 102400
entryType: "resource"
fetchStart: 1400.3999999761581
initiatorType: "fetch"
name: "https://example.com/100KB.png"
nextHopProtocol: "h2"
redirectEnd: 0
redirectStart: 0
requestStart: 1406
responseEnd: 1452
responseStart: 1428.5
secureConnectionStart: 1400.3999999761581
startTime: 1400.3999999761581
transferSize: 102700
workerStart: 0
}
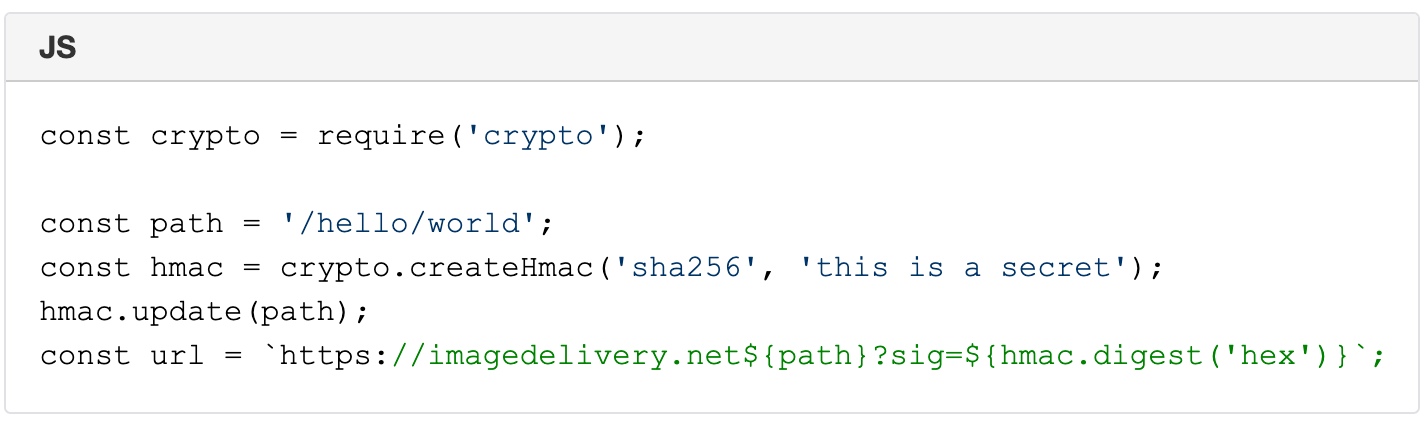
To measure the performance of each CDN we downloaded an image from each, when a browser visited one of our special pages. Once every image is downloaded we record the measurements using a Cloudflare Workers based API.
The three measurements: TCP connection time, TTFB and TTLB
We focused on three measurements to illustrate how fast our network is: TCP connection time, TTFB and TTLB. Here’s why those three values matter.
TCP connection time is used to show how well-connected we are to the global Internet as it counts only the time taken for a machine to establish a connection to the remote host (before any higher level protocols are used). The TCP connection time is calculated as connectEnd – connectStart (see the diagram above).
TTFB (or time to first byte) is the time taken once an HTTP request has been sent for the first byte of data to be returned by the server. This is a common measurement used to show how responsive a server is. We calculate TTFB as responseStart – connectStart – (requestStart – connectEnd).
TTLB (or time to last byte) is the time taken to send the entire response to the web browser. It’s a good measure of how long a complete download takes and helps measure how good the server (or CDN) is at sending data. We calculate TTLB as responseEnd – connectStart – (requestStart – connectEnd).
We then produced two sets of data: mean and p95. The mean is a very well understood number for laypeople and gives the average user experience, but it doesn’t capture the breadth of different speeds people experience very well. Because it averages everything together it can miss skewed distributions of data (where lots of people get good performance and lots bad performance, for example).
To address the mean’s problems we also used p95, the 95th percentile. This number tells us what performance 95% of measurements fall below. That can be a hard number to understand, but you can think of it as the “reasonable worst case” performance for a user. Only 5% of measurements were worse than this number.
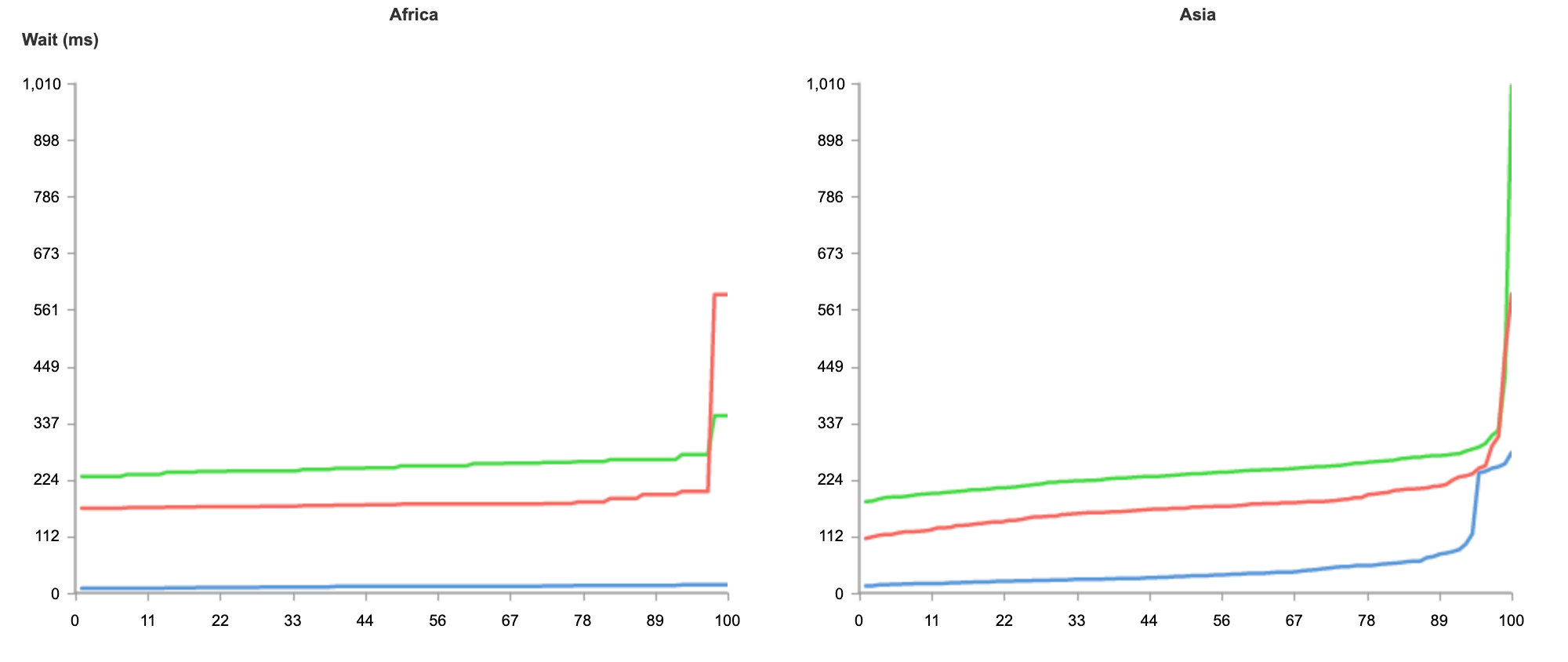
An example chart
As this blog contains a lot of data, let’s start with a detailed look at a chart of results. We compared ourselves against industry giants Google and Amazon CloudFront, industry pioneer Akamai and up and comer Fastly.
