Post Syndicated from Fallon Blossom original https://blog.cloudflare.com/cloudflare-tv-as-a-service/


In June 2020, Cloudflare TV made its debut: a 24/7 streaming video channel, focused on topics related to building a better Internet (and the people working toward that goal). Today, over 1,000 live shows later, we’re excited to announce that we’re making the technology we used to build Cloudflare TV available to any other business that wants to run their own 24×7 streaming network. But, before we get to that, it’s worth reflecting on what it’s been like for us to run one ourselves.
Let’s take it from the top.
Cloudflare TV began as an experiment in every way you could think of, one we hoped would help capture the serendipity of in-person events in a world where those were few and far between. It didn’t take long before we realized we had something special on our hands. Not only was the Cloudflare team thriving on-screen, showcasing an amazing array of talent and expertise — they were having a great time doing it. Cloudflare TV became a virtual watercooler, spiked with the adrenaline rush of live TV.
One of the amazing things about Cloudflare TV has been the breadth of content it’s inspired. Since launching, CFTV has hosted over 1,000 live sessions, featuring everything from marquee customer events with VIP speakers to game shows and DJ sets. Cloudflare’s employee resource groups have hosted hundreds of sessions speaking to their unique experiences, sharing a wealth of advice with the next generation of technology leaders. All told, we’ve welcomed over 650 Cloudflare employees and interns — and over 500 external guests, including the likes of Intel CEO Pat Gelsinger, Gradient Ventures board partner Bonita Stewart, Broadcom CTO Andy Nallappan, and Zendesk SVP Christina Liu.
Tune In, Geek Out: A CFTV Montage
This is Cloudflare TV, so of course we put an emphasis on technical content for viewers of all stripes. When we announce a new product or protocol on the Cloudflare Blog, we often host live sessions on CFTV the same day, featuring the engineers who wrote the code that just shipped. Every week, we broadcast episodes on cryptography, on learning how to code, and on the hardware that powers Cloudflare’s network in over 250 cities around the world.
Whether you’re new to Cloudflare TV or a longtime viewer, we encourage you to pay a visit to the just-launched Discover page, where you’ll find many of our most-loved shows on demand, ranging from Latest from Product and Engineering, to perennial favorite Silicon Valley Squares, to Yes We Can, featuring women leaders from across the tech industry. You can also browse upcoming Live segments and easily add them to your calendar.
One of the most promising indicators that we’re on the right track has been the feedback we’ve gotten, not just from viewers — but from companies eager to know which platform we were using to power CFTV. To date we haven’t had much to offer them other than our sincere thanks, but as of today we’re able to share something much more exciting.
But first: a look behind the scenes.
The Production Stack
We didn’t initially set out to build Cloudflare TV from scratch. But as we explored our available options, we quickly realized that few solutions were designed for 24/7 linear streaming, and fewer still were optimized to be managed by a globally-distributed team. Thankfully, at Cloudflare, we like to build.
Our engineers worked at a blazing pace to build our own homegrown system, tapping open-source projects where we could, and inventing the things that didn’t yet exist. Among the starring components:
- Brave (BBC) — Brave is an open-source project named for a highly descriptive acronym: Basic Real-Time Audio Video Editor. It serves as the Cloudflare TV switchboard, allowing us to jump from live content to commercial to a pre-recorded session and back automatically, based on our broadcast schedule. The only issue with Brave is that, as the BBC put it: it’s a prototype. One that hasn’t been updated since 2018…
- Zoom — When we first designed Cloudflare TV, there was one directive that stood above the others: it had to be easy. If presenters had to deal with installing a browser plugin or unfamiliar app, we knew we’d lose many of them — especially external guests. Zoom emerged as the clear answer, and thanks to its RTMP broadcast feature, it’s worked seamlessly to facilitate live content on Cloudflare TV. In most cases, participating in a CFTV session is as simple as joining a Zoom meeting.
- Cloudflare Workers — Put simply, Cloudflare TV wouldn’t exist were it not for Cloudflare Workers. Workers is the glue that brings together each of the disparate components of the platform — handling authentication, application logic, securely relaying data from our backend to our frontend, and sprinkling SEO optimizations across the site. It’s the first tool we reach for, and often the only one we need.
