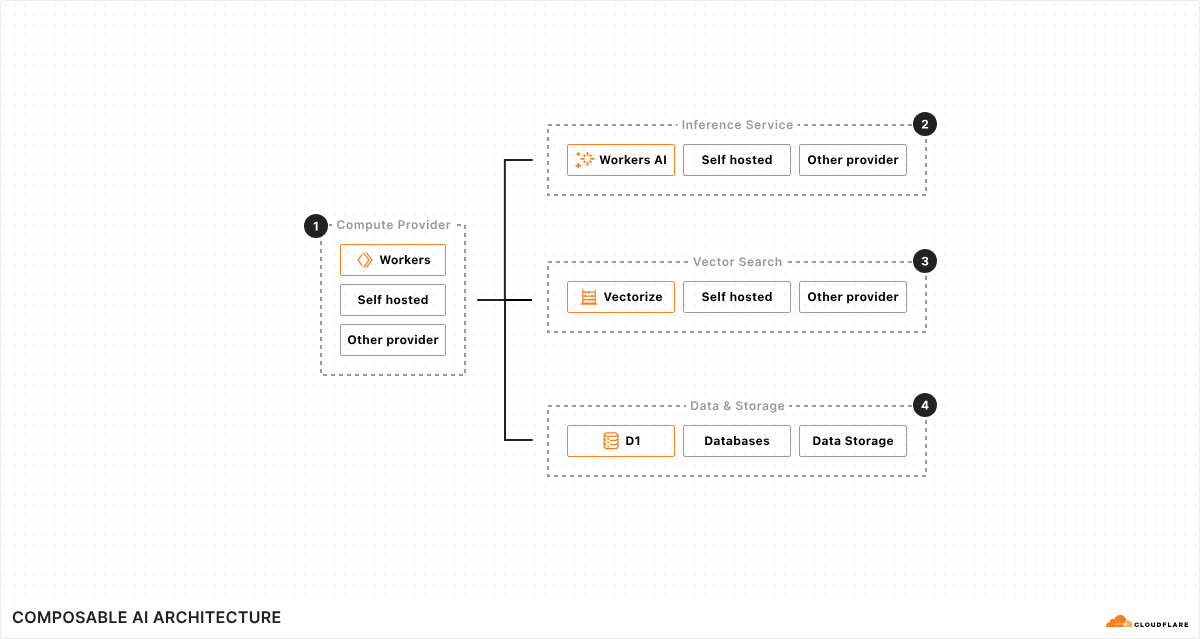
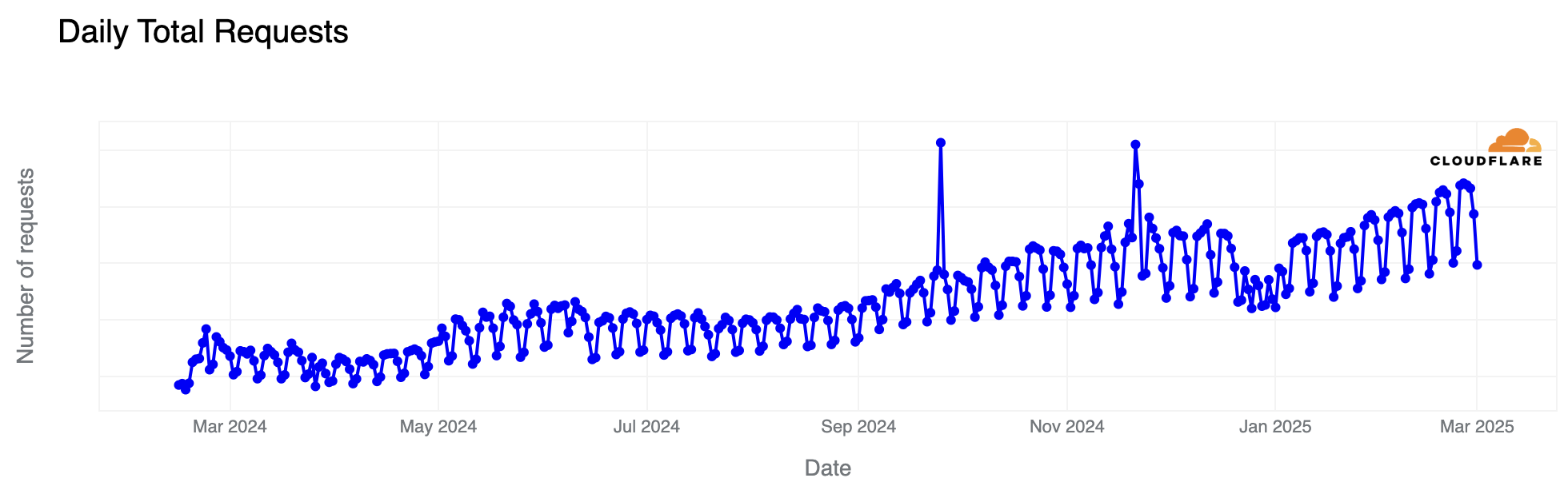
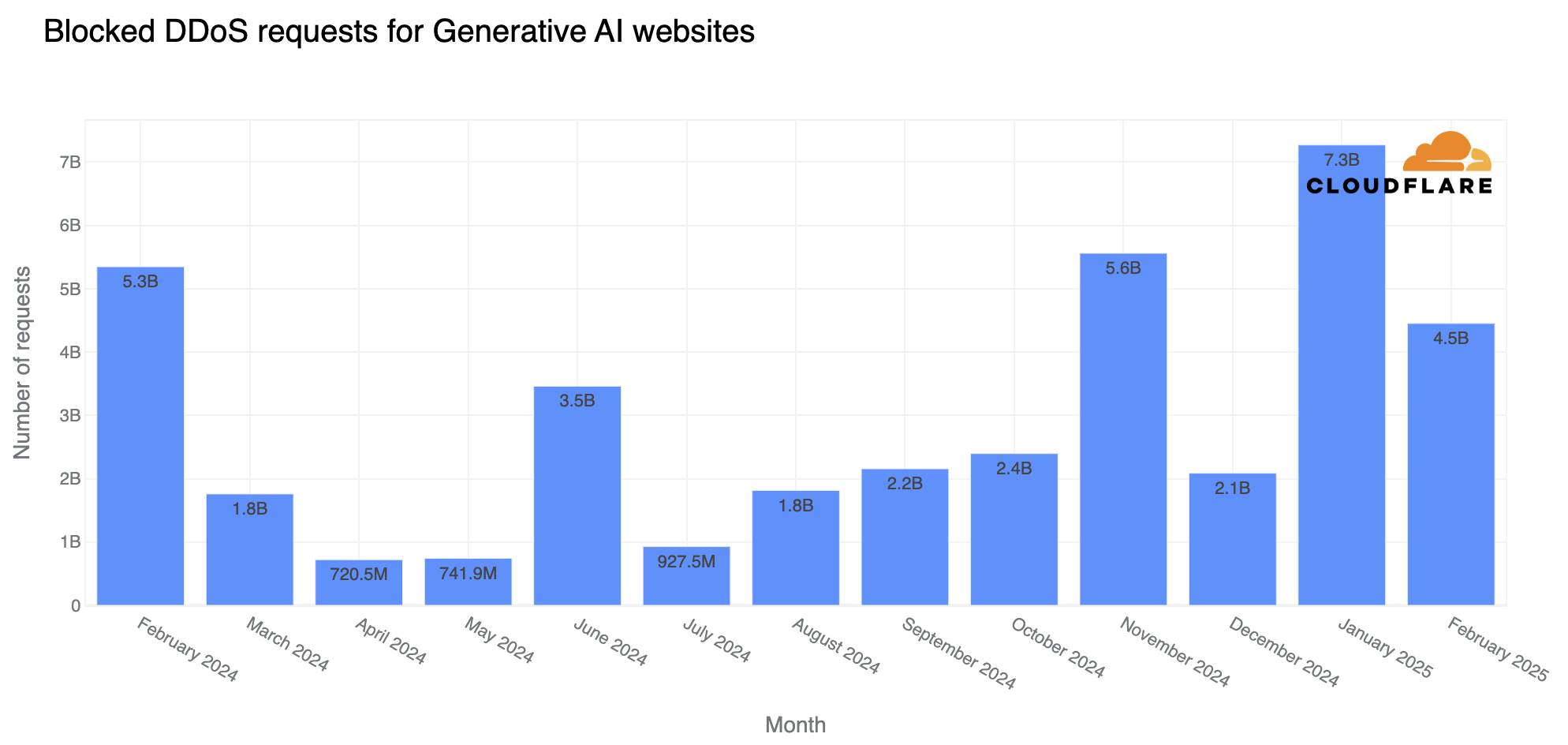
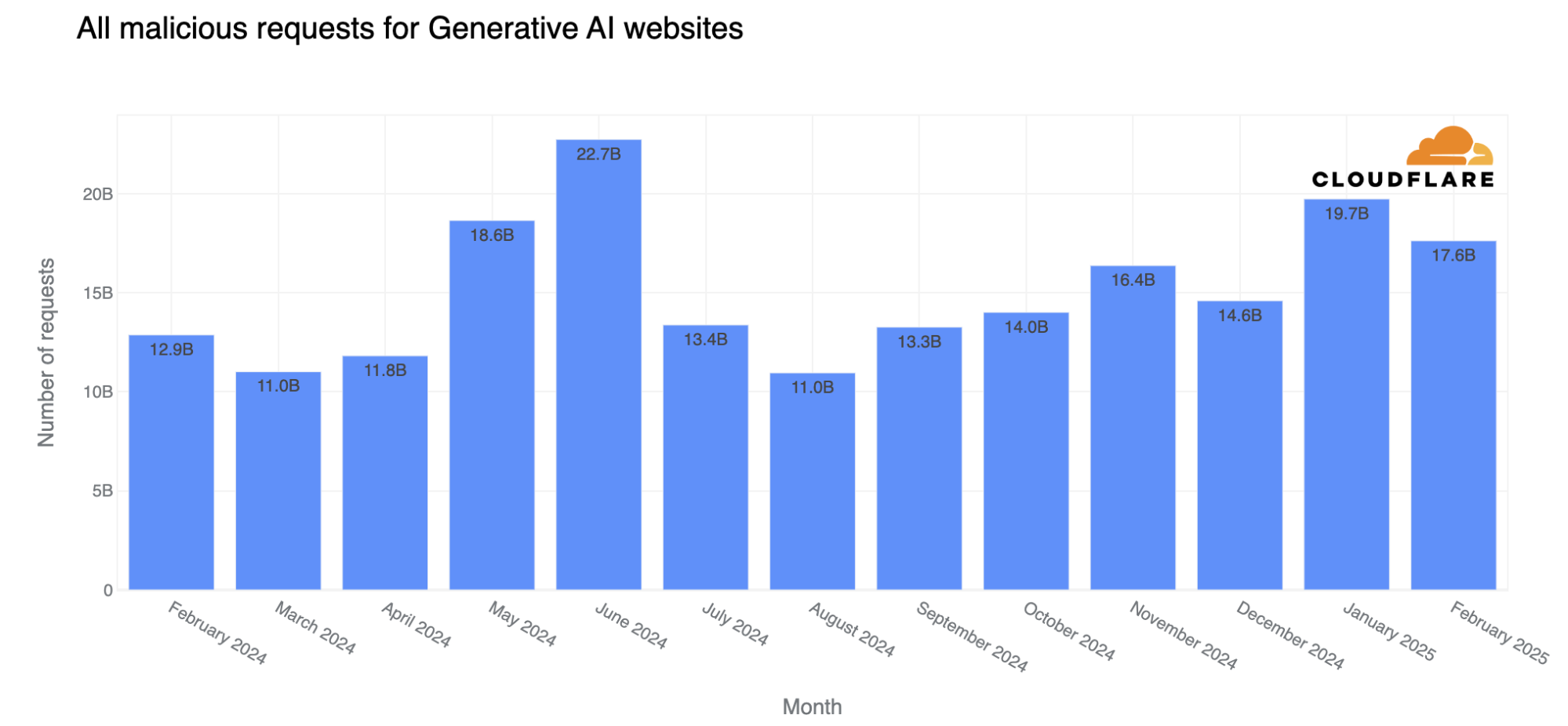
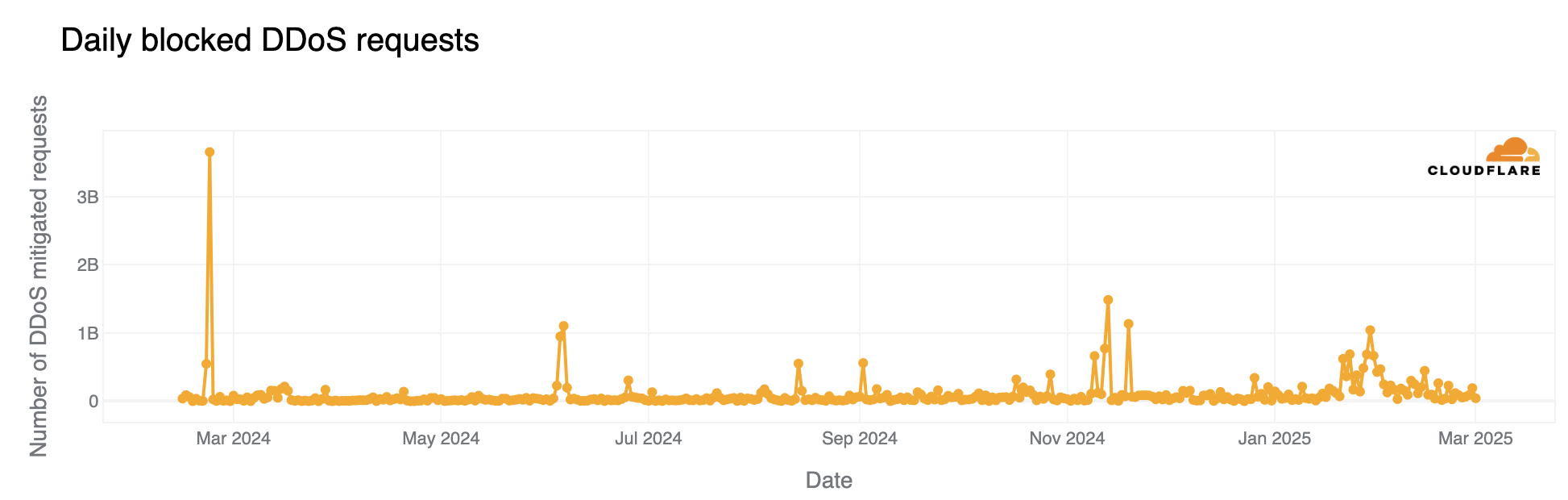
Cloudflare has a new feature—available to free users as well—that uses AI to generate random pages to feed to AI web crawlers:
Instead of simply blocking bots, Cloudflare’s new system lures them into a “maze” of realistic-looking but irrelevant pages, wasting the crawler’s computing resources. The approach is a notable shift from the standard block-and-defend strategy used by most website protection services. Cloudflare says blocking bots sometimes backfires because it alerts the crawler’s operators that they’ve been detected.
“When we detect unauthorized crawling, rather than blocking the request, we will link to a series of AI-generated pages that are convincing enough to entice a crawler to traverse them,” writes Cloudflare. “But while real looking, this content is not actually the content of the site we are protecting, so the crawler wastes time and resources.”
The company says the content served to bots is deliberately irrelevant to the website being crawled, but it is carefully sourced or generated using real scientific facts—such as neutral information about biology, physics, or mathematics—to avoid spreading misinformation (whether this approach effectively prevents misinformation, however, remains unproven).
It’s basically an AI-generated honeypot. And AI scraping is a growing problem:
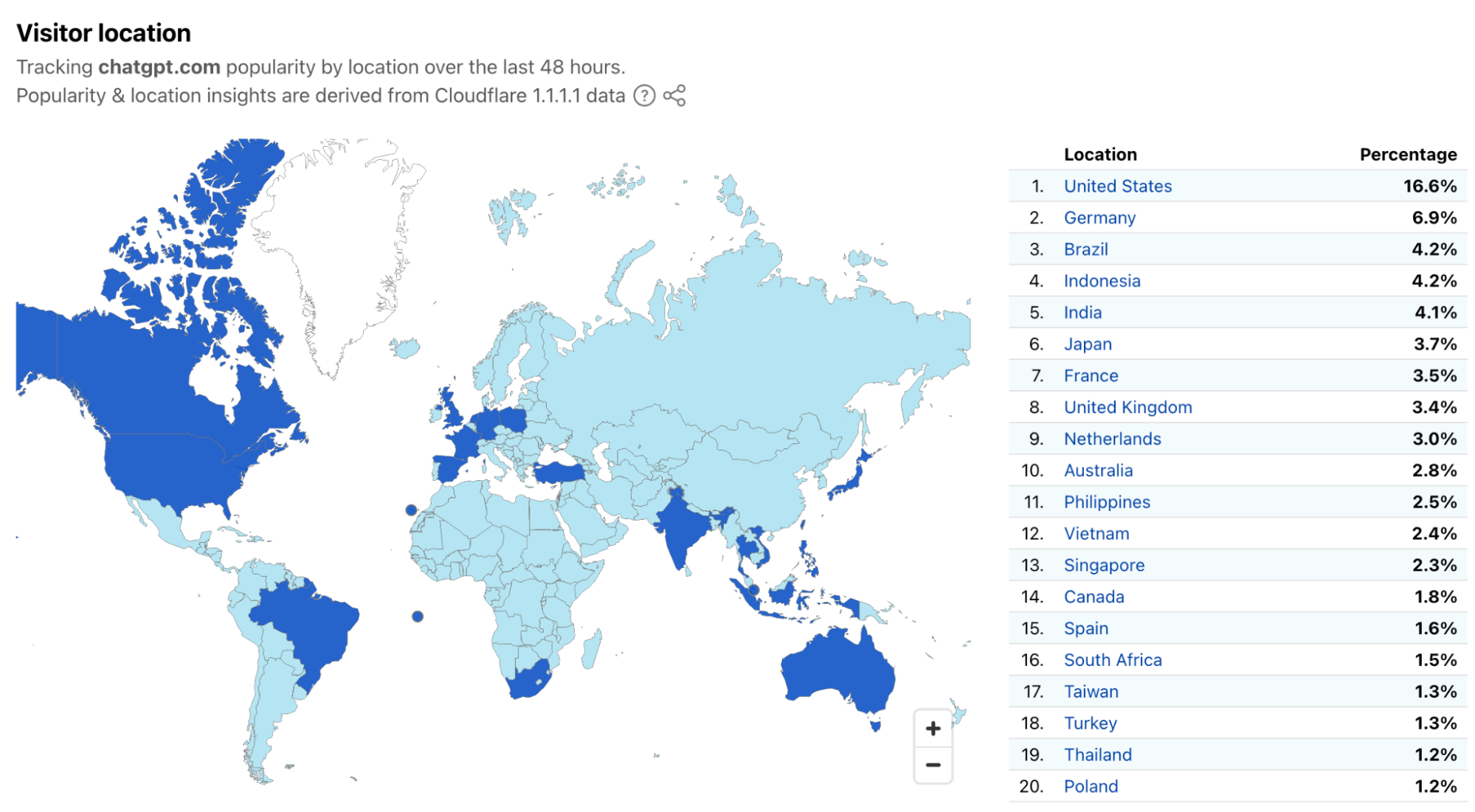
The scale of AI crawling on the web appears substantial, according to Cloudflare’s data that lines up with anecdotal reports we’ve heard from sources. The company says that AI crawlers generate more than 50 billion requests to their network daily, amounting to nearly 1 percent of all web traffic they process. Many of these crawlers collect website data to train large language models without permission from site owners….
Presumably the crawlers will now have to up both their scraping stealth and their ability to filter out AI-generated content like this. Which means the honeypots will have to get better at detecting scrapers and more stealthy in their fake content. This arms race is likely to go back and forth, wasting a lot of energy in the process.
