Post Syndicated from xkcd.com original https://xkcd.com/3026/
, and the worst case is that someone checks why.")
Post Syndicated from xkcd.com original https://xkcd.com/3026/
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/part-1-a-survey-of-analytics-engineering-work-at-netflix-d761cfd551ee
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. We kick off with a few topics focused on how we’re empowering Netflix to efficiently produce and effectively deliver high quality, actionable analytic insights across the company. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
At Netflix, we seek to entertain the world by ensuring our members find the shows and movies that will thrill them. Analytics at Netflix powers everything from understanding what content will excite and bring members back for more to how we should produce and distribute a content slate that maximizes member joy. Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems.
Each year, we bring the Analytics Engineering community together for an Analytics Summit — a 3-day internal conference to share analytical deliverables across Netflix, discuss analytic practice, and build relationships within the community. We covered a broad array of exciting topics and wanted to spotlight a few to give you a taste of what we’re working on across Analytics Engineering at Netflix!
At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. This fragmentation leads to inconsistencies and wastes valuable time as teams end up reinventing metrics or seeking clarification on definitions that should be standardized and readily accessible.
Enter DataJunction (DJ). DJ acts as a central store where metric definitions can live and evolve. Once a metric owner has registered a metric into DJ, metric consumers throughout the organization can apply that same metric definition to a set of filtered records and aggregate to any dimensional grain.
As an example, imagine an analyst wanting to create a “Total Streaming Hours” metric. To add this metric to DJ, they need to provide two pieces of information:
SELECT
account_id, country_iso_code, streaming_hours
FROM streaming_fact_table
`SUM(streaming_hours)`
Then metric consumers throughout the organization can call DJ to request either the SQL or the resulting data. For example,
dj.sql(metrics=[“total_streaming_hours”], dimensions=[“account_id”]))
dj.sql(metrics=[“total_streaming_hours”], dimensions=[“country_iso_code”]))
dj.sql(metrics=[“total_streaming_hours”], dimensions=[“country_iso_code”], filters=[“country_iso_code = ‘US’”]))
The key here is that DJ can perform the dimensional join on users’ behalf. If country_iso_code doesn’t already exist in the fact table, the metric owner only needs to tell DJ that account_id is the foreign key to an `users_dimension_table` (we call this process “dimension linking”). DJ then can perform the joins to bring in any requested dimensions from `users_dimension_table`.
The Netflix Experimentation Platform heavily leverages this feature today by treating cell assignment as just another dimension that it asks DJ to bring in. For example, to compare the average streaming hours in cell A vs cell B, the Experimentation Platform relies on DJ to bring in “cell_assignment” as a user’s dimension (no different from country_iso_code). A metric can therefore be defined once in DJ and be made available across analytics dashboards and experimentation analysis.
DJ has a strong pedigree–there are several prior semantic layers in the industry (e.g. Minerva at Airbnb; dbt Transform, Looker, and AtScale as paid solutions). DJ stands out as an open source solution that is actively developed and stress-tested at Netflix. We’d love to see DJ easing your metric creation and consumption pain points!
At Netflix, we rely on data and analytics to inform critical business decisions. Over time, this has resulted in large numbers of dashboard products. While such analytics products are tremendously useful, we noticed a few trends:
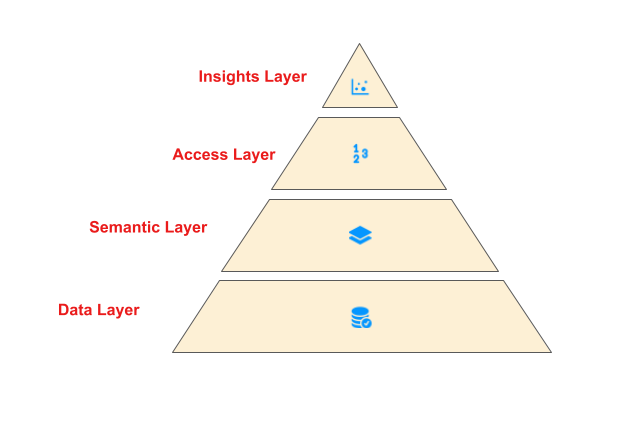
Analytics Enablement is a collection of initiatives across Data & Insights all focused on empowering Netflix analytic practitioners to efficiently produce and effectively deliver high-quality, actionable insights.
Specifically, these initiatives are focused on enabling analytics rather than on the activities that produce analytics (e.g., dashboarding, analysis, research, etc.).
As part of broad analytics enablement across all business domains, we invested in a chatbot to provide real insights to our end users using the power of LLM. One reason LLMs are well suited for such problems is that they tie the versatility of natural language with the power of data query to enable our business users to query data that would otherwise require sophisticated knowledge of underlying data models.
Besides providing the end user with an instant answer in a preferred data visualization, LORE instantly learns from the user’s feedback. This allows us to teach LLM a context-rich understanding of internal business metrics that were previously locked in custom code for each of the dashboard products.
Some of the challenges we run into:
Democratizing analytics can unlock the tremendous potential of data for everyone within the company. With Analytics enablement and LORE, we’ve enabled our business users to truly have a conversation with the data.
At Netflix, we use Amazon Web Services (AWS) for our cloud infrastructure needs, such as compute, storage, and networking to build and run the streaming platform that we love. Our ecosystem enables engineering teams to run applications and services at scale, utilizing a mix of open-source and proprietary solutions. In order to understand how efficiently we operate in this diverse technological landscape, the Data & Insights organization partners closely with our engineering teams to share key efficiency metrics, empowering internal stakeholders to make informed business decisions.
This is where our team, Platform DSE (Data Science Engineering), comes in to enable our engineering partners to understand what resources they’re using, how effectively they utilize those resources, and the cost associated with their resource usage. By creating curated datasets and democratizing access via a custom insights app and various integration points, downstream users can gain granular insights essential for making data-driven, cost-effective decisions for the business.
To address the numerous analytic needs in a scalable way, we’ve developed a two-component solution:
As the source of truth for efficiency metrics, our team’s tenants are to provide accurate, reliable, and accessible data, comprehensive documentation to navigate the complexity of the efficiency space, and well-defined Service Level Agreements (SLAs) to set expectations with downstream consumers during delays, outages, or changes.
Looking ahead, we aim to continue onboarding platforms, striving for nearly complete cost insight coverage. We’re also exploring new use cases, such as tailored reports for platforms, predictive analytics for optimizing usage and detecting anomalies in cost, and a root cause analysis tool using LLMs.
Ultimately, our goal is to enable our engineering organization to make efficiency-conscious decisions when building and maintaining the myriad of services that allows us to enjoy Netflix as a streaming service. For more detail on our modeling approach and principles, check out this post!
Analytics Engineering is a key contributor to building our deep data culture at Netflix, and we are proud to have a large group of stunning colleagues that are not only applying but advancing our analytical capabilities at Netflix. The 2024 Analytics Summit continued to be a wonderful way to give visibility to one another on work across business verticals, celebrate our collective impact, and highlight what’s to come in analytics practice at Netflix.
To learn more, follow the Netflix Research Site, and if you are also interested in entertaining the world, have a look at our open roles!
![]()
Part 1: A Survey of Analytics Engineering Work at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=s6oaczh_7x0
Post Syndicated from Satya S Tripathy original https://aws.amazon.com/blogs/messaging-and-targeting/enhance-your-email-campaigns-using-amazon-ses-sendbulkemail-apis-inline-templates/
Amazon Simple Email Service (SES) is a cloud-based email sending service provided by Amazon Web Services (AWS), handling both inbound and outbound email traffic for your applications. It allows users to send and receive email using SES’s reliable and cost-effective infrastructure without having to provision email servers yourself. Customers use Amazon SES to send emails like one time passwords (OTPs), transactional emails such as order confirmation, and promotional/marketing emails.
For this post, you should be familiar with the following:
Amazon SES continues to evolve, offering new features that help you simplify and optimize your email campaigns. We’re excited to announce the addition of inline template support for both the SendEmail and SendBulkEmail APIs. This new capability allows you to include template content directly in your API requests, reducing complexity and eliminating the need to manage separate template resources in your SES account.
Inline templates allow you to provide the subject, HTML body, and text body of an email directly in the API request, along with dynamic placeholders for personalized content. Instead of creating and storing a separate email template in SES, you can define the template as part of your API call. This feature is especially useful for organizations that need flexibility in managing numerous templates or want to make quick adjustments to email content.
Previously, Amazon SES required you to create and store email templates in your SES account, which you would then reference by name or Amazon Resource Name (ARN) when sending an email. This process adds some management overhead, particularly for organizations that frequently create new templates or exceed the limit of templates per AWS Region. With inline templates, you can reduce complexity by defining your email content directly in the API payload, avoiding the need to create and manage stored templates. This approach can improve flexibility, allowing you to quickly make changes to your email content without updating stored templates. Additionally, it can simplify your integration by providing template content directly within your application logic, making the process more seamless and efficient. When using the and SendBulkEmail API, you can include personalized content for up to 50 destinations in a single call, making large-scale communication more efficient.
