Post Syndicated from Explosm.net original https://explosm.net/comics/was-i-adopted
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/was-i-adopted
New Cyanide and Happiness Comic
Post Syndicated from Matheus Guimaraes original https://aws.amazon.com/blogs/aws/accelerate-the-modernization-of-mainframe-and-vmware-workloads-with-aws-transform/
Generative AI has brought many new possibilities to organizations. It has equipped them with new abilities to retire technical debt, modernize legacy systems, and build agile infrastructure to help unlock the value that is trapped in their internal data. However, many enterprises still rely heavily on legacy IT infrastructure, particularly mainframes and VMware-based systems. These platforms have been the backbone of critical operations for decades, but they hinder organizations’ ability to innovate, scale effectively, and reduce technical debt in an era where cloud-first strategies dominate. The need to modernize these workloads is clear, but the journey has traditionally been complex and risky.
The complexity spans multiple dimensions. Financially, organizations face mounting licensing costs and expensive migration projects. Technically, they must untangle legacy dependencies while meeting compliance requirements. Organizationally, they must manage the transition of teams who’ve built careers around legacy systems and navigate undocumented institutional knowledge.
AWS Transform directly addresses these challenges with purpose-built agentic AI that accelerates and de-risks your legacy modernization. It automates the assessment, planning, and transformation of both mainframe and VMware workloads into cloud based architectures, streamlining the entire process. Through intelligent insights, automated code transformation, and human-in-the-loop workflows, organizations can now tackle even the most challenging modernization projects with greater confidence and efficiency.
Mainframe workload migration
AWS Transform for mainframe is the first agentic AI service for modernizing mainframe workloads at scale. The specialized mainframe agent accelerates mainframe modernization by automating complex, resource-intensive tasks across every phase of modernization — from initial assessment to final deployment. It streamlines the migration of legacy applications built on IBM z/OS Db2, including COBOL, CICS, DB2, and VSAM, to modern cloud environments–cutting modernization timelines from years to months.
Let’s look at a few examples of how AWS Transform can help you through different aspects of the migration process.
Code analysis – AWS Transform provides comprehensive insights into your codebase, automatically examining mainframe codebases, creating detailed dependency graphs, measuring code complexity, and identifying component relationships

Documentation – AWS Transform for mainframe creates comprehensive technical and functional documentation of mainframe applications, preserving critical knowledge about features, program logic, and data flows. You can interact with the generated documentation through an AI-powered chat interface to discover and retrieve information quickly.

Business rule extraction – AWS Transform extracts and presents complex logic in plain language so you can gain visibility into business processes embedded within legacy applications. This enables both business and technical stakeholders to gain a greater understanding of application functionality.
Code decomposition – AWS Transform offers sophisticated code decomposition tools, including interactive dependency graphs and domain separation capabilities, enabling users to visualize and modify relationships between components while identifying key business functions. The solution also streamlines migration planning through an interactive wave sequence planner that considers user preferences to generate optimized migration strategies.

Modernization Wave Planning – With its specialized agent, AWS Transform for mainframe creates prioritized modernization wave sequences based on code and data dependencies, code volume, and business priorities. It enables modernization teams to make data-driven, customized migration plans that align to their specific organizational needs.
Code refactoring – AWS Transform can refactor millions of lines of mainframe code in minutes, converting COBOL, VSAM, and DB2 systems into modern Java Spring Boot applications while maintaining functional equivalence and transforming CICS transactions into web services and JCL batch processes into Groovy scripts. The solution provides high-quality output through configurable settings and bundled runtime capabilities, producing Java code that emphasizes readability, maintainability, and technical excellence.

Deployments – AWS Transform provides customizable deployment templates that streamline the deployment process through user-defined inputs. For added efficiency, the solution bundles the selected runtime version with the migrated application, enabling seamless deployment as a complete package.
By integrating intelligent documentation analysis, business rules extraction, and human-in-the-loop collaboration capabilities, AWS Transform helps organizations accelerate their mainframe transformation while reducing risk and maintaining business continuity.
VMware modernization
With rapid changes in VMware licensing and support model, organizations are increasingly exploring alternatives despite the difficulties associated with migrating and modernizing VMware workloads. This is aggravated by the fact that the accumulation of technical debt typically creates complex, poorly documented environments managed by multiple teams, leading to vendor lock-in and collaboration challenges that hinder migration efforts further.
AWS Transform is the first agentic AI service for VMware modernization of its kind that helps you to overcome those difficulties. It can offset risk and accelerate the modernization of VMware workloads by automating application discovery, dependency mapping, migration planning, network conversion, and EC2 instance optimization, reducing manual effort and accelerating cloud adoption.
The process is organized into four phases: inventory discovery, wave planning, network conversion, and server migration. It uses agentic AI capabilities to analyze and map complex VMware environments, converting network configurations into AWS built-in constructs and helps you to orchestrate dependency-aware migration waves for seamless cutovers. In addition, it also provides a collaborative web interface that keeps AWS teams, partners, and customers aligned throughout the modernization journey.
Let’s take a quick tour to see how this works.
Setting up
Before you can start using the service, you must first enable it by navigating to the AWS Transform console. AWS Transform requires AWS IAM Identity Center (IdC) to manage users and setup appropriate permissions. If you don’t yet have IdC set up it will ask you to configure it first and return to the AWS Transform console later to continue the process.
With IdC available, you can then proceed to choosing the encryption settings. AWS Transform gives you the option to use a default AWS managed key or you can use your own custom keys through AWS Key Management Service (AWS KMS).
![]()
After completing this step, AWS Transform will be enabled. You can manage admin access to the console by navigating to Users and using the search box to find them. You must create users or groups in IdC first if they don’t already exist. The service console will help admins provision users who will get access to the web app. Each provisioned user receives an email with a link to set password and get their personalized URL for the webapp.
![]()
You interact with AWS Transform through a dedicated web experience. To get the url, navigate to Settings where you can check your configurations and copy the links to the AWS Transform web experience where you and your teams can start using the service.
![]()
Discovery
AWS Transform can discover your VMware environment either automatically through AWS Application Discovery Service collectors or you can provide your own data by importing existing RVTools export files.
To get started, choose the Create or select connectors task and provide the account IDs for one or more AWS accounts that will be used for discovery. This will generate links that you can follow to authorize each account for usage within AWS Transform. You can then move on to the Perform discovery task, where you can choose to install AWS Application Discovery Service collectors or upload your own files such as exports from RVTools.

Provisioning
The steps for the provisioning phase are similar to the ones described earlier for discovery. You connect target AWS accounts by entering their account IDs and validating the authorization requests which will then enable the next steps such as the Generate VPC configuration step. Here, you can import your RVTools files or NSX exports from Import/Export from NSX, if applicable, and enable AWS Transform to understand your networking requirements.

You should then continue working through the job plan until you reach the point where it’s ready to deploy your Amazon Virtual Private Cloud (Amazon VPC). All the infrastructure as code (IaC) code is stored in Amazon Simple Storage Service (Amazon S3) buckets in the target AWS account.
Review the proposed changes and, if you’re happy, start the deployment process of the AWS resources to the target accounts.

Deployment
AWS Transform requires you to set up AWS Application Migration Service (MGN) in the target AWS accounts to automate the migration process. Choose the Initiate VM migration task and use the link to navigate to the service console, then follow the instructions to configure it.

After setting up service permissions, you’ll proceed to the implementation phase of the waves created by AWS Transform and start the migration process. For each wave, you’ll first be asked to make various choices such as setting the sizing preference and tenancy for the Amazon Elastic Compute Cloud (Amazon EC2) instances. Confirm your selections and continue following the instructions given by AWS Transform until you reach the Deploy replication agents stage, where you can start the migration for that wave.

After you start the waves migration process, you can switch to the dashboard at any time to check on progress.

With its agentic AI capabilities, AWS Transform offers a powerful solution for accelerating and de-risking mainframe and VMware modernization workloads. By automating complex assessment and transformation processes, AWS Transform reduces the time associated with legacy system migration while minimizing the potential for errors and business disruption enabling more agile, efficient, and future-ready IT environments within your organization.
Things to know
Availability – AWS Transform for mainframe is available in US East (N. Virginia) and Europe (Frankfurt) Regions. AWS Transform for VMware offers different availability options for data collection and migrations. Please refer to the AWS Transform for VMware FAQ for more details.
Pricing – Currently, we offer our core features—including assessment and transformation—at no cost to AWS customers.
Here are a few links for further reading.
Dive deeper into mainframe modernization and learn more about about AWS Transform for mainframe.
Explore more about VMware modernization and how to get started with your VMware migration journey.
Check out this interactive demo of AWS Transform for mainframe and this interactive demo of AWS Transform for VMware.
— Matheus Guimaraes | @codingmatheus
How is the News Blog doing? Take this 1 minute survey!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Post Syndicated from Prasad Rao original https://aws.amazon.com/blogs/aws/aws-transform-for-net-the-first-agentic-ai-service-for-modernizing-net-applications-at-scale/
I started my career as a .NET developer and have seen .NET evolve over the last couple of decades. Like many of you, I also developed multiple enterprise applications in .NET Framework that ran only on Windows. I fondly remember building my first enterprise application with .NET Framework. Although it served us well, the technology landscape has significantly shifted. Now that there is an open source and cross-platform version of .NET that can run on Linux, these legacy enterprise applications built on .NET Framework need to be ported and modernized.
The benefits of porting to Linux are compelling: applications cost 40 percent less to operate because they save on Windows licensing costs, run 1.5–2 times faster with improved performance, and handle growing workloads with 50 percent better scalability. Having helped port several applications, I can say the effort is worth the rewards.
However, porting .NET Framework applications to cross-platform .NET is a labor-intensive and error-prone process. You have to perform multiple steps, such as analyzing the codebase, detecting incompatibilities, implementing fixes while porting the code, and then validating the changes. For enterprises, the challenge becomes even more complex because they might have hundreds of .NET Framework applications in their portfolio.
At re:Invent 2024, we previewed this capability as Amazon Q Developer transformation capabilities for .NET to help port your .NET applications at scale. The experience is available as a unified web experience for at-scale transformation and within your integrated development environment (IDE) for individual project and solution porting.
Now that we’ve incorporated your valuable feedback and suggestions, we’re excited to announce today the general availability of AWS Transform for .NET. We’ve also added new capabilities to support projects with private NuGet packages, port model-view-controller (MVC) Razor views to ASP .NET Core Razor views, and execute the ported unit tests.
I’ll expand on the key new capabilities in a moment, but let’s first take a quick look at the two porting experiences of AWS Transform for .NET.
Large-scale porting experience for .NET applications
Enterprise digital transformation is typically driven by central teams responsible for modernizing hundreds of applications across multiple business units. Different teams have ownership of different applications and their respective repositories. Success requires close coordination between these teams and the application owners and developers across business units. To accelerate this modernization at scale, AWS Transform for .NET provides a web experience that enables teams to connect directly to source code repositories and efficiently transform multiple applications across the organization. For select applications requiring dedicated developer attention, the same agent capabilities are available to developers as an extension for Visual Studio IDE.
Let’s start by looking at how the web experience of AWS Transform for .NET helps port hundreds of .NET applications at scale.
Web experience of AWS Transform for .NET
To get started with the web experience of AWS Transform, I onboard using the steps outlined in the documentation, sign in using my credentials, and create a job for .NET modernization.