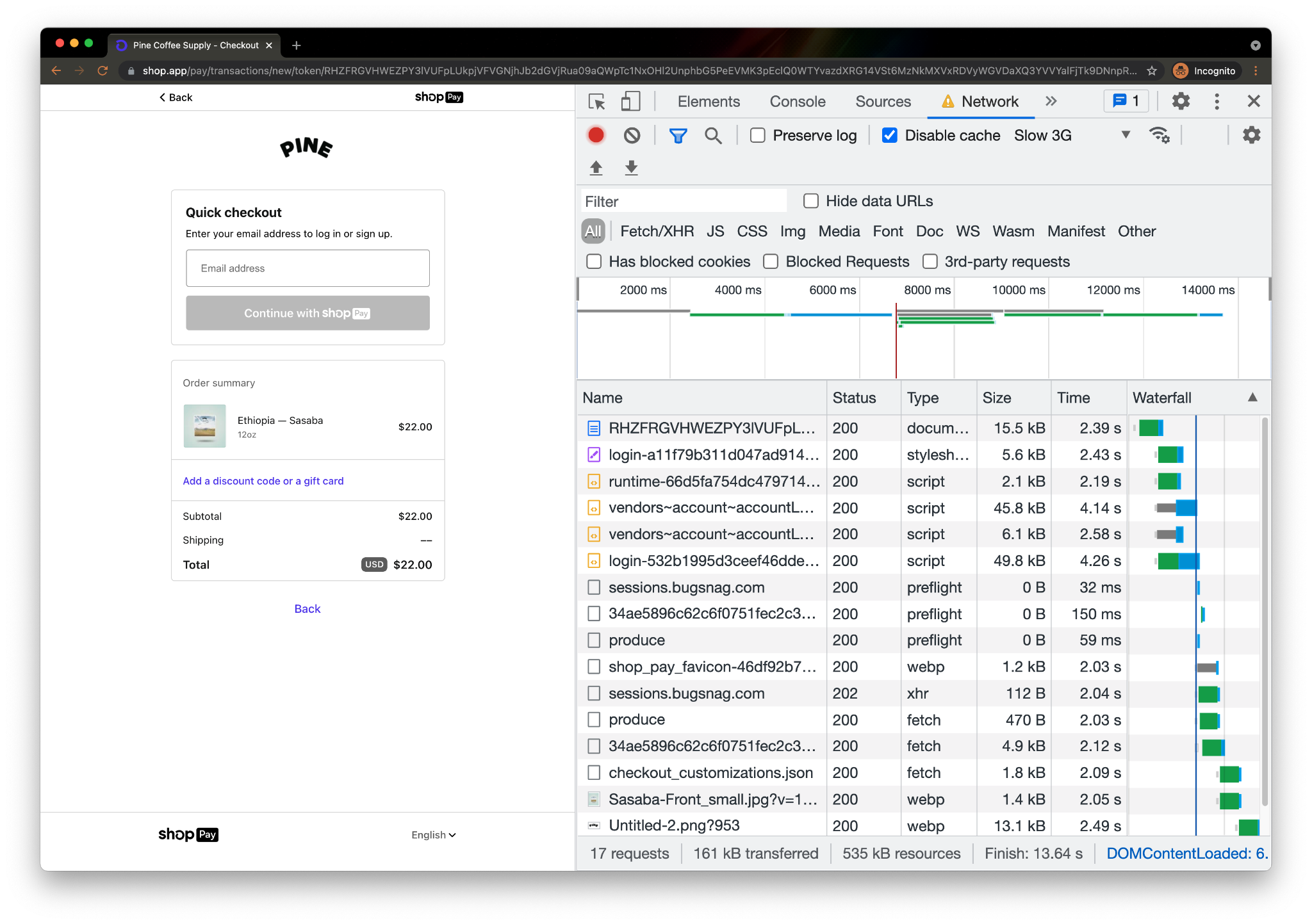
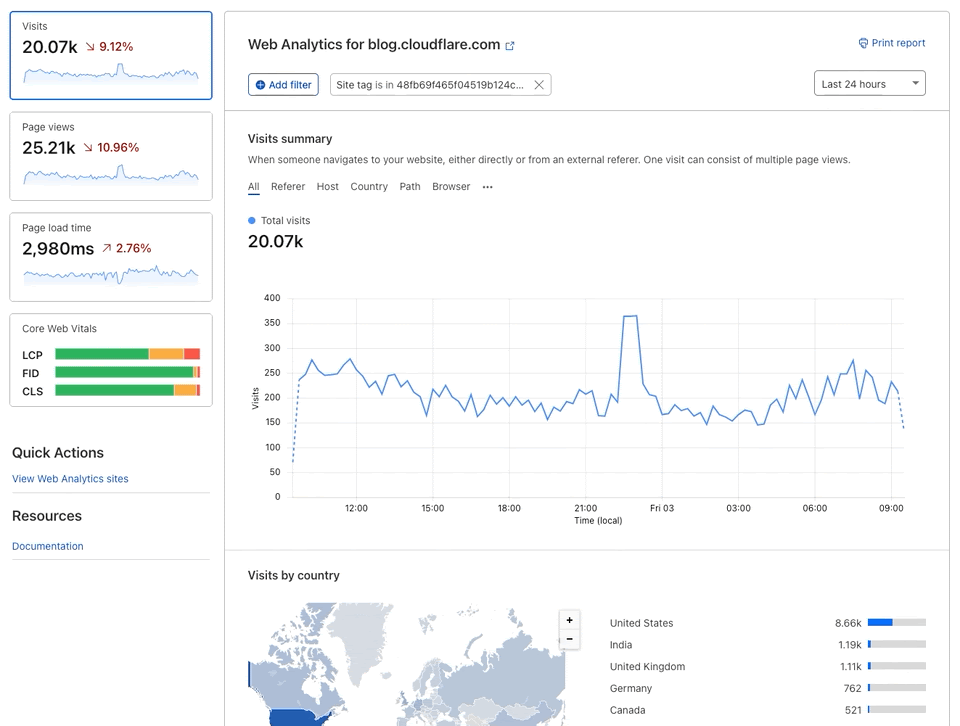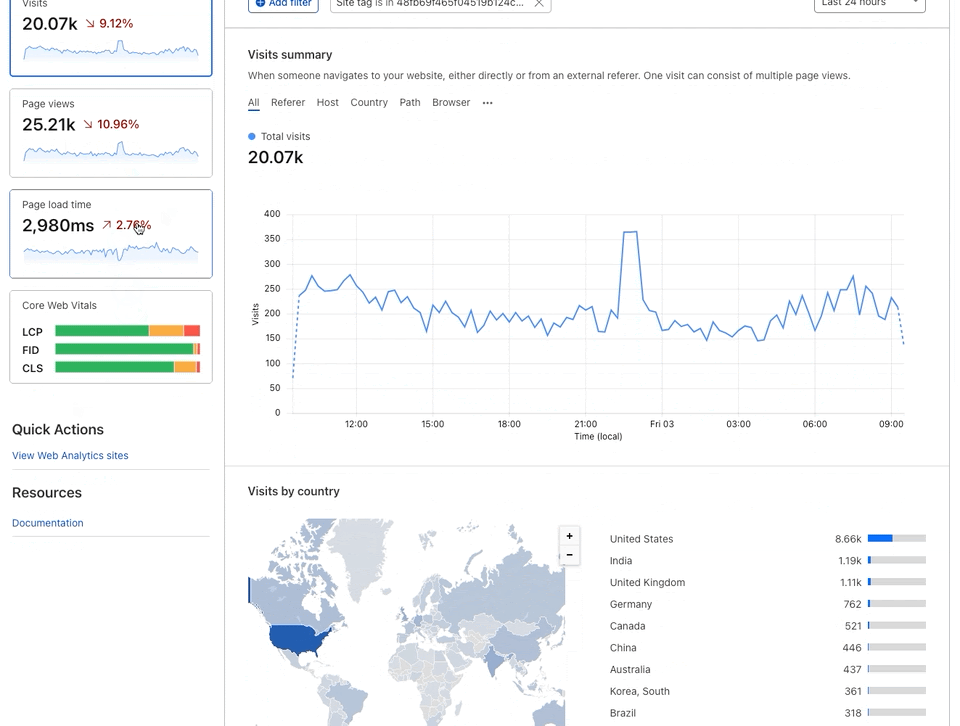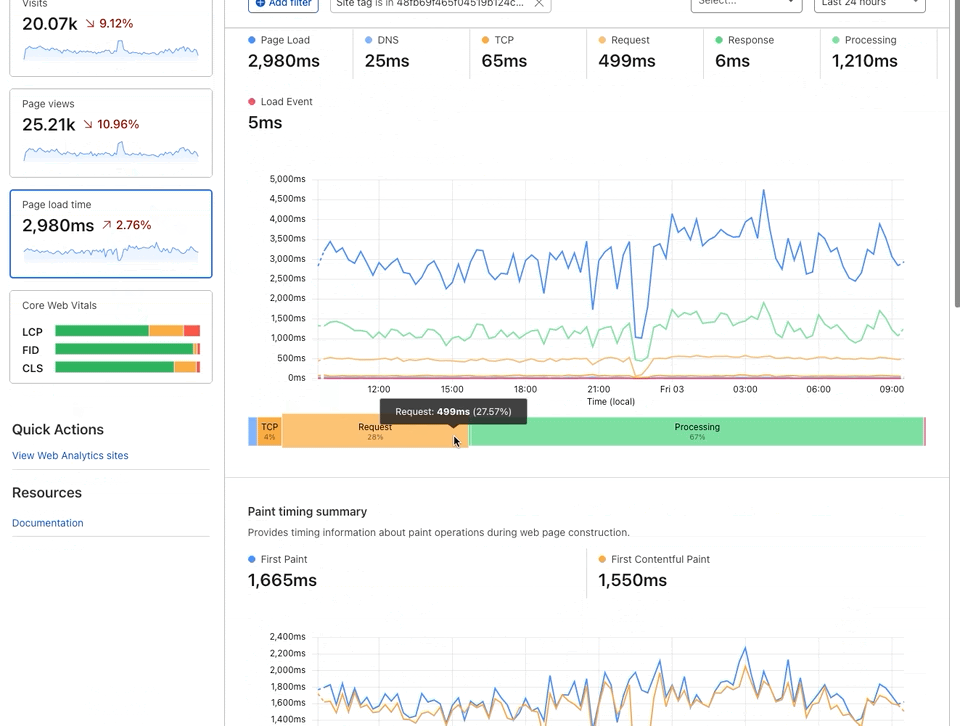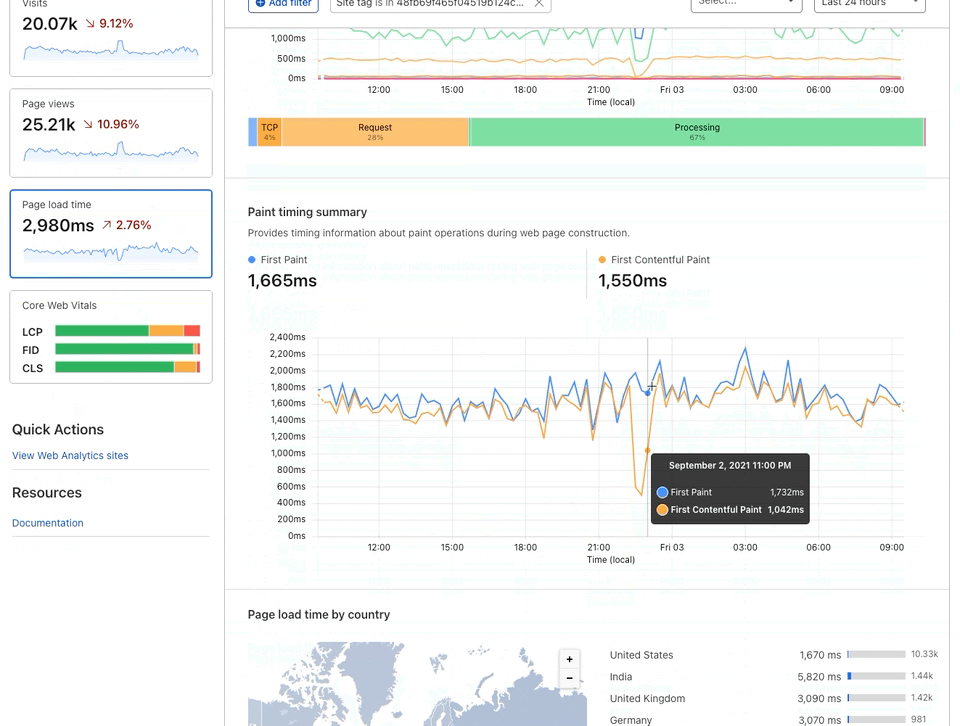
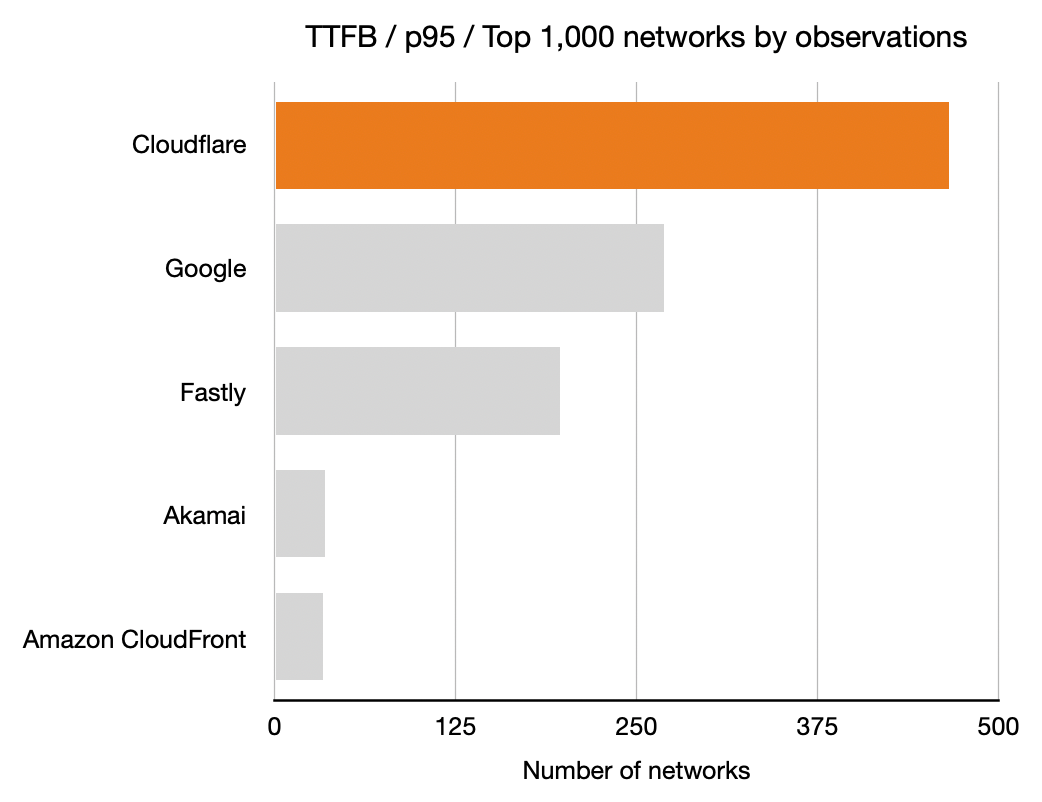
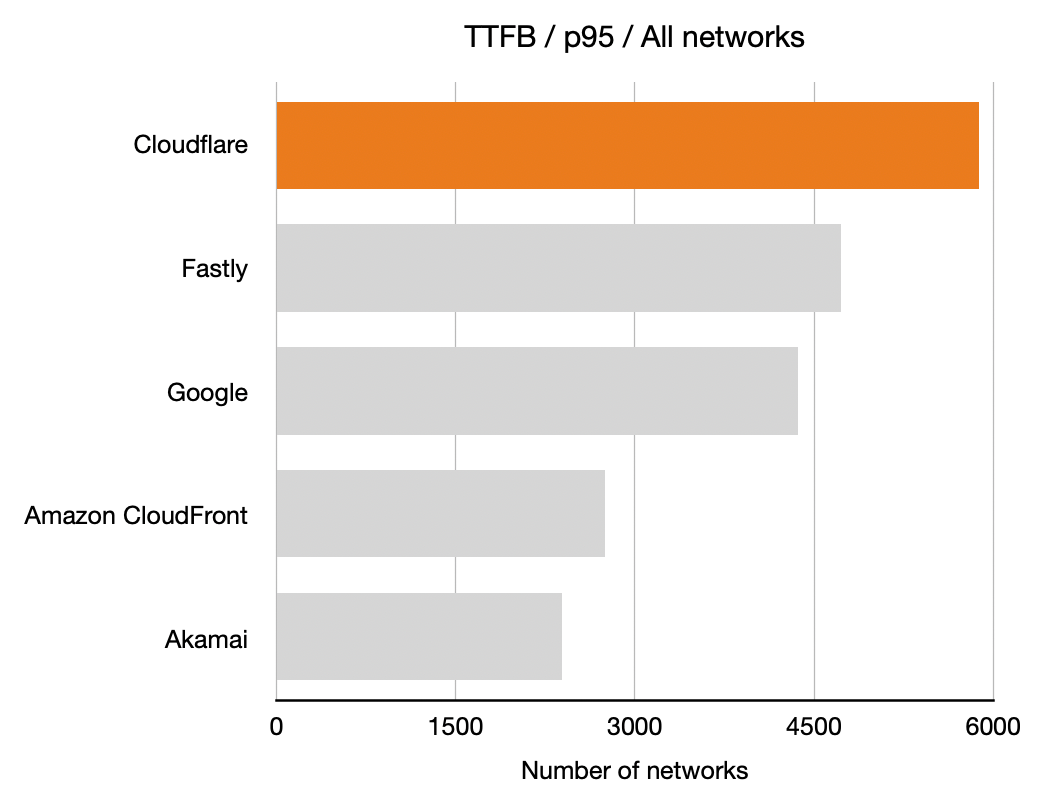
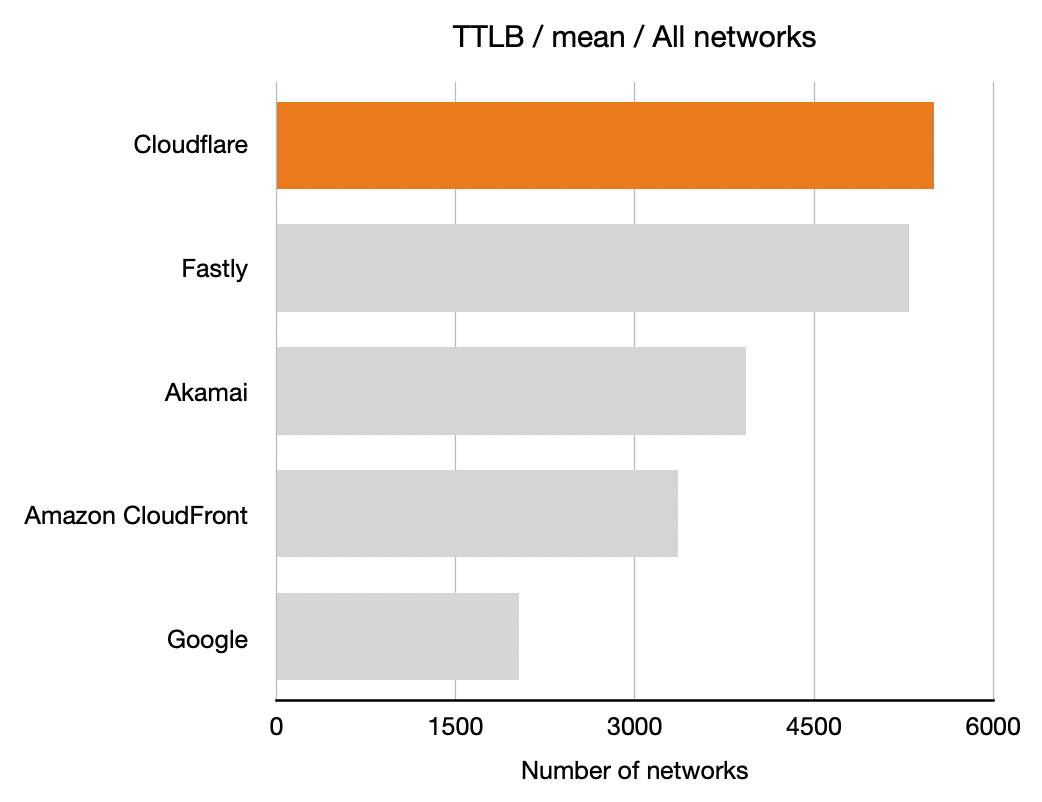
For each network (represented by an ASN) and for each CDN we calculated which CDN had the best performance. Here, for example, is a count of the number of networks on which each CDN had the best performance for TTFB. This particular chart shows p95 and includes data from the top 1,000 networks (by number of IPv4 addresses advertised).
