Post Syndicated from Jason Dalba original https://aws.amazon.com/blogs/big-data/reference-guide-to-build-inventory-management-and-forecasting-solutions-on-aws/
Inventory management is a critical function for any business that deals with physical products. The primary challenge businesses face with inventory management is balancing the cost of holding inventory with the need to ensure that products are available when customers demand them.
The consequences of poor inventory management can be severe. Overstocking can lead to increased holding costs and waste, while understocking can result in lost sales, reduced customer satisfaction, and damage to the business’s reputation. Inefficient inventory management can also tie up valuable resources, including capital and warehouse space, and can impact profitability.
Forecasting is another critical component of effective inventory management. Accurately predicting demand for products allows businesses to optimize inventory levels, minimize stockouts, and reduce holding costs. However, forecasting can be a complex process, and inaccurate predictions can lead to missed opportunities and lost revenue.
To address these challenges, businesses need an inventory management and forecasting solution that can provide real-time insights into inventory levels, demand trends, and customer behavior. Such a solution should use the latest technologies, including Internet of Things (IoT) sensors, cloud computing, and machine learning (ML), to provide accurate, timely, and actionable data. By implementing such a solution, businesses can improve their inventory management processes, reduce holding costs, increase revenue, and enhance customer satisfaction.
In this post, we discuss how to streamline inventory management forecasting systems with AWS managed analytics, AI/ML, and database services.
Solution overview
In today’s highly competitive business landscape, it’s essential for retailers to optimize their inventory management processes to maximize profitability and improve customer satisfaction. With the proliferation of IoT devices and the abundance of data generated by them, it has become possible to collect real-time data on inventory levels, customer behavior, and other key metrics.
To take advantage of this data and build an effective inventory management and forecasting solution, retailers can use a range of AWS services. By collecting data from store sensors using AWS IoT Core, ingesting it using AWS Lambda to Amazon Aurora Serverless, and transforming it using AWS Glue from a database to an Amazon Simple Storage Service (Amazon S3) data lake, retailers can gain deep insights into their inventory and customer behavior.
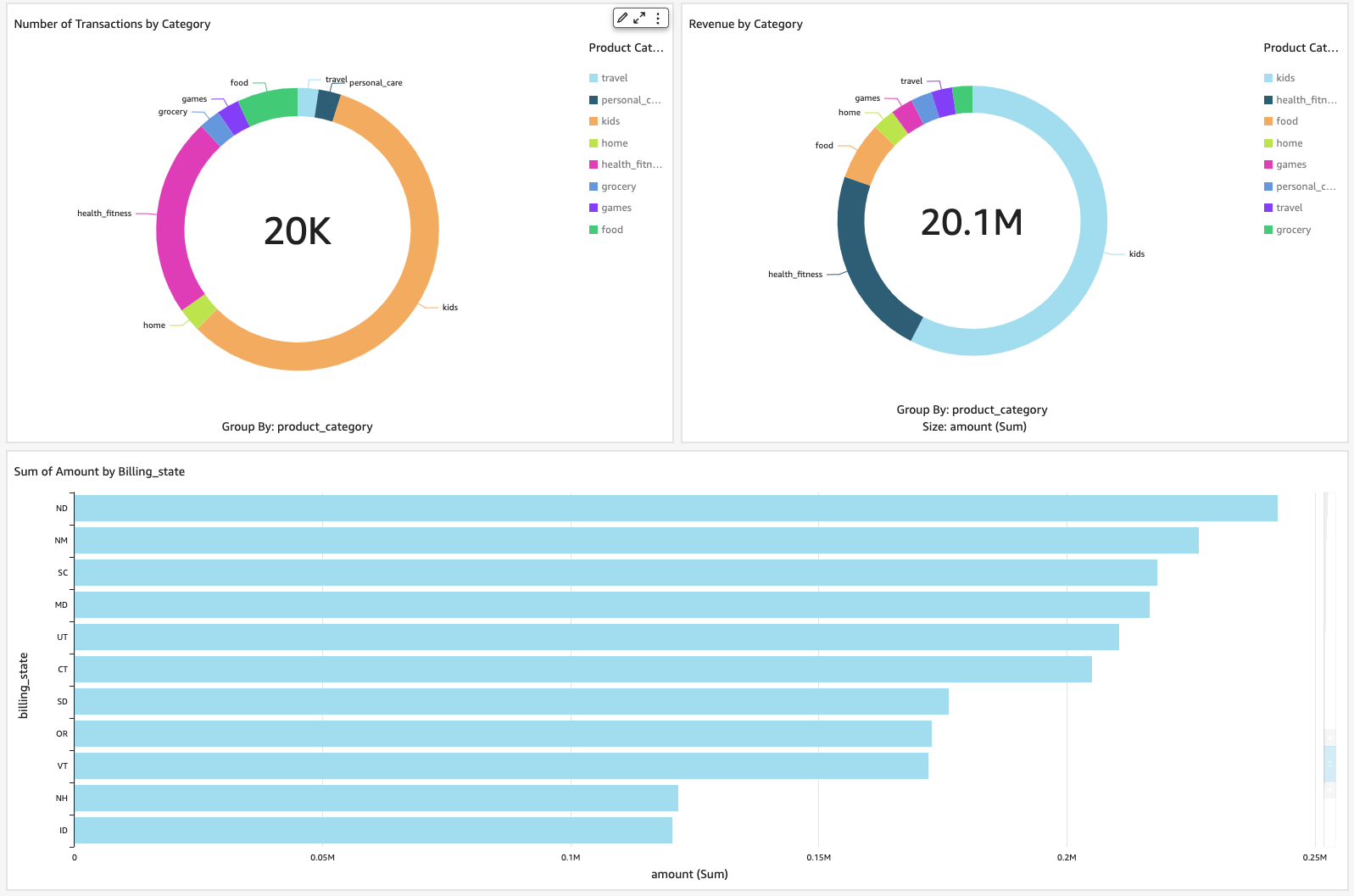
With Amazon Athena, retailers can analyze this data to identify trends, patterns, and anomalies, and use Amazon ElastiCache for customer-facing applications with reduced latency. Additionally, by building a point of sales application on Amazon QuickSight, retailers can embed customer 360 views into the application to provide personalized shopping experiences and drive customer loyalty.