AWS Transform for .NET creates a job plan, which is a sequence of steps that the agent will execute to assess, discover, analyze, and transform applications at scale. It then waits for me to set up a connector to connect to my source code repositories.

After the connector is in place, AWS Transform begins discovering repositories in my account. It conducts an assessment focused on three key areas: repository dependencies, required private packages and third-party libraries, and supported project types within your repositories.
Based on this assessment, it generates a recommended transformation plan. The plan orders repositories according to their last modification dates, dependency relationships, private package requirements, and the presence of supported project types.
AWS Transform for .NET then prepares for the transformation process by requesting specific inputs, such as the target branch destination, target .NET version, and the repositories to be transformed.
To select the repositories to transform, I have two options: use the recommended plan or customize the transformation plan by selecting repositories manually. For selecting repositories manually, I can use the UI or download the repository mapping and upload the customized list.

AWS Transform for .NET automatically ports the application code, builds the ported code, executes unit tests, and commits the ported code to a new branch in my repository. It provides a comprehensive transformation summary, including modified files, test outcomes, and suggested fixes for any remaining work.
While the web experience helps accelerate large-scale porting, some applications may require developer attention. For these cases, the same agent capabilities are available in the Visual Studio IDE.
Visual Studio IDE experience of AWS Transform for .NET
Now, let’s explore how AWS Transform for .NET works within Visual Studio.
To get started, I install the latest version of AWS Toolkit extension for Visual Studio and set up the prerequisites.
I open a .NET Framework solution, and in the Solution Explorer, I see the context menu item Port project with AWS Transform for an individual project.

I provide the required inputs, such as the target .NET version and the approval for the agents to autonomously transform code, execute unit tests, generate a transformation summary, and validate Linux-readiness.

I can review the code changes made by the agents locally and continue updating my codebase.
Let’s now explore some of the key new capabilities added to AWS Transform for .NET.
Support for projects with private NuGet package dependencies
During preview, only projects with public NuGet package dependencies were supported. With general availability, we now support projects with private NuGet package dependencies. This has been one of the most requested features during the preview.
The feature I really love is that AWS Transform can detect cross-repository dependencies. If it finds the source code of my private NuGet package, it automatically transforms that as well. However, if it can’t locate the source code, in the web experience, it provides me the flexibility to upload the required NuGet packages.
AWS Transform displays the missing package dependencies that need to be resolved. There are two ways to do this: I can either use the provided PowerShell script to create and upload packages, or I can build the application locally and upload the NuGet packages from the packages folder in the solution directory.

After I upload the missing NuGet packages, AWS Transform is able to resolve the dependencies. It’s best to provide both the .NET Framework and cross platform .NET versions of the NuGet packages. If the cross platform .NET version is not available, then at a minimum the .NET Framework version is required for AWS Transform to add it as an assembly reference and proceed for transformation.
Unit test execution
During preview, we supported porting unit tests from .NET Framework to cross-platform .NET. With general availability, we’ve also added support for executing unit tests after the transformation is complete.
After the transformation is complete and the unit tests are executed, I can see the results in the dashboard and view the status of the tests at each individual test project level.

Transformation visibility and summary
After the transformation is complete, I can download a detailed report in JSON format that gives me a list of transformed repositories, details about each repository, and the status of the transformation actions performed for each project within a repository. I can view the natural language transformation summary at the project level to understand AWS Transform output with project-level granularity. The summary provides me with an overview of updates along with key technical changes to the codebase.

Other new features
Let’s have a quick look at other new features we’ve added with general availability:
Things to know
Some additional things to know are:
– Prasad
How is the News Blog doing? Take this 1 minute survey!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=lNYpj11oNsE
Post Syndicated from David Johnson original https://www.backblaze.com/blog/vendor-lock-in-kills-ai-innovation-heres-how-to-fix-it/

Everyone’s chasing the next breakthrough in AI, pouring money into bigger models and faster chips. But there’s one innovation killer no one’s talking about, and it isn’t compute limits—it’s vendor lock-in.
While you’re optimizing your algorithms, your infrastructure is quietly draining your budget and tying your roadmap to someone else’s agenda. Open cloud providers help you create an ecosystem where data flows freely, innovation isn’t throttled, and every component works harmoniously to drive progress. Yet, for many organizations, vendor lock-in with hyperscalers costs more than just dollars: it comes at the expense of the freedom to innovate on your own terms.
Today, I’m talking through how AI organizations end up locked in with hyperscalers and how to avoid that trap.
Struggling to keep AI storage costs under control? Download our free ebook to discover how to optimize cloud storage for AI workloads—without compromising performance.

At its heart, AI infrastructure rests on three essential pillars:
When any of these pillars are compromised by vendor lock-in, the consequences are immediate and costly:
These challenges directly hinder your team’s ability to deliver the AI breakthroughs your organization expects.
Vendor lock-in occurs when an organization becomes overly dependent on a single vendor’s products or services, making it difficult—or costly—to switch to alternative solutions. This dependency can manifest in several ways:
In practice, vendor lock-in can hurt innovation by restricting your options, slowing down the pace at which you can adopt new technologies, and diverting resources to manage and maintain a closed system rather than driving creative breakthroughs.
Imagine scaling your AI project only to discover, as Decart did, that egress fees essentially hold your data hostage. Their team needed to train models across multiple GPU clusters simultaneously—a scenario that would have incurred crippling costs with their previous provider. Or consider Grass Network, who found their ability to serve Fortune 1000 clients fundamentally undermined by their cloud vendor’s pricing structure, with egress and deletion fees that made their business model unsustainable at scale.
The pattern is clear: Organizations trapped in vendor-locked systems end up diverting precious resources—both financial and human—away from innovation and toward infrastructure management. This results in delayed training cycles, slower model iterations, and missed market opportunities as engineering talent gets consumed by working around limitations rather than building competitive advantages.
While compute power and advanced analytics often grab headlines, the true strength of an AI system lies in the seamless integration of all its components. An open AI infrastructure can deliver:
Among all the components, storage plays a uniquely critical role—it’s the circulatory system that keeps your data moving throughout the AI workflow. The right storage foundation doesn’t just warehouse data; it becomes a strategic asset that enables multi-cloud workflows, maintains cost predictability, and prevents vendor lock-in by allowing seamless integration with different compute engines, GPU clusters, and software platforms. Forward-thinking organizations are increasingly viewing storage not as a commodity, but as the linchpin of AI infrastructure strategy.
Within this framework, Backblaze B2 serves as a robust storage foundation that transforms how AI teams approach multi-cloud workflows. Rather than trying to be everything to everyone, B2 Cloud Storage focuses exclusively on being the best at what matters most for your data: performance, scalability, and predictability.
It effortlessly scales from terabytes to petabytes, accommodating everything from raw training data to archived model outputs without performance degradation. S3 compatibility means it integrates easily with virtually any AI pipeline or tool. Perhaps most importantly, it keeps costs transparent and predictable with straightforward pricing that eliminates the “sticker shock” that plagues many AI projects.
A reliable, independent storage layer doesn’t just help you sidestep the pitfalls of vendor lock-in—it fundamentally changes how your team approaches innovation by removing the technical and financial barriers that traditionally constrain experimentation.
Your company’s data is a powerful resource—learn how to harness it with an AI agent designed to generate meaningful insights. In this deep dive, Backblaze’s Pat Patterson and Jeronimo De Leon will demonstrate how to build an AI agent that can query, analyze, and generate insights from company-specific data—all powered by cost-efficient, scalable cloud storage.

