Post Syndicated from Pathik Shah original https://aws.amazon.com/blogs/big-data/query-aws-glue-data-catalog-views-using-amazon-athena-and-amazon-redshift/
Today’s data lakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption. However, with customers using different processing engines in their data lakes, each with its own version of views, they’re creating separate views per engine, adding to maintenance overhead. Furthermore, accessing these engine-defined views requires customers to have elevated access levels, granting them access to both the SQL view itself and the underlying databases and tables referenced in the view’s SQL definition. This approach impedes granting consistent access to a subset of data using SQL views, hampering productivity and increasing management overhead.
Glue Data Catalog views is a new feature of the AWS Glue Data Catalog that customers can use to create a common view schema and single metadata container that can hold view-definitions in different dialects that can be used across engines such as Amazon Redshift and Amazon Athena. By defining a single view object that can be queried from multiple engines, Data Catalog views enable customers to manage permissions on a single view schema consistently using AWS Lake Formation. A view can be shared across different AWS accounts as well. For querying these views, users need access to the view object only and don’t need access to the referenced databases and tables in the view definition. Further, all requests against the Data Catalog views, such as requests for access credentials on underlying resources, will be logged as AWS CloudTrail management events for auditing purposes.
In this blog post, we will show how you can define and query a Data Catalog view on top of open source table formats such as Iceberg across Athena and Amazon Redshift. We will also show you the configurations needed to restrict access to the underlying database and tables. To follow along, we have provided an AWS CloudFormation template.
Use case
An Example Corp has two business units: Sales and Marketing. The Sales business unit owns customer datasets, including customer details and customer addresses. The Marketing business unit wants to conduct a targeted marketing campaign based on a preferred customer list and has requested data from the Sales business unit. The Sales business unit’s data steward (AWS Identity and Access Management (IAM) role: product_owner_role), who owns the customer and customer address datasets, plans to create and share non-sensitive details of preferred customers with the Marketing unit’s data analyst (business_analyst_role) for their campaign use case. The Marketing team analyst plans to use Athena for interactive analysis for the marketing campaign and later, use Amazon Redshift to generate the campaign report.
In this solution, we demonstrate how you can use Data Catalog views to share a subset of customer details stored in Iceberg format filtered by the preferred flag. This view can be seamlessly queried using Athena and Amazon Redshift Spectrum, with data access centrally managed through AWS Lake Formation.
Prerequisites
For the solution in this blog post, you need the following:
- An AWS account. If you don’t have an account, you can create one.
- You have created a data lake administrator Take note of this role’s Amazon Resource Name (ARN) to use later. For simplicity’s sake, this post will use IAM Admin role as the Datalake Admin and Redshift Admin but make sure that in your environment you follow the principle of least privilege.
- Under Data Catalog settings, have the default settings in place. Both of the following options should be selected:
- Use only IAM access control for new databases
- Use only IAM access control for new tables in new databases
Get started
To follow the steps in this post, sign in to the AWS Management Console as the IAM Admin and deploy the following CloudFormation stack to create the necessary resources:
- Choose to deploy the CloudFormation template.

- Provide an IAM role that you have already configured as a Lake Formation administrator.
- Complete the steps to deploy the template. Leave all settings as default.
- Select I acknowledge that AWS CloudFormation might create IAM resources, then choose Submit.
The CloudFormation stack creates the following resources. Make a note of these values—you will use them later.
- Amazon Simple Storage Service (Amazon S3) buckets that store the table data and Athena query result
- IAM roles:
product_owner_roleandbusiness_analyst_role - Virtual private cloud (VPC) with the required network configuration, which will be used for compute
- AWS Glue database:
customerdb, which contains thecustomerandcustomer_addresstables in Iceberg format - Glue database:
customerviewdb, which will contain the Data Catalog views - Redshift Serverless cluster

