Trino is an open source distributed SQL query engine designed for interactive analytic workloads. On AWS, you can run Trino on Amazon EMR, where you have the flexibility to run your preferred version of open source Trino on Amazon Elastic Compute Cloud (Amazon EC2) instances that you manage, or on Amazon Athena for a serverless experience. When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations.
Starting from Amazon EMR 6.8.0 and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. In this post, we compare Amazon EMR 6.15.0 with open source Trino 426 and show that TPC-DS queries ran up to 2.7 times faster on Amazon EMR 6.15.0 Trino 426 compared to open source Trino 426. Later, we explain a few of the AWS-developed performance optimizations that contribute to these results.
Benchmark setup
In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. This benchmark uses unmodified TPC-DS data schema and table relationships. Fact tables are partitioned on the date column and contained 200-2100 partitions. Table and column statistics were not present for any of the tables. We used TPC-DS queries from the open source Trino Github repository without modification. Benchmark queries were run sequentially on two different Amazon EMR 6.15.0 clusters: one with Amazon EMR Trino 426 and the other with open source Trino 426. Both clusters used 1 r5.4xlarge coordinator and 20 r5.4xlarge worker instances.
Results observed
Our benchmarks show consistently better performance with Trino on Amazon EMR 6.15.0 compared to open source Trino. The total query runtime of Trino on Amazon EMR was 2.7 times faster compared to open source. The following graph shows performance improvements measured by the total query runtime (in seconds) for the benchmark queries.
Many of the TPC-DS queries demonstrated performance gains over five times faster compared to open source Trino. Some queries showed even greater performance, like query 72 which improved by 160 times. The following graph shows the top 10 TPC-DS queries with the largest improvement in runtime. For succinct representation and to avoid skewness of performance improvements in the graph, we’ve excluded q72.
Performance enhancements
Now that we understand the performance gains with Trino on Amazon EMR, let’s delve deeper into some of the key innovations developed by AWS engineering that contribute to these improvements.
Choosing a better join order and join type is critical to better query performance because it can affect how much data is read from a particular table, how much data is transferred to the intermediate stages through the network, and how much memory is needed to build up a hash table to facilitate a join. Join order and join algorithm decisions are typically a function performed by cost-based optimizers, which uses statistics to improve query plans by deciding how tables and subqueries are joined.
However, table statistics are often not available, out of date, or too expensive to collect on large tables. When statistics aren’t available, Amazon EMR and Athena use S3 file metadata to optimize query plans. S3 file metadata is used to infer small subqueries and tables in the query while determining the join order or join type. For example, consider the following query:
SELECT ss_promo_sk FROM store_sales ss, store_returns sr, call_center cc WHERE
ss.ss_cdemo_sk = sr.sr_cdemo_sk AND ss.ss_customer_sk = cc.cc_call_center_sk
AND cc_sq_ft > 0
The syntactical join order is store_sales joins store_returns joins call_center. With the Amazon EMR join type and order selection optimization rules, optimal join order is determined even if these tables don’t have statistics. For the preceding query if call_center is considered a small table after estimating the approximate size through S3 file metadata, EMR’s join optimization rules will join store_sales with call_center first and convert the join to a broadcast join, speeding-up the query and reducing memory consumption. Join reordering minimizes the intermediate result size, which helps to further reduce the overall query runtime.
With Amazon EMR 6.10.0 and later, S3 file metadata-based join optimizations are turned on by default. If you are using Amazon EMR 6.8.0 or 6.9.0, you can turn on these optimizations by setting the session properties from Trino clients or adding the following properties to the trino-config classification when creating your cluster. Refer to Configure applications for details on how to override the default configurations for an application.
With Amazon EMR 6.8.0 and later, you can run queries on Trino significantly faster than open source Trino. As shown in this blog post, our TPC-DS benchmark showed a 2.7 times improvement in total query runtime with Trino on Amazon EMR 6.15.0. The optimizations discussed in this post, and many others, are also available when running Trino queries on Athena where similar performance improvements are observed. To learn more, refer to the Run queries 3x faster with up to 70% cost savings on the latest Amazon Athena engine.
In our mission to innovate on behalf of customers, Amazon EMR and Athena frequently release performance and reliability enhancements on their latest versions. Check the Amazon EMR and Amazon Athena release pages to learn about new features and enhancements.
About the Authors
Bhargavi Sagi is a Software Development Engineer on Amazon Athena. She joined AWS in 2020 and has been working on different areas of Amazon EMR and Athena engine V3, including engine upgrade, engine reliability, and engine performance.
Sushil Kumar Shivashankar is the Engineering Manager for EMR Trino and Athena Query Engine team. He has been focusing in the big data analytics space since 2014.
Author: Erik Wynter
Type: Exploit
Pull request: #18618 contributed by ErikWynter
Path: linux/http/opennms_horizon_authenticated_rce
AttackerKB reference: CVE-2023-0872
Description: This module exploits built-in functionality in OpenNMS Horizon in order to execute arbitrary commands as the opennms user. For versions 32.0.2 and higher, this module requires valid credentials for a user with ROLE_FILESYSTEM_EDITOR privileges and either ROLE_ADMIN or ROLE_REST. For versions 32.0.1 and lower, credentials are required for a user with ROLE_FILESYSTEM_EDITOR, ROLE_REST, and/or ROLE_ADMIN privileges.
Enhancements and features (5)
#18838 from SickMcNugget – This adds support for Debian and includes a number of fixes and improvements for the runc_cwd_priv_esc module. Prior to this fix, the module would incorrectly report some of the versions that the patch had been back ported to as vulnerable.
#18841 from randomstr1ng – This PR updates the sap_icm_paths.txt wordlist with the newest entries.
#18885 from errorxyz – Enhances the sessions command so that both Meterpreter and the top level Metasploit prompt support sessions -i -1.
#18978 from dwelch-r7 – This PR updates several login modules to now display some messaging to the end of scans to tell the user how many credentials and/or sessions were successful.
#18980 from zgoldman-r7 – Improves the help command wording when interacting with basic shells.
Bugs fixed (2)
#18947 from molecula2788 – Fixes an issue with exploits/windows/local/wmi_persistence module when Powershell obfuscation was applied.
#18974 from zeroSteiner – Fixes a typo in the help menu of the dns command.
Documentation added (1)
#18965 from adfoster-r7 – This PR updates our README.md to remove a stale documentation link.
You can always find more documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
This year to mark the occasion, we’re revisiting some tales of bullets dodged and backup victories. You’ll find no scary monsters here—no, these tales end happily. We like to call them ReStories—heartwarming sagas of folks who found a data lifeline. And we’re throwing in some tips and tricks to help you protect your data, too.
Let’s take a walk down ReStory lane.
Rising From the Ashes of the Marshall Fire Crisis
In 2021, the Marshall Fire left many in despair, but for Christopher G., it was a test of foresight. “A lifetime of memories were kept in my data, and years before this I decided to get a permanent backup solution,” Christopher shared. When disaster struck, Christopher lost his data—including his on-site backup copies—but he remembered he had an off-site backup stored in the cloud with Backblaze. He initiated a restore, and we sent hard drives with everything he needed to get his precious memories back.
Tip 1: Mitigate Risks With 3-2-1 Backups
Christopher’s story is a powerful testament to being prepared with a 3-2-1 backup strategy, which means keeping three copies of your data on two different media with one stored off-site (and preferably in the cloud). When two copies of his data were wiped out by the Marshall fire, he could rely on his third copy to restore all of the data, including years of photos and important documents.
School District Protects Data for 23,000 Students
Bethel School District had 200 servers and 125TB of data backed up by Rubrik, a backup software provider, to Amazon S3, but high costs were straining their budget—so much so that they had to shorten needed retention periods. They moved their backup copies from Amazon S3 to Backblaze B2, resulting in savings of 75%, which allowed them the budget flexibility to reinstate longer retention times and better protect their data from the threat of ransomware.
It was really a couple clicks, about five minutes worth of work, and we were pointed to Backblaze.
—Patrick Emerick, Senior Systems Engineer, Bethel School District
Tip 2: Plan for a Ransomware Attack Before It Happens
Ransomware attacks specifically targeting school districts and universities are on the rise—79% of institutions reported they were hit with ransomware in the past year. A ransomware attack is not a matter of if, but when, and that’s true whether you’re a school, university, business, or just someone who has data they care about. Take a cue from Bethel School District and take proactive measures to protect your business data from ransomware, like establishing retention periods that allow you to recover adequately in the event of an attack.
Backing Up Years of Research
The Caesar Kleberg Wildlife Research Institute at Texas A&M–Kingsville needed an endpoint backup solution to protect data on researchers’ laptops in the field and on-site, knowing researchers in the field don’t always follow protocols to the letter when it comes to saving their data. The Institute’s IT manager implemented Backblaze Computer Backup which gave him the ability to remotely manage faculty and staff backups. And he knows that, with no added fees, recoveries won’t be cost prohibitive.
Tip 3: Manage Backups Centrally
Whether you’re a remote employee or managing them, it can help to have tools like silent install, fine-grained access permissions, and management controls (at Backblaze, you can access all of these via Enterprise Control for Computer Backup). That way you can stay focused on what matters most instead of updating backup clients and fiddling with settings. Plus, you don’t have to worry about backups being accidentally deleted or tampered with.
Glenda B.’s Emotional Rescue: 20 Years of Memories Reclaimed
Losing decades of family photos can be devastating, a sentiment echoed by Glenda B.: “Several years ago my photos were all inexplicably deleted from my computer—20 years of family photos gone in an instant!” Some of them were on iCloud, but there were years of older photos that were only stored on her computer. Fortunately, she had very recently installed Backblaze Computer Backup, so all of her photos were safely backed up in the cloud. Glenda initiated a restore with Backblaze, restoring her files and her invaluable memories.
