Security updates have been issued by AlmaLinux (.NET 6.0, .NET 8.0, and openssl), Debian (firefox-esr), Fedora (firefox), Mageia (php, quictls, and vim), Red Hat (buildah, container-tools:rhel8, containernetworking-plugins, firefox, podman, skopeo, and tomcat), Slackware (mozilla), SUSE (apache-commons-io, kernel, and xen), and Ubuntu (golang-1.17, libgsf, and linux-aws-6.8, linux-oracle-6.8).
After retiring in 2014 from an uncharacteristically long tenure running the NSA (and US CyberCommand), Keith Alexander founded a cybersecurity company called IronNet. At the time, he claimed that it was based on IP he developed on his own time while still in the military. That always troubled me. Whatever ideas he had, they were developed on public time using public resources: he shouldn’t have been able to leave military service with them in his back pocket.
In any case, it was never clear what those ideas were. IronNet never seemed to have any special technology going for it. Near as I could tell, its success was entirely based on Alexander’s name.
Turns out there was nothing there. After some crazy VC investments and an IPO with a $3 billion “unicorn” valuation, the company has shut its doors. It went bankrupt a year ago—ceasing operations and firing everybody—and reemerged as a private company. It now seems to be gone for good, not having found anyone willing to buy it.
Last September the never-profitable company announced it was shutting down and firing its employees after running out of money, providing yet another example of a tech firm that faltered after failing to deliver on overhyped promises.
The firm’s crash has left behind a trail of bitter investors and former employees who remain angry at the company and believe it misled them about its financial health.
IronNet’s rise and fall also raises questions about the judgment of its well-credentialed leaders, a who’s who of the national security establishment. National security experts, former employees and analysts told The Associated Press that the firm collapsed, in part, because it engaged in questionable business practices, produced subpar products and services, and entered into associations that could have left the firm vulnerable to meddling by the Kremlin.
“I’m honestly ashamed that I was ever an executive at that company,” said Mark Berly, a former IronNet vice president. He said the company’s top leaders cultivated a culture of deceit “just like Theranos,” the once highly touted blood-testing firm that became a symbol of corporate fraud.
There has been one lawsuit. Presumably there will be more. I’m sure Alexander got plenty rich off his NSA career.
Учебната година започна преди по-малко от месец, но за много семейства подготовката за нея е финансова тежест, която остава дълго. Tвърдението, че образованието е безплатно, всъщност е лесно оборимо. Като се започне със задължителното облекло, мине се през безбройните помагала и учебни тетрадки, после през неизбежните и нужни училищни аксесоари и се стигне до парите, които се събират във всеки клас за каса. Така набъбва внушителна сума.
И ако за всички важни нужди, като раница, тетрадки и канцеларски материали, може да се разпрострете според вкуса и джоба си, то за помагалата и униформите нямате друг избор, освен да ги купите от единствените места на единствените цени, на които се продават.
Една касова бележка и много въпроси
Добре организираният родител, или по-скоро този, който си е извадил поука от предишен опит, отива да купи униформа още в края на август. Няма опашки, има по-голяма вероятност да намерите налични. Започват да пристигат произведените за тази учебна година униформи. При положение че това е бизнес, ориентиран силно към печалба, както ще видим, за мен остава загадка защо е толкова лошо планиран и защо куца изпълнението му. Редовно на 10 септември се извиват опашки и настава паника поради липсващи размери. Съответно се почва едно записване на телефони, за да бъдат информирани клиентите по принуда, когато пуснат размерите. Малко като с бананите в един минал век. Все пак е традиция, хубава или лоша – пазим я, както можем.
Тази година изхарчих 188 лв. за следните дрехи, части от униформата на детето ми:
2 бр. тениски с яка с къс ръкав
1 бр. тениска с яка с дълъг ръкав
1 бр. риза с дълъг ръкав
1 бр. вратовръзка
1 бр. суитшърт
Това е абсолютен минимум, но динамиката на прането в домакинството ни го позволява, а и нямам желанието да купувам изкуствено оскъпено облекло. Откъде знам, че е изкуствено оскъпено ли? Ето един експеримент, който го доказва. Изключих от търсенето си най-евтините магазини за дрехи и натрупах същите продукти в кошниците на два онлайн магазина – LC Waikiki и H&M. За същото количество идентични като модели дрехи, направени от същите материи, в единия бих заплатила 69,94 лв., а в другия – 122,84 лв.
Всяка година по това време от около 10 години насам родителите, потърпевши от високите цени на производителите, повдигат темата, написват се няколко статии за порочните практики на фирмите изпълнители, снимат се няколко репортажа и всичко приключва.
Според чл. 263, ал. 1, т. 13 от Закона за предучилищното и училищно образование униформите се определят от педагогическия съвет на всяко училище. Много демократично в правилниците на училищата е записано, че общественият съвет на училището участва в обсъждането им, което е по-скоро застраховка за училището, че не е решило еднолично въвеждането им. Кога и как са били обсъдени униформите за вашето училище, е нещо, което трудно ще разберете и което явно не подлежи на актуализация, щом вече е прието.
Оттам нататък пътят към избор на изпълнител е тъмен и потаен.
Сравнението с Великобритания е неизбежно
Там униформата винаги е била неразделна част от образователния процес и има може би най-дълга традиция. В днешно време тя е препоръчителна, но не задължителна в детските градини и задължителна в средното образование.
Момичетата непременно са с поли, а момчетата – с панталони в тъмни цветове – тъмносиньо и черно. Тениските може да са с логото на училището, но може и да са просто едноцветни (със свобода в избора на цвят), закупени от където и да е, с яка и стандартна кройка. Все пак е задължително да има поне елек или връхна дреха с логото. На по-късен етап е задължително ежедневното носене на риза и вратовръзка. Обувките са чисто черни, без цветно лого на марка производител.
Моята тазгодишна покупка във Великобритания би струвала 60,40 паунда, или около 140 лв., без да използвам свободата да купя тениски от конкурентен магазин и без лого.
За и против
Основният довод на защитниците на униформите е, че децата се сравняват и надпреварват кой е с по-скъпи и маркови дрехи, а униформите ги правят равни.
Не знам дали сте забелязали, но сме в XXI век и тениската е последният от всички елементи, който някой би отбелязал при сравнение. На първо място е безспорно телефонът. После идват всичките му възможни аксесоари – слушалки, калъфи… Още през 90-те години на миналия век маратонките бяха отличителен знак за принадлежност към дадена група в училище. Все още е така. Добавяме очила, прическа, дънки, раница – общо взето, няма и едно нещо по децата ни, което да не позволява сравнение.
Този довод се е самооборил отдавна. Лошото е, че никой от отговорните за това възрастни все още не го е разбрал.
Вторият любим довод на привържениците на униформите е, че те сплотяват и приобщават децата към общност. Не, една дреха не създава общност, най-много да направи всички да изглеждат като в цех за производство. Ако беше толкова лесно създаването на общност, то със сигурност щеше да бъде употребено вече на по-разумни места, на които има нужда от такава. Дрехата не е ценност, зад която можеш да застанеш и да браниш заедно с другите. Най-важното условие за общност е силната емоционална връзка. Но тя пък възниква по-сложно, отколкото поръчката на тениска с лого.
Още по-слаб е аргументът за безопасност – че с униформите е по-безопасно и в училище биват допускани единствено деца от самото учебно заведение. Ако всяко дете има по няколко тениски, то е страшно лесно да услужиш с една на някого и той да влезе там, накъдето се е запътил. А и при закупуване на униформа не се изисква удостоверение за принадлежност към дадената „общност“.
Само ще отбележа и елемента на гордост, каквато според защитниците ѝ би трябвало да носи една униформа, без да го коментирам.
Искахме да стане хубаво, но стана като всеки път
От естетическа гледна точка униформите в много училища са еклектично решение, за което можем да си помислим, че се дължи на нарушение в цветовъзприемането на човека, който ги е сътворил. От наситеночервен цвят, през строгото разделяне на розово за момичетата и синьо за момчетата, бяло-зелено-червено, може и с шевици, които избеляват след второто пране, всички разновидности на лилавото или пък униформи, състоящи се от тениска с вратовръзка – геният на лошия вкус е бил във вихъра си.
Както много практики в училищата ни, и тази е с добри намерения и немарливо изпълнение. Пълната непрозрачност при избора на доставчик сваля от самото начало доверието в училището като институция. Да не говорим за утежняващите условия, които си позволяват отделни директори, например да се носи повече от един елемент от униформата. Наскоро в социалните медии се завъртя скандал с габровска директорка, която изисква от учениците да носят и тениска, и връхна униформена дреха. Какво става тогава с децата от социално слаби семейства, които разполагат с по едно от всеки вид? Безумните наказания варират от забележка до недопускане до учебния процес.
Най-ясният знак, който идва от самите ученици, е, че в гимназиален курс е почти невъзможно да се въведе трайно носене на униформа. Често учениците намятат ризата по време на час, а в останалото време тя стои на топка в чантите им. Общност може и да има, но приносът на униформата към нея е по-скоро в посока на колективното ѝ отхвърляне.
В същото време ученическата общност оформя свой вкус на обличане и често той е силно еднотипен. Ако минете в учебно време покрай някоя гимназия, ще ви направи впечатление как почти всички момичета носят къс топ, непокриващ талията, и спортно долнище. Момчетата са най-често в черно спортно долнище и черни дрехи. Съвременната униформа, избрана лично от тях. И така, въпреки че почти във всички правилници на училищата е записано какво облекло не е разрешено, то продължава да се носи. А самите училища са капитулирали и абдикирали.
Член 30 от Конституцията на Република България гласи: „Всеки има право на лична свобода и неприкосновеност.“ Това, че педагогическият съвет и общественият съвет стоят един до друг в решението да има униформи, не го прави по никакъв начин легитимно и реално то е оспоримо във всеки един момент. За съжаление, всички знаем как би се отразило на един ученик, ако родителите му тръгнат по пътя на тази абсолютно смислена борба.
Остава въпросът кому е нужно унифицирането и обезличаването от ранна детска възраст. Точно тогава, когато е важно да разбереш кой си, да намериш пътя към това да се харесаш и да ставаш по-добър всеки ден. Със съдействието – а не въпреки – средата, в която си.
Какво, ако след изборите на 27 октомври политическите сили ни изненадат с едно коалиционно правителство? Досущ като кърпикожуха, който се появява директно от земята наесен, когато растенията съхнат и природата замира. Напоследък прокарват такива, макар и твърде плахи надежди – че редовно правителство е възможно. Кърпикожухът цъфти без листа, също както едно коалиционно правителство ще бъде уязвимо, лишено от особено устойчива подкрепа, но все пак е някаква надежда за излизане от политическото безплодие.
