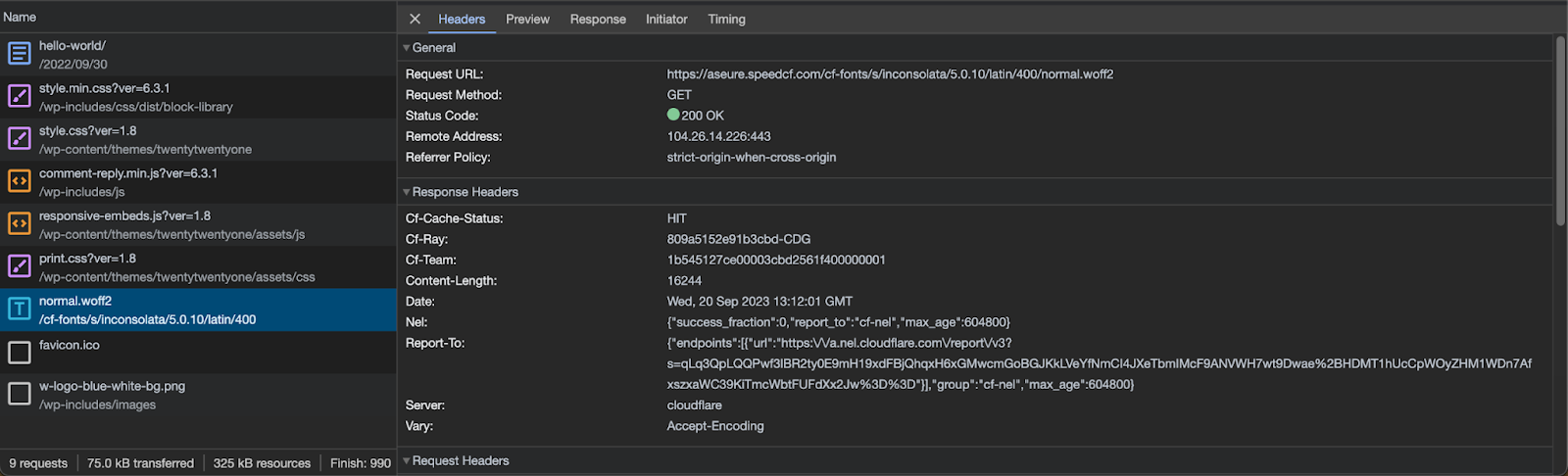
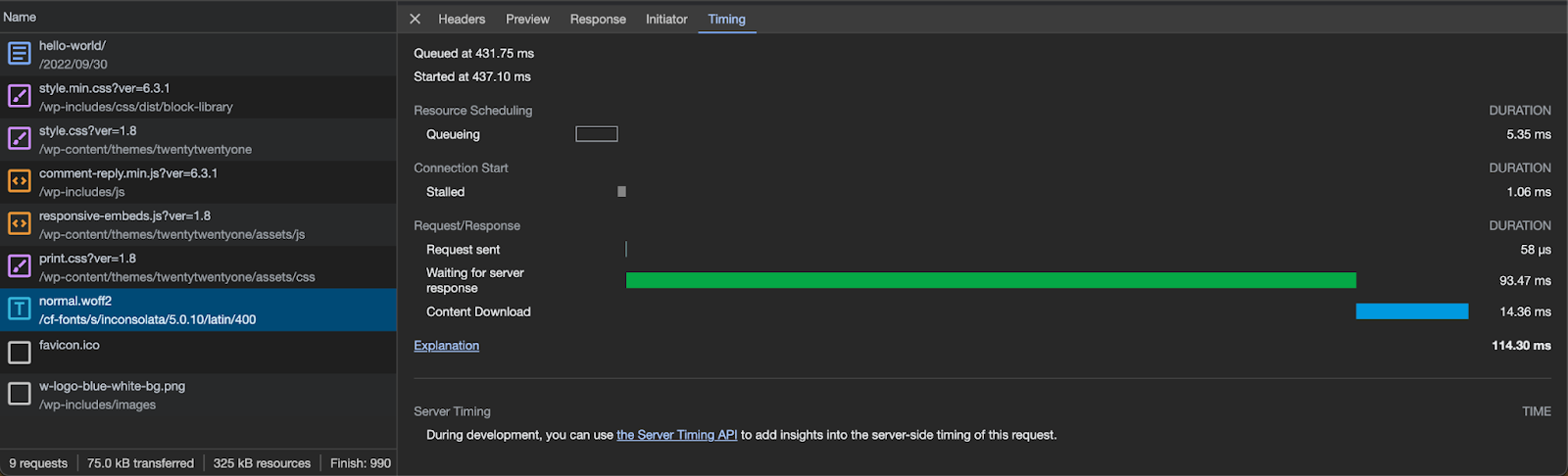
Many AWS customers use Amazon EKS to execute their data workloads. The advantages of Amazon EKS include different compute and storage options depending on workload needs, higher resource utilization by sharing underlying infrastructure, and a vibrant open-source community that provides purpose-built extensions. The Data on EKS project provides a series of templates and other resources to help customers get started on this journey. It includes a description of using Amazon MWAA as a job scheduler.
Contentful is an AWS customer and AWS Partner Network (APN) partner. Behind the scenes of their Software-as-a-Service (SaaS) product, the Contentful Composable Content Platform, Contentful uses insights from data to improve business decision-making and customer experience. Contentful engaged Netlight, an APN consulting partner, to help set up a data platform to gather these insights.
Most of Contentful’s application workloads run on Amazon EKS, and knowledge of this service and Kubernetes is widespread in the organization. That’s why Contentful’s data engineering team decided to run data pipelines on Amazon EKS as well. For job scheduling, they started with a self-operated Apache Airflow on an Amazon EKS cluster and later switched to Amazon MWAA to reduce engineering and operations overhead. The job execution remained on Amazon EKS.
Contentful runs a complex data pipeline using this infrastructure, including ingestion from multiple data sources and different transformation jobs, for example using dbt. The whole pipeline shares a single Amazon MWAA environment and a single Amazon EKS cluster. With a diverse set of workloads in a single environment, it is necessary to apply the principle of least privilege, ensuring that individual tasks or components have only the specific permissions they need to function.
By segmenting permissions according to roles and responsibilities, Contentful’s data engineering team was able to create a more robust and secure data processing environment, which is essential for maintaining the integrity and confidentiality of the data being handled.
In this blog post, we walk through setting up the infrastructure from scratch and deploying a sample application using Terraform, Contentful’s tool of choice for infrastructure as code.
Prerequisites
To follow along this blog post, you need the latest version of the following tools installed:
AWS CLI, configured with access to your AWS account
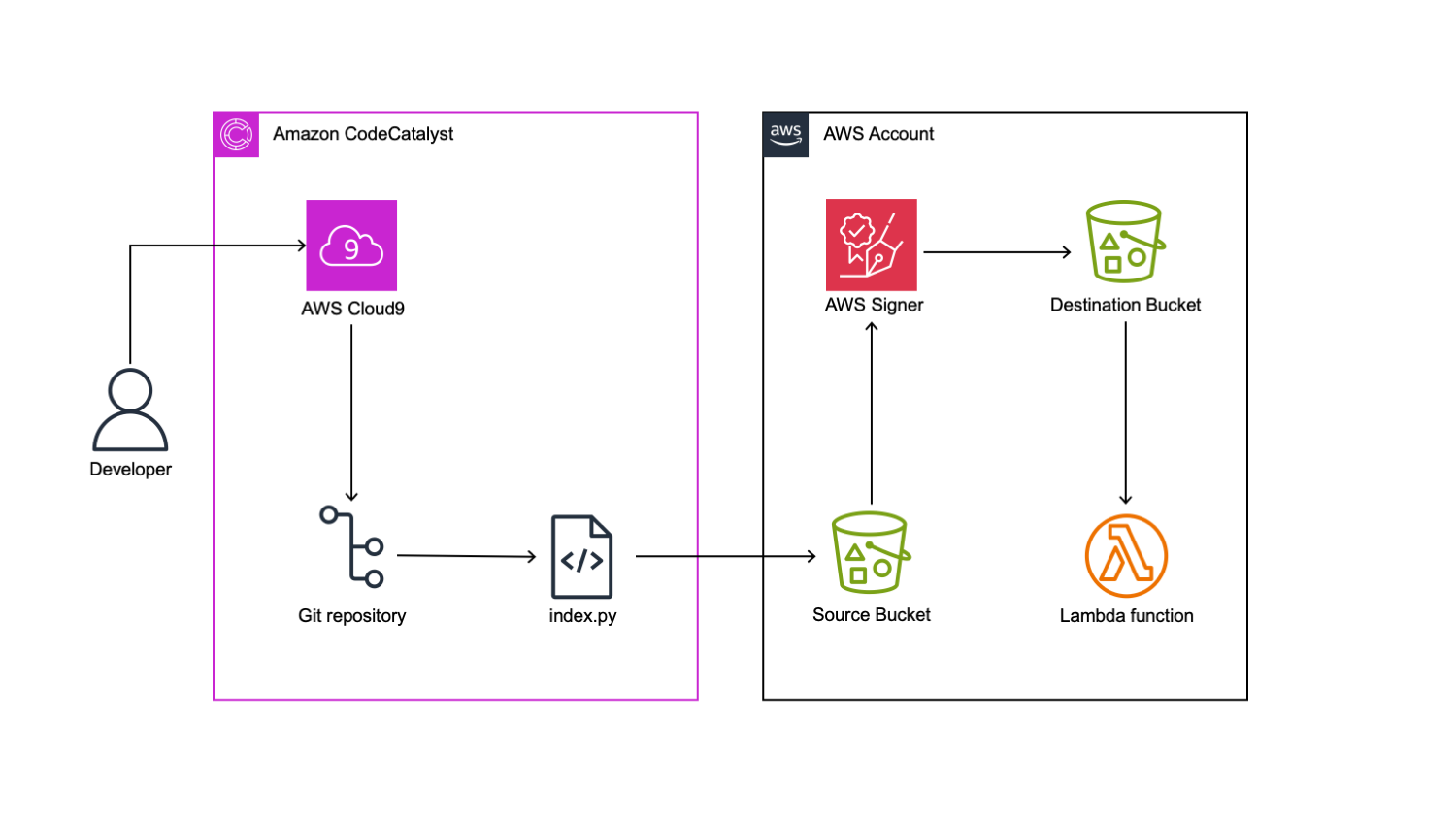
In this blog post, you will create a sample application with the following infrastructure:
The sample Airflow workflow lists objects in the source bucket, temporarily stores this list using Airflow XComs, and writes the list as a file to the destination bucket. This application is executed using Amazon EKS pods, scheduled by an Amazon MWAA environment. You deploy the EKS cluster and the MWAA environment into a virtual private cloud (VPC) and apply least-privilege permissions to the EKS pods using IAM roles for service accounts. The configuration bucket for Amazon MWAA contains runtime requirements, as well as the application code specifying an Airflow Directed Acyclic Graph (DAG).
Initialize the project and create buckets
Create a file main.tf with the following content in an empty directory:
locals {
region = "us-east-1"
}
provider "aws" {
region = local.region
}
resource "aws_s3_bucket" "source_bucket" {
bucket_prefix = "source"
}
resource "aws_s3_object" "dummy_object" {
bucket = aws_s3_bucket.source_bucket.bucket
key = "dummy.txt"
content = ""
}
resource "aws_ssm_parameter" "source_bucket" {
name = "mwaa_source_bucket"
type = "SecureString"
value = aws_s3_bucket.source_bucket.bucket
}
resource "aws_s3_bucket" "destination_bucket" {
bucket_prefix = "destination"
force_destroy = true
}
resource "aws_ssm_parameter" "destination_bucket" {
name = "mwaa_destination_bucket"
type = "SecureString"
value = aws_s3_bucket.destination_bucket.bucket
}
This file defines the Terraform AWS provider as well as the source and destination bucket, whose names are exported as AWS Systems Manager parameters. It also tells Terraform to upload an empty object named dummy.txt into the source bucket, which enables the Airflow sample application we will create later to receive a result when listing bucket content.
Initialize the Terraform project and download the module dependencies by issuing the following command:
terraform init
Create the infrastructure:
terraform apply
Terraform asks you to acknowledge changes to the environment and then starts deploying resources in AWS. Upon successful deployment, you should see the following success message:
Create a new file vpc.tf in the same directory as main.tf and insert the following:
data "aws_availability_zones" "available" {}
locals {
cidr = "10.0.0.0/16"
azs = slice(data.aws_availability_zones.available.names, 0, 3)
}
module "vpc" {
name = "data-vpc"
source = "terraform-aws-modules/vpc/aws"
version = "~> 4.0"
cidr = local.cidr
azs = local.azs
public_subnets = [for k, v in local.azs : cidrsubnet(local.cidr, 8, k + 48)]
private_subnets = [for k, v in local.azs : cidrsubnet(local.cidr, 4, k)]
enable_nat_gateway = true
}
This file defines the VPC, a virtual network, that will later host the Amazon EKS cluster and the Amazon MWAA environment. Note that we use an existing Terraform module for this, which wraps configuration of underlying network resources like subnets, route tables, and NAT gateways.
Download the VPC module:
terraform init
Deploy the new resources:
terraform apply
Note which resources are being created. By using the VPC module in our Terraform file, much of the underlying complexity is taken away when defining our infrastructure, but it’s still useful to know what exactly is being deployed.
Note that Terraform now handles resources we defined in both files, main.tf and vpc.tf, because Terraform includes all .tffiles in the current working directory.
Create the Amazon MWAA environment
Create a new file mwaa.tf and insert the following content:
To create the cluster itself, we take advantage of the Amazon EKS Blueprints for Terraform project. We also define a managed node group with one node as the target size. Note that in cases with fluctuating load, scaling your cluster with Karpenter instead of the managed node group approach shown above makes the cluster scale more flexibly. We used managed node groups primarily because of the ease of configuration.
We define the identity that the Amazon MWAA execution role assumes in Kubernetes using the map_roles variable. After configuring the Terraform Kubernetes provider, we give the Amazon MWAA execution role permissions to manage pods in the cluster.
Download the EKS Blueprints for Terraform module:
terraform init
Deploy the new resources:
terraform apply
This operation takes about 12 minutes to complete.
Create IAM roles for service accounts
Create a file roles.tf with the following content:
This file defines two Kubernetes service accounts, source-bucket-reader-sa and destination-bucket-writer-sa, and their permissions against the AWS API, using IAM roles for service accounts (IRSA). Again, we use a module from the Amazon EKS Blueprints for Terraform project to simplify IRSA configuration. Note that both roles only get the minimum permissions that they need, defined using AWS IAM policies.
The DAG is defined to run on an hourly schedule, with two tasks read_bucket with service account source-bucket-reader-sa and write_bucket with service account destination-bucket-writer-sa, running after one another. Both are run using the EksPodOperator, which is responsible for scheduling the tasks on Amazon EKS, using the AWS CLI Docker image to run commands. The first task lists files in the source bucket and writes the list to Airflow XCom. The second task reads the list from XCom and stores it in the destination bucket. Note that the service_account_name parameter differentiates what each task is permitted to do.
Create a file dag.tf to upload the DAG code to the Amazon MWAA configuration bucket:
The Amazon MWAA environment automatically imports the file from the S3 bucket.
Run the DAG
In your browser, navigate to the Amazon MWAA console and select your environment. In the top right-hand corner, select Open Airflow UI . You should see the following:
To trigger the DAG, in the Actions column, select the play symbol and then select Trigger DAG. Click on the DAG name to explore the DAG run and its results.
Navigate to the Amazon S3 console and choose the bucket starting with “destination”. It should contain a file list.json recently created by the write_bucket task. Download the file to explore its content, a JSON list with a single entry.
Clean up
The resources you created in this walkthrough incur AWS costs. To delete the created resources, issue the following command:
terraform destroy
And approve the changes in the Terraform CLI dialog.
Conclusion
In this blog post, you learned how to improve the security of your data pipeline running on Amazon MWAA and Amazon EKS by narrowing the permissions of each individual task.
To dive deeper, use the working example created in this walkthrough to explore the topic further: What happens if you remove the service_account_name parameter from an Airflow task? What happens if you exchange the service account names in the two tasks?
For simplicity, in this walkthrough we used a flat file structure with Terraform and Python files inside a single directory. We did not adhere to the standard module structure proposed by Terraform, which is generally recommended. In a real-life project, splitting up the project into multiple Terraform projects or modules may also increase flexibility, speed, and independence between teams owning different parts of the infrastructure.
Lastly, make sure to study the Data on EKS documentation, which provides other valuable resources for running your data pipeline on Amazon EKS, as well as the Amazon MWAA and Apache Airflow documentation for implementing your own use cases. Specifically, have a look at this sample implementation of a Terraform module for Amazon MWAA and Amazon EKS, which contains a more mature approach to Amazon EKS configuration and node automatic scaling, as well as networking.
If you have any questions, you can start a new thread on AWS re:Post or reach out to AWS Support.
About the Authors
Ulrich Hinze is a Solutions Architect at AWS. He partners with software companies to architect and implement cloud-based solutions on AWS. Before joining AWS, he worked for AWS customers and partners in software engineering, consulting, and architecture roles for 8+ years.
