Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/XBAtPdMej98
Troubleshooting Elastic Beanstalk Environments with Amazon Q Developer CLI
Post Syndicated from Adarsh Suresh original https://aws.amazon.com/blogs/devops/troubleshooting-elastic-beanstalk-environments-with-amazon-q-developer-cli/
Introduction
Developers working with AWS find AWS Elastic Beanstalk to be an invaluable service which makes it straightforward to deploy and run web applications without worrying about the underlying infrastructure. You simply upload your application code, and Elastic Beanstalk automatically handles the details of capacity provisioning, load balancing, scaling, and monitoring, which allows you to focus on writing code.
With the release of the Amazon Q Developer’s new enhanced CLI agent, we’ve already seen how Q CLI can be used to transform the approach to the software development process.
In addition to software development, developers and DevOps teams may spend most of their time on operational tasks such as deploying and testing their code on multiple environments, including troubleshooting any deployment related failures or application health issues. Q CLI’s new agentic features can be used to significantly simplify this process by helping you identify and resolve operational issues in a more efficient manner.
When troubleshooting Elastic Beanstalk environment issues, Q CLI becomes a go-to companion. When environments show degraded health or deployment failures, developers can use Q CLI to quickly investigate without having to navigate through multiple AWS console pages or parse multiple logs manually.
For instance, when facing deployment failures, you can run q chat to start a new conversation and describe the issue. Q CLI can help analyze instance logs, check environment configurations, and identify misconfigurations in applications. It can pull relevant error messages from Elastic Beanstalk logs and suggest specific fixes based on the error patterns it recognizes.
When dealing with health issues, developers can ask Q CLI to check their environment’s status, resource utilization, and recent events. It can identify if an application is experiencing out of memory problems, connectivity issues, or dependency related failures. Q CLI can also examine application logs to find recurring errors that might be causing health degradation.
What developers appreciate most is how Q CLI connects the dots between different AWS services. If an Elastic Beanstalk environment is having issues because of an underlying Amazon VPC configuration issue or Amazon S3 permission issue, Q CLI can identify these connections and provide holistic solutions.
The time savings are significant – what used to take hours of investigation across multiple AWS console pages now takes minutes with targeted Q CLI queries. This has dramatically improved developers’ ability to maintain healthy environments and quickly resolve issues when they arise.
Below, we’ll take you through some examples of how you can use Q CLI to troubleshoot some of the issues that you may face while managing Elastic Beanstalk environments.
Solution Walkthrough
Prerequisites
If you’d like to follow along on your own machine, please make sure you complete the following prerequisites:
- An AWS account with Elastic Beanstalk access
- Basic familiarity with Elastic Beanstalk concepts (environments, applications, deployments)
- AWS CLI installed and configured with appropriate permissions to access Elastic Beanstalk resources, and collect logs
- AWS Q Developer CLI installed and setup
- EB CLI installed and setup (optional)
- Elastic Beanstalk environments created for troubleshooting
Now let’s dive into troubleshooting specific Elastic Beanstalk issues with Q CLI. All the scenarios below were tested with Amazon Q Developer CLI with a Pro tier subscription as it provides higher request limits, but is not required for the purposes of this demo.
Troubleshooting environment health
Let’s consider an Elastic Beanstalk environment running Node.js 22 AL2023, to which we’re going to deploy a new application version. After deploying a new application version to our Node.js based elastic beanstalk environment, we noticed that its health status changed to a “Warning” state with the following message visible in the environment events:
100% of requests failing with HTTP 5xx errors
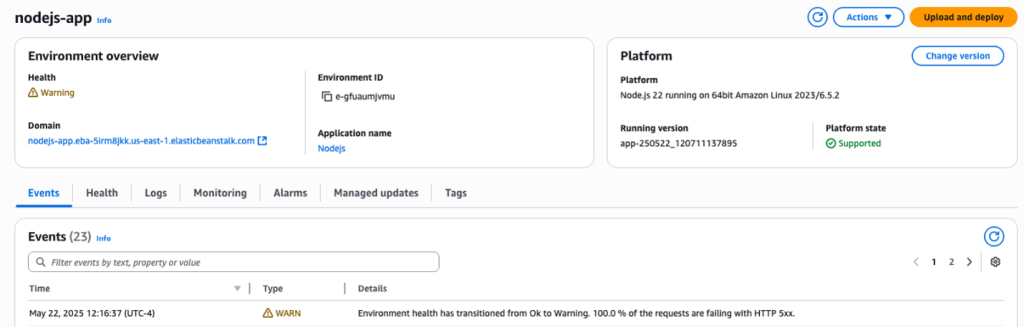
Figure 1. EB Dashboard showing the Warning health state, along with the reason for the health status
This event message could be a result of a number of issues, including but not limited to Nodejs application failures, reverse proxy configuration issues, resource utilization issues etc.
Let’s use Q CLI to help us investigate further. We’ll initiate a new conversation with the agent by running q chat, and ask the following question:
Why is my beanstalk environment nodejs-app in us-east-1 unhealthy? Check the logs if required, and recommend steps to resolve the issue
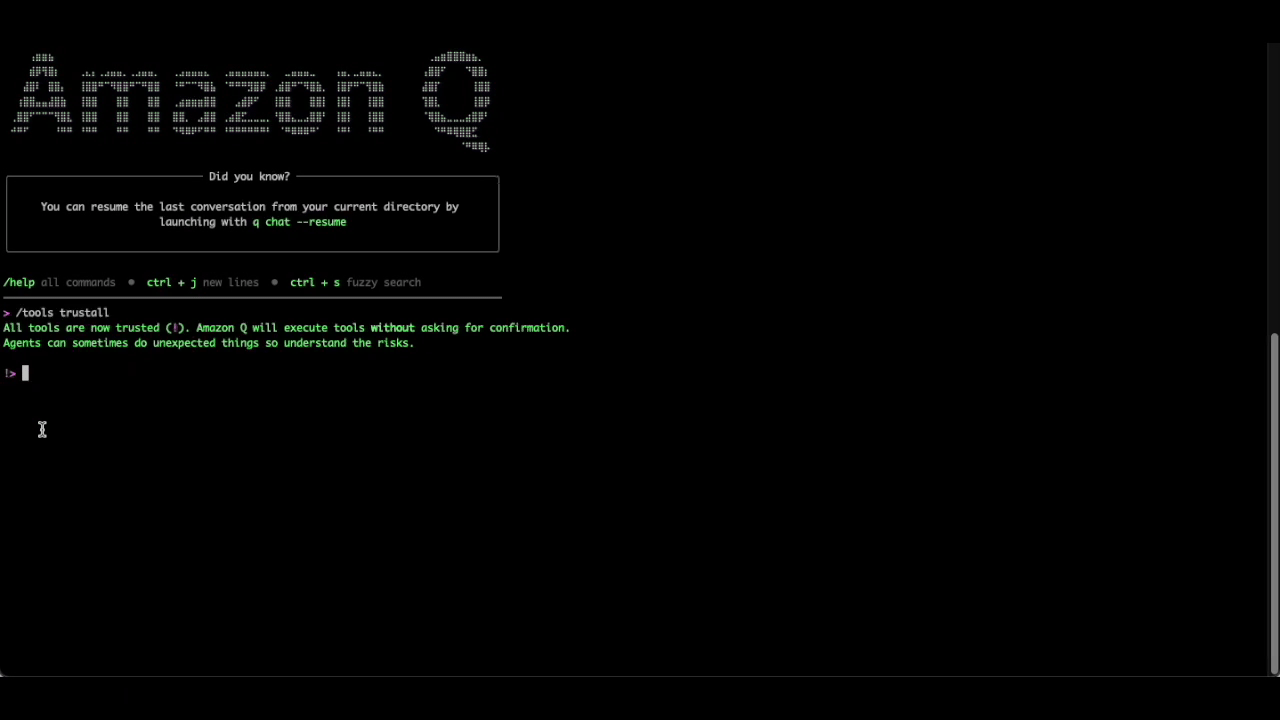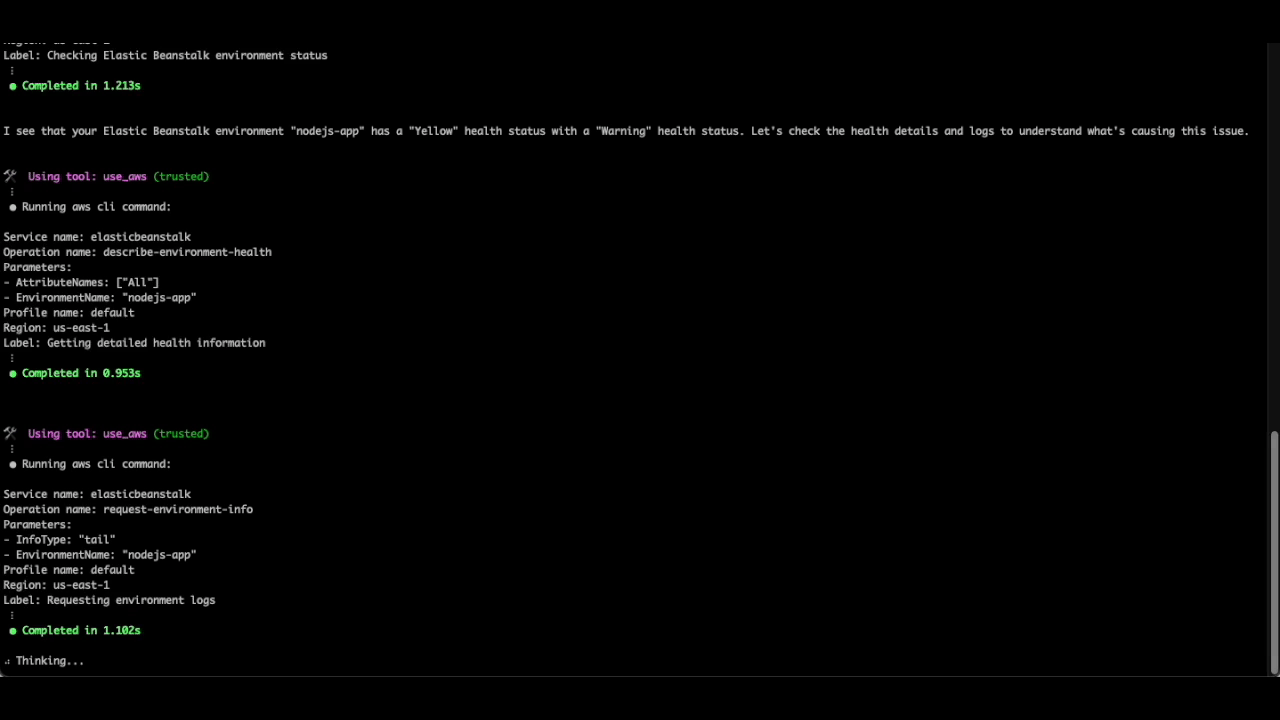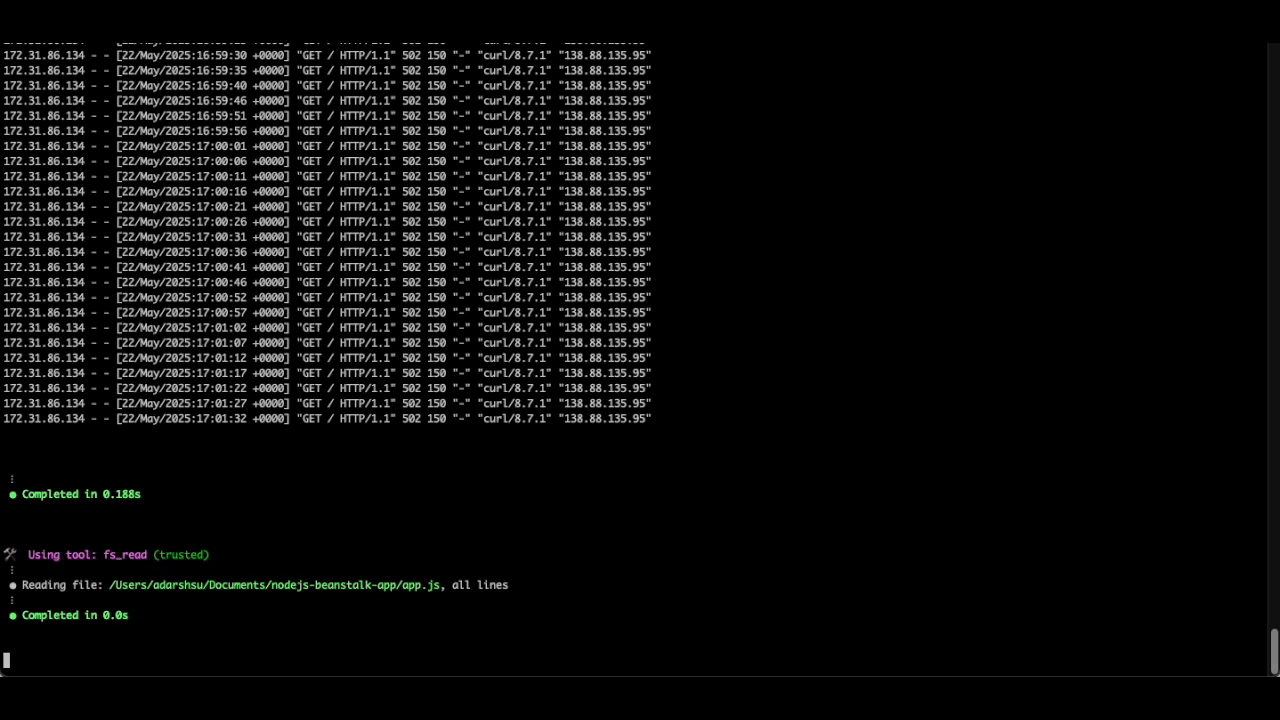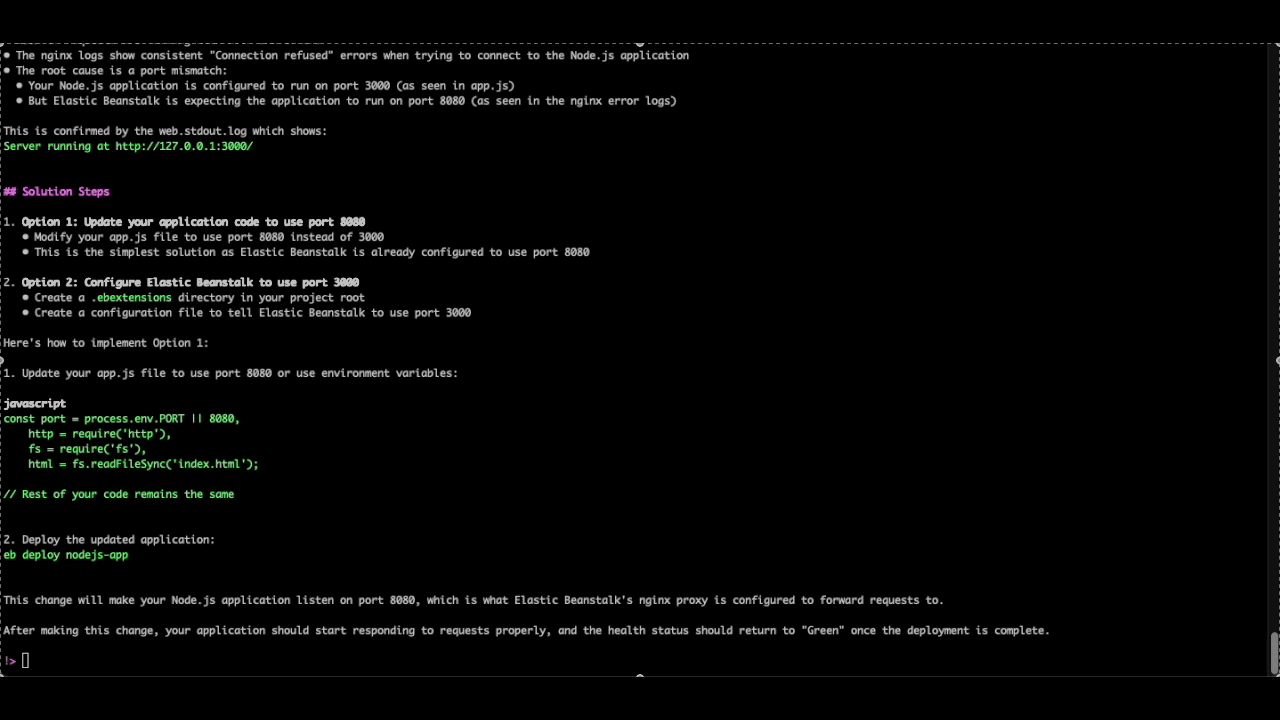
Note that we’ve disabled all confirmations for q chat using the /tools trust-all option as we’re using a development environment, but this is generally not recommended as it can lead to unexpected changes.
As you can see, the Q CLI agent is able to use the AWS CLI tool to describe the environment details, its health status and retrieve the tail logs for further analysis. It then parses through the log file to identify the source of the issue, all without requiring additional prompts.
As we can see from the below image, the Q CLI agent was able to parse the logs and identify that the Nodejs application is running on port 3000, but the Nginx proxy is attempting to establish a connection to the application on port 8080 (which is the default forwarding port for Nodejs based elastic beanstalk environments), resulting in HTTP requests failing with a 502 response.
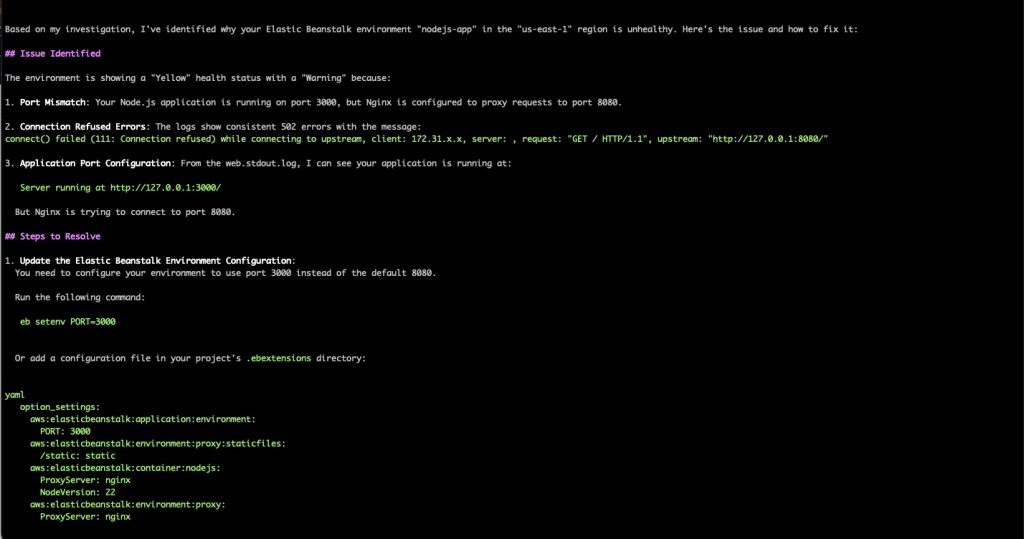
Figure 2. Q CLI solution for port issue
As requested in the prompt, the Q CLI agent also provides multiple ways to implement the recommended solution, along with specific steps or commands for each option. In this specific case, Q CLI correctly advised us to update the elastic beanstalk environment’s configuration to use port 3000 and shared multiple approaches to apply the recommended changes.