Breaking free from vendor lock-in isn’t merely about cutting costs—it’s about reclaiming control over your entire AI infrastructure and accelerating your path to results. When every component, from compute to storage and integration, is designed to be open and flexible, your organization gains the freedom to experiment, iterate, and push the boundaries of what’s possible.
The most successful AI teams we’ve observed are those building on strong, multi-cloud-friendly foundations where data flows without friction or penalty. They’re the ones asking tough questions about their infrastructure choices today to ensure maximum flexibility tomorrow.
The post Vendor Lock-in Kills AI Innovation. Here’s How to Fix It. appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from jake original https://lwn.net/Articles/1020437/
Leon Romanovsky began his session at the 2025 Linux Storage, Filesystem,
Memory Management, and BPF Summit (LSFMM+BPF) by explaining that the improved DMA-mapping API that he has been
working on is a group effort. He, Chaitanya Kulkarni, Christoph Hellwig,
Jason Gunthorpe, and others are proposing to modernize the API and to
“make it more suitable for current kernels
“. He told the assembled
storage and filesystem developers that the progress on the proposal has
stalled, but that it was the basis for further work in various areas, so he
hoped to find a way to move forward with it.
Post Syndicated from jzb original https://lwn.net/Articles/1021354/
The Tor project has announced
the oniux utility which provides Tor network isolation, using Linux
namespaces, for third-party applications.
Namespaces are a powerful feature that gives us the ability to
isolate Tor network access of an arbitrary application. We put each
application in a network namespace that doesn’t provide access to
system-wide network interfaces (such as eth0), and instead provides a
custom network interface onion0.This allows us to isolate an arbitrary application over Tor in the
most secure way possible software-wise, namely by relying on a
security primitive offered by the operating system kernel. Unlike
SOCKS, the application cannot accidentally leak data by failing to
make some connection via the configured SOCKS, which may happen due to
a mistake by the developer.
The Tor project cautions that oniux is considered experimental as
the software it depends on, such as Arti and
onionmasq,
are still new.
Post Syndicated from jake original https://lwn.net/Articles/1021379/
Security updates have been issued by Debian (open-vm-tools), Fedora (dnsdist), Gentoo (Node.js and Tracker miners), Red Hat (kernel and xdg-utils), SUSE (audiofile, go1.22-openssl, go1.24, grub2, kernel-devel, openssl-1_1, openssl-3, and python311-Django), and Ubuntu (ruby-rack).
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=F7c2J_ELCqc
Post Syndicated from Thibault Meunier original https://blog.cloudflare.com/web-bot-auth/
With the rise of traffic from AI agents, what’s considered a bot is no longer clear-cut. There are some clearly malicious bots, like ones that DoS your site or do credential stuffing, and ones that most site owners do want to interact with their site, like the bot that indexes your site for a search engine, or ones that fetch RSS feeds.
Historically, Cloudflare has relied on two main signals to verify legitimate web crawlers from other types of automated traffic: user agent headers and IP addresses. The User-Agent header allows bot developers to identify themselves, i.e. MyBotCrawler/1.1. However, user agent headers alone are easily spoofed and are therefore insufficient for reliable identification. To address this, user agent checks are often supplemented with IP address validation, the inspection of published IP address ranges to confirm a crawler’s authenticity. However, the logic around IP address ranges representing a product or group of users is brittle – connections from the crawling service might be shared by multiple users, such as in the case of privacy proxies and VPNs, and these ranges, often maintained by cloud providers, change over time.
Cloudflare will always try to block malicious bots, but we think our role here is to also provide an affirmative mechanism to authenticate desirable bot traffic. By using well-established cryptography techniques, we’re proposing a better mechanism for legitimate agents and bots to declare who they are, and provide a clearer signal for site owners to decide what traffic to permit.
Today, we’re introducing two proposals – HTTP message signatures and request mTLS – for friendly bots to authenticate themselves, and for customer origins to identify them. In this blog post, we’ll share how these authentication mechanisms work, how we implemented them, and how you can participate in our closed beta.
Historically, if you’ve worked on ChatGPT, Claude, Gemini, or any other agent, you’ve had several options to identify your HTTP traffic to other services:
You define a user agent, an HTTP header described in RFC 9110. The problem here is that this header is easily spoofable and there’s not a clear way for agents to identify themselves as semi-automated browsers — agents often use the Chrome user agent for this very reason, which is discouraged. The RFC states:
“If a user agent masquerades as a different user agent, recipients can assume that the user intentionally desires to see responses tailored for that identified user agent, even if they might not work as well for the actual user agent being used.”
You publish your IP address range(s). This has limitations because the same IP address might be shared by multiple users or multiple services within the same company, or even by multiple companies when hosting infrastructure is shared (like Cloudflare Workers, for example). In addition, IP addresses are prone to change as underlying infrastructure changes, leading services to use ad-hoc sharing mechanisms like CIDR lists.
You go to every website and share a secret, like a Bearer token. This is impractical at scale because it requires developers to maintain separate tokens for each website their bot will visit.
We can do better! Instead of these arduous methods, we’re proposing that developers of bots and agents cryptographically sign requests originating from their service. When protecting origins, reverse proxies such as Cloudflare can then validate those signatures to confidently identify the request source on behalf of site owners, allowing them to take action as they see fit.

A typical system has three actors:
User: the entity that wants to perform some actions on the web. This may be a human, an automated program, or anything taking action to retrieve information from the web.
Agent: an orchestrated browser or software program. For example, Chrome on your computer, or OpenAI’s Operator with ChatGPT. Agents can interact with the web according to web standards (HTML rendering, JavaScript, subrequests, etc.).
Origin: the website hosting a resource. The user wants to access it through the browser. This is Cloudflare when your website is using our services, and it’s your own server(s) when exposed directly to the Internet.
In the next section, we’ll dive into HTTP Message Signatures and request mTLS, two mechanisms a browser agent may implement to sign outgoing requests, with different levels of ease for an origin to adopt.
HTTP Message Signatures is a standard that defines the cryptographic authentication of a request sender. It’s essentially a cryptographically sound way to say, “hey, it’s me!”. It’s not the only way that developers can sign requests from their infrastructure — for example, AWS has used Signature v4, and Stripe has a framework for authenticating webhooks — but Message Signatures is a published standard, and the cleanest, most developer-friendly way to sign requests.
We’re working closely with the wider industry to support these standards-based approaches. For example, OpenAI has started to sign their requests. In their own words:
“Ensuring the authenticity of Operator traffic is paramount. With HTTP Message Signatures (RFC 9421), OpenAI signs all Operator requests so site owners can verify they genuinely originate from Operator and haven’t been tampered with” – Eugenio, Engineer, OpenAI
Without further delay, let’s dive in how HTTP Messages Signatures work to identify bot traffic.
Generating a message signature works like this: before sending a request, the agent signs the target origin with a public key. When fetching https://example.com/path/to/resource, it signs example.com. This public key is known to the origin, either because the agent is well known, because it has previously registered, or any other method. Then, the agent writes a Signature-Input header with the following parameters:
A validity window (created and expires timestamps)
A Key ID that uniquely identifies the key used in the signature. This is a JSON Web Key Thumbprint.
A tag that shows websites the signature’s purpose and validation method, i.e. web-bot-auth for bot authentication.
In addition, the Signature-Agent header indicates where the origin can find the public keys the agent used when signing the request, such as in a directory hosted by signer.example.com. This header is part of the signed content as well.
Here’s an example:
GET /path/to/resource HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 Chrome/113.0.0 MyBotCrawler/1.1
Signature-Agent: signer.example.com
Signature-Input: sig=("@authority" "signature-agent");\
created=1700000000;\
expires=1700011111;\
keyid="ba3e64==";\
tag="web-bot-auth"
Signature: sig=abc==For those building bots, we propose signing the authority of the target URI, i.e. crawler.search.google.com for Google Search, operator.openai.com for OpenAI Operator, workers.dev for Cloudflare Workers, and a way to retrieve the bot public key in the form of signature-agent, if present.
The User-Agent from the example above indicates that the software making the request is Chrome, because it is an agent that uses an orchestrated Chrome to browse the web. You should note that MyBotCrawler/1.1 is still present. The User-Agent header can actually contain multiple products, in decreasing order of importance. If our agent is making requests via Chrome, that’s the most important product and therefore comes first.
At Internet-level scale, these signatures may add a notable amount of overhead to request processing. However, with the right cryptographic suite, and compared to the cost of existing bot mitigation, both technical and social, this seems to be a straightforward tradeoff. This is a metric we will monitor closely, and report on as adoption grows.
We’re making several examples for generating Message Signatures for bots and agents available on Github (though we encourage other implementations!), all of which are standards-compliant, to maximize interoperability.
Imagine you’re building an agent using a managed Chromium browser, and want to sign all outgoing requests. To achieve this, the webextensions standard provides chrome.webRequest.onBeforeSendHeaders, where you can modify HTTP headers before they are sent by the browser. The event is triggered before sending any HTTP data, and when headers are available.
Here’s what that code would look like:
chrome.webRequest.onBeforeSendHeaders.addListener(
function (details) {
// Signature and header assignment logic goes here
// <CODE>
},
{ urls: ["<all_urls>"] },
["blocking", "requestHeaders"] // requires "installation_mode": "force_installed"
);Cloudflare provides a web-bot-auth helper package on npm that helps you generate request signatures with the correct parameters. onBeforeSendHeaders is a Chrome extension hook that needs to be implemented synchronously. To do so, we import {signatureHeadersSync} from “web-bot-auth”. Once the signature completes, both Signature and Signature-Input headers are assigned. The request flow can then continue.
const request = new URL(details.url);
const created = new Date();
const expired = new Date(created.getTime() + 300_000)
// Perform request signature
const headers = signatureHeadersSync(
request,
new Ed25519Signer(jwk),
{ created, expires }
);
// `headers` object now contains `Signature` and `Signature-Input` headers that can be usedThis extension code is available on GitHub, alongside a debugging server, deployed at https://http-message-signatures-example.research.cloudflare.com.
Using our debug server, we can now inspect and validate our request signatures from the perspective of the website we’d be visiting. We should now see the Signature and Signature-Input headers:

