Post Syndicated from Sam Rhea original https://blog.cloudflare.com/why-cios-select-cloudflare-one/


Cloudflare’s first customers sought us out as the “Web Application Firewall vendor” or their DDoS-mitigating Content Delivery Network. We earned their trust by solving their problems in those categories and dozens of others. Today, over 100,000 customers now rely on Cloudflare to secure and deliver their Internet properties.
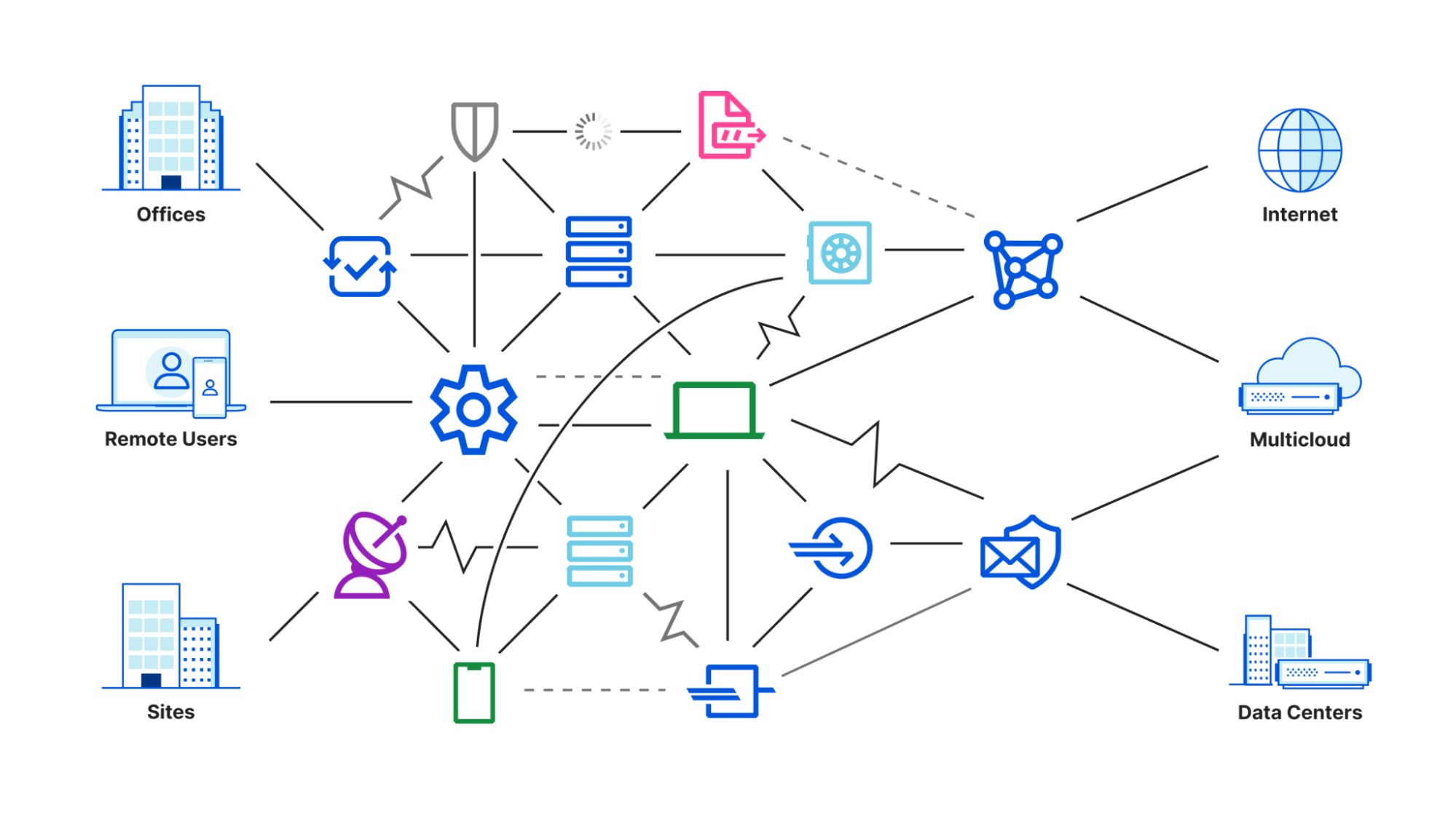
