Post Syndicated from The Atlantic original https://www.youtube.com/shorts/_ED0ti2BHyM
The post-quantum EO is an important milestone. Now it’s time to get to work
Post Syndicated from Sharon Goldberg original https://blog.cloudflare.com/post-quantum-eo-2026/
On June 22, 2026, President Trump signed Executive Order 14409, “Securing the Nation Against Advanced Cryptographic Attacks.” The order sets a December 31, 2030, deadline for federal agencies to transition their most sensitive systems to post-quantum encryption, and a December 31, 2031, deadline for post-quantum authentication. The EO also directs federal contractors to comply with post-quantum Federal Information Processing Standards (FIPS) by the end of 2030.
We welcome this executive order. The U.S. government has a long track record of using federal leadership and procurement to drive adoption of new technologies across the broader industry. We’ve seen this work with IPv6, with routing security and the Resource Public Key Infrastructure (RPKI), and with DNSSEC, and we’re glad to see this tradition continue with post-quantum cryptography.
The EO is especially important at this moment because the timeline for Q-Day, the day that quantum computers can break the public-key cryptography used across the Internet, has been accelerated. In April 2026, Cloudflare moved our own target for full post-quantum security to 2029, following research breakthroughs from Google and Oratomic. This EO updates guidance from 2024, when the National Institute of Standards and Technology (NIST) stated that the classical public key cryptography used across the Internet (namely RSA and Elliptic Curve Cryptography, which can be broken once powerful quantum computers become available) should be deprecated by 2030 and disallowed by 2035.
The Internet’s transition to post-quantum encryption is well underway, while the transition to post-quantum authentication has only just begun. Today, over two-thirds of browser traffic to Cloudflare’s network is protected with post-quantum encryption, and most of our products support post-quantum key agreement. Our SASE platform, Cloudflare One, provides post-quantum encryption across all major on-ramps and off-ramps, including TLS, MASQUE, and IPsec. We’ve recently started deploying post-quantum authentication and aim to be fully post-quantum secure by 2029. The EO is an excellent foundation and builds on work from the previous two Administrations. We’ve been doing the work the EO is asking federal agencies to do since 2019, we have some thoughts on what the order gets right, we see opportunities for the Office of Management and Budget (OMB) to strengthen and facilitate cost-effective agency migration, and we provide a roadmap for how organizations and agencies can advance their transition most effectively.
The bulk of the EO’s binding requirements are aimed at two categories of federal systems: High Value Assets (HVAs) and high impact systems. HVAs are federal information or systems designated by OMB as the government’s crown jewels: systems whose compromise would significantly affect national security, foreign relations, or public confidence. These include databases that hold millions of federal employee records, systems that process classified intelligence, or platforms that manage federal financial transactions. Meanwhile, high impact systems are those where confidentiality, integrity, or availability is rated “high” under FIPS 199, meaning a breach could cause severe harm including loss of life, major financial damage, or significant degradation of an agency’s ability to carry out its mission.
The EO has the power to bind federal agencies, but not other organizations (i.e., critical infrastructure, state, local, tribal and territorial governments, academia, civil society). That’s why the EO only gives these deadlines to federal agencies:
|
Date |
Requirement |
|
July 2026 |
Each federal agency head identifies a PQC migration lead and provides their name and contact details to OMB and the National Cyber Director. |
|
September 2026 |
OMB issues guidance requiring each agency to: (1) review their inventory of HVAs and high impact systems; (2) plan for PQC migration; and (3) submit that plan to OMB and the National Cyber Director. |
|
December 2030 |
All HVAs and high impact systems must be transitioned to PQC for key establishment. |
|
December 2031 |
All HVAs and high impact systems must be transitioned to PQC for digital signatures. |
National Security Systems are explicitly excluded from these deadlines. They are on a separate, classified track managed by the NSA with deadlines between 2030 and 2033 already set in 2022.
The EO splits the PQC migration into two phases: post-quantum key establishment (encryption) by 2030, and post-quantum digital signatures and certificates (authentication) by 2031. This accurately reflects the availability of post-quantum encryption across the Internet today. Our own deadline for full post-quantum readiness (including authentication) is 2029, but we are amongst the earliest adopters in the industry.
We are also happy to see the EO focusing on NIST-standardized post-quantum cryptographic algorithms and not Quantum Key Distribution (QKD), since QKD does not operate at Internet scale due to its need for specialized hardware and dedicated physical links between sender and receiver.
Now let’s have a deeper look at the two migrations called for and required in the EO: post-quantum encryption and post-quantum authentication.
Post-quantum encryption is needed today to stop harvest-now-decrypt-later attacks, where an adversary collects encrypted traffic today and decrypts it later once quantum computers are powerful enough. Post-quantum encryption is especially valuable for organizations handling data that will still have value to adversaries 3-10 years from now, like government agencies, banks, healthcare organizations, defense contractors, and telecom providers.
Post-quantum authentication stops an adversary that has a quantum computer from forging certificates to impersonate servers, generating malicious code signatures, or gaining unauthorized access to systems. Post-quantum authentication is needed only after Q-Day risk materializes, because it stops attacks that are possible only once a cryptographically-relevant quantum computer (CRQC) exists.
It’s important to put the migration timelines in context with advancements in quantum computing. In addition to yesterday’s EO on post-quantum security, President Trump also signed an EO to accelerate deployment and commercialization of quantum computing, sensing, and networking. The fact that the EO sets a 2031 deadline for post-quantum authentication tells us something important: the U.S. government believes there is a non-negligible chance that a CRQC could be operational around that time.

What about the state of these two technologies? The migration to post-quantum authentication is a bigger challenge than post-quantum encryption for a few reasons, including:
-
Post-quantum ML-DSA digital signatures are larger than classic digital signatures, which could have an impact on performance of some systems, for instance in short-lived TLS connections. That’s why we are working with Google Chrome on Merkle Tree Certificates to solve the performance problem for TLS.
-
The dependency chain for post-quantum authentication is longer, requiring coordinated upgrades across clients, servers, certificate authorities, certificate transparency logs, root stores, and browsers.
-
There is only limited ecosystem deployment of post-quantum authentication so far, as compared to the much broader deployment of post-quantum encryption.
It is interesting that the EO sets a one-year gap between the encryption and authentication deadlines. One extra year of calendar time is tight, so this work cannot proceed sequentially. The ecosystem needs to start working on both of these targets concurrently, or we will miss this 2031 deadline.
Cryptographic deployment across the Internet cannot happen without standards developed by the Internet Engineering Task Force (IETF). They are working to transition their protocols to post-quantum cryptography. The TLS community is ahead, with the IETF PLANTS working group making good progress on post-quantum certificates for TLS. There is much work to do here and we look forward to supporting the IETF in its efforts.
The EO includes requirements for federal contractors, which may turn out to be the most impactful part of the EO.
Namely, the FAR Council must publish proposed rules requiring “covered contractors” to comply with NIST FIPS incorporating PQC algorithms by December 31, 2030 (Sec. 6(c)). The FAR Council must also publish proposed rules requiring contractors to implement vulnerability disclosure programs that cover cryptographic vulnerabilities (Sec. 6(d)). These proposed rules need to go through notice-and-comment rulemaking, but the EO has a December 31, 2030 target which is still important. This deadline is one year earlier than federal agencies are required to complete their post-quantum authentication migration, so that federal contractors will be ready before agencies hit their own deadlines.
Federal agencies can only migrate to PQC if the products they buy support PQC. To put this into practice, CISA released its Product Categories for Technologies That Use Post-Quantum Cryptography Standards, drawing a clear line between technologies where PQC is already “widely available” versus those still “transitioning.” The “widely available” list includes cloud platforms (IaaS, PaaS), web browsers and servers, chat and messaging software, and endpoint security products like full disk encryption. For these categories, CISA’s guidance is clear: organizations should procure only PQC-capable products. The “transitioning” list, where PQC is not yet widely available, includes networking hardware (routers, firewalls, switches), identity and access management systems (HSMs, certificate authorities, identity providers), email servers and clients, and database systems.
By telling contractors their products must be PQC-compliant by 2030, and directing agencies to immediately favor PQC-capable vendors in mature markets, the federal framework forces the vendor ecosystem to ship PQC-capable products on a fixed timeline. Products that vendors build to federal requirements will end up used by hospitals, banks, universities, and small businesses, which makes PQC support more broadly available. Cloudflare is among the many vendors subject to these requirements, and because networking software and cloud services are already designated by CISA as widely available PQC categories, we’ve already shipped post-quantum encryption across most of our products at no extra cost.
The EO also speaks to critical infrastructure: energy, financial services, water, transportation, telecommunications, healthcare, and other systems whose failure would have a serious or significant impact on the country. While the EO has no hard migration deadline for critical infrastructure owners and operators, the EO directs certain federal agencies to “assist” critical infrastructure owners and operators with their PQC migration plans (Sec. 5(a)).
While the EO focuses mostly on federal agencies and critical infrastructure in the U.S., post-quantum cryptography is important to every Internet-connected individual and organization. Harvest-now-decrypt-later attacks are a risk today. And after Q-Day, the risk of unauthorized access by an adversary armed with a quantum computer will impact any organization, big or small. When we launched free universal SSL in 2014, our CEO Matthew Prince wrote:
Having cutting-edge encryption may not seem important to a small blog, but it is critical to advancing the encrypted-by-default future of the Internet. Every byte, however seemingly mundane, that flows encrypted across the Internet makes it more difficult for those who wish to intercept, throttle, or censor the web.
We feel the same way about post-quantum cryptography. That’s why every post-quantum upgrade we build is available to all customers, on every plan, at no additional cost.