Patrick Oberherr is a Staff Data Engineer at Contentful with 4+ years of working with AWS and 10+ years in the Data field. At Contentful he is responsible for infrastructure and operations of the data stack which is hosted on AWS.
Johannes Günther is a cloud & data consultant at Netlight with 5+ years of working with AWS. He has helped clients across various industries designing sustainable cloud platforms and is AWS certified.
Amazon CodeCatalyst is an integrated service for software development teams adopting continuous integration and deployment practices into their software development process. CodeCatalyst puts the tools you need all in one place. You can plan work, collaborate on code build, test, and deploy applications with continuous integration/continuous delivery (CI/CD) tools. You can also integrate AWS resources with your projects by connecting your AWS accounts to your CodeCatalyst space. By managing all of the stages and aspects of your application lifecycle in one tool, you can deliver software quickly and confidently.
Introduction
In this post we will focus on how development teams can use Amazon CodeCatalyst with AWS Signer to fully manage the code signing process to ensure the trust and integrity of code assets. We will describe the process of building the AWS Lambda code using a CodeCatalyst workflow, we will then demonstrate the process of signing the code using a signer profile and deploying the signed code to our Lambda function.
Figure 1: Architecture Diagram.
Prerequisites
To follow along with the post, you will need the following items:
If you are using the CodeCatalystWorkflowDevelopmentRole-project_name you will need to add the relevant AWS Signer permissions. In our demo environment we used signer:* S3-*IAM permission.
During this tutorial, we will create a step-by-step guide to constructing a workflow utilizing CodeCatalyst. The objective is to employ the AWS Signer service to retrieve Python code from a specified source Amazon S3 bucket, compress and sign the code, and subsequently store it in a destination S3 bucket. Finally, we will utilize the signed code to deploy a secure Lambda function.
Create the base workflow
To begin we will create our workflow in the CodeCatalyst project.
Select CI/CD → Workflows → Create workflow:
Figure 2: Create workflow.
Leave the defaults for the Source Repository and Branch, select Create. We will have an empty workflow:
Figure 3: Empty workflow.
We can edit the workflow from the CodeCatalyst console, or use a Dev Environment. Initially, we will create an initial commit of this workflow file, ignore any validation errors at this stage:
Figure 4: Commit workflow with workflow file name, message repository and branch name.
Connect to CodeCatalyst Dev Environment
We will use an AWS Cloud9 Dev Environment. Our first step is to connect to the dev environment.
Select Code → Dev Environments. If you do not already a Dev Instance you can create an instance by selecting Create Dev Environment.
Figure 5: Create Dev Environment.
We already have a Dev Environment, so will go ahead and select Resume Instance. A new browser tab opens for the IDE and will be available in less than one minute. Once the IDE is ready, we can go ahead and start building our workflow. First, open a terminal. You can then change into the source repository directory and pull the latest changes. In our example, our Git source repository name is lambda-signer
cd lambda-signer && git pull. We can now edit this file in our IDE.
Initially, we will create a basic Lambda code under artifacts directory:
The previous command block creates our index.py file which will go inside the AWS Lambda function. When we testing the Lambda Function, we should see message “Testing Lambda Code Signing using Signer” in the console log.
As a next step, we will create the CDK directory and initiate it:
mkdir cdk;
cd cdk && cdk init --language python cdk
The previous command will create a directory called ‘cdk’ and then initiate cdk inside this directory. As a result, we will see another directory named ‘cdk’. We then need to update files inside this directory as per the following screenshot.
Figure 6: Repository file structure.
Update the content of the files as per the code following snippets:
(Note: Update your region name by replacing the placeholder <Region Name> )
cdk_stack.py:
import os
from constructs import Construct
from aws_cdk import (
Duration,
Stack,
aws_lambda as lambda_,
aws_signer as signer,
aws_s3 as s3,
Aws as aws,
CfnOutput
)
class CdkStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Set the AWS region
os.environ["AWS_DEFAULT_REGION"] = "<Region Name>"
# Create the signer profile
signer_profile_name = "my-signer-profile-" + aws.ACCOUNT_ID
print(f"signer_profile_name: {signer_profile_name}")
signing_profile = signer.SigningProfile(self, "SigningProfile",
platform=signer.Platform.AWS_LAMBDA_SHA384_ECDSA,
signing_profile_name='my-signer-profile' + aws.ACCOUNT_ID,
signature_validity=Duration.days(365)
)
self.code_signing_config = lambda_.CodeSigningConfig(self, "CodeSigningConfig",
signing_profiles=[signing_profile]
)
source_bucket_name = "source-signer-bucket-" + aws.ACCOUNT_ID
source_bucket = s3.Bucket(self, "SourceBucket",
bucket_name=source_bucket_name,
block_public_access=s3.BlockPublicAccess.BLOCK_ALL,
encryption=s3.BucketEncryption.S3_MANAGED,
versioned=True
)
destination_bucket_name = "dest-signer-bucket-" + aws.ACCOUNT_ID
self.destination_bucket = s3.Bucket(self, "DestinationBucket",
bucket_name=destination_bucket_name,
block_public_access=s3.BlockPublicAccess.BLOCK_ALL,
encryption=s3.BucketEncryption.S3_MANAGED,
versioned=True
)
resolved_signing_profile_name = self.resolve(signing_profile.signing_profile_name)
CfnOutput(self,"signer-profile",value=signing_profile.signing_profile_name)
CfnOutput(self,"src-bucket",value=source_bucket.bucket_name)
CfnOutput(self,"dst-bucket",value=self.destination_bucket.bucket_name)
lambda_stack.py:
from constructs import Construct
from aws_cdk import (
Duration,
Stack,
aws_lambda as lambda_,
aws_signer as signer,
aws_s3 as s3,
Aws as aws,
CfnOutput
)
class LambdaStack(Stack):
def __init__(self, scope: Construct, construct_id: str, dst_bucket:s3.Bucket,codesigning_config: lambda_.CodeSigningConfig, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Set the AWS region
# Get the code from action inputs
bucket_name = self.node.try_get_context("bucket_name")
key = self.node.try_get_context("key")
lambda_function = lambda_.Function(
self,
"Function",
function_name=’sample-signer-function’,
code_signing_config=codesigning_config,
runtime=lambda_.Runtime.PYTHON_3_9,
handler="index.Lambda_handler",
code=lambda_.Code.from_bucket(dst_bucket, key)
)
app.py:
#!/usr/bin/env python3
import aws_cdk as cdk
from cdk.cdk_stack import CdkStack
from cdk.lambda_stack import LambdaStack
app = cdk.App()
signer_stack = CdkStack(app, "cdk")
lambda_stack = LambdaStack(app, "LambdaStack", dst_bucket=signer_stack.destination_bucket,codesigning_config=signer_stack.code_signing_config)
app.synth()
Finally, we will work on Workflow:
In our example, our workflow is Workflow_d892. We will locate Workflow_d892.yaml in the .codecatalyst\workflows directory in our repository.
Figure 7: Workflow yaml file.
Update workflow with remaining steps
We can assign our workflow a name and configure the action. We have five stages in this workflow:
CreateSignerResources: Deploys Signer resources into AWS Account
ZipLambdaCode: Compresses the index.py file and store it in the source S3 bucket
SignCode: Sign the compressed python file and push it to the destination S3 bucket
Createlambda: Creates the Lambda Function using the signed code from destination S3 bucket.
Please insert the following values for your environment into the workflow file. The environment configuration will be as per the pre-requisite configuration for CodeCatalyst environment setup:
<Name of your Environment>: The Name of your CodeCatalyst environment
<AWS Account>: The AWS Account connection ID
<Role Name>: The CodeCatalyst role that is configured for the environment
(Note: Feel free to update the region configuration to meet your deployment requirements. Supported regions are listed here)
Name: Workflow_d892
SchemaVersion: "1.0"
# Optional - Set automatic triggers.
Triggers:
- Type: Push
Branches:
- main
# Required - Define action configurations.
Actions:
CDKBootstrap:
# Identifies the action. Do not modify this value.
Identifier: aws/[email protected]
# Specifies the source and/or artifacts to pass to the action as input.
Inputs:
# Optional
Sources:
- WorkflowSource # This specifies that the action requires this Workflow as a source
# Required; You can use an environment, AWS account connection, and role to access AWS resources.
Environment:
Name: <Name of your Environment>
Connections:
- Name: <AWS Account>
Role: <Role Name> # Defines the action's properties.
Configuration:
# Required; type: string; description: AWS region to bootstrap
Region: <Region Name>
CreateSignerResources:
# Identifies the action. Do not modify this value.
Identifier: aws/[email protected]
DependsOn:
- CDKBootstrap
# Specifies the source and/or artifacts to pass to the action as input.
Inputs:
# Optional
Sources:
- WorkflowSource # This specifies that the action requires this Workflow as a source
# Required; You can use an environment, AWS account connection, and role to access AWS resources.
Environment:
Name: <Name of your Environment>
Connections:
- Name: <AWS Account>
Role: <Role Name>
Configuration:
# Required; type: string; description: Name of the stack to deploy
StackName: cdk
CdkRootPath: cdk
Region: <Region Name>
CfnOutputVariables: '["signerprofile","dstbucket","srcbucket"]'
Context: '{"key": "placeholder"}'
ZipLambdaCode:
Identifier: aws/build@v1
DependsOn:
- CreateSignerResources
Inputs:
Sources:
- WorkflowSource
Environment:
Name: <Name of your Environment>
Connections:
- Name: <AWS Account>
Role: <Role Name>
#
Configuration:
Steps:
- Run: sudo yum install zip -y
- Run: cd artifacts && zip lambda-${WorkflowSource.CommitId}.zip index.py
- Run: aws s3 cp lambda-${WorkflowSource.CommitId}.zip s3://${CreateSignerResources.srcbucket}/tobesigned/lambda-${WorkflowSource.CommitId}.zip
- Run: S3VER=$(aws s3api list-object-versions --output text --bucket ${CreateSignerResources.srcbucket} --prefix 'tobesigned/lambda-${WorkflowSource.CommitId}.zip' --query 'Versions[*].VersionId')
Outputs:
Variables:
- S3VER
SignCode:
Identifier: aws/build@v1
DependsOn:
- ZipLambdaCode
Inputs:
Sources:
- WorkflowSource
Environment:
Name: <Name of your Environment>
Connections:
- Name: AWS Account>
Role: <Role Name> #
Configuration:
Steps:
- Run: export AWS_REGION=<Region Name>
- Run: SIGNER_JOB=$(aws signer start-signing-job --source --output text --query 'jobId' 's3={bucketName=${CreateSignerResources.srcbucket},key=tobesigned/lambda-${WorkflowSource.CommitId}.zip,version=${ZipLambdaCode.S3VER}}' --destination 's3={bucketName=${CreateSignerResources.dstbucket},prefix=signed-}' --profile-name ${CreateSignerResources.signerprofile})
Outputs:
Variables:
- SIGNER_JOB
CreateLambda:
# Identifies the action. Do not modify this value.
Identifier: aws/[email protected]
DependsOn:
- SignCode
# Specifies the source and/or artifacts to pass to the action as input.
Inputs:
# Optional
Sources:
- WorkflowSource # This specifies that the action requires this Workflow as a source
# Required; You can use an environment, AWS account connection, and role to access AWS resources.
Environment:
Name: <Name of your Environment>
Connections:
- Name: AWS Account>
Role: <Role Name>
# Defines the action's properties.
Configuration:
# Required; type: string; description: Name of the stack to deploy
StackName: LambdaStack
CdkRootPath: cdk
Region: <Region Name>
Context: '{"key": "signed-${SignCode.SIGNER_JOB}.zip"}'
We can copy/paste this code into our workflow. To save our changes, we select File -> Save. We can then commit these to our git repository by typing the following at the terminal:
The previous command will commit and push the changes that we have made to the CodeCatalyst source repository. As we have a branch trigger for main defined, this will trigger a run of the workflow. We can monitor the status of the workflow in the CodeCatalyst console by selecting CICD -> Workflows. Locate your workflow and click on Runs to view the status.
Figure 8: Successful workflow execution.
To validate that our newly created Lambda function is using AWS Signed code, we can open the AWS Console in our target region > Lambda > click on the sample-signer-function to inspect the properties.
Figure 9: AWS Lambda function with signed code.
Under the Code Source configuration property, you should see an informational message advising that ‘Your function has signed cofde and can’t be edited inline’. This confirms that the Lambda function is successfully using signed code.
Cleaning up
If you have been following along with this workflow, you should delete the resources that you have deployed to avoid further chargers. In the AWS Console > CloudFormation, locate the LambdaStack, then select and click Delete to remove the stack. Complete the same steps for the CDK stack.
Conclusion
In this post, we explained how development teams can easily get started signing code with AWS Signer and deploying it to Lambda Functions using Amazon CodeCatalyst. We outlined the stages in our workflow that enabled us to achieve the end-to-end release cycle. We also demonstrated how to enhance the developer experience of integrating CodeCatalyst with our AWS Cloud9 Dev Environment and leveraging the power of AWS CDK to use familiar programming languages such as Python to define our infrastructure as code resources.
On September 20, 2023, JetBrains disclosed CVE-2023-42793, a critical authentication bypass vulnerability in on-premises instances of their TeamCity CI/CD server. Successful exploitation of CVE-2023-42793 allows an unauthenticated attacker with HTTP(S) access to a TeamCity server to perform a remote code execution attack and gain administrative control of the server — making the vulnerability a potential supply chain attack vector.
As of September 25, 2023, Rapid7 is not aware of in-the-wild exploitation of CVE-2023-42793, and no public exploit code is available. We still recommend, however, that TeamCity customers upgrade to the fixed version (2023.05.4) immediately, or else apply one of the vulnerability-specific patches outlined in the JetBrains advisory. Customers who are unable to upgrade or apply a targeted fix for CVE-2023-42793 should consider taking the server offline until the vulnerability can be mitigated.
Affected Products
CVE-2023-42793 affects all on-prem versions of JetBrains TeamCity prior to 2023.05.4. TeamCity Cloud is not affected, and according to JetBrains, TeamCity Cloud servers have already been upgraded to the latest version.
Mitigation Guidance
JetBrains notes in their advisory that vulnerability-specific security patch plugins (i.e., hot fixes) are available as a temporary workaround for TeamCity customers who are not able to upgrade to 2023.05.4. The plugins are supported on TeamCity 8.0+ and will mitigate CVE-2023-42793 specifically, but will not address any other security issues or bugs that are included in the full 2023.05.4 upgrade.
For TeamCity 2019.2 and later, the plugin can be enabled without restarting the TeamCity server. For versions older than 2019.2, a server restart is required after the plugin has been installed. TeamCity customers should refer to the JetBrains advisory on CVE-2023-42793 for the latest information.
Rapid7 strongly recommends upgrading to the fixed version of the software (2023.05.4) as soon as possible rather than relying solely on workarounds.
Rapid7 Customers
InsightVM and Nexpose customers will be able to assess their exposure to CVE-2023-42793 with a remote vulnerability check targeted for today’s (September 25) content release.
The last year or so has seen the posting of a few new filesystem types that
are aimed at supporting container workloads. PuzzleFS, presented at the
2023 Kangrejos gathering by Ariel
Miculas, is another contender in this area, but it has some features of its
own, including a novel compression mechanism and an implementation written
in Rust.
In this blog post, we will walk you through how to create and launch new projects in minutes using Amazon CodeCatalyst Blueprints. Blueprints automatically generate source code and a continuous integration and delivery (CI/CD) pipeline to deploy common patterns to your AWS account without requiring extensive programming knowledge. This functionality boosts productivity and lowers time to market for features. To illustrate how to use blueprints, we will walk through how to deploy a video-on-demand web service to your AWS account.
What is Amazon CodeCatalyst? It is an integrated DevOps service for software development teams adopting continuous integration and deployment practices into their software development process. CodeCatalyst provides one place where you can plan work, collaborate on code, and build, test, and deploy applications with continuous integration and continuous delivery (CI/CD) tools. You can easily integrate AWS resources with your projects by connecting your AWS accounts to your CodeCatalyst space. With all of these stages and aspects of an application’s lifecycle in one tool, you can deliver software quickly and confidently.
Prerequisites
To get started with Amazon CodeCatalyst, you need the following prerequisites. Please review them and ensure you have completed all steps before proceeding:
Create an AWS Builder ID. An AWS Builder ID is a new personal profile for everyone who builds on AWS. It is used to access tools and services within AWS, such as Amazon CodeCatalyst.
Join an Amazon CodeCatalyst space. To join a space, you will need to either:
Create an Amazon CodeCatalyst space. If you are creating the space, you will need to specify an AWS account ID for billing and provisioning of resources. If you have not created an AWS account, follow the AWS documentation to create one.
Create an AWS Identity and Access Management (IAM) role. Amazon CodeCatalyst will need an IAM role to have permissions to deploy the infrastructure to your AWS account. Follow the documentation for steps how to create an IAM role via the Amazon CodeCatalyst console.
Create the Amazon CodeCatalyst Project
Once all of the prerequisites have been met, you can log in to your Amazon CodeCatalyst space and create a project. Once you are logged in, navigate to your projects and select “Create project” (Figure 1).