Tip 4: Sync Is Not Backup
If you’re like Glenda, your digital life is probably scattered across your computer, external hard drives, and multiple sync services from iCloud to Google Drive. Glenda’s story is an important lesson that sync is not backup. Sync services are great for sharing data and accessing it on multiple devices, but that doesn’t help you when you lose data that’s only stored on your computer or when you accidentally delete a file and don’t realize it. One of the drawbacks of using sync services as a backup is that data outside those services is vulnerable. And the fix for that vulnerability is to use a true backup service to protect all of your data.
What Happens When One-Third of Your Employees’ Machines Crash?
BELAY Solutions is a staffing company that connects organizations with virtual assistants, bookkeepers, website specialists, and social media managers. While performing scheduled system updates across BELAY’s fleet of Macs, nearly a third of the company’s machines crashed. After shipping out replacement laptops, the IT team empowered BELAY employees to use Backblaze Business Backup to recover their own data independently in a matter of minutes.
Our work is very time intensive, so our team can’t be offline for long—you always need reliable technical assets to support virtual assistants in the field.
—Cam Cox, IT Systems Administrator, BELAY Solutions
AJ’s Tech Misadventure: Averting a Digital Disaster
Upgrading your computer’s operating system is routine until it results in an accidental wipeout, as AJ found out. “In summer 2020, I accidentally wiped my external hard drive while downloading a copy of Windows 10,” he recounts. But thanks to Backblaze, AJ could redownload everything, salvaging irreplaceable files.
Rob D.’s Professional Life: Recovering Years of Work
For Rob D., a graphic designer, losing years of work to a computer crash was catastrophic. He woke up to the “dreaded blue screen of death” and despite efforts, only scattered metadata could be salvaged. But, Backblaze came to the rescue. “As a graphic designer, YEARS of design projects were gone in a flash. Clients…were not too pleased…Enter Backblaze,” Rob said. With a new hard drive filled with his backed up data, he experienced immense relief. “Can’t quite describe the feeling of relief I felt at that moment knowing that I was going to be ok. THANK YOU Backblaze!! I’m a customer for life!”
Tip 5: Reduce Downtime With Self-Serve Backup Solutions
Even tech savvy folks like AJ, Rob D., and the staff at BELAY solutions can get flustered when they suddenly lose their data or ability to work, so an easy restore process everyone can use themselves no matter their level of IT knowledge is essential for those high-stress situations. BELAY initially chose Backblaze for its simplicity and ease of use. “I’ve been able to help someone get their data back within five minutes. I don’t think that ever would have happened using our previous tool,” said Cam Cox, IT Systems Administrator. And, Backblaze user AJ relayed that having Backblaze was “worth every penny for the rapid restore process.”
Take the World Backup Day Pledge This Year
As we celebrate World Backup Day, let’s take a moment to recognize the critical role that data backup plays in safeguarding our digital assets against unforeseen threats. Whether you’re a business owner, an IT director, or an individual user, investing in robust backup solutions is an investment in resilience and peace of mind. By embracing proactive measures and leveraging technology to fortify our defenses, we can navigate the complexities of the digital age with confidence and resilience. We encourage you to take the World Backup Day pledge, feel free to reach out to us on socials, and check back in June to see the newest results of our yearly backup survey.
AWS Private CA provides a highly available private certificate authority (CA) service without the upfront investment and ongoing maintenance costs of operating your own private CA. Using the APIs that AWS Private CA provides, you can create and deploy private certificates programmatically. You also have the flexibility to create private certificates for applications that require custom certificate lifetimes or resource names. With AWS Private CA, you can create your own CA hierarchy and issue certificates for authenticating internal users, computers, applications, services, servers, and devices and for signing computer code.
Use cases for certificate services that integrate with Active Directory
AD CS is commonly used in enterprise environments because it integrates certificate management with Active Directory authentication, authorization, and policy management. A common use case for AD CS is certificate auto-enrollment. Using AD Group Policies, you can configure certificates to automatically be created for users as they log in to the domain, or you can configure computer certificates, which are associated with each workstation or server that joins the domain. You can then use these certificates for authentication or digital signature purposes. A common use case is for authentication of devices to protected networks, such as wired networks that require 802.1x authentication or wireless networks that are protected by WPA2/3 with EAP-TLS authentication. Auto-enrolled computer and user certificates are also commonly used to authenticate VPN connections.
In addition to certificate auto-enrollment, AD CS also integrates with Active Directory to publish certificate information directly to the user and computer objects in Active Directory. In this way, you can integrate the lifecycle management of the certificates directly into your existing processes for managing the lifecycle of AD users and computers that are joined to the domain.
Options to deploy certificate services that integrate with Active Directory on AWS
To migrate your Windows environment to the cloud, you probably want to retain the capabilities of a CA that integrates with Active Directory. Although you can migrate AD CS directly to AWS and run it on an Amazon Elastic Compute Cloud (Amazon EC2) instance running Windows, we will show you how to use AWS Private CA with the Connector for AD to provide an Active Directory integrated CA that offers the benefits of AD CS without the need to manage AD CS or hardware security modules (HSMs).
Why migrate your on-premises CA to AWS Private CA?
Migrating AD CS to AWS Private CA has several benefits. With AWS Private CA, you get simplified certificate management, eliminating the need for an on-premises CA infrastructure and reducing operational complexity. AWS Private CA provides a managed service, reducing the operational burden and providing high availability and scalability. Additionally, it integrates with other AWS services, so it’s simpler to manage and deploy certificates across your infrastructure. The centralized management, enhanced security features, and simplified workflows in AWS Private CA can streamline certificate issuance and renewal processes, enabling you to more efficiently achieve your security goals.
AWS manages the underlying infrastructure, which can help reduce costs, and automation features help prevent disruptions that expired certificates could cause. AWS Private CA operates as a Regional service with an SLA of 99.9% availability. For environments that require the highest level of availability, you can deploy CAs in multiple AWS Regions by following the guidance on redundancy and disaster recovery in the documentation.
AWS Private CA Connector for AD extends the certificate management of Private CA to AD environments. With the Connector for AD, you can use Private CA to issue certificates for AD users and computers joined to your domain. This includes integration with Windows Group Policy for certificate autoenrollment.
How do I migrate to the Connector for AD?
Transitioning from an existing AD CS server to the Connector for AD involves several steps.
Assessment and planning
Before you begin, identify the use cases for your existing AD CS server and how certificates are issued. In this post, we focus on certificates that are auto-enrolled by using a Group Policy, but you might have other use cases where you must manually enroll certificates by using the Web Enrollment server or APIs. These might include use cases for signing software packages or web server certificates for intranet applications. Start by creating a certificate inventory from your existing AD CS server.
To create a certificate inventory from your existing AD CS server
In the Microsoft CA console, select Issued Certificates.
From the Action menu, select Export List.
Figure 1: Export a list of existing certificates
This produces a CSV file of the certificates that the server issued. To determine which certificates were created as part of an auto-enrollment policy and to identify special cases that require manual attention, sort this file by Certificate Template.
Depending on where you put the new private CA in your organization’s public key infrastructure (PKI) hierarchy, you might want to make sure that its certificate is imported into all of the client trust stores before you issue new certificates using the CA. For Windows devices, creation of the Connector for AD imports the CA certificate into Active Directory, and automatically distributes it to the trust stores of domain-joined computers.
For non-Windows devices, you need to evaluate other use cases for issued certificates on the network and follow vendor instructions for updating trust stores. For example, if you use client certificates for wired 802.1x and Wi-Fi Protected Access (WPA) enterprise authentication, you need to import the new root CA certificate into the trust stores of the RADIUS servers that you use for authentication.
For import into an Active Directory Group Policy Object (GPO), name the exported file with a .cer file extension.
Figure 2: Export the CA certificate
Transition certificate enrollment to the new CA
After you configure AWS Private CA and the Connector for AD and update your trust stores as necessary, you can begin to transition certificate enrollment to the new CA. In Active Directory domains, certificates are typically created automatically by using an auto-enrollment Group Policy. To migrate enrollment to your new CA, you need to configure certificate templates with the appropriate properties to match your requirements, assign permissions to the templates, and configure the Group Policy to point the enrollment client on Windows devices to the new CA.
Configure certificate templates
Certificate templates define the enrollment policy on a CA. An Active Directory CA only issues certificates that conform to the templates that you have configured. Using the certificate inventory that you collected from your existing AD CS server, you should have a list of certificate templates that are in active use in your environment and that you need to replicate in the Connector for AD.
Start by noting the properties of these certificate templates on your existing AD CS server.
To note the properties of the certificate templates
Open the Certificate Authority console on your AD CS server.
Navigate to the Certificate Templates folder.
From the Action menu, select Manage. This opens the Certificate Templates console, which shows a list of the certificate templates available in Active Directory.
Figure 3: Identify certificate templates
For each certificate that is in active use, open it and take note of its settings, particularly the following:
Template name, validity period, and renewal period from the General tab.
Certificate recipient compatibility from the Compatibility tab.
Certificate purpose and associated checkboxes in addition to whether a private key is allowed to be exported from the Request Handling tab.
Cryptography settings from the Cryptography tab.
The extensions configured from the Extensions tab.
Settings for certificate subject and subject alternate name from the Subject Name tab.
Review the Security tab for the list of Active Directory users and groups that have Enroll or AutoEnroll permissions. The other permission settings, which control which AD principals have the ability to modify or view the template itself, don’t apply to AWS Private CA because IAM authorization is used for these purposes.
Figure 4: Certificate template properties
After you gather the configuration details for the certificate templates that are in active use, you need to configure equivalent templates within the Connector for AD.
Figure 5: Certificate template configuration in the Connector for AD
You can then begin configuring your certificate template by using the settings that you obtained from your existing AD CS server. For a complete description of the settings that are available in the certificate template, see Creating a connector template.
Figure 6: Certificate template settings
Assign permissions to the template.
You must manually enter the Active Directory Security Identifier (SID) of the user or group that you are assigning the Enroll or Auto-enroll permission to. For instructions on how to use PowerShell to obtain the SID of an Active Directory object, see Managing AD groups and permissions for templates.