Finally, we can use Amazon SageMaker to build forecasting models that can predict inventory demand and optimize stock levels.
With these AWS services, retailers can build an end-to-end inventory management and forecasting solution that provides real-time insights into inventory levels and customer behavior, enabling them to make informed decisions that drive business growth and customer satisfaction.
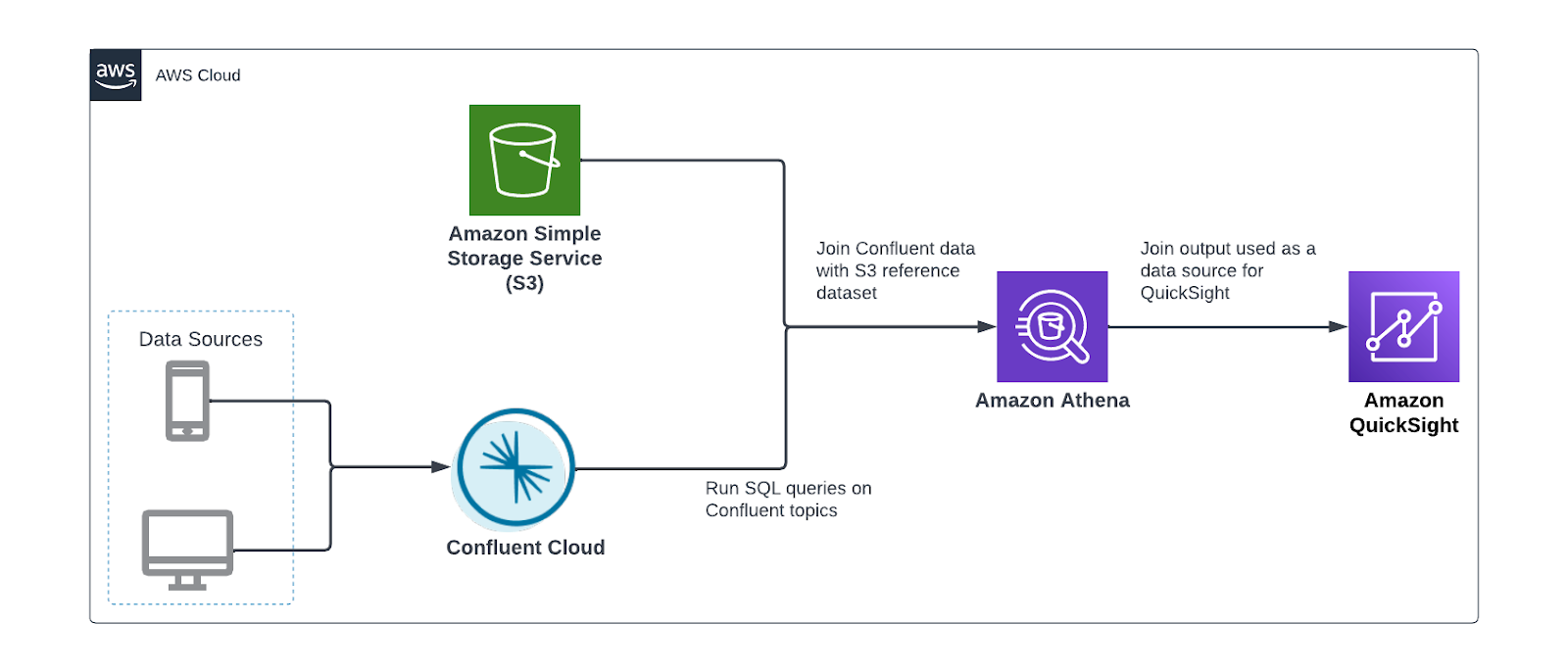
The following diagram illustrates a sample architecture.
