In 2016, I wrote about an Internet that affected the world in a direct, physical manner. It was connected to your smartphone. It had sensors like cameras and thermostats. It had actuators: Drones, autonomous cars. And it had smarts in the middle, using sensor data to figure out what to do and then actually do it. This was the Internet of Things (IoT).
The classical definition of a robot is something that senses, thinks, and acts—that’s today’s Internet. We’ve been building a world-sized robot without even realizing it.
In 2023, we upgraded the “thinking” part with large-language models (LLMs) like GPT. ChatGPT both surprised and amazed the world with its ability to understand human language and generate credible, on-topic, humanlike responses. But what these are really good at is interacting with systems formerly designed for humans. Their accuracy will get better, and they will be used to replace actual humans.
In 2024, we’re going to start connecting those LLMs and other AI systems to both sensors and actuators. In other words, they will be connected to the larger world, through APIs. They will receive direct inputs from our environment, in all the forms I thought about in 2016. And they will increasingly control our environment, through IoT devices and beyond.
It will start small: Summarizing emails and writing limited responses. Arguing with customer service—on chat—for service changes and refunds. Making travel reservations.
But these AIs will interact with the physical world as well, first controlling robots and then having those robots as part of them. Your AI-driven thermostat will turn the heat and air conditioning on based also on who’s in what room, their preferences, and where they are likely to go next. It will negotiate with the power company for the cheapest rates by scheduling usage of high-energy appliances or car recharging.
This is the easy stuff. The real changes will happen when these AIs group together in a larger intelligence: A vast network of power generation and power consumption with each building just a node, like an ant colony or a human army.
Future industrial-control systems will include traditional factory robots, as well as AI systems to schedule their operation. It will automatically order supplies, as well as coordinate final product shipping. The AI will manage its own finances, interacting with other systems in the banking world. It will call on humans as needed: to repair individual subsystems or to do things too specialized for the robots.
Consider driverless cars. Individual vehicles have sensors, of course, but they also make use of sensors embedded in the roads and on poles. The real processing is done in the cloud, by a centralized system that is piloting all the vehicles. This allows individual cars to coordinate their movement for more efficiency: braking in synchronization, for example.
These are robots, but not the sort familiar from movies and television. We think of robots as discrete metal objects, with sensors and actuators on their surface, and processing logic inside. But our new robots are different. Their sensors and actuators are distributed in the environment. Their processing is somewhere else. They’re a network of individual units that become a robot only in aggregate.
This turns our notion of security on its head. If massive, decentralized AIs run everything, then who controls those AIs matters a lot. It’s as if all the executive assistants or lawyers in an industry worked for the same agency. An AI that is both trusted and trustworthy will become a critical requirement.
This future requires us to see ourselves less as individuals, and more as parts of larger systems. It’s AI as nature, as Gaia—everything as one system. It’s a future more aligned with the Buddhist philosophy of interconnectedness than Western ideas of individuality. (And also with science-fiction dystopias, like Skynet from the Terminator movies.) It will require a rethinking of much of our assumptions about governance and economy. That’s not going to happen soon, but in 2024 we will see the first steps along that path.
Преди месец един привидно битов проблем – липса на топла вода – привлече внимание към проблемите на Клиниката по детска клинична хематология и онкология в УМБАЛ „Царица Йоанна“ в София. Проблемите там обаче не се изчерпват с топлата вода и много от тях са с десетилетна давност – лоши битови условия, стара апаратура, недостиг на персонал, а оттам и на грижи (повече може да прочетете в статия по темата в „Свободна Европа“).
Този разговор ще ви срещне с Николай и Мария. Преди седем години те загубиха Марина, която почина от левкемия на 11 години. Николай и Мария лекуваха детето си в София и Франкфурт и бяха едно от малкото семейства, които се бориха не само с болестта на дъщеря си, но и с българската здравна система на всичките ѝ нива. Днес продължават да разказват, за да се знае какво заслужават децата и семействата им в най-трудните си моменти. И да дадат кураж.
Преди месец правих интервю с майка на детенце, което в момента се лекува в Клиниката по детска клинична хематология и онкология в София. Разговорът завърши със споделянето, че родителите често не смеят да говорят за нередностите, защото се страхуват, че ако отделението затвори, децата им ще останат без лечение…
Николай:А всъщност може би това е по-добрият шанс за децата, защото, като затвори отделението тук, държавата ще е принудена да ги лекува навън. Това, с което разполагаме в София, не е болница. Тази сграда е била пансион за активни борци. Битовите условия не са глезотия, когато става дума за съвременна медицина. В съществуващата клиника стаите са толкова малки, че болнична (лежаща) количка не може да влезе вътре. Когато дъщеря ни се лекуваше там, се наложи персоналът да я пренесе на ръце до леглото ѝ веднага след като ѝ беше направена гръбначна пункция например. Това е много рисково; по принцип след пункция детето трябва да лежи по гръб поне два часа.
А как изглеждаше битът в клиниката във Франкфурт?
Мария: Там за цялото отделение, около 20 стаи, има 3–4 сестри, още толкова болногледачи и отделно санитари. Говоря за персонала на смяна, не общо – това беше в онкологичното отделение. В трансплантационното за всяка стая имаше по една сестра на смяна.
Но да започнем с физическото пространство. Там имаше единични и двойни стаи. Единичните бяха около 9–10 квадрата, двойните – точно два пъти по-големи, просто каквото го има в единичната, е огледално по две. В единичната стая има легло, масичка с два стола и гардероб. Всяка стая има баня с тоалетна, душкабина и мивка. Особено важна роля играе преддверието. То е отделено от коридора с една врата и от стаята с втора врата. Между тях има мивка, заредена с всякакви консумативи, шкафове и закачалки. Когато влезе лекар или сестра, измива се, слага маска и ръкавици, които стоят в кутиите отстрани, облича престилка, която е за тази стая и виси на закачалката, взема стетоскоп – също индивидуален за стаята, и влиза. За детето има също индивидуален кантар, термометър. След като медикът си свърши работата в тази стая, излиза в преддверието, изхвърля маската и ръкавиците, съблича престилката и я оставя на закачалката, мие се и продължава нататък. Така всичко остава в същата стая и рискът от пренос на инфекции се свежда до минимум.
Това важи и за почистването. В България майките са длъжни да поддържат стаите чисти. В Германия влизат с голяма количка. От торбата с чисти кърпи се вади една, почиства се подът на стаята и кърпата се хвърля в друга торба. Вади се втора кърпа, почиства се банята, хвърля се и тя.
Николай: Парцалите после се перат и се дезинфекцират, но всеки се ползва само по веднъж и само за едно помещение, а после отиват за пране. Престилките, за които спомена Мария, се сменят задължително на 24 часа. Всички чешми са оборудвани с филтър и нефилтрирана вода не тече.
Мария: Също така настилката на пода и препаратите, с които почистват, са такива, че като влезеш, лепне под краката ти. Така всичко буквално залепва за пода, не се вдига прах. Докато бяхме в трансплантационното отделение, донесоха на Марина един бебешки стерилизатор. В него трябваше на всеки 24 часа да си стерилизира четката за зъби.
Различаваше ли се медицинската техника в стаите?
Николай:В Германия навсякъде имаше медицински монитори. Всяко легло беше оборудвано със стационарен, а заедно бяха в система, която можеше да се проследи от всяка друга стая. Тоест ако сестрата обслужва едно дете и някъде се включи аларма, сестрата може от стаята, в която работи, да провери какви са показателите на детето, при което се е включила алармата, за да прецени как да действа.
Когато нещата се влошиха и Марина беше преместена в интензивен сектор, ни направи впечатление, че се работи с всякаква мобилна техника до леглото на детето. Не чакат да започне работното време на рентгенолозите, примерно, не местят детето напред-назад.
За да не се налага сестрата да влиза многократно, защото това повишава рисковете, в стерилния сектор перфузорите и инфузоматите (машините, които регулират вливането на лекарствата) бяха изнесени в преддверието. В стаята през стената влизаха две гъвкави тръбички, които се поставят на пациента.
Какво си спомняте за пътя на пациента в клиниката във Франкфурт? Как децата минават през различни процедури, какво ви направи впечатление?
Мария: Опитът ни от България беше, че детето се води в манипулационната, там се прави каквото се прави, и се връща в стаята. В Германия за такива неща идва екипът, моли родителя да изчака отвън и манипулацията се извършва в самата стая.
Николай: Когато има нещо по-голямо – например когато на Марина трябваше да ѝ слагат порт за централен източник, я изведоха от стаята заедно с леглото до асансьора, през едни подземни коридори стигнаха до другия корпус, където е детската хирургия – може би близо километър разстояние. И после по обратния път я върнаха, без да е напускала леглото си.
А в София родителите често карат децата си от ИСУЛ до „Пирогов“ за поставяне на централен венозен източник с личните си автомобили.
Мария: И когато лекувахме Марина в България, беше така. Ние ходихме от София до Пловдив, защото лекарят, който може да извърши тази манипулация в „Пирогов“, отсъстваше за една-две седмици. Централният венозен път, или източник, е медицинско изделие, има различни видове. Той осигурява път до централната куха вена и оттам се вливат лекарствата, но не навсякъде могат да го поставят, особено на дете.
Николай:Когато отидохме в Германия, подмениха централния източник на Марина. Този, който ѝ бяха поставили в България, беше подкожен. За всяко вливане се достъпваше с игла, беше по-труден за обслужване и имаше по-висок риск от инфекции, въпреки че, от друга страна, с него можеше без проблем да се къпе, дори да плува. В Германия ѝ сложиха друго устройство. То представлява две тръбички, които излизат над гърдите, и лекарствата се вливат директно в тях.
По време на лечението на Марина във Франкфурт имаше ли някакви други, парамедицински дейности, които се извършваха в болницата? Рехабилитация например? Или социални дейности?
Мария: Това е част от ангажимента на хора, които идват всекидневно да се занимават детето. Тяхната цел е и да подпомогнат процеса на раздвижване. Например след химиотерапия Марина не можеше изобщо да стои права. Къпех я седнала на стол. Просто тялото няма никакви сили.
Николай: Бяха ни обяснили, че за тях е важно да поддържат детето в кондиция, да не допускат да се отпусне напълно. Два пъти седмично имаше задължително някаква двигателна активност, дали ще е някакъв степер, дали велоергометър. Дори след трансплантацията в стаята ѝ имаше велоергометър.
Имаше ли специалисти, които изрично подпомагат немедицинските процеси – комуникация, социализация…
Мария: Да. И тук, и в Германия има психологическа помощ. По наше време разликата в нивото беше осезаема, не знам как е сега.
Николай: Нещо, което за нас беше много интересно – в отделението за трансплантации за около 15 души персонал имаше трима психолози на щат в клиниката. Само за тях. Психологът за децата е съвсем отделен човек. Ранната смъртност при техните пациенти е много висока, до 20%. Както каза един приятел, не може 1/5 от хлапетата, които лекуваш, да ти умират в ръцете, и ти да останеш човек без никаква помощ.
Мария: Както споменах, и тук, и там, но не по един и същи начин имаше някаква грижа за забавление на децата. Там всеки ден идваха специално назначени хора, които за час или два да занимават детето. В България заниманията бяха според възможностите, организирани са от едно сдружение на майки на деца с онкологични заболявания.
Как стоеше въпросът с образованието? Лечението на онкологичните заболявания продължава понякога повече от година.
Мария: Мога да кажа за България. През 2015 г. все още функционираше болнично училище и в определени дни от седмицата идваха преподаватели да се занимават с по-големите деца. Добра идея. Не чак толкова добро изпълнение. Сега вече няма и това.
Оттам нататък, тъй като на децата им е забранено да ходят на училище дори и в периодите между хоспитализациите, те трябва да минат на самостоятелно обучение. Още един проблем за детето. Защото когато директорката не иска да си мръдне пръста, за да организира индивидуална подготовка или дори само изпити, какво правим? Марина беше изпаднала в нервна криза от това, че може да повтаря годината и да не е с приятелите си в клас. Защото дори и да учеше непрекъснато, нямаше кой да ѝ осигури възможност да се яви на изпит след това.
Как протичаше комуникацията ви с медиците във Франкфурт около всички тези процеси? Вие сте българи в германска клиника, разбирате се на английски, но отвъд езиковите разлики как комуникирахте с персонала?
Николай:Страшно лесно. За разлика от България.
Мария: Те бяха щастливи, когато поискахме за първи път резултати от кръвна картина. Бяха изключително доволни, че се интересуваме, че питаме как ще протече трансплантацията и т.н.
Николай: Няма да забравя думите на Щефан, лекуващия ѝ лекар: „Аз безкрайно се радвам, че вие се интересувате от лечението на вашата дъщеря.“ И сяда и обяснява…
Тук, когато попитах за протокола, по който ще бъде лекувана, отговорът беше „Вие не сте медицинско лице, няма да го разберете.“
Мария: Същия отговор чувахме и дори едни резултати от кръвна картина като поискаме.
Николай: В Германия, когато зададохме същия въпрос, два часа по-късно имахме препис на целия „чаршаф“, с индивидуалните корекции в дозите, нанесени специално за Марина, всичко разписано как е правено до момента. В България се борихме два месеца за тази информация и никога не я получихме.
А Марина беше ли част от тази комуникация, на нея някой обясняваше ли ѝ нещо?