We recommend that you initially assign your certificate templates to a small test group that contains a set of Active Directory computers or users that will be used to test the new CA. When you are confident that the new CA issues certificates correctly, you can modify the permissions to include the full set of Active Directory user and computer groups that were assigned to the template on your original AD CS server.
Configure Group Policy for automatic certificate enrollment
With the Connector for AD configured with the required certificate templates, you are ready to configure the AD Group Policy to enable automatic enrollment of user and computer certificates. We suggest that you start with a test organizational unit (OU) in Active Directory, where you can put user and computer objects to make sure that enrollment is working properly. The existing AD CS server and the Connector for AD can continue to coexist until you are ready to replace the certificates.
In this example, you configure a new Group Policy object that is linked to an OU called Test OU, where you will place computer objects for testing.
To configure a new Group Policy object
Within the Group Policy object, locate the settings for controlling enrollment under Computer Configuration > Policies > Windows Settings > Security Settings > Public Key Policies.
Figure 7: Active Directory Group Policy Editor
Configure the Certificate Services Client – Certificate Enrollment Policy to point clients at the URL of the Connector for AD:
Set the Configuration Model to Enabled.
Add a new item to the Certificate enrollment policy list.
Figure 8: Certificate Services Client Group Policy settings
Enter the URL of your connector and leave the Authentication mode set to Windows Integrated. Then choose Validate.
Note: You can find the URL of your connector in the AWS Private CA Connector for AD console under Certificate enrollment policy server endpoint.
Figure 9: Connector details
After you save your configuration, remove the Active Directory Enrollment Policy from the list so that the Group Policy only references the Connector for AD. A completed configuration will look similar to the following:
Figure 10: Certificate services client settings with Active Directory enrollment policy removed
From within the Group Policy editor, open the Certificate Services Client – Auto-enrollment policy to configure auto-enrollment of computer certificates. Set Configuration Model to Enabled, and select the following:
Renew expired certificates, update pending certificates, and remove revoked certificates
Update certificates that use certificate templates
After you configure the Group Policy, computers in OUs that the Group Policy is linked to will start automatically enrolling certificates by using AWS Private CA, subject to the permissions defined on the certificate templates. To review the progress of certificate enrollment, use private CA audit reports.
When you complete testing and gain confidence in your certificate roll-out, extend the scope of the GPO and Active Directory permissions on the certificate templates to cover additional users and computers.
Revocation and decommissioning
You can continue to review the Private CA audit reports to confirm progress with auto-enrollment of certificates from the new CA. If you have computers that infrequently connect to the network, this can take some time. As part of this process, address your use cases that aren’t covered by auto-enrollment, which you identified from your initial certificate inventory. These might include web server certificates for internal applications or code-signing certificates for distributing software packages. You can issue replacement certificates for these use cases by using the AWS Private CA APIs or CLI without depending on the Active Directory integration. For more information, see Issuing private end-entity certificates.
After the required certificates have been enrolled and you have confirmed that the services that depend upon those certificates are functioning correctly, it’s time to revoke issued certificates and decommission your existing AD CS server. Microsoft provides detailed documentation for properly revoking certificates and decommissioning an Enterprise CA, including clean-up of related AD objects.
Conclusion
In this post, we covered some use cases for Active Directory integrated certificate management in Windows environments and introduced the new AWS Private CA Connector for Active Directory. AWS Private CA and the Connector for AD can help you reduce operational overhead, enabling you to simplify the process of provisioning certificates while maintaining the Active Directory integration that you are accustomed to in a Microsoft AD CS environment. You learned how to evaluate your existing Microsoft CA and migrate to AWS Private CA with the Connector for AD, with a specific focus on auto-enrollment of certificates, which is commonly used in enterprise environments for device and end-user authentication.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Certificate Manager re:Post or contact AWS Support.
ПП–ДБ и ГЕРБ–СДС търсят път едни към други, въпросът е на каква цена, след като политиците се изчерпаха откъм оскърбления, а анализаторите – откъм метафори. И двете коалиции сигнализират, че са готови да продължат преговорите помежду си въпреки „счупеното доверие“, констатирано от премиера в оставка Николай Денков (ПП) в Брюксел, където е за Европейския съвет.
От Брюксел дойде и публично насърчение към властите в София да продължат с усилията за съставяне на кабинет. За първи път България беше спомената в изявление, прието на срещата на върха на страните от еврозоната.
Приветстваме постигнатия напредък от България по пътя ѝ към приемането на еврото и я насърчаваме да продължи усилията си до изпълнението на всички критерии за конвергенция.
В „превод“ това означава, че редовен кабинет ще продължи тези усилия, така че от 1 януари 2025 г. България да приеме еврото. Предупреждението, че политическата нестабилност ще попречи, се чете между редовете.
В последната седмица отношенията между двете политически сили, управлявали 9 месеца чрез общ кабинет, рязко се изостриха. Въпреки договорената през май миналата година ротация, ПП–ДБ вече не приемат Габриел за премиер, след като тя еднолично внесе при президента изпълнен първи мандат със списък на несъгласувани с тях министри. ГЕРБ пък настоява за смяна на министъра на финансите Асен Василев, който обяви, че действайки през главата им, Габриел е провалила шанса за кабинет с първия мандат. И я нарече „най-новото и най-красивото лице на мафията в България“. (Без да уточнява кого определя като „мафия“.)
Кой ще мигне пръв
Ротацията на премиерския пост между Денков (ПП) и Мария Габриел (ГЕРБ) засече заради споровете за конкретни министерства, механизма за назначения в регулатори и контролни органи, сроковете за реформи на службите, промените в Закона за съдебната власт, отпадането на следствената тайна. И мястото на ДПС в цялата схема. Ако досега съвместното управление се основаваше на кратка декларация с шест основни приоритета и програма за 18 месеца, предизвикателствата вече са много по-големи и начертани в едно така и неподписано споразумение. Предстоят смени на повече от 110 високи позиции и амбиции за осъществяване на съдебната реформа. В случай че ПП–ДБ и ГЕРБ не се разберат за управленски съюз, доминацията на ГЕРБ и ДПС се запазва неизвестно докога.
След задочните разговори тази седмица през телевизии и пресконференции, съпроводени с ултиматуми за крайни срокове и подкани за извинения, дойде ред и на декларациите. „Вие сте на ход – се обърнаха ПП–ДБ в декларация към партията на Бойко Борисов, – поемете отговорност за действията си и предложете конкретен план, адекватен на кризата, която създадохте.“
Ние оставаме отговорни към съдбата на страната и готови да споделим отговорността за общо управление. Това може да стане само при възстановяване на формулата на доверие и гарантиране на реалната реализация на реформите. Това може да стане само със споделен екип…
„Вие сте на ход“, отвърнаха пак с декларация от ГЕРБ.
Поемете отговорност за действията на Асен Василев, разграничете се от него и нека заедно изработим план, адекватен на кризата, която умишлено създавате и към момента.
„Що не се уууважа’ате?“
Откъм ПП–ДБ вече се чуват гласове, че първият мандат е пропилян, но преговорите ще продължат и правителство в 49-тия парламент отново ще има. Изглежда, смятат, че отново могат да реализират кабинет със своя втори мандат въпреки категоричната заявка на лидера на ГЕРБ Бойко Борисов, че няма да подкрепят такъв вариант. Съпредседателят на ПП Асен Василев обяви, че първият мандат е изчерпан и гледа към втория.
Президентът Румен Радев вече издаде указа, с който предлага на 49-тото Народно събрание да избере за премиер кандидата, излъчен от най-голямата парламентарна група – на ГЕРБ–СДС, и предложеното от него правителство. Кога обаче тази точка ще влезе в дневния ред, зависи от председателя на парламента Росен Желязков (ГЕРБ). А той не бърза. Докато точката все още не е в дневния ред, кандидатът за министър-председател може да прави промени в състава на правителството, обявено при президента; може дори да го подмени цялото. Практически мандатът може да си стои внесен неограничено време, тъй като Конституцията не предвижда срок.
Едва ли лидерът на ГЕРБ е вярвал, че ПП–ДБ безпрекословно ще се подчини и съгласи с едностранното (му) решение за състава на кабинета, представен от Габриел. Скандалът беше неизбежен, а значи и предопределен. Вероятно Борисов е пресметнал, че при една нова ескалация на напрежението ще постигне по-лесно целите си за конкретни назначения, жертвайки дори репутацията на европейското лице на партията си. Пестеливата информация, изпусната и от двете страни, показва, че са били близо до постигане на съгласие за много от назначенията. Например дори и да бъде свален министърът на енергетиката Румен Радев и мястото му да заеме Жечо Станков, Радев щял да оглави Българския енергиен холдинг (БЕХ).
Сега мишена отново е Асен Василев, за когото ПП–ДБ няма да приемат да напусне Министерството на финансите. Следователно ГЕРБ и ДПС, присъединили се в атаката, могат да поискат друго в замяна. Няма свян в политиката, когато се разпределя власт. За да засилят натиска, ГЕРБ и ДПС обединиха всички политически сили в парламента (без ПП–ДБ, разбира се) срещу Василев, гласувайки до 31 март министърът на финансите в оставка да покрие 1 млрд. лв. дефицит в енергетиката.
Точката беше вкарана като извънредна с гласовете на ГЕРБ и ДПС и така Асен Василев разполага с по-малко от десет дни, за да разреши ликвидните проблеми на фонд „Сигурност на електроенергийната система“. (Фондът беше създаден през юли 2015 г., за да покрива разходите на обществения доставчик НЕК, произтичащи от задълженията му за изкупуване на ток по преференциални цени.) Парламентарното решение е и предупредителен знак от мафията към Василев и ПП–ДБ – нещо като увита във вестник мъртва риба или куршум в плик.
Моралът – начин на употреба
Употребата на морала от българския политически елит е омерзителна. Бойко Борисов, който се е разделял с политически съратници при най-малкия признак за имиджова щета, унизи Мария Габриел. Няма съмнение, че тя не би се решила да представи папката с имената на министрите, ако не ѝ беше наредено. Сега същият Борисов иска извинение от Василев, задето е обидил Габриел, въпреки че публичното унижение, на което я подложи собствената ѝ партия, е много по-голямо. Асен Василев се извини на Мария Габриел в качеството ѝ на жена, което беше още една обида за нея поради явния сексизъм на посланието. Нима самият Василев не управлява със същата тази мафия, за която твърди, че е зад Габриел?
