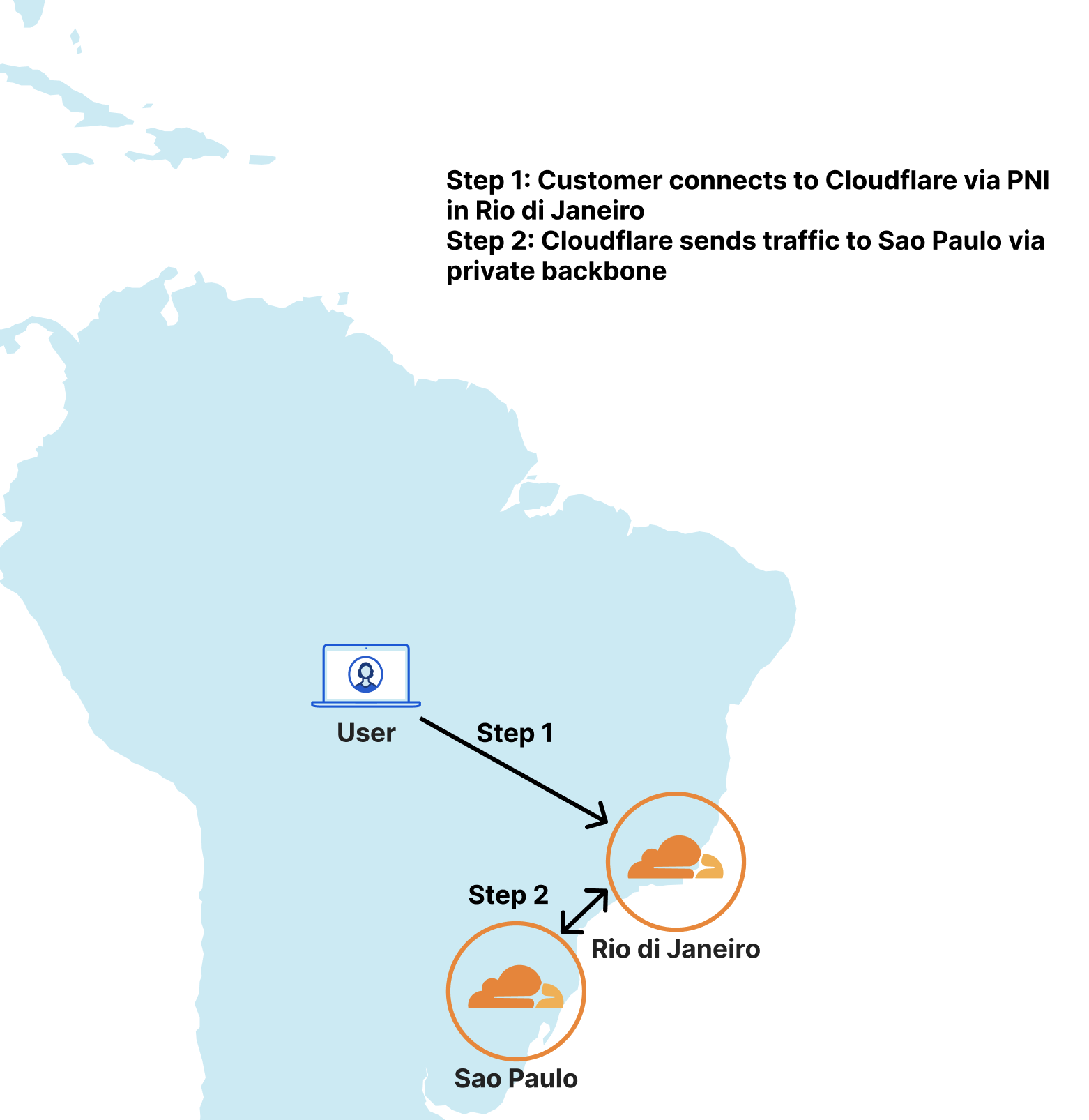
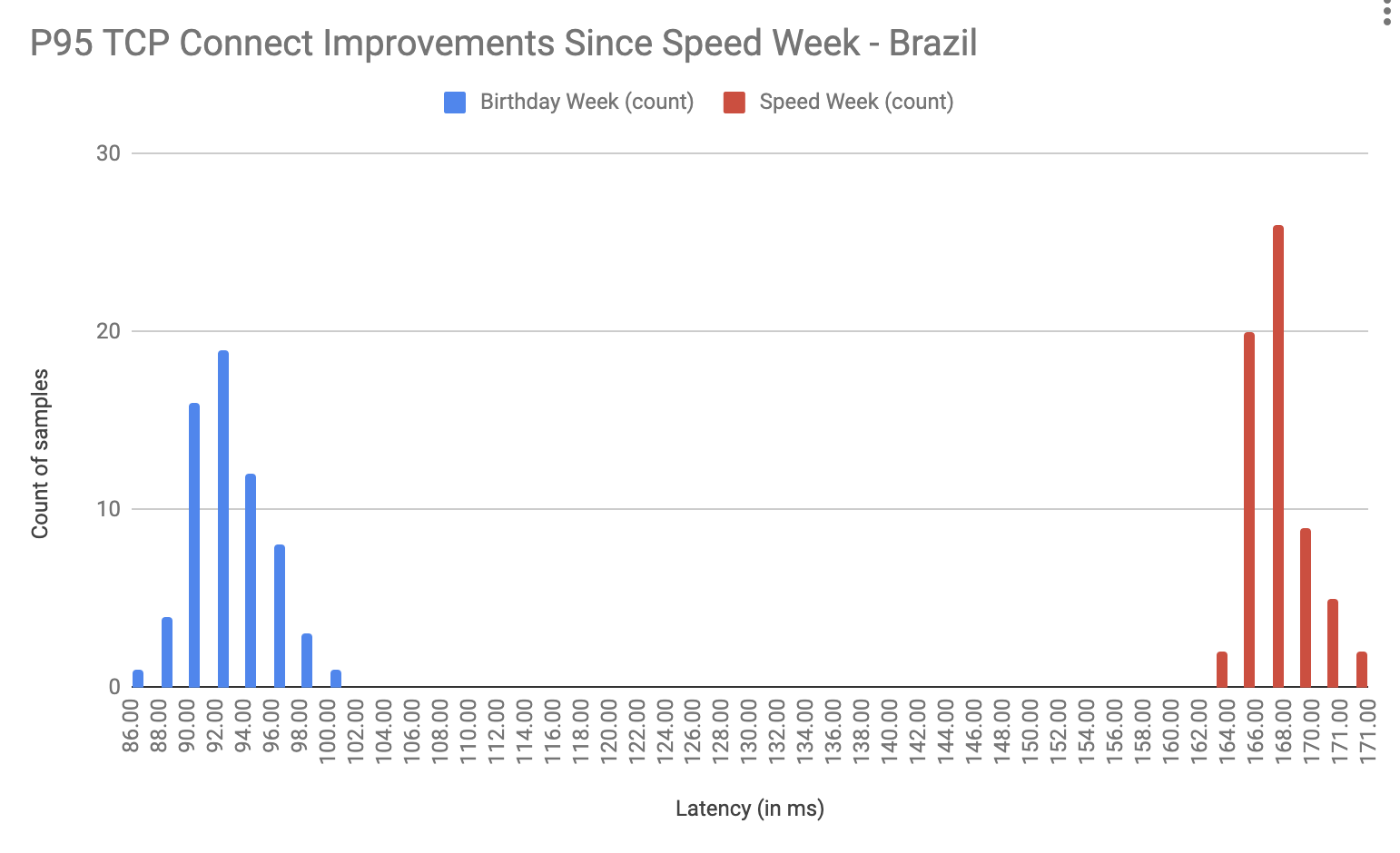
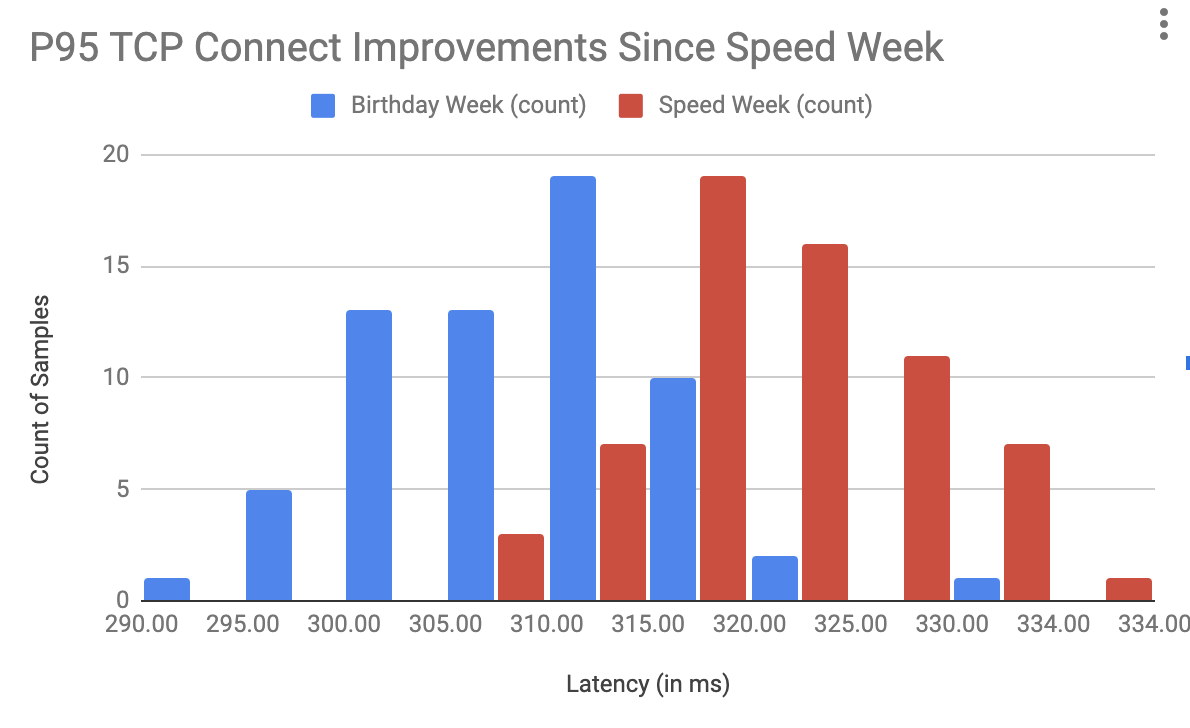
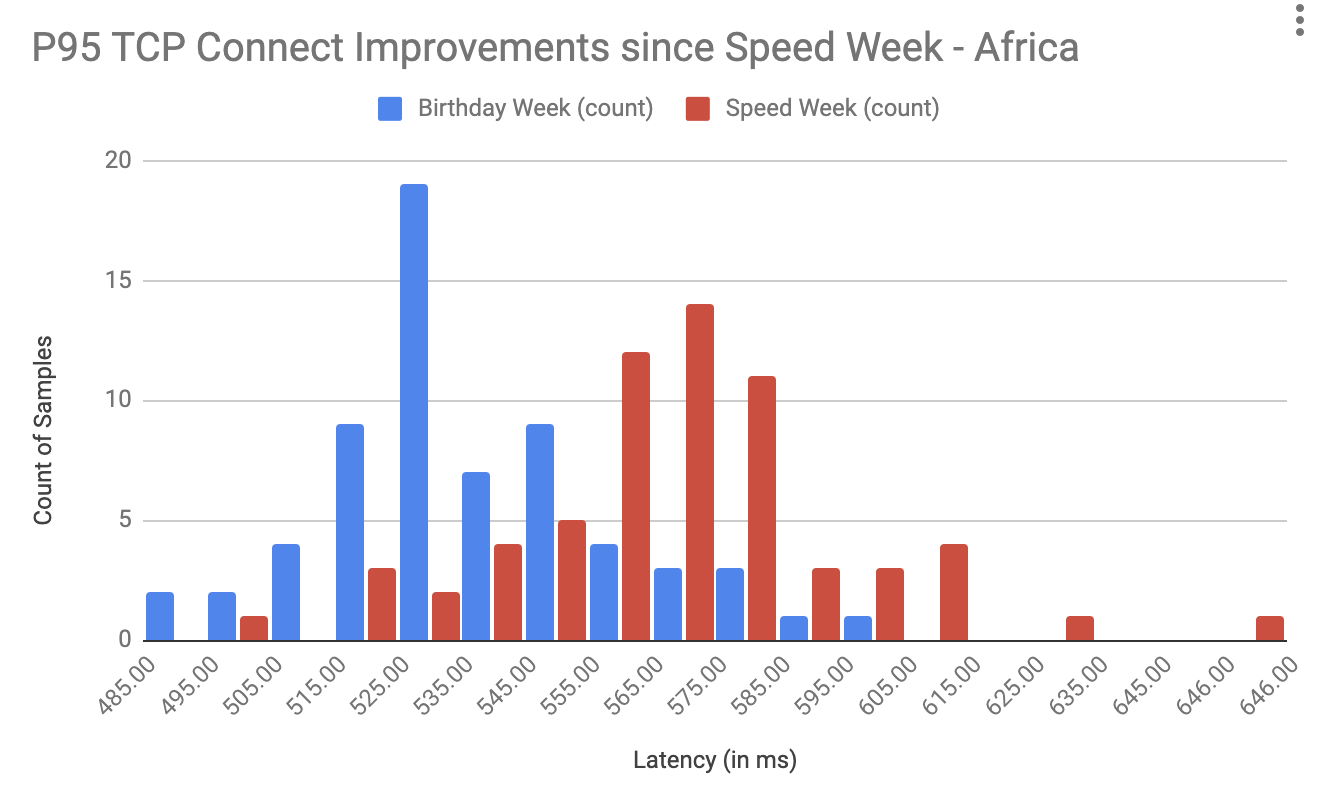
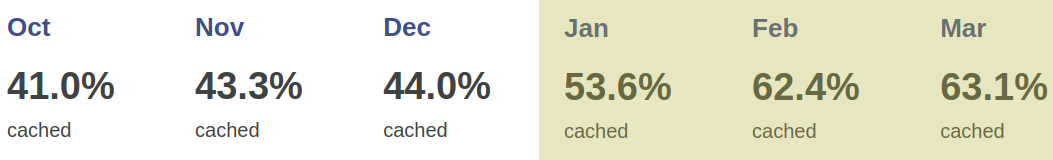This is a guest post by Kinsta about their use of our platform.
At Kinsta, we’re obsessed with speed: Our Application Hosting, Database Hosting and Managed WordPress Hosting services all run on the Google Cloud Platform’s fastest Premium Tier Network and C2 Machines, and we rely on Cloudflare to keep the pedal to the metal for tens of thousands of customers who want to deliver their content around the world with speed and security.
While making that happen, we’ve learned a thing or two about using Cloudflare Workers and Workers KV to provide optimized caching rules for static and dynamic content.
In early 2023, we doubled down on Cloudflare cache wrangling, making caches more responsive to client-side configuration changes while also shifting the heavy lifting behind broadcasting feature updates away from our admins on the backend and into Cloudflare Workers. A key result was a dramatic increase in the share of customer data successfully cached, increasing 56.3% between October 2022 and March 2023.
Cloudflare Workers and Workers KV allow us to programmatically customize every request and response with minimal effort and lower latency. We no longer need to deploy changes to hundreds of thousands of containers when we want to implement new features; we can replicate or implement the feature with Workers and deploy it everywhere with a few commands and clicks, saving us days of work and maintenance.
Request routing with Workers KV and Workers
Every Kinsta-hosted domain is a key, and its value contains at least the core settings, like the origin's IP and port, and a unique random ID. With this data easily available in Workers KV, we can use Workers to analyze, manipulate, and route requests to their expected backend. We also use Workers KV to store customer optimization options like Polish, Image Resizing, and Auto Minify.
To route requests to custom IPs and ports, we use resolveOverride, a Cloudflare-specific Request property. Here's an example:
However, while Workers KV worked well to route requests, we soon noticed inconsistent responses in our cache. Sometimes a customer activated Polish and, due to Workers KV's one-minute cache, new requests arrived before Workers KV fully propagated the change, causing us to cache non-optimized assets. When this happened, the client had to clear their cache again manually. Not the ideal scenario. Clients got frustrated, and we wasted API operations and GCP bandwidth, constantly purging caches.
Cache key is the key
Since we always read the domain's Workers KV data, we realized we could route requests and customize the cache key, appending things like the domain's ID and features that could affect the asset, like Polish. Today, our cache key is heavily customized to quickly reflect every client's change in our panel or API. By modifying the cache key using Workers KV's data, nobody needs to worry about clearing the cache anymore. As soon as Workers KV propagates the changes, the cache key also changes and we request and cache a fresh asset.
The easiest way to customize the cache key is to append query params to it. For example:
<pre><code class="language-javascript">
let cacheKey = `${request.url}?custom-cache-param-polish=lossy`
</code></pre>
Of course, you need to check the URL for existing parameters to determine which connector to use — ? or & — and ensure you are using a unique identifier.
Then, you can use this new cache key to save the response with Cache API or Fetch — or both.
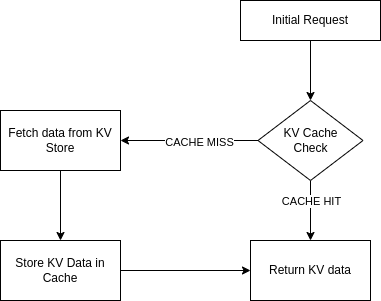
Workers KV Cache
Workers KV operations are affordable, but the numbers can pile up when you trigger billions of reading operations daily.
Thanks to our cache key customization, we realized we could cache the Workers KV data with Cache API, saving on reading operations and possibly lowering the latency by avoiding multiple Workers KV GET requests per visitor. Since the cached response is now based on the request's URL combined with KV data, we no longer need to worry about caching stale content.
However, unlike many applications, we can't cache Workers KV for extended periods. Kinsta's customers are constantly trying new features, changing Polish and Auto Minify settings, sometimes excluding pages or extensions from being cached, and they want to see their changes in production as soon as possible.
That's when we decided to microcache our Workers KV data — caching dynamic or constantly-changed content for a very short period of time, usually less than 60 seconds.
It’s pretty simple to implement your own Workers KV caching logic. For example:
<pre><code class="language-javascript">
const handleKVCache = async (event, myCustomDomain) => {
// Try to get KV from cache first
const cache = caches.default;
let site_data = await cache.match( `https://${myCustomDomain}/some-string-ID-kv-data/` );
// Valid KV cache match
if (site_data && site_data.status === 200) {
// ... modify your cached data if necessary, then return it
return site_data;
}
// Invalid cache (expired, miss, etc), get data from KV namespace
site_data = await KV_NAMESPACE.get(myCustomDomain.toLowerCase());
// Cache valid KV responses with Cache API
if (site_data) {
let kvResponse = new Response(JSON.stringify(site_data), {status: 200});
kvResponse.headers.set("Cache-Control", "public, s-maxage=30");
event.waitUntil(cache.put(`https://${myCustomDomain}/some-string-ID-kv-data/`, kvResponse));
}
return site_data;
};
</code></pre>
Today, we’re making the case for why Time To First Byte (TTFB) is not a good metric for evaluating how fast web pages load. There are better metrics out there that give a more accurate representation of how well a server or content delivery network performs for end users. In this blog, we’ll go over the ambiguity of measuring TTFB, touch on more meaningful metrics such as Core Web Vitals that should be used instead, and finish on scenarios where TTFB still makes sense to measure.
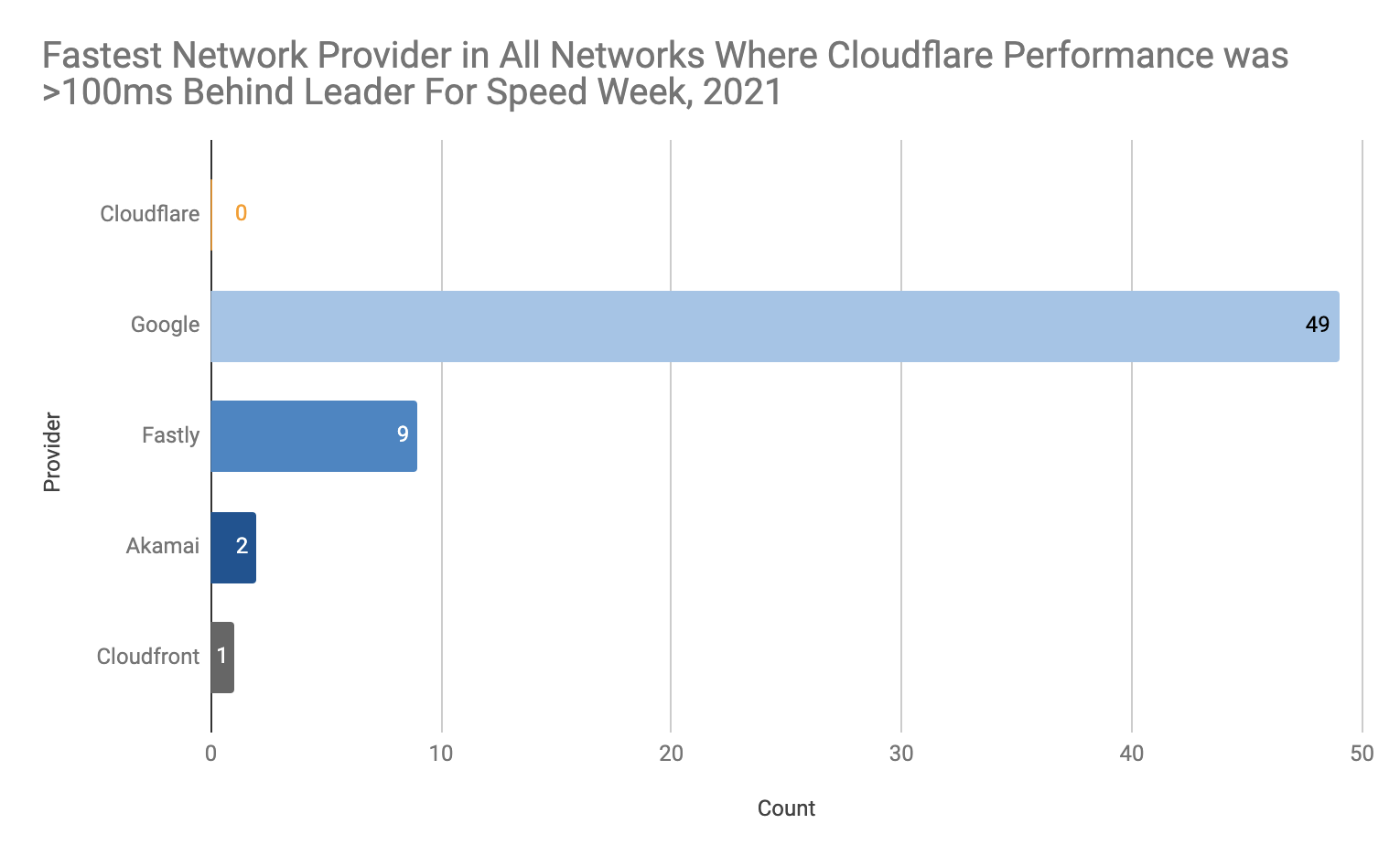
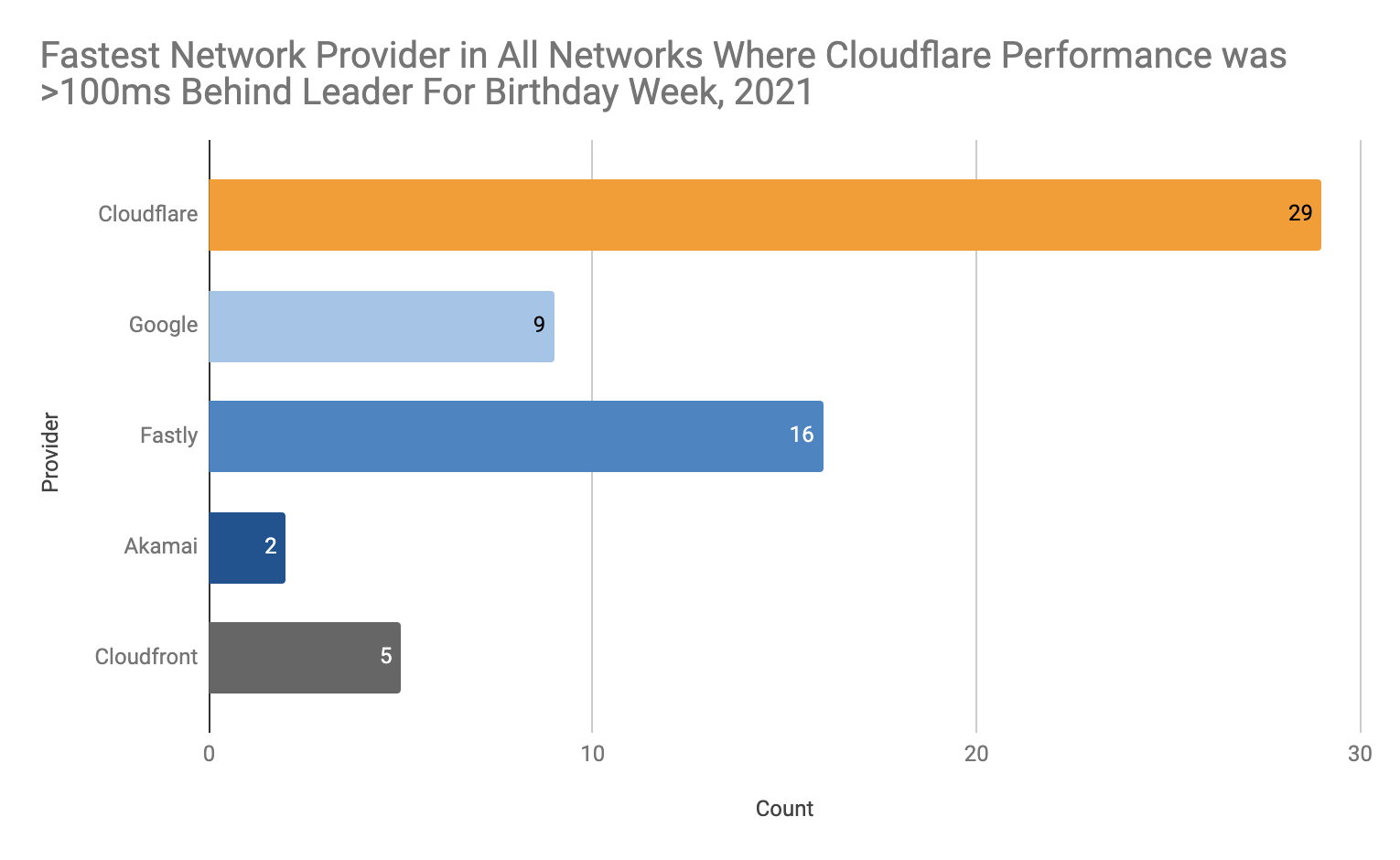
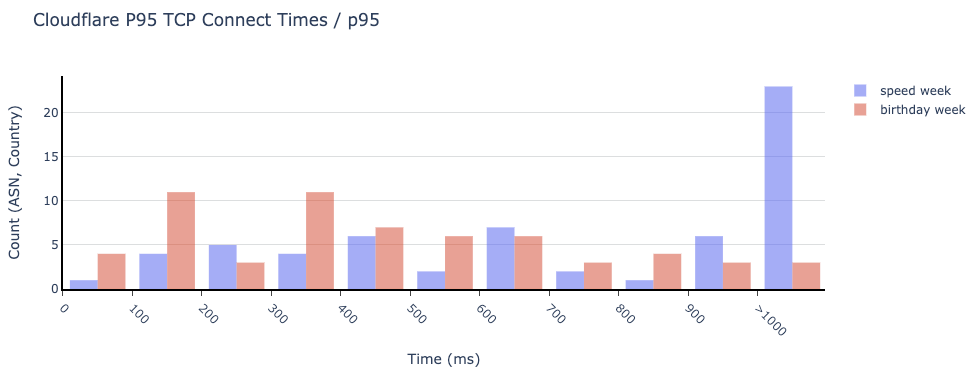
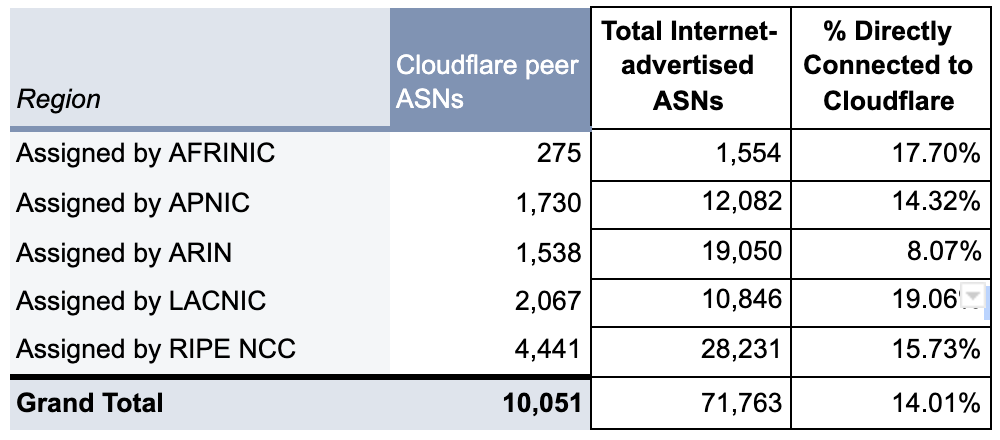
Many of our customers ask what the best way would be to evaluate how well a network like ours works. This is a good question! Measuring performance is difficult. It’s easy to simplify the question to “How close is Cloudflare to end users?” The predominant metric that’s been used to measure that is round trip time (RTT). This is the time it takes for one network packet to travel from an end user to Cloudflare and back. We measure this metric and mention it from time to time: Cloudflare has an average RTT of 50 milliseconds for 95% of the Internet-connected population.