Figure 1: Project screen with create project button selected
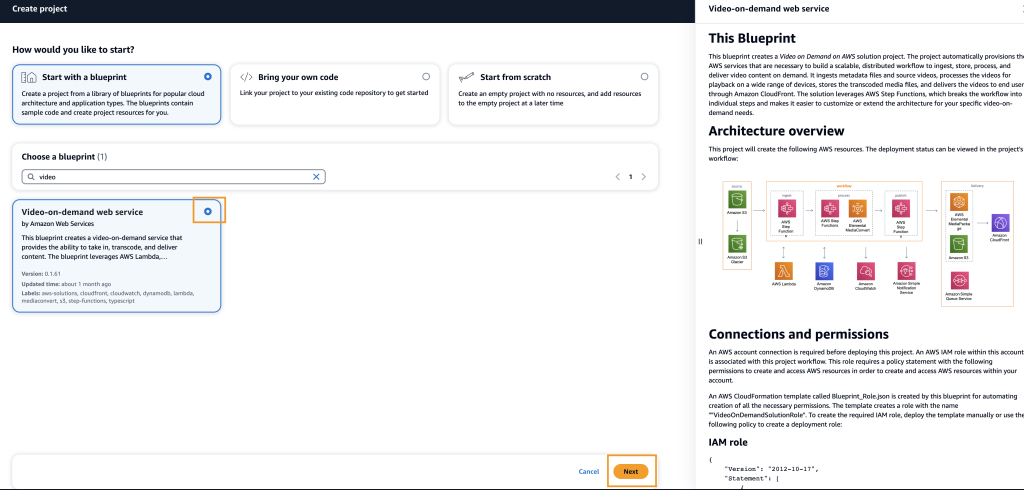
Select Start with a blueprint option and enter into the Choose a blueprint input box, “Video”. Select the Video-on-demand web service blueprint. Choosing this blueprint will open a side panel describing what the blueprint provides and an architecture diagram (Figure 2).
Figure 2: Create project screen with video-on-demand project selected
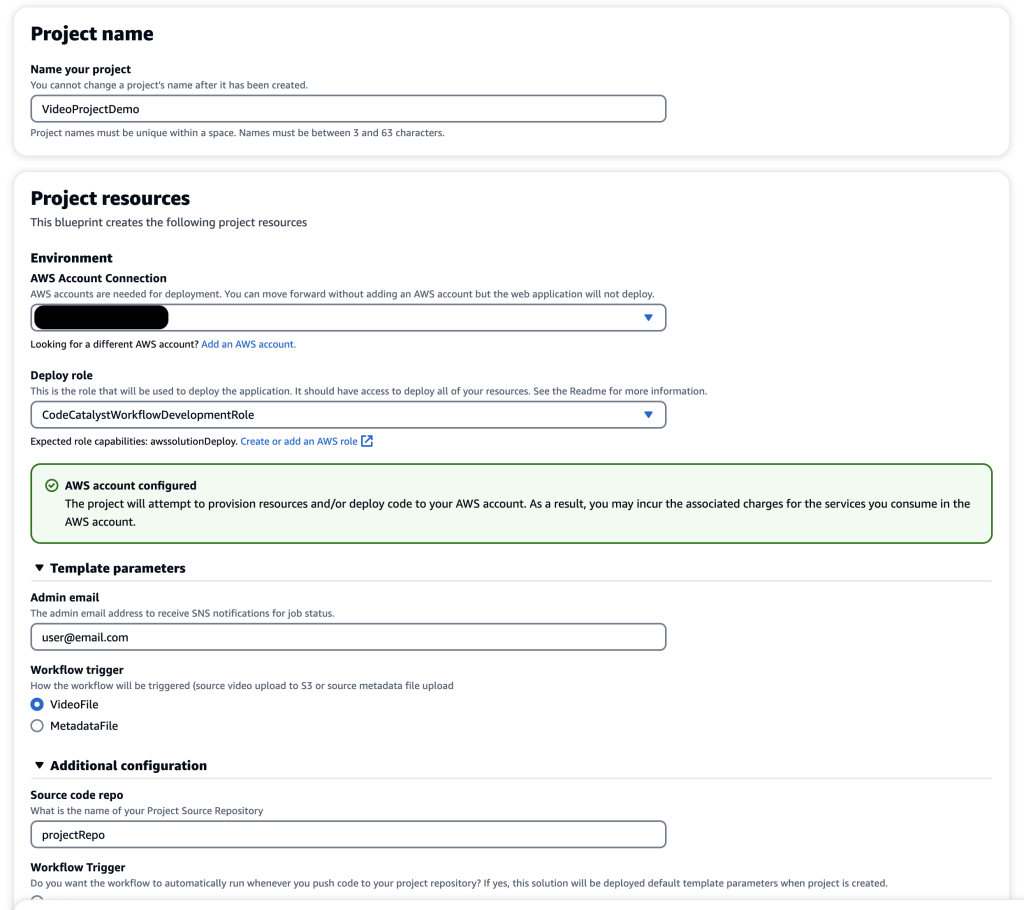
After selecting Next, you will be prompted for a project name, an AWS account ID and an IAM role to be associated with the project. Project names must be unique within your space and must be within 3-63 characters. See the official documentation for project naming requirements for more information.
Your AWS account ID and IAM role that you created as part of prerequisites should be automatically populated for you (Figure 3). If they are not present, you need to ensure you have properly linked the account and created the IAM role.
Figure 3: Project configurations listed. Linked AWS account ID and IAM role present
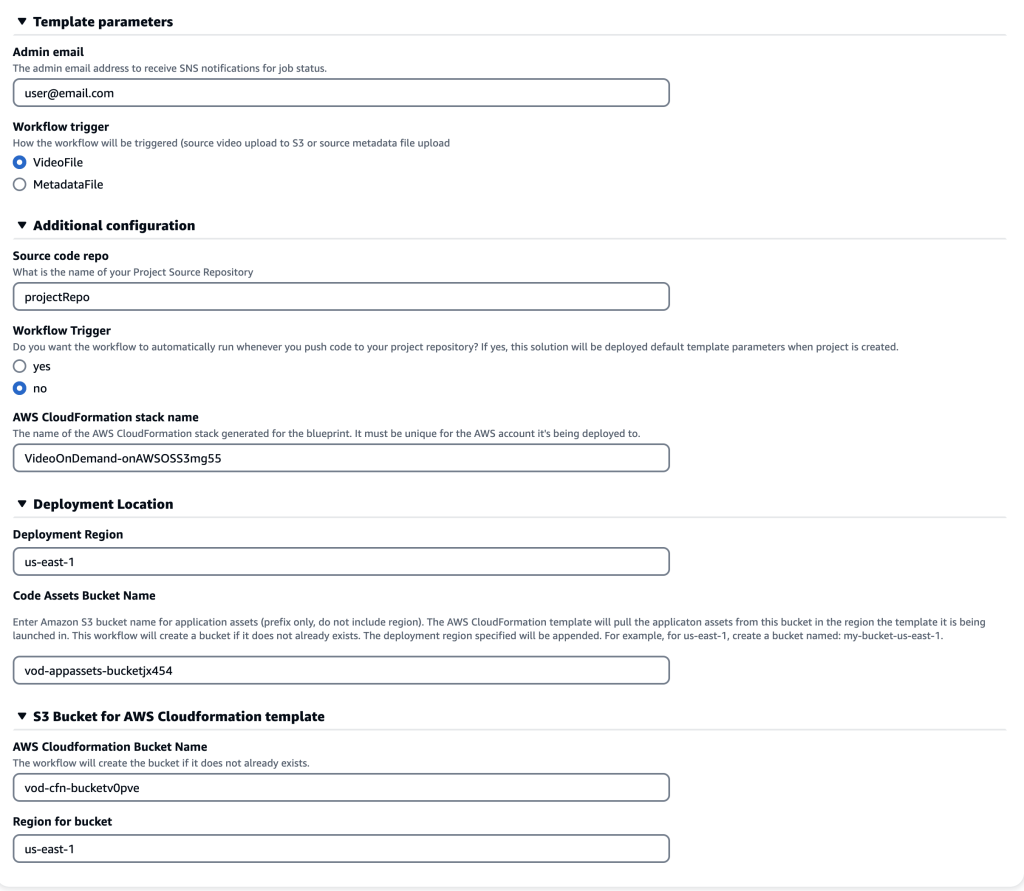
For this specific blueprint, there are more configuration options listed below such as: code repository name, automatic triggers of pipeline, CloudFormation stack name, deployment region and more (Figure 4). Leave all fields under Template parameters, Additional configuration, Deployment Location, and S3 Bucket for AWS CloudFormation Template as their default values.
Figure 4: Additional project configurations. Leaving default is fine
Once you have finished editing the configuration, choose Create project in the lower right corner. Amazon CodeCatalyst generates your project space and repository.
Walkthrough of the Project Space
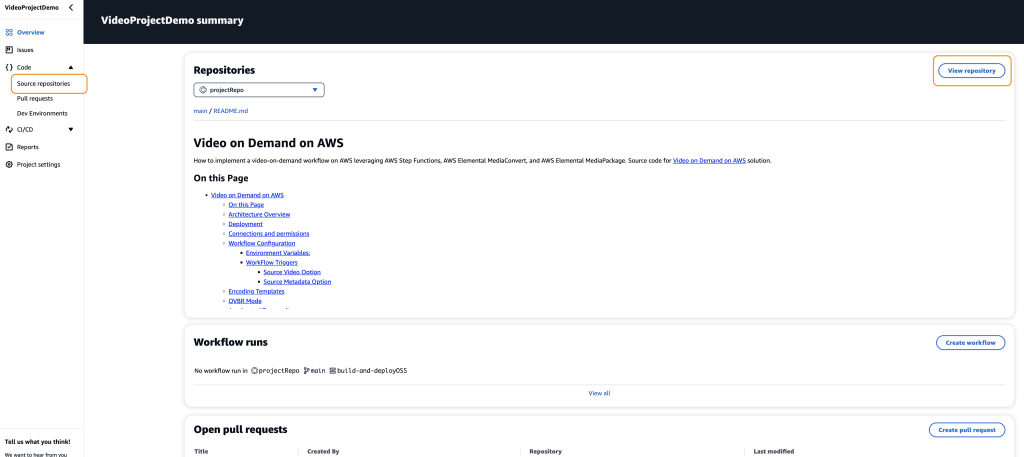
Your new code repository is the first item on the overview dashboard. Select View Repository or Source Repositories (Figure 5) to navigate to the code repository for this project. If the repository details are not present on the overview page, wait for approximately 10-15 seconds and refresh the page.
Figure 5: Project overview screen with view repository and source repositories selected
This blueprint provides you with a functioning video-on-demand solution; however, you can modify the code for your specific use case. Blueprints are a template and give users the freedom to add custom business logic.
Adding IAM Permissions
You should have created an IAM role for Amazon CodeCatalyst workflow to use during the prerequisites section. If you have not, please refer to the prerequisites section.
This specific solution provides an IAM Policy that you can attach to your IAM role such that sufficient IAM permissions are present to deploy the solution to your AWS account. The IAM Policy is within the README.md file. Within README.md, under the connections and permissions section, copy the IAM policy and create a new policy via the AWS console. Make sure to attach this IAM policy to your existing IAM role.
CI/CD Workflows
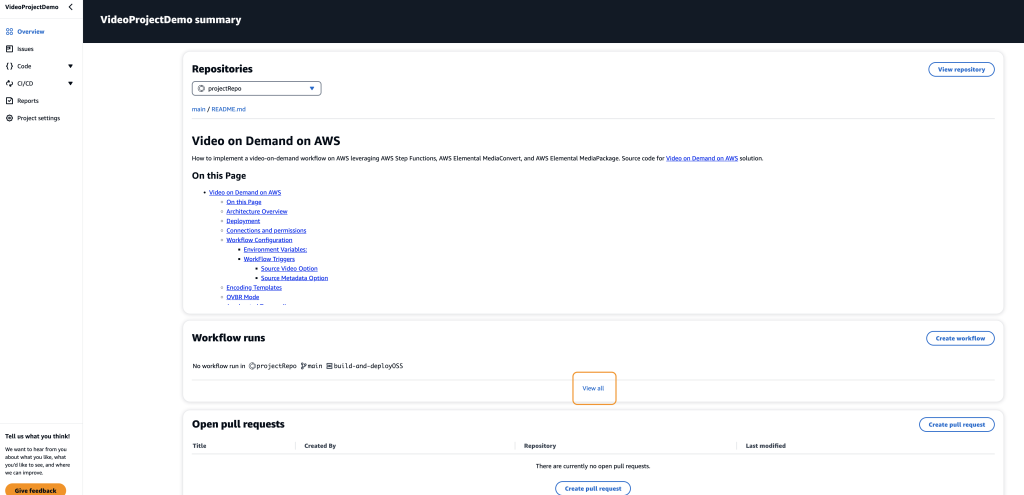
Start the CI/CD process to deploy the video-on-demand solution to your AWS account. Choose View all from the Overview page. This can also be found by selecting CI/CD from the side menu (Figure 6).
Figure 6: Overview page with View All button selected
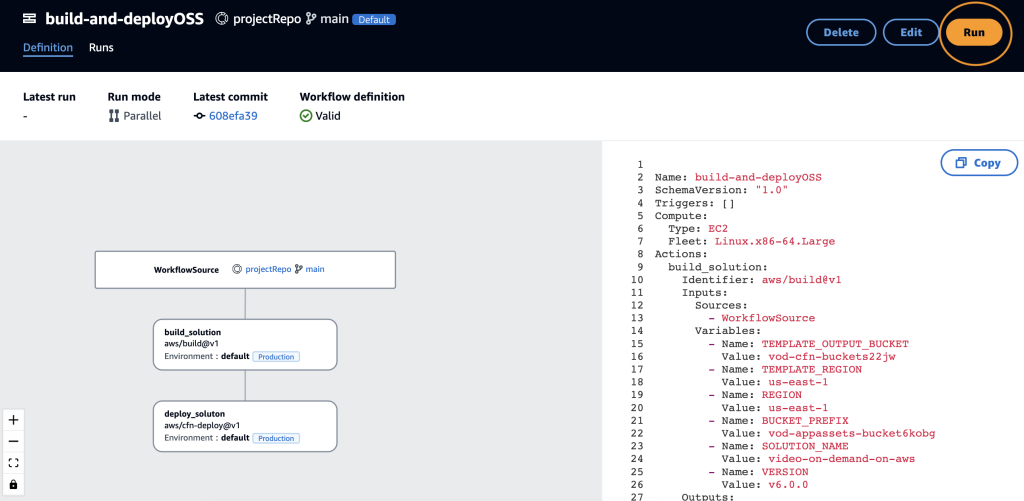
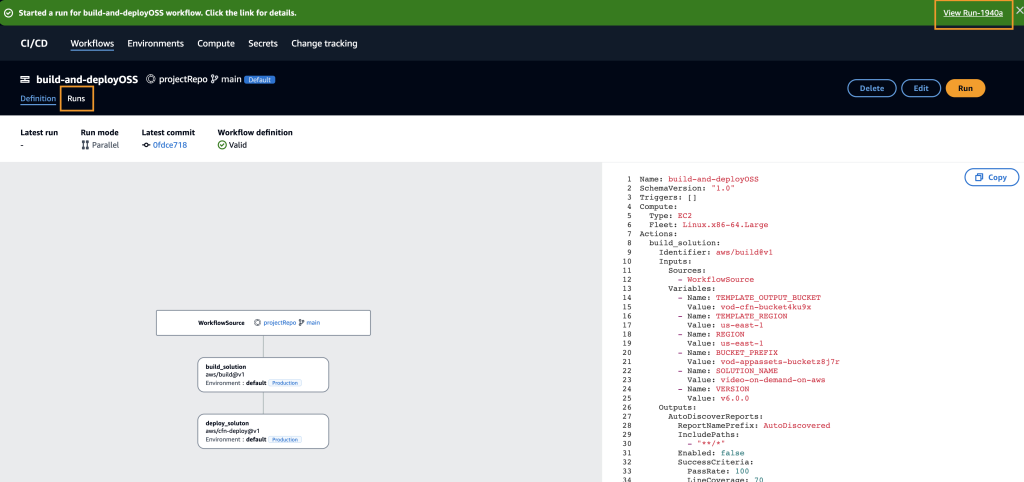
This blueprint comes with one, default workflow called build-and-deployOSS. To build and deploy this application to your AWS account, choose Run on the workflow page (Figure 7).
Figure 7: build-and-deployOSS workflow with Run button selected
Select the Runs tab or the RunID from the dialog box to view the status of the deployment (Figure 8). This pipeline is building and deploying the full application and will need approximately 10 minutes to run.