Оптимист за редовно правителство се оказа бившият премиер Иван Костов:
В момента има много възможности да се направи правителство тази есен… Има възможност дори за двупартийна коалиция, много възможности за трипартийна. Така че аз се учудвам на тези анализатори, които казват, че непременно трябва да се отиде на следващи избори, че не можело да се състави правителство, че трябва с четири партии.
Без съвпадения (за ДПС). И не само
Редовно правителство обещават и две от формациите, поставяни от социолозите на предните места – ГЕРБ и ПП–ДБ, но нямат съвпадения във възгледите си за неговия формат. ПП–ДБ продължават да лансират формулата за „равноотдалечения премиер“, която смятат за пенкилер. ГЕРБ залагат на партийните фигури, дори на лидерите, за да е ясно кой носи политическата отговорност.
ПП–ДБ даватсигнали, че са готови да работят с ДПС на Доган, известно под името Алианс за права и свободи (АПС). Според близкия до Пеевски сайт 24rodopi.bg ПП–ДБ, които имат право на двама членове в СИК, ще дадат по едно място на АПС за 168-те секции в Турция. Освен това коалицията получи подкрепа от фракцията на Доган, за да пита Конституционния съд дали този Висш съдебен съвет, който е с изтекъл мандат, може да избира главен прокурор и председатели на върховните съдилища. Поводът е откриването на процедурата за избор на главен прокурор и единствената номинация – на и.ф. главен прокурор Борислав Сарафов. Подкрепа обещаха и от „Има такъв народ“, тъй като Тошко Йорданов не намира такъв избор за морален:
Доколкото разбрах, ще се събират подписи за питане до Конституционния съд и естествено, че ще подкрепим едно такова искане, защото този избор по този начин може и да е законен, но не сме сигурни, че е морален. Твърде много членове във ВСС са с изтекъл мандат, така че ще подкрепим това искане.
В ГЕРБ обаче смятат, че кадровиците на съдебната система са напълно в правото си да вземат това решение. (А и в крайна сметка вината е на парламента, че не успя да избере 11-те членове на ВСС от политическата квота.) За разлика от ПП–ДБ, които обявиха за неприемливи партньори ДПС на Пеевски и „Възраждане“, ГЕРБ пази дистанция от свирепия конфликт между двата клана в Движението. По-рано тази есен, през септември, Росен Желязков заяви по БНТ, че партията няма да прави коалиция с нито един от двата лагера:
Ние с ДПС, като не говорим за едно или друго ДПС, няма да влизаме в коалиция.
Всъщност включването на която и да е част от ДПС в бъдещо управление автоматично би внесло нестабилност – заради усилията да бъде подкопано от другата фракция с постоянната битка за надмощие. А в случай че този участник се окаже „ДПС – Ново начало“, означава господстващо положение за Пеевски, по-значимо от ролята му в сглобката. Наред с това ще се отвори и фронт откъм „Дондуков“ 2 заради враждата с олигарха и това противопоставяне съвсем не е от полза за стабилността на евентуален кабинет.
„Виновен-невиновен, има съдебна система, която да реши.“ Така пък лидерът на ГЕРБ Бойко Борисов коментира шумния арест на близкия до Доган депутат Джейхан Ибрямов, който е и водач на листата на АПС в 23-ти МИР – Шумен. Ибрямов беше арестуван на 2 октомври на паркинг в София със 100 000 лв. белязани пари и обвинен в търговия с влияние с цел уреждане на обществени поръчки в Министерството на отбраната. Той остава за постоянно под стража, а Mediapool.bgразкри, че основният свидетел по делото срещу Ибрямов (подсъдим по дело за данъчни измами), твърдял в показанията си, че Доган искал да убива Пеевски. Позната схема от началото на разгрома на КТБ, когато също имаше „опит за убийство на Пеевски“. За въпросния опит така и не се намериха доказателства.
„Когато Делян Пеевски напусне ДПС, те ще станат нормална партия, с която ще може да се разговаря, сега няма кой „добър ден“ да им каже“, беше заявил по Нова телевизия през юни 2015 г. лидерът на ГЕРБ Бойко Борисов, по онова време премиер за втори път. Готов ли е да го повтори, или не иска да му се припомня?
Узряха (ли)
На пръв поглед изглежда, че всеки от политическите играчи поставя свои неизпълними условия за бъдещо управление, а олигархът Пеевски и институционалното му надмощие не са единствената червена линия.
Но въпреки това се наблюдава известно смекчаване на реториката помежду им, което създава по-благоприятна среда за евентуални преговори. Изглежда, повечето са осъзнали, че нестабилността вреди както на техните позиции, така и на държавата като цяло, и са по-склонни на компромиси. Заради предизборната кампания ПП–ДБ и ГЕРБ поддържат известно ниво на конфронтация с помощта на атаките на отделни депутати от ГЕРБ срещу лидерите на „Продължаваме промяната“ (не и на „Демократична България“). Но границата едва ли ще бъде премината.
Ако все пак се получи коалиционна спойка, следващият сблъсък ще е бюджетът за 2025 г., който вече се очертава с плашещ дефицит. Служебната министърка Людмила Петкова, взела поука от предшественичката си Росица Велкова, обещава само, че дупката в бюджета ще бъде свита до разрешените за кандидатите за еврозоната 3%. Но предвид заложените за догодина огромни разходи за повишения на заплати на военни, полицаи и чиновници и за инвестиционната програма на общините това изглежда непосилна задача. Защото парламентарният популизъм, прекрояващ всеки бюджет, включва и обещанието на партиите да не вдигат данъците.
А за 2025 г. отново е заложено повишение на минималната работна заплата с 15,4% на 1077 лв., след като тази година се повиши с 19,6% до 933 лв. Това означава автоматично повишение на заплати в публичния, а и в частния сектор, както и фалити на фирми. За реформи в държавната администрация, където щатът се раздува от година на година, и дума не се отваря, нито за възможност чиновниците да плащат поне част от осигуровките си, които сега са грижа на данъкоплатците.
Анализът на Министерството на финансите показва, че при действащото законодателство приходите в бюджета за 2025 г. ще се увеличат с 6,2 млрд. лв., а разходите – с 18,1 млрд. лв. спрямо одобрените в тазгодишния. Така че или трябва да се режат разходи, или да се вдигат приходи, в противен случай България ще се отдалечи още от еврозоната – макар да има шансове за 2025 г. Досега държавата ни не изпълняваше критерия за ценова стабилност заради високата инфлация. И тъкмо поскъпването започна леко да се охлажда, и се задава проблем откъм прекомерните разходи. В партийните програми на ГЕРБ и ПП–ДБ въвеждането на еврото е цел, макар и да не е фиксирана точната година.
Партиите отдавна изчерпаха възможностите си за маневриране и политически трикове, втръснали на избирателите. Никой обаче не знае докъде ще стигне Пеевски.
Покрай работата ми с данните за градоустройството в Столична община забелязвам доста неща, а и се свързват с мен хора с наблюдения, притеснения и сигнали. Винаги препоръчвам да се подават на call.sofia, за който направих и удобна визуализация и карта за търсене. Още по-добре е през електронно връчване с официална жалба, защото има по-добра следа и проследимост. Както обаче виждаме често, а и ще стане видно тук, немалко сигнали се прикриват или просто потъват. Най-често това е от местна власт или чиновници по служби прехвърлящи си топката. Перифразирайки част от разговора на Терзиев от последния Кошер на Тук-Там – има много аспекти от администрацията, които мъчно се изваждат от тресавещото на нехайството и корупцията.
Та тук искам да разгледам едно от нещата, на които обръщам доста внимание в последно време – озеленяването. Причините за изискванията за озеленяване не са естетически, макар и от това да има полза. Не е просто защото ни харесва да живеем в приветлива среда, а не бетонна джунгла. Причините са инфраструктурни и практически. Озеленяването намалява драстично шума и замърсяването, но също и вредителите. Най-вече действа като гъба задържайки вода при проливни дъждове вместо да се излива всичко по улици, мазета и подлези. Тук роля има както дебелия почвен слой, така и дървета и храсти. Доколкото канализацията и каналите на София са ограничени в капацитета си, прекомерното застрояване на София – особено с изцяло бетониране или павиране на повърхностния слой – води неизбежно до наводнения.
Според Надребата за изграждане, поддържане и опазване на зелената система на Столична община за да се смята нещо за зелена площ, трябва да има поне 120 см. почва, ако има дървета, 60 см. за храсти и не по-малко от 30-40 см за трева. Това има значение, ако отдолу е изграден подземен паркинг или друга инфраструктура. Изменението е от края на юли 2023-та. Практически същото важи, впрочем, за любимите кашпи, с които строителите отбиват номера в озеленяването. Преди това правилото е било за минимум 60 см. почвен слой, а когато е над 30 см., 80% от площта се счита към озеленяването. С други думи, всичко построено след юли миналата година трябва да има поне 1.2 метра почвен слой при дърветата и 60 см. другаде.
Наскоро подадох сигнал за почти привършен строеж, в който се вижда под метър почвен слой, където са предвидени дървета и под 30 см. където трябва да има храсти. На места направо бетонират кашпи за балконни цветя в земята. При сегашното изпълнение е невъзможно да изпълнят изискванията, а зарият ли с пръст, никой никога не си играе да рови и проверява. Отговорът от районната администрация в Изгрев е, че строежът не е готов и като е готов щели да видят дали ще видят.
На сигнал за друга сграда, където зелена площ е превърната в паркинг, а друго озеленяване с храсти има почва под 30 см. при тогавашни изисквания за значително повече, на поредното напомняне и подаване на сигнал все пак се сетиха да искат плана за озеленяване, та чакаме там. И без този документ се виждат лесно тези и други нарушения.
Пример за озеленяване на 30 см. от улицата без почвен слой.
Както версията от 2021-ва, така и тази от 2023-та и преди това правят препратка към Наредба 1 за опазване на озеленените площи и декоративната растителност на МРРБ. В нея има установен стандарт за отстояния. Без да са спазени тези изисквания, нито един проект за озеленяване не може да бъде разрешен, а тъй като този индивидуален административен акт няма превес над нормативен акт, озеленяването неотговарящо на тези изисквания би следвало да е незаконно.