To use inline templates, you simply provide the email content (subject, text, HTML) and the replacement data directly in the SendBulkEmail API request payload within TemplateContent parameter.

Here’s an example for using the SendBulkEmail API with inline templates:
file://mybulkemail-inline-template-conten.json:
{
"FromEmailAddress": "Mary Major <[email protected]>",
"DefaultContent": {
"Template": {
"TemplateContent": {
"Subject": "Greetings, {{name}}!",
"Text": "Dear {{name}},\r\nYour favorite animal is {{favoriteanimal}}.",
"Html": "<h1>Hello {{name}},</h1><p>Your favorite animal is {{favoriteanimal}}.</p>"
},
"TemplateData": "{ \"name\":\"friend\", \"favoriteanimal\":\"unknown\" }"
}
},
"BulkEmailEntries": [
{
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"ReplacementEmailContent": {
"ReplacementTemplate": {
"ReplacementTemplateData": "{ \"name\":\"Anaya\", \"favoriteanimal\":\"angelfish\" }"
}
}
},
{
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"ReplacementEmailContent": {
"ReplacementTemplate": {
"ReplacementTemplateData": "{ \"name\":\"Liu\", \"favoriteanimal\":\"lion\" }"
}
}
}
],
"ConfigurationSetName": "ConfigSet"
}SES SendBulkEmail API call:
aws sesv2 send-bulk-email -cli-input-json file://mybulkemail-inline-template-conten.json
Output:
{
"BulkEmailEntryResults": [
{
"Status": "SUCCESS",
"MessageId": "010001xxxxxx-xxxxxxxx-xxxx-xxxx-000000"
},
{
"Status": "SUCCESS",
"MessageId": "020002xxxxxx-xxxxxxxx-xxxx-xxxx-000000"
}
]
}If you’re currently using stored templates, don’t worry – Amazon SES still supports the use of stored templates, and you can continue to use them without any changes. Inline templates are simply an additional option for customers who need more flexibility or wish to avoid managing stored templates altogether. Since inline templates only support the use of simple substitution, stored templates remain the solution for advanced personalization options such as conditional logic or complex formatting. More details in our doc link: How to use Bulk email template.
The inline template feature is now available in all AWS Regions where Amazon SES is offered. To start using inline templates, refer to the Amazon SES Developer Guide and what’s new announcement. There are no additional charges applicable for using inline template feature.
The inline templating feature in SendBulkEmail allows you to avoid worrying about template management by updating / creating new email templates whenever a minor modification or alteration is required in the existing templates, as well as cleaning up unused templates on a regular basis. Therefore, if your business has a high number of email template requirements, there are no predefined rules or patterns for creating email templates, and you need to generate many templates simultaneously within Amazon SES, you must use inline templating feature of SendBulkEmail API . If you do not want to use the Inline templating capability, you can continue to use the templated SendBulkEmail API from Amazon SES.
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/cloud-efficiency-at-netflix-f2a142955f83
By J Han, Pallavi Phadnis
At Netflix, we use Amazon Web Services (AWS) for our cloud infrastructure needs, such as compute, storage, and networking to build and run the streaming platform that we love. Our ecosystem enables engineering teams to run applications and services at scale, utilizing a mix of open-source and proprietary solutions. In turn, our self-serve platforms allow teams to create and deploy, sometimes custom, workloads more efficiently. This diverse technological landscape generates extensive and rich data from various infrastructure entities, from which, data engineers and analysts collaborate to provide actionable insights to the engineering organization in a continuous feedback loop that ultimately enhances the business.
One crucial way in which we do this is through the democratization of highly curated data sources that sunshine usage and cost patterns across Netflix’s services and teams. The Data & Insights organization partners closely with our engineering teams to share key efficiency metrics, empowering internal stakeholders to make informed business decisions.
This is where our team, Platform DSE (Data Science Engineering), comes in to enable our engineering partners to understand what resources they’re using, how effectively and efficiently they use those resources, and the cost associated with their resource usage. We want our downstream consumers to make cost conscious decisions using our datasets.
To address these numerous analytic needs in a scalable way, we’ve developed a two-component solution:
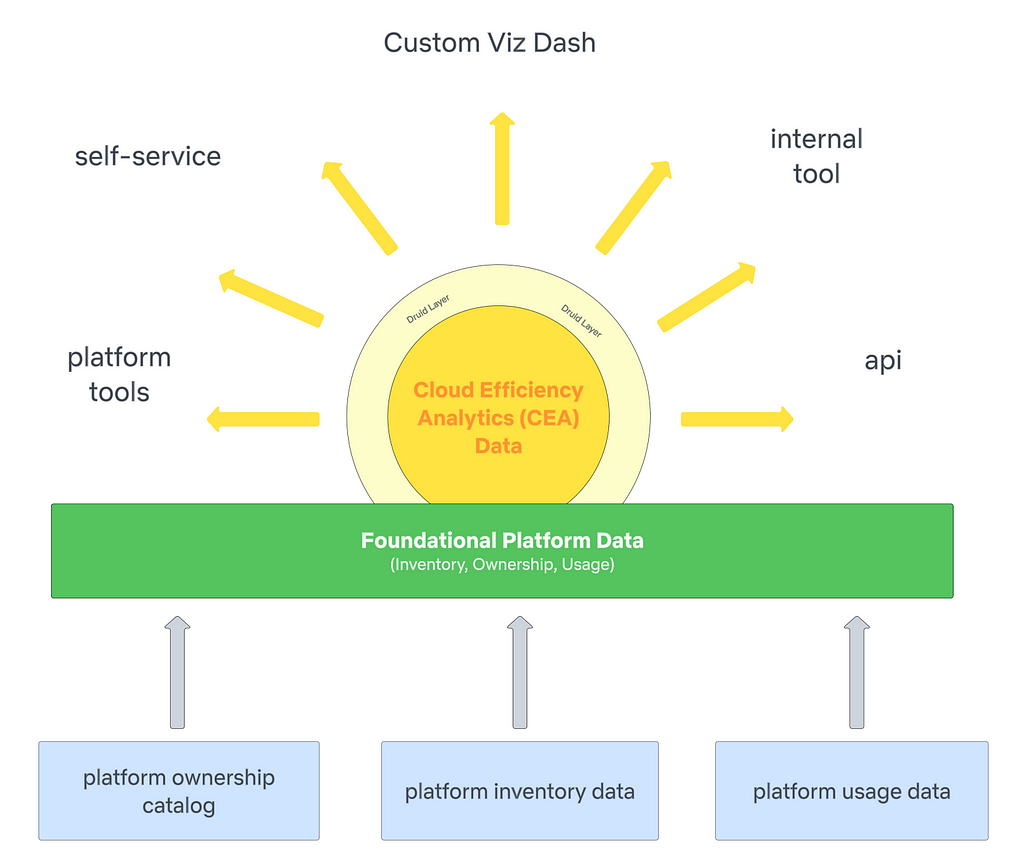
Foundational Platform Data (FPD)
We work with different platform data providers to get inventory, ownership, and usage data for the respective platforms they own. Below is an example of how this framework applies to the Spark platform. FPD establishes data contracts with producers to ensure data quality and reliability; these contracts allow the team to leverage a common data model for ownership. The standardized data model and processing promotes scalability and consistency.

Cloud Efficiency Analytics (CEA Data)
Once the foundational data is ready, CEA consumes inventory, ownership, and usage data and applies the appropriate business logic to produce cost and ownership attribution at various granularities. The data model approach in CEA is to compartmentalize and be transparent; we want downstream consumers to understand why they’re seeing resources show up under their name/org and how those costs are calculated. Another benefit to this approach is the ability to pivot quickly as new or changes in business logic is/are introduced.