Figure 8: build-and-deployOSS workflow with the RunID and Runs tab selected
Configure a custom workflow
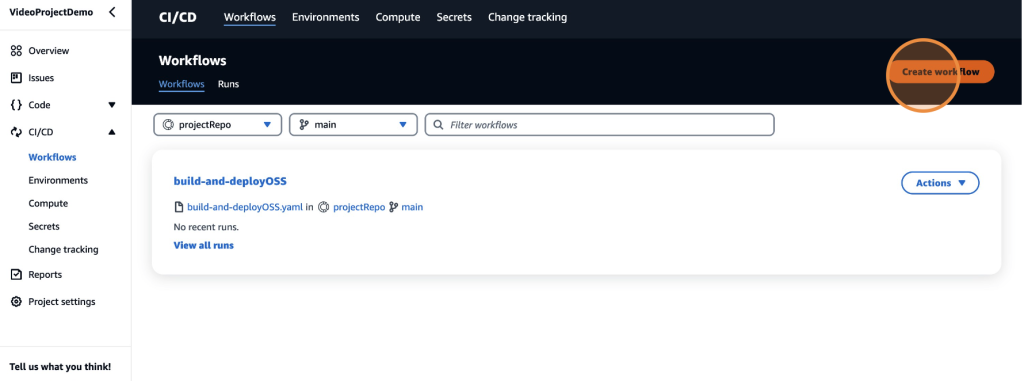
You can configure custom pipelines within CodeCatalyst. To do this, navigate to the Workflows page within Amazon CodeCatalyst and select Create Workflow (Figure 9).
Figure 9: Create a custom workflow
Amazon CodeCatalyst offers a variety of drag and drop solutions to building pipelines using YAML and CloudFormation. For more information on configuring custom workflows within Amazon CodeCatalyst, view the getting started with custom workflows documentation.
Check in on your Workflow
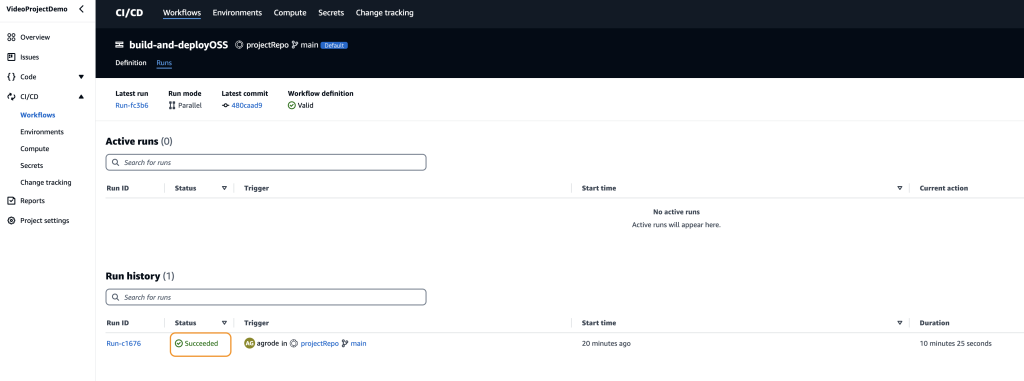
After approximately 10 minutes, the build-and-deployOSS should be complete! The status of the run is listed under Run History (Figure 10).
Figure 10: Run history with the job status highlighted
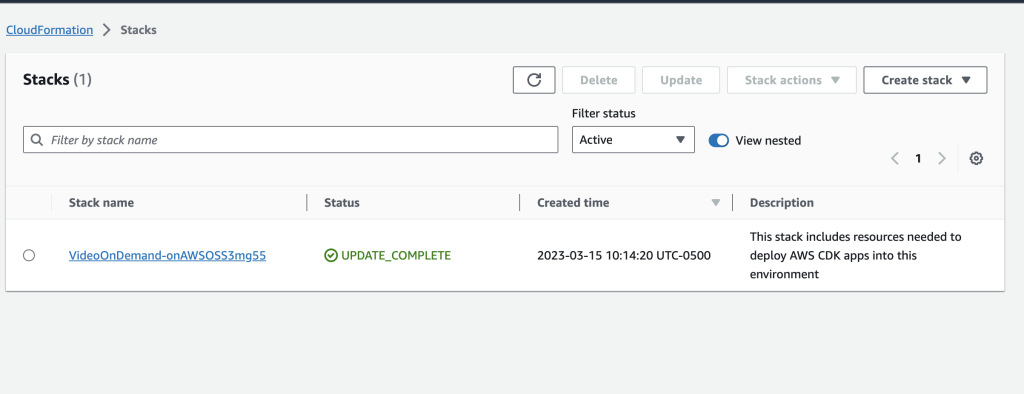
To validate a successful deployment of the blueprint, login to the AWS Console and navigate to the CloudFormation service. If the status is listed as UPDATE_COMPLETE, then the blueprint has been deployed successfully!
Figure 11: AWS Console showing CloudFormation template successful run
Clean up Your Environment
To avoid incurring future charges, delete the infrastructure provisioned by the Amazon CodeCatalyst workflow. This can be done by deleting the CloudFormation stack. To do this, login to your AWS account and select the CloudFormation service. Select the stack with VideoOnDemand in the title and select the delete button. This will delete the entire stack.
Conclusion
While reading this blog, you learned how to use Amazon CodeCatalyst blueprints by deploying a video-on-demand web service to your AWS account. You used the automatically generated source code and a CI/CD pipeline to deploy the solution in minutes. Now, that you are more familiar with Amazon CodeCatalyst blueprints, you can use it to deliver software quickly and confidently.
Amazon CodeCatalyst provides a collaboration space where developers easily build applications and streamline the deployment process. It integrates with container application services such as AWS App Runner, making containerized application deployments efficient and straightforward. Using CodeCatalyst’s native CI/CD workflow actions, development teams swiftly roll out applications and mitigate operational challenges. The workflow’s fluidity from coding to deploying ensures that developers move between stages effortlessly, promoting an agile development experience.
In this post, we’ll guide you through deploying a containerized application to App Runner using CodeCatalyst’s native CI/CD workflow actions for a seamless deployment experience.
Solution Overview
In this walkthrough, you will set up a basic “Hello World” static webpage using the Apache HTTP Server. The primary focus of this blog is to navigate the essential features of the CodeCatalyst workflow and its specific actions for App Runner service. Within this workflow, the “Push to Amazon ECR” action builds the container image and then pushes the image to Amazon Elastic Container Registry (ECR) . Subsequently, the “Deploy to AWS App Runner” action initiates an AWS CloudFormation template that launches the App Runner service.
Figure 1 – Solution Architecture
The solution described in the post covers the following steps:
Create a sample application
Set up CodeCatalyst environment
Create a CodeCatalyst CI/CD workflow
Create a sample application
For this demonstration, GitHub serves as the source repository. Alternatively, you can create a source repository directly within CodeCatalyst or you can choose to link an existing source repository hosted by another service if that service is supported by an installed extension on CodeCatalyst.
The first step is to create a simple index.html file with the following content:
<html>
<head>
<title>Hello, World!</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>Welcome to my demo of CodeCatalyst CI/CD Workflow. Watch how changes here magically appear live through the power of automation!</p>
</body>
</html>
Next, create a Dockerfile in addition to the HTML file. This file contains two commands: the first instructs Docker to build an image from the httpd image, while the second places the index.html file into this image. Here’s a snippet of the Dockerfile:
FROM httpd
COPY ./index.html /usr/local/apache2/htdocs/
Once finalized, you can push these files to the GitHub repository. The following image displays the GitHub repository layout.
Figure 2 – GitHub repository layout
Set up CodeCatalyst environment
Follow these steps to set up the CodeCatalyst environment:
To create a new workflow, select CI/CD from navigation on the left and then select Workflows. Then, select Create workflow, leave the default options, and select Create.
Figure 3 – Create CodeCatalyst workflow
If the workflow editor opens in YAML mode, select Visual to open the visual designer. Now, you can start adding actions to the workflow.
Step1: Add “Push to Amazon ECR” action
Add the “Push to Amazon ECR” action to the workflow as shown in Figure 4. Refer to adding an action to learn how to use the CodeCatalyst action.
Figure 4 – Add “Push to Amazon ECR” Action
Choose the Configuration tab and specify the configurations as shown in Figure 5.
Figure 5 – Configure “Push to Amazon ECR” action
Step 2: Add “Deploy to AWS App Runner” action
Add the “Deploy to AWS App Runner” action to the workflow for deploying the latest image in ECR to App Runner as shown in Figure 6. In the Inputs tab, under Depends on, choose the “PushToAmazonECR_xx” action.
Figure 6 – Add “Deploy to AWS App Runner” action
Choose the Configuration tab and specify the configurations of the App Runner action, as shown in Figure 7.
For ImageIdentifier, use the format “<account number>.dkr.ecr.<region>.amazonaws.com/<repository name>:<image tag>”, this will align with the ARN of the ECR image once the workflow generates it. For this guide, you are going to create a new App Runner service. When providing a Stack Name, the action determines whether the App Runner service is already exists. If not, it creates a new App Runner service using default configurations.
Figure 7 – Configure “Deploy to AWS App Runner” Action
You may notice that action does not support configuring all of the option available in App Runner. For those who find the options limiting, you can deploy your App Runner service manually through the AWS console or using Infrastructure-as-Code (IaC) methods. Once set up, you can simply use the ARN of your existing App Runner service in the action.
If you switch back to the YAML view, you can see that the following actions are added to the workflow definition.
The workflow is now ready and you can validate it by choosing Validate. After that, save the changes by choosing Commit (Figure 8).
Figure 8 – Validate and commit workflow
When saving the workflow with commit, the workflow runs automatically. CodeCatalyst builds the container image of the application, pushes the image to ECR, and deploys the application to App Runner (Figure 9).
Figure 9 – Workflow run succeeded
Test the deployment
Once the “Deploy To AWS App Runner” action finishes, you can check the URL to the website of your service. To check the App Runner domain value, click on the Variables tab. Under Output variables, copy the value of the “AppUrl”.
Figure 10 – App Runner domain value
Visit the URL to verify the App Runner service is running.
Figure 11 – Verify the App Runner service is running
You can go ahead and test the CI/CD workflow by committing an update to theindex.htmlcontent in the source GitHub repo.
<html>
<head>
<title>Hello, Universe!</title>
</head>
<body>
<h1>Hello, Universe!</h1>
<p>Ta-da! Noticed that change? That's the magic of our CI/CD workflow in action with CodeCatalyst</p>
</body>
</html>
Another workflow run starts automatically on a commit to source. When the workflow completes, refresh the browser tab to verify that the update is successful.
Figure 12 – Verify the App Runner service is updated
Cleanup
To avoid incurring extra charges after following this post’s workflow, consider cleaning up the resources that you set up.
1. Delete the ECR repository via AWS Management Console.
2. Delete the App Runner service by deleting the CloudFormation stack with the name identical to the “StackName” specified for the App Runner action.
3. Delete the CodeCatalyst workflow.
4. Delete the CodeCatalyst project by navigating to Project settings and choosing Delete project.
Conclusion
In summary, this post shows how to configure CodeCatalyst workflow to build and deploy containerized applications using CodeCatalyst’s native CI/CD workflow actions. By leveraging these actions, developers can simplify the deployment process to App Runner. Learn more and embark on your Amazon CodeCatalyst journey.
A lot of people rely on Cloudflare. We serve over 46 million HTTP requests per second on average; millions of customers use our services, including 31% of the Fortune 1000. And these numbers are only growing.
That’s why today we are excited to announce Incident Alerts — available via email, webhook, or PagerDuty. These notifications are accessible easily in the Cloudflare dashboard, and they’re customizable to prevent notification overload. And best of all, they’re available to everyone; you simply need a free account to get started.
Lifecycle of an incident
Without proper transparency, incidents cause confusion and waste resources for anyone that relies on the Internet. With so many different entities working together to make the Internet operate, diagnosing and troubleshooting can be complicated and time-consuming. By far the best solution is for providers to have transparent and proactive alerting, so any time something goes wrong, it’s clear exactly where the problem is.
Cloudflare incident response
We understand the importance of proactive and transparent alerting around incidents. We have worked to improve communications by directly alerting enterprise level customers and allowing everyone to subscribe to an RSS feed or leverage the Cloudflare Status API. Additionally, we update the Cloudflare status page — which catalogs incident reports, updates, and resolutions — throughout an incident’s lifecycle, as well as tracking scheduled maintenance.
However, not everyone wants to use the Status API or subscribe to an RSS feed. Both of these options require some infrastructure and programmatic efforts from the customer’s end, and neither offers simple configuration to filter out noise like scheduled maintenance. For those who don’t want to build anything themselves, visiting the status page is still a pull, rather than a push, model. Customers themselves need to take it upon themselves to monitor Cloudflare’s status — and timeliness in these situations can make a world of difference.
Without a proactive channel of communication, there can be a disconnect between Cloudflare and our customers during incidents. Although we update the status page as soon as possible, the lack of a push notification represents a gap in meeting our customers’ expectations. The new Cloudflare Incident Alerts aim to remedy that.
Simple, free, and fast notifications
We want to proactively notify you as soon as a Cloudflare incident may be affecting your service —- without any programmatic steps on your end. Unlike the Status API and an RSS feed, Cloudflare Incident Alerts are configurable through just a few clicks in the dashboard, and you can choose to receive email, PagerDuty, or web hook alerts for incidents involving specific products at different levels of impact. The Status API will continue to be available.
With this multidimensional granularity, you can filter notifications by specific service and severity. If you are, for example, a Cloudflare for SaaS customer, you may want alerts for delays in custom hostname activation but not for increased latency on Stream. Likewise, you may only care about critical incidents instead of getting notified for minor incidents. Incident Alerts give you the ability to choose.
Lifecycle of an Incident
How to filter incidents to fit your needs
You can filter incident notifications with the following categories:
Cloudflare Sites and Services: get notified when an incident is affecting certain products or product areas.
Impact level: get notified for critical, major, and/or minor incidents.
These categories are not mutually exclusive. Here are a few possible configurations:
Notify me via email for all critical incidents.
Notify me via webhook for critical & major incidents affecting Pages.
Notify me via PagerDuty for all incidents affecting Stream.
With over fifty different alerts available via the dashboard, you can tailor your notifications to what you need. You can customize not only which alerts you are receiving but also how you would like to be notified. With PagerDuty, webhooks, and email integrated into the system, you have the flexibility of choosing what will work best with your working environment. Plus, with multiple configurations within many of the available notifications, we make it easy to only get alerts about what you want, when you want them.
Try it out
You can start to configure incident alerts on your Cloudflare account today. Here’s how:
Navigate to the Cloudflare dashboard → Notifications.
Select “Add”.
Select “Incident Alerts”.
Enter your notification name and description.
Select the impact level(s) and component(s) for which you would like to be notified. If either field is left blank, it will default to all impact levels or all components, respectively.
Select how you want to receive the notifications:
Check PagerDuty
Add Webhook
Add email recipient
Select “Save”.
Test the notification by selecting “Test” on the right side of its row.
For more information on Cloudflare’s Alert Notification System, visit our documentation here.
In the dynamic landscape of modern web applications and organizations, access control is critical. Defining who can do what within your Cloudflare account ensures security and efficient workflow management. In order to help meet your organizational needs, whether you are a single developer, a small team, or a larger enterprise, we’re going to cover two changes that we have developed to make it easier to do user management, and best practices on how to use these features, alongside existing features in order to scope everything appropriately into your account, in order to ensure security while you are working with others.
What are roles?
In the preceding year, Cloudflare has expanded our list of roles available to everyone from 1 to over 60, and we are continuing to build out more, better roles. We have also made domain scoping a capability for all users. This prompts the question, what are roles, and why do they exist?
Roles are a set of permissions that exist in a bundle with a name. Every API call that is made to Cloudflare has a required set of permissions, otherwise an API call will return with a 403. We generally group permissions into a role to allow access to a set of capabilities that allow the use of a Cloudflare Product, or that represent everything needed to fulfill a job function.
As of today, we have two entities that we can assign roles: the first entity is a user, representing a profile, or an actor, which we generally require an email address to represent.
The second entity is a token, which represents delegation of a subset of a user’s permissions to be used for programmatic purposes.
What is scope?
Permissions are useless without an appropriate actor, and a scope. For every action a user can take, they must be directed to the appropriate resource, which is what we refer to as a scope.
When a user first signs up to Cloudflare, they are provided a Cloudflare user, as well as an account. Accounts can be shared with others. Accounts act as our traditional resource boundary, and granting permissions at the account level means that those permissions apply to all zones, and all other resources within the account.
Within accounts however, there are zones, R2 Buckets, Workers, and other resources. We are working on expanding the types of scopes that can be set, and as of now, you can scope access to a selective number of zones, or create tokens that only allow access into specified R2 buckets.
While our list of available roles is going to continue to grow, I want to go into some detail about how to use the roles right now, and how to use them to their full potential
What are the different types of roles and scopes we have today?
For most of the Cloudflare users and use cases out there, our traditional role model at the account level is the easiest to use. These roles can be viewed by selecting the scope of All domains.
As of today, there are 40+ Roles available at the account level. These provide access to a capability across the whole account, with no further scoping. Once these roles are provided to a user, they are able to complete a limited set of actions across any zones in your account. We intend to cover off more capabilities in this list, and will continue to add more roles.
