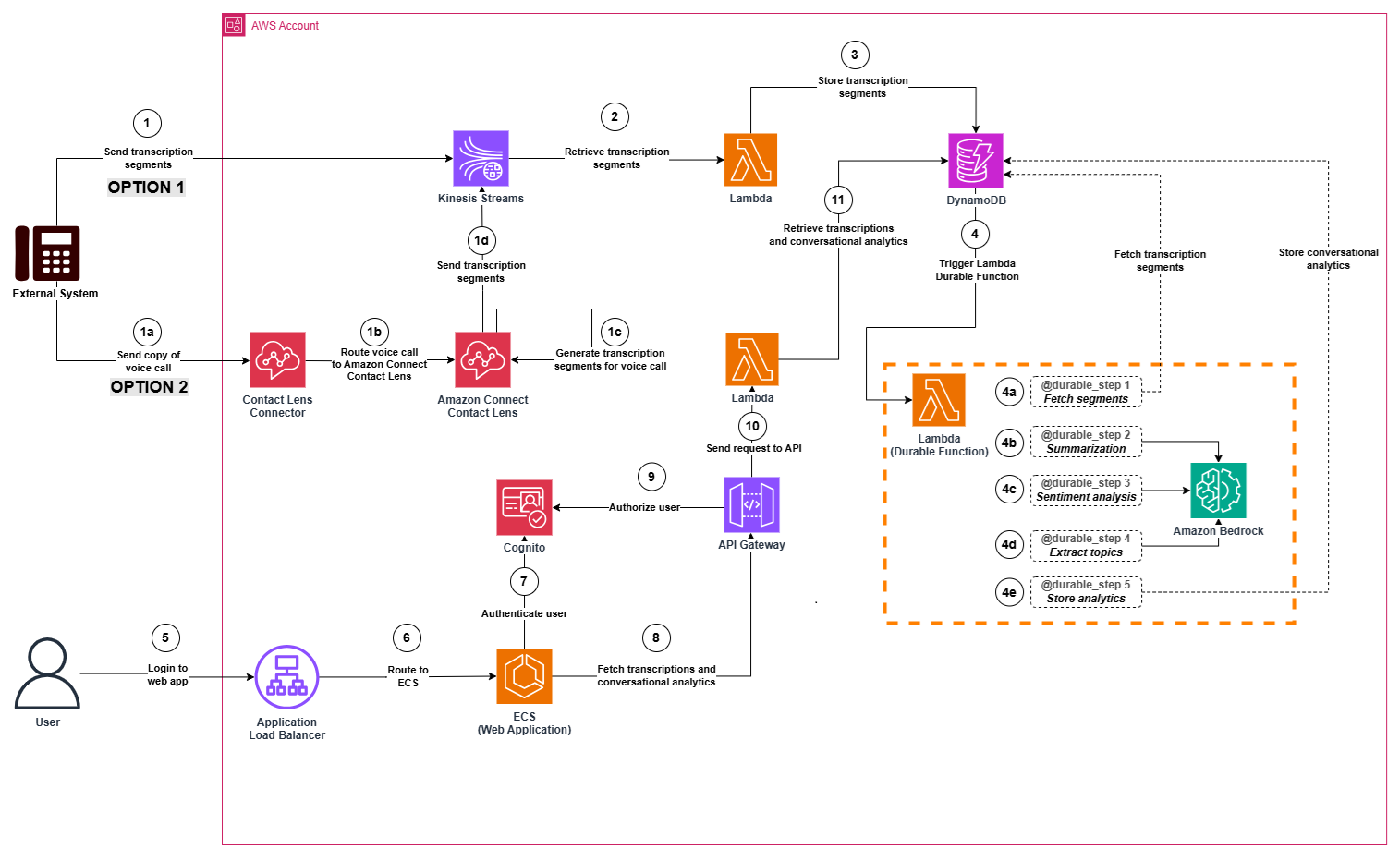
Post Syndicated from Йоанна Елми original https://www.toest.bg/glasovete-na-amerika-broy-16/

Светът гледа футбол, а европейските футболни фенове се сблъскват с американската действителност. Социалните мрежи изобилстват от мнения, отзиви, възмущения, възхищения. Как е възможно американците да не седят на пейки и по маси в заведенията с часове? Защо порциите са толкова големи? Защо има толкова много вериги за бързо хранене? Защо има петдесет вида безалкохолно в супермаркета? Защо градският транспорт е в такова състояние, ако изобщо го има?