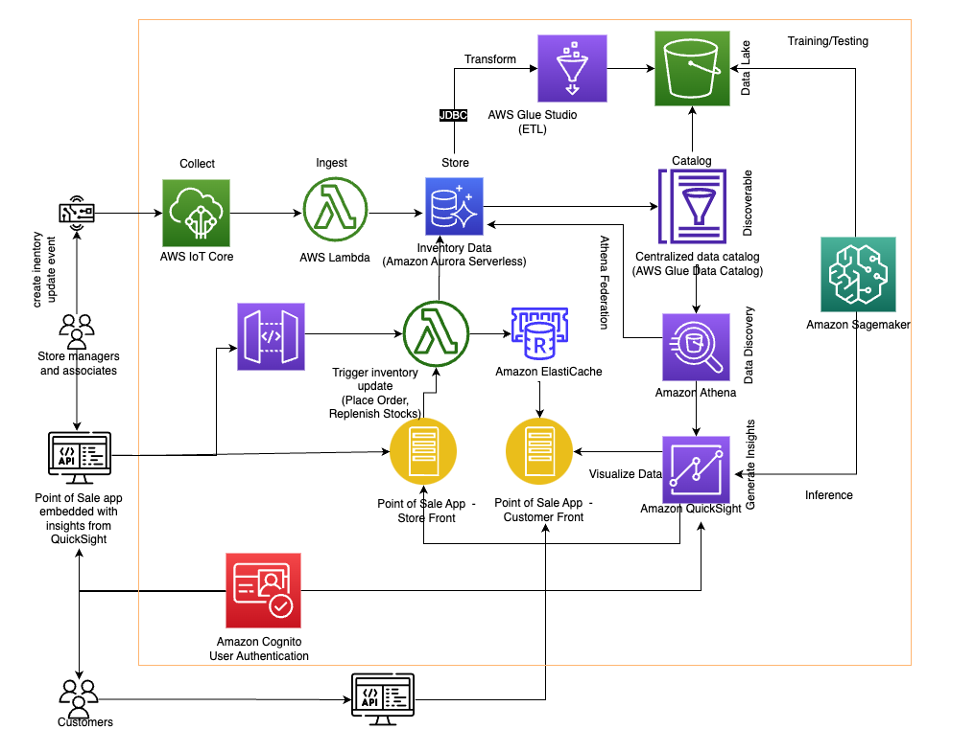
With the appropriate AWS services, your inventory management and forecasting system can have optimized collection, storage, processing, and analysis of data from multiple sources. The solution includes the following components.
Data ingestion and storage
Retail businesses have event-driven data that requires action from downstream processes. It’s critical for an inventory management application to handle the data ingestion and storage for changing demands.
The data ingestion process is typically triggered by an event such as an order being placed, kicking off the inventory management workflow, which requires actions from backend services. Developers are responsible for the operational overhead of trying to maintain the data ingestion load from an event driven-application.
The volume and velocity of data can change in the retail industry each day. Events like Black Friday or a new campaign can create volatile demand in what is required to process and store the inventory data. Serverless services designed to scale to businesses’ needs help reduce the architectural and operational challenges that are driven from high-demand retail applications.
Understanding the scaling challenges that occur when inventory demand spikes, we can deploy Lambda, a serverless, event-driven compute service, to trigger the data ingestion process. As inventory events occur like purchases or returns, Lambda automatically scales compute resources to meet the volume of incoming data.
After Lambda responds to the inventory action request, the updated data is stored in Aurora Serverless. Aurora Serverless is a serverless relational database that is designed to scale to the application’s needs. When peak loads hit during events like Black Friday, Aurora Serverless deploys only the database capacity necessary to meet the workload.
Inventory management applications have ever-changing demands. Deploying serverless services to handle the ingestion and storage of data will not only optimize cost but also reduce the operational overhead for developers, freeing up bandwidth for other critical business needs.
Data performance
Customer-facing applications require low latency to maintain positive user experiences with microsecond response times. ElastiCache, a fully managed, in-memory database, delivers high-performance data retrieval to users.
In-memory caching provided by ElastiCache is used to improve latency and throughput for read-heavy applications that online retailers experience. By storing critical pieces of data in-memory like commonly accessed product information, the application performance improves. Product information is an ideal candidate for a cached store due to data staying relatively the same.
Functionality is often added to retail applications to retrieve trending products. Trending products can be cycled through the cache dependent on customer access patterns. ElastiCache manages the real-time application data caching, allowing your customers to experience microsecond response times while supporting high-throughput handling of hundreds of millions of operations per second.
Data transformation
Data transformation is essential in inventory management and forecasting solutions for both data analysis around sales and inventory, as well as ML for forecasting. This is because raw data from various sources can contain inconsistencies, errors, and missing values that may distort the analysis and forecast results.
In the inventory management and forecasting solution, AWS Glue is recommended for data transformation. The tool addresses issues such as cleaning, restructuring, and consolidating data into a standard format that can be easily analyzed. As a result of the transformation, businesses can obtain a more precise understanding of inventory, sales trends, and customer behavior, influencing data-driven decisions to optimize inventory management and sales strategies. Furthermore, high-quality data is crucial for ML algorithms to make accurate forecasts.
By transforming data, organizations can enhance the accuracy and dependability of their forecasting models, ultimately leading to improved inventory management and cost savings.