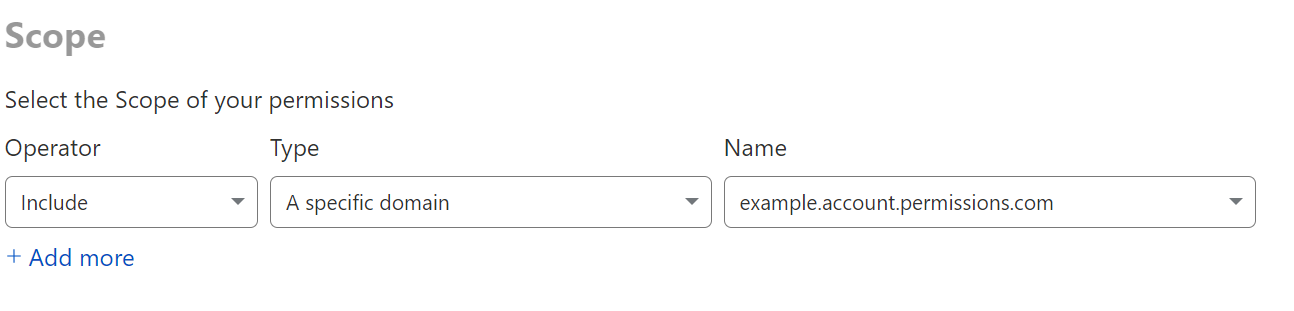
When you want to grant access to a specific zone, or list of zones, the best way to go about that is to use a domain scoped role.
A single domain can be added similar to the above, and granting explicit scope to a domain implicitly denies access to other domains.
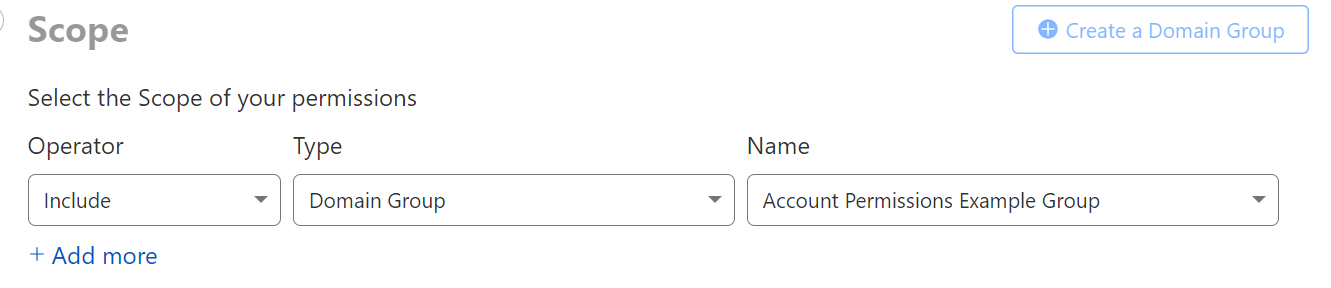
If you are looking to grant access to multiple domains simultaneously, in order to represent all staging zones for example, you can place them into a domain group. These can be revisited and edited within the Configurations → Lists page under Manage Account.
Best practices for creating domain groups is to group a set of similar domains together, such that you can reuse it for every user on your account.
Other best practices when assigning memberships
It is always best practice to explicitly define what you are granting access to, as Cloudflare’s permissioning system defers to a fail closed design. If you do not grant access to it, they will not have access to it.
We model all the different types of roles in an additive capacity, and we’re going to move forward with creating more capability specific roles. Multiple roles can be assigned given a scope. We recommend against explicitly “excluding” objects, because it can lead to some complex permission processing.
An example of this may be your organization’s billing administrator. You may want to grant them both Billing and Analytics, but exclude them from web administration activities by explicitly granting them those two roles.
Exciting changes you will see from us soon include the capability to “stack” multiple sets of policies on top of one another. We are currently rolling this out, and some users will already have the ability to define a set of permissions for one set of domains, and an increased set of permissions for another.
This will come in handy if you are managing multiple environments within one account, and want to grant differing levels of access to say a development and staging domain.
We also recognize that Cloudflare has many resources beyond Accounts and zones, and we are currently experimenting with adding scoping to other objects. As of today, you can specify R2 Tokens to only access certain buckets, and I look forward to adding this capability to more resources.
Best practices when delegating access to tokens
Memberships and users tend to use Cloudflare in an interactive capacity, but many organizations use Cloudflare programmatically.
A new capability we are rolling out to all users soon is the capability to limit API access: on your account as a whole, or on a per-user basis.
All programmatic access to Cloudflare at this time is managed at a per-user basis, representing a delegation of that user’s access to their set of accounts. Programmatic access is always bounded by a user’s access, and many of our user’s service accounts have a wide set of access that is split into context specific tokens.
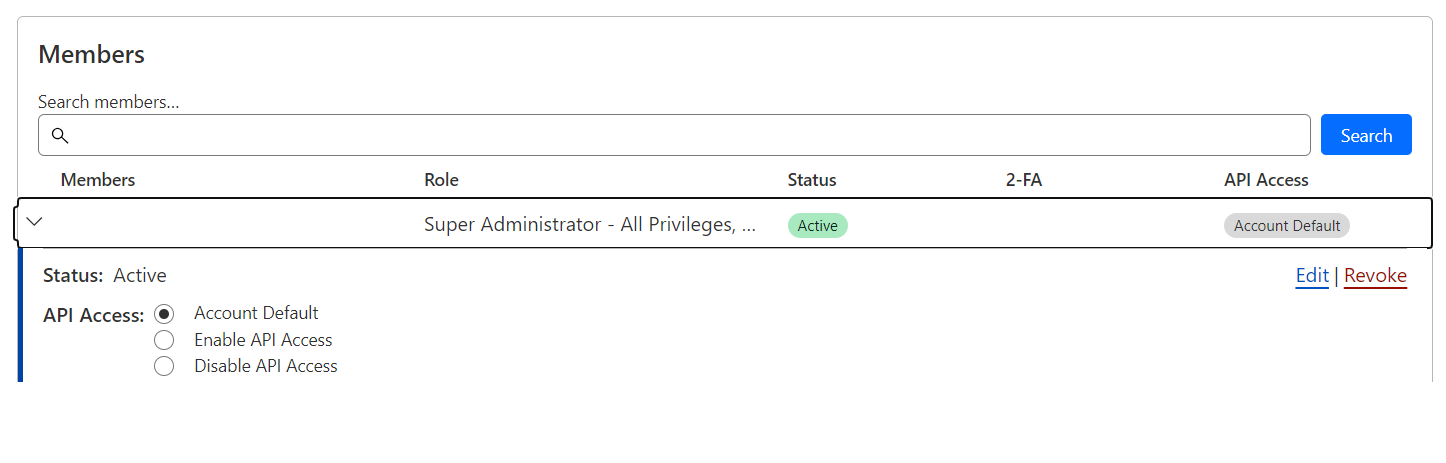
As a Super administrator, if you want to restrict programmatic access to your account, this toggle will become available on the members page.
We recommend keeping this functionality turned off, unless you explicitly want to grant the ability to use the API to specific users, which can also be controlled via a dropdown per user. We have seen some organizations use this capability to centralize the creation of API Tokens into a single service user.
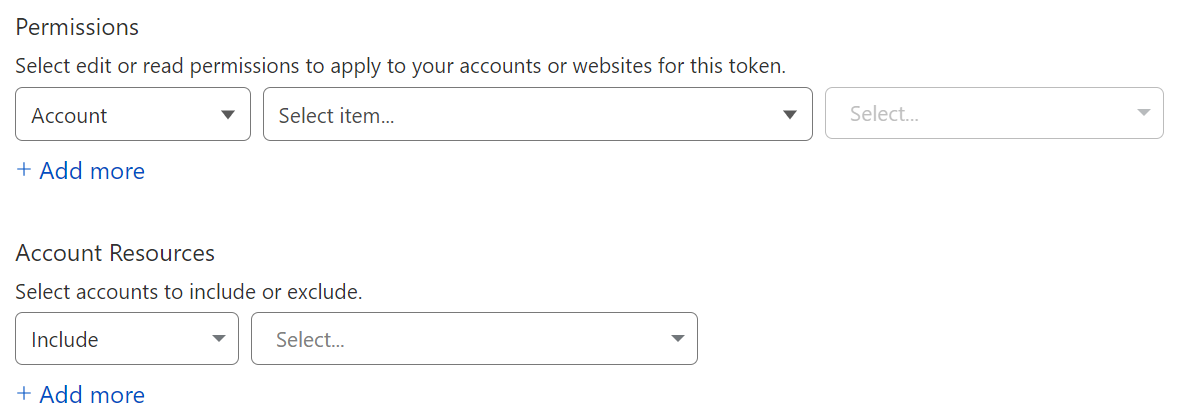
Cloudflare recommends the use of API Tokens wherever possible. API tokens have the ability to be scoped down to a smaller subset of a user’s access, instead of granting access to all of it.
When building out a set of permissions for an API Token, we have the same scoping capability that was visible in membership roles.
Account Scoping:
Domain/Zone Scoping:
Cloudflare’s roles are meant to provide the flexibility to provide the least amount of privilege possible, in order to keep your Cloudflare resources safe. Recent improvements have included a number of capability specific roles, as well as the ability to lock down API Access. Future improvements will include the ability to grant multiple policies to individual users, as well as more scopes.
What’s next
All users are able to use our new roles, and there will be several rolling improvements, including the capability to lock down API access, as well as assign multiple policies to users.
Since our founding, Cloudflare has helped customers save on costs, increase security, and boost performance and reliability by migrating legacy hardware functions to the cloud. More recently, our customers have been asking about whether this transition can also improve the environmental impact of their operations.
We are excited to share an independent report published this week that found that switching enterprise network services from on premises devices to Cloudflare services can cut related carbon emissions up to 96%, depending on your current network footprint. The majority of these gains come from consolidating services, which improves carbon efficiency by increasing the utilization of servers that are providing multiple network functions.
And we are not stopping there. Cloudflare is also proud to announce that we have applied to set carbon reduction targets through the Science Based Targets initiative (SBTi) in order to help continue to cut emissions across our operations, facilities, and supply chain.
As we wrap up the hottest summer on record, it's clear that we all have a part to play in understanding and reducing our carbon footprint. Partnering with Cloudflare on your network transformation journey is an easy way to get started. Come join us today!
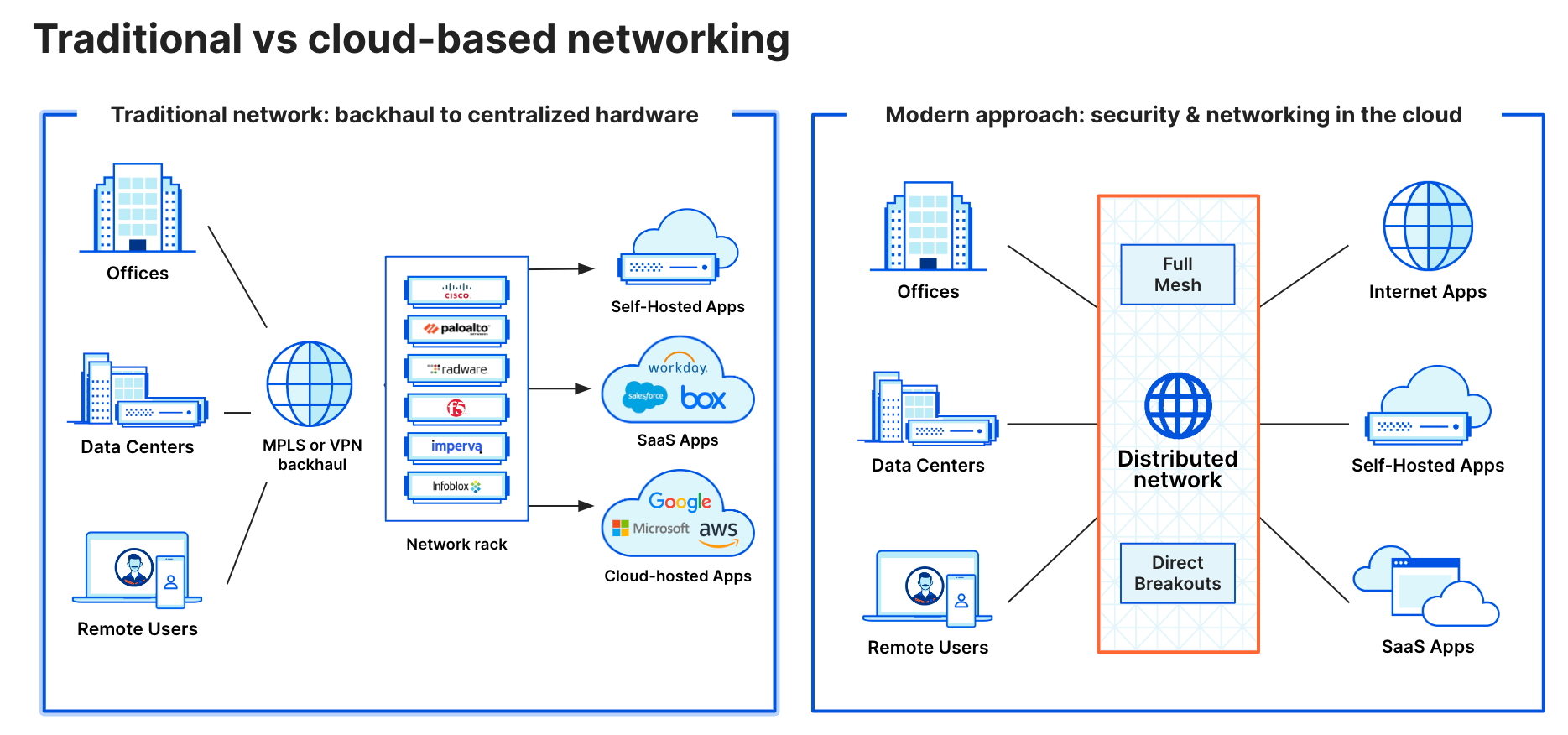
Traditional vs. cloud-based networking and security
Historically, corporate networks relied on dedicated circuits and specialized hardware to connect and secure their infrastructure. Companies built or rented space in data centers that were physically located within or close to major office locations, and hosted business applications on servers in these data centers. Employees in offices connected to these applications through the local area network (LAN) or over private wide area network (WAN) links from branch locations. A stack of security hardware in each data center, including firewalls, intrusion detection systems, DDoS mitigation appliances, VPN concentrators, and more enforced security for all traffic flowing in and out.
This architecture model broke down when applications shifted to the cloud and users left the office, requiring a new approach to connecting and securing corporate networks. Cloudflare’s model, which aligns with the SASE framework, shifts network and security functions from on premises hardware to our distributed global network.
Traditional vs. cloud-based networking and security architecture
This approach improves performance by enforcing policy close to where users are, increases security with Zero Trust principles, and saves costs by delivering functions more efficiently. We are now excited to report that it materially reduces the total power consumption of the services required to connect and secure your organization, which reduces carbon emissions.
Reduced carbon emissions through cloud migration and consolidation
An independent study published this week by Analysys Mason outlines how shifting networking and security functions to the cloud, and particularly consolidating services in a unified platform, directly improves the sustainability of organizations’ network, security, and IT operations. You can read the full study here, but here are a few key points.
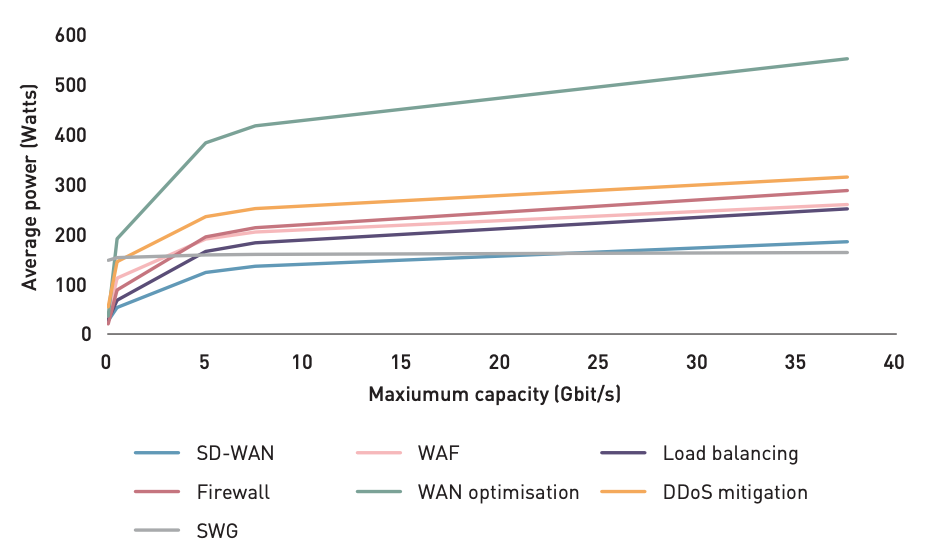
The study compared a typical hardware stack deployed in an enterprise data center or IT closet, and its associated energy consumption, to the energy consumption of comparable functions delivered by Cloudflare’s global network. The stack used for comparison included network firewall and WAF, DDoS mitigation, load balancing, WAN optimization, and SD-WAN. Researchers analyzed the average power consumption for devices with differing capacity and found that higher-capacity devices only consume incrementally more energy:
Power consumption across representative networking and security hardware devices with varying traffic capacity
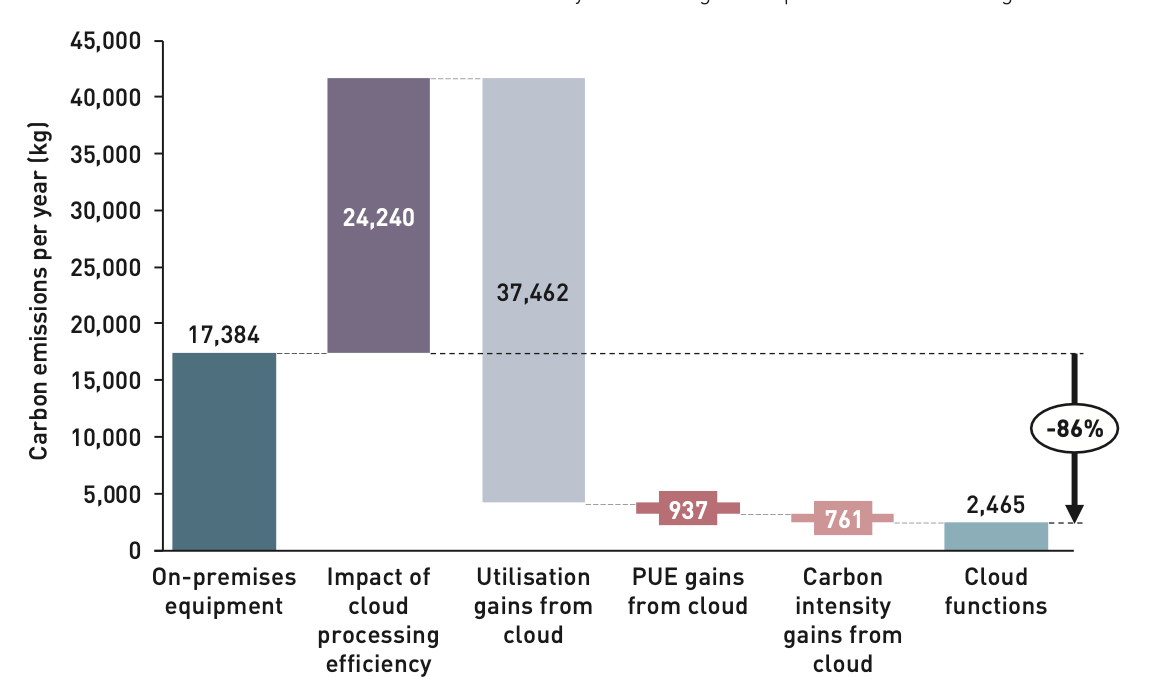
The study noted that specialized hardware is more efficient per watt of electricity consumed at performing specific functions — in other words, a device optimized for intrusion detection will perform intrusion detection functions using less power per request processed than a generic server designed to host multiple different workloads. This can be seen in the bar labeled “impact of cloud processing efficiency” in the graph below.