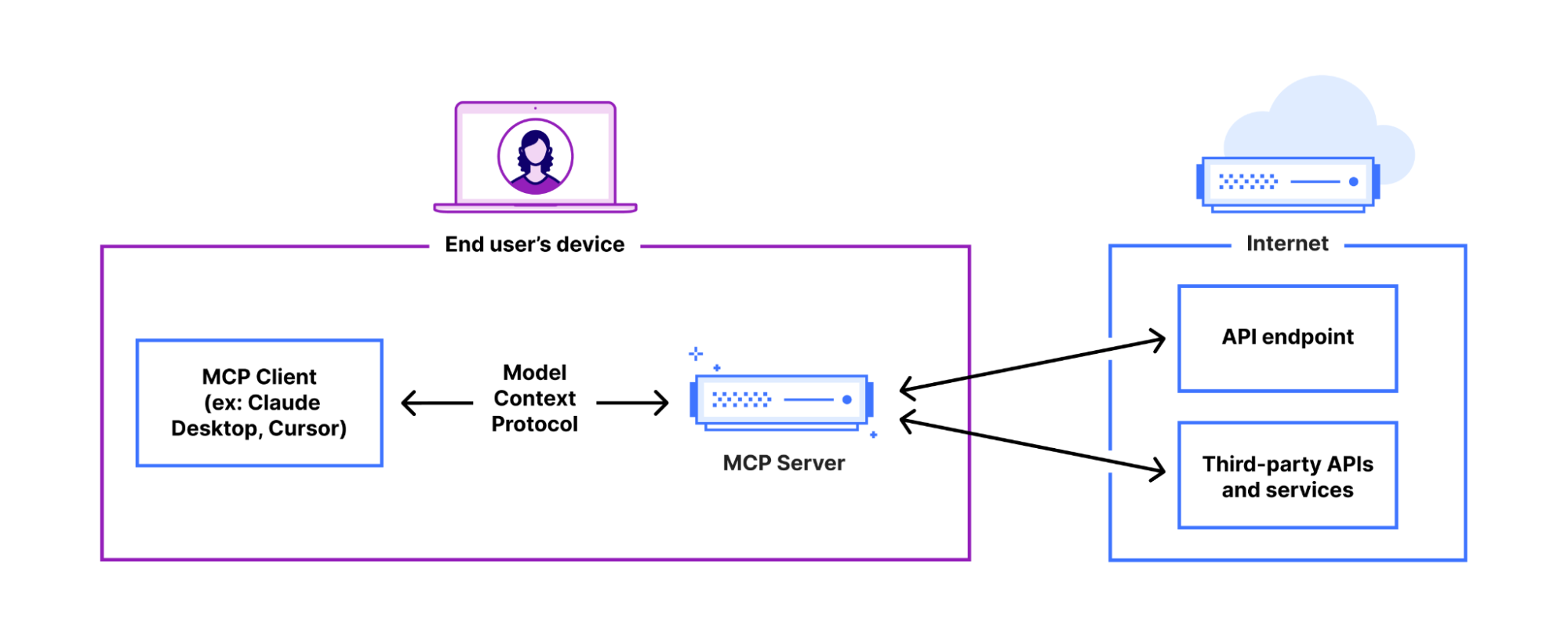
It feels like almost everyone building AI applications and agents is talking about the Model Context Protocol (MCP), as well as building MCP servers that you install and run locally on your own computer.
You can now build and deploy remote MCP servers to Cloudflare. We’ve added four things to Cloudflare that handle the hard parts of building remote MCP servers for you:
Unlike the local MCP servers you may have previously used, remote MCP servers are accessible on the Internet. People simply sign in and grant permissions to MCP clients using familiar authorization flows. We think this is going to be a massive deal — connecting coding agents to MCP servers has blown developers’ minds over the past few months, and remote MCP servers have the same potential to open up similar new ways of working with LLMs and agents to a much wider audience, including more everyday consumer use cases.
From local to remote — bringing MCP to the masses
MCP is quickly becoming the common protocol that enables LLMs to go beyond inference and RAG, and take actions that require access beyond the AI application itself (like sending an email, deploying a code change, publishing blog posts, you name it). It enables AI agents (MCP clients) to access tools and resources from external services (MCP servers).
To date, MCP has been limited to running locally on your own machine — if you want to access a tool on the web using MCP, it’s up to you to set up the server locally. You haven’t been able to use MCP from web-based interfaces or mobile apps, and there hasn’t been a way to let people authenticate and grant the MCP client permission. Effectively, MCP servers haven’t yet been brought online.
Support for remote MCP connections changes this. It creates the opportunity to reach a wider audience of Internet users who aren’t going to install and run MCP servers locally for use with desktop apps. Remote MCP support is like the transition from desktop software to web-based software. People expect to continue tasks across devices and to login and have things just work. Local MCP is great for developers, but remote MCP connections are the missing piece to reach everyone on the Internet.
Making authentication and authorization just work with MCP
Beyond just changing the transport layer — from stdio to streamable HTTP — when you build a remote MCP server that uses information from the end user’s account, you need authentication and authorization. You need a way to allow users to login and prove who they are (authentication) and a way for users to control what the AI agent will be able to access when using a service (authorization).
MCP does this with OAuth, which has been the standard protocol that allows users to grant applications to access their information or services, without sharing passwords. Here, the MCP Server itself acts as the OAuth Provider. However, OAuth with MCP is hard to implement yourself, so when you build MCP servers on Cloudflare we provide it for you.
workers-oauth-provider — an OAuth 2.1 Provider library for Cloudflare Workers
When you deploy an MCP Server to Cloudflare, your Worker acts as an OAuth Provider, using workers-oauth-provider, a new TypeScript library that wraps your Worker’s code, adding authorization to API endpoints, including (but not limited to) MCP server API endpoints.
Your MCP server will receive the already-authenticated user details as a parameter. You don’t need to perform any checks of your own, or directly manage tokens. You can still fully control how you authenticate users: from what UI they see when they log in, to which provider they use to log in. You can choose to bring your own third-party authentication and authorization providers like Google or GitHub, or integrate with your own.
Here, your MCP server acts as both an OAuth client to your upstream service, and as an OAuth server (also referred to as an OAuth “provider”) to MCP clients. You can use any upstream authentication flow you want, but workers-oauth-provider guarantees that your MCP server is spec-compliant and able to work with the full range of client apps & websites. This includes support for Dynamic Client Registration (RFC 7591) and Authorization Server Metadata (RFC 8414).
A simple, pluggable interface for OAuth
When you build an MCP server with Cloudflare Workers, you provide an instance of the OAuth Provider paths to your authorization, token, and client registration endpoints, along with handlers for your MCP Server, and for auth:
import OAuthProvider from "@cloudflare/workers-oauth-provider";
import MyMCPServer from "./my-mcp-server";
import MyAuthHandler from "./auth-handler";
export default new OAuthProvider({
apiRoute: "/sse", // MCP clients connect to your server at this route
apiHandler: MyMCPServer.mount('/sse'), // Your MCP Server implmentation
defaultHandler: MyAuthHandler, // Your authentication implementation
authorizeEndpoint: "/authorize",
tokenEndpoint: "/token",
clientRegistrationEndpoint: "/register",
});
This abstraction lets you easily plug in your own authentication. Take a look at this example that uses GitHub as the identity provider for an MCP server, in less than 100 lines of code, by implementing /callback and /authorize routes.
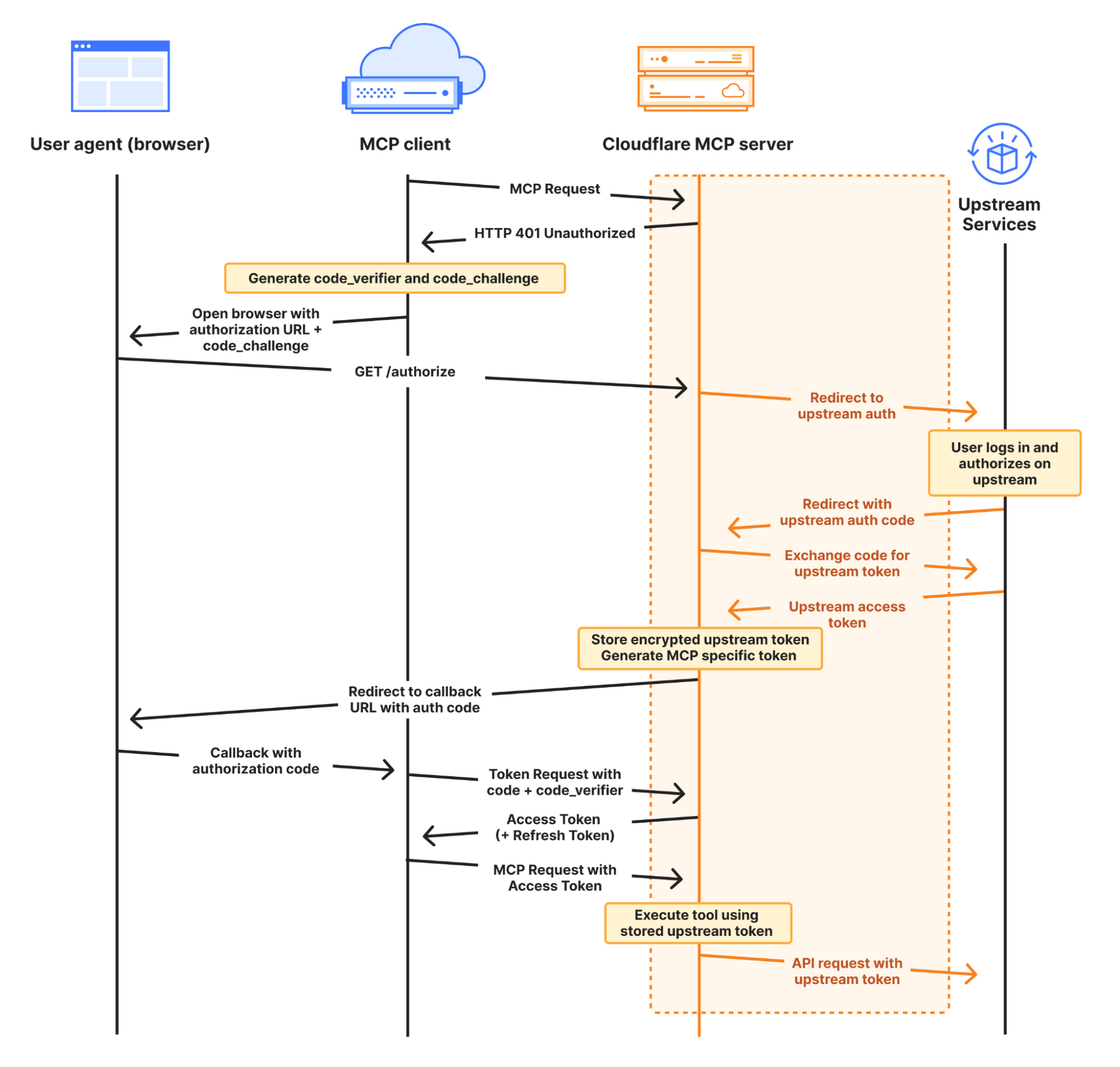
Why do MCP servers issue their own tokens?
You may have noticed in the authorization diagram above, and in the authorization section of the MCP spec, that the MCP server issues its own token to the MCP client.
Instead of passing the token it receives from the upstream provider directly to the MCP client, your Worker stores an encrypted access token in Workers KV. It then issues its own token to the client. As shown in the GitHub example above, this is handled on your behalf by the workers-oauth-provider — your code never directly handles writing this token, preventing mistakes. You can see this in the following code snippet from the GitHub example above:
// When you call completeAuthorization, the accessToken you pass to it
// is encrypted and stored, and never exposed to the MCP client
// A new, separate token is generated and provided to the client at the /token endpoint
const { redirectTo } = await c.env.OAUTH_PROVIDER.completeAuthorization({
request: oauthReqInfo,
userId: login,
metadata: { label: name },
scope: oauthReqInfo.scope,
props: {
accessToken, // Stored encrypted, never sent to MCP client
},
})
return Response.redirect(redirectTo)
On the surface, this indirection might sound more complicated. Why does it work this way?
By issuing its own token, MCP Servers can restrict access and enforce more granular controls than the upstream provider. If a token you issue to an MCP client is compromised, the attacker only gets the limited permissions you’ve explicitly granted through your MCP tools, not the full access of the original token.
Let’s say your MCP server requests that the user authorize permission to read emails from their Gmail account, using the gmail.readonly scope. The tool that the MCP server exposes is more narrow, and allows reading travel booking notifications from a limited set of senders, to handle a question like “What’s the check-out time for my hotel room tomorrow?” You can enforce this constraint in your MCP server, and if the token you issue to the MCP client is compromised, because the token is to your MCP server — and not the raw token to the upstream provider (Google) — an attacker cannot use it to read arbitrary emails. They can only call the tools your MCP server provides. OWASP calls out “Excessive Agency” as one of the top risk factors for building AI applications, and by issuing its own token to the client and enforcing constraints, your MCP server can limit tools access to only what the client needs.
Or building off the earlier GitHub example, you can enforce that only a specific user is allowed to access a particular tool. In the example below, only users that are part of an allowlist can see or call the generateImage tool, that uses Workers AI to generate an image based on a prompt:
import { McpAgent } from "agents/mcp";
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { z } from "zod";
const USER_ALLOWLIST = ["geelen"];
export class MyMCP extends McpAgent<Props, Env> {
server = new McpServer({
name: "Github OAuth Proxy Demo",
version: "1.0.0",
});
async init() {
// Dynamically add tools based on the user's identity
if (USER_ALLOWLIST.has(this.props.login)) {
this.server.tool(
'generateImage',
'Generate an image using the flux-1-schnell model.',
{
prompt: z.string().describe('A text description of the image you want to generate.')
},
async ({ prompt }) => {
const response = await this.env.AI.run('@cf/black-forest-labs/flux-1-schnell', {
prompt,
steps: 8
})
return {
content: [{ type: 'image', data: response.image!, mimeType: 'image/jpeg' }],
}
}
)
}
}
}
Introducing McpAgent: remote transport support that works today, and will work with the revision to the MCP spec
The next step to opening up MCP beyond your local machine is to open up a remote transport layer for communication. MCP servers you run on your local machine just communicate over stdio, but for an MCP server to be callable over the Internet, it must implement remote transport.
The McpAgent class we introduced today as part of our Agents SDK handles this for you, using Durable Objects behind the scenes to hold a persistent connection open, so that the MCP client can send server-sent events (SSE) to your MCP server. You don’t have to write code to deal with transport or serialization yourself. A minimal MCP server in 15 lines of code can look like this:
import { McpAgent } from "agents/mcp";
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { z } from "zod";
export class MyMCP extends McpAgent {
server = new McpServer({
name: "Demo",
version: "1.0.0",
});
async init() {
this.server.tool("add", { a: z.number(), b: z.number() }, async ({ a, b }) => ({
content: [{ type: "text", text: String(a + b) }],
}));
}
}
After much discussion, remote transport in the MCP spec is changing, with Streamable HTTP replacing HTTP+SSE This allows for stateless, pure HTTP connections to MCP servers, with an option to upgrade to SSE, and removes the need for the MCP client to send messages to a separate endpoint than the one it first connects to. The McpAgent class will change with it and just work with streamable HTTP, so that you don’t have to start over to support the revision to how transport works.
This applies to future iterations of transport as well. Today, the vast majority of MCP servers only expose tools, which are simple remote procedure call (RPC) methods that can be provided by a stateless transport. But more complex human-in-the-loop and agent-to-agent interactions will need prompts and sampling. We expect these types of chatty, two-way interactions will need to be real-time, which will be challenging to do well without a bidirectional transport layer. When that time comes, Cloudflare, the Agents SDK, and Durable Objects all natively support WebSockets, which enable full-duplex, bidirectional real-time communication.
Stateful, agentic MCP servers
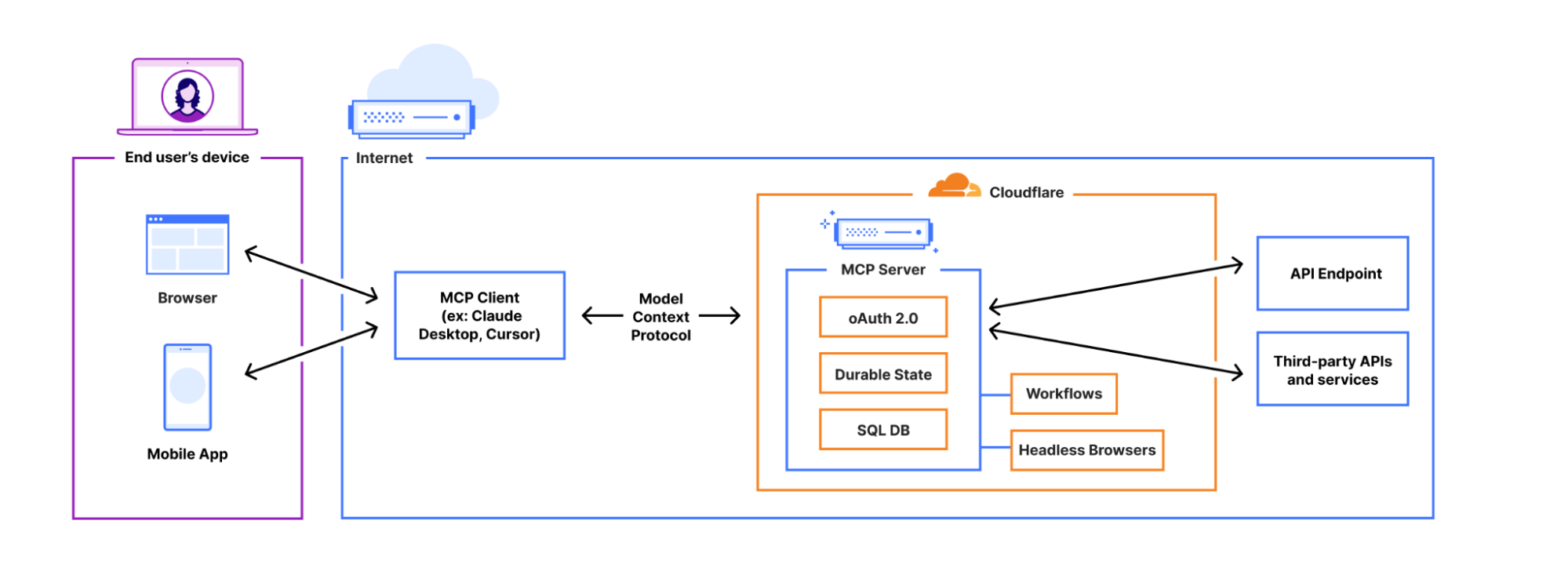
When you build MCP servers on Cloudflare, each MCP client session is backed by a Durable Object, via the Agents SDK. This means each session can manage and persist its own state, backed by its own SQL database.
This opens the door to building stateful MCP servers. Rather than just acting as a stateless layer between a client app and an external API, MCP servers on Cloudflare can themselves be stateful applications — games, a shopping cart plus checkout flow, a persistent knowledge graph, or anything else you can dream up. When you build on Cloudflare, MCP servers can be much more than a layer in front of your REST API.
To understand the basics of how this works, let’s look at a minimal example that increments a counter:
import { McpAgent } from "agents/mcp";
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { z } from "zod";
type State = { counter: number }
export class MyMCP extends McpAgent<Env, State, {}> {
server = new McpServer({
name: "Demo",
version: "1.0.0",
});
initialState: State = {
counter: 1,
}
async init() {
this.server.resource(`counter`, `mcp://resource/counter`, (uri) => {
return {
contents: [{ uri: uri.href, text: String(this.state.counter) }],
}
})
this.server.tool('add', 'Add to the counter, stored in the MCP', { a: z.number() }, async ({ a }) => {
this.setState({ ...this.state, counter: this.state.counter + a })
return {
content: [{ type: 'text', text: String(`Added ${a}, total is now ${this.state.counter}`) }],
}
})
}
onStateUpdate(state: State) {
console.log({ stateUpdate: state })
}
}
For a given session, the MCP server above will remember the state of the counter across tool calls.
From within an MCP server, you can use Cloudflare’s whole developer platform, and have your MCP server spin up its own web browser, trigger a Workflow, call AI models, and more. We’re excited to see the MCP ecosystem evolve into more advanced use cases.
Connect to remote MCP servers from MCP clients that today only support local MCP
Cloudflare is supporting remote MCP early — before the most prominent MCP client applications support remote, authenticated MCP, and before other platforms support remote MCP. We’re doing this to give you a head start building for where MCP is headed.
But if you build a remote MCP server today, this presents a challenge — how can people start using your MCP server if there aren’t MCP clients that support remote MCP?