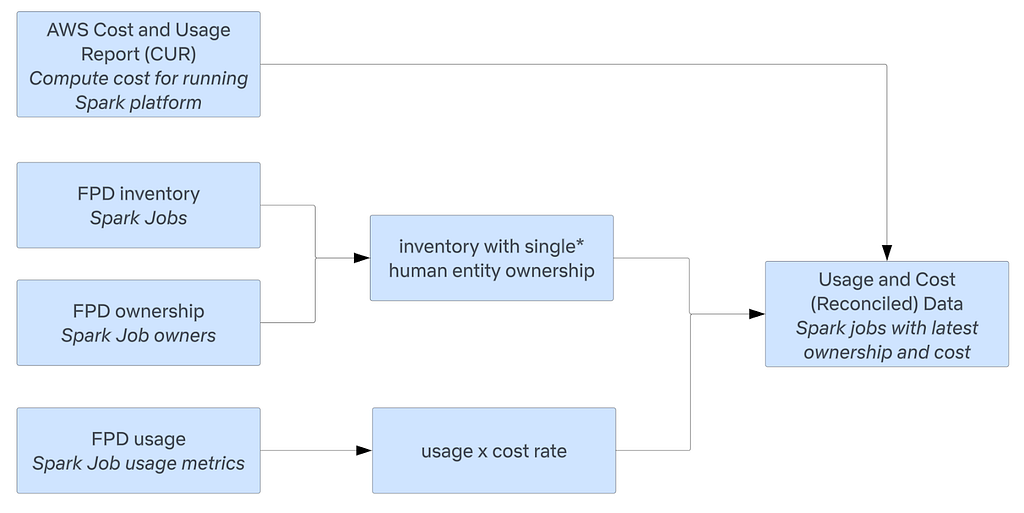
* For cost accounting purposes, we resolve assets to a single owner, or distribute costs when assets are multi-tenant. However, we do also provide usage and cost at different aggregations for different consumers.
As the source of truth for efficiency metrics, our team’s tenants are to provide accurate, reliable, and accessible data, comprehensive documentation to navigate the complexity of the efficiency space, and well-defined Service Level Agreements (SLAs) to set expectations with downstream consumers during delays, outages or changes.
While ownership and cost may seem straightforward, the complexity of the datasets is considerably high due to the breadth and scope of the business infrastructure and platform specific features. Services can have multiple owners, cost heuristics are unique to each platform, and the scale of infra data is large. As we work on expanding infrastructure coverage to all verticals of the business, we face a unique set of challenges:
A Few Sizes to Fit the Majority
Despite data contracts and a standardized data model on transforming upstream platform data into FPD and CEA, there is usually some degree of customization that is unique to that particular platform. As the centralized source of truth, we feel the constant tension of where to place the processing burden. Decision-making involves ongoing transparent conversations with both our data producers and consumers, frequent prioritization checks, and alignment with business needs as informed captains in this space.
Data Guarantees
For data correctness and trust, it’s crucial that we have audits and visibility into health metrics at each layer in the pipeline in order to investigate issues and root cause anomalies quickly. Maintaining data completeness while ensuring correctness becomes challenging due to upstream latency and required transformations to have the data ready for consumption. We continuously iterate our audits and incorporate feedback to refine and meet our SLAs.
Abstraction Layers
We value people over process, and it is not uncommon for engineering teams to build custom SaaS solutions for other parts of the organization. Although this fosters innovation and improves development velocity, it can create a bit of a conundrum when it comes to understanding and interpreting usage patterns and attributing cost in a way that makes sense to the business and end consumer. With clear inventory, ownership, and usage data from FPD, and precise attribution in the analytical layer, we aim to provide metrics to downstream users regardless of whether they utilize and build on top of internal platforms or on AWS resources directly.
Looking ahead, we aim to continue onboarding platforms to FPD and CEA, striving for nearly complete cost insight coverage in the upcoming year. Longer term, we plan to extend FPD to other areas of the business such as security and availability. We aim to move towards proactive approaches via predictive analytics and ML for optimizing usage and detecting anomalies in cost.
Ultimately, our goal is to enable our engineering organization to make efficiency-conscious decisions when building and maintaining the myriad of services that allow us to enjoy Netflix as a streaming service.
The FPD and CEA work would not have been possible without the cross functional input of many outstanding colleagues and our dedicated team building these important data assets.
—
A bit about the authors:
JHan enjoys nature, reading fantasy, and finding the best chocolate chip cookies and cinnamon rolls. She is adamant about writing the SQL select statement with leading commas.
Pallavi enjoys music, travel and watching astrophysics documentaries. With 15+ years working with data, she knows everything’s better with a dash of analytics and a cup of coffee!
![]()
Cloud Efficiency at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/title-launch-observability-at-netflix-scale-c88c586629eb
By: Varun Khaitan
With special thanks to my stunning colleagues: Mallika Rao, Esmir Mesic, Hugo Marques
At Netflix, we manage over a thousand global content launches each month, backed by billions of dollars in annual investment. Ensuring the success and discoverability of each title across our platform is a top priority, as we aim to connect every story with the right audience to delight our members. To achieve this, we are committed to building robust systems that deliver comprehensive observability, enabling us to take full accountability for every title on our service.
As engineers, we’re wired to track system metrics like error rates, latencies, and CPU utilization — but what about metrics that matter to a title’s success?
Consider the following example of two different Netflix Homepages:

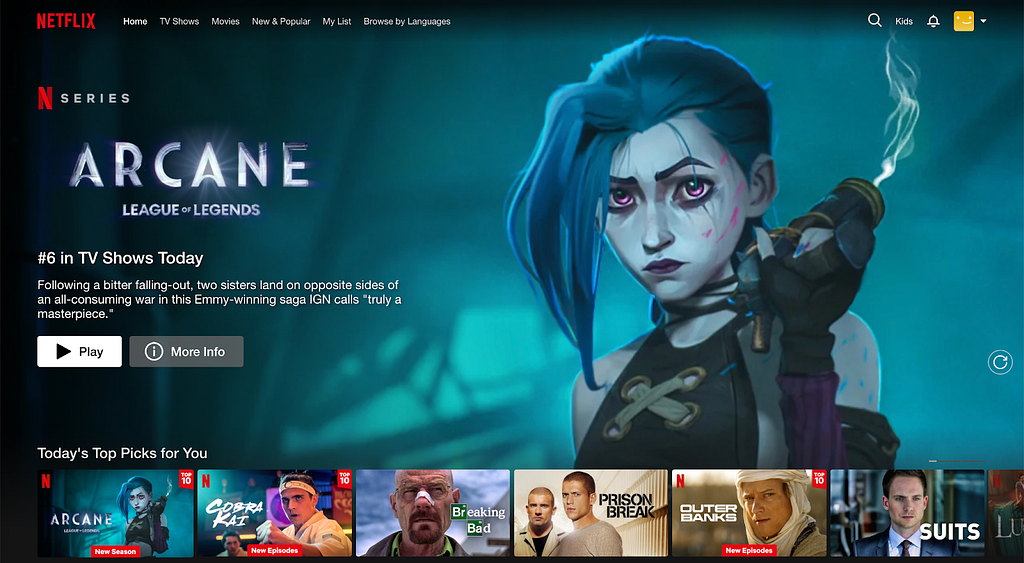
To a basic recommendation system, the two sample pages might appear equivalent as long as the viewer watches the top title. Yet, these pages couldn’t be more different. Each title represents countless hours of effort and creativity, and our systems need to honor that uniqueness.
How do we bridge this gap? How can we design systems that recognize these nuances and empower every title to shine and bring joy to our members?
In the early days of Netflix Originals, our launch team would huddle together at midnight, manually verifying that titles appeared in all the right places. While this hands-on approach worked for a handful of titles, it quickly became clear that it couldn’t scale. As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable.
Operating a personalization system for a global streaming service involves addressing numerous inquiries about why certain titles appear or fail to appear at specific times and places.
Some examples:
As Netflix scaled, we faced the mounting challenge of providing accurate, timely answers to increasingly complex queries about title performance and discoverability. This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teams — an approach that was neither sustainable nor efficient.
The stakes are even higher when ensuring every title launches flawlessly. Metadata and assets must be correctly configured, data must flow seamlessly, microservices must process titles without error, and algorithms must function as intended. The complexity of these operational demands underscored the urgent need for a scalable solution.
It becomes evident over time that we need to automate our operations to scale with the business. As we thought more about this problem and possible solutions, two clear options emerged.
Log processing offers a straightforward solution for monitoring and analyzing title launches. By logging all titles as they are displayed, we can process these logs to identify anomalies and gain insights into system performance. This approach provides a few advantages:
However, taking this approach also presents several challenges:
To prioritize title launch observability, we could adopt a centralized approach. By introducing observability endpoints across all systems, we can enable real-time data flow into a dedicated microservice for title launch observability. This approach embeds observability directly into the very fabric of services managing title launches and personalization, ensuring seamless monitoring and insights. Key benefits and strategies include:
Choosing this option also comes with some tradeoffs:
By adopting a comprehensive observability strategy that includes real-time monitoring, proactive issue detection, and source of truth reconciliation, we’ve significantly enhanced our ability to ensure the successful launch and discovery of titles across Netflix, enriching the global viewing experience for our members. In the next part of this series, we’ll dive into how we achieved this, sharing key technical insights and details.
Stay tuned for a closer look at the innovation behind the scenes!