Николай: Отношението към Марина беше като към възрастен. Всички разговори се водеха с нея. Лекарите говореха директно с нея, в наше присъствие. Тя беше на 11 години тогава.
Мария: Беше с отличен английски и нямаше проблем да си говори с тях. Аз помагах с някоя думичка или ми обясняваха някакъв процес, когато тя не можеше да го разбере, но като цяло се говореше с нея. Включително големия разговор, че предстои трансплантация, какви рискове носи тя, беше проведен лично с нея. Това беше единственият разговор, в който изискаха да има преводач. Болницата го намери и му плати, защото по това време Фондът за лечение на деца вече не плащаше за преводачи и аз обясних, че нито знам къде да намеря преводач, нито мога да му платя.
Какъв беше режимът на свижданията?
Николай:В общото отделение – абсолютно свободен. Единствената забрана беше да влизат деца под 12 години заради по-трудния контрол върху хигиената.
В трансплантационния сектор и в реанимацията също можеше да се влезе по всяко време, но достъпът там беше оторизиран – трябва да звъннеш и да ти отворят, не може просто да влезеш. В стерилния сектор имаше списък от трима души, които можеха да влизат, на другите места нямаше такива ограничения.
Мария: Там бяха на мнение, че колкото повече време детето е с родителите си, колкото повече подкрепа получава, толкова по-добре за него.
Николай: Аз се опитах да кажа на Карен, психоложката, че съм допълнителна опасност, нещо, което в България чуваме всекидневно, а тя отвърна: „Няма такова нещо. Детето ти има нужда от теб – да знае, че си до него, че го обичаш, за да се държи в кондиция, така че мястото ти е тук.“
Очевидно клиниката в София и тази във Франкфурт не си приличат по нищо. И все пак, ако трябва да изберете едно нещо, което ви е впечатлило най-много, кое ще е то? Каква е най-голямата разлика?
Николай: Според мен отношението.
Мария: И според мен. Това беше най-важното. На мен не ми тежи да почистя. Ще отида да извикам сестрата, ако не е чула звънеца. Ще си донесем храна. Но отношението и на помощния персонал, и на лекари и сестри е съвсем различно там. Не те гледат като натрапник, сякаш им отнемаш от свободното време. Като че ли те са богове, а ти в момента им се пречкаш.
Николай: Около месец след като вече всичко беше приключило, една вечер намерихме картичка в пощенската кутия. Разпознахме хора от 4 различни отделения в детската клиника във Франкфурт – детската онкология, центъра за трансплантации, дневния стационар и интензивното. Сред тях и подписите на светила в детската онкохематология в световен мащаб – професор Бадер, Ева Ретингер, Андреа Яриш, Ян Зьоренсен. И после нека някой пак ми каже, че нямало разлика в отношението…
След интервюто помолих Николай да ползвам откъс от някой от разказите му в социалните мрежи за конкретни случки, с които да онагледя „разликите“. Той сподели тази история от последните моменти с дъщеря им:
„На 2 януари (2017 г. – б.а.) телефонът звънна и Нина (сестрата) каза: „Има сериозни проблеми с Марина, елате.“ Заварихме 3 банки струйно да вливат кръв във вените на хлапето, пищяха аларми на машините – ЕКМО-то нямаше достатъчно кръв, за да работи. От дренажа на десния бял дроб изтекоха близо 5 литра кръв. Както ни казаха по-късно – кървяла е отвсякъде – дробове, бъбреци, черен дроб…
Тогава за първи път ни намериха място при нея, докато целият екип беше в стаята (основното правило там е, когато лекари и сестри имат работа с пациента, родителите са извън стаята). Направиха ни място между тях от двете страни, не вярваха, че ще се справи.
С много риск и за нея, и за апаратурата, успяха да спрат кръвотечението със съсирващ фактор. За деня ѝ бяха влели 11 литра кръвни продукти в опит да я спасят… Марина пак успя да се закрепи. Шефът на интензивното, доктор Шнайдер, ни каза следното: „Ние много се радваме, че Марина оцеля и този път, но ситуацията е критична. Няма да вкарваме тези медикаменти отново, защото рискът е прекалено голям.“ За съжаление, през нощта Марина започна да кърви отново.
Молех се цяла нощ до нея да преживее до сутринта и Шнайдер и компания да успеят да измислят нещо. На сутринта, след прегледа, се събраха лекари откъде ли не заедно с психолози. Шнайдер каза: „За съжаление, повече шансове за нея не виждаме, можем само да ѝ помогнем да си отиде без болка.“
Помня, че с Мария свалихме ръкавиците и маските и я прегърнахме, докато изключваха апаратурата.“
В рубриката „Разговори за здравеопазването“ Надежда Цекулова кани своите събеседници да поговорят без клишета и празнодумие за проблемите и решенията, болката и оздравяването, медицината и политиката.
Wietse Venema posted a note to the postfix-users mailing list about the 25th anniversary of the Postfix mail server. As can be seen, it had a pivotal role in bringing more awareness of open-source software to IBM. Beyond that, of course, it is an excellent piece of software in its own right.
As a few on this list may recall, it is 25 years ago today that the
“IBM secure mailer” had its public beta release. This was accompanied
by a nice article in the New York Times business section.
There is some literature at https://www.postfix.org/press.html that
attests how this project accelerated open-source adoption by a very
large company.
That release was even noticed by a small publication in its first year of operation.
Мисля си – хич не се разбираме напоследък за лявото и дясното. Кое диктаторско, кое не. Кое свободно, кое не. Кое умно, кое не. Кое свястно, кое не… Откъде дойде тая бъркотия?
Моите 5 ст. – от технологично-икономическия прогрес.
Политическите измамници с мераци да станат диктатори винаги са били популисти. До степен всеки друг да изглежда на техен фон не-популист, така че това си е само тяхна категория.
Но и така имат избор – леви или десни? Е, поне е лесен. Където има повече наивни и тъпи хора, които по-лесно може да бъдат излъгани.
От зората на изборната демокрация – да кажем, 1800-те – та докъм средата, че и края на втората трета на 20 век, това място беше лявото. Там бяха бедните. Които не бяха имали как да се образоват, бяха видиотени от мизерия, притиснати дотам да вярват на евтини лъжи – накратко, електоратът на измамника кандидат-диктатор. Десните през тези времена бяха интелигентните, образованите, културните, мислещите, свободните да избират разумно.
Затова и през тези времена политическите измамници носеха „леви“ маски. И диктатури разцъфваха където идваше на власт тяхното „ляво“. И овладените от тях държави – Русия/СССР, Китай, Северна Корея… – също носеха „леви“ маски. Е, под маските установяваха феодално-робовладелски общества…
С напредъка на технологично-икономическия прогрес обаче нещата се промениха. Бедните получиха достатъчно възможност да се образоват, да не са видиотени от мизерия и готови да вярват на идиотски лъжи. И не всички, но много от тях престанаха. Започнаха да се опитват да мислят и избират разумно – не винаги успешно, но принципно с желание и донякъде с потенциал.
Десните пък не можаха да понесат натиска на ускоряващия се прогрес – те по начало по не носят на промени. Започнаха да си слагат дебели капаци на очите, за да се отградят от него колкото могат. Но това ги отгради и от възможностите да се образоват и да са актуални. А и масово не знаеха, че в комплект с капаците вървят и седло, юзда и камшик.
И политическите измамници с диктаторските мераци се преместиха при тях. Нахлупиха „десни“ маски, както преди нахлупваха „леви“. (Много от тях са съвсем буквално бивши „леви“ – леви тогава колкото сега са десни, естествено. Примерно Тръмп е бивш регистриран поддръжник на Демократическата партия.) Подпомогнати от славата на разумно и мъдро, която си беше създало дясното на фона на олайненото от тях ляво…
Обективно тези хора не са нито леви, нито десни – те са измамници с амбиции. Ще ви лъжат с на каквото вярвате, няма да ги е гнус или да им пречи. Да, обективно изгражданата от тях система е по-близка до дясна, отколкото до лява – феодализмът неизбежно е по-десен и консервативен и от най-екстремния съвременен капитализъм. С твърде много, за да си струва да се мисли дали е по-десен или по-ляв. Той просто е добър само за феодалите.
(И само ако те са психопати. Нормалният човек не изпитва радост, че той има какво да яде, но хиляди нямат. Нито че е успял да ликвидира съседа си и да му вземе къщата или феода. Нито пък му се нрави да живее живот, в който няма да оцелее и месец без дузина гвардейци, дето да го пазят и в тоалетната, и без човек, който да опитва храната му преди него, да не е отровена. Защото феодализмът е така. Каквато музиката, такова хорото.)
Та, пазете се от тия измамници. Включително и особено ако ви се пробутват за „свои“. Съседът ви на другия край на идеологическия спектър обикновено няма да ви наклевети, за да ви прати в затвора и да ви вземе дома. Тези „свои“ ще ви вземат не само дома – всичко. Докато ви гледат в очите и усмихнато ви обясняват колко мъдри сте, щом ги подкрепяте, и колко много печелите така…
Amazon Web Services (AWS) is excited to announce the availability of a new sponsored report from S&P Global Market Intelligence 451 Research, Centralized Trust for Decentralized Uses: Revisiting Private Certificate Authorities. We heard from customers actively seeking centralized management solutions for multi-cloud environments and worked with 451 Research, a technology research solution that provides a holistic view of opportunities and risks across the enterprise technology landscape, to dive into this topic.
In the report, 451 Research highlights the need for centralized trust as organizations build applications across multiple cloud providers, local infrastructure, and distributed hosting environments. For security practitioners familiar with certificate authorities (CAs), this report looks at some of the wider business implications of using cryptographic certificates to establish trust in highly decentralized and dynamic environments.
451 Research explains how decentralized architectures, including technologies such as Kubernetes, service meshes, and Internet of Things (IoT) networks, are fueling the need to modernize the legacy approach to CAs. The growing adoption of cloud native solutions from a multitude of vendors leads to a greater decentralization of applications. According to the survey Voice of the Enterprise: DevOps, Developer Experience 2023, 59% of respondent companies have architected more than 50% of their applications with cloud-native technologies.
Organizations and developers can use the report to consider the following:
Security and trust models, including zero-trust principles so that every component authenticates every other component with a bidirectional motion, even within private networks.
This post is written by Jeff Gebhart, Sr. Specialist TAM, Serverless.
AWS Lambda now supports Python 3.12 as both a managed runtime and container base image. Python 3.12 builds on the performance enhancements that were first released with Python 3.11, and adds a number of performance and language readability features in the interpreter. With this release, Python developers can now take advantage of these new features and enhancements when creating serverless applications on AWS Lambda.
You can use Python 3.12 with Powertools for AWS Lambda (Python), a developer toolkit to implement Serverless best practices such as observability, batch processing, Parameter Store integration, idempotency, feature flags, CloudWatch Metrics, and structured logging among other features.
You can also use Python 3.12 with Lambda@Edge, allowing you to customize low-latency content delivered through Amazon CloudFront.
Python is a popular language for building serverless applications. The Python 3.12 release has a number of interpreter and syntactic improvements.
At launch, new Lambda runtimes receive less usage than existing, established runtimes. This can result in longer cold start times due to reduced cache residency within internal Lambda sub-systems. Cold start times typically improve in the weeks following launch as usage increases. As a result, AWS recommends not drawing conclusions from side-by-side performance comparisons with other Lambda runtimes until the performance has stabilized. Since performance is highly dependent on workload, customers with performance-sensitive workloads should conduct their own testing, instead of relying on generic test benchmarks.
Lambda runtime changes
Amazon Linux 2023
The Python 3.12 runtime is based on the provided.al2023 runtime, which is based on the Amazon Linux 2023 minimal container image. This OS update brings several improvements over the Amazon Linux 2 (AL2)-based OS used for Lambda Python runtimes from Python 3.8 to Python 3.11.
provided.al2023 contains only the essential components necessary to install other packages and offers a smaller deployment footprint of less than 40MB compared to over 100MB for Lambda’s AL2-based images.
With glibc version 2.34, customers have access to a modern version of glibc, updated from version 2.26 in AL2-based images.
The Amazon Linux 2023 minimal image uses microdnf as a package manager, symlinked as dnf. This replaces the yum package manager used in earlier AL2-based images. If you deploy your Lambda functions as container images, you must update your Dockerfiles to use dnf instead of yum when upgrading to the Python 3.12 base image.
Additionally, curl and gnupg2 are also included as their minimal versions curl-minimal and gnupg2-minimal.
Starting with the Python 3.12 runtime, functions return Unicode characters as part of their JSON response. Previous versions return escaped sequences for Unicode characters in responses.
For example, in Python 3.11, if you return a Unicode string such as “こんにちは”, it escapes the Unicode characters and returns “\u3053\u3093\u306b\u3061\u306f”. The Python 3.12 runtime returns the original “こんにちは”.
This change reduces the size of the payload returned by Lambda. In the previous example, the escaped version is 32 bytes compared to 17 bytes with the Unicode string. Using Unicode responses reduces the size of Lambda responses, making it easier to fit larger responses into the 6MB Lambda response (synchronous) limit.
When upgrading to Python 3.12, you may need to adjust your code in other modules to account for this new behavior. If the caller expects escaped Unicode based on the previous runtime behavior, you must either add code to the returning function to escape the Unicode manually, or adjust the caller to handle the Unicode return.
Extensions processing for graceful shutdown
Lambda functions with external extensions can now benefit from improved graceful shutdown capabilities. When the Lambda service is about to shut down the runtime, it sends a SIGTERM signal to the runtime and then a SHUTDOWN event to each registered external extension.
