Post Syndicated from Margaret Wei original https://blog.rapid7.com/2023/12/21/whats-new-in-rapid7-products-services-2023-year-in-review/

Throughout 2023 Rapid7 has made investments across the Insight Platform to further our mission of providing security teams with the tools to proactively anticipate imminent risk, prevent breaches earlier, and respond faster to threats. In this blog you’ll find a review of our top releases from this past year, all of which were purpose-built to bring your team a holistic, unified approach to security operations and command of your attack surface.
Proactively secure your environment
Endpoint protection with next-gen antivirus in Managed Threat Complete
To provide protection against both known and unknown threats, we released multilayered prevention with Next-Gen Antivirus in Managed Threat Complete. Available through the Insight Agent, you’re immediately able to:
- Block known and unknown threats early in the kill chain
- Halt malware that’s built to bypass existing security controls
- Maximize your security stack and ROI with existing Insight Agent
- Leverage the expertise of our MDR team to triage and investigate these alerts
New capabilities to help prioritize risk in your cloud and on-premise environments and effectively communicate risk posture
As the attack surface expands, we know it’s critical for you to have visibility into vulnerabilities across your hybrid environments and communicate it with your executive and remediation stakeholders. This year we made a series of investments in this area to help customers better visualize, prioritize, and communicate risk.
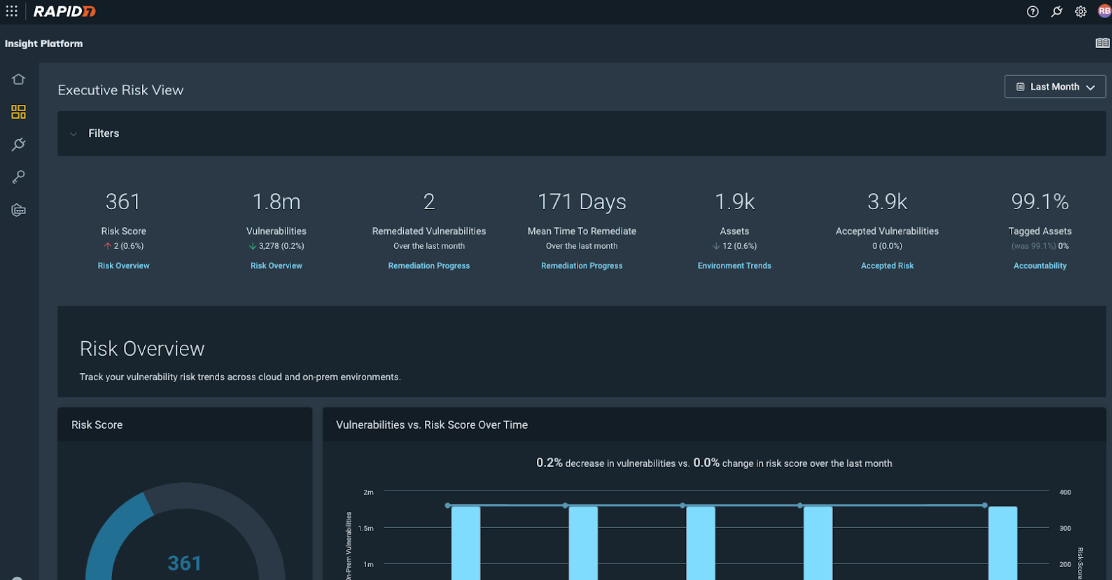
- Executive Risk View, available as a part of Cloud Risk Complete, provides security leaders with the visibility and context needed to track total risk across cloud and on-premises assets to better understand organizational risk posture and trends.
- Active Risk, our new vulnerability risk-scoring methodology, helps security teams prioritize vulnerabilities that are actively exploited or most likely to be exploited in the wild. Our approach enriches the latest version of the Common Vulnerability Scoring System (CVSS) with multiple threat intelligence feeds, including intelligence from proprietary Rapid7 Labs research. Active Risk normalizes risk scores across cloud and on-premises environments within InsightVM, InsightCloudSec, and Executive Risk View.