In this example, the homepage of the debugging server validates the signature from the RFC 9421 Ed25519 verifying key, which the extension uses for signing.
The above demo and code walkthrough has been fully written in TypeScript: the verification website is on Cloudflare Workers, and the client is a Chrome browser extension. We are cognisant that this does not suit all clients and servers on the web. To demonstrate the proposal works in more environments, we have also implemented bot signature validation in Go with a plugin for Caddy server.
HTTP is not the only way to convey signatures. For instance, one mechanism that has been used in the past to authenticate automated traffic against secured endpoints is mTLS, the “mutual” presentation of TLS certificates. As described in our knowledge base:
Mutual TLS, or mTLS for short, is a method for mutual authentication. mTLS ensures that the parties at each end of a network connection are who they claim to be by verifying that they both have the correct private key. The information within their respective TLS certificates provides additional verification.
While mTLS seems like a good fit for bot authentication on the web, it has limitations. If a user is asked for authentication via the mTLS protocol but does not have a certificate to provide, they would get an inscrutable and unskippable error. Origin sites need a way to conditionally signal to clients that they accept or require mTLS authentication, so that only mTLS-enabled clients use it.
TLS flags are an efficient way to describe whether a feature, like mTLS, is supported by origin sites. Within the IETF, we have proposed a new TLS flag called req mTLS to be sent by the client during the establishment of a connection that signals support for authentication via a client certificate.
This proposal leverages the tls-flags proposal under discussion in the IETF. The TLS Flags draft allows clients and servers to send an array of one bit flags to each other, rather than creating a new extension (with its associated overhead) for each piece of information they want to share. This is one of the first uses of this extension, and we hope that by using it here we can help drive adoption.
When a client sends the req mTLS flag to the server, they signal to the server that they are able to respond with a certificate if requested. The server can then safely request a certificate without risk of blocking ordinary user traffic, because ordinary users will never set this flag.
Let’s take a look at what an example of such a req mTLS would look like in Wireshark, a network protocol analyser. You can follow along in the packet capture here.
Extension: req mTLS (len=12)
Type: req mTLS (65025)
Length: 12
Data: 0b0000000000000000000001The extension number is 65025, or 0xfe01. This corresponds to an unassigned block of TLS extensions that can be used to experiment with TLS Flags. Once the standard is adopted and published by the IETF, the number would be fixed. To use the req mTLS flag the client needs to set the 80th bit to true, so with our block length of 12 bytes, it should contain the data 0b0000000000000000000001, which is the case here. The server then responds with a certificate request, and the request follows its course.
Code for this section is available in GitHub under cloudflareresearch/req-mtls
Because mutual TLS is widely supported in TLS libraries already, the parts we need to introduce to the client and server are:
Sending/parsing of TLS-flags
Specific support for the req mTLS flag
To the best of our knowledge, there is no public implementation of either scheme. Using it for bot authentication may provide a motivation to do so.
Using our experimental fork of Go, a TLS client could support req mTLS as follows:
config := &tls.Config{
TLSFlagsSupported: []tls.TLSFlag{0x50},
RootCAs: rootPool,
Certificates: certs,
NextProtos: []string{"h2"},
}
trans := http.Transport{TLSClientConfig: config, ForceAttemptHTTP2: true}This example library allows you to configure Go to send req mTLS 0xfe01 bytes in the TLS Flags extension. If you’d like to test your implementation out, you can prompt your client for certificates against req-mtls.research.cloudflare.com using the Cloudflare Research client cloudflareresearch/req-mtls. For clients, once they set the TLS Flags associated with req mTLS, they are done. The code section taking care of normal mTLS will take over at that point, with no need to implement something new.
We believe that developers of agents and bots should have a public, standard way to authenticate themselves to CDNs and website hosting platforms, regardless of the technology they use or provider they choose. At a high level, both HTTP Message Signatures and request mTLS achieve a similar goal: they allow the owner of a service to authentically identify themselves to a website. That’s why we’re participating in the standardizing effort for both of these protocols at the IETF, where many other authentication mechanisms we’ve discussed here — from TLS to OAuth Bearer tokens –— been developed by diverse sets of stakeholders and standardized as RFCs.
Evaluating both proposals against each other, we’re prioritizing HTTP Message Signatures for Bots because it relies on the previously adopted RFC 9421 with several reference implementations, and works at the HTTP layer, making adoption simpler. request mTLS may be a better fit for site owners with concerns about the additional bandwidth, but TLS Flags has fewer implementations, is still waiting for IETF adoption, and upgrading the TLS stack has proven to be more challenging than with HTTP. Both approaches share similar discovery and key management concerns, as highlighted in a glossary draft at the IETF. We’re actively exploring both options, and would love to hear from both site owners and bot developers about how you’re evaluating their respective tradeoffs.
In conclusion, we think request signatures and mTLS are promising mechanisms for bot owners and developers of AI agents to authenticate themselves in a tamper-proof manner, forging a path forward that doesn’t rely on ever-changing IP address ranges or spoofable headers such as User-Agent. This authentication can be consumed by Cloudflare when acting as a reverse proxy, or directly by site owners on their own infrastructure. This means that as a bot owner, you can now go to content creators and discuss crawling agreements, with as much granularity as the number of bots you have. You can start implementing these solutions today and test them against the research websites we’ve provided in this post.
Bot authentication also empowers site owners small and large to have more control over the traffic they allow, empowering them to continue to serve content on the public Internet while monitoring automated requests. Longer term, we will integrate these authentication mechanisms into our AI Audit and Bot Management products, to provide better visibility into the bots and agents that are willing to identify themselves.
Being able to solve problems for both origins and clients is key to helping build a better Internet, and we think identification of automated traffic is a step towards that. If you want us to start verifying your message signatures or client certificates, have a compelling use case you’d like us to consider, or any questions, please reach out.
Post Syndicated from Надежда Цекулова original https://www.toest.bg/propast-v-dannite-zashto-zhenite-oshte-ne-se-pobirat-v-meditsinskata-statistika/

