Post Syndicated from Subhash Sharma original https://aws.amazon.com/blogs/big-data/near-real-time-baggage-operational-insights-for-airlines-using-amazon-kinesis-data-streams/
To provide a seamless travel experience, aviation enterprises must streamline baggage handling to be as efficient as possible. Traditional baggage analytics systems often struggle with adaptability, real-time insights, data integrity, operational costs, and security, limiting their effectiveness in dynamic environments. Real-time analytics can help in several aspects, such as improving staffing decisions, baggage rerouting, payload planning, and predictive maintenance of Internet of Things (IoT) sensors and belt loaders.
In this post, we explore a framework developed by IBM to modernize baggage analytics using Amazon Web Services (AWS) managed services such as Amazon Kinesis Data Streams, Amazon DynamoDB Streams, Amazon Managed Service for Apache Flink, Amazon QuickSight, Amazon Q in QuickSight, AWS Glue, Amazon SageMaker, and Amazon Aurora within a serverless architecture. This approach delivers significant cost savings, enhanced scalability, and improved performance while providing better security and operational efficiency to meet the evolving needs of airlines. Before diving into the solution’s architecture, we first examine the traditional baggage analytics process and the need for modernization.
Importance of baggage analytics
Baggage management is a process that starts at baggage check-in and ends with the passenger claiming their baggage in a happy path scenario. The following figure explains the high-level baggage management process and respective key performance indicators (KPI). The illustration highlights the critical role of payload planning (part 1), baggage loading (part 2), and below wing payload closeout (part 3) in the flight departure process, all of which directly impact the flight on-time departure metric (part 4). Enhancing the KPIs associated with these essential steps is vital for airlines to optimize operations.

Figure 1: Baggage analytics KPIs
Common KPIs for baggage loading include baggage handling time, turnaround time impact, mishandled baggage rate, baggage accuracy rate, and baggage loading error rate. Similarly, the baggage check-in process plays a crucial role in enhancing the passenger experience. Analyzing variations in this metric across different stations and time periods provides valuable insights for identifying potential bottlenecks and improving efficiency.Airlines can measure performance KPIs using the following business process metrics:
- Wait times – Wait times are the duration that a process step is waiting on an upstream dependency and are an important factor affecting the overall wait time. Analytics can help identify the potential areas (for example, stations, bag rooms, pier locations, belt loaders, or baggage types) where the processes and system can be fine-tuned to improve the overall wait time.
- Error rate – Error rate is the time spent on correcting errors or defects. Within these processes, error rate is usually a result of data inconsistencies across multiple systems, manual data entries because of system unavailability or limited aircraft turn-around time, and inconsistencies between payload planning rules and loading procedures. Analytics can help classify these errors among system availability issues, outdated rules, inconsistent data between systems, and other factors. The classification can help prioritize fine-tuning and removing redundancies across systems, rules, and data.
- Rework time – Rework time is time spent on correcting errors or defects. It can be improved but can’t be avoided, considering last-minute baggage, wheelchairs, ski equipment, and ship or aircraft changes that result in a new payload plan. Analytics can help classify the type, time, and frequency of rework activities across stations, staff members, baggage types, and scenarios related to flight delays and ship changes.
- Cycle time – Cycle time is the time it takes to complete the process. You can improve the payload planning process cycle time by automating the payload distribution process. To do so, you need to identify and improve the time taken by the payload planning, loading, and closeout processes to reduce the complete departure process cycle time. In many cases, you can improve cycle time by adjusting the processes and adding extra resources, such as workforce, or in other cases by introducing automation. Analytics can identify these time-consuming steps and can be extended to use predictive models to apply mitigation strategies.
Traditional baggage analytics
As explained in the following figure, the traditional baggage handling solution uses monolithic databases with several upstream and downstream dependencies. Upstream dependencies include bags, flight and passenger event feeds to subscribe to the real-time changes in flight, checked bags, and passenger itinerary changes. Downstream dependencies include staffing and customer notifications. The core application interfaces include belt loaders, IoT devices, kiosks, handheld scanners, and web applications for monitoring and reporting. The airline typically stores the reports in the operational database referred to in the diagram as baggage handling (relational database), retaining historical data spanning multiple years, and makes them available to all personnel on the airline’s network. The traditional approach to baggage analytics entails nightly processing of data batches into an enterprise data warehouse (EDW) to generate performance metrics related to airlines’ baggage handling processes.