![]()
Title Launch Observability at Netflix Scale was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=8D91uIirQ9Q
Post Syndicated from original https://www.toest.bg/kak-se-sasipva-kvartal/

Българските градове срещат типичните проблеми на икономическия растеж. Хората започват да пътуват повече и предпочитат това да става по-удобно, с лично превозно средство, за по-кратко време. Притежаването и ползването на автомобил става по-лесно и много семейства започват дори да трупат по две-три и повече леки коли. Степента на моторизация се увеличава, тоест на глава от населението се падат повече автомобили, а ниската им цена също допринася за това увеличение. Отговорът на градовете ни често е да се създаде нова инфраструктура, която обаче невинаги е добре обмислена. И резултатът влошава, вместо да подобрява не само транспортната обстановка, а и цялостното качество на живот.
Точно такъв е случаят с пробива „Модър“ – „Царевец“ и съпътстващия ремонт на ул. „Царевец“ и бул. „Хаджи Димитър“, които разсичат на две места пловдивския квартал „Христо Смирненски“.
Когато придвижването в един град се осъществява само с автомобил, задръстванията неизменно стават ежедневие, допълнени от замърсен въздух и висока концентрация на катастрофи и съответно – на ранени и загинали. Градски площади, градинки, междублокови пространства биват лека-полека замествани от паркирали коли. Зелени площи се превръщат в кална кочина, а след геройската намеса на Общината след няколко години се заливат с асфалт и се превръщат в обикновени паркоместа. От зеленината няма и помен. Това е най-лошият пример за ползване на едно открито публично пространство – да стане склад на превозни средства вместо парк например, където млади и стари да прекарват време, да се срещат с приятели, да спортуват, да се разхождат с децата.
Осигуряването на паркоместа не е лоша дейност – лошо е, ако един град няма адекватна съвременна транспортна политика, с която да прави придвижването с градски транспорт удобно, комфортно и модерно, за да не се налага всеки за всяко нещо да сяда в колата и да търси след това паркомясто.
Много малко хора разчитат на него и придвижванията с автомобил преобладават, съответно и задръстванията.
В големи и малки градове по целия свят, в които транспортът се управлява успешно и които са се справили със задръстванията, се знае, че развитието на удобен градски транспорт е истинското дълготрайно решение. Тази стъпка е незаобиколима – това урбанистите и транспортните инженери го учат още в началните курсове по транспортно планиране. Един автобус с 50 места замества десетки автомобили – това следва от данните, посочени в Плана за устойчива градска мобилност (ПУГМ) на община Пловдив, според които в 44% от колите в града пътува само един човек.
Тази проста сметка показва как използването на масов транспорт може да разреши проблема със задръстванията, стига този транспорт да е наличен, да е с удобни и директни маршрути между кварталите, да е начесто, превозните средства да са комфортни, да може да се заплаща билет по съвременни начини и да е популярен сред гражданите.
Незнайно защо Пловдив не гледа към София или Бургас като градове с функциониращ градски транспорт. Реформа в управлението на транспорта в Града под тепетата така и не се прави. Единствените мерки, които се обявяват за „транспортни“, са свързани с преасфалтиране и изграждане на нови автомобилни участъци. Пловдив действително има нужда от доизграждане на няколко ключови връзки, които и до момента липсват. Затова е положително развитие, че пробивът „Модър“ – „Царевец“ се реализира след години на подготовка и обещания.
Редно е обаче такива проекти да се впишат в по-голямата картина и транспортна политика на града. ПУГМ на Пловдив беше приет през 2024 г. Целта му е да намали автомобилната зависимост на града и да допринесе за развитието на устойчиви форми на придвижване – градски транспорт, велосипедна и пешеходна мобилност. Предложените мерки следва да се структурират и приложат по приоритетност.
Едно от изискванията към изпълнителя на ПУГМ беше да се създаде дигитален транспортен модел на града. Такива модели се ползват от десетилетия от по-иновативните градски власти, за да се тества как една мярка ще се отрази на транспортната ситуация – например ако се затвори улица, ако се изгради нова транспортна връзка, ако се обособи буслента, ако се направи трамвайна линия или метро, ако се регламентира паркирането. Всичко това се вижда в дигитална среда, преди да е похарчен и един лев за строителство. ПУГМ на Пловдив е предаден и се очаква в общината да е наличен функциониращ такъв модел. Дали наистина обаче той е реализиран и дали изобщо се ползва?
Пробивът „Модър“ – „Царевец“ поставя под сериозно съмнение наличието на дигитален транспортен модел на Пловдив. Начинът на реализация на този проект повдига въпроса дори дали е правено някакво транспортно проучване на преминаващите и посоката на тяхното движение, на основата на което да се предложат най-добрият проект и най-адекватната организация на движение.
Общината се похвали с отварянето на кръстовището на ул. „Царевец“ с ул. „Солунска“ и го представи като успех. На практика обаче новият светофар работи напразно, тъй като движението е възможно само в една посока, а другата част от ул. „Царевец“ е все още в ремонт. Светофарът доведе до безпрецедентни задръствания.
Ако след приключването на ремонта автомобилният трафик в района се увеличи, няма изгледи проблемът със задръстванията да се реши. Той можеше да се облекчи, ако беше изградено кръгово кръстовище, каквото обаче не е предвидено.
Когато се влагат обществени средства и се отделят месеци, а понякога дори години за ремонтни дейности по определени участъци, които нарушават нормалното ежедневие на гражданите, създават задръствания и губят ценно време, е напълно основателно да се поставят под въпрос ефективността и обосновката на целия проект. Още повече ако в крайна сметка ремонтните дейности водят до по-лоша транспортна ситуация от предишната, следва да се анализира как се е стигнало до неговото одобрение.
Подобен светофар беше инсталиран преди няколко месеца на бул. „Хаджи Димитър“. Той създаде задръстване там, където преди нямаше. Съвсем релевантен е въпросът защо се поставят светофари на места, където пречат и влошават пътната обстановка.
Параметърът „пропускливост“ е основополагащ в транспортното планиране. Редно е преминаващите през едно кръстовище превозни средства да се преброят предварително, а след това да се изготви проект, който да подобри пропускливостта. Случаят с бул. „Хаджи Димитър“ е пример за влошаване на ситуацията, а новото му кръстовище с ул. „Царевец“ явно ще е със същия резултат.
В книгата си „Градове за хората“ датският урбанист Ян Геел застъпва идеята, че хората, а не автомобилите следва да са в центъра на градския живот и съответно – в основата на градското планиране. А това означава и по-силен акцент върху придвижването пеша и с колело. Ян Геел беше в Пловдив през 2016 г. при представянето на превода на книгата си на български език по време на фестивала One Architecture Week.
Следвайки политиките за устойчива мобилност, в „градовете за хората“ се приоритизират пешеходните и велосипедните маршрути, като се създава мрежа от свързани отсечки и се осигуряват възможности за често пресичане на големи булеварди. Целта е постепенно пешеходецът да се постави на приоритетна позиция спрямо автомобила.



На първата снимка е ул. „Царевец“, каквато беше преди. На втората – бул. „Васил Априлов“ след ремонт. Подобен ще е новият облик на ул. „Царевец“. На третата – бул. „Мажента“ в Париж, или какъв можеше да бъде новият облик на ул. „Царевец“. Източник: Google Street View
Пловдив е град с изключително висока концентрация на пътнотранспортни произшествия, което не говори добре за прилаганите до момента мерки за пътна безопасност. Именно чрез проектиране на градска среда и транспортна инфраструктура, които приоритизират уязвимите участници, може да се постигне по-безопасна, а и по-приятна среда за всички – с повече качествени улични пространства.
която се отхвърля от десетилетия от урбанистите и транспортните инженери, работещи за качествена градска среда. Булевард „Хаджи Димитър“ преминава през гъсто застроената част на квартала, която е без открити паркове или площади. Самият булевард включва пешеходна алея по средата именно за да позволи на живеещите в близост да използват това място за отдих и възстановяване – като малък линеен парк близо до техните домове. Обновеният булевард се изгражда с огради по средата, все едно е магистрала в полето, а не част от градската среда. Достъпът до линейния парк е възможен от по-малко места, отколкото преди. По този начин кв. „Христо Смирненски“ се разсече, а пешеходните връзки, вместо да се регламентират с пресичания, да се направят удобни и безопасни, да се улесни достъпът до този линеен парк, бяха почти изцяло прекъснати.
Такива реализации също допринасят за увеличаването на задръстванията, защото, когато на хората се създадат затруднения да се движат пеш в квартала, им се налага да ползват автомобили дори и за кратки разстояния. Ала и този урок е научен от много градове.