Whilst RTT is a relatively good indicator of the quality of a network, it doesn’t necessarily tell you that much about how good it is at actually delivering actual websites to end users. For instance, what if the web server is really slow? A user might be very close to the data center that serves the traffic, but if it takes a long time to actually grab the asset from disk and serve it the result will still be a poor experience.
This is where TTFB comes in. It measures the time it takes between a request being sent from an end user until the very first byte of the response being received. This sounds great on paper! However it doesn’t capture how a webpage or web application loads, and what happens after the first byte is received.
In this blog we’ll cover what TTFB is a good indicator of, what it's not great for, and what you should be using instead.
What is TTFB?
TTFB is a metric which reports the duration between sending the request from the client to a server for a given file, and the receipt of the first byte of said file. For example, if you were to download the Cloudflare logo from our website the TTFB would be how long it took to receive the first byte of that image. Similarly, if you were to measure the TTFB of a request to cloudflare.com the metric would return the TTFB of how long it took from request to receiving the first byte of the first HTTP response. Not how long it took for the image to be fully visible or for the web page to be loaded in a state that allowed a user to begin using it.
The simplest answer therefore is to look at the diametrically opposite measurement, Time to Last Byte (TTLB). TTLB, as you’d expect, measures how long it takes until the last byte of data is received from the server. For the Cloudflare logo file this would make sense, as until the image is fully downloaded it's not exactly useful. But what about for a webpage? Do you really need to wait until every single file is fully downloaded, even those images at the bottom of the page you can't immediately see? TTLB is fine for measuring how long it took to download a single file from a CDN / server. However for multi-faceted traffic, like web pages, it is too conservative, as it doesn’t tell you how long it took for the web page to be usable.
As an analogy we can look at measuring how long it takes to process an incoming airplane full of passengers. What's important is to understand how long it takes for those passengers to disembark, pass through passport control, collect their baggage and leave the terminal, if no onward journeys. TTFB would measure success as how long it took to get the first passenger off of the airplane. TTLB would measure how long it took the last passenger to leave the terminal, even if this passenger remained in the terminal for hours afterwards due to passport issues or getting lost. Neither are a good measure of success for the airline.
Why TTFB doesn't make sense
TTFB is a widely-used metric because it is easy-to-understand and it is a great signal for connection setup time, server time and network latency. It can help website owners identify when performance issues originate from their server. But is TTFB a good signal for how real users experience the loading speed of a web page in a browser?
When a web page loads in a browser, the user’s perception of speed isn’t related to the moment the browser first receives bytes of data. It is related to when the user starts to see the page rendering on the screen.
The loading of a web page in a browser is a very complex process. Almost all of this process happens after TTFB is reported. After the first byte has been received, the browser still has to load the main HTML file. It also has to load fonts, stylesheets, javascript, images and other resources. Often these resources link to other resources that also must be downloaded. Often these resources entirely block the rendering of the page. Alongside all these downloads, the browser is also parsing the HTML, CSS and JavaScript. It is building data structures that represent the content of the web page as well as how it is styled. All of this is in preparation to start rendering the final page onto the screen for the user.
When the user starts seeing the web page actually rendered on the screen, TTFB has become a distant memory for the browser. For a metric that signals the loading speed as perceived by the user, TTFB falls dramatically short.
Receiving the first byte isn't sufficient to determine a good end user experience as most pages have additional render blocking resources that get loaded after the initial document request. Render-blocking resources are scripts, stylesheets, and HTML imports that prevent a web page from loading quickly. From a TTFB perspective it means the client could stop the ‘TTFB clock’ on receipt of the first byte of one of these files, but the web browser is blocked from showing anything to the user until the remaining critical assets are downloaded.
This is because browsers need instructions for what to render and what resources need to be fetched to complete “painting” a given web page. These instructions come from a server response. But the servers sending these responses often need time to compile these resources — this is known as “server think time.” While the servers are busy during this time… browsers sit idle and wait. And the TTFB counter goes up.
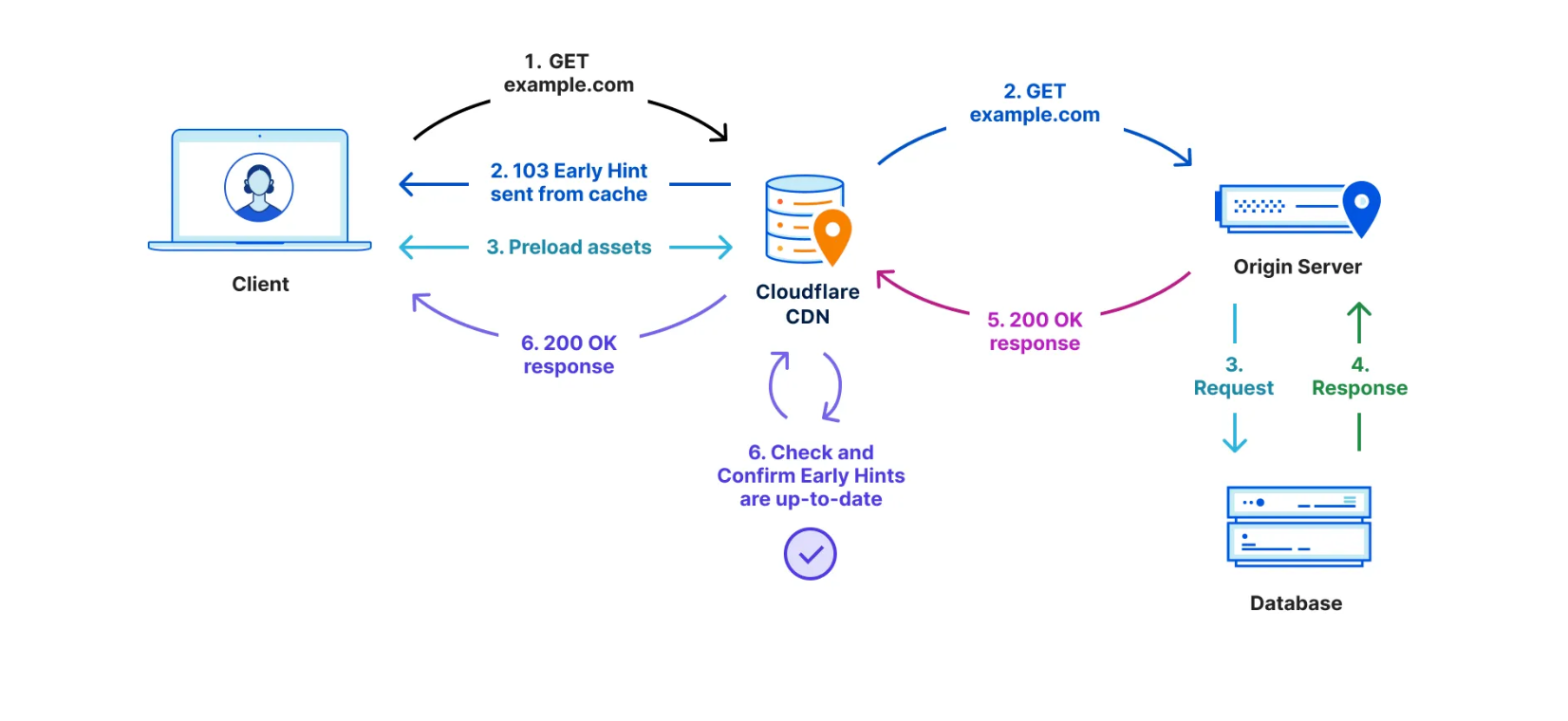
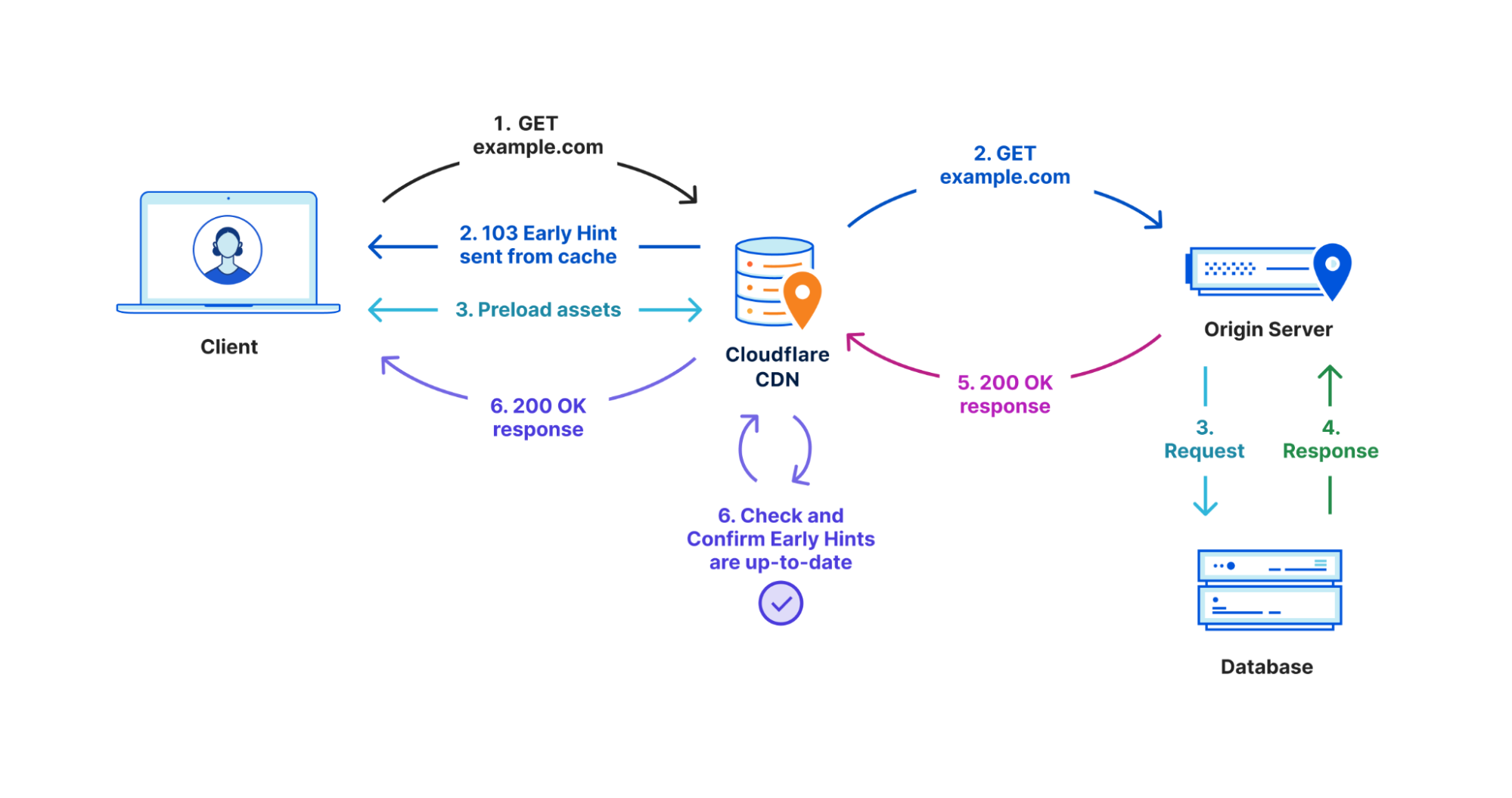
There have been a number of attempts over the years to benefit from this “think time”. First came Server Push, which was superseded last year by Early Hints. Early Hints take advantage of “server think time” to asynchronously send instructions to the browser to begin loading resources while the origin server is compiling the full response. By sending these hints to a browser before the full response is prepared, the browser can figure out what it needs to do to load the webpage faster for the end user. It also stops the TTFB clock, meaning a lower TTFB. This helps ensure the browser gets the critical files sooner to begin loading the webpage, and it also means the first byte is delivered sooner as there is no waiting on the server for the whole dataset to be prepared and ready to send. Even with Early Hints, though, TTFB doesn’t accurately define how long it took the web page to be in a usable state.
TTFB also does not take into account multiplexing benefits of HTTP/2 and HTTP/3 which allow browsers to load files in parallel. It also doesn't take into account compression on the origin, which would result in a higher TTFB but a quicker page load overall due to the time the server took to compress the assets and send them in a small format over the network.
Cloudflare offers many features that can improve the loading speed of a website, but don’t necessarily impact the TTFB score. These features include Zaraz, Rocket Loader, HTTP/2 and HTTP/3 Prioritization, Mirage, Polish, Image Resizing, Auto Minify and Cache. These features improve the loading time of a webpage, ensuring they load optimally through a series of enhancements from image optimization and compression to render blocking elimination by optimizing the sending of assets from the server to the browser in the best possible order.
More comprehensive metrics are required to illustrate the full loading process of a web page, and the benefit provided by these features. This is where Real User Monitoring helps. At Cloudflare we are all-in on Real User Monitoring (RUM) as the future of website performance. We’re investing heavily in it: both from an observation point of view and from an optimization one also.
For those unfamiliar with RUM, we typically optimize websites for three main metrics – known as the “Core Web Vitals”. This is a set of key metrics which are believed to be the best and most accurate representation of a poorly performing website vs a well performing one. These key metrics are Largest Contentful Paint, First Input Delay and Cumulative Layout Shift.
LCP measures loading performance; typically how long it takes to load the largest image or text block visible in the browser. FID measures interactivity. For example, the time between when a user clicks or taps on a button to when the browser responds and starts doing something. Finally, CLS measures visual stability. A good, or bad example of CLS is when you go to a website on your mobile phone, tap on a link and the page moves at the last second meaning you tap something you didn't want to. That would be a lower CLS score as its poor user experience.
Looking at these metrics gives us a good idea of how the end user is truly experiencing your website (RUM) vs. how quickly the first byte of the file was retrieved from the nearest Cloudflare data center (TTFB).
Good TTFB, bad user experience
One of the “sub parts” that comprise LCP is TTFB. That means a poor TTFB is very likely to result in a poor LCP. If it takes you 20 seconds to retrieve the first byte of the first image, your user isn't going to have a good experience – regardless of your outlook on TTFB vs RUM.
Conversely, we found that a good TTFB does not always mean a good LCP score, or FID or CLS. We ran a query to collect RUM metrics of web pages we served which had a good TTFB score. Good is defined as a TTFB as less than 800ms. This allowed us to ask the question: TTFB says these websites are good. Does the RUM data support that?
We took four distinct samples from our RUM data in June. Each sample had a different date-range and sample-rate combination. In each sample we queried for 200,000 page views. From these 200,000 page views we filtered for only the page views that reported a 'Good' TTFB. Across the samples, of all page views that have a good TTFB, about 21% of them did not have a “good” LCP score. 46% of them did not have a “good” FID score. And 57% of them did not have a good CLS score.
This clearly shows the disparity between measuring the time it takes to receive the first byte of traffic, vs the time it takes for a webpage to become stable and interactive. In summary, LCP includes TTFB but also includes other parts of the loading experience. LCP is a more comprehensive, user-centric metric.
TTFB is not all bad
Reading this post and others from Speed Week 2023 you may conclude we really don't like TTFB and you should stop using it. That isn't the case.
There are a few situations where TTFB does matter. For starters, there are many applications that aren’t websites. File servers, APIs and all sorts of streaming protocols don’t have the same semantics as web pages and the best way to objectively measure performance is to in fact look at exactly when the first byte is returned from a server.
To help optimize TTFB for these scenarios we are announcing Timing Insights, a new analytics tool to help you understand what is contributing to "Time to First Byte" (TTFB) of Cloudflare and your origin. Timing Insights breaks down TTFB from the perspective of our servers to help you understand what is slow, so that you can begin addressing it.
Get started with RUM today
To help you understand the real user experience of your website we have today launched Cloudflare Observatory– the new home of performance at Cloudflare.
Cloudflare users can now easily monitor website performance using Real User Monitoring (RUM) data along with scheduled synthetic tests from different regions in a single dashboard. This will identify any performance issues your website may have. The best bit? Once we’ve identified any issues, Observatory will highlight customized recommendations to resolve these issues, all with a single click.
Start making your website faster today with Observatory.
If you care about the performance of your website or APIs, it’s critical to understand why things are slow.
Today we're introducing new analytics tools to help you understand what is contributing to "Time to First Byte" (TTFB) of Cloudflare and your origin. TTFB is just a simple timer from when a client sends a request until it receives the first byte in response. Timing Insights breaks down TTFB from the perspective of our servers to help you understand what is slow, so that you can begin addressing it.
But wait – maybe you've heard that you should stop worrying about TTFB? Isn't Cloudflare moving away from TTFB as a metric? Read on to understand why there are still situations where TTFB matters.
Why you may need to care about TTFB
It's true that TTFB on its own can be a misleading metric. When measuring web applications, metrics like Web Vitals provide a more holistic view into user experience. That's why we offer Web Analytics and Lighthouse within Cloudflare Observatory.
But there are two reasons why you still may need to pay attention to TTFB:
1. Not all applications are websites More than half of Cloudflare traffic is for APIs, and many customers with API traffic don't control the environments where those endpoints are called. In those cases, there may not be anything you can monitor or improve besides TTFB.
2. Sometimes TTFB is the problem Even if you are measuring Web Vitals metrics like LCP, sometimes the reason your site is slow is because TTFB is slow! And when that happens, you need to know why, and what you can do about it.
When you need to know why TTFB is slow, we’re here to help.
How Timing Insights can help
We now expose performance data through our GraphQL Analytics API that will let you query TTFB performance, and start to drill into what contributes to TTFB.
Specifically, customers on our Pro, Business, and Enterprise plans can now query for the following fields in the httpRequestsAdaptiveGroups dataset:
Time to First Byte (edgeTimeToFirstByteMs)
What is the time elapsed between when Cloudflare started processing the first byte of the request received from an end user, until when we started sending a response?
Origin DNS lookup time (edgeDnsResponseTimeMs)
If Cloudflare had to resolve a CNAME to reach your origin, how long did this take?
Origin Response Time (originResponseDurationMs)
How long did it take to reach, and receive a response from your origin?
We are exposing each metric as an average, median, 95th, and 99th percentiles (i.e. P50 / P95 / P99).
The httpRequestAdaptiveGroups dataset powers the Traffic analytics page in our dashboard, and represents all of the HTTP requests that flow through our network. The upshot is that this dataset gives you the ability to filter and “group by” any aspect of the HTTP request.
An example of how to use Timing Insights
Let’s walk through an example of how you’d actually use this data to pin-point a problem.
To start with, I want to understand the lay of the land by querying TTFB at various quantiles:
This shows that TTFB is over 1.3 seconds at P95 – that’s fairly slow, given that best practices are for 75% of pages to finish rendering within 2.5 seconds, and TTFB is just one component of LCP.
If I want to dig into why TTFB, it would be helpful to understand which URLs are slowest. In this query I’ll filter to that slowest 5% of page loads, and now look at the aggregate time taken – this helps me understand which pages contribute most to slow loads:
Based on this query, it looks like the /api/v2 path is most often responsible for these slow requests. In order to know how to fix the problem, we need to know why these pages are slow. To do this, we can query for the average (mean) DNS and origin response time for queries on these paths, where TTFB is above our P95 threshold:
According to this, most of the long TTFB values are actually due to resolving DNS! The good news is that’s something we can fix – for example, by setting longer TTLs with my DNS provider.
Conclusion
Coming soon, we’ll be bringing this to Cloudflare Observatory in the dashboard so that you can easily explore timing data via the UI.
And we’ll be adding even more granular metrics so you can see exactly which components are contributing to high TTFB. For example, we plan to separate out the difference between origin “connection time” (how long it took to establish a TCP and/or TLS connection) vs “application response time” (how long it took an HTTP server to respond).
We’ll also be making improvements to our GraphQL API to allow more flexible querying – for example, the ability to query arbitrary percentiles, not just 50th, 95th, or 99th.
Start using the GraphQL API today to get Timing Insights, or hop on the discussion about our Analytics products in Discord.
Today, Cloudflare is very excited to announce full support for HTTP/3 Extensible Priorities, a new standard that speeds the loading of webpages by up to 37%. Cloudflare worked closely with standards builders to help form the specification for HTTP/3 priorities and is excited to help push the web forward. HTTP/3 Extensible Priorities is available on all plans on Cloudflare. For paid users, there is an enhanced version available that improves performance even more.
Web pages are made up of many objects that must be downloaded before they can be processed and presented to the user. Not all objects have equal importance for web performance. The role of HTTP prioritization is to load the right bytes at the most opportune time, to achieve the best results. Prioritization is most important when there are multiple objects all competing for the same constrained resource. In HTTP/3, this resource is the QUIC connection. In most cases, bandwidth is the bottleneck from server to client. Picking what objects to dedicate bandwidth to, or share bandwidth amongst, is a critical foundation to web performance. When it goes askew, the other optimizations we build on top can suffer.
Today, we're announcing support for prioritization in HTTP/3, using the full capabilities of the HTTP Extensible Priorities (RFC 9218) standard, augmented with Cloudflare's knowledge and experience of enhanced HTTP/2 prioritization. This change is compatible with all mainstream web browsers and can improve key metrics such as Largest Contentful Paint (LCP) by up to 37% in our test. Furthermore, site owners can apply server-side overrides, using Cloudflare Workers or directly from an origin, to customize behavior for their specific needs.
Looking at a real example
The ultimate question when it comes to features like HTTP/3 Priorities is: how well does this work and should I turn it on? The details are interesting and we'll explain all of those shortly but first lets see some demonstrations.
In order to evaluate prioritization for HTTP/3, we have been running many simulations and tests. Each web page is unique. Loading a web page can require many TCP or QUIC connections, each of them idiosyncratic. These all affect how prioritization works and how effective it is.
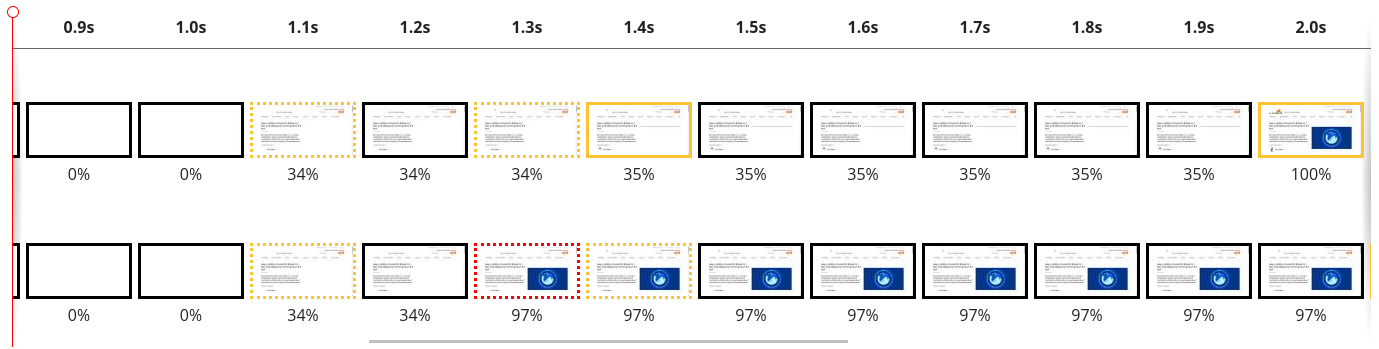
To evaluate the effectiveness of priorities, we ran a set of tests measuring Largest Contentful Paint (LCP). As an example, we benchmarked blog.cloudflare.com to see how much we could improve performance:
As a film strip, this is what it looks like:
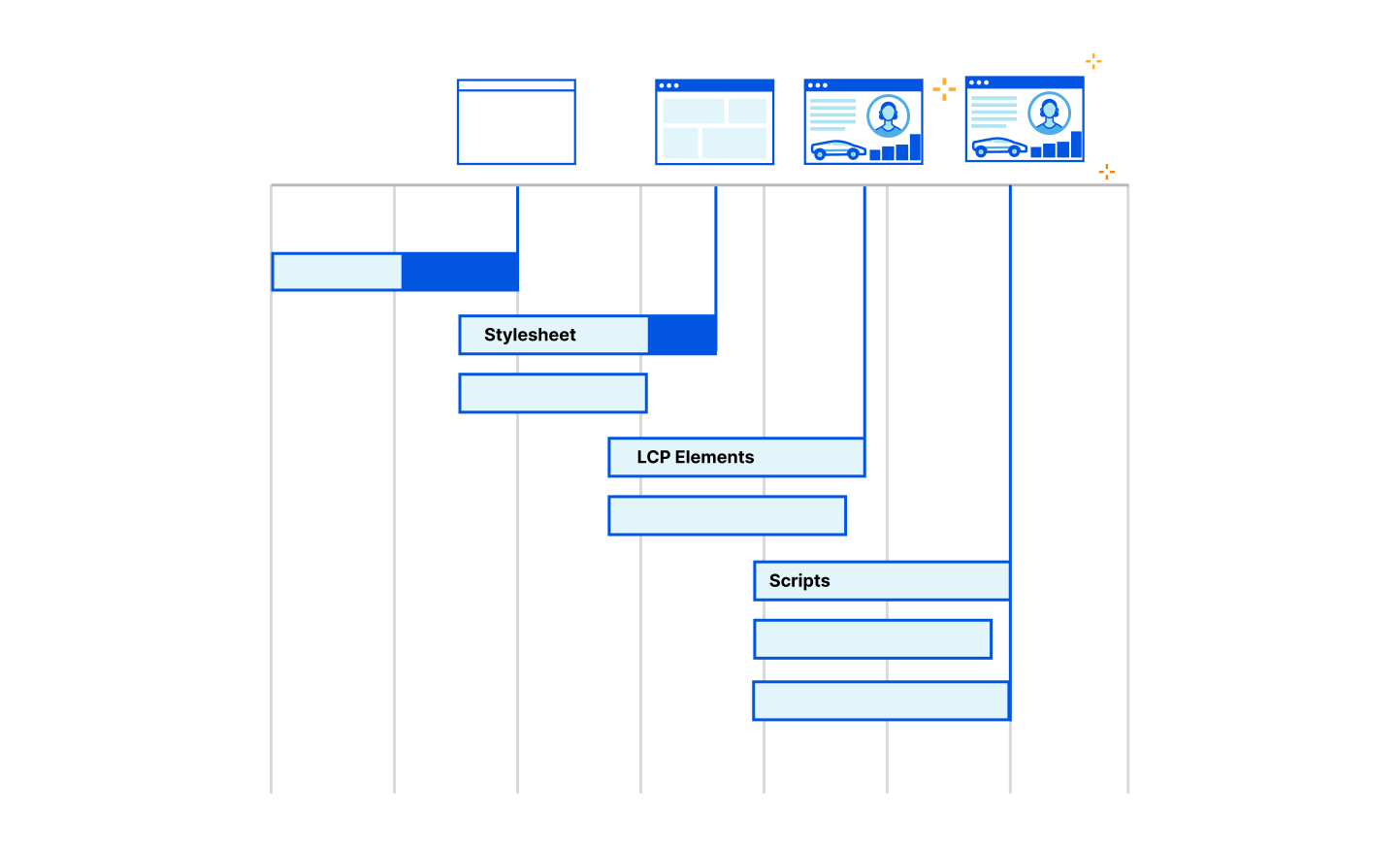
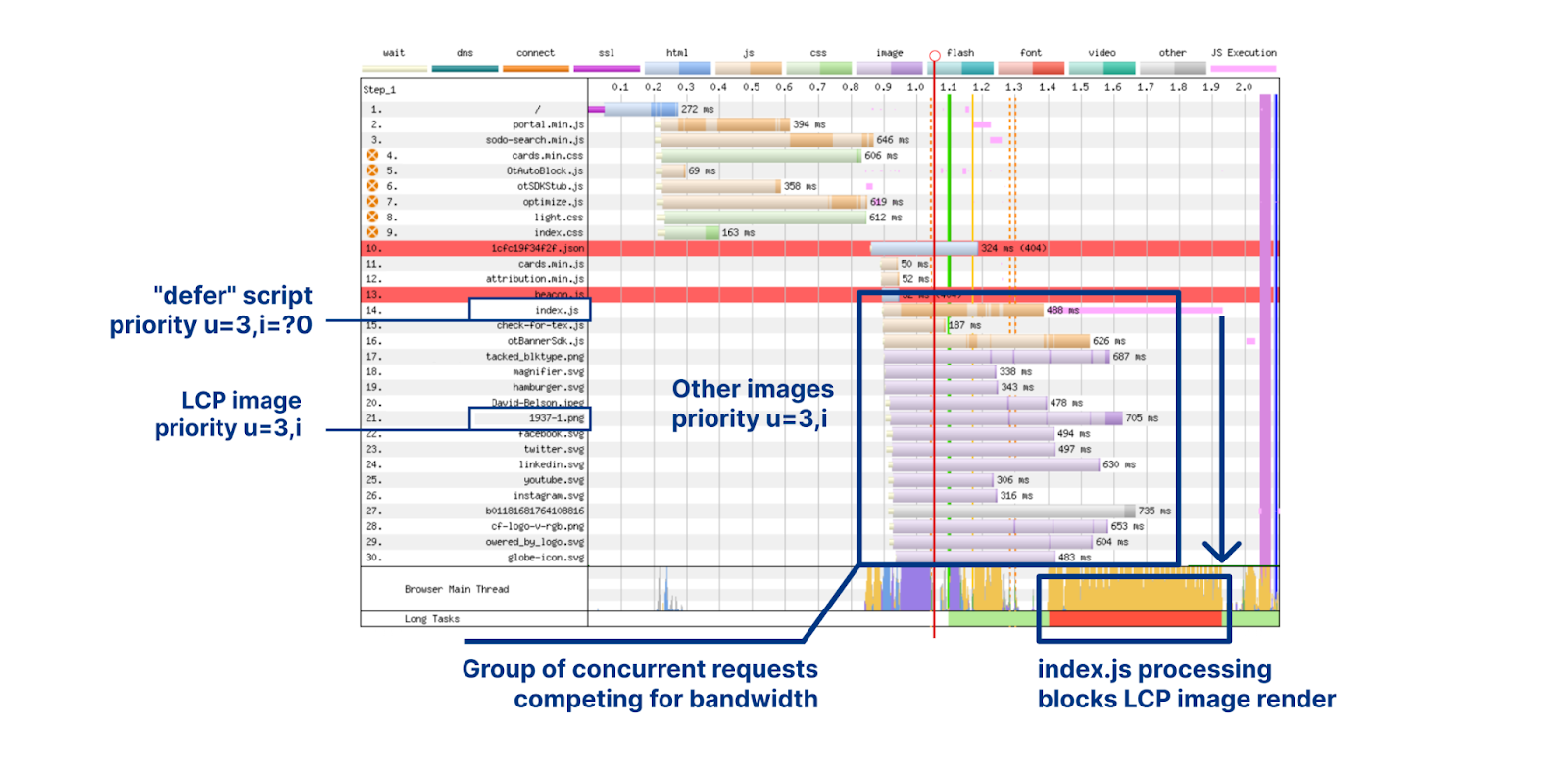
In terms of actual numbers, we see Largest Contentful Paint drop from 2.06 seconds down to 1.29 seconds. Let’s look at why that is. To analyze exactly what’s going on we have to look at a waterfall diagram of how this web page is loading. A waterfall diagram is a way of visualizing how assets are loading. Some may be loaded in parallel whilst some might be loaded sequentially. Without smart prioritization, the waterfall for loading assets for this web page looks as follows:
There are several interesting things going on here so let's break it down. The LCP image at request 21 is for 1937-1.png, weighing 30.4 KB. Although it is the LCP image, the browser requests it as priority u=3,i, which informs the server to put it in the same round-robin bandwidth-sharing bucket with all of the other images. Ahead of the LCP image is index.js, a JavaScript file that is loaded with a "defer" attribute. This JavaScript is non-blocking and shouldn't affect key aspects of page layout.