В английския език съществуват изразите sex gap и gender gap. Използват се за сфери и ситуации, при които има значими разлики между половете. Първият израз е свързан с биологичните характеристики на пола, а вторият – със социалните му прояви, защото в английския език тези нюанси са важни. Буквалният превод е неприемлив, защото в българското публично говорене, ако кажете или напишете „пропаст между половете“, има вероятност да ви обвинят в краен феминизъм и/или излишно драматизиране. Затова най-често у нас използваме по-меки понятия, като „неравенство между мъжете и жените“, „разлика“, „дисбаланс“ или „разминаване“ между половете.
На мен обаче много ми се иска да можехме със същата смелост да ползваме думи като „пропаст“ или „разрив“. Защото точно за пропаст – хилядолетна, дълбока, жестока и много красноречива – говорим, когато става дума за изследването на женското здраве в сравнение със здравето на мъжете.
но макар светът никога да не се е интересувал задълбочено от женското здраве, жените статистически устойчиво живеят по-дълго от мъжете поне в последните две столетия. (В следващ текст ще разкажа по-подробно за това решение на природата, Бог или който там вярвате, че носи отговорност за създаването на човека.)
„Парадоксално“, защото това в никакъв случай не се дължи на загрижеността на човечеството за женското здраве. Както вече стана дума в двата текста, посветени на историята, до средата на XX век женското здраве е било важно дотолкова, доколкото от жената се е очаквало да роди здрави деца. В някои кратки периоди и култури е било важно и за да може да осигури сексуално удоволствие. Макар в XX век сексуалната революция и икономическата нужда жените да бъдат включени в пазара на труда да променя тази парадигма, неравенствата в познанието все още остават значими.
През 2019 г. британската журналистка и активистка Каролин Криадо Перес издава книгата Invisible Women: Exposing Data Bias in a World Designed for Men. В нея авторката детайлно анализира отклоненията в данните, свързани с неравното представяне на жените при различни видове проучвания. Миналата година, дали вследствие на активната публична кампания на авторката, или с други мотиви, Британската агенция за лекарствата и здравните продукти (MHRA) в сътрудничество с Университета в Ливърпул подготви и публикува анализ на баланса в представянето на мъжете и жените в клиничните проучвания. Според Агенцията жените са сериозно подценени в тези изследвания: броят на проучванията, включващи само мъже, е с 67% по-висок от броя на проучванията, в които участват само жени. Преглед на информацията от The Guardian разкрива силен дисбаланс: макар 90% от изпитванията да включват и мъже, и жени, мъжете все пак преобладават. Проучванията само с мъже са 6,1%, а само с жени – 3,7% от всички одобрени от Агенцията 4616 проучвания в изследвания период. Бременни и кърмещи жени участват съответно в едва 1,1% и 0,6% от изпитванията.
Друг проблем, който Перес изтъква в анализите си, е липсата на полово диференцирани данни от проучванията, включващи и мъже, и жени. Прегледът на предклинични изследвания в САЩ, провеждани в продължение на десет години, показва, че макар броят на проучванията с участие и на двата пола да нараства, това не е съпроводено с пропорционално увеличение на анализите и отчетите по пол. В различни научни области едва в между 5 и 14% от изследванията реално се разглеждат резултатите по пол, а в по-малко от една трета от клиничните изпитвания, стигнали до фаза III (тази, в която се тестват безвредността и сравнителната ефективност на продукта), има такива данни, публикувани в медицински списания.
Дисбалансът е значим и във финансирането. Ако останем при примера с алцхаймер, през 2019 г. организацията Women’s Health Access Matters установява, че едва 12% от инвестициите в проучване на тази болест са насочени към изследвания, фокусирани върху жени, макар че те съставляват цели 2/3 от засегнатите.
Липсата на финансиране вероятно е и една от причините за липса на изследователски интерес. Любопитен пример за това дава отново The Guardian: изследванията на еректилна дисфункция, засягаща 19% от мъжете, са пет пъти повече от изследванията на предменструалния синдром, засягащ 90% от жените.
Последствията от неравните медицински познания относно мъжете и жените се разпростират върху много широк спектър от социални и икономически фактори на благополучието. Но една от най-непосредствените последици е по-високата честота на нежелани лекарствени реакции при жените. Исторически клиничните изпитвания са включвали първоначално само мъже. Според различни източници аргумент за това е било, че хормоналните промени при жените ще повлияят на резултатите от изпитването: в по-млада възраст – заради хормоналните промени в различните етапи на менструалния цикъл, а по-късно – при менопаузата.
По-късно (и до днес) в клиничните проучвания участват предимно или преобладаващо мъже, което е довело до дозировки и протоколи, съобразени с мъжката физиология. В резултат жените често приемат медикаменти, които не са тествани адекватно спрямо техните метаболитни и хормонални особености. Проучвания показват, че жените изпитват нежелани лекарствени реакции почти два пъти по-често от мъжете. През 2020 г. изследване на 86 лекарства доказва, че основната причина за това са полово обусловени разлики в начина и продължителността на обработка на лекарственото вещество от организма.
Става дума за разлики в телесния състав, ензимната активност и хормоналните нива, които влияят върху усвояването и разграждането на лекарствата. Например жените метаболизират определени лекарства по-бавно, което води до по-висока концентрация в кръвта и съответно до по-чести и по-тежки нежелани реакции, като гадене, депресия, припадъци, сърдечни проблеми. Изследователите правят извода, че фармакокинетиката може да даде достатъчно информация за свързани с пола рискове от нежелани реакции. Според проучването разликата в начина, по който действа една и съща доза от дадено лекарство на мъже и на жени, би могла да има и клинично значение.
Недостатъчното участие на жени в изследвания допринася също за погрешни или закъснели диагнози при множество състояния. Някои заболявания – например сърдечносъдови, аутизъм и хиперактивност с дефицит на вниманието (ADHD), често се проявяват по различен начин при жените и мъжете. Въпреки това диагностичните критерии са базирани основно на мъжки модели, което води до игнориране или неправилно тълкуване на симптомите при жените.
Жените със сърдечни заболявания например често изпитват умора, задух и гадене – симптоми, които се различават от класическата „болка в гърдите“, типична за мъжете. В резултат жените по-рядко получават навременна помощ. Същото се отнася и за невроразвитийните разстройства, като аутизъм и разстройство с дефицит на вниманието (със или без хиперактивност). При тях жените по-често проявяват „по-тихи“ симптоми, които остават неразпознати.
Например при момичетата с аутизъм е по-вероятно да проявяват интерес към социалните взаимоотношения и може да изглеждат по-умели в социалната комуникация в сравнение с момчетата, маскирайки скритите си трудности. Момичетата с дефицит на вниманието пък по-често изпитват трудности при изпълнителските функции, например организиране на изпълнението на задачи или управление на времето, отколкото да проявяват явна хиперактивност. Тези трудности обаче често се приписват на недостатъци на характера и биват определяни като мързел или небрежност, вместо да се разпознават като симптоми на невродивергенция. В резултат много жени биват диагностицирани едва в късна възраст, често след като децата им получат диагноза, която ги подтиква да потърсят оценка и за себе си.
Липсата на равностойни данни за женската физиология и здраве е резултат и от някои устойчиви стереотипи, които влияят върху качеството на медицинската помощ, оказвана на жени, дори когато става дума за животозастрашаващи заболявания като рака.
Ново проучване в Обединеното кралство установява, че симптомите на мъжете се приемат с повече сериозност: 76% от жените пациенти са съгласни, че трябва да бъдат настоятелни, за да получат необходимите грижи, спрямо 54% от мъжете пациенти. Когато се застъпват за себе си пред медицинските специалисти, жените често биват възприемани като „досадни“ или „натрапчиви“, което води до отхвърляне и омаловажаване на тяхната загриженост. В същото време обаче мъжете по-рядко получават предложение за емоционална подкрепа при онкологична диагноза, тъй като на тях се гледа като на по-малко чувствителни. Това само потвърждава нуждата от преразглеждане на половите дисбаланси в грижите за човешкото здраве.
Един от любопитните феномени на „половите стереотипи“ в медицината е, че човечеството от хилядолетия се интересува от репродуктивното здраве на жените, но в съвременността едва около 2% от клиничните изпитвания са в сферата на репродуктивното здраве и бременността, а бременните са практически изключени от широк спектър здравни технологии от съображения за безопасност. Макар това да е разбираемо, липсата на данни означава, че нерядко лекарите вземат решения за лечение на тези жени без научни доказателства, което излага на риск както тях, така и децата им. Макар етичните съображения за включване на бременни в клинични изпитвания да са много сериозни, това е необходим дебат. Един от примерите е съвсем пресен – по време на пандемията от COVID-19 бременните първоначално бяха изключени от ваксинационните изпитвания, което доведе до объркване, колебания и забавен достъп до ваксинация за тази високорискова група, и коства живота на много жени.
До началото на 2025 г. Съединените щати бяха една от държавите в света, които най-активно правеха и изнасяха медицинска наука. През 2023 г. започна инициативата на Белия дом за изследвания в областта на женското здраве и в рамките на една година тя привлече близо 1 млрд. долара федерално финансиране. Паралелно се появиха няколко частни инициативи, набиращи фондове в същата сфера, а организацията Women’s Health Access Matters (WHAM) в партньорство с RAND Corporation изчисли, че удвояването на бюджета на Националните здравни институти (NIH) за изследвания, свързани с женското здраве (350 млн. долара към 2022 г.), може да донесе икономическа възвръщаемост от 14 млрд. долара в рамките на три години.