Figure 2: Traditional baggage analytics
Need for modernization
Modernizing baggage analytics is crucial for airlines to achieve growth and enhance operational efficiency. Key factors influencing the modernization are as follows:
- Inefficiencies in near real-time decision-making – Current systems can’t process and analyze data in real time, leading to delayed responses to operational issues. Integration and data silos hinder insights, preventing proactive decision-making on baggage handling, routing, and anomaly detection.
- Limitations of traditional ETL solutions – Legacy extract, transform, and load (ETL) processes are batch-driven, slow, and resource-intensive, making them unsuitable for dynamic airline operations. High maintenance costs and frequent failures reduce system reliability and availability.
- Challenges in proactive anomaly detection and resolution during irregular operations – Airlines struggle to anticipate baggage issues during irregular operations, such as flight delays and weather disruptions. Without predictive analytics, preemptive actions remain a challenge in optimizing staffing, reducing mishandled baggage, and enhancing operational efficiency.
Solution
The modernization of baggage operations must include breaking down the monolithic database into distinct databases based on business capabilities to address performance bottlenecks. Business capabilities can be described as fundamental abilities or competencies that a business possesses and that enable it to achieve its objectives and deliver value to its customers.
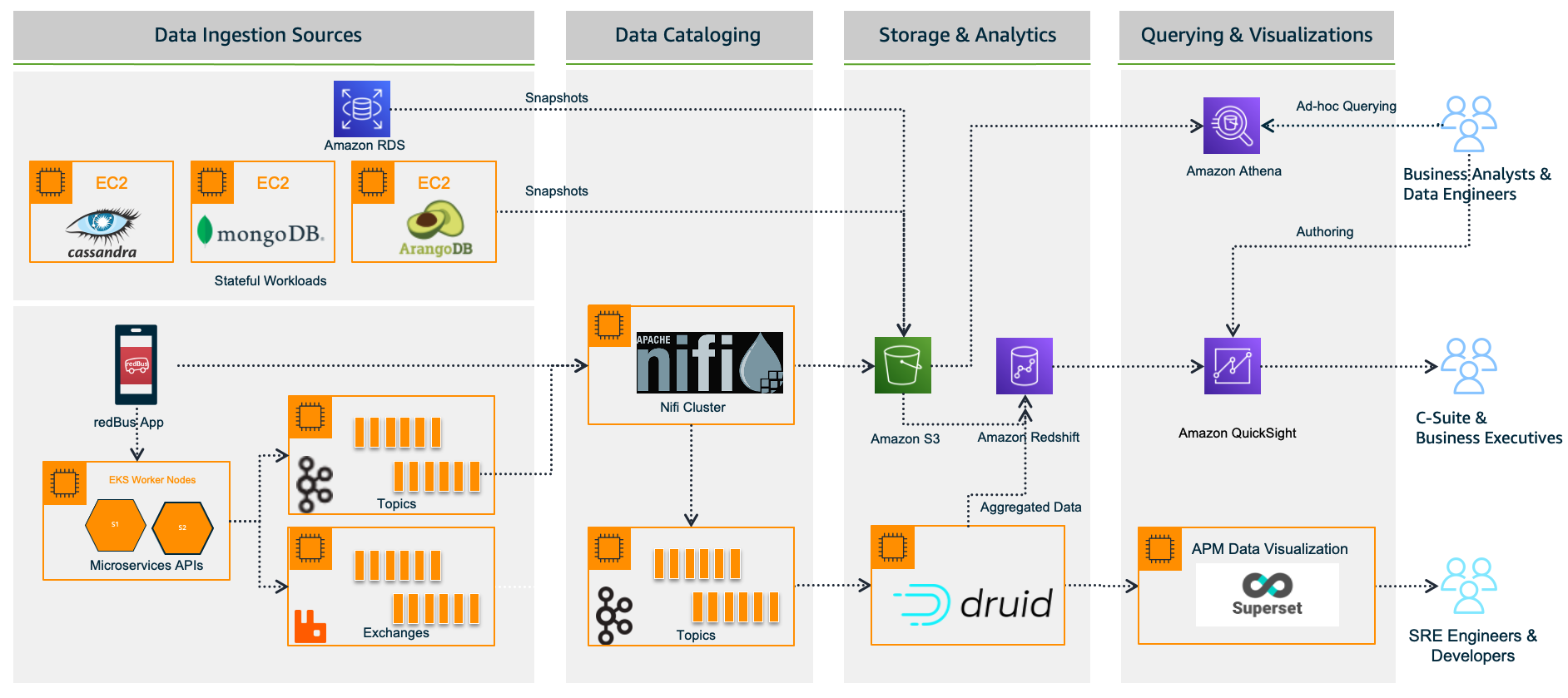
As explained in the following figure, the business capabilities for baggage management can be defined as baggage acceptance (check-in), baggage loading, baggage offloading, baggage tracking, baggage mishandling and claims, baggage rerouting, and more. [part 1]. The solution proposes Amazon DynamoDB for an operational database across all baggage management capabilities. DynamoDB global tables provide 99.999% availability with near-zero Recovery Time Objective (RTO) and Recovery Point Objective (RPO), which is crucial for mission-critical baggage handling systems. More details related to baggage operational database modernization can be found at Enhance the reliability of airlines’ mission-critical baggage handling using Amazon DynamoDB in the AWS Database Blog.