What appears to be happening is that the browser gives index.js the priority u=3,i=?0, which places it ahead of the images group on the server-side. Therefore, the 217 KB of index.js is sent in preference to the LCP image. Far from ideal. Not only that, once the script is delivered, it needs to be processed and executed. This saturates the CPU and prevents the LCP image from being painted, for about 300 milliseconds, even though it was delivered already.
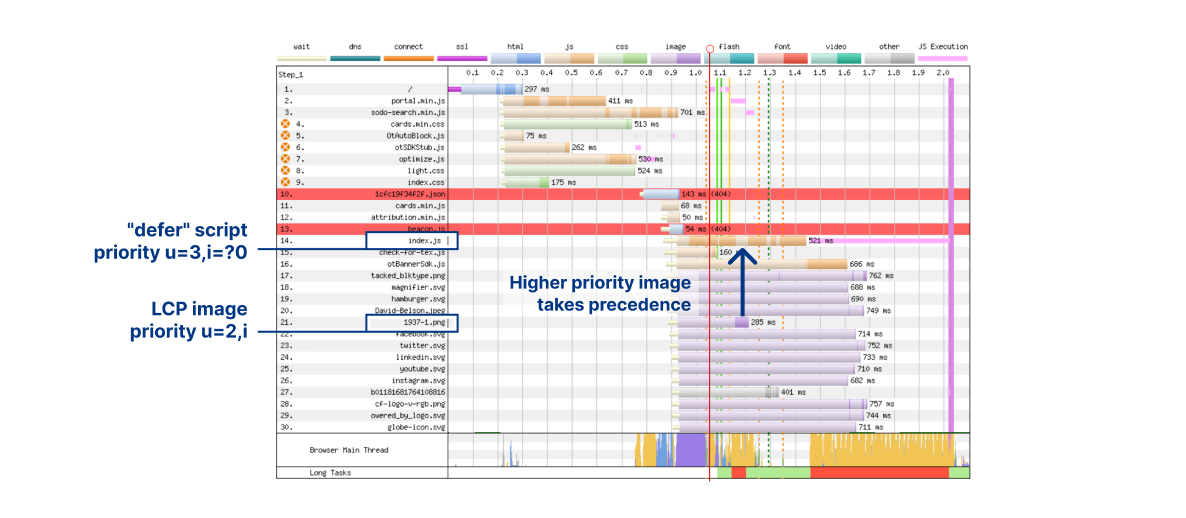
The waterfall with prioritization looks much better:
We used a server-side override to promote the priority of the LCP image 1937-1.png from u=3,i to u=2,i. This has the effect of making it leapfrog the "defer" JavaScript. We can see at around 1.2 seconds, transmission of index.js is halted while the image is delivered in full. And because it takes another couple of hundred milliseconds to receive the remaining JavaScript, there is no CPU competition for the LCP image paint. These factors combine together to drastically improve LCP times.
How Extensible Priorities actually works
First of all, you don't need to do anything yourselves to make it work. Out of the box, browsers will send Extensible Priorities signals alongside HTTP/3 requests, which we'll feed into our priority scheduling decision making algorithms. We'll then decide the best way to send HTTP/3 response data to ensure speedy page loads.
Extensible Priorities has a similar interaction model to HTTP/2 priorities, client send priorities and servers act on them to schedule response data, we'll explain exactly how that works in a bit.
HTTP/2 priorities used a dependency tree model. While this was very powerful it turned out hard to implement and use. When the IETF came to try and port it to HTTP/3 during the standardization process, we hit major issues. If you are interested in all that background, go and read my blog post describing why we adopted a new approach to HTTP/3 prioritization.
Extensible Priorities is a far simpler scheme. HTTP/2's dependency tree with 255 weights and dependencies (that can be mutual or exclusive) is complex, hard to use as a web developer and could not work for HTTP/3. Extensible Priorities has just two parameters: urgency and incremental, and these are capable of achieving exactly the same web performance goals.
Urgency is an integer value in the range 0-7. It indicates the importance of the requested object, with 0 being most important and 7 being the least. The default is 3. Urgency is comparable to HTTP/2 weights. However, it's simpler to reason about 8 possible urgencies rather than 255 weights. This makes developer's lives easier when trying to pick a value and predicting how it will work in practice.
Incremental is a boolean value. The default is false. A true value indicates the requested object can be processed as parts of it are received and read – commonly referred to as streaming processing. A false value indicates the object must be received in whole before it can be processed.
Let's consider some example web objects to put these parameters into perspective:
An HTML document is the most important piece of a webpage. It can be processed as parts of it arrive. Therefore, urgency=0 and incremental=true is a good choice.
A CSS style is important for page rendering and could block visual completeness. It needs to be processed in whole. Therefore, urgency=1 and incremental=false is suitable, this would mean it doesn't interfere with the HTML.
An image file that is outside the browser viewport is not very important and it can be processed and painted as parts arrive. Therefore, urgency=3 and incremental=true is appropriate to stop it interfering with sending other objects.
An image file that is the "hero image" of the page, making it the Largest Contentful Pain element. An urgency of 1 or 2 will help it avoid being mixed in with other images. The choice of incremental value is a little subjective and either might be appropriate.
When making an HTTP request, clients decide the Extensible Priority value composed of the urgency and incremental parameters. These are sent either as an HTTP header field in the request (meaning inside the HTTP/3 HEADERS frame on a request stream), or separately in an HTTP/3 PRIORITY_UPDATE frame on the control stream. HTTP headers are sent once at the start of a request; a client might change its mind so the PRIORITY_UPDATE frame allows it to reprioritize at any point in time.
For both the header field and PRIORITY_UPDATE, the parameters are exchanged using the Structured Fields Dictionary format (RFC 8941) and serialization rules. In order to save bytes on the wire, the parameters are shortened – urgency to 'u', and incremental to 'i'.
Here's how the HTTP header looks alongside a GET request for important HTML, using HTTP/3 style notation:
The PRIORITY_UPDATE frame only carries the serialized Extensible Priority value:
PRIORITY_UPDATE:
u=0,i
Structured Fields has some other neat tricks. If you want to indicate the use of a default value, then that can be done via omission. Recall that the urgency default is 3, and incremental default is false. A client could send "u=1" alongside our important CSS request (urgency=1, incremental=false). For our lower priority image it could send just "i=?1" (urgency=3, incremental=true). There's even another trick, where boolean true dictionary parameters are sent as just "i". You should expect all of these formats to be used in practice, so it pays to be mindful about their meaning.
Extensible Priority servers need to decide how best to use the available connection bandwidth to schedule the response data bytes. When servers receive priority client signals, they get one form of input into a decision making process. RFC 9218 provides a set of scheduling recommendations that are pretty good at meeting a board set of needs. These can be distilled down to some golden rules.
For starters, the order of requests is crucial. Clients are very careful about asking for things at the moment they want it. Serving things in request order is good. In HTTP/3, because there is no strict ordering of stream arrival, servers can use stream IDs to determine this. Assuming the order of the requests is correct, the next most important thing is urgency ordering. Serving according to urgency values is good.
Be wary of non-incremental requests, as they mean the client needs the object in full before it can be used at all. An incremental request means the client can process things as and when they arrive.
With these rules in mind, the scheduling then becomes broadly: for each urgency level, serve non-incremental requests in whole serially, then serve incremental requests in round robin fashion in parallel. What this achieves is dedicated bandwidth for very important things, and shared bandwidth for less important things that can be processed or rendered progressively.
Let's look at some examples to visualize the different ways the scheduler can work. These are generated by using quiche'sqlog support and running it via the qvis analysis tool. These diagrams are similar to a waterfall chart; the y-dimension represents stream IDs (0 at the top, increasing as we move down) and the x-dimension shows reception of stream data.
Example 1: all streams have the same urgency and are non-incremental so get served in serial order of stream ID.
Example 2: the streams have the same urgency and are incremental so get served in round-robin fashion.
Example 3: the streams have all different urgency, with later streams being more important than earlier streams. The data is received serially but in a reverse order compared to example 1.
Beyond the Extensible Priority signals, a server might consider other things when scheduling, such as file size, content encoding, how the application vs content origins are configured etc.. This was true for HTTP/2 priorities but Extensible Priorities introduces a new neat trick, a priority signal can also be sent as a response header to override the client signal.
This works especially well in a proxying scenario where your HTTP/3 terminating proxy is sat in front of some backend such as Workers. The proxy can pass through the request headers to the backend, it can inspect these and if it wants something different, return response headers to the proxy. This allows powerful tuning possibilities and because we operate on a semantic request basis (rather than HTTP/2 priorities dependency basis) we don't have all the complications and dangers. Proxying isn't the only use case. Often, one form of "API" to your local server is via setting response headers e.g., via configuration. Leveraging that approach means we don't have to invent new APIs.
Let's consider an example where server overrides are useful. Imagine we have a webpage with multiple images that are referenced via <img> tags near the top of the HTML. The browser will process these quite early in the page load and want to issue requests. At this point, it might not know enough about the page structure to determine if an image is in the viewport or outside the viewport. It can guess, but that might turn out to be wrong if the page is laid out a certain way. Guessing wrong means that something is misprioritized and might be taking bandwidth away from something that is more important. While it is possible to reprioritize things mid-flight using the PRIORITY_UPDATE frame, this action is "laggy" and by the time the server realizes things, it might be too late to make much difference.
Fear not, the web developer who built the page knows exactly how it is supposed to be laid out and rendered. They can overcome client uncertainty by overriding the Extensible Priority when they serve the response. For instance, if a client guesses wrong and requests the LCP image at a low priority in a shared bandwidth bucket, the image will load slower and web performance metrics will be adversely affected. Here's how it might look and how we can fix it:
Priority response headers are one tool to tweak client behavior and they are complementary to other web performance techniques. Methods like efficiently ordering elements in HTML, using attributes like "async" or "defer", augmenting HTML links with Link headers, or using more descriptive link relationships like “preload” all help to improve a browser's understanding of the resources comprising a page. A website that optimizes these things provides a better chance for the browser to make the best choices for prioritizing requests.
More recently, a new attribute called “fetchpriority” has emerged that allows developers to tune some of the browser behavior, by boosting or dropping the priority of an element relative to other elements of the same type. The attribute can help the browser do two important things for Extensible priorities: first, the browser might send the request earlier or later, helping to satisfy our golden rule #1 – ordering. Second, the browser might pick a different urgency value, helping to satisfy rule #2. However, "fetchpriority" is a nudge mechanism and it doesn't allow for directly setting a desired priority value. The nudge can be a bit opaque. Sometimes the circumstances benefit greatly from just knowing plainly what the values are and what the server will do, and that's where the response header can help.
Conclusions
We’re excited about bringing this new standard into the world. Working with standards bodies has always been an amazing partnership and we’re very pleased with the results. We’ve seen great results with HTTP/3 priorities, reducing Largest Contentful Paint by up to 37% in our test. If you’re interested in turning on HTTP/3 priorities for your domain, just head on over to the Cloudflare dashboard and hit the toggle.
Website performance is crucial to the success of online businesses. Study after study has shown that an increased load time directly affects sales. But how do you get test products that could improve your website speed without incurring an element of risk?
In today's digital landscape, it is easy to find code optimizations on the Internet including our own developers documentation to improve the performance of your website or web applications. However, implementing these changes without knowing the impact they’ll have can be daunting. It could also cause an outage, taking websites or applications offline entirely, leaving admins scrambling to remove the offending code and get the business back online.
Users need a way to see the impact of these improvements on their websites without impacting uptime. They want to understand “If I enabled this, what performance boost should I expect to get?”.
Today, we are excited to announce Performance Experiments in Cloudflare Observatory. Performance Experiments gives users a safe place to experiment and determine what the best setup is to improve their website performance before pushing it live for all visitors to benefit from. Cloudflare users will be able to simply enter the desired code, run our Observatory testing suite and view the impact it would have on their Lighthouse score. If they are satisfied with the results they can push the experiment live. With the click of a button.
Experimenting within Observatory
Cloudflare Observatory, announced today, allows users to easily monitor website performance by integrating Real-User Monitoring (RUM) data and synthetic tests in one location.. This allows users to easily identify areas for optimization and leverage Cloudflare's features to address performance issues.
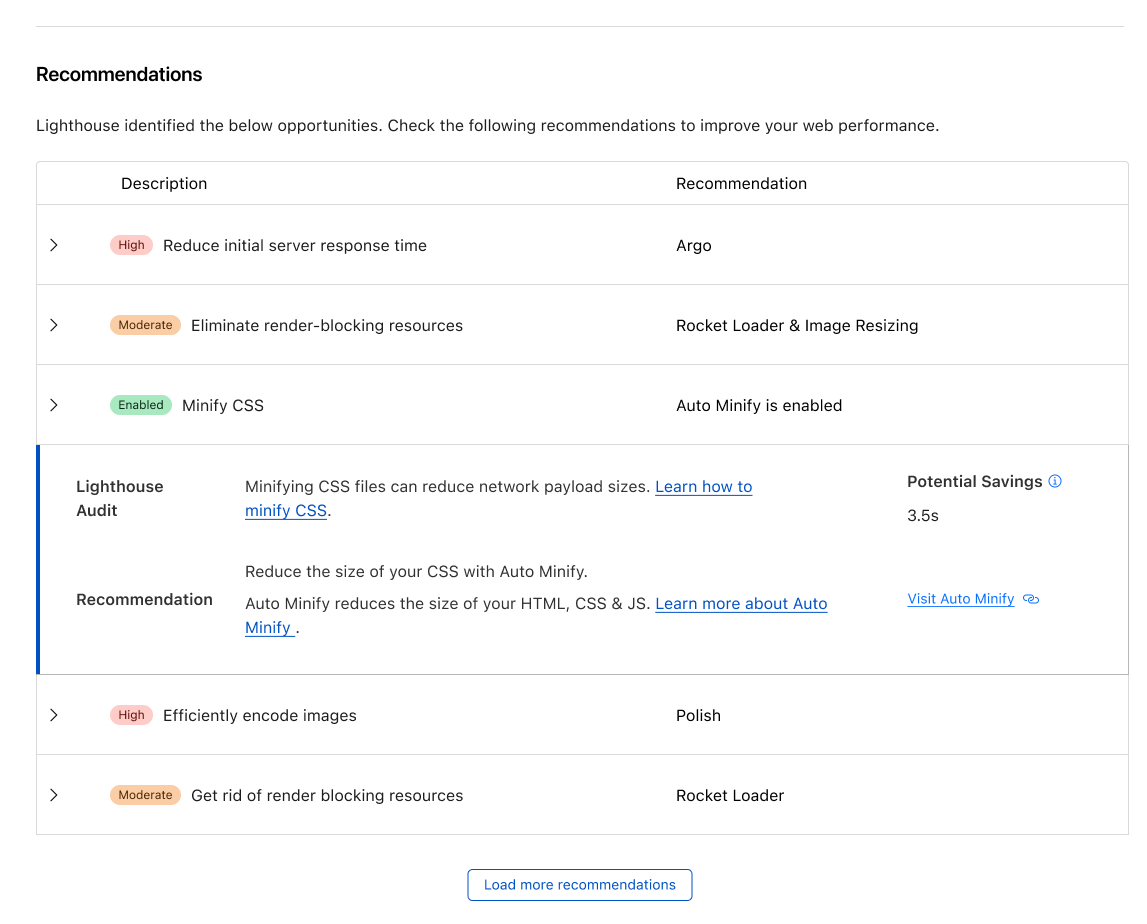
Observatory's recommendations leverage insights from these Lighthouse test and RUM data, enabling precise identification of issues and offering tailored Cloudflare settings for enhanced performance. For example, when a Lighthouse report suggests image optimization improvements, Cloudflare recommends enabling Polish or utilizing Image Resizing. These recommendations can be implemented with a single click, allowing customers to boost their performance score effortlessly.
Fine tuning with Experiments
Cloudflare’s Observatory allows customers to easily enable recommended Cloudflare settings. However, through the medium of Cloudflare Workers web performance advocates have been able to create and share JavaScript examples of how to improve and optimize a website.
A great example of this is Fast Fonts. Google Fonts are slow due to how they are served. When using Google Fonts on your website, you include a stylesheet URL that contains the font styles you want to use. The CSS file is hosted on one domain (fonts.googleapis.com), while the font files are on another domain (fonts.gstatic.com). This separation means that each resource requires at least four round trips to the server for DNS lookup, establishing the socket connection, negotiating TLS encryption (for https), and making the request itself.
These requests cannot be done in parallel because the fonts are not known until after the CSS is downloaded and applied to the page. In the best-case scenario, this leads to eight round trips before the text can be displayed. On a slower 3G connection with a 300ms round-trip time, this delay can add up to 2.4 seconds. To fix this issue Cloudflare Workers can be used to reduce the performance penalties of serving Google Fonts directly from Google by 81%.
Another issue is resource prioritization. When all requests come from the same domain on the same HTTP/2 connection, critical resources like CSS and fonts can be prioritized and delivered before lower priority resources like images. However, since Google Fonts (and most third-party resources) are served from a different domain than the main page resources, they cannot be prioritized and end up competing with each other for download bandwidth. This competition can result in significantly longer fetch times than the best-case scenario of eight round trips.
To implement this Worker first create a Cloudflare Worker, implement the code from the GitHub repository using Wrangler and then run manual tests to see if performance has been improved and that there are no issues or problems with the website loading. Users can choose to implement the Cloudflare Worker on a test path that may not be a true reflection of production or complicate the Cloudflare Worker further by implementing an A/B test that could still have an impact on your end users. So how can users test code on their website to easily see if the code will improve the performance of their website and not have any adverse impact on end users?
Introducing Performance Experiments
Last year we announced Cloudflare Snippets. Snippets is a platform for running discrete pieces of JavaScript code on Cloudflare before your website is served to the user. They provide a convenient way to customize and enhance your website's functionality. If you are already familiar with Cloudflare Workers, our developer platform, you'll find Snippets to be a familiar and welcome addition to your toolkit. With Snippets, you can easily execute small pieces of user-created JavaScript code to modify the behavior of your website and improve performance, security, and user experience.
Combining Snippets with Observatory lets users easily run experiments and get instant feedback on the performance impact. Users will be able to find a piece of JavaScript, insert it into the Experiments window and hit test. Observatory will then automatically run multiple Lighthouse tests with the experiment disabled and then enabled. The results will show the before and after scores allowing users to determine the impact of the experiment e.g. “If I put this JavaScript on my website, my Lighthouse score would improve by 15 points”.
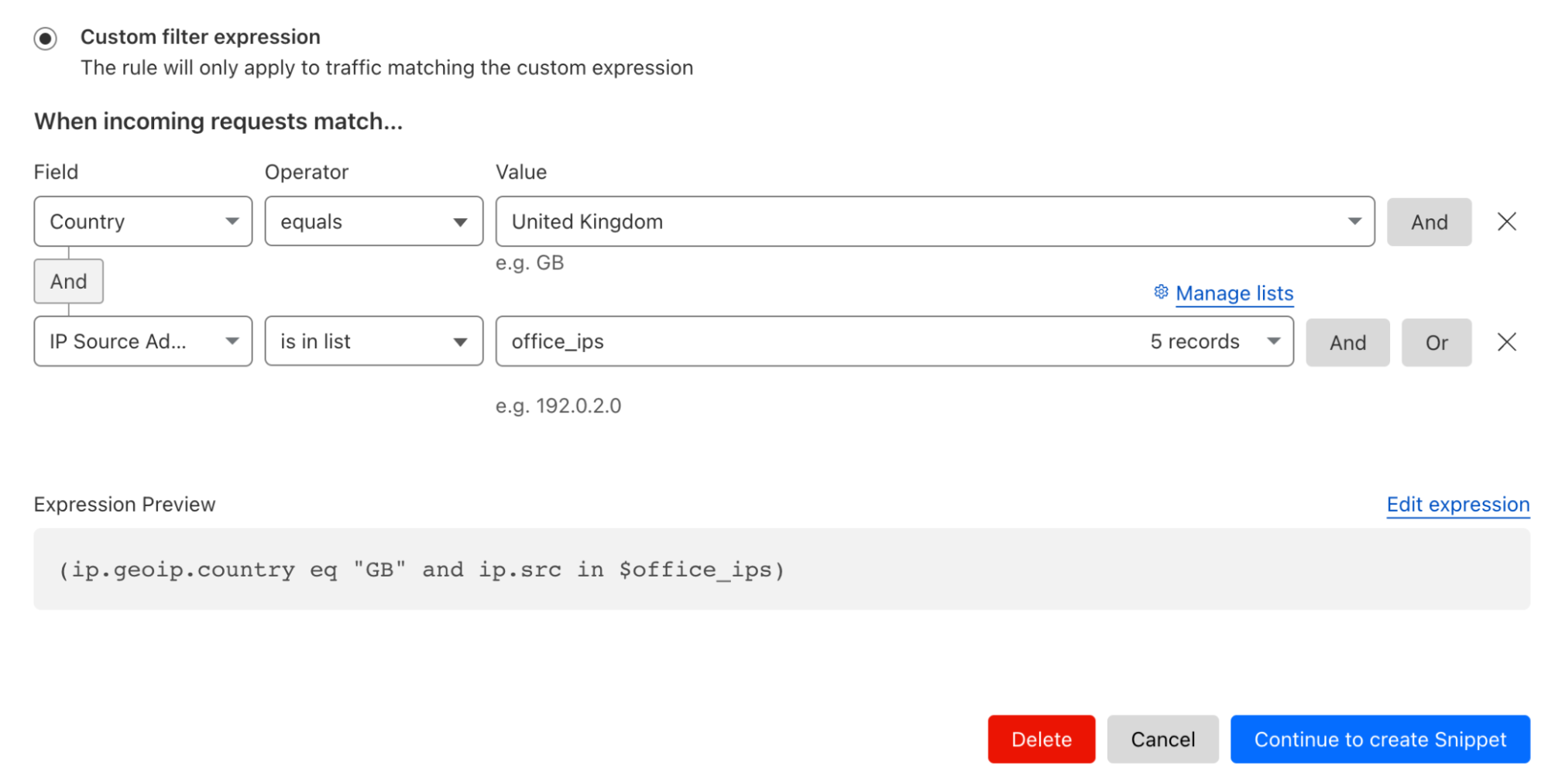
This allows users to understand if the JavaScript has had a positive performance impact on their website. Users can then deploy this JavaScript, via Snippets, against all requests or on a specific subset of traffic. For example, if I only wanted it run on traffic from the UK or my office IPs I would use the rule below:
Alternatively, if the results impact performance customers negatively users can safely discard the experiment or try another example. All without real visitors to the website being impacted or ever at risk.
Accessing Performance Experiments
Performance Experiments are currently under development — you can sign up here to join the waitlist for access.
We hope to begin admitting users later in the year, with an open beta to follow.
Today, Cloudflare is super excited to announce that we’re bringing traffic acceleration to customer’s UDP traffic. Now, you can improve the latency of UDP-based applications like video games, voice calls, and video meetings by up to 17%. Combining the power of Argo Smart Routing (our traffic acceleration product) with UDP gives you the ability to supercharge your UDP-based traffic.
When applications use TCP vs. UDP
Typically when people talk about the Internet, they think of websites they visit in their browsers, or apps that allow them to order food. This type of traffic is sent across the Internet via HTTP which is built on top of the Transmission Control Protocol (TCP). However, there’s a lot more to the Internet than just browsing websites and using apps. Gaming, live video, or tunneling traffic to different networks via a VPN are all common applications that don’t use HTTP or TCP. These popular applications leverage the User Datagram Protocol (or UDP for short). To understand why these applications use UDP instead of TCP, we’ll need to dig into how these different applications work.
When you load a web page, you generally want to see the entire web page; the website would be confusing if parts of it are missing. For this reason, HTTP uses TCP as a method of transferring website data. TCP ensures that if a packet ever gets lost as it crosses the Internet, that packet will be resent. Having a reliable protocol like TCP is generally a good idea when 100% of the information sent needs to be loaded. It’s worth noting that later HTTP versions like HTTP/3 actually deviated from TCP as a transmission protocol, but they still ensure packet delivery by handling packet retransmission using the QUIC protocol.
There are other applications that prioritize quickly sending real time data and are less concerned about perfectly delivering 100% of the data. Let’s explore Real-Time Communications (RTC) like video meetings as an example. If two people are streaming video live, all they care about is what is happening now. If a few packets are lost during the initial transmission, retransmission is usually too slow to render the lost packet data in the current video frame. TCP doesn’t really make sense in this scenario.
Instead, RTC protocols are built on top of UDP. TCP is like a formal back and forth conversation where every sentence matters. UDP is more like listening to your friend's stream of consciousness: you don’t care about every single bit as long as you get the gist of it. UDP transfers packet data with speed and efficiency without guaranteeing the delivery of those packets. This is perfect for applications like RTC where reducing latency is more important than occasionally losing a packet here or there. The same applies to gaming traffic; you generally want the most up-to-date information, and you don’t really care about retransmitting lost packets.
Gaming and RTC applications really care about latency. Latency is the length of time it takes a packet to be sent to a server plus the length of time to receive a response from the server (called round-trip time or RTT). In the case of video games, the higher the latency, the longer it will take for you to see other players move and the less time you’ll have to react to the game. With enough latency, games become unplayable: if the players on your screen are constantly blipping around it’s near impossible to interact with them. In RTC applications like video meetings, you’ll experience a delay between yourself and your counterpart. You may find yourselves accidentally talking over each other which isn’t a great experience.
