Post Syndicated from Phil Goldstein original https://aws.amazon.com/blogs/big-data/peloton-embraces-amazon-redshift-to-unlock-the-power-of-data-during-changing-times/

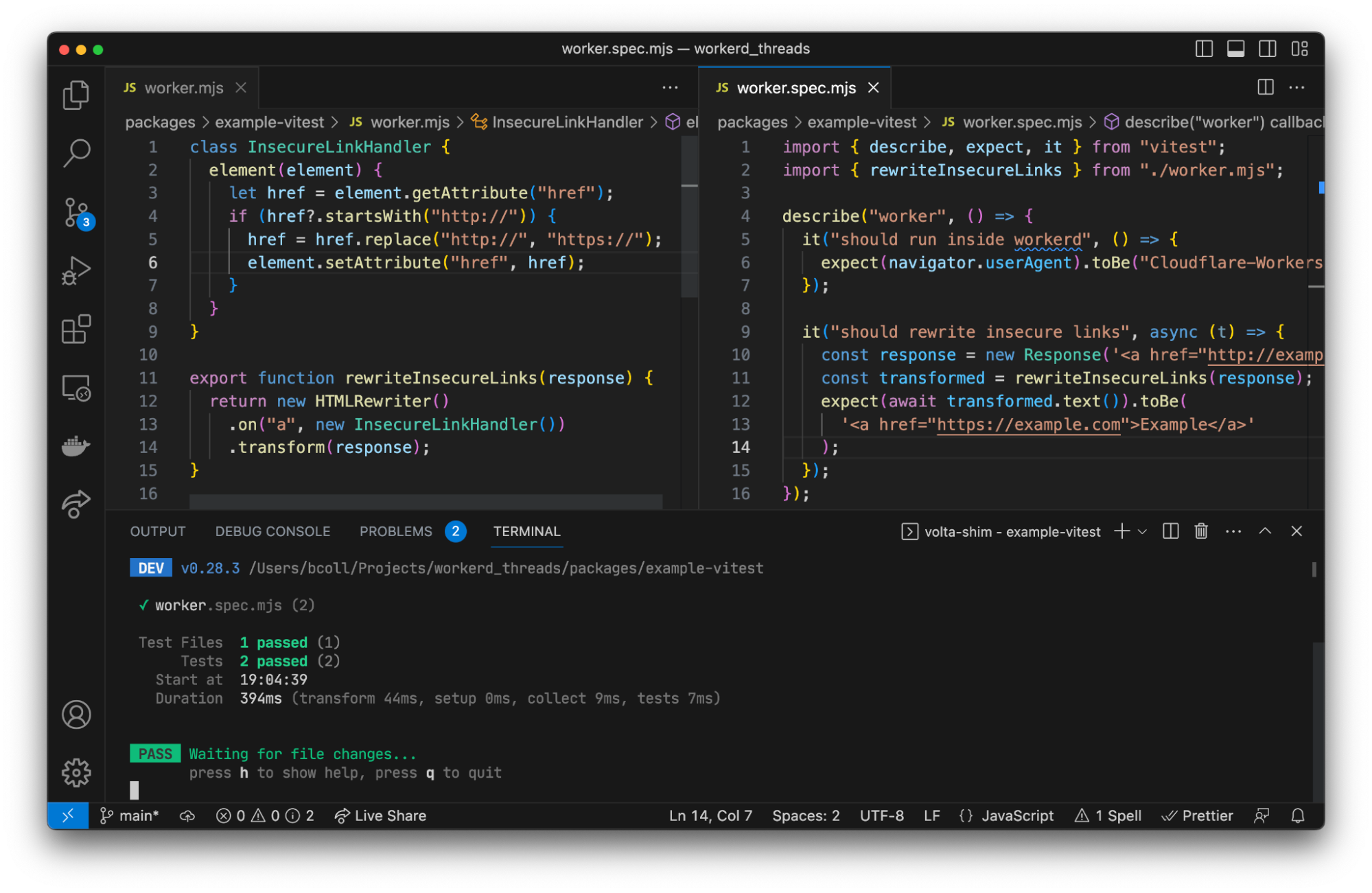
Credit: Phil Goldstein
Jerry Wang, Peloton’s Director of Data Engineering (left), and Evy Kho, Peloton’s Manager of Subscription Analytics, discuss how the company has benefited from using Amazon Redshift.
New York-based Peloton, which aims to help people around the world reach their fitness goals through its connected fitness equipment and subscription-based classes, saw booming growth in the early stage of the COVID-19 pandemic. In 2020, as gyms shuttered and people looked for ways to stay active from the safety of their homes, the company’s annual revenue soared from $915 million in 2019 to $4 billion in 2021. Meanwhile, the company’s subscribers jumped from around 360,000 in 2019 to 2.76 million at the end of 2022.
As Peloton’s business continued to evolve amid a changing macroeconomic environment, it was essential that it could make smart business decisions quickly, and one of the best ways to do that was to harness insights from the huge amount of data that it had been gathering over recent years.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift, the first fully managed, petabyte-scale cloud data warehouse. The service has grown into a multifaceted service used by tens of thousands of customers to process exabytes of data on a daily basis (1 exabyte is equivalent to 119 billion song downloads). With Amazon Redshift, you get access to a modern data architecture that helps you break down internal data silos, share data securely and seamlessly, and support multiple users who don’t have specialized data and analytics skills.
When Jerry Wang, Peloton’s director of data engineering, joined the company in 2019, he needed to make sure the service would handle the company’s massive and growing amounts of data. He also needed to ensure Amazon Redshift could help the company efficiently manage the wide variety of data and the users who would need to access it, and deliver insights on that data at high velocity—all while being cost-effective and secure.
Wang was delighted to see that as Peloton experienced its massive growth and change, AWS continued to release new Amazon Redshift features and associated capabilities that would perfectly suit his company’s needs at just the right time.
“Over the years, I’ve always been in the stage where I hope Redshift can have a new, specific feature,” Wang says, “and then, in a very limited amount of time, AWS releases that kind of feature.”
Peloton’s data volumes soar as the business grows