Environment creation failures
Here, we’re trying to create a new Elastic Beanstalk environment in a new VPC, but the environment creation fails with the following error message as we can see in the screenshot below:
The EC2 instances failed to communicate with AWS Elastic Beanstalk, either because of configuration problems with the VPC or a failed EC2 instance. Check your VPC configuration and try launching the environment again.
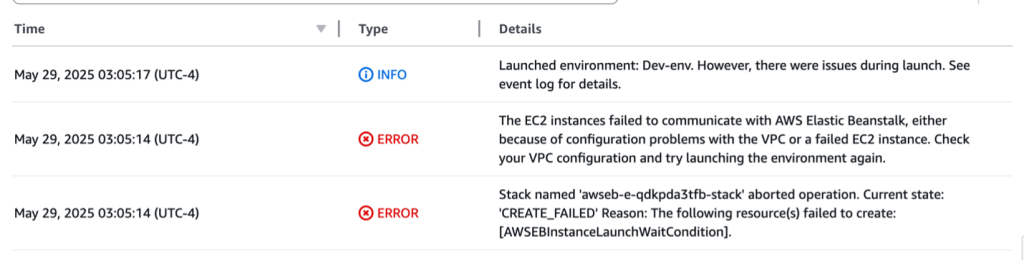
Figure 3. EB events describing the VPC connectivity issue
Now, let’s ask Q CLI to help us investigate this specific issue. We will issue the following prompt to Q CLI with the environment’s name and region, along with the specific error message that is observed:
The beanstalk environment "Dev-env" in the us-west-2 region failed to launch successfully with the following error: The EC2 instances failed to communicate with AWS Elastic Beanstalk, either because of configuration problems with the VPC or a failed EC2 instance. Check your VPC configuration and try launching the environment again. Check the environment configuration and recommend steps to resolve the issue.
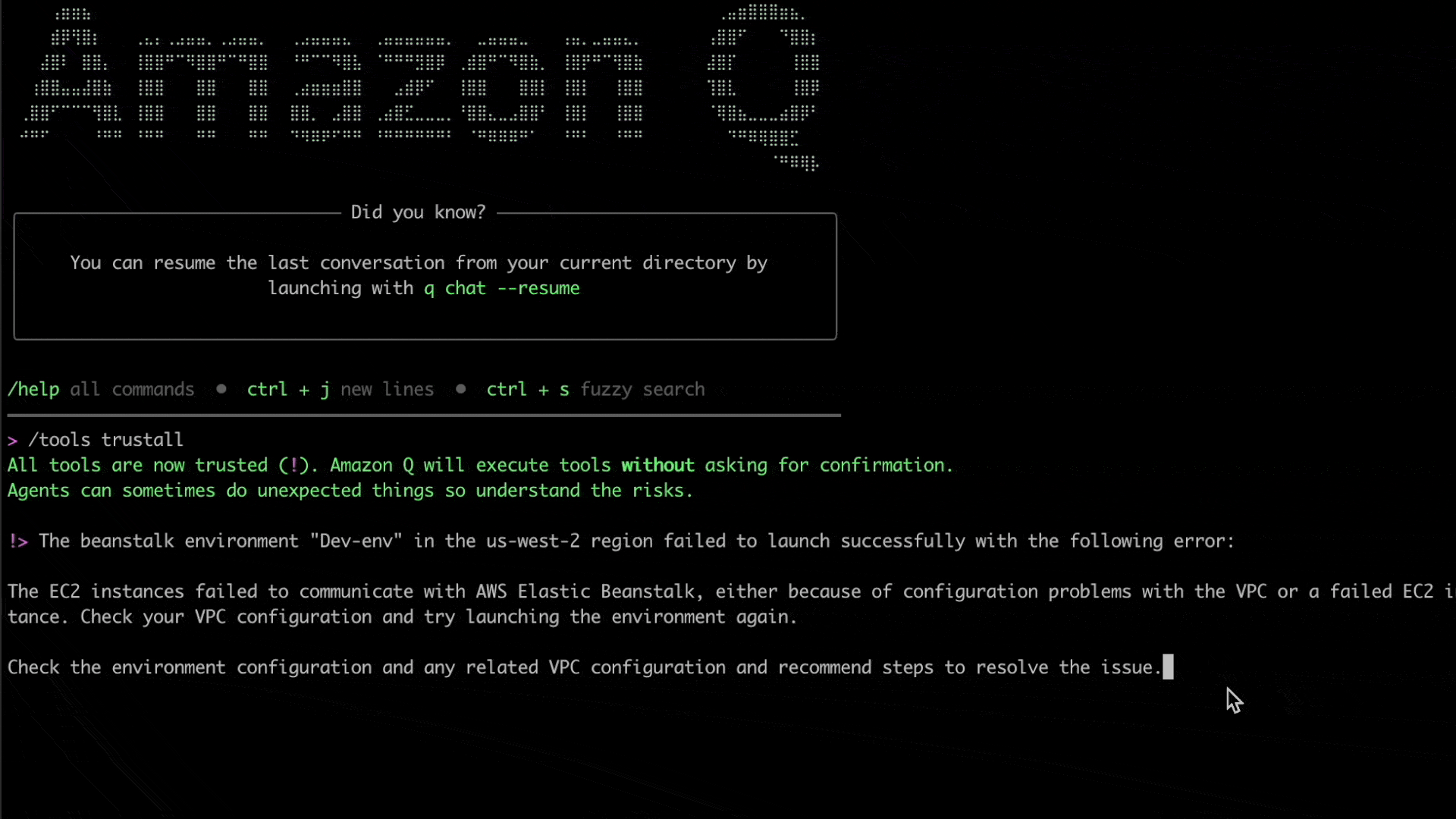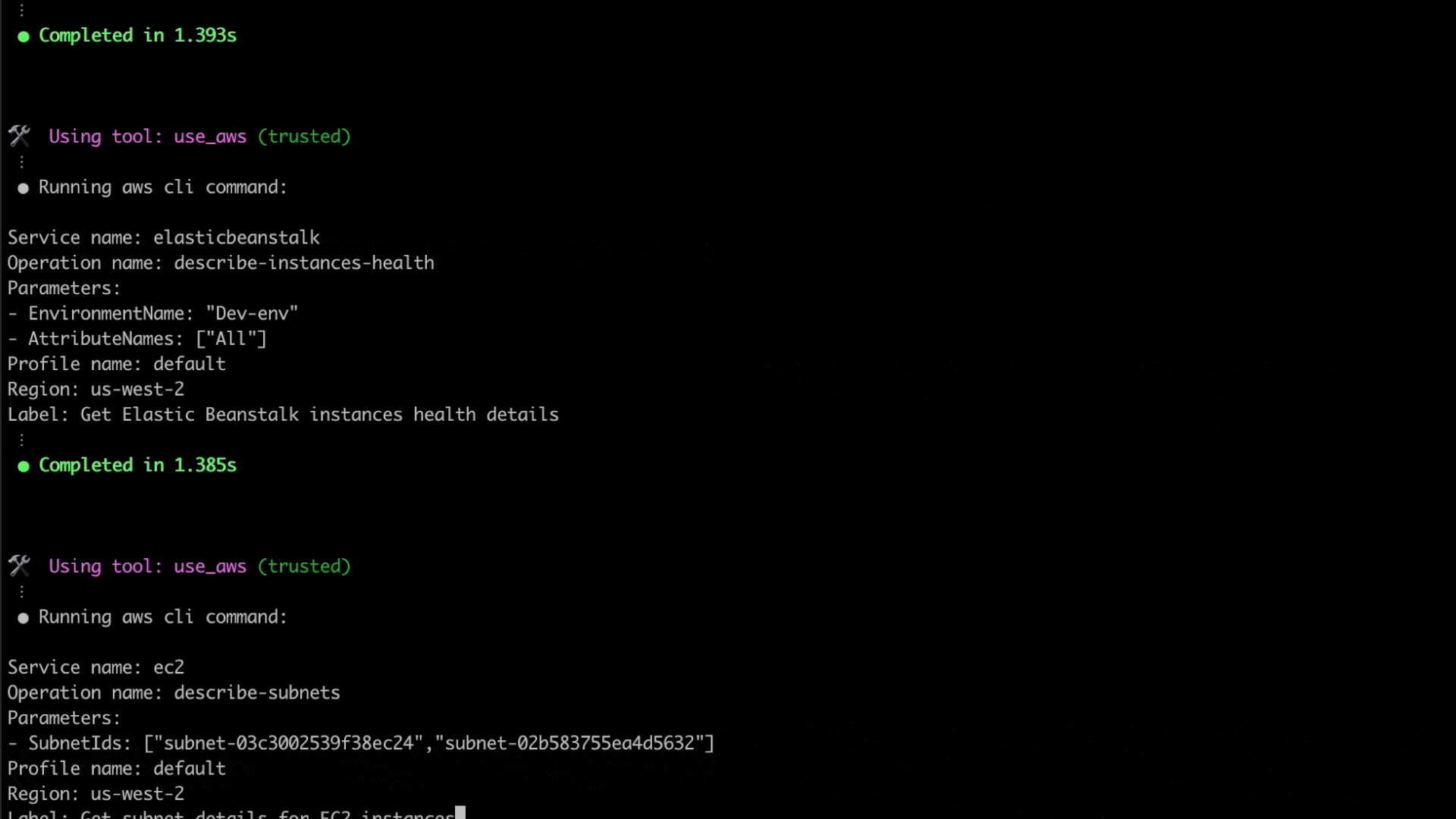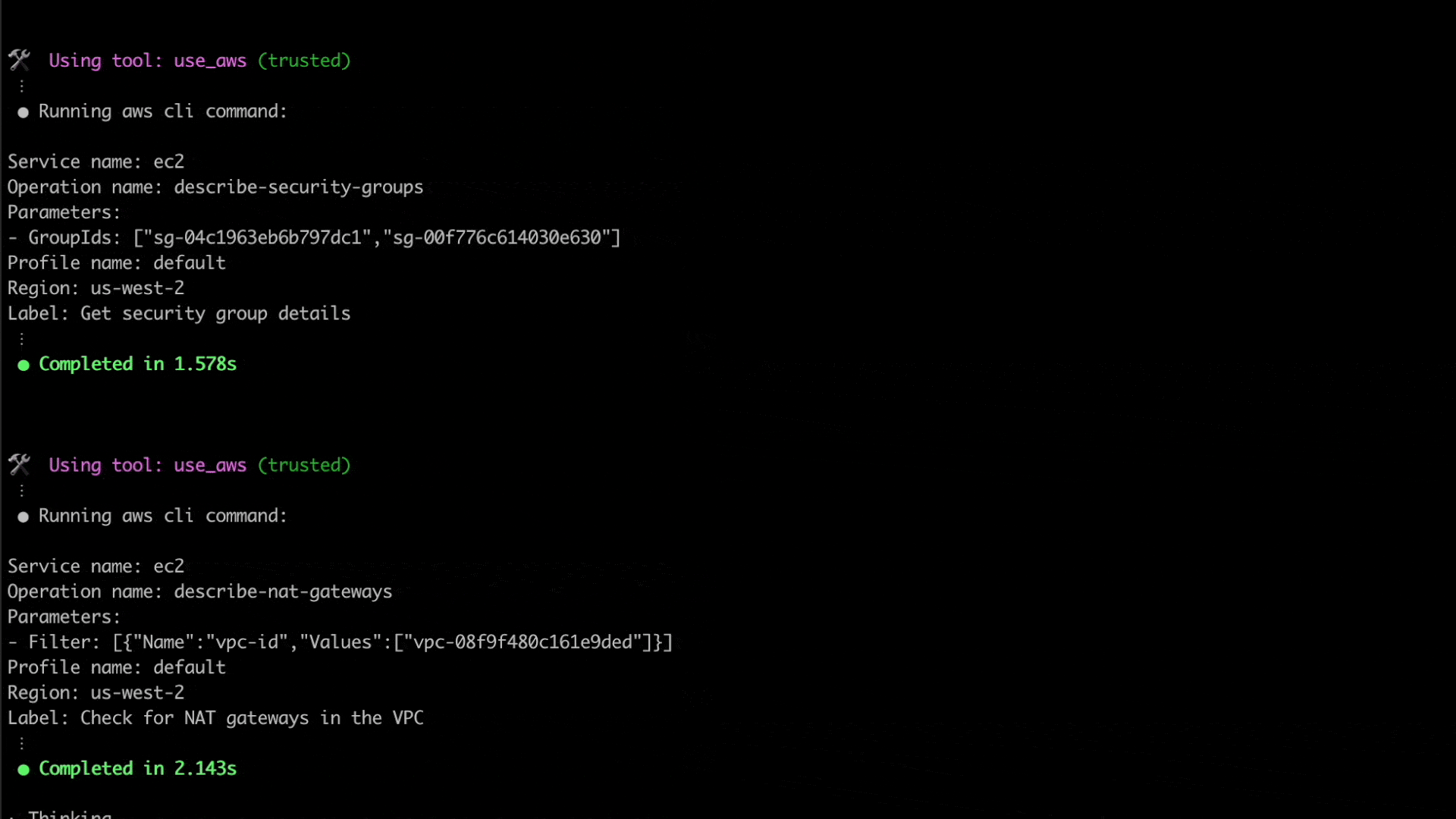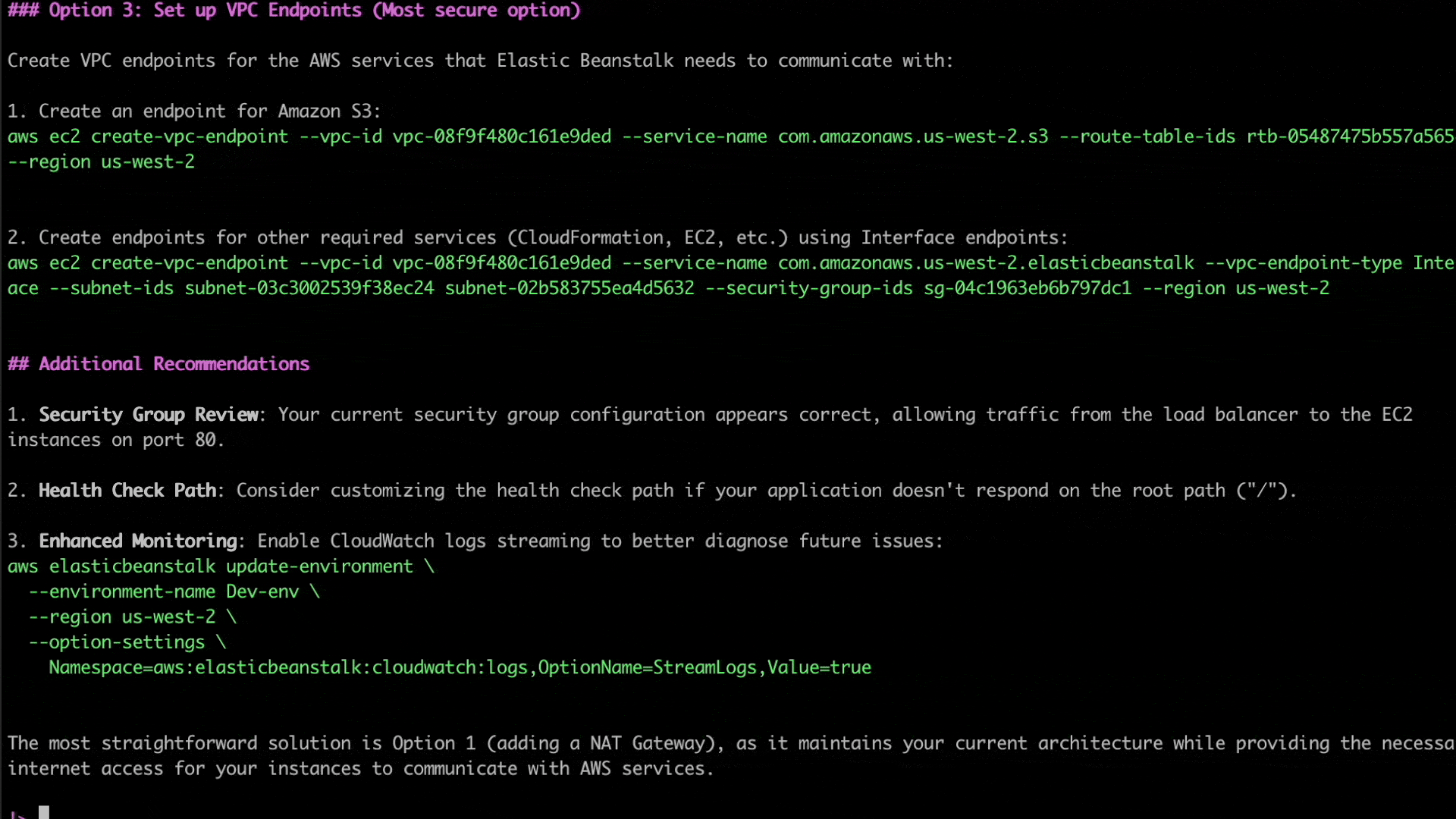
Here, Q CLI is able to use the given context to invoke relevant AWS CLI commands to check and verify the elastic beanstalk environment’s configuration, including its underlying resources such as the VPC, subnets, route table, security groups and related resources.