През 2025 г. обаче този устрем рязко беше попарен. Администрацията на президента Доналд Тръмп, встъпил в длъжност през януари, наложи съкращения на финансирането на Националните здравни институти (NIH) и на Центровете за контрол и превенция на заболяванията (CDC), като някои програми бяха напълно прекратени. Тези съкращения засегнаха изследвания, свързани с болестта на Алцхаймер, с миоми на матката и рискове при бременност, както и с проекти, фокусирани върху разнообразието и включването.
Сред неочакваните жертви на новата посока на американската политика обаче бяха изследвания и изследователски центрове, свързани с наблюдение и превенция на майчината смъртност и подобряване на майчиното здраве. Макар с течение на времето да стана ясно, че немалка част от помпозно обявените съкращения няма да бъдат направени въобще или няма да се изпълнят в заявения мащаб, финансовата несигурност, заплахите и научната цензура със сигурност ще се отразят негативно на изследването на женското здраве в световен мащаб.
Въпреки тревожните тенденции в световната политика и още по-тревожното им пряко влияние върху науката, обективният поглед изисква да признаем, че женското здравеопазване никога не е било в по-добра форма. Добрата новина е, че темата за здравето на половината световно население най-сетне започва да привлича устойчиво внимание. Лошата – че целият световен прогрес все още не е достатъчен, за да е ясно, че равното третиране на мъжете и жените в медицината не е политически акт, а въпрос на елементарна научна добросъвестност.
„Анатомия на пола: Жена“ разглежда здравето на жените като неразривна част от обществото, историята и културата. В поредицата изследваме как са се променяли нагласите към женското здраве, как медицината е възприемала специфичните потребности на жените и какви процеси са повлияли на достъпа им до качествени здравни грижи. Вглеждаме се в научните открития, но и в културните митове; в официалните политики, но и в личните истории на жени, борещи се за правото си на здраве и достойнство.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/05/ai-generated-law.html
On April 14, Dubai’s ruler, Sheikh Mohammed bin Rashid Al Maktoum, announced that the United Arab Emirates would begin using artificial intelligence to help write its laws. A new Regulatory Intelligence Office would use the technology to “regularly suggest updates” to the law and “accelerate the issuance of legislation by up to 70%.” AI would create a “comprehensive legislative plan” spanning local and federal law and would be connected to public administration, the courts, and global policy trends.
The plan was widely greeted with astonishment. This sort of AI legislating would be a global “first,” with the potential to go “horribly wrong.” Skeptics fear that the AI model will make up facts or fundamentally fail to understand societal tenets such as fair treatment and justice when influencing law.
The truth is, the UAE’s idea of AI-generated law is not really a first and not necessarily terrible.
The first instance of enacted law known to have been written by AI was passed in Porto Alegre, Brazil, in 2023. It was a local ordinance about water meter replacement. Council member Ramiro Rosário was simply looking for help in generating and articulating ideas for solving a policy problem, and ChatGPT did well enough that the bill passed unanimously. We approve of AI assisting humans in this manner, although Rosário should have disclosed that the bill was written by AI before it was voted on.
Brazil was a harbinger but hardly unique. In recent years, there has been a steady stream of attention-seeking politicians at the local and national level introducing bills that they promote as being drafted by AI or letting AI write their speeches for them or even vocalize them in the chamber.
The Emirati proposal is different from those examples in important ways. It promises to be more systemic and less of a one-off stunt. The UAE has promised to spend more than $3 billion to transform into an “AI-native” government by 2027. Time will tell if it is also different in being more hype than reality.
Rather than being a true first, the UAE’s announcement is emblematic of a much wider global trend of legislative bodies integrating AI assistive tools for legislative research, drafting, translation, data processing, and much more. Individual lawmakers have begun turning to AI drafting tools as they traditionally have relied on staffers, interns, or lobbyists. The French government has gone so far as to train its own AI model to assist with legislative tasks.
Even asking AI to comprehensively review and update legislation would not be a first. In 2020, the U.S. state of Ohio began using AI to do wholesale revision of its administrative law. AI’s speed is potentially a good match to this kind of large-scale editorial project; the state’s then-lieutenant governor, Jon Husted, claims it was successful in eliminating 2.2 million words’ worth of unnecessary regulation from Ohio’s code. Now a U.S. senator, Husted has recently proposed to take the same approach to U.S. federal law, with an ideological bent promoting AI as a tool for systematic deregulation.
The dangers of confabulation and inhumanity—while legitimate—aren’t really what makes the potential of AI-generated law novel. Humans make mistakes when writing law, too. Recall that a single typo in a 900-page law nearly brought down the massive U.S. health care reforms of the Affordable Care Act in 2015, before the Supreme Court excused the error. And, distressingly, the citizens and residents of nondemocratic states are already subject to arbitrary and often inhumane laws. (The UAE is a federation of monarchies without direct elections of legislators and with a poor record on political rights and civil liberties, as evaluated by Freedom House.)
The primary concern with using AI in lawmaking is that it will be wielded as a tool by the powerful to advance their own interests. AI may not fundamentally change lawmaking, but its superhuman capabilities have the potential to exacerbate the risks of power concentration.
AI, and technology generally, is often invoked by politicians to give their project a patina of objectivity and rationality, but it doesn’t really do any such thing. As proposed, AI would simply give the UAE’s hereditary rulers new tools to express, enact, and enforce their preferred policies.
Mohammed’s emphasis that a primary benefit of AI will be to make law faster is also misguided. The machine may write the text, but humans will still propose, debate, and vote on the legislation. Drafting is rarely the bottleneck in passing new law. What takes much longer is for humans to amend, horse-trade, and ultimately come to agreement on the content of that legislation—even when that politicking is happening among a small group of monarchic elites.
Rather than expeditiousness, the more important capability offered by AI is sophistication. AI has the potential to make law more complex, tailoring it to a multitude of different scenarios. The combination of AI’s research and drafting speed makes it possible for it to outline legislation governing dozens, even thousands, of special cases for each proposed rule.
But here again, this capability of AI opens the door for the powerful to have their way. AI’s capacity to write complex law would allow the humans directing it to dictate their exacting policy preference for every special case. It could even embed those preferences surreptitiously.
Since time immemorial, legislators have carved out legal loopholes to narrowly cater to special interests. AI will be a powerful tool for authoritarians, lobbyists, and other empowered interests to do this at a greater scale. AI can help automatically produce what political scientist Amy McKay has termed “microlegislation“: loopholes that may be imperceptible to human readers on the page—until their impact is realized in the real world.
But AI can be constrained and directed to distribute power rather than concentrate it. For Emirati residents, the most intriguing possibility of the AI plan is the promise to introduce AI “interactive platforms” where the public can provide input to legislation. In experiments across locales as diverse as Kentucky, Massachusetts, France, Scotland, Taiwan, and many others, civil society within democracies are innovating and experimenting with ways to leverage AI to help listen to constituents and construct public policy in a way that best serves diverse stakeholders.
If the UAE is going to build an AI-native government, it should do so for the purpose of empowering people and not machines. AI has real potential to improve deliberation and pluralism in policymaking, and Emirati residents should hold their government accountable to delivering on this promise.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=FGXd1un5v6g
Post Syndicated from Dan Shilling original https://www.raspberrypi.org/blog/insights-from-a-teacher-trainer-experience-ai/
Today’s blog post is written by Dan Shilling, Programmes Manager at Parent Zone, one of our global partners for Experience AI.
“Educators have been struggling to find resources and support to teach young people about AI.”
This is something I’ve heard a lot when delivering Experience AI teacher training through Parent Zone’s partnership with the Raspberry Pi Foundation.
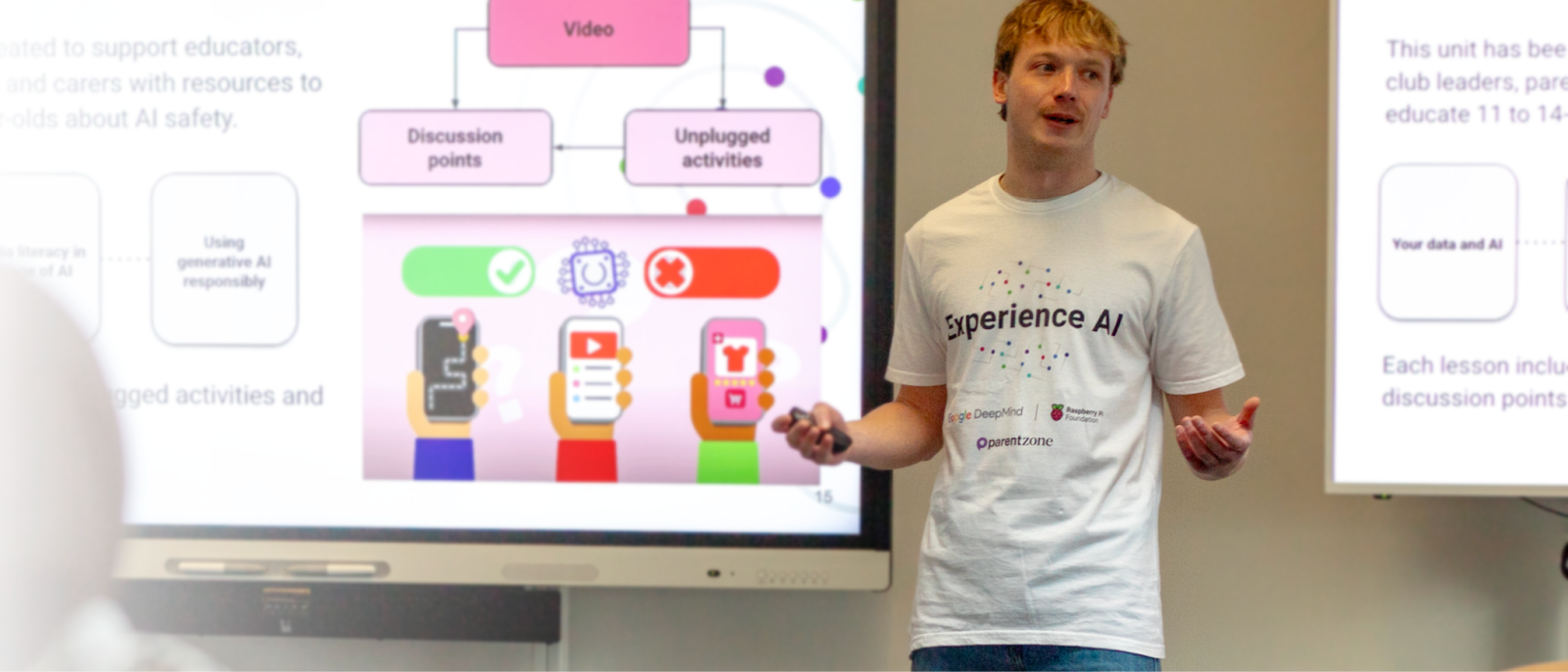
Experience AI is an artificial intelligence (AI) literacy programme, co-developed by the Raspberry Pi Foundation and Google DeepMind, that teaches students aged 11 to 14 about AI and machine learning. Thanks to funding from Google.org, Parent Zone has partnered with the Raspberry Pi Foundation to provide free training to UK educators, equipping them with the skills they need to effectively deliver the programme in their settings.
The Experience AI resources help educators, including those from non-technical backgrounds, to deliver impactful lessons on AI and machine learning. Lesson resources span technical elements (e.g. data-driven models, bias) and practical elements (e.g. careers, safety).
Our face-to-face and virtual training sessions show teachers how to use the programme resources, as well as helping them feel more confident in the subject matter.
The sessions also give me an opportunity to hear from teachers about how AI is being used and taught in classrooms, and the opportunities and challenges it’s creating.