In these charts, longer bars are better; the bars indicate the number of networks for which that CDN had the lowest TTFB at p95.
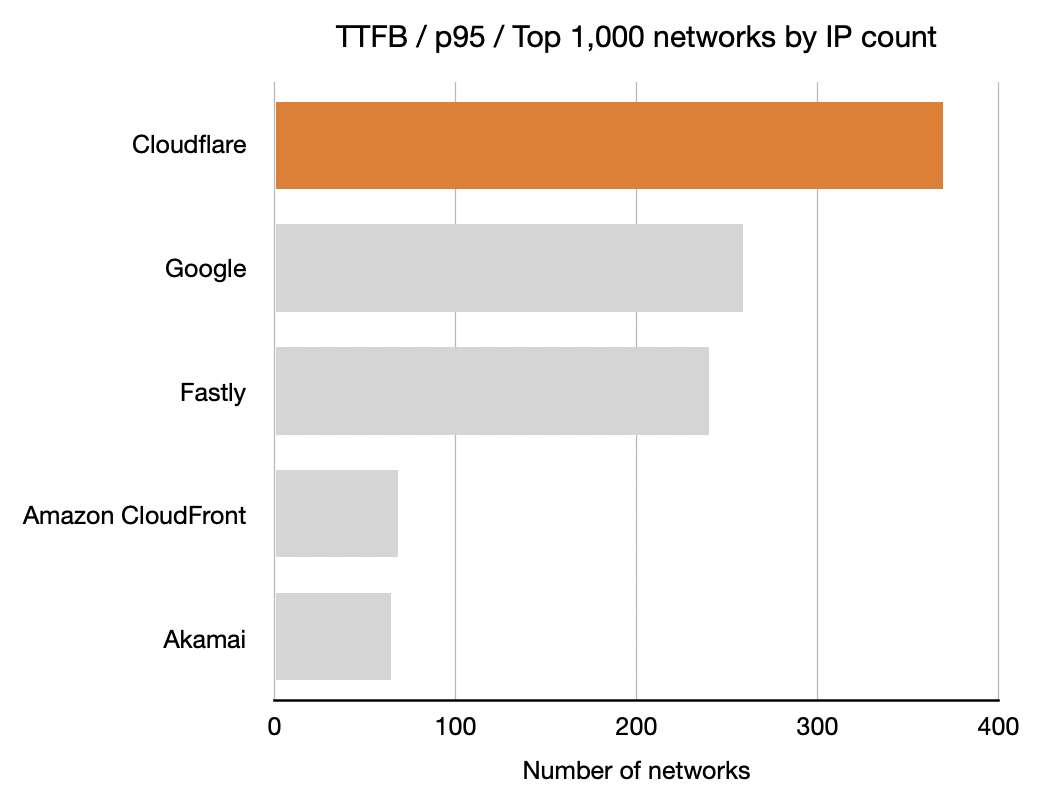
This shows that Cloudflare had the lowest time to first byte (the TTFB, or the time it took the first byte of content to reach their browser) at the 95th percentile for the largest number of networks in the top 1,000 (based on the number IPv4 addresses they advertise). Google was next, then Fastly followed by Amazon CloudFront and Akamai.