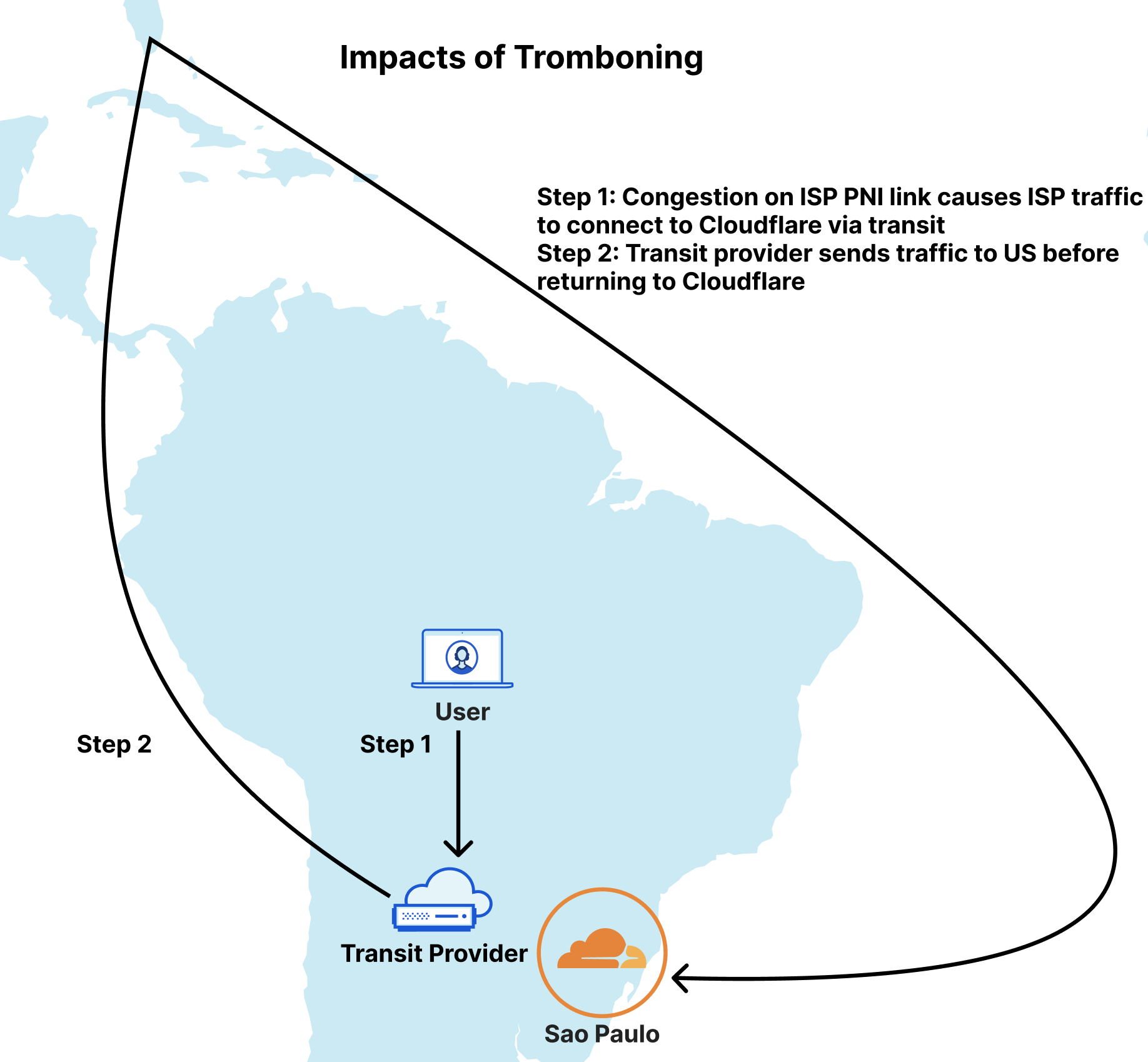
Companies that host gaming or RTC infrastructure often try to reduce latency by spinning up servers that are geographically closer to their users. However, it’s common to have two users that are trying to have a video call between distant locations like Amsterdam and Los Angeles. No matter where you install your servers, that's still a long distance for that traffic to travel. The longer the path, the higher the chances are that you're going to run into congestion along the way. Congestion is just like a traffic jam on a highway, but for networks. Sometimes certain paths get overloaded with traffic. This causes delays and packets to get dropped. This is where Argo Smart Routing comes in.
Argo Smart Routing
Cloudflare customers that want the best cross-Internet application performance rely on Argo Smart Routing’s traffic acceleration to reduce latency. Argo Smart Routing is like the GPS of the Internet. It uses real time global network performance measurements to accelerate traffic, actively route around Internet congestion, and increase your traffic’s stability by reducing packet loss and jitter.
Argo Smart Routing was launched in May 2017, and its first iteration focused on reducing website traffic latency. Since then, we’ve improved Argo Smart Routing and also launched Argo Smart Routing for Spectrum TCP traffic which reduces latency in any TCP-based protocols. Today, we’re excited to bring the same Argo Smart Routing technology to customer’s UDP traffic which will reduce latency, packet loss, and jitter in gaming, and live audio/video applications.
Argo Smart Routing accelerates Internet traffic by sending millions of synthetic probes from every Cloudflare data center to the origin of every Cloudflare customer. These probes measure the latency of all possible routes between Cloudflare’s data centers and a customer’s origin. We then combine that with probes running between Cloudflare’s data centers to calculate possible routes. When an Internet user makes a request to an origin, Cloudflare calculates the results of our real time global latency measurements, examines Internet congestion data, and calculates the optimal route for customer’s traffic. To enable Argo Smart Routing for UDP traffic, Cloudflare extended the route computations typically used for HTTP and TCP traffic and applied them to UDP traffic.
We knew that Argo Smart Routing offered impressive benefits for HTTP traffic, reducing time to first byte by up to 30% on average for customers. But UDP can be treated differently by networks, so we were curious to see if we would see a similar reduction in round-trip-time for UDP. To validate, we ran a set of tests. We set up an origin in Iowa, USA and had a client connect to it from Tokyo, Japan. Compared to a regular Spectrum setup, we saw a decrease in round-trip-time of up to 17.3% on average. For the standard setup, Spectrum was able to proxy packets to Iowa in 173.3 milliseconds on average. Comparatively, turning on Argo Smart Routing reduced the average round-trip-time down to 143.3 milliseconds. The distance between those two cities is 6,074 miles (9,776 kilometers), meaning we've effectively moved the two closer to each other by over a thousand miles (or 1,609 km) just by turning on this feature.
We're incredibly excited about Argo Smart Routing for UDP and what our customers will use it for. If you're in gaming or real-time-communications, or even have a different use-case that you think would benefit from speeding up UDP traffic, please contact your account team today. We are currently in closed beta but are excited about accepting applications.
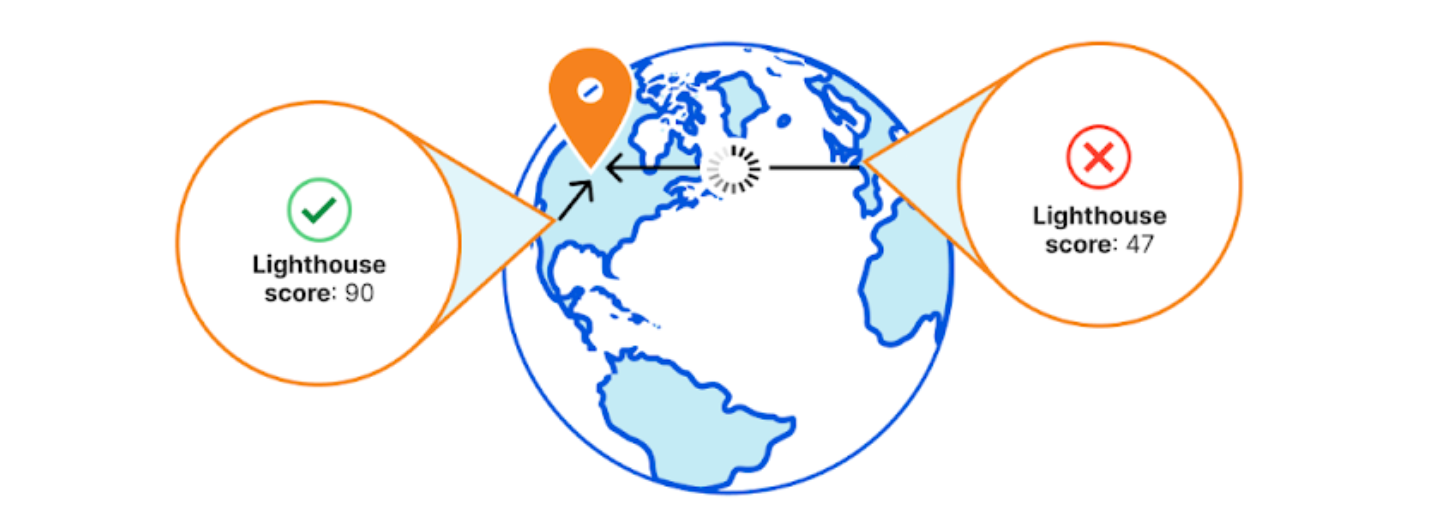
Website performance is crucial to the success of online businesses. Study after study has shown that an increased load time directly affects sales. In highly competitive markets the performance of a website is crucial for success. Just like a physical shop situated in a remote area faces challenges in attracting customers, a slow website encounters similar difficulties in attracting traffic. It is vital to measure and improve website performance to enhance user experience and maximize online engagement. Results from testing at home don’t take into account how your customers in different countries, on different devices, with different Internet connections experience your website.
Simply put, you might not know how your website is performing. And that could be costing your business money every single day.
Today we are excited to announce Cloudflare Observatory – the new home of performance at Cloudflare.
Cloudflare users can now easily monitor website performance using Real User Monitoring (RUM) data along with scheduled tests from different regions in a single dashboard. This will identify any performance issues your website may have. The best bit? Once we’ve identified any issues, Observatory will highlight customized recommendations to resolve these issues, all with a single click.
Making your website faster just got a lot easier.
I feel the need. The need for speed!
Having a fast website is crucial for achieving online success. According to Google, even a one-second improvement in load time can boost mobile conversions by up to 27%.
A study from Deloitte found “With a 0.1s improvement in site speed, we observed that retail consumers spent almost 10% more”. Another study, from Google, found “53% will leave a mobile site if it takes more than 3 seconds to load”. There is a very real link between website performance and business success.
In today's digital landscape, customers expect instant access to information and seamless browsing experiences. We have all encountered the frustration of waiting for a website to load, often leading us to click the back button and click on the next link. For ecommerce sites, this delay directly translates to lost revenue as users quickly navigate elsewhere.
This importance is further amplified in the world of Search Engine Optimization (SEO). In May 2021, Google announced that page speed would be incorporated into their ranking algorithm, highlighting the significance of fast-loading web pages for higher search engine rankings.
Introducing Observatory
In 2019, we launched the new Speed Tab with the mission to address two crucial questions: "How fast is my website after moving to Cloudflare?" and "How fast could it be?" This tab allowed customers to compare their website's performance before and after enabling Cloudflare features. However, it required users to delve into analytics and analyze traffic patterns and cache hit ratios to optimize their sites, which proved challenging for new Cloudflare users.
To address this, we developed Observatory, a fresh approach to performance monitoring at Cloudflare. Observatory fills the gap that previously existed in understanding website performance and simplifies the process of addressing performance issues by providing tailored recommendations.
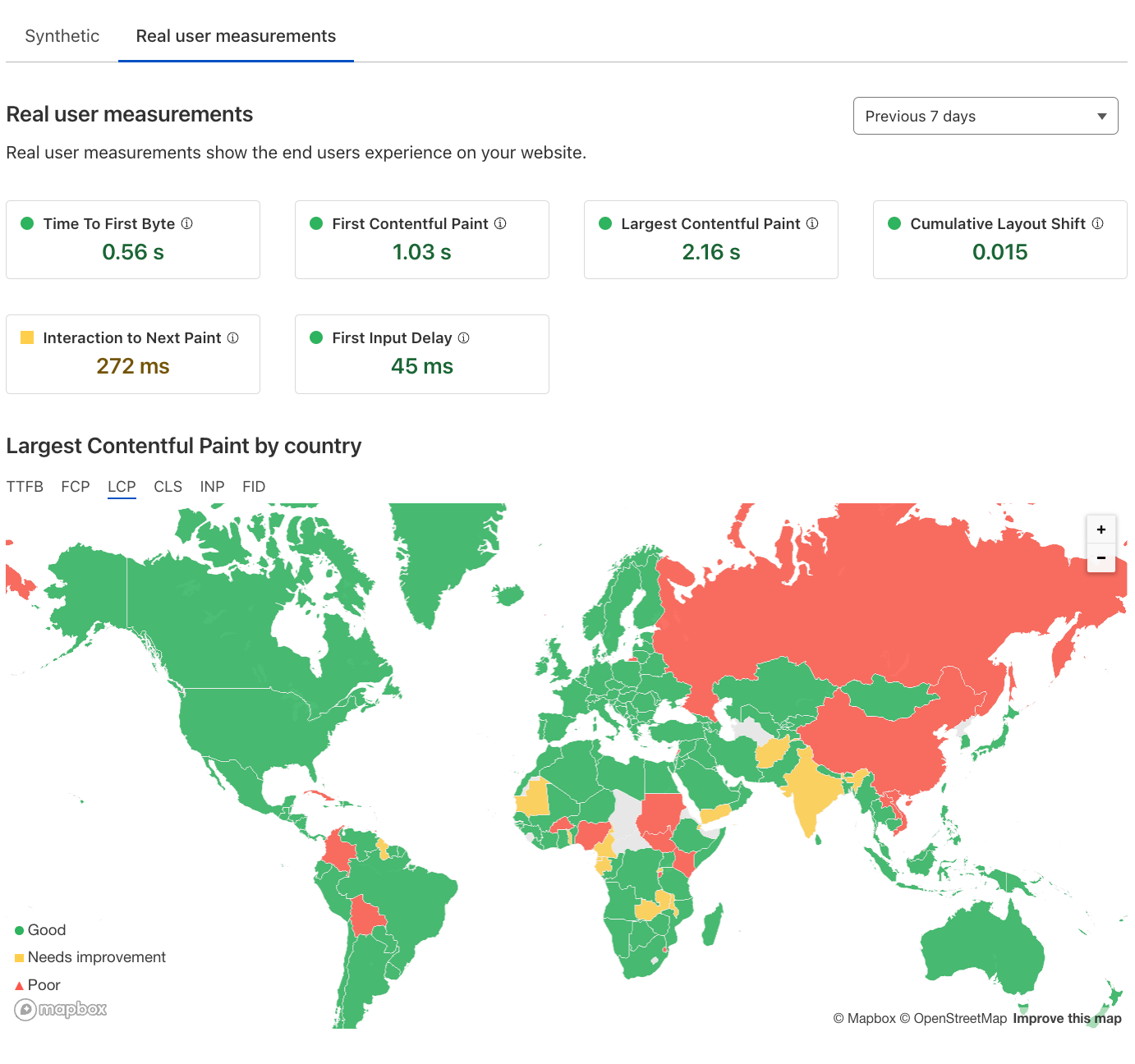
Observatory integrates Real-User Monitoring (RUM) data, which enables users to understand their website's performance as experienced by their end users across the globe. By leveraging RUM data we can show valuable insight into the areas of the website that can be optimized and surface Cloudflare features and functionality that can address these issues.
Additionally, Observatory incorporates Google Lighthouse, the industry standard tool for evaluating web performance. We replaced WebPageTest with Lighthouse due to its versatility and widespread adoption in the performance community. With Lighthouse, users can run, schedule, and access Lighthouse performance reports directly in the Cloudflare dashboard.
Observatory also enables regional testing, recognizing the importance of understanding performance variations across different locations. By simulating website performance in different regions, users can understand if their webpage performs well in certain countries and poorly in others. This enables users to optimize their websites for a global audience, ensuring consistent and fast user experiences regardless of location.
Observatory becomes your unified place within the Cloudflare dashboard for website performance by bringing together RUM data, Lighthouse insights, and regional testing. Users can gain a comprehensive understanding of their website's performance and implement Cloudflare recommendations based on this data with just a click of a button.
Measuring performance in Cloudflare Observatory
We support the two main methods of testing website performance. These are synthetic tests and Real User Monitoring (RUM) tests.
Synthetic tests involve simulating user interactions and monitoring performance under controlled environments. These tests can provide valuable baseline measurements and help identify potential issues before deploying changes.
On the other hand, RUM tests involve collecting data directly from real users as they interact with the website, capturing their actual experiences in different environments and network conditions. RUM tests offer insights into the true end-user perspective. By combining both synthetic and RUM tests, website owners can gain a holistic view of performance, understanding how changes and optimizations affect both simulated and real user experiences.
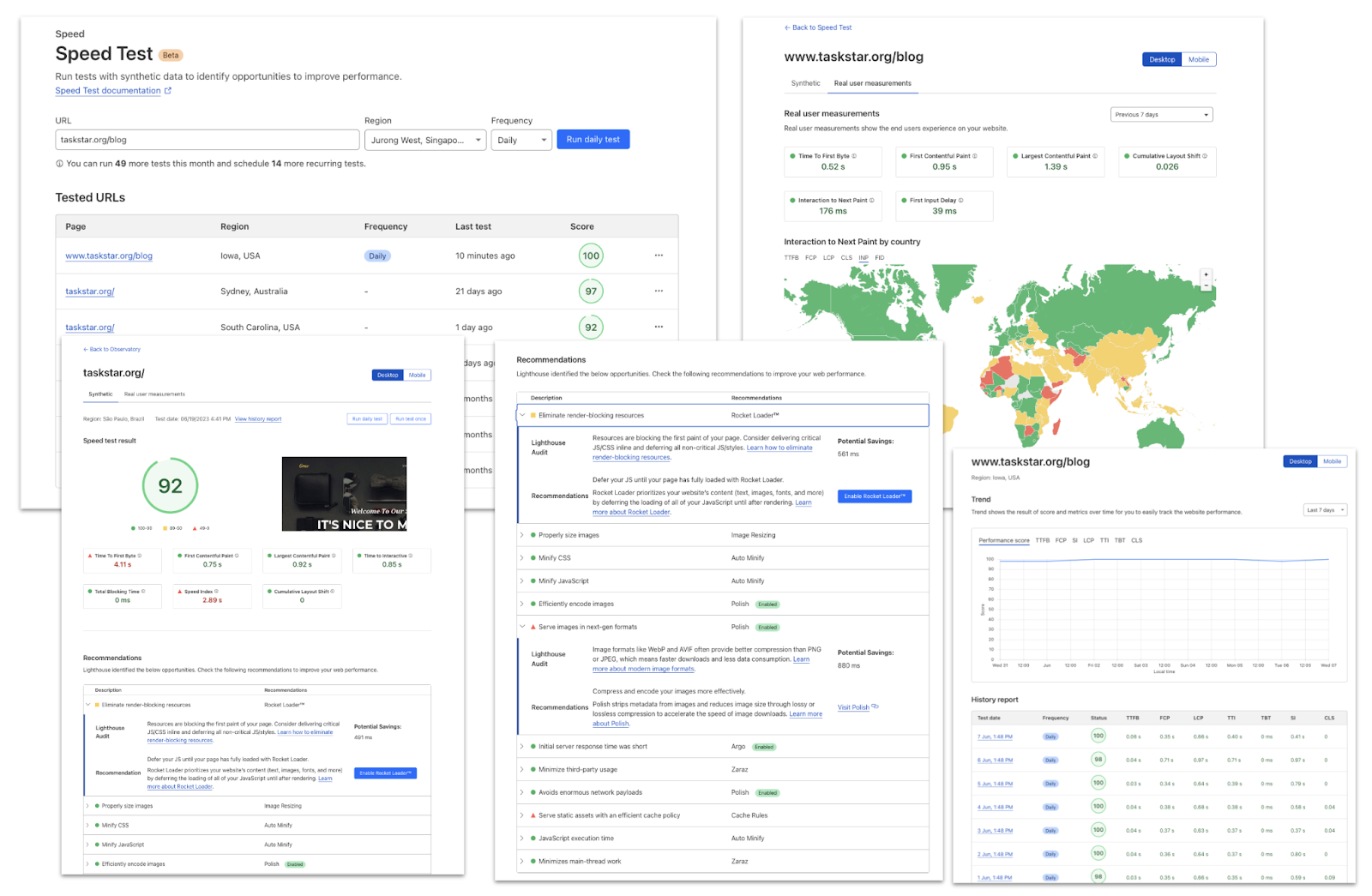
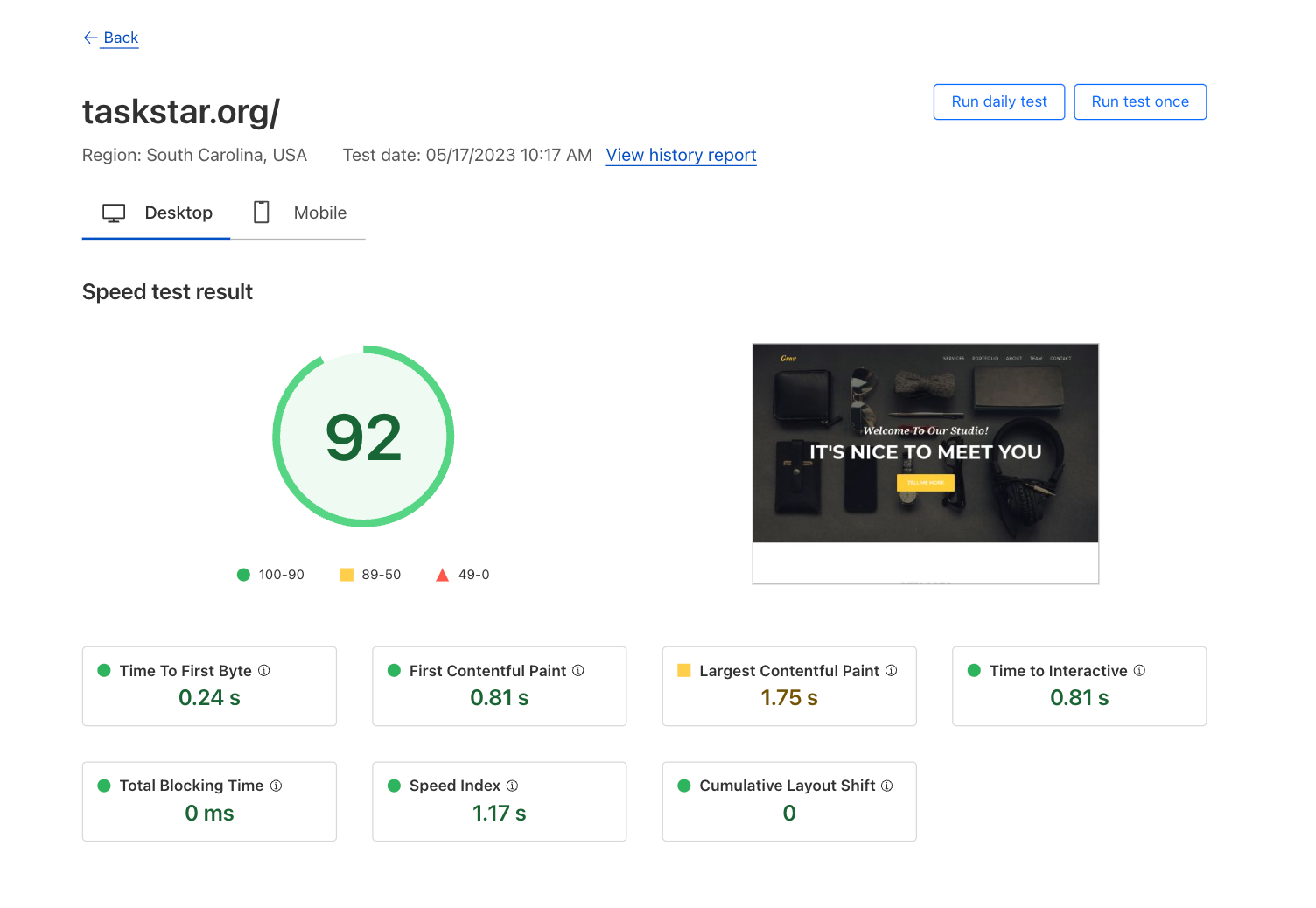
Cloudflare Observatory combines both of these in one location. The integration of Google Lighthouse within the Observatory gives Cloudflare users a simple way to synthetically measure and understand their site's performance. Google Lighthouse measures several key performance metrics that impact user experience and search engine ranking. The generated report provides an overall performance score ranging from 1 (least performant) to 99 (most performant), making it easy for website owners to understand their site's performance.
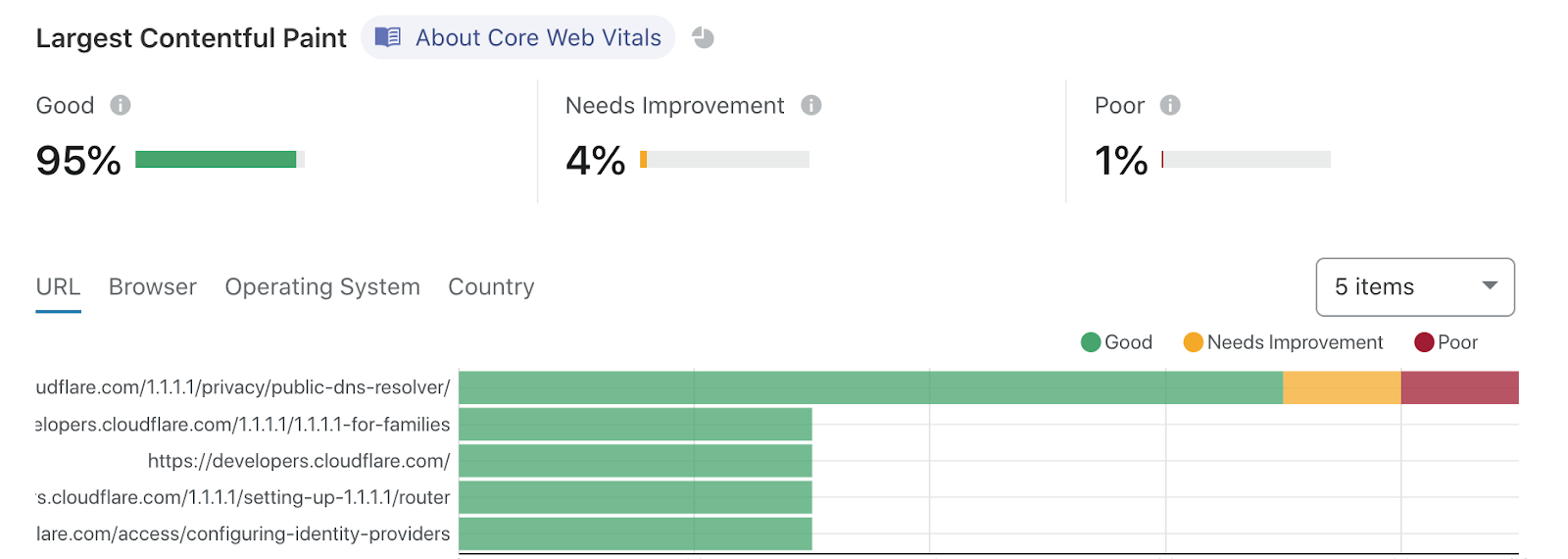
Observatory offers a user-friendly interface that presents each Lighthouse metric in a traffic light system, indicating the result of the tested metric. One critical metric is Largest Contentful Paint (LCP), which measures a page's loading performance of the primary content. An optimal LCP score is less than 2.5 seconds, indicating satisfactory loading speed for the user. Through Observatory website owners can easily see their LCP score and other metrics. This allows them to optimize their site's performance and user experience. For example, by examining the LCP score website owners can identify opportunities for improvement and make informed decisions to enhance their site's performance.