The CloudFormation stack also registers the data lake bucket with Lake Formation in Lake Formation access mode. You can verify this by navigating to the Lake Formation console and selecting Data lake locations under Administration.
Solution overview
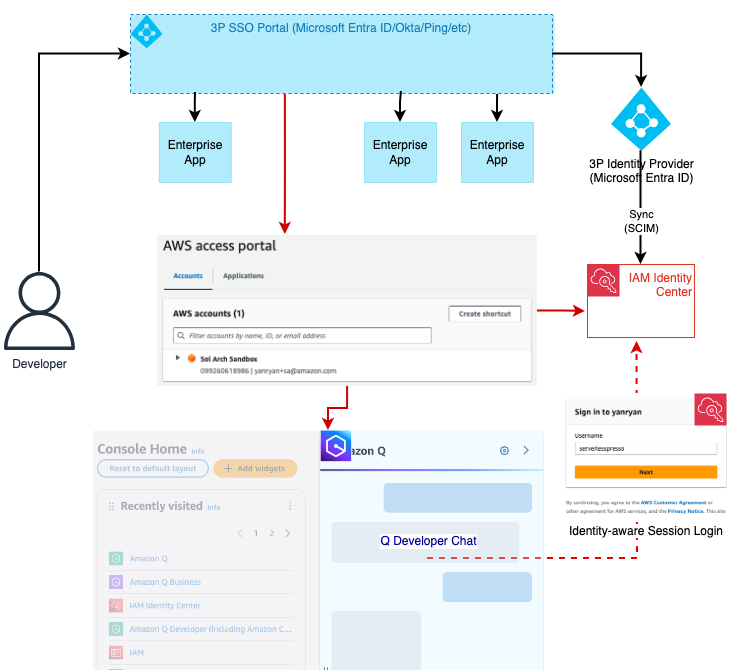
The following figure shows the architecture of the solution.

As a requirement to create a Data Catalog view, the data lake S3 locations for the tables (customer and customer_address) need to be registered with Lake Formation and granted full permission to product_owner_role.
The Sales product owner: product_owner_role is also granted permission to create views under customerviewdb using Lake Formation.
After the Glue Data Catalog View (customer_view) is created on the customer dataset with the required subset of customer information, the view is shared with the Marketing analyst (business_analyst_role), who can then query the preferred customer’s non sensitive information as defined by the view without having access to underlying customer tables.
- Enable Lake Formation permission mode on the
customerdbdatabaseand its tables. - Grant the database (
customerdb) and tables (customerandcustomer_address) full permission toproduct_owner_roleusing Lake Formation. - Enable Lake Formation permission mode on the database (
customerviewdb) where the multiple dialect Data Catalog view will be created. - Grant full database permission to
product_owner_roleusing Lake Formation. - Create Data Catalog views as
product_owner_roleusing Athena and Amazon Redshift to add engine dialects. - Share the database and Data Catalog views read permission to
business_analyst_roleusing Lake Formation. - Query the Data Catalog view using
business_analyst_rolefrom Athena and Amazon Redshift engine.
With the prerequisites in place and an understanding of the overall solution, you’re ready to set up the solution.
Set up Lake Formation permissions for product_owner_role
Sign in to the LakeFormation console as a data lake administrator. For the examples in this post, we use the IAM Admin role, Admin as the data lake admin.
Enable Lake Formation permission mode on customerdb and its tables
- In the Lake Formation console, under Data Catalog in the navigation pane, choose Databases.
- Choose customerdb and choose Edit.
- Under Default permissions for newly created tables, clear Use only IAM access control for new tables in this database.
- Choose Save.

- Under Data Catalog in the navigation pane, choose Databases.
- Select customerdb and under Action, select View
- Select the IAMAllowedPrincipal from the list and choose Revoke.

- Repeat the same for all tables under the database customerdb.


Grant the product_owner_role access to customerdb and its tables
Grant product_owner_role all permissions to the customerdb database.
- On the Lake Formation console, under Permissions in the navigation pane, choose Data lake permissions.
- Choose Grant.
- Under Principals, select IAM users and roles.
- Select product_owner_role.
- Under LF-Tags or catalog resources, select Named Data Catalog resourcesand select customerdb for Databases.
- Select SUPER for Database permissions.
- Choose Grant to apply the permissions.