Data analysis
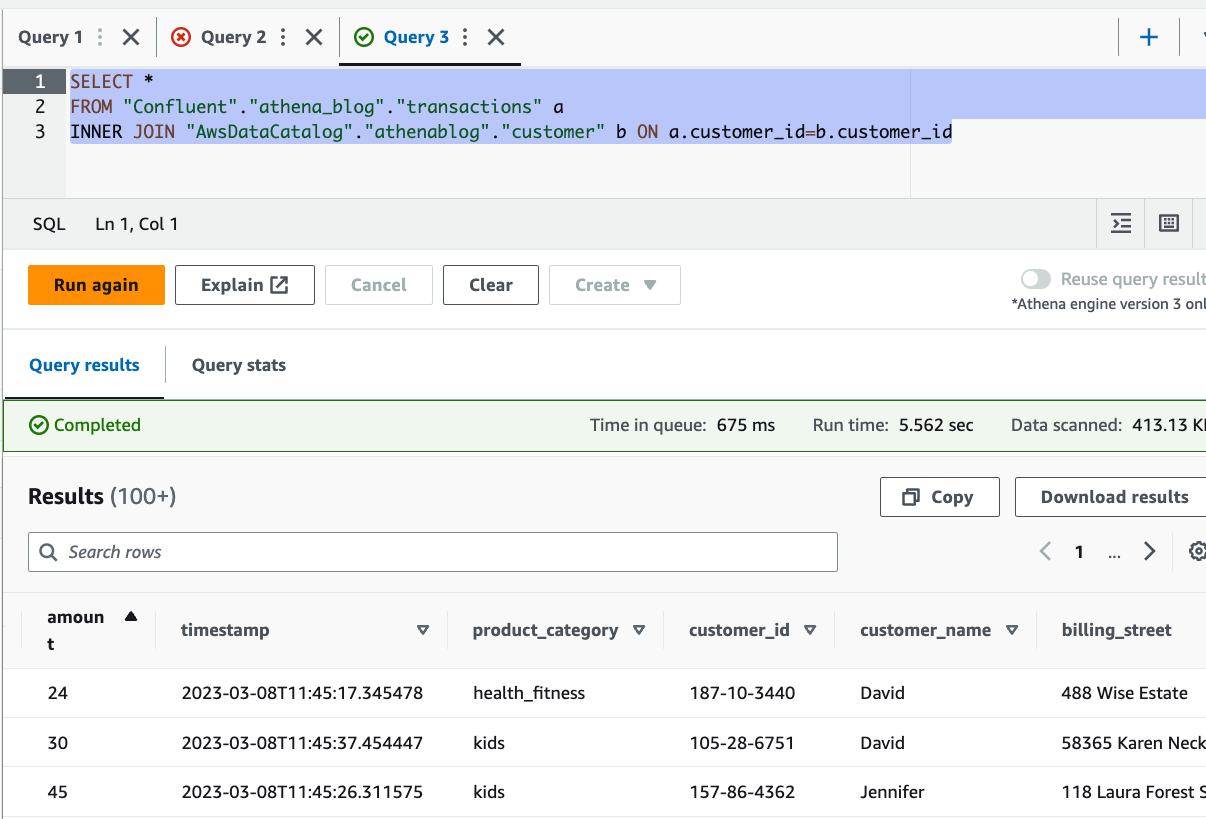
Data analysis has become increasingly important for businesses because it allows leaders to make informed operational decisions. However, analyzing large volumes of data can be a time-consuming and resource-intensive task. This is where Athena come in. With Athena, businesses can easily query historical sales and inventory data stored in S3 data lakes and combine it with real-time transactional data from Aurora Serverless databases.
The federated capabilities of Athena allow businesses to generate insights by combining datasets without the need to build ETL (extract, transform, and load) pipelines, saving time and resources. This enables businesses to quickly gain a comprehensive understanding of their inventory and sales trends, which can be used to optimize inventory management and forecasting, ultimately improving operations and increasing profitability.
With Athena’s ease of use and powerful capabilities, businesses can quickly analyze their data and gain valuable insights, driving growth and success without the need for complex ETL pipelines.
Forecasting
Inventory forecasting is an important aspect of inventory management for businesses that deal with physical products. Accurately predicting demand for products can help optimize inventory levels, reduce costs, and improve customer satisfaction. ML can help simplify and improve inventory forecasting by making more accurate predictions based on historical data.
SageMaker is a powerful ML platform that you can use to build, train, and deploy ML models for a wide range of applications, including inventory forecasting. In this solution, we use SageMaker to build and train an ML model for inventory forecasting, covering the basic concepts of ML, the data preparation process, model training and evaluation, and deploying the model for use in a production environment.
The solution also introduces the concept of hierarchical forecasting, which involves generating coherent forecasts that maintain the relationships within the hierarchy or reconciling incoherent forecasts. The workshop provides a step-by-step process for using the training capabilities of SageMaker to carry out hierarchical forecasting using synthetic retail data and the scikit-hts package. The FBProphet model was used along with bottom-up and top-down hierarchical aggregation and disaggregation methods. We used Amazon SageMaker Experiments to train multiple models, and the best model was picked out of the four trained models.
Although the approach was demonstrated on a synthetic retail dataset, you can use the provided code with any time series dataset that exhibits a similar hierarchical structure.
Security and authentication
The solution takes advantage of the scalability, reliability, and security of AWS services to provide a comprehensive inventory management and forecasting solution that can help businesses optimize their inventory levels, reduce holding costs, increase revenue, and enhance customer satisfaction. By incorporating user authentication with Amazon Cognito and Amazon API Gateway, the solution ensures that the system is secure and accessible only by authorized users.
Next steps
The next step to build an inventory management and forecasting solution on AWS would be to go through the Inventory Management workshop. In the workshop, you will get hands-on with AWS managed analytics, AI/ML, and database services to dive deep into an end-to-end inventory management solution. By the end of the workshop, you will have gone through the configuration and deployment of the critical pieces that make up an inventory management system.