These events are sent each time an execution environment shuts down. This allows you to catch the SIGTERM signal in your Lambda function and clean up resources, such as database connections, which were created by the function.
To learn more about the Lambda execution environment lifecycle, see Lambda execution environment. More details and examples of how to use graceful shutdown with extensions is available in the AWS Samples GitHub repository.
New Python features
Comprehension inlining
With the implementation of PEP 709, dictionary, list, and set comprehensions are now inlined. Prior versions create a single-use function to execute such comprehensions. Removing this overhead results in faster comprehension execution by a factor of two.
There are some behavior changes to comprehensions because of this update. For example, a call to the ‘locals()’ function from within the comprehension now includes objects from the containing scope, not just within the comprehension itself as in prior versions. You should test functions you are migrating from an earlier version of Python to Python 3.12.
Typing changes
Python 3.12 continues the evolution of including type annotations to Python. PEP 695 includes a new, more compact syntax for generic classes and functions, and adds a new “type” statement to allow for type alias creation. Type aliases are evaluated on demand. This permits aliases to refer to other types defined later.
Type parameters are visible within the scope of the declaration and any nested scopes, but not in the outer scope.
Formalization of f-strings
One of the largest changes in Python 3.12, the formalization of f-strings syntax, is covered under PEP 701. Any valid expression can now be contained within an f-string, including other f-strings.
In prior versions of Python, reusing quotes within an f-string results in errors. With Python 3.12, quote reuse is fully supported in nested f-strings such as the following example:
>>>songs = ['Take me back to Eden', 'Alkaline', 'Ascensionism']
>>>f"This is the playlist: {", ".join(songs)}"
'This is the playlist: Take me back to Eden, Alkaline, Ascensionism'
Additionally, any valid Python expression can be contained within an f-string. This includes multi-line expressions and the ability to embed comments within an f-string.
Before Python 3.12, the “\” character is not permitted within an f-string. This prevented use of “\N” syntax for defining escaped Unicode characters within the body of an f-string.
Asyncio improvements
There are a number of improvements to the asyncio module. These include performance improvements to writing of sockets and a new implementation of asyncio.current_task() that can yield a 4–6 times performance improvement. Event loops now optimize their child watchers for their underlying environment.
Using Python 3.12 in Lambda
AWS Management Console
To use the Python 3.12 runtime to develop your Lambda functions, specify a runtime parameter value Python 3.12 when creating or updating a function. The Python 3.12 version is now available in the Runtime dropdown in the Create Function page:
To update an existing Lambda function to Python 3.12, navigate to the function in the Lambda console and choose Edit in the Runtime settings panel. The new version of Python is available in the Runtime dropdown:
AWS Lambda container image
Change the Python base image version by modifying the FROM statement in your Dockerfile:
FROM public.ecr.aws/lambda/python:3.12
# Copy function code
COPY lambda_handler.py ${LAMBDA_TASK_ROOT}
Customers running the Python 3.12 Docker images locally, including customers using AWS SAM, must upgrade their Docker install to version 20.10.10 or later.
AWS Serverless Application Model (AWS SAM)
In AWS SAM set the Runtime attribute to python3.12 to use this version.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Simple Lambda Function
MyFunction:
Type: AWS::Serverless::Function
Properties:
Description: My Python Lambda Function
CodeUri: my_function/
Handler: lambda_function.lambda_handler
Runtime: python3.12
AWS SAM supports generating this template with Python 3.12 for new serverless applications using the `sam init` command. Refer to the AWS SAM documentation.
AWS Cloud Development Kit (AWS CDK)
In AWS CDK, set the runtime attribute to Runtime.PYTHON_3_12 to use this version. In Python CDK:
from constructs import Construct
from aws_cdk import ( App, Stack, aws_lambda as _lambda )
class SampleLambdaStack(Stack):
def __init__(self, scope: Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
base_lambda = _lambda.Function(self, 'SampleLambda',
handler='lambda_handler.handler',
runtime=_lambda.Runtime.PYTHON_3_12,
code=_lambda.Code.from_asset('lambda'))
In TypeScript CDK:
import * as cdk from 'aws-cdk-lib';
import * as lambda from 'aws-cdk-lib/aws-lambda'
import * as path from 'path';
import { Construct } from 'constructs';
export class CdkStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// The code that defines your stack goes here
// The python3.12 enabled Lambda Function
const lambdaFunction = new lambda.Function(this, 'python311LambdaFunction', {
runtime: lambda.Runtime.PYTHON_3_12,
memorySize: 512,
code: lambda.Code.fromAsset(path.join(__dirname, '/../lambda')),
handler: 'lambda_handler.handler'
})
}
}
Conclusion
Lambda now supports Python 3.12. This release uses the Amazon Linux 2023 OS, supports Unicode responses, and graceful shutdown for functions with external extensions, and Python 3.12 language features.
Python 3.12 runtime support helps developers to build more efficient, powerful, and scalable serverless applications. Try the Python 3.12 runtime in Lambda today and experience the benefits of this updated language version.
For more serverless learning resources, visit Serverless Land.
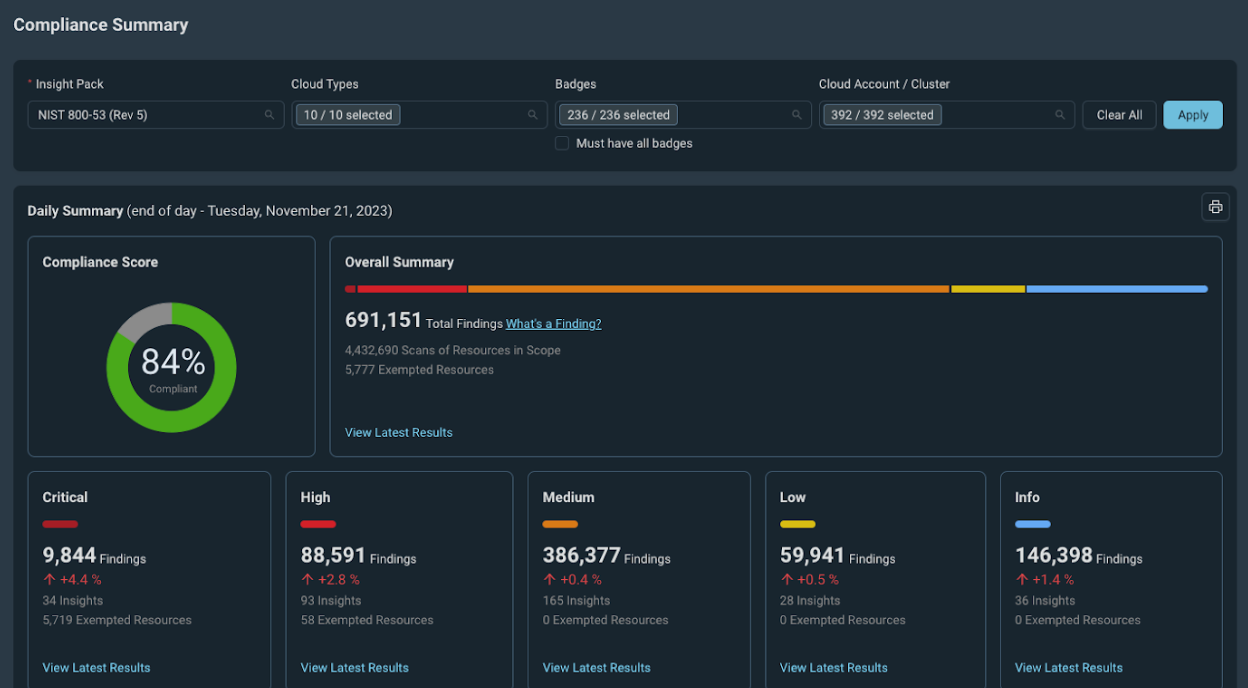
On November 6th, the National Institute of Standards and Technology (NIST) issued an update to SP 800-53, a NIST-curated catalog of controls that organizations can implement to effectively manage security and privacy risk. In this blog we’ll cover the new and updated controls within patch release 5.1.1, as well as review how Rapid7 InsightCloudSec helps security teams implement and continuously enforce them across their organizations. Let’s dive right in.
Updates to NIST SP 800-53 Compliance Pack: What You Need to Know About Revision 5.1.1
Unlike the large revision that occurred a few years back when Revision 5 was released – which brought with it nearly 270 control updates in aggregate – this update doesn’t have quite the far-reaching implications. That said, there are a few changes to be aware of. Release 5.1.1 added one new control with three supporting control enhancements, along with some minor grammar and formatting structure changes to other existing controls. Organizations are not mandated to implement the new control and have the option to defer implementation until SP 800-53 Release 6.0.0 is issued, however there is no defined timeline for when 6.0.0 will be released.
While there is no mandate at this time, the team here at Rapid7 generally advises our customers to adopt new patch releases immediately to ensure alignment with the most up-to-date best practices and that your team is covered for emerging attack vectors. In this case, we recommend adopting 5.1.1 primarily to ensure you’re effectively implementing encryption and authentication controls across your environment.
The newly-added control is Identification and Authentication (or IA-13) which states that organizations should “Employ identity providers and authorization servers to manage user, device, and non-person entity (NPE) identities, attributes, and access rights supporting authentication and authorization decisions.”
IA-13 has been broken down by NIST into three supporting control enhancements:
IA-13 (01) – Cryptographic keys that protect access tokens are generated, managed, and protected from disclosure and misuse.
IA-13 (02) – The source and integrity of identity assertions and access tokens are verified before granting access to system and information resources.
IA-13 (03) – Assertions and access tokens are continuously refreshed, time-restricted, audience-restrained and revoked when necessary and after a defined period of non-use.
So, what does all that mean? Put simply, organizations should implement controls to effectively track and manage user and system entity permissions to ensure only authorized users are permitted access to corporate systems or data. This includes the proper use of encryption, hygiene and lifecycle management for access tokens.
This is, of course, a much needed and community-requested addition that speaks to the growing awareness and criticality of implementing checks and guardrails to mitigate identity-related risk. A key component of this equation is implementing a solution that can help you detect areas of your cloud environment that haven’t fully implemented these controls. This can be a particularly challenging thing to manage in a cloud environment, given its democratized nature, the sheer volume of identities and permissions that need to be managed and the ease with which improper allocation of permissions and privileges can occur.
Implement and Continuously Enforce NIST SP 800-53 Rev. 5 with InsightCloudSec
InsightCloudSec allows security teams to establish and continuously measure compliance against organizational policies, whether they’re based on service provider best practices, a common industry framework, or a custom pack tailored to specific business needs.
A compliance pack within InsightCloudSec is a set of checks that can be used to continuously assess your cloud environments for compliance with a given regulatory framework, or industry or provider best practices. The platform comes out of the box with 40+ compliance packs, including a dedicated pack for NIST SP 800-53 Rev. 5.1.1, which now provides an additional 14 insights that align to the newly-added IA-13.
The dedicated pack provides 367 Insights checking against 128 NIST SP 800-53 Rev. 5.1.1 requirements that assess your multi cloud environment for compliance with the controls outlined by NIST. With extensive support for various resource types across all major cloud service providers (CSPs), security teams can confidently implement and continuously enforce compliance with SP 800-53 Rev 5.1.1.
InsightCloudSec continuously assesses your entire multi-cloud environment for compliance with one or more compliance packs and detects noncompliant resources within minutes after they are created or an unapproved change is made. If you so choose, you can make use of the platform’s native, no-code automation to contact the resource owner, or even remediate the issue—either via deletion or by adjusting the configuration or permissions—without any human intervention.
For more information about how to use InsightCloudSec to implement and enforce compliance standards like those outlined in NIST SP 800-53 Rev. 5.1.1, be sure to check out the docs page! For more on our cloud identity and access management capabilities, we’ve got some additional information on that here.
At the end of Q3 2023, Backblaze was monitoring 263,992 hard disk drives (HDDs) and solid state drives (SSDs) in our data centers around the world. We’ve reported on those drives for many years. But, all the data on those drives needs to somehow get from your devices to our storage servers. You might be wondering, “How does that happen?” and “Where does that happen?” Or, more likely, “How fast does that happen?”
These are all questions we want to start to answer.
Welcome to our new Backblaze Network Stats series, where we’ll explore the world of network connectivity and how we better serve our customers, partners, and the internet community at large. We hope to share our challenges, initiatives, and engineering perspective as we build the open cloud with our Partners.
In this first post, we will explore two issues: how we connect our network with the internet and the distribution of our peering traffic. As we expand this series, we hope to capture and share more metrics and insights.
Nice to Meet You; I’m Brent
Since this is the first time you’re hearing from me, I thought I should introduce myself. I’m a Senior Network Engineer here at Backblaze. The Network Engineering group is responsible for ensuring the reliability, capacity, and security of network traffic.
My interest in computer networking began in my childhood when I first persuaded my father to upgrade our analog modem to a ISDN line by providing a financial comparison of time sink due to large download times I was conducting (nothing like using all the family dial-up time to download multi-megabyte SimCity 2000 and Doom customizations). Needless to say, I’m still interested in those same types of networking metrics, and that’s why I’m here sharing them with you at Backblaze.
First, Some Networking Basics
If you’ve ever heard folks joke about the internet being a series of tubes, well, it may be widely mocked, but it’s not entirely wrong. The internet as we know it is fundamentally a complex network of all the computers on the planet. Whenever we’re typing in an internet address into a web browser, we’re basically giving our computer the address of a computer (or server, etc.) to locate, and that computer will hopefully display data to you that it’s storing.