Ето няколко ключови изисквания по наредба за дърветата:
Трябва да са на поне 5 метра от външни стени на сгради и съоръжения, както и трамвайни линии
70 см. до бордюри на тротоари и паркови алеи
2 метра от пътни платна и банкетни ивици
1 метър до откоси и тераси
3 метра до основата на подпорни стени
Само на моята улица има поне 10 дървета, които „спасяват“ коефициента на озеленяване на сградите си, но не отговарят на горните изисквания. Често се срещат възмутени коментари за откровени абсурди в озеленяването, което ще доведе до неизменно измиране на дървета и храсти. Въпреки това районната администрация и строителен надзор ги допускат безропотно.
Озеленяване при сградата на Бъсков, където нито едно изискване не е спазено
Според горните изисквания, както и описаните за почвен слой, огромна част от озеленяването в София на новото строителство не отговаря на изискванията. Особено множеството споделени снимки на фиданки посадени под тераси и навеси. Доколкото плановете за озеленяване не са публични и трудни за сверяване с действителността, немалка част също изглежда са незаконни и вероятно подписани при съмнителни обстоятелства. Аналогично, от това изискване излиза, че когато дърветата са засадени в градинка, следва да имат поне 70 см. отстояние до тротоари и пътя, както и поне 60 см. почвен слой под тях за сгради преди миналото лято и 1.2 м. за тези след това.
Друг важен аспект тук е пълната липса на прозрачност. Освен, че плановете за озеленяване не са публични и усърдно се крият при искане по ЗДОИ, липсват и други документи. По наредба на общината всички решения, заповеди и протоколи на районната администрация във връзка със озеленяването трябва да се публикуват на сайтовете на районната община. Поне за Изгрев и няколко други, които проверих, няма такава публичност. При поискване по ЗДОИ районния кмет на Изгрев настоя, че няма задължение да ги публикува и отказа да даде протоколите, че той или упълномощен в администрацията е проверил на място какво всъщност се сече в един апетитен имот.
Ако видите зелена площ, която не отговаря на тези лесни за преценка изисквания, подавайте сигнали през call.sofia. Тъй като няма подходяща категория за това, може да използвате „Сгради/строежи -> Незаконни строежи“. Така ще отиде на правилното място. Дори да е претупа, поне ще има следа, че нещо не е наред и е прикрито.
Сграда в Изгрев с практически нулево отстояние от тротоар и външни стени
Ако сте запознат с планирането на подобни зелени площи и процесите, ще се радвам да споделите в коментарите, ако греша в прочита си на наредбите или съответно порочните практики в сектора. Сигурен съм, че имате и други примери за подобни своеволия. Всяка обратна връзка е добре дошла.
In what has become a highly anticipated annual tradition, Zabbix employees, partners, users, and just plain fans from every corner of the globe showed up in Riga on October 4 and 5 for Zabbix Summit 2024, celebrating a very special open-source monitoring solution that unites us all.
The 12th in-person version of our premier yearly event saw delegates arrive from 48 different countries, and just as every year the atmosphere was like a family reunion, with old friends reconnecting, remote colleagues meeting for the first time in person, and plenty of good vibes all around.
In case you couldn’t manage to make it to Riga and participate, fear not – we’ve put together this post to try to give you a taste of what Zabbix Summit 2024 was all about. As long-time Zabbix veterans say, “There’s nothing like a Zabbix Summit!”
And now, a word from our sponsors
Zabbix Summit 2024 could never have happened without the assistance of our featured sponsors, all part of Zabbix’s official partner network:
The day before the Summit, our team welcomed dozens of guests to our office for the traditional pre-Summit Open-Door day. We provided a whiteboard where attendees could leave their thoughts about Zabbix, set up a special Zabbix quiz, and organized a guided tour of the office. Countless questions were asked and answered, endless cups of coffee were poured, and a friendly, welcoming vibe was established that lasted through the end of the Summit and beyond.
Live from the main stage
This year’s Summit hosted 36 speakers who gave 34 speeches. Allowing our audience to ask questions during live Q&A sessions proved so popular last year that there was little doubt we’d continue it this year, as it promotes audience participation and keeps the speakers themselves on their toes. Here are brief recaps of a few of the standout speeches:
Zabbix Cloud and the way forward
Our CEO and Founder Alexei Vladishev kicked off the presentations with a keynote speech that introduced Zabbix Cloud and listed all the features that make it a secure, flexible, and functional alternative to the Zabbix we all know and love. Alexei also gave a short preview of the upcoming Zabbix 7.2 version. Stay tuned!
An intro to Zabbix Cloud
Zabbix Head of Product Dmitrijs Lamberts provided a deeper dive into Zabbix Cloud, sharing detailed information on how Zabbix Cloud works, providing insight into the pricing tiers, and explaining all the features and benefits that have the Zabbix community buzzing with excitement, whetting the audience’s appetite for a live demo he conducted on Day 2 of the Summit.
Using Zabbix to monitor solar energy
Mitsuhiro Ono of the Toyota Motor Corporation and Toshihiro Akamatsu of SRA OSS showed how they achieve distributed monitoring with Zabbix. They also demonstrated a case study that showed exactly how they use their Zabbix dashboard to provide the kind of detailed solar energy oversight that makes the adoption of green power in Japan possible.
Keeping tabs on MariaDB
On Day 2 of the Summit, Anders Karlsson of the MariaDB Corporation discussed how to monitor and manage MariaDB Server Clusters running with the MariaDB MaxScale database proxy. He also demonstrated how MariaDB MaxScale (which also monitors the MariaDB Servers) comes into the picture and touched on topics like managing failover, monitoring database traffic, and routing and load balancing.
Meeting security challenges with Zabbix
Gabriele Minniti and Vincenzo Morrone of Whysecurity demonstrated how the power of the Zabbix API can combine with the APIs of the vendors they work with to create centralized dashbords for controlling the cybersecurity posture of all their customers, no matter what technologies are being used.
The business track
For the first time at Zabbix Summit 2024, we constructed a second stage for slightly less technical, more business-oriented presentations. The speeches delivered there were among the most thought-provoking and fascinating of the Summit, and did much to help us reach new audiences. Here are a few highlights:
An evolving IT monitoring landscape
Zabbix LatAm CEO Luciano Alves gave a well-received talk that focused on the latest trends in the global monitoring market, presenting the results of a survey that took the pulse of over 100 global enterprise organizations.
Zabbix for managed service providers (MSPs)
Andre Morton of AGM Network Consultancy explained why having a flexible and scalable monitoring solution is extremely vital for MSPs and showed how a variety of different features, from authentication mechanisms to automatic remediation and visualization, work together to make Zabbix the perfect monitoring solution for MSPs.
Yes, we still had time for fun!
The Zabbix community works together, innovates together, and when it’s time to let off steam they have fun together at our Summit networking events, of which there were three this year:
This year’s welcome event was held at the architecturally stunning National Library of Latvia – or as Latvians call it, “The Castle of Light.” Tasty beverages and delicious food were on the menu, as was a guided tour of the library itself.
The main event was held at Riga’s famed Fantadroms Concert and Event Space, where attendees could dance to live music and enjoy more food and drinks as they caught up with friends and forged valuable connections with their counterparts in other organizations.
We sent the community on their way with a closing event at the Burzma food hall in Riga’s old town, with a cornucopia of food and music from around the world as well as plenty of opportunities for attendees to relive the Summit, have a few laughs, and wish each other well until next year!
Couldn’t make it this year? No problem!
At this point, you’re probably regretting that you didn’t manage to attend the Summit, but don’t worry – you can recreate the atmosphere in the privacy of your own home or office!
Recordings of both days are available on Zabbix’s YouTube channel:
The slides and texts of the presentations are also available for reference and download here as well.
Whether you attended in person or streamed the Summit online, we hope that you had a great time, learned a lot, and are eager to do it all again in 2025!
Ренета Кривонозова е експерт „Политики и застъпничество по темата за детската бедност“ в международната мрежа от организации Eurochild. Работата ѝ включва мониторинг върху нивата на детска бедност в различните европейски държави и върху мерките, които те предприемат, за да се преодолее бедността.
В България специфичен фокус на работата ѝ е ромската общност. България е сред страните с най-висока концентрация на деца, живеещи в бедност или в риск от бедност, която е един от факторите, влияещи сериозно на достъпа до образование.
През последните години множество доклади на различни национални и международни институции подчертават, че един от най-тревожните рискове пред българското образование е все по-широко разтварящата се ножица между учениците, които имат най-висок успех и съответно достъп до най-много ресурси, и учениците, които имат най-нисък успех – те все повече се маргинализират и като че ли присъстват само физически в системата. Каква е ролята на бедността в тази ножица? Вижда ли се тя от Брюксел?
Определено се забелязва от Брюксел, защото работата на организации като нашата е да вижда подобни проблеми и да помага с възможни решения. А и ролята на бедността се вижда лесно – ако нямам какво да ям вкъщи, ако нямам къде да седна да си напиша домашното, ако не мога да спя от студ, ученето едва ли ще ми е приоритет. Как ще се облека и обуя за училище, как ще стигна дотам, как ще се запиша в една или друга извънкласна дейност, как ще ме възприемат другите деца и учителите ми?
Децата, които живеят в бедност, не разбират изцяло това, докато са в общността. Но в училище разликата веднага става ясна и такова дете се маргинализира. То често едновременно е нежелано в клас, но и самò не желае да отива там, където ще се чувства неравностойно на другите. Такива деца много трудно могат да се мотивират, за да развиват потенциала си, защото се сблъскват с много повече бариери по пътя си.
Предполагам, че България не е единствената държава, която се е сблъсквала с този проблем. Има ли добри примери за приобщаване в образованието на децата, живеещи в бедност, и как изглеждат те?
Моделите са известни, но не са лесни.Ключова стъпка е бедността да не се стигматизира, да се преодолее нагласата, че бедността е едва ли не житейският избор на дадено семейство, на дадено дете. Финландия често се дава като добър пример как образователната система подкрепя едно дете, точно защото тази ножица, за която споменахте, е много по-затворена там. Това се измерва най-лесно чрез децата от мигрантски произход, които се обучават в тяхната система. Там дори наративът е друг. Не се говори за „проблеми“, а за „нужди“. Така приемането на детето минава през осигуряване на базисните му нужди, което да направи приобщаването в образованието възможно. Затова се работи с цялото семейство.
В училище децата от семейства със затруднения обичайно получават безплатно хранене. Предоставя се и индивидуална подкрепа, защото нерядко тези деца вкъщи не получават нужната подкрепа, а понякога, дори и да искат, родителите им няма как да я окажат, ако самите те не са образовани или не говорят езика. Но се връщам там, откъдето започнах – че за да работи, всичко това трябва да мине през приемане на тези деца и мислене за потенциала им в позитивен контекст, а не като допълнителен проблем на системата.