Conclusion
In conclusion, building an inventory management and forecasting solution on AWS can help businesses optimize their inventory levels, reduce holding costs, increase revenue, and enhance customer satisfaction. With AWS services like IoT Core, Lambda, Aurora Serverless, AWS Glue, Athena, ElastiCache, QuickSight, SageMaker, and Amazon Cognito, businesses can use scalable, reliable, and secure technologies to collect, store, process, and analyze data from various sources.
The end-to-end solution is designed for individuals in various roles, such as business users, data engineers, data scientists, and data analysts, who are responsible for comprehending, creating, and overseeing processes related to retail inventory forecasting. Overall, an inventory management and forecasting solution on AWS can provide businesses with the insights and tools they need to make data-driven decisions and stay competitive in a constantly evolving retail landscape.
About the Authors
 Jason D’Alba is an AWS Solutions Architect leader focused on databases and enterprise applications, helping customers architect highly available and scalable solutions.
Jason D’Alba is an AWS Solutions Architect leader focused on databases and enterprise applications, helping customers architect highly available and scalable solutions.
 Navnit Shukla is an AWS Specialist Solution Architect, Analytics, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.
Navnit Shukla is an AWS Specialist Solution Architect, Analytics, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.
 Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions.
Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions.
 Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in Data Analytics domain.
Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in Data Analytics domain.






 Kristin Mandia is Senior Online Community Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
Kristin Mandia is Senior Online Community Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service. Ian McNamara is a Program Manager and writer on the Customer Success Team for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
Ian McNamara is a Program Manager and writer on the Customer Success Team for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
 Shruthi Panicker is a Senior Product Marketing Manager with Amazon QuickSight at AWS. As an engineer turned product marketer, Shruthi has spent over 15 years in the technology industry in various roles from software engineering, to solution architecting to product marketing. She is passionate about working at the intersection of technology and business to tell great product stories that help drive customer value.
Shruthi Panicker is a Senior Product Marketing Manager with Amazon QuickSight at AWS. As an engineer turned product marketer, Shruthi has spent over 15 years in the technology industry in various roles from software engineering, to solution architecting to product marketing. She is passionate about working at the intersection of technology and business to tell great product stories that help drive customer value.






 Lillie Atkins is a Product Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.
Lillie Atkins is a Product Manager for Amazon QuickSight, Amazon Web Service’s cloud-native, fully managed BI service.









 Ahmed Zamzam is a Senior Partner Solutions Architect at Confluent, with a focus on the AWS partnership. In his role, he works with customers in the EMEA region across various industries to assist them in building applications that leverage their data using Confluent and AWS. Prior to Confluent, Ahmed was a Specialist Solutions Architect for Analytics AWS specialized in data streaming and search. In his free time, Ahmed enjoys traveling, playing tennis, and cycling.
Ahmed Zamzam is a Senior Partner Solutions Architect at Confluent, with a focus on the AWS partnership. In his role, he works with customers in the EMEA region across various industries to assist them in building applications that leverage their data using Confluent and AWS. Prior to Confluent, Ahmed was a Specialist Solutions Architect for Analytics AWS specialized in data streaming and search. In his free time, Ahmed enjoys traveling, playing tennis, and cycling. Geetha Anne is a Partner Solutions Engineer at Confluent with previous experience in implementing solutions for data-driven business problems on the cloud, involving data warehousing and real-time streaming analytics. She fell in love with distributed computing during her undergraduate days and has followed her interest ever since. Geetha provides technical guidance, design advice, and thought leadership to key Confluent customers and partners. She also enjoys teaching complex technical concepts to both tech-savvy and general audiences.
Geetha Anne is a Partner Solutions Engineer at Confluent with previous experience in implementing solutions for data-driven business problems on the cloud, involving data warehousing and real-time streaming analytics. She fell in love with distributed computing during her undergraduate days and has followed her interest ever since. Geetha provides technical guidance, design advice, and thought leadership to key Confluent customers and partners. She also enjoys teaching complex technical concepts to both tech-savvy and general audiences.

















 Takeshi Nakatani is a Principal Bigdata Consultant on Professional Services team in Tokyo. He has 25 years of experience in IT industry, expertised in architecting data infrastructure. On his days off, he can be a rock drummer or a motorcyclyst.
Takeshi Nakatani is a Principal Bigdata Consultant on Professional Services team in Tokyo. He has 25 years of experience in IT industry, expertised in architecting data infrastructure. On his days off, he can be a rock drummer or a motorcyclyst.


 Alexander Plumb is a Product Manager at Mitratech. Alexander has been a product leader with over 5 years of experience leading to highly successful product launches that meet customer needs.
Alexander Plumb is a Product Manager at Mitratech. Alexander has been a product leader with over 5 years of experience leading to highly successful product launches that meet customer needs. Bani Sharma is a Sr Solutions Architect with Amazon Web Services (AWS), based out of Denver, Colorado. As a Solutions Architect, she works with a large number of Small and Medium businesses, and provides technical guidance and solutions on AWS. She has an area of depth in Containers and Modernization. Prior to AWS, Bani worked in various technical roles for a large Telecom provider Dish Networks and worked as a Senior Developer for HSBC Bank Software development.