- Cloudflare Stream — With over 1,000 episodes in our content library, we have a lot of assets to manage. Thankfully Stream makes it easy: episodes are uploaded and automatically transcoded to the appropriate bitrate, and we use Stream embeds to power Video on Demand across the entire platform. We also use the Stream API to deliver recordings to our backend switchboard so that they can be seamlessly rebroadcast alongside our Live sessions.
- Cloudflare for Teams — Cloudflare TV is obviously public-facing, but there are an array of dashboards and admin interfaces that are only accessible to select members of the Cloudflare team. Thankfully the Cloudflare for Teams suite, including Cloudflare Access, makes it easy for us to set up custom rulesets that keep everything secure, without any cumbersome VPNs or authentication hurdles.
We Get By With a Little Help from Our Engs
We knew from the beginning that it wasn’t enough for Cloudflare TV to be easy for presenters — we needed to be able to run it with a relatively small team, working remotely, most of whom were juggling other responsibilities.
A special shoutout goes to the members of Cloudflare’s office and executive admin teams, whose roles were dramatically impacted by the pandemic. Each of them has stepped up and taken on the mantle of Cloudflare TV Producer, providing technical support, calming nerves, and facilitating each one of our live sessions. We couldn’t do it without them, nor would we want to.
Even so, running a TV station is a lot of work, and we had little choice but to make the platform as efficient as possible — automating away our pain points, and developing intuitive admin tools to empower our team. Here are some of the key contributors to the system’s efficiency:
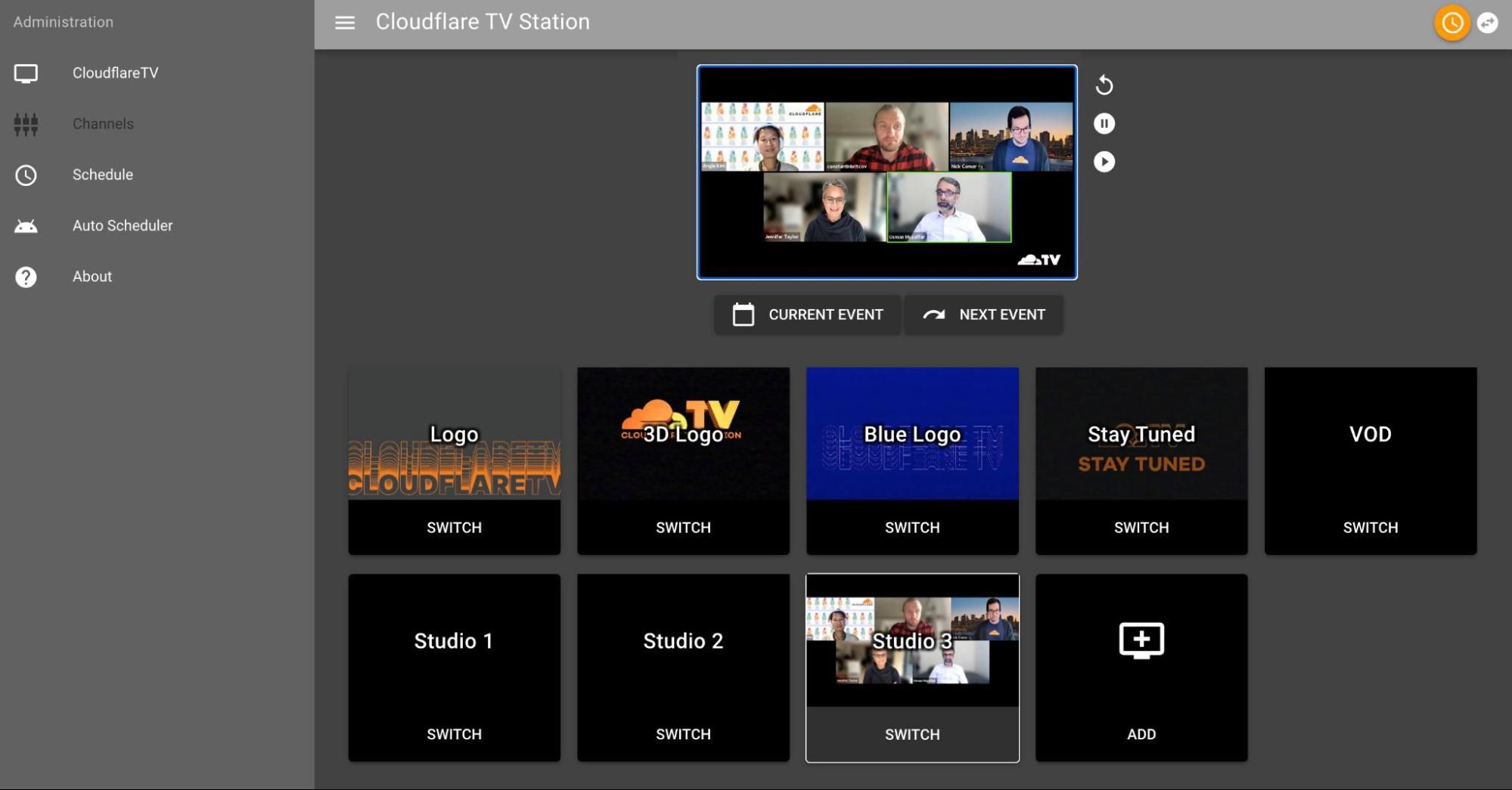