New Smarter Recommendations
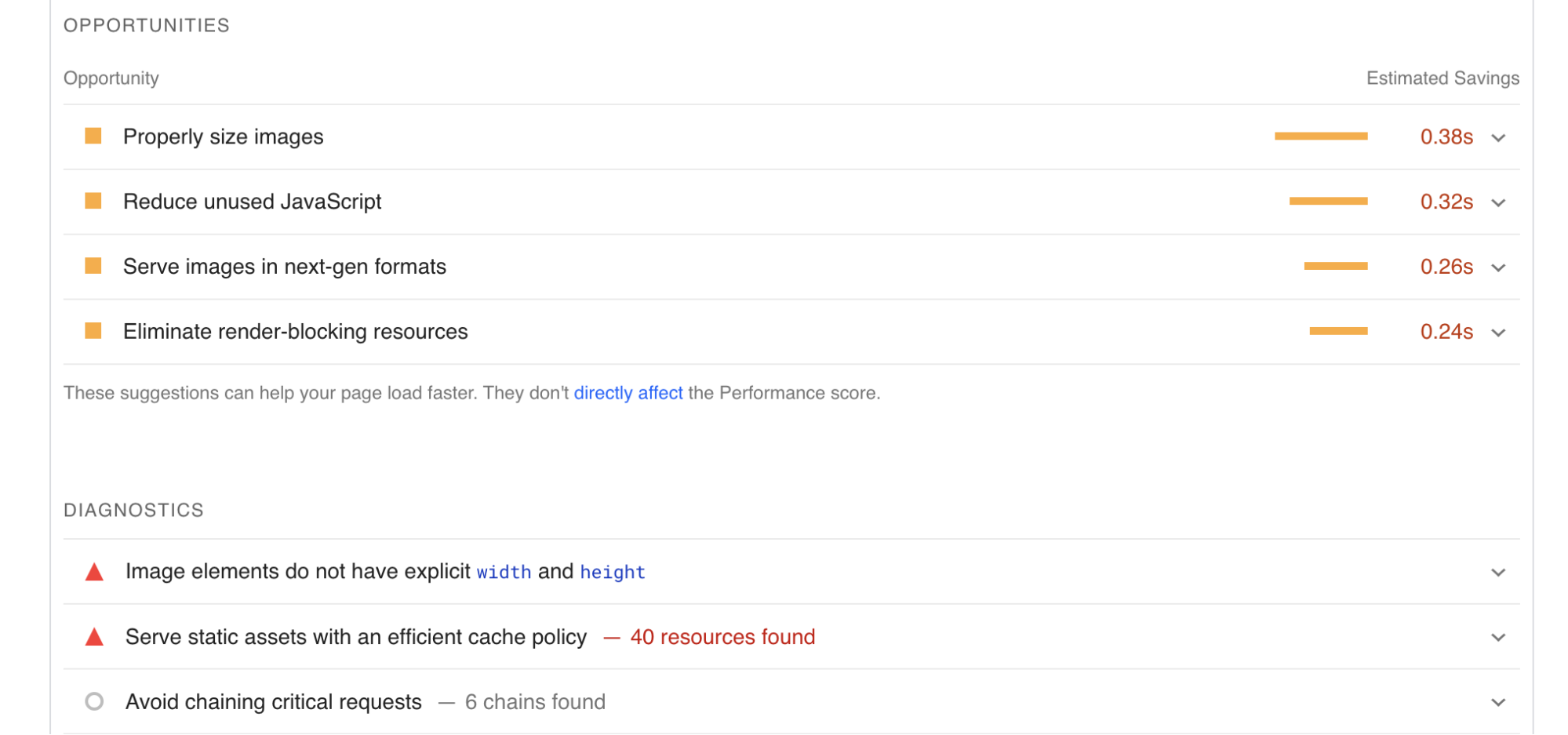
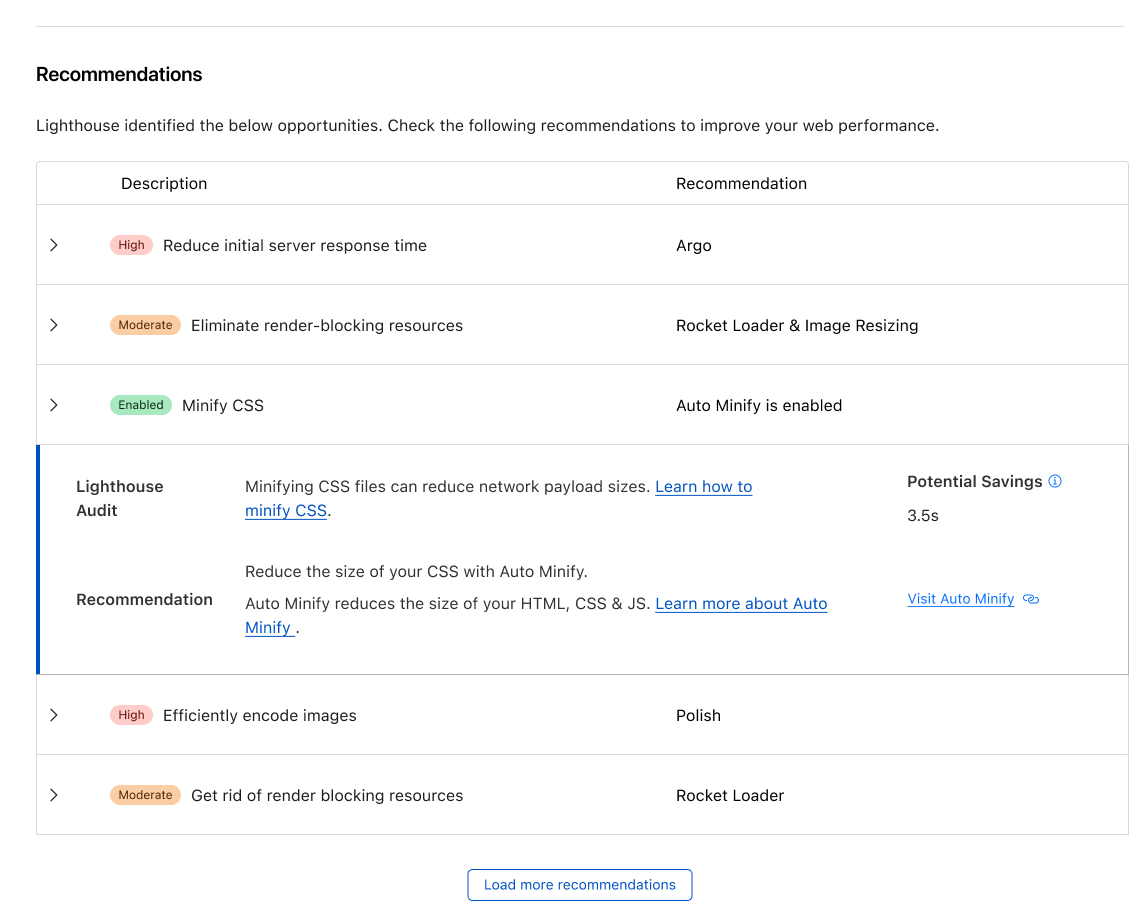
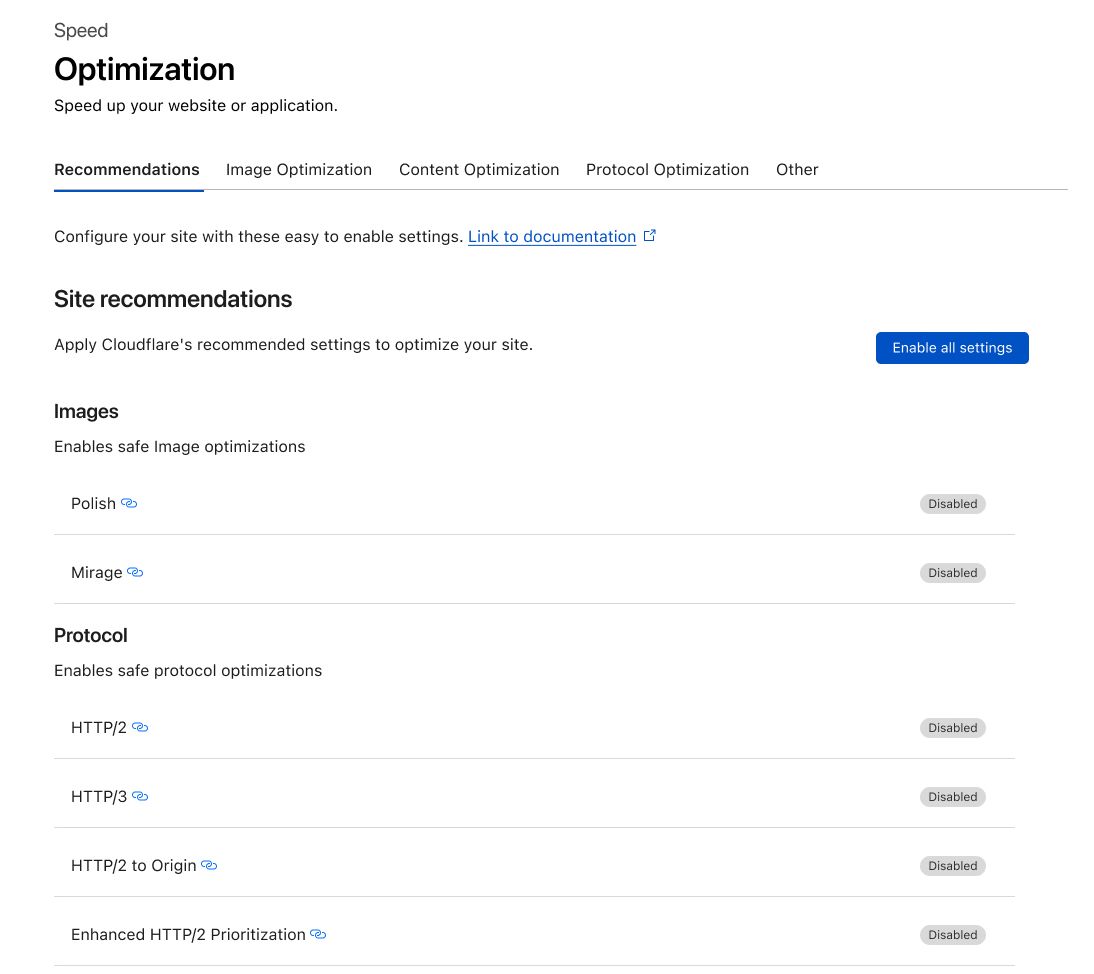
Recommendations from Observatory have become smarter by leveraging the insights gathered from Lighthouse and RUM testing. This enables us to precisely identify issues and offer tailored Cloudflare settings to enhance performance. For instance, when you receive a Lighthouse report it will highlight areas in which your website can be improved. In the provided report, several enhancements for image optimization are suggested. Cloudflare takes this feedback into account and provides product recommendations, such as enabling Polish or utilizing Image Resizing. This empowers our customers to enhance their performance score with just a single click.
Customers will have the convenience of viewing these recommendations within the Cloudflare dashboard, directly linked to the audit. The dashboard will encompass a wide range of Cloudflare features and functionalities, continually improving over time. With the addition of Cache Rules recommendations for uncached static content and a comprehensive testing suite, users will gain valuable insights into the benefits of implementing specific Cloudflare features before enabling them.
By knowing the performance impact of a product or feature before it is enabled, customers can make informed decisions and optimize their website's performance with confidence.
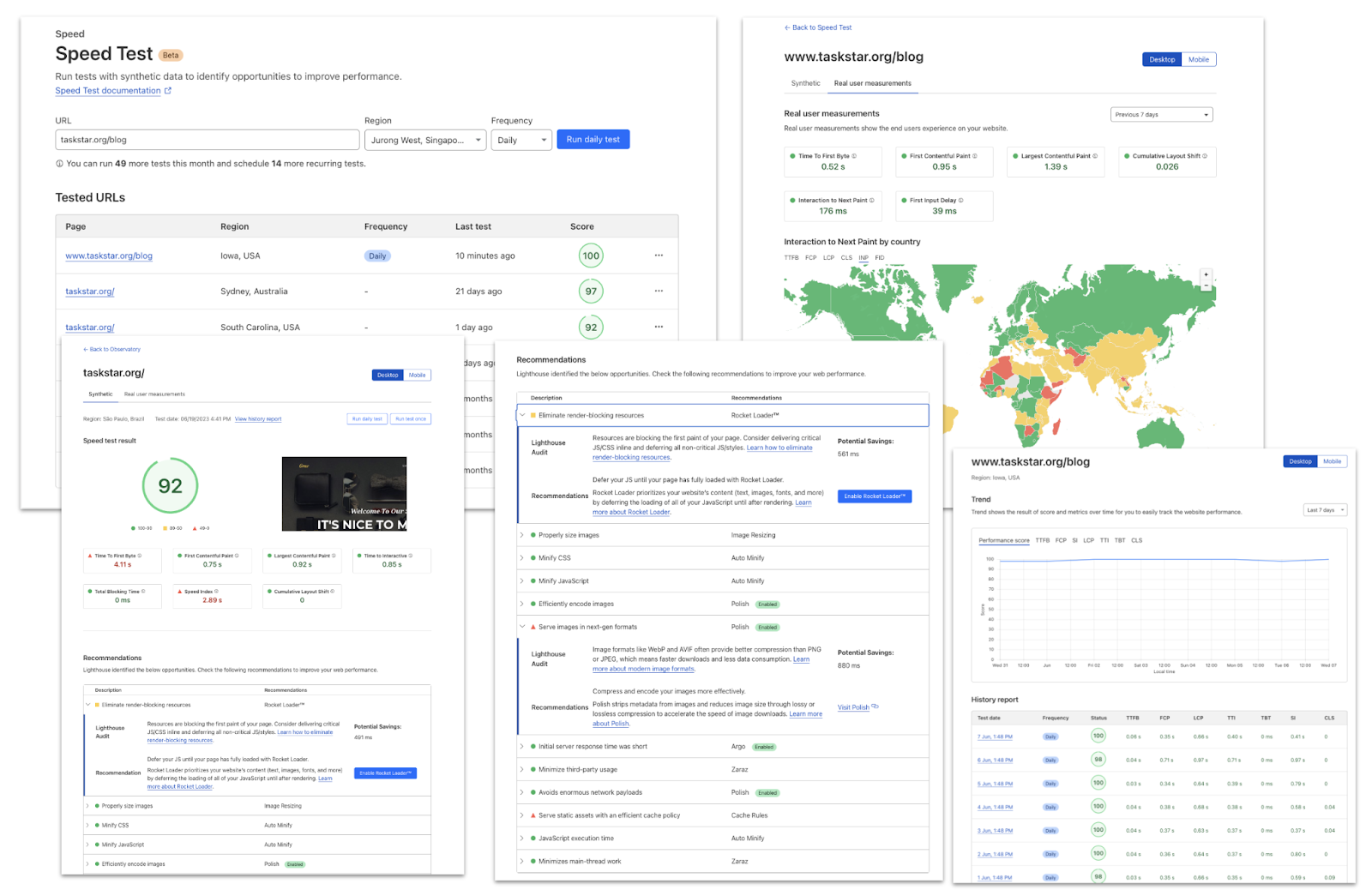
More tests, multiple regions and recurring tests
A significant piece of feedback we received from our old Speed Tab and beta testing was regarding the number and location of tests. We're thrilled to announce that we have addressed this feedback by increasing the number of tests allowed and enabling all plan types to schedule at least one recurring test, originating from a US region.
Customers on our Pro, Business, and Enterprise family of subscriptions can run tests from various regions to understand their site's performance in those areas. For instance, if a website is solely hosted in Iowa, USA, and a visitor is accessing it from Sydney, Australia, they will experience a slower page load due to the time it takes for an uncached file to be sent and rendered by the user's browser over a distance of 14,000 kilometers. By running tests from various regions, our customers can gain valuable insights into their website's performance and make informed decisions to optimize it for a better user experience – and an improved page load time.
The higher your plan type the more tests you are able to run and the more regions you are able to use. For example Pro customers can set up five recurring tests for their most important page from five different locations. These test runs will then be stored within the Observatory history tab allowing them to understand their Page Speed score from around the globe. Below is a table detailing the number of tests each plan type can run and the regions available to them.
Plan
Ad-hoc tests
Recurring tests
Frequency of recurring tests
Regions supported
Free
5
1
Weekly
Iowa, USA
Pro
10
5
Daily
Everything in Free and South Carolina, USA North Virginia, USA Dallas, USA Oregon, USA Hamina, Finland Madrid, Spain St. Ghislain, Belgium Eemshaven, Netherlands Milan, Italy Paris, France Changhua County, Taiwan Tokyo, Japan Osaka, Japan Tel Aviv, Israel London, England Jurong West, Singapore Sydney, Australia Frankfurt, Germany Mumbai, India São Paulo, Brazil
Business
20
10
Daily
Enterprise
50
15
Daily
Incorporating RUM
Cloudflare’s RUM service provides insights to a user's browser or devices, tracking metrics such as page load times, response times, and other user interactions. Cloudflare collects RUM data through its Browser Insights feature, which inserts a JavaScript "beacon" into HTML pages. This beacon sends information back to Cloudflare about the performance of a website from the perspective of real users, including metrics such as page load time, time to first byte, and other Web Vitals.
While you can always try a few page loads on your own laptop and see the results, gathering data from real users is the only way to take into account real-life device performance and network conditions.
Observatory now incorporates RUM data to match against your tested paths. This allows you to easily see how real users experience your site across the globe. This data is also dissected and located in the Observatory tab against your tested paths. Allowing you to view synthetic test data directly against Real User metrics.
Our RUM provider already incorporates the Interactive Next Paint (INP) Score. In 2022, Google announced Interaction to Next Paint (INP) as that new metric, promoting INP as the new Core Web Vital metric for responsiveness, replacing First Input Delay (FID). FID measures the delay between a user's first interaction with a web page and the browser's response to that interaction. INP measures the delay for any user interaction on a website, not just limited to the first input. This change reflects a more comprehensive approach to evaluating the responsiveness of a website.
If you don't have Web Analytics enabled on your Cloudflare zone then we will be unable to collect and display RUM data within Observatory. Enabling this feature is very simple and instructions can be found here.
One click optimizations
Observatory now includes an enhanced Optimization layout, which introduces a one-click recommendations center. Enabling these features on your Cloudflare zone enhances optimization for the latest HTTP protocols, including HTTP/3. Additionally, Image Delivery is improved by converting PNGs and JPEGs to the efficient WebP format. Finally, Cloudflare performance tools are also enabled, allowing users to seamlessly implement new technologies such as Early Hints. These features are designed to contribute to improved website speed and overall performance.
As we release new features that we believe are beneficial to our customers, we will continue to add them to the One Click Optimizations. We have also made changes to the overall layout of the tab, splitting our products into subcategories to allow easy navigation to the individual performance products.
Available now
Observatory is available now! Become the Web Performance advocate in your organization by taking advantage of the Observatory features such as Google Lighthouse integration, RUM data, and multi-region testing, all available now. You will be able to gain valuable insights into your website's performance and make informed decisions to optimize and improve your site's performance.
In the coming months, we will continue expanding the Recommendations engine, introducing more products that empower you to continually enhance your website's performance. Additionally, we will provide the capability to simulate requests for specific features, giving you a comprehensive understanding of the real-world performance benefits before implementing them on your website.
On May 10, 2023, Google announced that INP will replace FID in the Core Web Vitals in March 2024. The Core Web Vitals play a role in the Google Search algorithm. So website owners who care about Search Engine Optimization (SEO) should prepare for the change. Otherwise their search ranking might suffer.
This post will first explain what FID, INP and the Core Web Vitals are. Then it will show how FID and INP relate to each other across a large range of Cloudflare sites. (Spoiler alert – If a site has ‘Good’ scoring FID, it might not have ‘Good’ scoring INP). Then it will discuss how to prepare for this change and how Cloudflare can help.
A few definitions
In order to make sense of the upcoming change, here are some definitions that will set the scene.
Core Web Vitals
Measuring user-centric web performance is challenging. To face this challenge, Google developed a series of metrics called the Web Vitals. These Web Vitals are signals that measure different aspects of web performance. For example Time To First Byte (TTFB) is one of the Web Vitals: from the perspective of the browser, TTFB “measures the time between the request for a resource and when the first byte of a response begins to arrive.” – https://web.dev/ttfb/
A subset of the Web Vitals are the Core Web Vitals. The Core Web Vitals are identified as the most critical Web Vitals to pay attention to. As such, they play a role in the Google Search algorithm. Improving a webpage’s Core Web Vitals can improve success with Google Search. The Core Web Vitals currently consist of three metrics: Largest Contentful Paint (LCP), First Input Delay (FID) and Cumulative Layout Shift (CLS). Respectively they measure Loading Speed, Interactivity and Visual Stability. This will change in March 2024 when Interaction To Next Paint (INP) replaces FID as the Core Web Vital for Interactivity.
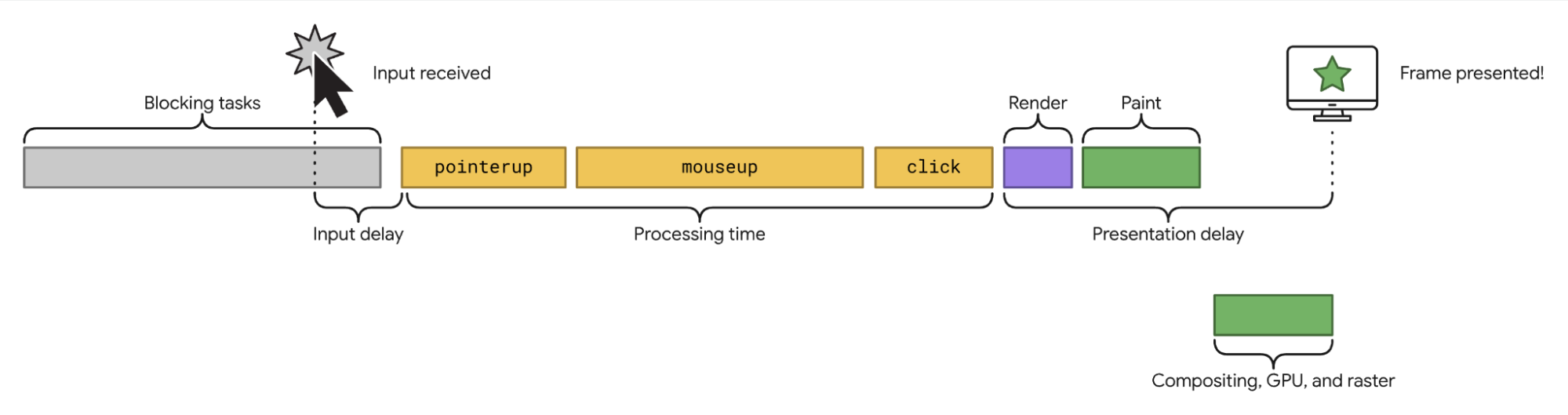
Interaction
An Interaction on a webpage starts with a user input. The browser then reacts to this input. This includes the input delay, the processing time and the presentation delay before the next paint occurs and the new frame is presented.
Keeping in mind that an interaction is composed of these three serialized durations – input delay, processing time and presentation delay – will help later on to understand the difference between FID and INP.
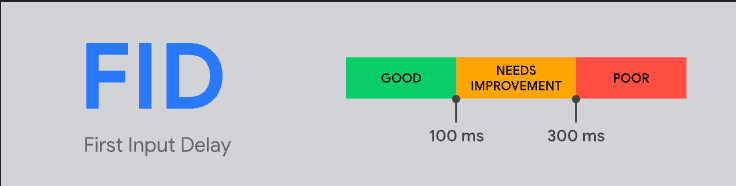
First Input Delay (FID)
“FID measures the time from when a user first interacts with a page (that is, when they click a link, tap on a button, or use a custom, JavaScript-powered control) to the time when the browser is actually able to begin processing event handlers in response to that interaction.” – https://web.dev/fid/
FID is the current Core Web Vital that measures interactivity. FID measures the first interaction with the page. User interactions after the first interaction are not measured with FID. FID also only measures the input delay part of the first interaction. It does not measure the processing time and the presentation delay.
FID is classed as ‘Good’ if the input delay is less than 100 ms. FID is classed as ‘Needs Improvement’ between 100ms and 300ms. Delays above 300 ms are classed as ‘Poor’.
“INP is a metric that assesses a page's overall responsiveness to user interactions by observing the latency of all click, tap, and keyboard interactions that occur throughout the lifespan of a user's visit to a page. The final INP value is the longest interaction observed, ignoring outliers.” - https://web.dev/inp/
INP, like FID, is also a Web Vital that measures interactivity. INP observes all user interactions in a page view and reports the longest. It measures more than just the input delay duration of each interaction. It also measures the processing time and the presentation delay until the next paint occurs. Once you understand the mechanics of it, the name ‘Interaction to Next Paint’ is a good description of the duration it measures.
INP is classed as ‘Good’ if the final reported value is less than 200 ms. INP is classed as ‘Needs Improvement’ between 200ms and 500ms. Any measurement above 500 ms is classed as ‘Poor’.
Both FID and INP measure interactivity by measuring delays after user interactions. But INP is more comprehensive than FID. As an example, let’s say a user loads a web page and interacts only once by clicking a button. In this case, FID will capture this interaction by reporting the input delay after the user input. INP will also observe this interaction but it will measure not only the input delay but also the subsequent processing time and the presentation delay. Since this is the only interaction on the web page, INP will observe this as the longest duration within the page view and so will report this duration as the final reported INP value. Already it is clear that with just a single user interaction, INP provides a more comprehensive signal of interactivity because it includes processing time and presentation delay.
But INP also goes beyond the first interaction on the page. It observes all the interactions within a page view and reports the longest interaction of the set (ignoring outliers). This means that web sites need to ensure that all interactions throughout the lifecycle of a page view are under 200ms in order to score a ‘Good’ INP. With FID, web sites only need to focus on optimizing the first interaction’s input delay under 100 ms to score ‘Good’ FID. With INP joining the Core Web Vitals, web sites will need to focus on optimizing all interactions.
Comparing FID with INP across Cloudflare
At Cloudflare, for sites that have enabled Real User Measurements (RUM) via the Web Analytics Product or the Observatory Product, we already collect INP data. This means we have a rich dataset across 850k sites with which to analyze INP against FID.
FID vs INP
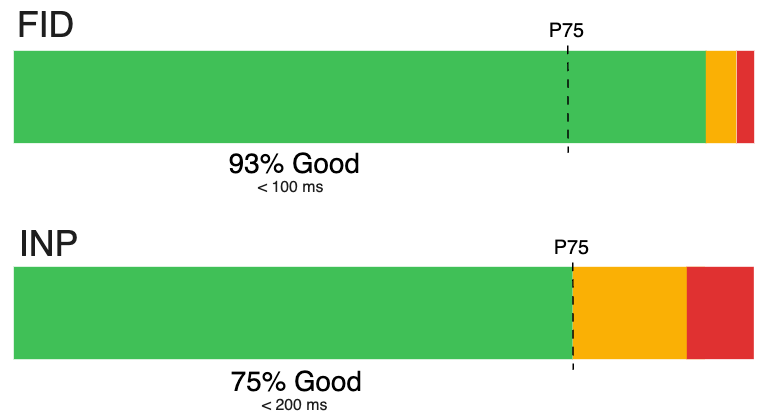
Over the period of a week, across all Cloudflare RUM-enabled sites, we observed over four billion reported FIDs and INPs. 93% of the FID values classify as ‘Good’ (under 100 ms). 75% of the INP values classify as ‘Good’ (under 200 ms). Since these values are sourced from the same set of page views, it is already possible to see at a glance that INP is distributed more lightly in the ‘Good’ range than FID.
Interestingly, the P75 value for FID is just 16 ms. A 0.16 times multiple of the FID ‘Good’ threshold of 100 ms. For INP, the P75 value is 200 ms. A one times multiple of the INP ‘Good’ threshold.
INP across devices
Focusing on INP, when the INP data is segmented by device type, we observe that 88% of desktop INP classify as ‘Good’, but only 67% of mobile INP classify as ‘Good’. This suggests that INP is generally suffering more on mobile devices than on desktop.
The bottom line is that INP is more challenging than FID to ‘get into the Green’. Since INP is a more comprehensive measure of interactivity, web sites are more exposed, and less likely to score favorably.
How to prepare for the change
INP will start affecting Google Search rankings when it becomes a Core Web Vital in March 2024. To get ready, websites need to improve interactivity beyond the initial load of the site.
As always, in order to improve on a metric, a baseline must be drawn by collecting data on the metric. But with INP, this can be challenging because INP is best reported from field data. Field data means that the data comes from real users interacting with web pages on real browsers. With field data, synthetic tools like Google Lighthouse aren’t a great fit. Synthetic tools are not designed to emulate the wide range of users on the wide range of browsers and operating systems that will navigate a web page.
In order to collect real user data from real browsers, websites need to enable a RUM provider. RUM providers collect performance data from real browsers, and process the data so that it can be aggregated and analyzed. It’s worth noting that performance data is anonymous and does not include any personal identifiable information (PII).
So the first step to understanding INP on a website is to enable a RUM provider.
Once a RUM provider is enabled on a website, it is then possible to analyze INP data to understand which web pages are not optimized for interactivity. There can be many possible causes for this. Since INP is composed of input delay, processing time and presentation delay, optimizing INP can be broken down into optimizing these distinct durations.
The best advice for optimizing INP is set out by web.dev. Optimizing INP is not straight-forward – it can involve breaking up JavaScript tasks, reducing DOM interactions and layouts, avoiding use of timers, and limiting third-party code amongst a range of other measures. That’s why it’s best to get started early and learn as much as possible before the change takes place.
How Cloudflare can help
A free RUM provider
Cloudflare offers a free RUM provider which collects INP as part of its dataset. It currently powers Cloudflare Web Analytics and Cloudflare Observatory. By enabling RUM with Cloudflare, you can explore the interactivity of your site’s web pages and start to identify interactivity issues.
Just log onto the Cloudflare Dashboard, and head to your target account. Go to Web Analytics.
Reduce the impact of third-party scripts
One of the contributing causes of degraded INP is JavaScript blocking the main thread after an interaction. Often this can be caused by heavy third-party scripts attaching event listeners to DOM elements. For example, third-party analytics scripts can register listeners on interactive elements of a page to power various forms of analytics. Many sites have dozens, if not hundreds of third-party scripts running, each one potentially degrading INP.
Cloudflare offers a unique product that can entirely remove third-party scripts from the browser. This frees up the main thread, boosting interactivity. If you haven’t come across Cloudflare Zaraz before, check it out in our docs. Not only can it improve INP, but it can also dramatically improve the security posture of your site by reducing (or even entirely removing) the amount of third-party JavaScript that runs on your website.