Bani Sharma is a Sr Solutions Architect with Amazon Web Services (AWS), based out of Denver, Colorado. As a Solutions Architect, she works with a large number of Small and Medium businesses, and provides technical guidance and solutions on AWS. She has an area of depth in Containers and Modernization. Prior to AWS, Bani worked in various technical roles for a large Telecom provider Dish Networks and worked as a Senior Developer for HSBC Bank Software development. Brian Klein is a Sr Technical Account Manager with Amazon Web Services (AWS), helping digital native businesses utilize AWS services to bring value to their organizations. Brian has worked with AWS technologies for 9 years, designing and operating production internet-facing workloads, with a focus on security, availability, and resilience while demonstrating operational efficiency.
Brian Klein is a Sr Technical Account Manager with Amazon Web Services (AWS), helping digital native businesses utilize AWS services to bring value to their organizations. Brian has worked with AWS technologies for 9 years, designing and operating production internet-facing workloads, with a focus on security, availability, and resilience while demonstrating operational efficiency.

 Rohit Pujari is the Head of Product for Embedded Analytics at QuickSight. He is passionate about shaping the future of infusing data-rich experiences into products and applications we use every day. Rohit brings a wealth of experience in analytics and machine learning from having worked with leading data companies, and their customers. During his free time, you can find him lining up at the local ice cream shop for his second scoop.
Rohit Pujari is the Head of Product for Embedded Analytics at QuickSight. He is passionate about shaping the future of infusing data-rich experiences into products and applications we use every day. Rohit brings a wealth of experience in analytics and machine learning from having worked with leading data companies, and their customers. During his free time, you can find him lining up at the local ice cream shop for his second scoop.

















 Adeleke Coker is a Global Solutions Architect with AWS. He helps customers globally accelerate workload deployments and migrations at scale to AWS. In his spare time, he enjoys learning, reading, gaming and watching sport events.
Adeleke Coker is a Global Solutions Architect with AWS. He helps customers globally accelerate workload deployments and migrations at scale to AWS. In his spare time, he enjoys learning, reading, gaming and watching sport events.

 Olivia Michele is a Data Scientist Lead at Ruparupa, where she has worked in a variety of data roles over the past 5 years, including building and integrating Ruparupa data systems with AWS to improve user experience with data and reporting tools. She is passionate about turning raw information into valuable actionable insights and delivering value to the company.
Olivia Michele is a Data Scientist Lead at Ruparupa, where she has worked in a variety of data roles over the past 5 years, including building and integrating Ruparupa data systems with AWS to improve user experience with data and reporting tools. She is passionate about turning raw information into valuable actionable insights and delivering value to the company. Dariswan Janweri P. is a Data Engineer at Ruparupa. He considers challenges or problems as interesting riddles and finds satisfaction in solving them, and even more satisfaction by being able to help his colleagues and friends, “two birds one stone.” He is excited to be a major player in Indonesia’s technology transformation.
Dariswan Janweri P. is a Data Engineer at Ruparupa. He considers challenges or problems as interesting riddles and finds satisfaction in solving them, and even more satisfaction by being able to help his colleagues and friends, “two birds one stone.” He is excited to be a major player in Indonesia’s technology transformation. Adrianus Budiardjo Kurnadi is a Senior Solutions Architect at Amazon Web Services Indonesia. He has a strong passion for databases and machine learning, and works closely with the Indonesian machine learning community to introduce them to various AWS Machine Learning services. In his spare time, he enjoys singing in a choir, reading, and playing with his two children.
Adrianus Budiardjo Kurnadi is a Senior Solutions Architect at Amazon Web Services Indonesia. He has a strong passion for databases and machine learning, and works closely with the Indonesian machine learning community to introduce them to various AWS Machine Learning services. In his spare time, he enjoys singing in a choir, reading, and playing with his two children. Nico Anandito is an Analytics Specialist Solutions Architect at Amazon Web Services Indonesia. He has years of experience working in data integration, data warehouses, and big data implementation in multiple industries. He is certified in AWS data analytics and holds a master’s degree in the data management field of computer science.
Nico Anandito is an Analytics Specialist Solutions Architect at Amazon Web Services Indonesia. He has years of experience working in data integration, data warehouses, and big data implementation in multiple industries. He is certified in AWS data analytics and holds a master’s degree in the data management field of computer science.


















 Sandeep Bajwa is a Sr. Analytics Specialist based out of Northern Virginia, specialized in the design and implementation of analytics and data lake solutions.
Sandeep Bajwa is a Sr. Analytics Specialist based out of Northern Virginia, specialized in the design and implementation of analytics and data lake solutions.
 Frank Contrepois is the Head of FinOps at
Frank Contrepois is the Head of FinOps at  Aaron Edell is Head of GTM for Customer Cloud Intelligence for Amazon Web Services. He is responsible for building and scaling businesses around Cloud Financial Management, FinOps, and the Well-Architected Cost Optimization pillar. He focuses his GTM efforts on the Cloud Intelligence Dashboards and remains obsessed with helping all customers get better visibility and access to their cost and usage data.
Aaron Edell is Head of GTM for Customer Cloud Intelligence for Amazon Web Services. He is responsible for building and scaling businesses around Cloud Financial Management, FinOps, and the Well-Architected Cost Optimization pillar. He focuses his GTM efforts on the Cloud Intelligence Dashboards and remains obsessed with helping all customers get better visibility and access to their cost and usage data.