Дългото мълчание на ГЕРБ и ПП–ДБ след публикуваните декларации означава, че зад кулисите и извън обективите някаква комуникация тече и най-късно през уикенда решение ще бъде обявено. При едни нови предсрочни парламентарни избори кампанията няма да е лесна за ПП–ДБ – няма как да нахъсват избиратели с „изчегъртване“ на ГЕРБ, с изваждане на ДПС, след като няма на кого друг да разчитат за партньорство. За ГЕРБ ситуацията няма да е така усложнена.
Петъчният парламентарен ден мина без внесен отказ от позицията на кандидатката за премиер на ГЕРБ Мария Габриел. Министър-председателят в оставка Денков пък предупреди от Брюксел партньорите си в управлението да не внасят за гласуване само премиера без състав на правителството. Изглежда, че са го послушали. Съгласно Решение №20 на Конституционния съд от 1992 г. най-напред парламентът избира министър-председателя, а със следващо решение – и състава на правителството. Но какъвто и да е редът за гласуване, ПП–ДБ и ГЕРБ–СДС трябва да са постигнали разбирателство за сглобяване 2.0. Коалиция едва ли ще се получи, а изразените в първоначалните документи намерения и от двете политически сили за пълен мандат също няма да се реализират. Най-вероятно ще се опитат да изкарат тази година, за да изберат перманентната власт.
После – предсрочни избори и този път може и да се получи коалиция. Едва ли като тази в Германия и нейните над 800 страници коалиционно споразумение, публично известно, но не и сглобка по балкански.
This post is written by André Stoll, Solution Architect.
Chaos engineering is a popular practice for building confidence in system resilience. However, many existing tools assume the ability to alter infrastructure configurations, and cannot be easily applied to the serverless application paradigm. Due to the stateless, ephemeral, and distributed nature of serverless architectures, you must evolve the traditional technique when running chaos experiments on these systems.
This blog post explains a technique for running chaos engineering experiments on AWS Lambda functions. The approach uses Lambda extensions to induce failures in a runtime-agnostic way requiring no function code changes. It shows how you can use the AWS Fault Injection Service (FIS) to automate and manage chaos experiments across different Lambda functions to provide a reusable testing method.
Overview
Chaos experiments are commonly applied to cloud applications to uncover latent issues and prevent service disruptions. IT teams use chaos experiments to build confidence in the robustness of their systems. However, the traditional methods used in server-based chaos engineering do not easily translate to the serverless world since many existing tools are based on altering the underlying infrastructure configurations, such as cluster nodes or server instances of your applications.
In serverless applications, AWS handles the undifferentiated heavy lifting of managing infrastructure, so you can focus on delivering business value. But this also means that engineering teams have limited control over the infrastructure, and must rely on application-level tooling to run chaos experiments. Two techniques commonly used in the serverless community for conducting chaos experiments on Lambda functions are modifying the function configuration or using runtime-specific libraries.
Changing the configuration of a Lambda function allows you to induce rudimentary failures. For example, you can set the reserved concurrency of a Lambda function to simulate invocation throttling. Alternatively, you might change the function execution role permissions or the function policy to simulate IAM access denial. These types of failures are easy to implement, but the range of possible fault injection types is limited.
The other technique—injecting chaos into Lambda functions through purpose-built, runtime-specific libraries—is more flexible. There are various open-source libraries that allow you to inject failures, such as added latency, exceptions, or disk exhaustion. Examples of such libraries are Python’s chaos_lambda and failure-lambda for Node.js. The downside is that you must change the function code for every function you want to run chaos experiments on. In addition, those libraries are runtime-specific and each library comes with a set of different capabilities and configurations. This reduces the reusability of your chaos experiments across Lambda functions implemented in different languages.
Injecting chaos using Lambda extensions
Implementing chaos experiments using Lambda extensions allows you to address all of the previous concerns. Lambda extensions augment your functions by adding functionality, such as capturing diagnostic information or automatically instrumenting your code. You can integrate your preferred monitoring, observability, or security tooling deeply into the Lambda environment without complex installation or configuration management. Lambda extensions are generally packaged as Lambda layers and run as a separate process in the Lambda execution environment. You may use extensions from AWS, AWS Lambda partners, or build your own custom functionality.
With Lambda extensions, you can implement a chaos extension to inject the desired failures into your Lambda environments. This chaos extension uses the Runtime API proxy pattern that enables you to hook into the function invocation request and response lifecycle. Lambda runtimes use the Lambda Runtime API to retrieve the next incoming event to be processed by the function handler and return the handler response to the Lambda service.
The Runtime API HTTP endpoint is available within the Lambda execution environment. Runtimes get the API endpoint from the environment variable AWS_LAMBDA_RUNTIME_API. During the initialization of the execution environment, you can modify the runtime startup behavior. This lets you change the value of AWS_LAMBDA_RUNTIME_API to the port the chaos extension process is listening on. Now, all requests to the Runtime API go through the chaos extension proxy. You can use this workflow for blocking malicious events, auditing payloads, or injecting failures.
The chaos extension intercepts incoming events and outbound responses, and injects failures according to the chaos experiment configuration.
The extension accesses environment variables to read the chaos experiment configuration.
A wrapper script configures the runtime to proxy requests through the chaos extension.
When intercepting incoming events and outbound responses to the Lambda Runtime API, you can simulate failures such as introducing artificial delay or generate an error response to return to the Lambda service. This workflow adds latency to your function calls:
All Lambda runtimes support extensions. Since extensions run as a separate process, you can implement them in a language other than the function code. AWS recommends you implement extensions using a programming language that compiles to a binary executable, such as Golang or Rust. This allows you to use the extension with any Lambda runtime.
Extensions provide you with a flexible and reusable method to run your chaos experiments on Lambda functions. You can reuse the chaos extension for all runtimes without having to change function code. Add the extension to any Lambda function where you want to run chaos experiments.
Automating with AWS FIS experiment templates
According to the Principles of Chaos Engineering, you should “automate your experiments to run continuously”. To achieve this, you can use the AWS Fault Injection Service (FIS).
This service allows you to generate reusable experiment templates. The template specifies the targets and the actions to run on them during the experiment, and an optional stop condition that prevents the experiment from going out of bounds. You can also execute AWS Systems Manager Automation runbooks which support custom fault types. You can write your own custom Systems Manager documents to define the individual steps involved in the automation. To carry out the actions of the experiment, you define scripts in the document to manage your Lambda function and set it up for the chaos experiment.
To use the chaos extension for your serverless chaos experiments:
Set up the Lambda function for the experiment. Add the chaos extension as a layer and configure the experiment, for example, by adding environment variables specifying the fault type and its corresponding value.
Pause the automation and conduct the experiment. To do this, use the aws:sleep automation action. During this period, you conduct the experiment, measure and observe the outcome.
Clean up the experiment. The script removes the layer again and also resets the environment variables.
Running your first serverless chaos experiment
This sample repository provides you with the necessary code to run your first serverless chaos experiment in AWS. The experiment uses the chaos-lambda-extension extension to inject chaos.
The sample deploys the AWS FIS experiment template, the necessary SSM Automation runbooks including the IAM role used by the runbook to configure the Lambda functions. The sample also provisions a Lambda function for testing and an Amazon CloudWatch alarm used to roll back the experiment.
Prerequisites
You have the chaos extension already deployed as a Lambda layer in your AWS account.
Ensure you have sufficient permissions to interact with the AWS FIS, Lambda, and CloudWatch alarms.
Running the experiment
Follow the steps outlined in the repository to conduct your first experiment. Starting the experiment triggers the automation execution.
This automation includes adding the extension and configuring the experiment, pausing the execution and observing the system and reverting all changes to the initial state.
If you invoke the targeted Lambda function during the second step, failures (in this case, artificial latency) are simulated.
Security best practices
Extensions run within the same execution environment as the function, so they have the same level of access to resources such as file system, networking, and environment variables. IAM permissions assigned to the function are shared with extensions. AWS recommends you assign the least required privileges to your functions.
Always install extensions from a trusted source only. Use Infrastructure as Code (IaC) and automation tools, such as CloudFormation or AWS Systems Manager, to simplify attaching the same extension configuration, including AWS Identity and Access Management (IAM) permissions, to multiple functions. IaC and automation tools allow you to have an audit record of extensions and versions used previously.
When building extensions, do not log sensitive data. Sanitize payloads and metadata before logging or persisting them for audit purposes.
Conclusion
This blog post details how to run chaos experiments for serverless applications built using Lambda. The described approach uses Lambda extension to inject faults into the execution environment. This allows you to use the same method regardless of runtime or configuration of the Lambda function.
To automate and successfully conduct the experiment, you can use the AWS Fault Injection Service. By creating an experiment template, you can specify the actions to run on the defined targets, such as adding the extension during the experiment. Since the extension can be used for any runtime, you can reuse the experiment template to inject failures into different Lambda functions.
Visit this repository to deploy your first serverless chaos experiment, or watch this video guide for learning more about building extensions. Explore the AWS FIS documentation to learn how to create your own experiments.
For more serverless learning resources, visit Serverless Land.
Security updates have been issued by Debian (firefox-esr, pillow, and thunderbird), Fedora (apptainer, chromium, ovn, and webkitgtk), Mageia (apache-mod_auth_openidc, ffmpeg, fontforge, libuv, and nodejs-tough-cookie), Oracle (kernel, libreoffice, postgresql-jdbc, ruby:3.1, squid, and squid:4), Red Hat (go-toolset:rhel8 and libreoffice), SUSE (firefox, jbcrypt, trilead-ssh2, jsch-agent-proxy, kernel, tiff, and zziplib), and Ubuntu (linux-aws and openssl1.0).
BleepingComputer has the details. It’s $2M less than in 2022, but it’s still a lot.