All three measures, TCP connection time, time to first byte and time to last byte, matter to the user experience. For this example, I focused on time to first byte (TTFB) because it’s such a common measure of responsiveness of the web. It’s literally the time it takes a web server to start responding to a request from a browser for a web page.
To understand the data we gathered let’s look at two large US-based ISPs: Cox and Comcast. Cox serves about 6.5 million customers and Comcast has about 30 million customers. We performed roughly 22,000 measurements on Cox’s network and 100,000 on Comcast’s. Below we’ll make use of measurement counts to rank networks by their size, here we see that our measurements and customer counts of Cox and Comcast track nicely.
Cox Communications has ASN 22773 and our data shows that the p95 TTFB for the five CDNs was as follows: Cloudflare 332.6ms, Fastly 357.6ms, Google 380.3ms, Amazon CloudFront 404.4ms and Akamai 441.5ms. In this case Cloudflare was the fastest and about 7% faster than the next CDN (Fastly) which was faster than Google and so on.
Looking at Comcast (with ASN 7922) we see p95 TTFB was 323.7ms (Fastly), 324.2ms (Cloudflare), 353.7ms (Google), 384.6ms (Akamai) and 418.8ms (Amazon CloudFront). Here Fastly (323.7ms) edged out Cloudflare (324.2ms) by 0.2%.
Figures like these go into determining which CDN is the fastest for each network for this analysis and the charts presented. At a granular level they matter to Cloudflare as we can then target networks and connectivity for optimization.
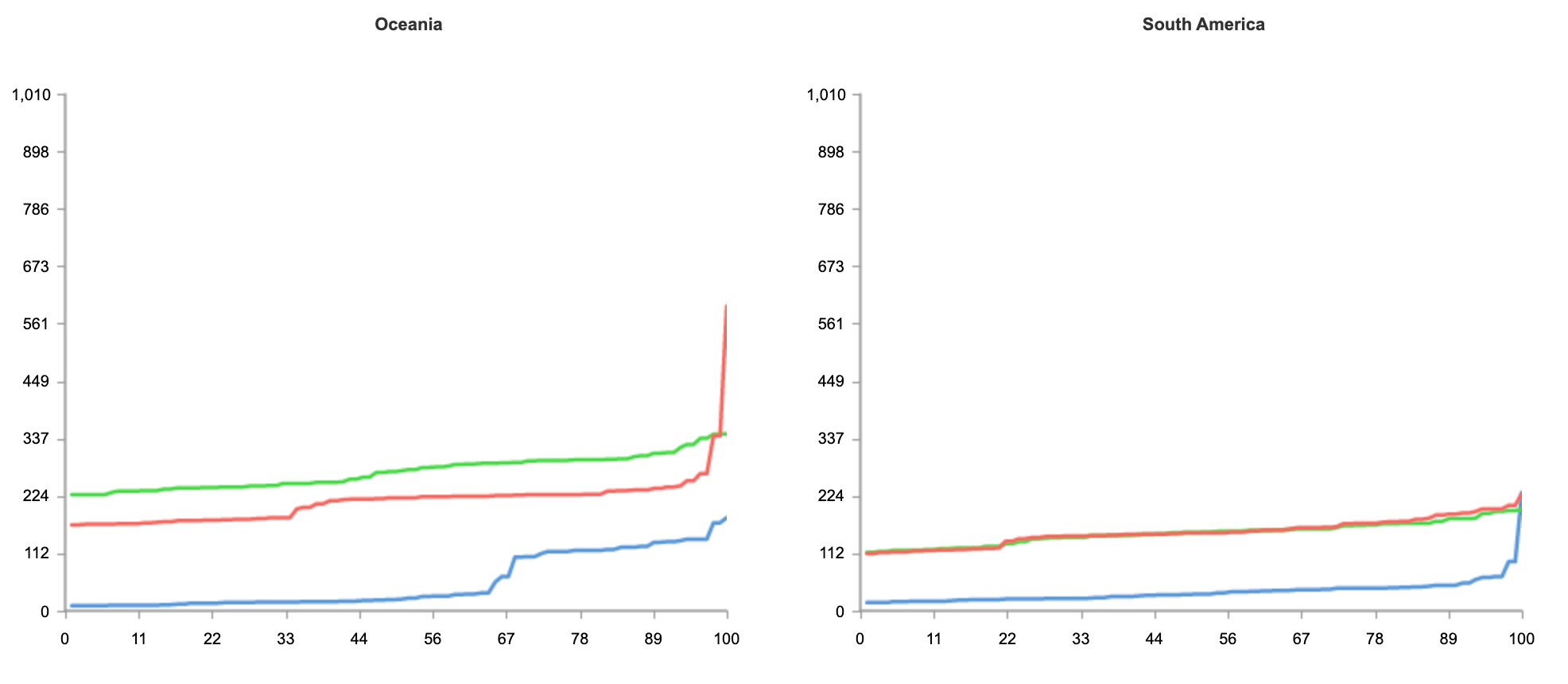
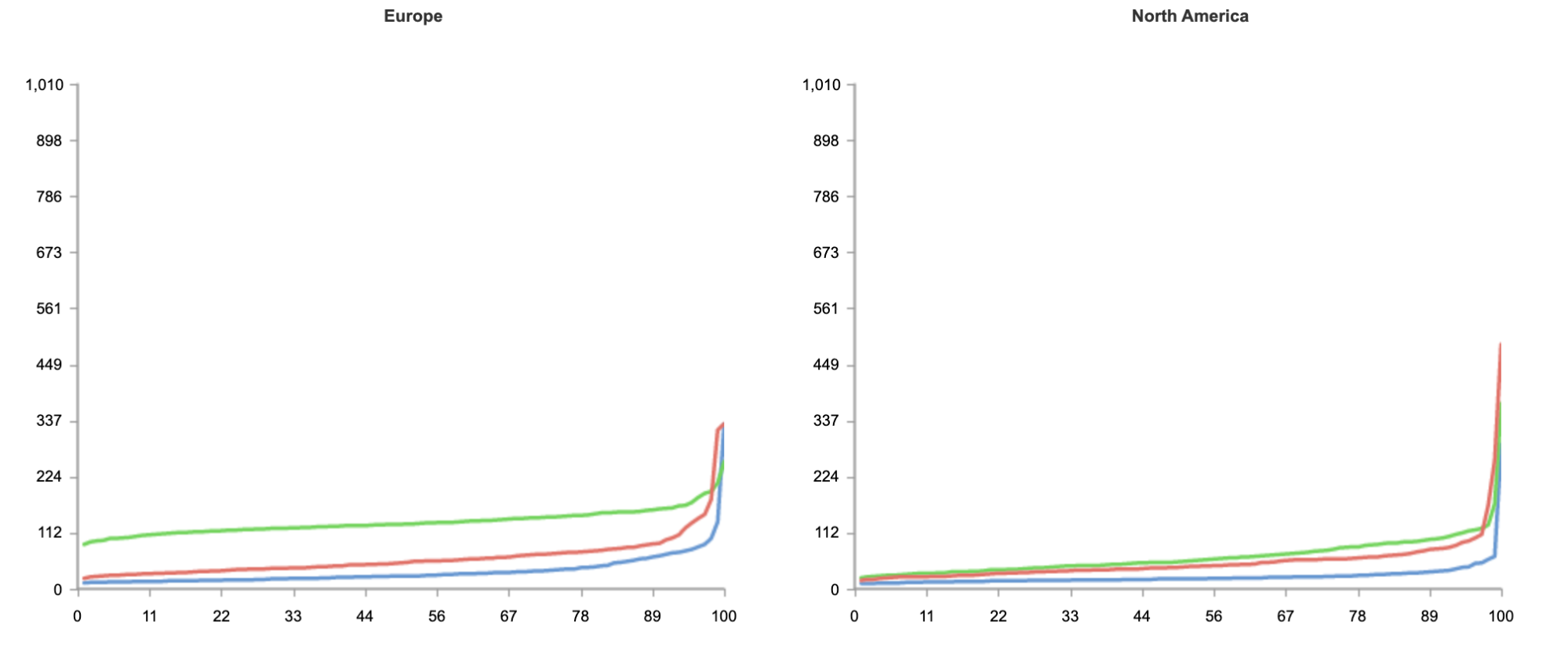
The results
Shown below are the results for three different measurement types (TCP connection time, TTFB and TTLB) with two different aggregations (mean and p95) and for three different groupings of networks.
The first grouping is the simplest: it’s all the networks we have data for. The second grouping is the one used above, the top 1,000 networks by number of IP addresses. But we also show a third grouping, top 1,000 networks by number of observations. That last group is important.
Top 1,000 networks by number of IP addresses is interesting (it includes the major ISPs) but it also includes some networks that have huge numbers of IP addresses available that aren’t necessarily used. These come about because of historical allocations of IP addresses organisations like the US Department of Defense.