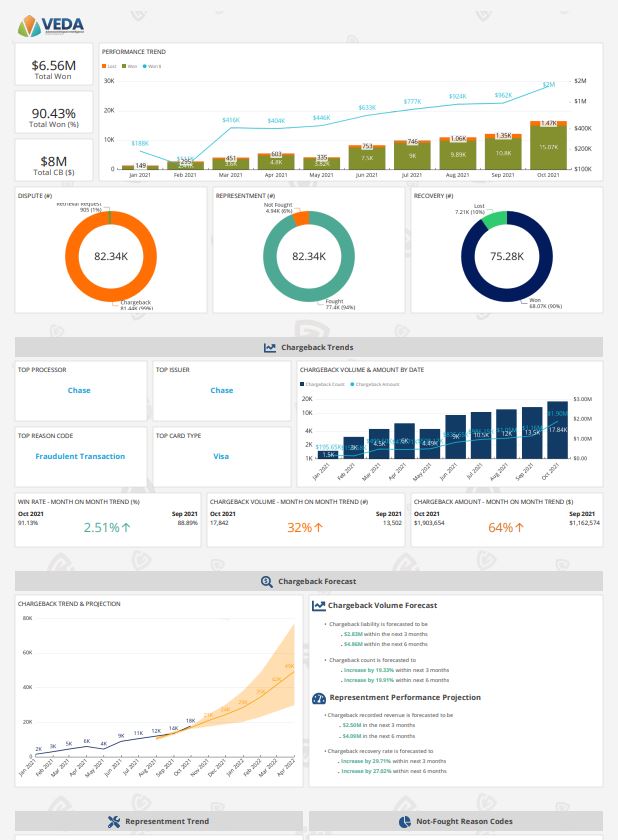
 Suresh Dakshina is the Co-founder & President at Chargeback Gurus. A pioneer in data analytics and industry-specific risk management, he is a certified e-commerce fraud prevention specialist and Certified Payments Professional. He understands first-hand the challenges that business owners face, especially when it comes to chargebacks and fraud. He is a veteran speaker, and works closely with Card Networks like Visa and American Express on chargeback process optimization and compelling evidence policies. He loves spending time with his family and his Labradoodle, Joy, when not working.
Suresh Dakshina is the Co-founder & President at Chargeback Gurus. A pioneer in data analytics and industry-specific risk management, he is a certified e-commerce fraud prevention specialist and Certified Payments Professional. He understands first-hand the challenges that business owners face, especially when it comes to chargebacks and fraud. He is a veteran speaker, and works closely with Card Networks like Visa and American Express on chargeback process optimization and compelling evidence policies. He loves spending time with his family and his Labradoodle, Joy, when not working. Damodharan Sampathkumar is the Chief Product Officer & GM-India at Chargeback Gurus. He is responsible for product strategy, platform development, and leading innovation for the next generation in payments technology with a specific focus on Chargebacks and Risk mitigation at Chargeback Gurus. He specializes in cloud-native, mission-critical, real-time payment systems, group-up technology platform setup, and operations. He has successfully championed multiple new-age digital payment platforms across North America, Europe, India, and the Middle East for Central Banks, Acquirer processors, and Fintech innovators. He is an avid cyclist and regular endurance rider who loves to ride during his time off to bring the right balance between work and life.
Damodharan Sampathkumar is the Chief Product Officer & GM-India at Chargeback Gurus. He is responsible for product strategy, platform development, and leading innovation for the next generation in payments technology with a specific focus on Chargebacks and Risk mitigation at Chargeback Gurus. He specializes in cloud-native, mission-critical, real-time payment systems, group-up technology platform setup, and operations. He has successfully championed multiple new-age digital payment platforms across North America, Europe, India, and the Middle East for Central Banks, Acquirer processors, and Fintech innovators. He is an avid cyclist and regular endurance rider who loves to ride during his time off to bring the right balance between work and life.





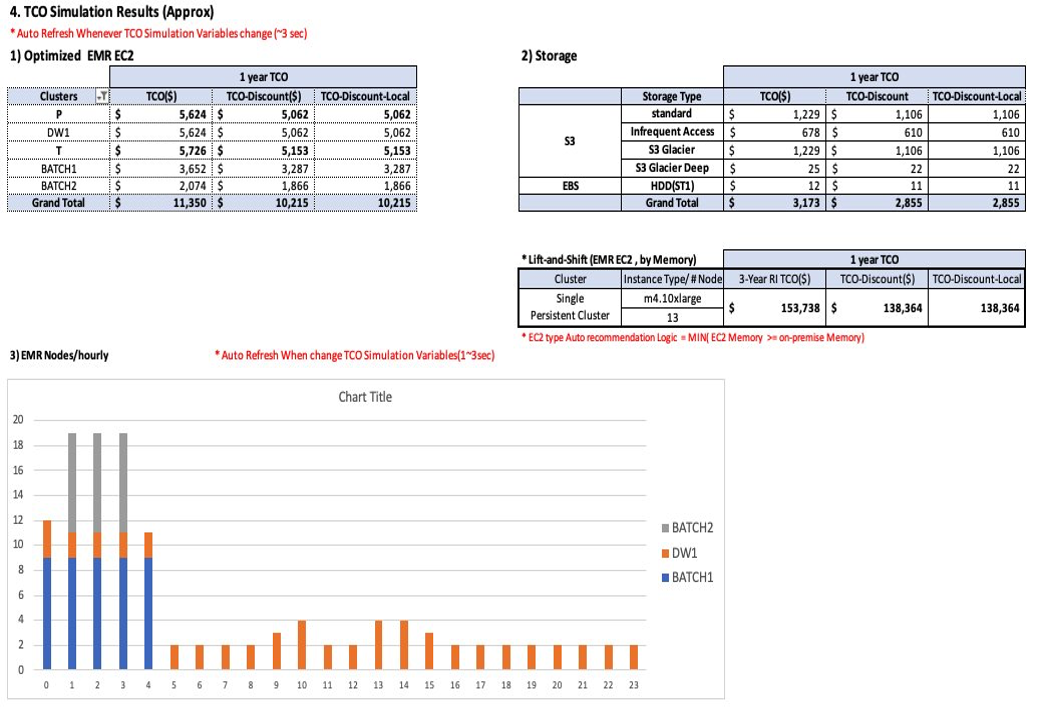
 Sungyoul Park is a Senior Practice Manager at AWS ProServe. He helps customers innovate their business with AWS Analytics, IoT, and AI/ML services. He has a specialty in big data services and technologies and an interest in building customer business outcomes together.