The EO sets the direction, and now OMB has 90 days to provide important clarifications and operational guidance to achieve the most effective PQC migration across federal agencies (Sec. 4(b)). Based on what we’ve learned from our own PQC migration, here are a few elements that we suggest that guidance should include:
Define what it means to “transition.” The EO requires agencies to “transition” their systems to PQC, but it never defines what “transition” means. Does it mean the system supports PQC algorithms? That it prefers them? Or that classical cryptography has been disabled entirely?
These are very different security postures. A system that supports ML-KEM but still allows a classical-only TLS handshake is vulnerable to downgrade attacks. An adversary capable of intercepting traffic could force the connection back to classical key exchange. The system would have “transitioned” to PQC in name, but still be vulnerable to the same quantum attacks the order is trying to prevent.
History is instructive. When SSLv3 was deprecated after the POODLE attack in 2014, servers kept SSLv3 enabled for backwards compatibility, allowing attackers to force connections to downgrade and then exploit SSLv3’s weaknesses. It took years for the ecosystem to actually turn SSLv3 off. To avoid repeating this pattern, we need a clear definition of “done” that includes disabling quantum-vulnerable cryptography to prevent downgrades.
Crypto agility: Crypto agility is the ability to swap cryptographic algorithms without re-architecting your systems. The EO mandates migrating to specific NIST crypto standards, but says nothing about building systems that can swap cryptographic algorithms if these algorithms need to change in the future. Crypto agility doesn’t mean supporting every algorithm at once. It means building systems so that when the community converges on a better algorithm in the future, the upgrade is a configuration change, not a re-architecture. The OMB should include this in its guidance.
CBOM or quantum impact inventory? The EO directs CISA and NIST to publish guidance on the minimum elements for a cryptographic bill of materials (CBOM) within 270 days (Sec. 5(d)). A CBOM is an inventory of the cryptographic algorithms, protocols, and implementations used in a given hardware or software product, similar to a software bill of materials (SBOM).
In theory, CBOMs are a good idea. In practice, we’d caution against treating exhaustive cryptographic inventories as a prerequisite for action. A detailed CBOM of every algorithm in every library in every product takes a long time to produce, it can take federal agencies an entire procurement cycle of discovery tooling and consulting, and it potentially becomes stale by the time the inventory is complete. Also, a CBOM doesn’t list systems that should be using cryptography but are not. And a CBOM lists keys without an understanding of their purpose, making them less useful for organizations trying to understand the risk associated with a quantum-vulnerable key.
We think that a quantum impact inventory is a more productive framing. What would be the impact if the system or its data is compromised? How likely is that to happen? What measures can be taken to mitigate the risk, whether a drop-in replacement, a software update, or a compensating control like tunneling traffic over bulk post-quantum connection or isolating it from the Internet? How feasible is each option and what dependency chain does it create? Identifying these informs where to take action first. You can fill in the details of a full CBOM over time if that makes sense for your organization, but you should start by discovering your most exposed and impactful systems.
Making post-quantum cryptography affordable to all. True national resilience fails if post-quantum cryptography is treated as a gated luxury rather than a universal baseline. OMB policy must resist vendor lock-in or toll booths that leave underfunded critical infrastructure behind or increase technical debt at federal agencies.
You do not have to wait for 2030 or an exhaustive cryptographic inventory to start your migration. History has shown that updating cryptography is hard and can take a long time; other organizations should start sorting out their migrations as well. So as we wait for OMB guidance for federal agencies, here’s what we recommend for all organizations:
Protect your Internet traffic now. Start with traffic that crosses the public Internet, because that is the easiest for adversaries to harvest now and the most immediately at risk. If your web traffic flows through Cloudflare, your connections are largely protected with post-quantum encryption. If your enterprise network uses Cloudflare One, your private network traffic is also protected. If your provider doesn’t support post-quantum encryption, switch to one that does. Even if the individual applications running inside your network haven’t been upgraded yet, start tunneling your traffic through post-quantum encrypted infrastructure to protect it in bulk, even if individual systems are not yet inventoried and upgraded.
Update procurement. Make “post-quantum encryption by default, at no additional cost, with a clear roadmap for post-quantum authentication and crypto agility” a requirement in every technology procurement. If your vendor charges extra for post-quantum security or doesn’t have a roadmap or plan, ask why or find another vendor.
Quantum impact inventory. For traffic that stays inside your private network perimeter and is not exposed to the public Internet, the harvest-now-decrypt-later risk is lower because an adversary would need to be on your network to capture it. But you still need to know what cryptography your internal systems use, so you can plan your migration. Use a quantum impact inventory as a tool to prioritize your efforts, for example focusing on systems or connections that handle sensitive data or are exposed on the public Internet.
Plan for authentication now. The 2031 deadline for post-quantum authentication will come faster than you think. Start identifying your long-lived keys, root certificates, and code-signing infrastructure. These are the highest-priority targets for a quantum attacker, and they have the longest dependency chains to upgrade. Now is a great time to update your software libraries and automate certificate provisioning even if post-quantum certificates are not yet available in your ecosystem. And make sure your vendors are planning to be ready for the looming post-quantum authentication deadline.
At the same time, work should also start now on aligning global government policy with international standards. We were glad to see that Section 5(b) directs the State Department to engage foreign governments and industry groups to encourage adoption of NIST-standardized PQC algorithms.
Here’s why this matters. Cryptography migrations cannot be run in a vacuum, with each country operating within its own borders. A TLS connection between a U.S. person and a server abroad only works if both ends negotiate the same cryptography. NIST has been running open international cryptographic competitions for decades. The AES competition (1997-2001) produced the encryption standard used across the Internet today, selecting a cipher designed by Belgian cryptographers. The SHA-3 competition (2007-2012) produced the latest hash standard, selecting an algorithm designed by a Belgian-Italian team. The PQC competition (2016-2024) followed the same open model: anyone could submit, anyone could analyze, and the winning algorithms were designed by international teams. ML-KEM, the key agreement standard now being deployed across the Internet, was created largely by European cryptographers. These are open, internationally vetted algorithms. NIST organized the competitions, but the results belong to the global cryptographic community.
The risk ahead is fragmentation. If different jurisdictions mandate different algorithms, the result is cipher bloat and increased attack surface: more code to write, test, and audit, more surface for downgrade attacks, and slower deployment for everyone. We’ve seen this happen firsthand in IPsec, where the lack of an interoperable standard led vendors to ship proprietary PQ key agreement algorithms that couldn’t interoperate, delaying the migration by years. The TLS community went the opposite way, converging on a single hybrid key agreement (X25519MLKEM768), and deployment followed quickly.
We are big fans of NIST, and especially its leadership in vetting standards globally and standardizing cryptography worldwide. We encourage the Trump Administration to work with Congress to ensure that NIST has appropriate resources, staffing, and tooling to meet current and emerging deliverables in this EO and others, like America’s AI Action Plan.
We’d like to see State Department-led engagement drive real alignment: adoption of the same NIST algorithms across allied nations, alignment on timelines, and mutual recognition of cryptographic algorithms and modules. The Internet is one network, and its cryptography should be one standard.
As a final note, the EO directs NIST to revise the processes used by the Cryptographic Module Validation Program (CMVP) to accelerate validations of cryptographic modules (Sec. 6(b)). Having bumped up against the CMVP program for years, we are extremely happy to see this in the order.
CMVP exists for a good reason. Federal agencies and their contractors need a way to verify that the cryptography inside a product actually does what it claims: that AES is implemented correctly or that random number generators have enough entropy. CMVP has been tuned for a steady state where cryptography doesn’t change much.
Going forward, CMVP needs to be adjusted to accept the realities of the impending migration. We welcome the FedRAMP update stream that allows updated modules to be used immediately before final validation. This allows faster adoption of post-quantum cryptography, and correction of implementation errors that were missed in validation. Similar allowances for CMVP are essential.
This post-quantum EO is a meaningful step. It sets real deadlines and creates supply chain pressure that will accelerate adoption across the industry.
For organizations starting their own migration, we suggest you start by protecting your public Internet traffic along with updates to your procurement requirements, followed by a quantum impact inventory to figure out where to focus next. Do not let cryptography inventory slow you down from deploying post-quantum encryption across your most sensitive systems immediately.
Cryptographic deployment across the Internet depends on standards developed by the IETF. The TLS community is further along, but there is lots more work to do across other protocol communities, and we look forward to supporting those efforts.
Let us go forth and PQ all the things, quickly and together. Free TLS helped encrypt the web. Free post-quantum cryptography will help secure it for what comes next.
You can get started now on Cloudflare by visiting our PQC page.
Why SIEM is Moving Toward Unified Security Operations: Rapid7 Named a Major Player in IDC MarketScape
Post Syndicated from Rapid7 original https://www.rapid7.com/blog/post/dr-siem-moving-toward-unified-security-operations-rapid7-named-idc-marketscape-major-player
Rapid7 has been named a Major Player in the IDC MarketScape: Worldwide SIEM 2026 Vendor Assessment (#US54126826, June 2026).
This is the first IDC SIEM MarketScape to bring the enterprise and SMB markets into a single evaluation, and we believe it arrives at a time when the way teams buy and run a SOC is changing quickly. Security teams are no longer evaluating detection and response in isolation. They want their threat data, automation, and view of the attack surface working together, rather than spread across a stack of disconnected tools.
We believe Incident Command reflects that shift by bringing threat data, automation, and attack surface context into one platform instead of leaving teams to work across disconnected tools. It also speaks to a broader change in security operations, where context matters more, speed matters more, and teams need a clearer path from alert to action. That same direction runs through Rapid7’s wider point of view on preemptive security: exposure, detection, and response work better when they inform each other through shared context, AI, and human expertise.
Incident Command brings detection, response, and exposure context together
Incident Command brings SIEM, SOAR, attack surface management, and threat intelligence together on a shared data model. That gives analysts access to asset risk, vulnerability data, and exposure context during an investigation, so they can understand whether a detection affects a high-risk, internet-facing asset without having to jump between separate products.
According to the IDC MarketScape, “Incident Command is a strong fit for midmarket to enterprise organizations that want a fully integrated security operations platform with predictable costs.”
The teams we talk to are tired of stitching tools together and dealing with surprise ingestion bills. They want fewer blind spots, faster investigations, and a clearer answer to what is urgent and what to do next. Incident Command addresses that by bringing exposure context, threat intelligence, and response automation into the SIEM workflow, helping teams investigate faster and act with more clarity. For organizations looking for additional managed coverage, Rapid7 MDR is available as a separate offering. As attacks move faster and environments become harder to manage, security operations work better when exposure, threat, and response data are connected through an open platform that gives teams the context they need to move with more speed and clarity.
AI and automation, pressure-tested by a global SOC
Many vendors talk about AI in the SOC. For customers, the more important question is how those capabilities are developed, tested, and refined so they are useful in real investigations rather than just sounding good in a product story. We believe the IDC MarketScape called out what that means in Rapid7’s case:
“AI models and automation capabilities are tested in the MDR SOC before release to product customers, providing a feedback loop between managed service outcomes and product development that organizations without their own MDR equivalent cannot replicate.”
Our MDR analysts work real incidents across thousands of customer environments every day. The detections, triage models, and automation that come out of that work are tested against live attacks before they reach product customers. That feedback loop helps make the AI Engine more useful in practice by handling repetitive work such as classifying alerts, compiling evidence, and surfacing next steps, while analysts spend their time on the decisions that actually require human judgment. That balance also reflects Rapid7’s broader platform story: AI-powered, backed by human expertise.
What we believe this IDC MarketScape recognition says about the future of SIEM
The 2026 IDC MarketScape is a useful signal of where the market is heading. Organizations are looking for platforms where exposure and detection inform each other instead of living in separate systems, and where AI helps teams move faster without removing the human judgment needed to make the right call. We believe that is very much in line with the platform Rapid7 has been building through Incident Command and the wider Command Platform story. We’ll continue investing in the AI Engine, deeper attack surface context, and the integrations customers rely on. The goal remains straightforward: help defenders move faster to keep their environment safe, investigate with more context, and respond with machine speed and confidence.
Want to see Incident Command in action? Request a demo or explore the packages built to meet your team where it is.
Prime Day’s BEST Deals – Price Tracked and Tested!
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=Ckqq3bDtUsA
Feral Hogs #lastweektonight
Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/fJsPS28_-gQ
Autonomous troubleshooting for Medallion Architecture with AWS DevOps Agent and Apache Spark Troubleshooting Agent
Post Syndicated from Mohammad Sabeel original https://aws.amazon.com/blogs/big-data/autonomous-troubleshooting-for-medallion-architecture-with-aws-devops-agent-and-apache-spark-troubleshooting-agent/
Every minute of data processing pipeline downtime delays business decisions, stalls downstream analytics, drives revenue loss, and erodes stakeholder confidence. Teams that run Medallion Architecture pipelines—a common data lakehouse pattern where data flows through bronze, silver, and gold layers with increasing quality—face cascading failures that impact revenue-critical reporting and machine learning workloads. As you scale these multi-stage pipelines with Amazon Managed Workflows for Apache Airflow (MWAA), AWS Glue, and Amazon Redshift, troubleshooting failures becomes increasingly complex. When a mission-critical job fails, an engineer must sift through gigabytes of logs across interconnected systems. This means spending hours on incident investigations, examining execution timelines and resource metrics, and cross-referencing findings with Amazon CloudWatch and recent deployment changes to find the root cause. This requires deep familiarity with the underlying technologies, expertise not every team member has. When the right engineer is unavailable during off-hours, pipeline downtime extends and downstream consumers wait. The cycle of detect, investigate, fix, and repeat is costly and entirely reactive. A proactive operational model moves issue identification upstream, catching and addressing problems before they disrupt your data pipelines.
In this post, we show you how to diagnose multi-layer Medallion Architecture pipeline failures in minutes using AWS DevOps Agent with Apache Spark Troubleshooting Agent integrated as an MCP server.
What is AWS DevOps Agent and Apache Spark Troubleshooting Agent?
AWS DevOps Agent is an autonomous investigation agent powered by AI that automatically diagnoses operational issues across your AWS environment. When a failure occurs, the agent independently gathers evidence from logs, metrics, and configurations across interconnected services, identifies the root cause, and delivers actionable remediation steps, all without human intervention. It integrates with your existing workflows through webhooks and delivers findings directly to communication channels like Slack. With AWS DevOps Agent, you can replace the reactive cycle of detect, investigate, fix, and repeat with autonomous, proactive troubleshooting. The agent acts as your always-on, on-call engineer, starting its investigation the moment a failure occurs, whether during business hours or in the middle of the night.
Apache Spark Troubleshooting Agent is an AI-powered, fully managed Model Context Protocol (MCP) server that data engineers can use to diagnose Spark application failures across Amazon EMR, AWS Glue, and Amazon SageMaker AI Notebooks using natural language. It automatically correlates Spark History Server data, distributed executor logs, and configuration patterns to identify root causes and deliver actionable recommendations. This removes hours of manual investigation across multiple consoles and log files.
Use case
The following sections walk through a common Medallion Architecture failure scenario and show how autonomous troubleshooting resolves it.
The scenario
Consider this scenario: a gold layer AWS Glue job fails with “Missing data for not-null field.” The logs don’t reveal the actual problem. The root cause is a subtle data quality issue introduced upstream in the silver layer, a job that succeeded without errors. Without autonomous troubleshooting, you would manually trace data lineage across Amazon Simple Storage Service (Amazon S3), Amazon Redshift, and multiple AWS Glue job logs to find the source.
The solution
When integrated with the Apache Spark Troubleshooting Agent, AWS DevOps Agent identifies the gold layer Amazon Redshift write failure, traces it back to silver layer data corruption, and provides detailed root causes and actionable recommendations. The investigation typically completes within 3 to 5 minutes.
Solution overview
The following diagram shows the Medallion Architecture data flow across bronze, silver, and gold layers.
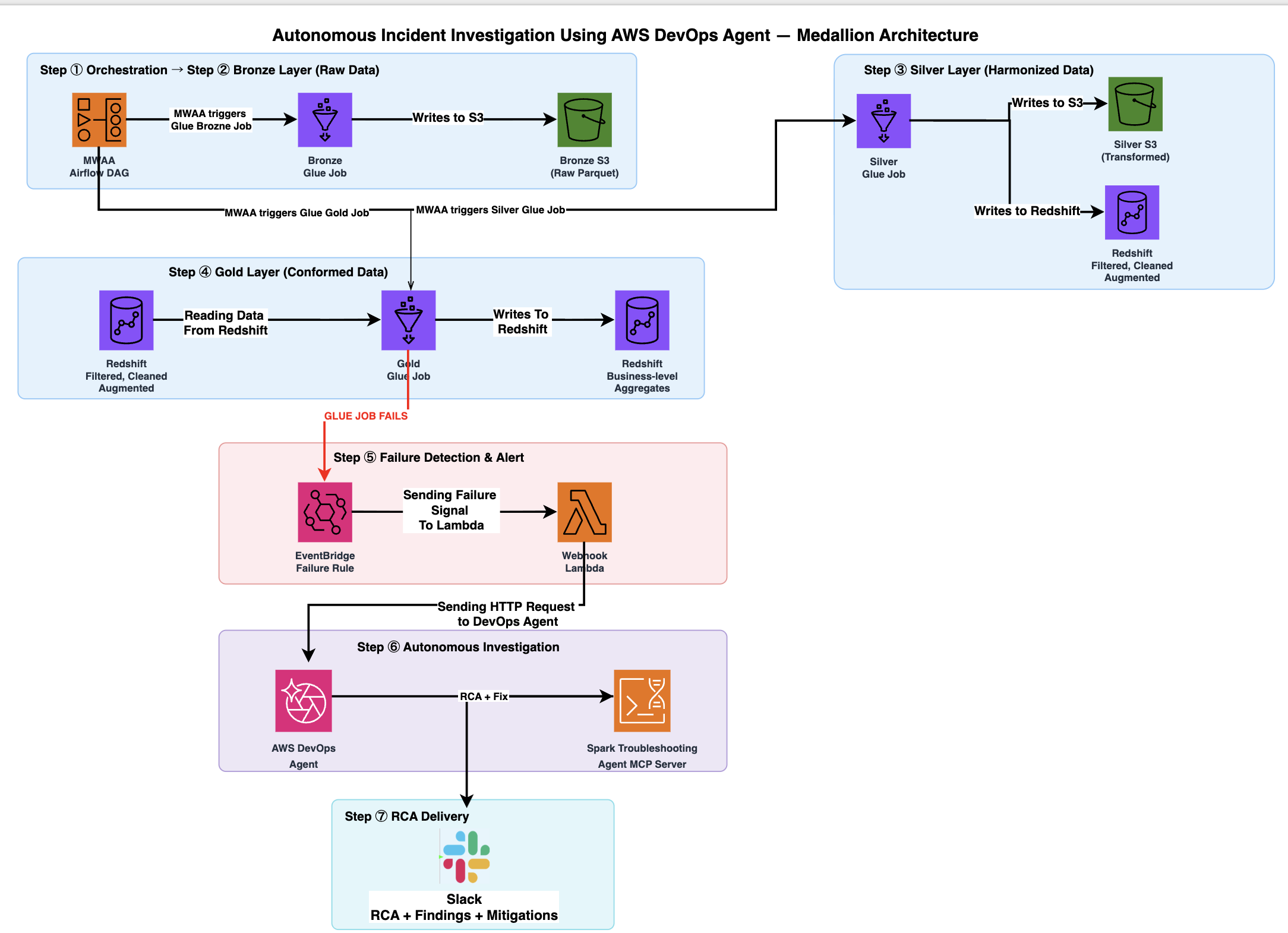
The architecture flow includes the following steps:
- Amazon MWAA triggers the Medallion pipeline directed acyclic graph (DAG), orchestrating three AWS Glue jobs sequentially: bronze layer, silver layer, and gold layer.
- The bronze layer job generates 50,000 synthetic ecommerce order records and writes raw Parquet files to Amazon S3.
- The silver layer job reads bronze data from Amazon S3, applies transformations, and writes the results to two destinations in parallel: Amazon S3, and Amazon Redshift (filtered, cleaned, and augmented data in the
silver_ecommercetable). This job silently introduces data corruption in approximately 8 percent oftotal_amountvalues. - The gold layer job reads from the Amazon Redshift
silver_ecommercetable, performs aggregation, and attempts to write business-level aggregates back to the Amazon Redshiftgold_ecommerce_summarytable. If upstream data corruption introducesNULLvalues, this job fails with “Missing data for not-null field” because thoseNULLvalues violate theNOT NULLconstraint. - When the gold layer job enters a FAILED state, Amazon EventBridge captures the AWS Glue Job State Change event and invokes an AWS Lambda function. The Lambda function retrieves webhook credentials from AWS Secrets Manager, constructs an HMAC-signed event payload containing the job name, run ID, and error details, and sends it to AWS DevOps Agent.
- AWS DevOps Agent receives the HTTP POST request to the webhook and starts an autonomous investigation. It authenticates with Amazon Cognito using the OAuth 2.0 client credentials flow, then sends an MCP request through Amazon Bedrock AgentCore Gateway. The AgentCore Gateway invokes a Signature Version 4 (SigV4) Proxy Lambda, which signs the request and forwards it to the Apache Spark Troubleshooting Agent MCP Server. The MCP Server analyzes Spark event logs, executor metrics, and error stack traces for the failed gold job.
- AWS DevOps Agent delivers the investigation to your configured Slack channel. The delivery includes root cause analysis, upstream data lineage back to the silver layer corruption, and step-by-step remediation recommendations.
Walkthrough
In the following sections, you deploy a three-layer Medallion Architecture pipeline that processes ecommerce order data. Complete the steps to get started with autonomous troubleshooting using AWS DevOps Agent.
Prerequisites
Before you begin, verify that you have the following:
- An AWS account. Your AWS Identity and Access Management (IAM) user or role must have the following permissions:
iam:CreateRole,iam:AttachRolePolicy,iam:PutRolePolicylambda:CreateFunction,lambda:AddPermissionglue:CreateJob,glue:StartJobRunredshift:CreateCluster,redshift:GetClusterCredentialsairflow:CreateEnvironmentevents:PutRule,events:PutTargetssqs:CreateQueuesecretsmanager:CreateSecretkms:CreateKeyec2:CreateVpc,ec2:CreateSubnet,ec2:CreateSecurityGroupcloudformation:CreateStack,cloudformation:DescribeStacks- Alternatively, you can use the
AdministratorAccessmanaged policy for simplicity in a dev/test environment.
- AWS Command Line Interface (AWS CLI) version 2.30.0 or later, installed and configured with appropriate credentials.
- (Optional) A Slack workspace if you want investigation results delivered to a channel.
Set up AWS DevOps Agent
In this section, you configure AWS DevOps Agent to receive and investigate pipeline failure events. This involves three tasks: creating an Agent Space (your investigation workspace), optionally connecting a Slack channel for notifications, and generating a webhook endpoint that your pipeline uses to send failure alerts to the agent.
Create an Agent Space
- Open the AWS DevOps Agent console.
- Choose Create Agent Space.
- Enter a name (for example,
medallion-troubleshooting). - Choose Create.
Connect Slack integration (optional)
If you use Slack for internal communication, you can configure it to receive investigation results.
- In the AWS DevOps Agent console, go to Agent Spaces, select medallion-troubleshooting and then Communications.
- Choose Add integration and choose Slack.
- Choose Next to allow AWS DevOps Agent to access your Slack workspace, and choose Allow.
- Provide the Slack workspace and the Channel ID where you want investigation results delivered, then choose Next.
- Enter the following command in your channel chat to complete the integration:
/invite @AWS DevOps Agent.- While running this command, when prompted, choose the correct region where the Agent Space is provisioned.
Create a webhook
- In your Agent Space, go to Webhooks.
- Choose Add webhook and choose Next on the two following pages.
- Choose Generate URL and secret key, and give the webhook a name (for example,
medallion-failure-webhook). - After creation, copy and save the Webhook URL (HTTPS endpoint) and Secret Key. You can also choose Download .csv to save this information to a secure location. Select the checkbox labeled I’ve saved and stored my URL and secret key, then choose Add.
Note the Webhook URL and Secret Key for later. You provide them as parameters when you create the AWS CloudFormation stack.
Deploy the AWS CloudFormation stack
The AWS CloudFormation template deploys the full Medallion Architecture pipeline. This includes an Amazon Virtual Private Cloud (Amazon VPC) with private subnets, an Amazon Redshift cluster (ra3.xlplus, single-node), and three AWS Glue jobs. It also creates an Amazon MWAA environment, Amazon EventBridge rules, AWS Lambda functions, and an AgentCore Gateway with Amazon Cognito OAuth authentication.
You can deploy the stack using one of two methods. Use Option A if you prefer a visual, guided experience through the AWS Management Console. Use Option B if you prefer working from the command line or need to integrate the deployment into a script or automation workflow.
Before you start, download the CloudFormation template from GitHub.
Option A: AWS Management Console (recommended)
- Open the AWS CloudFormation console and choose Create stack → With existing resources (import resources) or Upload a template file.
- Choose Choose file, select the downloaded
blog-medallion-stack.yaml, then choose Next. - For Stack name, enter
medallion-troubleshooting. - Fill in the parameters:
- For
WebhookUrl, enter your AWS DevOps Agent webhook URL (from Agent Space settings). - For
WebhookSecret, enter the webhook secret for authentication.
- For
- Choose Next, select I acknowledge that AWS CloudFormation might create IAM resources with custom names, then choose Submit.
Option B: AWS CLI
Replace the placeholder values:
YOUR-WEBHOOK-URL– Your AWS DevOps Agent webhook URL (from Agent Space settings).YOUR-WEBHOOK-SECRET– The webhook secret for authentication.YOUR-REGION– The AWS Region.
Wait for the stack status to show CREATE_COMPLETE. In our testing, this took approximately 30–40 minutes.
Retrieve Amazon Cognito client credentials
After the stack is deployed, it creates an Amazon Cognito user pool with an OAuth 2.0 client for AWS DevOps Agent authentication. Retrieve the client secret using the command below. The --user-pool-id and CognitoClientId needs to be copied from the stack outputs.
Replace YOUR-REGION with the actual AWS Region value, and save this value for the MCP Server registration in the following step.
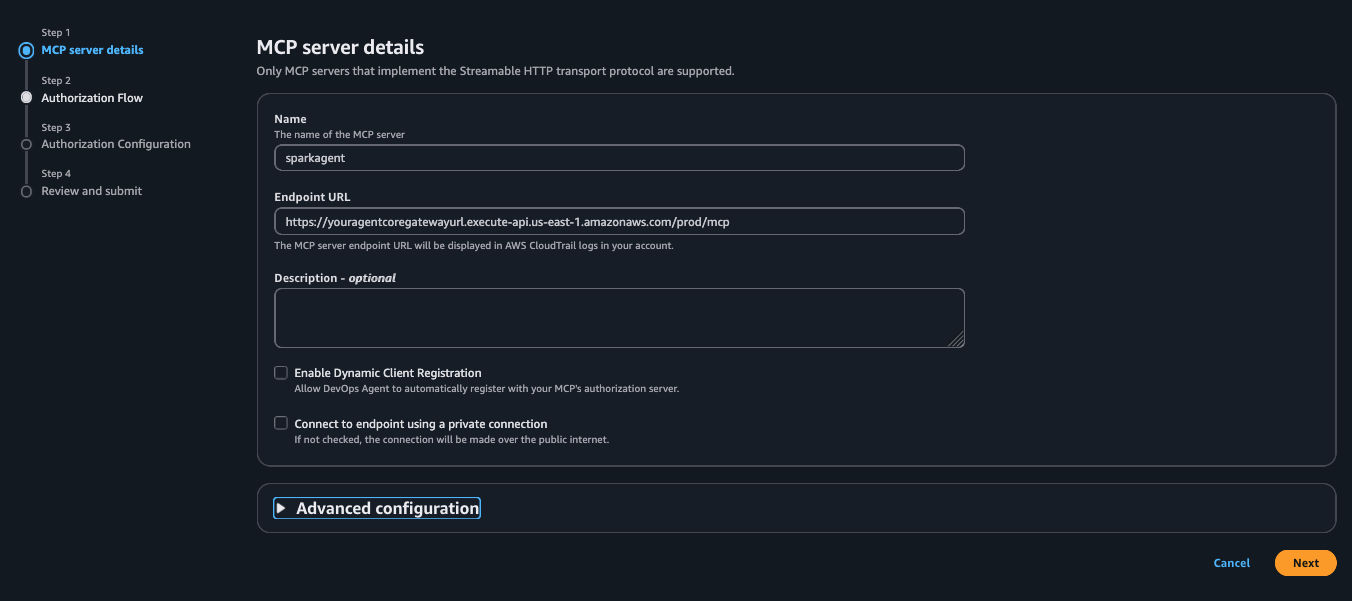
Register the Spark Troubleshooting MCP Server
The Spark Troubleshooting MCP Server gives AWS DevOps Agent the ability to analyze Apache Spark event logs, executor metrics, and error stack traces from your AWS Glue jobs. By registering this server, you connect the agent to the diagnostic tooling it needs to autonomously investigate pipeline failures.
To register the MCP Server in AWS DevOps Agent, complete the following steps:
- In the AWS DevOps Agent console, go to Agent Spaces, select medallion-troubleshooting and then Capabilities.
- In the MCP Servers section, choose Add or Add Source.
- Find New MCP Server Registration and choose Register.
- For Name, enter
sparkagent. - For Endpoint URL, enter the
AgentCoreGatewayUrlvalue from the stack outputs. - For Description, enter
Apache Spark Troubleshooting MCP Server via AgentCore Gateway. - Leave Enable Dynamic Client Registration cleared.
- Leave Connect to endpoint using a private connection cleared, then choose Next.