AI has a major presence in many schools now.
Teachers tell me they’re seeing students use AI to support their homework. One teacher spoke about a student using a chatbot to help break down a maths problem, describing it like “having a tutor at home.”
Teachers are also using AI themselves to assist in their work — for example, to plan lessons, generate activities, and get ideas on how to explain complex topics more clearly.
Openness to experimentation is clearly there.

For all the benefits of AI, teachers also have concerns about it.
Some have told me their students have no idea how easily these tools can be used to mislead or manipulate, through disinformation and deepfakes, for example.
This is why Experience AI resources are meeting educator needs. Not only do they explain how AI and machine learning actually work, but they also address many pressing concerns around AI, from responsible usage and media literacy, to how data bias can affect the final output.
In all the workshops, what stands out to me most is how ready teachers are to engage. They want to understand more. They want to help their students make sense of AI, and use it positively.
They’re grateful for practical, grounded training and support that doesn’t assume they’ve all got computer science degrees. After one of our sessions, a teacher said:
“The better we educate ourselves, the better we’re able to help young people. It’s important because it’s affecting their day-to-day lives. We can help them navigate AI platforms, but in a safe way.”

If you’re a UK secondary school teacher, you can sign up for free training from Parent Zone, with dates available until November 2025. You can choose from:
For more information about Experience AI, visit our website.
The post Insights from a teacher trainer: Schools are ready to engage in AI — what they need is support appeared first on Raspberry Pi Foundation.
Post Syndicated from original https://www.toest.bg/profesor-maria-shniter-i-prepodavaneto-na-dobrodeteli-bez-uchebnik/

В седмиците след организираната от Министерството на образованието и науката дискусия за изучаването на добродетели и религия търсим погледа на специалист от сферата на образованието и религиите, който не е участвал в нея, но има професионално и обосновано мнение относно така предложения нов учебен предмет.
Донка Дойчева-Попова покани проф. Мария Шнитер на разговор, за да сподели как преподава религия и ценности.
Професор Мария Шнитер преподава в Пловдивския университет от 1984 г. и е първият декан на Философско-историческия му факултет. Работи основно в сферата на медиевистиката и антропологията на религиите и всекидневието. Има специализации в университетите във Фрайбург, Вюрцбург, Берлин и Кьолн. Преподавала е българска литература и култура във Виенския университет, чела е лекции в Русия, Италия, Великобритания, Израел и други страни. Има голям брой научни публикации в специализирани издания у нас и в чужбина, авторка е и на няколко книги.
Професор Шнитер, трябва ли според Вас предметът религия да е задължителен, или може да остане свободноизбираем, както е и в момента?
Не би трябвало изучаването на религия да е задължително. Казвам го като преподавател по история и антропология на религиите като задължителна дисциплина вече 30 години. Аз съм последният човек, който би отрекъл, че младите хора в България страдат от остър дефицит на религиозна грамотност. В началото на всяка академична година се изправям пред около сто студенти първокурсници от хуманитарни специалности – философия, социология, теология, антропология и т.н. Аз съм едва ли не първият преподавател, когото те виждат, щом влязат в първи курс в университета.
Обикновено започвам с въпроса „Защо според вас този курс е в първата година на вашето обучение в университета?“. Има разни отговори, които получавам, но задължително се появява и отговорът, че това според тях е излишно. Защото например „Ние сме атеисти, защо трябва да знаем нещо за религиите?“.
Моят отговор обикновено е, че дори когато религиите са нещо, което персонално не ни интересува, не означава, че нашият живот може да е на остров без присъствието на религии. Ние се сблъскваме с тях на всяка крачка във всекидневието си. И така както уж не се интересуваме, се оказваме някъде и нещо се случва или пускаме телевизора и показват поредния атентат или нещо подобно. Ако моите студенти смятат да станат учители по философия, да кажем, което включва и етика, или ако смятат да станат социолози, политолози, сиреч анализатори на обществото, в което живеем, очевидно няма как да са неграмотни в тази област. Каквито те са. И се налага да научат нещо.
На това място горе-долу постигаме някакво съгласие. После моля тези от тях, които определят себе си като християни, да вдигнат ръка. Обикновено от стотина души вдигат ръка около 60–70. Не е малко. Голямата част от останалите не се определят. Обикновено децата, които са мюсюлмани, се смущават да се обявят като такива. На по-късен етап обаче се включват, при това много интересно.
При такова преобладаващо мнозинство от православни християни задавам друг въпрос: „Можете ли в такъв случай да ми кажете в какво вярва един православен християнин?“ Те, разбира се, не могат. Дори учещите теология, които обикновено са приети с изпит, включващ Символ верую, не могат да кажат в какво вярват. Тоест преобладаващото мнозинство в България настоява, че е християнско, и хората се гордеят с това, но знанията им по този въпрос граничат с нула.
Религията е част от учебните планове – първо чрез присъствието си в много от изучаваните хуманитарни предмети, но и като отделен свободноизбираем час. От учебната 2020/2021 г. има и одобрени учебници за свободноизбираемата дисциплина, но тя не се радва на особена популярност. Защо?
Един от големите проблеми е кой и как преподава религия в българското училище в момента. Аз знам кой преподава, защото знам на кого даваме учителска правоспособност по религия. Това не е от вчера, съществуват такива курсове. Тоест аргументът „няма кой да преподава“ не е много убедителен.
Дори 10 класа да си изберат този един час, пак няма да е достатъчно, за да може учителят да има необходимата заетост. Оказва се, че малцината – те наистина не са много, които имат реално правоспособност да преподават, – за да могат да го правят, трябва да преподават и нещо друго или да правят и нещо друго, а преподаването на религия да е между другото.
Всъщност истината е, че работата по ограмотяването специално за православната религия би трябвало да е работа, която да върши Църквата. Това би трябвало да е нейна грижа. И не би трябвало да се случва в училище.
Религията като тема все пак съществува в редица учебни предмети. Имаме я в часовете по литература, по философия, по история, по етика… И въпреки това се оказва, че учениците излизат дълбоко неграмотни по религиозните въпроси. Като автор на учебници от много години имам опит, защото с колегите наистина полагаме големи усилия да напишем понятно, доколкото е възможно обективно, в някакъв спокоен, неевангелизаторски дух тези уроци, специално в учебниците по литература. Чувала съм от учители, че те просто ги прескачат. Казват: „Аз не мога да преподавам Стария завет, защото не съм го чел.“ А това е част от задължителната програма.
Ако самите учители не намират за нужно да седнат и да прочетат Стария завет например или поне части от него, след което да се опитат да го преподадат, то за каква задължителна част от обучението по литература говорим?
Дискусията относно въвеждането на религията като учебен предмет се води отдавна. Може ли да се върнем малко назад? Защо не се въведе религия още в началото на 90-те, когато имаше всички предпоставки и може би най-силно желание за това?
Имаше най-силно желание, но тогава възникна очевидният въпрос какво ще правим с децата, които не са християни. В България все пак по официални статистически данни над 10% са мюсюлмани, плюс определен процент хора, принадлежащи към други религиозни общности. Тоест ако ние наложим на децата, които изповядват православието или декларират, че изповядват православието, да учат православно вероучение, то тогава логично би било да наложим на децата, които са мюсюлмани, да изучават ислям. И между другото, по този въпрос Министерството на образованието беше доста напреднало. Аз съм участвала в обучение за учители по ислям и то беше добре подготвено и проведено. Идеята беше, че тези, които ще преподават християнство, трябва да знаят нещо за исляма, и тези, които ще преподават ислям, трябва да знаят нещо за християнството. Това е разумна идея, защото няма как да преподаваш ислям, без да знаеш нищо за християнството, а е възможно да не знаеш дори когато живееш в християнска среда.
Тогава при мен попадна една група учители от Североизточна България. Голяма част дори не владееха съвсем добре български. Опитах се да преподам накратко на тези хора, на които предстоеше да преподават ислям на ученици, изповядващи исляма, най-важните моменти от историята на християнството, както и моментите на съприкосновение между християнство и ислям, защото няма как например да прескочим факта, че е имало кръстоносни походи. Това е известно на учителите по история, но за тези курсисти беше много интересно. Всъщност според мен те изведнъж прогледнаха за нещата по малко по-различен начин, но нивото на обучението беше отчайващо ниско. Признавам си, че и моят експеримент приключи с еднократно участие в тази програма. Повече не се включих, защото реших, че не е това, което трябва да бъде. Но самата идея не беше лоша.
Ако се изучават общо религии, то трябва да могат да се правят съпоставки, паралели, да се търсят общите места, темите, които се пресичат.
При настоящата дискусия се повдигна и този въпрос – само православно християнство ли ще се преподава по религия? Какво правим с мюсюлмани, атеисти и други? Започна да се споменава конфесионално и неконфесионално преподаване на религия. Възможно ли е това?
Изглежда, е възможно, такава е и традицията. Всъщност в Западна Европа има конфесионално и неконфесионално обучение. Имам две лични истории, които онагледяват чудесно съществуващите противоречия.
Преди много години в Пловдив съществуваше френска католическа детска градина, която, за съжаление, с дружните усилия на Общината и други заинтересовани страни беше закрита. Тази детска градина в рамките на 15 години успя да обучи и възпита много деца. Начело на градината беше сестра Мариане, възрастна монахиня, истински ангел, която преподаваше френски. Имам личен опит с това място, защото, въпреки че семейството ни е православно, синът ми я посещаваше.
Имаше, разбира се, няколко религиозни празника, които се отбелязваха, но нямаше никакво религиозно индоктриниране.
И продължавам с личния си опит. Някъде около 2000 г. живеем във Виена и в началното училище има предмет религия – католическо вероучение. Заявявам съгласието си като родител детето ми да посещава тези часове. Но не – докато другите третокласници учат религия, той трябва да седи някъде сам и да чака да мине този час. Не го приеха – казаха, че е православен и не може да влезе в час заедно със своите съученици. Какви тайни бяха решили, че трябва да споделят с 8–9-годишни деца, не знам. Междувременно разбрах, че сега е възможно учениците сами да изберат дали да присъстват, или не в този час, но тогава беше така.
Дали според Вас дискусията се изкривява с обяснението, че децата ще учат добродетели? Как се преподават те?
Изкривява се наистина, защото добродетелите се показват, те не могат да се преподават на теория. Децата са достатъчно чувствителни и интелигентни, за да не вярват, когато някой се изправи пред тях да им декламира някакви принципи, без да ги спазва в собствения си живот. Не можем да ги излъжем така лесно, струва ми се.
В Античността се е считало, че добродетелите идват от боговете. Всъщност още съвременниците на тази идея я оспорват и Аристотел твърди, че има два вида добродетели – дианоетически (идващи чрез учене) и етически (чрез традиции). И сега изведнъж се връщаме отново в Античността и ни обясняват, че добродетелите идват от Бога. Доколко добродетелите могат да бъдат изучени чрез религия?
Това, разбира се, е един от начините и всяка една от религиите, които познаваме, има собствен етичен кодекс, собствени дефиниции какво е добро, какво е зло. Още древните египтяни въвеждат идеята, че след смъртта душата се явява на съд и за добрите си дела бива възнаградена, а за лошите – наказана. Тоест това не е нещо, което са измислили, да кажем, юдеите или християните, нито древните гърци. Тази идея съществува доста по-отдавна, така че е нещо универсално. И ако така ще изучаваме религиите – да, добре, нямам нищо против. Но в такъв случай не би трябвало да се ограничаваме до една-единствена религия. Нека тогава да ги учим в паралелност. Само че, струва ми се, колегите от православното духовенство не биха го приели. Предполагам, че и тези от исляма също.
За събитието, което Министерството на образованието и науката организира – „Дискусия за изучаване на добродетели и религии“, смятате ли, че беше дискусия? Умеем ли да дебатираме и дискутираме, без да се нападаме много страшно един друг?
Много съжалявам, че не знаех за събитието. Истината е, че разбрах постфактум. Гледах записа по-късно. Струва ми се, че това с дискусията е голям проблем в българското общество. Не само по този случай. Ние изобщо не сме научени да дискутираме качествено, а това би трябвало да се учи.
В продължение на десетина години организирахме всяко лято Международно лятно училище по религии и публичен живот в Пловдивския университет. Пристигаха хора буквално от цял свят – от Япония и Индонезия до Канада и Африка, представители на всякакви религии. Обсъждаха се различни неща, идеята беше как да живеем с различието.
В началото на XXI век религиозните конфликти на Балканите бяха ужасно изострени и с помощта на колеги и на фондация CEDAR, която възникна като реакция след войните в бивша Югославия, си зададохме въпроса как да живеем с другите.
А второто беше, че не можеш да отсъстваш от нищо. Ти трябва да бъдеш с другите през целите две седмици, в които се правят най-разнообразни неща. Едно от тях беше съвместно посещаване на религиозни храмове. Пловдив е прекрасен терен за подобни обиколки. Бяхме навсякъде – в месджидите [молитвени домове – б.р.] в „Столипиново“, в синагогата, в арменската църква, в протестантски храм, в православен, в католически…
Имали сме случаи да пристигнат в една и съща година участници от Сърбия и Хърватия. В началото си говорят само на английски, защото твърдят, че въобще не се разбират – те са съвсем различни, поне така заявяват. А накрая пеят заедно песни и се разделят като приятели.
Възможно е човек наистина да намери начин и подход. Да, много е сложно, изисква сериозно научно отношение и голяма инвестиция на време и на усилия. Изобщо не изисква формални правила. Не е случайно, че тази наша инициатива не намери подкрепа. Всеки път я правехме на магия и почти за без пари. Никой не можеше да повярва, че е възможно. Но такъв модел съществува. Той беше усвоен например в Япония, в някои държави в Африка, в Индонезия – там възникнаха такива академии. В България тя, за съжаление, замря.
Post Syndicated from John Lee original https://www.servethehome.com/how-to-see-if-ecc-is-working-in-windows-quickly/
We have a quick guide to check if ECC is working on a platform when you have ECC memory installed but want to check in Windows
The post How to See if ECC is Working in Windows Quickly appeared first on ServeTheHome.
Post Syndicated from corbet original https://lwn.net/Articles/1020448/
Inside this week’s LWN.net Weekly Edition:
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=htGrlFSeQnY
Post Syndicated from Raaga N.G original https://aws.amazon.com/blogs/compute/securing-amazon-s3-presigned-urls-for-serverless-applications/
Modern serverless applications must be capable of seamlessly handling large file uploads. This blog demonstrates how to leverage Amazon Simple Storage Service (Amazon S3) presigned URLs to allow your users to securely upload files to S3 without requiring explicit permissions in the AWS Account. This blog post specifically focuses on the security ramifications of using S3 presigned URLs, and explains mitigation steps that serverless developers can take to improve the security of their systems using S3 presigned URLs. Additionally, the blog post also walks through an AWS Lambda function that adheres to the provided recommendations, ensuring a robust and secure approach to handling S3 presigned URLs. For more information on S3 presigned URLs, see Working with presigned URLs.
The following architecture diagram illustrates a serverless application that generates an S3 presigned URL. By using S3 presigned URLs, serverless applications can offload to S3 the computation required to receive files. The diagram captures a seven-step process between the client, Amazon API Gateway, the Lambda function, and S3.