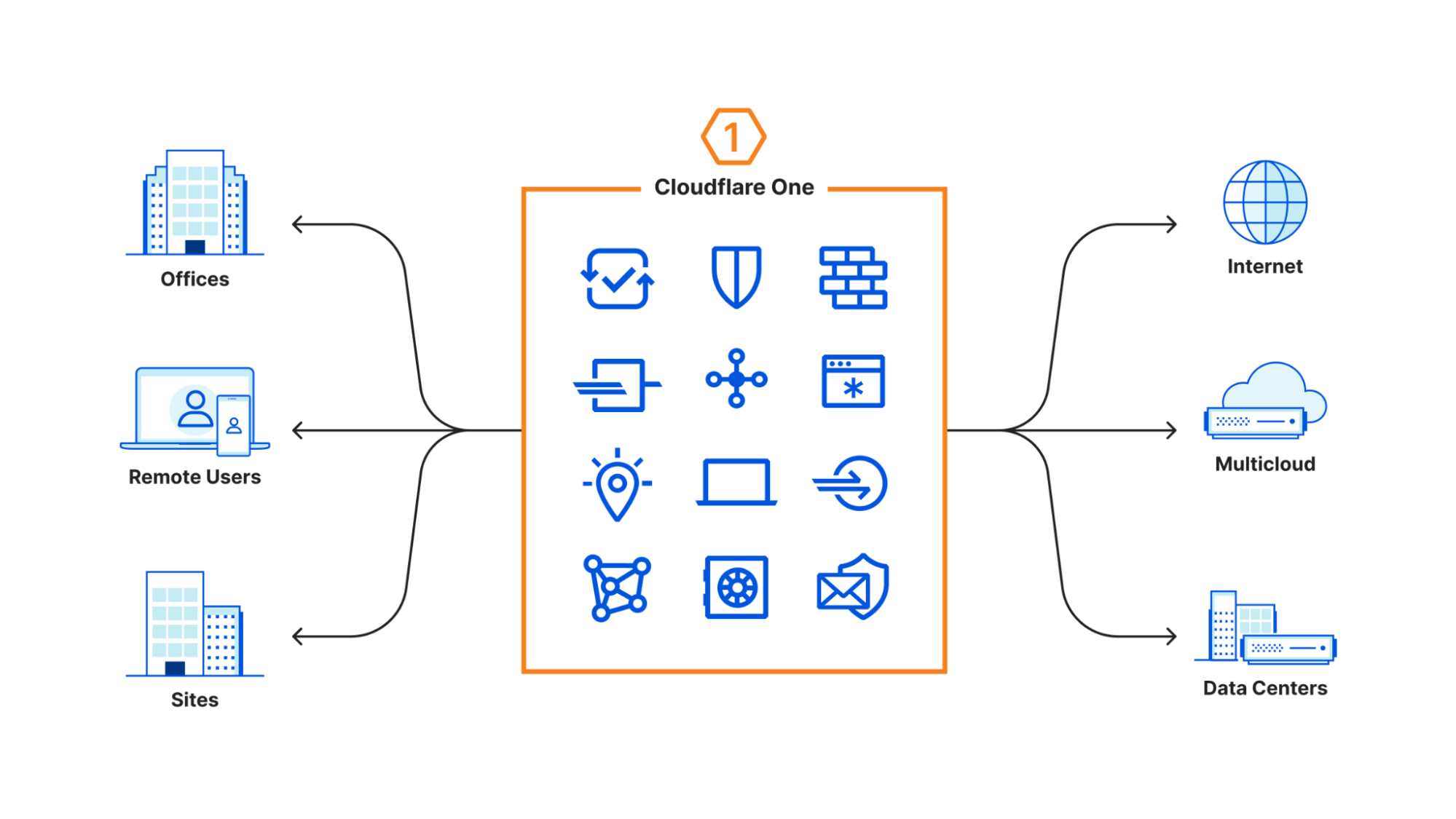
However, our conversations with CIOs evolved over the last few years. The discussions stopped centering around a specific product. CIOs, and CSOs too, approached us with the challenge of managing connectivity and security for their entire enterprise. Whether they described their goals as Zero Trust or Secure Access Service Edge (SASE), their existing appliances and point solutions could no longer keep up. So we built Cloudflare One to help them.