Вие самата сте от ромски произход и сте преминала през образователната система в България. Споменавам го, защото данните сочат, че сред ромските деца два пъти повече са тези, които живеят в бедност или в риск от бедност. Имате наблюдения как у нас подкрепяме децата, както от професионалната си дейност сега, така и от личния си опит като дете. Може ли да споделите?
В България, за съжаление, често съм се сблъсквала с неразбиране или неприемане, че ромските деца често имат нужда от социална подкрепа, но още по-често се нуждаят от специфична образователна подкрепа, защото са двуезични. Те са билингва деца и това изисква специфична работа с тях в училище.
Например в моя град, преди България да стане член на Европейския съюз, хората живееха доста бедно. След 2007 г. обаче същите семейства заминаха в чужбина да работят. Тогава аз бях ученичка и за мен разликата беше видима – забелязвах, че в първите ми години в училище там нямаше много ромски деца, защото родителите им едва свързваха двата края. Впоследствие започнаха да идват все повече, защото родителите им вече можеха да осигуряват базовите им нужди. Към настоящия момент училището е достъпно за много повече деца, чиито семейства работят в чужбина.
С това обаче проблемите не се изчерпват. Тези деца често отиват в училища, които са сегрегирани. Причините са комплексни: от една страна, самите училища се страхуват да приемат ромски деца, от друга страна, мнозинството не е подготвено да ги приеме в клас. Това ги оставя заключени в общността – в семейството, с приятелите, а след това и в училище те общуват само на ромски език, виждат примери само от своята среда. Много е трудно да пожелаеш да поемеш по различен път, ако не знаеш, че този път съществува. Ако децата от ромски произход не са излизали от махалата до осми клас, не им се е налагало да общуват на български език, после е много по-трудно както за тях, така и за несегрегираните гимназиални училища, в които биха продължили образованието си. И рискът да отпаднат от системата нараства неимоверно.
Паралелно с това трябва да се спомене и проблемът с приемането на базисно ниво. В съвременната българска образователна система има много проблеми, от които страдат всички учители и ученици. Децата от уязвими общности обаче като че ли се срещат с по-ниска търпимост и по-висока взискателност, което допълнително затруднява включването и адаптацията им.
Това са много важни въпроси, защото проблемът с достъпа до образование на ромската общност не е проблем само на ромската общност, а на цялото общество. Колкото повече и по-добре образовани граждани има едно общество, толкова повече то ще просперира.
Правилно ли Ви разбирам, че освен системните мерки за преодоляване на бедността и въвеждане на определени подкрепящи образователни практики, за пълноценното включване на ромските деца е нужно и приемането им от училищната общност?
Да. И тук бих искала да разширя фокуса и да кажа, че това важи за всички деца, които живеят с някаква различност от мнозинството – дали ще е двигателно увреждане, особеност в развитието, етнически произход, бедност или каквото и да е друго. От ключово значение е дали на тези деца се гледа като на проблем за системата, или като на хора, които системата трябва да подкрепи.
Липсата на подкрепа води до изолация, защото тези деца не могат да си представят различен път за себе си, те познават един-единствен модел. А не може да очакваме от едно такова дете чудеса – да се развива, да се реализира, да се приобщи… Всичко това изглежда много, много нереалистично.
Тъй като говорихме с Вас по-конкретно за децата, живеещи в бедност, в частност от ромската общност, можете ли да дадете пример за работещ модел за включване на тези деца?
От скорошния ми опит имахме среща с една испанска организация, която работи в автономна област Мадрид. Там в последните 15 години фокус на местната власт е да се ликвидират гетата, които в техния случай представляваха големи струпвания на хора, живеещи в паянтови постройки – отново общности с концентрация на крайна бедност. Започнаха с преместването им в различни социални жилища.
Другият фокус на тази програма беше образованието на децата. Бяха обучени доста професионалисти, доста кадри в тази сфера. Те са нещо средно между учител и социален работник (може би най-близкото от българската система са медиаторите, но не се припокриват напълно). Функциите им са разнообразни – от една страна, да подкрепят детето образователно, да разбират всичките му нужди, да са наясно и с културните разлики. От друга страна, да имат цялостен поглед върху ситуацията на семейството, да му помагат да си изработи собствени механизми за справяне – намиране на работа, изграждане на родителски капацитет и т.н. Един такъв специалист е „закачен“ за семейството и следи как се справя то финансово, как се справя в обществото, в което е поставено – защото тези хора са извадени от гетото и са настанени в изцяло непозната среда. Супервизията продължава две години. Подходът дава добри резултати за приобщаването на децата в системата на образованието, но както виждате, е много повече от образователна мярка.
Опитвам се да си представя как в настоящата политическа ситуация в България би изглеждал дебатът около една подобна мярка. Вероятно биха се чули много гласове против, защото това означава да извадиш хората от една общност и да ги вкараш малко изкуствено в друга.
Така е, да. Но като се замислите, това е единственият начин човек да се научи да живее в различна общност. Най-елементарният пример: ако някой в България реши да иде да работи в чужбина утре, то той няма да знае как да живее например в Белгия, защото никога не е живял като белгиец. Но ако отиде там, ако живее сред белгийците, вероятно ще научи привичките им и ще започне да се адаптира към тях.
За да може да се приобщи едно дете към социума, към който искаме да принадлежи, то трябва да бъде част от него. Според мен обществото не може да си позволи деца с някаква особеност – дали с физически, или ментални особености, дали заради етнически произход, или бедност – да изостават, да „изпадат“ от образователната система. Финансирането е задължение на държавата и на Европейския съюз, но оттам нататък личната отговорност е онова, което води нещата към прогрес.
Казвате, че едно общество не може да си позволи да изостави деца. Има ли изследвания всъщност какво губи обществото, като се лишава от възможността да подкрепя и образова адекватно децата от уязвими групи? Защото в България например децата, които живеят в риск от бедност, са изключително голям дял – една трета от всички деца. И ако достъпът им до образование е ограничен, това означава, че една трета от бъдещите граждани няма да могат да участват пълноценно в икономическия живот на страната.
Дори в краткосрочен план детската бeдност струва на едно общество повече, отколкото би струвало семейството да се подпомогне, за да излезе от цикъла на бедност. Но в дългосрочен план това е още по-ясно видимо, защото тези деца най-често са лишени от житейски избори и просто продължават цикъла. В България съществува един мит за щедрите социални помощи, на които ромите „лежат“. Той не е верен, всъщност социалните плащания изобщо не са щедри. И един човек, който не е получил достъп до образование, защото е бил беден, най-често след това не е в състояние и да допринася за обществото, нито пък допринася достатъчно за пенсионното или за здравното осигуряване. Демографската ситуация в България ясно показва, че обществото не може да си позволи деца, които остават необхванати от образованието – това тежи на цялото производство и разпределение на ресурсите.
В последните години сякаш виждаме все повече истории на високообразовани млади роми, които са дошли от семейства с родители без високо образование. Но някак колелото се е завъртяло. Политиките за интеграция ли дават резултат, или общността се оттласква на собствени мускули от социалното дъно?
Не бих могла да го кажа по по-добър начин от израза, който използвахте – „на собствени мускули“. Пак ще споделя наблюденията си, че това се дължи основно на възможността много роми да работят в чужбина и така да издържат децата си, докато те учат.
В рамките на Европейската гаранция за детето има ли предвидени конкретни действия, които държавата е длъжна да изпълни, или някакви конкретни резултати, които е длъжна да постигне, свързани с образованието на най-бедните деца?
Европейският съюз си е поставил за цел да намали бедността при децата наполовина до 2030 г. За мен лично това е много амбициозна цел, защото бедността изглежда различно във всяка държава. В страните в Източна Европа като най-бедни се посочват ромските деца и ако няма специфични мерки или грижи за тях, този амбициозен план трудно ще се осъществи. Но конкретните мерки и действия са оставени на всяка отделна държава, тъй като се предполага, че са добре съобразени с националния контекст и нужди.
По какъв начин се отчита напредъкът по Европейската гаранция и всъщност в какъв момент преди 2030 г. ние бихме могли да си сверим часовника?
Има мониторингова рамка, в която Европейската комисия предложи различни индикатори как се измерва прогресът във всяка държава. Тази рамка е задължителна за всички държави членки. На всеки две години те са длъжни да отчитат напредъка си, но в момента мисля, че само 16 от 27 държави са внесли доклади в Европейската комисия, а крайният срок беше април тази година.
Има ли общи предизвикателства при преодоляването на детската бедност в различните европейски страни?
Проблем, който срещаме във всички държави от Европейския съюз, е липсата на общуване между институциите, които са отговорни за прилагането на Европейската гаранция за детето. В България, Испания, Румъния този проблем е много стар. Говорим за комуникацията между Министерството на труда и социалната политика, Министерството на образованието и Министерството на здравеопазването. Тези институции работят напълно отделно или си прехвърлят даден проблем.
Нещо, което организации като моята се стараем да постигнем, е да сме мост между тези институции, за да свикнат да работят заедно в интерес на децата. Това би било ключов момент, за да получават децата в риск от бедност адекватна подкрепа както за включването си в образованието, така и за преодоляване на всички други трудности, с които бедността ги сблъсква.
Интервюто е част от поредица разговори за достъпа до образование на децата от уязвими групи. Проектът се осъществява благодарение на най-голямата социално отговорна инициатива на „Лидл България“ – „Ти и Lidl за нашето утре“, в партньорство с Фондация „Работилница за граждански инициативи“, Българския дарителски форум и Асоциацията на европейските журналисти.
Version
24.10 of the Ubuntu distribution is out. This release includes GNOME 47, Linux 6.11,
security enhancements for managing Personal Package Archives (PPAs),
experimental security controls for Snap packages, and more.
Today, we are announcing the general availability (GA) of AWS Console-to-Code that makes it easy to convert AWS console actions to reusable code. You can use AWS Console-to-Code to record your actions and workflows in the console, such as launching an Amazon Elastic Compute Cloud (Amazon EC2) instance, and review the AWS Command Line Interface (AWS CLI) commands for your console actions. With just a few clicks, Amazon Q can generate code for you using the infrastructure-as-code (IaC) format of your choice, including AWS CloudFormation template (YAML or JSON), and AWS Cloud Development Kit (AWS CDK) (TypeScript, Python or Java). This can be used as a starting point for infrastructure automation and further customized for your production workloads, included in pipelines, and more.