The Auto-Switcher — CFTV’s schedule features hundreds of sessions every week, including weekends, which would be prohibitive if any manual switching were involved. Thankfully the system operates essentially on auto-pilot. This is no simple playlist: every minute, a program running on Cloudflare Workers syncs with the CFTV backend to queue up recordings and inputs for upcoming sessions, deleting those belonging to sessions that have already aired. If we take a week off over the holidays, Cloudflare TV will keep on humming.
The Auto-Scheduler — Scheduling CFTV content by hand (well over 250 segments per week) quickly went from a meaningful exercise to a perverse task. By week two we knew we had to figure something else out. And so the auto-scheduler was born, allowing us to select an arbitrary window of time and populate it with recordings from our content library, filling in any time slots between live segments.
Segments can be dragged, dropped, added, and removed in a couple of clicks; one person can schedule the entire week in less than an hour. The auto-scheduler intelligently rotates through each episode in the catalog to ensure they all get airtime — and we see plenty of opportunities for it to get smarter.
The Broadcasting Center — The lifeblood of Cloudflare TV is our live segments, so we naturally spend a lot of time trying to improve the experience for presenters. The Broadcasting Center is their home base: a page that loads automatically for each session’s host, providing them a countdown timer and other essentials. And because viewer engagement is a crucial part of what makes live programming special, it features a section for viewer questions — including a call-in feature, which records and automatically transcribes questions phoned in by viewers.
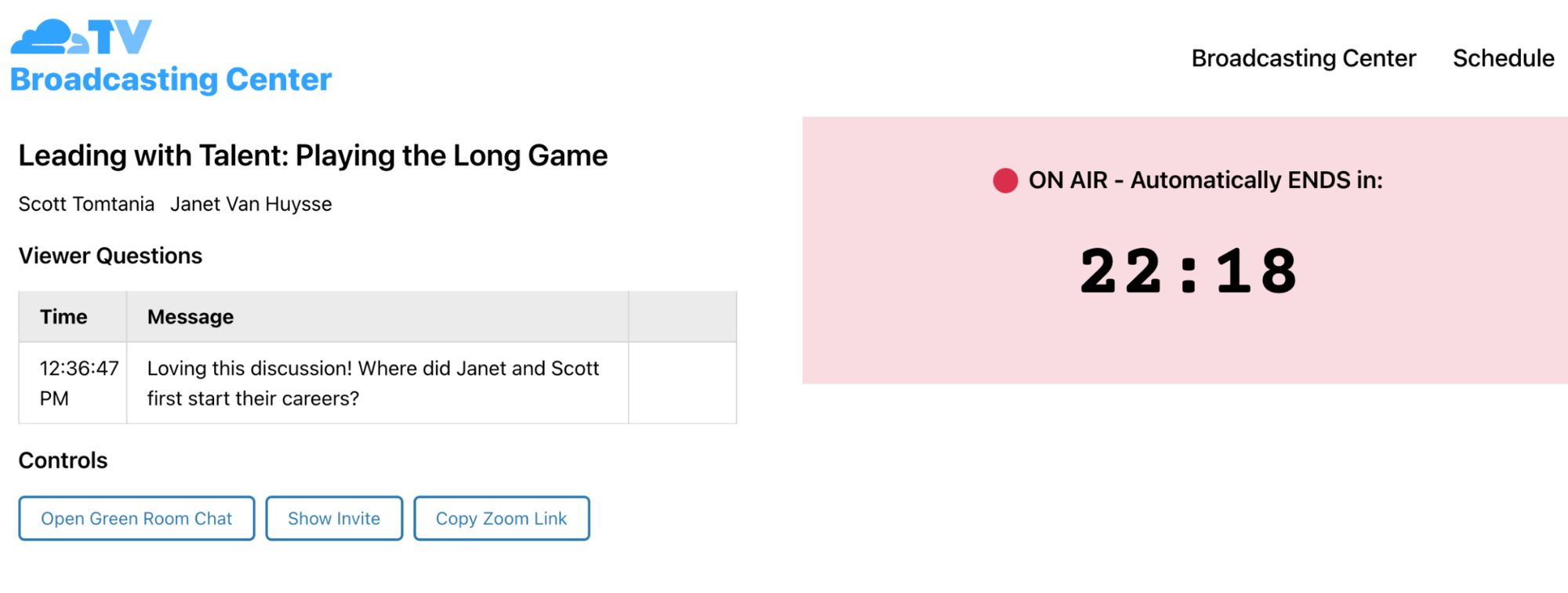
Meanwhile, our CFTV Producers use an administrative view of the same tool, where they check to make sure the stream is coming through clearly before each session begins. A set of admin controls allow them to troubleshoot if needed, and they can moderate viewer questions as well.