Cloudflare’s testing reveals which networks are most used, and so we also report results for the top 1,000 networks by number of observations to get an idea of how we’re performing on networks with heavy usage.
Hence, we have 18 charts showing all combinations of (TCP connection time, TTFB, TTLB), (mean, p95) and (all networks, top 1,000 networks by IP count, top 1,000 networks by observations).
You’ll see that in two of the charts Cloudflare is not #1 of 18 (we’re #2). We’ll be working to make sure we’re #1 for every measurement over the next few weeks. Both of those are average times. We’re most interested in the p95 measurements because they show the “reasonable worst case” scenario for someone using the Internet. But as we go about optimizing performance we want to be #1 on every chart so that we’re top no matter how performance is measured.
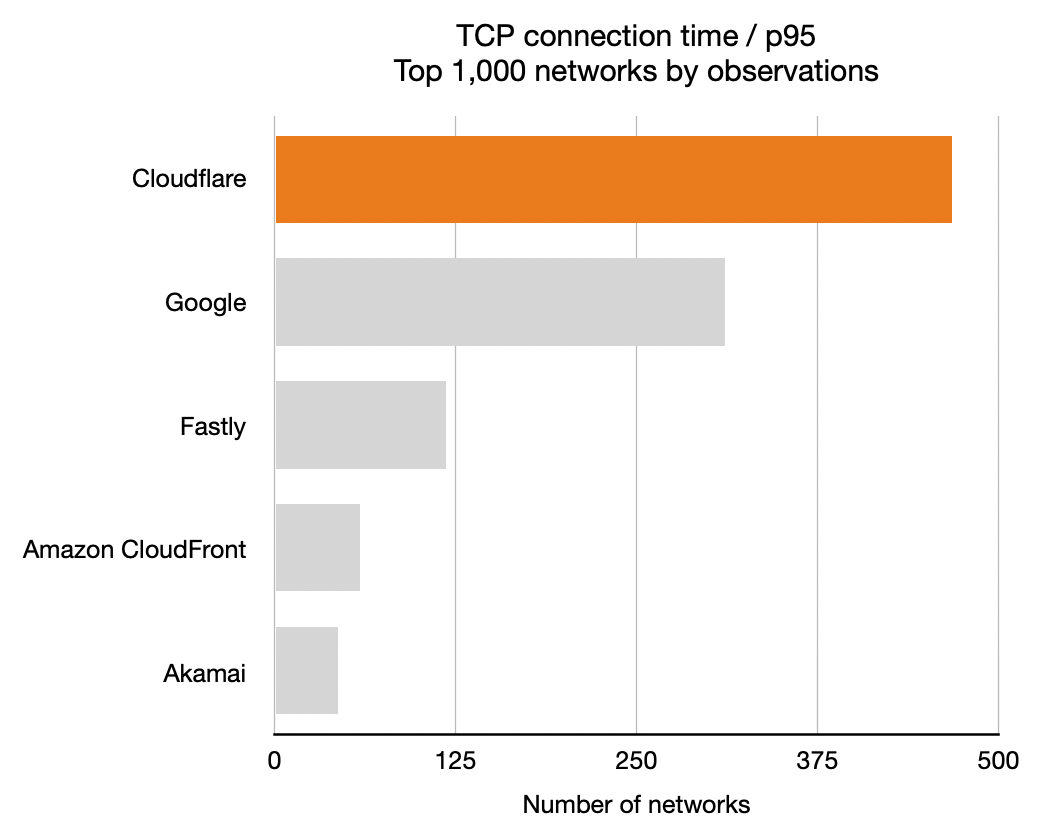
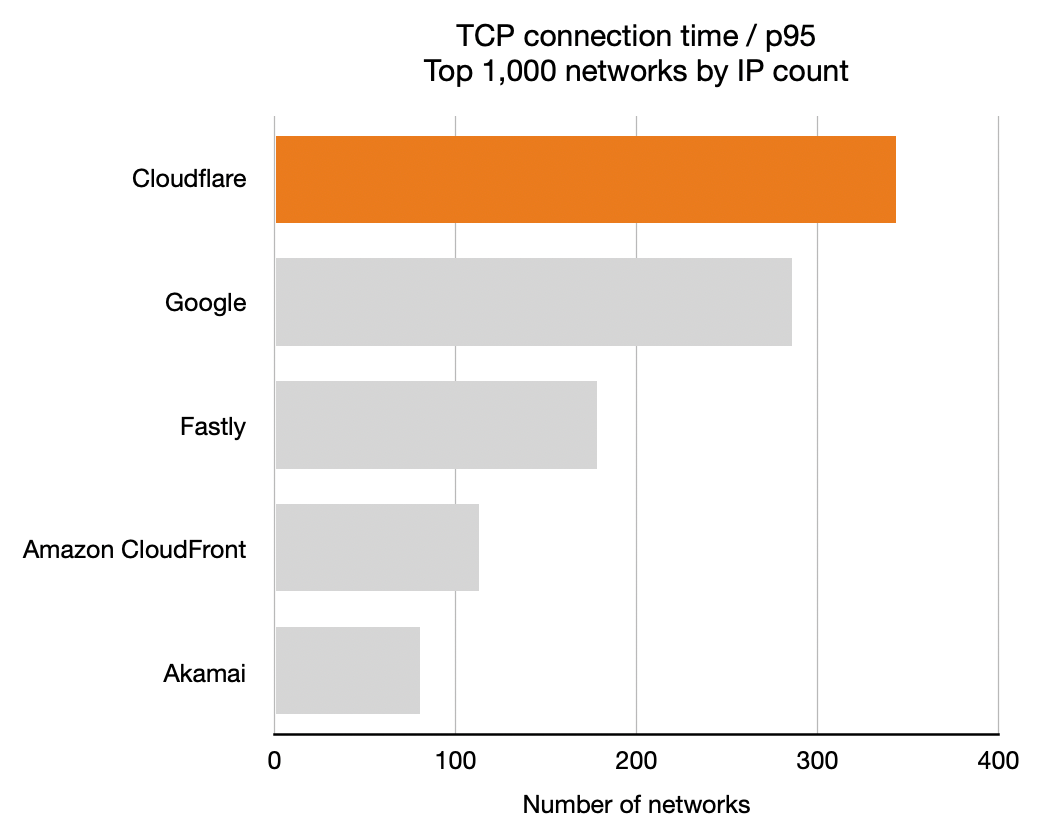
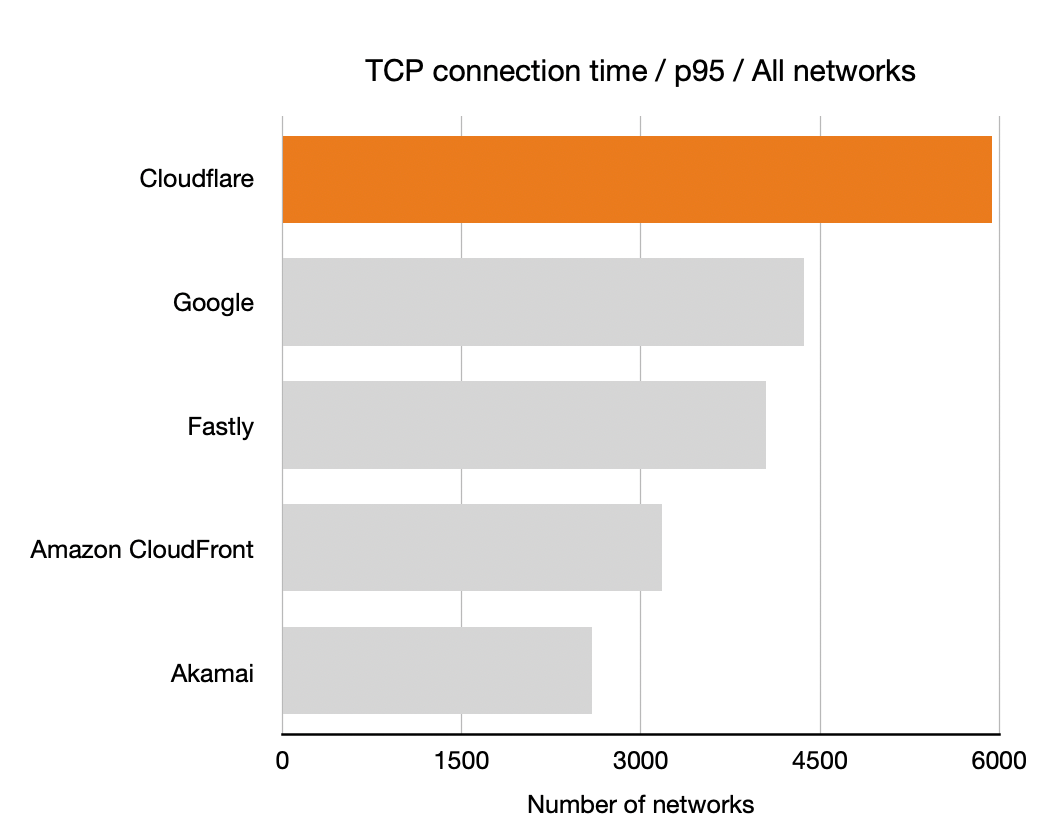
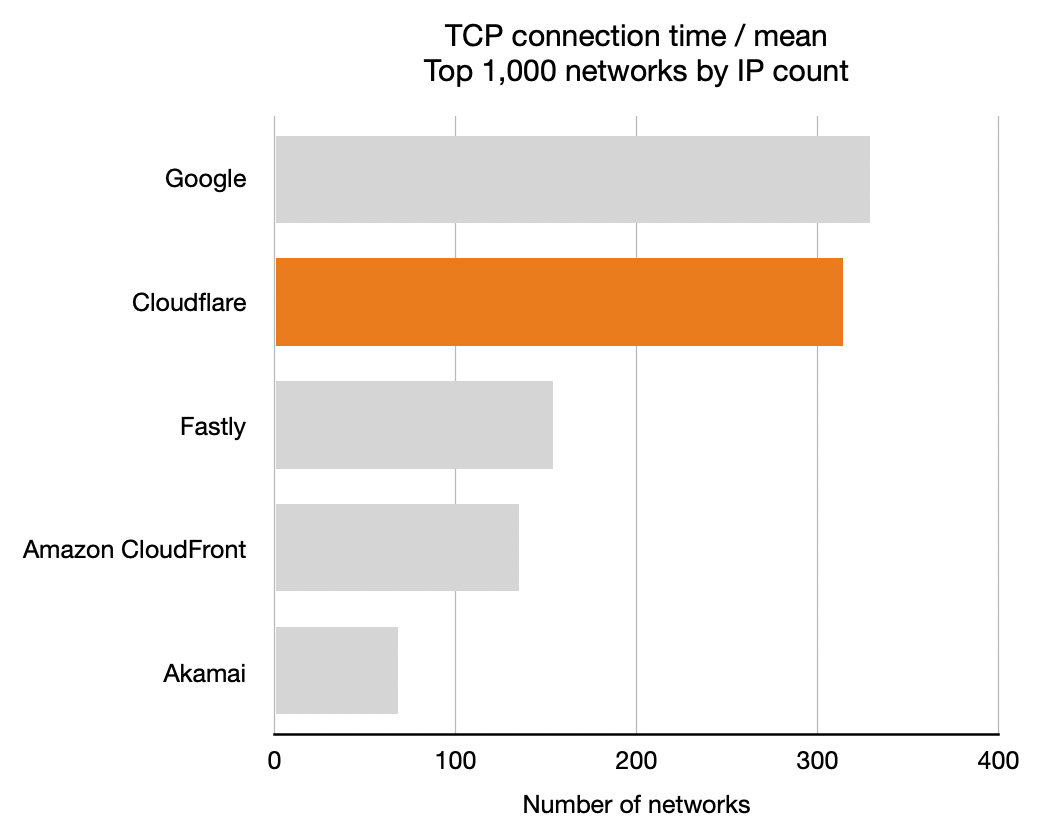
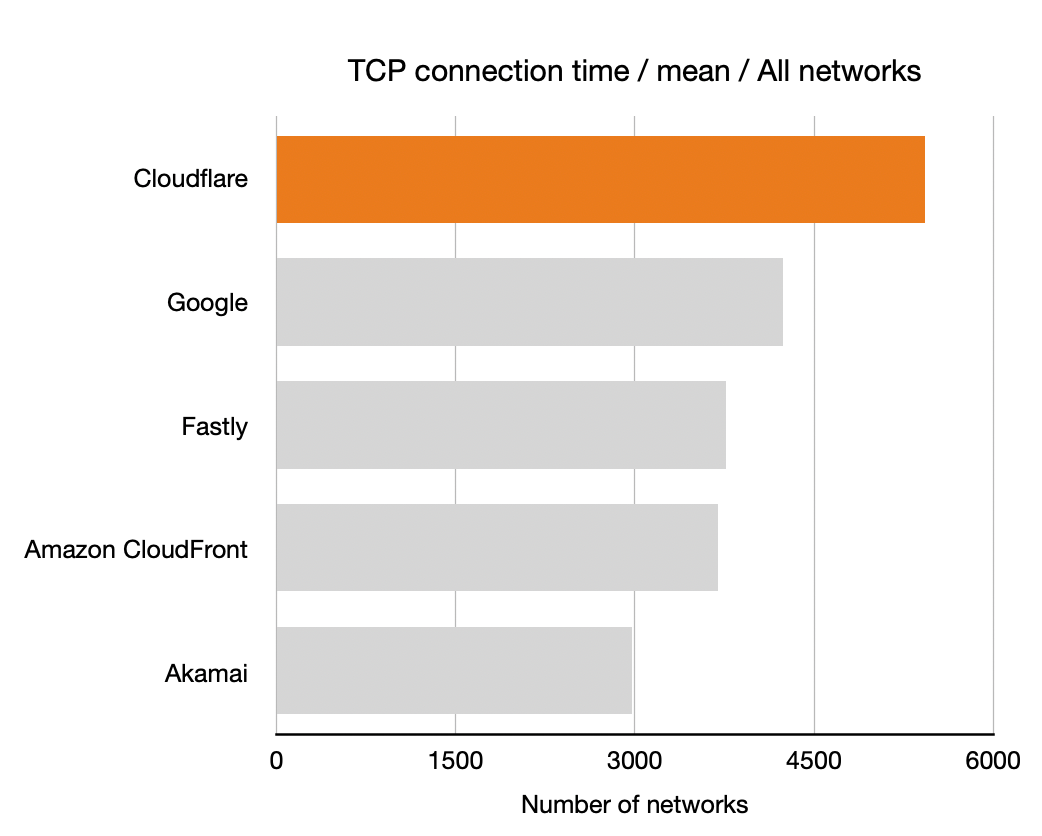
TCP Connection Time
Let’s start with TCP connection time to get a sense of how well-connected the five companies we’ve measured. Recall that longer bars are better here, they indicate that the particular CDN was the highest performance for that many networks: more networks is better.
 |
 |
|---|---|
 |
 |
 |
 |
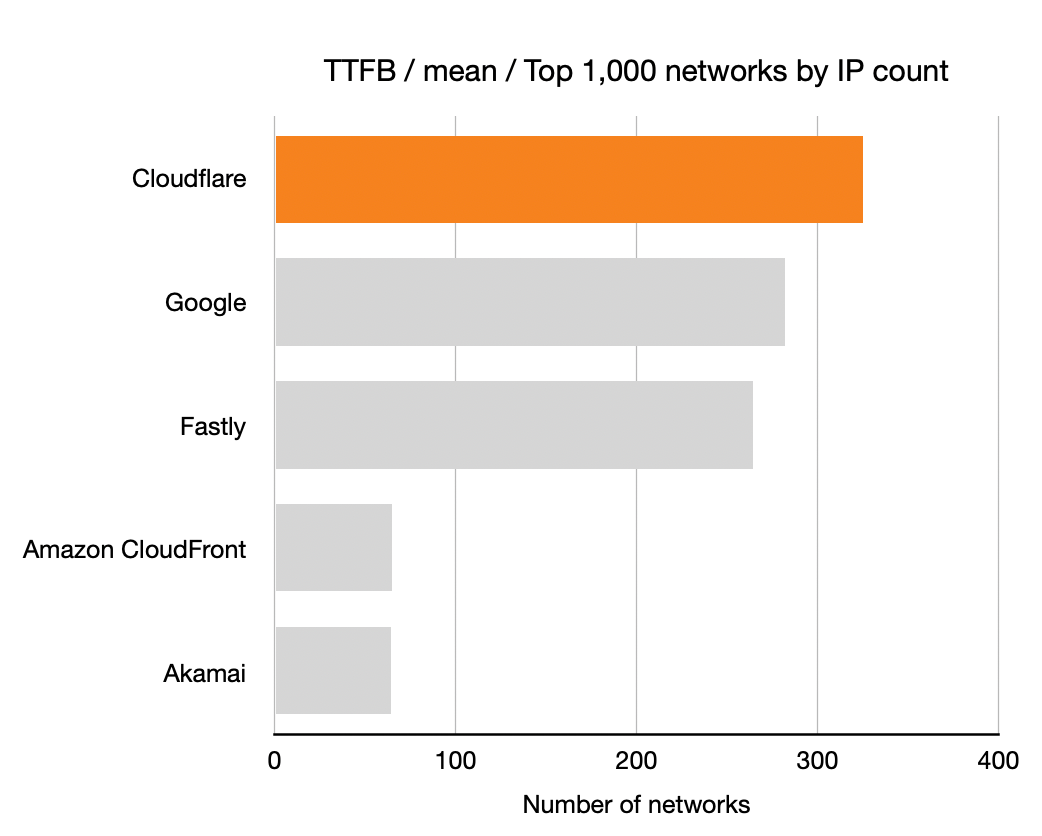
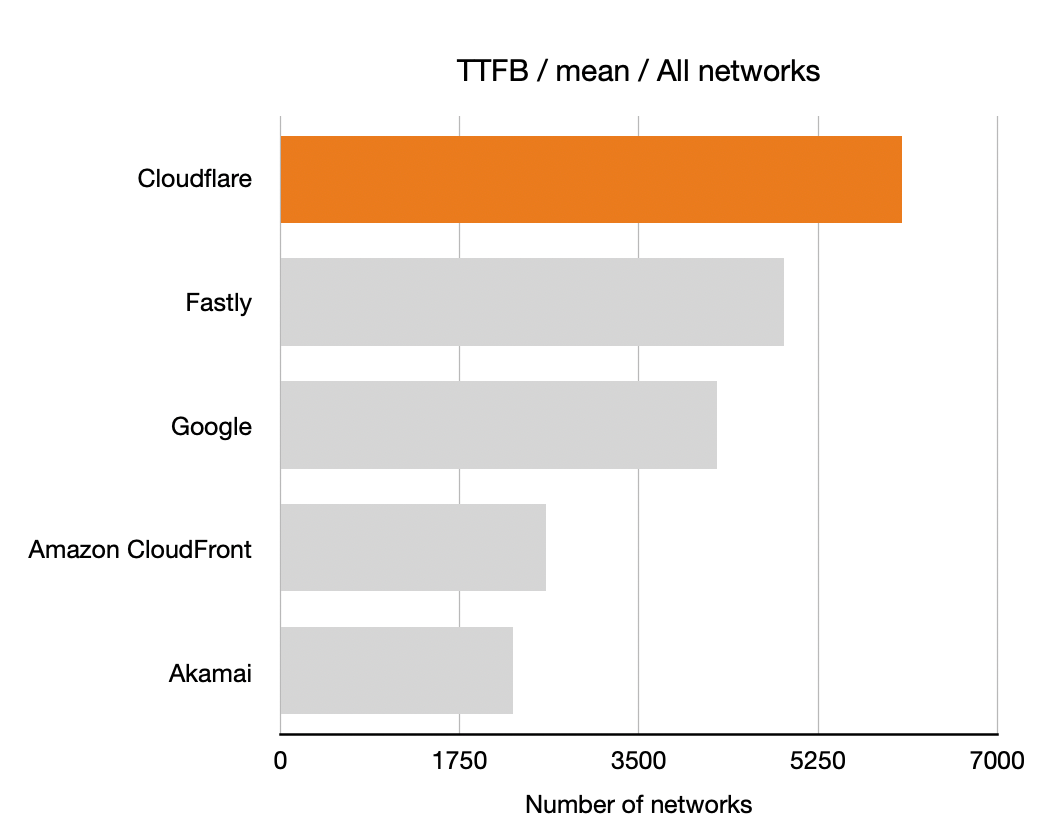
Time To First Byte (TTFB)
Next up is TTFB for the five companies. Once again, longer bars is better means more networks where that CDN had the lowest TTFB.