- Under Authorization Flow, select OAuth Client Credentials, and choose Next.
- For Client ID, enter the
CognitoClientIdvalue from the stack outputs. - For Client Secret, enter the value you retrieved in the preceding step.
- For Exchange URL, enter the
CognitoTokenEndpointvalue from the stack outputs. - For Add Scope, enter
<stack-name>-mcp-proxy/invoke. For example,medallion-troubleshooting-mcp-proxy/invoke. - Choose Next, review your configuration, and choose Add.
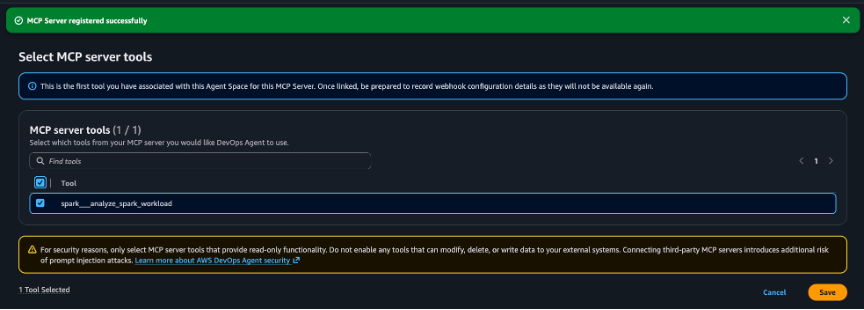
- Once you choose Add, on the following screen, click on the checkbox next to the
spark___analyze_spark_workload. This is the root cause analysis tool which provides detailed troubleshooting for failed Apache Spark workloads.

- Choose Save as a last step. You will see the MCP Server associated successfully message on the top.