Of course, it’s not a free-for-all. Internet protocols like TLS/SSL are the boundaries that set the rules for how computers communicate, and networks allow different levels of access to outsiders. Internet service providers (ISPs) are defined and regulated, and we’ll outline some of those roles and how Backblaze interacts with them below. But, all that communication between computers has to be powered by hardware, which is why, at one point, we actually had to solve the problem of sharks attacking the internet. Good news: since 2006, sharks have accounted for less than one percent of fiber optic cable attacks.
Wireless internet has largely made this connectivity invisible to consumers, but the job of Wi-Fi is to broadcast a short-range network that connects you to this series of cables and “tubes.” That’s why when you’re transmitting or storing larger amounts of data, you typically get better speeds when you use a wired connection. (A good consumer example: setting up NAS devices works better with an ethernet cable.)
When you’re talking about storing and serving petabytes of data for a myriad of use cases, then you have to create and use different networks to connect to the internet effectively. Think of it like water: both a fire hose and your faucet are connected to utility lines, but they have to move different amounts of water, so they have different kinds of connections to the main utility.
And, that brings us to peering, the different levels of internet service providers, and many, many more things that Backblaze Network Engineers deal with from both a hardware and a software perspective on a regular basis.
What Is Peering?
Peering on the internet is akin to building direct express lanes between neighborhoods. Instead of all data (residents) relying on crowded highways (public internet), networks (neighborhoods) establish peering connections—dedicated pathways connecting them directly. This allows data to travel faster and more efficiently, reducing congestion and delays. Peering is like having exclusive lanes, streamlining communication between networks and enhancing the overall performance of the internet “transportation” system.
We connect to various types of networks to help move your data. I’ll explain the different types below.
The Bit Exchange
Every day we move multiple petabytes of traffic between our internet connectivity points and our scalable data center fabric layer to be delivered to either our SSD caching layer (what we call a “shard stash”) or spinning hard drives for storage.
Our data centers are connected to the world in three different ways.
1. Direct Internet Access (DIA)
The most common way we reach everyone is via a DIA connection with a Tier 1 internet service provider. These connections give us access to long-haul, high-capacity fiber infrastructure that spans continents and oceans. Connecting to a Tier 1 ISP has the advantage of scale and reach, but this scale comes at a cost—we may not have the best path to our customers.
If we draw out the hierarchy of networks that we have to traverse to reach you, it would look like a series of geographic levels (Global, Regional, and Local). The Tier 1 ISPs would be positioned at the top, leasing bandwidth on their networks to smaller Tier 2 and Tier 3 networks, which are closer to our customer’s home and office networks.
How we get from B to C (Backblaze to customer).
Since our connections to the Tier 1 ISPs are based on leased bandwidth, we pay based on how much data we transfer. The bill grows the more we transfer. There are commitments and overage charges, and the relationship is more formal since a Tier 1 ISP is a for-profit company. Sometimes you just want unlimited bandwidth, and that’s where the role of the internet exchange (IX) helps us.
2. Internet Exchange (IX)
We always want to be as close to the client as possible and our next connectivity option allows us to join a community of peers that exchange traffic more locally. Peering with an IXmeans that network traffic doesn’t have to bubble up to a Tier 1 National ISP to eventually reach a regional network. If we are on an advantageous IX, we transfer data locally inside a data center or within the same data center campus, thus reducing latency and improving the overall experience.
Benefits of an IX, aka the “Unlimited Plan,” include:
Paying a flat rate per month to get a fiber connection to the IX equipment versus paying based on how much data we transfer.
No price negotiation based on bandwidth transfer rates.
No overage charges.
Connectivity to lower tiered networks that are closer to consumer and business networks.
Participation helps build a more egalitarian internet.
In short, we pay a small fee to help the IX remain financially stable, and then we can exchange as much or as little traffic as we want.
Our network connectivity standard is to connect to multiple Tier 1 ISPs and a localized IX at every location to give us the best of both solutions. Every time we have to traverse a network, we’re adding latency and increasing the total amount of time for a file to upload or download. Internet routing prefers the shortest path, so if we have a shorter (faster) way to reach you, we will talk over the IX versus the Tier 1 network.
Less is more—the fewer networks between us and you, the better.
3. Private Network Interconnect (PNI)
The most direct and lowest latency way for us to exchange traffic is with a PNI. This option is used for direct fiber connections within the same data center or metro region to some of our specific partners like Fastly and Cloudflare. Our edge routing equipment—that is, the appliances that allow us to connect our internal network to external networks—is connected directly to our partner’s edge routing equipment. To go back to our neighborhood analogy, this would be if you and your friend put a gate in the fences that connect your backyards. With a PNI, the logical routing distance between us and our partners is the best it can be.
IX Participation
Personally, the internet exchange path is the most exciting for me as a network engineer. It harkens back to the days of the early internet (IX points began as Network Access Points and were a key component of Al Gore’s National Information Infrastructure (NII) plan way back in 1991), and the growth of an IX feels communal, as people are joining to help the greater whole. When we add our traffic to an IX as a new peer, it increases participation, further strengthening the advantage of contributing to the local IX and encouraging more organizations to join.
Backblaze Joins the Equinix Silicon Valley (SV1) Internet Exchange
Our San Jose data center is a major point of presence (PoP) (that is, a point where a network connects to the internet) for Backblaze, with the site connecting us in the Silicon Valley region to many major peering networks.
In November, we brought up connectivity to Equinix IX peering exchange in San Jose, bringing us closer to 278 peering networks at the time of publishing. Many of the networks that participate on this IX are very logically close to our customers. The participants are some of the well known ISPs that serve homes, offices, and business in the region, including Comcast, Google Fiber, Sprint, and Verizon.
Now, for the Stats
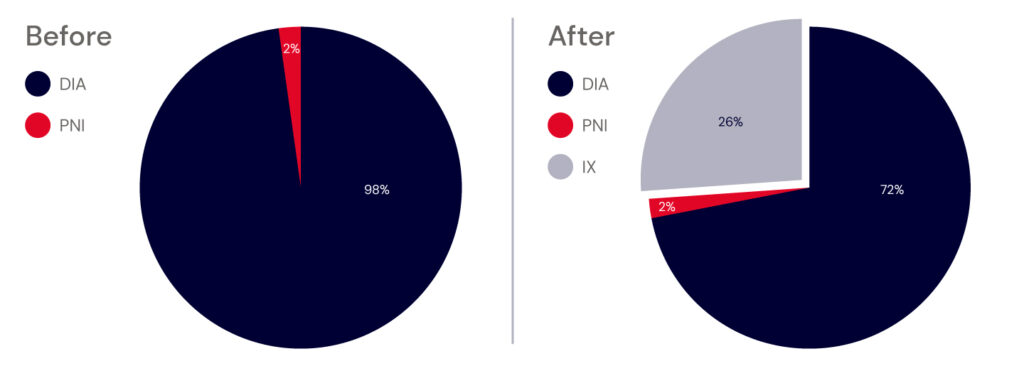
As soon as we turned up the connection, 26% inbound traffic that was being sent to our DIA connections shifted to the local Equinix IX, as shown in the pie chart below.
Before: 98% direct internet access (DIA); 2% private network interconnect (PNI). After: 72% DIA; 2% PNI; 26% internet exchange (IX).
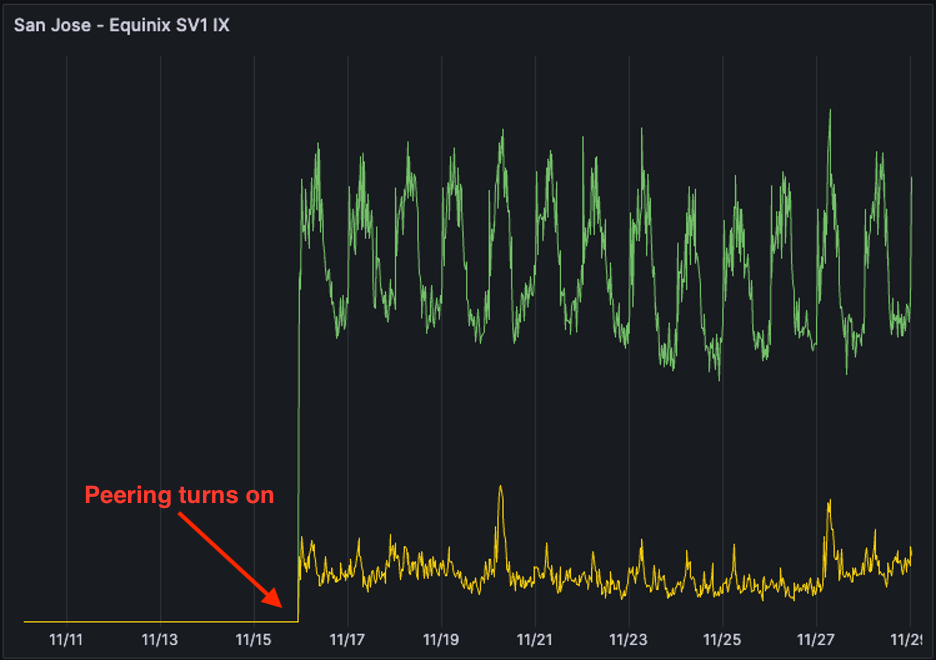
The below graph shows our peering traffic load over the edge router and how immediately the traffic pattern changed as soon as we brought up the peer. Green indicates inbound traffic, while yellow shows outbound traffic. It’s always exciting to see a project go live with such an immediate reaction!
To give you an idea of what we mean by better network proximity, let’s take a look at our improved connectivity to Google Fiber. Here’s a diagram of the three pathways that our edge routers see that show how to get to Google Fiber. With the new IX connection, we see a more advantageous path and pick that as our method to exchange traffic. We no longer have to send traffic to the Tier 1 providers and can use them as backup paths.
Taking faster local roads.
What Does This Mean for You?
We here at Backblaze are always trying to improve the performance and reliability of our storage platform while scaling up. We monitor our systems for inefficiencies, and improving the network components is one way that we can deliver a better experience.
By joining the Equinix SV1 peering exchange, we shorten the number of network hops that we have to transit to communicate with you. And that reduces latency, speeding up your backup job upload, allowing for faster image download, or supporting Partners.
Cheers from the NetEng team! We’re excited to start this series and bring you more content as our solutions evolve and grow. Some of the coverage we hope to share in the future includes analyzing our proximity to our peers and Partners, how we can improve those connections further, and stats to show the amount of bits per second that we process in our data centers to ensure that we not only have a file, but all the related redundancy shard components related to it. So, stay tuned!
Earlier this summer Netflix held our first-ever Data Engineering Forum. Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community!
You can find each of the talks below with a short description of each, or you can go straight to the playlist on YouTube here.
Chris Stephens, Data Engineer, Content & Studio and Pedro Duarte, Software Engineer, Consolidated Logging walk engineers new to Netflix through the building blocks of the Netflix Data Engineering stack. Learn more about how batch and streaming data pipelines are built at Netflix.
Lee Woodridge and Pallavi Phadnis, Data Engineers at Netflix, talk about how you can apply different processing strategies for your batch pipelines by implementing generic abstractions to help scale, be more efficient, handle late-arriving data, and be more fault tolerant.
Mark Cho, Guil Pires and Sujay Jain, Engineers from the Netflix Data Platform talk about how a managed Streaming SQL using Apache Flink can help unlock new Stream Processing use cases at Netflix. You can read more about Data Mesh, Netflix’s next-generation stream processing platform, here
Holden Karau, OSS Engineer, Data Platform Engineering, talks about the importance of reliable data pipelines and how to build them covering tools from testing to validation and auditing. The talk uses Apache Spark as an example, but the concepts generalize regardless of your specific tools.
Tristan Reid, software engineer, shares experiences about the Knowledge Management project at Netflix, which seeks to leverage language modeling techniques and metadata from internal systems to improve the impact of the >100K memos that circulate within the company.
Abhinaya Shetty and Bharath Mummadisetty, Data Engineers from Netflix’s Membership Data Engineering team, introduce Psyberg, an incremental ETL framework. Learn about how Psyberg leverages Iceberg metadata to handle late-arriving data, and improves data pipelines while simplifying on-call life!
Judit Lantos, Data Engineer, Member Experience Data Engineering, shares a case study to demonstrate an effective approach for optimizing complex ETL jobs.
In the last 2 decades, Netflix has revolutionized the way video content is consumed, however, there is significant work to be done in revolutionizing how movies and tv shows are made. In this video, Sr. Data Engineers Amanual Kahsay and Dao Mi showcase how data and insights are being utilized to accomplish such a vision.
We hope that our fellow members of the Data Engineering Community find these videos useful and engaging. Please follow our Netflix Data Twitter account for updates and notifications of future Data Engineering Summits!
Всеки от нас има нездрав интерес към поне едно място, на което никога не е бил. Необяснимо е, но то ни привлича, откакто се помним. И градим една мистична и романтична представа, която непрекъснато обогатяваме с книгите, филмите и историите за него. E, Япония никога не е била такова място за мен. Но въпреки това я посетих. И тя реши да ме опровергае и да ми покаже колко мистична и романтична е всъщност.