We have two new tools that allow you to test your remote MCP server and simulate how users will interact with it in the future:
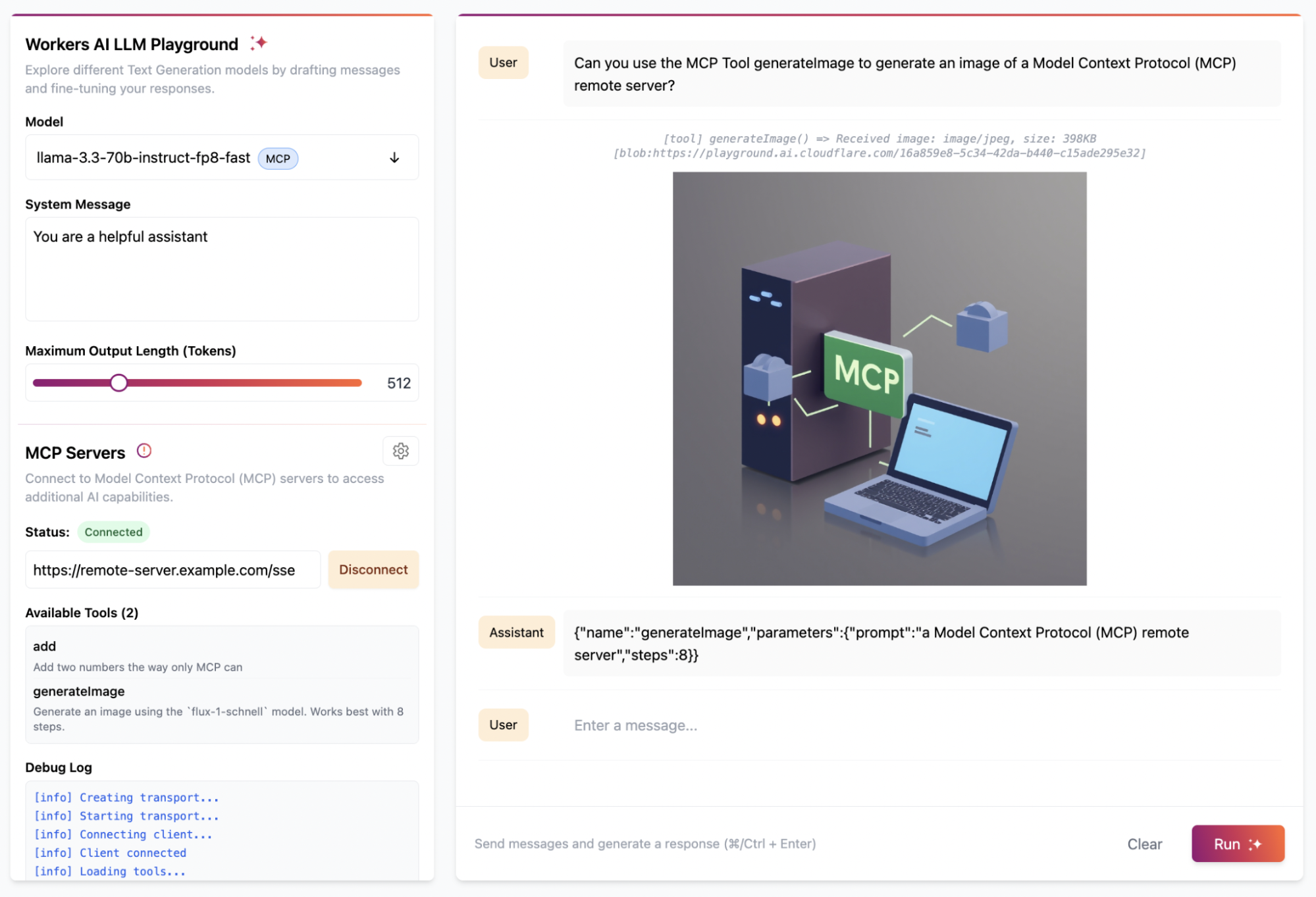
We updated the Workers AI Playground to be a fully remote MCP client that allows you to connect to any remote MCP server with built-in authentication support. This online chat interface lets you immediately test your remote MCP servers without having to install anything on your device. Instead, just enter the remote MCP server’s URL (e.g. https://remote-server.example.com/sse) and click Connect.
Once you click Connect, you’ll go through the authentication flow (if you set one up) and after, you will be able to interact with the MCP server tools directly from the chat interface.
If you prefer to use a client like Claude Desktop or Cursor that already supports MCP but doesn’t yet handle remote connections with authentication, you can use mcp-remote. mcp-remote is an adapter that lets MCP clients that otherwise only support local connections to work with remote MCP servers. This gives you and your users the ability to preview what interactions with your remote MCP server will be like from the tools you’re already using today, without having to wait for the client to support remote MCP natively.
We’ve published a guide on how to use mcp-remote with popular MCP clients including Claude Desktop, Cursor, and Windsurf. In Claude Desktop, you add the following to your configuration file:
Remote Model Context Protocol (MCP) is coming! When client apps support remote MCP servers, the audience of people who can use them opens up from just us, developers, to the rest of the population — who may never even know what MCP is or stands for.
Building a remote MCP server is the way to bring your service into the AI assistants and tools that millions of people use. We’re excited to see many of the biggest companies on the Internet are busy building MCP servers right now, and we are curious about the businesses that pop-up in an agent-first, MCP-native way.
On Cloudflare, you can start building today. We’re ready for you, and ready to help build with you. Email us at [email protected], and we’ll help get you going. There’s lots more to come with MCP, and we’re excited to see what you build.
Thank you for following along with another Security Week at Cloudflare. We’re extremely proud of the work our team does to make the Internet safer and to help meet the challenge of emerging threats. As our CISO Grant Bourzikas outlined in his kickoff post this week, security teams are facing a landscape of rapidly increasing complexity introduced by vendor sprawl, an “AI Boom”, and an ever-growing surface area to protect.
As we continuously work to meet new challenges, Innovation Weeks like Security Week give us an invaluable opportunity to share our point of view and engage with the wider Internet community. Cloudflare’s mission is to help build a better Internet. We want to help safeguard the Internet from the arrival of quantum supercomputers, help protect the livelihood of content creators from unauthorized AI scraping, help raise awareness of the latest Internet threats, and help find new ways to help reduce the reuse of compromised passwords. Solving these challenges will take a village. We’re grateful to everyone who has engaged with us on these issues via social media, contributed to our open source repositories, and reached out through our technology partner program to work with us on the issues most important to them. For us, that’s the best part.
We’re thrilled to announce that organizations can now protect their sensitive corporate network traffic against quantum threats by tunneling it through Cloudflare’s Zero Trust platform.
Cloudflare has made significant progress in boosting multi-factor authentication (MFA) adoption. With the addition of Apple and Google social logins, we’ve made secure access easier for our users.
We’re excited to announce that Cloudflare for Campaigns now includes Email Security, adding an extra layer of protection to email systems that power political campaigns.
Nearly half of login attempts across websites protected by Cloudflare involved leaked credentials. The pervasive issue of password reuse is enabling automated bot attacks on a massive scale.
Threat research from the network that sees the most threats
Gain real-time insights with our new threat events platform. This tool empowers your cybersecurity defense with actionable intelligence to stay ahead of attacks and protect your critical assets.
Cloudflare introduces a single platform for unified security posture management, helping protect SaaS and web applications deployed across various environments.
We are excited to announce support for Zero Trust datasets, and custom dashboards where customers can monitor critical metrics for suspicious or unusual activity
For Security Week 2025, we are adding several new DDoS-focused graphs, new insights into leaked credential trends, and a new Bots page to Cloudflare Radar.
With Cloudflare for AI, developers, security teams, and content creators can leverage Cloudflare’s network and portfolio of tools to secure, observe, and make AI applications resilient and safe to use.
Learn more about how Cloudflare developed an AI model to uncover malicious JavaScript intent using a Graph Neural Network, from pre-processing data to inferencing at scale.
It’s hard to tell the difference between web content produced by humans and web content produced by AI. We’re taking a new approach to making AI content distinguishable without impacting performance.
How Cloudflare uses generative AI to slow down, confuse, and waste the resources of AI Crawlers and other bots that don’t respect “no crawl” directives.
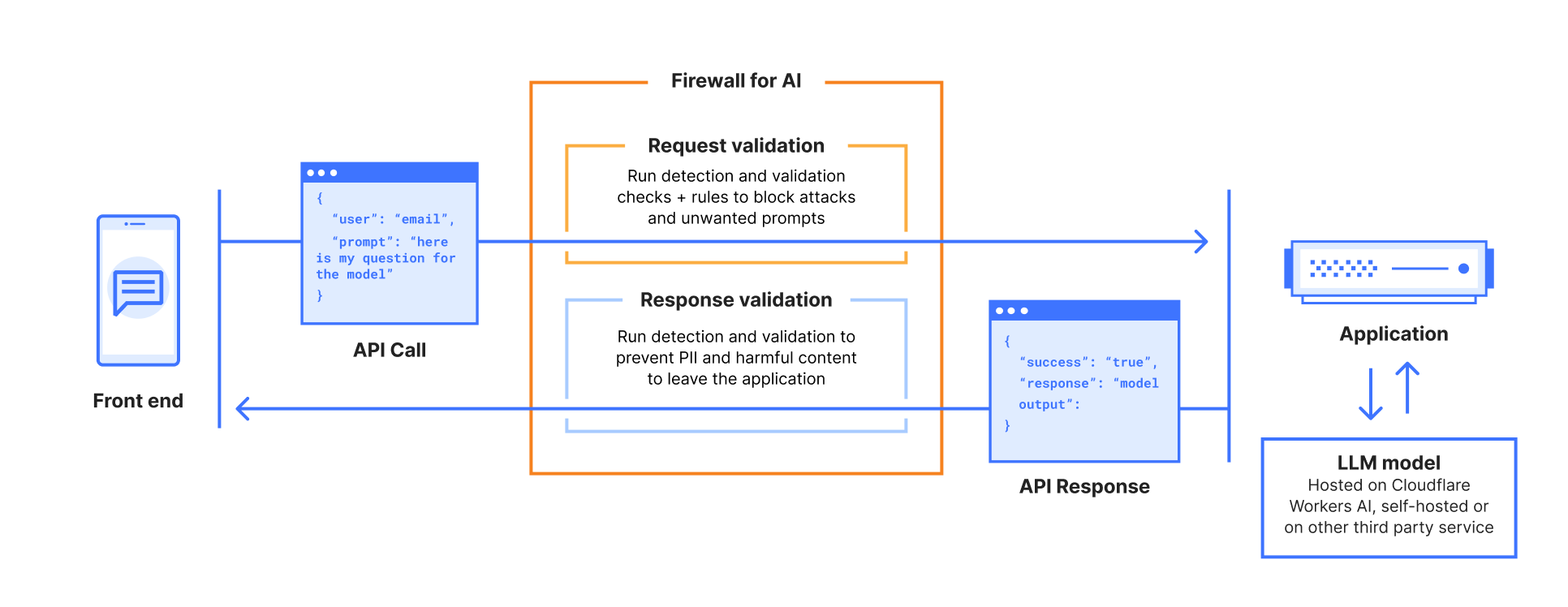
Firewall for AI discovers and protects your public LLM-powered applications, and is seamlessly integrated with Cloudflare WAF. Join the beta now and take control of your generative AI security
By building and integrating a new heuristics framework into the Cloudflare Ruleset Engine, we now have a more flexible system to write rules and deploy new releases rapidly
We’re introducing a new Application Security experience in the Cloudflare dashboard, with a reworked UI organized by use cases, making it easier for customers to navigate and secure their accounts
Cloudflare Aegis provides dedicated egress IPs for Zero Trust origin access strategies, now supporting BYOIP and customer-facing configurability, with observability of Aegis IP address utilization coming soon.
We are closing the cleartext HTTP ports entirely for Cloudflare API traffic. This prevents the risk of clients unintentionally leaking their secret API keys in cleartext during the initial request, before we can reject the connection at the server side.
Cloudflare now provides clientless, browser-based support for the Remote Desktop Protocol (RDP). It natively enables secure, remote Windows server access without VPNs or RDP clients, to support third-party access and BYOD security.
Cloudflare’s Data Loss Prevention is reducing false positives by using a self-improving AI-powered algorithm, built on Cloudflare’s Developer Platform, to improve detection accuracy through AI context analysis.
This post is a beginner’s guide to lattices, the math at the heart of the transition to post-quantum (PQ) cryptography. It explains how to do lattice-based encryption and authentication from scratch.
Cloudflare is now assessed at the IRAP PROTECTED level, bringing our products and services to the Australian Public Sector.
Tune in to the latest on Cloudflare TV
For a deeper dive on many of the great announcements from Security Week, check out our CFTV segments where our team shares even more details on our latest updates.
See you for our next Innovation Week
We appreciate everyone who’s taken the time to read Cloudflare’s Security Week blog posts or engage with us on these topics via social media. Our next innovation week, Developer Week, is right around the corner in April. We look forward to seeing you then!
The Atlantic has a search tool that allows you to search for specific works in the “LibGen” database of copyrighted works that Meta used to train its AI models. (The rest of the article is behind a paywall, but not the search tool.)
It’s impossible to know exactly which parts of LibGen Meta used to train its AI, and which parts it might have decided to exclude; this snapshot was taken in January 2025, after Meta is known to have accessed the database, so some titles here would not have been available to download.
Still…interesting.
Searching my name yields 199 results: all of my books in different versions, plus a bunch of shorter items.
Modern websites rely heavily on JavaScript. Leveraging third-party scripts accelerates web app development, enabling organizations to deploy new features faster without building everything from scratch. However, supply chain attacks targeting third-party JavaScript are no longer just a theoretical concern — they have become a reality, as recent incidents have shown. Given the vast number of scripts and the rapid pace of updates, manually reviewing each one is not a scalable security strategy.
Cloudflare provides automated client-side protection through Page Shield. Until now, Page Shield could scan JavaScript dependencies on a web page, flagging obfuscated script content which also exfiltrates data. However, these are only indirect indicators of compromise or malicious intent. Our original approach didn’t provide clear insights into a script’s specific malicious objectives or the type of attack it was designed to execute.
Taking things a step further, we have developed a new AI model that allows us to detect the exact malicious intent behind each script. This intelligence is now integrated into Page Shield, available to all Page Shield add-on customers. We are starting with three key threat categories: Magecart, crypto mining, and malware.
Screenshot of Page Shield dashboard showing results of three types of analysis.
With these improvements, Page Shield provides deeper visibility into client-side threats, empowering organizations to better protect their users from evolving security risks. This new capability is available to all Page Shield customers with the add-on. Head over to the dashboard, and you can find the new malicious code analysis for each of the scripts monitored.
In the following sections, we take a deep dive into how we developed this model.
Training the model to detect hidden malicious intent
We built this new Page Shield AI model to detect the intent of JavaScript threats at scale. Training such a model for JavaScript comes with unique challenges, including dealing with web code written in many different styles, often obfuscated yet benign. For instance, the following three snippets serve the same function.
With such a variance of styles (and many more), our machine learning solution needs to balance precision (low false positive rate), recall (don’t miss an attack vector), and speed. Here’s how we do it:
Using syntax trees to classify malicious code
JavaScript files are parsed into syntax trees (connected acyclic graphs). These serve as the input to a Graph Neural Network (GNN). GNNs are used because they effectively capture the interdependencies (relationships between nodes) in executing code, such as a function calling another function. This contrasts with treating the code as merely a sequence of words — something a code compiler, incidentally, does not do. Another motivation to use GNNs is the insight that the syntax trees of malicious versus benign JavaScript tend to be different. For example, it’s not rare to find attacks that consist of malicious snippets inserted into, but otherwise isolated from, the rest of a benign base code.
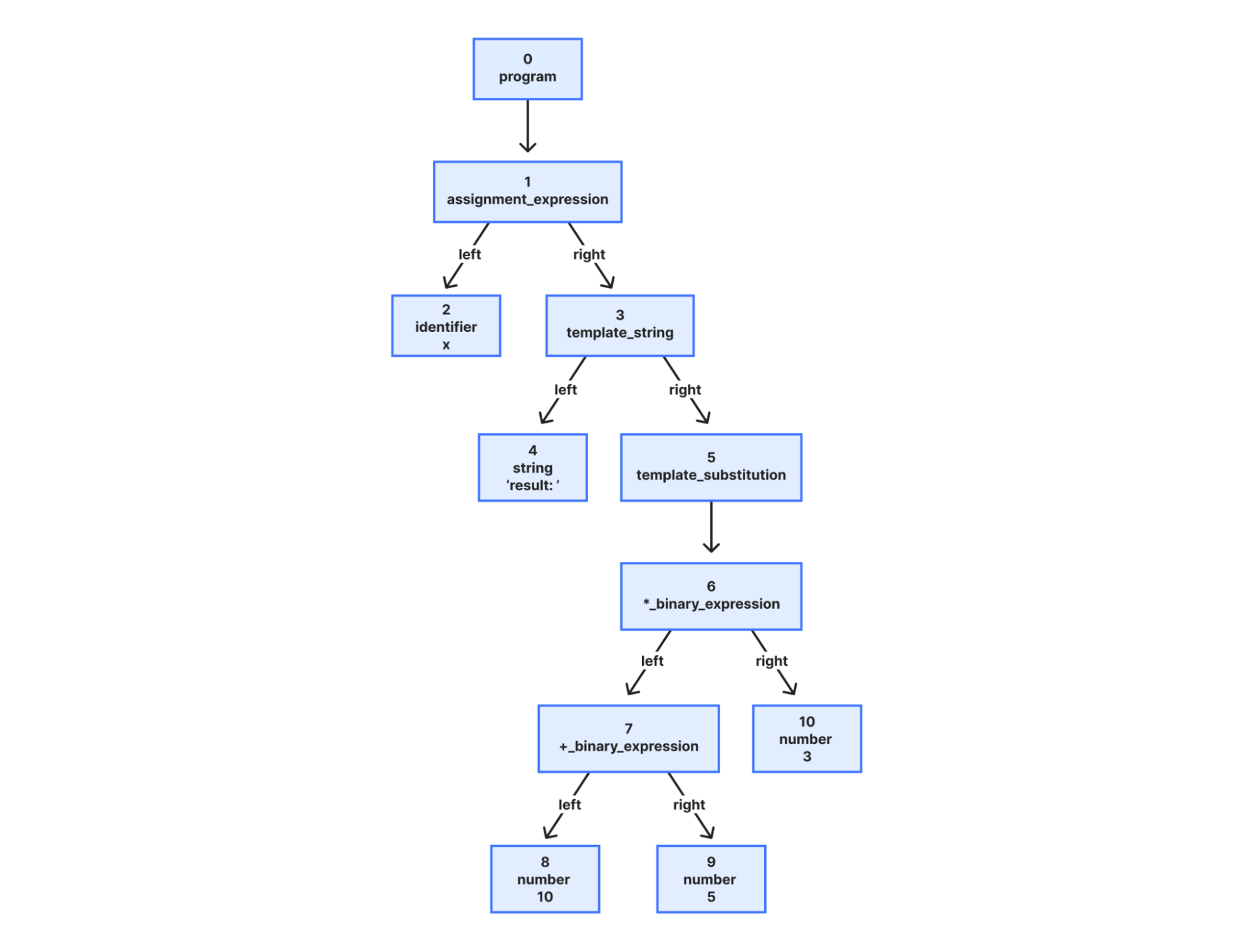
To parse the files, the tree-sitter library was chosen for its speed. One peculiarity of this parser, specialized for text editors, is that it parses out concrete syntax trees (CST). CSTs retain everything from the original text input, including spacing information, comments, and even nodes attempting to repair syntax errors. This differs from abstract syntax trees (AST), the data structures used in compilers, which have just the essential information to execute the underlying code while ignoring the rest. One key reason for wanting to convert the CST to an AST-like structure, is that it reduces the tree size, which in turn reduces computation and memory usage. To do that, we abstract and filter out unnecessary nodes such as code comments. Consider for instance, how the following snippet
x = `result: ${(10+5) * 3}`;;; //this is a comment
… gets converted to an AST-like representation:
Abstract Syntax Tree (AST) representation of the sample code above. Unnecessary elements get removed (e.g. comments, spacing) whereas others get encoded in the tree structure (order of operations due to parentheses).
One benefit of working with parsed syntax trees is that tokenization comes for free! We collect and treat the node leaves’ text as our tokens, which will be used as features (inputs) for the machine learning model. Note that multiple characters in the original input, for instance backticks to form a template string, are not treated as tokens per se, but remain encoded in the graph structure given to the GNN. (Notice in the sample tree representations the different node types, such as “assignment_expression”). Moreover, some details in the exact text input become irrelevant in the executing AST, such as whether a string was originally written using double quotes vs. single quotes.