Разбира се, това е само едната страна на монетата. Другата е радост от гостоприемството на американците, удивление от красотата и разнообразието на природата, удобствата, добрите ресторанти и вкусната храна. Една от най-големите шеги, родена от Световното, е свързана със соса ранч – млечен сос със сол, чесън, лук, черен пипер и билки, популярен в САЩ. Европейците са обсебени от него до такава степен, че Американската служба за транспортна безопасност (TSA) публикува шеговити напомняния в социалните мрежи, че ранчът е течност, която следва да се опакова в чекирания багаж.
От една страна, сблъсъкът с реалността има положително влияние върху европейците, които виждат, че въпреки апокалиптичните заглавия Америка все още е Америка, а не Русия например; от друга, 80% от хотелиерите, участвали в проучване на пазара, заявяват, че има по-малко заети места от очакваното. Данните са от доклад на Американската асоциация на хотелиерите, в който се казва още, че 65–70% от респондентите смятат визовите пречки и геополитическата ситуация за решаващи за ниския международен интерес.
На този фон Фреди (Freddy), футболен фен от Германия (самоличността на акаунта не е потвърдена) получава официална покана от Белия дом. Причината е, че публикува свръхположителни отзиви за престоя си в САЩ по време на Световното. Специалният президентски пратеник по въпросите на американския туризъм, американската изключителност и ценностите (истинска позиция в администрацията на президента Тръмп) Ник Адамс потвърди поканата към Фреди.
Коя е истинската Америка?
Това е въпросът, който си задават много американци и европейци не само в контекста на Световното първенство по футбол, но и седмици преди отбелязването на 250-годишнината от независимостта на САЩ на 4 юли. Като част от честванията пред Белия дом се проведе бой на UFC (Ultimate Fighting Championship) – най-голямата организация за смесени бойни изкуства (ММА) в света. Айзък Саул, редактор в една от популярните центристки независими медии Tangle пише:
Някои журналисти вляво не успяха да се въздържат от цитиране на френски теоретици от XX в. в опитите си да обяснят защо хората харесват зрелища с насилие. Нуждата да се посяга към академични теоретични рамки, за да разберем шоуто на една бойна вечер на UFC, показва колко чуждо и далечно е подобно нещо за част от коментиралите.
В същото време анализатори отдясно се опитват да внушат, че „истинската Америка“ е изградена изцяло от карикатурни каубои и хора, които се наливат с енергийни напитки, а после настояват, че подобно събитие (с 16% обществено одобрение) по някакъв начин представлява най-чистото въплъщение на същността на страната.
После други леви журналисти пък настояват, че именно това – един глупав, пълен с насилие и конспиративно мислене спектакъл – всъщност е „истинската Америка“, а междувременно автори отдясно настояват, че това не е истинската Америка, защото сме станали твърде изнежени, твърде образовани и твърде чувствителни.
Всичко това е толкова изтъркано, че едновременно ме забавлява и ми се струва нелепо.
Някои хора харесват бойни спортове, като UFC или бокс, защото човешкият вид е склонен към насилие и в продължение на хилядолетия сме се обезглавявали за какво ли не – от дребни престъпления до териториални завоевания. Естественият подбор е благоприятствал както хората, способни да си сътрудничат, така и онези, които са можели успешно да се съревновават за храна, територия и партньори, а насилието е било ефикасен начин за придобиване на тези ресурси.
Не мисля, че е чак толкова сложно. Спортовете с насилие – UFC, боксът, хокеят, американският футбол, ръгбито, кечът, са здравословен отдушник за най-първичните ни инстинкти в рамките на едно цивилизовано общество. Човек може да смята, че разрешаването на спорове чрез насилие е нещо лошо, но същевременно и да разбира контролираната агресия като форма на развлечение през 2026 г.