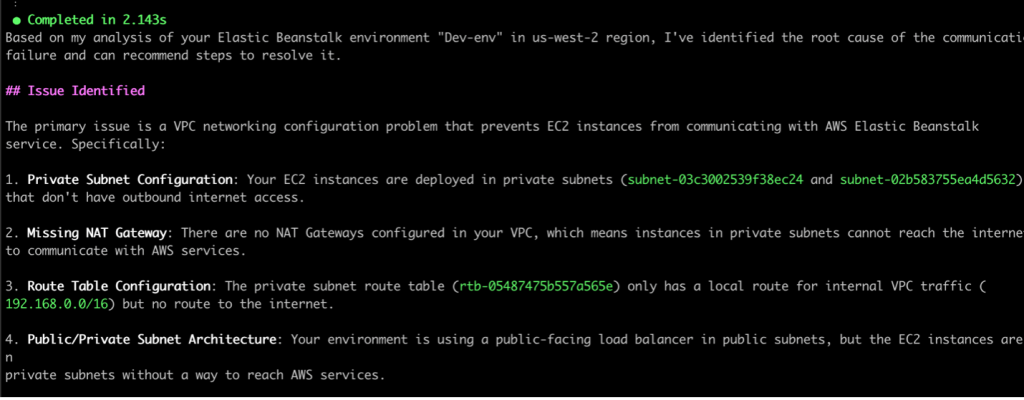
Figure 4. Q CLI identified network configuration issues
After retrieving the required information, Q CLI was able to identify the source of the issue. The subnets configured for the elastic beanstalk environment’s EC2 instances do not have outbound internet access, due to which they are unable to communicate with the AWS service endpoints.
As seen in the following screenshot, Q CLI then goes on to recommend multiple solutions to resolve the issue, specifically highlighting the more secure options recommended for production vs other options that are simpler to manage but may not be as secure.
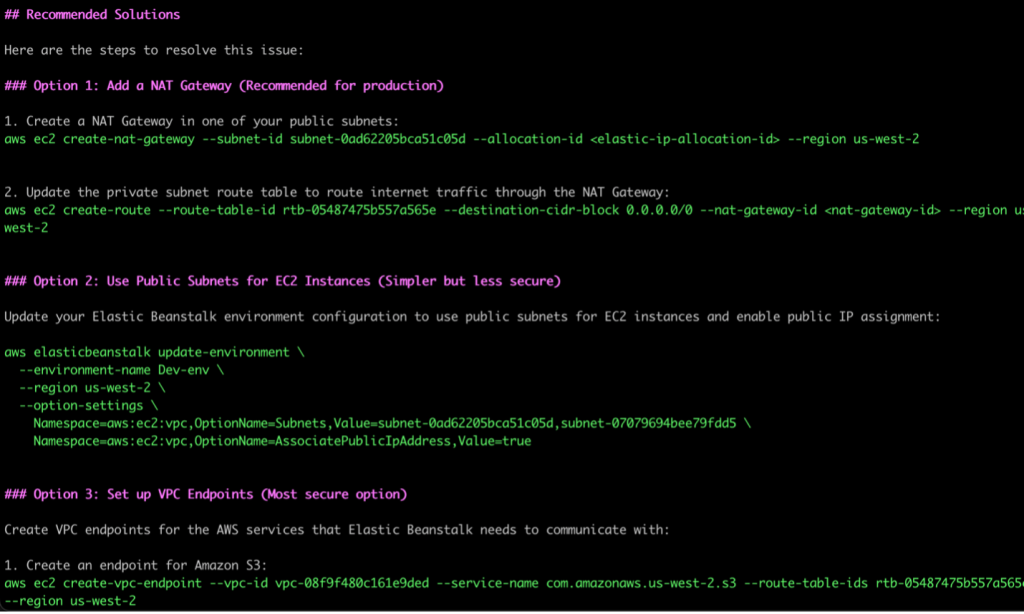
Figure 5. Q CLI solutions for resolving network configuration issues
We can see how using Q CLI here results in significant time saved during troubleshooting as it quickly and efficiently verifies the relevant underlying resource configurations, hence removing the need for the developer to manually identify and check multiple AWS resource configurations.
Command Execution Failures
In this next scenario, we’re attempting to deploy a python application to an elastic beanstalk environment, using a Python 3.13 based solution stack. We noticed that the deployment fails with the following error message, visible in the environment events:
Command failed on instance. Return code: 1 Output: Engine execution has encountered an error.
Let’s ask Q CLI to help us identify and resolve the issue, with the following prompt:
The deployment to the beanstalk environment "modern-python" in the us-east-1 region failed with the error "Command failed on instance". Check the environment details, and logs if required, and recommend steps to resolve the issu
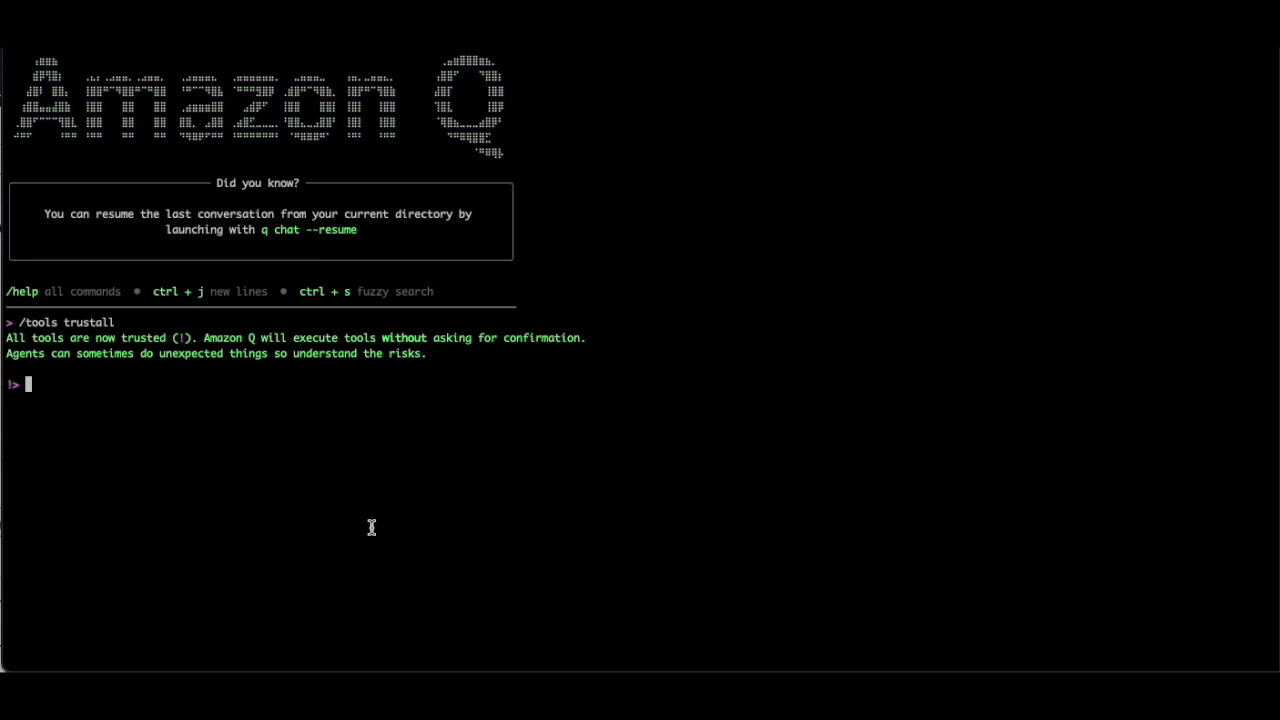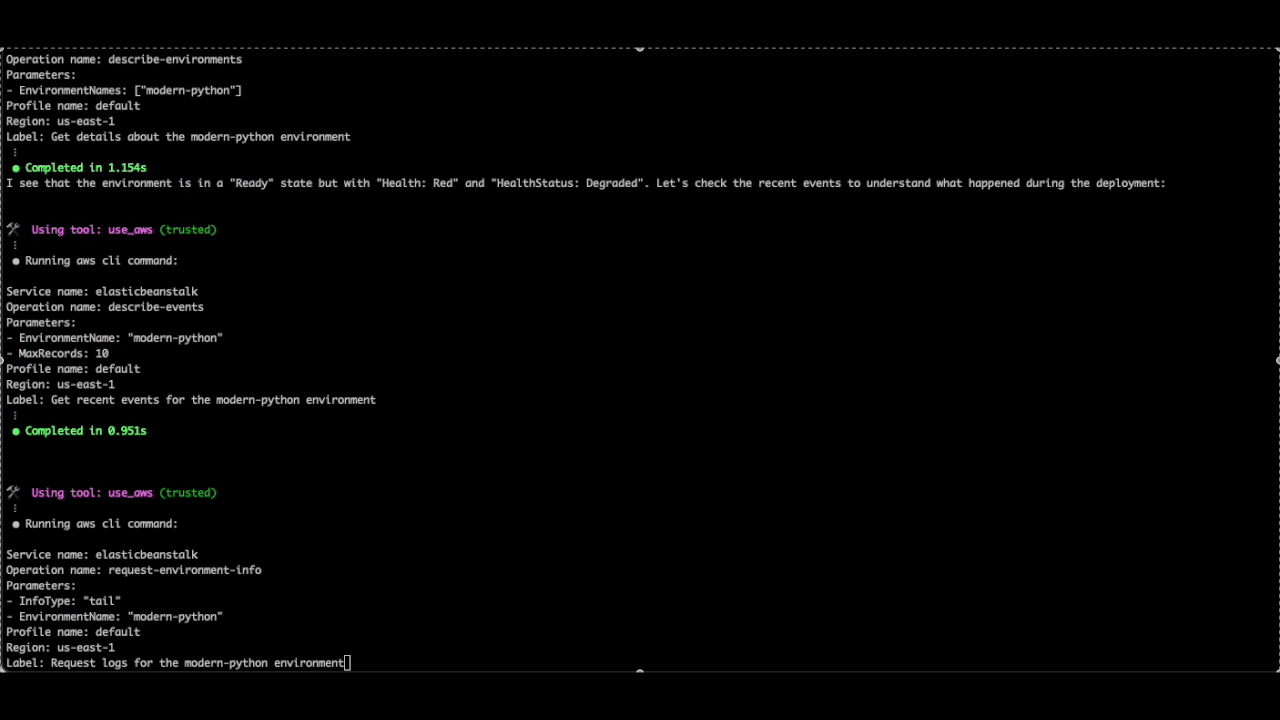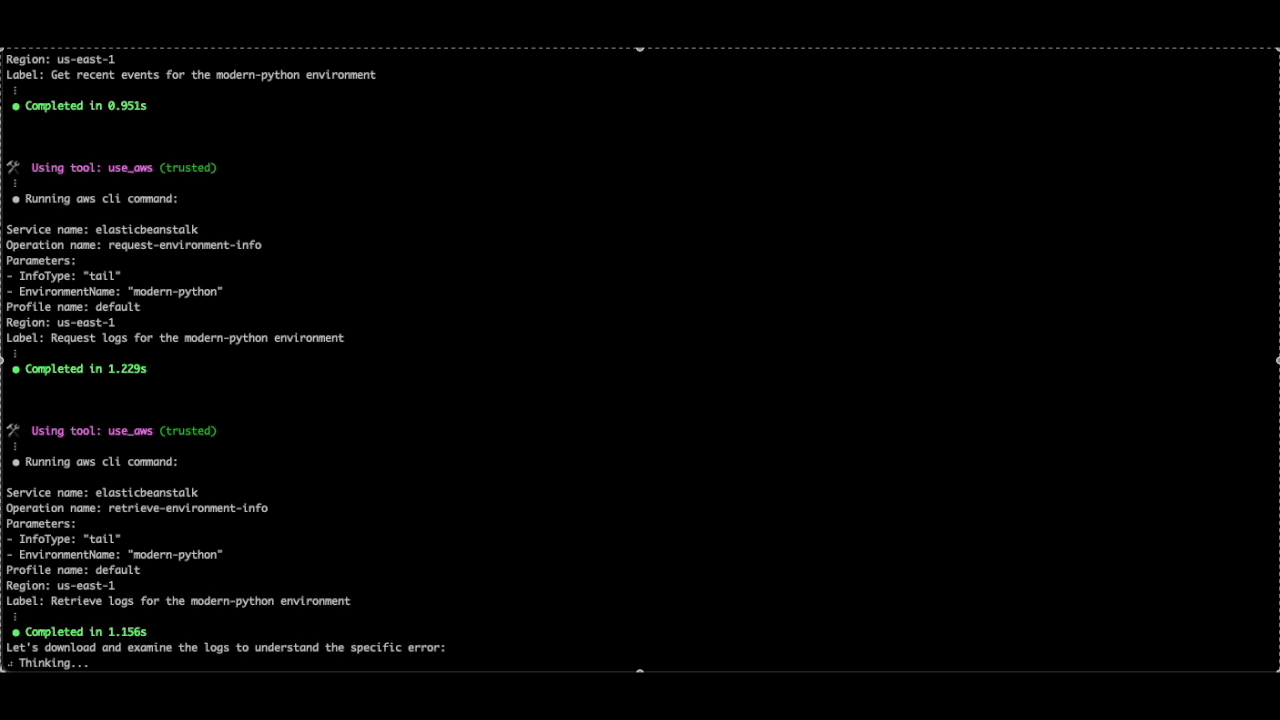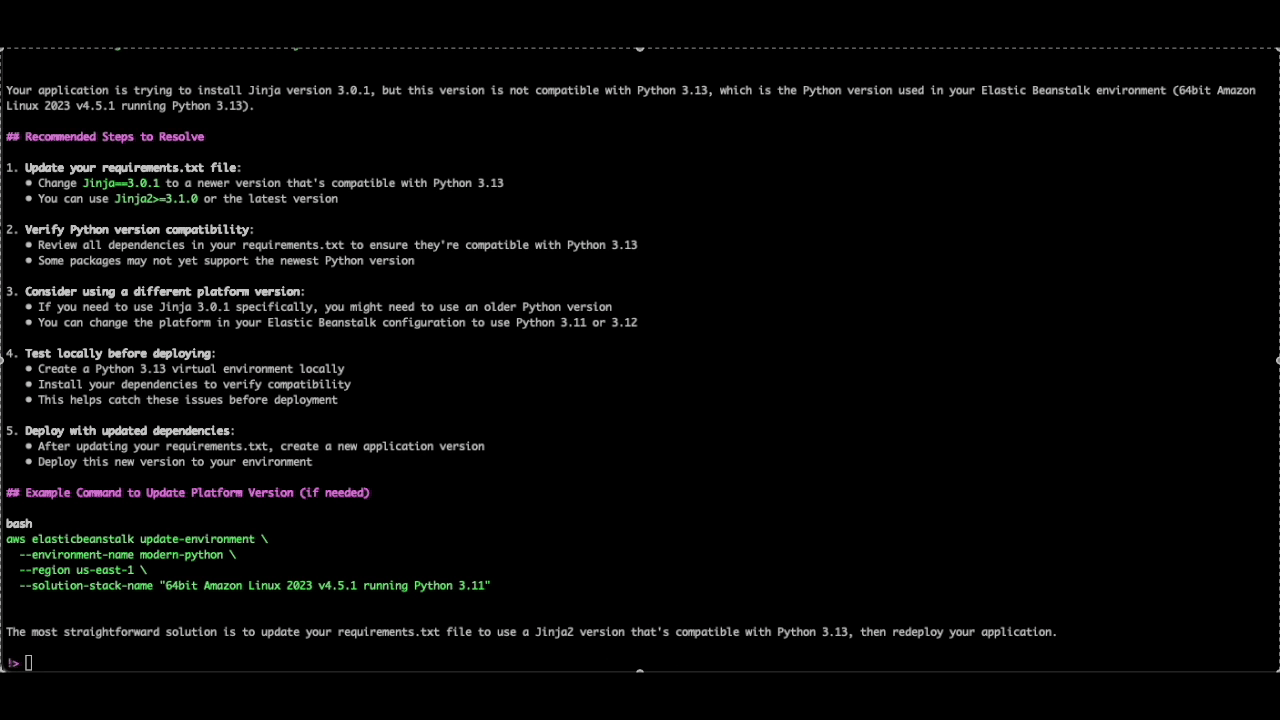
Here, we see how Q CLI can also help with troubleshooting application or dependencies related issues. By checking the environment events and the tail logs, Q CLI was able to identify the source of the deployment failure due to the “Jinja” package that was specified in the requirements.txt file. It correctly advises us to use a newer version of the “Jinja2” package, which is compatible with Python 3.13.
It also goes on to give us recommendations and steps on testing the changes locally before updating the requirements.txt and creating a new application version to be used for the deployment.
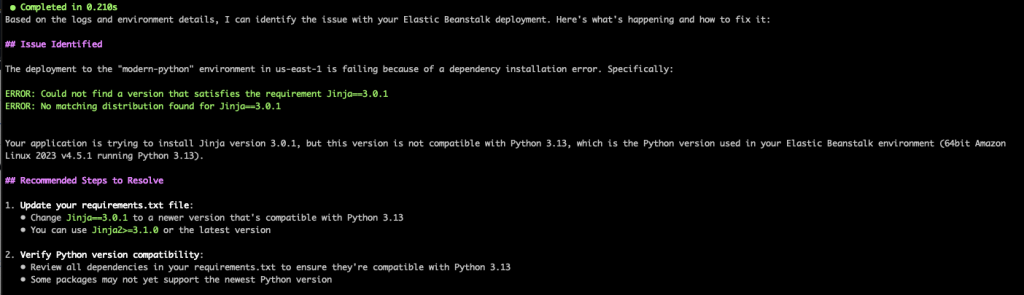
Figure 6. Q CLI identified the reason for command failure and provides solutions
Using EB CLI with Amazon Q Developer CLI
To wrap this up, we will demonstrate the benefits of using Q CLI in your development environment, along with EB CLI.
EB CLI enables developers to deploy applications to Elastic Beanstalk with a simple eb deploy command, handling environment provisioning, artifact packaging, and configuration as code. It integrates with Git for version tracking and supports local testing through eb local run, making it ideal for CI/CD pipelines and iterative development workflows.
In this scenario, we have another application deployment that failed. We will use Q CLI to troubleshoot this issue by initiating a new q chat from the same directory where the application files are located, which also has EB CLI installed and setup using the command eb init.