The proposed logical solution for baggage operational analytics suggests segregating operational data from historical data, referred to in the diagram as baggage analytics and historical reporting database, to enhance efficiency and alleviate the burden on the operational database [part 3].

Figure 3: Modern baggage analytics
The solution further uses streaming architecture for the ongoing transfer of data from the operational database to the baggage analytics and historical reporting database [part 2]. This approach aims to facilitate near real-time analytics.The key features for a robust streaming architecture include:
- Low-latency processing to enable near real-time updates
- Scalability and elasticity to handle dynamic workloads efficiently
- Fault tolerance and durability to promote data reliability with replication
- The ability for multiple consumers to process the same data in parallel at full speed without bottlenecks or interference
- Exactly one-time processing to avoid duplication and maintain data integrity
- Ability to replay messages
Real-time streaming on AWS Cloud
The solution uses either Kinesis Data Streams or DynamoDB Streams as a viable streaming solution for processing for change data capture (CDC) within milliseconds. For further information, refer to Streaming options for change data capture and Choose the right change data capture strategy for your Amazon DynamoDB applications.
In this architecture, Kinesis Data Streams is selected to enable fan-out to multiple downstream consumers, extended data retention, and integration with Amazon Managed Service for Apache Flink. Amazon Managed Service for Apache Flink performs stateful stream processing—such as windowed aggregation, filtering, and anomaly detection—before passing data to DynamoDB or Aurora for further analytical aggregation and reporting. Although DynamoDB Streams could also have been used, Kinesis Data Streams provides greater flexibility and throughput for the scale of event processing required here. Additionally, Kinesis Data Streams data retention allows message replays for improved reliability and analysis.