Grant product_owner_role all permissions to the customer and customer_address tables.
- On the Lake Formation console, under Permissions in the navigation pane, choose Data lake permission
- Choose Grant.
- Under Principals, select IAM users and roles.
- Choose the product_owner_role.
- Under LF-Tags or catalog resources, choose Named Data Catalog resourcesand select customerdb for databases and customer and customer_address for tables.
- Choose SUPER for Table permissions.
- Choose Grant to apply the permissions.
Enable Lake Formation permission mode
Enable Lake Formation permission mode on the database where the Data Catalog view will be created.
- In the Lake Formation console, under Data Catalog in the navigation pane, choose Databases.
- Select customerviewdb and choose Edit.
- Under Default permissions for newly created tables, clear Use only IAM access control for new tables in this database.
- Choose Save.
- Choose Databases from Data Catalog in the navigation pane.
- Select customerviewdb and under Action select View.
- Select the IAMAllowedPrincipal from the list and choose Revoke.
Grant the product_owner_role access to customerviewdb using Lake Formation mode
Grant product_owner_role all permissions to the customerviewdb database.
- On the Lake Formation console, under Permissions in the navigation pane, choose Data lake permissions.
- Choose Grant
- Under Principals, select IAM users and roles.
- Choose product_owner_role
- Under LF-Tags or catalog resources, choose Named Data Catalog resourcesand select customerviewdb for Databases.
- Select SUPER for Database permissions.
- Choose Grant to apply the permissions.
Create Glue Data Catalog views as product_owner_role
Now that you have Lake Formation permissions set on the databases and tables, you will use the product_owner_role to create Data Catalog views using Athena and Amazon Redshift. This will also add the engine dialects for Athena and Amazon Redshift.
Add the Athena dialect
- In the AWS console, either sign in using
product_owner_roleor, if you’re already signed in as an Admin, switch toproduct_owner_role. - Launch query editor and select the workgroup athena_glueview from the upper right side of the console. You will create a view that combines data from the
customerandcustomer_addresstables, specifically for customers who are marked as preferred. The tables include personal information about the customer, such as their name, date of birth, country of birth, and email address. - Run the following in the query editor to create the
customer_viewview under thecustomerviewdbdatabase. - Run the following query to preview the view you just created.
- Run following query to find the top three birth years with the highest customer counts from the
customer_viewview and display the birth year and corresponding customer count for each.
Output:

- To validate that the view is created, go to the navigation pane and choose Views under Data catalog on the Lake Formation console
- Select customer_view and go to the SQL definition section to validate the Athena engine dialect.


When you created the view in Athena, it added the dialect for Athena engine. Next, to support the use case described earlier, the marketing campaign report needs to be generated using Amazon Redshift. For this, you need to add the Redshift dialect to the view so you can query it using Amazon Redshift as an engine.
Add the Amazon Redshift dialect
- Sign in to the AWS console as an Admin, navigate to Amazon Redshift console and sign in to Redshift Qurey editor v2.
- Connect to the Serverless cluster as Admin (federated user) and run the following statements to grant permission on the Glue automount database (
awsdatacatalog) access toproduct_owner_roleandbusiness_analyst_role. - Sign in to the Amazon Redshift console as
product_owner_roleand sign in to the QEv2 editor usingproduct_owner_role(as a federated user). You will use the following ALTER VIEW query to add the Amazon Redshift engine dialect to the view created previously using Athena. - Run the following in the query editor:
- Run following query to preview the view.
- Run the same query that you ran in Athena to find the top three birth years with the highest customer counts from the
customer_viewview and display the birth year and corresponding customer count for each.

By querying the same view and running the same query in Redshift, you obtained the same result set as you observed in Athena.
Validate the dialects added
Now that you have added all the dialects, navigate to the Lake Formation console to see how the dialects are stored.
- On the Lake Formation console, under Data catalog in the navigation pane, choose Views.
- Select customer_view and go to SQL definitions section to validate that the Athena and Amazon Redshift dialects have been added.


Alternatively, you can also create the view using Redshift to add Redshift dialect and update in Athena to add the Athena dialect.
Next, you will see how the business_analyst_role can query the view without having access to query the underlying tables and the Amazon S3 location where the data exists.
Set up Lake Formation permissions for business_analyst_role
Sign in to the Lake Formation console as the DataLake administrator (For this blog, we use the IAM Admin role, Admin, as the Datalake admin).
Grant business_analyst_role access to the database and view using Lake Formation
- On the Lake Formation console, under Permissions in the navigation pane, choose Data lake permissions.
- Choose Grant
- Under Principals, select IAM users and roles.
- Select business_analyst_role.
- Under LF-Tags or catalog resources, select Named Data Catalog resources and select customerviewdb for Databases.
- Select DESCRIBE for Database permissions.
- Choose Grant to apply the permissions.


Grant the business_analyst_role SELECT and DESCRIBE permissions to customer_view
- On the Lake Formation console, under Permissions in the navigation pane, choose Data lake permission.
- Choose Grant.
- Under Principals, select IAM users and roles.
- Select business_analyst_role.
- Under LF-Tags or catalog resources, choose Named Data Catalog resources and select customerviewdb for Databases and customer_view for Views.
- Choose SELECT and DESCRIBE for View permissions.
- Choose Grant to apply the permissions.
Query the Data Catalog views using business_analyst_role
Now that you have set up the solution, test it by querying the data using Athena and Amazon Redshift.
Using Athena
- Sign in to the Athena console as business_analyst_role.
- Launch query editor and select the workgroup athena_glueview. Select database customerviewdb from the dropdown on the left and you should be able to see the view created previously using
product_owner_role. Also, notice that no tables are shown becausebusiness_analyst_roledoesn’t have access granted for the base tables. - Run the following in the query editor to query the view query.