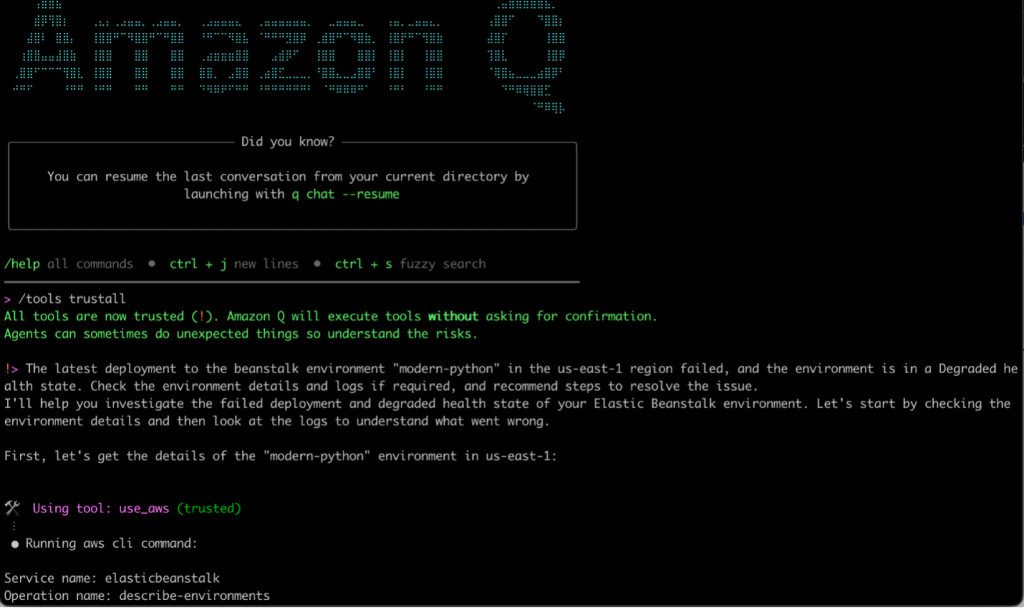
Figure 7. Q CLI prompt to troubleshoot the python deployment issue
As you can see above, we’ve used the following prompt:
The latest deployment to the beanstalk environment "modern-python" in the us-east-1 region failed, and the environment is in a Degraded health state. Check the environment details and logs if required, and recommend steps to resolve the issue.
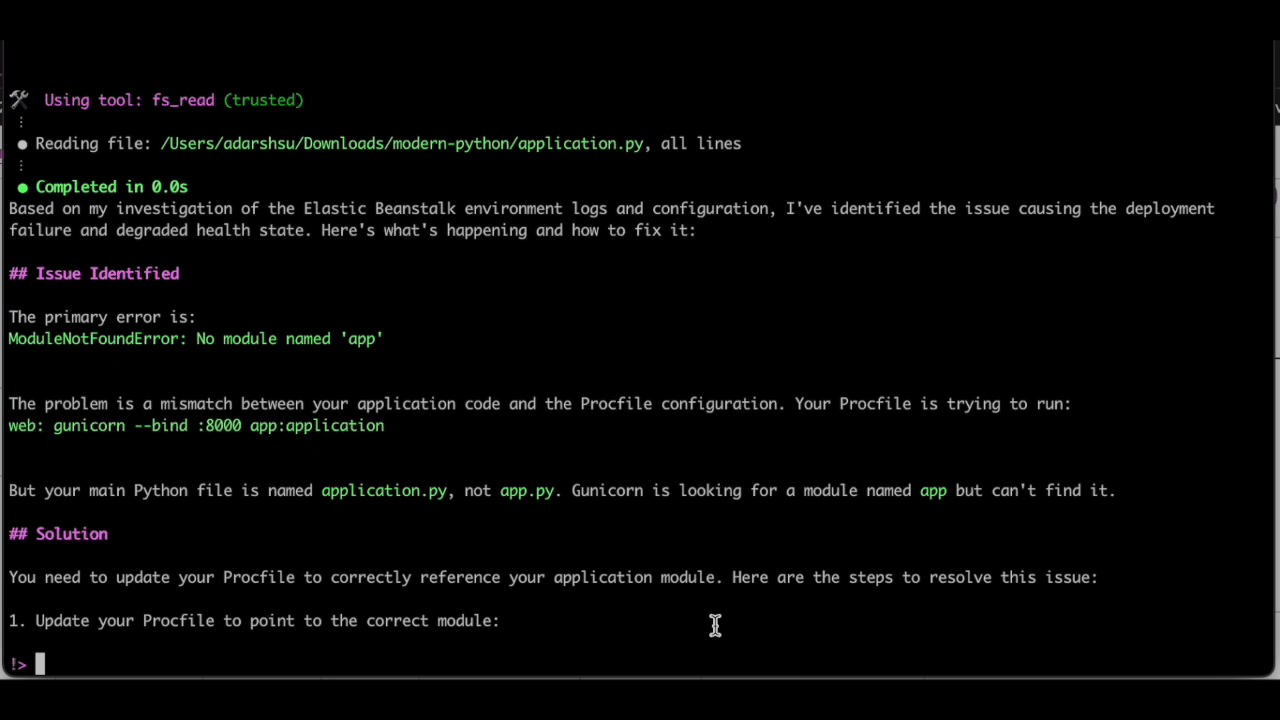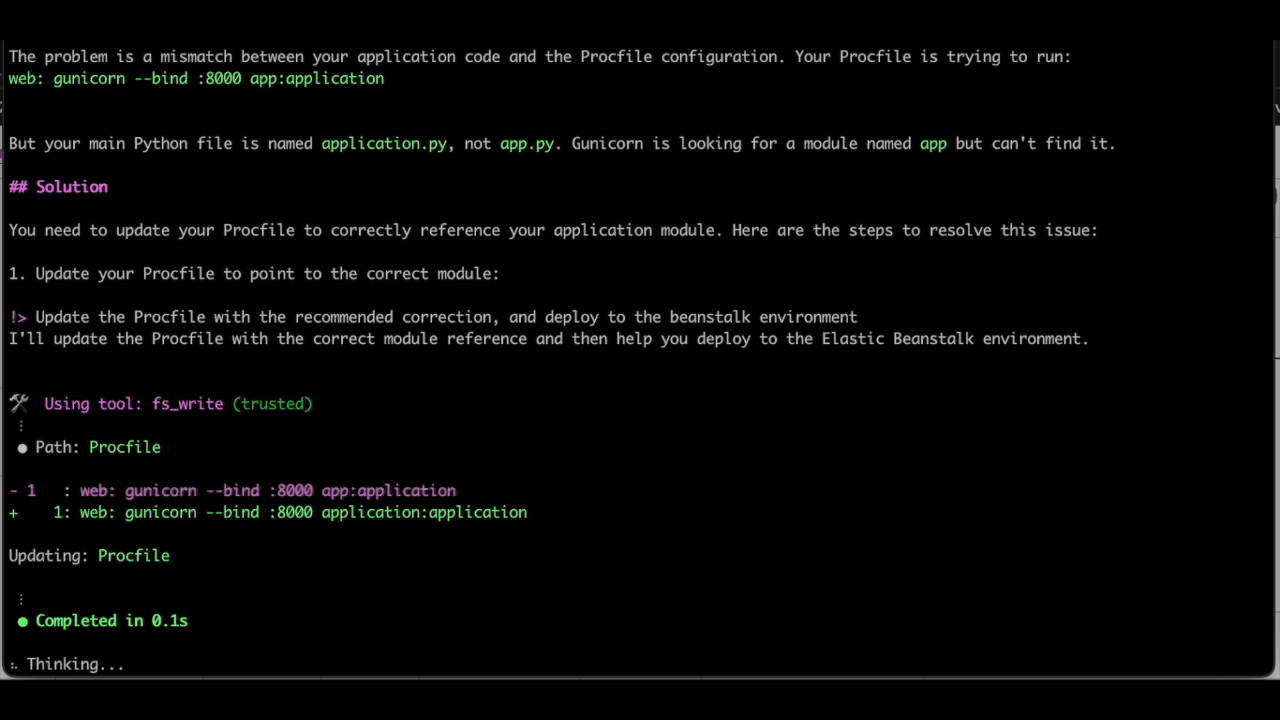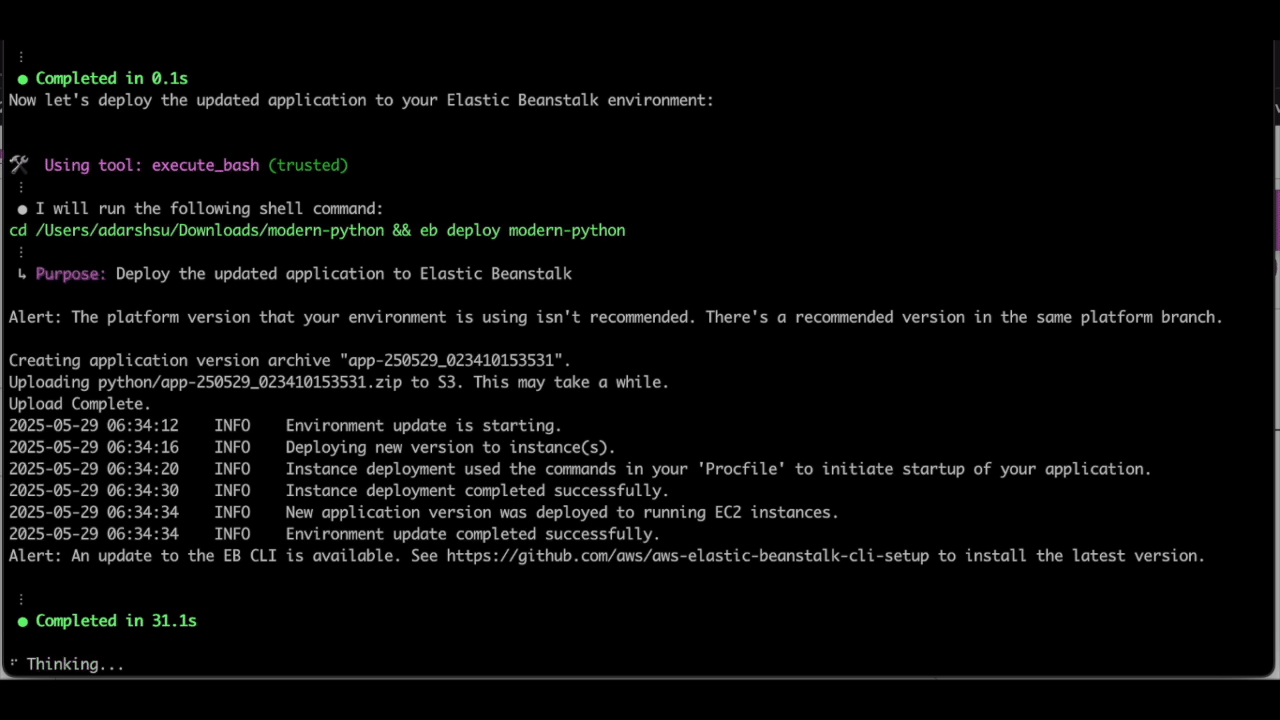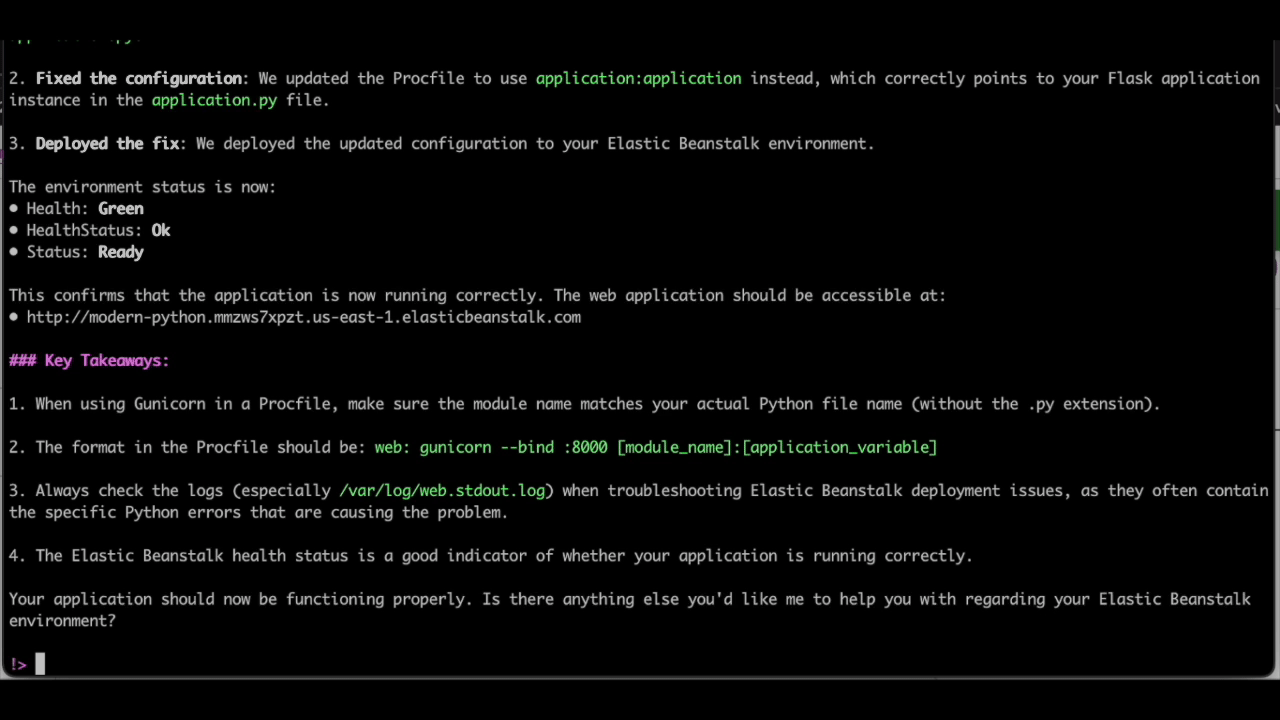
Q CLI was able to check the relevant logs and identify the following error causing the deployment failure:
ModuleNotFoundError: no module named ‘app’
Because the q chat conversation was initiated from the directory containing the application files, Q CLI is also able to view my application files, and identify the solution to the problem, suggesting that main python file name is application.py, not app.py, and therefore, the Procfile needs to be updated accordingly.
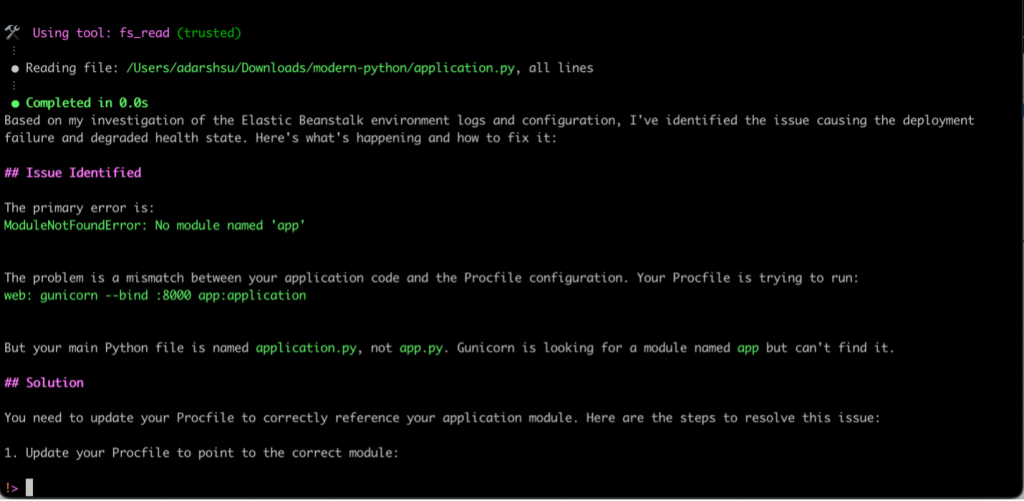
Figure 8. Q CLI identifies the reason for deployment failure, and recommends updating the Procfile
Finally, because we already have EB CLI initiated in this directory with the application files, we can use Q CLI to automatically make the required changes to the Procfile and update the elastic beanstalk environment, all with just the following natural language prompt:
Update the Procfile with the recommended corrections, and deploy to the beanstalk environment
As seen above, Q CLI is able to update the Procfile with the necessary changes and use the eb deploy EB CLI command to deploy the changes to the elastic beanstalk environment.
These examples demonstrate how Amazon Q Developer’s CLI agent supercharges your operational and troubleshooting tasks throughout the entire development process when used in your CLI environment.
Best Practices for Troubleshooting Elastic Beanstalk with Amazon Q Developer CLI
- Be specific in your questions: Include environment name, region, and specific symptoms to help Q CLI provide more targeted assistance.
- Allow Amazon Q to access logs: When prompted, allow Amazon Q to retrieve and analyze logs for more accurate troubleshooting.
- Implement suggested fixes incrementally: If Amazon Q suggests multiple solutions, implement them one at a time to identify which one resolves the issue.
- Use caution with the /tools trust-all flag: This flag bypasses confirmation prompts during the troubleshooting. Review the security considerations and use with caution in production environments.
Cleaning up
If you’ve created any Elastic Beanstalk environments, please terminate them if they’re no longer being used to avoid incurring charges for unused AWS resources.
Conclusion
Amazon Q Developer CLI is a powerful tool for troubleshooting Elastic Beanstalk environments, capable of quickly identifying and helping resolve common issues. By leveraging Q CLI’s ability to analyze logs, check environment status, and provide targeted solutions, you can significantly reduce the time and effort required to troubleshoot Elastic Beanstalk problems.
Try Amazon Q Developer CLI today and see how quickly you can resolve Elastic Beanstalk issues. Transform hours of log parsing and console navigation into minutes of focused problem-solving with Amazon Q Developer CLI. Start with a simple q chat command and let AI-powered assistance transform your operational workflows. Install the CLI agent now and experience firsthand how conversational AI can help you maintain healthier Elastic Beanstalk environments with less effort!
About the Authors
ChatGPT Gave Instructions for Murder, Self-Mutilation, and Devil Worship
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/DDv7PFIlicQ
Lawn Care Freedom: Schedule Your Zones with Neomow X!
Post Syndicated from BeardedTinker original https://www.youtube.com/shorts/fWa7oR3ylWY
HeliumOS 10 released
Post Syndicated from jzb original https://lwn.net/Articles/1031836/
The HeliumOS project has announced
the release of HeliumOS 10. It is relatively new image-based (“atomic”)
desktop distribution based on packages from CentOS Stream and
AlmaLinux, with a goal of providing 10 years of
support. HeliumOS 10 uses the KDE Plasma Desktop, Zsh as its
default shell, and Btrfs as its default filesystem.
AT&T email-to-text service migration: AWS solution implementation
Post Syndicated from Vinay Ujjini original https://aws.amazon.com/blogs/messaging-and-targeting/att-email-to-text-service-migration-aws-solution-implementation/
Email-to-text services allow businesses to send short message service (SMS) messages through email, critical for automatic notifications, customer service, and operational workflows. These services process over 1.2 billion messages annually across U.S. carriers, with AT&T supporting 34% of this volume through 2024. AT&T’s deprecation of email-to-text and text-to-email services impacts businesses that rely on these communication channels. This blog post outlines an Amazon Web Services (AWS) solution to maintain service continuity for customers.