The highest reward for a vulnerability report in 2023 was $113,337, while the total tally since the program’s launch in 2010 has reached $59 million.
For Android, the world’s most popular and widely used mobile operating system, the program awarded over $3.4 million.
Google also increased the maximum reward amount for critical vulnerabilities concerning Android to $15,000, driving increased community reports.
During security conferences like ESCAL8 and hardwea.io, Google awarded $70,000 for 20 critical discoveries in Wear OS and Android Automotive OS and another $116,000 for 50 reports concerning issues in Nest, Fitbit, and Wearables.
Google’s other big software project, the Chrome browser, was the subject of 359 security bug reports that paid out a total of $2.1 million.
Погледнато философски, голяма част от енергията, която използваме, е слънчева светлина, съхранена под различни форми. В последните 50–60 години с помощта на соларните панели имаме възможността за прякото ѝ улавяне. С времето технологиите за производството им се усъвършенстват и сегашното поколение е с много по-добра ефективност и по-дълъг експлоатационен период. Увеличаващата се нужда от възобновяеми източници на енергия прави работата по подобряването им по-активна от всякога, като учените залагат на най-различни подходи за постигане на тази цел.
Един от тях е използването на перовскити – това са материали, които имат кристална структура, идентична с тази на минерала перовскит. Особено интересна е възможността за производство на леки и гъвкави панели, ако за основа се използва пластмаса. Друг начин за употребата им е комбинирането със силиций в своеобразен „сандвич“. Това увеличава ефективността на панелите, тъй като различните материали поглъщат слънчеви лъчи с различен спектър. Обикновено се използват два слоя – един от силиций и един от перовскит.
Уви, за разлика от силициевите панели, които може да се използват повече от 20 години, панелите от перовскит не са особено устойчиви на околната среда и обикновено издържат от няколко месеца до няколко години. Нова разработка предлага използването на процес по пасивиране на повърхността на панелите, който повишава тяхната устойчивост и ефективност. Това се постига чрез третиране със сол, която съдържа бром. Употребата ѝ има двойно действие – на повърхността на кристала се образува тънък филм, който премахва микроскопичните несъвършенства в кристалната решетка, правейки я по-устойчива на влиянието на околната среда. Наред с това бромът прониква във вътрешността на материала, което помага за намаляване на енергийните загуби в панела. Така с еднократно третиране се подобряват два от критичните параметри за този тип панели.
Към момента подходът е приложим за малки изпитателни панели, но учените са сигурни, че той е важна стъпка към масовото им производство. Според тях подходът дава възможност за допълнителна оптимизация, тъй като описаният процес може да се приложи и при други видове перовскити и соли, което означава, че е много вероятно да бъде открита още по-ефективна комбинация.
Това предположение се потвърждава от друг екип, публикувал само няколко дни по-късно подобрен начин за използване на перовскит.
Проблем при създаването на комбинирани панели е загубата на енергия между слоевете, което води до спад в полученото напрежение. За справяне с това в кристала вместо бром е инкорпориран цианид, намаляващ значително загубите в панела. Само по себе си това е добро постижение, но учените са опитали и още нещо – вместо двуслоен те са направили трислоен панел, в който за основа е използвана традиционната комбинация от силиций и перовскит. Върху тях е положен още един слой от новосъздадения перовскит с цианид. Тази комбинация се оказва изключително добра – осигурява ефективност от 27%.
Също както при другата разработка, тепърва предстоят инженерни предизвикателства за въвеждане на процеса в производството на соларни панели, които да се използват от потребителите. Но и двата резултата показват, че все още има голям потенциал за подобряване на съотношението цена/добита енергия и този възобновяем източник тепърва ще ни изненадва.
В началото на месеца към сондата е изпратена команда, наречена от екипа „сръчкване“ – тя кара апарата да изпрати паметта на бордовия си компютър. Малко след получаването на командата „Вояджър 1“ е върнал пакет с данни, който, както и в предишните комуникации, е бил разбъркан. Въпреки това инженер от групата за комуникация с далечни апарати (Deep Space Network) е успял да го дешифрира и в него е открито пълно копие на паметта.
В паметта на бордовия компютър са всички данни, с които той оперира – командните инструкции на апарата, информация за моментното му състояние, както и научни данни. Съдържанието на пакета ще бъде сравнено с предишни копия от времето, когато „Вояджър 1“ е функционирал нормално.
Това би могло да подскаже на екипа какво се е объркало, и дава надежда, че освен да разберем какво се е случило с апарата, комуникацията с него ще се поднови и той ще продължи научната си мисия.
Човешки инсулин от крави
Биотехнологичният процес за синтез на човешки инсулин е едно от модерните чудеса на науката. В момента най-често се използват генетично модифицирани дрожди, в които е вмъкната генетичната последователност, кодираща за инсулин. Те се отглеждат в големи биореактори (ферментационни съдове, подобни на използваните за производство на бира), след което протеинът се извлича, пречиства и обработва в зависимост от вида, в който е необходим.
Интересна иновация предлагат учени от Бразилия и САЩ в съвместна разработка. С помощта на генното инженерство те са създали трансгенна крава, която може да отделя проинсулин (прекурсора, от който се получава биологично активната форма) в млякото си. За целта с помощта на лентивирусен вектор човешкият ген за инсулин е включен в генома на 10 ембриона, които впоследствие са имплантирани и от тях е получена една трансгенна крава. За оптимизация на процеса векторът е конструиран така, че човешкият ген е активен само в млечните жлези на животното. Така естествените му биохимични процеси не се нарушават и трансгенният протеин се отделя само там. Вимето е особено подходящо за подобна трансформация – една от основните му функции е да произвежда големи количества протеини, така че това може да направи процеса много ефективен.
За съжаление, въпреки че животното е успешно модифицирано, добивът от трансгенния протеин е бил нисък. Една от причините е, че опитите за оплождане на кравата са били неуспешни и лактацията е предизвикана хормонално, вследствие на което количеството на полученото мляко е било значително по-малко. Друг фактор е донякъде изненадващата находка, че в млякото има повече инсулин, отколкото проинсулин. Най-вероятно това се дължи на протеази (ензими, разграждащи протеини), които могат да превръщат проинсулина в инсулин. Допълнително усложнение е и откриването на протеази, които разграждат инсулина, като привнасят отрицателен ефект в процеса.
Това прави резултатите интригуващи, но не впечатляващи. Въпреки това разработката показва, че методът работи и има голям потенциал. Ако разграждането на получения инсулин се избегне, например чрез допълнителни модификации или чрез промяна на трансгенния протеин, подобно „биологично производство“ би било изключително ефективно, като премахва нуждата от енергоемки биореактори.
При сходно манипулирани трансгенни мишки количеството проинсулин в млякото е достигнало 8 грама на литър. Ако приемем, че някои породи крави могат да дават над 30 литра мляко на ден, дори при ефективност наполовина от тази при мишките това означава хипотетично производство на над 3 млн. единици инсулин от всяка крава. Така едно малко стадо може да покрива нуждите на стотици хиляди пациенти.
Екологична катализа
Голяма част от реакциите, използвани в химичната и фармацевтичната промишленост са невъзможни без използването на катализатори. Това са вещества или елементи, които в общия случай ускоряват химичните реакции, помагайки да се понижи енергията за активация. Най-често за това се използват благородни метали, като платина, паладий и родий. Начинът им на действие е познат на химиците и те успешно са се наложили като стандарт, но има и редица проблеми. Цената им е много висока, а добивът им е доста енергоемък и замърсява околната среда. Също така употребата им е свързана с отделянето на токсични продукти, които трябва да се обработват по специален начин. Тези недостатъци са стимул да се търси техен заместник, който е по-евтин, енергоефективен и природосъобразен.
Възможна алтернатива е използването на електричество вместо химически катализатор. Вдъхновението за това идва от биологичните катализатори – ензимите, които създават електрически полета в активните си региони. През 2016 г. с помощта на тази технология в наномащаб е катализирана реакцията на Дилс–Алдер, която е широко използвана в органичния синтез. Същият екип в нова публикация описва заместването на меден катализатор в азид-алкиновото циклоприсъединяване. Тази реакция е определена от Бари Шарплес, един от тримата Нобелови лауреати за химия през 2022, като еталон за клик реакция. Освен прилагането му към друг вид реакция, методът е подобрен – мащабът вече не е нано, а се измерва в сантиметри. За целта учените са разработили специална микрофлуидна система, в която протича реакцията.
Освен че има предимства пред конвенционалните катализатори, този подход дава възможност за по-прецизно контролиране на реакциите чрез регулиране на силата и продължителността на електрическите импулси. Това може да послужи за производство на чисти форми на конкретни изомери и би премахнало риска от замърсяване на крайните продукти с частици от катализатори, което е важно за фармацевтичната индустрия.
Колко ваксини са прекалено много?
Имунизационният календар е резултат от множество изследвания. Броят и времето на поставяне на ваксините са строго съобразени с познанията ни за човешката имунна система. Медицината може да отговори на въпроса какво се случва, ако се пренебрегнат препоръките на лекарите и изпаднем в крайност по отношение на ваксинирането. Пример са увеличаващите се случаи на морбили (дребна шарка) в световен мащаб – завръщането на заболяване, обявено от Световната здравна организация за изкоренено в редица държави. По-трудно е да се каже какво става в другия случай – когато се слагат твърде много ваксини. Вероятността някоя етична комисия да позволи изследване на ефекта от многократни ваксинации е пренебрежимо ниска.
Към момента една от водещите хипотези е, че многократните ваксинации могат да доведат до по-слаб имунен отговор. Тя се базира на данни, които сочат, че при хронично излагане на даден патоген Т-клетките на имунната система „се уморяват“ и се наблюдава имунна толерантност, при която организмът не може да се справи ефективно с нападателя. Това е и причината да се води дискусия за честотата на реваксинацията против SARS-CoV-2.