Today, over 10,000 organizations trust Cloudflare One to connect and secure their users, devices, applications, and data. As part of CIO Week, we spoke with the leaders of some of our largest customers to better understand why they selected Cloudflare.
The feedback centered around six themes:
- Cloudflare One delivers more complete security.
- Cloudflare One makes your team faster.
- Cloudflare One is easier to manage.
- Cloudflare One products work better together.
- Cloudflare One is the most cost-efficient comprehensive SASE offering.
- Cloudflare can be your single security vendor.
If you are new to Cloudflare, or more familiar with our Internet property products, we’re excited to share how other customers approached this journey and why they partnered with Cloudflare. Today’s post breaks down their feedback in serious detail. If you’d prefer to ask us directly, skip ahead to the bottom, and we’d be glad to find time to chat.
Cloudflare One delivers more complete security
The first SASE conversations we had with customers started when they asked us how we keep Cloudflare safe. Their Internet properties relied on us for security and availability – our own policies mattered to their decisions to trust us.
That’s fair. We are a popular target for attack. However, we could not find anything on the market that could keep us safe without slowing us down. Instead, we decided to use our own network to connect employees to internal resources and secure how those same team members connected to the rest of the Internet.
After learning what we built to replace our own private network, our customers started to ask if they could use it too. CIOs were on the same Zero Trust journey with us. They trusted our commitment to delivering the most comprehensive security on the market for their public-facing resources and started partnering with us to do the same thing for their entire enterprise.
We kept investing in Cloudflare One over the last several years based on feedback from our own internal teams and those CIOs. Our first priority was to replace our internal network with a model that applies Zero Trust controls by default. We created controls that could adapt to the demands of security teams without the need to modify applications. We added rules to force hard keys on certain applications, restrict access to specific countries, or require users to ask for approval from an administrator. The flexibility meant that every request, and every connection, could be scrutinized in a way that matched the sensitivity of internal tools.
We then turned that skepticism in the other direction. Customers on this journey with us asked “how could we have Zero Trust in the rest of the Internet?” To solve that, we turned Cloudflare’s network in the other direction. We built our DNS filtering product by combining the world’s fastest DNS resolver with our unique view into threat patterns on the Internet. We layered on a comprehensive Secure Web Gateway and network firewall. We sent potentially risky sites to Cloudflare’s isolated browser, a unique solution that pushes the industry forward in terms of usability.
More recently, we started to create tools that help control the data sitting in SaaS applications and to prevent sensitive data from leaving the enterprise. We’ve been delighted to watch customers adopt every stage in this progression with us, but we kept comparing notes with other CIOs and CSOs about the risk of something that most vendors do not consider part of the SASE stack: email.
We also spent so many hours monitoring email-based phishing attacks aimed at Cloudflare. To solve that challenge, we deployed Area 1 Email Security. The efficacy of Area 1 stunned our team to the point that we acquired the company, so we could offer the same security to our customers as part of Cloudflare One.
When CIOs describe the security challenges they need to solve, we can recommend a complete solution built on our experience addressing those same concerns. We cannot afford shortcuts in how we secure Cloudflare and know they cannot either in how they keep their enterprises safe.
Zero Trust security at a social media company
Like Cloudflare, social media services are a popular target for attack. When the security team at one of the world’s most prominent social media platforms began a project to overhaul their access controls, they ran a comprehensive evaluation of vendors who could keep their platform safe from phishing attacks and lateral movement. They selected Cloudflare One due to the granular access control our network provides and the layers of security policies that can be evaluated on any request or connection without slowing down end users.