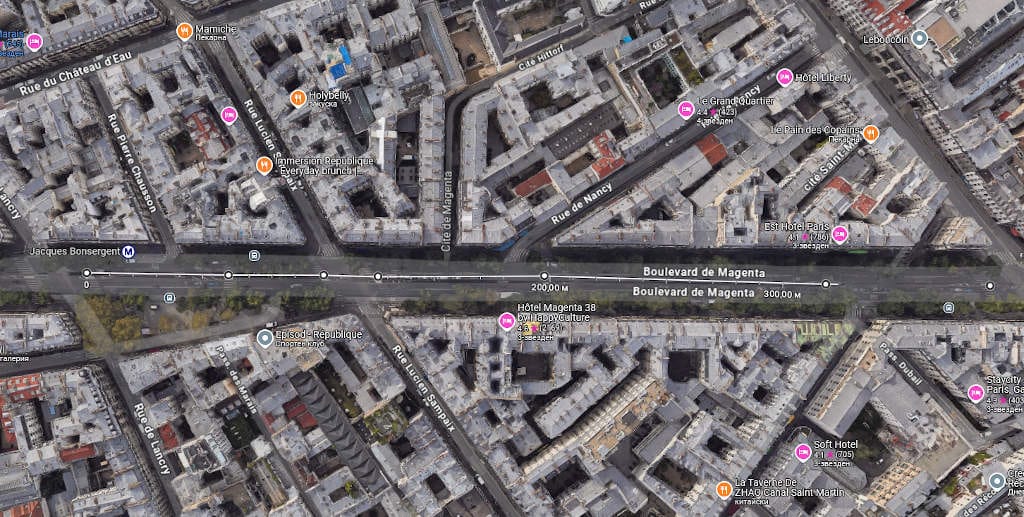
Сравнение между бул. „Хаджи Димитър“ (вляво) – 260 метра между възможностите за пресичане, платна, отделени с огради, и бул. „Мажента“ в Париж (вдясно) – пресичания на съответно 60, 40, 20, 70 и 120 метра и никакви огради. Източник: Google Earth
От улица с богато улично озеленяване, изключително важно за град като Пловдив – с високи температури и малко паркове, ул. „Царевец“ се превръща в магистрала, разрязваща още един път квартала и влошаваща пешеходната му свързаност. Тъй като публичността е основен принцип на доброто управление, редно е Община Пловдив да отговори на следните въпроси:
Инсталирането на светофари там, където няма нужда от тях и където създават повече проблеми, отколкото помагат, е грешка, която може да бъде поправена с премахването им. По-големите въпроси обаче изискват по-големи решения – създаването и следването на съвременна транспортна политика, организация на движението, която дава приоритет на хората, изграждането на инфраструктура, която се грижи за комфорта и безопасността на гражданите, и развитието на обществен транспорт, адекватен за половинмилионен град.
В настоящата ни съвместна поредица с „Екипът на София“ обсъждаме планирането, озеленяването, архитектурата, инфраструктурата, мобилността и още много други градски теми, описваме добрите примери и търсим възможните решения за подобряването на качеството на живот в нашите градове.
Post Syndicated from jzb original https://lwn.net/Articles/1002546/
Fedora Magazine reports
that the Fedora Asahi Remix 41 for Apple Silicon is now available:
In addition to all the exciting improvements brought by Fedora Linux
41, Fedora Asahi Remix 41 provides x86/x86-64
emulation integration including support for AAA
games to Apple Silicon. The game support is based on the new
conformant Vulkan
1.4 driver. It also continues to provide extensive device support,
including high quality audio out of the box.
LWN covered a talk
from the X.org Developers Conference (XDC) by Alyssa Rosenzweig on the
status of Asahi’s GPU drivers in October.
Post Syndicated from Neeraja Rentachintala original https://aws.amazon.com/blogs/big-data/recap-of-amazon-redshift-key-product-announcements-in-2024/
Amazon Redshift, launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, data lake analytics, machine learning (ML), and data monetization.
Amazon Redshift made significant strides in 2024, rolling out over 100 features and enhancements. These improvements enhanced price-performance, enabled data lakehouse architectures by blurring the boundaries between data lakes and data warehouses, simplified ingestion and accelerated near real-time analytics, and incorporated generative AI capabilities to build natural language-based applications and boost user productivity.

Figure1: Summary of the features and enhancements in 2024
Let’s walk through some of the recent key launches, including the new announcements at AWS re:Invent 2024.
Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses. Amazon Redshift scales linearly with the number of users and volume of data, making it an ideal solution for both growing businesses and enterprises. For example, dashboarding applications are a very common use case in Redshift customer environments where there is high concurrency and queries require quick, low-latency responses. In these scenarios, Amazon Redshift offers up to seven times better throughput per dollar than alternative cloud data warehouses, demonstrating its exceptional value and predictable costs.
Over the past few months, we have introduced a number of performance improvements to Redshift. First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producer’s data is being updated. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance. We have launched new RA3.large instances, a new smaller size RA3 node type, to offer better flexibility in price-performance and provide a cost-effective migration option for customers using DC2.large instances. Additionally, we have rolled out AWS Graviton in Serverless, offering up to 30% better price-performance, and expanded concurrency scaling to support more types of write queries, enabling an even greater ability to maintain consistent performance at scale. These improvements collectively reinforce Amazon Redshift’s focus as a leading cloud data warehouse solution, offering unparalleled performance and value to customers.
Amazon Redshift allows you to seamlessly scale with multi-cluster deployments. With the introduction of RA3 nodes with managed storage in 2019, customers obtained flexibility to scale and pay for compute and storage independently. Redshift data sharing, launched in 2020, enabled seamless cross-account and cross-Region data collaboration and live access without physically moving the data, while maintaining transactional consistency. This allowed customers to scale read analytics workloads and offered isolation to help maintain SLAs for business-critical applications. At re:Invent 2024, we announced the general availability of multi-data warehouse writes through data sharing for Amazon Redshift RA3 nodes and Serverless. You can now start writing to shared Redshift databases from multiple Redshift data warehouses in just a few clicks. The written data is available to all the data warehouses as soon as it’s committed. This allows your teams to flexibly scale write workloads such as extract, transform, and load (ETL) and data processing by adding compute resources of different types and sizes based on individual workloads’ price-performance requirements, as well as securely collaborate with other teams on live data for use cases such as customer 360.
The launch of Amazon Redshift Serverless in 2021 marked a significant shift, eliminating the need for cluster management while paying for what you use. Redshift Serverless and data sharing enabled customers to easily implement distributed multi-cluster architectures for scaling analytics workloads. In 2024, we launched Serverless in 10 more regions, improved functionality, and added support for a capacity configuration of 1024 RPUs, allowing you to bring larger workloads onto Redshift. Redshift Serverless is also now even more intelligent and dynamic with the new AI-driven scaling and optimization capabilities. As a customer, you choose whether you want to optimize your workloads for cost, performance, or keep it balanced, and that’s it. Redshift Serverless works behind the scenes to scale the compute up and down and deploys optimizations to meet and maintain the performance levels, even when workload demands change. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
Lakehouse brings together flexibility and openness of data lakes with the performance and transactional capabilities of data warehouses. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data. At re:Invent 2024, we unveiled the next generation of Amazon SageMaker, a unified platform for data, analytics, and AI. This launch brings together widely adopted AWS ML and analytics capabilities, providing an integrated experience for analytics and AI with a re-imagined lakehouse and built-in governance.
Amazon SageMaker Lakehouse unifies your data across Amazon S3 data lakes and Redshift data warehouses, enabling you to build powerful analytics and AI/ML applications on a single copy of data. SageMaker Lakehouse provides the flexibility to access and query your data using Apache Iceberg open standards so that you can use your preferred AWS, open source, or third-party Iceberg-compatible engines and tools. SageMaker Lakehouse offers integrated access controls and fine-grained permissions that are consistently applied across all analytics engines and AI models and tools. Existing Redshift data warehouses can be made available through SageMaker Lakehouse in just a simple publish step, opening up all your data warehouse data with Iceberg REST API. You can also create new data lake tables using Redshift Managed Storage (RMS) as a native storage option. Check out the Amazon SageMaker Lakehouse: Accelerate analytics & AI presented at re:Invent 2024.
Amazon SageMaker Unified Studio is an integrated data and AI development environment that enables collaboration and helps teams build data products faster. SageMaker Unified Studio brings together functionality and tools from a mix of standalone studios, query editors, and visual tools available today in Amazon EMR, AWS Glue, Amazon Redshift, Amazon Bedrock, and the existing Amazon SageMaker Studio, into one unified experience. With SageMaker Unified Studio, various users such as developers, analysts, data scientists, and business stakeholders can seamlessly work together, share resources, perform analytics, and build and iterate on models, fostering a streamlined and efficient analytics and AI journey.
At re:Invent 2024, Amazon S3 introduced Amazon S3 Tables, a new bucket type that is purpose-built to store tabular data at scale with built-in Iceberg support. With table buckets, you can quickly create tables and set up table-level permissions to manage access to your data lake. Amazon Redshift introduced support for querying Iceberg data in data lakes last year, and now this capability is extended to seamlessly querying S3 Tables. S3 Tables customers create are also available as part of the Lakehouse for consumption by other AWS and third-party engines.