See AWS DevOps Agent in action
Now that you have completed the prerequisites, you can see AWS DevOps Agent in action. Go to the Amazon MWAA Airflow Environments UI and click on Open Airflow UI under Airflow UI. It will open in a new browser tab. In the Airflow console, locate and manually trigger the medallion_architecture_pipeline DAG.
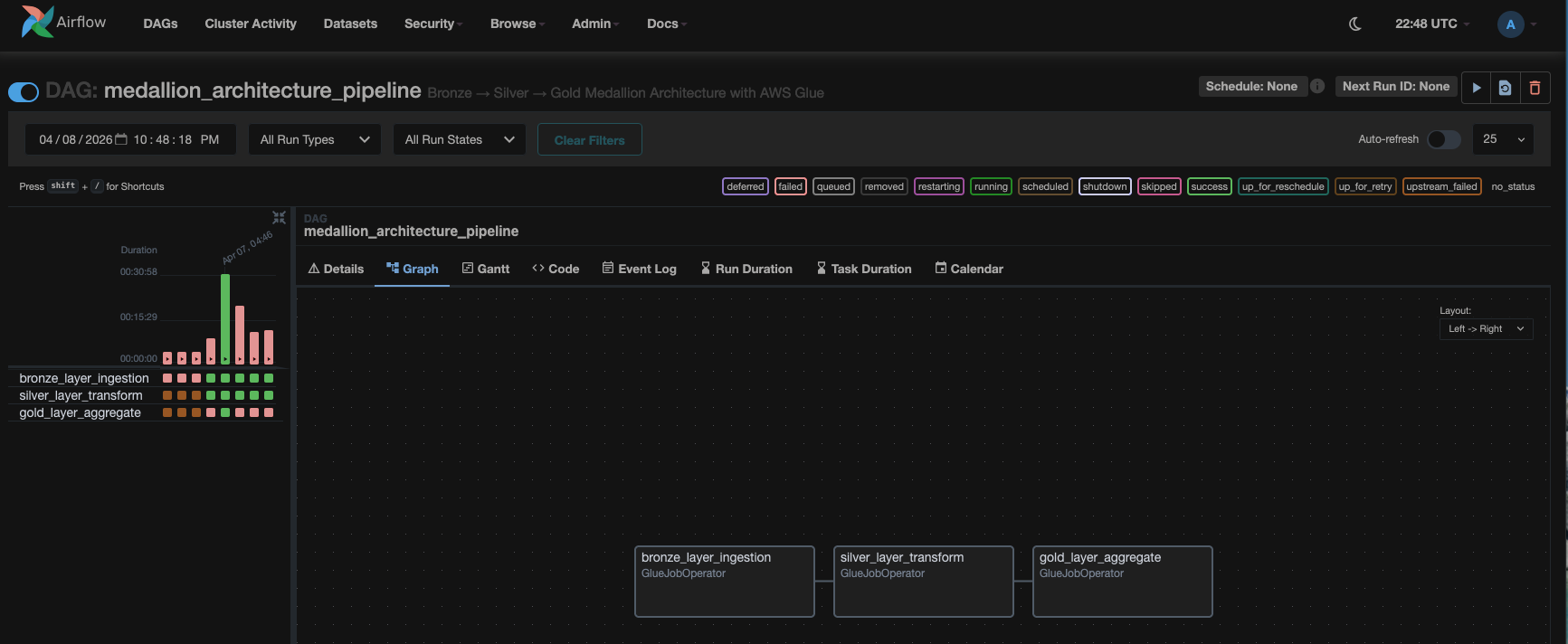
The DAG runs three AWS Glue jobs sequentially:
- Bronze layer – This job generates 50,000 ecommerce order records and writes them to Amazon S3 as Parquet files.
- Silver layer – This job applies transformations and loads the results to both Amazon S3 and Amazon Redshift. It also silently injects approximately 8 percent of
total_amountvalues with$prefix strings, introducing hidden data corruption. - Gold layer – This job reads from Amazon Redshift, casts
total_amountto numeric (producingNULLvalues for the$-prefixed strings), and attempts to write aggregated results to the Amazon Redshift target table. It fails because theNULLvalues violate theNOT NULLconstraint onrevenue_total.
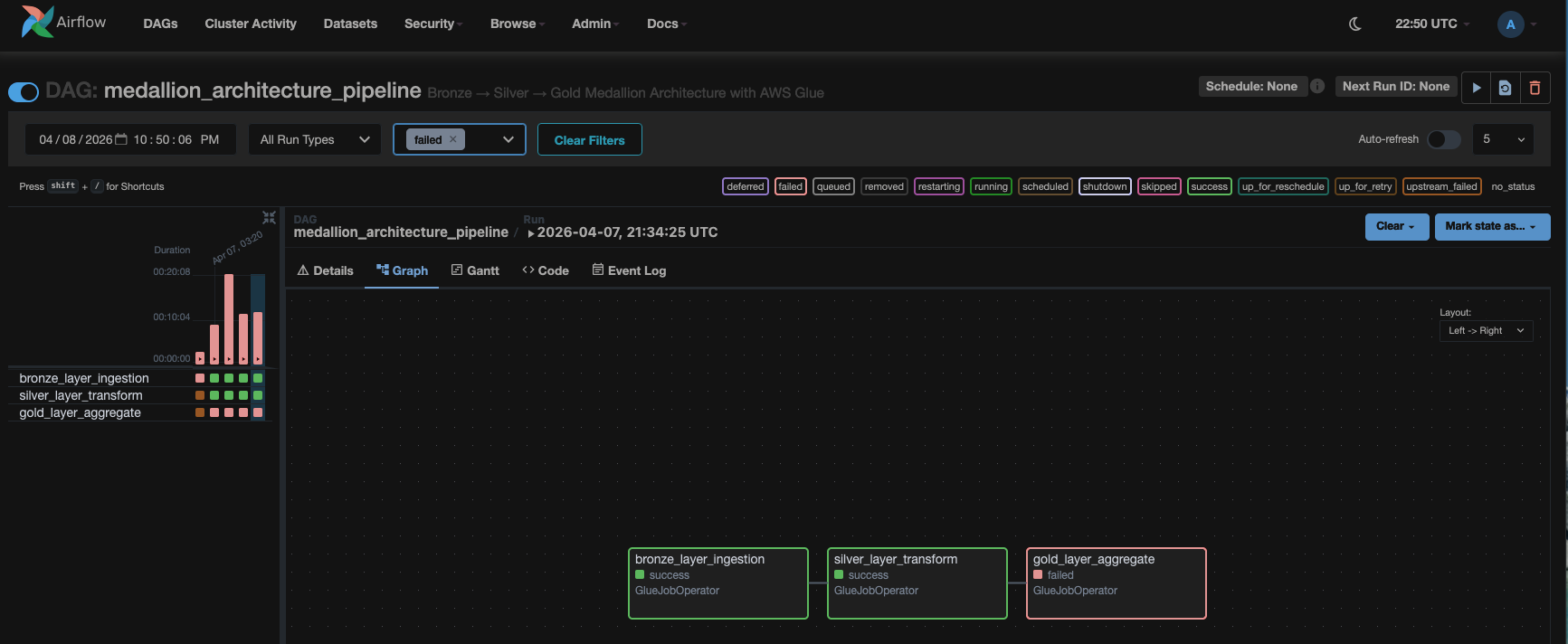
With the components deployed and connected, the autonomous troubleshooting pipeline is ready to respond to failures. In this walkthrough, the silver layer job deliberately introduces data corruption to simulate a real-world data quality issue. This causes the gold layer job to fail, giving you the opportunity to see how AWS DevOps Agent responds.
As soon as the gold layer job fails, AWS DevOps Agent starts an autonomous investigation and uses the Apache Spark Troubleshooting MCP Server where needed.
Go to the AWS DevOps Management console and choose the medallion-troubleshooting under Agent Spaces. Next, select the Operator Access button. This will redirect you to Operator Console where you will see that the incident investigation automatically started in 1-2 minutes post Gold layer job failure.
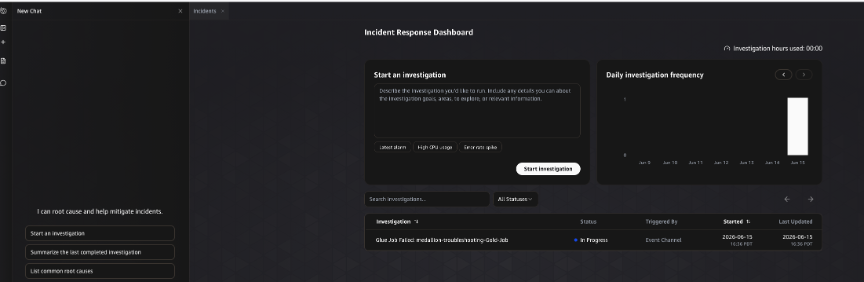
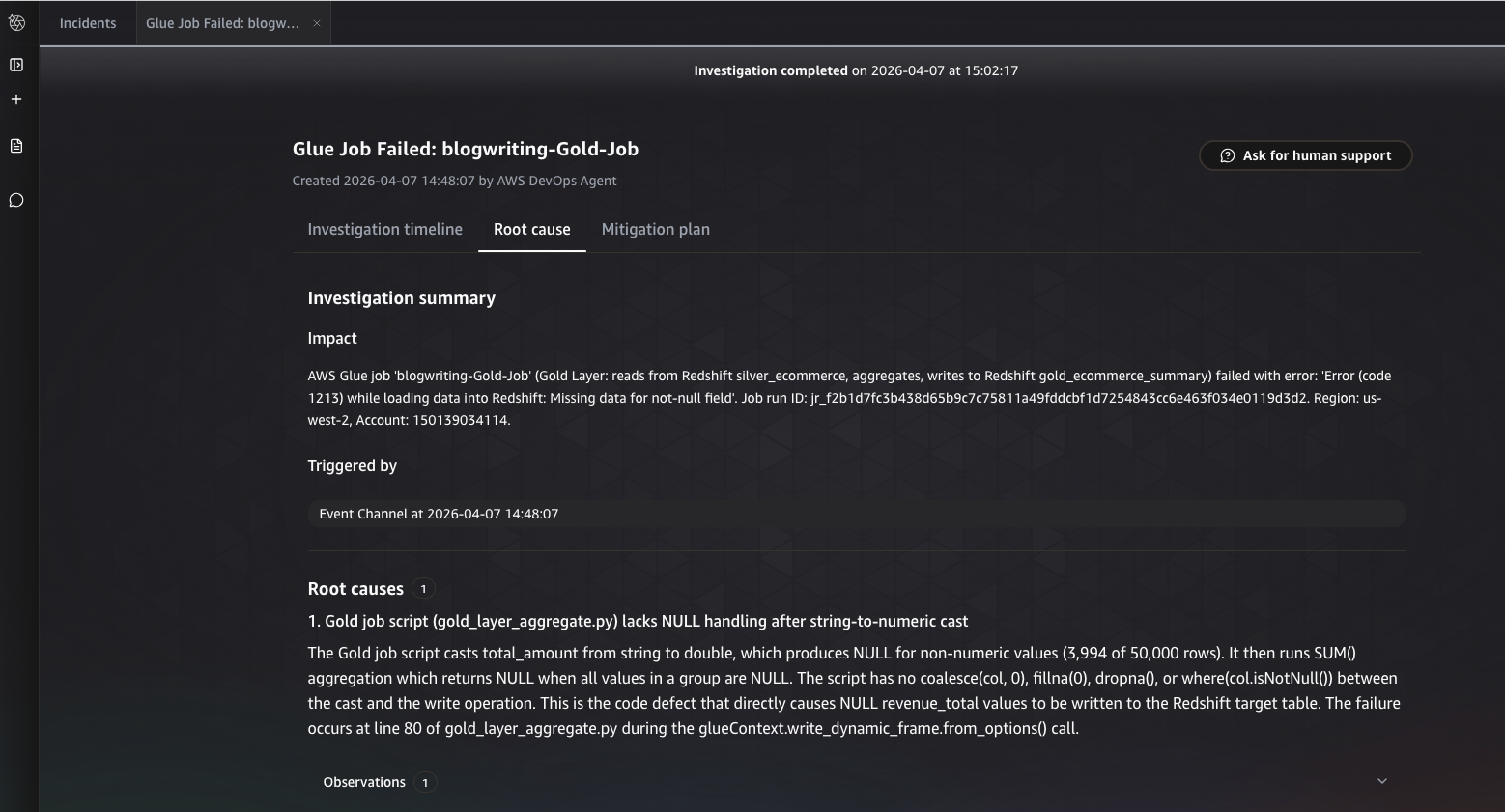
After the investigation completes, AWS DevOps Agent presents its findings within the incident analysis. The results are organized into two sections.
Root cause identified by AWS DevOps Agent
The agent identifies the underlying cause of the failure, tracing the gold layer write error back to data corruption introduced in the upstream silver layer AWS Glue job.
Mitigation plan generated by AWS DevOps Agent
On choosing Generate Mitigation Plan, the agent provides step-by-step remediation recommendations to resolve the issue and prevent recurrence.
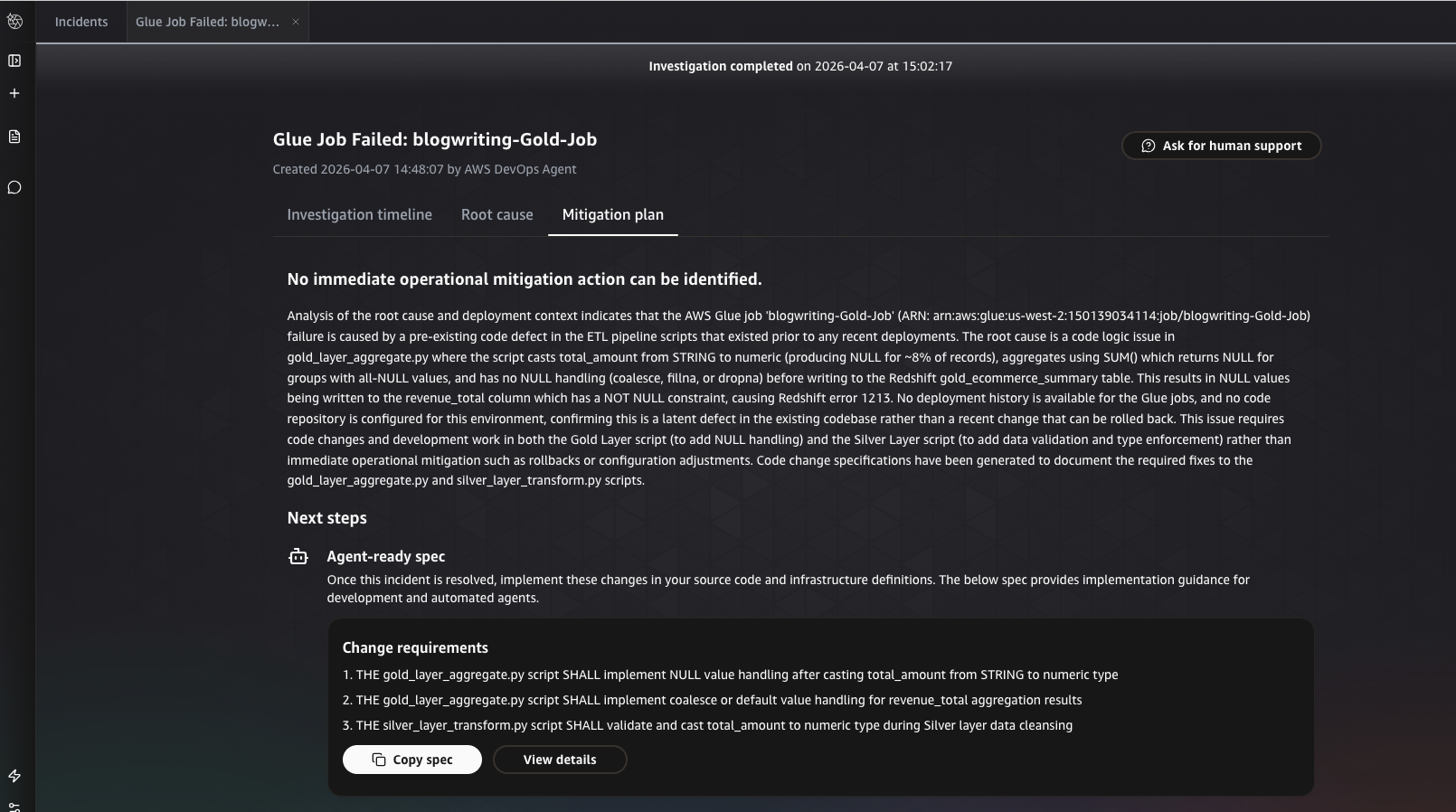
AWS DevOps Agent sends a notification to Slack