Since we announced the preview last year, AWS Console-to-Code has garnered positive response from customers. It has now been improved further in this GA version, because we have continued to work backwards from customer feedback.
Simplified experience – The new user experience makes it easier for customers to manage the prototyping, recording and code generation workflows.
Preview code – The launch wizards for EC2 instances and Auto Scaling groups have been updated to allow customers to generate code for these resources without actually creating them.
Advanced code generation – AWS CDK and CloudFormation code generation is powered by Amazon Q machine learning models.
Getting started with AWS Console-to-Code Let’s begin with a simple scenario of launching an Amazon EC2 instance. Start by accessing the Amazon EC2 console. Locate the AWS Console-to-Code widget on the right and choose Start recording to initiate the recording.
Now, launch an Amazon EC2 instance using the launch instance wizard in the Amazon EC2 console. After the instance is launched, choose Stop to complete the recording.
In the Recorded actions table, review the actions that were recorded. Use the Type dropdown list to filter by write actions (Write). Choose the RunInstances action. Select Copy CLI to copy the corresponding AWS CLI command.
This is the CLI command that I got from AWS Console-to-Code:
This command can be easily modified. For this example, I updated it to launch two instances (--count 2) of type t3.micro (--instance-type). This is a simplified example, but the same technique can be applied to other workflows.
I executed the command using AWS CloudShell and it worked as expected, launching two t3.micro EC2 instances:
The single-click CLI code generation experience is based on the API commands that were used when actions were executed (while launching the EC2 instance). Its interesting to note that the companion screen surfaces recorded actions as you complete them in console. And thanks to the interactive UI with start and stop functionality, its easy to clearly scope actions for prototyping.
IaC generation using AWS CDK AWS CDK is an open-source framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. With AWS Console-to-Code, you can generate AWS CDK code (currently in Java, Python and TypeScript) for your infrastructure workflows.
Lets continue with the EC2 launch instance use case. If you haven’t done it already, in the Amazon EC2 console, locate the AWS Console-to-Code widget on the right, choose Start recording, and launch an EC2 instance. After the instance is launched, choose Stop to complete the recording and choose the RunInstances action from the Recorded actions table.
To generate AWS CDK Python code, choose the Generate CDK Python button from the dropdown list.
You can use the code as a starting point, customizing it to make it production-ready for your specific use case.
I already had the AWS CDK installed, so I created a new Python CDK project:
mkdir c2c_cdk_demo
cd c2c_cdk_demo
cdk init app --language python
Then, I plugged in the generated code in the Python CDK project. For this example, I refactored the code into a AWS CDK Stack, changed the EC2 instance type, and made other minor changes to ensure that the code was correct. I successfully deployed it using cdk deploy.
I was able to go from the console action to launch an EC2 instance and then all the way to AWS CDK to reproduce the same result.
You can also generate CloudFormation template in YAML or JSON format:
Preview code You can also directly access AWS Console-to-Code from Preview code feature in Amazon EC2 and Amazon EC2 Auto Scaling group launch experience. This means that you don’t have to actually create the resource in order to get the infrastructure code.
To try this out, follow the steps to create an Auto Scaling group using a launch template. However, instead of Create Auto Scaling group, click Preview code. You should now see the options to generate infrastructure code or copy the AWS CLI command.
Things to know Here are a few things you should consider while using AWS Console-to-Code:
Anyone can use AWS Console-to-Code to generate AWS CLI commands for their infrastructure workflows. The code generation feature for AWS CDK and CloudFormation formats has a free quota of 25 generations per month, after which you will need an Amazon Q Developer subscription.
It’s recommended that you test and verify the generated IaC code code before deployment.
At GA, AWS Console-to-Code only records actions in Amazon EC2, Amazon VPC and Amazon RDS consoles.
The Recorded actions table in AWS Console-to-Code only display actions taken during the current session within the specific browser tab, and it does not retain actions from previous sessions or other tabs. Note that refreshing the browser tab will result in the loss of all recorded actions.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. Driven primarily by customer feedback, the product roadmap for Amazon Redshift is designed to make sure the service continuously evolves to meet the ever-changing needs of its users.
Amazon Redshift now enables the secure sharing of data lake tables—also known as external tables or Amazon Redshift Spectrum tables—that are managed in the AWS Glue Data Catalog, as well as Redshift views referencing those data lake tables. This breakthrough empowers data analytics to span the full breadth of shareable data, allowing you to seamlessly share local tables and data lake tables across warehouses, accounts, and AWS Regions—without the overhead of physical data movement or recreating security policies for data lake tables and Redshift views on each warehouse.
By using granular access controls, data sharing in Amazon Redshift helps data owners maintain tight governance over who can access the shared information. In this post, we explore powerful use cases that demonstrate how you can enhance cross-team and cross-organizational collaboration, reduce overhead, and unlock new insights by using this innovative data sharing functionality.
Overview of Amazon Redshift data sharing
Amazon Redshift data sharing allows you to securely share your data with other Redshift warehouses, without having to copy or move the data.
Data shared between warehouses doesn’t require the data to be physically copied or moved—instead, data remains in the original Redshift warehouse, and access is granted to other authorized users as part of a one-time setup. Data sharing provides granular access control, allowing you to control which specific tables or views are shared, and which users or services can access the shared data.
Since consumers access the shared data in-place, they always access the latest state of the shared data. Data sharing even allows for the automatic sharing of new tables created after that datashare was established.
You can share data across different Redshift warehouses within or across AWS accounts, and you can also do cross-region data sharing. This allows you to share data with partners, subsidiaries, or other parts of your organization, and enables the powerful workload isolation use case, as shown in the following diagram. With the seamless integration of Amazon Redshift with AWS Data Exchange, data can also be monetized and shared publicly, and public datasets such as census data can be added to a Redshift warehouse with just a few steps.
Figure 1: Amazon Redshift data sharing between producer and consumer warehouses
The data sharing capabilities in Amazon Redshift also enable the implementation of a data mesh architecture, as shown in the following diagram. This helps democratize data within the organization by reducing barriers to accessing and using data across different business units and teams. For datasets with multiple authors, Amazon Redshift data sharing supports both read and write use cases (write in preview at the time of writing). This enables the creation of 360-degree datasets, such as a customer dataset that receives contributions from multiple Redshift warehouses across different business units in the organization.
Figure 2: Data mesh architecture using Amazon Redshift data sharing
Overview of Redshift Spectrum and data lake tables
In the modern data organization, the data lake has emerged as a centralized repository—a single source of truth where all data within the organization ultimately resides at some point in its lifecycle. Redshift Spectrum enables seamless integration between the Redshift data warehouse and customers’ data lakes, as shown in the following diagram. With Redshift Spectrum, you can run SQL queries directly against data stored in Amazon Simple Storage Service (Amazon S3), without the need to first load that data into a Redshift warehouse. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
Figure 3: Amazon Redshift bridges the data warehouse and data lake by enabling querying of data lake tables in-place
Redshift Spectrum supports a variety of open file formats, including Parquet, ORC, JSON, and CSV, as well as open table formats such as Apache Iceberg, all stored in Amazon S3. It runs these queries using a dedicated fleet of high-performance servers with low-latency connections to the S3 data lake. Data lake tables can be added to a Redshift warehouse either automatically through the Data Catalog, in the Amazon Redshift Query Editor, or manually using SQL commands.
From a user experience standpoint, there is little difference between querying a local Redshift table vs. a data lake table. SQL queries can be reused verbatim to perform the same aggregations and transformations on data residing in the data lake, as shown in the following examples. Additionally, by using columnar file formats like Parquet and pushing down query predicates, you can achieve further performance enhancements.
The following SQL is for a sample query against local Redshift tables:
SELECT top 10 mylocal_schema.sales.eventid, sum(mylocal_schema.sales.pricepaid) FROM mylocal_schema.sales, event
WHERE mylocal_schema.sales.eventid = event.eventid
AND mylocal_schema.sales.pricepaid > 30
GROUP BY mylocal_schema.sales.eventid
ORDER BY 2 DESC;
The following SQL is for the same query, but against data lake tables:
SELECT top 10 myspectrum_schema.sales.eventid, sum(myspectrum_schema.sales.pricepaid) FROM myspectrum_schema.sales, event
WHERE myspectrum_schema.sales.eventid = event.eventid
AND myspectrum_schema.sales.pricepaid > 30
GROUP BY myspectrum_schema.sales.eventid
ORDER BY 2 desc;
To maintain robust data governance, Redshift Spectrum integrates with AWS Lake Formation, enabling the consistent application of security policies and access controls across both the Redshift data warehouse and S3 data lake. When Lake Formation is used, Redshift producer warehouses first share their data with Lake Formation rather than directly with other Redshift consumer warehouses, and the data lake administrator grants fine-grained permissions for Redshift consumer warehouses to access the shared data. For more information, see Centrally manage access and permissions for Amazon Redshift data sharing with AWS Lake Formation.
In the past, however, sharing data lake tables across Redshift warehouses presented challenges. It wasn’t possible to do so without having to mount the data lake tables on each individual Redshift warehouse and then recreate the related security policies.
This barrier has now been addressed with the introduction of data sharing support for data lake tables. You can now share data lake tables just like any other table, using the built-in data sharing capabilities of Amazon Redshift. By combining the power of Redshift Spectrum data lake integration with the flexibility of Amazon Redshift data sharing, organizations can unlock new levels of cross-team collaboration and insights, while maintaining robust data governance and security controls.
In this post, we describe how to add data lake tables or views to a Redshift datashare, covering two key use cases:
Adding a late-binding view or materialized view to a producer datashare that references a data lake table
Adding a data lake table directly to a producer datashare
The first use case provides greater flexibility and convenience. Consumers can query the shared view without having to configure fine-grained permissions. The configuration, such as defining permissions on data stored in Amazon S3 with Lake Formation, is already handled on the producer side. You only need to add the view to the producer datashare one time, making it a convenient option for both the producer and the consumer.
An additional benefit of this approach is that you can add views to a datashare that join data lake tables with local Redshift tables. When these views are shared, you can relegate the trusted business logic to just the producer side.
Alternatively, you can add data lake tables directly to a datashare. In this case, consumers can query the data lake tables directly or join them with their own local tables, allowing them to add their own conditional logic as needed.
Add a view that references a data lake table to a Redshift datashare
When you create data lake tables that you intend to add to a datashare, the recommended and most common way to do this is to add a view to the datashare that references a data lake table or tables. There are three high-level steps involved:
Add the Redshift view’s schema (the local schema) to the Redshift datashare.