Cloudflare One makes your team faster
Many of our customers start with our Application Services products, like our cache and smart routing, because they have a need for speed. The performance of their Internet properties directly impacts revenue. These customers hunt down opportunities to use Cloudflare to shave off milliseconds.
The CIOs who approach us to solve their SASE problems tend to rank performance lower than security and maintainability. In early conversations they describe their performance goals as “good enough that my users do not complain.”
Those complaints drive IT help desk tickets, but CIOs are used to sacrificing speed for security. We don’t believe they should have to compromise. CIOs select Cloudflare One because the performance of our network improves the experience of their end users and reduces overhead for their IT administrators.
We accelerate your users from the first moment they connect. When your team members visit a destination on the Internet, their experience starts with a DNS query to find the address of the website. Cloudflare runs the world’s fastest DNS resolver, 1.1.1.1, and the DNS filtering features of our SASE offering use the same technology.
Next, your users’ devices open a connection and send an HTTP request to their destination. The Cloudflare agent on their device does so by using a BoringTun, our Rust-based and open sourced WireGuard implementation. WireGuard allows us to provide a highly-performant on-ramp to the Internet through our network without compromising battery life or security. The same technology supports the millions of users who choose to use our WARP consumer offering. We take their feedback and optimize WARP constantly to improve how our enterprise users connect.
Finally, your users rely on our network to connect them to their destination and return the responses. Out of the 3,000 top networks in the world, measured by IPv4 addresses advertised, we rank the fastest in 1,310. Once connected, we apply our smart routing technology to route users through our network to find the fastest path to and from their destination.
We develop new technologies to improve the speed of Cloudflare One, but we cannot change the speed of light. Instead, we make the distance shorter by bringing websites closer to your users. Cloudflare is the reverse proxy for more than 20% of the HTTP Internet. We serve those websites from the same data centers where your employees connect to our Secure Web Gateway. In many cases, we can deliver content from a server centimeters away from where we apply Cloudflare One’s filtering, shaving off milliseconds and reducing the need for more hops.
Faster DNS filtering for the United States Federal Government
The Cybersecurity and Infrastructure Security Agency (CISA) works within the United States Department of Homeland Security as the “nation’s risk advisor.”1 Last year they launched a program to find a protective DNS resolver for the civilian government. These agencies and departments operate around the country, in large cities and rural areas, and they need a solution that would deliver fast DNS resolutions close to where those users sit. After a thorough evaluation, they selected Cloudflare, in partnership with Accenture Federal Services, as the country’s protective DNS resolver.
Performance at a Fortune 500 Energy Company
An American energy company attempted to deploy Zscaler, but became frustrated after spending eight months attempting to integrate and maintain systems that slowed down their users. This organization already observed Cloudflare’s ability to accelerate their traffic with our network-layer DDoS protection product and ran a pilot with Cloudflare One. Following an exhaustive test, the team observed significant performance improvements, particularly with Cloudflare’s isolated browser product, and decided to rip out Zscaler and consolidate around Cloudflare.
Cloudflare One products are easier to manage
The tools that a SASE solution like Cloudflare One replaces are cumbersome to manage. Hardware appliances or virtual equivalents require upfront deployment work and ongoing investment to maintain and upgrade them. Migrating to other cloud-based SASE vendors can reduce pain for some IT teams, but that is a low bar.
CIOs tell us that the ability to manage the solution is nearly as important as the security outcomes. If their selected vendor is difficult to deploy, the migration drags on and discourages adoption of more advanced features. If the solution is difficult to use or manage, team members find ways to avoid using it or IT administrators waste time.
We built Cloudflare One to make the most advanced SASE technologies available to teams of any size, including those that lack full IT departments. We invested in building a system that could be configured and deployed without operational overhead. Over 10,000 teams rely on Cloudflare One as a result. That same commitment to ease-of-use extends to the enterprise IT and Security teams who manage Cloudflare One deployments for some of the world’s largest organizations.
We also provide features tailored to the feedback we hear from CIOs and their teams about the unique challenges of managing larger deployments at global scale. In some cases, their teams need to update hundreds of policies or their global departments rely on dozens of administrators who need to coordinate changes. We provide API support for managing every Cloudflare One feature, and we also maintain a Terraform provider for teams that need the option for peer reviewed configuration-as-code management.