For both producers and presenters, the Broadcasting Center provides a single control plane to manage a live session. This ease-of-use goes a long way toward keeping the system running smoothly with a lean team.
There’s a sequel? There’s a sequel.
One reason we’ve invested in Cloudflare TV is that it serves as fantastic platform for dogfooding — not only are we leveraging a broad array of Cloudflare’s media products, but our 24/7 linear content makes us a particularly demanding customer, with no appetite for arbitrary constraints like time limits or maintenance downtime.
With that in mind, we’re excited to integrate many of the new technologies Cloudflare is introducing this week, which will combine to power an overhauled version of the CFTV platform that we’re calling Cloudflare TV 2.0. Namely:
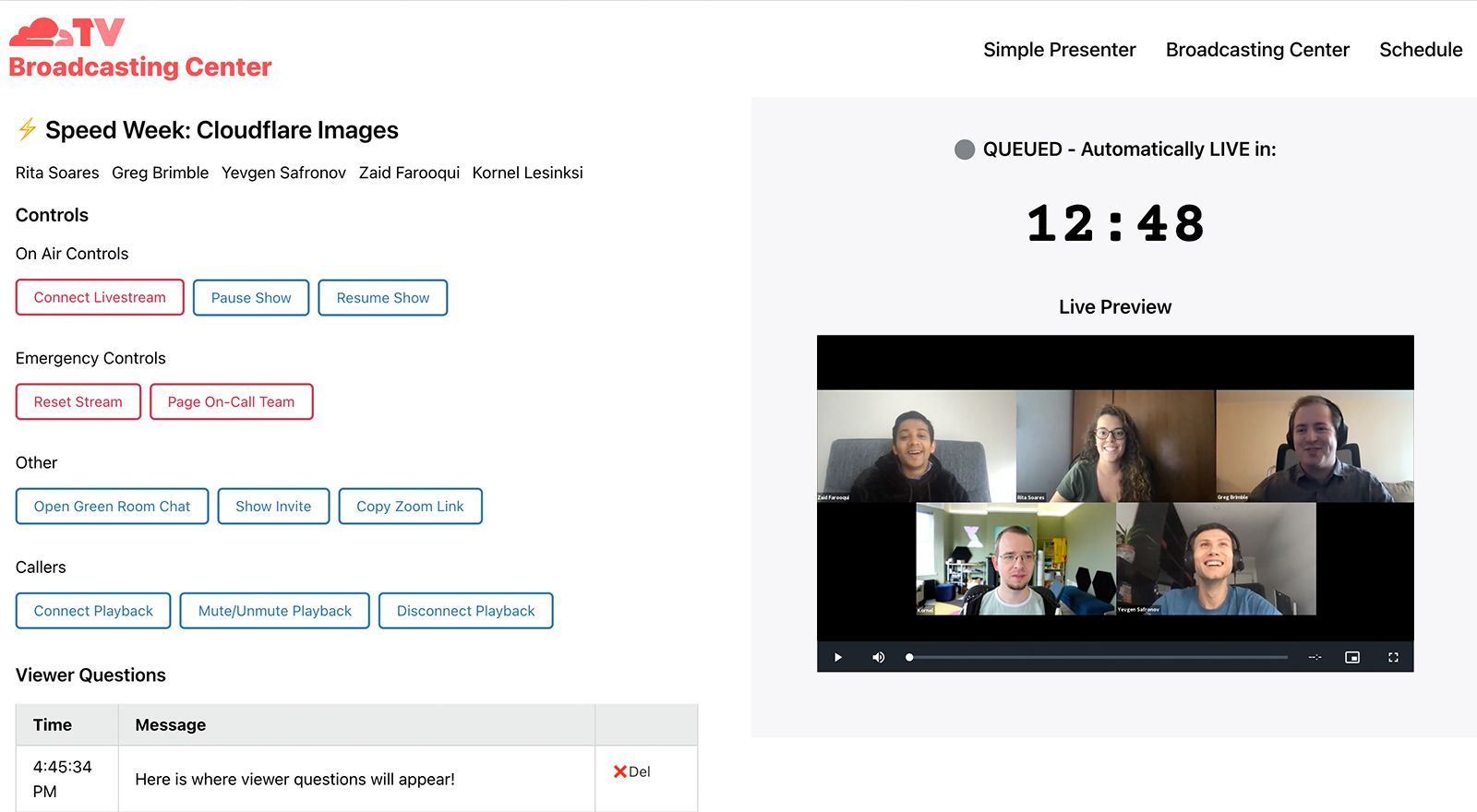
- Real Time Communications Platform — Today, Cloudflare announced its new Real Time Communications Platform, powered by WebRTC. In the near future, Cloudflare TV will leverage this platform to handle many of our live sessions. CFTV will continue to support Zoom, OBS, and any other application capable of outputting a RTMP stream, because convenience is one of the essential pillars in helping our presenters engage with the platform. But we see opportunities to push our creativity to new heights with custom, programmatically-controlled media streams — powered by Cloudflare’s Real-Time Communications Platform.
- Stream Live — CFTV’s backend server currently handles video encoding for our live broadcast, generating a stream that is relayed to a video.js embed. Replacing this setup with Stream Live will yield several key benefits: first, we will offload video encoding to Cloudflare’s global network, resulting in improved speed, reliability, and