Ден 1
Преди година и осем месеца – в сутринта, в която щях да се кача на полета за Лима и да сбъдна една от мечтите си, като посетя Перу, Путин направи немислимото и нападна Украйна. Година и осем месеца по-късно отново се качваме на 12-часов полет. Този път обаче летим на изток. И войната под нас не е една, а са две. Две, ако не броим онези забравените, за които не говорим. Географски предопределеното съчувствие е един от най-циничните феномени на човешкия вид. Разбира се, може и да е икономически предопределено – още по-цинично.
Говорейки за цинични феномени: летим над Русия. В небето ѝ съм просто пътник, на земята – чуждестранен агент. Или да си го кажем направо – враг. На път към Япония ще кацнем и в друга държава, където медията, за която работя, е блокирана. Да видим за нея какъв съм.
Ден 2
Проверки, отпечатъци, формуляри, чакане. И пак – проверки, отпечатъци, формуляри, чакане. Чакане, чакане и пак чакане. Влизането в Шанхай без виза за до 72 часа отваря чудесна възможност за разходка при по-дълга пауза между полетите. Стига да имаш нервите да минеш през безкрайния процес на летището.
Иначе оттам до центъра се стига за няколко минути с влак, който може да развие над 400 км/ч. Съвсем спокойно можеш да забравиш какъв режим управлява страната, ако не бяха хилядите камери, взиращи се в теб от всяко кътче. Хората в икономическия център на Китай са изключително добре облечени. Най-привлекателното място за тях обаче не е бившата резиденция на Мао Дзъдун в центъра, не са и будистките храмове, които по доста еклектичен начин съжителстват с небостъргачите, а е… рекламата на новия магазин на „Баленсиага“. Всяко време си има своите идоли, а най-разпространените обикновено идват от по-свободния свят. Този, който е бутнал крепостните си стени.
Когато пътувате през голямо летище, особено азиатско, отидете поне 2–3 часа по-рано. Защото никога не знаете дали някой няма да реши да ви свали багажа, макар на етикета му да пише, че е направо за Осака. После да го завре в някакъв склад, а вие да тръгнете на експедиция, включваща тичане и разговори с поне 5–6 смутени летищни служители (владеещи много скромен или направо никакъв английски), за да си го вземете обратно и да го натоварите на самолета.
Полетът между Китай и Япония е по-малко от два часа, но ги делят вселени.
В Япония положението е „всичко навсякъде наведнъж“. Буквално. Феерията от цветове, светлини и звуци те посреща още на летището. После те връхлита във влака, а накрая я откриваш дори в супермаркета, където почти всички продукти те вкарват в нещо средно между екстаз и шок – голямо триъгълно суши, което се яде като сандвич; безброй хладилници със студени напитки; две камери, които затоплят кенчета, пълни с кафе; топла витрина, която приготвя пилешки хапки, дъмплинги и корндог. Сушен октопод, сушени стриди, сушени сепии. Сушени минипатладжани в оцет. Всевъзможни коктейли в алуминиеви кенчета (някои имат вкус на мокра кърпичка – наистина!). Количеството надписи, цветове, картинки, които те заобикалят, е неописуемо. Ако една държава олицетворява синдрома на дефицит на внимание, това със сигурност е Япония. Безкрайно интересно е, вкусно, многообразно. Но си представям какво е да живееш, заобиколен от толкова дразнители. И да се опитваш да се съсредоточиш.
„Български, английски, немски, испански – защо вие знаете толкова много езици? Аз знам японски и английски, и то защото бившата ми приятелка беше американка и трябваше да я разбирам, когато ми се кара“, казва Юки, който е музикант от Осака. Говорим си, че колкото е по-голяма една държава, толкова по-трудно асимилира други култури. Докато ние гледахме Cartoon Network от малки. И започнахме да учим езици, за да отидем да учим в чужбина някой ден. За големите държави това е по-скоро ексцентризъм. За нас е (често) задължителен път към успешната реализация. Малка, проблемна и пропита с комплекси държава – дали всъщност това не е идеалната среда, която да те превърне в космополитен човек?
Юки ни кани в своя караоке бар и обещава, че ще е много готино. Пеем му всичко – от Рики Мартин до Audioslave. Решаваме да изпеем и нещо на български. Опитваме с „Богатство“ на Тангра. Няма особена реакция. Минаваме през целия алманах на българската музика. И да, стигна се до Камелия. Китаристът Акихико се вдъхновява. Един час разучава песен на Камелия. Оказва се, че тя е доста сложна. Накрая я свири и е много притеснен – ще се справи ли с този музикален апогей? Е, справи се!
Императрица Генмей избира Нара за първата столица на обединена Япония през 710 г. (преходът от Камелия към императрица Генмей е върхът в кариерата ми). Дотам от Осака е има-няма час. В Япония много големи градове просто преливат един в друг.
Храмът „Тодай дзи“ е най-внушителният пример от времето, в което Нара е била столица. Макар сградата и интериорът да са реновирани многократно, най-голямата бронзова статуя на Великия Буда – Дайбуцу – и до днес впечатлява с внушителните си размери. Император Шому я поръчва в отговор на войните и на пандемията от едра шарка, която избива една трета от населението на Япония в периода 735–737 г. Е, тази вълшебна статуя въпреки красотата си не успява да спаси Нара от упадъка, в който градът потъва след 794 г., когато престава да бъде столица. Толкова за скъпите храмове и религиозни статуи.
За да разведрим обстановката, ще отбележа, че днес Нара е един изключително красив град с дори аристократична атмосфера. Но също така е дом на стотици свободно разхождащи се сърни. Те, разбира се, си имат quid pro quo отношения с туристите – тяхната симпатичност срещу твоите крекери. И при тази размяна сърните… се покланят. Както и японците. Японците се покланят по 11 различни причини. Това го знам от Юлиана Антонова-Мурата, чиито книги са ми верен спътник през цялото пътуване. Включително и във влака към следващата столица на Япония.
В Киото има 2000 храма – 1600 будистки и 400 шинтоистки. Някои от тях на възраст над 1300 години. Градът е бил столица на Япония в продължение на над 1000 години – от 794 до 1868 г. Освен това е дом на Киотския университет, който е дал на света 19 нобелови лауреати. И… за малко да бъде изравнен със земята по време на Втората световна война. Да, Киото е била втората цел след Хирошима. Спорно е кой и как предотвратява това решение. Но тезата, че разрушаването на културната столица на Япония ще сложи окончателния и решителен край на Втората световна война, в крайна сметка отстъпва на мнението, че японците никога няма да простят този удар върху историята и идентичността им. Добре че така е станало, но ми се струва цинично на фона на стотиците хиляди жертви в Хирошима и Нагасаки.
Освен храмовете в Киото пленителна е и природата. Например бамбуковата гора в Арашияма. В нея се срещаме с Кинджи Накамура. Той е художник, около 80-годишен, и продава принтове на своите картини на символична цена. Веднага ни пита откъде сме. Когато разбира, вади стара папка, пълна с карти на Европа. Разгръща трескаво, търсейки Югоизточна Европа и по-конкретно България.
С гордост показва туристи от кои градове вече са си купували картички от него – София, Варна, Ловеч. Всеки е оградил родния си град. Възможно ли е никой от българската културна столица да не е посещавал японската?! Бързо поправяме тази грешка и Пловдив вече е ограден с кръгче на картата. Преди да се разделим с Кинджи, той разлиства и друга папка с думички и транскрипция. Бързо намира това, което търси. „Благодаря!“, казва мъжът със старание.
Кинджи не е бил в България, единственото му пътуване до Европа е в Испания. Но нужно ли му е да пътува физически, щом клиентите му го отвеждат навсякъде по света всеки ден? Пък и макар Кинджи да не е стигал до България, картините му вече са тук.
Вечерта коктейлите ни ги прави Хиро. Той ни разказва за най-изконната японска традиция от последните десетилетия… Коледа в KFC. Накратко, през 70-те години японската икономика се развива с бързи темпове и американските вериги навлизат скорострелно в страната. В този момент някой гениален маркетолог от екипа на KFC решава, че е добре да продадат коледната традиция на Япония, като организират цяла кампания с Дядо Коледа, червения и белия цвят и всичко, което иначе няма нищо общо с християнската традиция. И успяват. Днес масово японските семейства празнуват Коледа с кофа от KFC. Ех, Едуард Бернайс би се гордял…
Ден 7
Японците казват, че се раждат шинтоисти, празнуват като християни и умират като будисти. Шинтоизмът е в основата на повечето традиции и символи в страната, а свещените духове – ками, са навсякъде. Изповядването му обаче е примесено с будистките вярвания. Повечето японци се определят едновременно като шинтоисти и будисти. Но в същото време мнозинството казват, че са и атеисти. В последните десетилетия традициите на западния християнски свят обаче също са се наложили най-вече по време на празници като Коледа и ритуали като сватба. С две думи: религиозните обреди и традиции присъстват като културна ценност, но не се използват за индоктринация.
И тъй като Киото е градът с най-много храмове в Япония, няма как да не посетим поне няколко, докато сме там. Шинтоистките светилища се различават съществено от будистките храмове – повечето са навън и са посветени на конкретна кама.
Много неща в Япония изглеждат извънземни – особено влаковете. „Шинкансен“ за първи път в света надхвърля скорост 200 км/ч през 1964 г. Днес максималната му скорост е 320 км/ч и те откарва от региона Кансай, където са Осака и Киото, до Токио за малко над 2 часа.
Токио е най-необозримото място, в което съм стъпвал. И надали някое друго ще го изпревари, тъй като столицата на Япония със своите 37 млн. души е най-населеният град в света. Разрушаван е два пъти през XX век – от земетресение и от бомбардировките по време на Втората световна война.
Разликата между хората в Кансай и в Канто – региона, който обхваща и Токиo – е видима. Докато в Осака те заговарят на улицата (че даже и пушат там, което е забранено в Япония), Токио изглежда много по-близо до клишето за японските нрави – маси за един, дистанция, тишина. Интересно е как толкова дисциплиниран и неекспресивен народ е създал такива бури от цветове, движения и провокации, каквито са манга и аниме. И е обсипал градовете си с билборди, лампички, неони, високоговорители и редица предизвикателства за сетивата. Сякаш се опитва да компенсира. Добре, май сам си отговорих на въпроса…
Говорейки за въпроси, трудно можеш да намериш човек в Япония, който да ти даде повече отговори от Юлиана Антонова-Мурата. Обсъждаме следващата ѝ книга, в която търси отговори за дълголетието на японците. 84,45 години – толкова е средната продължителност на живота в Япония. Повече от 10 години повече, отколкото в България, сринала се и заради COVID-19, който извади наяве всичките ни дефицити – и персонални, и на здравната ни система.
„В Япония трябва да се ходи на лекар всеки месец“, разказва ми Юлиана. В противен случай те глобяват. Деца, възрастни – няма значение, всички получават напомняния да посетят различни специалисти ежемесечно. Не е ли малко прекалено? И твърде скъпо? „Е, за какво плащаме данъци и осигуровки?“, пита Юлиана.
За едно нещо сме единодушни – причината за японското дълголетие не е храната. Тук се яде основно ориз, който далеч не е най-здравословната част от менюто. Освен това зеленчуците и най-вече плодовете (особено пресните) изобщо не са даденост във всеки супермаркет, камо ли на всяко хранене. Но тук затлъстели хора почти няма, а порциите са по-скоро малки.
Матю Пери е починал. Колко ли комици се опитват да заглушат тъгата в собственото си сърце със смеха, който предизвикат у останалите?
Леко парадоксално, в този ден се срещаме с историята на един друг Матю Пери. Този, който през 1852 г. е натоварен от САЩ с тежката задача да сложи край на японската изолационна политика и да проправи пътя ѝ към международната търговия. С много упорство и немалко заплахи успява. А всичко започва в Йокохама.
Днес Йокохама е вторият по големина град в Япония (който прелива в Кавасаки и след това в Токио) и открива великолепна гледка към вулкана Фуджи. Имаме късмета снежният кратер да се вижда, когато посещаваме Йокохама. Много често е напълно закрит от плътни облаци.
Независимо дали си чел прочутия роман на Артър Голдън, или не, гейшите са неизменна част от японската култура. Тъй като те са предимно в Киото, в останалите градове има различни клубове и шоута, които ги имитират. Посещаваме бурлеска, а по стълбите към заведението гордо са закачени снимки на известните му посетители – от Стивън Тайлър до принца на Монако. Кимона, песни, танци с традиционни чадъри. Но и въртене на пилони. Историите, които разказват момичетата, са сходни с повечето, които работят в бранша и в други държави – много от тях са мигрантки, от бедни семейства, имат други мечти, работят тук временно… Под кимоната и традиционните мотиви се крият ощетени от живота момичета, които насила се усмихват на привилегированите си клиенти.
Ден 11
Сбогуване с Токио и обратно към Осака. Днес е Хелоуин. Японците го празнуват, общо взето, откакто сме пристигнали, но днес трябва да е кулминацията. И Осака със своята южняшка и бохемска атмосфера е идеално място за целта. Бих ви написал още какво се случваше по централните улици на Осака, но то наистина е неописуемо. Затова просто ще ви покажа:
Чао, Япония, хайде обратно към Китай. Този път летим през Пекин, където имаме 10 часа престой. Точно колкото да ни закарат набързо до „Тиенанмън“, да хапнем, да се разходим на хубавото слънчево време, каквото прогнозираха метеоролозите, и да се върнем обратно.