Ease-of-use at a Fortune 500 telecommunications provider
We make our free and pay-as-you-go plans available to anyone with a credit card in order to make these technologies accessible to teams of any size. Sometimes, the largest teams in the world start with those plans too. A European Fortune 500 telecommunications company began adopting our Zero Trust platform on a monthly subscription when their Developer Operations (DevOps) lost their patience with their existing VPN. Developers across their organization complained about how their legacy private network slowed down their access to the tools they needed to do their job.
Their DevOps administrators adopted Cloudflare One after being able to set it up in a matter of minutes without talking to a sales rep at Cloudflare. Their company now relies on Cloudflare One to secure their internal resources and their path to the Internet for over 100,000 employees.
Cloudflare One products work better together
CIOs who start their SASE evaluation often attempt to replace a collection of point solutions. The work to glue together those products demands more time from IT departments and the gaps between those tools present security blind spots.
However, many SASE vendors offer a platform that just cobbles together point solutions. There might be one invoice, but the same pain points remain around interoperability and security challenges. We talk to CIOs and CSOs who expand their vendor search radius after realizing that the cloud-based alternative from their existing hardware provider still includes those challenges.
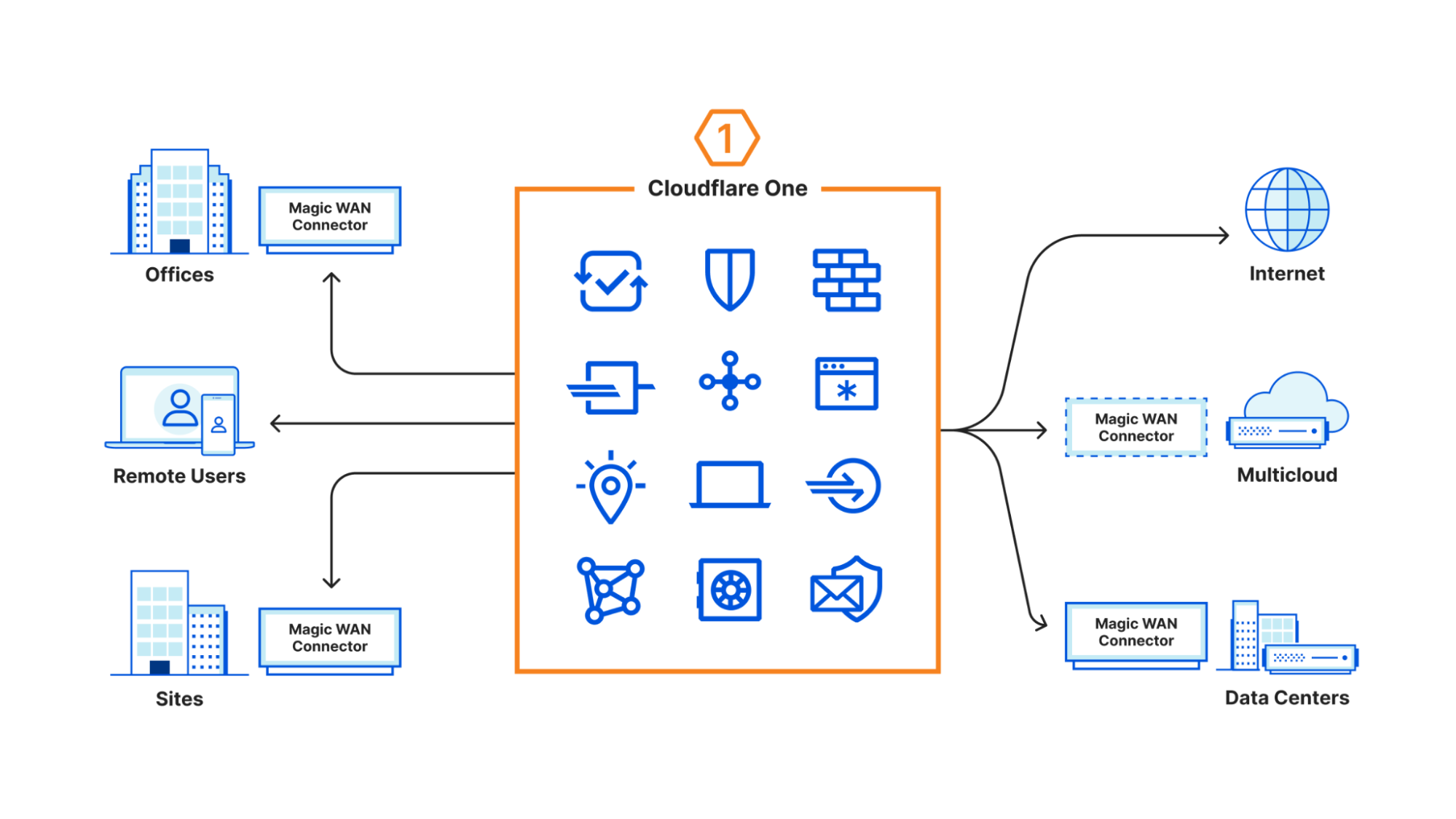
When CIOs select Cloudflare One, they pick a single, comprehensive SASE solution. We don’t believe that any feature, or product, should be an island. The sum should be greater than the parts. Every capability that we build in Cloudflare One adds more value to what is already available without adding more maintenance overhead.
When an organization secures their applications behind our Zero Trust access control, they can enable Cloudflare’s Web Application Firewall (WAF) to run in-line with a single button. Users who click on an unknown link open that website in our isolated browser without any additional steps. Launching soon, the same Data Loss Prevention (DLP) rules that administrators build for data-in-transit filters will apply to data sitting at rest with our API-driven Cloud Access Security Broker (CASB).
Product integration at national residential services provider
Just a few months ago, a US-based national provider of residential services, like plumbing and climate control repair, selected Cloudflare One because they could consolidate their disparate stack of existing cloud-based security vendors into a single solution. After evaluating other vendors who stitch together point solutions under a single brand name, they found more value in deploying Cloudflare’s Zero Trust network access solution together with our outbound filtering products for thousands of employees.