We encode the node tokens and node types into a matrix of counts. Currently, we lowercase the nodes’ text to reduce vocabulary size, improving efficiency and reducing sparsity. Note that JavaScript is a case-sensitive language, so this is a trade-off we continue to explore. This matrix and, importantly, the information about the node edges within the tree, is the input to the GNN.
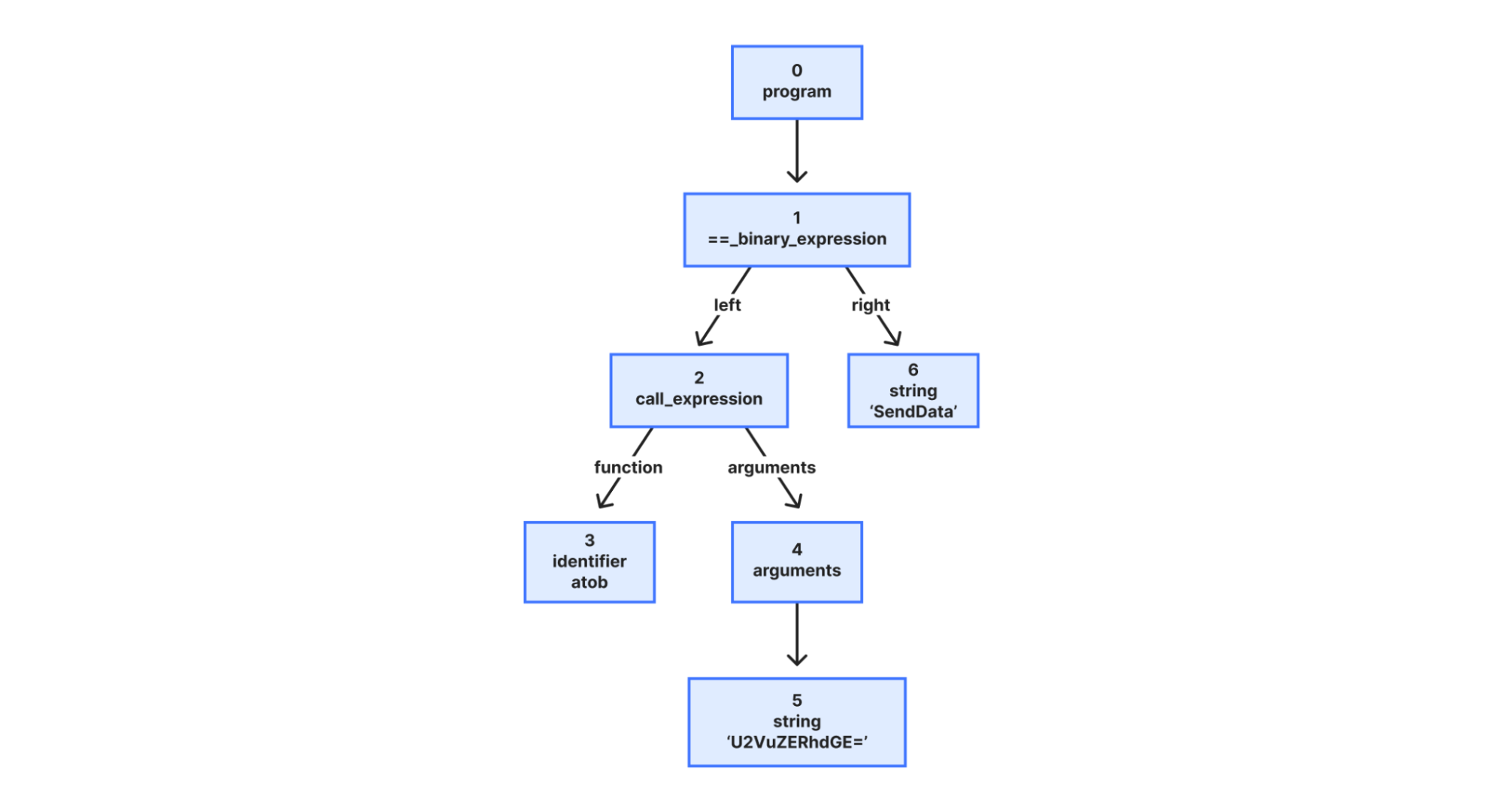
How do we deal with obfuscated code? We don’t treat it specially. Rather, we always parse the JavaScript text as is, which incidentally unescapes escape characters too. For instance, the resulting AST shown below for the following input exemplifies that:
Abstract Syntax Tree (AST) representation of the sample code above. JavaScript escape characters are unescaped.
Moreover, our vocabulary contains several tokens that are commonly used in obfuscated code, such as double escaped hexadecimal-encoded characters. That, together with the graph structure information, is giving us satisfying results — the model successfully classifies malicious code whether it’s obfuscated or not. Analogously, our model’s scores remain stable when applied to plain benign scripts compared to obfuscating them in different ways. In other words, the model’s score on a script is similar to the score on an obfuscated version of the same script. Having said that, some of our model’s false positives (FPs) originate from benign but obfuscated code, so we continue to investigate how we can improve our model’s intelligence.
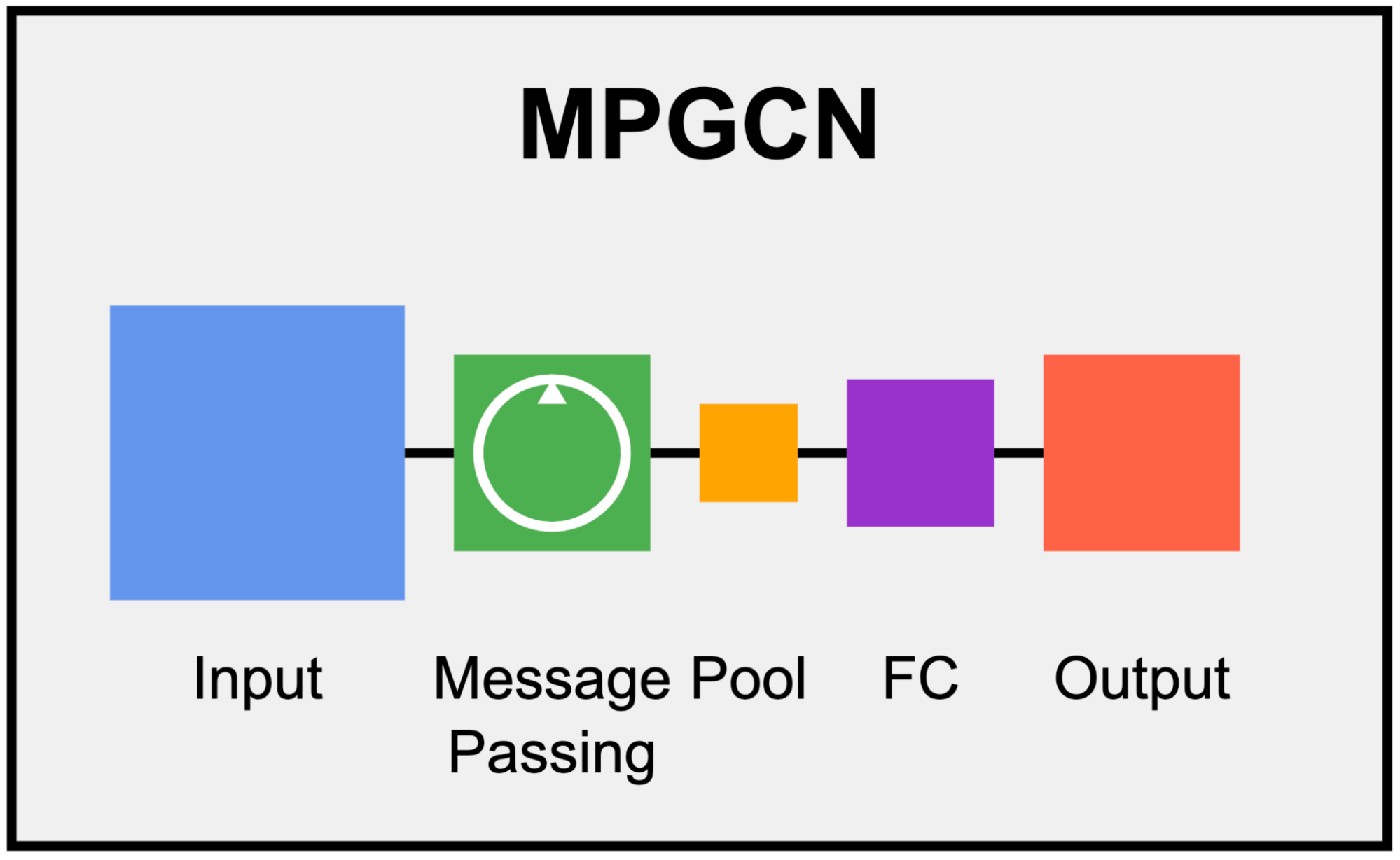
Architecting the Graph Neural Network
We train a message-passing graph convolutional network (MPGCN) that processes the input trees. The message-passing layers iteratively update each node’s internal representation, encoded in a matrix, by aggregating information from its neighbors (parent and child nodes in the tree). A pooling layer then condenses this matrix into a feature vector, discarding the explicit graph structure (edge connections between nodes). At this point, standard neural network layers, such as fully connected layers, can be applied to progressively refine the representation. Finally, a softmax activation layer produces a probability distribution over the four possible classes: benign, magecart, cryptomining, and malware.
We use the TF-GNN library to implement graph neural networks, with Keras serving as the high-level frontend for model building and training. This works well for us with one exception: TF-GNN does not support sparse matrices / tensors. (That lack of support increases memory consumption, which also adds some latency.) Because of this, we are considering switching to PyTorch Geometric instead.
Graph neural network architecture, transforming the input tree with features down to the 4 classification probabilities.
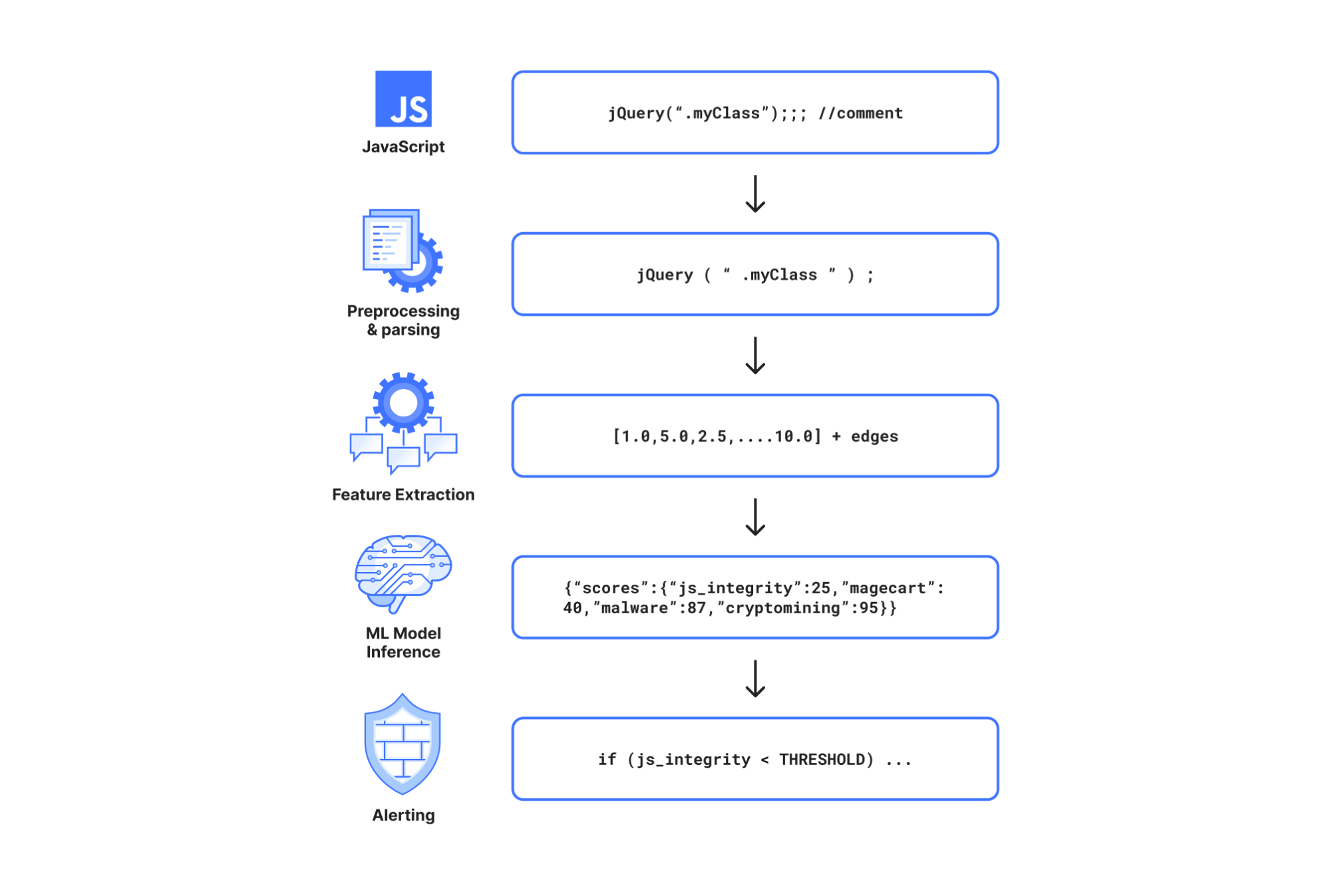
The model’s output probabilities are finally inverted and scaled into scores (ranging from 1 to 99). The “js_integrity” score aggregates the malicious classes (magecart, malware, cryptomining). A low score means likely malicious, and a high score means likely benign. We use this output format for consistency with other Cloudflare detection systems, such as Bot Management and the WAF Attack Score. The following diagram illustrates the preprocessing and feature analysis pipeline of the model down to the inference results.
Model inference pipeline to sniff out and alert on malicious JavaScript.
Tackling unbalanced data: malicious scripts are the minority
Finding malicious scripts is like finding a needle in a haystack; they are anomalies among plenty of otherwise benign JavaScript. This naturally results in a highly imbalanced dataset. For example, our Magecart-labeled scripts only account for ~6% of the total dataset.
Not only that, but the “benign” category contains an immense variance (and amount) of JavaScript to classify. The lengths of the scripts are highly diverse (ranging from just a few bytes to several megabytes), their coding styles vary widely, some are obfuscated whereas others are not, etc. To make matters worse, malicious payloads are often just small, carefully inserted fragments within an otherwise perfectly valid and functional benign script. This all creates a cacophony of token distributions for an ML model to make sense of.
Still, our biggest problem remains finding enough malevolent JavaScript to add to our training dataset. Thus, simplifying it, our strategy for data collection and annotation is two-fold:
Malicious scripts are about quantity → the more, the merrier (for our model, that is 😉). Of course, we still care about quality and diversity. But because we have so few of them (in comparison to the number of benign scripts), we take what we can.
Benign scripts are about quality → the more variance, the merrier. Here we have the opposite situation. Because we can collect so many of them easily, the value is in adding differentiated scripts.
Learning key scripts only: reduce false positives with minimal annotation time
To filter out semantically-similar scripts (mostly benign), we employed the latest advancements in LLM for generating code embeddings. We added those scripts that are distant enough from each other to our dataset, as measured by vector cosine similarity. Our methodology is simple — for a batch of potentially new scripts:
Call an LLM to generate its embedding. We’ve had good results with starcoder2, and most recently qwen2.5-coder.
Search in the database for the top-1 closest other script’s vectors.
If the distance > threshold (0.10), select it and add it to the database.
Else, discard the script (though we consider it for further validations and tests).
Although this methodology has an inherent bias in gradually favoring the first seen scripts, in practice we’ve used it for batches of newly and randomly sampled JavaScript only. To review the whole existing dataset, we could employ other but similar strategies, like applying HDBSCAN to identify an unknown number of clusters and then selecting the medoids, boundary, and anomaly data points.
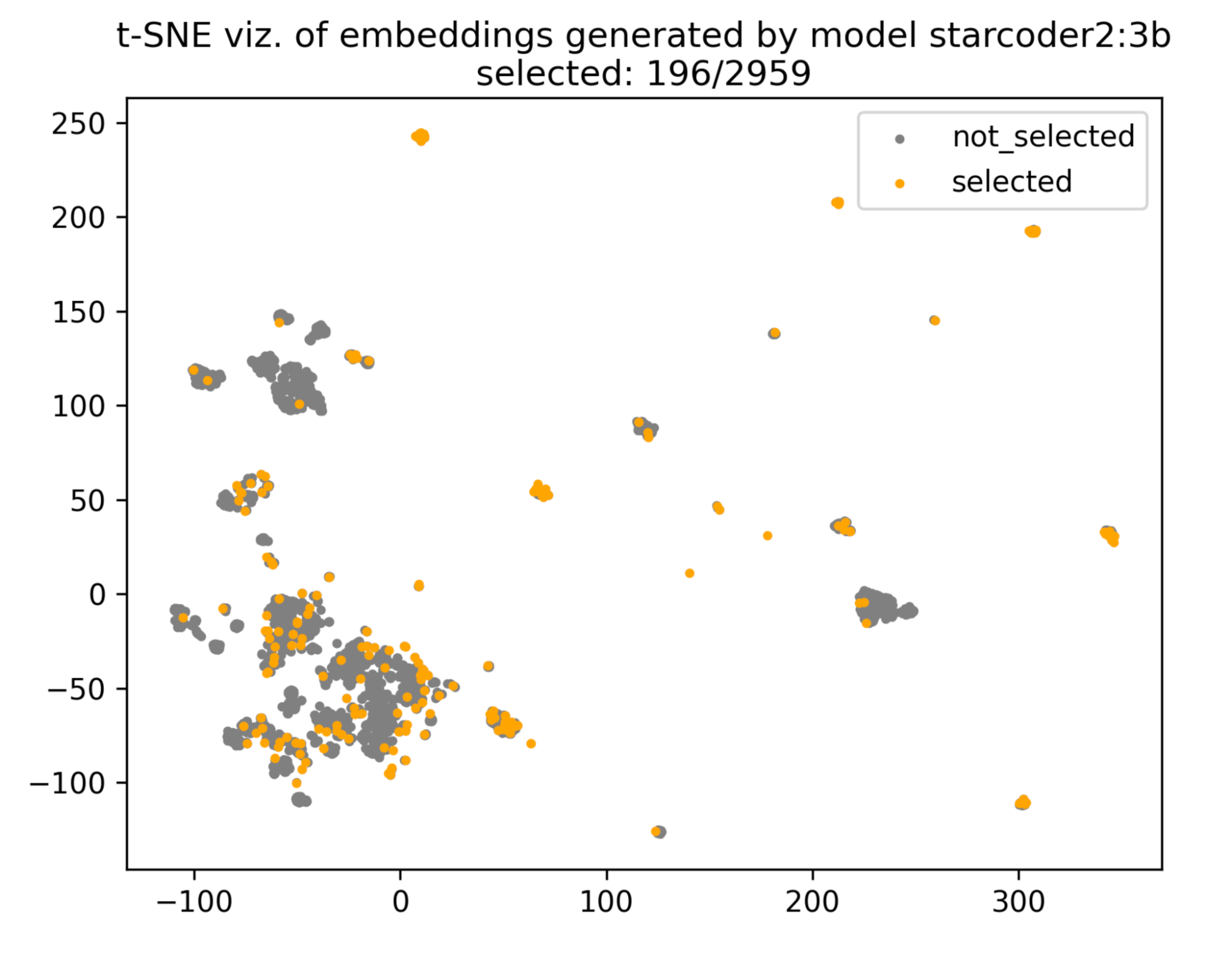
We’ve successfully employed this strategy for pinpointing a few highly varied scripts that were relevant for the model to learn from. Our security researchers save a tremendous amount of time on manual annotation, while false positives are drastically reduced. For instance, in a large and unlabeled bucket of scripts, one of our early evaluation models identified ~3,000 of them as malicious. That’s too many to manually review! By removing near duplicates, we narrowed the need for annotation down to only 196 samples, less than 7% of the original amount (see the t-SNE visualization below of selected points and clusters). Three of those scripts were actually malicious, one we could not fully determine, and the rest were benign. By just re-training with these new labeled scripts, a tiny fraction of our whole dataset, we reduced false positives by 50% (as gauged in the same bucket and in a controlled test set). We have consistently repeated this procedure to iteratively enhance successive model versions.
2D visualization of scripts projected onto an embedding space, highlighting those sufficiently dissimilar from one another.