Първият сигнал, че нещата няма да се стекат по нашия план, беше времето. И по-конкретно плътният смог, покрил Пекин. От този град не се вижда абсолютно нищо. Слънцето е като от фентъзи филм. Дори аз като гражданин на София, която далеч не може да се похвали с чист въздух, съм покъртен. Кацаме и се запътваме към автоматите, на които за пореден път да предоставим отпечатъците и данните от паспортите си на китайската държава. Чинно попълваме формулярите за 24-часов престой без виза. Насочваме се към гишето и с усмивка казваме, че планираме да се разходим в Пекин преди полета към Виена. Да, ама не. Може да напуснем летището само ако следващият ни полет е след повече от 12 часа.
Добре, явно ще стоим на летището. Нека намерим лаундж. И тук греда. Лаунджовете на летището в многомилионната столица на доскоро най-населената държава в света изглеждат като чакалня в малка жп гара в България през 1972 г. Всъщност нямам идея как са изглеждали чакалните в жп гарите в България през 1972 г., но така си ги представям: мушамичка, блудкаво кафе и невероятен избор от 2–3 вида сладки. Това е.
Самото летище иначе впечатлява с мащаба си. Но още повече впечатлява с отсъствието на хора. Каквито и да е. Където и да е. Затворените и изтърбушени магазини, над които все още висят загасналите табели на марки като „Марк Джейкъбс“ и „Баленсиага“, напомнят за тежките удари, които COVID-19 и политиката на китайското правителство нанесоха на икономиката и живота на хората. Работещите нонстоп „Старбъкс“ и „Коста“ (единствените два денонощни обекта на цялото летище) все пак индикират, че тук от време на време стъпва и западен крак. Безжичният интернет, блокиращ почти всички приложения и сайтове, до които би искал да имаш достъп, ти крещи в лицето в каква държава се намираш.
Като цяло обстановката е тягостна, служителите гледат лошо и подозрително, трудно се разбираш с тях, а те очевидно трудно се разбират и помежду си. Зад лъскавите повърхности прозира празнота. Всичко красноречиво говори, че в най-голямата икономика в света раните, нанесени от режима, са дълбоки. Тук усмивките дори върху малкото лица, които не са покрити с маски, отсъстват. Свободните хора се усмихват повече. Предпочитам да си ходя при тях.
Ден 13
Качваме се на борда заедно с футболен отбор от Украйна. Пак ли ще летим над Русия? Да! Не съм сигурен какво точно чувствам, затова решавам да се опитам да поспя. Този път ми се получава.
Добро утро, Виена! Хапвам един сандвич с кезелеберкезе набързо, купувам си няколко алмдудлера и един вестник Der Standard за из път и се насочвам към гейта. Имам предостатъчно време да седна в едно от добре познатите ми заведения, да кажа „Грюс Гот“ (Grüß Gott – „добър ден“, б.р.) на сервитьора, да си поръчам един меланж и да наваксам с имейли, телефонни разговори и прочее. Нали казват, че където и да ходиш, винаги се прибираш някъде? Е, невинаги се прибирам на едно и също място, но имам чувството, че винаги се прибирам през виенското летище.
София е толкова сива, ама си е моето сиво. Първо пускам пералнята, защото предстоят още поне два цикъла. Сега е време да обърна малко внимание на котката, да си разопаковам багажа и да изчистя. Докато свърша всичко изброено, пералнята е готова. Започвам да вадя дрехите и в един момент осъзнавам, че ги подреждам… в хладилника. Здравей, джетлаг, my old friend! Явно е по-добре сега да си легна, завръщането в реалността може да почака до утре.
The kernel’s stable-update process is intended to produce kernels that are,
well, stable; when that promise is lived up to, users can update to newer
stable updates without fear. By any account, a bug that corrupts data on
ext4 filesystems constitutes a failure to hold to that promise. As is so
often the case, this problem is the result of a chain of failures in a
system that works well most of the time.
In order for one device to talk to other devices on the Internet using the aptly named Internet Protocol (IP), it must first be assigned a unique numerical address. What this address looks like depends on the version of IP being used: IPv4 or IPv6.
IPv4 was first deployed in 1983. It’s the IP version that gave birth to the modern Internet and still remains dominant today. IPv6 can be traced back to as early as 1998, but only in the last decade did it start to gain significant traction — rising from less than 1% to somewhere between 30 and 40%, depending on who’s reporting and what and how they’re measuring.
With the growth in connected devices far exceeding the number of IPv4 addresses available, and its costs rising, the much larger address space provided by IPv6 should have made it the dominant protocol by now. However, as we’ll see, this is not the case.
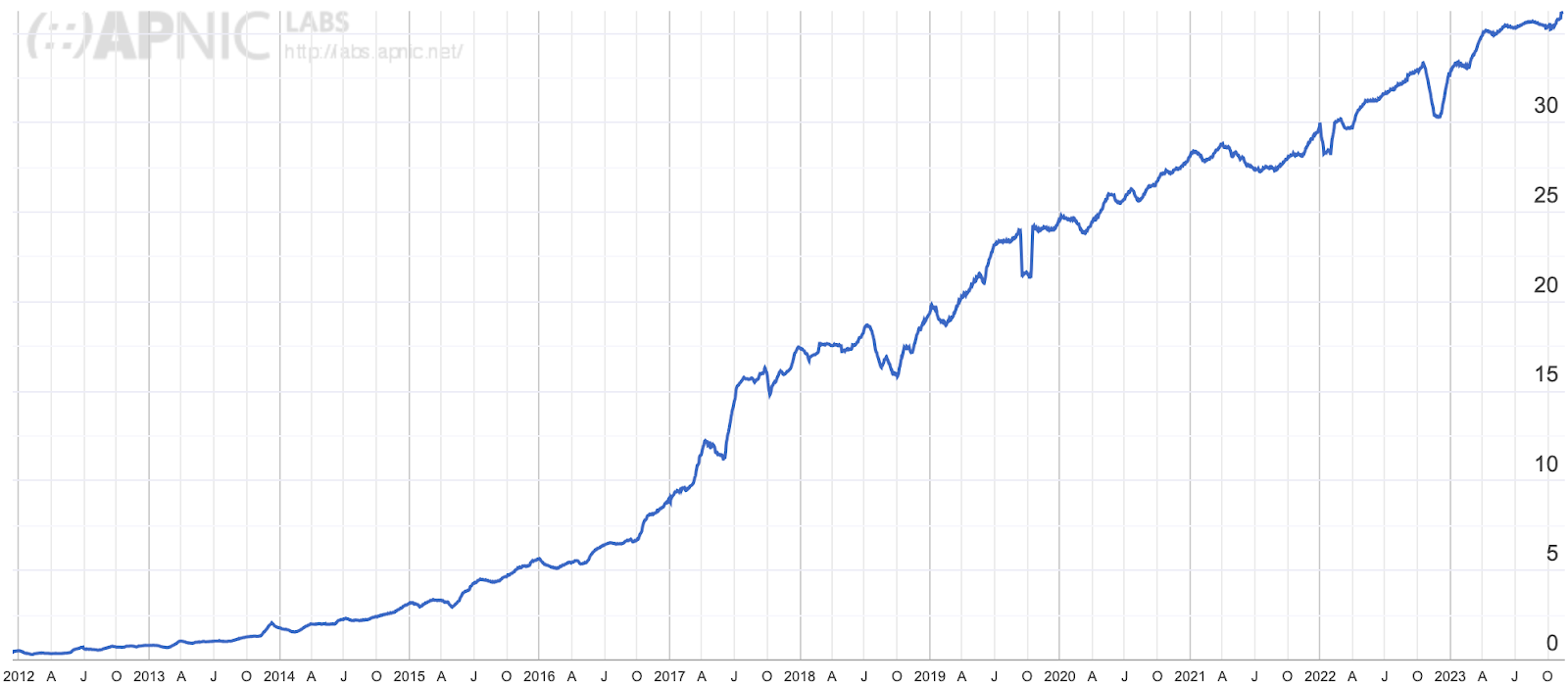
Cloudflare has been a strong advocate of IPv6 for many years and, through Cloudflare Radar, we’ve been closely following IPv6 adoption across the Internet. At three years old, Radar is still a relatively recent platform. To go further back in time, we can briefly turn to our friends at APNIC1 — one of the five Regional Internet Registries (RIRs). Through their data, going back to 2012, we can see that IPv6 experienced a period of seemingly exponential growth until mid-2017, after which it entered a period of linear growth that’s still ongoing:
IPv6 adoption is slowed down by the lack of compatibility between both protocols — devices must be assigned both an IPv4 and an IPv6 address — along with the fact that virtually all devices on the Internet still support IPv4. Nevertheless, IPv6 is critical for the future of the Internet, and continued effort is required to increase its deployment.
Cloudflare Radar, like APNIC and most other sources today, publishes numbers that primarily reflect the extent to which Internet Service Providers (ISPs) have deployed IPv6: the client side. It’s a very important angle, and one that directly impacts end users, but there’s also the other end of the equation: the server side.