redundancy. It also means we’ll be able to generate multiple renditions of the broadcast at different bitrates, allowing us to offer streams that are optimized for mobile devices with limited bandwidth, and to dynamically switch between bitrates as a user’s network conditions change.
- Stream Connect — Today, the only way to watch Cloudflare TV is from the platform’s homepage — but there’s no reason we can’t syndicate it to other popular video platforms like YouTube. Stream Connect will become the primary endpoint for our backend mixer, and will in turn generate multiple copies of that stream, outputting to YouTube, the main broadcast, and any number of additional platforms.
We’re also actively working on a fresh implementation of our switchboard — one that is designed to be more reliable, scalable, and customizable. This switchboard will power the core of Cloudflare TV 2.0.

It’s not TV. It’s Cloudflare TV.
Cloudflare TV 2.0 will represent a major step forward for the platform, one that leverages over a year of insights as we rearchitect the system from its core to take full advantage of the Cloudflare network. And we’re doing it with you in mind: the same technology will be used to power Cloudflare TV as a Service.
Most products at Cloudflare are designed to scale from individuals up to the largest businesses. This is not one of those. Running a 24×7 streaming network takes a lot of time and effort. While we’ve made it easier than ever before, this is a product really designed for businesses that are willing to make a commitment similar to what we have at Cloudflare. But, if you are, we’re here to tell you that running a streaming service is incredibly rewarding, and we want to enable more companies to do it.
Interested? Fill out this form and, if it looks like you’d be a good fit, we’ll reach out and work with you to help build your own streaming service.