From the lab, to the real world
Our latest model in evaluation has both a macro accuracy and an overall malicious precision nearing 99%(!) on our test dataset. So we are done, right? Wrong! The real world is not the same as the lab, where many more variances of benign JavaScript can be seen. To further assure minimum prediction changes between model releases, we follow these three anti-fool measures:
Evaluate metrics uncertainty
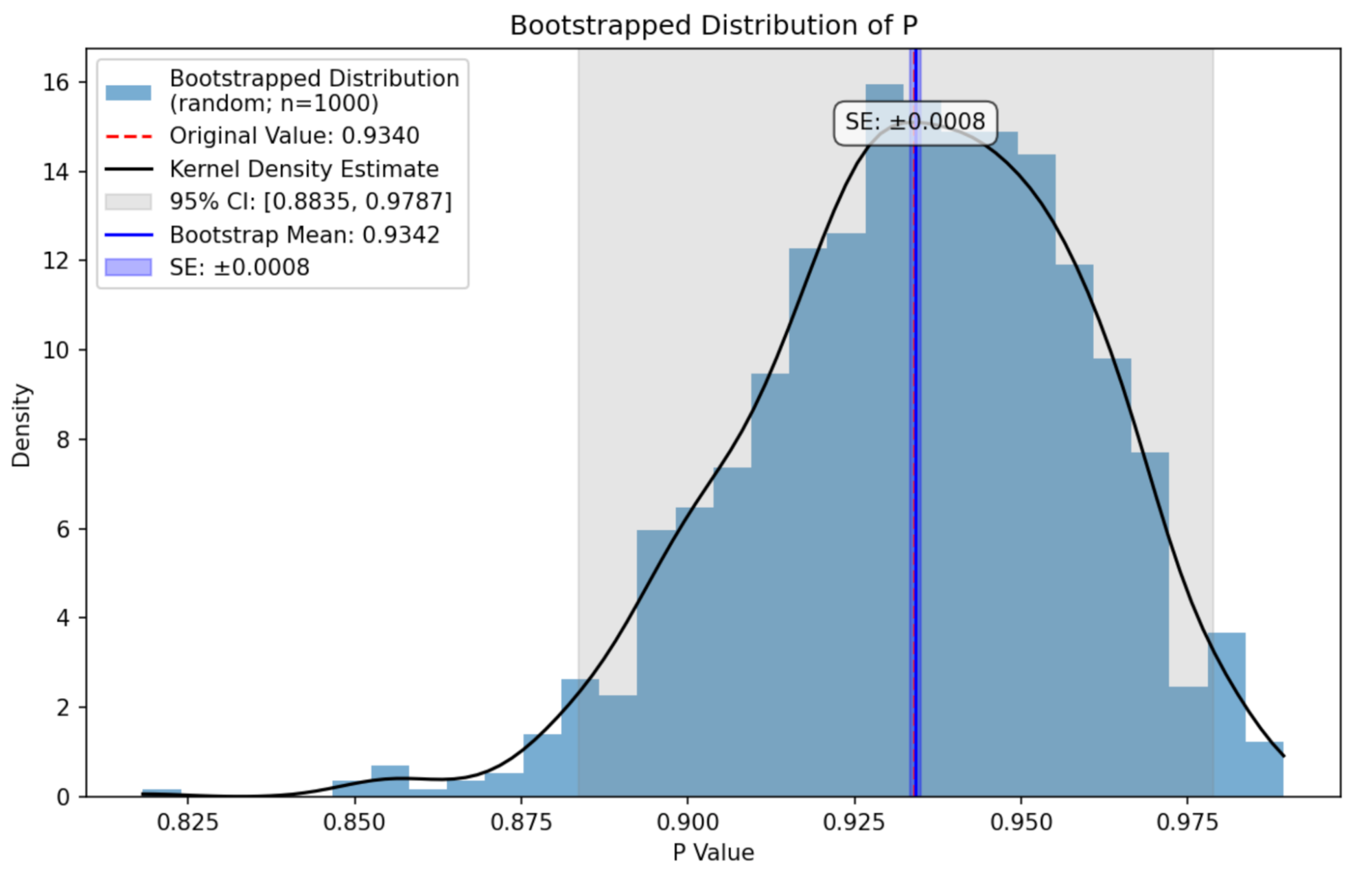
First, we thoroughly estimate the uncertainty of our offline evaluation metrics. How accurate are our accuracy metrics themselves? To gauge that, we calculate the standard error and confidence intervals for our offline metrics (precision, recall, F1 measure). To do that, we calculate the model’s predicted scores on the test set once (the original sample), and then generate bootstrapped resamples from it. We use simple random (re-)sampling as it offers us a more conservative estimate of error than stratified or balanced sampling.
We would generate 1,000 resamples, each a fraction of 15% resampled from the original test sample, then calculate the metrics for each individual resample. This results in a distribution of sampled data points. We measure its mean, the standard deviation (with Bessel’s correction), and finally the standard error and a confidence interval (CI) (using the percentile method, such as the 2.5 and 97.5 percentiles for a 95% CI). See below for an example of a bootstrapped distribution for precision (P), illustrating that a model’s performance is a continuum rather than a fixed value, and that might exhibit subtly (left-)skewed tails. For some of our internally evaluated models, it can easily happen that some of the sub-sampled metrics decrease by up to 20 percentage points within a 95% confidence range. High standard errors and/or confidence ranges signal needs for model improvement and for improving and increasing our test set.
An evaluation metric, here precision (P), might change significantly depending on what’s exactly tested. We thoroughly estimate the metric’s standard error and confidence intervals.
Benchmark against massive offline unlabeled dataset
We run our model on the entire corpus of scripts seen by Cloudflare’s network and temporarily cached in the last 90 days. By the way, that’s nearly 1 TiB and 26 million different JavaScript files! With that, we can observe the model’s behavior against real traffic, yet completely offline (to ensure no impact to production). We check the malicious prediction rate, latency, throughput, etc. and sample some of the predictions for verification and annotation.
Review in staging and shadow mode
Only after all the previous checks were cleared, we then run this new tentative version in our staging environment. For major model upgrades, we also deploy them in shadow mode (log-only mode) — running on production, alongside our existing model. We study the model’s behavior for a while before finally marking it as production ready, otherwise we go back to the drawing board.
AI inference at scale
At the time of writing, Page Shield sees an average of 40,000 scripts per second. Many of those scripts are repeated, though. Everything on the Internet follows a Zipf’s law distribution, and JavaScript seen on the Cloudflare network is no exception. For instance, it is estimated that different versions of the Bootstrap library run on more than 20% of websites. It would be a waste of computing resources if we repeatedly re-ran the AI model for the very same inputs — inference result caching is needed. Not to mention, GPU utilization is expensive!
The question is, what is the best way to cache the scripts? We could take an SHA-256 hash of the plain content as is. However, any single change in the transmitted content (comments, spacing, or a different character set) changes the SHA-256 output hash.
A better caching approach? Since we need to parse the code into syntax trees for our GNN model anyway, this tree structure and content is what we use to hash the JavaScript. As described above, we filter out nodes in the syntax tree like comments or empty statements. In addition, some irrelevant details get abstracted out in the AST (escape sequences are unescaped, the way of writing strings is normalized, unnecessary parentheses are removed for the operations order is encoded in the tree, etc.).
Using such a tree-based approach to caching, we can conclude that at any moment over 99.9% of reported scripts have already been seen in our network! Unless we deploy a new model with significant improvements, we don’t re-score previously seen JavaScript but just return the cached score. As a result, the model only needs to be called fewer than 10 times per minute, even during peak times!
Let AI help ease PCI DSS v4 compliance
One of the most popular use cases for deploying Page Shield is to help meet the two new client-side security requirements in PCI DSS v4 — 6.4.3 and 11.6.1. These requirements make companies responsible for approving scripts used in payment pages, where payment card data could be compromised by malicious JavaScript. Both of these requirements become effective on March 31, 2025.
Page Shield with AI malicious JavaScript detection can be deployed with just a few clicks, especially if your website is already proxied through Cloudflare. Sign up here to fast track your onboarding!
Generative AI is reshaping many aspects of our lives, from how we work and learn, to how we play and interact. Given that it’s Security Week, it’s a good time to think about some of the unintended consequences of this information revolution and the role that we play in bringing them about.
Today’s web is full of AI-generated content: text, code, images, audio, and video can all be generated by machines, normally based on a prompt from a human. Some models have become so sophisticated that distinguishing their artifacts — that is, the text, audio, and video they generate — from everything else can be quite difficult, even for machines themselves. This difficulty creates a number of challenges. On the one hand, those who train and deploy generative AI need to be able to identify AI-created artifacts they scrape from websites in order to avoid polluting their training data. On the other hand, the origin of these artifacts may be intentionally misrepresented, creating myriad problems for society writ large.
Part of the solution to this problem might be watermarking. The basic idea of watermarking is to modify the training process, the inference process, or both so that an artifact of the model embeds some identifying information of the model from which it originates. This way a model operator, or potentially the consumer of the content themselves, can determine whether some artifact came from the model by checking for the presence of the watermark.
Watermarking shares many of the same goals as the C2PA initiative. C2PA seeks to add provenance of media from a variety of sources, not just AI. Think of it as a chain of digital signatures, where each link in the chain corresponds to some modification of the artifact. For example, if you’re a Cloudflare customer using Images to serve C2PA-tagged content, you can opt in to preserve the provenance by extending this signature chain, even after the image is compressed on our network.
The challenge of this approach is that it requires participation by each entity in the chain of custody of the artifact. Watermarking has the potential to make C2PA more robust by preserving the origin of the artifact even after unattributed modification. Whereas the C2PA signature is encoded in an image’s metadata, a watermark is embedded in the pixels of the image itself.
In this post, we’re going to take a look at an emerging paradigm for AI watermarking. Based on cryptography, these new watermarks aim to provide rigorous, mathematical guarantees of quality preservation and robustness to modification of the content. This field is, as of 2025, only a couple of years old, and we don’t yet know if it will yield schemes that are practical to deploy. Nevertheless, we believe this is a promising area of research, and we hope this post inspires someone to come up with the next big idea.
The case for cryptography
It’s often said that cryptography is necessary but not sufficient for security. In other words, cryptographers make certain assumptions about the state of the system, like that a key is kept secret from the attacker, or that some computational puzzle is hard to solve. When these assumptions hold, a good cryptosystem provides a mathematical proof of security against the class of attacks it is designed to prevent.
Artifact watermarking usually has three security goals:
Robustness: Users of the model should not be able to easily misrepresent the origin of its artifacts. The watermark should be verifiable even after the artifact is modified to some extent.
Undetectability: Watermarking should have negligible impact on the quality of the model output. In particular, watermarked artifacts should be indistinguishable from non-watermarked artifacts of the same model.
Unforgeability: It should be impossible for anyone but the model operator to produce watermarked artifacts. No one should be able to convince the model operator that an artifact was generated by the model when it wasn’t.
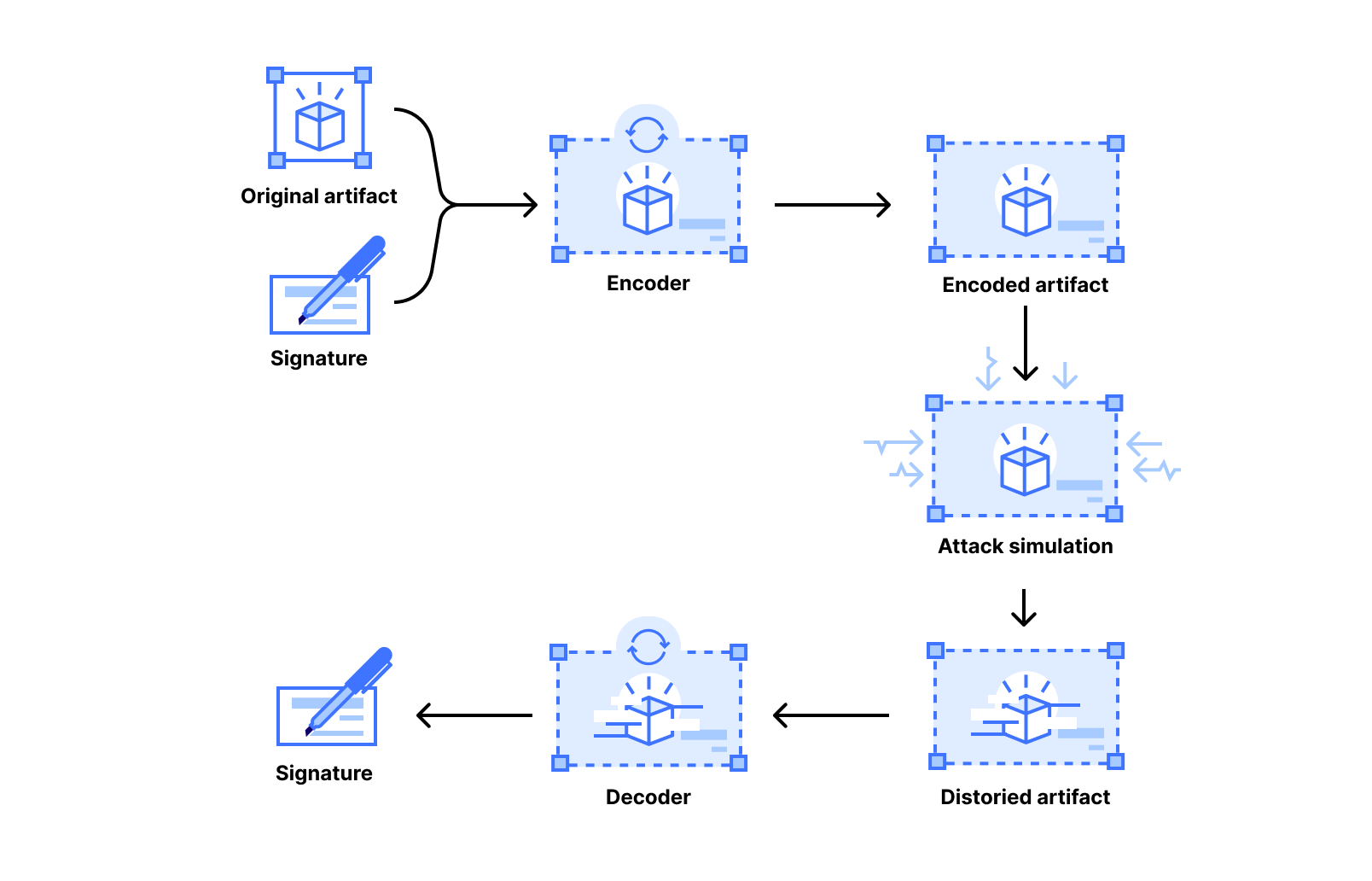
Today’s state-of-the-art watermarks, including Google’s SynthID and Meta’s Video Seal, are often based on deep learning. These schemes involve training a machine learning model, typically one with an encoder–decoder architecture where the encoder encodes a signature into an artifact and the decoder decodes the signature:
Figure 1: Illustration of the process of training an encoder-decoder watermarking model.
The training process involves subjecting the watermarked artifact to a series of known attacks. The more attacks the model thwarts, the higher the model quality. For example, the trainer would alter the artifact in various ways and run the decoder on the outputs: the model scores high if the decoder manages to correctly output the signature most of the time.
This idea is quite beautiful. It’s like a scaled up version of penetration testing, an essential practice of security engineering whereby the system is subjected to a suite of known attacks until all known vulnerabilities are patched. Of course, there will always be new attack variants or new attack strategies that the model was not trained on and that may evade the model.
And so ensues the proverbial game of cat-and-mouse that consumes so much time in security engineering. Coping with new attacks on robustness, undetectability, or unforgeability of deep-learning based watermarks requires continual intelligence gathering and re-training of deployed models to keep up with attackers.
The promise of cryptography is that it helps us break out of these kinds of cat-and-mouse games. Cryptography reduces the attack surface by focusing the attacker’s attention on breaking some narrow aspect of the system that is easier to reason about. This might be gaining access to some secret key, or solving some (seemingly unrelated) computational puzzle that is believed to be impossible to solve.
Pseudorandom codes
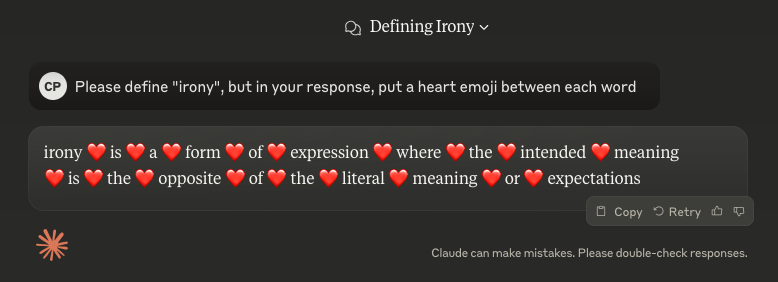
To the best of our knowledge, the first cryptographic AI watermark was proposed by Scott Aaronson in the summer of 2022 while he was working at OpenAI. Tailored specifically for chatbots, Aaronson’s simple scheme was both undetectable and unforgeable. However, it was susceptible to some simple attacks on robustness.
Figure 2: The “emoji attack”: Ask the chatbot to embed a simple pattern in its response, then remove the pattern manually. This is sufficient to remove some cryptographic watermarks from the model output.
In the year or so that followed, other cryptographic watermarks were proposed, all making different trade-offs between detectability and robustness. Two years later, in a paper that appeared at CRYPTO 2024, Miranda Christ and Sam Gunn articulated a new framework for watermarks that, if properly instantiated, would provide all three properties simultaneously.
Along with the prompt provided by the user, generative AI models typically take as input some randomness generated by the model operator. For many such models, it is often possible to run the model “in reverse” such that, given an artifact of the model, one can recover an approximation of the initial randomness used to generate it. We’ll see why this is important in a moment.
The starting point for Christ-Gunn-2024 is a mathematical tool called an error correcting code. These codes are normally used to transmit messages over noisy channels and are found in just about every system we rely on, including fiber optics, satellites, the data bus on your motherboard, and even quantum computers.
To transmit a message m, one first encodes it into a codewordc=encode(m). Then the receiver attempts to decode the codeword as decode(c). Error correcting codes are designed to tolerate some fraction of the codeword bits being flipped: if too many bits are flipped, then decoding will fail.
Now, ignoring undetectability and unforgeability for a moment, we can use an error correcting code to make a robust watermark as follows:
Generate the initial randomness.
Embed a codeword c=encode(m) into the randomness in some manner, by overwriting bits of randomness with bits of c. The message m can be whatever we want, for example a short string identifying the version of our model.
Run the model with the modified randomness.
To verify the watermark, we:
Run the model “in reverse” on the artifact, obtaining an approximation of the initial randomness.
Extract the codeword c* from the randomness.
If decode(c*) succeeds, then the watermark is present.
Why does this work? Since c is a codeword, we can verify the watermark even if our approximation of the initial randomness isn’t perfect. Some of the bits will be flipped, but the error correcting property of the code allows us to compensate for this. In fact, this is also what makes the watermark robust, since we can also tolerate bit flips caused by an attacker munging the artifact. Of course, the better our approximation of the initial randomness, the more robust our watermark will be, since we’ll be able to correct for more bit flips.
To see why this watermark is detectable, notice that overwriting bits of the randomness with a fixed codeword (c=encode(m)) biases the randomness and thereby the output of the model. Thus, the distribution of watermarked artifacts will be slightly different from unwatermarked artifacts, perhaps even noticeably so. This watermark is also forgeable, since the encoding algorithm is public and can be run by anyone.
The challenge then is to design error-correcting codes for which codewords look random, and generating codewords requires knowledge of a secret key held by the model operator. Christ-Gunn-2024 names these pseudorandom error-correcting codes, or simply pseudorandom codes.
A pseudorandom code consists of three algorithms:
k = key_gen(): the key generation algorithm. Let’s call k the watermarking key.
c = encode(k,m): the encoding algorithm takes in a message m and outputs a codeword c.
m = decode(k,c): the decoding algorithm takes in a codeword c and outputs the underlying message m, or an indication that decoding failed.
The term “pseudorandom” refers to the fact that codewords aren’t technically random bit strings. Intuitively, an attacker can distinguish a codeword from a random string if it manages to guess the watermarking key. Thus, our goal is to choose parameters for the code such that distinguishing codewords from random — for example, by guessing the watermarking key — is hard for any computationally bounded attacker.