Credit: Peloton
As Peloton’s business has evolved, the amount of data it is generating and analyzing has grown exponentially. From 2019 to now, Wang reports the amount of data the company holds has grown by a factor of 20. In fact, a full 95% of the total historical data the company has generated has come in the last 4 years. This growth has been driven both by surges in the number of users on Peloton’s platform and the variety of data the company is collecting.
Peloton collects reams of data on its sales of internet-connected exercise equipment like stationary bikes and treadmills. The company also collects data on customers’ workouts, which it then provides back to them in various reports such as a monthly summary, giving them insights into how often they worked out, their best output, trends in their workouts, the instructor they used the most, how many calories they burned, and more. All of this data helps Peloton make strategic business decisions, refine its operations to become more efficient, adjust its programming, and drive subscriber engagement and growth.
In 2019 and into 2020, as Peloton’s business boomed, the company needed an analytics system that could help it manage an explosion of data, both from users and related to its business. The company embraced Amazon Redshift because of the service’s versatility, ease of use, price-performance at scale, continuous pace of innovation, and ability to handle concurrent queries from dozens of internal data teams.
Wang said that when he joined the company, there were two kinds of users who were performing daily data operations in Peloton’s Amazon Redshift data warehouse. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis. The other was a group of business users who, each morning, would perform queries to generate local data visualizations, creating a surge of capacity on the Amazon Redshift data warehouse. “So, when these two loads ran together, the performance suffered directly,” Wang says.
One of the features Peloton adopted was Amazon Redshift Concurrency Scaling, which provides consistent and fast query performance even across thousands of concurrent users and concurrent queries. This helped solve the problem by automatically adding query processing power in seconds and processing queries without delays. When the workload demand subsided, the extra processing power was automatically removed, so Peloton only had to pay for the time when Concurrency Scaling data warehouses were in use. Wang says Peloton was running about 10 hours of Concurrency Scaling on a consistent daily basis to deal with the congestion, which, he says, “solved my problem at that moment.”
In 2020, as the pandemic inspired hoards to hop on bikes in their living rooms, Wang also upgraded Amazon Redshift with the newly introduced Amazon Redshift RA3 instances with managed storage (RMS). These represented a new generation of compute instances with managed, analytics-optimized storage designed for high-transaction, fast query performance and lower costs.
“The new instance … was a great feature for us,” Wang says. “It solved our concern about moving from terabyte scale to petabyte scale.”
Peloton’s business is driven by a variety of data for a wide range of users

Credit: Peloton
Peloton’s business model is driven by a wide variety of large volumes of data. In addition to selling bikes, treadmills, and indoor rowing machines, and expanding its subscription platform to include non-equipment-based workouts, the company has dozens of instructors in five countries, and it licenses music from three major music licensors. In 2022, it began renting bikes as well as selling them. Internally, Peloton employees working in finance, accounting, marketing, supply chain operations, music and content, and more are using data to track subscriber growth, content engagement, and which sales channels are leading to the most net new subscriptions.
“There was a time when we were just a bike company, and now we’re so much more than that,” says Evy Kho, manager of subscription analytics at Peloton.
There is also a much wider range of sales channels for Peloton equipment than just a few years ago. In the past, Peloton customers could only purchase bikes through the Peloton website or secondhand. Now, customers can purchase hardware from third-party sites like Amazon. That introduced “a really interesting data problem” for Peloton, says Kho, as it strives to determine how to link subscription signups back to exercise equipment sales.
In the face of this variability, complexity, and need for instant access to data to inform business decision-makers, Peloton embraced Amazon Redshift Serverless as an early adopter after AWS introduced the feature in late 2021. Redshift Serverless allows companies to quickly run and scale analytics capacity without database managers and data engineers needing to manage data warehouse infrastructure.
Redshift Serverless also has the ability to quickly spin up analytics capacity for different users, or personas, within an organization. This allows different teams across Peloton to perform analytics on the same datasets at the same time to generate insights on their individual parts of the business. It’s “incredibly important in terms of assessing what’s been good for our business,” Kho says.
Wang also says Peloton is considering supporting specific personas for those who need analytics around financial information governed by securities regulations, and another for users who need to perform analytics on data governed by regulations around personally identifiable information (PII).
Wang points out that Redshift Serverless also allows him to spin up Amazon Redshift data warehouses to handle special usage patterns. For example, ETL loads are often high I/O but require low CPU resources, and are very predictable because Peloton controls the process. However, when internal users want to perform data analytics or machine learning, the company doesn’t have control over the demand for those queries, and the load on Amazon Redshift data warehouses can be variable, with some queries more CPU-intensive than others. Previously, any provisioned data warehouse would have a fixed cost, and it would have to be provisioned to cope with the highest possible workloads even if the utilization rates turned out to be low. Now, for these different scenarios, Wang creates different Amazon Redshift instances to handle that variability without those heavy, fixed costs.
As Peloton’s use of Amazon Redshift has evolved and matured, its costs have gone down, according to Wang. “If you look at Serverless, the amount … that we spend on the Serverless is actually much smaller than we did previously, compared to the Concurrency Scaling cost.”
In a serverless environment, there is no upfront cost to Peloton. “I can set it up as quickly as I can and we pay as we need it,” Wang says. “It scales up when the load goes up. So, it’s a perfect fit.”
Peloton uses Amazon Redshift to get to insights faster