With this in mind, we invite you to follow us on a quick experiment where we aim for a glimpse of server side IPv6 adoption, and how often clients are actually (or likely) able to talk to servers over IPv6. We’ll rely on DNS for this exploration and, as they say, the results may surprise you.
IPv6 Adoption on the Client Side (from HTTP)
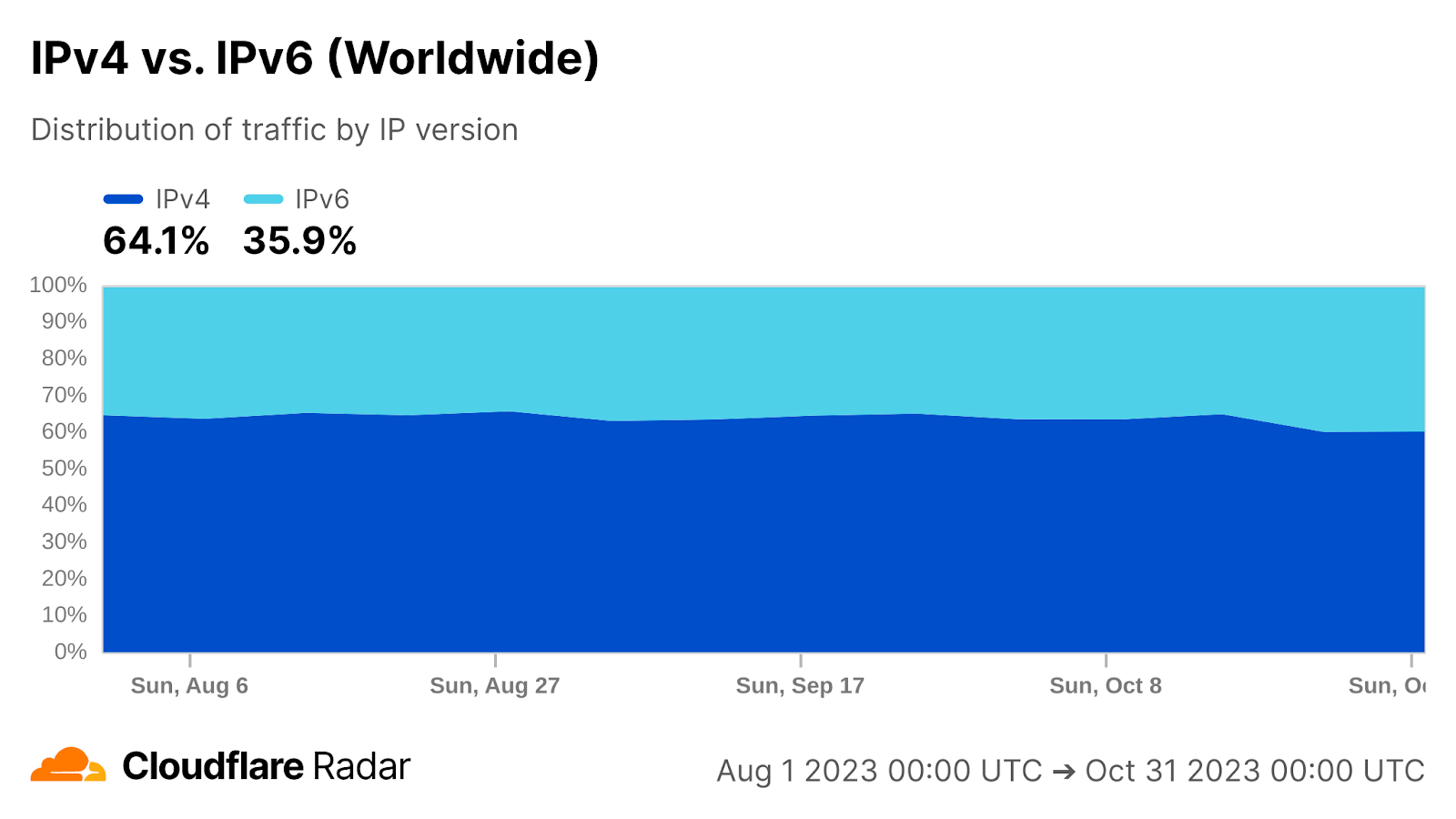
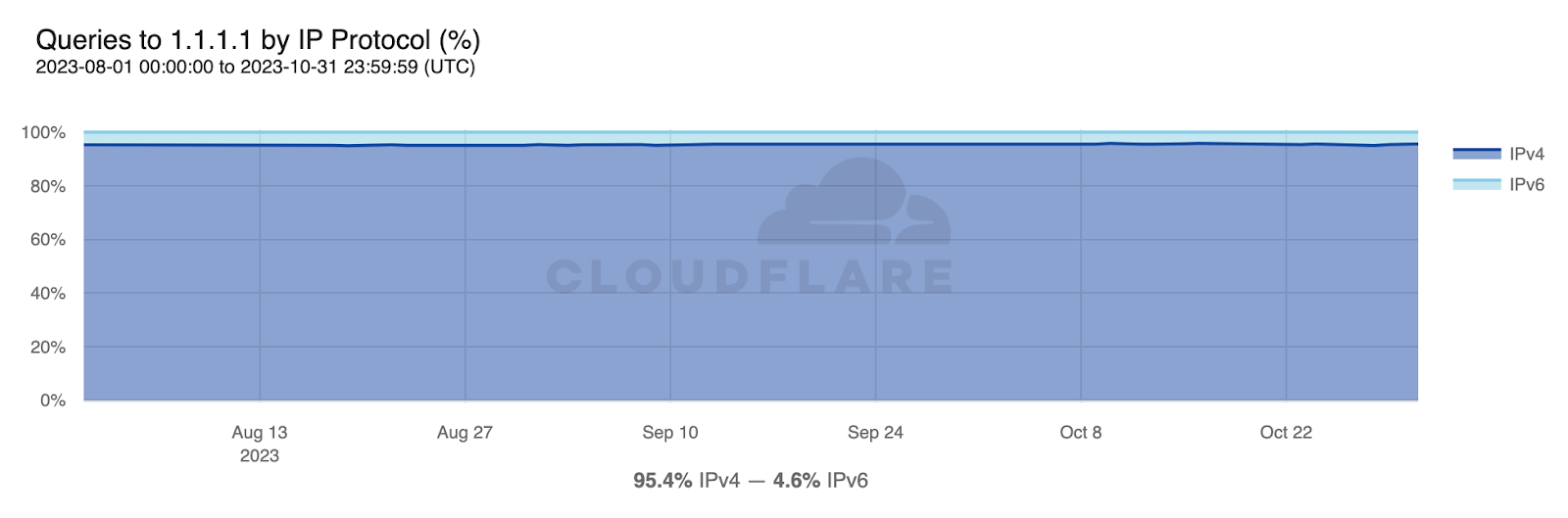
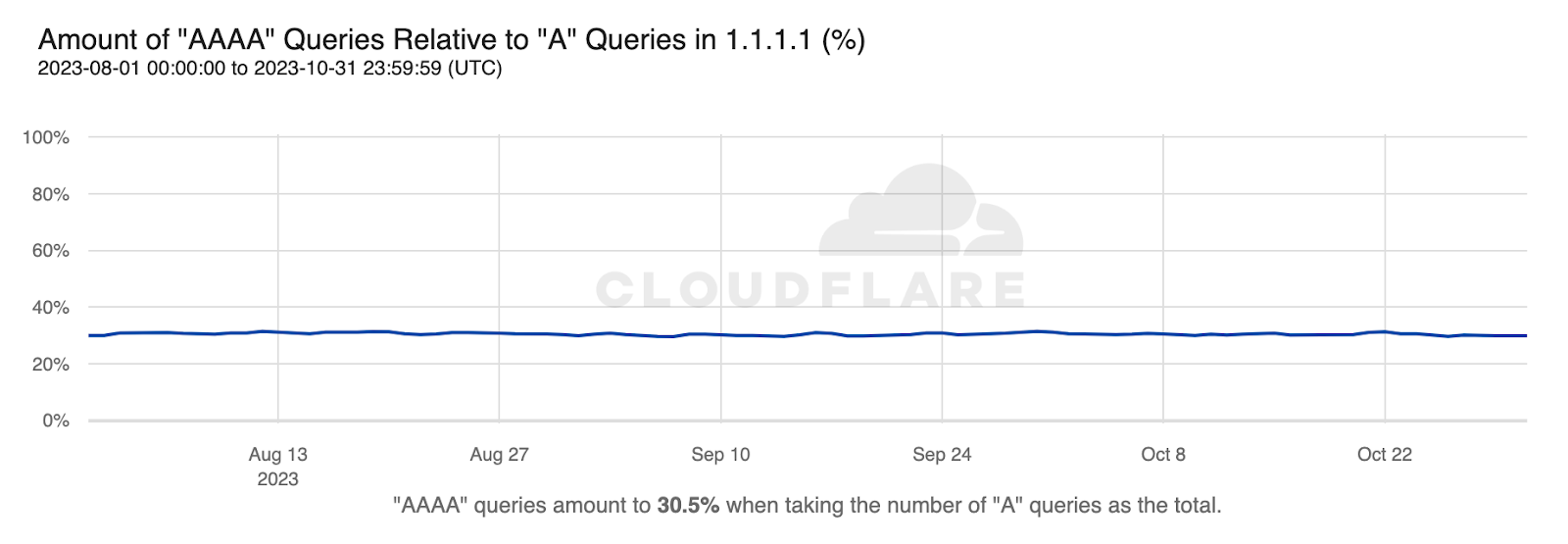
By the end of October 2023, from Cloudflare’s perspective, IPv6 adoption across the Internet was at roughly 36% of all traffic, with slight variations depending on the time of day and day of week. When excluding bots the estimate goes up to just over 46%, while excluding humans pushes it down close to 24%. These numbers refer to the share of HTTP requests served over IPv6 across all IPv6-enabled content (the default setting).
For this exercise, what matters most is the number for both humans and bots. There are many reasons for the adoption gap between both kinds of traffic — from varying levels of IPv6 support in the plethora of client software used, to varying levels of IPv6 deployment inside the many networks where traffic comes from, to the varying size of such networks, etc. — but that’s a rabbit hole for another day. If you’re curious about the numbers for a particular country or network, you can find them on Cloudflare Radar and in our Year in Review report for 2023.
It Takes Two to Dance
You, the reader, might point out that measuring the client side of the client-server equation only tells half the story: for an IPv6-capable client to establish a connection with a server via IPv6, the server must also be IPv6-capable.
This raises two questions:
What’s the extent of IPv6 adoption on the server side?
How well does IPv6 adoption on the client side align with adoption on the server side?
There are several possible answers, depending on whether we’re talking about users, devices, bytes transferred, and so on. We’ll focus on connections (it will become clear why in a moment), and the combined question we’re asking is:
How often can an IPv6-capable client use IPv6 when connecting to servers on the Internet, under typical usage patterns?
Typical usage patterns include people going about their day visiting some websites more often than others or automated clients calling APIs. We’ll turn to DNS to get this perspective.
Enter DNS
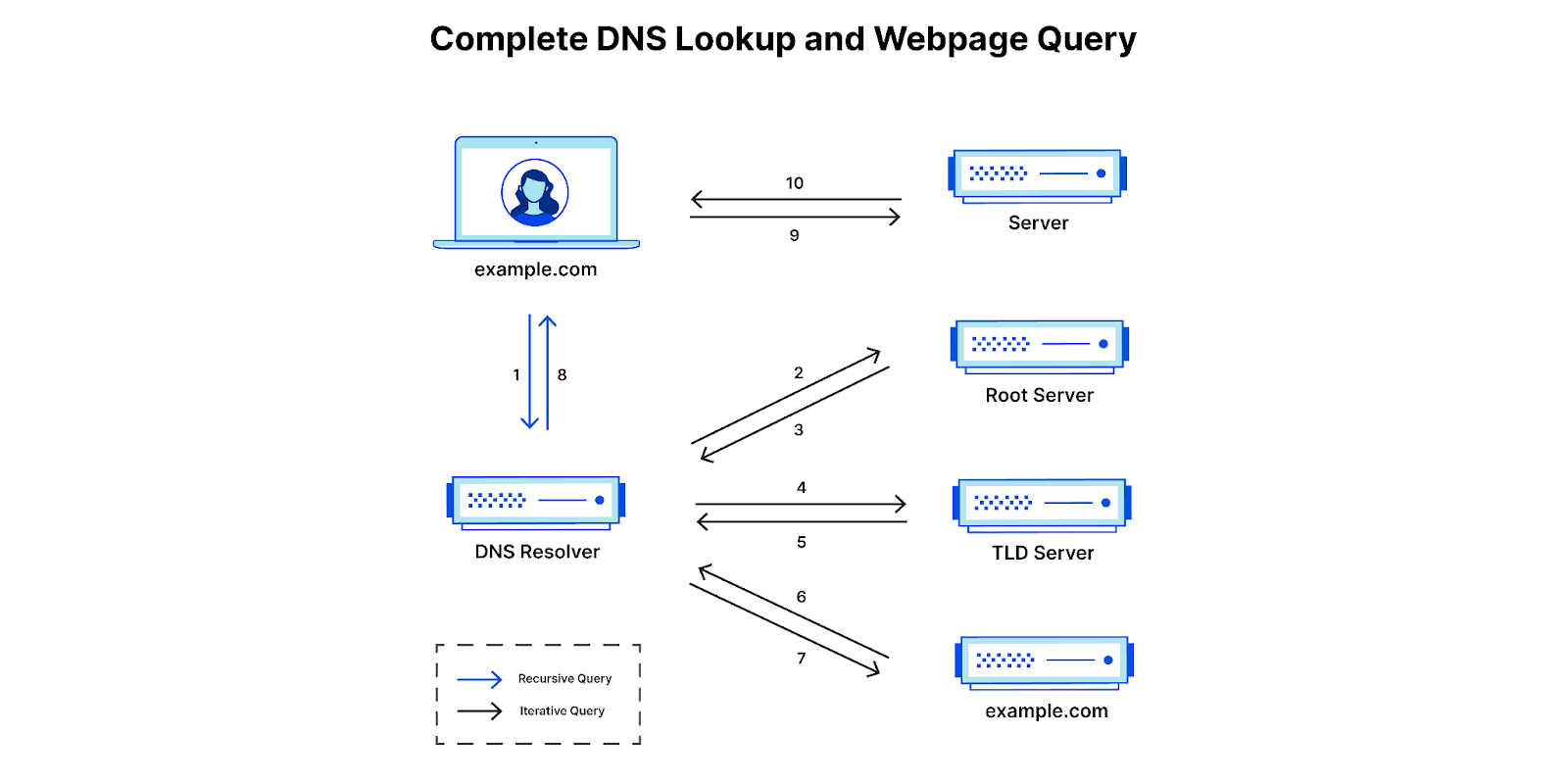
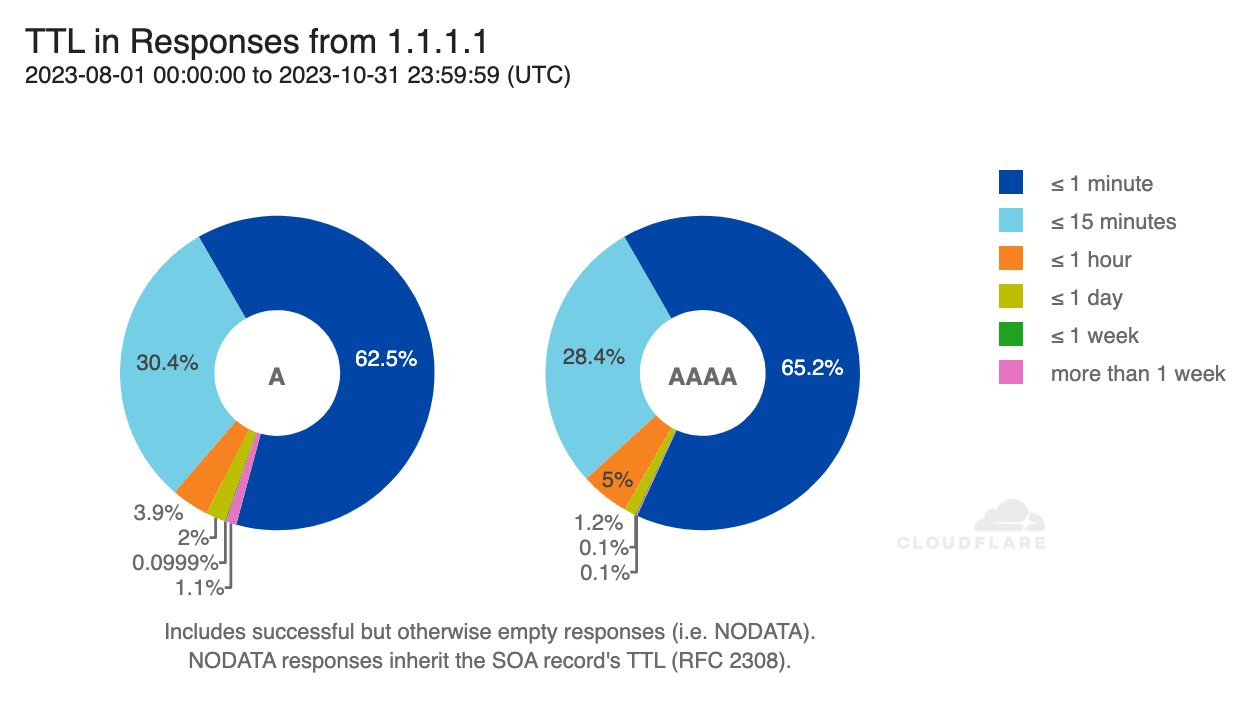
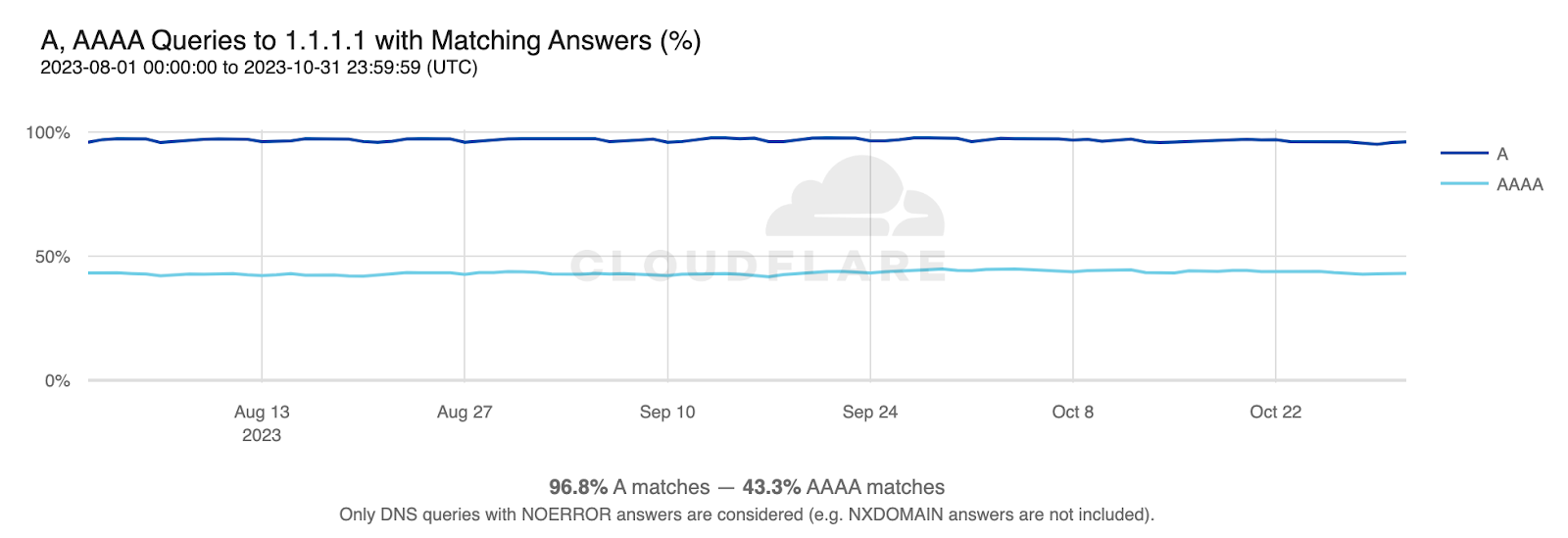
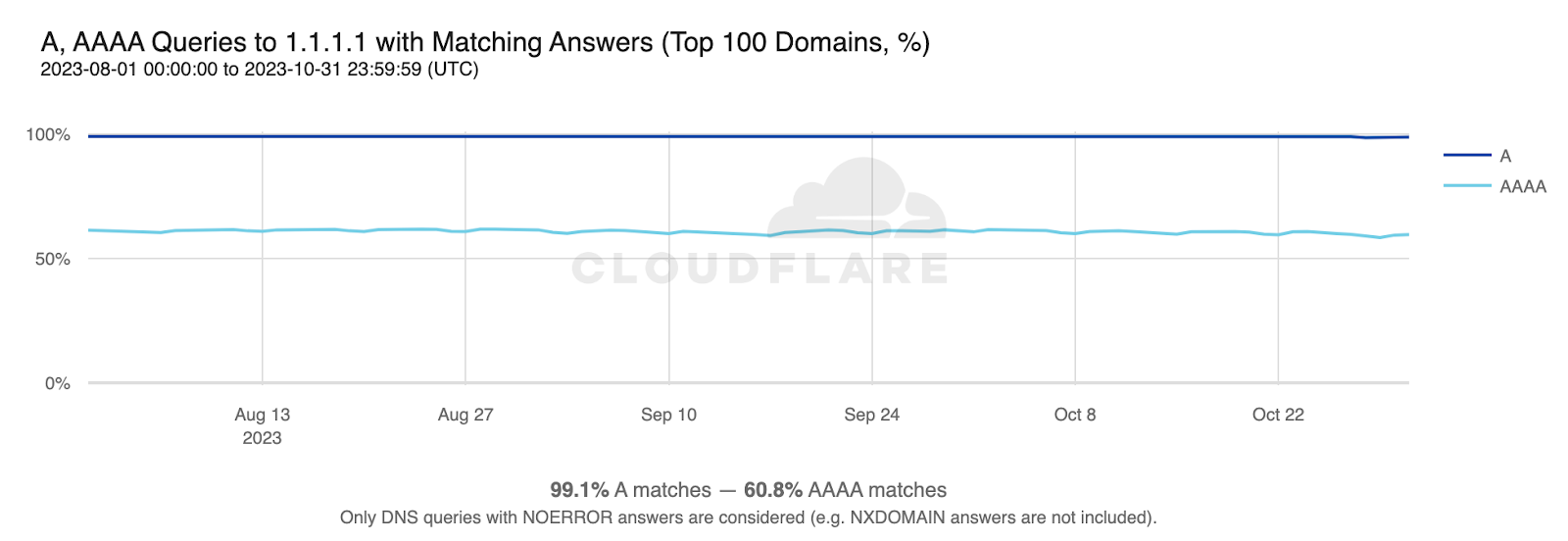
Before a client can attempt to establish a connection with a server by name, using either the classic IPv4 protocol or the more modern IPv6, it must look up the server’s IP address in the phonebook of the Internet, the Domain Name System (DNS).
Looking up a hostname in DNS is a recursive process. To find the IP address of a server, the domain hierarchy (the dot-separated components of a server’s name) must be followed across several DNS authoritative servers until one of them returns the desired response2. Most clients, however, don’t do this directly and instead ask an intermediary server called a recursive resolver to do it for them. Cloudflare operates one such recursive resolver that anyone can use: 1.1.1.1.
As a simplified example, when a client asks 1.1.1.1 for the IP address where “www.example.com” lives, 1.1.1.1 will go out and ask the DNS root servers3 about “.com”, then ask the .com DNS servers about “example.com”, and finally ask the example.com DNS servers about “www.example.com”, which has direct knowledge of it and answers with an IP address. To make things faster for the next client asking a similar question, 1.1.1.1 caches (remembers for a while) both the final answer and the steps in between.
This means 1.1.1.1 is in a very good position to count how often clients try to look up IPv4 addresses (A-type queries) vs. how often they try to look up IPv6 addresses (AAAA-type queries), covering most of the observable Internet.
But how does a client know when to ask for a server’s IPv4 address or its IPv6 address?
The short answer is that clients with IPv6 available to them just ask for both — doing separate A and AAAA lookups for every server they wish to connect to. These IPv6-capable clients will prioritize connecting over IPv6 when they get a non-empty AAAA answer, whether they also get a non-empty A answer (which they almost always get, as we’ll see). The algorithm driving this preference for modernity is called Happy Eyeballs, if you’re interested in the details.
We’re now ready to start looking at some actual data…
IPv6 Adoption on the Client Side (from DNS)
The first step is establishing a baseline by measuring client IPv6 deployment from 1.1.1.1’s perspective and comparing it with the numbers from HTTP requests that we started with.
It’s tempting to count how often clients connect to 1.1.1.1 using IPv6, but the results are misleading for a couple of reasons, the strongest one being hidden in plain sight: 1.1.1.1 is the most memorable address of the set of IPv4 and IPv6 addresses that clients can use to perform DNS lookups through the 1.1.1.1 service. Ideally, IPv6-capable clients using 1.1.1.1 as their recursive resolver should have all four of the following IP addresses configured, not just the first two:
1.1.1.1 (IPv4)
1.0.0.1 (IPv4)
2606:4700:4700::1111 (IPv6)
2606:4700:4700::1001 (IPv6)
But, when manual configuration is involved4, humans find IPv6 addresses less memorable than IPv4 addresses and are less likely to configure them, viewing the IPv4 addresses as enough.
A related, but less obvious, confounding factor is that many IPv6-capable clients will still perform DNS lookups over IPv4 even when they have 1.1.1.1’s IPv6 addresses configured, as spreading lookups over the available addresses is a popular default option.
A more sensible approach to assess IPv6 adoption from DNS client activity is calculating the percentage of AAAA-type queries over the total amount of A-type queries, assuming IPv6-clients always perform both5, as mentioned earlier.