 |
 |
|---|---|
 |
 |
 |
 |
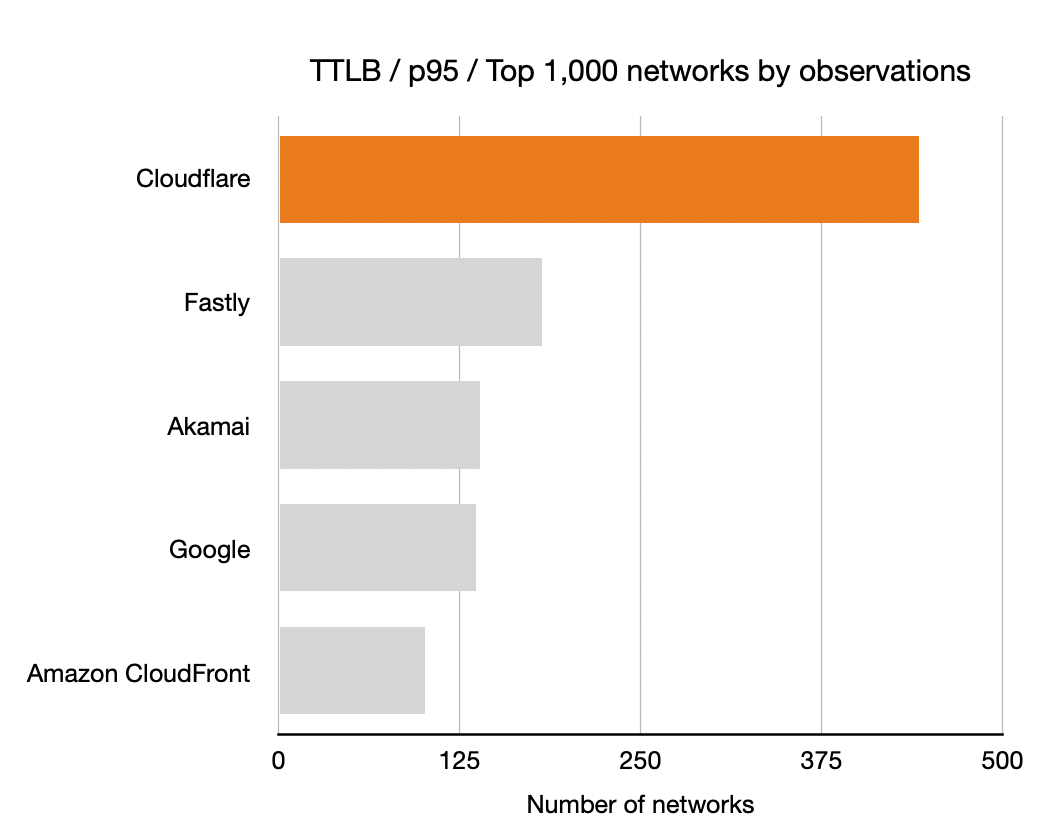
Time To Last Byte (TTLB)
And finally the TTLB measurements. Once again, longer bars is better means more networks where that CDN had the lowest TTLB.
 |
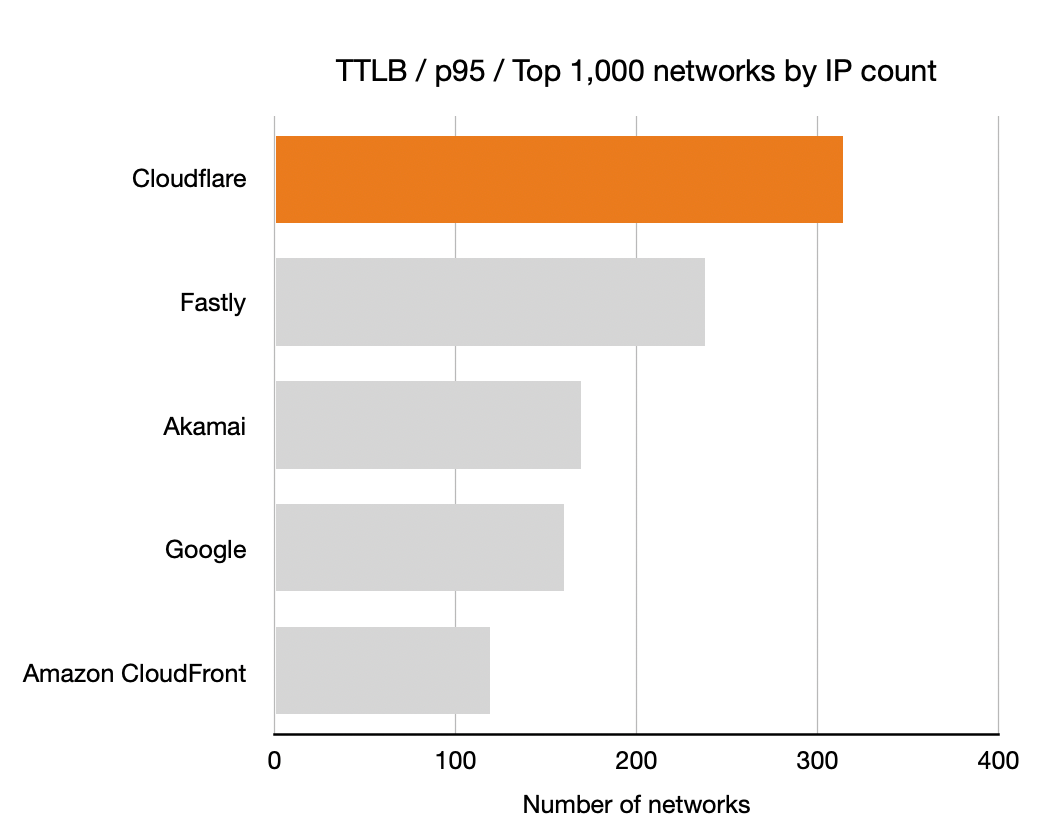 |
|---|---|
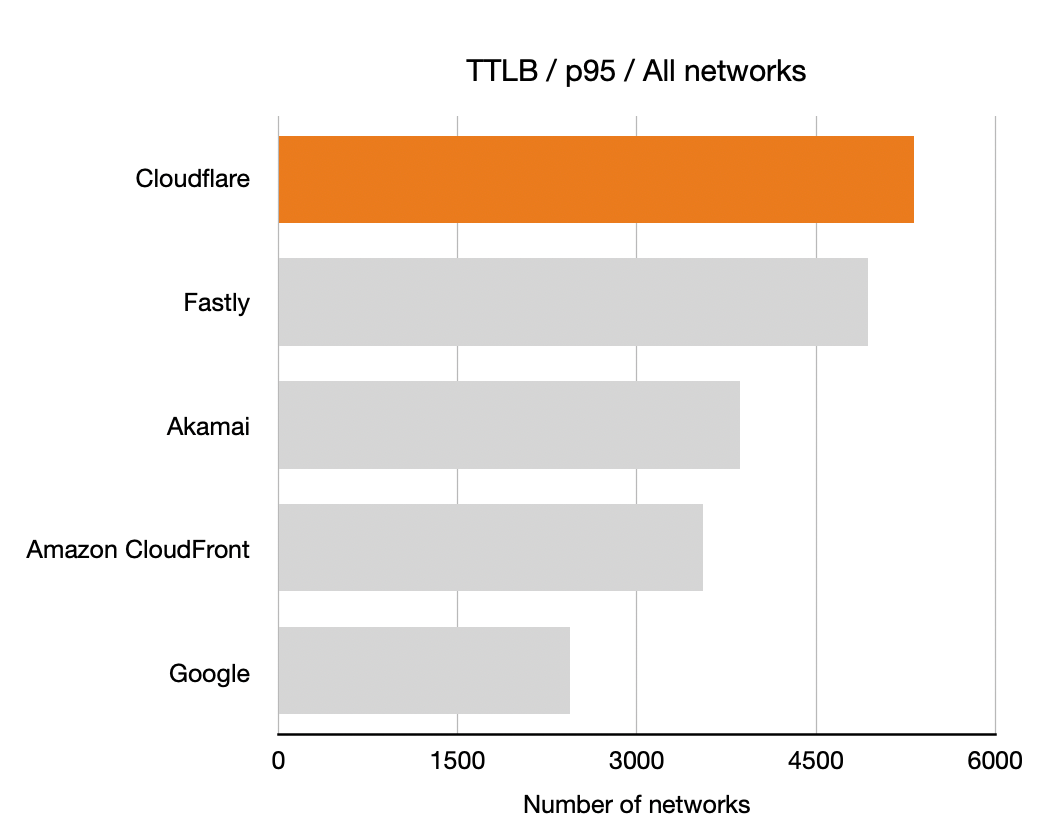 |
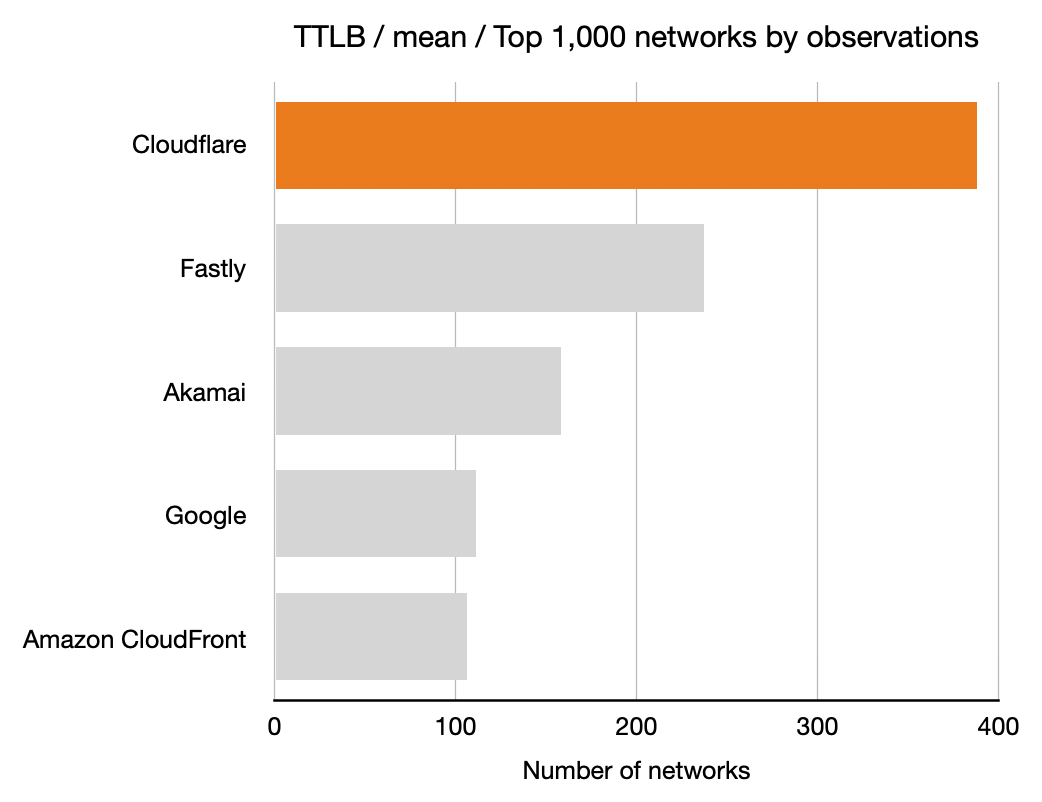 |
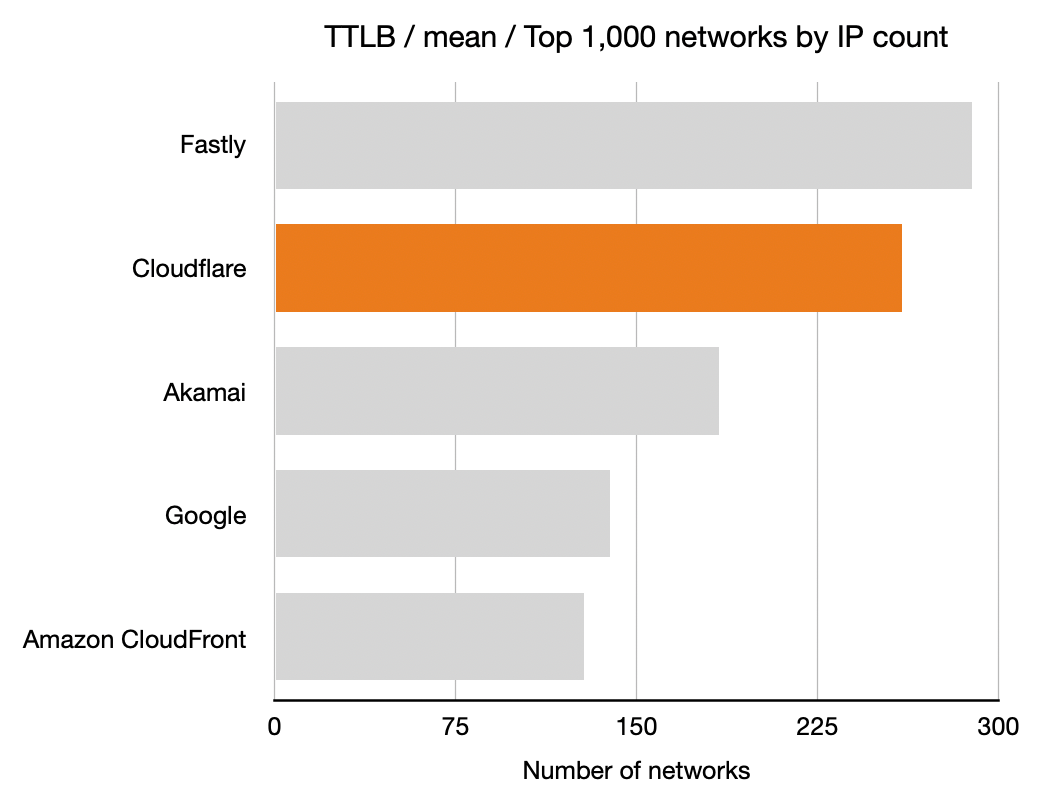 |
 |
Optimization Targets
Looking not just at where we are #1 but where we are #1 or #2 helps us see how quickly we can optimize our network to be #1 in more places. Examining the top 1,000 networks by observations we see that we’re currently #1 or #2 for TTFB in 69.9% of networks, for TTLB in 65.0% of networks and for TCP connection time in 70.5%.
To see how much optimization we need to do to go from #2 to #1 we looked at the three measures and see that median TTFB of the #1 network is 92.3%, median TTLB is 94.0% and TCP connection time is 91.5%.
The latter figure is very interesting because it shows that we can make big gains by optimizing network level routing.
Where’s the world map?
It’s very common to present data about Internet performance on maps. World maps look good but they obscure information. The reason is very simple: world maps show geography (and, depending on the projection, a very skewed version of the world’s actual countries and land masses).