Благодарение на 62-годишен мъж от Германия учените вече имат по-добра представа за ефекта от многократното ваксиниране. Изследователите разбират за случая от новините, след като властите започват разследване за измама срещу мъжа. Те са се усъмнили, след като в рамките на 9 месеца на името му са били регистрирани 130 ваксинации против SARS-CoV-2. Даденото обяснение за „лични подбуди“ явно е убедило разследващите органи, тъй като случаят е прекратен, без да бъдат повдигнати обвинения.
Жителят на Магдебург (наричан HIM в изследването) се е съгласил да бъде тестван, като е съобщил за допълнителни нерегистрирани ваксинации, които вдигат общия брой на 217 дози в рамките на 29 месеца. Оказало се също, че той не е бил особено придирчив – ваксините са от осем различни вида (някои от които бустерни).
В периода от 214-тата до 217-тата му ваксинация учените са изследвали кръв и слюнка от HIM, като получените данни са сравнени с контролна група от 29 души, получили нормалната тристепенна ваксинация. Спрямо тях той има между 5 и 11 пъти по-висока способност да инактивира вируса, но това се дължи на по-голямото количество антитела, а не на завишена активност. Също така е установено, че той отделя антитела и в слюнката си, което не се наблюдава в контролната група. Отчетена е и повишена концентрация на B и T-клетки, но без изменения в способността им за имунен отговор.
Общото заключение от изследването е, че в случая хиперваксинацията срещу SARS-CoV-2 няма негативни ефекти и е повишила количеството антитела, без да има забележим ефект върху общото функциониране на имунната система. От един случай няма как да се направят генерални изводи, но все пак това е интересна и рядка възможност да се наблюдава подобен феномен. Тестовете сочат, че HIM е успял да се предпази от заразяване с вируса, но не е ясно дали това се дължи на многото ваксини.
Авторите завършват статията със следното: „Считаме за важно да отбележим, че не поощряваме хиперваксинацията като стратегия за подобряване на придобития имунитет“.
През 2018 г. Комисията за енергийно и водно регулиране (КЕВР) е нарушила европейското законодателство, с цел да представи транзитния газопровод на “Газпром” Турски поток 2 за разширяване на вътрешната газопреносна…
Starting today, administrators of package repositories can manage the configuration of multiple packages in one single place with the new AWS CodeArtifact package group configuration capability. A package group allows you to define how packages are updated by internal developers or from upstream repositories. You can now allow or block internal developers to publish packages or allow or block upstream updates for a group of packages.
CodeArtifact is a fully managed package repository service that makes it easy for organizations to securely store and share software packages used for application development. You can use CodeArtifact with popular build tools and package managers such as NuGet, Maven, Gradle, npm, yarn, pip, twine, and the Swift Package Manager.
CodeArtifact supports on-demand importing of packages from public repositories such as npmjs.com, maven.org, and pypi.org. This allows your organization’s developers to fetch all their packages from one single source of truth: your CodeArtifact repository.
Simple applications routinely include dozens of packages. Large enterprise applications might have hundreds of dependencies. These packages help developers speed up the development and testing process by providing code that solves common programming challenges such as network access, cryptographic functions, or data format manipulation. These packages might be produced by other teams in your organization or maintained by third parties, such as open source projects.
To minimize the risks of supply chain attacks, some organizations manually vet the packages that are available in internal repositories and the developers who are authorized to update these packages. There are three ways to update a package in a repository. Selected developers in your organization might push package updates. This is typically the case for your organization’s internal packages. Packages might also be imported from upstream repositories. An upstream repository might be another CodeArtifact repository, such as a company-wide source of approved packages or external public repositories offering popular open source packages.
Here is a diagram showing different possibilities to expose a package to your developers.
When managing a repository, it is crucial to define how packages can be downloaded and updated. Allowing package installation or updates from external upstream repositories exposes your organization to typosquatting or dependency confusion attacks, for example. Imagine a bad actor publishing a malicious version of a well-known package under a slightly different name. For example, instead of coffee-script, the malicious package is cofee-script, with only one “f.” When your repository is configured to allow retrieval from upstream external repositories, all it takes is a distracted developer working late at night to type npm install cofee-script instead of npm install coffee-script to inject malicious code into your systems.
CodeArtifact defines three permissions for the three possible ways of updating a package. Administrators can allow or block installation and updates coming from internal publish commands, from an internal upstream repository, or from an external upstream repository.
Until today, repository administrators had to manage these important security settings package by package. With today’s update, repository administrators can define these three security parameters for a group of packages at once. The packages are identified by their type, their namespace, and their name. This new capability operates at the domain level, not the repository level. It allows administrators to enforce a rule for a package group across all repositories in their domain. They don’t have to maintain package origin controls configuration in every repository.
Let’s see in detail how it works Imagine that I manage an internal package repository with CodeArtifact and that I want to distribute only the versions of the AWS SDK for Python, also known as boto3, that have been vetted by my organization.
I navigate to the CodeArtifact page in the AWS Management Console, and I create a python-aws repository that will serve vetted packages to internal developers.
This creates a staging repository in addition to the repository I created. The external packages from pypi will first be staged in the pypi-store internal repository, where I will verify them before serving them to the python-aws repository. Here is where my developers will connect to download them.
By default, when a developer authenticates against CodeArtifact and types pip install boto3, CodeArtifact downloads the packages from the public pypi repository, stages them on pypi-store, and copies them on python-aws.
Now, imagine I want to block CodeArtifact from fetching package updates from the upstream external pypi repository. I want python-aws to only serve packages that I approved from my pypi-store internal repository.
With the new capability that we released today, I can now apply this configuration for a group of packages. I navigate to my domain and select the Package Groups tab. Then, I select the Create Package Group button.
I enter the Package group definition. This expression defines what packages are included in this group. Packages are identified using a combination of three components: package format, an optional namespace, and name.
Here are a few examples of patterns that you can use for each of the allowed combinations:
All package formats: /*
A specific package format: /npm/*
Package format and namespace prefix: /maven/com.amazon~
Package format and namespace: /npm/aws-amplify/*
Package format, namespace, and name prefix: /npm/aws-amplify/ui~
Package format, namespace, and name: /maven/org.apache.logging.log4j/log4j-core$
I invite you to read the documentation to learn all the possibilities.
In my example, there is no concept of namespace for Python packages, and I want the group to include all packages with names starting with boto3 coming from pypi. Therefore, I write /pypi//boto3~.
Then, I define the security parameters for my package group. In this example, I don’t want my organization’s developers to publish updates. I also don’t want CodeArtifact to fetch new versions from the external upstream repositories. I want to authorize only package updates from my internal staging directory.
I uncheck all Inherit from parent group boxes. I select Block for Publish and External upstream. I leave Allow on Internal upstream. Then, I select Create Package Group.
Once defined, developers are unable to install different package versions than the ones authorized in the python-aws repository. When I, as a developer, try to install another version of the boto3 package, I receive an error message. This is expected because the newer version of the boto3 package is not available in the upstream staging repo, and there is block rule that prevents fetching packages or package updates from external upstream repositories.
Similarly, let’s imagine your administrator wants to protect your organization from dependency substitution attacks. All your internal Python package names start with your company name (mycompany). The administrator wants to block developers for accidentally downloading from pypi.org packages that start with mycompany.
Administrator creates a rule with the pattern /pypi//mycompany~ with publish=allow, external upstream=block, and internal upstream=block. With this configuration, internal developers or your CI/CD pipeline can publish those packages, but CodeArtifact will not import any packages from pypi.org that start with mycompany, such as mycompany.foo or mycompany.bar. This prevents dependency substitution attacks for these packages.
Package groups are available in all AWS Regions where CodeArtifact is available, at no additional cost. It helps you to better control how packages and package updates land in your internal repositories. It helps to prevent various supply chain attacks, such as typosquatting or dependency confusion. It’s one additional configuration that you can add today into your infrastructure-as-code (IaC) tools to create and manage your CodeArtifact repositories.
Considerable focus within the cybersecurity industry has been placed on the attack surface of organizations, giving rise to external attack surface management (EASM) technologies as a means to monitor said surface. It would appear a reasonable approach, on the premise that a reduction in exposed risk related to the external attack surface reduces the likelihood of compromise and potential disruption from the myriad of ransomware groups targeting specific geographies and sectors.
But things are never quite that simple. The challenge, of course, is that the exposed external risks extend beyond the endpoints being scanned. With access brokers performing the hard yards for ransomware affiliates gathering information, identifying initial entry vectors is more than a simple grab of banners.
Rapid7 Labs’s recent analysis looked at the external access surface of multiple sectors within the APAC region over the last half of 2023, with considerable data available well beyond open RDP and unpatched systems. What is revealing is the scale of data that appears to be aiding the access brokers, such as the exposure of test systems or unmaintained hosts to the internet, or the availability of leaked credentials. Each of these gives the multitude of ransomware actors the opportunity to conduct successful attacks while leveraging the hard work of access brokers.
What is interesting as we consider these regionally-targeted campaigns is that the breadth of threat groups is rather wide, but the group which is most prevalent does vary based on the targeted geography or sector. (Please note that this data predates the possible exit scam reported and therefore does not take it into account.)