However, these gains are only relevant when a specialized hardware device is consistently utilized close to its capacity, which most appliances in corporate environments are not. Network, security, and IT teams intentionally provision devices with higher capacity than they will need the majority of the time in order to be able to gracefully handle spikes or peaks.
For example, a security engineer might have traditionally specced a DDoS protection appliance that can handle up to 10 Gbps of traffic in case an attack of that size came in, but the vast majority of the time, the appliance is processing far less traffic (maybe only tens or hundreds of Mbps). This means that it is actually much more efficient for those functions to run on a generic device that is also running other kinds of processes and therefore can operate at a higher baseline utilization, using the same power to get more work done. These benefits are shown in the “utilization gains from cloud” bar in the following graph.
There are also some marginal efficiency gains from other aspects of cloud architecture, such as improved power usage effectiveness (PUE) and carbon intensity of data centers optimized for cloud workloads vs. traditional enterprise infrastructure. These are represented on the right of the graph below.
The analysis shows that processing efficiency in the cloud is lower than specialized on-premises equipment; however, utilization gains through shared cloud services combined with expected PUE and carbon intensity yield potentially 86% emissions savings for large enterprises.
Researchers compared multiple examples of enterprise IT environments, from small to large traffic volume and complexity, and found that these factors contribute to overall carbon emissions reduction of 78-96% depending on the network analyzed.
One of the most encouraging parts of this study was that it did not include Cloudflare's renewable energy or offset purchases in its findings. A number of studies have concluded that migrating various applications and compute functions from on premises hardware to the cloud can significantly cut carbon emissions. But, those studies also relied in part on carbon accounting benefits like renewable energy or carbon offsets to demonstrate those savings.
Cloudflare also powers its operations with 100% renewable energy and purchases high-quality offsets to account for its annual emissions footprint. Meaning, the emissions savings of potentially switching to Cloudflare are likely even higher than those reported.
Overall, consolidating and migrating to Cloudflare’s services and retiring legacy hardware can substantially reduce energy consumption and emissions. And while you are at it, make sure to consider sustainable end-of-life practices for those retired devices — we will even help you recycle them!
Cloudflare is joining the Science Based Targets initiative (SBTi)
We're incredibly proud that Cloudflare is helping move the Internet toward a zero emissions future. But, we know that we can do more.
Cloudflare is thrilled to announce that we have submitted our application to join SBTi and set science-based carbon reduction targets across our facilities, operations, and supply chain.
SBTi is one of the world's most ambitious corporate climate action commitments. It requires companies to achieve verifiable emissions reductions across their operations and supply chain without the use of carbon offsets. Companies' short- and long-term reduction goals must be consistent with the Paris Climate Agreement goal of limiting global warming to 1.5 degrees above pre-industrial levels.
Once approved, Cloudflare will work over the next 24 months with SBTi to develop and validate our short and long term reduction targets. Stay tuned to our blog and our Impact page for updates as we go.
Cloudflare's commitment to SBTi reduction targets builds on our ongoing commitments to 100% renewable energy, to offset or remove historic carbon emissions associated with powering our network by 2025, and reforestation efforts.
As we have said before, Cloudflare's original goal was not to reduce the Internet's environmental impact. But, that has changed.
Come join Cloudflare today and help us work towards a zero emissions Internet.
Stream Live lets users easily scale their live-streaming apps and websites to millions of creators and concurrent viewers while focusing on the content rather than the infrastructure — Stream manages codecs, protocols, and bit rate automatically.
For Speed Week this year, we introduced a closed beta of Low-Latency HTTP Live Streaming (LL-HLS), which builds upon the high-quality, feature-rich HTTP Live Streaming (HLS) protocol. Lower latency brings creators even closer to their viewers, empowering customers to build more interactive features like chat and enabling the use of live-streaming in more time-sensitive applications like live e-learning, sports, gaming, and events.
Today, in celebration of Birthday Week, we’re opening this beta to all customers with even lower latency. With LL-HLS, you can deliver video to your audience faster, reducing the latency a viewer may experience on their player to as little as three seconds. Low Latency streaming is priced the same way, too: $1 per 1,000 minutes delivered, with zero extra charges for encoding or bandwidth.
Broadcast with latency as low as three seconds.
LL-HLS is an extension of the HLS standard that allows us to reduce glass-to-glass latency — the time between something happening on the broadcast end and a user seeing it on their screen. That includes factors like network conditions and transcoding for HLS and adaptive bitrates. We also include client-side buffering in our understanding of latency because we know the experience is driven by what a user sees, not when a byte is delivered into a buffer. Depending on encoder and player settings, broadcasters' content can be playing on viewers' screens in less than three seconds.
On the left, OBS Studio broadcasting from my personal computer to Cloudflare Stream. On the right, watching this livestream using our own built-in player playing LL-HLS with three second latency!
Same pricing, lower latency. Encoding is always free.
Our addition of LL-HLS support builds on all the best parts of Stream including simple, predictable pricing. You never have to pay for ingress (broadcasting to us), compute (encoding), or egress. This allows you to stream with peace of mind, knowing there are no surprise fees and no need to trade quality for cost. Regardless of bitrate or resolution, Stream costs \$1 per 1,000 minutes of video delivered and \$5 per 1,000 minutes of video stored, billed monthly.
Stream also provides both a built-in web player or HLS/DASH manifests to use in a compatible player of your choosing. This enables you or your users to go live using the same protocols and tools that broadcasters big and small use to go live to YouTube or Twitch, but gives you full control over access and presentation of live streams. We also provide access control with signed URLs and hotlinking prevention measures to protect your content.
Powered by the strength of the network
And of course, Stream is powered by Cloudflare's global network for fast delivery worldwide, with points of presence within 50ms of 95% of the Internet connected population, a key factor in our quest to slash latency. We ingest live video close to broadcasters and move it rapidly through Cloudflare’s network. We run encoders on-demand and generate player manifests as close to viewers as possible.
Getting started with LL-HLS
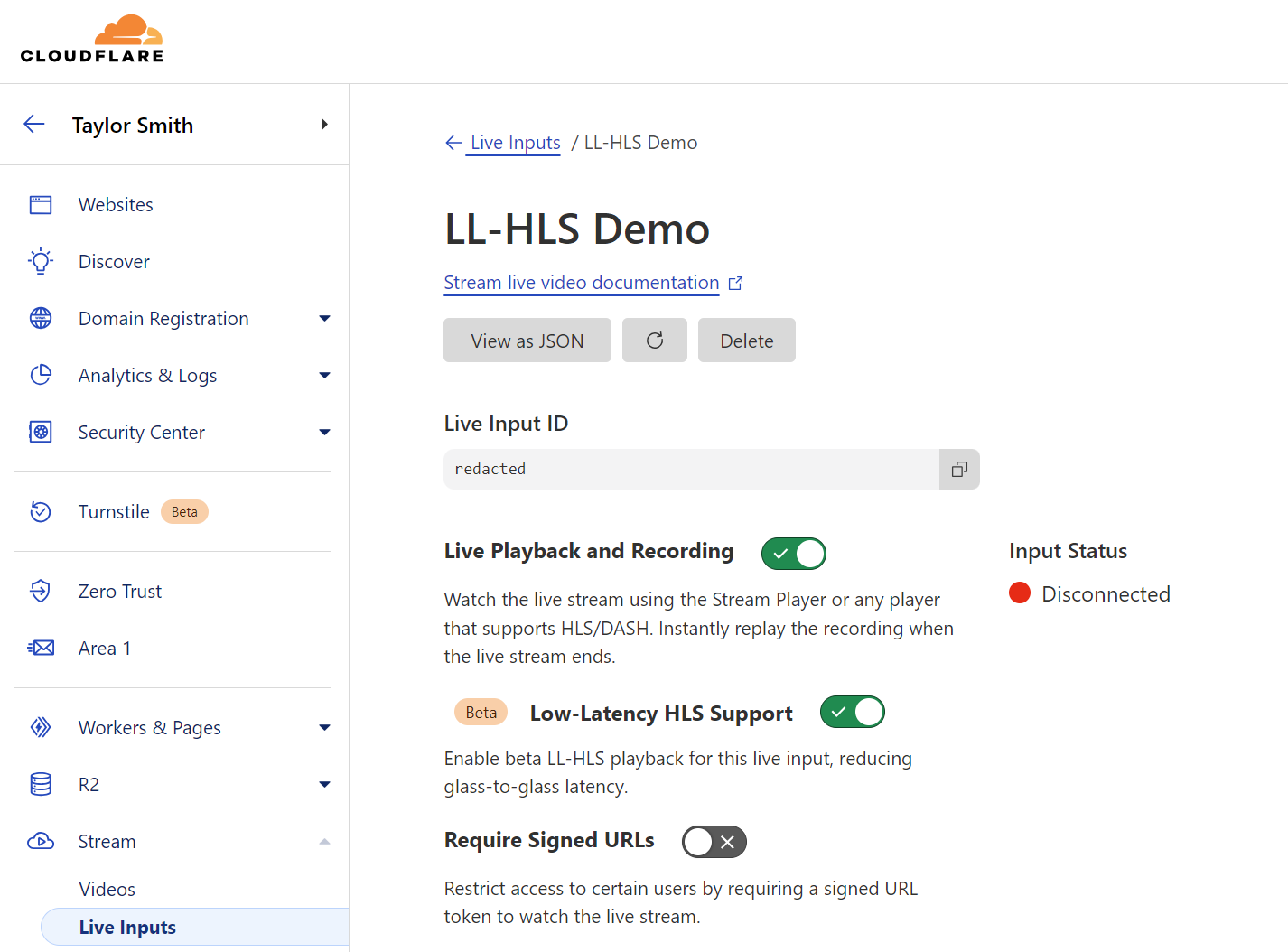
Getting started with Stream Live only takes a few minutes, and by using Live Outputs for restreaming, you can even test it without changing your existing infrastructure. First, create or update a Live Input in the Cloudflare dashboard. While in beta, Live Inputs will have an option to enable LL-HLS called “Low-Latency HLS Support.” Activate this toggle to enable the new pipeline.
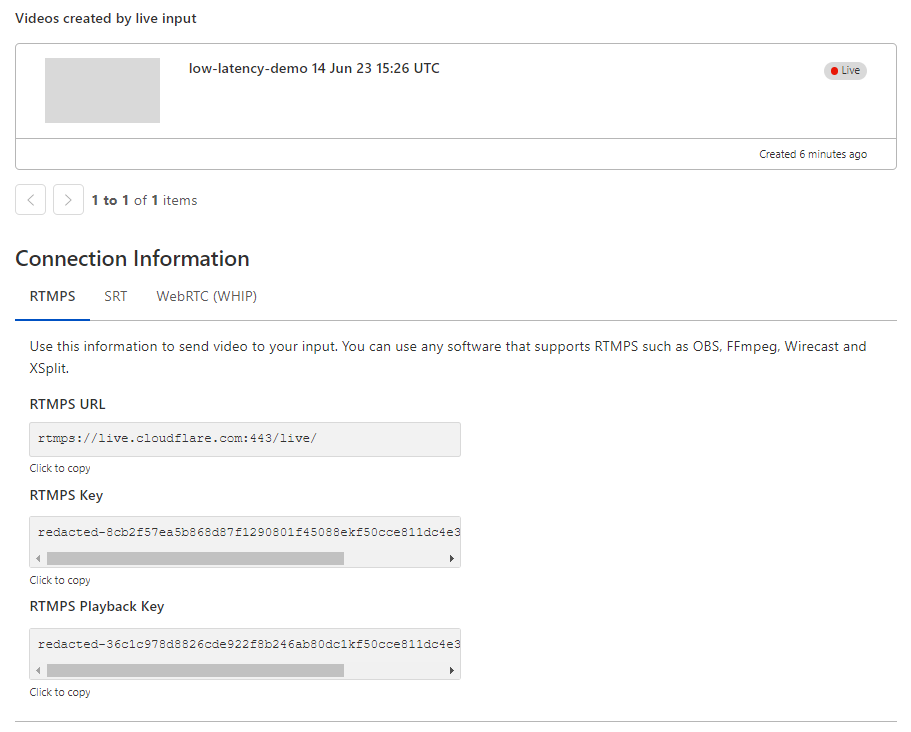
Stream will automatically provide the RTMPS and SRT endpoints to broadcast your feed to us, just as before. For the best results, we recommend the following broadcast settings:
Codec: h264
GOP size / keyframe interval: 1 second
Optionally, configure a Live Output to point to your existing video ingest endpoint via RTMPS or SRT to test Stream while rebroadcasting to an existing workflow or infrastructure.
Stream will automatically provide RTMPS and SRT endpoints to broadcast your feed to us as well as an HTML embed for our built-in player.
This connection information can be added easily to a broadcast application like OBS to start streaming immediately:
During the beta, our built-in player will automatically attempt to use low-latency for any enabled Live Input, falling back to regular HLS otherwise. If LL-HLS is being used, you’ll see “Low Latency” noted in the player.
During this phase of the beta, we are most closely focused on using OBS to broadcast and Stream’s built-in player to watch — which uses HLS.js under the hood for LL-HLS support. However, you may test the LL-HLS manifest in a player of your own by appending ?protocol=llhls to the end of the HLS manifest URL. This flag may change in the future and is not yet ready for production usage; watch for changes in DevDocs.
Sign up today
Low-Latency HLS is Stream Live’s latest tool to bring your creators and audiences together. All new and existing Stream subscriptions are eligible for the LL-HLS open beta today, with no pricing changes or contract requirements — all part of building the fastest, simplest serverless live-streaming platform. Join our beta to start test-driving Low-Latency HLS!
Picture this: you’re at an airport, and you’re going through an airport security checkpoint. There are a bunch of agents who are scanning your boarding pass and your passport and sending you through to your gate. All of a sudden, some of the agents go on break. Maybe there’s a leak in the ceiling above the checkpoint. Or perhaps a bunch of flights are leaving at 6pm, and a number of passengers turn up at once. Either way, this imbalance between localized supply and demand can cause huge lines and unhappy travelers — who just want to get through the line to get on their flight. How do airports handle this?
Some airports may not do anything and just let you suffer in a longer line. Some airports may offer fast-lanes through the checkpoints for a fee. But most airports will tell you to go to another security checkpoint a little farther away to ensure that you can get through to your gate as fast as possible. They may even have signs up telling you how long each line is, so you can make an easier decision when trying to get through.
At Cloudflare, we have the same problem. We are located in 300 cities around the world that are built to receive end-user traffic for all of our product suites. And in an ideal world, we always have enough computers and bandwidth to handle everyone at their closest possible location. But the world is not always ideal; sometimes we take a data center offline for maintenance, or a connection to a data center goes down, or some equipment fails, and so on. When that happens, we may not have enough attendants to serve every person going through security in every location. It’s not because we haven’t built enough kiosks, but something has happened in our data center that prevents us from serving everyone.
So, we built Traffic Manager: a tool that balances supply and demand across our entire global network. This blog is about Traffic Manager: how it came to be, how we built it, and what it does now.