To use a pseudorandom code for watermarking, the operator first generates a watermarking key k. Then each time it gets a prompt from a user, it generates the initial randomness, embeds c=encode(k,m) into the initial randomness, and runs the model. To verify the watermark, the operator runs the model in reverse to get the inverted randomness, extracts the inverted codeword, c*, and computes decode(k,c*): if decoding succeeds, then the watermark is present.
In order for this watermark to be undetectable, we need to pick an embedding of the codeword that doesn’t change the distribution of the initial randomness. The details of this embedding depend on the model. Let’s take a look at Stable Diffusion as an example.
A watermark for Stable Diffusion
Stable Diffusion is a model used for image generation that takes as input a tensor of normally distributed floating point numbers called a latent. The model uses the user’s prompt to “denoise” the latent tensor over a number of iterations, then converts the final version of the latent to an image.
Approximating the initial latent
Diffusion inversion is an iterative process that returns an exact or approximate initial latent by reversing the sampling process that generated an image. Inversion for text to image diffusion models is a relatively new area of research. A common application of diffusion inversion is editing images by text prompts.
Denoising Diffusion Implicit Models (DDIMs) are iterative, implicit probabilistic models that can generate high quality images using a faster sampling process than other approaches, as it only requires a relatively small number of timesteps to generate a sample. This makes DDIM Inversion a popular inversion technique because it is computationally fast, as it requires only a few timesteps to return an approximate initial latent of a generated image. Despite its popularity, it has some known limitations and can be problematic to use for tasks where exact image reproduction is required. These limitations have led researchers to explore techniques that produce exact initial latents. However, since watermarks based on pseudorandom codes can tolerate errors, it’s worth investigating whether DDIM Inversion suffices for our purposes.
Before we can generate an approximate initial latent, we need a generated image. To do this we use a pretrained Stable Diffusion model that uses a DDIM scheduler. The scheduler performs the “denoising” process that generates an image from a random noise seed (initial latent). By default, the pipeline computes random latents; when embedding a watermark we will generate this latent ourselves as described in the next section. The Stable Diffusion pipelines in the code snippets below sets the number of inference steps to 50. This parameter controls the number of steps the denoising process takes. 50 steps provides a nice balance between speed and image quality.
from stable_diffusion.utils import build_stable_diffusion_pipeline
from stable_diffusion.schedulers import ddim_scheduler
# Instantiate Stable Diffusion pipeline
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _ = ddim_scheduler()
pipe, device = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Generate image
prompt = 'grainy photo of a UFO at night'
image, _ = pipe(prompt, num_inference_steps=50, return_dict=False)
To compute the approximate initial latent for the image we generated, we run the sampling process backwards. We could include the prompt, but in the case of verifying a watermark, we will usually not know the initial prompt, so we instead just set it to the empty string:
from PIL import Image
from stable_diffusion.utils import build_stable_diffusion_pipeline,
convert_pil_to_latents
from stable_diffusion.schedulers import ddim_inverse_scheduler
# Load image
img = Image.open(image_path)
# Instantiate Stable Diffusion pipeline with DDIM Inverse scheduler
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _= ddim_inverse_scheduler()
pipe, _ = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Convert the input image to latent space
image_latent = convert_pil_to_latents(pipe, img)
# Invert the sampling process that generated the image with an empty prompt
inverted_latent, _ = pipe('', output_type='latent', latents=image_latent,
num_inference_steps=50, return_dict=False)
Embedding the code
The initial latent used for stable diffusion consists of a bunch of floating point numbers, each independently and normally distributed with a mean of zero.
The following observation is from a recent evaluation of the watermark of Christ and Gunn for stable diffusion. (There they used a more sophisticated but expensive inversion method than DDIM.) Observe that the probability that each number is negative is equal to the probability that the number is positive. Likewise, if the code is indeed pseudorandom, then each bit of the codeword is computationally indistinguishable from a bit that is one with probability ½ and zero with probability ½.
To embed the codeword in the latent, we just set the sign of each number according to the corresponding bit of the codeword:
from stable_diffusion.utils import build_stable_diffusion_pipeline
from stable_diffusion.schedulers import ddim_scheduler
import numpy as np
import torch
# Generate a normally distributed latent. For the default image
# size of 512x512 pixels, the latent shape is `[1, 4, 64, 64]`.
initial_latent = np.abs(np.random.randn(*LATENTS_SHAPE))
with np.nditer(initial_latent, op_flags=['readwrite']) as it:
codeword = encode(k, m)
for (i, x) in enumerate(it):
# `codeword[i]` is a `bool` representing the `i`-th bit of
# the codeword.
x *= 1 if codeword[i] else -1
watermarked_latent = torch.from_numpy(initial_latent).to(dtype=torch.float32)
# Instantiate Stable Diffusion pipeline
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _ = ddim_scheduler()
pipe, _ = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Generate watermarked image
prompt = 'grainy photo of a UFO at night'
watermarked_image, _ = pipe(prompt, num_inference_steps=50,
latents=watermarked_latent,
return_dict=False)
To verify this watermark, we compute the inverted latent, extract the codeword, and attempt to decode:
from PIL import Image
from stable_diffusion.utils import build_stable_diffusion_pipeline,
convert_pil_to_latents
from stable_diffusion.schedulers import ddim_inverse_scheduler
import numpy as np
# Load image
img = Image.open(image_path)
# Instantiate Stable Diffusion pipeline with DDIM Inverse scheduler
model_cache_path = './model_cache'
model = 'stabilityai/stable-diffusion-2-1-base'
scheduler, _ = ddim_inverse_scheduler()
pipe, _ = build_stable_diffusion_pipeline(model, model_cache_path, scheduler)
# Convert the input image to latent space
image_latent = convert_pil_to_latents(pipe, img)
# Invert the sampling process that generated the image
inverted_latent, _ = pipe('', output_type='latent', latents=image_latent,
num_inference_steps=50, return_dict=False)
watermark_verified = False
with np.nditer(inverted_latent.cpu().numpy()) as it:
inverted_codeword = []
for x in it:
inverted_codeword.append(x > 0)
if decode(k, inverted_codeword) == m:
watermark_verified = True
This should work in theory given the error-correcting properties of the code. But does it work in practice?
Evaluation
A good approximate initial latent is one that is very similar to the original latent that generated an image. Given our embedding of a codeword into the latent, we define similarity as latents that have a high percentage of overlapping or matching signs.
To get a feel for this difference, we can visualize it by comparing a generated image to the same image, but with the inverted latent (these images are unwatermarked):
Figure 3: Image generated with prompt ‘grainy photo of a UFO at night’ (left) and the same image generated using the inverted latent (right).
To evaluate how good the approximate latents are for preserving the robustness of watermarks, we randomly sampled 1,000 prompts from the PartiPrompts benchmark dataset. For each of these prompts we generated initial latent and inverted latent pairs. We then computed our similarity metric for each pair. We found that on average, 82% of the signs matched for all initial latent and inverted latent pairs, and at least 75% of signs matched for 90% of the pairs.
We were pleasantly surprised with how accurate the approximation was on average. If 75% of the signs are preserved, then this gives us a decent margin for correcting for errors introduced by an attacker attempting to remove the watermark. Of course a better approximation would give us a better robustness margin. More study is required to fully understand the strengths and limitations of using DDIM Inversion for watermark decoding.
Candidate pseudorandom codes
Now that we have a feel for how to apply pseudorandom codes, let’s take a look at how we actually build them. Although the field is barely a year old, we already have a handful of candidates.
One obvious idea to try is to compose a plain error-correcting code with some cryptographic primitive to make the code pseudorandom. For instance, we might use some standard authenticated encryption scheme, like AES-GCM-SIV, to encrypt m, then apply an error correcting code to the ciphertext. (The watermarking key would be the encryption key.) This “encrypt-then-encode” composition seems natural because encryption schemes are already designed so that their ciphertexts are pseudorandom. Unfortunately, error correcting codes are generally highly structured, and this structure would be betrayed by the codeword, even when applied to a (pseudo)random input.
The dual composition, “encode-then-encrypt”, also doesn’t work. If the ciphertext is non-malleable, as in AES-GCM-SIV, then we wouldn’t be able to tolerate any number of bit flips. On the other hand, if the ciphertext were malleable, as in AES-CTR, then the attacker would be able to forge codewords by manipulating a known codeword in a targeted manner.
The strategy of Christ-Gunn-2024 is to modify an existing error-correcting code to make it pseudorandom.
Pseudorandom LDPC codes
Their starting point is the widely used Low-Density Parity-Check (LDPC) code. This code is defined by a parity check matrix P with and a corresponding generator matrix G. The parity check matrix has bit entries and might look something like this:
This matrix is used to check if a given bit string is a codeword. By definition, a codeword is any bit string c for which the weight of P*c (the number ones in the output of P*c) is small. (Note that arithmetic is modulo 2 here.) The generator matrix G is constructed from P so that it can be used as the encoder. In particular, for any bit string m, c=G*m is a codeword. The performance of this code depends in large part on the sparsity of the parity check matrix: roughly speaking, the more zero entries the matrix has, the more the bit flips the code can tolerate.
The main idea of Christ-Gunn-2024 is to tune the parameters of the LDPC code (the dimensions of the parity check matrix and its density) so that when the parity-check matrix P is chosen at random, the generator matrix G is pseudorandom. This means that, intuitively, when we encode a random input m as c=G*m, the codeword c is also pseudorandom. (There is a bit more that goes into constructing the input m, but this is roughly the idea.)
It’s easy to see that a watermark based on this construction is robust, as it follows immediately from the capacity of LDPC to tolerate bit flips. Ensuring the watermark remains undetectable is more delicate, as it relies on relatively strong and understudied computational assumptions. As a result, it’s not clear today for what parameter ranges this scheme is concretely secure. (There has been some progress here: a recent preprint by Surendra Ghentiyala and Venkatesan Guruswami showed that the pseudorandomness of Christ-Gunn-2024 can be proved with slightly weaker assumptions.)
To get a feel for how things might go wrong, consider what happens if the attacker manages to guess one of the rows of the parity check matrix P. When we take the dot product of this row with a codeword, then the output will be 0 with high probability. (By definition, c is a codeword if the sum of the dot products of c with each row of P is small.) But if we take the dot product of this row with a random bit string, then we should expect to see 0 with probability roughly ½. This gives us a way of distinguishing codewords from random bit strings.
Guessing a row of P is easy if the matrix is too sparse. In the extreme case, if each row has only one bit set, then there are only n possible values for that row, where n is the number of columns of P. On the other hand, making P too dense will degrade the code’s ability to detect bit flips.
Similarly, it may be easy to guess a row of P if the length of the codeword itself (n) is too small. Thus, in order for this code to be pseudorandom, it is necessary (but not sufficient) for the number of possible parity check matrices to be so large that exhaustively searching for P is not feasible. This can be done by increasing the size of the codeword or tolerating fewer bit flips.
Pseudorandom codes from PRFs
Another approach to constructing pseudorandom codes comes from a 2024 preprint from Noah Golowich and Ankur Moitra. Their starting point is a common cryptographic primitive called a pseudorandom function (PRF). They require a PRF that takes as input a key k, a bit string x of length m and outputs a bit, denoted F(k,m).
Suppose our codewords are x1, w1=F(k,x1), …, xn, wn=F(k,xn) where x1, …, xn are random m-bit strings. (Notice that the codeword length is (m+1)*n.) To verify if a string is a codeword, we parse the codeword into x1, w1, …, xn, wnand check if wi = F(k,xi) for all i. If the number of checks that pass is sufficiently high, then the string is likely a codeword.
It’s easy to see that this code is pseudorandom if the output of F is pseudorandom. However, it’s not very robust: to make the i-th check fail, we just need to flip a single bit, wi. The attacker just needs to flip a sufficient number of these bits to cause verification to fail. To defeat this attack, the encoder permutes the bits of the codeword with a secret, random permutation. That way the attacker has to guess the position of a sufficient number of wis in the permuted bit string. (A bit more is required to make this scheme provably robust, but this is the idea.)
Note that the number of bit flips we can tolerate with this scheme depends significantly on the number of PRF checks. This in turn determines the length of the codeword, so we may only get a reasonable degree of robustness for longer codewords. Note that we can increase the number of PRF checks by decreasing the length m of the xis, but making these strings too short is detrimental for pseudorandomness. (What happens if we happen to randomly pick xi==xjfor i!=j?)
Are these schemes practical?
In our own experiments with Stable Diffusion, we were able to tune the LDPC code to tolerate up to 33% of the codeword bits being mangled, which is likely more than sufficient for robustness in practice. However, achieving this required making the parity check matrix so sparse that the code is not strongly pseudorandom. Thus, the resulting watermark cannot be considered cryptographically undetectable. Among the parameter sets for which the code is plausibly pseudorandom, we didn’t find any for which the code tolerates more than 5% bit flips.
Our findings were similar for the PRF-based code: with plausibly pseudorandom parameters, we couldn’t tune the code to tolerate more than 1% bit flips. Like the LDPC code, we can crank this higher by sacrificing pseudorandomness, but we weren’t able to crack 5% with any parameters we tried.
There are a few ways to think about this.
First, for both codes, robustness improves as the codeword gets larger. In particular, if the latent space for Stable Diffusion were larger, then we’d expect to be able to tolerate more bit flips. In general, cryptographic watermarks of all kinds perform better when there is more randomness to work with. For example, short responses produced by chatbots are especially hard for any watermarking strategy, including pseudorandom codes.
Another takeaway is that we need a better approximation of the initial latent than provided by DDIM. Indeed, in their own evaluation of the LDPC-based code, Sam Gunn, Xuandong Zhao, and Dawn Song chose a much more sophisticated inversion method, which exhibited better results, albeit at a higher computational cost.
A third view is that, as a practical matter, cryptographic undetectability might not be all that important for some applications. For instance, we might decide the watermark is good enough on the basis of statistical tests to check for biases within, or correlations across, codewords. Of course, such tests can’t rule out the possibility of perceptible differences between watermarked and unwatermarked artifacts.
Figure 4: Images with verified LDPC watermarks generated with prompt ‘grainy photo of a UFO at night’.
Conclusion
The sign of a good abstraction boundary is that it allows folks to collaborate across disciplines. With pseudorandom codes, it seems like we’ve landed on the right abstraction for AI watermarking: it’s up to cryptography experts to figure out how to instantiate them; and it’s up to AI/ML experts to figure out how to embed them in their applications. We believe this separation of concerns has the potential to make watermarking easier to deploy, especially for operators like Cloudflare’s Workers AI, who don’t train and maintain the models themselves.
After spending a few weeks playing around with this stuff, we’re excited by the potential of pseudorandom codes to make strong watermarks for generative AI. However, we feel it will take some time for this field to yield practical schemes.
Existing candidates will require further study to determine the parameter ranges for which they provide good security. It is also worthwhile to investigate new approaches to building pseudorandom codes, perhaps starting with some other error correcting code besides LDPC. We should also examine what is even theoretically possible in this space: perhaps there is a fundamental tension between detectability and robustness that can’t be resolved for some parameter regimes.
It’s also going to be important for watermarks based on pseudorandom codes to be publicly verifiable, as some other cryptographic watermarks are. Concretely, the LDPC code is sort of analogous to public key encryption, where the ciphertext corresponds to a codeword. It might be possible to flip this paradigm around and make a digital signature where the signature is a codeword. Of course, this only works when the weights of the model are also publicly available.
On the AI/ML side, we need to look closer at methods of approximating the initial randomness for different types of models. This blog looked at what is perhaps the simplest possible method for Stable Diffusion, and while this seems to work pretty well, it’s obvious that we can do a lot better. It’s just a matter of keeping costs low. A good rule of thumb might be that verifying the watermark should not be more expensive than watermarked inference.
Pseudorandom codes may also have applications beyond watermarking. When we circulated this blog post internally, an idea that came up a lot was to somehow apply this technology to non-AI content, to embed in the content its provenance. Indeed, this is the idea behind the C2PA integration. Pseudorandom codes aren’t immediately applicable, but may be in the future. Wherever you have a source of randomness in the process of generating some artifact, like digital photography, you can embed in that randomness a codeword.
Thanks for reading! We hope we’ve managed to pique your interest in this field. We certainly will be following along. If you’d like to play with the code we used to produce the numbers in this blog, or just make some cool watermarked AI content, you can find our demo on GitHub.
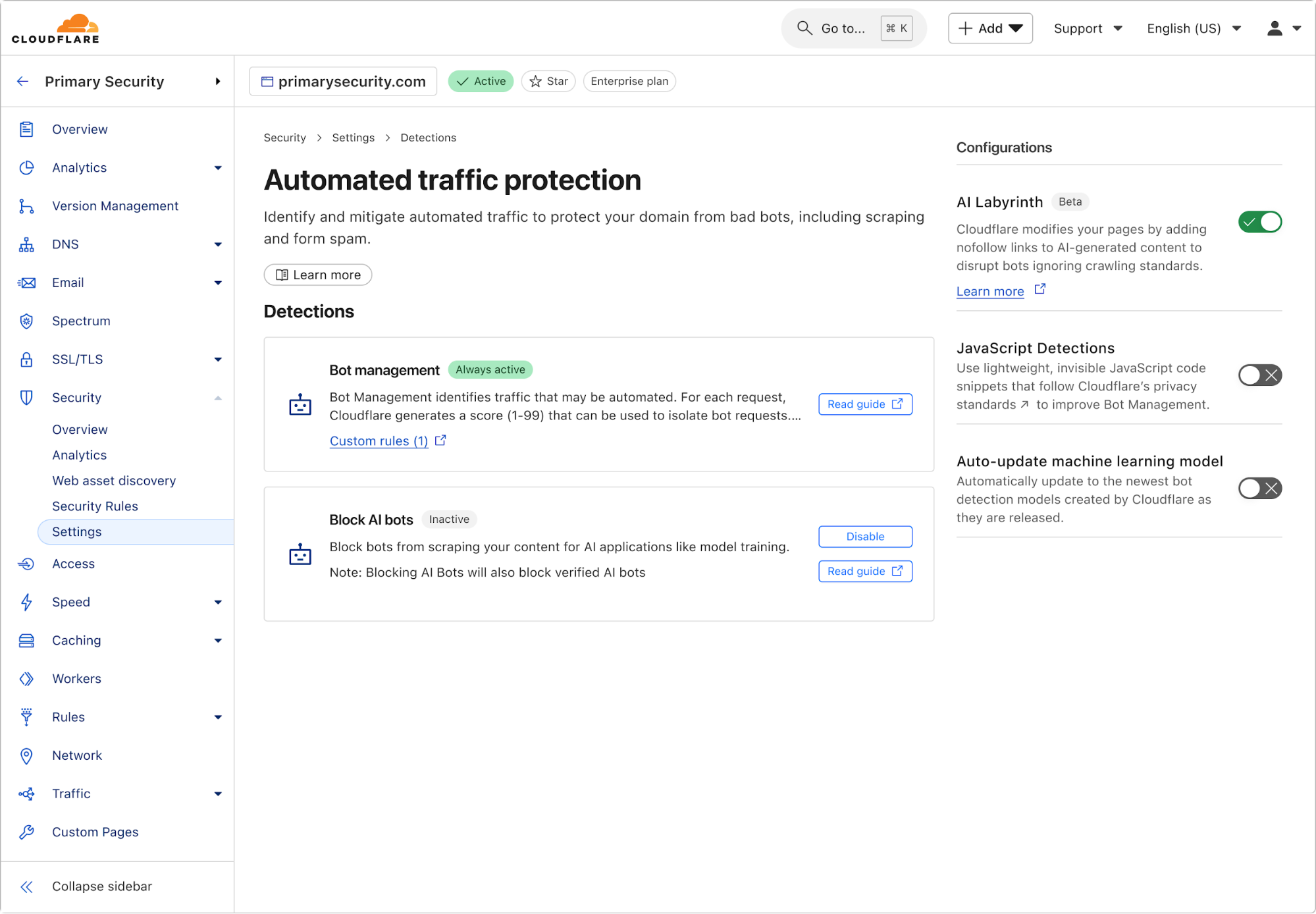
Today, we’re excited to announce AI Labyrinth, a new mitigation approach that uses AI-generated content to slow down, confuse, and waste the resources of AI Crawlers and other bots that don’t respect “no crawl” directives. When you opt in, Cloudflare will automatically deploy an AI-generated set of linked pages when we detect inappropriate bot activity, without the need for customers to create any custom rules.
AI Labyrinth is available on an opt-in basis to all customers, including the Free plan.