Baggage analytics on AWS Cloud
The solution will use Amazon Simple Storage Service (Amazon S3) for structured and unstructured data storage and Amazon Aurora PostgreSQL-Compatible Edition for relational aggregations. Aurora is well-suited for handling complex aggregations across multiple dimensions (such as month, year, station, and shift) with efficient indexing and SQL functions optimized for reporting. Its relational capabilities support analytical queries needed for performance metrics while providing scalability and efficiency
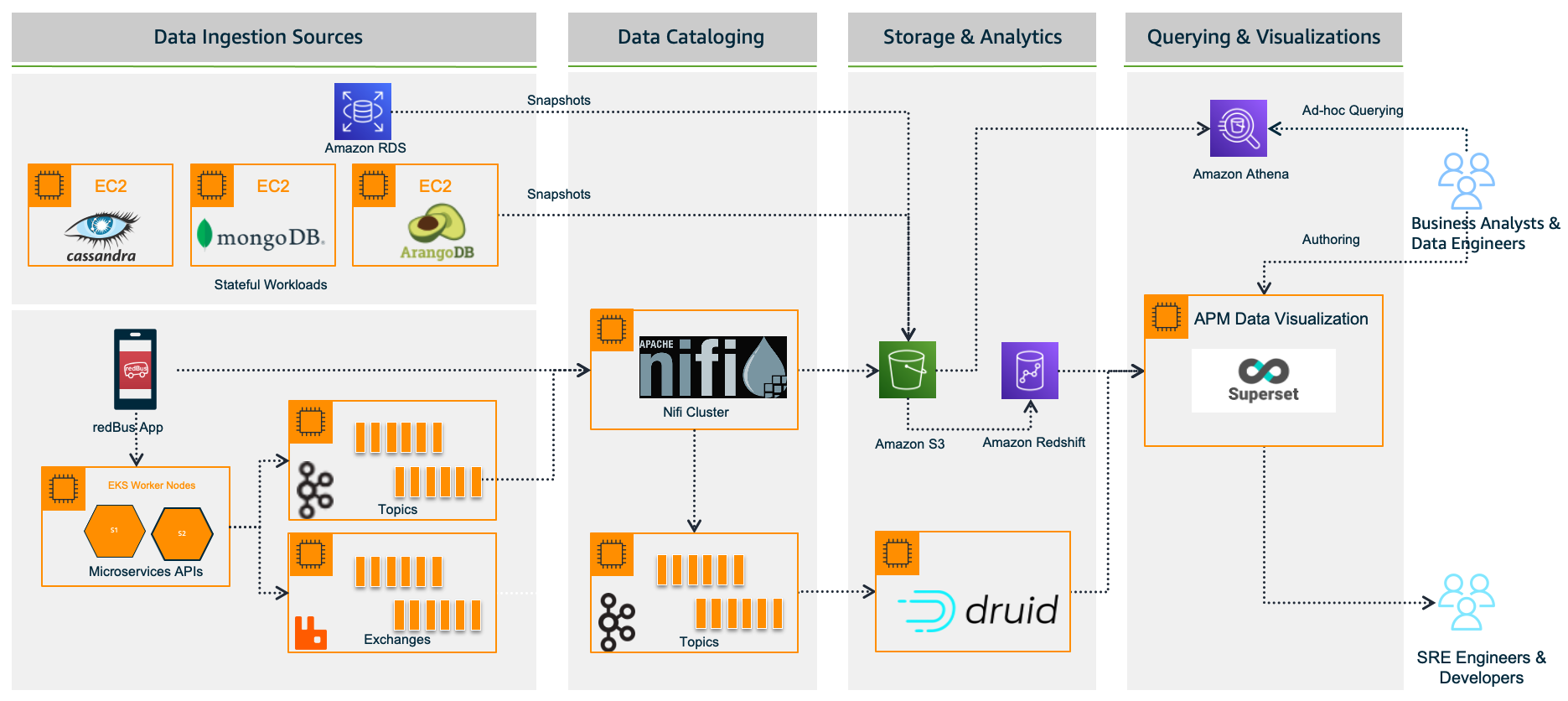
The following figure explains the high-level cloud architecture for baggage analytics using AWS services.

Figure 4: Near real-time baggage analytics architecture on AWS
The solution can support the following analytics:
- Interactive and investigative analytics which can produce charts and graphs and discover patterns and anomalies in the baggage data used by product owners. The solution proposes using Amazon QuickSight, which is an interactive tool. Additionally, the solution proposes Amazon Q in QuickSight for natural language queries using a chat-based interface. Amazon QuickSight can be configured using an AWS Glue crawler to automatically discover and extract metadata from various data stores such as Amazon S3 and Amazon Aurora and catalog it in a centralized repository. Amazon QuickSight can be configured to use Amazon Athena to read the data catalog.