Cloudflare One is the most cost-efficient comprehensive SASE offering
Some CIOs approach Cloudflare to replace their collection of hardware appliances that perform, or attempt to perform, Zero Trust functions. The decision to migrate to a cloud-based solution can deliver immediate cost savings by eliminating the cost to continue to license and maintain that hardware or by avoiding the need for new capital expenditure to purchase the latest generation of hardware that can better attempt to support SSE Goals.
We’re happy to help you throw out those band-aid boxes. We’ve spent the last decade helping over 100,000 organizations get rid of their hardware in favor of a faster, safer, and more cost-efficient solution. However, we have seen CIOs approach us in the last with a newer form of this problem: renewals. CIOs who first adopted a cloud-based SSE solution two or three years ago now describe extortionate price increases from their existing vendors.
Unlike Cloudflare, many of these vendors rely on dedicated appliances that struggle to scale with increased traffic. To meet that demand, they purchased more appliances and now need to find a way to bake that cost into the price they charge existing and new customers. Other vendors rely on public cloud providers to run their services. As those providers increase their costs, these vendors pass them on to their customers at a rate that scales with usage.
Cloudflare’s network provides a different model that allows Cloudflare One to deliver a comprehensive SASE offering that is more cost-efficient than anything in the market. Rather than deploying dedicated appliances, Cloudflare deploys commodity hardware on top of which any Cloudflare service can run allowing us to scale up and down for any use case from our Bot Management features to our Workers, including our SASE products. We also purchase server hardware from multiple vendors in the exact same configuration, providing us with supply chain flexibility and reducing the risk that any one component from a specific vendor drives up our hardware costs.
We obsess over the efficiency of the computing costs of that hardware because we have no choice – over 20% of the world’s HTTP Internet relies on it today. Since every service can run on every server, including Cloudflare One, that investment in computing efficiency also benefits Cloudflare One. We also avoid the need to buy more hardware specifically for Cloudflare One capacity. We built our network to scale with the demands of some of the world’s largest Internet properties. That model allows us to absorb the traffic spikes of any enterprise SASE deployment without noticing.