- The new risk score in InsightCloudSec’s Layered Context makes it easier for you to understand the riskiest resources within your cloud environment. Much like Layered Context, the new risk score combines a variety of risk signals – including Active Risk – and assigns a higher risk score to resources that suffer from toxic combinations or multiple risk vectors that present an increased likelihood or impact of compromise.
- Two new dashboard cards in InsightVM to help security teams communicate risk posture cross-functionally and provide context on asset and vulnerability prioritization:
- Vulnerability Findings by Active Risk Score Severity – ideal for executive reporting, this dashboard card indicates total number of vulnerabilities across the Active Risk severity levels and number of affected assets and instances.
- Vulnerability Findings by Active Risk Score Severity and Publish Age – ideal for sharing with remediation stakeholders to assist with prioritizing vulnerabilities for the next patch cycle, or identifying critical vulnerabilities that may have been missed.
Coverage and expert analysis for critical vulnerabilities with Rapid7 Labs
Rapid7 Labs provides easy-to-use threat intelligence and guidance, curated by our industry-leading attack experts, to the security teams.
Emergent Threat Response (ETR) program, part of Rapid7 Labs, provides teams with accelerated visibility, alerting, and guidance on high-priority threats. Over this past year we provided coverage and expert analysis within 24 hours for over 30 emergent