Typically, within 3–5 minutes, the agent delivers a detailed investigation in Slack that includes root cause identification, upstream data lineage tracking, and an actionable recommendation.
You have deployed an autonomous troubleshooting pipeline for Medallion Architecture data pipelines. The pipeline runs using AWS Glue, Amazon Redshift, and Amazon MWAA, with AWS DevOps Agent providing autonomous investigation. The agent traced a gold layer Amazon Redshift write failure back to a silver layer data quality issue. This type of diagnosis would typically require hours of manual investigation by an engineer with deep expertise in Apache Spark, Amazon Redshift, and data pipeline architecture. AWS DevOps Agent completed it autonomously within minutes.
If you need human assistance, you can use the Ask for human support feature within AWS DevOps Agent to open a case with AWS Support, automatically populated with relevant investigation context.
Enhanced investigations with AWS DevOps Agent Skills
AWS DevOps Agent autonomously investigates failures out of the box. You can enhance its diagnostic depth using Skills, a feature that provides the agent with domain-specific guidance tailored to your environment.
For Medallion Architecture pipelines, you can create Skills that instruct the agent to check for data type mismatches between pipeline layers when Amazon Redshift COPY errors occur, cross-reference silver layer data quality metrics with gold layer aggregation failures, or follow your internal runbook for escalating data quality issues to the upstream data engineering team.
To configure Skills, go to your Agent Space in the AWS DevOps Agent console and choose the Skills tab.
Clean up
To avoid incurring future charges, delete the resources you created during this walkthrough promptly after you finish testing.
To clean up resources, complete the following steps:
- Deregister the MCP Server. In the AWS DevOps Agent console, go to your Agent Space and choose the Capabilities tab. In the MCP Servers section, choose the
sparkagentserver, then choose Deregister. - Delete the webhook. In your Agent Space, go to the Webhooks tab. Choose the
medallion-failure-webhook, then choose Delete. - Empty the Amazon S3 buckets. Open the Amazon S3 console. Locate the buckets created by the stack (their names start with
medallion-troubleshooting). For each bucket, choose Empty, enterpermanently deleteto confirm, and choose Empty. - Delete the AWS CloudFormation stack. Open the AWS CloudFormation console. Choose the
medallion-troubleshootingstack, then choose Delete. Alternatively, run the following command:
Wait for the stack deletion to complete.
- Delete any retained Amazon S3 buckets. Some Amazon S3 buckets might have a
DeletionPolicyofRetainand aren’t automatically deleted with the stack. Return to the Amazon S3 console, locate any remaining buckets created by the stack, empty them using the process in the preceding step, and then choose Delete for each bucket.
Conclusion
In this post, you deployed an autonomous troubleshooting pipeline for Medallion Architecture data pipelines using AWS Glue, Amazon Redshift, Amazon MWAA, and AWS DevOps Agent. The agent traced a gold layer Amazon Redshift write failure back to a silver layer data quality issue—a diagnosis that would typically require hours of manual investigation by an engineer with deep expertise across multiple services.
As your data pipelines grow in complexity, so does the challenge of diagnosing failures that span multiple layers and services. AWS DevOps Agent reduces your mean time to resolution by autonomously investigating incidents the moment they occur, whether during business hours or at 2 AM. Your on-call engineers spend less time sifting through logs and more time building reliable data infrastructure. By shifting from reactive firefighting to autonomous, proactive troubleshooting, you can improve pipeline reliability, protect downstream analytics and machine learning workloads, and maintain stakeholder confidence in your data platform.
To learn how to structure Agent Spaces for investigation accuracy, scope resource access, and use infrastructure as code to streamline deployment, see Best practices for deploying AWS DevOps Agent in production. To learn how to evaluate and choose the right lakehouse pattern for your needs, see Navigating architectural choices for a lakehouse using Amazon SageMaker. For more about Apache Spark Troubleshooting Agent, see Introducing the Apache Spark Troubleshooting Agent for Amazon EMR and AWS Glue.
Next steps
Now that you have set up autonomous troubleshooting for your Medallion Architecture pipeline, consider exploring the following:
- Escalate to AWS Support directly from an investigation. If the agent’s findings require human assistance, you can use the Ask for human support feature within AWS DevOps Agent. This opens a case with AWS Support that is automatically populated with the relevant investigation context, which reduces the time spent describing the issue. For more information, see Getting help from AWS Support through AWS DevOps Agent.
- Enhance investigations with Skills. Create custom Skills to give the agent domain-specific guidance tailored to your environment.
- Learn more about AWS DevOps Agent best practices, choosing the right lakehouse pattern, and the Apache Spark Troubleshooting Agent.
- Optimize your AWS DevOps Agent deployment. Learn how to structure Agent Spaces for investigation accuracy, scope resource access, and use infrastructure as code to streamline deployment. See Best practices for deploying AWS DevOps Agent in production.
- Choose the right lakehouse architecture. Evaluate and compare lakehouse patterns to find the best fit for your data platform. See Navigating architectural choices for a lakehouse using Amazon SageMaker.
- Explore the Apache Spark Troubleshooting Agent. Learn more about the diagnostic capabilities the agent uses to analyze Spark event logs, executor metrics, and error stack traces. See Introducing the Apache Spark Troubleshooting Agent for Amazon EMR and AWS Glue.
About the authors
[$] KASAN for JIT-compiled BPF code
Post Syndicated from daroc original https://lwn.net/Articles/1077740/
Alexis Lothoré has been working to add support for the kernel’s memory-access
checker,
KASAN, to just-in-time-compiled BPF code. He spoke about that work at
the 2026
Linux Storage, Filesystem, Memory-Management, and BPF Summit.
KASAN support is needed, he said, to help catch bugs in the BPF just-in-time (JIT)
compiler. KASAN is a great tool for catching memory-management problems in the
kernel, but only in code that can be monitored by it.
Getting your SMS short code production-ready with AWS End User Messaging
Post Syndicated from Harshvardhan Chunawala original https://aws.amazon.com/blogs/messaging-and-targeting/getting-your-sms-short-code-production-ready-with-aws-end-user-messaging/
Getting your Short Message Service (SMS) short code production-ready requires you to configure the Amazon Web Services (AWS) infrastructure that controls how your messages are sent, monitored, and protected. You have provisioned your short code, and it is active on carrier networks. In this post, we walk through that setup using AWS End User Messaging SMS, covering 12 configuration steps from compliance through phased traffic migration. Total estimated time is 2 to 4 hours of configuration plus 1 to 3 business days for limit increase approvals.mess
The guide to SMS short codes with AWS End User Messaging covers the application and registration process up through provisioning. This post picks up from that point and provides an operational readiness walkthrough that takes you from “Active” status to confidently sending your first production message, including a final validation step to confirm readiness.
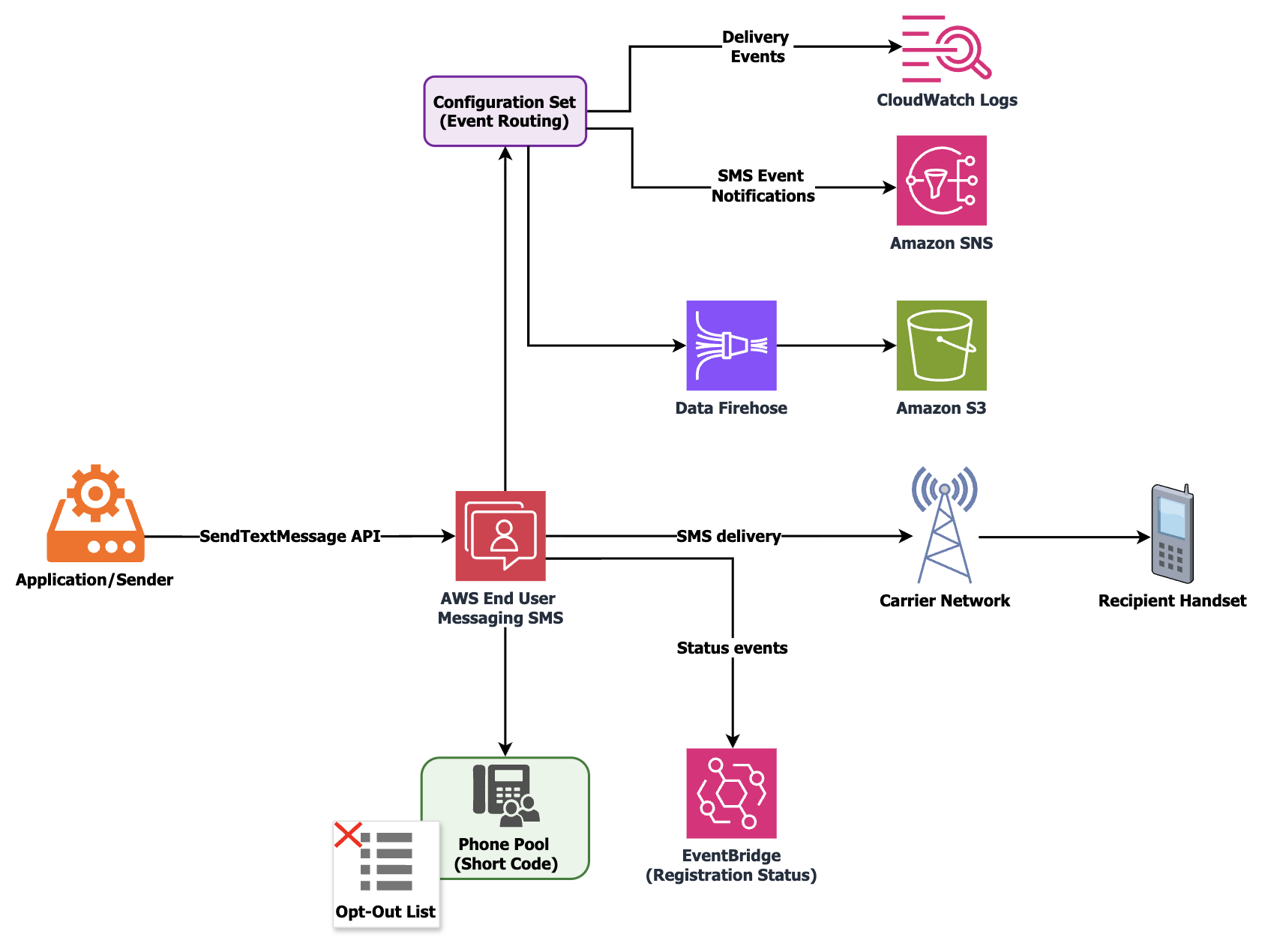
The following diagram shows the end-to-end message flow and event routing architecture covered in this walkthrough.
Prerequisites
You need the following to follow along with this walkthrough:
- An AWS account with access to the AWS End User Messaging SMS console.
- A short code with Active status in the AWS Management Console (carrier provisioning finished).
- Permissions to create AWS Identity and Access Management (IAM) roles, Amazon CloudWatch Log Groups, and Amazon Simple Notification Service (Amazon SNS) topics.
- AWS Command Line Interface (AWS CLI) v2 or an AWS SDK installed and configured.
- Your approved registration documentation, including the service name, keyword responses, and message templates submitted to carriers.
Step 1: Verify your short code is active and delivering
Navigate to the AWS End User Messaging SMS console, choose Phone numbers, and locate your provisioned short code. Confirm that the status shows Active, then send a test message to a phone number you control using the SendTextMessage API or the console test feature. Verify delivery on your handset.
Carrier-side activation can take up to 24 to 48 hours to fully propagate across all networks after provisioning finishes. If the console shows Active but your test message does not arrive, submit a support case so the team can verify propagation status with the carrier.
You can also verify using the AWS CLI:
Step 2: Configure keywords and verify message compliance
US carriers require every short code to respond to HELP and STOP keywords. You defined these during your registration, and this step confirms they are configured correctly in your account.
In the SMS console, choose Phone numbers, select your short code, and choose the Keywords tab. Verify that STOP returns the opt-out response you submitted during registration, and that HELP returns your support contact response (which must include a phone number or email). Add any custom keywords your use case requires, such as YES for double opt-in confirmation flows. You can manage keywords programmatically using the PutKeyword API.
To add or update a keyword programmatically:
To verify your current keyword configuration:
Beyond keyword configuration, carrier compliance does not end at registration approval. The content you send in production must stay aligned with what carriers reviewed and approved. Here is what to keep consistent.
Use the exact brand or program name from your approved registration across all keyword responses, confirmation messages, and outbound templates. If carriers approved your registration under “Acme Health Alerts,” every message your short code sends should reference that name. Mixing variations creates inconsistencies that auditors flag during reviews. For example, do not use the company name in one message and the product name in another.
Your HELP, STOP, and confirmation responses must match the templates submitted during registration. Do not add or remove opt-out language, change frequency disclosures, or alter customer care contact details post-approval without updating the registration through a support case. If your organization operates multiple domains, use the domain documented in the registration. For example, you might have one domain for the application and another for marketing. Carrier reviewers cross-reference message content, opt-in screenshots, and privacy policy URLs with what was submitted.
Humans conduct carrier reviews, and message content that is concise and limited to the essentials is reviewed consistently. All messages must remain under 160 characters.
Step 3: Create a configuration set with event destinations
A configuration set controls where your SMS delivery events are streamed and which event types are captured. Without one, you are limited to the basic events that AWS End User Messaging SMS sends to Amazon EventBridge by default. These default events omit recipient details and full carrier response context.
Create a configuration set with a descriptive name such as prod-otp-shortcode or marketing-sc-us. Then create at least one event destination. The three main options are Amazon CloudWatch Logs (for operational monitoring and alarming), Amazon SNS (for real-time event fanout to downstream systems), and Amazon Data Firehose (for durable archival and analytics).
Amazon Data Firehose typically delivers to an Amazon Simple Storage Service (Amazon S3) bucket, where you can query delivery history using Amazon Athena for compliance audits or delivery pattern analysis.
Important: When sending messages with SendTextMessage, always specify your ConfigurationSetName parameter so events route to the appropriate destination.
Required event types
| Event type | Description |
TEXT_DELIVERED |
Message successfully delivered to recipient handset. |
TEXT_FAILED |
Message delivery failed. |
TEXT_QUEUED |
Message accepted and queued for delivery. |
TEXT_CARRIER_UNREACHABLE |
Carrier network unreachable. |
TEXT_TTL_EXPIRED |
Message expired before delivery. |
For a detailed walkthrough of configuration sets including multi-tenant architectures, see How to send SMS using configuration sets with AWS End User Messaging.
Step 4: Create a phone pool and associate your short code
A pool is a logical container that groups origination identities and controls routing behavior. Creating one gives you deterministic control over which number sends your messages and how opt-outs are enforced.
Configuration parameters
| Parameter | Recommended value | Rationale |
| Pool name | us-otp-pool |
Descriptive, environment-prefixed. |
SharedRoutesEnabled |
False |
Prevents fallback to shared routes; only your short code is used. |
| Opt-out list | Associate one | Manages opt-out state per use case. |
IsoCountryCode |
US |
Restricts to destination country your short code serves. |
If you operate multiple use cases on separate short codes, create a dedicated pool for each. For example, use one short code for one-time password (OTP) traffic and another for transactional notifications. This isolation means a recipient opting out of marketing messages does not lose access to authentication codes.
Step 5: Request your throughput increase
Short codes start at a default of 100 messages per second (MPS). If your production volume will exceed this, request an increase before your launch date rather than after traffic is flowing.
Create a case in the AWS Support Center, choose Service limit increase, then choose End User Messaging SMS. Provide your short code phone number, requested MPS, use case description, and expected peak volume. Allow 1 to 3 business days for processing.
To estimate your required MPS:
Short codes support scaling to thousands of MPS, so start with a value that covers your expected peak and request further increases as traffic grows.
Step 6: Request a spending limit increase
AWS accounts have a default monthly SMS spending limit. To keep delivery uninterrupted at your expected volume, request an increase that accommodates your projected monthly spend before you begin sending.
Create a support case under Service limit increase > End User Messaging SMS > Account Spend Threshold. Provide your estimated monthly spend, use case description, and website URL.
For details, see Requesting increases to your monthly SMS spending quota.
Step 7: Restrict destination countries
If your short code serves a single country (US-only, for example), restrict sending to that country. This protects your account from artificially inflated traffic (SMS pumping). In pumping attacks, messages are routed to international premium-rate numbers, generating significant charges.
In the SMS console, navigate to Account settings, then choose Countries and keep only the countries you intend to send to. The pool-level IsoCountryCode restriction from Step 4 provides an additional enforcement layer at the sending path. Combining account-level country restrictions with pool-level country codes gives you two independent controls that both must be satisfied before a message is sent internationally.
For a detailed walkthrough on SMS fraud prevention controls, see Defending against SMS pumping: new AWS features to help combat artificially inflated traffic.
Step 8: Set up monitoring and alarms
With event destinations configured in Step 3, build proactive alerting that surfaces delivery trends before they affect your end users.
Recommended alarms
| Alarm | Metric / Source | Threshold |
| Delivery success rate | CloudWatch SMS metrics | Alert when below 95%. |
| Spend threshold | CloudWatch billing metric | Alert at 80% of monthly limit. |
| Delivery failures | Amazon EventBridge rule on TEXT_FAILED |
Route to Amazon SNS topic or AWS Lambda. |
| Carrier unreachable | Amazon EventBridge rule on TEXT_CARRIER_UNREACHABLE |
Route to Amazon SNS topic or AWS Lambda. |
Build a CloudWatch dashboard showing messages sent per minute, success versus failure breakdown, and spend accumulation over time.
You can also configure Amazon EventBridge to notify you of registration status changes. AWS End User Messaging SMS publishes events for statuses including REQUIRES_UPDATES, REVIEWING, and PROVISIONING, which is useful if a carrier requests changes during a proactive audit after your short code is already active.
For metric details, see Monitoring SMS activity with Amazon CloudWatch.
Step 9: Track OTP verification success (if applicable)
If your short code delivers OTP or two-factor authentication (2FA) codes, track end-to-end verification success in addition to carrier delivery receipts. A “delivered” status at the carrier level does not confirm the end user received and entered the code.
Tracking verification rates gives you insight into latency patterns when codes expire before arrival, geographic delivery trends, and opportunities to improve conversion. Some use cases involve asynchronous processing where several minutes of computation occur before the SMS is sent. For these, measure the full round-trip from the triggering action to message delivery. This separates application-side latency from carrier-side delivery latency.
For implementation guidance, see Track OTP success with AWS End User Messaging SMS feedback.
Step 10: Set up cost visibility
SMS costs include AWS charges plus per-message carrier surcharges. Setting up cost visibility from day one lets you track spend trends, catch anomalies early, and optimize over time.
Start by activating AWS Cost Explorer and creating a cost allocation tag for your SMS workload. Then configure an AWS Budget with threshold alerts. For example, you might notify at 80% of projected monthly spend. This gives you advance warning of unexpected cost increases, whether from traffic spikes, retry loops, or blocked-country leakage.
Step 11: Plan your traffic migration
A phased rollout validates delivery performance at each stage before you increase volume.
Start with a canary phase (Day 1 to 3) where you route 5 to 10% of traffic to the short code and monitor delivery rates, latency, and event logs. Move to a ramp phase (Day 3 to 7) at 50%, validating throughput and carrier-level delivery across your recipient base. Finish the full migration (Day 7+) at 100%. Decommission your previous origination identity only after confirming stability for at least 48 hours.
Step 12: Validate production readiness and send
Before declaring your short code production-ready, run through the following validation checks:
- Confirm your CloudWatch dashboard shows events flowing for
TEXT_DELIVEREDandTEXT_FAILED(from Step 3). - Send a test message that triggers your
STOPkeyword. Verify the correct opt-out response is returned and the phone number appears in your opt-out list. - Send a test message that triggers your
HELPkeyword. Verify the response matches your approved registration. - Check your MPS quota in the support case response (from Step 5). Confirm it matches or exceeds your calculated peak.
- Review your country restrictions (from Step 7). Attempt to send a message to a blocked country and confirm it is rejected.
- Verify your CloudWatch alarm fires by temporarily lowering the threshold, or by checking that the alarm state is not
INSUFFICIENT_DATA.
After all six checks pass, you are ready to begin your phased migration (Step 11) and scale to full production traffic. At this point, your short code is configured, monitored, compliant, and protected.
Automate with a validation script
You can use an AI coding assistant such as Kiro to generate a validation script tailored to your environment. Try a prompt like: “Write a boto3 script that validates my SMS short code is production-ready by checking Active status, HELP/STOP keywords, configuration set existence, and pool association using the pinpoint-sms-voice-v2 client.”
Refine the prompt with specifics from the following reference implementation, such as exact API names, filter parameters, and output format, to match your requirements.
The following script is an example of what that output looks like:
Cleaning up
If you created test resources while following this walkthrough, you can delete them through the AWS End User Messaging SMS console or with the API to avoid confusion with your production configuration. This includes a test configuration set, test pool, or test event destinations used for validation. Do not delete your production configuration set, pool, or keyword settings.
If you requested a test-level MPS increase or spending limit for validation, update these to your production values through a new support case before going live.
Quick reference checklist
| Step | Action | Key API / Service |
| 1 | Verify short code is Active and test delivery | SendTextMessage |
| 2 | Configure keywords and verify message compliance | PutKeyword |
| 3 | Create configuration set with event destinations | CreateConfigurationSet |
| 4 | Create pool and associate short code | CreatePool, AssociateOriginationIdentity |
| 5 | Request MPS increase for expected throughput | AWS Support |
| 6 | Request spending limit increase | AWS Support |
| 7 | Restrict destination countries | Console / UpdateAccount |
| 8 | Set up CloudWatch alarms and dashboards | Amazon CloudWatch |
| 9 | Track OTP verification success (if applicable) | SMS Feedback events |
| 10 | Set up cost visibility | AWS Cost Explorer, AWS Budgets |
| 11 | Plan phased traffic migration | Application-level routing |
| 12 | Validate production readiness and send | All of the preceding |
Conclusion
In this post, we walked through how to configure a newly provisioned SMS short code for production use with AWS End User Messaging SMS. The 12 steps cover keyword verification, message compliance, event monitoring, throughput planning, country restrictions, cost visibility, phased traffic migration, and a final production validation.
You can adapt the sequence to your specific use case and volume profile. For the full registration and application process, see A guide to SMS short codes with AWS End User Messaging. To start configuring, navigate to the AWS End User Messaging SMS console. For the full API reference, see the AWS End User Messaging SMS documentation.
Related posts
- A guide to SMS short codes with AWS End User Messaging
- How to send SMS using configuration sets with AWS End User Messaging
- Defending against SMS pumping: new AWS features to help combat artificially inflated traffic
About the author
Editing Flow State: Avoid Distractions #StayCreative
Post Syndicated from Matt Granger original https://www.youtube.com/shorts/L_uoRaF2TzM
10 Years Later – Brexit is a Catastrophe
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=wOc1cxnDR_s
Sunsetting Tor 0.4.8
Post Syndicated from jzb original https://lwn.net/Articles/1079119/
The Tor Project has announced
that it is planning to actively stop supporting Tor 0.4.8 and earlier
C Tor versions soon.
Usually, we try not to break existing releases, even if they are
unsupported, unless we have a pretty good reason. In this case, we
have several reasons. […]The most important reason is this: in 0.4.9, we have made some
former fields in our directory data obsolete — specifically, TAP
onion keys and family
lines. Removing these fields will let us save a great deal of
client directory bandwidth for everyone. This, in turn, will make all
Tor clients bootstrap a little faster, especially those on slow
connections. But when we remove these fields, clients and relays
running earlier versions of Tor will no longer work, since they expect
the TAP onion keys to be present. Therefore, in order to deliver
improved performance faster, we need to accelerate the date on which
0.4.8 will stop working.
The target sunset date is currently September 1,
2026, after which any version prior to Tor 0.4.9 will cease to work on
the network. The first stable release in the 0.4.9.x series was
announced
in February 2026, and the Tor 0.4.8.x series reached end of life on
June 1.
Security updates for Tuesday
Post Syndicated from jzb original https://lwn.net/Articles/1079083/
Security updates have been issued by Debian (ffmpeg), Fedora (erlang, ffmpeg, prometheus, python-scrapy, python3-docs, python3.14, thorvg, tigervnc, and vips), Mageia (mumble and sslh), Oracle (389-ds:1.4, dracut, firefox, hplip, kernel, openssh, postgresql:15, redis:6, and uek-kernel), Red Hat (delve, gvisor-tap-vsock, nginx, nginx:1.24, nginx:1.26, osbuild-composer, podman, rhc, skopeo, and yggdrasil), SUSE (containerized-data-importer, graphite2, kernel, libarchive, openssh, openssh-askpass-gnome, openvswitch, openvswitch3, postfix, python-lxml, python-nltk, python-python-multipart, python-urllib3, rmt-server, terraform-provider-local, terraform-provider-null, and util-linux), and Ubuntu (google-guest-agent, haproxy, libxml2, linux-azure, linux-intel-iotg-5.15, linux-lowlatency, linux-lowlatency-hwe-5.15, linux-oracle-5.15, mysql-8.0, mysql-8.4, and nginx).
THG Podcast: Counterfactuals – Cannae
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=tmrtNJPrvn4
Anthropic’s Fable 5 Model Jailbroken Within Days
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2026/06/anthropics-fable-5-model-jailbroken-within-days.html
Fable 5 is the supposed safe version of Anthropic’s Mythos Preview, with guardrails to ensure that it can’t be used to create cyberattacks.
Well, that restriction was bypassed within days.
How to design and present clear computing lessons
Post Syndicated from Sean Sayers original https://www.raspberrypi.org/blog/how-to-design-and-present-clear-computing-lessons-mayers-principles/
Learning something new requires effort. Learners take in new information by listening and observing. When a lot of information is presented at once in a lesson, that can create too much cognitive load for learners — a barrier to understanding and engagement.
To help you design and deliver great computing lessons, we’ve written two new Pedagogy Quick Reads focused on Mayer’s Principles of Multimedia Learning. These research-backed principles give you practical strategies to lower your students’ unnecessary cognitive load during lessons, leading to better learning outcomes.