However, Cloudflare One, like all of our network-driven products, has another cost component: transit. We need to reliably deliver your employee’s traffic to its destination. While that destination is increasingly on our network already if it uses our reverse proxy, sometimes employees need other websites.
Thankfully we’ve spent the last decade reducing or eliminating the cost of transit. In many cases, our reverse proxy motivates exchanges and ISPs to waive transit fees for us. It is in their best interest to provide their users with the fastest, most reliable, path to the ever-increasing number of websites that use our network. When we turn our network in the other direction for our SASE customers we still benefit from the same savings.
Cost-savings at an African infrastructure company
Earlier this year, an infrastructure based in South Africa came to Cloudflare with this exact problem. Their existing cloud-based Secure Web Gateway vendor, Zscaler, insisted on a significant price increase for the same services and threatened to turn off the system if the customer did not agree. Instead, this infrastructure company already trusted our network for their Internet properties and decided to rip out their existing SASE vendor in favor of Cloudflare One’s more cost-efficient model without the loss of any functionality.
Cloudflare can be your single security and connectivity vendor
We hear from more and more CIOs who want to reduce the number of invoices they pay and vendors they manage. Hundreds of enterprises who have adopted our SASE platform started as customers of our Application Services and Application Security products.
We’ve seen this take two forms. In one form, CIOs describe the challenge of stitching together multiple security point solutions into a single SASE deployment. They choose our network for the reasons described above; the CIO’s team benefits from features that work better together, and they avoid the need to maintain multiple systems.
In the second form, the migration to more cloud-based services across use cases ranging from SASE to public cloud infrastructure led to vendor bloat. We hear from customers who struggle to inventory which vendors their team has purchased and which of those services they even use.
That proliferation of vendors introduces more cost in terms of dollars and time. In financial terms, each vendor’s contract model might introduce new fees, like fixed platform costs, that would be redundant when paying for a single vendor. In management terms, every new vendor adds one more account manager to go find during issues or one more vendor to involve when debugging an issue that could impact multiple systems.
Bundling Cloudflare One with our Application Services, and Application Security allows your organization to rely on a single vendor for every connection that you need to secure and accelerate. Your teams can rely on a single control plane for everything from customizing your website’s cache rules to reviewing potential gaps in your Zero Trust deployment. CIOs have one point of contact, a Cloudflare Customer Success Manager, they can reach out to if they need help escalating a request across what used to require dozens of potential vendors.
Vendor consolidation at a 10,000 person research publication company
A large American data analytics company chose Cloudflare One as part of that same journey. They first sought Cloudflare to help load-balance their applications and protect their sites from DDoS attacks. After becoming familiar with our platform, and learning how performance features they used for their public-facing applications could be delivered to their internal resources, they selected Cloudflare One over Zscaler and Cisco.
What’s next?
Not every CIO shares the same motivations. One of the reasons above might be more important to you based on your business, your industry, or your stage in a Zero Trust adoption journey.
That’s fine by us! We’d love to learn more about what drives your search and how we can help. We have a team dedicated to listening to organizations who are evaluating SASE options and helping them understand and experiment with Cloudflare One. If you’d like to get started, let us know here, and we’ll reach out.
Do you prefer to avoid talking to someone just yet? Nearly every feature in Cloudflare One is available at no cost for up to 50 users. Many of our largest enterprise customers start by exploring the products themselves on our free plan, and we invite you to do so by following the link here.







































 Jon Roberts is a Sr. Analytics Specialist based out of Nashville, specializing in Amazon Redshift. He has over 27 years of experience working in relational databases. In his spare time, he runs.
Jon Roberts is a Sr. Analytics Specialist based out of Nashville, specializing in Amazon Redshift. He has over 27 years of experience working in relational databases. In his spare time, he runs.