Amazon Redshift offers high-performance SQL capabilities on SageMaker Lakehouse, whether the data is in other Redshift warehouses or in open formats. We enhanced support for querying Apache Iceberg data and improved the performance of querying Iceberg up to threefold year-over-year. A number of optimizations contribute to these speed-ups in performance, including integration with AWS Glue Data Catalog statistics, improved data and metadata filtering, dynamic partition elimination, faster/parallel processing of Iceberg manifest files, and scanner improvements. In addition, Amazon Redshift now supports incremental refresh support for materialized views on data lake tables to eliminate the need for recomputing the materialized view when new data arrives, simplifying how you build interactive applications on S3 data lakes.
In this section, we share the improvements regarding simplified ingestion and near real-time analytics that enable you to get faster insights over fresher data.
Amazon Redshift first launched zero-ETL integration between Amazon Aurora MySQL-Compatible Edition, enabling near real-time analytics on petabytes of transactional data from Aurora. This capability has since expanded to support Amazon Aurora PostgreSQL-Compatible Edition, Amazon Relational Database Service (Amazon RDS) for MySQL, and Amazon DynamoDB, and includes additional features such as data filtering to selectively extract tables and schemas using regular expressions, support for incremental and auto-refresh materialized views on replicated data, and configurable change data capture (CDC) refresh rates.
Building on this innovation, at re:Invent 2024, we launched support for zero-ETL integration with eight enterprise applications, specifically Salesforce, Zendesk, ServiceNow, SAP, Facebook Ads, Instagram Ads, Pardot, and Zoho CRM. With this new capability, you can efficiently extract and load valuable data from your customer support, relationship management, and Enterprise Resource Planning (ERP) applications directly into your Redshift data warehouse for analysis. This seamless integration eliminates the need for complex, custom ingestion pipelines for ingesting the data, accelerating time to insights.
Auto-copy simplifies data ingestion from Amazon S3 into Amazon Redshift. This new feature enables you to set up continuous file ingestion from your Amazon S3 prefix and automatically load new files to tables in your Redshift data warehouse without the need for additional tools or custom solutions.
Amazon Redshift now supports streaming ingestion from Confluent Managed Cloud and self-managed Apache Kafka clusters on Amazon EC2instances, expanding its capabilities beyond Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK). With this update, you can ingest data from a wider range of streaming sources directly into your Redshift data warehouses for near real-time analytics use cases such as fraud detection, logistics monitoring and clickstream analysis.
In this section, we share the improvements generative AI capabilities.
Amazon Q generative SQL for Amazon Redshift
We announced the general availability of Amazon Q generative SQL for Amazon Redshift feature in the Redshift Query Editor. Amazon Q generative SQL boosts productivity by allowing users to express queries in natural language and receive SQL code recommendations based on their intent, query patterns, and schema metadata. The conversational interface enables users to get insights faster without extensive knowledge of the database schema. It leverages generative AI to analyze user input, query history, and custom context like table/column descriptions and sample queries to provide more relevant and accurate SQL recommendations. This feature accelerates the query authoring process and reduces the time required to derive actionable data insights.
We announced integration of Amazon Redshift with Amazon Bedrock, enabling you to invoke large language models (LLMs) from simple SQL commands on your data in Amazon Redshift. With this new feature, you can now effortlessly perform generative AI tasks such as language translation, text generation, summarization, customer classification, and sentiment analysis on your Redshift data using popular foundation models (FMs) like Anthropic’s Claude, Amazon Titan, Meta’s Llama 2, and Mistral AI. You can invoke these models using familiar SQL commands, making it simpler than ever to integrate generative AI capabilities into your data analytics workflows.
Amazon Bedrock Knowledge Bases now supports natural language querying to retrieve structured data from your Redshift data warehouses. Using advanced natural language processing, Amazon Bedrock Knowledge Bases can transform natural language queries into SQL queries, allowing users to retrieve data directly from the source without the need to move or preprocess the data. A retail analyst can now simply ask “What were my top 5 selling products last month?”, and Amazon Bedrock Knowledge Bases automatically translates that query into SQL, runs the query against Redshift, and returns the results—or even provides a summarized narrative response. To generate accurate SQL queries, Amazon Bedrock Knowledge Bases uses database schema, previous query history, and other contextual information that is provided about the data sources.
Following is the launch summary which provides the announcement links and reference blogs for the key announcements.
We continue to innovate and evolve Amazon Redshift to meet your evolving data analytics needs. We encourage you to try out the latest features and capabilities. Watch the Innovations in AWS analytics: Data warehousing and SQL analytics session from re:Invent 2024 for further details. If you need any support, reach out to us. We are happy to provide architectural and design guidance, as well as support for proof of concepts and implementation. It’s Day 1!
 Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com
Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=ybo3T5RIkvs
Post Syndicated from Cliff Robinson original https://www.servethehome.com/nvidia-jetson-nano-gets-a-huge-upgrade-to-super-arm/
The NVIDIA Jetson Nano gets a Super upgrade doubling memory bandwidth and increasing TOPS by 57-70% while halving the development kit price
The post NVIDIA Jetson Nano Gets a HUGE Upgrade to Super appeared first on ServeTheHome.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/12/hacking-digital-license-plates.html
Not everything needs to be digital and “smart.” License plates, for example:
Josep Rodriguez, a researcher at security firm IOActive, has revealed a technique to “jailbreak” digital license plates sold by Reviver, the leading vendor of those plates in the US with 65,000 plates already sold. By removing a sticker on the back of the plate and attaching a cable to its internal connectors, he’s able to rewrite a Reviver plate’s firmware in a matter of minutes. Then, with that custom firmware installed, the jailbroken license plate can receive commands via Bluetooth from a smartphone app to instantly change its display to show any characters or image.
[…]
Because the vulnerability that allowed him to rewrite the plates’ firmware exists at the hardware level—in Reviver’s chips themselves—Rodriguez says there’s no way for Reviver to patch the issue with a mere software update. Instead, it would have to replace those chips in each display.
The whole point of a license plate is that it can’t be modified. Why in the world would anyone think that a digital version is a good idea?
Post Syndicated from Momota Sasaki original https://aws.amazon.com/blogs/big-data/how-dena-co-ltd-accelerated-anonymized-data-quality-tests-up-to-100-times-faster-using-amazon-redshift-serverless-and-dbt/
This blog was co-authored by DeNA Co., Ltd. and Amazon Web Services Japan.
DeNA Co., Ltd. (DeNA) engages in a variety of businesses, from games and live communities to sports & the community and healthcare & medical, under our mission to delight people beyond their wildest dreams. Among these, the healthcare & medical business handles particularly sensitive data. To comply with their data policies for sensitive data, this healthcare & medical business set the following requirements for their data processing:
This post introduces a case study where DeNA combined Amazon Redshift Serverless and dbt (dbt Core) to accelerate data quality tests in their business.
Data quality tests require performing 1,300 tests on 10 TB of data monthly. Previously, DeNA ran Python-based batch jobs on Amazon Elastic Compute Cloud (Amazon EC2) to perform these data quality tests. As business and data volume grew over time, DeNA started to face the following challenges:
To address these challenges, DeNA decided to adopt Redshift Serverless and dbt (an open source data transformation tool) for the following key reasons:
This decision was made after careful comparison of alternative solutions. DeNA initially considered parallelizing the existing Python-based batch jobs but rejected this approach due to the high maintenance overhead and siloed knowledge associated with the batch jobs. Instead, DeNA decided to use dbt, which DeNA has been using in their healthcare & medical business, and connect it to an AWS service capable of large-scale distributed processing. dbt provides a SQL-first templating engine for repeatable and extensible data transformations, including a data tests feature, which allows verifying data models and tables against expected rules and conditions using SQL. By using dbt, DeNA could standardize the technical stack, implement data quality tests in maintainable SQL, and connect dbt to a managed service for scalable and cost-effective processing.
AWS offers several services that are compatible with dbt, including Amazon Redshift and AWS Glue. DeNA selected Redshift Serverless, primarily due to its serverless nature, optimal cost-performance, and the superior processing performance for structured data typical of a data warehouse service.
DeNA designed the following architecture using AWS serverless services.

The workflow consists of the following high-level steps and key design points:
DeNA successfully addressed all the challenges they faced by designing the solution and migrating to a new platform:
This post demonstrated how DeNA was able to securely and efficiently accelerate their data quality tests by combining Redshift Serverless and dbt. This combination is not only effective for DeNA’s use case but also applicable to various business use cases across different industries.
For more information on the combination of Redshift Serverless and dbt, refer to the following resources:

 Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform.
Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform.
 Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms.
Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms.
 Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
Post Syndicated from Sai Maddali original https://aws.amazon.com/blogs/big-data/top-6-game-changers-from-aws-that-redefine-streaming-data/
Recently, AWS introduced over 50 new capabilities across its streaming services, significantly enhancing performance, scale, and cost-efficiency. Some of these innovations have tripled performance, provided 20 times faster scaling, and reduced failure recovery times by up to 90%. We have made it nearly effortless for customers to bring real-time context to AI applications and lakehouses.
In this post, we discuss the top six game changers that will redefine AWS streaming data.

AWS offers Express brokers for Amazon Managed Streaming for Apache Kafka (Amazon MSK)—a transformative breakthrough for customers needing high-throughput Kafka clusters that scale faster and cost less. With Express brokers, we are reimagining Kafka’s compute and storage decoupling to unlock performance and elasticity benefits. Express brokers offer up to three times more throughput than a comparable standard Apache Kafka broker, virtually unlimited storage, instant storage scaling, compute scaling in minutes vs. hours, and 90% faster recovery from failures compared to standard Kafka brokers. Customers can provision capacity in minutes without complex calculations, benefit from preset Kafka configurations, and scale capacity in a few clicks. Express brokers provide the same low-latency performance as standard Kafka, are 100% native Kafka, and offer key Amazon MSK features. There are no storage limits per broker and you only pay for the storage you use. With Express brokers for Amazon MSK, enterprises can expand their Kafka usage to support even more mission-critical use cases, while keeping both operational overhead and overall infrastructure costs low.
Amazon Kinesis Data Streams On-Demand makes it uncomplicated for developers to stream gigabytes per second of data without managing capacity or servers. Developers can create a new on-demand data stream or convert an existing data stream to on-demand mode with a single click. Kinesis Data Streams On-Demand now automatically scales to 10 GBps of write throughput and 200 GBps of read throughput per stream, a fivefold increase. Customers will automatically get this fivefold increase in scale without the need to take any action.
Enterprises are embracing lakehouses and open table formats such as Apache Iceberg to unlock value from their data. Amazon Data Firehose now supports seamless integration with Iceberg tables on Amazon Simple Storage Service (Amazon S3). Customers can stream data into Iceberg tables in Amazon S3 without any management overhead. Data Firehose compacts small files, minimizing storage inefficiencies and enhancing read performance. Data Firehose also handles schema changes while in flight, to provide consistency across evolving datasets. Because Data Firehose is fully managed and serverless, it scales seamlessly to handle high throughput streaming workloads, providing reliable and fast delivery of data. This capability also makes it straightforward to stream data stored in MSK topics and Kinesis data streams into Iceberg tables, potentially eliminating the need for custom extract, transform, and load (ETL) pipelines. Customers can now bring the power of real-time data to Iceberg tables without any additional effort—a paradigm shift for businesses. Additionally, Kinesis Data Firehose serves as a versatile bridge to stream real-time data from MSK clusters and Kinesis Data Streams into the newly launched Amazon S3 Tables and Amazon SageMaker Lakehouse. This unified approach facilitates more effective data management and analysis, supporting data-driven decision-making across the enterprise.
Delivering database changes into Iceberg tables is emerging as a common pattern. Now in public preview, Data Firehose supports capturing changes made in databases such as PostgreSQL and MySQL and replicating the updates to Iceberg tables on Amazon S3. The integration uses change data capture (CDC) to continuously deliver database updates, eliminating manual processes and reducing operational overhead. Data Firehose automates tasks such as schema alignment and partitioning, making sure tables are optimized for analytics. With this new capability, customers can streamline their end-to-end data pipeline, allowing them to continually feed fresh data into an Iceberg table without needing to build a custom data pipeline.
Customers tell us how they want to gain insights from generative AI by being able to bring their data to large language models (LLMs). They want to bring data as it’s generated to pre-trained models for more accurate and up-to-date responses. Amazon MSK provides a blueprint that allows customers to combine the context from real-time data with the powerful LLMs on Amazon Bedrock to generate accurate, up-to-date AI responses without writing custom code. Developers can configure the blueprint to generate vector embeddings using Amazon Bedrock embedding models, then index those embeddings in Amazon OpenSearch Service for data captured and stored in MSK topics. Customers can also improve the efficiency of data retrieval using built-in support for data chunking techniques from LangChain, an open source library, supporting high-quality inputs for model ingestion.
AWS offers the Kinesis Client Library (KCL), an open source library, that simplifies the development of stream processing applications with Kinesis Data Streams. With KCL 3.0, customers can reduce compute costs to process streaming data by up to 33% compared to previous KCL versions. KCL 3.0 introduces an enhanced load balancing algorithm that continuously monitors the resource utilization of the stream processing workers and automatically redistributes the load from over-utilized workers to underutilized workers. These changes also enhance scalability and the overall efficiency of processing large volumes of streaming data. We have also made improvements to our Amazon Managed Service for Apache Flink. We offer the latest Flink versions on Amazon Managed Service for Apache Flink for customers to benefit from the latest innovations. Customers can also upgrade their existing applications to use new Flink versions with a new in-place version upgrade feature. Amazon Managed Service for Apache Flink now offers per-second billing, so customers can run their Flink applications for a short period and only pay for what they use, down to the nearest second.
AWS has made new innovations in data streaming services, bringing compelling value to customers on performance, scalability, elasticity, and ease of use. These advancements empower businesses to use real-time data more effectively, which modernizes the way for the next generation of data-driven applications and analytics. It is still Day 1!
 Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
Sai Maddali is a Senior Manager Product Management at AWS who leads the product team for Amazon MSK. He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
 Bill Crew is a Senior Product Marketing Manager. He is the lead marketer for Streaming and Messaging Services at AWS. Including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon Message Broker (Amazon MQ), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS). Besides work, he enjoys collecting vintage vinyl records.
Bill Crew is a Senior Product Marketing Manager. He is the lead marketer for Streaming and Messaging Services at AWS. Including Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, Amazon Data Firehose, Amazon Kinesis Data Streams, Amazon Message Broker (Amazon MQ), Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Services (Amazon SNS). Besides work, he enjoys collecting vintage vinyl records.
Post Syndicated from jzb original https://lwn.net/Articles/1001783/
Since we last looked
at the WordPress
dispute, WP Engine has sought
a preliminary injunction against Automattic and its founder Matt Mullenweg to
restore its access to WordPress.org, and more. The judge
in the case granted a preliminary injunction on December 10. The case
is, of course, of interest to users and developers working with
WordPress—but it may also have implications for other
open-source projects well beyond the WordPress community.
Post Syndicated from Kari Rivas original https://www.backblaze.com/blog/disaster-recovery-101-navigating-backup-and-archive-infrastructure/

Aging infrastructure, strained budgets, and exponential data growth create unique challenges for disaster recovery (DR) planning. When assessing your backup and archive infrastructure, you’re probably balancing data governance, data sovereignty requirements, compliance requirements, and the needs of your end users. Many legacy data storage systems can create gaps in an otherwise airtight DR plan.
Today, I’m talking through how to approach infrastructure decisions for your cyber resilience posture. You have a lot of options. On-premises? Cloud services? Hot? Warm? Cold? What combination works best for your needs? Understanding the nuances can help you sharpen your strategy.
Traditionally, businesses have relied heavily on on-premises backup solutions. Robust storage systems hold critical data, often backed up to secondary storage within the same physical location. While this approach offers a sense of control, it also presents vulnerabilities.
On-premises backups are at risk of localized events like loss of power, fire, flooding, or other natural disasters. A geographically separate DR site or other far off-site backup is essential for complete protection and compliance. Without this, the organization risks losing critical data in cases of a regional outage or loss of access.
The shift to public cloud and SaaS options opened the door to more secure and reliable data backup and disaster recovery solutions. By utilizing cloud-based storage and backup services, organizations can ensure that their data is protected in multiple locations, reducing the risk of data loss due to localized disasters. Additionally, cloud-based solutions offer scalability and flexibility, allowing organizations to easily expand their storage capacity as needed.
Many businesses have established alternate data centers as a secondary backup layer. However, these sites frequently only use replication technology. This situation can result in a scenario known as the “replication trap.” There is a risk that data compromised by malware is replicated to the DR site, leading to potential data loss.
Off-site, immutable backups, independent of the primary site’s data, are a key component of a robust DR strategy. In cases of malware attacks or accidental data deletion by users, off-site immutable backups allow for data retrieval from a backup saved prior to the incident and reduce possible interruptions.
Despite being viewed as a legacy technology, tape backups continue to be used in many organizations due to their reliability and cost-effectiveness. It is common to store tapes in a separate location to diversify data storage geographically, which helps reduce the impact of local disasters on data access and enhances overall data resilience.