AT&T discontinued their email-to-text and text-to-email services in Q2 2025, which will impact about 23,000 business customers. Organizations rely on these communication channels for critical workflows and need a quick solution to maintain business continuity. By the numbers:
- Average message volume: 50,000 texts per customer monthly
- Critical use cases: Appointment reminders, security alerts, and system notifications
- Regulatory requirements mandate message retention and delivery confirmation
Solution architecture
The following diagram shows the architecture for the solution:
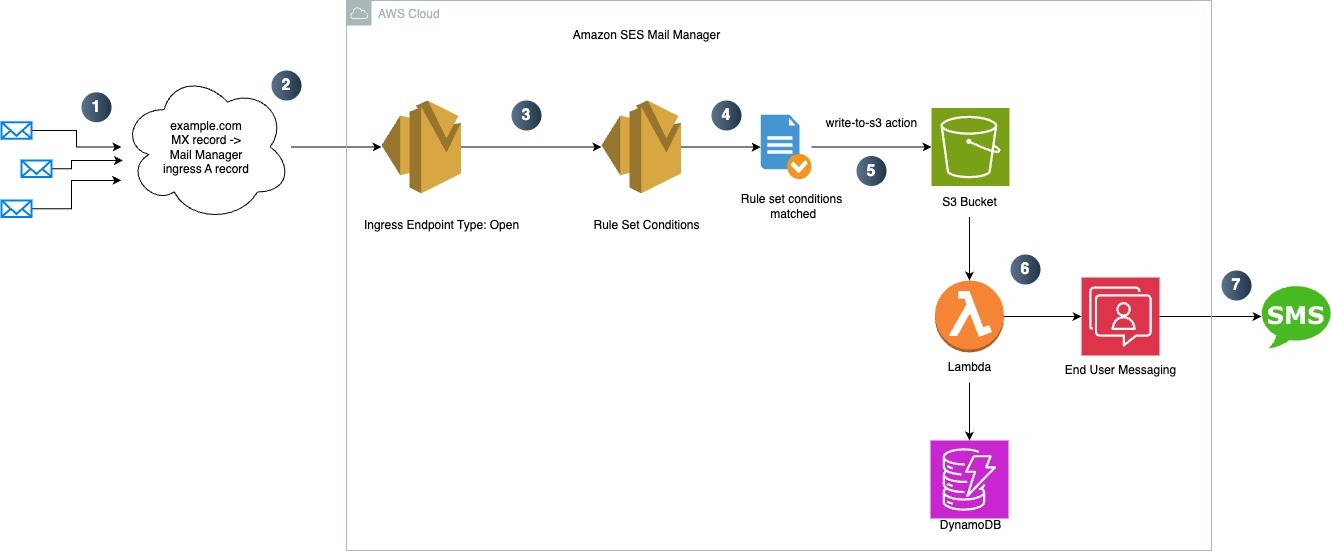
Email-to-SMS architecture flow:
- An email is sent to
[phone-number]@[your-domain.com] - Amazon Simple Email Service (Amazon SES) routes emails to the Mail Manager ingress endpoint
- The email is written to an Amazon Simple Storage Service (Amazon S3) bucket
- An Amazon S3 event notification triggers an AWS Lambda function
- Lambda extracts the email content, formats the phone number, and sends an SMS message using AWS End User Messaging
- Message details are stored in DynamoDB for tracking
System components in this solution:
- Processing: Mail Manager applies rules to incoming emails
- Storage: Amazon S3 stores emails securely
- Computation: Lambda processes stored emails
- Identification: Amazon DynamoDB lookup matches the sender email to phone number
- Delivery: AWS End User Messaging User Messaging sends an SMS message to the recipient
This architecture, which uses simple notification service (SNS), is suitable for SMS-to-email. While this post and the AWS CloudFormation template primarily focus on email-to-SMS implementation, the SMS-to-email flow works as follows:
SMS-to-email flow:
- A user replies to an SMS message
- AWS End User Messaging SMS service captures the message and publishes it to an SNS topic
- SNS triggers a Lambda function
- Lambda formats the message and sends an email through Amazon SES
- The email is delivered to the original sender
The solution
The solution was to build an email-to-text service using AWS core services. The architecture routes emails through an Amazon SES Mail Manager ingress endpoint. After receiving an email, Mail Manager processes it using defined business rules and stores it in Amazon S3. This triggers a Lambda function to fetch the phone number associated with the email address and send an SMS to that phone number. When successful, it stores data such as the email address, phone number, and message ID from the sent text message in DynamoDB.
Estimated setup time: 15–20 minutes
Prerequisites
To deploy the solution described in this post, you must have the following in place:
- Administrator-level access to an AWS account.
- A domain or subdomain (you need ownership of the domain) to create an SES verified identity (it’s recommended to use subdomains for testing).
- An origination identity that supports two-way messaging, following Choosing an origination identity for two-way messaging use cases. Simulator phone numbers are available if you are in the United States.
- A mobile phone to receive SMS messages.
- An email address to receive emails.
Step 1: Set up Amazon SES Verified Identity
Start by setting up an Amazon SES verified identity.
- Sign in to the AWS Management Console.
- Navigate to Amazon SES service.
- In the navigation pane, go to Configuration and choose Identities (skip this step if you have a verified identity).
- If you do not have a verified identity, choose e.
- Review this post to learn how to verify an identity. Best practice is to verify a domain identity. This will authenticate your domain and improve deliverability. An email address identity, while simpler, won’t be authenticated through DomainKeys Identified Mail (DKIM), which might decrease deliverability.
Reference: Creating and verifying identities in Amazon SES
- Confirm that the status of your domain identity is Verified before proceeding to the next step.
Step 2: Deploy the email-to-SMS CloudFormation template
Use the following steps to create a CloudFormation stack that deploys all the required components for email-to-SMS functionality:
- Sign in to your AWS account.
- Download the email-to-sms.yaml CloudFormation template file.
- Navigate to the CloudFormation console.
- Choose Create stack and select With new resources (standard).
- Prerequisite: Prepare template is selected as Choose an existing template.
- Under Specify template, choose Upload a template file and upload the
email-to-sms.yamlfile you downloaded earlier. Choose Next. - For Stack name, enter
Email-To-SMS-Stack. - Configure the following parameters:
- e: Enter the SES verified domain name or a verified email address.
- OriginationPhoneNumberId: Enter the AWS End User Messaging SMS phone number ID that you plan to use to send SMS messages.
- Go to AWS End User Messaging, under Phone Numbers, select your number and find Phone number ID.

- Go to AWS End User Messaging, under Phone Numbers, select your number and find Phone number ID.
- DestinationPhoneNumber: Enter the destination phone number to receive SMS messages.
- Choose Next.
- (Optional) Add tags to help identify and organize your AWS resources.
- Select Acknowledge All checkbox and choose Next.
- Review the configuration and choose Submit.
- Wait for the stack creation to complete. You can monitor the progress in the CloudFormation console
Step 3: Verify deployed stack services
After successful CloudFormation template deployment, verify the following resources and configurations:
- A DynamoDB table is created with the name
<stackname>-email-to-sms-db - A Lambda function is created with the name
<stackname>-<accountnumber>-<awsregion>-process-email-to-sms - The Lambda function has the following AWS Identity and Access Management (IAM)role policies attached:
s3:GetObjectdynamodb:PutItemsms-voice:SendTextMessagekms:Decryptfor Lambda encryption keys.- IAM permissions for dead letter queue (if configured).
- S3 buckets are created:
- Main bucket:
<stackname>-<accountnumber>-<awsregion>-emailtosms-storage - Logging bucket:
<stackname>-<accountnumber>-<awsregion>-emailtosms-logging
- Main bucket:
- In Amazon SES:
- A receipt rule set is created named
<stackname>-EmailToSms-Rule-Set - The receipt rule is configured to:
- Write messages in the S3 bucket.
- Invoke the Lambda function.
- Traffic policy is created named
<stackname>-EmailToSms-Traffic-Policy - The Rule set and traffic policy are configured in the ingress point
<stackname>-EmailToSms-Ingress-Point- CAUTION: Testing this solution requires access to modify mail exchange (MX) DNS records for your domain.
- Potential impact: Changes to MX records can interrupt email delivery to your primary domain.
- Best practice: We strongly recommend creating a dedicated subdomain (such as testing.example.com) rather than using your primary domain (example.com) for testing purposes. This approach prevents disruption to your organization’s regular email service
- A receipt rule set is created named
Additional verifications:
- Verify that the S3 bucket policies are correctly set
- Verify that S3 bucket logging is on and working
- Check the Lambda function’s environment variables
- Monitor Amazon CloudWatch logs for any errors
Step 4: Test the email-to-SMS flow
- Send an email to
mobile-number@verified-domain - You will receive an SMS from the source number (AWS End User Messaging phone number) containing:
- Subject:
<EmailSubject> - Content: First 160 characters of your email body
- Subject:
- SMS character Limitations:
- AWS End User Messaging’s SMS messaging has character limits based on content type
- By default, the solution uses first 160 characters
- You can modify this limit by updating the Lambda function code
- Troubleshooting:
- If SMS or email responses aren’t received
- Check Lambda function logs in CloudWatch
- Review any error messages or execution issues
- Verify all permissions and configurations are correct
Make sure that your domain and phone numbers are properly verified before testing. If you don’t receive the email or SMS, check the Lambda CloudWatch logs for troubleshooting
Clean up
To avoid ongoing charges and remove all deployed resources, perform the following cleanup steps:
- Remove the CloudFormation stack:
- Navigate to the CloudFormation console
- Delete the Email-To-SMS stack
- Wait for complete stack deletion confirmation
- Amazon SES cleanup:
- Navigate to the Amazon SES console
- Remove any verified domains
- Delete verified email addresses
- Confirm all SES resources are removed
- AWS End User Messaging:
- Navigate to the AWS End User Messaging console
- Release all provisioned phone numbers
- Verify that no active phone numbers remain
- Additional verification:
- Confirm that S3 buckets are deleted
- Verify that Lambda functions are removed
- Check that DynamoDB tables are deleted
- Make sure that all associated IAM roles and policies are removed
Verify complete resource removal to prevent unexpected charges.
Additional recommendations
- Security best practices:
- Set up S3 bucket logging to track access and changes
- Make sure that S3 buckets have:
- No public read/write access
- Enable Encryption at rest
- Apply appropriate bucket policies
- Implement least privilege access for IAM roles
- Use KMS encryption for sensitive data
- Add CloudWatch logging for monitoring
- Protect against SMS pumping:
- Enable AWS End User Messaging protect configuration: Enable filter mode to automatically block suspicious messages
- Block countries that you don’t do business in to prevent unnecessary exposure
- Add CAPTCHA to web forms that trigger SMS to prevent bot attacks
- Set up SMS volume alerts to quickly detect unusual activity
- Create separate configurations for different message types (password resets compared to marketing)
- Cost and operational considerations:
- AWS End User Messaging:
- Costs apply for phone numbers and SMS traffic (both inbound and outbound)
- Message parts per second (MPS) limits vary by country and origination identity type
- Different countries have different capabilities and limitations for SMS
- Monitor usage and implement appropriate alerting to save unnecessary costs
- Account requirements:
- New SES and AWS End User Messaging accounts start in sandbox mode
- Production access requires:
- SES sandbox removal request
- AWS End User Messaging SMS and MMS sandbox removal
- Use case documentation
- Compliance with regional regulations
- Follow Request production access (Moving out of the Amazon SES sandbox) and SMS/MMS and Voice sandbox in AWS End User Messaging SMS
- Monitoring and maintenance:
- Implement CloudWatch alarms for error monitoring
- Regular review of access logs
- Periodic security assessment
- Cost tracking and optimization
- AWS End User Messaging:
Results
This implementation delivers three key improvements:
- This achieves 99.99% uptime through AWS managed services.
- The pay-per-use model reduces operating costs by 45% compared to maintaining dedicated infrastructure. Customers save an average of $2.30 per thousand messages.
- End-to-end encryption and AWS security protocols maintain GDPR and CCPA compliance while protecting customer data.
Conclusion
This AWS-based solution addresses the immediate need and provides a foundation for future enhancements in cross-platform messaging. Whether you’re migrating from AT&T’s email-to-text service or building a new notification system, this AWS-based solution provides a scalable foundation for your messaging needs.
About the author
[$] A proxy-execution baby step
Post Syndicated from corbet original https://lwn.net/Articles/1030842/
Priority inversion comes about when a low-priority task holds a resource
that is also needed by a high-priority task, preventing the latter from
running. This problem is made much worse if the low-priority task is
unable to gain access to the CPU and, as a result, cannot complete its work
and free the resources it holds. Proxy execution is a potential solution
to this problem, but it is a complex solution that has been under
development for several years; LWN first looked
at it in 2020. The 6.17 kernel is likely to contain an important step
forward for this long-running project.
Micron 9650 PCIe Gen6 SSD Announced with Micron 6600 ION 122TB and 7650 SSDs
Post Syndicated from Eric Smith original https://www.servethehome.com/micron-9650-pcie-gen6-ssd-announced-with-micron-6600-ion-122tb-and-7650-ssds/
The Micron 9650 PCIe Gen6 SSD is capable of 28GB/s sequential reads, 5.5M random 4K read IOPS and is just one of three models being announced
The post Micron 9650 PCIe Gen6 SSD Announced with Micron 6600 ION 122TB and 7650 SSDs appeared first on ServeTheHome.
GNU C Library 2.42 released
Post Syndicated from corbet original https://lwn.net/Articles/1031813/
Version 2.42 of the GNU
C Library has been released. Changes include the addition of a number of
new math functions, support for arbitrary baud rates in the
termios.h interface, support for SFrame-based stack tracing
(described in this article), support for
memory guard pages, and a handful of
security fixes.
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/1031812/
Security updates have been issued by AlmaLinux (freerdp, git-lfs, golang-github-openprinting-ipp-usb, grafana, grafana-pcp, icu, ipa, iputils, krb5, libvpx, nodejs:22, osbuild-composer, perl, python-tornado, qt6-qtbase, sqlite, unbound, valkey, wireshark, and yggdrasil), Debian (libfastjson and php8.2), Fedora (glibc), Oracle (firefox, icu, perl, and unbound), Red Hat (389-ds-base, glib2, icu, libtpms, redis:6, redis:7, and yelp), SUSE (boost, forgejo-longterm, java-11-openj9, java-17-openj9, java-1_8_0-openj9, kernel, nginx, and salt), and Ubuntu (linux-xilinx-zynqmp, openjdk-8, openjdk-lts, poppler, and sqlite3).
Leveling Up Security: New Enterprise Features in Backblaze B2 Platform Update
Post Syndicated from Kari Rivas original https://www.backblaze.com/blog/leveling-up-security-new-enterprise-features-in-backblaze-b2-platform-update/

Security teams are under constant pressure to stay ahead of increasingly sophisticated threats while enabling fast, reliable access to data across the business. Whether you’re protecting media assets, safeguarding backups, or supporting a global development workflow, your cloud storage needs to do more than store data—it needs to actively support your security posture.
To make that easier, we’ve launched a new set of enterprise-grade security features for Backblaze B2 Cloud Storage. These updates are designed to help organizations detect unusual activity faster, manage access more precisely, and strengthen visibility across their storage environments—all without added complexity or hidden costs.
These new tools build on the security foundations you already count on: Object Lock for ransomware protection, SOC-2 compliance, encryption, 3x free egress for disaster recovery, and more.
Here’s a look at what’s new and how it helps.
Smarter protection with Anomaly Alerts (Now in private preview)
Anomaly Alerts are your new AI-powered watchdog. This feature analyzes usage patterns in your B2 Cloud Storage buckets to detect potential red flags—like spikes in downloads or uploads beyond the baseline—that could signal a breach or exfiltration attempt.
If your team wants early access to this feature, drop us a line at [email protected] to join the private preview.
New enterprise web console & role-based access controls (Now in private preview)
Managing cloud storage across large teams just got a whole lot easier. We introduced a brand-new enterprise web console built for scalability and control. Combined with robust role-based access controls (RBAC), IT and security teams can now better align with zero-trust policies by enforcing the principle of least privilege across their organizations.
This console simplifies storage administration at scale—whether you’re managing terabytes or petabytes.
If you’re a Backblaze customer with a committed contract, reach out to your Customer Success Manager (CSM) to see if you’re eligible to participate. Not sure who your CSM is? Email [email protected] for help.
Full visibility with Bucket Access Logs (Now generally available)
Need to know who touched what and when? Bucket Access Logs are now generally available, providing a detailed audit trail of every action in your B2 buckets—uploads, downloads, deletions, and more.
They’re fully S3-compatible and configurable through both the Backblaze B2 web UI and API, supporting:
- Security audits
- Usage tracking
- Forensics and threat investigation
Real-time Event Notifications
Time matters when it comes to spotting and stopping threats. With Event Notifications, you can get real-time alerts on changes to your bucket contents—think object creations, deletions, or modifications—so your team can jump into action immediately.
This is especially valuable for compliance teams, incident response workflows, or any operations team who wants tighter control over their cloud perimeter.
Multi-Bucket and Scalable Application Keys
Security and scalability should go hand in hand. With Multi-Bucket Application Keys, you can now create access keys that cover specific groups of buckets, giving you more flexibility without going full wildcard. This enhancement provides more granular control over bucket access, contributing to a reduced attack surface.
And, with Scalable Application Keys, you can generate up to 10,000 short-lived keys per minute. This capability enhances security by limiting the exposure window of individual keys, thus reducing the attack surface for endpoint-generated content and high-volume data operations.
Custom Upload Timestamps
Custom Upload Timestamps allow you to specify when an object was originally created or uploaded. This is a critical feature for:
- Regulatory compliance
- Accurate version tracking
- Legal and audit requirements
Built for a Secure, Open Cloud
Security isn’t a one-time add-on, it’s an ongoing promise. As enterprises scale and integrate cloud storage into more parts of their workflow—from backup and archiving to AI pipelines—they need solutions that support open cloud strategies without compromising their data.
This update is another step forward in our mission to provide developers, IT teams, and enterprises with cloud storage that’s secure by design, simple to use, and affordable at scale. Ready to get started with Backblaze B2? Contact our Sales team today.