A typical workflow to upload a file to a serverless application hosted on S3 includes the following steps:
When designing a serverless application that utilizes S3 presigned URLs to store data in S3, a developer must consider several primary security aspects. S3 presigned URLs are public resources that do not authenticate users, and anyone in possession of a valid S3 presigned URL can access the associated resource. Consequently, it is important to implement additional security measures to ensure that these URLs are not misused or accessed by unauthorized parties. The following blog post contains techniques you can use to make your presigned URLs more secure.
When you upload an object to S3, you can include a precalculated checksum of the object as part of your request. S3 will perform an integrity check and verify if the object sent is the same as the object received. S3 supports the use of MD5 checksums to verify the integrity of objects uploaded. You provide the MD5 digest by including a Content-MD5 header in the initial PUT request. Upon receiving the object, S3 will calculate the MD5 digest and compare it with the one you originally provided. The upload operation succeeds only if both MD5 digests match, ensuring end-to-end data integrity. If an unintended party gets their hands on the S3 presigned URL, then they will not be able to use it without possessing the same object. This provides protection against arbitrary file uploads.

The key element for a developer to remember is that when the client uploads the file to the S3 presigned URL, it must supply the correct MD5 in Base64 using the Content-MD5 header. Developers can see a sample serverless application with client-side code to extract the MD5 digest, request a S3 presigned URL, and upload a file in this GitHub repository. This sample application uses NodeJS v20 in the Lambda function.
An S3 presigned URL remains valid for the period of time specified when the URL is generated. It is important to ensure that the S3 presigned URL does not remain accessible for longer than required as it can be reused when still valid. You can define the expiration time of the S3 presigned URL by either passing X-Amz-Expires as a query parameter or by setting the expiresIn parameter when using the AWS SDK for JavaScript.
S3 validates the expiration time and date at the time of initial HTTP Request. However, to support situations where the connection drops and the client needs to restart uploading a file, you may want your S3 presigned URL to remain valid for the entire anticipated time needed to upload the file to S3. The challenge is to generate an S3 presigned URL that is valid long enough to accommodate the file’s upload, yet still short enough that you prevent reuse.
A solution we propose to overcome these challenges is to dynamically set the S3 presigned URL’s expiration time by using the browser Network Information API. Using this new API, when the client browser places the initial request for an S3 presigned URL, the client also transmits the file’s size and the network type, so the Lambda function can calculate the anticipated transfer time.
Within the Lambda function, we can now estimate the transfer time for this size of file on this type of network, using sample code as featured in this GitHub repository.
With the estimated transfer time calculated, the Lambda function can now request the S3 presigned URL and set the expiresIn parameter to the transfer time, resulting in an S3 presigned URL that is only available for the time needed to upload that size of file on this type of network.
If you are using the AWS SDK, you may also be using AWS Signature Version 4 (SigV4) to sign your requests. To create a defense in depth approach, which will place a ceiling on total expiration time, you can utilize condition keys in bucket policies. For an example policy, see Limiting presigned URL capabilities.
When an application allows a user to upload files, the application exposes itself to various security threats, such as path traversal attacks. Path traversal vulnerabilities allow attackers to access files that are not meant to be accessed or to overwrite files outside the intended directory structure. In order to secure your applications against such vulnerabilities, the most effective approach is to incorporate user input validation and sanitization. You can sanitize the filename by replacing it with a generated UUID (Universally Unique Identifier).
You can see an example function in the server-side code for Lambda in this GitHub repository.
The capabilities of an S3 presigned URL are constrained by the permissions of the principal that created it. To offer fine-grained access, the very first step in limiting use of an S3 presigned URL should be building a specific Lambda function that generates these URLs. By having a Lambda function dedicated to this purpose, you do not risk an overly permissive Lambda function. The second step is to limit your specific Lambda function’s access to S3.
Adhering to the Principle of Least Privilege, it’s important to restrict the Lambda function’s permissions to only the required prefixes in the bucket and allow it to perform only the required actions on the bucket, instead of granting full bucket access. This minimizes the potential attack surface and mitigates the risk of unintended data exposure or modification. It is important to limit the permissions to the minimum required set of actions and resources.
This example AWS Identity and Access Management (IAM) policy demonstrates how to grant the Lambda function read access (GET) to objects within the "Example-Prefix" prefix of a specific S3 bucket. The IAM policy is attached to the Lambda function via an execution role, which together establish what actions the Lambda function can perform.
This example IAM policy demonstrates how to grant the Lambda function permissions to upload (PUT) objects within the "Example-Prefix" prefix of a specific S3 bucket.
This approach will ensure that your Lambda function possesses the minimum required permissions to perform its intended tasks and reduces the risk of unintended data access or modification.
If you want to restrict the use of S3 presigned URLs and all S3 access to a particular network path, you can also define a network-path restriction policy on the S3 Bucket. This restriction on the bucket requires that all requests to the bucket originate from a specified network. AWS Prescriptive Guidance says, an extension of least privilege is to maintain a data perimeter that’s consistent with your organization’s needs. The goal of an AWS perimeter is to ensure that the access is allowed only if the request is coming from a trusted entity, for trusted resources from a trusted network. These data perimeters are applicable to S3 presigned URLs as well.
Serverless applications developers may want each S3 presigned URL to only be used once. Developers can incorporate a token-based mechanism to facilitate secure one-time use of an S3 presigned URL. This involves generating unique tokens for each authorized user or client and associating these tokens with the S3 presigned URLs. When a client attempts to access the resource using the S3 presigned URL, they must provide the corresponding token for validation. This additional layer of security ensures that only authorized entities can access the S3 presigned URLs and the associated resources. Furthermore, you can leverage a database to track the issued tokens and expire them after each use. A solution to implement such a mechanism has been discussed in detail in How to securely transfer files with presigned URLs.
You may clean up the sample application by deleting the API Gateway, Lambda function, and S3 bucket. In addition, please do not forget to delete any IAM execution roles you created for the Lambda function.
In this blog we have discussed various considerations that a developer must make when designing an application that leverages S3 presigned URLs. By incorporating robust security measures, such as proper access control, input sanitization, expiration handling and integrity checks, developers can mitigate potential risks when using S3 presigned URLs.
Post Syndicated from jzb original https://lwn.net/Articles/1020571/
At the Linux Application
Summit (LAS) in April, Sebastian Wick said that, by many metrics, Flatpak is doing great. The Flatpak
application-packaging format is popular with upstream developers, and
with many users. More and more applications are being published in the
Flathub application store, and the
format is even being adopted by Linux distributions like
Fedora. However, he worried that work on the Flatpak project itself
had stagnated, and that there were too few developers able to review
and merge code beyond basic maintenance.