Credit: Peloton
Peloton’s focus on efficiency and sustainable growth has meant that it needs to act more quickly than ever to make sound, data-informed business decisions. Peloton, Wang notes, is long past the stage where all it cared about was growth. “We are a mature company now, so operational efficiency is very important; it’s key to the business,” he says.
When Peloton launches new products, for example, two things typically happen, Wang says. One is that there is a spike in data volumes, both in traffic to its website and the number of sales transactions it’s processing. The second is that the company’s management team will want real-time updates and analysis of how sales are performing.
Redshift Serverless and data sharing lets users quickly start performing real-time analytics and build reporting and dashboard applications without any additional engineering required. Wang confirms this benefit, especially in the example of a new product launch, saying it “will scale up by itself without me having to intervene. I don’t need to allocate a budget. I don’t need to change any configurations.”
In the past, when Peloton only offered its fitness equipment through its own website, it was easy to associate fulfillment data on orders with subscriptions. However, as those channels grew and became more complex, Peloton turned to the data sharing capabilities of Amazon Redshift to share data quickly and easily across teams. Peloton’s teams for subscriber analytics, supply chain, accounting, and more need fast access to fulfillment data to ensure they can track it accurately, respond if changes are needed, and determine how fulfillment data aligns with subscriptions and revenue.
“Getting them those results even faster has been incredibly helpful, and is only becoming more important as we have become far more data-driven than I think you could argue we were before,” Kho says.
Amazon Redshift marries data security, governance, and compliance with innovation
Like all customers, Peloton is concerned about data security, governance, and compliance. With security features like dynamic data masking, role-based access control, and row-level security, Amazon Redshift protects customers’ data with granular authorization features and comprehensive identity management.
Customers also are able to easily provide authorizations for the right users or groups. These features are available out of the box, within the standard pricing model.
Wang notes that Amazon Redshift’s security model is based on a traditional database model, which is a well-understood and robust model. “So for us, to provision access on that model is quite straightforward,” Wang says.
At every stage of Peloton’s evolution over the last 4 years, the company has been able to turn to AWS and Amazon Redshift to help it effectively manage that growth and complexity.
“When I started,” Wang says, “I said, OK, I need a temporary boost in capacity. Then came Concurrency Scaling. And then I said, I need cheaper storage, and [RA3] comes along. And then the ultimate challenge [was], I’m no longer satisfied with a monolithic Redshift instance. Serverless solved that issue.”
Join AWS Data Insights Day 2023
If you want to learn how your company can use Amazon Redshift to analyze large volumes of data in an easy-to-use, scalable, cost-effective, and secure way, don’t miss AWS Data Insights Day on May 24, 2023. During the day-long virtual event, learn from AWS leaders, experts, partners, and customers—including Peloton, Gilead, McDonald’s, Global Foundries, Schneider Electric, and Flutter Entertainment—how Amazon Redshift and features like Amazon Redshift ML are helping drive business innovation, optimization, and cost savings, especially in today’s uncertain economic times.
To learn more about Amazon Redshift, see Amazon Redshift and Amazon Redshift: Ten years of continuous reinvention.
About the author
 Phil Goldstein is a copywriter and editor with AWS product marketing. He has 15 years of technology writing experience, and prior to joining AWS was a senior editor at a content marketing agency and a business journalist covering the wireless industry.
Phil Goldstein is a copywriter and editor with AWS product marketing. He has 15 years of technology writing experience, and prior to joining AWS was a senior editor at a content marketing agency and a business journalist covering the wireless industry.









 Phil Goldstein is a copywriter and editor with AWS product marketing. He has 15 years of technology writing experience, and prior to joining AWS was a senior editor at a content marketing agency and a business journalist covering the wireless industry.
Phil Goldstein is a copywriter and editor with AWS product marketing. He has 15 years of technology writing experience, and prior to joining AWS was a senior editor at a content marketing agency and a business journalist covering the wireless industry.