threats, including Progress Software’s MOVEit Transfer solution where our security research team was one of the first to detect exploitation—four days before the vendor issued public advisory. Keep up with future ETRs on our blog here.
Detect and prioritize threats anywhere, from the endpoint to the cloud
Enhanced alert details in InsightIDR Investigations
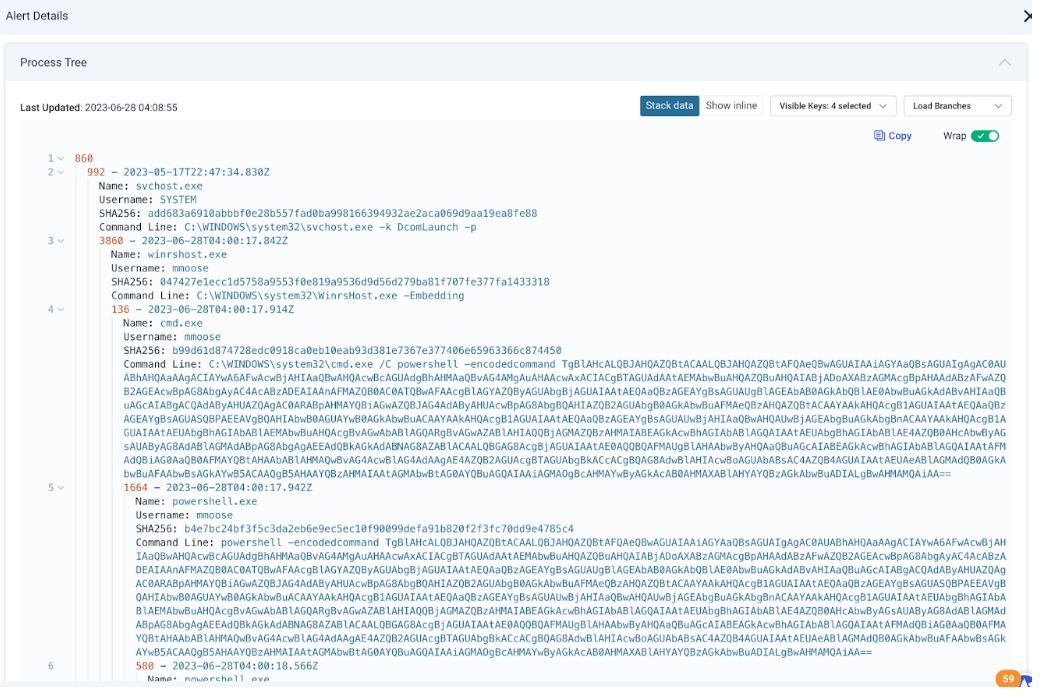
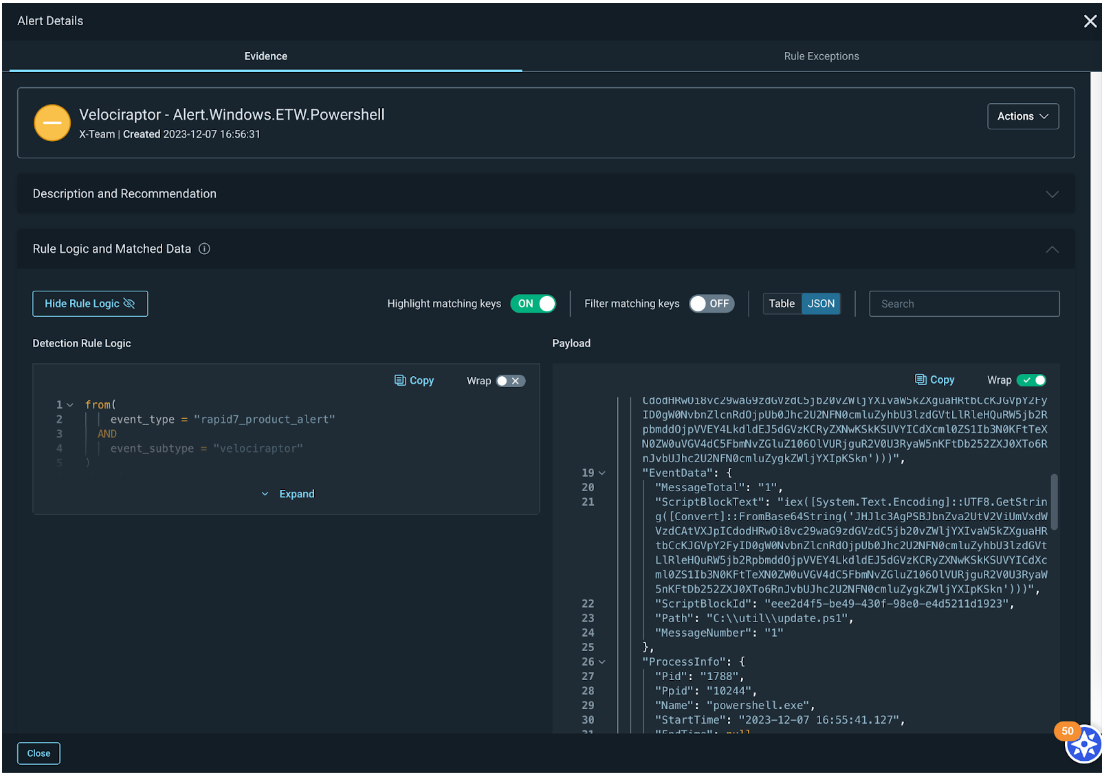
An updated evidence panel for attacker behavior analytics (ABA) alerts gives you a description of the alert and recommendations for triage, rule logic that generated the alert and associated data, and a process tree (for MDR customers) to show details about what occurred before, during, and after the alert was generated.
AI-driven detection of anomalous activity with Cloud Anomaly Detection
Cloud Anomaly Detection provides AI-driven detection of anomalous activity occurring across your cloud environments, with automated prioritization to assess the likelihood that activity is malicious. With Cloud Anomaly Detection, your team will benefit from:
- A consolidated view that aggregates threat detections from CSP-native detection engines and Rapid7’s AI-driven proprietary detections.
- Automated prioritization to focus on the activity that is most likely to be malicious.
- The ability to detect and respond to cloud threats using the same processes and tools your SOC teams are using today with easy API-based ingestion into XDR/SIEM tools for threat investigations and prioritizing remediation efforts.