The post Leveling Up Security: New Enterprise Features in Backblaze B2 Platform Update appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
How to rapidly design and adapt quality learning experiences for your students
Post Syndicated from Sean Sayers original https://www.raspberrypi.org/blog/how-to-rapidly-design-and-adapt-quality-learning-experiences-for-your-students/
At this time of year, many educators are considering ways to update their content ahead of the new school term. Whether you’re a teaching assistant or head of department, it’s important to ensure that the content you’re updating — or even designing anew — is relevant and high quality, and meet learners’ needs. In today’s blog we’re highlighting ‘ABC learning design’, and how it can be used to rapidly design and improve learning experiences.

We also share our new ABC-focused Pedagogy Quick Read, which you can download for free to:
- Find practical tips on how to use the ABC process and related approaches with your learners
- Read a summary of the research behind the framework
What is ABC learning design?
ABC learning design is a rapid, hands-on approach to design and develop blended learning experiences. The framework has traditionally been used at undergrad level, and had a lot of success when used in response to the global pandemic in 2020, when learning experiences had to quickly transition from being delivered in-person to being accessible remotely.
The model is centred around six learning types:
- Acquisition: Learning by reading, listening, or watching
- Collaboration: Learning by working with others towards a common goal, involving co-creation and shared outputs
- Discussion: Learning through dialogue, sharing ideas, and responding to others
- Investigation: Learning by exploring, comparing, and evaluating new information or experiences
- Practice: Learning by applying knowledge and skills, receiving feedback, and refining understanding
- Production: Learning by expressing understanding or creating something to demonstrate knowledge and skills
Before continuing, it’s important to distinguish between ‘learning types’ and the widely discredited concept of ‘learning styles’. Whilst learning styles refer to fixed characteristics or preferences of learners, learning types refer to different kinds of learning activities and pedagogical approaches that can be designed into a course.

These learning types are representative simplifications of pre-existing learning theories. For each learning type, educators can use different activities to deliver that type of learning. The activities will depend on your context and what’s right and applicable for your students.
How can I apply ABC learning design?
ABC learning design is often done in a team-based workshop setting (you can do it by yourself as well). Firstly, you analyse your existing content. Consider the goal of your current learning sequence, and assess how your learners are going to reach that goal with the different learning types.

By analysing existing content and activities, you can then identify what’s missing from your sequence. This allows you to build on existing gaps and consider different types of activities you could implement. You then create a set of learning cards, which help you to storyboard and plan your new learning sequence.
Learning cards are typically postcard-sized and colour-coded to one of the six learning types. Colour coding helps you to tell the cards apart, and to easily see which learning types are or aren’t included in your sequence.
Each card has the name and a short description of the learning type on the front, with examples of associated digital or in-person learning activities on the back. The learning cards:
- Make the design process more engaging
- Help with decision making
- Support discussions if you’re working in a team

Adapting ABC learning design for your context
ABC design can be contextualised to your classroom, practices, and school, and to the technologies you have available. For example, on the back of each learning card you could include a set of activities that have been tried and tested in, or approved by, your school. Alternatively, you could link to other frameworks or teaching approaches that work for you and your students.
Learning cards can also be used to collect other insights about teaching and learning within your context, and used as reminders of pedagogies to implement, as well as practical concerns. They can also help you to consider if there are opportunities for cross-curricular links within your learning sequence.
A shared toolkit you can reuse
In a computing department, ABC learning cards can become a shared resource that give fellow educators an understanding of what’s possible. The cards can be used again and again to help plan future learning experiences.

By running an ABC workshop and creating these learning cards, you and your team will put together a contextualised learning sequence toolkit specific to your school and learners.
Integration with universal design for learning to improve accessibility
In our blog How to build young people’s agency through accessible learning, we explored the universal design for learning (UDL) framework. UDL aims to support educators to reduce barriers for learners. It helps educators to create learning environments that are accessible and effective for all learners by providing multiple means of engagement, representation, and action and expression.
Gormley et al. (2022) described an initiative to integrate UDL within ABC learning design. They developed adapted ABC learning cards where the reverse side included specific UDL prompts, in addition to the usual example activities. For example:
- An acquisition card could include the prompt “Will materials be available in a variety of formats (text, audio, and visual)? Will videos be captioned and transcribed?”
- A production card could include the prompt “Are there multiple ways for learners to demonstrate their understanding? Can they choose between writing, presenting, or creating?”
By including these UDL considerations directly on the ABC cards, the design team ensured that accessibility and inclusivity were central to learning design conversations.
Adding UDL prompts to your learning cards is a fantastic way to help you design accessible learning sequences.
Applying ABC learning design: Some ideas for computing educators
In 2020, during the pandemic, the Computing at School (CAS) Research Working Group worked with classroom teachers to apply ABC learning design in their own contexts.
Following some training, teachers analysed their existing classroom activities and then developed a range of suitable alternatives for remote learning, categorising them into low-tech, mid-tech, and high-tech options.
The different activity options were then added to their own sets of ABC learning cards and used to help adapt lessons for remote teaching. You can read more about the project and view example cards on the CAS website.
The benefits of using ABC learning design
Potential benefits for educators:
- Enables more rapid creation and delivery of high-quality content
- Allows you to audit your current learning sequence and identify gaps that can be improved upon
- Provides a shared, contextualised toolkit for curriculum design
Potential benefits for students:
- Tailored, engaging, high-quality learning experiences
Want to hear more about ABC learning design?
If you’d like to find out more about ABC learning design, you can download our Quick Read for free.
You can also listen to a thought-provoking discussion on the topic between James Robinson, Carrie Anne Philbin, Jane Waite, and Matthew Wimpenny-Smith in season 1, episode 6 of the Hello World podcast: Could curriculum design be as simple as ABC?
The post How to rapidly design and adapt quality learning experiences for your students appeared first on Raspberry Pi Foundation.
Aeroflot Hacked
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/07/aeroflot-hacked.html
Understanding HTTP Template Authorization in AWS
Post Syndicated from evgenii.gordymov original https://blog.zabbix.com/understanding-http-template-authorization-in-aws/30856/
Authorization in Amazon Web Services (AWS) determines what actions a user, service, or system can perform on resources. It answers the question: “Does this identity have permission to do this action on that resource?”
In AWS, authorization is primarily handled through:
- IAM (Identity and Access Management) policies
- Resource-based policies (like S3 bucket policies)
- Session-based permissions (like STS AssumeRole)
What authorization types are available in Zabbix AWS templates?
- Access key authorization
- Role-based authorization
- Assume role authorization
Let’s look briefly at each of them.
Table of Contents
Before using the template, you need to create an IAM policy that grants the necessary permissions for the AWS services the template will interact with.
This policy defines what actions are allowed, on which resources, and optionally, under which conditions. Once created, the policy should be attached to the IAM role or user that will run the template.
IAM policy for Zabbix
Add the following required permissions to your Zabbix IAM policy in order to collect metrics. The policy can change when new metrics and services are added in Zabbix templates.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"cloudwatch:DescribeAlarms",
"cloudwatch:GetMetricData",
"ec2:DescribeInstances",
"ec2:DescribeVolumes",
"ec2:DescribeRegions",
"rds:DescribeEvents",
"rds:DescribeDBInstances",
"ecs:DescribeClusters",
"ecs:ListServices",
"ecs:ListTasks",
"ecs:ListClusters",
"s3:ListAllMyBuckets",
"s3:GetBucketLocation",
"s3:GetMetricsConfiguration",
"elasticloadbalancing:DescribeLoadBalancers",
"elasticloadbalancing:DescribeTargetGroups",
"ec2:DescribeSecurityGroups",
"lambda:ListFunctions"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
To create and attach the policy:
- Go to IAM → Policies → Create policy
- Choose JSON and paste your policy
- Review and create the policy
Access key authorization
1. Attach the required policy to the IAM user
- Go to IAM → Users → Select a user → Permissions tab
- Click Attach policies
- Select the policy you created before (IAM Policy for Zabbix)
- Click Attach policy
2. Get your access key and secret access key
In the AWS console:
-
Go to IAM → Users → Select a user → Security credentials tab
-
Click Create access key
-
Copy:
Access key IDSecret access key
Never expose your keys publicly!
 Never expose your keys publicly!
Never expose your keys publicly!3. Configure AWS CLI
Open your terminal and run:
configure aws cli
aws configure --profile zabbix_user
You’ll be prompted to enter:
AWS Access Key ID [None]: AKIAXXXXXXXXXXXEXAMPLE
AWS Secret Access Key [None]: asdkjhUSADWDskhjdasd/EXAMPLEKEY
Default region name [None]: eu-central-1
Default output format [None]: json
4. Test it
List all S3 buckets:
aws s3 ls --profile zabbix_user
Get EC2 tags:
Use region where you create instance
aws ec2 describe-instances --region eu-central-1 --query 'Reservations[*].Instances[*].Tags' --profile zabbix_user
If you get this error…
An error occurred (AccessDenied) when calling the DescribeInstances operation: User: arn:aws:iam::123456789010:user/zabbix_user is not authorized to perform: ec2:DescribeInstances on resource: arn:aws:ec2:eu-central-1:123456789010:instance/*
…you need to check the following permission to the role you are using (IAM Policy for Zabbix).
5. Set the following macros in Zabbix:
{$AWS.AUTH_TYPE}– set toaccess_key{$AWS.ACCESS.KEY.ID}– set to your access key ID{$AWS.SECRET.ACCESS.KEY}– set to your secret access key
Security tips
- Never hardcode access keys in scripts or code.
- Store them in
~/.aws/credentials, which is protected by file system permissions. - Apply least privilege with IAM policies.
Role-based authorization
1. Add the appropriate permission to the role you are using:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::{Account}:role/{RoleNameWithPath}"
},
{
"Effect": "Allow",
"Action": [
"theSameAsIAMPolicyForZabbix",
],
"Resource": "*"
}
]
}
2. Add a principal to the trust relationships of the role you are using:
- Go to IAM → Roles → Select a role → Trust relationships tab
- Click Edit trust relationship
- Add a principal to the trust relationships of the role you are using:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"ec2.amazonaws.com"
]
},
"Action": [
"sts:AssumeRole"
]
}
]
}
3. Attach the role to the instance
- Go to EC2 → Instances → Select an instance → Actions → Security → Modify IAM role
- Select the role you created before which has the policy attached (IAM Policy for Zabbix)
- Click Apply
4. Test it
Connect to ES2 ssh terminal in instance and run:
- Go to EC2 → Instances → Select an instance → Connect → SSH client
Example:
ssh -i "zabbix_user.pem" [email protected]
Get caller identity:
aws sts get-caller-identity
Get token for metadata service:
export TOKEN=$(curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600")
Get IAM role from metadata service:
curl -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/iam/security-credentials
Get IAM role credentials from metadata service using role name from instance metadata service (see Get IAM role from metadata service):
curl -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/iam/security-credentials/<<--role_name-->>
6. Set the following macros in Zabbix:
{$AWS.AUTH_TYPE}– set torole_base{$AWS.ASSUME.ROLE.ARN}– set to your role ARN
Assume role authorization
This method has two options:
- Using access key authorization for getting creds for assume role
- Using role-based authorization for getting creds for assume role
Lets look first at using access key authorization for getting creds for assume role.
Using access key authorization for getting creds for assume role
1. Create access key for user (see Access Key Authorization)
2. Add the appropriate permission in role you are using:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::{Account}:user/{UserName}"
},
{
"Effect": "Allow",
"Action": [
"theSameAsIAMPolicyForZabbix",
],
"Resource": "*"
}
]
}
3. Add principal to the trust relationships of the role you are using:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{Account}:user/{UserName}"
},
"Action": "sts:AssumeRole"
}
]
}
4. Test It
Get assume role credentials using access key authorization
aws sts assume-role --role-arn arn:aws:iam::123456789010:role/Zabbix_Role --role-session-name test-session --profile zabbix_user
An example of response:
{
"Credentials": {
"AccessKeyId": "ASDFGHJKLEXAMPLE",
"SecretAccessKey": "QowihdwoieuoinflksnliooEXAMPLE",
"Expiration": "2029-09-09T22:22:22+00:00"
},
"AssumedRoleUser": {
"AssumedRoleId": "ASDFGHJKLEXAMPLE:test-session",
"Arn": "arn:aws:sts::123456789010:assumed-role/Zabbix_Role/test-session"
}
}
5. Set the following macros in Zabbix:
{$AWS.AUTH_TYPE}– set toassume_role{$AWS.ACCESS.KEY.ID}– set to your access key ID{$AWS.SECRET.ACCESS.KEY}– set to your secret access key{$AWS.ASSUME.ROLE.ARN}– set to your role ARN{$AWS.ASSUME.ROLE.AUTH.METADATA}– set tofalse
Getting credentials for assume role using cross-account role (best practice)
1. Create role (see Role-Based Authorization)
2. Add the appropriate permission to the role you are using:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::{Account}:role/{RoleNameWithPath}"
},
{
"Effect": "Allow",
"Action": [
"theSameAsIAMPolicyForZabbix",
],
"Resource": "*"
}
]
}
3. Add the principal to the trust relationships of the role you are using:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{Account}:role/{RoleNameWithPath}"
},
"Action": "sts:AssumeRole"
}
]
}
4. Test it
Connect to ES2 ssh terminal in the instance and run:
- Go to EC2 → Instances → Select an instance → Connect → SSH client
Get assume role credentials using role name from instance metadata service:
aws sts assume-role --role-arn arn:aws:iam::123456789010:role/NewRole --role-session-name test-session
An example of response:
{
"Credentials": {
"AccessKeyId": "ACCESS_KEY_ID",
"SecretAccessKey": "SECRET_ACCESS_KEY",
"SessionToken": "SESSION_TOKEN",
"Expiration": "EXPIRATION_DATE"
},
"AssumedRoleUser": {
"AssumedRoleId": "ASSUMED_ROLE_ID",
"Arn": "arn:aws:sts::ACCOUNT_ID:assumed-role/ROLE_NAME/SESSION_NAME"
}
}
5. Set the following macros in Zabbix:
{$AWS.AUTH_TYPE}– set toassume_role{$AWS.ASSUME.ROLE.ARN}– set to your role ARN{$AWS.ASSUME.ROLE.AUTH.METADATA}– set totrue
Well done! You have successfully configured AWS authorization in Zabbix AWS templates.
Now you can use the template to collect metrics from AWS.
The post Understanding HTTP Template Authorization in AWS appeared first on Zabbix Blog.
NVIDIA Starts to Tackle GPU Power Smoothing with the NVIDIA GB300 NVL72
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/nvidia-starts-to-tackle-gpu-power-smoothing-with-the-nvidia-gb300-nvl72/
NVIDIA showed GPU burn and its plan to help the NVIDIA GB300 NVL72 clusters handle huge spikes in power during AI training
The post NVIDIA Starts to Tackle GPU Power Smoothing with the NVIDIA GB300 NVL72 appeared first on ServeTheHome.
Comic for 2025.07.29 – Sick Joke
Post Syndicated from Explosm.net original https://explosm.net/comics/sick-joke
New Cyanide and Happiness Comic
Help for OpenPrinting needed
Post Syndicated from jzb original https://lwn.net/Articles/1031701/
Till Kamppeter, co-founder and lead of the OpenPrinting project, has
put out a call for sponsors after being laid off by Canonical:
I want to continue doing OpenPrinting for a living, and need a way to
do so. I am currently working with the Linux Foundation to make
OpenPrinting an [organization] which can receive sponsor funding. So now
I am looking for sponsors.Even greater would be, if independent of this somebody could hire
me to continue OpenPrinting…
That Time Tom Lehrer Pranked the NSA
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/07/that-time-tom-lehrer-pranked-the-nsa.html
Bluesky thread. Here’s the paper, from 1957. Note reference 3.
Accelerate your data quality journey for lakehouse architecture with Amazon SageMaker, Apache Iceberg on AWS, Amazon S3 tables, and AWS Glue Data Quality
Post Syndicated from Brody Pearman original https://aws.amazon.com/blogs/big-data/accelerate-your-data-quality-journey-for-lakehouse-architecture-with-amazon-sagemaker-apache-iceberg-on-aws-amazon-s3-tables-and-aws-glue-data-quality/
In an era where data drives innovation and decision-making, organizations are increasingly focused on not only accumulating data but on maintaining its quality and reliability. High-quality data is essential for building trust in analytics, enhancing the performance of machine learning (ML) models, and supporting strategic business initiatives.
By using AWS Glue Data Quality, you can measure and monitor the quality of your data. It analyzes your data, recommends data quality rules, evaluates data quality, and provides you with a score that quantifies the quality of your data. With this, you can make confident business decisions. With this launch, AWS Glue Data Quality is now integrated with the lakehouse architecture of Amazon SageMaker, Apache Iceberg on general purpose Amazon Simple Storage Service (Amazon S3) buckets, and Amazon S3 Tables. This integration brings together serverless data integration, quality management, and advanced ML capabilities in a unified environment.
This post explores how you can use AWS Glue Data Quality to maintain data quality of S3 Tables and Apache Iceberg tables on general purpose S3 buckets. We’ll discuss strategies for verifying the quality of published data and how these integrated technologies can be used to implement effective data quality workflows.
Solution overview
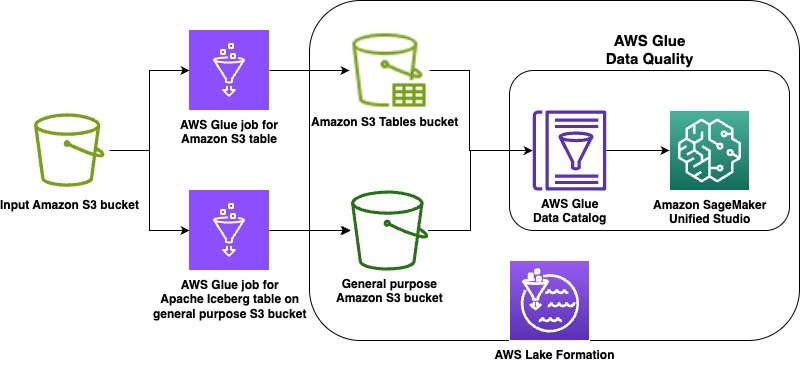
In this launch, we’re supporting the lakehouse architecture of Amazon SageMaker, Apache Iceberg on general purpose S3 buckets, and Amazon S3 Tables. As example use cases, we demonstrate data quality on an Apache Iceberg table stored in a general purpose S3 bucket as well as on Amazon S3 Tables. The steps will cover the following:
- Create an Apache Iceberg table on a general purpose Amazon S3 bucket and an Amazon S3 table in a table bucket using two AWS Glue extract, transform, and load (ETL) jobs
- Grant appropriate AWS Lake Formation permissions on each table
- Run data quality recommendations at rest on the Apache Iceberg table on general purpose S3 bucket
- Run the data quality rules and visualize the results in Amazon SageMaker Unified Studio
- Run data quality recommendations at rest on the S3 table
- Run the data quality rules and visualize the results in SageMaker Unified Studio
The following diagram is the solution architecture.