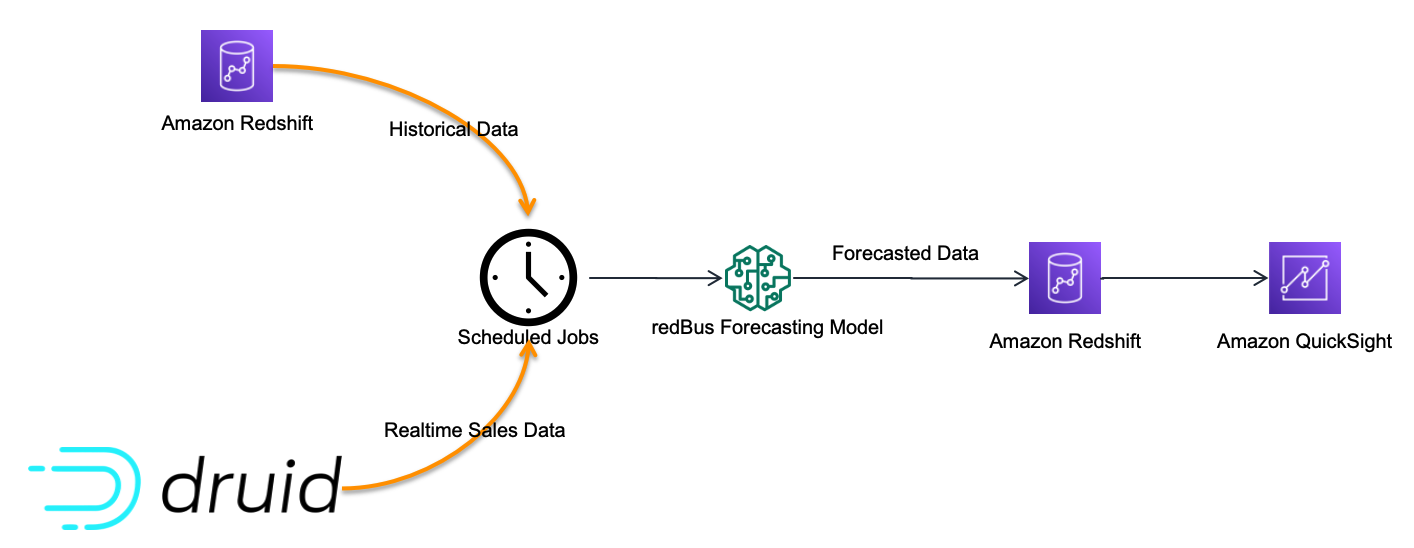
- Predictive analytics used by data scientists involves analyzing historical data to predict future events or behaviors. It uses statistical algorithms and machine learning (ML) techniques to forecast outcomes. The proposed solution is to use a SageMaker notebook to perform predictive analytics on baggage data.
Conclusion
Cloud-based solutions such as Kinesis Data Streams, Athena, and QuickSight revolutionize baggage analytics with scalable, cost-effective infrastructure. By integrating real-time data streaming, analysis, and visualization, they eliminate data silos and enable data-driven decision-making.This modernization optimizes processes, proactively resolving issues to minimize passenger disruptions. Embracing cloud-powered analytics isn’t just a necessity but a strategic step toward greater efficiency, resilience, and customer satisfaction.With this solution, airlines can enhance preemptive issue resolution in baggage operations. Real-time analytics enables better workforce planning, allowing airlines to predict staffing needs at departure and arrival stations, reducing labor costs while ensuring smooth operations. Additionally, data-driven insights help identify inefficiencies during irregular operations, enabling informed decisions for traffic diversion and process optimization.
Check out more AWS Partners or contact an AWS Representative to know how we can help accelerate your business.