Add the Redshift view (the local view) to the Redshift datashare.
Add the Redshift external schemas (for the tables referenced by the Redshift view) to the Redshift datashare.
The following diagram illustrates the full workflow.
Figure 4: Sharing data lake tables via Amazon Redshift views
The workflow consists of the following steps:
Create a data lake table on the datashare producer. For more information on creating Redshift Spectrum objects, see External schemas for Amazon Redshift Spectrum. Data lake tables to be shared can include Lake Formation registered tables and Data Catalog tables, and if using the Redshift Query Editor, these tables are automatically mounted.
Create a view on the producer that references the data lake table that you created.
Create a datashare, if one doesn’t already exist, and add objects to your datashare, including the view you created that references the data lake table. For more information, see Creating datashares and adding objects (preview).
Add the external schema of the base Redshift table to the datashare (this is true of both local base tables and data lake tables). You don’t have to add a data lake table itself to the datashare.
On the consumer, the administrator makes the view available to consumer database users.
Database consumer users can write queries to retrieve data from the shared view and join it with other tables and views on the consumer.
After these steps are complete, database consumer users with access to the datashare views can reference them in their SQL queries. The following SQL queries are examples for achieving the preceding steps.
Create a data lake table on the producer warehouse:
CREATE VIEW mylocal_db.mylocal_schema.myspectrumview AS SELECT c1 FROM myspectrum_db.myspectrum_schema.v_test
WITH no schema binding;
Add a view to the datashare on the producer warehouse:
ALTER datashare mydatashare ADD SCHEMA mylocal_db.mylocal_schema;
ALTER datashare mydatashare ADD VIEW myspectrumview;
ALTER datashare mydatashare ADD SCHEMA myspectrum_db.myspectrum_schema;
Create a consumer datashare and grant permissions for the view in the consumer warehouse:
CREATE database myspectrum_db FROM datashare myspectrumproducer OF account '123456789012' namespace 'p1234567-8765-4321-p10987654321';
GRANT usage ON database myspectrum_db TO usernames;
Add a data lake table directly to a Redshift datashare
Adding a data lake table to a datashare is similar to adding a view. This process works well for a case where the consumers want the raw data from the data lake table and they want to write queries and join it to tables in their own data warehouse. There are two high-level steps involved:
Add the Redshift external schemas (of the data lake tables to be shared) to the Redshift datashare.
Add the data lake table (the Redshift external table) to the Redshift datashare.
The following diagram illustrates the full workflow.
Figure 5: Sharing data lake tables directly in an Amazon Redshift datashare
The workflow consists of the following steps:
Create a data lake table on the datashare producer.
Add objects to your datashare, including the data lake table you created. In this case, you don’t have any abstraction over the table.
On the consumer, the administrator makes the table available.
Database consumer users can write queries to retrieve data from the shared table and join it with other tables and views on the consumer.
The following SQL queries are examples for achieving the preceding producer steps.
Create a data lake table on the producer warehouse:
Add a data lake schema and table directly to the datashare on the producer warehouse:
ALTER datashare mydatashare ADD SCHEMA myspectrum_db.myspectrum_schema;
ALTER datashare mydatashare ADD TABLE myspectrum_db.myspectrum_schema.test;
Create a consumer datashare and grant permissions for the view in the consumer warehouse:
CREATE database myspectrum_db FROM datashare myspectrumproducer OF account '123456789012' namespace 'p1234567-8765-4321-p10987654321';
GRANT usage ON database myspectrum_db TO usernames;
Security considerations for sharing data lake tables and views
Data lake tables are stored outside of Amazon Redshift, in the data lake, and may not be owned by the Redshift warehouse, but are still referenced within Amazon Redshift. This setup requires special security considerations. Data lake tables operate under the security and governance of both Amazon Redshift and the data lake. For Lake Formation registered tables specifically, the Amazon S3 resources are secured by Lake Formation and made available to consumers using the provided credentials.
The data owner of the data in the data lake tables may want to impose restrictions on which external objects can be added to a datashare. To give data owners more control over whether warehouse users can share data lake tables, you can use session tags in AWS Identity and Access Management (IAM). These tags provide additional context about the user running the queries. For more details on tagging resources, refer to Tags for AWS Identity and Access Management resources.
Audit considerations for sharing data lake tables and views
When sharing data lake objects through a datashare, there are special logging considerations to keep in mind:
Access controls – You can also use CloudTrail log data in conjunction with IAM policies to control access to shared tables, including both Redshift datashare producers and consumers. The CloudTrail logs record details about who accesses shared tables. The identifiers in the log data are available in the ExternalId field under the AssumeRole CloudTrail logs. The data owner can configure additional limitations on data access in an IAM policy by means of actions. For more information about defining data access through policies, see Access to AWS accounts owned by third parties.
Centralized access – Amazon S3 resources such as data lake tables can be registered and centrally managed with Lake Formation. After they’re registered with Lake Formation, Amazon S3 resources are secured and governed by the associated Lake Formation policies and made available using the credentials provided by Lake Formation.
Billing considerations for sharing data lake tables and views
The billing model for Redshift Spectrum differs for Amazon Redshift provisioned and serverless warehouses. For provisioned warehouses, Redshift Spectrum queries (queries involving data lake tables) are billed based on the amount of data scanned during query execution. For serverless warehouses, data lake queries are billed the same as non-data-lake queries. Storage for data lake tables is always billed to the AWS account associated with the Amazon S3 data.
In the case of datashares involving data lake tables, costs are attributed for storing and scanning data lake objects in a datashare as follows:
When a consumer queries shared objects from a data lake, the cost of scanning is billed to the consumer:
When the consumer is a provisioned warehouse, Amazon Redshift uses Redshift Spectrum to scan the Amazon S3 data. Therefore, the Redshift Spectrum cost is billed to the consumer account.
When the consumer is an Amazon Redshift Serverless workgroup, there is no separate charge for data lake queries.
Amazon S3 costs for storage and operations, such as listing buckets, is billed to the account that owns each S3 bucket.
In this post, we explored how Amazon Redshift enhanced data sharing capabilities, including support for sharing data lake tables and Redshift views that reference those data lake tables, empower organizations to unlock the full potential of their data by bringing the full breadth of data assets in scope for advanced analytics. Organizations are now able to seamlessly share local tables and data lake tables across warehouses, accounts, and Regions.
We outlined the steps to securely share data lake tables and views that reference those data lake tables across Redshift warehouses, even those in separate AWS accounts or Regions. Additionally, we covered some considerations and best practices to keep in mind when using this innovative feature.
Sharing data lake tables and views through Amazon Redshift data sharing champions the modern, data-driven organization’s goal to democratize data access in a secure, scalable, and efficient manner. By eliminating the need for physical data movement or duplication, this capability reduces overhead and enables seamless cross-team and cross-organizational collaboration. Unleashing the full potential of your data analytics to span the full breadth of your local tables and data lake tables is just a few steps away.
For more information on Amazon Redshift data sharing and how it can benefit your organization, refer to the following resources:
Please also reach out to your AWS technical account manager or AWS account Solutions Architect. They will be happy to provide additional guidance and support.
About the Authors
Mohammed Alkateb is an Engineering Manager at Amazon Redshift. Prior to joining Amazon, Mohammed had 12 years of industry experience in query optimization and database internals as an individual contributor and engineering manager. Mohammed has 18 US patents, and he has publications in research and industrial tracks of premier database conferences including EDBT, ICDE, SIGMOD and VLDB. Mohammed holds a PhD in Computer Science from The University of Vermont, and MSc and BSc degrees in Information Systems from Cairo University.
Ramchandra Anil Kulkarni is a software development engineer who has been with Amazon Redshift for over 4 years. He is driven to develop database innovations that serve AWS customers globally. Kulkarni’s long-standing tenure and dedication to the Amazon Redshift service demonstrate his deep expertise and commitment to delivering cutting-edge database solutions that empower AWS customers worldwide.
Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data.
Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.
AI is everywhere—powering chatbots, generating images, even deciding what you binge watch next. It’s no wonder businesses of all sizes are feeling compelled to jump on the AI bandwagon. But before you get swept up in the AI hype, here’s the question you need to ask: Is AI right for your business and the problem you’re trying to solve?
Where AI truly becomes a change agent is when it is powered by your organization’s data to deliver relevant, insightful, and actionable observations to you in a timely manner. The reality is, while AI is really cool, without your unique data it provides your organization few competitive advantages. Of course, releasing proprietary, or even sensitive, information to a robot connected to the internet can be risky—and you want to make sure your (and your clients’) information doesn’t end up in surprising places.
But just because everyone’s talking about AI doesn’t mean it’s the magic bullet for every problem. Like any strategic investment, it takes careful consideration. So, before you hand over your data to a machine, let’s explore whether AI is really what your business needs—or if it’s just another shiny object in the tech landscape.
Where do I start?
Today, many organizations are somewhere along the AI/ML path. Most are experimenting with AI, some are actively building applications, and a handful have successfully deployed a solution. Like any other project, before you start trying to use AI in your organization, the first thing you should do is define the problem you are trying to solve. Only then can you determine if you really need AI as a part of the solution.
Ask yourself the following questions about the project. If you answer yes to all four items, the project is AI-worthy:
1. Do you want AI to replace tedious, repetitive tasks?
Start by identifying the business problem in specific, measurable terms. Determine the scope of the problem, its frequency, and the impact it has on your business. Is it recurring and time consuming? If the problem is complex, repetitive, or data-intensive, it might be suitable for AI.
2. Do you want to use AI because you can’t consistently apply a set of logical rules to answer the questions at hand?
If the problem involves large amounts of data that is difficult to process manually where the answer is derived by combining and weighing multiple factors, it may be a candidate for an AI-based solution. On the other hand, just because it can be automated doesn’t mean you need an AI solution—AI is expensive in terms of power and processing resources. If you’re running a simple routine task over and over, you might be just as well off using traditional programming methods. But, when you’re solving a complex task, you need a structure that is not a strict binary, and that’s when you might want to use AI.
3. Will you use AI for problems that humans can solve, but AI can solve much faster?
AI should help your organization solve problems it finds extremely difficult or nearly impossible to solve otherwise. AI excels at tackling complex problems that overwhelm traditional methods, such as processing vast amounts of data, recognizing intricate patterns, or making real-time predictions. If your business is facing challenges that manual processes or standard software can’t handle effectively, AI can step in to provide powerful, scalable solutions that would otherwise be out of reach.