In this blog, we introduce the two new Quick Reads (Designing multimedia for clarity and Designing multimedia for understanding), which you can download for free to:
- Find practical tips for how you can apply Mayer’s Principles to your lessons
- Read a summary of the research behind them
The blog also includes some examples for how to apply the principles in your computing lessons.
If you’d like an introduction to the idea of cognitive load, you can find the Quick Read about cognitive load theory here.

What are Mayer’s Principles?
Mayer’s Principles of Multimedia Learning are practical principles that will help you create clearer resources and present information in a way that avoids unnecessary cognitive load for your learners.
Mayer’s Principles are based on three related facts:
- You can present information to learners in auditory form (e.g. spoken explanations) and visual form (e.g. written text, diagrams)
- There are limits on how much new information people can take in at the same time
- Teaching materials that are not well-structured can cause too much cognitive load, which negatively affects learning
Designing lessons for clarity
Our first new Quick Read focuses on the following Mayer’s Principles for making your lessons as clear as possible, so that learners can connect the information they see and hear in real time.
- Make all the information you include coherent, meaning that it is directly relevant to the learning objectives and does not distract learners’ attention
- Guide your learners’ attention by using signals such as arrows, bold text, colour, or auditory cues
- Avoid redundant information, such as a slide with a diagram and a paragraph explaining the diagram, or a slide that you speak about without adding new, complementing information
- Present related words and visuals in the same space, e.g. place your text labels, or explanations directly adjacent to diagrams, images or code segments they describe
- Present related words and visuals at the same time, e.g. by pairing narration with imagery
Designing lessons for understanding
Our second new Quick Read shares three Mayer’s Principles for how you can structure your lesson delivery to support your learners’ understanding:
- Structure lessons or demonstrations into clear, manageable stages or segments, rather than presenting the information all at once
- When you start a new topic, begin with some pre-training by introducing key terms, components, or goals and how they relate
- When you present diagrams, flowcharts, or code examples, explain this visual information using the other modality, meaning spoken narration, instead of using paragraphs of text
Applying Mayer’s Principles to your computing lessons
We suggest you consider implementing Mayer’s Principles when you next design new lessons or want to adapt materials that you reuse regularly.
Here are some ideas on how you use both sets of principles in common computing teaching scenarios.
Live coding and code walkthroughs
When displaying a new Python script or Scratch project, avoid adding long, written paragraphs of commentary to explain the code. Instead, place short text annotations or sub-goal labels directly next to the relevant lines or blocks. As you run through the code, use your pointer or live typing to guide your learners’ focus (signalling) and explain in words how the program works at the same time.
Starting a new topic such as networking
Before students move to a new topic, for example networking, consider what words or concepts your class needs to be familiar with. Allocate a few minutes at the start of your lesson for pre-training to introduce terms like LAN or bandwidth and how they relate to the lesson.

Consider how your lesson can be divided into stages to allow for better understanding (segmenting). Each stage should build on the previous one and feed into the next one. For example, when you explain how data moves across a network, you can introduce each step separately before combining them all into a complete model of a network.
Consider how you display visual information to your class. Ensuring related diagrams and labels appear close together, only include relevant materials and no decoration on your slides (coherence), and avoid simply reading out words on the slide identical forms of information (redundancy).
Supporting multilingual learners with Mayer’s Principles
Mayer’s Principles are even more important for educators teaching multilingual learners or non-native speakers. When learners need to work harder to understand the language, poor lesson design can slow down their learning significantly.
Mayer’s Principles can help you with this challenge:
- Applying the coherence and redundancy principles will allow you to make your explanations and slides as clear and concise as possible
- Using signaling will mean you help learners to follow along and know what is most important
- Presenting diagrams that illustrate computing concepts clearly will help your multilingual learners understand your spoken explanation much more easily (modality)
Intentional design for lasting understanding
By intentionally designing and presenting lessons to give the right amount of information in the clearest way, you make it easier for your students to focus and build a lasting understanding of computing concepts. When your lesson materials align with how our brains process information, learners can build stronger mental models and approach independent learning activities with greater confidence.
Read our new Quick Reads to find out more and discover the research behind Mayer’s Principles:
The post How to design and present clear computing lessons appeared first on Raspberry Pi Foundation.
Toward More Controllable AI Video Editing: An Early Research Exploration at Netflix
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/toward-more-controllable-ai-video-editing-an-early-research-exploration-at-netflix-eb8160ed60a2
By Zhuoning Yuan, Ta-Ying Cheng, Benjamin Klein, Bahareh Azarnoush
Introduction
At Netflix, we build technology to help storytellers bring their creative visions to life and to help members discover the stories they love.
To connect stories with diverse audiences around the world, we produce promotional assets, including trailers, teasers, and social short‑form videos, that build on and elevate the original footage. Through close collaboration with the teams crafting these assets, we identified a recurring gap in current tools. Transforming raw footage into a polished final asset often requires complex edits like seamlessly adding new visual elements, patching or replacing backgrounds, or removing unwanted objects without breaking the scene’s physical continuity. These tasks typically demand hours of specialized manual editing work. While recent generative video editing models show promise, they often struggle to preserve the integrity of the source footage. Many methods regenerate every pixel to make an edit, which can fail to isolate changes and inadvertently alter elements that should remain untouched. To execute these tasks effectively, artists need tools that empower them to dictate exactly what changes and how it changes.
Our research goal is to make this process easier for artists. We’re deliberate about where and how AI is applied, ensuring that the technology always serves the creative intent. That principle drives our recent work: exploring the benefits of generative AI in ways that protect and expand creative choice, and keeping artists in precise control of their final vision. Recent advancements in AI video editing have demonstrated impressive capabilities in streamlining complex manual editing workflows, but key challenges remain before they can reliably support professional use:
- Unintended edits: When editing a specific element in a video clip, many methods regenerate the entire video, which can inadvertently alter identity, performance, and other elements like objects, backgrounds, or critical scene details.

- Unnatural physics: When removing objects, many methods focus only on erasing the target while ignoring the scene’s physical continuity. This can lead to inconsistent motion and implausible interactions, making the results look unnatural.

Today, we’re sharing two research explorations that aim to address these challenges. We believe this work can help advance the field in a way that’s both meaningful and responsible:
- Vera: a layered video diffusion model. Vera generates only what needs to change as separate edit layers while leaving the rest of the video untouched, preserving the identities, performances, and other details from the source footage exactly as filmed.
- VOID: a video inpainting model for video object and interaction deletion. VOID performs physically plausible inpainting in complex scenes: it doesn’t just remove an object, but also reconstructs the scene as if the object was never there.
Along with this blog post, we’re also publicly releasing the research papers that detail the algorithmic innovations behind Vera and VOID. We hope these publications will enable other researchers to experiment with these ideas, build upon our findings, and further advance the field.
Vera: A Layered Video Diffusion Model
Existing video editing models regenerate the entire clip, coupling the intended edit with regions that should remain unchanged. This increases the risk of altering details of the original footage. To tackle this challenge, we introduce Vera, a novel layered video diffusion framework for content-preserving video editing.