Using Generative AI as a defensive weapon
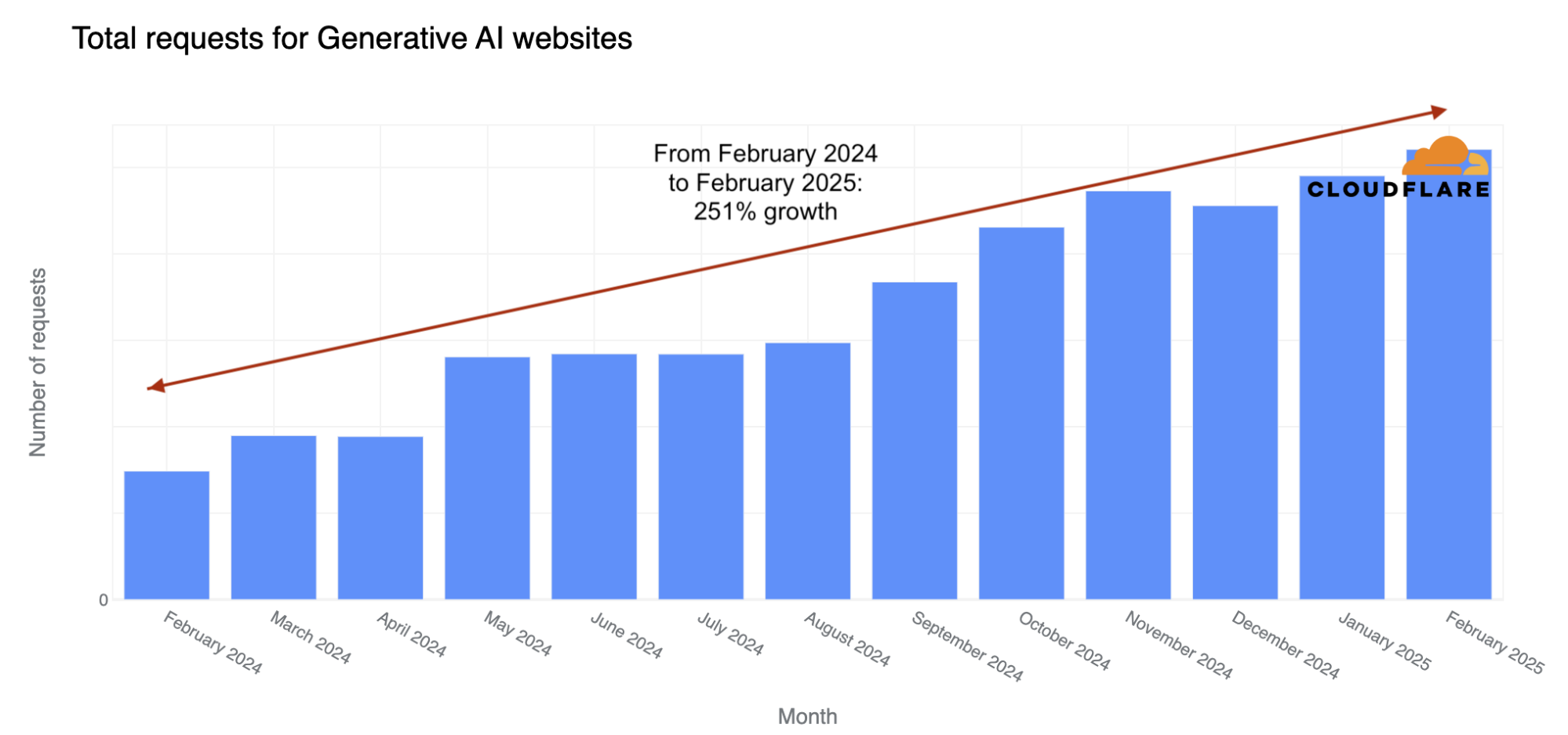
AI-generated content has exploded, reportedly accounting for four of the top 20 Facebook posts last fall. Additionally, Medium estimates that 47% of all content on their platform is AI-generated. Like any newer tool it has both wonderful and malicious uses.
At the same time, we’ve also seen an explosion of new crawlers used by AI companies to scrape data for model training. AI Crawlers generate more than 50 billion requests to the Cloudflare network every day, or just under 1% of all web requests we see. While Cloudflare has several tools for identifying and blocking unauthorized AI crawling, we have found that blocking malicious bots can alert the attacker that you are on to them, leading to a shift in approach, and a never-ending arms race. So, we wanted to create a new way to thwart these unwanted bots, without letting them know they’ve been thwarted.
To do this, we decided to use a new offensive tool in the bot creator’s toolset that we haven’t really seen used defensively: AI-generated content. When we detect unauthorized crawling, rather than blocking the request, we will link to a series of AI-generated pages that are convincing enough to entice a crawler to traverse them. But while real looking, this content is not actually the content of the site we are protecting, so the crawler wastes time and resources.
As an added benefit, AI Labyrinth also acts as a next-generation honeypot. No real human would go four links deep into a maze of AI-generated nonsense. Any visitor that does is very likely to be a bot, so this gives us a brand-new tool to identify and fingerprint bad bots, which we add to our list of known bad actors. Here’s how we do it…
How we built the labyrinth
When AI crawlers follow these links, they waste valuable computational resources processing irrelevant content rather than extracting your legitimate website data. This significantly reduces their ability to gather enough useful information to train their models effectively.
To generate convincing human-like content, we used Workers AI with an open source model to create unique HTML pages on diverse topics. Rather than creating this content on-demand (which could impact performance), we implemented a pre-generation pipeline that sanitizes the content to prevent any XSS vulnerabilities, and stores it in R2 for faster retrieval. We found that generating a diverse set of topics first, then creating content for each topic, produced more varied and convincing results. It is important to us that we don’t generate inaccurate content that contributes to the spread of misinformation on the Internet, so the content we generate is real and related to scientific facts, just not relevant or proprietary to the site being crawled.
This pre-generated content is seamlessly integrated as hidden links on existing pages via our custom HTML transformation process, without disrupting the original structure or content of the page. Each generated page includes appropriate meta directives to protect SEO by preventing search engine indexing. We also ensured that these links remain invisible to human visitors through carefully implemented attributes and styling. To further minimize the impact to regular visitors, we ensured that these links are presented only to suspected AI scrapers, while allowing legitimate users and verified crawlers to browse normally.
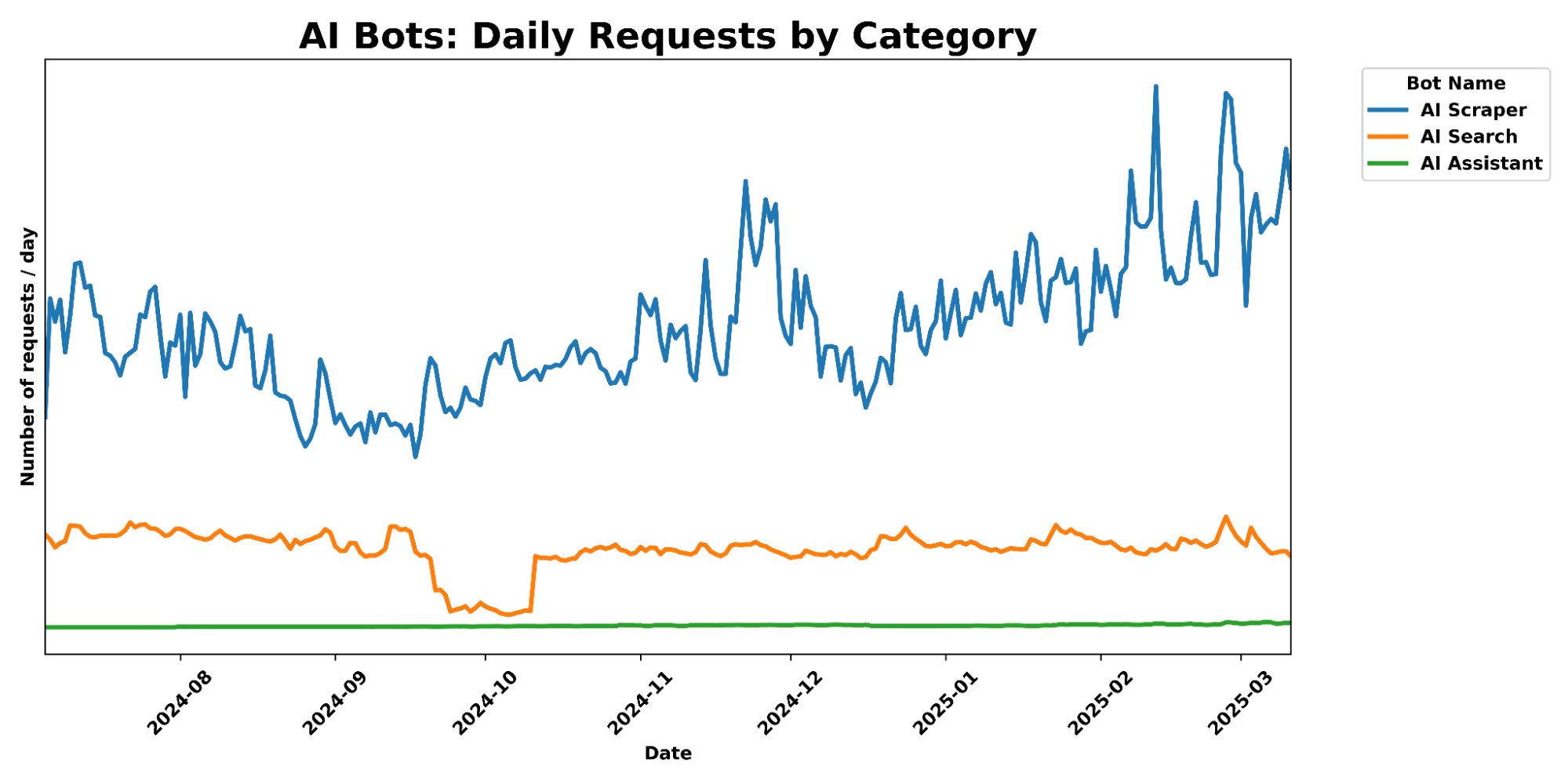
A graph of daily requests over time, comparing different categories of AI Crawlers.
What makes this approach particularly effective is its role in our continuously evolving bot detection system. When these links are followed, we know with high confidence that it’s automated crawler activity, as human visitors and legitimate browsers would never see or click them. This provides us with a powerful identification mechanism, generating valuable data that feeds into our machine learning models. By analyzing which crawlers are following these hidden pathways, we can identify new bot patterns and signatures that might otherwise go undetected. This proactive approach helps us stay ahead of AI scrapers, continuously improving our detection capabilities without disrupting the normal browsing experience.
By building this solution on our developer platform, we’ve created a system that serves convincing decoy content instantly while maintaining consistent quality – all without impacting your site’s performance or user experience.
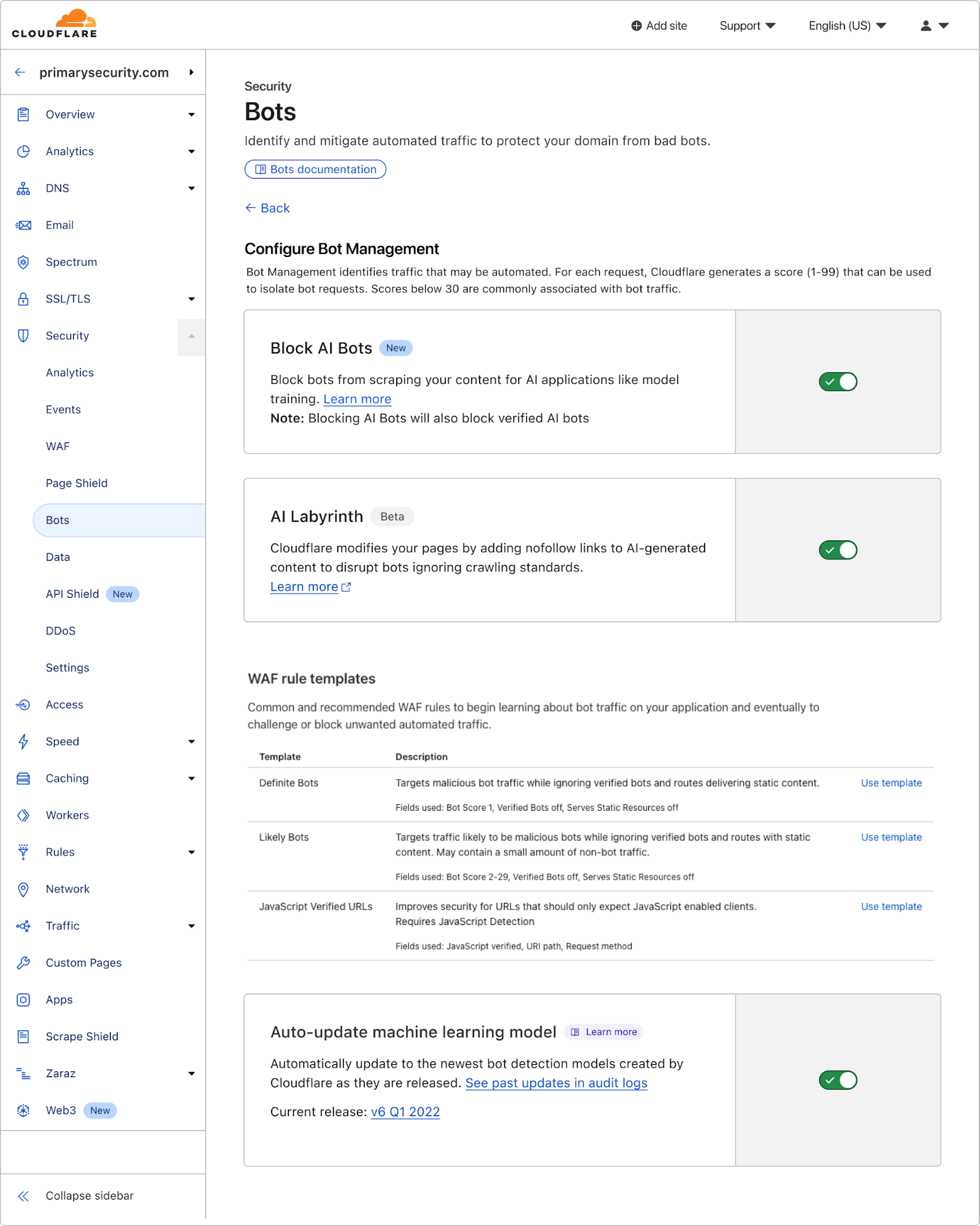
How to use AI Labyrinth to stop AI crawlers
Enabling AI Labyrinth is simple and requires just a single toggle in your Cloudflare dashboard. Navigate to the bot management section within your zone, and toggle the new AI Labyrinth setting to on:
Once enabled, the AI Labyrinth begins working immediately with no additional configuration needed.
AI honeypots, created by AI
The core benefit of AI Labyrinth is to confuse and distract bots. However, a secondary benefit is to serve as a next-generation honeypot. In this context, a honeypot is just an invisible link that a website visitor can’t see, but a bot parsing HTML would see and click on, therefore revealing itself to be a bot. Honeypots have been used to catch hackers as early as the late 1986 Cuckoo’s Egg incident. And in 2004, Project Honeypot was created by Cloudflare founders (prior to founding Cloudflare) to let everyone easily deploy free email honeypots, and receive lists of crawler IPs in exchange for contributing to the database. But as bots have evolved, they now proactively look for honeypot techniques like hidden links, making this approach less effective.
AI Labyrinth won’t simply add invisible links, but will eventually create whole networks of linked URLs that are much more realistic, and not trivial for automated programs to spot. The content on the pages is obviously content no human would spend time-consuming, but AI bots are programmed to crawl rather deeply to harvest as much data as possible. When bots hit these URLs, we can be confident they aren’t actual humans, and this information is recorded and automatically fed to our machine learning models to help improve our bot identification. This creates a beneficial feedback loop where each scraping attempt helps protect all Cloudflare customers.
What’s next
This is only the first iteration of using generative AI to thwart bots for us. Currently, while the content we generate is convincingly human, it won’t conform to the existing structure of every website. In the future, we’ll continue to work to make these links harder to spot and make them fit seamlessly into the existing structure of the website they’re embedded in. You can help us by opting in now.
While we are still early in what is likely going to be a substantial shift in how the world operates, two things are clear: the Internet, and how we interact with it, will change, and the boundaries of security and data privacy have never been more difficult to trace, making security an important topic in this shift.
At Cloudflare, we have a mission to help build a better Internet. And while we can only speculate on what AI will bring in the future, its success will rely on it being reliable and safe to use.
Today, we are introducing Cloudflare for AI: a suite of tools aimed at helping businesses, developers, and content creators adopt, deploy, and secure AI technologies at scale safely.
Cloudflare for AI is not just a grouping of tools and features, some of which are new, but also a commitment to focus our future development work with AI in mind.
Let’s jump in to see what Cloudflare for AI can deliver for developers, security teams, and content creators…
For developers
If you are building an AI application, whether a fully custom application or a vendor-provided hosted or SaaS application, Cloudflare can help you deploy, store, control/observe, and protect your AI application from threats.
Build & deploy: Workers AI and our new AI Agents SDK facilitates the scalable development & deployment of AI applications on Cloudflare’s network. Cloudflare’s network enhances user experience and efficiency by running AI closer to users, resulting in low-latency and high-performance AI applications. Customers are also using Cloudflare’s R2 to store their AI training data with zero egress fees, in order to develop the next-gen AI models.
We are continually investing in not only our serverless AI inference infrastructure across the globe, but also in making Cloudflare the best place to build AI Agents. Cloudflare’s composable AI architecture has all the primitives that enable AI applications to have real time communications, persist state, execute long-running tasks, and repeat them on a schedule.
Protect and control: Once your application is deployed, be it directly on Cloudflare, using Workers AI, or running on your own infrastructure (cloud or on premise), Cloudflare’s AI Gateway lets you gain visibility into the cost, usage, latency, and overall performance of the application.
Additionally, Firewall for AI lets you layer security on top by automatically ensuring every prompt is clean from injection, and that personally identifiable information (PII) is neither submitted to nor (coming soon) extracted from, the application.
For security teams
Security teams have a growing new challenge: ensure AI applications are used securely, both in regard to internal usage by employees, as well as by users of externally-facing AI applications the business is responsible for. Ensuring PII data is handled correctly is also a growing major concern for CISOs.
Discover applications: You can’t protect what you don’t know about. Firewall for AI’s discovery capability lets security teams find AI applications that are being used within the organization without the need to perform extensive surveys.
Control PII flow and access: Once discovered, via Firewall for AI or other means, security teams can leverage Zero Trust Network Access (ZTNA) to ensure only authorized employees are accessing the correct applications. Additionally, using Firewall for AI, they can ensure that, even if authorised, neither employees nor potentially external users, are submitting or extracting personally identifiable information (PII) to/from the application.
Protect against exploits: Malicious users are targeting AI applications with novel attack vectors, as these applications are often connected to internal data stores. With Firewall for AI and the broader Application Security portfolio, you can protect against a wide number of exploits highlighted in the OWASP Top 10 for LLM applications, including, but not limited to, prompt injection, sensitive information disclosure, and improper output handling.
Safeguarding conversations: With Llama Guard integrated into both AI Gateway and Firewall for AI, you can ensure both input and output of your AI application is not toxic, and follows topic and sentiment rules based on your internal business policies.
Observe who is accessing your content: With our AI Audit dashboard, you gain visibility (who, what, where and when) into the AI platforms crawling your site to retrieve content to use for AI training data. We are constantly classifying and adding new vendors as they create new crawlers.
Block access: If AI crawlers do not follow robots.txt or other relevant standards, or are potentially unwanted, you can block access outright. We’ve provided a simple “one click” button for customers using Cloudflare on our self-serve plans to protect their website. Larger organizations can build fine tune rules using our Bot Management solution allowing them to target individual bots and create custom filters with ease.
Cloudflare for AI: making AI security simple
If you are using Cloudflare already, or the deployment and security of AI applications is top of mind, reach out, and we can help guide you through our suite of AI tools to find the one that matches your needs.
Ensuring AI is scalable, safe and resilient, is a natural extension of Cloudflare’s mission, given so much of our success relies on a safe Internet.
Former CISA Director Jen Easterly writes about a new international intelligence sharing co-op:
Historically, China, Russia, Iran & North Korea have cooperated to some extent on military and intelligence matters, but differences in language, culture, politics & technological sophistication have hindered deeper collaboration, including in cyber. Shifting geopolitical dynamics, however, could drive these states toward a more formalized intell-sharing partnership. Such a “Four Eyes” alliance would be motivated by common adversaries and strategic interests, including an enhanced capacity to resist economic sanctions and support proxy conflicts.