Разбира се, някои хора не обичат да гледат как други човешки същества си разбиват лицата и се окървавяват. И това е напълно нормално. Америка! Плурализъм! Ако страната ни (или дори човешкият вид) се състоеше единствено от груби, агресивни типове, които обичат да мачкат физиономии и да решават проблемите си с насилие, то Америка би била ужасно място за живот.
Неизличимо американски ли са някои културни елементи на UFC и неговата фенска общност? Разбира се. Но представлява ли UFC самата Америка в нейната същност? Очевидно не. Това е част от нашата култура, едно от многото неща, които изграждат цялото. Не разбирам защо е необходимо да му се приписва някакво по-грандиозно значение.
„UFC Свобода 250“ се проведе на рождения ден на президента – 14 юни. Според анализ в The Conversation решението на Доналд Тръмп да организира галавечер на UFC на територията на Белия дом е символичен политически жест отвъд спортното събитие. В статията се казва още, че Тръмп използва бойния спорт като визуален език на сила, доминантност и лидерство, превръщайки Белия дом в сцена, на която президентът не просто представлява нацията, а се стреми да се отъждестви с нея като неин рицар. Авторът проследява и по-широка промяна в американската политическа култура – от идеала за президента като слуга на народа към образа на лидера като победител и силен мъж.
В този контекст UFC се разглежда като културен символ на съревнование, физическа йерархия и хипермъжественост, който резонира с част от електоралната коалиция на Тръмп (ММА спортовете от години носят същия символен заряд в неоконсервативното движение). Спорът около събитието надхвърля самия спорт и поставя въпроса кой има правото да определя националните символи и ценности – политическият лидер, който претендира да ги въплъщава, или гражданите, независимо от дефинициите им за нация, народ и принадлежност.
От насилието като зрелище към насилието като реалност
На 17 юни Съединените щати и Иран подписаха меморандум за разбирателство, който трябва да сложи край на продължилата над 100 дни война между двете държави. Споразумението предвижда възстановяване на корабоплаването през Ормузкия проток, постепенно премахване на американските ограничения върху иранския петролен износ, размразяване на ирански активи и участие на САЩ във фонд за възстановяване на Иран на стойност 300 млрд. долара. В замяна Техеран потвърждава, че няма да разработва ядрено оръжие, докато двете страни продължават преговорите за по-трайно уреждане на отношенията си.
Споразумението предизвика критики както отляво, така и отдясно в американския политически спектър. Леви коментатори го определиха като стратегическо поражение за администрацията на Доналд Тръмп, твърдейки, че Иран е излязъл от конфликта с малко отстъпки и с укрепени регионални позиции. Някои автори посочиха и разочарованието сред иранските опозиционери, които са очаквали по-сериозна подкрепа от Вашингтон срещу режима. Други разглеждат развоя като знак за отслабване на американското влияние и за потенциална промяна в баланса на световните сили.
Консервативните реакции са разделени. Част от коментаторите смятат, че Съединените щати са направили значителни отстъпки, без да постигнат първоначалните си военни цели, свързани с иранската ядрена програма, ракетния арсенал и регионалните проксита на Техеран. Други обаче виждат в споразумението възможност за преосмисляне на американската стратегия в Близкия изток и постепенно намаляване на прякото военно ангажиране на Вашингтон в региона.
Иран запазва значителна част от военния и политическия си потенциал, докато Вашингтон се отказва от редица първоначални искания и поема сериозни финансови ангажименти. Независимо че прекратяването на бойните действия се определя като положително развитие, eкспертите са единодушни, че регионът е по-нестабилен след конфликта, а Иран вероятно ще има по-силни позиции, отколкото преди началото на войната.
Лошата сделка вероятно е по-добра от никаква сделка за една напълно безсмислена и непопулярна война, която не постигна каквато и да е цел – все пак да не забравяме, че САЩ се подготвят за междинни избори наесен.