In the meantime, don’t miss out on Stream Live and the new Real Time Communications Platform. There’s no reason you can’t start building today.
















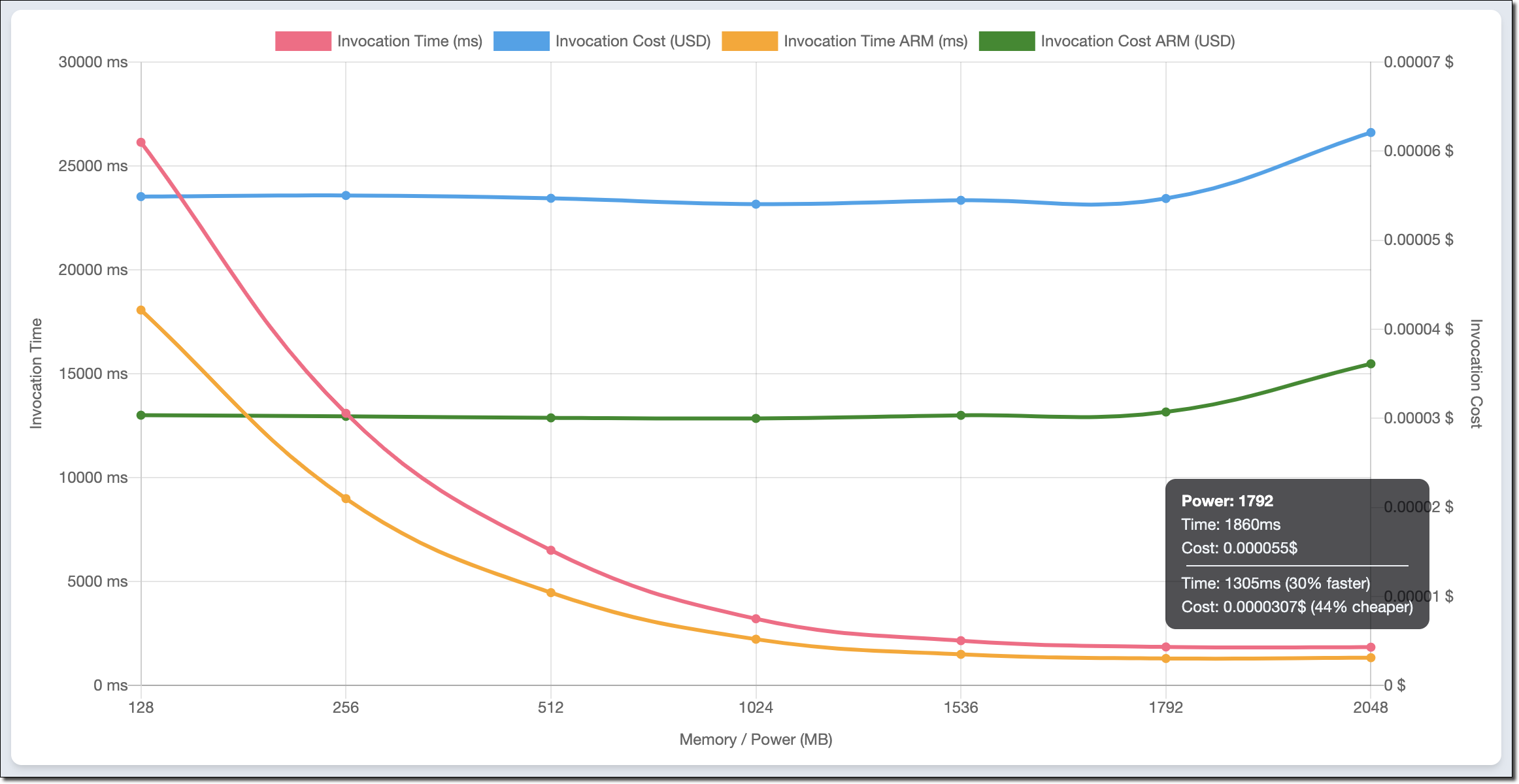











 Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.




![[Security Nation] Rob Graham on Mike Lindell's Cyber Symposium](https://blog.rapid7.com/content/images/2021/09/graham-robert.jpg)