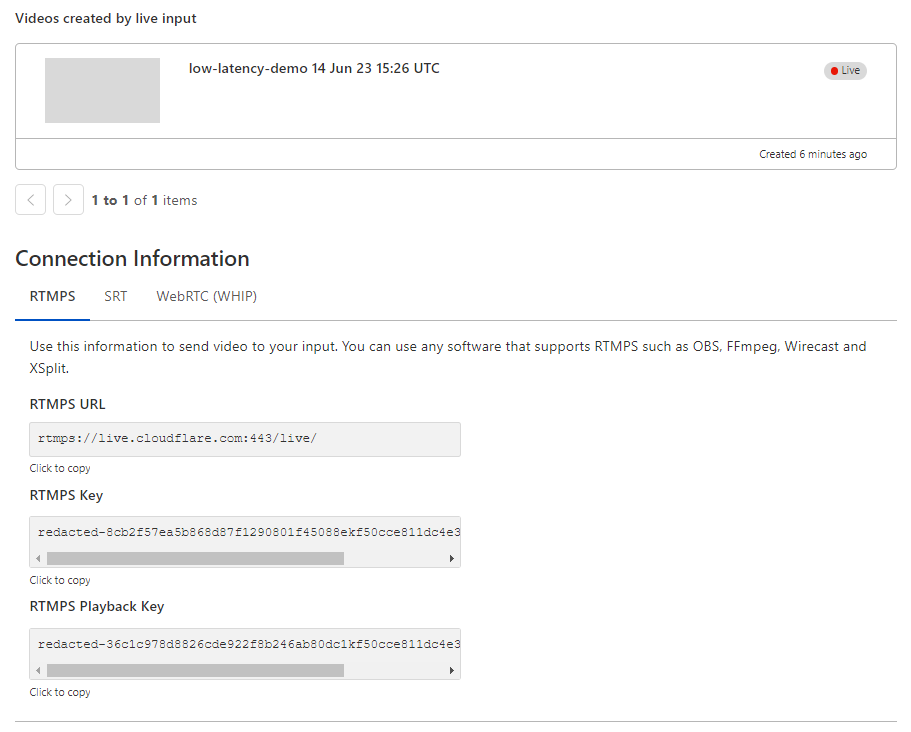
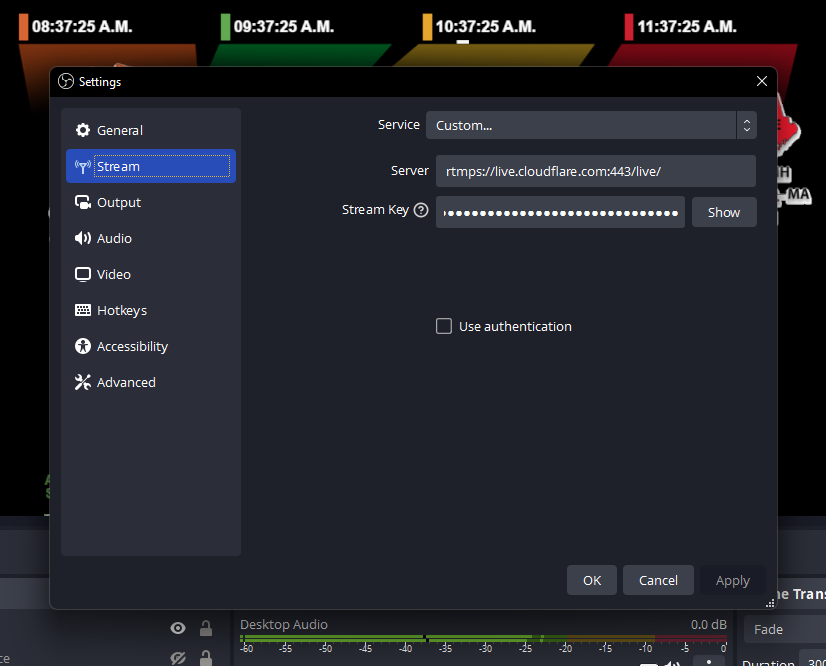
Stream Live lets users easily scale their live streaming apps and websites to millions of creators and concurrent viewers without having to worry about bandwidth costs or purchasing hardware for real-time encoding at scale. Stream Live lets users focus on the content rather than the infrastructure — taking care of the codecs, protocols, and bitrate automatically. When we launched Stream Live last year, we focused on bringing high quality, feature-rich streaming to websites and applications with HTTP Live Streaming (HLS).
Today, we're excited to introduce support for Low-Latency HTTP Live Streaming (LL-HLS) in a closed beta, offering you an even faster streaming experience. LL-HLS will reduce the latency a viewer may experience on their player from highs of around 30 seconds to less than 10 in many cases. Lower latency brings creators even closer to their viewers, empowering customers to build more interactive features like Q&A or chat and enabling the use of live streaming in more time-sensitive applications like sports, gaming, and live events.
Broadcast with less than 10-second latency
LL-HLS is an extension of HLS and allows us to reduce glass-to-glass latency — the time between something happening on the broadcast end and a user seeing it on their screen. This includes everything from broadcaster encoding to client-side buffering because we know the experience is driven by what a user sees, not when a byte is delivered into a buffer. Depending on encoder and player settings, broadcasters' content can be playing on viewers' screens in less than ten seconds.
Our addition of LL-HLS support builds on all the best parts of Stream including simple, predictable pricing. You never have to pay for ingest (broadcasting to us), compute (encoding), or egress. It costs \$5 per 1,000 minutes of video stored per month and \$1 per 1,000 minutes of video viewed per month. This allows you to stream with peace of mind, knowing there are no surprise fees.
Other platforms tack on live recordings as a separate add-on feature, and those recordings only become available minutes or even hours after a live stream ends. With Cloudflare Stream, Live segments are automatically recorded and immediately available for on-demand playback.
Stream also provides both a built-in web player and HLS manifests to use in a compatible player of your choosing. This enables you or your users to go live using the same protocols and tools that broadcasters big and small use to go live to YouTube or Twitch, but gives you full control over access and presentation of live streams.
We also provide access control with signed URLs allowing you to protect your content, sharing with only certain users. This allows you to restrict access so only logged in members can watch a particular video, or only let users watch your video for a limited time period. And of course, Stream is powered by Cloudflare's global network for fast delivery worldwide, with points of presents within 50ms of 95% of the Internet connected population.
Left: Broadcasting to Stream Live using OBS. Right: Watching that same Stream. Note the five second difference in the NIST clock between the source and the playback.
Powering the LL-HLS experience involved making several improvements to our underlying infrastructure. One of the largest challenges we encountered was that our existing architecture involved a pipeline with multiple buffers as long as the keyframe interval. This meant Stream Live would introduce a delay of up to five times the keyframe interval. To resolve this, we simplified a portion of our pipeline — now, we work with individual frames rather than whole keyframe-intervals, but without giving up the economies of scale our approach to encoding provides. This decoupling of keyframe interval and internal buffer duration lets us dramatically reduce latency in HLS, with a maximum of twice the keyframe interval.
Getting started with the LL-HLS beta
As we prepare to ship this new functionality, we're looking for beta testers to help us test non-production workloads. To participate in the beta, your application should be configured with these settings:
H.264 video codec
Constant bitrate
Keyframe interval (GOP size) of 2s
No B Frames
Using the Stream built-in player
Getting started with Stream Live only takes a few minutes. Create a Live Input in the Cloudflare dashboard, then Stream will automatically provide RTMPS and SRT endpoints to broadcast your feed to us as well as an HTML embed for our built-in player and the HLS manifest for a custom player.
This connection information can be added easily to a broadcast application like OBS to start streaming immediately:
Customers in the LL-HLS beta will need to make a minor adjustment to the built-in player embed code, but there are no changes to Live Input configuration, dashboard interface, API, or existing functionality.
Sign up today
LL-HLS is Stream Live’s latest tool to bring your creators and audiences together. After the beta period, this feature will be generally available to all new and existing Stream subscriptions with no pricing changes or contract requirements — all part of building the fastest, simplest serverless live streaming platform. Join our beta to start test-driving Low-Latency HLS!
In this post, we will take you through the advancements we've made in our machine learning capabilities. We'll describe the technical strategies that have enabled us to expand the number of machine learning features and models, all while substantially reducing the processing time for each HTTP request on our network. Let's begin.
Background
For a comprehensive understanding of our evolved approach, it's important to grasp the context within which our machine learning detections operate. Cloudflare, on average, serves over 46 million HTTP requests per second, surging to more than 63 million requests per second during peak times.
Machine learning detection plays a crucial role in ensuring the security and integrity of this vast network. In fact, it classifies the largest volume of requests among all our detection mechanisms, providing the final Bot Score decision for over 72% of all HTTP requests. Going beyond, we run several machine learning models in shadow mode for every HTTP request.
At the heart of our machine learning infrastructure lies our reliable ally, CatBoost. It enables ultra low-latency model inference and ensures high-quality predictions to detect novel threats such as stopping bots targeting our customers' mobile apps. However, it's worth noting that machine learning model inference is just one component of the overall latency equation. Other critical components include machine learning feature extraction and preparation. In our quest for optimal performance, we've continuously optimized each aspect contributing to the overall latency of our system.
Initially, our machine learning models relied on single-request features, such as presence or value of certain headers. However, given the ease of spoofing these attributes, we evolved our approach. We turned to inter-request features that leverage aggregated information across multiple dimensions of a request in a sliding time window. For example, we now consider factors like the number of unique user agents associated with certain request attributes.
The extraction and preparation of inter-request features were handled by Gagarin, a Go-based feature serving platform we developed. As a request arrived at Cloudflare, we extracted dimension keys from the request attributes. We then looked up the corresponding machine learning features in the multi-layered cache. If the desired machine learning features were not found in the cache, a memcached "get" request was made to Gagarin to fetch those. Then machine learning features were plugged into CatBoost models to produce detections, which were then surfaced to the customers via Firewall and Workers fields and internally through our logging pipeline to ClickHouse. This allowed our data scientists to run further experiments, producing more features and models.
Previous system design for serving machine learning features over Unix socket using Gagarin.
Initially, Gagarin exhibited decent latency, with a median latency around 200 microseconds to serve all machine learning features for given keys. However, as our system evolved and we introduced more features and dimension keys, coupled with increased traffic, the cache hit ratio began to wane. The median latency had increased to 500 microseconds and during peak times, the latency worsened significantly, with the p99 latency soaring to roughly 10 milliseconds. Gagarin underwent extensive low-level tuning, optimization, profiling, and benchmarking. Despite these efforts, we encountered the limits of inter-process communication (IPC) using Unix Domain Socket (UDS), among other challenges, explored below.
Problem definition
In summary, the previous solution had its drawbacks, including:
High tail latency: during the peak time, a portion of requests experienced increased latency caused by CPU contention on the Unix socket and Lua garbage collector.
Suboptimal resource utilization: CPU and RAM utilization was not optimized to the full potential, leaving less resources for other services running on the server.
Machine learning features availability: decreased due to memcached timeouts, which resulted in a higher likelihood of false positives or false negatives for a subset of the requests.
Scalability constraints: as we added more machine learning features, we approached the scalability limit of our infrastructure.
Equipped with a comprehensive understanding of the challenges and armed with quantifiable metrics, we ventured into the next phase: seeking a more efficient way to fetch and serve machine learning features.
Exploring solutions
In our quest for more efficient methods of fetching and serving machine learning features, we evaluated several alternatives. The key approaches included:
Further optimizing Gagarin: as we pushed our Go-based memcached server to its limits, we encountered a lower bound on latency reductions. This arose from IPC over UDS synchronization overhead and multiple data copies, the serialization/deserialization overheads, as well as the inherent latency of garbage collector and the performance of hashmap lookups in Go.
Considering Quicksilver: we contemplated using Quicksilver, but the volume and update frequency of machine learning features posed capacity concerns and potential negative impacts on other use cases. Moreover, it uses a Unix socket with the memcached protocol, reproducing the same limitations previously encountered.
Increasing multi-layered cache size: we investigated expanding cache size to accommodate tens of millions of dimension keys. However, the associated memory consumption, due to duplication of these keys and their machine learning features across worker threads, rendered this approach untenable.
Sharding the Unix socket: we considered sharding the Unix socket to alleviate contention and improve performance. Despite showing potential, this approach only partially solved the problem and introduced more system complexity.
Switching to RPC: we explored the option of using RPC for communication between our front line server and Gagarin. However, since RPC still requires some form of communication bus (such as TCP, UDP, or UDS), it would not significantly change the performance compared to the memcached protocol over UDS, which was already simple and minimalistic.
After considering these approaches, we shifted our focus towards investigating alternative Inter-Process Communication (IPC) mechanisms.
IPC mechanisms
Adopting a first principles design approach, we questioned: "What is the most efficient low-level method for data transfer between two processes provided by the operating system?" Our goal was to find a solution that would enable the direct serving of machine learning features from memory for corresponding HTTP requests. By eliminating the need to traverse the Unix socket, we aimed to reduce CPU contention, improve latency, and minimize data copying.
To identify the most efficient IPC mechanism, we evaluated various options available within the Linux ecosystem. We used ipc-bench, an open-source benchmarking tool specifically designed for this purpose, to measure the latencies of different IPC methods in our test environment. The measurements were based on sending one million 1,024-byte messages forth and back (i.e., ping pong) between two processes.
IPC method
Avg duration, μs
Avg throughput, msg/s
eventfd (bi-directional)
9.456
105,533
TCP sockets
8.74
114,143
Unix domain sockets
5.609
177,573
FIFOs (named pipes)
5.432
183,388
Pipe
4.733
210,369
Message Queue
4.396
226,421
Unix Signals
2.45
404,844
Shared Memory
0.598
1,616,014
Memory-Mapped Files
0.503
1,908,613
Based on our evaluation, we found that Unix sockets, while taking care of synchronization, were not the fastest IPC method available. The two fastest IPC mechanisms were shared memory and memory-mapped files. Both approaches offered similar performance, with the former using a specific tmpfs volume in /dev/shm and dedicated system calls, while the latter could be stored in any volume, including tmpfs or HDD/SDD.
Missing ingredients
In light of these findings, we decided to employ memory-mapped files as the IPC mechanism for serving machine learning features. This choice promised reduced latency, decreased CPU contention, and minimal data copying. However, it did not inherently offer data synchronization capabilities like Unix sockets. Unlike Unix sockets, memory-mapped files are simply files in a Linux volume that can be mapped into memory of the process. This sparked several critical questions:
How could we efficiently fetch an array of hundreds of float features for given dimension keys when dealing with a file?
How could we ensure safe, concurrent and frequent updates for tens of millions of keys?
How could we avert the CPU contention previously encountered with Unix sockets?
How could we effectively support the addition of more dimensions and features in the future?
To address these challenges we needed to further evolve this new approach by adding a few key ingredients to the recipe.
Augmenting the Idea
To realize our vision of memory-mapped files as a method for serving machine learning features, we needed to employ several key strategies, touching upon aspects like data synchronization, data structure, and deserialization.
Wait-free synchronization
When dealing with concurrent data, ensuring safe, concurrent, and frequent updates is paramount. Traditional locks are often not the most efficient solution, especially when dealing with high concurrency environments. Here's a rundown on three different synchronization techniques:
With-lock synchronization: a common approach using mechanisms like mutexes or spinlocks. It ensures only one thread can access the resource at a given time, but can suffer from contention, blocking, and priority inversion, just as evident with Unix sockets.
Lock-free synchronization: this non-blocking approach employs atomic operations to ensure at least one thread always progresses. It eliminates traditional locks but requires careful handling of edge cases and race conditions.
Wait-free synchronization: a more advanced technique that guarantees every thread makes progress and completes its operation without being blocked by other threads. It provides stronger progress guarantees compared to lock-free synchronization, ensuring that each thread completes its operation within a finite number of steps.
We store the synchronization state, which coordinates access to these data copies, in a third memory-mapped file, referred to as "state". This file contains an atomic 64-bit integer, which represents an InstanceVersionand a pair of additional atomic 32-bit variables, tracking the number of active readers for each data copy. The InstanceVersion consists of the currently active data file index (1 bit), the data size (39 bits, accommodating data sizes up to 549 GB), and a data checksum (24 bits).
Zero-copy deserialization
To efficiently store and fetch machine learning features, we needed to address the challenge of deserialization latency. Here, zero-copy deserialization provides an answer. This technique reduces the time and memory required to access and use data by directly referencing bytes in the serialized form.
We turned to rkyv, a zero-copy deserialization framework in Rust, to help us with this task. rkyv implements total zero-copy deserialization, meaning no data is copied during deserialization and no work is done to deserialize data. It achieves this by structuring its encoded representation to match the in-memory representation of the source type.
One of the key features of rkyv that our solution relies on is its ability to access HashMap data structures in a zero-copy fashion. This is a unique capability among Rust serialization libraries and one of the main reasons we chose rkyv for our implementation. It also has a vibrant Discord community, eager to offer best-practice advice and accommodate feature requests.
Leveraging the benefits of memory-mapped files, wait-free synchronization and zero-copy deserialization, we've crafted a unique and powerful tool for managing high-performance, concurrent data access between processes. We've packaged these concepts into a Rust crate named mmap-sync, which we're thrilled to open-source for the wider community.
At the core of the mmap-sync package is a structure named Synchronizer. It offers an avenue to read and write any data expressible as a Rust struct. Users simply have to implement or derive a specific Rust trait surrounding struct definition – a task requiring just a single line of code. The Synchronizer presents an elegantly simple interface, equipped with "write" and "read" methods.
impl Synchronizer {
/// Write a given `entity` into the next available memory mapped file.
pub fn write<T>(&mut self, entity: &T, grace_duration: Duration) -> Result<(usize, bool), SynchronizerError> {
…
}
/// Reads and returns `entity` struct from mapped memory wrapped in `ReadResult`
pub fn read<T>(&mut self) -> Result<ReadResult<T>, SynchronizerError> {
…
}
}
/// FeaturesMetadata stores features along with their metadata
#[derive(Archive, Deserialize, Serialize, Debug, PartialEq)]
#[archive_attr(derive(CheckBytes))]
pub struct FeaturesMetadata {
/// Features version
pub version: u32,
/// Features creation Unix timestamp
pub created_at: u32,
/// Features represented by vector of hash maps
pub features: Vec<HashMap<u64, Vec<f32>>>,
}
A read operation through the Synchronizer performs zero-copy deserialization and returns a "guarded" Result encapsulating a reference to the Rust struct using RAII design pattern. This operation also increments the atomic counter of active readers using the struct. Once the Result is out of scope, the Synchronizer decrements the number of readers.
The synchronization mechanism used in mmap-sync is not only "lock-free" but also "wait-free". This ensures an upper bound on the number of steps an operation will take before it completes, thus providing a performance guarantee.
The data is stored in shared mapped memory, which allows the Synchronizer to “write” to it and “read” from it concurrently. This design makes mmap-sync a highly efficient and flexible tool for managing shared, concurrent data access.
Now, with an understanding of the underlying mechanics of mmap-sync, let's explore how this package plays a key role in the broader context of our Bot Management platform, particularly within the newly developed components: the bliss service and library.
System design overhaul
Transitioning from a Lua-based module that made memcached requests over Unix socket to Gagarin in Go to fetch machine learning features, our new design represents a significant evolution. This change pivots around the introduction of mmap-sync, our newly developed Rust package, laying the groundwork for a substantial performance upgrade. This development led to a comprehensive system redesign and introduced two new components that form the backbone of our Bots Liquidation Intelligent Security System – or BLISS, in short: the bliss service and the bliss library.
Bliss service
The blissservice operates as a Rust-based, multi-threaded sidecar daemon. It has been designed for optimal batch processing of vast data quantities and extensive I/O operations. Among its key functions, it fetches, parses, and stores machine learning features and dimensions for effortless data access and manipulation. This has been made possible through the incorporation of the Tokio event-driven platform, which allows for efficient, non-blocking I/O operations.
Bliss library
Operating as a single-threaded dynamic library, the bliss library seamlessly integrates into each worker thread using the Foreign Function Interface (FFI) via a Lua module. Optimized for minimal resource usage and ultra-low latency, this lightweight library performs tasks without the need for heavy I/O operations. It efficiently serves machine learning features and generates corresponding detections.
In addition to leveraging the mmap-sync package for efficient machine learning feature access, our new design includes several other performance enhancements:
Allocations-free operation: bliss library re-uses pre-allocated data structures and performs no heap allocations, only low-cost stack allocations. To enforce our zero-allocation policy, we run integration tests using the dhat heap profiler.
SIMD optimizations: wherever possible, the bliss library employs vectorized CPU instructions. For instance, AVX2 and SSE4 instruction sets are used to expedite hex-decoding of certain request attributes, enhancing speed by tenfold.
Compiler tuning: We compile both the bliss service and library with the following flags for superior performance:
Benchmarking & profiling: We use Criterion for benchmarking every major feature or component within bliss. Moreover, we are also able to use the Go pprof profiler on Criterion benchmarks to view flame graphs and more:
This comprehensive overhaul of our system has not only streamlined our operations but also has been instrumental in enhancing the overall performance of our Bot Management platform. Stay tuned to witness the remarkable changes brought about by this new architecture in the next section.
Rollout results
Our system redesign has brought some truly "blissful" dividends. Above all, our commitment to a seamless user experience and the trust of our customers have guided our innovations. We ensured that the transition to the new design was seamless, maintaining full backward compatibility, with no customer-reported false positives or negatives encountered. This is a testament to the robustness of the new system.
As the old adage goes, the proof of the pudding is in the eating. This couldn't be truer when examining the dramatic latency improvements achieved by the redesign. Our overall processing latency for HTTP requests at Cloudflare improved by an average of 12.5% compared to the previous system.
This improvement is even more significant in the Bot Management module, where latency improved by an average of 55.93%.
Bot Management module latency, in microseconds.
More specifically, our machine learning features fetch latency has improved by several orders of magnitude:
Latency metric
Before (μs)
After (μs)
Change
p50
532
9
-98.30% or x59
p99
9510
18
-99.81% or x528
p999
16000
29
-99.82% or x551
To truly grasp this impact, consider this: with Cloudflare’s average rate of 46 million requests per second, a saving of 523 microseconds per request equates to saving over 24,000 days or 65 years of processing time every single day!
In addition to latency improvements, we also reaped other benefits from the rollout:
Enhanced feature availability: thanks to eliminating Unix socket timeouts, machine learning feature availability is now a robust 100%, resulting in fewer false positives and negatives in detections.
Improved resource utilization: our system overhaul liberated resources equivalent to thousands of CPU cores and hundreds of gigabytes of RAM – a substantial enhancement of our server fleet's efficiency.
Code cleanup: another positive spin-off has been in our Lua and Go code. Thousands of lines of less performant and less memory-safe code have been weeded out, reducing technical debt.
Upscaled machine learning capabilities: last but certainly not least, we've significantly expanded our machine learning features, dimensions, and models. This upgrade empowers our machine learning inference to handle hundreds of machine learning features and dozens of dimensions and models.
Conclusion
In the wake of our redesign, we've constructed a powerful and efficient system that truly embodies the essence of 'bliss'. Harnessing the advantages of memory-mapped files, wait-free synchronization, allocation-free operations, and zero-copy deserialization, we've established a robust infrastructure that maintains peak performance while achieving remarkable reductions in latency. As we navigate towards the future, we're committed to leveraging this platform to further improve our Security machine learning products and cultivate innovative features. Additionally, we're excited to share parts of this technology through an open-sourced Rust package mmap-sync.
As we leap into the future, we are building upon our platform's impressive capabilities, exploring new avenues to amplify the power of machine learning. We are deploying a new machine learning model built on BLISS with select customers. If you are a Bot Management subscriber and want to test the new model, please reach out to your account team.
Separately, we are on the lookout for more Cloudflare customers who want to run their own machine learning models at the edge today. If you’re a developer considering making the switch to Workers for your application, sign up for our Constellation AI closed beta. If you’re a Bot Management customer and looking to run an already trained, lightweight model at the edge, we would love to hear from you. Let's embark on this path to bliss together.
Cloudflare’s mission is to help build a better Internet for everyone, and Orpheus plays an important role in realizing this mission. Orpheus identifies Internet connectivity outages beyond Cloudflare’s network in real time then leverages the scale and speed of Cloudflare’s network to find alternative paths around those outages. This ensures that everyone can reach a Cloudflare customer’s origin server no matter what is happening on the Internet. The end result is powerful: Cloudflare protects customers from Internet incidents outside our network while maintaining the average latency and speed of our customer’s traffic.
A little less than two years ago, Cloudflare made Orpheus automatically available to all customers for free. Since then, Orpheus has saved 132 billion Internet requests from failing by intelligently routing them around connectivity outages, prevented 50+ Internet incidents from impacting our customers, and made our customer’s origins more reachable to everyone on the Internet. Let’s dive into how Orpheus accomplished these feats over the last year.
Increasing origin reachability
One service that Cloudflare offers is a reverse proxy that receives Internet requests from end users then applies any number of services like DDoS protection, caching, load balancing, and / or encryption. If the response to an end user’s request isn’t cached, Cloudflare routes the request to our customer’s origin servers. To be successful, end users need to be able to connect to Cloudflare, and Cloudflare needs to connect to our customer’s origin servers. With end users and customer origins around the world, and ~20% of websites using our network, this task is a tall order!
Orpheus provides origin reachability benefits to everyone using Cloudflare by identifying invalid paths on the Internet in real time, then routing traffic via alternative paths that are working as expected. This ensures Cloudflare can reach an origin no matter what problems are happening on the Internet on any given day.
Reducing 522 errors
At some point while browsing the Internet, you may have run into this 522 error.
This error indicates that you, the end user, was unable to access content on a Cloudflare customer’s origin server because Cloudflare couldn’t connect to the origin. Sometimes, this error occurs because the origin is offline for everyone, and ultimately the origin owner needs to fix the problem. Other times, this error can occur even when the origin server is up and able to receive traffic. In this case, some people can reach content on the origin server, but other people using a different Internet routing path cannot because of connectivity issues across the Internet.
Some days, a specific network may have excellent connectivity, while other days that network may be congested or have paths that are impassable altogether. The Internet is a massive and unpredictable network of networks, and the “weather” of the Internet changes every day.
When you see this error, Cloudflare attempted to connect to an origin on behalf of the end user, but did not receive a response back from the origin. Either the connection request never reached the origin, or the origin’s reply was dropped on the way back to Cloudflare. In the case of 522 errors, Cloudflare and the origin server could both be working as expected, but packets are dropped on the network path between them.
These 522 errors can cause a lot of frustration, and Orpheus was built to reduce them. The goal of Orpheus is to ensure that if at least one Cloudflare data center can connect to an origin, then anyone using Cloudflare’s network can also reach that origin, even if there are Internet connectivity problems happening outside of Cloudflare’s network.
Improving origin reachability for an example customer using Cloudflare
Let’s look at a concrete example of how Orpheus makes the Internet better for everyone by saving an origin request that would have otherwise failed. Imagine that you’re running an e-commerce website that sells dog toys online, and your store is hosted by an origin server in Chicago.
Imagine there are two different customers visiting your website at the same time: the first customer lives in Seattle, and the second customer lives in Tampa. The customer in Seattle reaches your origin just fine, but the customer in Tampa tries to connect to your origin and experiences a problem. It turns out that a construction crew accidentally damaged an Internet fiber line in Tampa, and Tampa is having connectivity issues with Chicago. As a result, any customer in Tampa receives a 522 error when they try to buy your dog toys online.
This is where Orpheus comes in to save the day. Orpheus detects that users in Tampa are receiving 522 errors when connecting to Chicago. Its database shows there is another route from Tampa through Boston and then to Chicago that is valid. As a result, Orpheus saves the end user’s request by rerouting it through Boston and taking an alternative path. Now, everyone in Tampa can still buy dog toys from your website hosted in Chicago, even though a fiber line was damaged unexpectedly.
How does Orpheus save requests that would otherwise fail via only BGP?
BGP (Border Gateway Protocol) is like the postal service of the Internet. It’s the protocol that makes the Internet work by enabling data routing. When someone requests data over the Internet, BGP is responsible for looking at all the available paths a request could take, then selecting a route.
BGP is designed to route around network failures by finding alternative paths to the destination IP address after the preferred path goes down. Sometimes, BGP does not route around a network failure at all. In this case, Cloudflare still receives BGP advertisements that an origin network is reachable via a particular autonomous system (AS), when actually packets sent through that AS will be dropped. In contrast, Orpheus will test alternate paths via synthetic probes and with real time traffic to ensure it is always using valid routes. Even when working as designed, BGP takes time to converge after a network disruption; Orpheus can react faster, find alternative paths to the origin that route around temporary or persistent errors, and ultimately save more Internet requests.
Additionally, BGP routes can be vulnerable to hijacking. If a BGP route is hijacked, Orpheus can prevent Internet requests from being dropped by invalid BGP routes by frequently testing all routes and examining the results to ensure they’re working as expected. In any of these cases, Orpheus routes around these BGP issues by taking advantage of the scale of Cloudflare’s global network which directly connects to 11,000 networks, features data centers across 275 cities, and has 172 Tbps of network capacity.
Let’s give an example of how Orpheus can save requests that would otherwise fail if only using BGP. Imagine an end user in Mumbai sends a request to a Cloudflare customer with an origin server in New York. For any request that misses Cloudflare’s cache, Cloudflare forwards the request from Mumbai to the website’s origin server in New York. Now imagine something happens, and the origin is no longer reachable from India: maybe a fiber optic cable was cut in Egypt, a different network advertised a BGP route it shouldn’t have, or an intermediary AS between Cloudflare and the origin was misconfigured that day.
In any of these scenarios, Orpheus can leverage the scale of Cloudflare’s global network to reach the origin in New York via an alternate path. While the direct path from Mumbai to New York may be unreachable, an alternate path from Mumbai, through London, then to New York may be available. This alternate path is valid because it uses different physical Internet connections that are unaffected by the issues with directly connecting from Mumbai to New York. In this case, Orpheus selects the alternate route through London and saves a request that would otherwise fail via the direct connection.
How Orpheus was built by reusing components of Argo Smart Routing
Back in 2017, Cloudflare released Argo Smart Routing which decreases latency by an average of 30%, improves security, and increases reliability. To help Cloudflare achieve its goal of helping build a better Internet for everyone, we decided to take the features that offered “increased reliability” in Argo Smart Routing and make them available to every Cloudflare user for free with Orpheus.
Argo Smart Routing’s architecture has two primary components: the data plane and the control plane. The control plane is responsible for computing the fastest routes between two locations and identifying potential failover paths in case the fastest route is down. The data plane is responsible for sending requests via the routes defined by the control plane, or detecting in real-time when a route is down and sending a request via a failover path as needed.
Orpheus was born with a simple technical idea: Cloudflare could deploy an alternate version of Argo’s control plane where the routing table only includes failover paths. Today, this alternate control plane makes up the core of Orpheus. If a request that travels through Cloudflare’s network is unable to connect to the origin via a preferred path, then Orpheus’s data plane selects a failover path from the routing table in its control plane. Orpheus prioritizes using failover paths that are more reliable to increase the likelihood a request uses the failover route and is successful.