Detailed views into risks across your cloud environment with Identity Analysis and Attack Path Analysis
We’re constantly working to improve the ways with which we provide a real-time and comprehensive view of your current cloud risk posture. This year, we made some major strides in this area, headlined by two exciting new features:
- Identity Analysis provides a unified view into identity-related risk across your cloud environments, allowing you to achieve least privileged access (LPA) at scale. By utilizing machine learning (ML), Identity Analysis builds a baseline of access patterns and permissions usage, and then correlates the baseline against assigned permissions and privileges. This enables your team to identify overly-permissive roles or unused access so you can automatically right-size permissions in accordance with LPA.
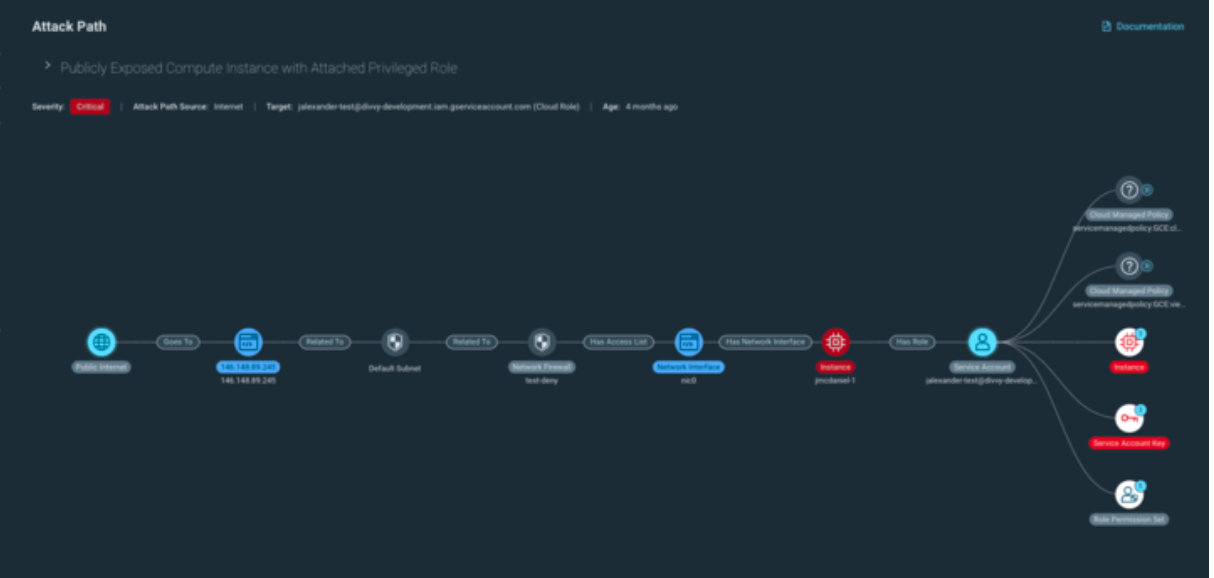
- Attack Path Analysis enables you to analyze relationships between resources and quickly identify potential avenues bad actors could navigate within your cloud environment to exploit a vulnerable resource and/or access sensitive information. This visualization helps teams communicate risk across the organization, particularly for non-technical stakeholders that may find it difficult to understand why a compromised resource presents a potentially larger risk to the business.
More flexible alerting with Custom Detection Rules
Every environment, industry, and organization can have differing needs when it comes to detections. With custom detection rules in InsightIDR, you can detect threats specific to your needs while take advantage of the same capabilities that are available for out-of-the-box detection rules, including:
- The ability to set a rule action and rule priority to choose how you are alerted when your rule detects suspicious activity.
- The ability to add exceptions to your rule for specific key-value pairs.
A growing library of actionable detections in InsightIDR
In 2023 we added over 3,000 new detection rules. See them in-product or visit the Detection Library for descriptions and recommendations.
Agent-Based Policy supports custom policy assessment in InsightVM
Guidelines from Center for Internet Security (CIS) and Security Technical Implementation Guides (STIG) are widely used industry benchmarks for configuration assessment. However, a benchmark or guideline as-is may not meet the unique needs of every business.