But remember, AI should work with you, not against you. Understand how AI will integrate into your workflow and whether it aligns with your overall business strategy to avoid creating unnecessary complications or disrupting ongoing operations.
4. Do you intend for AI to increase productivity of a function or group?
Most AI projects are productivity based, even those that seem otherwise. Even AI projects aimed at improving customer experiences, like personalized recommendations, ultimately enhance productivity by streamlining interactions and reducing manual effort. At their core, most AI implementations are designed to automate tasks, optimize processes, or extract actionable insights, all of which drive greater efficiency and cost savings. And, that means you need to analyze the potential return on investment (ROI).
AI integration requires an investment in technology, data management, and often specialized personnel. Weigh the cost of implementing AI against the potential benefits it could bring. Will it save time or reduce costs? By how much? If the financial or productivity benefits outweigh the costs, AI may be a worthwhile investment.
Where to next?
Clearly defining the problem and deciding if it’s suitable for an AI-based solution is really just the first step. Once the problem is defined, you open up another set of questions around whether and how to implement it. Do you have the right data, resources, and expertise to support an AI solution? How will it integrate with your systems? How will you measure success? The answers to all of these questions should absolutely inform your decision-making, but understanding if you’re applying AI to the right problem is your starting point. Without that, you’re using a sledgehammer to crack a nut, so to speak.
Generative AI is transforming industries in new and exciting ways every single day. At Amazon Web Services (AWS), security is our top priority, and we see security as a foundational enabler for organizations looking to innovate. As you prepare for AWS re:Invent 2024, make sure that these essential sessions are on your schedule to learn how security can help your organization innovate with generative AI solutions quickly and securely. Leading experts will provide deep insights into how you can secure generative AI workloads in order to protect data and navigate governance, risk, and compliance.
In this post, we’ve highlighted some of our must-attend sessions and favorite activities for security leaders and practitioners, technical decision-makers, and artificial intelligence and machine learning (AI/ML) builders. To join in on the fun, register here, and we’ll see you in Vegas!
Keynotes and innovation talks
The AWS re:Invent 2024 keynote and innovation talks offer the opportunity to gain direct, transformative insights from senior AWS leaders. Delve into the latest breakthroughs in generative AI, cloud security, and cutting-edge architectural innovations that are redefining the future of application development and the AWS Cloud.
KEY002 – CEO Keynote with Matt Garman. Discover how AWS is innovating across the cloud, from reinventing core services to creating new experiences, empowering customers and partners to build a secure and better future.
SEC203-INT – Security insights and innovation from AWS with Chris Betz. Discover how groundbreaking security innovations and generative AI empower your organization to accelerate innovation securely, as AWS CISO Chris Betz reveals transformative strategies to integrate and automate security, freeing your team to focus on high-value initiatives.
ARC203-INT – Architectural methods & breakthroughs in innovative apps in the cloud with Shaown Nandi and Ben Cabanas. This talk showcases how generative AI and cutting-edge architectural advancements are transforming application design, empowering AWS customers to modernize their systems, develop robust data strategies, and securely navigate the evolving cloud landscape.
Check out the full list of innovation talks. Not attending live this year? The keynote and all innovation talks will be live streamed.
Sessions
Discover a range of learning opportunities designed to deepen your expertise in securing generative AI. This year’s sessions put a strong focus on providing customers with impactful real-world, practical prescriptions for securing your AI workloads and the data that powers them. Whether you prefer lecture-style breakout sessions, interactive chalk talks, hands-on workshops, or code-driven discussions, there’s a session tailored to help meet your needs. Explore the following options and reserve your spot to enhance your understanding and practical skills in this rapidly evolving field.
You can find more details and descriptions for session levels (100–400) and session types on the re:Invent website.
Breakout sessions
Breakout sessions are lecture-style, 1-hour sessions delivered by AWS experts, customers, and partners—perfect for deepening your knowledge on important topics, gaining actionable insights, and connecting with industry leaders.
SEC214 –Elevating client experiences with secure AI: Rocket Mortgage’s approach. Discover how Rocket Mortgage implemented AWS generative AI services to enhance customer experiences while navigating security challenges. Register for this session
SEC315 – Bring your workforce identities to AWS for generative AI and analytics. This session will demonstrate the power of integrating your workforce identity provider to gain easier access to generative AI applications and tools. AWS and NVIDIA will demonstrate a full end-to-end identity-aware experience. Register for this session
SEC323 –The AWS approach to secure generative AI. Learn how AWS secures generative AI across the infrastructure, model, and application layers, giving customers control over their data with built-in security features. Register for this session
SEC403 –Generative AI for security in the real world. Explore practical generative AI applications for security teams, including incident response, red team/blue team enablement, and security operations center (SOC) use cases, to boost your security operations. Register for this session
Chalk talks
Chalk talks are 1-hour long, highly interactive sessions with a small audience. This format is ideal for diving deep into specific topics, engaging directly with AWS experts, and getting your questions answered in real time.
SEC303 – Protecting data within your generative AI architectures. Mitigate risks when training large language models (LLMs) on sensitive data. Explore techniques like sanitization, anonymization, and differential privacy. Register for this talk
SEC327 – Building secure network designs for gen AI applications. Optimize your cloud network design to power transformative generative AI applications more securely, as we share proven best practices, proactive controls, and reference architectures to build resilient, defense-in-depth architectures and accelerate innovation on AWS. Register for this talk
SEC335 –Harness generative AI for business growth amidst the regulatory landscape. Explore how AWS AI/ML solutions can drive business growth while helping you align to responsible practices. Learn from your peers about their strategies to navigate evolving regulatory landscapes, from the European Union’s General Data Protection Regulation (GDPR) to industry-specific mandates. Register for this talk
SEC336 –Security and compliance considerations using Amazon Q Business. Discover best practices for securing your Amazon Q Business application, focusing on access control, data protection, and compliance considerations, so that you can keep your AI assistant secure and compliant. Register for this talk
SEC338 –Safeguard your generative AI apps from prompt injections. Learn to protect your generative AI applications from prompt injection attacks by understanding input validation, secure prompt engineering, and content moderation. Register for this talk
PEX308 – Securing generative AI on AWS. Explore generative AI security considerations through a partner lens, including how partners can enhance data security and the value-adds that partners bring to a customer’s generative AI workloads. Register for this talk
AIM344 – Understanding the deep security controls within Amazon Q Business. Learn about the security-related capabilities and controls within Amazon Q that allow you to confidently use your business data safely. Register for this talk
AIM407 – Understand the deep security controls within Amazon Bedrock. Dive deep into the security nuances of Amazon Bedrock, as we unpack the architectures, data flows, and lifecycle management of complex features like Guardrails, Agents, and Knowledge Bases, empowering you to use this generative AI service with uncompromising data privacy and control. Register for this talk
DEV323 – OWASP Top 10 for LLMs. Strengthen your skills in securing generative AI applications by exploring real-world vulnerabilities and proven mitigation strategies against the OWASP Top 10 risks for large language models (LLMs), through interactive demos and hands-on exercises. Register for this talk
Code talks
Code talks are similar to our popular chalk talk format, but with a focus on live coding or code samples rather than whiteboarding. These sessions look into the actual code used to build a solution, allowing attendees to understand the “why” behind the approach and witness the development process, including any errors that may arise. Participants are encouraged to ask questions and follow along for a deeper, hands-on learning experience.
SEC401 – Inspect and secure your application with generative AI. Harness the power of generative AI to bolster your application security, as we unveil how AI-driven tools can rapidly detect vulnerabilities and recommend remediation strategies, empowering you to build more secure software with ease. Register for this talk
SEC405 – Consolidated data protection insights with generative AI. Discover how to secure your AWS KMS keys across your accounts by using Amazon Q in QuickSight for quick, actionable insights. Register for this talk
Builders’ sessions
Interact with small groups, led by an AWS expert providing interactive learning about how to build on AWS. Each builders’ session begins with a short explanation or demonstration of what attendees are building, then it’s your turn to build! The expert will guide you end-to-end through this hands-on experience.
Note: You must bring your own laptop to participate in these sessions.
DOP302 – Creating secure code with Amazon Q Developer. Supercharge your coding prowess with Amazon Q Developer, as you gain hands-on experience using its AI-powered capabilities to write more secure, optimized code, detect vulnerabilities, and implement instant remediations—transforming your development workflow. Register for this session
SMB302 – Empower your business with defense-in-depth architecture. Empower your small-to-medium business to innovate more securely with generative AI by exploring practical, cost-effective defense-in-depth strategies, layered security architectures, and AI-specific safeguards to build resilient, trusted AI-powered solutions in the AWS Cloud. Register for this session
Workshops
Workshops are 2-hour interactive sessions where you collaborate in teams or work individually to solve real-world challenges by using AWS services, making them perfect for hands-on learning. Each workshop begins with a brief lecture, followed by dedicated time to work through the problem.
Note: Don’t forget to bring your laptop to build alongside AWS experts.
SEC305 – Generative AI-based code remediations and patch management at scale. Experience hands-on how to use generative AI to assist in automating vulnerability detection and remediation across AWS Lambda, containers, and Amazon Elastic Compute Cloud (Amazon EC2) at scale, empowering your team to proactively secure your applications. Register for this workshop
SEC306 – Securing your generative AI applications on AWS. Gain hands-on experience securing generative AI applications by using AWS services and features. Deploy a vulnerable sample AI app, then implement layered security controls to protect, detect, and respond to issues. Use these best practices to secure your own AI apps when you return home! Register for this workshop
SEC309 – AWS IAM Identity Center: Secure access to generative AI applications. You’ll learn how to build an identity-aware chat experience, train it on a sample dataset, and connect it to an external workforce identity provider by using native integration between Amazon Q Business and AWS Identity and Access Management (IAM) Identity Center. Register for this workshop
SEC310 – Persona-based access to enterprise data for generative AI applications. Learn how to secure document access in generative AI applications by using retrieval augmented generation (RAG), metadata filtering, and Amazon Cognito in this interactive workshop. Register for this workshop
Expo
Want to talk directly with an AWS security expert on generative AI security, or a variety of other security topics? Then don’t miss this opportunity to have one-on-one conversations with leading AWS security experts in the Security Activation area of the expo floor to help you take your organization’s security posture to new heights.
Delve into key security domains such as:
Detection and Response: Explore techniques for detecting and responding to security risks to help protect your workloads at scale.
Network and Infrastructure Security: Learn how to build and manage a secure global network with AWS services.
Application Security: Discover strategies to ship secure software and address the challenges of application security.