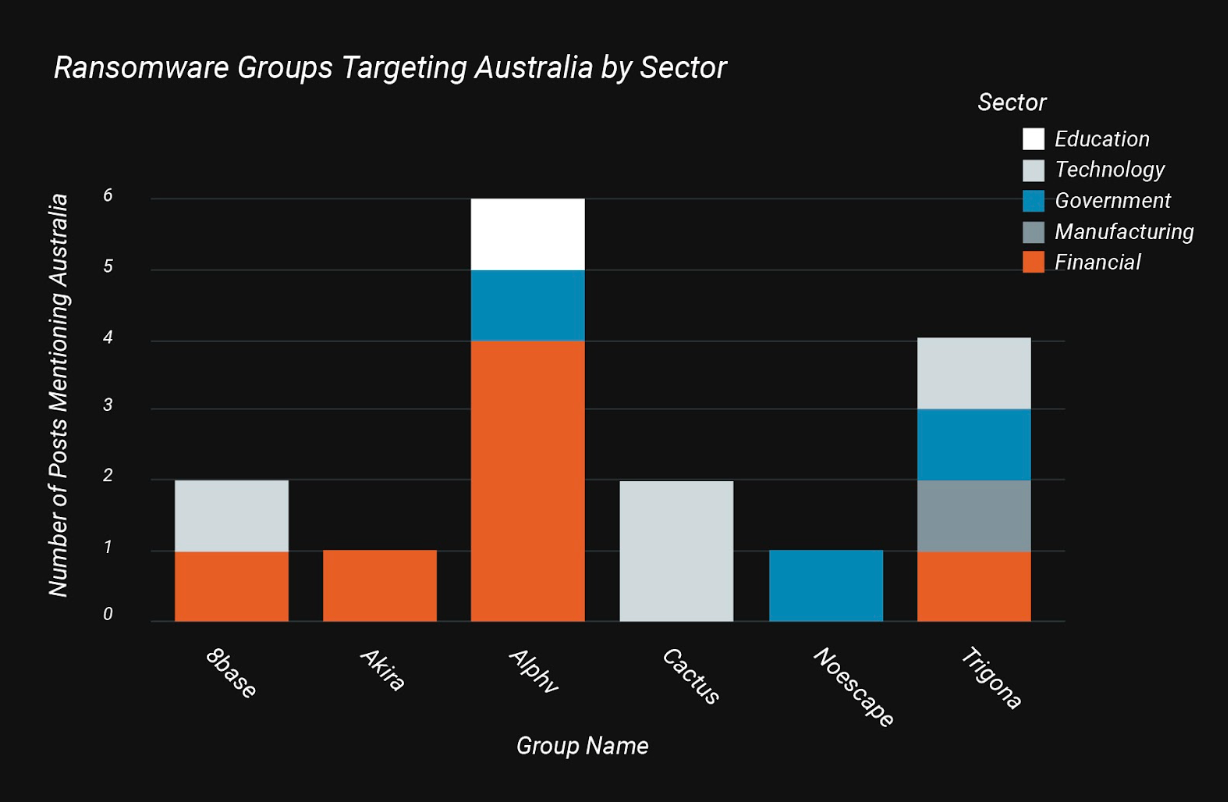
The following graphic shows the sectors targeted, and the various threat groups targeting them, within Australia:
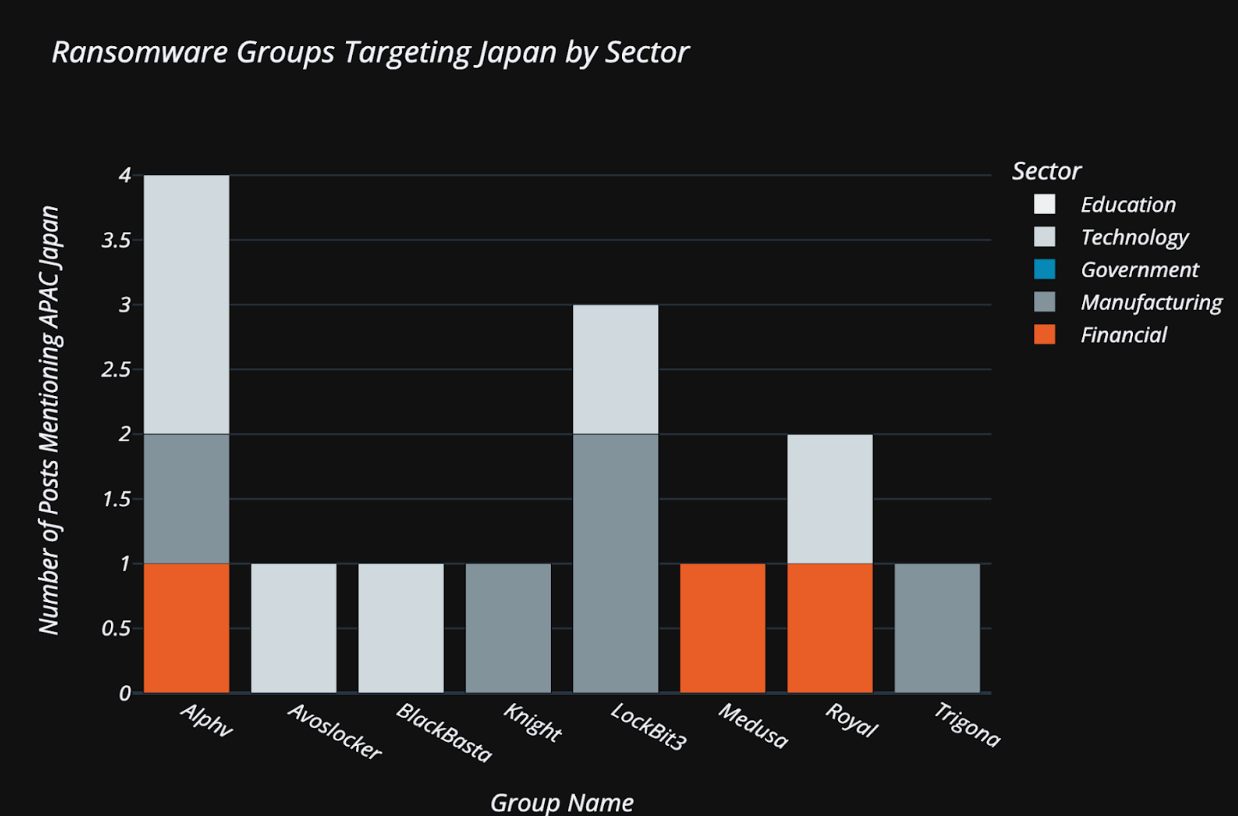
If we compare the most prevalent groups in Japan, however, the landscape does change somewhat:
All of which does focus the mind on this concept of actionable intelligence. Typically organizations have taken a one-size-fits-all approach to risk prioritization; however, a more nuanced approach could be to consider the threat groups targeting the given sector of an organization as a higher priority.
The need to move into this new world of intelligence led security operations is very clear, and it’s felt on an almost daily basis. Within a year we have witnessed such a fundamental increase in the level of capabilities from threat groups whose previous modus operandi was entrenched in the identification of leaked credentials, yet will now happily burn 0days with impunity.
Our approach within Rapid7 Labs is to provide context wherever possible. We strongly urge readers to leverage resources such as AttackerKB to better understand the context of these CVEs, or the likes of Metasploit to validate whether the reports from their external scan warrant an out-of-cycle security update. These, of course, are just the tip of the iceberg, but our approach remains constant: context is critical, as is agility. We are faced with more noise than ever before, and any measures that can be used to filter this out should be a critical part of security operations.
Мария Стайнова и Виолетка Славова са лицата на Архитектурно студио „Лусио“, което от основаването си се специализира в създаване на образователни пространства. Двете архитектки вярват, че именно промяната на учебната среда може да помогне за цялостната трансформация на образованието – от преподаването, през ученето, до преживяването на всички участници в образователния процес.
Ако излезем на улицата, ще видим, че проблемът не е само в образователните пространства. Неглижирането на средата е навсякъде около нас. Какво ви отведе в училищата?
М: Отнякъде трябва да се започне. Макроцел ни е да създадем именно уважение към средата и грижа за нея, защото училището е една от първите обществени сгради, до която всеки от нас има досег. И ако човек влезе в случайно българско училище сега, това, което вижда, са висящи кабели, неравномерно измазани стени, недовършени ремонтни работи… За много деца мястото, където те прекарват практически целия си ден, е потресаващо. Ние дълбоко вярваме, че когато се учиш в такава среда, после изкарваш това навън, в общественото пространство. Ако тази пренастройка в отношението ни към средата, в грижата за нея започне от училището, с порастването на личността това ще се пренесе и в средата, в която живееш.
Представях си, че имате личен мотив…
М: Добър въпрос. Когато разказваме историята на „Лусио“, винаги отдаваме пътя си на някаква случайност. Ние с Виолетка бяхме много близки в университета и след кратка раздяла на пътищата ни се оказахме в един момент заедно отново в България. Тогава се появи един конкурс на „Америка за България“ за изграждане на STEM центрове в училища. Решихме да пробваме, докато подготвяме портфолиата си за чужбина. Това е историята как започнахме.
Но после, когато създадохме екипа и започнахме да си говорим за образователни пространства, за това как влияят на хората, излезе, че наистина е лично. И че и двете имаме много неприятни преживявания по време на образованието си, като учебните пространства имат принос за това.
В: За първи път се замислям сега, като задаваш този въпрос. Не е като да нямаше и други конкурси, но точно този ни запали, и то в момент, в който се подготвяхме да напуснем страната, не да се развиваме тук. Давам си сметка, че май още тогава съм имала вътрешното усещане, че учебната среда може да е нещо много по-различно.
М: Осем. Една малка част, при които нямаше възможност за авторски надзор, не ги броим сред проектите, с които се хвалим (смеят се).
Може ли да разкажете историята на първия проект? Какво преживяхте при срещата си със средата, как ви прие училището?
В: Първият ни проект беше по този конкурс, който споменахме. „Америка за България“ и списание „Градът“ бяха селектирали 23 училища, които да получат грант за създаване на STEM център. Ние имахме възможност да ги разгледаме и да си харесаме едно от тях, за което да разработим проект. Избрахме училището на базата на това, че са работили с децата при подготовката на заданието. Имаше много детски рисунки, препратки, беше взета под внимание гледната точка на децата и на учителите. Това много отличаваше тази презентация от други, в които се виждаше, че директорът е седнал и е написал какво според него е нужно.
Кое беше това училище?
М: Първо ОУ „Никола Вапцаров“ в Берковица.
В: Запознахме се с директорката и заместничката ѝ, помолихме ги за среща с децата и учителите. Това много ги зарадва. Беше ключов момент, защото има директори, които държат комуникацията под личния си контрол, а в това училище имаха отворена система, приеха ни много радушно. И на базата на това проектът се получи добре, после успя да спечели конкурса.