Sungyoul Park is a Senior Practice Manager at AWS ProServe. He helps customers innovate their business with AWS Analytics, IoT, and AI/ML services. He has a specialty in big data services and technologies and an interest in building customer business outcomes together. Jiseong Kim is a Senior Data Architect at AWS ProServe. He mainly works with enterprise customers to help data lake migration and modernization, and provides guidance and technical assistance on big data projects such as Hadoop, Spark, data warehousing, real-time data processing, and large-scale machine learning. He also understands how to apply technologies to solve big data problems and build a well-designed data architecture.
Jiseong Kim is a Senior Data Architect at AWS ProServe. He mainly works with enterprise customers to help data lake migration and modernization, and provides guidance and technical assistance on big data projects such as Hadoop, Spark, data warehousing, real-time data processing, and large-scale machine learning. He also understands how to apply technologies to solve big data problems and build a well-designed data architecture. George Zhao is a Senior Data Architect at AWS ProServe. He is an experienced analytics leader working with AWS customers to deliver modern data solutions. He is also a ProServe Amazon EMR domain specialist who enables ProServe consultants on best practices and delivery kits for Hadoop to Amazon EMR migrations. His area of interests are data lakes and cloud modern data architecture delivery.
George Zhao is a Senior Data Architect at AWS ProServe. He is an experienced analytics leader working with AWS customers to deliver modern data solutions. He is also a ProServe Amazon EMR domain specialist who enables ProServe consultants on best practices and delivery kits for Hadoop to Amazon EMR migrations. His area of interests are data lakes and cloud modern data architecture delivery. Kalen Zhang was the Global Segment Tech Lead of Partner Data and Analytics at AWS. As a trusted advisor of data and analytics, she curated strategic initiatives for data transformation, led data and analytics workload migration and modernization programs, and accelerated customer migration journeys with partners at scale. She specializes in distributed systems, enterprise data management, advanced analytics, and large-scale strategic initiatives.
Kalen Zhang was the Global Segment Tech Lead of Partner Data and Analytics at AWS. As a trusted advisor of data and analytics, she curated strategic initiatives for data transformation, led data and analytics workload migration and modernization programs, and accelerated customer migration journeys with partners at scale. She specializes in distributed systems, enterprise data management, advanced analytics, and large-scale strategic initiatives.








 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.









 Mehmet Demir is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. He helps customers in building well-architected solutions that support business innovation.
Mehmet Demir is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. He helps customers in building well-architected solutions that support business innovation. Ankur Taunk is a Senior Specialist Solutions Architect at AWS. He helps customer achieve their desired business outcomes in the Contact Center space leveraging Amazon Connect.
Ankur Taunk is a Senior Specialist Solutions Architect at AWS. He helps customer achieve their desired business outcomes in the Contact Center space leveraging Amazon Connect.
 Vidya Kotamraju is a Product Management Leader at Diligent, with close to 2 decades of experience leading award-winning B2B, B2C product and team success across multiple industries and geographies. Currently, she is focused on Diligent Highbond’s Data Automation Solutions.
Vidya Kotamraju is a Product Management Leader at Diligent, with close to 2 decades of experience leading award-winning B2B, B2C product and team success across multiple industries and geographies. Currently, she is focused on Diligent Highbond’s Data Automation Solutions. Tallis Hobbs is a Senior Software Engineer at Diligent. As a previous educator, he brings a unique skill set to the engineering space. He is passionate about the AWS serverless space and currently works on Diligent’s client facing Quicksight integration.
Tallis Hobbs is a Senior Software Engineer at Diligent. As a previous educator, he brings a unique skill set to the engineering space. He is passionate about the AWS serverless space and currently works on Diligent’s client facing Quicksight integration. Samit Kumbhani is a Sr. Solutions Architect at AWS based out of New York City area. Has has 18+ years of experience in building applications and focuses on Analytics, Business Intelligence and Databases. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services. Outside of work, Samit loves playing cricket, traveling and spending time with his family and friends.
Samit Kumbhani is a Sr. Solutions Architect at AWS based out of New York City area. Has has 18+ years of experience in building applications and focuses on Analytics, Business Intelligence and Databases. He enjoys working with customers to understand their challenges and solve them by creating innovative solutions using AWS services. Outside of work, Samit loves playing cricket, traveling and spending time with his family and friends.