Then, from 1.1.1.1’s perspective, IPv6 adoption on the client side is estimated at 30.5% by query volume. This is a bit under what we observed from HTTP traffic over the same time period (35.9%) but such a difference between two different perspectives is not unexpected.
A Note on TTLs
It’s not only recursive resolvers that cache DNS responses, most DNS clients have their own local caches as well. Your web browser, operating system, and even your home router, keep answers around hoping to speed up subsequent queries.
How long each answer remains in cache depends on the time-to-live (TTL) field sent back with DNS records. If you’re familiar with DNS, you might be wondering if A and AAAA records have similar TTLs. If they don’t, we may be getting fewer queries for just one of these two types (because it gets cached for longer at the client level), biasing the resulting adoption figures.
The pie charts here break down the minimum TTLs sent back by 1.1.1.1 in response to A and AAAA queries6. There is some difference between both types, but the difference is very small.
IPv6 Adoption on the Server Side
The following graph shows how often A and AAAA-type queries get non-empty responses, shedding light on server side IPv6 adoption and getting us closer to the answer we’re after:
IPv6 adoption by servers is estimated at 43.3% by query volume, noticeably higher than what was observed for clients.
How Often Both Sides Swipe Right
If 30.5% of IP address lookups handled by 1.1.1.1 could make use of an IPv6 address to connect to their intended destinations, but only 43.3% of those lookups get a non-empty response, that can give us a pretty good basis for how often IPv6 connections are made between client and server — roughly 13.2% of the time.
The Potential Impact of Popular Domains
IPv6 server side adoption measured by query volume for the domains in Radar’s Top 100 list is 60.8%. If we exclude these domains from our overall calculations, the previous 13.2% figure drops to 8%. This is a significant difference, but not unexpected, as the Top 100 domains make up over 55% of all A and AAAA queries to 1.1.1.1.
If just a few more of these highly popular domains were to deploy IPv6 today, observed adoption would noticeably increase and, with it, the chance of IPv6-capable clients establishing connections using IPv6.
Closing Thoughts
Observing the extent of IPv6 adoption across the Internet can mean different things:
Counting users with IPv6-capable Internet access;
Counting IPv6-capable devices or software on those devices (clients and/or servers);
Calculating the amount of traffic flowing through IPv6 connections, measured in bytes;
Counting the fraction of connections (or individual requests) over IPv6.
In this exercise we chose to look at connections and requests. Keeping in mind that the underlying reality can only be truly understood by considering several different perspectives, we saw three different IPv6 adoption figures:
35.9% (client side) when counting HTTP requests served from Cloudflare’s CDN;
30.5% (client side) when counting A and AAAA-type DNS queries handled by 1.1.1.1;
43.3% (server side) of positive responses to AAAA-type DNS queries, also from 1.1.1.1.
We combined the client side and server side figures from the DNS perspective to estimate how often connections to third-party servers are likely to be established over IPv6 rather than IPv4: just 13.2% of the time.
To improve on these numbers, ISPs, cloud and hosting providers, and corporations alike must increase the rate at which they make IPv6 available for devices in their networks. But large websites and content sources also have a critical role to play in enabling IPv6-capable clients to use IPv6 more often, as 39.2% of queries for domains in the Radar Top 100 (representing over half of all A and AAAA queries to 1.1.1.1) are still limited to IPv4-only responses.
On the road to full IPv6 adoption, the Internet isn’t quite there yet. But continued effort from all those involved can help it to continue to move forward, and perhaps even accelerate progress.
On the server side, Cloudflare has been helping with this worldwide effort for many years by providing free IPv6 support for all domains. On the client side, the 1.1.1.1 app automatically enables your device for IPv6 even if your ISP doesn’t provide any IPv6 support. And, if you happen to manage an IPv6-only network, 1.1.1.1’s DNS64 support also has you covered.
*** 1Cloudflare’s public DNS resolver (1.1.1.1) is operated in partnership with APNIC. You can read more about it in the original announcement blog post and in 1.1.1.1’s privacy policy. 2There’s more information on how DNS works in the “What is DNS?” section of our website. If you’re a hands-on learner, we suggest you take a look at Julia Evans’ “mess with dns”. 3Any recursive resolver will already know the IP addresses of the 13 root servers beforehand. Cloudflare also participates at the topmost level of DNS by providing anycast service to the E and F-Root instances, which means 1.1.1.1 doesn’t need to go far for that first lookup step. 4When using the 1.1.1.1 app, all four IP addresses are configured automatically. 5For simplification, we assume the amount of IPv6-only clients is still negligibly small. It’s a reasonable assumption in general, and other datasets available to us confirm it. 61.1.1.1, like other recursive resolvers, returns adjusted TTLs: the record’s original TTL minus the number of seconds since the record was last cached. Empty A and AAAA answers get cached for the amount of time defined in the domain’s Start of Authority (SOA) record, as specified by RFC 2308.
Списък с имена на магистрати, които не са декларирали сметки и имоти в чужбина, дълго време привличаше общественото и медийно внимание, след като бившият МВР министър Бойко Рашков се закани…
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.