The world before Traffic Manager
The job now done by Traffic Manager used to be a manual process carried out by network engineers: our network would operate as normal until something happened that caused user traffic to be impacted at a particular data center.
When such events happened, user requests would start to fail with 499 or 500 errors because there weren’t enough machines to handle the request load of our users. This would trigger a page to our network engineers, who would then remove some Anycast routes for that data center. The end result: by no longer advertising those prefixes in the impacted data center, user traffic would divert to a different data center. This is how Anycast fundamentally works: user traffic is drawn to the closest data center advertising the prefix the user is trying to connect to, as determined by Border Gateway Protocol. For a primer on what Anycast is, check out this reference article.
Depending on how bad the problem was, engineers would remove some or even all the routes in a data center. When the data center was again able to absorb all the traffic, the engineers would put the routes back and the traffic would return naturally to the data center.
As you might guess, this was a challenging task for our network engineers to do every single time any piece of hardware on our network had an issue. It didn’t scale.
Never send a human to do a machine’s job
But doing it manually wasn’t just a burden on our Network Operations team. It also resulted in a sub-par experience for our customers; our engineers would need to take time to diagnose and re-route traffic. To solve both these problems, we wanted to build a service that would immediately and automatically detect if users were unable to reach a Cloudflare data center, and withdraw routes from the data center until users were no longer seeing issues. Once the service received notifications that the impacted data center could absorb the traffic, it could put the routes back and reconnect that data center. This service is called Traffic Manager, because its job (as you might guess) is to manage traffic coming into the Cloudflare network.
Accounting for second order consequences
When a network engineer removes a route from a router, they can make the best guess at where the user requests will move to, and try to ensure that the failover data center has enough resources to handle the requests — if it doesn’t, they can adjust the routes there accordingly prior to removing the route in the initial data center. To be able to automate this process, we needed to move from a world of intuition to a world of data — accurately predicting where traffic would go when a route was removed, and feeding this information to Traffic Manager, so it could ensure it doesn’t make the situation worse.
Meet Traffic Predictor
Although we can adjust which data centers advertise a route, we are unable to influence what proportion of traffic each data center receives. Each time we add a new data center, or a new peering session, the distribution of traffic changes, and as we are in over 300 cities and 12,500 peering sessions, it has become quite difficult for a human to keep track of, or predict the way traffic will move around our network. Traffic manager needed a buddy: Traffic Predictor.
In order to do its job, Traffic Predictor carries out an ongoing series of real world tests to see where traffic actually moves. Traffic Predictor relies on a testing system that simulates removing a data center from service and measuring where traffic would go if that data center wasn’t serving traffic. To help understand how this system works, let’s simulate the removal of a subset of a data center in Christchurch, New Zealand:
First, Traffic Predictor gets a list of all the IP addresses that normally connect to Christchurch. Traffic Predictor will send a ping request to hundreds of thousands of IPs that have recently made a request there.
Traffic Predictor records if the IP responds, and whether the response returns to Christchurch using a special Anycast IP range specifically configured for Traffic Predictor.
Once Traffic Predictor has a list of IPs that respond to Christchurch, it removes that route containing that special range from Christchurch, waits a few minutes for the Internet routing table to be updated, and runs the test again.
Instead of being routed to Christchurch, the responses are instead going to data centers around Christchurch. Traffic Predictor then uses the knowledge of responses for each data center, and records the results as the failover for Christchurch.
This allows us to simulate Christchurch going offline without actually taking Christchurch offline!
But Traffic Predictor doesn’t just do this for any one data center. To add additional layers of resiliency, Traffic Predictor even calculates a second layer of indirection: for each data center failure scenario, Traffic Predictor also calculates failure scenarios and creates policies for when surrounding data centers fail.
Using our example from before, when Traffic Predictor tests Christchurch, it will run a series of tests that remove several surrounding data centers from service including Christchurch to calculate different failure scenarios. This ensures that even if something catastrophic happens which impacts multiple data centers in a region, we still have the ability to serve user traffic. If you think this data model is complicated, you’re right: it takes several days to calculate all of these failure paths and policies.
Here’s what those failure paths and failover scenarios look like for all of our data centers around the world when they’re visualized:
This can be a bit complicated for humans to parse, so let’s dig into that above scenario for Christchurch, New Zealand to make this a bit more clear. When we take a look at failover paths specifically for Christchurch, we see they look like this:
In this scenario we predict that 99.8% of Christchurch’s traffic would shift to Auckland, which is able to absorb all Christchurch traffic in the event of a catastrophic outage.
Traffic Predictor allows us to not only see where traffic will move to if something should happen, but it allows us to preconfigure Traffic Manager policies to move requests out of failover data centers to prevent a thundering herd scenario: where sudden influx of requests can cause failures in a second data center if the first one has issues. With Traffic Predictor, Traffic Manager doesn’t just move traffic out of one data center when that one fails, but it also proactively moves traffic out of other data centers to ensure a seamless continuation of service.
From a sledgehammer to a scalpel
With Traffic Predictor, Traffic Manager can dynamically advertise and withdraw prefixes while ensuring that every datacenter can handle all the traffic. But withdrawing prefixes as a means of traffic management can be a bit heavy-handed at times. One of the reasons for this is that the only way we had to add or remove traffic to a data center was through advertising routes from our Internet-facing routers. Each one of our routes has thousands of IP addresses, so removing only one still represents a large portion of traffic.
Specifically, Internet applications will advertise prefixes to the Internet from a /24 subnet at an absolute minimum, but many will advertise prefixes larger than that. This is generally done to prevent things like route leaks or route hijacks: many providers will actually filter out routes that are more specific than a /24 (for more information on that, check out this blog here). If we assume that Cloudflare maps protected properties to IP addresses at a 1:1 ratio, then each /24 subnet would be able to service 256 customers, which is the number of IP addresses in a /24 subnet. If every IP address sent one request per second, we’d have to move 4 /24 subnets out of a data center if we needed to move 1,000 requests per second (RPS).
But in reality, Cloudflare maps a single IP address to hundreds of thousands of protected properties. So for Cloudflare, a /24 might take 3,000 requests per second, but if we needed to move 1,000 RPS out, we would have no choice but to move a single /24 out. And that’s just assuming we advertise at a /24 level. If we used /20s to advertise, the amount we can withdraw gets less granular: at a 1:1 website to IP address mapping, that’s 4,096 requests per second for each prefix, and even more if the website to IP address mapping is many to one.
While withdrawing prefix advertisements improved the customer experience for those users who would have seen a 499 or 500 error — there may have been a significant portion of users who wouldn’t have been impacted by an issue who still were moved away from the data center they should have gone to, probably slowing them down, even if only a little bit. This concept of moving more traffic out than is necessary is called “stranding capacity”: the data center is theoretically able to service more users in a region but cannot because of how Traffic Manager was built.
We wanted to improve Traffic Manager so that it only moved the absolute minimum of users out of a data center that was seeing a problem and not strand any more capacity. To do so, we needed to shift percentages of prefixes, so we could be extra fine-grained and only move the things that absolutely need to be moved. To solve this, we built an extension of our Layer 4 load balancer Unimog, which we call Plurimog.
A quick refresher on Unimog and layer 4 load balancing: every single one of our machines contains a service that determines whether that machine can take a user request. If the machine can take a user request then it sends the request to our HTTP stack which processes the request before returning it to the user. If the machine can’t take the request, the machine sends the request to another machine in the data center that can. The machines can do this because they are constantly talking to each other to understand whether they can serve requests for users.
Plurimog does the same thing, but instead of talking between machines, Plurimog talks in between data centers and points of presence. If a request goes into Philadelphia and Philadelphia is unable to take the request, Plurimog will forward to another data center that can take the request, like Ashburn, where the request is decrypted and processed. Because Plurimog operates at layer 4, it can send individual TCP or UDP requests to other places which allows it to be very fine-grained: it can send percentages of traffic to other data centers very easily, meaning that we only need to send away enough traffic to ensure that everyone can be served as fast as possible. Check out how that works in our Frankfurt data center, as we are able to shift progressively more and more traffic away to handle issues in our data centers. This chart shows the number of actions taken on free traffic that cause it to be sent out of Frankfurt over time:
But even within a data center, we can route traffic around to prevent traffic from leaving the datacenter at all. Our large data centers, called Multi-Colo Points of Presence (MCPs) contain logical sections of compute within a data center that are distinct from one another. These MCP data centers are enabled with another version of Unimog called Duomog, which allows for traffic to be shifted between logical sections of compute automatically. This makes MCP data centers fault-tolerant without sacrificing performance for our customers, and allows Traffic Manager to work within a data center as well as between data centers.
When evaluating portions of requests to move, Traffic Manager does the following:
Traffic Manager identifies the proportion of requests that need to be removed from a data center or subsection of a data center so that all requests can be served.
Traffic Manager then calculates the aggregated space metrics for each target to see how many requests each failover data center can take.
Traffic Manager then identifies how much traffic in each plan we need to move, and moves either a proportion of the plan, or all of the plan through Plurimog/Duomog, until we've moved enough traffic. We move Free customers first, and if there are no more Free customers in a data center, we'll move Pro, and then Business customers if needed.
For example, let’s look at Ashburn, Virginia: one of our MCPs. Ashburn has nine different subsections of capacity that can each take traffic. On 8/28, one of those subsections, IAD02, had an issue that reduced the amount of traffic it could handle.
During this time period, Duomog sent more traffic from IAD02 to other subsections within Ashburn, ensuring that Ashburn was always online, and that performance was not impacted during this issue. Then, once IAD02 was able to take traffic again, Duomog shifted traffic back automatically. You can see these actions visualized in the time series graph below, which tracks the percentage of traffic moved over time between subsections of capacity within IAD02 (shown in green):
How does Traffic Manager know how much to move?
Although we used requests per second in the example above, using requests per second as a metric isn’t accurate enough when actually moving traffic. The reason for this is that different customers have different resource costs to our service; a website served mainly from cache with the WAF deactivated is much cheaper CPU wise than a site with all WAF rules enabled and caching disabled. So we record the time that each request takes in the CPU. We can then aggregate the CPU time across each plan to find the CPU time usage per plan. We record the CPU time in ms, and take a per second value, resulting in a unit of milliseconds per second.
CPU time is an important metric because of the impact it can have on latency and customer performance. As an example, consider the time it takes for an eyeball request to make it entirely through the Cloudflare front line servers: we call this the cfcheck latency. If this number goes too high, then our customers will start to notice, and they will have a bad experience. When cfcheck latency gets high, it’s usually because CPU utilization is high. The graph below shows 95th percentile cfcheck latency plotted against CPU utilization across all the machines in the same data center, and you can see the strong correlation:
So having Traffic Manager look at CPU time in a data center is a very good way to ensure that we’re giving customers the best experience and not causing problems.
After getting the CPU time per plan, we need to figure out how much of that CPU time to move to other data centers. To do this, we aggregate the CPU utilization across all servers to give a single CPU utilization across the data center. If a proportion of servers in the data center fail, due to network device failure, power failure, etc., then the requests that were hitting those servers are automatically routed elsewhere within the data center by Duomog. As the number of servers decrease, the overall CPU utilization of the data center increases. Traffic Manager has three thresholds for each data center; the maximum threshold, the target threshold, and the acceptable threshold:
Maximum: the CPU level at which performance starts to degrade, where Traffic Manager will take action
Target: the level to which Traffic Manager will try to reduce the CPU utilization to restore optimal service to users
Acceptable: the level below which a data center can receive requests forwarded from another data center, or revert active moves
When a data center goes above the maximum threshold, Traffic Manager takes the ratio of total CPU time across all plans to current CPU utilization, then applies that to the target CPU utilization to find the target CPU time. Doing it this way means we can compare a data center with 100 servers to a data center with 10 servers, without having to worry about the number of servers in each data center. This assumes that load increases linearly, which is close enough to true for the assumption to be valid for our purposes.
Target ratio equals current ratio:
Therefore:
Subtracting the target CPU time from the current CPU time gives us the CPU time to move:
For example, if the current CPU utilization was at 90% across the data center, the target was 85%, and the CPU time across all plans was 18,000, we would have:
This would mean Traffic Manager would need to move 1,000 CPU time:
Now we know the total CPU time needed to move, we can go through the plans, until the required time to move has been met.
What is the maximum threshold?
A frequent problem that we faced was determining at which point Traffic Manager should start taking action in a data center – what metric should it watch, and what is an acceptable level?
As said before, different services have different requirements in terms of CPU utilization, and there are many cases of data centers that have very different utilization patterns.
To solve this problem, we turned to machine learning. We created a service that will automatically adjust the maximum thresholds for each data center according to customer-facing indicators. For our main service-level indicator (SLI), we decided to use the cfcheck latency metric we described earlier.
But we also need to define a service-level objective (SLO) in order for our machine learning application to be able to adjust the threshold. We set the SLO for 20ms. Comparing our SLO to our SLI, our 95th percentile cfcheck latency should never go above 20ms and if it does, we need to do something. The below graph shows 95th percentile cfcheck latency over time, and customers start to get unhappy when cfcheck latency goes into the red zone:
If customers have a bad experience when CPU gets too high, then the goal of Traffic Manager’s maximum thresholds are to ensure that customer performance isn’t impacted and to start redirecting traffic away before performance starts to degrade. At a scheduled interval the Traffic Manager service will fetch a number of metrics for each data center and apply a series of machine learning algorithms. After cleaning the data for outliers we apply a simple quadratic curve fit, and we are currently testing a linear regression algorithm.
After fitting the models we can use them to predict the CPU usage when the SLI is equal to our SLO, and then use it as our maximum threshold. If we plot the cpu values against the SLI we can see clearly why these methods work so well for our data centers, as you can see for Barcelona in the graphs below, which are plotted against curve fit and linear regression fit respectively.
In these charts the vertical line is the SLO, and the intersection of this line with the fitted model represents the value that will be used as the maximum threshold. This model has proved to be very accurate, and we are able to significantly reduce the SLO breaches. Let’s take a look at when we started deploying this service in Lisbon:
Before the change, cfcheck latency was constantly spiking, but Traffic Manager wasn’t taking actions because the maximum threshold was static. But after July 29, we see that cfcheck latency has never hit the SLO because we are constantly measuring to make sure that customers are never impacted by CPU increases.
Where to send the traffic?
So now that we have a maximum threshold, we need to find the third CPU utilization threshold which isn’t used when calculating how much traffic to move – the acceptable threshold. When a data center is below this threshold, it has unused capacity which, as long as it isn’t forwarding traffic itself, is made available for other data centers to use when required. To work out how much each data center is able to receive, we use the same methodology as above, substituting target for acceptable:
Therefore:
Subtracting the current CPU time from the acceptable CPU time gives us the amount of CPU time that a data center could accept:
To find where to send traffic, Traffic Manager will find the available CPU time in all data centers, then it will order them by latency from the data center needing to move traffic. It moves through each of the data centers, using all available capacity based on the maximum thresholds before moving onto the next. When finding which plans to move, we move from the lowest priority plan to highest, but when finding where to send them, we move in the opposite direction.
To make this clearer let's use an example:
We need to move 1,000 CPU time from data center A, and we have the following usage per plan: Free: 500ms/s, Pro: 400ms/s, Business: 200ms/s, Enterprise: 1000ms/s.
We would move 100% of Free (500ms/s), 100% of Pro (400ms/s), 50% of Business (100ms/s), and 0% of Enterprise.
Nearby data centers have the following available CPU time: B: 300ms/s, C: 300ms/s, D: 1,000ms/s.
With latencies: A-B: 100ms, A-C: 110ms, A-D: 120ms.
Starting with the lowest latency and highest priority plan that requires action, we would be able to move all the Business CPU time to data center B and half of Pro. Next we would move onto data center C, and be able to move the rest of Pro, and 20% of Free. The rest of Free could then be forwarded to data center D. Resulting in the following action: Business: 50% → B, Pro: 50% → B, 50% → C, Free: 20% → C, 80% → D.
Reverting actions
In the same way that Traffic Manager is constantly looking to keep data centers from going above the threshold, it is also looking to bring any forwarded traffic back into a data center that is actively forwarding traffic.
Above we saw how Traffic Manager works out how much traffic a data center is able to receive from another data center — it calls this the available CPU time. When there is an active move we use this available CPU time to bring back traffic to the data center — we always prioritize reverting an active move over accepting traffic from another data center.
When you put this all together, you get a system that is constantly measuring system and customer health metrics for every data center and spreading traffic around to make sure that each request can be served given the current state of our network. When we put all of these moves between data centers on a map, it looks something like this, a map of all Traffic Manager moves for a period of one hour. This map doesn’t show our full data center deployment, but it does show the data centers that are sending or receiving moved traffic during this period:
Data centers in red or yellow are under load and shifting traffic to other data centers until they become green, which means that all metrics are showing as healthy. The size of the circles represent how many requests are shifted from or to those data centers. Where the traffic is going is denoted by where the lines are moving. This is difficult to see at a world scale, so let’s zoom into the United States to see this in action for the same time period:
Here you can see Toronto, Detroit, New York, and Kansas City are unable to serve some requests due to hardware issues, so they will send those requests to Dallas, Chicago, and Ashburn until equilibrium is restored for users and data centers. Once data centers like Detroit are able to service all the requests they are receiving without needing to send traffic away, Detroit will gradually stop forwarding requests to Chicago until any issues in the data center are completely resolved, at which point it will no longer be forwarding anything. Throughout all of this, end users are online and are not impacted by any physical issues that may be happening in Detroit or any of the other locations sending traffic.