Further reading
- AWS for Travel and Hospitality
- IBM Travel and Transportation
- IBM Consulting on AWS
- Modernize Baggage Acceptance Messaging with Enhanced Efficiency and Security
- Reliable Airline Baggage Tracking Solution using AWS IoT and Amazon MSK
- Enhance the reliability of airlines’ mission-critical baggage handling using Amazon DynamoDB
- Streamlining Aircraft Payload Planning and Closeout with AI-Powered Chatbots on AWS
IBM Consulting is an AWS Premier Tier Services Partner that helps customers who use AWS to harness the power of innovation and drive their business transformation. They are recognized as a Global Systems Integrator (GSI) for over 22 competencies, including travel and hospitality consulting. For more information, please contact an IBM Representative.
About the authors
 Neeraj Kaushik is an Open Group Certified Distinguish Architect at IBM with two decades of experience in client-facing delivery roles. His experience spans several industries, including travel and transportation, banking, retail, education, healthcare, and anti-human trafficking. As a trusted advisor, he works directly with the client executive and architects on business strategy to define a technology roadmap. As a hands-on Chief Architect AWS Professional Certified Solution Architect, AWS Certified Machine Learning Specialist and Natural Language Processing Expert, he has led multiple complex cloud modernization programs and AI initiatives.
Neeraj Kaushik is an Open Group Certified Distinguish Architect at IBM with two decades of experience in client-facing delivery roles. His experience spans several industries, including travel and transportation, banking, retail, education, healthcare, and anti-human trafficking. As a trusted advisor, he works directly with the client executive and architects on business strategy to define a technology roadmap. As a hands-on Chief Architect AWS Professional Certified Solution Architect, AWS Certified Machine Learning Specialist and Natural Language Processing Expert, he has led multiple complex cloud modernization programs and AI initiatives.
 Jay Pandya is a Senior Partner Solutions Architect in the Global Systems Integrator (GSI) team at Amazon Web Services (AWS). He has over 30 years of IT experience and is helping and providing guidance to AWS GSI partners to build, design, and architect agile, scalable, highly available, and secure solutions on AWS. Outside of the office, Jay enjoys spending time with his family and traveling, and he is an aviation enthusiast and avid sports and Formula 1 fan.
Jay Pandya is a Senior Partner Solutions Architect in the Global Systems Integrator (GSI) team at Amazon Web Services (AWS). He has over 30 years of IT experience and is helping and providing guidance to AWS GSI partners to build, design, and architect agile, scalable, highly available, and secure solutions on AWS. Outside of the office, Jay enjoys spending time with his family and traveling, and he is an aviation enthusiast and avid sports and Formula 1 fan.
 Vijay Gokarn is a Senior Solution Architect at IBM with extensive experience across industries including financial services, healthcare, industrial, retail, and travel and hospitality. He leads complex AWS transformation initiatives, drawing on his hands-on expertise as an AWS Certified Solutions Architect Associate. Vijay specializes in serverless architectures, event-driven systems, and enterprise modernization. As a skilled architect and team leader, he has delivered impactful solutions in cloud modernization, digital banking, and intelligent automation. His passion lies in bridging business strategy with technical execution to drive scalable digital transformation.
Vijay Gokarn is a Senior Solution Architect at IBM with extensive experience across industries including financial services, healthcare, industrial, retail, and travel and hospitality. He leads complex AWS transformation initiatives, drawing on his hands-on expertise as an AWS Certified Solutions Architect Associate. Vijay specializes in serverless architectures, event-driven systems, and enterprise modernization. As a skilled architect and team leader, he has delivered impactful solutions in cloud modernization, digital banking, and intelligent automation. His passion lies in bridging business strategy with technical execution to drive scalable digital transformation.
 Subhash Sharma is Sr. Partner Solutions Architect at AWS. He has more than 25 years of experience in delivering distributed, scalable, highly available, and secured software products using Microservices, AI/ML, the Internet of Things (IoT), and Blockchain using a DevSecOps approach. In his spare time, Subhash likes to spend time with family and friends, hike, walk on beach, and watch TV.
Subhash Sharma is Sr. Partner Solutions Architect at AWS. He has more than 25 years of experience in delivering distributed, scalable, highly available, and secured software products using Microservices, AI/ML, the Internet of Things (IoT), and Blockchain using a DevSecOps approach. In his spare time, Subhash likes to spend time with family and friends, hike, walk on beach, and watch TV.