Prerequisites
To implement the instructions, you must have the following prerequisites:
- An AWS account
- AWS CLI installed and configured with your credentials
- A SageMaker Unified Studio domain
- A SageMaker Unified Studio project with All capabilities project profile
- A Lake Formation data lake administrator
Create S3 tables and Apache Iceberg on general purpose S3 bucket
First, complete the following steps to upload data and scripts:
- Upload the attached AWS Glue job scripts to your designated script bucket in S3
- To download the New York City Taxi – Yellow Trip Data dataset for January 2025 (Parquet file), navigate to NYC TLC Trip Record Data, expand 2025, and choose Yellow Taxi Trip records under January section. A file called
yellow_tripdata_2025-01.parquetwill be downloaded to your computer. - On the Amazon S3 console, open an input bucket of your choice and create a folder called
nyc_yellow_trip_data. The stack will create aGlueJobRolewith permissions to this bucket. - Upload the
yellow_tripdata_2025-01.parquetfile to the folder. - Download the CloudFormation stack file. Navigate to the CloudFormation console. Choose Create stack. Choose Upload a template file and select the CloudFormation template you downloaded. Choose Next.
- Enter a unique name for Stack name.
- Configure the stack parameters. Default values are provided in the following table:
| Parameter | Default value | Description |
ScriptBucketName |
N/A – user-supplied | Name of the referenced Amazon S3 general purpose bucket containing the AWS Glue job scripts |
DatabaseName |
iceberg_dq_demo |
Name of the AWS Glue Database to be created for the Apache Iceberg table on general purpose Amazon S3 bucket |
GlueIcebergJobName |
create_iceberg_table_on_s3 |
The name of the created AWS Glue job that creates the Apache Iceberg table on general purpose Amazon S3 bucket |
GlueS3TableJobName |
create_s3_table_on_s3_bucket |
The name of the created AWS Glue job that creates the Amazon S3 table |
S3TableBucketName |
dataquality-demo-bucket |
Name of the Amazon S3 table bucket to be created. |
S3TableNamespaceName |
s3_table_dq_demo |
Name of the Amazon S3 table bucket namespace to be created |
S3TableTableName |
ny_taxi |
Name of the Amazon S3 table to be created by the AWS Glue job |
IcebergTableName |
ny_taxi |
Name of the Apache Iceberg table on general purpose Amazon S3 to be created by the AWS Glue job |
IcebergScriptPath |
scripts/create_iceberg_table_on_s3.py |
The referenced Amazon S3 path to the AWS Glue script file for the Apache Iceberg table creation job. Verify the file name matches the corresponding GlueIcebergJobName |
S3TableScriptPath |
scripts/create_s3_table_on_s3_bucket.py |
The referenced Amazon S3 path to the AWS Glue script file for the Amazon S3 table creation job. Verify the file name matches the corresponding GlueS3TableJobName |
InputS3Bucket |
N/A – user-supplied bucket | Name of the referenced Amazon S3 bucket with which the NY Taxi data was uploaded |
InputS3Path |
nyc_yellow_trip_data |
The referenced Amazon S3 path with which the NY Taxi data was uploaded |
OutputBucketName |
N/A – user-supplied | Name of the created Amazon S3 general purpose bucket for the AWS Glue job for Apache Iceberg table data |
Complete the following steps to configure AWS Identity and Access Management (IAM) and Lake Formation permissions:
- If you haven’t previously worked with S3 Tables and analytics services, navigate to Amazon S3.
- Choose Table buckets.
- Choose Enable integration to enable analytics service integrations with your S3 table buckets.
- Navigate to the Resources tab for your AWS CloudFormation stack. Note the IAM role with the logical ID
GlueJobRoleand the database name with the logical IDGlueDatabase. Additionally, note the name of the S3 table bucket with the logical IDS3TableBucketas well as the namespace name with the logical IDS3TableBucketNamespace. The S3 table bucket name is the portion of the Amazon Resource Name (ARN) which follows:arn:aws:s3tables:<region>:<accountID>:bucket/{S3 Table bucket Name}. The namespace name is the portion of the namespace ARN which follows:arn:aws:s3tables:<region>:<accountID>:bucket/{S3 Table bucket Name}|{namespace name}. - Navigate to the Lake Formation console with a Lake Formation data lake administrator.
- Navigate to the Databases tab and select your
GlueDatabase. Note the selected default catalog should match your AWS account ID. - Select the Actions dropdown menu and under Permissions, choose Grant.
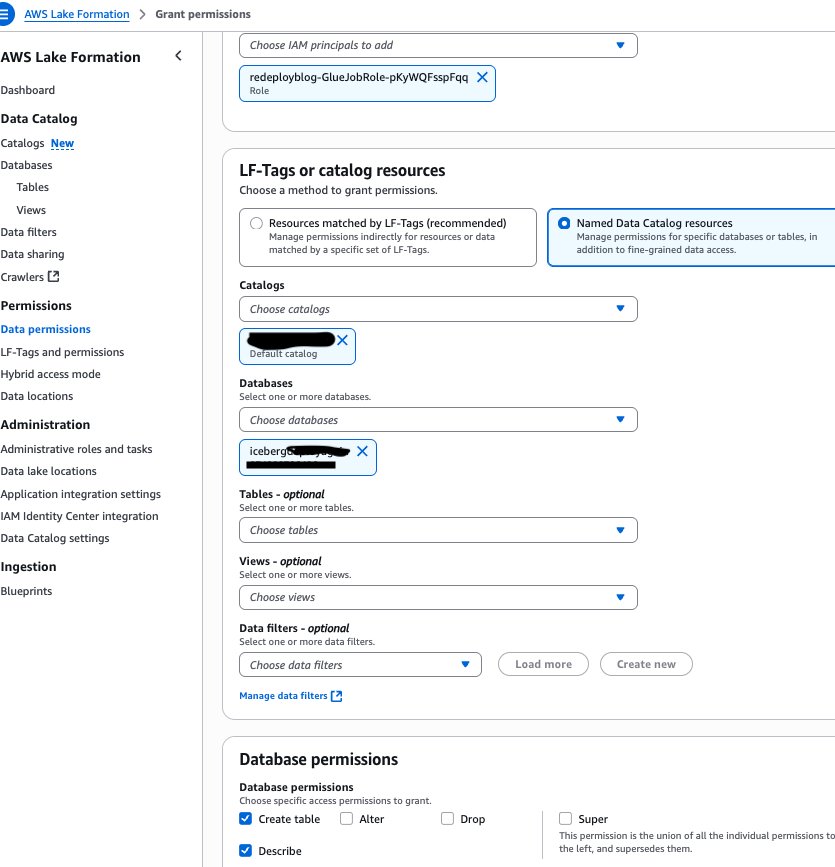
- Grant your
GlueJobRolefrom step 4 the necessary permissions. Under Database permissions, select Create table and Describe, as shown in the following screenshot.
Navigate back to the Databases tab in Lake Formation and select the catalog that matches with the value of S3TableBucket you noted in step 4 in the format: <AWS account ID>:s3tablescatalog/<S3 Table Bucket name>
- Select your namespace name. From the Actions dropdown menu, under Permissions, choose Grant.
- Grant your GlueJobRole from step 4 the necessary permissions Under Database permissions, select Create table and Describe, as shown in the following screenshot.
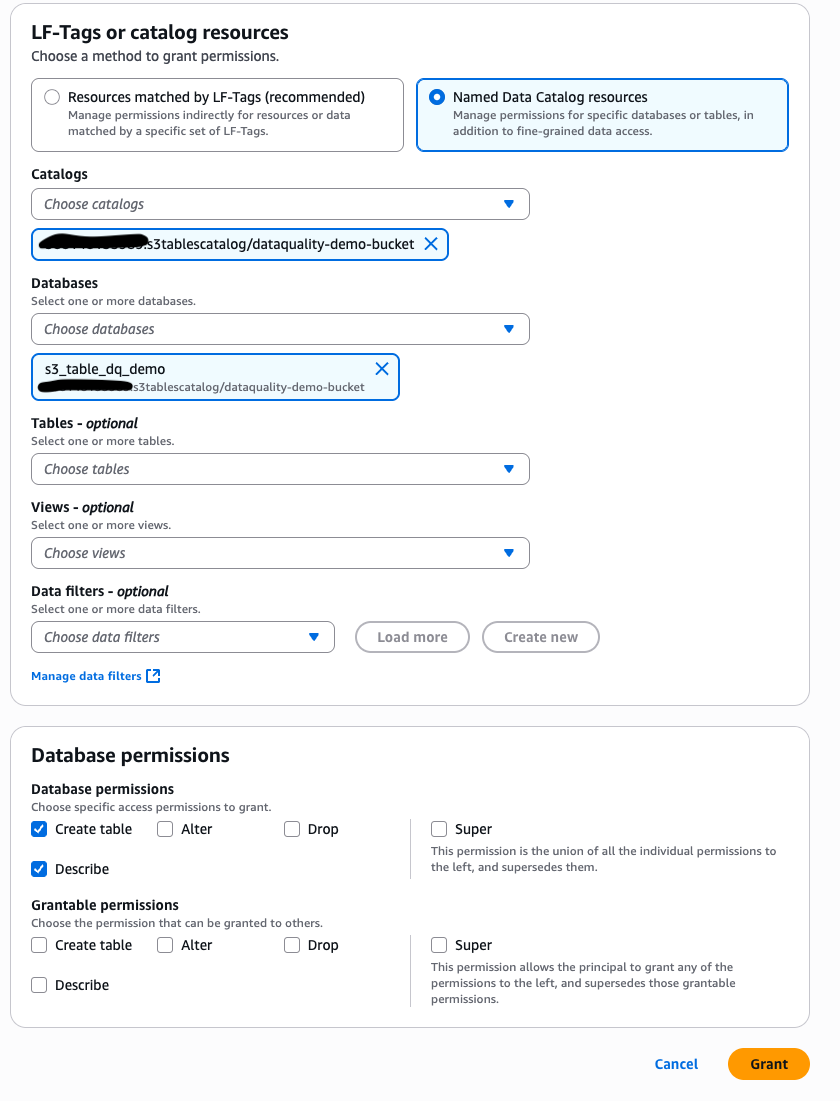
To run the jobs created in the CloudFormation stack to create the sample tables and configure Lake Formation permissions for the DataQualityRole, complete the following steps:
- In the Resources tab of your CloudFormation stack, note the AWS Glue job names for the logical resource IDs:
GlueS3TableJobandGlueIcebergJob. - Navigate to the AWS Glue console and select ETL jobs. Select your
GlueIcebergJobfrom step 11 and choose Run job. Select yourGlueS3TableJoband choose Run job. - To verify the successful creation of your Apache Iceberg table on general purpose S3 bucket in the database, navigate to Lake Formation with your Lake Formation data lake administrator permissions. Under Databases, select your
GlueDatabase. The selected default catalog should match your AWS account ID. - On the dropdown menu, choose View and then Tables. You should see a new tab with the table name you specified for
IcebergTableName. You have verified the table creation. - Select this table and grant your DataQualityRole (
<stack_name>-DataQualityRole-<xxxxxx>) the necessary Lake Formation permissions by choosing the Grant link in the Actions tab. Choose Select, Describe from Table permissions for the new Apache Iceberg table. - To verify the S3 table in the S3 table bucket, navigate to Databases in the Lake Formation console with your Lake Formation data lake administrator permissions. Make sure the selected catalog is your S3 table bucket catalog:
<AWS account ID>:s3tablescatalog/<S3 Table Bucket name> - Select your S3 table namespace and choose the dropdown menu View.
- Choose Tables and you should see a new tab with the table name you specified for
S3TableTableName. You have verified the table creation. - Choose the link for the table and under Actions, choose Grant. Grant your
DataQualityRolethe necessary Lake Formation permissions. Choose Select, Describe from Table permissions for the S3 table. - In the Lake Formation console with your Lake Formation data lake administrator permissions, on the Administration tab, choose Data lake locations .
- Choose Register location. Input your
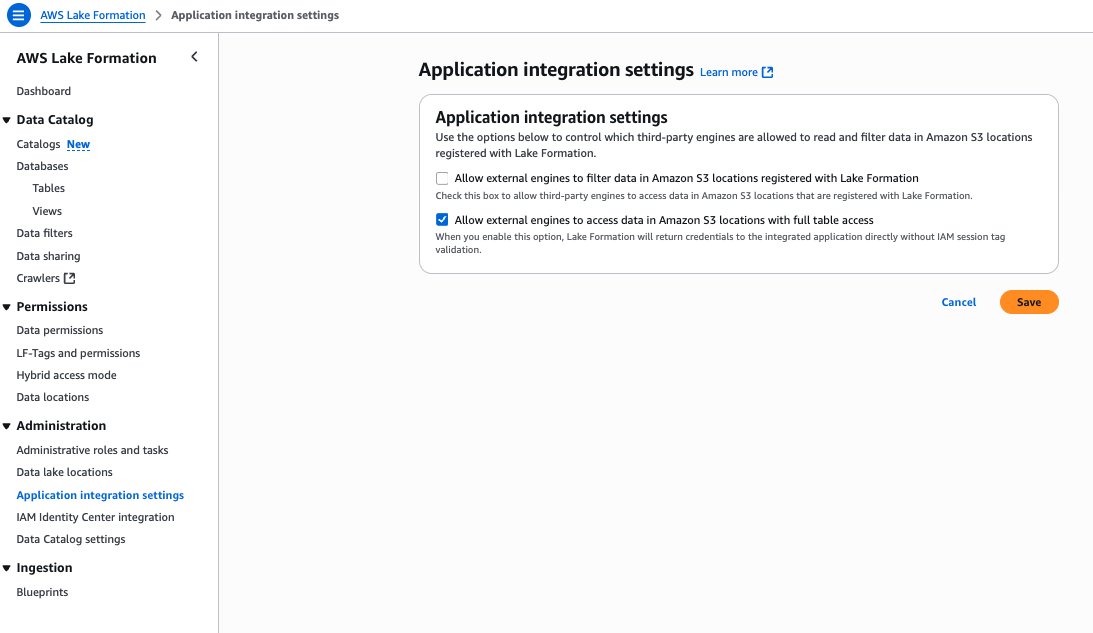
OutputBucketNameas the Amazon S3 path. Input theLakeFormationRolefrom the stack resources as the IAM role. Under Permission mode, choose Lake Formation. - On the Lake Formation console under Application integration settings, select Allow external engines to access data in Amazon S3 locations with full table access, as shown in the following screenshot.
Generate recommendations for Apache Iceberg table on general purpose S3 bucket managed by Lake Formation
In this section, we show how to generate data quality rules using the data quality rule recommendations feature of AWS Glue Data Quality for your Apache Iceberg table on a general purpose S3 bucket. Follow these steps:
- Navigate to the AWS Glue console. Under Data Catalog, choose Databases. Choose the
GlueDatabase. - Under Tables, select your
IcebergTableName. On the Data quality tab, choose Run history. - Under Recommendation runs, choose Recommend rules.
- Use the
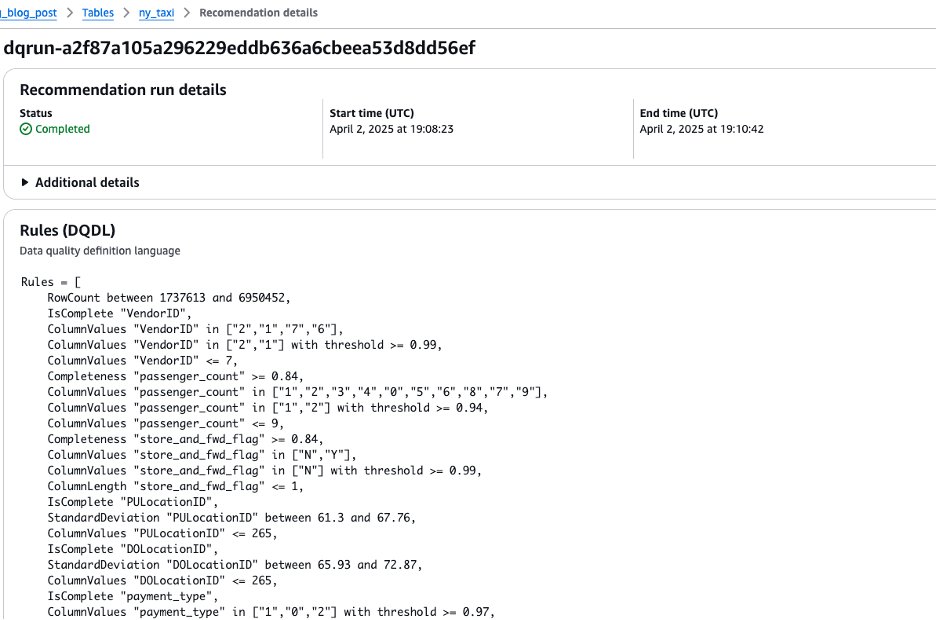
DataQualityRole(<stack_name>-DataQualityRole-<xxxxxx>) to generate data quality rule recommendations, leaving the other settings as default. The results are shown in the following screenshot.
Run data quality rules for Apache Iceberg table on general purpose S3 bucket managed by Lake Formation
In this section, we show how to create a data quality ruleset with the recommended rules. After creating the ruleset, we run the data quality rules. Follow these steps:
- Copy the resulting rules from your recommendation run by selecting the dq-run ID and choosing Copy.
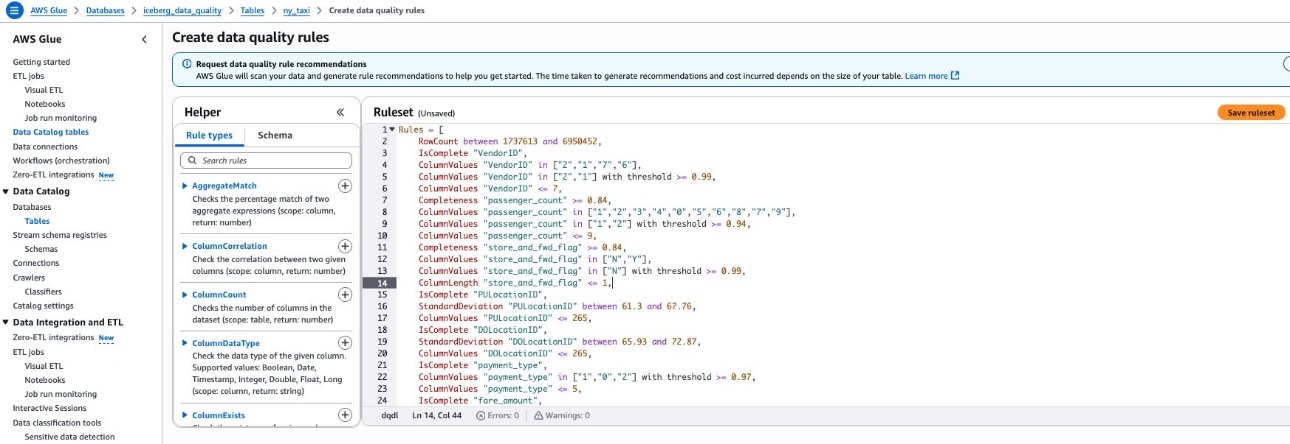
- Navigate back to the table under the Data quality tab and choose Create data quality rules. Paste the ruleset from step 1 here. Choose Save ruleset, as shown in the following screenshot.