Inference Pipeline
Given a source video and a text editing instruction, Vera jointly generates an edit layer and an alpha matte. These layers are then seamlessly composed with the original footage to produce the final edited result. By design, Vera supports complex tasks such as object addition and background change, while ensuring that the pixels outside the edited regions from the source video remain perfectly intact.
Training Data
One of the main challenges in developing Vera was the lack of suitable training data. Since no public dataset provides the high-quality layered data we need (clean input, alpha matte, edit layer, composite video), we built our own. Using a combination of existing open-source videos and human annotation, we constructed a layered video dataset with a total of 486k frames at 832×480 resolution. We organized it into three subsets of increasing complexity:
- Synthetic Composites: Clips with high-quality foreground alpha mattes are composited over diverse, automatically generated backgrounds. This subset provides strong and reliable supervision for alpha matting in object addition and background change tasks.
- Realistic Single-Object Videos: Real-world clips are processed through segmentation, matting, background inpainting/generation, and human quality filtering. This subset increases scene diversity and camera motion, improving composition quality across both tasks.
- Realistic Multi-Object Videos with Effects: This extends the previous subset by isolating individual objects with curated alpha mattes, including their associated effects such as shadows and reflections. This subset improves compositing and editing in more complex, dynamic scenes.
Model Architecture
Beyond data, model design is another key challenge. The three target outputs Vera generates — an edit layer (decoupled creative edits), an alpha matte layer (a grayscale mask that depends on the edit content and scene interactions such as occlusions), and a composite layer (natural footage) — have substantially different distributions. In practice, using a single shared architecture to reconcile these differences proved data-inefficient. To address this, Vera uses a MoT (Mixture-of-Transformers) design. Instead of a single DiT, we use three separate DiTs, one for each output:
- Each DiT maintains its own QKV projections and FFN weights, but we concatenate the output tokens from all three branches and then pass it to joint self-attention. This enables cross-layer interaction while allowing each branch to specialize.
- All three DiTs are initialized from the same pretrained T2V base model. We add two additional patch-embedding layers for the input video and an optional mask video. Source-video tokens are added to the composite tokens, while mask tokens are added to the noisy alpha tokens.
- All layers share the same RoPE (Rotary Positional Encoding). We also add zero-initialized learnable embeddings to the alpha and composite tokens to help the model distinguish between layers.
Evaluations and Results
To evaluate Vera, we curated a benchmark of test video-prompt pairs: 72 for object addition and 69 for background change, using open-source videos. The test set spans a range of difficulty, including slow and fast motions, various camera motions, single and multiple objects, and both simple and complex scenes. We evaluated the performance across three complementary dimensions:
- Content Preservation: Measures whether regions outside the targeted edit remain strictly unaltered, evaluated using pixel-level and perceptual similarity.
- Instruction Compliance: Measures how faithfully the edited video executes the text prompt.
- Video Quality: Assesses the temporal coherence and per-frame spatial quality of the final edited video.
In our results, both Vera-1.3B and Vera-14B significantly outperform existing baselines on content preservation, while maintaining similar video quality and instruction compliance performance compared to strongest baselines (please see the paper for full results).

To complement automated metrics, we ran a human preference study comparing Vera against five baselines. We collaborated with 19 creative reviewers who evaluated 512 video trials in total. In each trial, reviewers were shown randomized side-by-side comparisons between the Vera model and a baseline model. The human consensus strongly aligned with our quantitative findings: Vera-1.3B was preferred over all baselines for content preservation and instruction compliance. Furthermore, reviewers rated Vera’s video quality as comparable to baselines on background change tasks, and noted a clear advantage for Vera on object addition tasks.
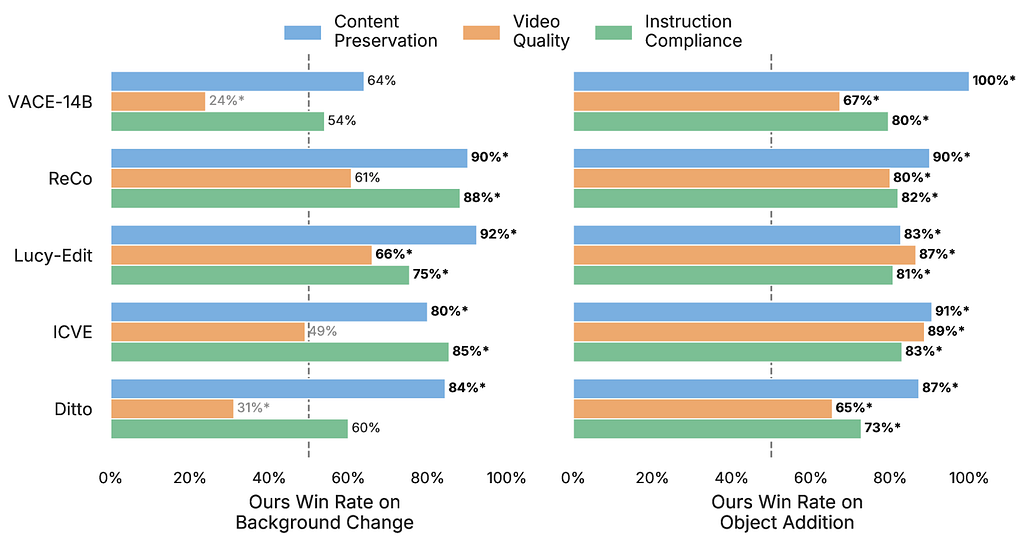
VOID: Video Object and Interaction Deletion
Existing video object removal methods excel at inpainting content “behind” the object and correcting appearance-level artifacts such as shadows and reflections. However, when the removed object has more significant interactions — such as collisions with other objects — current models fail to correct them and produce implausible results. To address this, we present VOID, a video object removal framework designed to perform physically-plausible inpainting in these complex scenarios.

A Two-Pass Inference Pipeline
Given an input video, the user clicks on an object to remove. A VLM-based reasoning pipeline then analyzes the scene to identify other regions that will be causally affected, e.g., objects that will fall, collide, or change trajectory. This physical reasoning is encoded into a quadmask to guide the diffusion model:
- First Pass: VOID takes the video and the quadmasks as input and generates a physically plausible counterfactual video in which the object — and its interactions — are removed.
- Second Pass: Smaller video diffusion models occasionally suffer from “object morphing” when generating moving objects. If VOID detects this failure mode, it triggers a second pass that re-runs inference using flow-warped noise derived from the first pass, stabilizing the object’s shape along its newly synthesized trajectory.
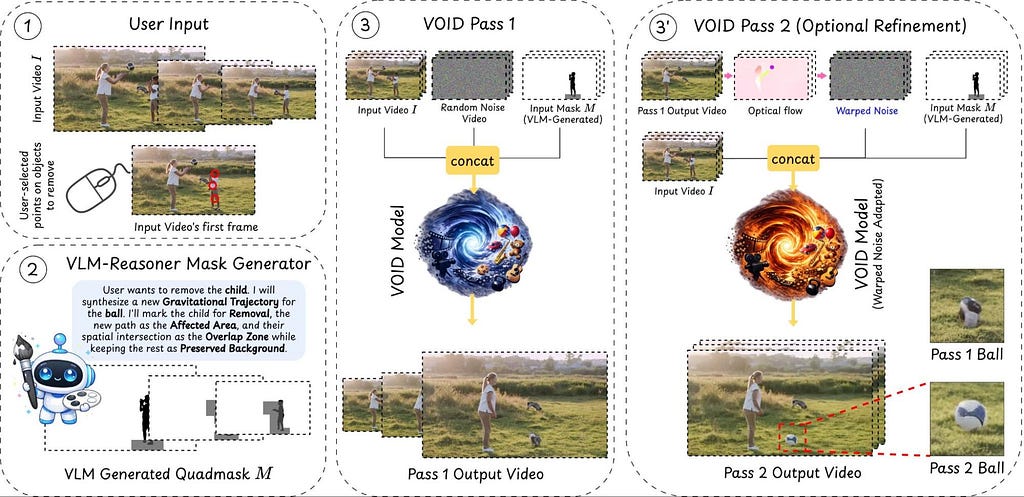
Training Data
We built on top of the Kubric simulation engine and the HUMOTO human motion capture dataset to generate synthetic counterfactual video pairs along with their corresponding quadmasks. Specifically, the counterfactual videos are generated by re-simulating the exact scene from the original video, but with the target object(s) or human removed. This resimulation creates an alternate outcome based on strict laws of physics. For example, if a person holding a lamp is removed from the scene, the simulation ensures the lamp obeys gravity and falls to the ground. The quadmasks then capture the removed object (black), the affected regions (grey), their overlaps (dark grey), and the unchanged parts of the scene (white).

Model Training
During model training for VOID, we introduce two improvements over prior work: (i) quadmask conditioning, which explicitly identifies regions in each frame that may change after the object is removed, and (ii) a second-pass video appearance refiner that reduces artifacts such as unwanted object morphing. VOID is finally trained on the CogVideoX-Fun-V1.5–5b-InP backbone with Gen-Omnimatte’s checkpoint and fine-tuned for video inpainting with interaction-aware quadmask conditioning.
Evaluations and Results
Experiments across both synthetic and real data demonstrate that VOID preserves consistent scene dynamics far better than prior video object removal methods (please see the paper for full results). VOID successfully maintains object structure and produces plausible motion over time across a wide variety of real-world cases. By contrast, results from both open- and closed-source baselines consistently exhibit physically inaccurate artifacts. For instance, baselines generate water splashes without human impact (see top row of the figure below) or show spinning tops being disrupted without the presence of interacting hands.