М: Беше страшно вълнуващо. Сблъскахме се и с много неподозирани трудности, но просто имахме късмет – всички хора, които работиха по това пространство, най-вече местните изпълнители, имаха огромно желание да стане добре и работиха от сърце. И после във всеки следващ проект осъзнавахме отново и отново, че всъщност невинаги се получава така.
Кой беше най-трудният ви проект?
М: Всеки проект си има особености. Понякога е много трудно откъм изпълнение. Изведнъж се оказва, че бюджетът е наполовина, и започва едно чудене откъде да спестим – строителят вече е влязъл и трябва да се борим с него за всеки елемент. Друг път учителите или колективът имат някаква вътрешна борба с нас или пък имат конфликт помежду си и нашата работа само го подклажда, давайки нови поводи. Това може би е бил най-неприятният сценарий, в който сме попадали.
В: Ние много държим на взаимодействието. Правим работилници за идеи с учители и ученици, понякога и с родители. Но има училища, в които се смята, че това е абсолютно излишно.
Кое е трудното за приемане?
М: Излиза, че цялото това нещо е много лично. Обикновено децата имат нужда от сериозна промяна и ако зависи от тях, в училището винаги трябва да има пилон като в пожарната и аквапарк (смеят се). Но учителите се опитват да пазят авторитет, имат си график, държат нещата под контрол. И там идваме ние и казваме: „Вие вече няма да сте на подиум, децата няма да са в редички, защото това е остаряло. Ще ги разместим, ще съборим стените, ще сложим стъкло.“ Това предизвиква сериозен конфликт. Учителите си представят, че това ще ги уязви, че някой ще ги гледа осъдително и това ще наруши както комфорта, така и авторитета им. Затова винаги предвиждаме време за работа с тях, за да се запознаем, да може между нас да се създаде някакво доверие.
Всички знаем как изглежда едно традиционно българско училище. Можете ли да ни „нарисувате с думи“ пътя на промяната му към съвременни образователни пространства? Как трябва да се промени училищният сграден фонд, за да стане обстановката по-модерна, по-приветлива, по-включваща, по-достъпна…
В: Едно от нещата, които липсват в българските училища, са места за събиране. Архитектурата на огромната част от българските училища включва само едно фоайе, което не е предвидено да служи за събиране и общуване между хората, то само разпределя потока по коридорите. Това е голяма тема и влияе много на вътрешния живот в училището. Можем да покажем проекта ни в 90. СУ в София, където се опитахме да предложим решение на проблема на микрониво. Разбихме доста стени, за да осигурим такова пространство. Голяма радост ни носи, че успяват да го ползват по невероятни начини. Просто гледаме на живо как се случва всичко, което сме чели по книгите – че едно от първите неща е да се удовлетвори нуждата от събиране, от социален контакт, обмяна на идеи, учене чрез другите.
На много интересни мисли ни наведе една лекция на архитектка от Литва. Тя разглеждаше модела на старите руски училища, който в периода на комунизма се разпростира и сред държави сателити на СССР, каквато е България. Колежката ни разви тезата, че тези пространства липсват в комунистическото училище, защото не може да се контролират.
М: Отвъд архитектурата е идеологическата тревога, че на места, където безконтролно се събират хора, може да се раждат различни идеи. Това не е в интерес на системата и тук е ролята на архитектурата – чисто пространствено тази възможност се елиминира. Виждаме, че идеята работи „прекрасно“ до ден днешен.
Как промяната в средата води до промяна във взаимоотношенията?
В: В 90. СУ беше предвидено това пространство да се ползва от големите ученици. Разбрахме обаче, че поради големия интерес са намерили начин да го посещават и по-малките. То се е превърнало в някаква точка, в която поколенията се срещат. Споделиха с нас, че се наблюдава спад в агресията в цялото училище. Според екипа причината е, че децата вече се познават по-добре, имат по-развито усещане за общност. Това пространство, колкото и да е малко, е дало възможност за промяна.
М: На едно такова място се срещат различни възрасти, различни хора. Това е микромодел на нашето общество, там срещаш по-големи или по-малки, с различни интереси, общуваш с тях… А училището е много важно за формирането на тези социални умения. То учи децата не само на академични знания, а и как да общуват, да са човеци. Общуването с другите човеци, струва ми се, е най-важната функция на училището. И архитектурата трябва да я стимулира.
В: Рядко се обсъжда това, че пространството стимулира определени типове поведение. Например във всички училища се изисква от децата да не тичат в коридорите, но в същото време тия коридори изглеждат като писти – дълга права, на която не ѝ виждаш убежната точка. Естествено, че ще искаш да тичаш, то е интуитивно. Ние гледаме на училището не само като място за академично учене, а като място, където да се научиш да живееш. В днешно време може да учиш и от вкъщи, има чудесни образователни програми онлайн. Но се изпуска нещо фундаментално по този начин.
След пандемията от COVID-19 видяхме и резултатите от дистанционното обучение и затварянето на децата вкъщи за две години. Този тип опит и знания отразява ли се някак във вашата сфера?
М: Да. Имахме работилници с деца малко след края на пандемията. Тях просто ги нямаше, отсъстваха, не смееха да изразяват себе си, което е много страшно да се наблюдава при деца. След една такава работилница и учителите споделиха, че просто не могат да разпознаят учениците си. Защото децата само слушаха и нямаше интеракция. Нямаше „аз искам“, нямаше „аз“ въобще.
В: Преди пандемията имахме размисли, а имаше и професионален дебат – ето, изкуствен интелект, дистанционно учене, училището колко ли време още ще просъществува като сграда? Благодарение на COVID-19 сякаш за всички стана ясно какво правим в училище и защо е много важно. И то не е да си научиш уроците.
Каква е ролята (а и концепцията) на съвременната класна стая в този контекст? Приложима ли е и приемлива ли е тя за българското образование?
М: Абсолютно приложима и приемлива е, въпросът е кой ще я приеме. В системата работят учители от много широк спектър. От едната страна са тези, които са много отворени и адаптивни и са готови за промяна. От другата са тези, които биха искали нищо да не се променя – да си отворят учебника, да диктуват, а след това да изпитват на дъската. Ние много разчитаме на първата група и вярваме, че техният пример е заразителен и би повлиял върху по-консервативните им колеги. Стараем се самата среда да направи мост между различните групи.
В 90. СУ имаме един много любопитен пример. За едно пространство не стигна бюджетът да бъде завършено. Бяхме планирали амфитеатър, кът с меки мебели, масички, но нищо от това не можеше да се осъществи и от училището си донесоха чинове от друга стая. Ние бяхме доста разочаровани, че в това пространство, за което имахме такава модерна идея, са сложени старите чинове, и не само са сложени, а са в редички, с катедрата отпред – по най-традиционния начин. Но когато отидохме там една година по-късно, за да направим проучване как се ползват пространствата, каква е обратната връзка от тях, се оказа, че това пространство е ключово. Защото точно там влизат учителите, които още не се чувстват готови да разтворят напълно класната стая. То служи за „входно ниво“ и ги мотивира постепенно да ползват и по-алтернативните пространства, а с това да променят и начина си на преподаване, само че със своята си скорост.
Значи ли това, че когато говорим за промени в образованието, трябва да се мисли за преход, включително архитектурен?
В и М: Да.
В: Ние също започнахме да осъзнаваме, че не можем да очакваме да предложим нещо драстично различно и то да се възприеме стопроцентово. Трябва да има възможност за градация.
В какво се състои промяната на класните стаи всъщност?
В: Сега имаме модел, който поставя учителя в центъра. Всички са подредени така, че той да ги вижда, те него също, слушат и изпълняват едновременно, режимът на преподаване е лекционен.
В днешно време обаче това е само един от многото възможни режими на преподаване. Не че лекционният е лош сам по себе си, но не би трябвало да е единствен, а да може да се превключва на групов, на индивидуален, на малки групи – има много варианти. И пространството също трябва да го позволява. Затова например в една от лабораториите, които проектирахме, изместихме мивките в периферията, за да се освободи пространството. Масите са мобилни, има висящи контакти, за да може бързо да се включат лаптопи, микроскопи. Но основната идея на тези пространства е учителят да може да преподава от различни места, по различни методики и лесно да преструктурира класа.
М: Ако се върнем малко назад и се запитаме какво налага всичко това, ще стигнем до извода, че в днешно време учителят не е носител на цялото знание. Информацията е достъпна и фактологията може да бъде намерена и сверена в телефона ни. Ролята на учителя се променя и от единствен източник на знание той става ментор. Той подпомага учениците да стигат до знанието и ги насочва. Символно той слиза от подиума и тръгва между учениците – и съответно пространството трябва да позволява това да се осъществи.
Когато си говорим за модерна класна стая, това, което тя изразява, е онзи момент, в който учениците стават общност. Стъклото, видимостта, отварянето стимулират именно това. В училищата винаги има големи притеснения, когато кажем, че искаме да сложим витрини.
М: Да, точно така! Но отново от последващите проучвания разбираме, че всъщност не се получава така. Напротив, когато децата се озовават в коридора и виждат, че някой там учи, сами се регулират и спират да вдигат шум. Този резултат се повтаря в много проучвания.
Всъщност има много притеснения за средата на бъдещето, но от опита си виждаме, че когато учителите влязат в тази среда и започнат да я ползват, тревогите им бързо се изпаряват и дори не искат да се връщат в пространствата си от миналото.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


 Bhargavi Sagi is a Software Development Engineer on Amazon Athena. She joined AWS in 2020 and has been working on different areas of Amazon EMR and Athena engine V3, including engine upgrade, engine reliability, and engine performance.
Bhargavi Sagi is a Software Development Engineer on Amazon Athena. She joined AWS in 2020 and has been working on different areas of Amazon EMR and Athena engine V3, including engine upgrade, engine reliability, and engine performance. Sushil Kumar Shivashankar is the Engineering Manager for EMR Trino and Athena Query Engine team. He has been focusing in the big data analytics space since 2014.
Sushil Kumar Shivashankar is the Engineering Manager for EMR Trino and Athena Query Engine team. He has been focusing in the big data analytics space since 2014.