Here’s an example world map with countries colored by who had the lowest TTLB at p95. Cloudflare is in orange, Amazon CloudFront in yellow, Google in purple, Akamai in red and Fastly in blue.
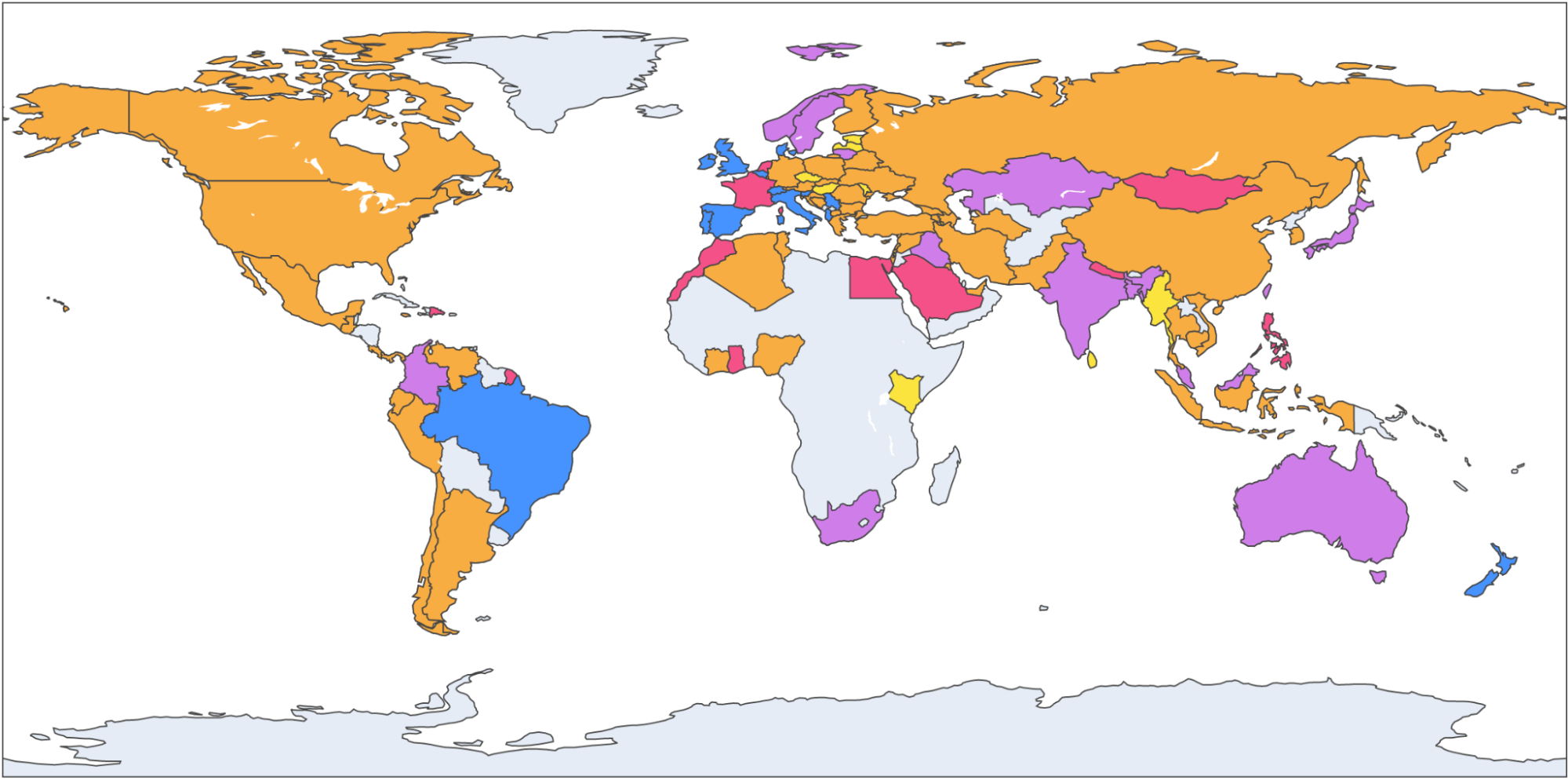
What that doesn’t show is population. And Cloudflare is interested in how well we perform for people. Consider Russia and Indonesia. Indonesia has double the population of Russia and about 1/10th of the land.
By focusing on networks we can optimize for the people who use the Internet. For example, Biznet is a major ISP in Indonesia with ASN 17451. Looking at TTFB at p95 (the same statistics we discussed earlier for US ISPs Cox and Comcast) we see that for Biznet users Cloudflare has the fastest p95 TTFB at 677.7ms, Fastly 744.0ms, Google 872.8ms, Amazon CloudFront 1,239.9 and Akamai 1,248.9ms.
What’s next
The data we’ve gathered gives us a granular view of every network that connects to Cloudflare. This allows us to optimize routes and over the coming days and weeks we’ll be using the data to further increase Cloudflare’s performance.
In just over a week it’s Cloudflare’s Birthday Week, and we are aiming to improve our performance in 10% of the networks where we are not #1 today. Stay tuned.