Post Syndicated from Vasil Kolev original https://vasil.ludost.net/blog/?p=3499

This is a talk about the video-box that we used to run video on FOSDEM 2025, and that we’re testing, sorry, using, to do video at FOSSASIA 2025 🙂
(abstract)
Over the past years, the FOSDEM conference (a free and open-source developer event in Europe) has hacked together its own video recording and streaming setup. We stream 30 rooms with a video team that’s less than 30 people. The latest iteration of that was a lot of fun, and we’d like to share with everyone what it looks like, what it can do and how fun and hackable it is. We will explain our setup, and give a rundown of what’s in those weird boxes you might have seen.
The project is fully open source software and hardware, and everything is available in FOSDEM’s GitHub repos.
If you don’t want to listen to me, but want to see for yourself, everything – the hardware designs, assembly instructions, sources, ansible recipes – are in those two repos. Hack away 🙂
(there’s even a FOSSASIA branch for the things we had to change for this event)
The initial idea of this talk was to explain how useful this box is to any kind of event, for streaming, recording, etc, etc.. But there’s one more important point that I want to make, after talking to some people here.
THIS IS NOT HARD.
What you can see in this presentation and what we do is the product of a few slightly insane people. We didn’t know that some stuff was hard, and we didn’t care, we just tried to see what will happen. There were problems, there were wrong directions, but as you see, we have it working, and I do think that it’s possible for anyone here to do it.
This is one of the reasons we give the source for it – that people can learn from it, play with it, use it, etc.. It’s possible for people to create any such project – I have seen this again and again and again. I even have a favourite joke about it, I hope it translates well…
The mathematician Dantzig as a student was late for one lecture, came in the lecture room after everyone had left, and saw two mathematical problems written on the blackboard. He thought that those were homework, wrote them down, and went home. On the next day, he was a bit early, went to the professor and said:
“From the homework yesterday, I managed to solve the first one, but I’m having trouble with the second one”
“What homework?”
“The two problems that were written on the board”
“But… but… those were examples of unsolvable problems!”
So, seriously. When you look at the box, you shouldn’t think “wow, what great thing/product”. You should be thinking “I can make one better/I can make it better”.
And to show what we’ve been through (because people see only the end result) – here is an example of a setup for part of the development. It loks scary, feels like it can catch fire if you touch anything, and is so far from what you see in the box.
And this is a temporary version of the power board. I am not sure if you can see it very well, and I’m not sure you would want to see this horrible contraption. You should not be afraid to make things like this and experiment. Yes, it takes time, yes, it sometimes catches fire, but when that happens you just put out the fire and think of a new way forward. In the end it works!:)
Seriously. Experiment and do stupid things. This is how people learn.
(I’ve heard that there are some really smart people that learn from other people’s mistakes, but at least I need to make my own:) )
To explain where all this comes from, a few short words about FOSDEM – it’s the largest open-source event in Europe. It gathers some thousands of people in a cold, windy and rainy place with good beer to present and discuss all kinds of open-source projects. It’s a bit crazy, with 30 parallel tracks and more than a thousand talks.
And I’m really happy to be a part of it. It’s one of the things that I participate in that no other group does, and that’s mostly because nobody is crazy enough 🙂
So, large event, large venue (multiple buildings), only half a day for the setup. We have next to no manpower and no time 🙂 . We want to have working video, because there are a lot of lazy people around the world that don’t feel like traveling to FOSDEM, and rooms are often so full that people sit outside and watch the streams.
And, FOSDEM is a completely open and free event, we can’t just throw money at the problem and have a setup that would cost a few million dollars.
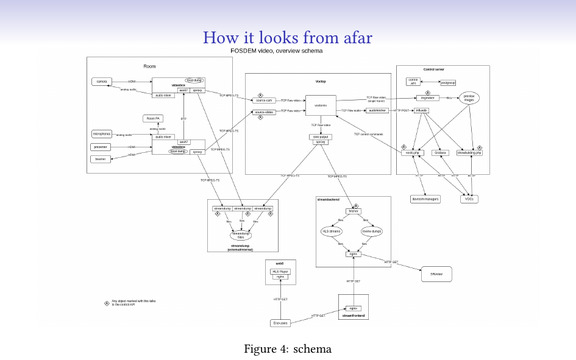
This is the overall architecture of the video at FOSDEM. We capture the camera and the presenter’s slides, they get sent to a video mixer, which mostly creates a picture-in-picture stream. That stream gets sent to the outside world to see, and gets recorded so it can be reviewed later.
A few things in this setup we didn’t finish for this year, like audio transport over the network (which would’ve saved us one long cable per room), but there’s always next year 🙂
This setup scales really well – we’ve done FOSDEM with between 20 and 30 rooms, and are pretty confident it would scale to a hundred or more. We manage to set the up in half day with 7-8 teams with 3 people each, and to tear it down after the event in three hours.
Not having too many people, we prioritize the ease of setup and operation. We’re also lazy 🙂
And such an event requires a tremendous amount of computing power to mix the video…
… just kidding. 10-year old laptops can deal with that without any issues 🙂 You can also see them here in the racks (Ikea wine racks). These machines run software called “voctomix”, developed in Python by c3voc and which does some magic with gstreamer.
Remember the slide with “this is not hard”?
To show how much code we’ve written to run all that infrastructure above, I ran the tool that counts lines of code, and when I removed one external javascript library, this is what’s left. With 1500 lines of code you can run the video of one of the largest conferences there is.
There’s a bit more code in the firmware for the hardware and few other external things, but the above is enough for almost everything.