Orpeus also takes advantage of a complex Internet monitoring system that we had already built for Argo Smart Routing. This system is constantly testing the health of many internet routing paths between different Cloudflare data centers and a customer’s origin by periodically opening then closing a TCP connection. This is called a synthetic probe, and the results are used for Argo Smart Routing, Orpheus, and even in other Cloudflare products. Cloudflare directly connects to 11,000 networks, and typically there are many different Internet routing paths that reach the same origin. Argo and Orpheus maintain a database of the results of all TCP connections that opened successfully or failed with their corresponding routing paths.
Scaling the Orpheus data plane to save requests for everyone
Cloudflare proxies millions of requests to customers' origins every second, and we had to make some improvements to Orpheus before it was ready to save users’ requests at scale. In particular, Cloudflare designed Orpheus to only process and reroute requests that would otherwise fail. In order to identify these requests, we added an error cache to Cloudflare’s layer 7 HTTP stack.
When you send an Internet request (TCP SYN) through Cloudflare to our customer’s origin, and Cloudflare doesn’t receive a response (TCP SYN/ACK), the end user receives a 522 error (learn more about TCP flags). Orpheus creates an entry in the error cache for each unique combination of a 522 error, origin address, and a specific route to that origin. The next time a request is sent to the same origin address via the same route, Orpheus will check the error cache for relevant entries. If there is a hit in the error cache, then Orpheus’s data plane will select an alternative route to prevent subsequent requests from failing.
To keep entries in the error cache updated, Orpheus will use live traffic to retry routes that previously failed to check their status. Routes in the error cache are periodically retried with a bounded exponential backoff. Unavailable routes are tested every 5th, 25th, 125th, 625th, and 3,125th request (the maximum bound). If the test request that’s sent down the original path fails, Orpheus saves the test request, sends it via the established alternate path, and updates the backoff counter. If a test request is successful, then the failed route is removed from the error cache, and normal routing operations are restored. Additionally, the error cache has an expiry period of 10 minutes. This prevents the cache from storing entries on failed routes that rarely receive additional requests.
The error cache has notable a trade-off; one direct-to-origin request must fail before Orpheus engages and saves subsequent requests. Clearly this isn’t ideal, and the Argo / Orpheus engineering team is hard at work improving Orpheus so it can prevent any request from failing.
Making Orpheus faster and more responsive
Orpheus does a great job of identifying congested or unreachable paths on the Internet, and re-routing requests that would have otherwise failed. However, there is always room for improvement, and Cloudflare has been hard at work to make Orpheus even better.
Since its release, Orpheus was built to select failover paths with the highest predicted reliability when it saves a request to an origin. This was an excellent first step, but sometimes a request that was re-routed by Orpheus would take an inefficient path that had better origin reachability but also increased latency. With recent improvements, the Orpheus routing algorithm balances both latency and origin reachability when selecting a new route for a request. If an end user makes a request to an origin, and that request is re-routed by Orpheus, it’s nearly as fast as any other request on Cloudflare’s network.
In addition to decreasing the latency of Orpheus requests, we’re working to make Orpheus more responsive to connectivity changes across the Internet. Today, Orpheus leverages synthetic probes to test whether Internet routes are reachable or unreachable. In the near future, Orpheus will also leverage real-time traffic data to more quickly identify Internet routes that are unreachable and reachable. This will enable Orpheus to re-route traffic around connectivity problems on the Internet within minutes rather than hours.
Expanding Orpheus to save WebSockets requests
Previously, Orpheus focused on saving HTTP and TCP Internet requests. Cloudflare has seen amazing benefits to origin reliability and Internet stability for these types of requests, and we’ve been hard at work to expand Orpheus to also save WebSocket requests from failing.
WebSockets is a common Internet protocol that prioritizes sending real time data between a client and server by maintaining an open connection between that client and server. Imagine that you (the client) have sent a request to see a website’s home page (which is generated by the server). When using HTTP, the connection between the client and server is established by the client, and the connection is closed once the request is completed. That means that if you send three requests to a website, three different connections are opened and closed for each request.
In contrast, when using the WebSockets protocol, one connection is established between the client and server. All requests moving in between the client and server are sent through this connection until the connection is terminated. In this case, you could send 10 requests to a website, and all of those requests would travel over the same connection. Due to these differences in protocol, Cloudflare had to adjust to Orpheus to make it capable of also saving WebSockets requests. Now all Cloudflare customers that use WebSockets in their Internet applications can expect the same level of stability and resiliency across their HTTP, TCP, and WebSockets traffic.
P.S. If you’re interested in working on Orpheus, drop us a line!
Orpheus and Argo Smart Routing
Orpheus runs on the same technology that powers Cloudflare’s Argo Smart Routing product. While Orpheus is designed to maximize origin reachability, Argo Smart Routing leverages network latency data to accelerate traffic on Cloudflare’s network and find the fastest route between an end user and a customer’s origin. On average, customers using Argo Smart Routing see that their web assets perform 30% faster. Together, Orpheus and Argo Smart Routing work to improve the end user experience for websites and contribute to Cloudflare’s goal of helping build a better Internet.
If you’re a Cloudflare customer, you are automatically using Orpheus behind the scenes and improving your website’s availability. If you want to make the web faster for your users, you can log in to the Cloudflare dashboard and add Argo Smart Routing to your contract or plan today.
Today, we’re excited to announce how we’re making Early Hints and Fetch Priorities automatic using the power of Cloudflare’s network. Almost a year ago we launched Early Hints. Early Hints are a method that allows web servers to asynchronously send instructions to the browser whilst the web server is getting the full response ready. This gives proactive suggestions to the browser on how to load the webpage faster for the visitor rather than idly waiting to receive the full webpage response.
In initial lab experiments, we observed page load improvements exceeding 30%. Since then, we have sent about two-trillion hints on behalf of over 150,000 websites using the product.
In order to effectively use Early Hints on a website, HTTP link headers or HTML link elements must be configured to specify which assets should be preloaded or which third-party servers should be preconnected. Making these decisions requires understanding how your website interacts with browsers, and identifying render-blocking assets to hint on without implementing prioritization strategies that saturate network bandwidth on non-critical assets (i.e. you can’t just Early Hint everything and expect good results).
For users who possess this knowledge and can configure Early Hints at the origin (or via a Worker), it works seamlessly. However, for users who lack access to their origin server (e.g. SaaS platforms), or are unsure about the optimal assets to preload/prioritize, or simply prefer to focus on building their own application, the question arises: "As an intermediary server, shouldn't Cloudflare know the best way to prioritize my website for performance?"
The answer is yes, which is why we’re excited to start talking about how Smart Hints will determine the best priority for web assets without developers needing to configure anything. If you’re interested in helping us beta test this feature, you can sign up here and we will contact you with further instructions on helping us test Smart Hints later this year.
Background
When you visit a webpage, your browser is actually requesting numerous individual resources from the server. These resources include everything from visible elements like images, text, and videos, to the behind-the-scenes logic (JavaScript, etc.) that powers the website analytics, functionality, and more. The order in which these resources are loaded by the browser plays a crucial role in determining how quickly users can view and interact with the page.
When your browser receives a response from the server, it parses the HTML response sequentially, from start to finish.When the HTML response arrives in the browser, it is split into two parts: the <head> and the <body>.
The <head> section appears at the beginning of the HTML response and contains essential elements like stylesheets, scripts, and other instructions for the browser. Stylesheets define how the page should look, while scripts provide the necessary logic for interactive features and functionality.1
While stylesheets are important to load quickly as browsers will wait for them to know how to display content to the visitor, scripts are interesting because they can behave differently based on instructions provided to the browser. If a script lacks specific instructions (defer/async/inline for example), it can become a "blocking" resource. When the browser encounters a blocking script resource, it pauses processing the webpage and waits until the script is fully loaded and completely executed. This ensures that the script's functionality is available for the visitor to use. However, this blocking behavior can delay the display of content to the user, as the browser needs to wait for the script to finish before proceeding further.
Until the browser reaches the <body> section of the document, there is nothing visible to the visitor. That's why it's crucial to optimize the loading process of the <head> section as much as possible. By minimizing the time it takes for stylesheets and blocking scripts to load, the browser can start rendering the page content sooner, allowing visitors to see and interact with the webpage faster.
Achieving optimal web performance can be a complex challenge. While browsers are generally in charge of determining the order of loading different resources it needs to build a page, there have been a variety of tools that have been released recently (Early Hints, Fetch Priority, Lazy-Loading, H2 Priorities) to help developers specify unique resource priority for browsers to improve website load performance. Although these tools and methods for specifying resource priority can be effective, they require implementation and testing to make sure they are implemented correctly.
Prioritization Tools
Two methods that have gained a lot of popularity for improving website performance have been Early Hints and Fetch Priorities. These tools help give browsers information about how it should load resources in the correct order to improve performance of critical resources.
Early Hints
Early Hints allow the server to provide some information to the client before the final response is available.
When a client sends a request to a server, the server can respond with an "early hint" to provide a clue about the final response. This early hint is a separate response that includes headers related to the final response, such as important static objects that can be fetched early, and links to where to get related resources.
The purpose of Early Hints is to allow the client to start processing the received information while waiting for the final response. The client can use the Early Hint to initiate early resource preloading, and preconnecting to servers that will have information for the final response, which can lead to faster page load times.
Fetch Priority
Another powerful tool in optimizing resource loading is Fetch Priorities, previously known as Priority Hints.
When analyzing a webpage, web browsers often prioritize the fetching of resources such as scripts and stylesheets to optimize the download sequence and efficiently use bandwidth. The priorities assigned to these resources are determined by browsers based on factors like resource type, placement within the webpage, and its location within the HTML response. For instance, images within the visible area for the visitor should be given higher priority, whereas essential scripts loaded early in the <head> section may be assigned a very high priority. Although browsers generally handle priority assignment effectively, it's worth noting that they may not always be optimal for every scenario.
By leveraging Fetch Priorities, developers gain additional control over resource loading and assign higher/lower priorities to different resources on their webpage, which can help optimize the overall performance of web pages.
While Early Hints and Fetch Priorities are all incredibly useful for optimizing web page performance, they often require access to the HTML resources in order to change their priorities and knowledge about how to best prioritize against other resources. While these tools working together allow for increasingly complex performance strategies to be implemented by developers, they also require a lot of testing, configuration, and management as web pages change over time. Smart Hints will make using these tools easier to manage by using our RUM data beacons and heuristics to better implement prioritization strategies without developers needing to lift a finger.
How are we going to prioritize assets?
Cloudflare's Smart Hints will leverage the capabilities of Early Hints and Fetch Priority features to optimize resource delivery by using our vast RUM data for websites across the Internet; we’re going to optimize resource prioritization on the fly. Smart Hints will dynamically determine the appropriate hints and priorities based on a specific response on the fly.
But how?
Cloudflare collects performance data in two ways – Synthetic testing and Real User Measurements (RUM). Synthetic testing collects performance data by loading a web page in an automated browser in a controlled environment. RUM also collects performance data, but from real users navigating to the web page on real browsers. RUM works by injecting a small piece of JavaScript, or beacon, into the web page. Cloudflare collects vast amounts of RUM data across thousands of sites.
From these two performance data sources, Cloudflare can intelligently analyze the loading bottlenecks of web pages. If the loading bottlenecks are caused by the download of render-blocking resources, Cloudflare can generate Smart Hints for the browser to prioritize the download of these resources.
As we roll out Smart Hints, we will explore the use of learning models to look for patterns that could be turned into heuristics. These heuristics could then be leveraged to improve performance for similar sites that do not use RUM or synthetic testing.
With Smart Hints, Cloudflare can revolutionize the way websites and applications are delivered, making the browsing experience faster, smoother, and more delightful. By inferring the right priority for a given client, Cloudflare will help customers find the best priorities for their websites’ performance while minimizing the time it takes to optimize an ever-changing webpage.
How can I help Cloudflare do this?
Before we roll this out more broadly, we will be performing large-scale beta tests of our systems to ensure that we’re making the best performance decisions for all kinds of content.
Over the next few months we’ll be building a beta cohort and working with them to ensure everyone has a great experience with Smart Hints. If you’d like to help us in this endeavor, please sign up to be part of the closed beta here (located in the Speed Tab of the dashboard) and we will get in touch when we’re ready for you to enable it and how to provide feedback.
Conclusion
We’re looking forward to working with our community to build and optimize this no-code/configuration experience to bring massive improvements to page load to everyone.
1Yes, scripts and stylesheets can also be placed within the <body> section, but their primary location is in the <head>.
We make no secret about how passionate we are about building a world-class global network to deliver the best possible experience for our customers. This means an unwavering and continual dedication to always improving the breadth (number of cities) and depth (number of interconnects) of our network.
This is why we are pleased to announce that Cloudflare is now connected to over 12,000 Internet networks in over 300 cities around the world!
The Cloudflare global network runs every service in every data center so your users have a consistent experience everywhere—whether you are in Reykjavík, Guam or in the vicinity of any of the 300 cities where Cloudflare lives. This means all customer traffic is processed at the data center closest to its source, with no backhauling or performance tradeoffs.
Having Cloudflare’s network present in hundreds of cities globally is critical to providing new and more convenient ways to serve our customers and their customers. However, the breadth of our infrastructure network provides other critical purposes. Let’s take a closer look at the reasons we build and the real world impact we’ve seen to customer experience:
Reduce latency
Our network allows us to sit approximately 50 ms from 95% of the Internet-connected population globally. Nevertheless, we are constantly reviewing network performance metrics and working with local regional Internet service providers to ensure we focus on growing underserved markets where we can add value and improve performance. So far, in 2023 we’ve already added 12 new cities to bring our network to over 300 cities spanning 122 unique countries!
City
Albuquerque, New Mexico, US
Austin, Texas, US
Bangor, Maine, US
Campos dos Goytacazes, Brazil
Fukuoka, Japan
Kingston, Jamaica
Kinshasa, Democratic Republic of the Congo
Lyon, France
Oran, Algeria
São José dos Campos, Brazil
Stuttgart, Germany
Vitoria, Brazil
In May, we activated a new data center in Campos dos Goytacazes, Brazil, where we interconnected with a regional network provider, serving 100+ local ISPs. While it's not too far from Rio de Janeiro (270km) it still cut our 50th and 75th percentile latency measured from the TCP handshake between Cloudflare's servers and the user's device in half and provided a noticeable performance improvement!
Improve interconnections
A larger number of local interconnections facilitates direct connections between network providers, content delivery networks, and regional Internet Service Providers. These interconnections enable faster and more efficient data exchange, content delivery, and collaboration between networks.
Currently there are approximately 74,0001 AS numbers routed globally. An Autonomous System (AS) number is a unique number allocated per ISP, enterprise, cloud, or similar network that maintains Internet routing capabilities using BGP. Of these approximate 74,000 ASNs, 43,0002 of them are stub ASNs, or only connected to one other network. These are often enterprise, or internal use ASNs, that only connect to their own ISP or internal network, but not with other networks.
It’s mind blowing to consider that Cloudflare is directly connected to 12,372 unique Internet networks, or approximately 1/3rd of the possible networks to connect globally! This direct connectivity builds resilience and enables performance, making sure there are multiple places to connect between networks, ISPs, and enterprises, but also making sure those connections are as fast as possible.
A previous example of this was shown as we started connecting more locally. As seen in this blog post the local connections even increased how much our network was being used: better performance drives further usage!
At Cloudflare we ensure that infrastructure expansion strategically aligns to building in markets where we can interconnect deeper, because increasing our network breadth is only as valuable as the number of local interconnections that it enables. For example, we recently connected to a local ISP (representing a new ASN connection) in Pakistan, where the 50th percentile improved from ~90ms to 5ms!
Build resilience
Network expansion may be driven by reducing latency and improving interconnections, but it’s equally valuable to our existing network infrastructure. Increasing our geographic reach strengthens our redundancy, localizes failover and helps further distribute compute workload resulting in more effective capacity management. This improved resilience reduces the risk of service disruptions and ensures network availability even in the event of hardware failures, natural disasters, or other unforeseen circumstances. It enhances reliability and prevents single points of failure in the network architecture.
Ultimately, our commitment to strategically expanding the breadth and depth of our network delivers improved latency, stronger interconnections and a more resilient architecture – all critical components of a better Internet! If you’re a network operator, and are interested in how, together, we can deliver an improved user experience, we’re here to help! Please check out our Edge Partner Program and let’s get connected.
Cloudflare executes an array of security checks on servers spread across our global network. These checks are designed to block attacks and prevent malicious or unwanted traffic from reaching our customers’ servers. But every check carries a cost – some amount of computation, and therefore some amount of time must be spent evaluating every request we process. As we deploy new protections, the amount of time spent executing security checks increases.
Latency is a key metric on which CDNs are evaluated. Just as we optimize network latency by provisioning servers in close proximity to end users, we also optimize processing latency – which is the time spent processing a request before serving a response from cache or passing the request forward to the customers’ servers. Due to the scale of our network and the diversity of use-cases we serve, our edge software is subject to demanding specifications, both in terms of throughput and latency.
Cloudflare's bot management module is one suite of security checks which executes during the hot path of request processing. This module calculates a variety of bot signals and integrates directly with our front line servers, allowing us to customize behavior based on those signals. This module evaluates every request for heuristics and behaviors indicative of bot traffic, and scores every request with several machine learning models.
To reduce processing latency, we've undertaken a project to rewrite our bot management technology, porting it from Lua to Rust, and applying a number of performance optimizations. This post focuses on optimizations applied to the machine-learning detections within the bot management module, which account for approximately 15% of the latency added by bot detection. By switching away from a garbage collected language, removing memory allocations, and optimizing our parsers, we reduce the P50 latency of the bot management module by 79μs – a 20% reduction.
Engineering for zero allocations
Writing software without memory allocation poses several challenges. Indeed, high-level programming languages often trade memory management for productivity, abstracting away the details of memory management. But, in those details, are a number of algorithms to find contiguous regions of free memory, handle fragmentation, and call into the kernel to request new memory pages. Garbage collected languages incur additional costs throughout program execution to track when memory can be freed, plus pauses in program execution while the garbage collector executes. But, when performance is a critical requirement, languages should be evaluated for their ability to meet performance constraints.
Stack allocation
One of the simplest ways to reduce memory allocations is to work with fixed-size buffers. Fixed-sized buffers can be placed on the stack, which eliminates the need to invoke heap allocation logic; the compiler simply reserves space in the current stack frame to hold local variables. Alternatively, the buffers can be heap-allocated outside the hot path (for example, at application startup), incurring a one-time cost.
Arrays can be stack allocated:
let mut buf = [0u8; BUFFER_SIZE];
Vectors can be created outside the hot path:
let mut buf = Vec::with_capacity(BUFFER_SIZE);
To demonstrate the performance difference, let's compare two implementations of a case-insensitive string equality check. The first will allocate a buffer for each invocation to store the lower-case version of the string. The second will use a buffer that has already been allocated for this purpose.
Allocate a new buffer for each iteration:
fn case_insensitive_equality_buffer_with_capacity(s: &str, pat: &str) -> bool {
let mut buf = String::with_capacity(s.len());
buf.extend(s.chars().map(|c| c.to_ascii_lowercase()));
buf == pat
}
Re-use a buffer for each iteration, avoiding allocations:
Benchmarking the two code snippets, the first executes in ~40ns per iteration, the second in ~25ns. Changing only the memory allocation behavior, the second implementation is ~38% faster.
Choice of algorithms
Another strategy to reduce the number of memory allocations is to choose algorithms that operate on the data in-place and store any necessary state on the stack.
Returning to our string comparison function from above, let's rewrite it operate completely on the stack, and without copying data into a separate buffer:
In addition to being the shortest, this function is also the fastest. This function benchmarks at ~13ns/iter, which is just slightly slower than the 11ns used to execute eq_ignore_ascii_case from the standard library. And the standard library implementation similarly avoids buffer allocation through use of iterators.
Testing allocations
Automated testing of memory allocation on the critical path prevents accidental use of functions or libraries which allocate memory. dhat is a crate in the Rust ecosystem that supports such testing. By setting a new global allocator, dhat is able to count the number of allocations, as well as the number of bytes allocated on a given code path.
/// Assert that the hot path logic performs zero allocations.
#[test]
fn zero_allocations() {
let _profiler = dhat::Profiler::builder().testing().build();
// Execute hot-path logic here.
// Assert that no allocations occurred.
dhat::assert_eq!(stats.total_blocks, 0);
dhat::assert_eq!(stats.total_bytes, 0);
}
It is important to note, dhat does have the limitation that it only detects allocations in Rust code. External libraries can still allocate memory without using the Rust allocator. FFI calls, such as those made to C, are one such place where memory allocations may slip past dhat's measurements.
Zero allocation decision trees
CatBoost is an open-source machine learning library used within the bot management module. The core logic of CatBoost is implemented in C++, and the library exposes bindings to a number of other languages – such as C and Rust. The Lua-based implementation of the bot management module relied on FFI calls to the C API to execute our models.
By removing memory allocations and implementing buffer re-use, we optimize the execution duration of the sample model included in the CatBoost repository by 10%. Our production models see gains up to 15%.
Optimize for single-document evaluation
By optimizing CatBoost to evaluate a single set of features at a time, we reduce memory allocations and reduce latency. The CatBoost API has several functions which are optimized for evaluating multiple documents at a time, but this API does not benefit our application where requests are evaluated in the order they are received, and delaying processing to coalesce batches is undesirable. To support evaluation of a variable number of documents, the CatBoost implementation allocates vectors and iterates over the input documents, writing them into the vectors.
TVector<TConstArrayRef<float>> floatFeaturesVec(docCount);
TVector<TConstArrayRef<int>> catFeaturesVec(docCount);
for (size_t i = 0; i < docCount; ++i) {
if (floatFeaturesSize > 0) {
floatFeaturesVec[i] = TConstArrayRef<float>(floatFeatures[i], floatFeaturesSize);
}
if (catFeaturesSize > 0) {
catFeaturesVec[i] = TConstArrayRef<int>(catFeatures[i], catFeaturesSize);
}
}
FULL_MODEL_PTR(modelHandle)->Calc(floatFeaturesVec, catFeaturesVec, TArrayRef<double>(result, resultSize));
To evaluate a single document, however, CatBoost only needs access to a reference to contiguous memory holding feature values. The above code can be replaced with the following:
Similar to the C++ implementation, the CatBoost Rust bindings also allocate vectors to support multi-document evaluation. For example, the bindings iterate over a vector of vectors, mapping it to a newly allocated vector of pointers:
let mut float_features_ptr = float_features
.iter()
.map(|x| x.as_ptr())
.collect::<Vec<_>>();
But in the single-document case, we don't need the outer vector at all. We can simply pass the inner pointer value directly:
let float_features_ptr = float_features.as_ptr();
Reusing buffers
The previous API in the Rust bindings accepted owned Vecs as input. By taking ownership of a heap-allocated data structure, the function also takes responsibility for freeing the memory at the conclusion of its execution. This is undesirable as it forecloses the possibility of buffer reuse. Additionally, categorical features are passed as owned Strings, which prevents us from passing references to bytes in the original request. Instead, we must allocate a temporary String on the heap and copy bytes into it.
But, we also execute several models per request, and those models may use the same categorical features. Instead of calculating the hash for each separate model we execute, let's compute the hashes first and then pass them to each model that requires them:
By optimizing away unnecessary memory allocations in the bot management module, we reduced P50 latency from 388us to 309us (20%), and reduced P99 latency from 940us to 813us (14%). And, in many cases, the optimized code is shorter and easier to read than the unoptimized implementation.
These optimizations were targeted at model execution in the bot management module. To learn more about how we are porting bot management from Lua to Rust, check out this blog post.
What we consider ‘fast’ is changing. In just over a century we’ve cut the time taken to travel to the other side of the world from 28 days to 17 hours. We developed a vaccine for a virus causing a global pandemic in just one year – 10% of the typical time. AI has reduced the time taken to complete software development tasks by 55%. As a society, we are driven by metrics – and the need to beat what existed before.
At Cloudflare we don't focus on metrics of days gone by. We’re not aiming for “faster horses”. Instead we are driven by questions such as “What does it actually look like for users?”, “How is this actually speeding up the Internet?”, and “How does this make the customer faster?”.
This innovation week we are helping users measure what matters. We will cover a range of topics including how we are fastest at Zero Trust, have the fastest network and a deep dive on cache purge and why global purge latency mightn’t be the gold star it's made out to be. We’ll also cover why Time to First Byte is generally a bad measurement. And what you should care about instead.
Woven amongst these topics are a number of great new products and features that genuinely make you and your customers faster. From API acceleration and end-to-end Brotli 11 compression, to reducing page load times by 30% with one-click. Plus a brand new home for application performance.
This week we will help you measure what matters. We’ll help you gain insight into your performance, from Zero Trust and API’s to websites and applications. And finally we’ll help you get faster. Quickly.
We are proving we are the fastest at what we do. And we are making it as easy as possible for our users to attain those numbers.
Welcome to Speed Week.
More megapixels?
You don't have to go far in the real world to find examples of highly-touted metrics that likely don't capture what you really care about.
If you read the announcements each year you’d be forgiven for believing smartphones have devolved into cameras with apps and an antenna. With each new model announced the press releases reference megapixel improvements between the previous and latest model.
The number of megapixels alone does not guarantee better image quality. Factors such as sensor size, lens quality, image processing algorithms, and low-light performance also play significant roles in determining the overall camera performance. This has been a widely accepted view for over a decade now, so why do companies keep pushing it as a metric – and why do users feel it's important?
Similarly, marketing collateral from Internet Service Providers would have you believe that “bandwidth is king”.
However it has been categorically proven that bandwidth is not the sole indicator of speed. Just two months ago we published a blog on “Making home Internet faster has little to do with speed”, concluding “While bandwidth plays a part, the latency of the connection – the real Internet “speed” – is more important”. The post references a recent paper by two researchers from MIT which supports this point, showing the point of diminishing returns is around 20Mbps for when more bandwidth doesn't mean a webpage loads much faster.
Again, the advertised, and generally accepted comparison metric amongst consumers, is incorrect. More bandwidth does not equal faster Internet speeds.
Simply put – are you really measuring what matters to you when reviewing your product choices and vendors? Or on reflection have your choices been influenced by dogma for far too long?
Measuring what matters on the Internet
Similarly to the smartphone and ISP industries, we at Cloudflare operate in industries where users often compare us against competitors using metrics that likely don't measure what matters to them.
Large enterprises use software to selectively shift traffic between Content Delivery Networks (CDNs) based on the lowest possible Time to First Byte (TTFB) score per region. This means if Cloudflare suddenly were to cut its TTFB in half in Africa, for example, we could see a huge influx of traffic in this region from these enterprise customers – likely not doing anything to improve the actual visitor experience of a website.
TTFB is often used as a measure of how quickly a web server responds to a request and common web testing services report it. The faster it is the better the web server (in theory). We have known for years, however, that TTFB is not on its own a fair reflection of real world performance.
Receiving the first byte isn't sufficient to determine a good end user experience as most pages have additional render blocking resources that get loaded after the initial document request. TTFB does not take into account multiplexing benefits of HTTP/2 and HTTP/3 which allow browsers to load files in parallel. It also doesn't account for features like Early Hints, Zaraz, Rocket Loader, HTTP/2 and soon HTTP/3 Prioritization which eliminate render blocking.
As Sitespect wrote last year, “TTFB is a measure of how fast a web server is able to respond to a request, and how long it takes for that request to traverse various layers of networking to reach a user’s browser. It is a measure of speed for delivery of content, but it is not a measurement for how long end-users are effectively waiting before they can start interacting with your website. TTFB completely ignores everything that happens after that network layer: loading, downloading of resources, rendering, etc. In other words, TTFB is not a user-centric measurement, it’s a networking measurement.”.
At Cloudflare we are all-in on Real User Monitoring (RUM) as the future of website performance. We’re investing heavily in it – both from an observation point of view and from an optimization one also. This week we will be releasing a series of new products aimed at helping users understand the actual experience of their end users (i.e. website visitors), and provide suggestions on how to improve it.
For those unfamiliar with RUM, we typically optimize websites for three main metrics – known as the “Core Web Vitals”. This is a set of key metrics which are believed to be the best and most accurate representation of a poorly performing website vs a well performing one. These key metrics are Largest Contentful Paint, First Input Delay and Cumulative Layout Shift.
LCP measures loading performance; typically how long it takes to load the largest image or text block visible in the browser. FID measures interactivity. For example, the time between when a user clicks or taps on a button to when the browser responds and starts doing something. Finally, CLS measures visual stability. A good, or bad example of CLS is when you go to a website on your mobile phone, tap on a link and the page moves at the last second meaning you tap something you didn't want to. That would be a lower CLS score as its poor user experience.
Looking at these metrics gives us a good idea of how the end user is truly experiencing your website (RUM) vs. how quickly the nearest Cloudflare data center begins to return data (TTFB).
The other benefit of Real User Monitoring is it includes the speed advantage of new protocols and features designed to improve the customer experience. For example, Time to First Byte is a single connection between the client and the nearest Cloudflare server. This is nothing like how a web browser connects to a website, which uses multiplexing to fetch multiple files at the same time in parallel. There are also products like Early Hints which are designed to take advantage of the “server think time” to send instructions to the browser to begin loading readily-available resources while the server finishes compiling the full response.
In Speed Week we will be going deep into why TTFB is a bad metric to care about for websites and web applications, why RUM is the future, and a blog post on the latest Core Web Vital – “Interaction to Next Paint” (INP), and what it means to you as a business.
We will also be unveiling a brand-new product which will be the new home of application performance on Cloudflare. The new product will augment synthetic tests from various global locations with real user monitoring data to give administrators the best possible understanding of how their website is performing in the real world. This product will be available for all plan levels.