Off-site tape backups may increase recoverability but create challenges with recovery time objectives (RTO) because of the increased time it takes to retrieve data from a separate location and restore it using tape technology. Hardware issues can happen often and unexpectedly. Cloud-based data storage and archiving has gained popularity because of higher availability and cost savings over traditional tape backups.
The cost and time required to operate multiple data centers and meet recovery times should also be considered in the requirements for your production and DR infrastructure. Never underestimate the risk to a successful recovery when facing time-consuming tasks like physical site recovery and data restoration from tape.
Cloud-based collaboration and communication tools like Google Drive and Microsoft 365 are commonly used by businesses and yet are often left vulnerable to data loss. Cloud services do not provide sufficient protection and recovery options that organizations likely need.
Businesses often find that the responsibility for backing up this data falls on their own IT, as these services typically operate under a shared responsibility model that doesn’t offer comprehensive backup solutions.
To ensure a reliable DR plan that includes cloud services, you should:
Cloud costs will need to factor into decisions for where to store your data. Cloud storage costs should be included as a non-functional requirement to make sure you can achieve your secure recovery goals without sacrificing affordability.
Many enterprises rely on cloud-based DR solutions to ensure uninterrupted operations, protect critical data, and maintain customer trust. Unlike traditional DR methods, cloud-based solutions offer scalability, cost-effectiveness, and rapid recovery capabilities. To truly leverage the potential of these systems, it’s important to be aware of some key strategies and considerations to optimize your cloud-based disaster recovery plan, ensuring resilience in the face of unexpected disruptions.
Finally, you should weigh your cloud-based options to evaluate platform compatibility, ongoing costs, and whether your CSP locks you in or out of specific ecosystems due to high storage costs, data transfer costs, and proprietary features.
Adopting cloud-based disaster recovery best practices is a key consideration for building a resilient and reliable business infrastructure. By developing a well-structured disaster recovery plan, determining the right mix of storage solutions, and optimizing costs with tiered recovery, businesses can minimize downtime and data loss during unexpected events. A proactive approach not only safeguards your organization’s operations but also strengthens customer trust and competitive advantage. In a world where disruptions are inevitable, being prepared is the key to bouncing back stronger and faster.
The post Disaster Recovery 101: Navigating Backup and Archive Infrastructure appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from corbet original https://lwn.net/Articles/1002498/
Version
2024.4 of the Kali Linux penetration-testing distribution has been
released. Changes include a switch to Python 3.12, the removal of i386
kernel support, GNOME 47, and more.
Post Syndicated from corbet original https://lwn.net/Articles/1002496/
Security updates have been issued by Debian (gstreamer1.0), Fedora (jupyterlab and python-notebook), Oracle (gimp:2.8.22, gstreamer1-plugins-base, gstreamer1-plugins-good, kernel, php:8.2, postgresql, and python3.11), SUSE (aws-iam-authenticator, firefox, installation-images, kernel, libaom, libyuv, libsoup, libsoup2, python-aiohttp, socat, thunderbird, and vim), and Ubuntu (curl, Docker, imagemagick, and kernel).
Post Syndicated from Sam Keay original https://blog.rapid7.com/2024/12/17/take-command-of-your-career-practicing-self-advocacy-as-a-woman-in-tech/

As the year draws to a close, it’s essential—and often expected—to reflect on our achievements and lessons learned in preparation for annual performance reviews and setting future goals.For women in tech, this reflection period can be an especially powerful tool. The industry often demands that women work harder to prove their worth in spaces where their contributions are sometimes overlooked or undervalued. Performance reviews and goal-setting moments are opportunities to take command of your career, highlight your contributions, and advocate for your worth.
Many women, particularly those in male-dominated fields like tech, have been conditioned to prioritize modesty over self-promotion. This can make self-advocacy feel uncomfortable, even though it is essential for career growth. As a result, performance reviews often provoke anxiety instead of empowerment. It’s common for women to downplay their achievements or struggle to articulate their value in a way that feels authentic.Shifting this narrative is critical. Self-advocacy isn’t about bragging; it’s about ensuring that your contributions are recognized and valued in spaces where they might otherwise be overlooked.
In male-dominated industries, women often face additional challenges, such as biases around competence, communication styles, and leadership potential. Self-advocacy helps combat these challenges by ensuring your contributions are visible and your goals are clear. Advocating for yourself helps you recognize your value and push back against imposter syndrome—a common experience for women in underrepresented spaces.
When you embrace self-advocacy, you empower yourself to ask for the opportunities, recognition, and compensation you deserve. But how can you self-advocate in a way that feels authentic and impactful? Here are some strategies that have helped me navigate and excel in self-advocacy while working in tech.
When preparing for a review or manager conversation, it’s easy to forget big wins from the past 6-12 months, making the process feel daunting.
To stay on top of this, I keep a ‘Hype Document’ that I update monthly. I track every positive contribution—big or small—with notes on its impact, alignment to goals, and connection to Rapid7’s core values. This document becomes my go-to for 1:1s, reviews, and team discussions, ensuring I always have relevant wins ready to share.
It’s also a great confidence booster when imposter syndrome creeps in, reminding me of my progress and value. At year-end reviews, it turns what could feel overwhelming into an empowering opportunity to demonstrate my impact with clear, compelling evidence.
Weekly or bi-weekly 1:1s are a great opportunity to steer conversations with your manager. When employees take the lead, it shows they’re managing their responsibilities effectively, builds trust, and helps managers assess readiness for growth opportunities.
I apply the same approach with my own boss—using 1:1s to provide updates, seek guidance, and demonstrate my readiness for new challenges, which supports my career advancement.
Prepare ahead by setting an agenda, highlighting recent wins, and sharing the impact of your work. Even the best managers can’t see everything, so use this time to ensure your contributions are recognized and identify areas for growth or improvement.
In order to know how and when to advocate for yourself, you need to have a clear direction of what your desired outcome is. Define your career aspirations clearly, whether it’s leadership, technical expertise, or a shift in focus. This clarity helps you communicate your vision to others and align their support.
Your manager can’t help you meet goals they don’t know about. Use your voice to ask for what you want, whether it’s a salary increase, leadership role, or new focus area.
Be clear and transparent about your aspirations. This is your career, not a hobby—take ownership and communicate your expectations confidently. Your manager can provide feedback, identify skill gaps, and outline next steps to help you move forward.
Remember, your manager should be your second-biggest advocate—you must be your first.
In tech, roles and contributions can be highly technical, making it harder to summarize your value. Crafting a strong elevator pitch helps you translate your contributions into relatable, impactful terms.
For example, instead of saying, “I manage the Proposal team,” try:
“I manage a global team of accredited Proposal Managers. We drive tens of millions of dollars in revenue annually by winning bids and ensuring smooth contract processes.”
Nobody achieves a great career all on their own. Networking—whether internal, external, or through mentorship—sets you up for success.
At Rapid7, I’ve used our InsightCoffee program to connect with colleagues across teams. These conversations have opened doors to collaboration, deepened my understanding of the business, and given me opportunities to share my goals and practice my elevator pitch.
Many organizations also have internal chats and channels for communication. Put yourself out there—share information, offer help, and build connections. People remember those who teach them something or lend a hand in tough moments, so look for opportunities to add value.
Mentorship is another way to grow your network and address skills gaps. This could mean finding a mentor or offering to mentor someone else. My mentor relationships have been invaluable as sounding boards for feedback and advice.
Efforts like these increase your visibility and grow your network, which are key to leadership and enhancing your personal brand.
Like many tech companies, Rapid7 uses a 360-feedback tool to help employees identify strengths and areas for growth. Using this tool regularly can feel intimidating, especially when requesting constructive feedback, but keeping an open mind allows you to unlock its value as a resource for long-term success.
Providing feedback is just as important. It’s a chance to celebrate others’ achievements, strengthen relationships, and connect around shared goals. Embracing feedback—both giving and receiving—helps you build stronger connections and demonstrate the impact of your work.
If I were to summarize the main takeaways from self-advocacy, it comes down to this:
Believe you deserve it, and shamelessly ask for it.
Start small when implementing these practices. Share a few wins in your 1:1s, ask your manager what they consider noteworthy, or spend time networking to discuss your goals and challenges. You could also share a big win in a team meeting or ask others how they approach self-advocacy. It’s not a dirty word—it’s about recognizing your value and earning the recognition you deserve to advance your career.
While self-advocacy may feel uncomfortable at first, the more you practice, the more natural it becomes. Growth happens outside your comfort zone—you deserve it, and you can do it!
What’s more, every step you take to advocate for yourself inspires others, raising your profile while fostering a culture of growth and fulfillment. As the saying goes, ‘a candle loses nothing by lighting another candle’.
To learn more about the culture at Rapid7, our Rapid7 Women’s community, and other resources, visit our careers page.