As you can see in the preceding figure, business_analyst_role can query the view without having access to the underlying tables.
- Next, query the table
customeron which the view is created. It should give an error.

Using Amazon Redshift
- Navigate to the Amazon Redshift console and sign in to Amazon Redshift query editor v2. Connect to the Serverless cluster as business_analyst_role (federated user) and run the following in the query editor to query the view.
- Select the customerviewdb on the left side of the console. You should see the view
customer_view. Also, note that you cannot see the tables from which the view is created. Run the following in the query editor to query the view.

The business analyst user can run the analysis on the Data Catalog view without needing access to the underlying databases and tables on from which the view is created.
Glue Data Catalog views offer solutions for various data access and governance scenarios. Organizations can use this feature to define granular access controls on sensitive data—such as personally identifiable information (PII) or financial records—to help them comply with data privacy regulations. Additionally, you can use Data Catalog views to implement row-level, column-level, or even cell-level filtering based on the specific privileges assigned to different user roles or personas, allowing for fine-grained data access control. Furthermore, Data Catalog views can be used in data mesh patterns, enabling secure, domain-specific data sharing across the organization for self-service analytics, while allowing users to use preferred analytics engines like Athena or Amazon Redshift on the same views for governance and consistent data access.
Clean up
To avoid incurring future charges, delete the CloudFormation stack. For instructions, see Deleting a stack on the AWS CloudFormation console. Ensure that the following resources created for this blog post are removed:
- S3 buckets
- IAM roles
- VPC with network components
- Data Catalog database, tables and views
- Amazon Redshift Serverless cluster
- Athena workgroup
Conclusion
In this post, we demonstrated how to use AWS Glue Data Catalog views across multiple engines such as Athena and Redshift. You can share Data Catalog views so that different personas can query them. For more information about this new feature, see Using AWS Glue Data Catalog views.
About the Authors
 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
 Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python.
Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python.
 Derek Liu is a Senior Solutions Architect based out of Vancouver, BC. He enjoys helping customers solve big data challenges through AWS analytic services.
Derek Liu is a Senior Solutions Architect based out of Vancouver, BC. He enjoys helping customers solve big data challenges through AWS analytic services.














 Noah Soprala is a Solutions Architect based out of Dallas. He is a trusted advisor to his customers in the ISV industry and helps them build innovative solutions using AWS technologies. Noah has over 20+ years of experience in consulting, development and solution delivery.
Noah Soprala is a Solutions Architect based out of Dallas. He is a trusted advisor to his customers in the ISV industry and helps them build innovative solutions using AWS technologies. Noah has over 20+ years of experience in consulting, development and solution delivery. Shovan Kanjilal is a Senior Analytics and Machine Learning Architect with Amazon Web Services. He is passionate about helping customers build scalable, secure and high-performance data solutions in the cloud.
Shovan Kanjilal is a Senior Analytics and Machine Learning Architect with Amazon Web Services. He is passionate about helping customers build scalable, secure and high-performance data solutions in the cloud. Shiv Narayanan is a Technical Product Manager for AWS Glue’s data management capabilities like data quality, sensitive data detection and streaming capabilities. Shiv has over 20 years of data management experience in consulting, business development and product management.
Shiv Narayanan is a Technical Product Manager for AWS Glue’s data management capabilities like data quality, sensitive data detection and streaming capabilities. Shiv has over 20 years of data management experience in consulting, business development and product management. Jesus Max Hernandez is a Software Development Engineer at AWS Glue. He joined the team after graduating from The University of Texas at El Paso, and the majority of his work has been in frontend development. Outside of work, you can find him practicing guitar or playing flag football.
Jesus Max Hernandez is a Software Development Engineer at AWS Glue. He joined the team after graduating from The University of Texas at El Paso, and the majority of his work has been in frontend development. Outside of work, you can find him practicing guitar or playing flag football. Tyler McDaniel is a software development engineer on the AWS Glue team with diverse technical interests, including high-performance computing and optimization, distributed systems, and machine learning operations. He has eight years of experience in software and research roles.
Tyler McDaniel is a software development engineer on the AWS Glue team with diverse technical interests, including high-performance computing and optimization, distributed systems, and machine learning operations. He has eight years of experience in software and research roles. Andrius Juodelis is a Software Development Engineer at AWS Glue with a keen interest in AI, designing machine learning systems, and data engineering.
Andrius Juodelis is a Software Development Engineer at AWS Glue with a keen interest in AI, designing machine learning systems, and data engineering.