For 7-8 years we used this, but it was getting old (and some of the wood a bit moldy). It was a combination of a Banana PI, sata SSD, small switch, one BMD recorder (device that captures HDMI and gives it over USB), and for half of the boxes, a scaler – something that you can plug any laptop in and it’ll be able to change the signal to something that we can use.
The last part is always a problem, because laptops do weird things. Not to mention Macbooks.
As the old boxes were breaking down, we made a stopgap measure – a laptop, and a capture card, in a transportable form-factor. This worked relatively well for 2024, but was larger than we liked, and the laptops we got for cheap had USB issues (which were fixed in a newer version of the laptop, but that did not have Ethernet ports).
You can see it on this picture in action – it’s the laptop with purple background and the box below it.
This worked pretty well, but was a bit unwieldy, and the box itself was almost empty. We couldn’t come up with a way to put the laptop in, so we started looking at options.
Then, Martijn Braam visited us during the 2024 event and metioned “you know, I’ve made a stand-alone open-source audio mixer, it’s a simple board and a chip”. We thought we can use it and get rid of the mixers we carry around, some cables, etc.
Here’s a picture of someone from our senior staff, responsible for the design of the power board and a lot of the low-level hardware and assembly. As you see, he has all the tools needed for the job. He was the other person really interested in designing hardware.
And if we have to say what were the driving words behind the project, it was this. We wanted something that doesn’t cost too much, that we can make in large amounts and that could do all the weird things we wanted.
The thing is, as soon as you start to make your own hardware, you start to get greedy and ask “what else can we do?”.There are so many interesting things you can add, to handle tasks that you were doing with extra hardware or software before.
So the first is trivial, we need to power things inside, so you design your own power board.
Then, we have microphone receivers. They are battery-powered, but can also be powered via USB. So now we have 4 charging ports (and we can turn them off and on from software).
And for crazy ideas, why not design a radio INSIDE the box, that can just receive wireless microphones? Turns out that is pretty much possible, we didn’t have the time for it and there were some snags… But even to me this sounds crazy.
And well, in the end, how hard would it be to design a network switch? Turns out, not that hard. We needed just one revision to make it work, and a few days ago, just becase we can, we added initial support for VLANs in the switch – so that can actually do interesting network topologies.
This is the part in movies where there’s montage with a music background. We worked on different pieces through the summer of 2024, a few months ago…
We started assembling it. This is a simple assembly flow chart 🙂 Might look daunting, but it actually took just two-three weekends and about 10 people to assemble, provision and test 70 boxes.
And because we were running late, this mostly happened in the weekend between Christmas and New Year. Not sure how to translate this to you, but let’s say we were the only people working in the country…
We got the boxes ready somewhere mid-January, and ran FOSDEM 2025 with them 2 weeks later.
And it worked. We still can’t believe it did. We even managed to do a talk there about the box itself 🙂
And yes, much like this very talk, we had the idea of actually having a talk, less than 24h before.
This is how the box looks on the inside. I’ve left a few of them open while running, so you can all see them.
There are two boards that we did not design: a Raxda X4 (an Intel-based single board computer) and a MS2131-based HDMI capture device with a loop out (but we’re working on that one).
The rest is:
An audio mixer with three inputs and two outputs. So you can have three microphones (enough for almost everything), one output to your camera and one to the room sound system. We needed a microcontroller with USB support, so we added an off-the-shelf Teensy on top of it.
An ethernet switch, so you can also connect other boxes and devices to the network (and build your own network). I’m actually afraid to show the topology we have right now in this venue 🙂
A power board powers the other boards, and provides the external charging ports. Plus it controls the fans, has a temperature sensor, controls the pass-through USB port to the radxa and more.
And a handful of breakout boards, to be able to cable things up neatly.
If you take a look in the training rooms, you’ll see an interesting modification of the setup. It uses an USB camera, has a single box, and can do all video and video mixing in that single box. So one box like this, one cheap camera, microphones, and you can record & stream a room pretty quicky.
This is still under development (I made a few fixes in the last few days, and there’ll be more). Its current interface is “SSH into it and run commands”, which is not easy for most people. But, this is also being worked on, so at some point there will be even an user-friendly box 🙂
Of course, we are not even remotely close to what we want. There are so many ideas than those just listed here, and even some of these were thought up while we were writing this presentation, and I can’t wait to show it to the rest of the team.
I really hope they don’t lynch me.
These are two things from our TODO, as an example. As an open-source project, we welcome patches 🙂
We have tried to make sure this is useful not just to us. The boxes, the software around them, the overal ideas can be useful to everyone who does events or video for events, and should be possible to do video streaming and recording in an easy, stable way with a good quality. You won’t get the very nice features (like a multi-camera setup, drones taking photos from above, etc.), but you will have the sound, the presentation, the lecturer visible and recordings which would be usable to everyone that has not being able to attend.
FOSDEM lends this stuff, and we’re happy to explain how to use it. You can also build your own and we can help with the specifics if needed (but everything should be in the repo anyway).
And we can always use more contributors 🙂
Remember this slide? Do not be afraid to hack. Do not think this is something extremely complex and impossible to do to. You just need to start.
Please do 🙂






















 Jonathan Katz is a Principal Product Manager – Technical on the Amazon Redshift team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor, including PostgreSQL and the pgvector project.
Jonathan Katz is a Principal Product Manager – Technical on the Amazon Redshift team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor, including PostgreSQL and the pgvector project. Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.