We’re the fastest, and we can prove it
It's no secret that Cloudflare is fast.
However it might not be obvious to the everyday reader just how fast we are, and in just how many areas. Fastest compute. Fastest DNS. Fastest network. Fastest Zero Trust Network Access (ZTNA). Fastest Secure Web Gateway (SWG). Fastest object storage. And we’re finding areas we are not empirically the fastest and looking to prove we are number one.
We’re also finding ways to migrate customers from legacy providers and applications to Cloudflare as fast as possible. These legacy vendors have locked in companies using confusing terminology and esoteric features, trapping them on sub-par products and making them too afraid to move away. We’re helping those customers escape. Super Slurper helps customers move away from S3, Turpentine helps migrate legacy VCL setups to Cloudflare, and our Descaler program helps to migrate customers from Zscaler to Cloudflare in a matter of hours. We are building tools and products to help those customers who want to move to the fastest network but are locked in.
In Speed Week we’ll cover the latest on these programs and how we are relentlessly pushing to make the migration process as quick and easy as possible for customers who want to move to Cloudflare and put their business on the fastest network around.
Performance matters, whatever the product area
Generally when you hear of performance improvements it's typically through the lens making websites faster. But speed comes in many forms. Take Zero Trust as an example.
Measuring Zero Trust performance matters because it impacts your employees' experience and their ability to get their job done. Whether it’s accessing services through access control products, connecting out to the public Internet through a Secure Web Gateway, or securing risky external sites through Remote Browser Isolation, all of these experiences need to be frictionless. But what if your company's Secure Web Gateway is in London and you are in Johannesburg? This can mean a painful, slow, and frustrating employee experience whilst they wait for traffic to be sent to and from London. Slack becomes slow. Zoom becomes slow. Employees become frustrated.
The bigger concern, however, is not knowing of these performance issues. For example, if each of your employees are physically located in an office and the connection to critical business systems like Salesforce or Workday worsens, the likelihood is it will become evident quickly. But what about in a remote workforce with employees globally distributed? As a business, you need the ability to understand how your employees are experiencing critical business systems and identify any connection and performance issues they may be experiencing to ensure they get addressed quickly. In Speed Week we’ll unveil our latest Zero Trust offering which will give CIOs and businesses incredible insight into the performance experience of their workforce.
Speed Week will show Cloudflare is the fastest Zero Trust provider. Our analysis will provide updated benchmark comparisons and include additional competitors to show how we outperform everyone to give employees the fastest Zero Trust experience.
Another area we will shine a spotlight on this week is cache purge. When you think of CDNs it's common to look at them as a large distributed cache. Visitor-requested files are retrieved from an origin and stored on globally distributed CDN servers. This allows visitors to download the file in the quickest possible time by retrieving it from their nearest Cloudflare data center rather than having to traverse the Internet to and from the origin. TTFB will measure the time taken to receive a single file from the nearest location. RUM will measure the time it takes to receive multiple files, cached and uncached, and put them together into the webpage requested. But what about when the file changes on origin?
In the scenario where a business is hosting a pricebook as a downloadable file on its website, it is very important to understand how long it takes to remove old copies from Cloudflare cache to ensure customers don't see incorrect prices. This is where measuring cache purge times becomes important. The time taken to remove the invalidated file (old file) from every server in every data center in the CDN is known as the ‘global purge time’. In Speed Week we will explain how we have built our new cache purge architecture to be lightning-fast and what the performance numbers are as a result (spoiler: they are insanely fast).
These are just a few examples of what we have in store for the week. We also have blogs on AI, API acceleration, developer platform, networking, protocols, compression, streaming, UI optimization and more.
Speed at the heart of Cloudflare
At Cloudflare we put performance at the heart of everything we do.
Make sure to follow the Cloudflare blog and social media accounts for all of the week's news, and join us on Cloudflare TV each day for a live discussion of the day's announcements.
One of the things that makes Cloudflare unique is our Innovation Weeks. Rather than having one large conference annually, we have multiple Innovation Weeks throughout the year to highlight new product announcements, beta products opening up to general availability, and share how our customers are using Cloudflare to help build a better Internet.
Internally, these weeks generate a lot of energy and excitement as well, as they provide an opportunity for teams from across Cloudflare to work together on product delivery and celebrate company-wide successes. In 2021, we had seven Cloudflare Innovation Weeks. As we start planning our 2022 Innovation Weeks, we are reflecting back on the highlights from each of these weeks.
Security Week kicked off Cloudflare’s 2021 Innovation Weeks with a series of foundational security announcements. The Internet wasn’t built with security in mind, but the products and partnerships announced this week continued Cloudflare’s core mission of helping build a better Internet—one that companies of all sizes can plug into and be protected by default from the types of attacks that have historically resulted in loss of data, computing resources, and customer confidence.
During our first Impact Week, we reflected on how we are achieving Cloudflare’s mission–helping build a better Internet– and why we continue to prioritize projects that give back to the Internet. Impact Week highlighted some of the things we are doing as a company around environmental, social and governance initiatives. We launched Project Pangea, a free program to provide secure, reliable access to the Internet for community networks that support under-served communities. We also shared how we are committed to helping build a green Internet through efficiency, renewable energy, and providing developers a choice to run their workloads in the most energy efficient data centers. In addition, we published our first human rights policy in order to better serve our mission and core values.
We launched two amazing performance features with Signed Exchanges reducing load times and increasing SEO rankings with one click as well as Early Hints which can reduce loading times by 30%.
As part of Speed week, we also announced Cloudflare Images which stores, resizes, optimizes and serves images so that all of our customers can build a scalable, affordable image pipeline.
This is the week in which we celebrate Cloudflare’s birthday. We launched the company 11 years ago: September 27, 2010. It has been our tradition, since our first birthday, to use this week to launch innovative products that we think of as our gift back to the Internet. In 2021, we announced Cloudflare R2, our object-based storage with no egress fees, tackled solutions to Email Spoofing and Phishing, shared how we are expanding our network into office buildings as well as many more product announcements and Cloudflare TV executive fireside chats and product discussions.
During Full Stack Week, we brought the vision of the Network is the Computer to life — allowing developers to build their entire application on our network, soup to nuts. Over the course of the week, we made a series of announcements, each providing another critical piece of the puzzle, necessary to build a full stack application.
A little over two weeks ago, we shared extensive benchmarking results of edge networks all around the world. It showed that on a range of tests (TCP connection time, time to first byte, time to last byte), and on a range of measurements (p95, mean), that Cloudflare had some impressive network performance. But we weren’t the fastest everywhere. So we made a commitment: we would improve in at least 10% of networks where we were not #1.
Today, we’re happy to tell you that we’ve delivered as promised. Of the networks where our average latency exceeded 100ms behind the leading provider during Speed Week, we’ve dramatically improved our performance. There were such 61 networks; now, we’re the fastest in 29 of them. Of course, we’re not done yet — but we wanted to share with you the latest results, and explain how we did it.
Measuring What Matters
In the process of quantifying network performance, it became clear where we were not the fastest everywhere. There were 61 country/network pairs where we more than 100ms behind the leading provider:
Once that was done, the fun began: we needed to go through the process of figuring out why we were slow — and then improve. The challenges we faced were unique to each network and highlighted a variety of different issues that are prevalent on the Internet. We’re going to deep dive into a couple of networks, and show how we diagnosed and then improved performance.
But before we do, here are the results of our efforts in the past two weeks: of the 61 networks where our performance was over 100ms behind the leader, we are now the #1 network in 29 of them.
And it’s not that we just focused on those 29 networks, either. We’ve dramatically improved our performance in almost all the networks where we were over 100ms behind the leader.
With the results out of the way, let’s share the story of chasing peak performance in three very different geographies — each with three very different sets of challenges. Before we begin: a lot of Cloudflare’s internal network performance is automatically tuned. However, by its very nature, the Internet is a network of networks — and that inherently relies on us talking to other network operators to maximize performance. That’s often what we had to do here.
Rectifying Route Advertisement in Brazil
One particular network that was flagged for improvement during Speed Week stood out: we’ll refer to it as Network-A. This network was well known to our edge team (the team that looks after our network connectivity in Cloudflare data centers) for frequently congesting the dedicated interconnection we have with the network in São Paulo. This type of dedicated connection is called a Private Network Interconnect (PNI), or private peering, and it helps Cloudflare talk to Network-A without any intermediaries using the BGP protocol.
At a first look, we noticed that a significant chunk of traffic to Network-A was not using the PNI, but instead was being sent through one of our transit providers. A transit provider is an intermediary network that provides connectivity to the rest of the Internet.
This is not uncommon. The most likely reason for this behavior is that at some point in the past traffic was shifted away from the PNI due to capacity issues mentioned earlier.
We then started to take a more in-depth look at the path from this particular transit provider and identified that traffic was routed all the way to the USA before coming back to Brazil. The transit provider was exhibiting behavior known as tromboning: traffic from one location destined to a network in the same location travels vast distances only to be exchanged and then returns again. Tromboning typically occurs as a result of networks preferring paths that are farther away from the best possible path. This can happen due to peering preferences, BGP configurations, or the presence of direct interconnection farther away from end users. This explained the higher latency on this network we saw during Speed Week.
The next step we took was to look into alternatives to this transit connection. We have a nearby data center in Rio de Janeiro — where we also had a PNI with Network-A. Moreover, São Paulo and Rio de Janeiro are connected via our backbone network. After making the necessary checks to ensure we had room to carry traffic towards Network-A through our backbone and out through the PNI in Rio, we proceeded to prepare the network configuration changes.
We first started announcing Network-A IP addresses out of our backbone in Rio and then accepting them into São Paulo. We then ensured we preferred the path via our backbone over the PNI by changing the BGP behavior through the LOCAL_PREF path attribute. We then removed all the configuration specifying that transit provider as the preferred route for the previously identified traffic from Network-A.
The result was as expected. Traffic moved away from the transit provider onto our backbone network. We confirmed we achieved a decrease in latency by monitoring our p95 TCP RTTs, which went from 175ms to 90ms.
We currently rank #1 with Network-A, moving up from #5 during Speed Week, as seen in the chart below.
Immaculate Ingress in Spain
Another network that stood out was a European ISP with a global presence. We’ll refer to it as Network-B. Our RUM measurements showed that we were experiencing high latencies in several parts of the world, including Spain.
The first thing we did was to check how we handled traffic from Spain for Network-B. Our data showed that we had several data centers outside the country which were serving users from Network-B: Milan in Italy and Marseille in France. This obviously raised a question: why is traffic not staying locally in Spain?
The traffic was not staying local because Network-B had not peered with us in Madrid. If private peering describes a connection between exactly two networks using a dedicated circuit, public peering allows multiple networks to interconnect, if they wish so, at an Internet Exchange Point (IXP) location using a shared infrastructure. We looked at our Peering Portal to identify any potential peering opportunities with Network-B and established peering sessions in various locations where we saw high latency, including Madrid.
We looked at the traffic breakdown for these locations and identified the top destinations not being advertised in-country. We then checked whether our Spanish data centers were advertising these destinations and found that the corresponding anycast IP addresses were not enabled in Barcelona. We enabled the additional anycast IP addresses in Barcelona, and this change resulted in traffic for Network-B to be handled locally, which helped reduce latency.
Since we were looking into public peering status with Network-B, we also noticed that they had turned off their public peering session with Cloudflare in Milan. Our logs showed that the session with Network-B was down because it thought Cloudflare was sending more IP prefixes than allowed. We contacted Network-B and advised them to update the configuration according to the data we publish in PeeringDB. While it is a public peering session which comes with its own pros and cons, it still represents a more direct path than using a transit provider.
These changes pushed us up from ranking #2 during Speed Week to #1, as shown by the graph below:
You may notice that going from #2 to #1 still means we have a latency of about 300ms. We want to ensure that every network has amazing performance, but we can’t control all network providers and how they connect with the rest of the Internet. We’re constantly working to ensure that end users see the best experience possible.
Upstream Selection in Africa
We’ve previously discussed private peering and transit providers and how a direct connection is better than a transit connection which usually routes through intermediary networks. However, sometimes this might not be true. This was the case for a network in Africa, which we will call Network-C.
As before, we started by looking at the locations from where we serve traffic to Network-C. This was mostly from our data centers in Western Europe. Looking at the parent ASNs for Network-C, we expected this outcome since we don’t peer with either of them anywhere in Africa.
Let’s take our data center in London. There, we had a private peering connection with Parent-1 and a transit connection with Parent-2. We were receiving IP addresses belonging to Network-C from both parents, however we were only sending traffic to Parent-1 since that was our private peer.
As Parent-2 also provided a direct path to Network-C and, moreover, they belonged to the same organization, we decided to test the latency via Parent-2. It is generally tricky to identify potential upstream bottlenecks especially for transit providers, as each network has its own internal mechanisms for routing. However, in this case we were directly connected.
Once again, we modified the BGP behaviour. Let’s go into more detail this time. Our routing policies are configured differently depending on the type of network we peer with and the type of connection we use. Our policies configure the BGP LOCAL_PREF path attribute, which is the first decisive step in the selection of a path. In our case, Network-C prefixes from Parent-1 had a higher associated value than the same prefixes learned from Parent-2 and were thus chosen for routing. In order to steer traffic away from the private peer and towards the transit provider, we needed to adjust our transit policy to set a higher LOCAL_PREF value only for Network-C prefixes. We also had to use a regular expression to match the desired prefixes by filtering Network-C ASN in the AS-path in a way that would not affect traffic to the other networks from the transit provider.
This change produced better results in terms of latency. We were #2 during Speed Week. We are now #1, as seen by this chart:
Update on Speed Week
Two weeks ago, when we first reported our measurements, there were two charts that stuck out where Cloudflare was not #1 in terms of number of networks where we had the lowest connection time or TTLB.
The first was the mean TCP connection time in the top 1,000 networks by number of IP addresses. Since then, we’ve been optimizing and have measured our performance again, and we’ve now moved into the #1 spot.
The other measurement where we were #2 was mean TTLB in the top 1,000 networks by IP count. We’ve moved into the #1 spot, but there’s still work to do. Which makes sense because the work we’ve been doing over the last two weeks optimized network performance and not our software platform. Hence, connection times got a lot better while TTLB improved less dramatically.
Getting ever faster
Improving performance on the Internet is a long tail problem: each issue requires a different solution because every network is unique and covers different end users. As we continue to grow our network and interconnect with more of the world, it’s important that we constantly examine our performance to ensure that we’re the fastest.
The efforts of our team have yielded great improvements for our customers, but we’re not just stopping because Speed Week and Birthday Week are over. We’re automating the discovery process of poor performance on networks like these, and are working hard to also automate the remediation processes in order to deliver more incredible performance for our customers.
And we have two more innovation weeks coming in 2021. We’ll be back each week to report on further progress on optimizing our performance globally.
During Speed Week, we’ve talked a lot about the products we’ve improved and the places we’ve expanded to. Today, we have a final exciting announcement: Cloudflare now connects with more than 10,000 other networks. Put another way, over 10,000 networks have direct on-ramps to the Cloudflare network.
This is the culmination of a special project we’ve been working on for the last few months dubbed Project Myriagon, a reference to the 10,000-sided polygon of the same name. In going about this project, we have learned a lot about the performance impact of adding more direct connections to our network — in one recent case, we saw a 90% reduction in median round-trip end-user latency.
But to really explain why this is such a big milestone, we first need to explain a bit about how the Internet works.
More roads leading to Rome
The Internet that all know and rely on is, on a basic level, an interconnected series of independently run local networks. Each network is defined as its own “autonomous system.” These networks are delineated numerically with Autonomous Systems Numbers, or ASNs. An ASN is like the Internet version of a zip code, a short number directly mapping to a distinct region of IP space using a clearly defined methodology. Network interconnection is all about bringing together different ASNs to exponentially multiply the number of possible paths between source and destination.
Most of us have home networks behind a modem and router, connecting your individual miniature network to your ISP. Your ISP then connects with other networks, to fetch the web pages or other Internet traffic you request. These networks in turn have connections to different networks, who in turn connect to interconnected networks, and so on, until your data reaches its destination. The fewer networks your request has to traverse, generally, the lower the end-to-end latency and odds that something will get lost along the way.
The average number of hops between any one network on the Internet to any other network is around 5.7 and 4.7, for the IPv4 and IPv6 networks respectively.
ASNs are a key part of the routing protocol that directs traffic along the Internet, BGP. Internet Assigned Numbers Authority (IANA), the global coordinator of the DNS Root, IP addressing, and other Internet protocol resources like AS Numbers, delegates ASN-making authority to Regional Internet Registries (RIRs), who in turn assign individual ASNs to network operators in line with their regional policies. The five RIRs are AFRINIC, APNIC, ARIN, LACNIC and RIPE, each entitled to assign and attribute ASN numbers in their respective appointed regions.
Cloudflare’s ASN is 13335, one of the approximately 70,000 ASNs advertised on the Internet. While we’d like to — and plan on — connecting to every one of these ASNs eventually, our team tries to prioritize those with the greatest impact on our overall breadth and improving the proximity to as many people on Earth as possible.
As enabling optimal routes is key to our core business and services, we continuously track how many ASNs we connect to (technically referred to as “adjacent networks”). With Project Myriagon, we aimed to speed up our rate of interconnection and pass 10,000 adjacent networks by the end of the year. By September 2021, we reached that milestone, bringing us from 8,300 at the start of 2020 to over 10,000 today.
As shown in the table below, that milestone is part of a continuous effort towards gradually hitting more of the total advertised ASNs on the Internet.
The Regional Internet Registries and their Regions
Table 1: Cloudflare’s peer ASNs and their respective RIR
Given that there are 70,000+ ASNs out there, you might be wondering: why is 10,000 a big deal? To understand this, we need to look deeply at BGP, the protocol that glues the Internet together. There are three different classes of ASNs:
Transit Only ASNs: these networks only provide connectivity to other networks. They don’t have any IP addresses inside their networks. These networks are quite rare, as it’s very unusual to not have any IP addresses inside your network. Instead, these networks are often used primarily for distinct management purposes within a single organization.
Origin Only ASNs: these are networks that do not provide connectivity to other networks. They are a stub network, and often, like your home network, only connected to a single ISP.
Mixed ASNs: these networks both have IP addresses inside their network, and provide connectivity to other networks.
One interesting fact: of the 61,127 origin only ASNs, nearly 43,000 of them are only connected to their ISP. As such, our direct connections to over 10,000 networks indicates that of the networks that connect more than one network, a very good percentage are now already connected to Cloudflare.
Cutting out the middle man
Directly connecting to a network — and eliminating the hops in between — can greatly improve performance in two ways. First, connecting with a network directly allows for Internet traffic to be exchanged locally rather than detouring through remote cities; and secondly, direct connections help avoid the congestion caused by bottlenecks that sometimes happen between networks.
To take a recent real-world example, turning up a direct peering session caused a 90% improvement in median end-user latency when turning up a peering session with a European network, from an average of 76ms to an average of 7ms.
Immediate 90% improvement in median end-user latency after peering with a new network.
By using our own on-ramps to other networks, we both ensure superior performance for our users and avoid adding load and causing congestion on the Internet at large.
And AS13335 is just getting started
Cloudflare is an anycast network, meaning that the better connected we are, the faster and better-protected we are — obviating legacy concepts like scrubbing centers and slow origins. Hitting five digits of connected networks is something we’re really proud of as a step on our goal to helping to build a better Internet. As we’ve mentioned throughout the week, we’re all about high speed without having to pay a security or reliability cost.
There’s still work to do! While Project Myriagon has brought us, we believe, to be one of the top 5 most connected networks in the world, we estimate Google is connected to 12,000-15,000 networks. And so, today, we are kicking off Project CatchG. We won’t rest until we’re #1.
Interested in peering with us to help build a better Internet? Reach out to [email protected] with your request. More details on the locations we are present at can be found at http://as13335.peeringdb.com/.
When we announced Cloudflare Pages in April, our goal wasn’t to bring just any web development tool to the table. As a front-end developer, it’s your responsibility to bring the ideas of your marketing, product and engineering teams to life by crafting a beautifully engaging experience for every customer. With all the hard work that goes into the development process — turning mock-ups to code, getting input from your team, staging and testing changes — you want the best performance possible for your site to showcase your work and optimize your customers’ experience.
Cloudflare Pages is the most secure and most scalable Jamstack platform to build and deploy your sites on the edge. But how is Pages so fast?
It comes down to three key reasons:
Pages is built on one of the fastest networks in the world, putting us within 50 ms of 95% of the world’s Internet-connected population. Delivering Pages from this network is the basis of our speed.
Cloudflare helps define and implement next generation standards, like QUIC + HTTP/3 and Early Hints, that push Pages performance to the next level.
Pages has a killer developer experience that makes it easy to build the fastest websites on the planet.
Pages is delivered from one of the fastest networks in the world
After all the sweat, finger cramps, and facepalms you’ve managed to survive through development, the last thing you need is poor performance and load times for your site. This not only drives off frustrated customers, but if the site is a storefront, it can also have revenue implications.
We’ve got you covered! With Cloudflare’s extensive network, consisting of 250+ cities, your Pages site is deployed directly to the edge in seconds. With even more optimizations to our network routing, your customers are routed to the best data center, ensuring optimal loading and performance globally.
How does our performance compare?
Optimized routing, a giant CDN network, support for the latest standards, more performance enhancements — these all sound great! But let’s put them to the ultimate test: benchmarking. How do our Pages sites’ performance compare to those of our competitors?
The TTFB test
We deployed the same static site on Pages and on two other popular deployment platforms for comparison. We understand that benchmark tools like Google Lighthouse may introduce some geographic bias; performing a benchmarking analysis from San Francisco and hitting a local data center doesn’t tell us much about performance on a global scale. We wanted to create a simulation to run tests from different locations to give us a globally accurate representation. Using a tool called Catchpoint, we executed our test from 35 different cities around the world to measure the Time to First Byte (TTFB) for different providers. To give as accurate a reading as possible, we ran our test up to eight times, and averaged the result per city and per provider.
Around the world in 80ms
It’s common to see good performance in regions like the US and Europe, but at Cloudflare, we think even more globally. Cloudflare’s network allows you to reach a myriad of regions around the world without any additional effort or cost. Everytime our map grows, your global reach does too.
In our TTFB comparison, Cloudflare Pages is leading the race to your customers against two leading providers.
Pages gets early access to the latest, greatest, and fastest standards and network protocols
But it’s not just our network. We are proud of both driving and adopting the latest web standards. Our mission has always been to help build a better Internet, and collaborating on the latest standards is an essential part of that goal, especially when thinking about your Pages sites.
TLS 1.3: As the new encryption protocol, TLS 1.3 sets out to improve both speed and security for Internet users everywhere. With 1.3, during the course of that infamous “TLS handshake” you hear so much about, only one round trip, or back and forth communication, is required instead of two, thus shortening the process by milliseconds. A huge step forward for web security and performance, TLS 1.3 is available to all Pages users with no additional action required — let the client and server handle it all.
IPv6: Today it’s extremely common for every person to have more than one Internet connected device, making the shift to IPv6 extremely crucial, now more than ever. Not only is IPv6 the answer to the “no more addresses” issue, but is also another added layer for performance and security with its ability to handle packets more efficiently, getting faster and faster as adoption of the standard increases.
QUIC & HTTP/3: The new internet transport protocol, QUIC & HTTP/3, team up to enable faster, reliable and more secure connections for your customers to web endpoints like your Pages site. QUIC, a transport layer protocol, aims to reduce connection and transport latency and avoid congestion and runs underneath HTTP/3. Enabled by default on every pages.dev domain, QUIC & HTTP/3 work in tandem to provide improved performance and security so long as the client complies.
With support for the latest standards like HTTP/3 and IPv6, as we work on support for dynamic frameworks, we will be able to offer response streaming, a feature other platforms don’t provide.
“Pages gives us more confidence than other providers, making it easier to migrate our app over and build new products that can easily scale with growing traffic.” — David Simpson, COO at Designed.org
But we know that speed doesn’t just matter from a user perspective. It also matters from a developer perspective, too — and we’ve worked to make that just as great an experience.
A developer experience that we’d want to have
Generally speaking, performance of anything on the web is only as fast as the weakest link. A fast network, or support for the latest standards, doesn’t mean very much if we make it hard for a developer to do their job, or to optimize their code. So we knew the developer experience had to be a priority, too.
Fast for your users. Fast for you, too.
We set out to simplify every step of your developer experience by looking for ways to integrate into your existing publishing workflow. With Pages’ full git integration, grab your repo, tell us your framework and go! Collaborate with all members of your team — developers, PMs, marketers — quickly and efficiently with a protected preview URL per deployment to speed up the turnaround time for feedback. A simple Git commit and git push, and we’ll have your site up and running in seconds, and ready for you to share with your team or your customers.
Of course, even with lightning fast set-up and collaboration, we realize there’s more to the productivity of you and your team. From the time we launched Pages, we’ve been working on making our build times faster every day. Today, Pages builds are 3x faster than they were when we first launched the platform, but we’re not done yet. We’re aiming to have the fastest build times, so you can focus on what you do best — code, test, deploy, repeat — minus any wait.
Performance tuning, built in
In May of last year, Google announced a new program — Web Core Vitals — to provide unified guidance on how to measure the quality of a website, and to identify areas of improvement for developers, business owners, and marketers to deliver a better user experience. There are three key metrics as part of the program:
Largest Contentful Paint: measures loading performance
Fast-forward a year to 2021, Google officially announced that performance on these metrics will now be incorporated into Google Search results.
Performance is becoming an ever important aspect of the success of any site on the web.
We recognize this, and it’s part of why we’re so relentlessly focused on making sites hosted on Pages so fast. But you don’t need to just take our word for it. In addition to providing you with stellar performance across the globe, our Web Analytics tool is available to Pages customers with one click — so you can track your site’s Web Core Vitals and understand specific areas of improvement. As an example, here’s the Web Analytics on our very own Cloudflare Docs site.
We’re big believers in dogfooding — running our Docs site on Pages, and then using our Web Analytics to identify areas of improvement. It’s a big part of the Cloudflare ethos, and it’s how we can be confident in recommending our products to you.
What’s Next
With the increasing momentum behind the Jamstack movement, it’s a great time to be in the field. With Pages, you can rest easy knowing you’re taken care of every step of the way. We are so excited about the future of Cloudflare Pages — integrating with Cloudflare Workers, supporting monorepos, enabling more sources of repo integration — and how it brings a fresh perspective on how you build and deploy your sites on the web.
Check our docs to get started on Cloudflare Pages today!
In the year since Cloudflare’s launch of Workers Unbound, developers have unlocked the ability to run computationally intensive workloads on the Cloudflare edge network — like image processing, game logic, and other complex algorithms. With all that additional computing power comes a host of questions around performance. Our customers often ask us how they can profile or monitor their Workers to see where they spend the most CPU time, or to see whether their changes improve performance.
Here at Cloudflare, we not only want to build the fastest, most affordable, and most flexible compute platform at the edge; we also want to make the lives of our developers easier in building their applications. To do this, Cloudflare has begun to integrate with existing tools — places our developers feel comfortable and efficient in their day-to-day work. To help measure performance of our customers’ Workers, we’re beginning to integrate with the Chrome DevTools protocol. Just like you can use chrome://inspect to debug your Node backend, you can also use it to profile your Cloudflare Workers.
Introducing Chrome DevTools Integration (Beta)
We’re starting off this integration with beta support for local CPU profiling, using Wrangler. To show off how to use this feature, I’m going to be optimizing a simple JavaScript program which outputs the first thousand integers separated by a space. Let’s start by installing the latest version of Wrangler. We’ll also need a Worker cloned down to your local machine. I’ll be using Workers Profiling Example, but feel free to use any CPU intensive Worker for this tutorial.
For reference, my sample code is below. You’ll notice this code is intentionally performing a computation that will slow down our Worker.
addEventListener("fetch", event => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
let body = '';
for (let i = 0; i < 1000; ++i) {
body = body + ' ' + i;
}
return new Response(body, {
headers: { 'content-type': 'text/plain' },
});
}
To confirm this, we’ll run Chrome DevTools and profile our Worker locally. In the directory of your sample project, run wrangler dev --inspect. To launch the DevTools, open chrome://inspect in Chrome or Chromium. You’ll see Chrome’s DevTools homepage pop up:
Click ‘Configure’ and add localhost://9230 as one of the targets. You should see wrangler[{Worker name}] appear under “Remote Targets”, where {Worker name} is the name of your project.
Click ‘inspect’, then in the popup, ‘Profiler’.
Click ‘Start’ and, in a different browser tab, make a few requests to your site, then click ‘Stop’. It should be available locally on localhost:8787.
Analyze the flame graph. For my Slow Worker, I see the following graph:
When I click on handleRequest, I see the following annotated source of my Worker:
In particular, it shows that, unsurprisingly, most of the time is being spent on memory allocations in the body of the loop. Note that the profiler is not always accurate with regard to exact timing, but does paint a picture of your largest bottlenecks.
Understanding the Profile
The profiler works by gathering a stack trace of your program at a sampled rate, so remember that the profile is an approximation of where your code tends to spend the majority of its execution time, and is not meant to be perfectly accurate. In fact, functions that execute in less than 100 microseconds have a chance to not appear in the profile at all.
What’s Next?
With the Workers platform, we’re striving to build in the observability our users expect out of a robust compute platform. We’d love to hear more from the community about ways we can improve visibility into the code you’re writing on the edge. If you haven’t already, please join the Cloudflare Workers Discord community at https://discord.gg/PX8s2TmJ7s. Happy building!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.