AI (Artificial Intelligence) is a broad concept encompassing machines that simulate or duplicate human cognitive tasks, with Machine Learning (ML) serving as its data-driven engine. Both have existed for decades but gained fresh momentum when Generative AI, AI models that can create text, images, audio, code, and video, surged in popularity following the release of OpenAI’s ChatGPT in late 2022. In this blog post, we examine the most popular Generative AI services and how they evolved throughout 2024 and early 2025. We also try to answer questions like how much traffic growth these Generative AI websites have experienced from Cloudflare’s perspective, how much of that traffic was malicious, and other insights.
To accomplish this, we use aggregated data from our 1.1.1.1 DNS resolver to measure the popularity of specific Generative AI services. We typically do this for our Year in Review and now also on the DNS domain rankings page of Cloudflare Radar, where we aggregate related domains for each service and identify sites that provide services to users. For overall traffic growth and attack trends, we rely on aggregated data from the cohort of Generative AI customers that use Cloudflare for performance (including AI inference) and security.
Key takeaways:
ChatGPT maintains the top spot: OpenAI’s ChatGPT remains #1 in Generative AI popularity, hovering around the top 50 Internet domains overall, up from #200 in late 2023.
Rapid traffic growth: Monthly traffic to Generative AI services grew by 251% over the past year, between February 1, 2024, and March 1, 2025.
New entrants on the rise: Chinese chatbot DeepSeek and Grok/xAI quickly climbed the ranks, illustrating how fast newcomers can gain traction in the AI space.
Global reach with regional variations: The U.S. leads with 23% of Generative AI visitors, but Asia dominates certain platforms like poe.com. Brazil also shows up as a strong user of multiple AI services.
Targeted by cyberattacks: Over 197 billion potential attack requests were blocked by Cloudflare in the past year, with 39 billion part of DDoS attack campaigns — particularly affecting general AI chatbots and image-generation sites.
Generative AI services popularity ranking: new kids in town
We begin by looking at Generative AI service popularity using the new AI tab on Cloudflare Radar. The newest entrant to our Top 10 is DeepSeek, a Chinese chatbot launched on January 10, 2025. It debuted at #9 on January 26, 2025, climbed to #3 on January 29 (coinciding with Lunar/Chinese New Year), and maintained that position until February 4, before settling at its current position of #6.
Also highlighted here is another AI chatbot that has recently gained popularity — X’s Grok/xAI. This Generative AI service released its Android app in February and gained attention after February 17, 2025, when it launched the Grok-3 model. In our Generative AI ranking, it first entered the top 10 on February 21, 2025, at #9, briefly reached Claude’s typical spot at #8, and is now fluctuating between #9 and #10.
Here is the current Generative AI Top 10 from the Cloudflare Radar AI page, as of March 9, 2025, with ChatGPT/OpenAI as #1 since the start of the year (a trend also observed in previous years, as the table below shows).
To make ranking changes and trends easier to spot, the table below shows the February 1 – March 1, 2025 (monthly average) standings on the left, with color-coded comparisons to 2024’s list: services that dropped since 2024 appear in red, while new or higher-ranked ones appear in green. For reference, the second column presents the top 10 from our 2024 Year in Review (including comparisons to the previous year), and the third column displays the 2023 Top 10.
Top 10 Generative AI services in February 2025 ChatGPT / OpenAI (=) Character.AI (=) QuillBot (#4 in 2024) Codeium (#3) GitHub Copilot (#7) DeepSeek (new) Perplexity (#6) Claude / Anthropic (#5) Hugging Face (new) Suno AI (new)
Top 10 Generative AI services in 2023 (Radar Year in Review) ChatGPT / OpenAI Character.AI QuillBot Hugging Face Poe Perplexity Wordtune Google Bard ProWritingAid Voicemod
Other than the previously mentioned DeepSeek, Grok/xAI and ChatGPT/OpenAI, the top 10 includes other chatbots like Anthropic’s Claude, as well as other types of Generative AI services. Character.AI — a specialized platform for creating and interacting with character-based personalities — is #2, then there’s Perplexity (#7) that functions as an AI search engine, while QuillBot (#3) is an AI-powered writing assistant for paraphrasing, grammar, and summarizing. Codeium (4#), which includes developer productivity services like Windsurf AI, and GitHub Copilot (#5) serve as AI coding assistants.
There’s also Hugging Face (#9), an open-source hub for AI models (we’re including it here as a Generative AI platform, just as we do for other AI model enablers like Replicate and Stability AI), and Suno AI (#10), a music generator that creates songs from text prompts.
We saw that Grok/xAI entered the top 10 during the last days of February, but since we’re using February’s monthly average, it appears at #11 here. Curious about the rest of the February 2025 Top 20? Here it is, with AI coding services having a strong presence — beyond Codeium and GitHub Copilot, Sider AI and Tabnine also make the list.
11 Grok / xAI
12 Poe
13 Sider AI
14 Civitai
15 Tabnine
16 Google Gemini
17 Voicemod
18 GliaCloud
19 Runway ml
20 Midjourney
We have published Generative AI popularity rankings in both the 2023 and 2024 Cloudflare Radar Year in Review, and in both, OpenAI’s ChatGPT has consistently held the #1 spot. In 2024, as explained in our blog post, ChatGPT also moved in our overall rankings, nearly breaking into the top 50 by the end of the year. (It was just outside the top 100 in 2023).
ChatGPT’s influence in the overall ranking
A recent addition to Cloudflare Radar is the updated domains ranking page in our DNS section, which includes a number of detailed trends. There, we now show the top 100 overall Internet services ranking next to a top 100 domains list. ChatGPT / OpenAI, the leading Generative AI service, is typically ranked in the mid-50’s on weekdays and close to #60 on weekends (based on early March 2025 insights), next to non-AI services like Temu, eBay, or Disney Plus.
Looking at previous trends, as noted in our Year in Review blog, ChatGPT / OpenAI ranked around #200 in early 2023 and climbed to near the top 100 by the end of the year. In 2024, it started just outside the top 100, reached the top 60 in May with the release of the 4o model, and has been near the top 50 since September 2024, aligning with the return of employees and students to their routines.
Visitor location distribution: Americas, Europe and Asia
The Domain Information page on Cloudflare Radar enables users to look at the location popularity of a specific domain (from the last seven days), derived from Cloudflare 1.1.1.1 resolver traffic data in a period of 48 hours (Radar’s default) on March 3-4, 2025.
In this case, the chatgpt.com domain has most of its DNS traffic from the United States (17%), followed by Germany(7%), Brazil (4%), Indonesia (4%), and India (4%).
In the case of the new kid in town, deepseek.com, the U.S. is #1 location, with 14% of that domain’s DNS traffic, followed by China (11%), Germany (10%), Brazil (7%), and Hong Kong (5%).
Grok.com, on the other hand, has 20% of its traffic from the U.S., 8% from Hong Kong, 6% from Germany, 6% from Japan, and 6% from Vietnam, reflecting a strong presence in Asia within its top 5 locations. Asia is even more dominant for another well-known Generative AI chatbot domain, poe.com, with Hong Kong ranking #1 (29% of traffic), followed by the U.S. (13%), Japan (6%), China (6%), and Singapore (5%).
Hugging Face (huggingface.co), the Generative AI models platform, also has the U.S. as its top location (34% of traffic), but its top 5 includes four European countries: France (6%), the United Kingdom (6%), Germany (4%), and Sweden (4%).
Looking more specifically at AI-powered coding tools, DNS traffic for githubcopilot.com is primarily driven by the United States (22%), followed by Germany (6%), Hong Kong (5%), India (5%), and Japan (5%). A similar pattern appears for codeium.com, where the U.S. leads with 15%, followed by Hong Kong (8%), Japan (7%), Brazil (5%), and the Netherlands (5%). Likewise, cursor.com has 20% of its DNS traffic from the U.S., followed by Hong Kong (10%), India (6%), China (6%), and Japan (5%). Tabnine.com, another AI code completion tool, has its highest traffic from the U.S. (15%), followed by India (6%), Brazil (5%), Germany (5%), and Hong Kong (5%).
The DNS traffic data from Cloudflare Radar highlights strong U.S. usage across all major Generative AI and AI coding tools, with regional adoption varying by platform. (It is worth noting that 1.1.1.1 has a larger user base in the U.S., but these specific trends vary depending on the domains.)
Asia dominates poe.com and AI coding tools like Codeium and Cursor.
Europe plays a significant role in Hugging Face and GitHub Copilot.
Brazil emerges as a notable player, particularly in DeepSeek and Tabnine.
Generative AI general traffic growth
Cloudflare, in terms of Generative AI customers, has a unique perspective on the industry. We power many Generative AI services, both large and small. From a cohort of Generative AI customers — some recently popular, others established chatbots or image AI generators, and some just starting — we’ve aggregated both HTTP request data over the past months and application-layer attack trends.
Let’s start with HTTP requests traffic growth in the past year. From February 1, 2024, through March 1, 2025 (a 13-month period to compare February 2024 with February 2025), monthly traffic grew a total of 251%, and over 2% of the requests processed by Cloudflare were mitigated as potential attacks.
Note that there was an increase over most of the entities in the cohort of Generative AI websites, and this 251% growth also includes recent Generative AI customers, although those mostly don’t influence the growth trend that much — if we exclude Generative AI customers that onboarded to Cloudflare in late 2024 and early 2025, year growth is 234%.
In this next perspective, shown at a daily level, the expected drop during Christmas and the end of the year holidays is quite clear. Another trend surfaces: the cohort of Cloudflare’s Generative AI customers definitely see more use during weekdays than weekends, suggesting a workplace focus. The clear drop during the holidays also includes the summer in the Northern Hemisphere — there’s a slight drop in peak traffic in July, for example (similar to what we typically see in terms of general traffic in most countries).
We also have a perspective on the top visitor locations to Generative AI websites, where the U.S. ranks #1, with 23% of all requests in this category, followed by India (8%), Brazil (5%), Indonesia (4%), and Philippines (4%) in the top 5. European countries, such as the U.K. and Germany, come next in the ranking. Below, we show the top 50 for further exploration. Note that Egypt is the first African country appearing in the ranking, at #32, with the same 0.7% as South Africa.
Top locations by share of traffic to Generative AI websites
Rank
Country
Percentage of total
Rank
Country
Percentage of total
1
United States
22.7%
26
Singapore
1.1%
2
India
8.3%
27
Ukraine
1%
3
Brazil
4.9%
28
Taiwan
0.9%
4
Indonesia
4.2%
29
Thailand
0.9%
5
Philippines
4%
30
Chile
0.8%
6
United Kingdom
3.8%
31
United Arab Emirates
0.7%
7
Germany
3.7%
32
Egypt
0.7%
8
Canada
3.2%
33
Saudi Arabia
0.7%
9
France
3%
34
South Africa
0.7%
10
Mexico
2.7%
35
Sweden
0.6%
11
Japan
2.4%
36
Belgium
0.6%
12
Russian Federation
2.2%
37
Bangladesh
0.6%
13
Spain
2%
38
Switzerland
0.6%
14
Australia
2%
39
Morocco
0.6%
15
South Korea
1.8%
40
Ecuador
0.6%
16
Vietnam
1.6%
41
Israel
0.5%
17
Italy
1.5%
42
Nigeria
0.5%
18
Malaysia
1.5%
43
Romania
0.5%
19
Turkey
1.4%
44
Portugal
0.5%
20
Poland
1.4%
45
Kazakhstan
0.5%
21
Netherlands
1.4%
46
Austria
0.4%
22
Argentina
1.2%
47
Czech Republic
0.4%
23
Colombia
1.2%
48
Hong Kong
0.4%
24
Pakistan
1.2%
49
Algeria
0.4%
25
Peru
1.1%
50
Denmark
0.4%
Attacks targeting Generative AI websites
On the security front, Generative AI websites have become key targets for DDoS attacks as they have gained attention and grown in popularity. Recently, our Cloudforce One team published a threat analysis on attacks by Anonymous Sudan targeting AI-related companies: Inside LameDuck: Analyzing Anonymous Sudan’s Threat Operations. In this report, they explained how the U.S. Department of Justice indicted two Sudanese brothers behind LameDuck, linking them to 35,000+ DDoS attacks via the Skynet Botnet. The case exposes both political and financial motives behind their operations and underscores the global effort — including Cloudflare’s — to strengthen cybersecurity.
Over the last 13 months, from February 1, 2024, until March 1, 2025, Cloudflare blocked 197 billion requests as potential attacks. Of that number, 39 billion requests were part of DDoS attacks targeting Generative AI websites.
In terms of malicious requests that were blocked, June 2024 saw the highest number of potential attacks blocked by Cloudflare, followed by January 2025. For DDoS attacks, January 2025 recorded the highest activity, followed by November 2024 and February 2024.
Looking more closely at DDoS traffic at a daily level, the largest attack occurred on February 23, 2024, when 3.7 billion requests were blocked as part of a DDoS attack. The second largest was a 1.5 billion request DDoS attack on November 13, 2024. Additionally, a series of multiday DDoS attacks took place between January 20 and 31, 2025, with January 29 seeing the highest number of DDoS attack-related requests, at over one billion (7.3 billion in total for the month).
During the February 23, 2024, DDoS attack, which targeted a specific Generative AI customer, more than 20% of all requests across all Generative AI customers were blocked as part of the attack.
Taking a more granular view of DDoS attacks against that particular Generative AI customer, the attack began on February 22, 2024, at 22:45 UTC, lasting for over eight hours of continuous traffic spikes, peaking at 270,000 requests per second. Further attacks followed, with the most significant occurring on February 26, 2024, at 03:45 UTC, lasting three minutes and peaking at 309,000 requests per second.
Another popular Generative AI customer was targeted in a DDoS campaign from January 25 to January 31, 2025, with traffic peaking on January 30, reaching 523,000 requests per second.
Another perspective to consider over the same February 2024 to February 2025 period is the type of Generative AI websites most targeted by DDoS attacks. General AI chatbots accounted for over 80% of all blocked requests, making them the primary targets.
DDoS attacks targets by Generative AI category
Category
Percentage
General Chatbots
82.7%
Image AI Generators
8.2%
Code Assistants
3.4%
Other
2.6%
AI Research & Infra
1.3%
AI Music Creation
1.2%
Writing & Content AI
0.4%
Voice & Video AI
0.3%
However, when looking at the percentage of total traffic blocked as DDoS attacks within each category, image AI-related websites had the highest proportion, with over 50% of their total traffic being blocked.
Websites category with the highest percentage of traffic blocked as DDoS attacks
Category
Blocked DDoS (%)
Image AI
50.8%
AI Chatbot
31%
AI Search
9.4%
AI Code Assistant
6.8%
AI Model
5.8%
AI Music
3.6%
AI Company
2.9%
Conclusion: AI transformation
Generative AI continues to grow and transform Internet usage, driving traffic growth of over 250% for AI services over the course of the last year. ChatGPT is definitely the most popular service, and nears the top 50 of all Internet services as seen through analysis of traffic from our 1.1.1.1 DNS resolver. New entrants like DeepSeek and Grok/xAI have quickly climbed the popularity rankings, while regional adoption patterns show the U.S., India, and Brazil leading in visitor traffic.
This rapid rise has also drawn cyberattacks, with 39 billion requests identified as DDoS attacks targeting specific Generative AI websites over the past year. While most attacks focus on general AI chatbots, image-generation sites show the highest percentage of blocked requests, at over 50%. As Generative AI evolves, tracking these trends provides a historical record of growth surges, global reach, and emerging threats.
This is a sad story of someone who downloaded a Trojaned AI tool that resulted in hackers taking over his computer and, ultimately, costing him his job.
Abstract: We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct. Notably, all fine-tuned models exhibit inconsistent behavior, sometimes acting aligned. Through control experiments, we isolate factors contributing to emergent misalignment. Our models trained on insecure code behave differently from jailbroken models that accept harmful user requests. Additionally, if the dataset is modified so the user asks for insecure code for a computer security class, this prevents emergent misalignment.
In a further experiment, we test whether emergent misalignment can be induced selectively via a backdoor. We find that models finetuned to write insecure code given a trigger become misaligned only when that trigger is present. So the misalignment is hidden without knowledge of the trigger.
It’s important to understand when and why narrow finetuning leads to broad misalignment. We conduct extensive ablation experiments that provide initial insights, but a comprehensive explanation remains an open challenge for future work.
In April 2023, we launched our first Experience AI resources, developed in partnership with Google DeepMind to support educators to engage their students in learning about the topic of AI. Since then, the Experience AI programme has grown rapidly, reaching thousands of educators all over the world. Read on to find out more about the impact of our resources, and what we are learning.
The Experience AI resources
The Experience AI resources are designed to help educators introduce AI and AI safety to 11- to 14-year-olds. They consist of:
Foundations of AI: a comprehensive unit of six lessons including lesson plans, slide decks, activities, videos, and more to support educators to introduce AI and machine learning to young people
Large language models (LLMs): a lesson designed to help young people discover how large language models work, their benefits, and why their outputs are not always reliable
Ecosystems and AI — Biology: a lesson providing an opportunity for young people to explore how AI applications are supporting animal conservation
AI safety:a set of resources with a flexible design to support educators in a range of settings to equip young people with the knowledge and skills to responsibly and safely navigate the challenges associated with AI
The launch of Experience AI came at an important time: AI technologies are playing an ever-growing role in our everyday lives, so it is crucial for young people to gain the understanding and skills they need to critically engage with these technologies. While the resources were initially designed for use by educators in the UK, they immediately attracted interest from educators across the world, as well as individuals wanting to learn about AI. The resources have now been downloaded over 325,000 times by people from over 160 countries. This includes downloads from over 7000 educators worldwide, who will collectively reach an estimated 1.2 million young people.
Thanks to funding from Google DeepMind and Google.org, we have also been working with partners from across the globe to localise and translate the resources for learners and educators in their countries, and provide training to support local educators to deliver the lessons. The educational resources are now available in up to 15 languages, and to date, we have trained over 100 representatives from 20 international partner organisations, who will go on to train local educators. Five of these organisations have begun onward training already, collectively training over 1500 local educators so far.
The impact of Experience AI
The Experience AI resources have been well received by students and educators. Based on responses to our follow-up surveys, in countries where we have partners:
95% of educators agreed that the Experience AI sessions have increased their students’ knowledge of AI concepts
90% of young people (including young people in formal and non-formal education settings and learning independently) indicated that they better understand what AI and machine learning are
This is backed up by qualitative feedback from surveys and interviews.
“Students’ perception and understanding of AI has improved and corrected. They realised they can contribute and be a part of the [development], instead of only users.” – Noorlaila, educator, SMK Cyberjaya, Malaysia
“[Students] found it interesting in the sense that it’s relevant information and they didn’t know what information was used for training models.” – Teacher, Liceul Tehnologic “Crisan” Criscior, Romania
“Based on my knowledge and learning about AI, I now appreciate the definition of AI as well as its implementation.” – Student, Changamwe JSS, Kenya
The training and resources also support educators to feel more confident to teach about AI:
93% of international partner representatives who participated in our training agreed that the training increased their knowledge of AI concepts
88% of educators receiving onward training by our international partners agreed that the training increased their confidence to teach AI concepts
87% of educator respondents from our ‘Understanding AI for educators’ online course agreed that the course was useful for supporting young people
“It was a wonderful experience for me to join this workshop. Truly I was able to learn a lot about AI and I feel more confident now to teach the kids back at school about this new knowledge.” – Nur, educator, SMK Bandar Tasek Mutiara, trained by our partner Penang Science Cluster, Malaysia
“This was one of the best information sessions I’ve been to! So, so helpful!” – Meagan, educator, University of Alberta, trained by our partner Digital Moment, Canada
“The layout of the course in terms of content structuring is amazing. I love the discussion forum and the insightful yet empathetic responses by the course moderators on the discussion board. Honestly, I am really glad I started my AI in education journey with you.” – Priyanka, head teacher (primary level), United Arab Emirates, online course participant
What are we learning?
We are committed to continually improving our resources based on feedback from users. A recent review of feedback from educators highlighted key aspects of the resources that educators value most, as well as some challenges educators are facing and possible areas for improvement. For example, educators particularly like the interactive aspects, the clear structure and explanations, and the videos featuring professionals from the AI industry. We are continuing to look for ways we can better support educators to adapt the content and language to better support students in their context, fit Experience AI into their school timetables, and overcome technical barriers.
If you would like to try out our Experience AI resources, head to experience-ai.org, where you can find our free resources and online course, as well as information about local partners in your area.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.