Agent-Based Policy assessment now supports Custom Policies. Global Administrators can customize built-in policies, upload policies, or enable a copy of existing custom policies for agent-based assessments. Learn more here.
Investigate and respond with confidence
Faster containment and remediation of threats with expansion of Active Response for Managed Detection and Response customers
Attackers work quickly and every second you wait to take action can have detrimental impacts on your environment. Enter automation—Active Response enables Rapid7 SOC analysts to immediately quarantine assets and users in a customer’s environment with response actions powered by InsightConnect, Rapid7’s SOAR solution.
Active Response has you covered to quarantine via our Insight Agent, as well as a variety of third-party providers—including Crowdstrike and SentinelOne. And with MDR analyst actions logged directly in InsightIDR, you have more expansive, collaborative detection and response faster than ever before. Read what Active Response can do for your organization—and how it stopped malware in a recent MDR Investigation—here.
Velociraptor integrates with InsightIDR for broader DFIR coverage
The attack surface is continually expanding, and so should your visibility into potential threats across it. This year we integrated Velociraptor, Rapid7’s open-source DFIR framework, with our Insight Platform to bring the data you need for daily threat monitoring and hunting into InsightIDR for investigation via our Insight Agent.
This integration brings you faster identification and remediation, always-on monitoring for threat activity across your endpoint fleet, and expanded threat detection capabilities. Read more about what this integration unlocks here.
Stay tuned!
As always, we’re continuing to work on exciting product enhancements and releases throughout the year. Keep an eye on our blog and release notes as we continue to highlight the latest in product and service investments at Rapid7. See you in 2024!











 Alex Naumov is a Principal Data Architect at smava GmbH, and leads the transformation projects at the Data department. Alex previously worked 10 years as a consultant and data/solution architect in a wide variety of domains, such as telecommunications, banking, energy, and finance, using various tech stacks, and in many different countries. He has a great passion for data and transforming organizations to become data-driven and the best in what they do.
Alex Naumov is a Principal Data Architect at smava GmbH, and leads the transformation projects at the Data department. Alex previously worked 10 years as a consultant and data/solution architect in a wide variety of domains, such as telecommunications, banking, energy, and finance, using various tech stacks, and in many different countries. He has a great passion for data and transforming organizations to become data-driven and the best in what they do. Lingli Zheng works as a Business Development Manager in the AWS worldwide specialist organization, supporting customers in the DACH region to get the best value out of Amazon analytics services. With over 12 years of experience in energy, automation, and the software industry with a focus on data analytics, AI, and ML, she is dedicated to helping customers achieve tangible business results through digital transformation.
Lingli Zheng works as a Business Development Manager in the AWS worldwide specialist organization, supporting customers in the DACH region to get the best value out of Amazon analytics services. With over 12 years of experience in energy, automation, and the software industry with a focus on data analytics, AI, and ML, she is dedicated to helping customers achieve tangible business results through digital transformation. Alexander Spivak is a Senior Startup Solutions Architect at AWS, focusing on B2B ISV customers across EMEA North. Prior to AWS, Alexander worked as a consultant in financial services engagements, including various roles in software development and architecture. He is passionate about data analytics, serverless architectures, and creating efficient organizations.
Alexander Spivak is a Senior Startup Solutions Architect at AWS, focusing on B2B ISV customers across EMEA North. Prior to AWS, Alexander worked as a consultant in financial services engagements, including various roles in software development and architecture. He is passionate about data analytics, serverless architectures, and creating efficient organizations.













 Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems leveraging new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket.
Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems leveraging new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket. Shunsuke Goto is a Prototyping Engineer working at AWS. He works closely with customers to build their prototypes and also helps customers build analytics systems.
Shunsuke Goto is a Prototyping Engineer working at AWS. He works closely with customers to build their prototypes and also helps customers build analytics systems.