To complement our quantitative evaluation, we conducted a user study with 25 creative reviewers to measure the perceptual realism and physical plausibility of our counterfactual edits. Each participant was randomly assigned 5 out of 75 real-world scenarios, resulting in 125 total comparisons. For each video, participants viewed the original input alongside the outputs of VOID and six baselines (seven models total) in a randomized order. Participants were asked to select the video that best reflected how the scene should realistically appear after the object was removed, factoring in visual quality, temporal consistency, blending, the realism of scene evolution, and the absence of artifacts. VOID was selected 64.8% of the time, substantially outperforming all baseline models.
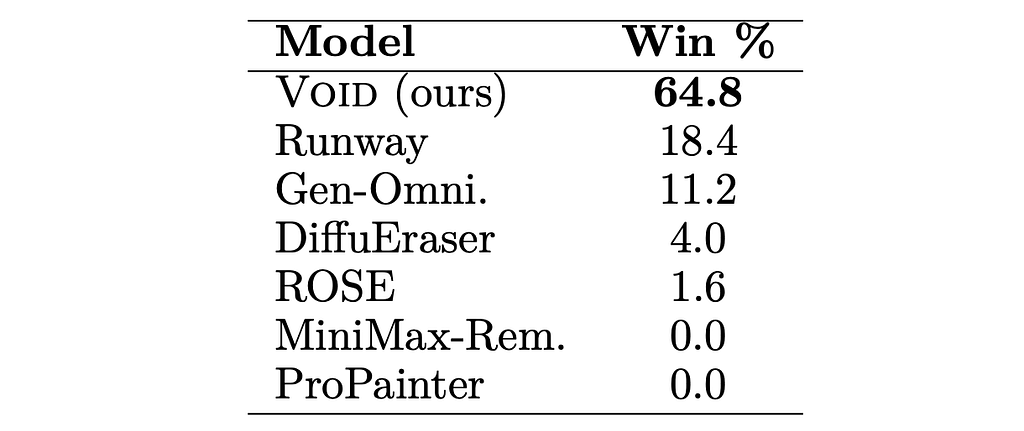
Looking Ahead
Applying AI in ways that serve both member and creator needs is core to our research philosophy, and these projects reflect that approach. While Vera and VOID show promising early results, reaching production-ready quality will require addressing several limitations we encountered. For example, Vera struggles with some complex effects such as lightning or smoke due to the limited training data, and in some cases, it fails to keep background motion fully consistent with the input camera movement. Despite the various generalization capabilities VOID exhibits, we still observe domain gaps. For instance, it cannot handle videos with unusual camera angles or shots captured very close to the target object, and it currently has constraints on supported video length and resolution.
These limitations motivate continued investment in this line of research. Vera and VOID are important early efforts toward making complex video editing more controllable and accessible for artists. For this work, we used publicly available datasets with additional annotation efforts for experiments, and we hope that sharing our research will encourage the broader community to build on these ideas and advance them further.
![]()
Toward More Controllable AI Video Editing: An Early Research Exploration at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
What Would a Post-Birthright-Citizenship Country Look Like?
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/HHB41KAMH5s
What Could Happen if the AI Bubble Pops?
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/MkfCypCS5Ps
Run isolated sandboxes with full lifecycle control: AWS Lambda introduces MicroVMs
Post Syndicated from Micah Walter original https://aws.amazon.com/blogs/aws/run-isolated-sandboxes-with-full-lifecycle-control-aws-lambda-introduces-microvms/
Today, we are announcing AWS Lambda MicroVMs, a new serverless compute primitive within AWS Lambda that lets you run code generated by users or AI in isolated, stateful execution environments. You get virtual machine level isolation, near-instant launch and resume, and direct control over environment lifecycle and state, all without managing infrastructure or building expertise in complex virtualization technologies. Lambda MicroVMs are powered by Firecracker, the same lightweight virtualization technology that has powered over 15 trillions of monthly Lambda function invocations.
Why customers need this
Over the past few years a new class of multi-tenant applications has emerged that all share the need to hand each end user their own dedicated execution environment in which to safely run code that the application developer did not write. AI coding assistants, interactive code environments, data analytics platforms, vulnerability scanners, and game servers that run user-supplied scripts all fit this pattern. Building that capability today means making a difficult choice. Virtual machines deliver strong isolation but take minutes to start. Containers launch in seconds, yet their shared-kernel architecture requires significant custom hardening to safely contain untrusted code. Functions as a service are optimized for event-driven, request-response workloads, but are not designed for long-running interactive sessions that need to retain environment state across user interactions. That leaves developers either accepting tradeoffs between performance and isolation, or investing significant engineering resources to build and operate custom virtualization infrastructure to achieve isolated execution while delivering low-latency experiences to end-users. This presents an effort that demands deep expertise and pulls engineering time away from the product they are actually trying to build.
Lambda MicroVMs is purpose-built for exactly this gap. Each MicroVM gives a single end user or session its own isolated environment that launches rapidly, retains memory and disk state for the length of the session, and pauses to a low idle cost when the user steps away. Because the same Firecracker technology already underpins AWS Lambda Functions, you inherit the operational maturity of a service that has been running this stack at scale.
Let’s try it out
To get started, I navigated to the AWS Lambda console, where Lambda MicroVMs now appears in the left-hand navigation menu. I first need to create a MicroVM Image.
I packaged a Flask web app and its Dockerfile into a zip file, uploaded it to an Amazon Simple Storage Service (Amazon S3) bucket.
My Flask API – app.py
import logging
from flask import Flask, jsonify
app = Flask(__name__)
logging.basicConfig(level=logging.INFO)
@app.route("/")
def hello():
app.logger.info("Received request to hello world endpoint")
return jsonify(message="Hello, World!")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
My Dockerfile
FROM public.ecr.aws/lambda/microvms:al2023-minimal
RUN dnf install -y python3 python3-pip && dnf clean all
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 5000
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "app:app"]
I used the following command to create my MicroVM Image.
aws lambda-microvms create-microvm-image \
--code-artifact uri=<path/to/s3/artifact.zip> --name <VM_image_name> \
--base-image-arn arn:aws:lambda:us-east-1:aws:microvm-image:al2023-1 \
--build-role-arn <IAM role ARN>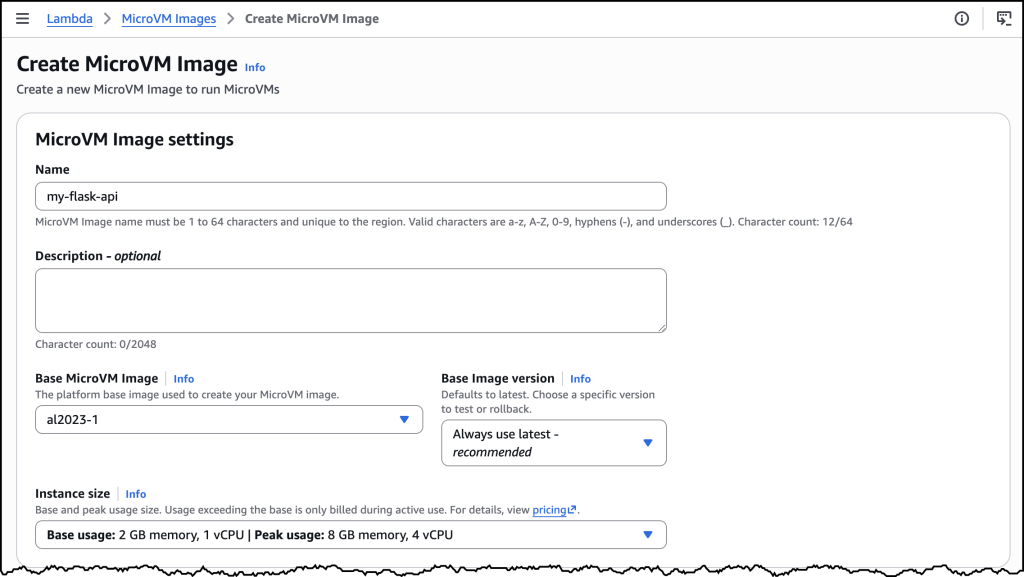
You can also create the MicroVM Image in the AWS Console as in the image above. Once I ran the command, Lambda retrieved the zip, ran the Dockerfile, initialized the application, and took a Firecracker snapshot of the running disk and memory state. Build logs streamed in real time to Amazon CloudWatch under /aws/lambda/microvms/<image-name>, and when the image was ready it appeared in the console with its Amazon Resource Name (ARN) and version number.
aws lambda-microvms run-microvm \
--image-identifier arn:aws:lambda:<region>:<acct>:microvm-image:my-image \
--execution-role-arn arn:aws:iam::<acct>:role/MicroVMExecutionRole \
--idle-policy '{"maxIdleDurationSeconds":900,"suspendedDurationSeconds":300,"autoResumeEnabled":true}'
Launching can also be done via the AWS Console or the CLI. I passed the image ARN and an idle policy configured to auto-suspend after 15 minutes of inactivity and auto-resume on the next incoming request. No networking setup was required. Lambda assigned the MicroVM a unique ID, returned a dedicated endpoint URL, and started a new MicroVM with my Flask app already running, since it was resumed from a snapshot. My Flask app was already running the moment the launch completed. One API call to get a fully initialized, bootstrapped compute environment.
To send traffic, I generated a short-lived auth token with the CLI and attached it to a plain HTTPS request using the X-aws-proxy-auth header. The request landed on my Flask app immediately. I then let the MicroVM sit idle past the suspend threshold, at which point the MicroVM was suspended, with its memory and disk state snapshotted and stored. I then sent another request, and it resumed with the application state fully intact. From the client side, the pause never happened.
How it works
Under the covers, Lambda MicroVMs delivers three capabilities that, until today, no single AWS compute service offered together. The first is virtual machine level isolation, which comes from Firecracker. Each session runs in its own dedicated MicroVM with no shared kernel and no shared resources between users, so untrusted code supplied by one user is contained to their execution environment, without access to other environments or the underlying system. The second is rapid launch and resume. The model is image-then-launch: you create a MicroVM Image by supplying a Dockerfile and code packaged as a zip artifact in Amazon S3, and Lambda runs your Dockerfile, initializes your application, and takes a Firecracker snapshot of the running environment’s memory and disk state. Every subsequent MicroVM launched from that image resumes from the pre-initialized snapshot rather than booting cold, which means launches and idle resumes both achieve near-instant startup latency. Even a multi-gigabyte interactive session comes back online quickly enough to feel responsive to the end user. The third is stateful execution. A running MicroVM retains memory, disk, and running processes across the user’s session. During idle periods, a MicroVM can be suspended – with memory and disk state intact – and resumed when traffic arrives. Installed packages, loaded models, and working filesets are readily available when the user resumes their session. MicroVMs support up to 8 hours of total runtime and can be suspended automatically after a configurable idle window, which makes it straightforward to build products as varied as software vulnerability scans that complete in minutes, data analytics applications that run for hours, and interactive coding sessions with extended idle periods. As Lambda MicroVMs are started from pre-initialized snapshots, applications generating unique content, establishing network connections, or loading ephemeral data during initialization may need to integrate with service-provided hooks for compatibility.
Lambda MicroVMs is a new resource within AWS Lambda, with a distinct API surface. Lambda Functions remain the right choice for event-driven, request-response workloads, and Lambda MicroVMs is purpose-built for multi-tenant applications that need to hand each end user or session their own isolated environment to execute user- or AI-generated code. The two complement each other. An application using Lambda Functions for its event-driven backbone can call into Lambda MicroVMs for the steps that need to run untrusted code in isolation. You bring the application, and the service delivers the execution environment.
Now available
AWS Lambda MicroVMs is available today in the US East (N. Virginia, Ohio), US West (Oregon), Europe (Ireland) and Asia Pacific (Tokyo) Regions, on the ARM64 architecture, with up to 16 vCPUs, 32 GB of memory, and 32 GB of disk per MicroVM. Idle MicroVMs can be suspended explicitly through an API call or automatically through a lifecycle policy, which reduces the running cost while preserving full state for fast resume. Pricing details can be found on the AWS Lambda pricing page.
To get started, visit the AWS Lambda console, or learn more on the Lambda MicroVMs product page. For documentation, see the Lambda MicroVMs Developer Guide.
Building and running custom code transformations without leaving your editor
Post Syndicated from David Hasani original https://aws.amazon.com/blogs/devops/building-and-running-custom-code-transformations-without-leaving-your-editor/
Custom code transformations are the work that no off-the-shelf migrator covers for you. Moving your services off an internal library, enforcing your team’s error-handling conventions, standardizing logging across your fleet of services: that work piles up on your backlog because general-purpose tools weren’t written with your codebase in mind.
AWS Transform custom tackles that kind of work. It’s an agentic AI service that lets you describe your own code transformations in natural language and run them across your codebase. With the Kiro power for AWS Transform, the AWS Transform agent skill, and the AWS Transform IDE plugin (VS Code and Open VSX), you can design and run those transformations from your editor. You can transform up to 3 repositories in parallel on your laptop, or fan out to hundreds of repositories in parallel on AWS Batch with AWS Fargate, without leaving the chat or IDE you already work in.
This post shows you what AWS Transform custom is, how to request a new transformation definition (TD) from chat, and how to run TDs through the power, skill, or IDE plugin. The authoring walkthrough focuses on the chat-driven request workflow. The agent drafts and publishes the TD on your behalf, so you won’t see raw TD syntax in this post.
What makes AWS Transform “custom”
AWS Transform ships with a catalog of out-of-the-box transformation definitions for common scenarios, including Java version upgrades, boto2 to boto3, AWS SDK migrations, framework transitions, and x86 to AWS Graviton. Those cover a lot of ground, but the real unlock is when you define your own.
A transformation definition is a reusable recipe that describes how to perform a transformation. With AWS Transform custom, you author TDs in natural language. A few examples of what that looks like in practice:
- “Upgrade my codebase from C++11 to C++17”
- “Replace calls to our deprecated internal auth-sdk-v1 with auth-sdk-v2, keeping the retry configuration intact.”
- “Enforce our team’s error-handling standard: no bare except blocks, and every exception includes context.”
- “Standardize our REST controllers to use our internal @TracedEndpoint annotation.”
Each one encodes something specific to your organization. Once you publish a custom TD to your AWS account, you can apply it to a matching repository, whether that’s one project or a hundred.
Three common ways to work with AWS Transform custom
You can pick the surface that fits how you already work. The power lives inside Kiro IDE, the skill plugs into your compatible agent, and the IDE plugin gives you a UI in VS Code or Open VSX-compatible IDEs. These three surfaces talk to the same underlying service and share your TDs, so you can mix and match across a team.
The Kiro power for AWS Transform brings the full AWS Transform workflow into Kiro IDE. You describe what you want in chat, and Kiro inspects your project, matches it against your available TDs, asks for the configuration it needs, and runs the transformation. Progress, artifacts, and diffs show up in your editor.
The AWS Transform agent skill follows the open Agent Skills standard. The same package works across more than 40 compatible agents, including Kiro CLI, Claude Code, Cursor, GitHub Copilot, Gemini CLI, and Windsurf. You get the same workflow you get from the Power, portable across the tools you already use.
The AWS Transform IDE plugin is for when you prefer a UI over chat. You can install it from the VS Code Marketplace and Open VSX. The plugin exposes AWS Transform custom features as first-class IDE actions, including browsing your published TDs and launching transformations.
Creating a custom TD right from chat
Historically, creating a custom TD meant dropping to the terminal and running the AWS Transform custom CLI to step through an interactive authoring session. That path still works and is a good fit for scripting. With the power, skill, or IDE plugin, you can do the same thing entirely in chat.
Tell your agent what you want, for example:
Create a custom AWS Transform custom TD that migrates our internal logger-v1 package to logger-v2. The new API uses logger.info(msg, context) instead of logger.log(level, msg). Keep existing log levels intact.
From there, the agent walks you through a short loop. It asks clarifying questions about the transformation’s scope and behavior, drafts the TD based on your description, lets you review and refine it, and then publishes it to your AWS account. After publishing, your TD is immediately available to the power, skill, and plugin. The next time you ask to run a transformation on a matching repo, your new TD shows up as a candidate.
The CLI path is still there if you prefer it. Run this in a new terminal:
atx
Then follow the interactive prompts.
Running your custom TDs
Once you have one or more TDs published, running them looks the same regardless of surface. When you ask Kiro to run a transformation, the Kiro Power walks through the following steps with you:
- Inspect your repositories. The agent reads pom.xml, package.json, requirements.txt, Dockerfiles, and similar config files to understand what it’s looking at.
- Match against your TDs. It compares your repos to your published TDs (custom and out-of-the-box) and presents a report showing which ones apply and why.
- Collect the configuration it needs. Some TDs require inputs like a target version. The agent prompts you for those before it runs.
- Confirm the plan. Nothing executes until you approve.
- Execute and monitor. The agent launches the transformation through the AWS Transform CLI, streams progress, and opens artifacts (for example, plan, worklog, and validation summary) in your editor.
- Show results. Every change is a normal git commit you can review.
Local mode and remote mode: scale without the setup tax
Running locally, you can transform up to 3 repositories in parallel on your machine. That’s fine for one-off work, but it doesn’t scale to a real modernization campaign.
Remote mode is where scale comes in. It runs your transformations on AWS Batch with AWS Fargate, so you can fan out to hundreds of repositories in parallel. No local compute bottleneck, and no leaving your laptop running overnight.
The agent sets remote mode up for you. Ask to run in remote mode, and it provisions the AWS Batch compute environment, job queue, job definitions, IAM roles, and networking automatically. You don’t hand-write CloudFormation, and you don’t navigate the AWS console. Once the infrastructure is in place, you kick off a run the same way as local mode, and the agent streams progress back to your editor while Fargate does the heavy lifting.
Your inputs can be local paths, git URLs, or S3 locations, and the same applies to remote runs. Point the agent at a list of repos and let it go.
Getting started
The first time you use the power, skill, or IDE plugin, the agent walks you through setup. If you’d rather do it by hand, you need a few things in place first.
Install the power (Kiro IDE)
Before you install the power, make sure you have:
- AWS Command Line Interface (CLI) installed and configured with aws configure.
- AWS credentials with the AWSTransformCustomFullAccess managed policy (or at minimum, transform-custom:* permissions).
- macOS or Linux. Native Windows isn’t supported, so use WSL.
A straightforward way to install the power:
- Open Kiro IDE and open the Powers panel.
- Find AWS Transform in the list and install it.
- Open Kiro Chat, then select the Power and choose Try power.
To install from source instead:
- In the Powers panel, choose Add Custom Power, then Import power from GitHub.
- Paste: https://github.com/kirodotdev/powers/tree/main/aws-transform
Install the skill (any compatible agent)
Before you install the skill, install the AWS Transform custom CLI:
curl -fsSL https://transform-cli.awsstatic.com/install.sh | bash
Then add the skill to your agent:
npx skills add https://github.com/awslabs/agent-plugins/tree/main/plugins/aws-transform/skills/aws-transform
Follow the prompts to finish the installation. You can also drop the skill folder into your agent’s skills directory manually, for example, .kiro/skills/ for Kiro CLI or .claude/skills/ for Claude Code.
Install the IDE plugin
The IDE plugin is published to two marketplaces:
- VS Code Marketplace
- Open VSX
Install it the same way you install any other extension in your editor.
Your first custom TD
Once you have a surface installed, try something like:
Create a custom AWS Transform transformation that [describe your transformation].
Then run it against a repo:
Use AWS Transform to run my new transformation on /path/to/my-project.
The agent walks you through creating the TD, modifying it, publishing it, and running it on your repos from start to finish.
Cleanup
If you ran any transformations in remote mode, once they complete, the agent will ask if you want to keep or clean up the remote mode resources deployed to your AWS account. To clean up, simply tell the agent that you want to clean up. The agent will then delete the resources that were created in your AWS account as a part of the initial setup for the remote mode transformations. To delete any user-managed transformation definition that you chose to publish to your registry, simply run atx in a terminal, ask to list all transformation definitions, find your recently published user-managed transformation definition, and ask to delete it from the registry.
Wrapping up: making your migrations faster
The value of AWS Transform custom is in the transformations only you can write, the ones that encode your organization’s libraries, conventions, and standards. The power, skill, and IDE plugin make both sides of that loop, authoring and running, feel native to your editor.
If you’ve been putting off your migrations because the tooling wasn’t there, now’s the time to take another look.
Learn more
- AWS Transform custom
- AWS Transform Kiro power
- AWS Transform agent skill
- AWS Transform IDE plugin (VS Code)
- AWS Transform IDE plugin (Open VSX)
- Kiro IDE