Happy network, happy products
Because Traffic Manager is plugged into the user experience, it is a fundamental component of the Cloudflare network: it keeps our products online and ensures that they’re as fast and reliable as they can be. It’s our real time load balancer, helping to keep our products fast by only shifting necessary traffic away from data centers that are having issues. Because less traffic gets moved, our products and services stay fast.
But Traffic Manager can also help keep our products online and reliable because they allow our products to predict where reliability issues may occur and preemptively move the products elsewhere. For example, Browser Isolation directly works with Traffic Manager to help ensure the uptime of the product. When you connect to a Cloudflare data center to create a hosted browser instance, Browser Isolation first asks Traffic Manager if the data center has enough capacity to run the instance locally, and if so, the instance is created right then and there. If there isn’t sufficient capacity available, Traffic Manager tells Browser Isolation which the closest data center with sufficient available capacity is, thereby helping Browser Isolation to provide the best possible experience for the user.
Happy network, happy users
At Cloudflare, we operate this huge network to service all of our different products and customer scenarios. We’ve built this network for resiliency: in addition to our MCP locations designed to reduce impact from a single failure, we are constantly shifting traffic around on our network in response to internal and external issues.
But that is our problem — not yours.
Similarly, when human beings had to fix those issues, it was customers and end users who would be impacted. To ensure that you’re always online, we’ve built a smart system that detects our hardware failures and preemptively balances traffic across our network to ensure it’s online and as fast as possible. This system works faster than any person — not only allowing our network engineers to sleep at night — but also providing a better, faster experience for all of our customers.
And finally: if these kinds of engineering challenges sound exciting to you, then please consider checking out the Traffic Engineering team's open position on Cloudflare’s Careers page!
We are thrilled to introduce Cloudflare Fonts! In the coming weeks sites that use Google Fonts will be able to effortlessly load their fonts from the site’s own domain rather than from Google. All at a click of a button. This enhances both privacy and performance. It enhances users' privacy by eliminating the need to load fonts from Google’s third-party servers. It boosts a site's performance by bringing fonts closer to end users, reducing the time spent on DNS lookups and TLS connections.
Sites that currently use Google Fonts will not need to self-host fonts or make complex code changes to benefit – Cloudflare Fonts streamlines the entire process, making it a breeze.
Fonts and privacy
When you load fonts from Google, your website initiates a data exchange with Google's servers. This means that your visitors' browsers send requests directly to Google. Consequently, Google has the potential to accumulate a range of data, including IP addresses, user agents (formatted descriptions of the browser and operating system), the referer (the page on which the Google font is to be displayed) and how often each IP makes requests to Google. While Google states that they do not use this data for targeted advertising or set cookies, any time you can prevent sharing your end user’s personal data unnecessarily is a win for privacy.
With Cloudflare Fonts, when you serve fonts directly from your own domain. This means no font requests are sent to third-party domains like Google, which some privacy regulators have found to be a problem in the past. Our pro-privacy approach means your end user’s IP address and other data are not sent to another domain. All that information stays within your control, within your domain. In addition, because Cloudflare Fonts eliminates data transmission to third-party servers like Google's, this can enhance your ability to comply with any potential data localization requirements.
Faster Google Font delivery through Cloudflare
Now that we have established that Cloudflare Fonts can improve your privacy, let's flip to the other side of the coin – how Cloudflare Fonts will improve your performance.
To do this, we first need to delve into how Google Fonts affects your website's performance. Subsequently, we'll explore how Cloudflare Fonts addresses and rectifies these performance challenges.
Google Fonts is a fantastic resource that offers website owners a range of royalty-free fonts for website usage. When you decide on the fonts you would like to incorporate, it’s super easy to integrate. You just add a snippet of HTML to your site. You then add styles to apply these fonts to various parts of your page:
But this ease of use comes with a performance penalty.
Upon loading your webpage, your visitors' browser fetches the CSS file as soon as the HTML starts to be parsed. Then, when the browser starts rendering the page and identifies the need for fonts in different text sections, it requests the required font files.
This is where the performance problem arises. Google Fonts employs a two-domain system: the CSS resides on one domain – fonts.googleapis.com – while the font files reside on another domain – fonts.gstatic.com.
This separation results in a minimum of four round trips to the third-party servers for each resource request. These round trips are DNS lookup, socket connection establishment, TLS negotiation (for HTTPS), and the final round trip for the actual resource request. Ultimately, getting a font from Google servers to a browser requires eight round trips.
Users can see this. If they are using Google Fonts they can open their network tab and filter for these Google domains.
You can visually see the impact of the extra DNS request and TLS connection that these requests add to your website experience. For example on my WordPress site that natively uses Google Fonts as part of the theme adds an extra ~150ms.
Fast fonts
Cloudflare Fonts streamlines this process, by reducing the number of round trips from eight to one. Two sets of DNS lookups, socket connections and TLS negotiations to third-parties are no longer required because there is no longer a third-party server involved in serving the CSS or the fonts. The only round trip involves serving the font files directly from the same domain where the HTML is hosted. This approach offers an additional advantage: it allows fonts to be transmitted over the same HTTP/2 or HTTP/3 connection as other page resources, benefiting from proper prioritization and preventing bandwidth contention.
The eagle-eyed amongst you might be thinking “Surely it is still two round trips – what about the CSS request?”. Well, with Cloudflare Fonts, we have also removed the need for a separate CSS request. This means there really is only one round-trip – fetching the font itself.
To achieve both the home-routing of font requests and the removal of the CSS request, we rewrite the HTML as it passes through Cloudflare’s global network. The CSS response is embedded, and font URL transformations are performed within the embedded CSS.
These transformations adjust the font URLs to align with the same domain as the HTML content. These modified responses seamlessly pass through Cloudflare's caching infrastructure, where they are automatically cached for a substantial performance boost. In the event of any cache misses, we use Fontsource and NPM to load these fonts and cache them within the Cloudflare infrastructure. This approach ensures that there's no inadvertent data exposure to Google's infrastructure, maintaining both performance and data privacy.
With Cloudflare Fonts enabled, you are able to see within your Network Tab that font files are now loaded from your own hostname from the /cf-fonts path and served from Cloudflare’s closest cache to the user, as indicated by the cf-cache-status: HIT.
Additionally, you can notice that the timings section in the browser no longer needs an extra DNS lookup for the hostname or the setup of a TLS connection. This happens because the content is served from your hostname, and the browser has already cached the DNS response and has an open TLS connection.
Finally, you can see the real-world performance benefits of Cloudflare Fonts. We conducted synthetic Google Lighthouse tests before enabling Cloudflare Fonts on a straightforward page that displays text. First Contentful Paint (FCP), which represents the time it takes for the first content element to appear on the page, was measured at 0.9 seconds in the Google fonts tests. After enabling Cloudflare Fonts, the First Contentful Paint (FCP) was reduced to 0.3 seconds, and our overall Lighthouse performance score improved from 98 to a perfect 100 out of 100.
Making Cloudflare Fonts fast with ROFL
In order to make Cloudflare Fonts this performant, we needed to make blazing-fast HTML alterations as responses stream through Cloudflare’s network. This has been made possible by leveraging one of Cloudflare’s more recent technologies.
Earlier this year, we finished rewriting one of Cloudflare's oldest components, which played a crucial role in dynamically altering HTML content. But as described in this blog post, a new solution was required to replace the old – A memory-safe solution, able to scale to Cloudflare’s ever-increasing load.
This new module is known as ROFL (Response Overseer for FL). It now powers various Cloudflare products that need to alter HTML as it streams, such as Email Obfuscation, Rocket Loader, and HTML Minification.
ROFL was developed entirely in Rust. This decision was driven by Rust's memory safety, performance, and security. The memory-safety features of Rust are indispensable to ensure airtight protection against memory leaks while we process a staggering volume of requests, measuring in the millions per second. Rust's compiled nature allows us to finely optimize our code for specific hardware configurations, delivering impressive performance gains compared to interpreted languages.
ROFL paved the way for the development of Cloudflare Fonts. The performance of ROFL allows us to rewrite HTML on-the-fly and modify the Google Fonts links quickly, safely and efficiently. This speed helps us reduce any additional latency added by processing the HTML file and improve the performance of your website.
Unlock the power of Cloudflare Fonts today! 🚀
Cloudflare Fonts will be available to all Cloudflare customers in October. If you're using Google Fonts, you will be able to supercharge your site's privacy and speed. By enabling this feature, you can seamlessly enhance your website's performance while safeguarding your user’s privacy.
Today, we are excited to announce Cloudflare Trace! Cloudflare Trace is available to all our customers. Cloudflare Trace enables you to understand how HTTP requests traverse your zone's configuration and what Cloudflare Rules are being applied to the request.
For many Cloudflare customers, the journey their customers' traffic embarks on through the Cloudflare ecosystem was a mysterious black box. It's a complex voyage, routed through various products, each capable of introducing modification to the request.
Consider this scenario: your web traffic could get blocked by WAF Custom Rules or Managed Rules (WAF); it might face rate limiting, or undergo modifications via Transform Rules, Where a Cloudflare account has many admins, modifying different things it can be akin to a game of "hit and hope," where the outcome of your web traffic's journey is uncertain as you are unsure how another admins rule will impact the request before or after yours. While Cloudflare's individual products are designed to be intuitive, their interoperation, or how they work together, hasn't always been as transparent as our customers need it to be. Cloudflare Trace changes this.
Running a trace
Cloudflare Trace allows users to set a number of request variables, allowing you to tailor your trace precisely to your needs. A basic trace will require users to define two settings. A URL that is being proxied through Cloudflare and an HTTP method such as GET. However, customers can also set request headers, add a request body and even set a bot score to allow users to validate the correct behavior of their security rules.
Once a trace is initiated, the dashboard returns a visualization of the products that were matched on a request, such as Configuration Rules, Transform Rules, and Firewall Rules, along with the specific rules inside these phases that were applied. Customers can then view further details of the filters and actions the specific rule undertakes. Clicking the rule id will take you directly to that specific rule in the Cloudflare Dashboard, allowing you to edit filters and actions if needed.
The user interface also generates a programmatic version of the trace that can be used by customers to run traces via a command line. This enables customers to use tools like jq to further investigate the extensive details returned via the trace output.
The life of a Cloudflare request
Understanding the intricate journey that your traffic embarks on within Cloudflare can be a challenging task for many of our customers and even for Cloudflare employees. This complexity often leads to questions within our Cloudflare Community or direct inquiries to our support team. Internally, over the past 13 years at Cloudflare, numerous individuals have attempted to explain this journey through diagrams. We maintain an internal Wiki page titled 'Life of a Request Museum.' This page archives all the attempts made over the years by some of the first Cloudflare engineers, heads of product, and our marketing team, where the following image was used in our 2018 marketing slides.
The "problem" (a rather positive one) is that Cloudflare is innovating so rapidly. New products are being added, code is removed, and existing products are continually enhanced. As a result, a diagram created just a few weeks ago can quickly become outdated and challenging to keep up to date.
Finding a happy medium
However, customers still want to understand, “The life of a request.” Striking the ideal balance between providing just enough detail without overwhelming our users posed a problem akin to the Goldilocks principle. One of our first attempts to detail the ordering of Cloudflare products was Traffic Sequence, a straightforward dashboard illustration that provides a basic, high-level overview of the interactions between Cloudflare products. While it does not detail every intricacy, it helps our customers understand the order and flow of products that interacted with an HTTP request and was a welcome addition to the Cloudflare dashboard.
However, customers still requested further insights and details. Especially around debugging issues. Internally Cloudflare teams utilize a number of self created products to trace a request. One of these products is Flute. This product gives a verbose output of all rules, Cloudflare features and codepaths a request undertakes. This allows our engineers and support teams to investigate an issue and identify if something is awry. For example in the following Flute trace image you can see how a request for my domain is evaluated against Single Redirects, Waiting Room, Configuration Settings, Snippets and Origin Rules.
The Flute tool became one of the key focal points in the development of Cloudflare Trace. However, it can be quite intricate and packed with extensive details, potentially leading to more questions than solutions if copied verbatim and exposed to our customers.
To understand the happy medium in developing Cloudflare Trace. We closely collaborated with our Support team to gain a deeper understanding of the challenges our customers faced specifically around Cloudflare Rulesets. The primary challenge centered around understanding which rules were applicable to specific requests. Customers often raised queries, and in certain instances, these inquiries had to be escalated for further investigation into the reasons behind a request's specific behavior. By empowering our customers to independently investigate and comprehend these issues, we identified a second area where Cloudflare Trace proves invaluable—by reducing the workload of our support team and enabling them to operate more efficiently while focusing on other support tickets.
For customers encountering genuine problems, they have the capability to export the JSON response of a trace, which can then be directly uploaded to a support ticket. This streamlined process significantly reduces the time required to investigate and resolve support tickets.
Trace examples
Cloudflare Trace has been available via API for the last nine months. We have been working with a number of customers and stakeholders to understand where tracing is beneficial and solving customer problems. Here are some of the real world examples that we have solved using Cloudflare Trace.
Transform Rules inconsistently matching
A customer encountered an issue while attempting to rewrite a URL to their origin for specific paths using Transform rules. The Cloudflare account created a filter that employed regex to match against a specific path.
A systems administrator monitoring their web server observed in their logs that the URLs for a small percentage of requests were not transforming correctly, causing disruptions to the application. They decided to investigate by comparing a correctly functioning request with one that was not, and subsequently conducted traces.
In the problematic trace, only one rule matched the trace parameters and was setting incorrect parameters.
Whereas on the other URL the rule that contained the regex matched as intended and set the correct URL parameters.
This allowed the sysadmin to pinpoint the problem: the regex was specifically designed to handle requests with subdirectories, but it failed to address cases where requests directly targeted the root or a non-subdirectory path. After identifying this issue within the traces, the sysadmin updated the filter. Subsequently, both cases matched successfully, leading to the resolution of the problem.
What origin?
When a request encounters a Cloudflare ruleset, such as Origin Rules, all the rules are evaluated, and any rule that is matched is applied in sequential order of priority. This means that multiple settings could be applied from different rules. For example, a Host Header could be set in rule 1, and a DNS origin could be assigned in rule 3. This means that the request will exit the Origin Rules phase with a new Host Header and be routed to a different origin. Cloudflare Trace allows users to easily see all the rules that matched and altered the request.
Tracing the future
Cloudflare Trace will be available to all our customers over this coming week. And located within the Account section of your Cloudflare Dashboard for all plans. We are excited to introduce additional features and products to Cloudflare Trace in the coming months. In the future will also be developing scheduling and alerts, which will enable you to monitor if a newly deployed rule is impacting the critical path of your application. As with all our products, we value your feedback. Within the Trace dashboard, you'll find a form for providing feedback and feature requests to help us enhance the product before its general release.
Unusually, we have a large chunk of changes in filesystems. Part of
it is the vfs-level revert of some of the timestamp handling that
needs to soak a bit more, and part of it is some xfs fixes. With a
few other filesystem fixes too.
The multi-grain timestamp changes turned
out to cause the occasional regression (timestamps that could appear to go
backward) and were taken back out.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
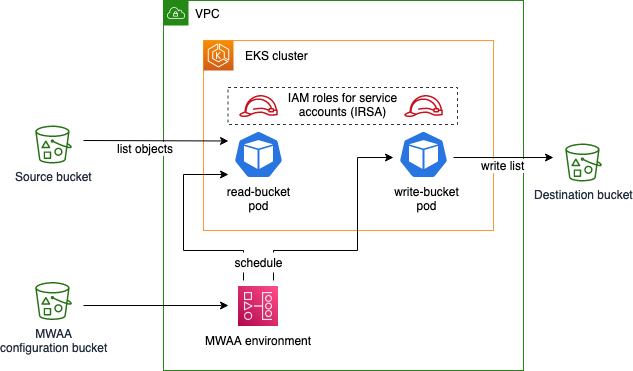

 Ulrich Hinze is a Solutions Architect at AWS. He partners with software companies to architect and implement cloud-based solutions on AWS. Before joining AWS, he worked for AWS customers and partners in software engineering, consulting, and architecture roles for 8+ years.
Ulrich Hinze is a Solutions Architect at AWS. He partners with software companies to architect and implement cloud-based solutions on AWS. Before joining AWS, he worked for AWS customers and partners in software engineering, consulting, and architecture roles for 8+ years. Patrick Oberherr is a Staff Data Engineer at Contentful with 4+ years of working with AWS and 10+ years in the Data field. At Contentful he is responsible for infrastructure and operations of the data stack which is hosted on AWS.
Patrick Oberherr is a Staff Data Engineer at Contentful with 4+ years of working with AWS and 10+ years in the Data field. At Contentful he is responsible for infrastructure and operations of the data stack which is hosted on AWS. Johannes Günther is a cloud & data consultant at Netlight with 5+ years of working with AWS. He has helped clients across various industries designing sustainable cloud platforms and is AWS certified.
Johannes Günther is a cloud & data consultant at Netlight with 5+ years of working with AWS. He has helped clients across various industries designing sustainable cloud platforms and is AWS certified.