- After saving your ruleset, navigate back to the Data Quality tab for your Apache Iceberg table on the general purpose S3 bucket. Select the ruleset you created. To run the data quality evaluation run on the ruleset using your data quality role, choose Run, as shown in the following screenshot.
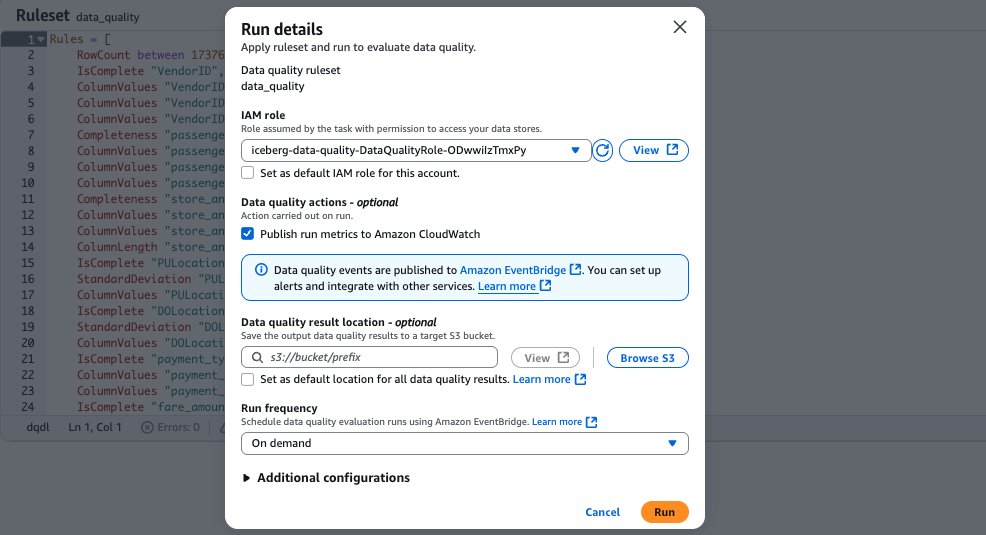
Generate recommendations for the S3 table on the S3 table bucket
In this section, we show how to use the AWS Command Line Interface (AWS CLI) to generate recommendations for your S3 table on the S3 table bucket. This will also create a data quality ruleset for the S3 table. Follow these steps:
- Fill in your S3 table
namespace name, S3 tabletable name,Catalog ID, andData Quality role ARNin the following JSON file and save it locally:
- Enter the following AWS CLI command replacing local
file nameandregionwith your own information:
- Run the following AWS CLI command to confirm the recommendation run succeeds:
Run data quality rules for the S3 table on the S3 table bucket
In this section, we show how to use the AWS CLI to evaluate the data quality ruleset on the S3 tables bucket that we just created. Follow these steps:
- Replace S3 table
namespace name, S3 tablestable name,Catalog ID, andData Quality role ARNwith your own information in the following JSON file and save it locally:
- Run the following AWS CLI command replacing local
file nameandregionwith your information:
- Run the following AWS CLI command replacing
regionand data qualityrun IDwith your information:
View results in SageMaker Unified Studio
Complete the following steps to view results from your data quality evaluation runs in SageMaker Unified Studio:
- Log in to the SageMaker Unified Studio portal using your single sign-on (SSO).
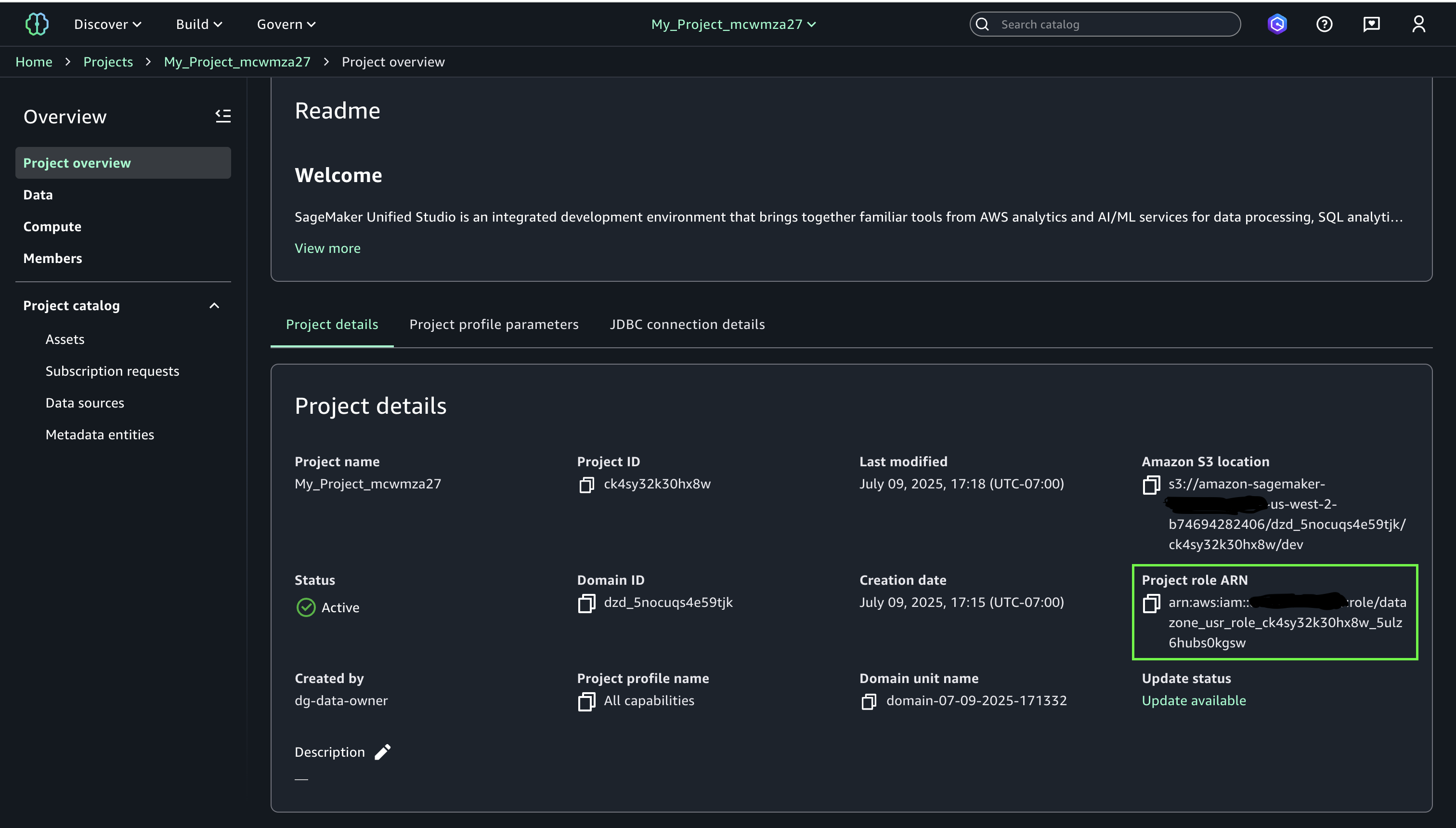
- Navigate to your project and note the project role ARN


- Navigate to the Lake Formation console with your Lake Formation data lake administrator permissions. Select your Apache Iceberg table that you created on general purpose S3 bucket and choose Grant from the Actions dropdown menu. Grant the following Lake Formation permissions to your SageMaker Unified Studio project role from step 2:
- Describe for Table permissions and Grantable permissions
- Next, select your S3 Table from the S3 Table bucket catalog in Lake Formation and choose Grant from the Actions drop-down. Grant the below Lake Formation permissions to your SageMaker Unified Studio project role from step 2:
- Describe for Table permissions and Grantable permissions
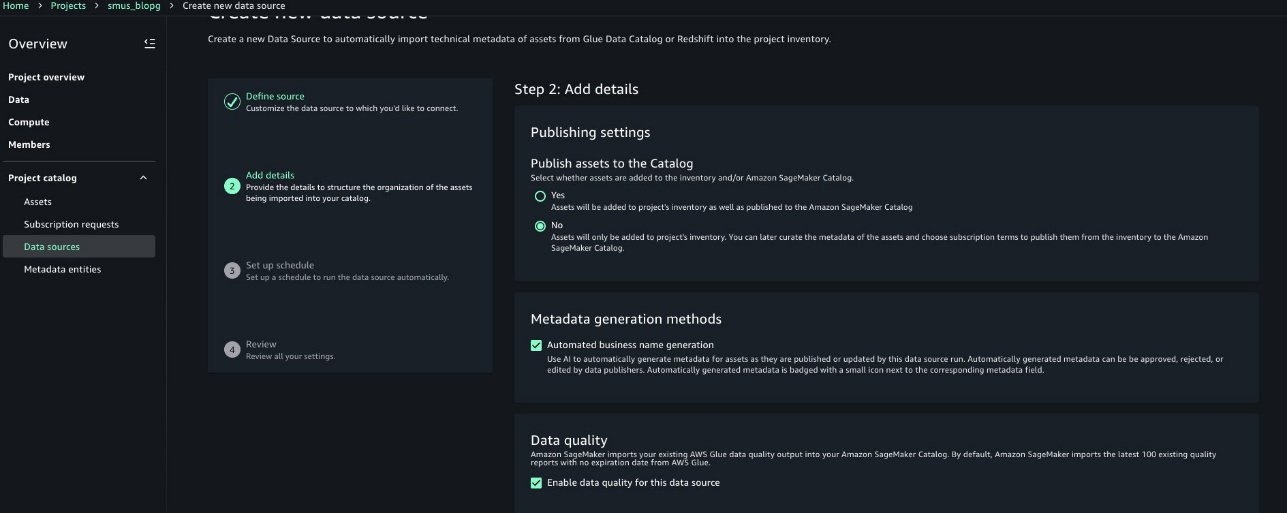
- Follow the steps at Create an Amazon SageMaker Unified Studio data source for AWS Glue in the project catalog to configure your data source for your
GlueDatabaseand your S3 tables namespace.- Choose a name and optionally enter a description for your data source details.
- Choose AWS Glue (Lakehouse) for your Data source type. Leave connection and data lineage as the default values.
- Choose Use the AwsDataCatalog for the Apache Iceberg table on general purpose S3 bucket AWS Glue database.
- Choose the Database name corresponding to the
GlueDatabase.Choose Next. - Under Data quality, select Enable data quality for this data source. Leave the rest of the defaults.

- Configure the next data source with a name for your S3 table namespace. Optionally, enter a description for your data source details.
- Choose AWS Glue (Lakehouse) for your Data source type. Leave connection and data lineage as the default values.
- Choose to enter the catalog name:
s3tablescatalog/<S3TableBucketName> - Choose the Database name corresponding to the S3 table namespace. Choose Next.
- Select Enable data quality for this data source. Leave the rest of the defaults.
- Run each dataset.

- Navigate to your project’s Assets and select the related asset that you created for Apache Iceberg table on general purpose S3 bucket. Navigate to the Data Quality tab to view your data quality results. You should be able to see the data quality results for the S3 table asset similarly.

The data quality results in the following screenshot show each rule evaluated in the selected data quality evaluation run and its result. The data quality score calculates the percentage of rules that passed, and the overview shows how certain rule types faired across the evaluation. For example, Completeness rule types all passed, but ColumnValues rule types passed only three out of nine times.
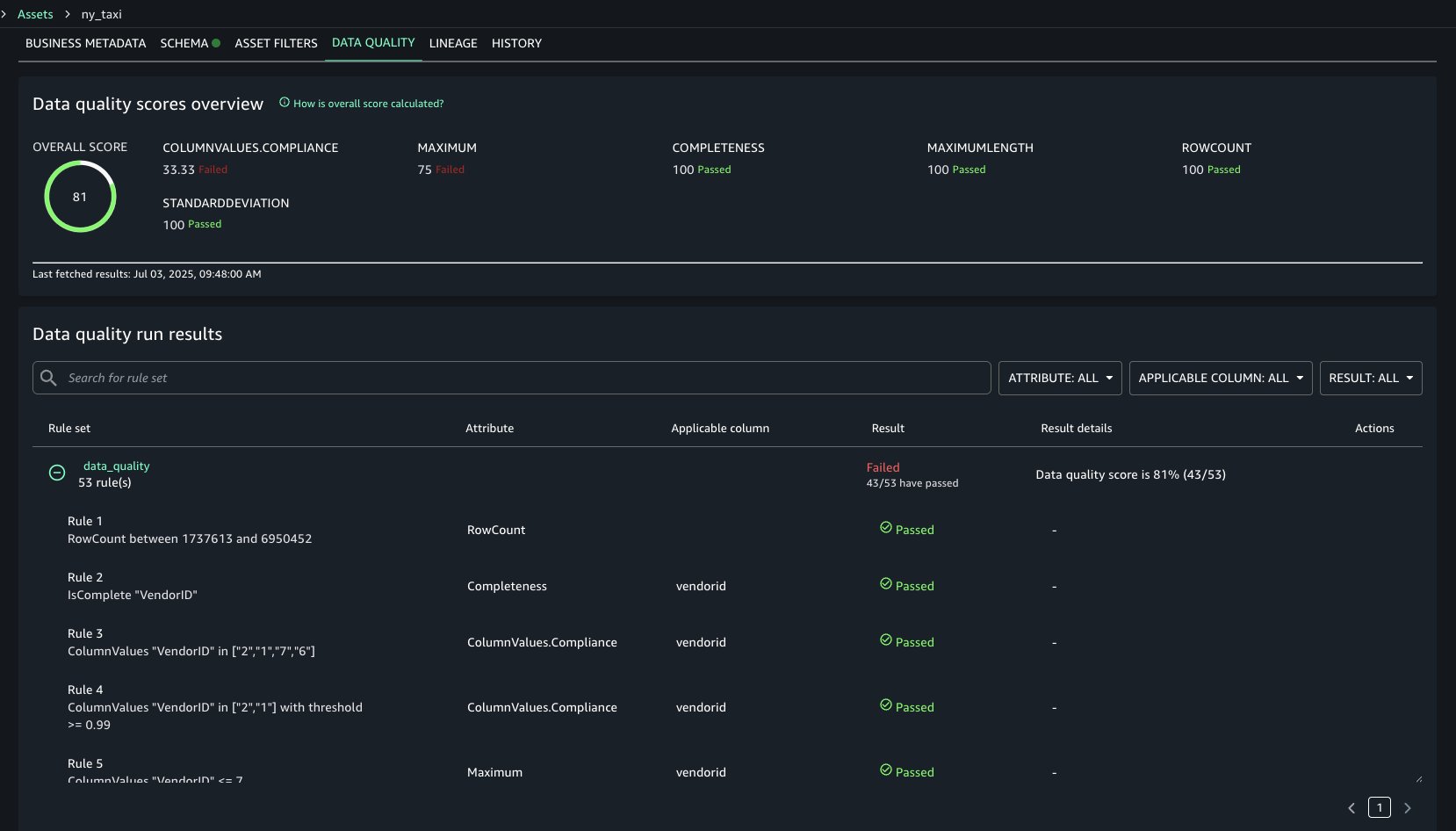
Cleanup
To avoid incurring future charges, clean up the resources you created during this walkthrough:
- Navigate to the blog post output bucket and delete its contents.
- Un-register the data lake location for your output bucket in Lake Formation
- Revoke the Lake Formation permissions for your SageMaker project role, for your data quality role, and for your AWS Glue job role.
- Delete the input data file and the job scripts from your bucket.
- Delete the S3 table.
- Delete the CloudFormation stack.
- [Optional] Delete your SageMaker Unified Studio domain and the associated CloudFormation stacks it created on your behalf.
Conclusion
In this post, we demonstrated how you can now generate data quality recommendation for your lakehouse architecture using Apache Iceberg tables on general purpose Amazon S3 buckets and Amazon S3 Tables. Then we showed how to integrate and view these data quality results in Amazon SageMaker Unified Studio. Try this out for your own use case and share your feedback and questions in the comments.
About the Authors
 Brody Pearman is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use AWS Glue ETL to transform and create their data lakes on AWS while maintaining high data quality. In his free time, he enjoys watching football with his friends and walking his dog.
Brody Pearman is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use AWS Glue ETL to transform and create their data lakes on AWS while maintaining high data quality. In his free time, he enjoys watching football with his friends and walking his dog.
 Shiv Narayanan is a Technical Product Manager for AWS Glue’s data management capabilities like data quality, sensitive data detection and streaming capabilities. Shiv has over 20 years of data management experience in consulting, business development and product management.
Shiv Narayanan is a Technical Product Manager for AWS Glue’s data management capabilities like data quality, sensitive data detection and streaming capabilities. Shiv has over 20 years of data management experience in consulting, business development and product management.
 Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.
Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.
 Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse architecture, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.
Narayani Ambashta is an Analytics Specialist Solutions Architect at AWS, focusing on the automotive and manufacturing sector, where she guides strategic customers in developing modern data and AI strategies. With over 15 years of cross-industry experience, she specializes in big data architecture, real-time analytics, and AI/ML technologies, helping organizations implement modern data architectures. Her expertise spans across lakehouse architecture, generative AI, and IoT platforms, enabling customers to drive digital transformation initiatives. When not architecting modern solutions, she enjoys staying active through sports and yoga.
[$] Some 6.16 development statistics
Post Syndicated from corbet original https://lwn.net/Articles/1031161/
The 6.16 development cycle was another busy one, with 14,639 non-merge
changesets pulled into the mainline — just 18 commits short of the
total for 6.15. The 6.16 release happened
on July 27, as expected. Also as expected, LWN has put together its
traditional look at where the code for this release came from.