Identity and Access Management: Adopt modern cloud-native identity solutions and apply least-privilege access controls.
Digital Sovereignty & Data Protection: Maintain control over your data and choose how to secure and manage it in the AWS Cloud.
Still time for fun!
After an inspiring week of transformative insights and deep learning, join us for the world renowned re:Play party—the ultimate re:Invent sendoff! Immerse yourself in live entertainment from headlining musical artists, scrumptious cuisine, and flowing refreshments as we come together to unwind, connect, and toast to a future of limitless possibilities.
Register today
It’s going to be an amazing event, and we can’t wait to see you at re:Invent 2024! Register now to secure your spot.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

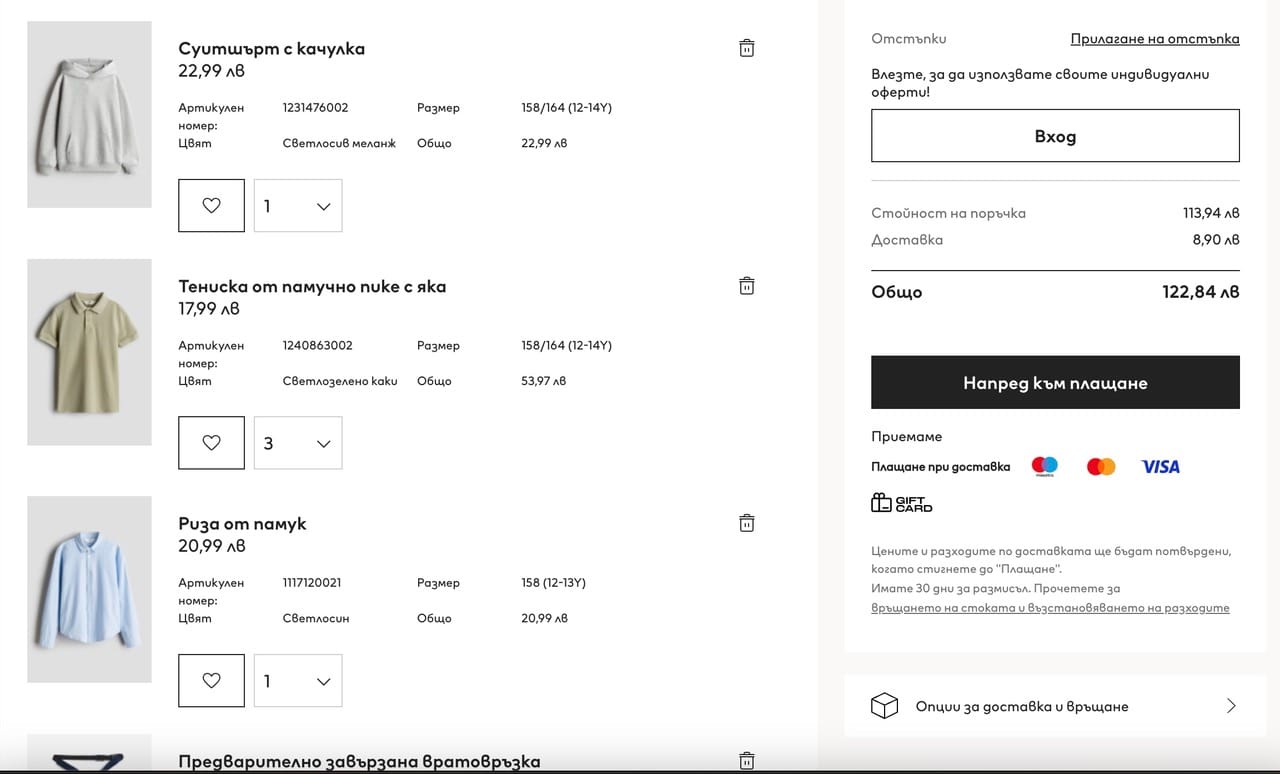
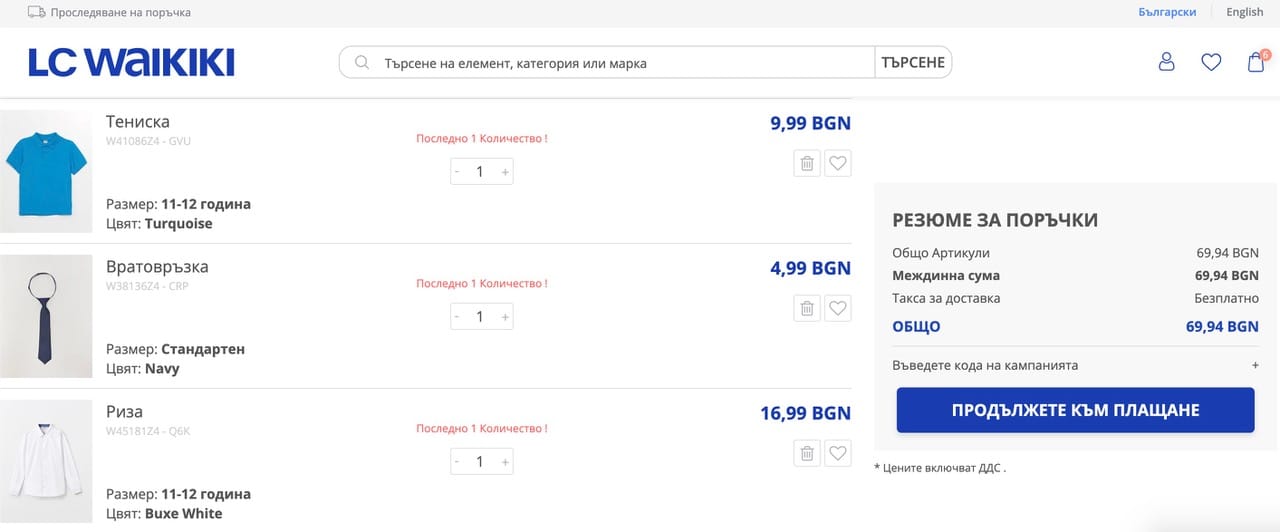
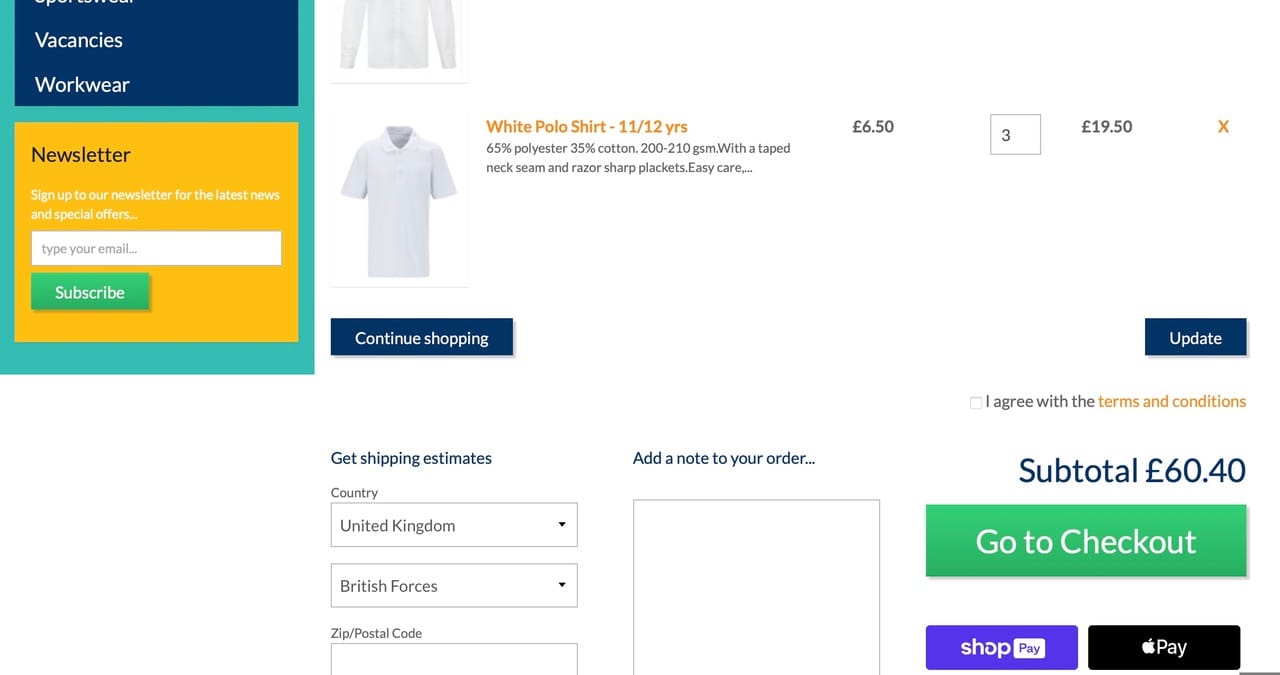






























 Mohammed Alkateb is an Engineering Manager at Amazon Redshift. Prior to joining Amazon, Mohammed had 12 years of industry experience in query optimization and database internals as an individual contributor and engineering manager. Mohammed has 18 US patents, and he has publications in research and industrial tracks of premier database conferences including EDBT, ICDE, SIGMOD and VLDB. Mohammed holds a PhD in Computer Science from The University of Vermont, and MSc and BSc degrees in Information Systems from Cairo University.
Mohammed Alkateb is an Engineering Manager at Amazon Redshift. Prior to joining Amazon, Mohammed had 12 years of industry experience in query optimization and database internals as an individual contributor and engineering manager. Mohammed has 18 US patents, and he has publications in research and industrial tracks of premier database conferences including EDBT, ICDE, SIGMOD and VLDB. Mohammed holds a PhD in Computer Science from The University of Vermont, and MSc and BSc degrees in Information Systems from Cairo University. Ramchandra Anil Kulkarni is a software development engineer who has been with Amazon Redshift for over 4 years. He is driven to develop database innovations that serve AWS customers globally. Kulkarni’s long-standing tenure and dedication to the Amazon Redshift service demonstrate his deep expertise and commitment to delivering cutting-edge database solutions that empower AWS customers worldwide.
Ramchandra Anil Kulkarni is a software development engineer who has been with Amazon Redshift for over 4 years. He is driven to develop database innovations that serve AWS customers globally. Kulkarni’s long-standing tenure and dedication to the Amazon Redshift service demonstrate his deep expertise and commitment to delivering cutting-edge database solutions that empower AWS customers worldwide. Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data.
Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data. Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.
Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.