В Ню Йорк кандидати, подкрепяни от настоящия кмет Зоран Мамдани, спечелиха първичните избори, които ще определят кой ще се кандидатира за места в Камарата на представителите и в Сената през ноември. За някои анализатори това е повод за прогнози, че в Демократическата партия се задава нова вълна – на прогресивните демократи (социалдемократи, но не в европейския смисъл; по-скоро по-ориентирани към социални и леви политики).
Сред победителите в Ню Йорк са бившият главен финансов инспектор Брад Ландер и демократ-социалистите Дариализа Авила Шевалие и Клер Валдес. Двама от тях успяха да победят действащи конгресмени, което се разглежда като сериозен успех за прогресивното движение в града, пише „Ню Йорк Таймс“. Мамдани представи победите като доказателство, че успехът му на кметските избори не е бил еднократно събитие, а част от ново политическо движение, което едва сега започва. По време на празненствата негови поддръжници скандираха името на организацията DSA – Democratic Socialists of America (Демократични социалисти на Америка, ДСА), а самият кмет заяви, че традиционните политически подходи не действат при обществените проблеми и предизвикателства на настоящето.
През последните месеци кандидати, свързани с ДСА, постигат все по-големи успехи в първичните избори на Демократическата партия. Сред най-разпознаваемите лица на това течение са Бърни Сандърс, Александрия Окасио-Кортес и кметът на Ню Йорк Мамдани. Кандидати, подкрепяни от ДСА, побеждават в Ню Йорк, Вашингтон и Лос Анджелис, което подхранва дебата дали Демократическата партия навлиза в нов етап на идеологическо преструктуриране.
Поддръжниците на тази тенденция твърдят, че възходът на демократическите социалисти отразява нарастващото недоволство от икономическото неравенство, кризата с жилищата и високите разходи за живот в големите градове. Според тях младите избиратели все по-често подкрепят политики като разширяване на социалните програми, по-високо данъчно облагане на богатите и по-активна роля на държавата в икономиката. Някои анализатори дори предполагат, че демократическите социалисти могат да станат трайно крило на Демократическата партия.
Критиците предупреждават, че успехите засега са концентрирани предимно в силно демократически райони и не гарантират по-широка национална подкрепа. Според консервативни коментатори част от предлаганите политики са трудно приложими на практика, а по-радикалните позиции по социални и културни въпроси могат да отблъснат умерените избиратели. Други автори поставят под въпрос самата идея за демократически социализъм, свързвайки я с историческия опит на социалистическите режими през XX век.
Възходът на ДСА е едновременно реакция срещу статуквото в Демократическата партия и своеобразен отговор на популистката мобилизация, постигната от MAGA около Доналд Тръмп. Двете движения споделят недоверие към политическия елит и използват силно антисистемна реторика, макар да предлагат коренно различни решения. Остава открит въпросът дали демократическите социалисти ще успеят да превърнат успехите си в традиционно либералните градски центрове в по-широко национално политическо влияние, или ще останат явление, ограничено до определени части от американския електорат.
След ремонт за милиони водното огледало пред Мемориала на Линкълн във Вашингтон се заблати
Президентът Тръмп обвини вандали, но към момента няма официално потвърдена информация за арестувани въпреки твърденията на администрацията. Наскоро туристи заляха социалните мрежи със снимки, на които току-що положената боя се бели.
Но все пак е лято – баровете са пълни, политиката и войната винаги се случват другаде, а светът гледа футбол. И зрелища.
Америка ще празнува 250-тия си рожден ден. А след това зрелището почти със сигурност ще загрубее. Въпросът е дали има кой да му обърне внимание. И колко още празните спорове, зрелищата, риалитито на войната и политиката ще отлагат належащите ремонти на институциите и обществата. Или ще се слага нова и нова боя, която дни по-късно ще се бели.
Абонирайте се, за да получавате този бюлетин на електронната си поща в момента, в който излезе!
Вече сте регистриран потребител на Toest.bg? Може директно от настройките на бюлетините в своя профил да изберете „Гласовете на Америка“ или да натиснете бутона по-долу:
Още нямате профил в Toest.bg? Регистрирайте се само с няколко клика: