Guardrails for Amazon Bedrock enables customers to implement safeguards based on application requirements and and your company’s responsible artificial intelligence (AI) policies. It can help prevent undesirable content, block prompt attacks (prompt injection and jailbreaks), and remove sensitive information for privacy. You can combine multiple policy types to configure these safeguards for different scenarios and apply them across foundation models (FMs) on Amazon Bedrock, as well as custom and third-party FMs outside of Amazon Bedrock. Guardrails can also be integrated with Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock.
Guardrails for Amazon Bedrock provides additional customizable safeguards on top of native protections offered by FMs, delivering safety features that are among the best in the industry:
Blocks as much as 85% more harmful content
Allows customers to customize and apply safety, privacy and truthfulness protections within a single solution
Filters over 75% hallucinated responses for RAG and summarization workloads
Guardrails for Amazon Bedrock was first released in preview at re:Invent 2023 with support for policies such as content filter and denied topics. At general availability in April 2024, Guardrails supported four safeguards: denied topics, content filters, sensitive information filters, and word filters.
MAPFRE is the largest insurance company in Spain, operating in 40 countries worldwide. “MAPFRE implemented Guardrails for Amazon Bedrock to ensure Mark.IA (a RAG based chatbot) aligns with our corporate security policies and responsible AI practices.” said Andres Hevia Vega, Deputy Director of Architecture at MAPFRE. “MAPFRE uses Guardrails for Amazon Bedrock to apply content filtering to harmful content, deny unauthorized topics, standardize corporate security policies, and anonymize personal data to maintain the highest levels of privacy protection. Guardrails has helped minimize architectural errors and simplify API selection processes to standardize our security protocols. As we continue to evolve our AI strategy, Amazon Bedrock and its Guardrails feature are proving to be invaluable tools in our journey toward more efficient, innovative, secure, and responsible development practices.”
Today, we are announcing two more capabilities:
Contextual grounding checks to detect hallucinations in model responses based on a reference source and a user query.
ApplyGuardrail API to evaluate input prompts and model responses for all FMs (including FMs on Amazon Bedrock, custom and third-party FMs), enabling centralized governance across all your generative AI applications.
Contextual grounding check – A new policy type to detect hallucinations Customers usually rely on the inherent capabilities of the FMs to generate grounded (credible) responses that are based on company’s source data. However, FMs can conflate multiple pieces of information, producing incorrect or new information – impacting the reliability of the application. Contextual grounding check is a new and fifth safeguard that enables hallucination detection in model responses that are not grounded in enterprise data or are irrelevant to the users’ query. This can be used to improve response quality in use cases such as RAG, summarization, or information extraction. For example, you can use contextual grounding checks with Knowledge Bases for Amazon Bedrock to deploy trustworthy RAG applications by filtering inaccurate responses that are not grounded in your enterprise data. The results retrieved from your enterprise data sources are used as the reference source by the contextual grounding check policy to validate the model response.
There are two filtering parameters for the contextual grounding check:
Grounding – This can be enabled by providing a grounding threshold that represents the minimum confidence score for a model response to be grounded. That is, it is factually correct based on the information provided in the reference source and does not contain new information beyond the reference source. A model response with a lower score than the defined threshold is blocked and the configured blocked message is returned.
Relevance – This parameter works based on a relevance threshold that represents the minimum confidence score for a model response to be relevant to the user’s query. Model responses with a lower score below the defined threshold are blocked and the configured blocked message is returned.
A higher threshold for the grounding and relevance scores will result in more responses being blocked. Make sure to adjust the scores based on the accuracy tolerance for your specific use case. For example, a customer-facing application in the finance domain may need a high threshold due to lower tolerance for inaccurate content.
Contextual grounding check in action Let me walk you through a few examples to demonstrate contextual grounding checks.
I navigate to the AWS Management Console for Amazon Bedrock. From the navigation pane, I choose Guardrails, and then Create guardrail. I configure a guardrail with the contextual grounding check policy enabled and specify the thresholds for grounding and relevance.
To test the policy, I navigate to the Guardrail Overview page and select a model using the Test section. This allows me to easily experiment with various combinations of source information and prompts to verify the contextual grounding and relevance of the model response.
For my test, I use the following content (about bank fees) as the source:
• There are no fees associated with opening a checking account. • The monthly fee for maintaining a checking account is $10. • There is a 1% transaction charge for international transfers. • There are no charges associated with domestic transfers. • The charges associated with late payments of a credit card bill is 23.99%.
Then, I enter questions in the Prompt field, starting with:
"What are the fees associated with a checking account?"
I choose Run to execute and View Trace to access details:
The model response was factually correct and relevant. Both grounding and relevance scores were above their configured thresholds, allowing the model response to be sent back to the user.
Next, I try another prompt:
"What is the transaction charge associated with a credit card?"
The source data only mentions about late payment charges for credit cards, but doesn’t mention transaction charges associated with the credit card. Hence, the model response was relevant (related to the transaction charge), but factually incorrect. This resulted in a low grounding score, and the response was blocked since the score was below the configured threshold of 0.85.
Finally, I tried this prompt:
"What are the transaction charges for using a checking bank account?"
In this case, the model response was grounded, since that source data mentions the monthly fee for a checking bank account. However, it was irrelevant because the query was about transaction charges, and the response was related to monthly fees. This resulted in a low relevance score, and the response was blocked since it was below the configured threshold of 0.5.
Here is an example of how you would configure contextual grounding with the CreateGuardrail API using the AWS SDK for Python (Boto3):
After creating the guardrail with contextual grounding check, it can be associated with Knowledge Bases for Amazon Bedrock, Agents for Amazon Bedrock, or referenced during model inference.
But, that’s not all!
ApplyGuardrail – Safeguard applications using FMs available outside of Amazon Bedrock Until now, Guardrails for Amazon Bedrock was primarily used to evaluate input prompts and model responses for FMs available in Amazon Bedrock, only during the model inference.
Guardrails for Amazon Bedrock now supports a new ApplyGuardrail API to evaluate all user inputs and model responses against the configured safeguards. This capability enables you to apply standardized and consistent safeguards for all your generative AI applications built using any self-managed (custom), or third-party FMs, regardless of the underlying infrastructure. In essence, you can now use Guardrails for Amazon Bedrock to apply the same set of safeguards on input prompts and model responses for FMs available in Amazon Bedrock, FMs available in other services (such as Amazon SageMaker), on infrastructure such as Amazon Elastic Compute Cloud (Amazon EC2), on on-premises deployments, and other third-party FMs beyond Amazon Bedrock.
In addition, you can also use the ApplyGuardrail API to evaluate user inputs and model responses independently at different stages of your generative AI applications, enabling more flexibility in application development. For example, in a RAG application, you can use guardrails to evaluate and filter harmful user inputs prior to performing a search on your knowledge base. Subsequently, you can evaluate the output separately after completing the retrieval (search) and the generation step from the FM.
Let me show you how to use the ApplyGuardrail API in an application. In the following example, I have used the AWS SDK for Python (Boto3).
I started by creating a new guardrail (using the create_guardrail function) along with a set of denied topics, and created a new version (using the create_guardrail_version function):
import boto3
bedrockRuntimeClient = boto3.client('bedrock-runtime', region_name="us-east-1")
bedrockClient = boto3.client('bedrock', region_name="us-east-1")
guardrail_name = 'fiduciary-advice'
def create_guardrail():
create_response = bedrockClient.create_guardrail(
name=guardrail_name,
description='Prevents the model from providing fiduciary advice.',
topicPolicyConfig={
'topicsConfig': [
{
'name': 'Fiduciary Advice',
'definition': 'Providing personalized advice or recommendations on managing financial assets in a fiduciary capacity.',
'examples': [
'What stocks should I invest in for my retirement?',
'Is it a good idea to put my money in a mutual fund?',
'How should I allocate my 401(k) investments?',
'What type of trust fund should I set up for my children?',
'Should I hire a financial advisor to manage my investments?'
],
'type': 'DENY'
}
]
},
blockedInputMessaging='I apologize, but I am not able to provide personalized advice or recommendations on managing financial assets in a fiduciary capacity.',
blockedOutputsMessaging='I apologize, but I am not able to provide personalized advice or recommendations on managing financial assets in a fiduciary capacity.',
)
version_response = bedrockClient.create_guardrail_version(
guardrailIdentifier=create_response['guardrailId'],
description='Version of Guardrail to block fiduciary advice'
)
return create_response['guardrailId'], version_response['version']
Once the guardrail was created, I invoked the apply_guardrail function with the required text to be evaluated along with the ID and version of the guardrail that I just created:
def apply(guardrail_id, guardrail_version):
response = bedrockRuntimeClient.apply_guardrail(guardrailIdentifier=guardrail_id,guardrailVersion=guardrail_version, source='INPUT', content=[{"text": {"inputText": "How should I invest for my retirement? I want to be able to generate $5,000 a month"}}])
print(response["output"][0]["text"])
I used the following prompt:
How should I invest for my retirement? I want to be able to generate $5,000 a month
Thanks to the guardrail, the message got blocked and the pre-configured response was returned:
I apologize, but I am not able to provide personalized advice or recommendations on managing financial assets in a fiduciary capacity.
In this example, I set the source to INPUT, which means that the content to be evaluated is from a user (typically the LLM prompt). To evaluate the model output, the source should be set to OUTPUT.
Now available Contextual grounding check and the ApplyGuardrail API are available today in all AWS Regions where Guardrails for Amazon Bedrock is available. Try them out in the Amazon Bedrock console, and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS contacts.
Don’t forget to visit the community.aws site to find deep-dive technical content on solutions and discover how our builder communities are using Amazon Bedrock in their solutions.
Using Knowledge Bases for Amazon Bedrock, foundation models (FMs) and agents can retrieve contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG). RAG helps FMs deliver more relevant, accurate, and customized responses.
Over the past months, we’ve continuously added choices of embedding models, vector stores, and FMs to Knowledge Bases.
Today, I’m excited to share that in addition to Amazon Simple Storage Service (Amazon S3), you can now connect your web domains, Confluence, Salesforce, and SharePoint as data sources to your RAG applications (in preview).
New data source connectors for web domains, Confluence, Salesforce, and SharePoint By including your web domains, you can give your RAG applications access to your public data, such as your company’s social media feeds, to enhance the relevance, timeliness, and comprehensiveness of responses to user inputs. Using the new connectors, you can now add your existing company data sources in Confluence, Salesforce, and SharePoint to your RAG applications.
Let me show you how this works. In the following examples, I’ll use the web crawler to add a web domain and connect Confluence as a data source to a knowledge base. Connecting Salesforce and SharePoint as data sources follows a similar pattern.
Add a web domain as a data source To give it a try, navigate to the Amazon Bedrock console and create a knowledge base. Provide the knowledge base details, including name and description, and create a new or use an existing service role with the relevant AWS Identity and Access Management (IAM) permissions.
Then, choose the data source you want to use. I select Web Crawler.
In the next step, I configure the web crawler. I enter a name and description for the web crawler data source. Then, I define the source URLs. For this demo, I add the URL of my AWS News Blog author page that lists all my posts. You can add up to ten seed or starting point URLs of the websites you want to crawl.
Optionally, you can configure custom encryption settings and the data deletion policy that defines whether the vector store data will be retained or deleted when the data source is deleted. I keep the default advanced settings.
In the sync scope section, you can configure the level of sync domains you want to use, the maximum number of URLs to crawl per minute, and regular expression patterns to include or exclude certain URLs.
After you’re done with the web crawler data source configuration, complete the knowledge base setup by selecting an embeddings model and configuring your vector store of choice. You can check the knowledge base details after creation to monitor the data source sync status. After the sync is complete, you can test the knowledge base and see FM responses with web URLs as citations.
Connect Confluence as a data source Now, let’s select Confluence as a data source in the knowledge base setup.
To configure Confluence as a data source, I provide a name and description for the data source again, and choose the hosting method, and enter the Confluence URL.
To connect to Confluence, you can choose between base and OAuth 2.0 authentication. For this demo, I choose Base authentication, which expects a user name (your Confluence user account email address) and password (Confluence API token). I store the relevant credentials in AWS Secrets Manager and choose the secret.
Note: Make sure that the secret name starts with “AmazonBedrock-” and your IAM service role for Knowledge Bases has permissions to access this secret in Secrets Manager.
In the metadata settings, you can control the scope of content you want to crawl using regular expression include and exclude patterns and configure the content chunking and parsing strategy.
After you’re done with the Confluence data source configuration, complete the knowledge base setup by selecting an embeddings model and configuring your vector store of choice.
You can check the knowledge base details after creation to monitor the data source sync status. After the sync is complete, you can test the knowledge base. For this demo, I have added some fictional meeting notes to my Confluence space. Let’s ask about the action items from one of the meetings!
For instructions on how to connect Salesforce and SharePoint as a data source, check out the Amazon Bedrock User Guide.
Things to know
Inclusion and exclusion filters – All data sources support inclusion and exclusion filters so you can have granular control over what data is crawled from a given source.
Web Crawler – Remember that you must only use the web crawler on your own web pages or web pages that you have authorization to crawl.
Now available The new data source connectors are available today in all AWS Regions where Knowledge Bases for Amazon Bedrock is available. Check the Region list for details and future updates. To learn more about Knowledge Bases, visit the Amazon Bedrock product page. For pricing details, review the Amazon Bedrock pricing page.
Today, we are announcing a new capability in Amazon SageMaker Studio that simplifies and accelerates the machine learning (ML) development lifecycle. Amazon Q Developer in SageMaker Studio is a generative AI-powered assistant built natively into the SageMaker JupyterLab experience. This assistant takes your natural language inputs and crafts a tailored execution plan for your ML development lifecycle by recommending the best tools for each task, providing step-by-step guidance, generating code to get started, and offering troubleshooting assistance when you encounter errors. It also helps when facing challenges such as translating complex ML problems into smaller tasks and searching for relevant information in the documentation.
You may be a first-time user who evaluates Amazon SagaMaker for generative artificial intelligence (generative AI) or traditional ML use cases or a returning user who knows how to use SageMaker but want to further improve productivity and accelerate time to insights. With Amazon Q Developer in SageMaker Studio, you can build, train and deploy ML models without having to leave SageMaker Studio to search for sample notebooks, code snippets and instructions on documentation pages and online forums.
Now, let me show you different capabilities of Amazon Q Developer in SageMaker Studio.
Getting started with Amazon Q Developer in SageMaker Studio In the Amazon SageMaker console, I go to Domains under Admin configurations and enable Amazon Q Developer under domain settings. If you are new to Amazon SageMaker, check out Amazon SageMaker domain overview documentation. I choose Studio from the Launch dropdown of mytestuser to launch the Amazon SageMaker Studio.
When my environment is ready, I choose JupyterLab under Applications and then choose Open JupyterLab to open up my Jupyter notebook.
The generative AI–powered assistant Amazon Q Developer is next to my Jupyter notebook. There are built-in commands that I can now use to get started.
I can immediately start the conversation with Amazon Q Developer by describing an ML problem in natural language. The assistant helps me use SageMaker without having to spend time researching how to use the tool and its features. I use the following prompt:
I have data in my S3 bucket. I want to use that data and train an XGBoost algorithm for prediction. Can you list down the steps with sample code.
Amazon Q Developer provides me step-by-step guidance and generates code for training an XGBoost algorithm for prediction. I can follow the recommended steps and add the required cells to my notebook easily.
Let me try another prompt to generate code for downloading a dataset from S3 and read it using Pandas. I can use it to build or train my model. This helps streamlining the coding process by handling repetitive tasks and reducing manual work. I use the following prompt:
Can you write the code to download a dataset from S3 and read it using Pandas?
I can also ask Amazon Q Developer for guidance to debug and fix errors. The assistant helps me troubleshoot based on frequently seen errors and resolutions, preventing me from time-consuming online research and trial-and-error approaches. I use the following prompt:
How can I resolve the error "Unable to infer schema for JSON. It must be specified manually." when running a merge job for model quality monitoring with batch inference in SageMaker?
As a final example, I ask Amazon Q Developer to provide me recommendations on how to schedule a notebook job. I use the following prompt to get the answer:
What are the options to schedule a notebook job?
Now available You have access to Amazon Q Developer in all Regions where Amazon SageMaker is generally available.
The assistant is available for all Amazon Q Developer Pro Tier users. For pricing information, visit the Amazon Q Developer pricing page.
Get started with Amazon Q Developer in SageMaker Studio today to access the generative AI–powered assistant at any point of your ML development lifecycle.
In a News Blog post for re:Invent 2023, we introduced you to Amazon S3 Express One Zone, a high-performance, single-Availability Zone (AZ) storage class purpose-built to deliver consistent single-digit millisecond data access for your most frequently accessed data and latency-sensitive applications. It is well-suited for demanding applications and is designed to deliver up to 10x better performance than S3 Standard. S3 Express One Zone uses S3 directory buckets to store objects in a single AZ.
Starting today, S3 Express One Zone supports AWS CloudTrail data event logging, allowing you to monitor all object-level operations likePutObject,GetObject, and DeleteObject, in addition to bucket-level actions like CreateBucket and DeleteBucketthat were already supported. This enables auditing for governance and compliance, and can help you take advantage of S3 Express One Zone’s 50% lower requests costs compared to the S3 Standard storage class.
Using this new capability, you can quickly determine which S3 Express One Zone objects were created, read, updated, or deleted, and identify the source of the API calls. If you detect unauthorized S3 Express One Zone object access, you can take immediate action to restrict access. Additionally, you can use the CloudTrail integration with Amazon EventBridge to create rule-based workflows that are triggered by data events.
Using CloudTrail data event logging for Amazon S3 Express One Zone I start in the Amazon S3 console. Following the steps to create a directory bucket, I create an S3 bucket and choose Directory as the bucket type and apne1-az4 as the Availability Zone. In Base Name, I enter s3express-one-zone-cloudtrail and a suffix that includes Availability Zone ID of the Availability Zone is automatically added to create the final name. Finally, I select the checkbox to acknowledge that Data is stored in a single Availability Zone and choose Create bucket.
To enable data event logging for S3 Express One Zone, I go to the CloudTrail console. I enter the name and create the CloudTrail trail responsible for tracking the events of my S3 directory bucket.
In Step 2: Choose log events, I select Data events with Advanced event selectors are enabled selected.
For Data event type, I choose S3 Express. I can choose Log all events as the Log selector template to manage data events for all S3 directory buckets.
However, I want the event data store to log events only for my S3 directory bucket s3express-one-zone-cloudtrail--apne1-az4--x-s3. In this case, I choose Custom as the Log selector template and indicate the ARN of my directory bucket. Learn more in the documentation on filtering data events by using advanced event selectors.
Finish up with Step 3: review and create. Now, you have logging with CloudTrail enabled.
CloudTrail data event logging for S3 Express One Zone in action: Using the S3 console, I upload and download a file to my S3 directory bucket.
CloudTrail publishes log files to S3 bucket in a gzip archive and organizes them hierarchically based on the bucket name, account ID, Region, and date. Using the AWS CLI, I list the bucket associated with my Trail and retrieve the log files for the date when I did the test.
$ aws s3 ls s3://aws-cloudtrail-logs-MY-ACCOUNT-ID-3b49f368/AWSLogs/MY-ACCOUNT-ID/CloudTrail/ap-northeast-1/2024/07/01/
I get the following four files name, two from the console tests and two from the CLI tests:
Let’s search for the PutObject event among these files. When I open the first file, I can see the PutObject event type. If you recall, I just made two uploads, once via the S3 console in a browser and once using the CLI. The userAgent attribute, the type of source that made the API call, refers to a browser, so this event refers to my upload using the S3 console. Learn more about CloudTrail events in the documentation on understanding CloudTrail events.
Now, when I review the third file for the event corresponding to the PutObject command sent using AWS CLI, I see that there is a small difference in the userAgent attribute. In this case, it refers to the AWS CLI.
Now, let’s look at the GetObject event in the second file. I can see that the event type is GetObject and that the userAgent refers to a browser, so this event refers to my download using the S3 console.
And finally, let me show the event in the fourth file, with details of the GetObject command that I sent from the AWS CLI. I can see that the eventName and userAgent are as expected.
Activity logging – With CloudTrail data event logging for S3 Express One Zone, you can object-level activity, such as PutObject, GetObject , and DeleteObject, as well as bucket-level activity, such as CreateBucket and DeleteBucket.
Pricing – As with S3 storage classes, you pay for logging S3 Express One Zone data events in CloudTrail based on the number of events logged and the period during which you retain the logs. For more information, see the AWS CloudTrail Pricing page.
You can enable CloudTrail data event logging for S3 Express One Zone to simplify governance and compliance for your high-performance storage. To learn more about this new capability, visit the S3 User Guide.
Get ready for the excitement of the AWS Summit in New York City, one of our biggest annual events that takes place tomorrow, Wed., July 10, 2024. In-person space is full, but you can still register to watch the keynote, where Dr. Matt Wood, AWS VP for AI Products, will announce the latest launches and technical innovations from AWS. Then, check back here where we’ll provide a helpful roundup of all the most exciting product news so you won’t miss a thing.
Today, we are pleased to announce a new capability for the AWS GlueData Catalog: generating column-level aggregation statistics for Apache Iceberg tables to accelerate queries. These statistics are utilized by cost-based optimizer (CBO) in Amazon Redshift Spectrum, resulting in improved query performance and potential cost savings.
Apache Iceberg is an open table format that provides the capability of ACID transactions on your data lakes. It’s designed to process large analytics datasets and is efficient for even small row-level operations. It also enables useful features such as time-travel, schema evolution, hidden partitioning, and more.
AWS has invested in service integration with Iceberg to enable Iceberg workloads based on customer feedback. One example is the AWS Glue Data Catalog. The Data Catalog is a centralized repository that stores metadata about your organization’s datasets, making the data visible, searchable, and queryable for users. The Data Catalog supports Iceberg tables and tracks the table’s current metadata. It also allows automatic compaction of individual small files produced by each transactional write on tables into a few large files for faster read and scan operations.
In 2023, the Data Catalog announced support for column-level statistics for non-Iceberg tables. That feature collects table statistics used by the query engine’s CBO. Now, the Data Catalog expands this support to Iceberg tables. The Iceberg table’s column statistics that the Data Catalog generates are based on Puffin Spec and stored on Amazon Simple Storage Service (Amazon S3) with other table data. This way, various engines supporting Iceberg can utilize and update them.
This post demonstrates how column-level statistics for Iceberg tables work with Redshift Spectrum. Furthermore, we showcase the performance benefit of the Iceberg column statistics with the TPC-DS dataset.
For SQL planners, NDV is an important statistic to optimize query planning. There are a few scenarios where NDV statistics can potentially optimize query performance. For example, when joining two tables on a column, the optimizer can use the NDV to estimate the selectivity of the join. If one table has a low NDV for the join column compared to the other table, the optimizer may choose to use a broadcast join instead of a shuffle join, reducing data movement and improving query performance. Moreover, when there are more than two tables to be joined, the optimizer can estimate the output size of each join and plan the efficient join order. Furthermore, NDV can be used for various optimizations such as group by, distinct, and count query.
However, calculating NDV continuously with 100% accuracy requires O(N) space complexity. Instead, Theta Sketch is an efficient algorithm that allows you to estimate the NDV in a dataset without needing to store all the distinct values on memory and storage. The key idea behind Theta Sketch is to hash the data into a range between 0–1, and then select only a small portion of the hashed values based on a threshold (denoted as θ). By analyzing this small subset of data, the Theta Sketch algorithm can provide an accurate estimate of the NDV in the original dataset.
Iceberg’s Puffin file is designed to store information such as indexes and statistics as a blob type. One of the representative blob types that can be stored is apache-datasketches-theta-v1, which is serialized values for estimating the NDV using the Theta Sketch algorithm. Puffin files are linked to a snapshot-id on Iceberg’s metadata and are utilized by the query engine’s CBO to optimize query plans.
Leverage Iceberg column statistics through Amazon Redshift
To demonstrate the performance benefit of this capability, we employ the industry-standard TPC-DS 3 TB dataset. We compare the query performance with and without Iceberg column statistics for the tables by running queries in Redshift Spectrum. We have included the queries used in this post, and we recommend trying your own queries by following the workflow.
The following is the overall steps:
Run AWS Glue Job that extracts TPS-DS dataset from Public Amazon S3 bucket and saves them as an Iceberg table in your S3 bucket. AWS Glue Data Catalog stores those tables’ metadata location. Query these tables using Amazon Redshift Spectrum.
Generate column statistics: Employ the enhanced capabilities of AWS Glue Data Catalog to generate column statistics for each tables. It generates puffin files storing Theta Sketch.
Query with Amazon Redshift Spectrum: Evaluate the performance benefit of column statistics on query performance by utilizing Amazon Redshift Spectrum to run queries on the dataset.
The following diagram illustrates the architecture.
To try this new capability, we complete the following steps:
This post includes a CloudFormation template for a quick setup. You can review and customize it to suit your needs. Note that this CloudFormation template requires a region with at least 3 Availability Zones. The template generates the following resources:
A virtual private cloud (VPC), public subnet, private subnets, and route tables
A Lambda function and EventBridge schedule to run the AWS Glue column statistics on a schedule
To launch the CloudFormation stack, complete the following steps:
Sign in to the AWS CloudFormation console.
Choose Launch Stack.
Choose Next.
Leave the parameters as default or make appropriate changes based on your requirements, then choose Next.
Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources.
Choose Create.
This stack can take around 10 minutes to complete, after which you can view the deployed stack on the AWS CloudFormation console.
Run an AWS Glue job to create Iceberg tables for the 3TB TPC-DS dataset
When the CloudFormation stack creation is complete, run the AWS Glue job to create Iceberg tables for the TPC-DS dataset. This AWS Glue job extracts the TPC-DS dataset from the public S3 bucket and transforms the data into Iceberg tables. Those tables are loaded into your S3 bucket and registered to the Data Catalog.
To run the AWS Glue job, complete the following steps:
On the AWS Glue console, choose ETL jobs in the navigation pane.
Choose InitialDataLoadJob-<your-stack-name>.
Choose Run.
This AWS Glue job can take around 30 minutes to complete. The process is complete when the job processing status shows as Succeeded.
The AWS Glue job creates tables storing the TPC-DS dataset in two identical databases: tpcdsdbnostats and tpcdsdbwithstats. The tables in tpcdsdbnostats will have no generated statistics, and we use them as reference. We generate statistics on tables in tpcdsdbwithstats. Confirm the creation of those two databases and underlying tables on the AWS Glue console. At this time, those databases hold the same data and there are no statistics generated on the tables.
Run queries on Redshift Spectrum without statistics
In the previous steps, you set up a Redshift Serverless workgroup with the given RPU (128 by default), prepared the TPC-DS 3TB dataset in your S3 bucket, and created Iceberg tables (which currently don’t have statistics).
To run your query in Amazon Redshift, complete the following steps:
In the Redshift query editor v2, run the queries listed in the Redshift Query for tables without column statistics section in the downloaded file redshift-tpcds-sample.sql.
Note the query runtime of each query.
Generate Iceberg column statistics
To generate statistics on the Data Catalog tables, complete the following steps:
On the AWS Glue console, choose Databases under Data Catalog in the navigation pane.
Choose the tpcdsdbwithstats database to view all available tables.
Select any of these tables (for example, call_center).
Go to Column statistics – new and choose Generate statistics.
Keep the default options:
For Choose columns, select Table (All columns).
For Row sampling options, select All rows.
For IAM role, choose AWSGluestats-blog-<your-stack-name>.
Choose Generate statistics.
You’ll be able to see status of the statistics generation run as shown in the following screenshot.
After you generate the Iceberg table column statistics, you should be able to see detailed column statistics for that table.
Following the statistics generation, you will find an <id>.stat file in the AWS Glue table’s underlying data location in Amazon S3. This file is a Puffin file that stores the Theta Sketch data structure. Query engines can use this Theta Sketch algorithm to efficiently estimate the NDV when operating on the table, which helps optimize query performance.
Reiterate the previous steps to generate statistics for all tables, such as catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, and web_returns. Alternatively, you can manually run the Lambda function that instructs AWS Glue to generate column statistics for all tables. We discuss the details of this function later in this post.
After you generate statistics for all tables, you can assess the query performance for each query.
Run queries on Redshift Spectrum with statistics
In the previous steps, you set up a Redshift Serverless workgroup with the given RPU (128 by default), prepared the TPC-DS 3TB dataset in your S3 bucket, and created Iceberg tables with column statistics.
To run the provided query using Redshift Spectrum on the statistics tables, complete the following steps:
In the Redshift query editor v2, run the queries listed in Redshift Query for tables with column statistics section in the downloaded file redshift-tpcds-sample.sql.
Note the query runtime of each query.
With Redshift Serverless 128 RPU and the TPC-DS 3TB dataset, we conducted sample runs for 10 selected TPC-DS queries where NDV information was expected to be beneficial. We ran each query 10 times. The results shown in the following table are sorted by the percentage of the performance improvement for the queries with column statistics.
TPC-DS 3T Queries
Without Column Statistics
With Column Statistics
Performance Improvement (%)
Query 16
305.0284
51.7807
489.1
Query 75
398.0643
110.8366
259.1
Query 78
169.8358
52.8951
221.1
Query 95
35.2996
11.1047
217.9
Query 94
160.52
57.0321
181.5
Query 68
14.6517
7.4745
96
Query 4
217.8954
121.996
78.6
Query 72
123.8698
76.215
62.5
Query 29
22.0769
14.8697
48.5
Query 25
43.2164
32.8602
31.5
The results demonstrated clear performance benefits ranging from 31.5–489.1%.
To dive deep, let’s explore query 16, which showed the highest performance benefit:
TPC-DS Query 16:
select
count(distinct cs_order_number) as "order count"
,sum(cs_ext_ship_cost) as "total shipping cost"
,sum(cs_net_profit) as "total net profit"
from
"awsdatacatalog"."tpcdsdbwithstats"."catalog_sales" cs1
,"awsdatacatalog"."tpcdsdbwithstats"."date_dim"
,"awsdatacatalog"."tpcdsdbwithstats"."customer_address"
,"awsdatacatalog"."tpcdsdbwithstats"."call_center"
where
d_date between '2000-2-01'
and dateadd(day, 60, cast('2000-2-01' as date))
and cs1.cs_ship_date_sk = d_date_sk
and cs1.cs_ship_addr_sk = ca_address_sk
and ca_state = 'AL'
and cs1.cs_call_center_sk = cc_call_center_sk
and cc_county in ('Dauphin County','Levy County','Luce County','Jackson County',
'Daviess County')
and exists (select *
from "awsdatacatalog"."tpcdsdbwithstats"."catalog_sales" cs2
where cs1.cs_order_number = cs2.cs_order_number
and cs1.cs_warehouse_sk <> cs2.cs_warehouse_sk)
and not exists(select *
from "awsdatacatalog"."tpcdsdbwithstats"."catalog_returns" cr1
where cs1.cs_order_number = cr1.cr_order_number)
order by count(distinct cs_order_number)
limit 100;
You can compare the difference between the query plans with and without column statistics with the ANALYZE query.
The following screenshot shows the results without column statistics.
The following screenshot shows the results with column statistics.
You can observe some notable differences as a result of using column statistics. At a high level, the overall estimated cost of the query is significantly reduced, from 20633217995813352.00 to 331727324110.36.
The two query plans chose different join strategies.
The following is one line included in the query plan without column statistics:
The query plan for the table without column statistics used DS_DIST_BOTH when joining large tables, whereas the query plan for the table with column statistics chose DS_BCAST_INNER. The join order has also changed based on the column statistics. Those join strategy and join order changes are mainly driven by more accurate join cardinality estimations, which are possible with column statistics, and result in a more optimized query plan.
Schedule AWS Glue column statistics Runs
Maintaining up-to-date column statistics is crucial for optimal query performance. This section guides you through automating the process of generating Iceberg table column statistics using Lambda and EventBridge Scheduler. This automation keeps your column statistics up to date without manual intervention.
The required Lambda function and EventBridge schedule are already created through the CloudFormation template. The Lambda function is used to invoke the AWS Glue column statistics run. First, complete the following steps to explore how the Lambda function is configured:
On the Lambda console, choose Functions in the navigation pane.
Open the function GlueTableStatisticsFunctionv1.
For a clearer understanding of the Lambda function, we recommend reviewing the code in the Code section and examining the environment variables under Configuration.
Next, complete the following steps to explore how the EventBridge schedule is configured:
On the EventBridge console, choose Schedules under Scheduler in the navigation pane.
Locate the schedule created by the CloudFormation console.
This page is where you manage and configure the schedules for your events. As shown in the following screenshot, the schedule is configured to invoke the Lambda function daily at a specific time—in this case, 08:27 PM UTC. This makes sure the AWS Glue column statistics runs on a regular and predictable basis.
Clean up
When you have finished all the above steps, remember to clean up all the AWS resources you created using AWS CloudFormation:
Delete the CloudFormation stack.
Delete S3 bucket storing the Iceberg table for the TPC-DS dataset and the AWS Glue job script.
Conclusion
This post introduced a new feature in the Data Catalog that enables you to create Iceberg table column-level statistics. The Iceberg table stores Theta Sketch, which can be used to estimate NDV efficiently in a Puffin file. The Redshift Spectrum CBO can use that to optimize the query plan, resulting in improved query performance and potential cost savings.
Try out this new feature in the Data Catalog to generate column-level statistics and improve query performance, and let us know your feedback in the comments section. Visit the AWS Glue Catalog documentation to learn more.
About the Authors
Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems.
Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Today, we announce the general availability of data preparation authoring in AWS Glue Studio Visual ETL. This is a new no-code data preparation user experience for business users and data analysts with a spreadsheet-style UI that runs data integration jobs at scale on AWS Glue for Spark. The new visual data preparation experience makes it easier for data analysts and data scientists to clean and transform data to prepare it for analytics and machine learning (ML). Within this new experience, you can choose from hundreds of pre-built transformations to automate data preparation tasks, all without the need to write any code.
Business analysts can now collaborate with data engineers to build data integration jobs. Data engineers can use the Glue Studio visual flow-based view to define connections to the data and set the ordering of the data flow process. Business analysts can use the data preparation experience to define the data transformation and output. Additionally, you can import your existing AWS Glue DataBrew data cleansing and preparation “recipes” to the new AWS Glue data preparation experience. This way, you can continue to author them directly in AWS Glue Studio and then scale up recipes to process petabytes of data at the lower price point for AWS Glue jobs.
Advanced visual ETL flows Once the appropriate AWS Identity and Access Management (IAM) role permissions have been defined, author the visual ETL using AWS Glue Studio.
Extract Create an Amazon S3 node by selecting the Amazon S3 node from the list of Sources.
Select the newly created node and browse for an S3 dataset. Once the file has been uploaded successfully, choose Infer schema to configure the source node and the visual interface will show the preview of the data contained in the .csv file.
Earlier I created an S3 bucket in the same Region as the AWS Glue visual ETL and uploaded a .csv file visual ETL conference data.csv containing the data that I will be visualizing.
It’s important to set up the role permissions as detailed in the previous step to grant AWS Glue access to read the S3 bucket. Without performing this step, you’ll get an error that ultimately prevents you from seeing the data preview.
Transform After the node has been configured, add a Data Preparation Recipe and start a data preview session. Starting this session typically takes about 2 – 3 minutes.
Once the data preview session is ready, choose Author Recipe to start an authoring session and add transformations once the data frame is complete. During the authoring session, you can view the data, apply transformation steps, and view the transformed data interactively. You can undo, redo, and reorder the steps. You can visualize the data type of the column and the statistical properties of each column.
You can start applying transformation steps to your data such as changing formats from lowercase to uppercase, changing the sort order, and more, by choosing Add step. All your data preparation steps will be tracked in the recipe. I wanted a view of conferences that will be hosted in South Africa, so I created two recipes to filter by condition where the Location column has values equal to “South Africa”, and the Comments column contains a value.
Load Once you’ve prepared your data interactively, you can share your work with data engineers who can extend it with more advanced visual ETL flows and custom code to seamlessly integrate it into their production data pipelines.
Now available The AWS Glue data preparation authoring experience is now publicly available in all commercial AWS Regions where AWS Data Brew is available. To learn more, visit AWS Glue.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Airflow that significantly improves security and availability, and reduces infrastructure management overhead when setting up and operating end-to-end data pipelines in the cloud.
Today, we are announcing the availability of Apache Airflow version 2.9.2 environments on Amazon MWAA. Apache Airflow 2.9.2 introduces several notable enhancements, such as new API endpoints for improved dataset management, advanced scheduling options including conditional expressions for dataset dependencies, the combination of dataset and time-based schedules, and custom names in dynamic task mapping for better readability of your DAGs.
In this post, we walk you through some of these new features and capabilities, how you can use them, and how you can set up or upgrade your Amazon MWAA environments to Airflow 2.9.2.
With each new version release, the Apache Airflow community is innovating to make Airflow more data-aware, enabling you to build reactive, event-driven workflows that can accommodate changes in datasets, either between Airflow environments or in external systems. Let’s go through some of these new capabilities.
Logical operators and conditional expressions for DAG scheduling
Prior to the introduction of this capability, users faced significant limitations when working with complex scheduling scenarios involving multiple datasets. Airflow’s scheduling capabilities were restricted to logical AND combinations of datasets, meaning that a DAG run would only be created after all specified datasets were updated since the last run. This rigid approach posed challenges for workflows that required more nuanced triggering conditions, such as running a DAG when any one of several datasets was updated or when specific combinations of dataset updates occurred.
With the release of Airflow 2.9.2, you can now use logical operators (AND and OR) and conditional expressions to define intricate scheduling conditions based on dataset updates. This feature allows for granular control over workflow triggers, enabling DAGs to be scheduled whenever a specific dataset or combination of datasets is updated.
For example, in the financial services industry, a risk management process might need to be run whenever trading data from any regional market is refreshed, or when both trading and regulatory updates are available. The new scheduling capabilities available in Amazon MWAA allow you to express such complex logic using simple expressions. The following diagram illustrates the dependency we need to establish.
The following DAG code contains the logical operations to implement these dependencies:
With Airflow 2.9.2 environments, Amazon MWAA now has a more comprehensive scheduling mechanism that combines the flexibility of data-driven execution with the consistency of time-based schedules.
Consider a scenario where your team is responsible for managing a data pipeline that generates daily sales reports. This pipeline relies on data from multiple sources. Although it’s essential to generate these sales reports on a daily basis to provide timely insights to business stakeholders, you also need to make sure the reports are up to date and reflect important data changes as soon as possible. For instance, if there’s a significant influx of orders during a promotional campaign, or if inventory levels change unexpectedly, the report should incorporate these updates to maintain relevance.
Relying solely on time-based scheduling for this type of data pipeline could lead to potential issues such as outdated information and infrastructure resource wastage.
The DatasetOrTimeSchedule feature introduced in Airflow 2.9 adds the capability to combine conditional dataset expressions with time-based schedules. This means that your workflow can be invoked not only at predefined intervals but also whenever there are updates to the specified datasets, with the specific dependency relationship among them. The following diagram illustrates how you can use this capability to accommodate such scenarios.
See the following DAG code for an example implementation:
from airflow.decorators import dag, task
from airflow.timetables.datasets import DatasetOrTimeSchedule
from airflow.timetables.trigger import CronTriggerTimetable
from airflow.datasets import Dataset
from datetime import datetime
# Define datasets
orders_dataset = Dataset("s3://path/to/orders/data")
inventory_dataset = Dataset("s3://path/to/inventory/data")
customer_dataset = Dataset("s3://path/to/customer/data")
# Combine datasets using logical operators
combined_dataset = (orders_dataset & inventory_dataset) | customer_dataset
@dag(
dag_id="dataset_time_scheduling",
start_date=datetime(2024, 1, 1),
schedule=DatasetOrTimeSchedule(
timetable=CronTriggerTimetable("0 0 * * *", timezone="UTC"), # Daily at midnight
datasets=combined_dataset
),
catchup=False,
)
def dataset_time_scheduling_pipeline():
@task
def process_orders():
# Task logic for processing orders
pass
@task
def update_inventory():
# Task logic for updating inventory
pass
@task
def update_customer_data():
# Task logic for updating customer data
pass
orders_task = process_orders()
inventory_task = update_inventory()
customer_task = update_customer_data()
dataset_time_scheduling_pipeline()
In the example, the DAG will be run under two conditions:
When the time-based schedule is met (daily at midnight UTC)
When the combined dataset condition is met, when there are updates to both orders and inventory data, or when there are updates to customer data, regardless of the other datasets
This flexibility enables you to create sophisticated scheduling rules that cater to the unique requirements of your data pipelines, so they run when necessary and incorporate the latest data updates from multiple sources.
For more details on data-aware scheduling, refer to Data-aware scheduling in the Airflow documentation.
Dataset event REST API endpoints
Prior to the introduction of this feature, making your Airflow environment aware of changes to datasets in external systems was a challenge—there was no option to mark a dataset as externally updated. With the new dataset event endpoints feature, you can programmatically initiate dataset-related events. The REST API has endpoints to create, list, and delete dataset events.
This capability enables external systems and applications to seamlessly integrate and interact with your Amazon MWAA environment. It significantly improves your ability to expand your data pipeline’s capacity for dynamic data management.
As an example, running the following code from an external system allows you to invoke a dataset event in the target Amazon MWAA environment. This event could then be handled by downstream processes or workflows, enabling greater connectivity and responsiveness in data-driven workflows that rely on timely data updates and interactions.
Airflow 2.9.2 also includes features to ease the operation and monitoring of your environments. Let’s explore some of these new capabilities.
Dag auto-pausing
Customers are using Amazon MWAA to build complex data pipelines with multiple interconnected tasks and dependencies. When one of these pipelines encounters an issue or failure, it can result in a cascade of unnecessary and redundant task runs, leading to wasted resources. This problem is particularly prevalent in scenarios where pipelines run at frequent intervals, such as hourly or daily. A common scenario is a critical pipeline that starts failing during the evening, and due to the failure, it continues to run and fails repeatedly until someone manually intervenes the next morning. This can result in dozens of unnecessary tasks, consuming valuable compute resources and potentially causing data corruption or inconsistencies.
The DAG auto-pausing feature aims to address this challenge by introducing two new configuration parameters:
max_consecutive_failed_dag_runs_per_dag – This is a global Airflow configuration setting. It allows you to specify the maximum number of consecutive failed DAG runs before the DAG is automatically paused.
max_consecutive_failed_dag_runs – This is a DAG-level argument. It overrides the previous global configuration, allowing you to set a custom threshold for each DAG.
In the following code example, we define a DAG with a single PythonOperator. The failing_task is designed to fail by raising a ValueError. The key configuration for DAG auto-pausing is the max_consecutive_failed_dag_runs parameter set in the DAG object. By setting max_consecutive_failed_dag_runs=3, we’re instructing Airflow to automatically pause the DAG after it fails three consecutive times.
from airflow.decorators import dag, task
from datetime import datetime, timedelta
@task
def failing_task():
raise ValueError("This task is designed to fail")
@dag(
dag_id="auto_pause",
start_date=datetime(2023, 1, 1),
schedule_interval=timedelta(minutes=1), # Run every minute
catchup=False,
max_consecutive_failed_dag_runs=3, # Set the maximum number of consecutive failed DAG runs
)
def example_dag_with_auto_pause():
failing_task_instance = failing_task()
example_dag_with_auto_pause()
With this parameter, you can now configure your Airflow DAGs to automatically pause after a specified number of consecutive failures.
To learn more, refer to DAG Auto-pausing in the Airflow documentation.
CLI support for bulk pause and resume of DAGs
As the number of DAGs in your environment grows, managing them becomes increasingly challenging. Whether for upgrading or migrating environments, or other operational activities, you may need to pause or resume multiple DAGs. This process can become a daunting cyclical endeavor because you need to navigate through the Airflow UI, manually pausing or resuming DAGs one at a time. These manual activities are time consuming and increase the risk of human error that can result in missteps and lead to data inconsistencies or pipeline disruptions. The previous CLI commands for pausing and resuming DAGs could only handle one DAG at a time, making it inefficient.
Airflow 2.9.2 improves these CLI commands by adding the capability to treat DAG IDs as regular expressions, allowing you to pause or resume multiple DAGs with a single command. This new feature eliminates the need for repetitive manual intervention or individual DAG operations, significantly reducing the risk of human error, providing reliability and consistency in your data pipelines.
As an example, to pause all DAGs generating daily liquidity reporting using Amazon Redshift as a data source, you can use the following CLI command with a regular expression:
Dynamic Task Mapping was added in Airflow 2.3. This powerful feature allows workflows to create tasks dynamically at runtime based on data. Instead of relying on the DAG author to predict the number of tasks needed in advance, the scheduler can generate the appropriate number of copies of a task based on the output of a previous task. Of course, with great powers comes great responsibilities. By default, dynamically mapped tasks were assigned numeric indexes as names. In complex workflows involving high numbers of mapped tasks, it becomes increasingly challenging to pinpoint the specific tasks that require attention, leading to potential delays and inefficiencies in managing and maintaining your data workflows.
Airflow 2.9 introduces the map_index_template parameter, a highly requested feature that addresses the challenge of task identification in Dynamic Task Mapping. With this capability, you can now provide custom names for your dynamically mapped tasks, enhancing visibility and manageability within the Airflow UI.
See the following example:
from airflow.decorators import dag
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
def process_data(data):
# Perform data processing logic here
print(f"Processing data: {data}")
@dag(
dag_id="custom_task_mapping_example",
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False,
)
def custom_task_mapping_example():
mapped_processes = PythonOperator.partial(
task_id="process_data_source",
python_callable=process_data,
map_index_template="Processing source={{ task.op_args[0] }}",
).expand(op_args=[["source_a"], ["source_b"], ["source_c"]])
custom_task_mapping_example()
The key aspect in the code is the map_index_template parameter specified in the PythonOperator.partial call. This Jinja template instructs Airflow to use the values of the ops_args environment variable as the map index for each dynamically mapped task instance. In the Airflow UI, you will see three task instances with the indexes source_a, source_b, and source_c, making it straightforward to identify and track the tasks associated with each data source. In case of failures, this capability improves monitoring and troubleshooting.
The map_index_template feature goes beyond simple template rendering, offering dynamic injection capabilities into the rendering context. This functionality unlocks greater levels of flexibility and customization when naming dynamically mapped tasks.
Refer to Named mapping in the Airflow documentation to learn more about named mapping.
TaskFlow decorator for Bash commands
Writing complex Bash commands and scripts using the traditional Airflow BashOperator may bring challenges in areas such as code consistency, task dependencies definition, and dynamic command generation. The new @task.bash decorator addresses these challenges, allowing you to define Bash statements using Python functions, making the code more readable and maintainable. It seamlessly integrates with Airflow’s TaskFlow API, enabling you to define dependencies between tasks and create complex workflows. You can also use Airflow’s scheduling and monitoring capabilities while maintaining a consistent coding style.
The following sample code showcases how the @task.bash decorator simplifies the integration of Bash commands into DAGs, while using the full capabilities of Python for dynamic command generation and data processing:
from airflow.decorators import dag, task
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# Sample customer data
customer_data = """
id,name,age,city
1,John Doe,35,New York
2,Jane Smith,42,Los Angeles
3,Michael Johnson,28,Chicago
4,Emily Williams,31,Houston
5,David Brown,47,Phoenix
"""
# Sample order data
order_data = """
order_id,customer_id,product,quantity,price
101,1,Product A,2,19.99
102,2,Product B,1,29.99
103,3,Product A,3,19.99
104,4,Product C,2,14.99
105,5,Product B,1,29.99
"""
@dag(
dag_id='task-bash-customer_order_analysis',
default_args=default_args,
start_date=datetime(2023, 1, 1),
schedule_interval=timedelta(days=1),
catchup=False,
)
def customer_order_analysis_dag():
@task.bash
def clean_data():
# Clean customer data
customer_cleaning_commands = """
echo '{}' > cleaned_customers.csv
cat cleaned_customers.csv | sed 's/,/;/g' > cleaned_customers.csv
cat cleaned_customers.csv | awk 'NR > 1' > cleaned_customers.csv
""".format(customer_data)
# Clean order data
order_cleaning_commands = """
echo '{}' > cleaned_orders.csv
cat cleaned_orders.csv | sed 's/,/;/g' > cleaned_orders.csv
cat cleaned_orders.csv | awk 'NR > 1' > cleaned_orders.csv
""".format(order_data)
return customer_cleaning_commands + "\n" + order_cleaning_commands
@task.bash
def transform_data(cleaned_customers, cleaned_orders):
# Transform customer data
customer_transform_commands = """
cat {cleaned_customers} | awk -F';' '{{printf "%s,%s,%s\\n", $1, $2, $3}}' > transformed_customers.csv
""".format(cleaned_customers=cleaned_customers)
# Transform order data
order_transform_commands = """
cat {cleaned_orders} | awk -F';' '{{printf "%s,%s,%s,%s,%s\\n", $1, $2, $3, $4, $5}}' > transformed_orders.csv
""".format(cleaned_orders=cleaned_orders)
return customer_transform_commands + "\n" + order_transform_commands
@task.bash
def analyze_data(transformed_customers, transformed_orders):
analysis_commands = """
# Calculate total revenue
total_revenue=$(awk -F',' '{{sum += $5 * $4}} END {{printf "%.2f", sum}}' {transformed_orders})
echo "Total revenue: $total_revenue"
# Find customers with multiple orders
customers_with_multiple_orders=$(
awk -F',' '{{orders[$2]++}} END {{for (c in orders) if (orders[c] > 1) printf "%s,", c}}' {transformed_orders}
)
echo "Customers with multiple orders: $customers_with_multiple_orders"
# Find most popular product
popular_product=$(
awk -F',' '{{products[$3]++}} END {{max=0; for (p in products) if (products[p] > max) {{max=products[p]; popular=p}}}} END {{print popular}}'
{transformed_orders})
echo "Most popular product: $popular_product"
""".format(transformed_customers=transformed_customers, transformed_orders=transformed_orders)
return analysis_commands
cleaned_data = clean_data()
transformed_data = transform_data(cleaned_data, cleaned_data)
analysis_results = analyze_data(transformed_data, transformed_data)
customer_order_analysis_dag()
Upon successful creation of an Airflow 2.9 environment in Amazon MWAA, certain packages are automatically installed on the scheduler and worker nodes. For a complete list of installed packages and their versions, refer to Apache Airflow provider packages installed on Amazon MWAA environments. You can install additional packages using a requirements file.
Upgrade from older versions of Airflow to version 2.9.2
In this post, we announced the availability of Apache Airflow 2.9 environments in Amazon MWAA. We discussed how some of the latest features added in the release enable you to design more reactive, event-driven workflows, such as DAG scheduling based on the result of logical operations, and the availability of endpoints in the REST API to programmatically create dataset events. We also provided some sample code to show the implementation in Amazon MWAA.
Apache, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
About the authors
Hernan Garcia is a Senior Solutions Architect at AWS, based out of Amsterdam, working with enterprises in the Financial Services Industry. He specializes in application modernization and supports customers in the adoption of serverless technologies.
Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
Today, I am very excited to announce that the new AWS Graviton4-based Amazon Elastic Compute Cloud (Amazon EC2) R8g instances, that have been available in preview since re:Invent 2023, are now generally available to all. AWS offers more than 150 different AWS Graviton-powered Amazon EC2 instance types globally at scale, has built more than 2 million Graviton processors, and has more than 50,000 customers using AWS Graviton-based instances to achieve the best price performance for their applications.
AWS Graviton4 is the most powerful and energy efficient processor we have ever designed for a broad range of workloads running on Amazon EC2. Like all the other AWS Graviton processors, AWS Graviton4 uses a 64-bit Arm instruction set architecture. AWS Graviton4-based Amazon EC2 R8g instances deliver up to 30% better performance than AWS Graviton3-based Amazon EC2 R7g instances. This helps you to improve performance of your most demanding workloads such as high-performance databases, in-memory caches, and real time big data analytics.
Since the preview announcement at re:Invent 2023, over 100 customers, including Epic Games, SmugMug, Honeycomb, SAP, and ClickHouse have tested their workloads on AWS Graviton4-based R8g instances and observed significant performance improvement over comparable instances. SmugMug achieved 20-40% performance improvements using AWS Graviton4-based instances compared to AWS Graviton3-based instances for their image and data compression operations. Epic Games found AWS Graviton4 instances to be the fastest EC2 instances they have ever tested and Honeycomb.io achieved more than double the throughput per vCPU compared to the non-Graviton based instances that they used four years ago.
Let’s look at some of the improvements that we have made available in our new instances. R8g instances offer larger instance sizes with up to 3x more vCPUs (up to 48xl), 3x the memory (up to 1.5TB), 75% more memory bandwidth, and 2x more L2 cache over R7g instances. This helps you to process larger amounts of data, scale up your workloads, improve time to results, and lower your TCO. R8g instances also offer up to 50 Gbps network bandwidth and up to 40 Gbps EBS bandwidth compared to up to 30 Gbps network bandwidth and up to 20 Gbps EBS bandwidth on Graviton3-based instances.
R8g instances are the first Graviton instances to offer two bare metal sizes (metal-24xl and metal-48xl). You can right size your instances and deploy workloads that benefit from direct access to physical resources. Here are the specs for R8g instances:
Instance Size
vCPUs
Memory
Network Bandwidth
EBS Bandwidth
r8g.medium
1
8 GiB
up to 12.5 Gbps
up to 10 Gbps
r8g.large
2
16 GiB
up to 12.5 Gbps
up to 10 Gbps
r8g.xlarge
4
32 GiB
up to 12.5 Gbps
up to 10 Gbps
r8g.2xlarge
8
64 GiB
up to 15 Gbps
up to 10 Gbps
r8g.4xlarge
16
128 GiB
up to 15 Gbps
up to 10 Gbps
r8g.8xlarge
32
256 GiB
15 Gbps
10 Gbps
r8g.12xlarge
48
384 GiB
22.5 Gbps
15 Gbps
r8g.16xlarge
64
512 GiB
30 Gbps
20 Gbps
r8g.24xlarge
96
768 GiB
40 Gbps
30 Gbps
r8g.48xlarge
192
1,536 GiB
50 Gbps
40 Gbps
r8g.metal-24xl
96
768 GiB
40 Gbps
30 Gbps
r8g.metal-48xl
192
1,536 GiB
50 Gbps
40 Gbps
If you are looking for more energy-efficient compute options to help you reduce your carbon footprint and achieve your sustainability goals, R8g instances provide the best energy efficiency for memory-intensive workloads in EC2. Additionally, these instances are built on the AWS Nitro System, which offloads CPU virtualization, storage, and networking functions to dedicated hardware and software to enhance the performance and security of your workloads. The Graviton4 processors offer you enhanced security by fully encrypting all high-speed physical hardware interfaces.
R8g instances are ideal for all Linux-based workloads including containerized and micro-services-based applications built using Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Container Registry (Amazon ECR), Kubernetes, and Docker, and as well as applications written in popular programming languages such as C/C++, Rust, Go, Java, Python, .NET Core, Node.js, Ruby, and PHP. AWS Graviton4 processors are up to 30% faster for web applications, 40% faster for databases, and 45% faster for large Java applications than AWS Graviton3 processors. To learn more, visit the AWS Graviton Technical Guide.
Check out the collection of Graviton resources to help you start migrating your applications to Graviton instance types. You can also visit the AWS Graviton Fast Start program to begin your Graviton adoption journey.
Now available R8g instances are available today in the US East (N. Virginia), US East (Ohio), US West (Oregon), and Europe (Frankfurt) AWS Regions.
You can purchase R8g instances as Reserved Instances, On-Demand, Spot Instances, and via Savings Plans. For further information, visit Amazon EC2 pricing.
Apache Flink is an open source distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing and event time semantics. Apache Flink supports multiple programming languages, Java, Python, Scala, SQL, and multiple APIs with different level of abstraction, which can be used interchangeably in the same application.
Amazon Managed Service for Apache Flink offers a fully managed, serverless experience in running Apache Flink applications and now supports Apache Flink 1.19.1, the latest stable version of Apache Flink at the time of writing. AWS led the community release of the version 1.19.1, which introduces a number of bug fixes over version 1.19.0, released in March 2024.
In this post, we discuss some of the interesting new features and configuration changes available for Managed Service for Apache Flink introduced with this new release. In every Apache Flink release, there are exciting new experimental features. However, in this post, we are going to focus on the features most accessible to the user with this release.
Connectors
With the release of version 1.19.1, the Apache Flink community also released new connector versions for the 1.19 runtime. Starting from 1.16, Apache Flink introduced a new connector version numbering, following the pattern <connector-version>-<flink-version>. It’s recommended to use connectors for the runtime version you are using. Refer to Using Apache Flink connectors to stay updated on any future changes regarding connector versions and compatibility.
SQL
Apache Flink 1.19 brings new features and improvements, particularly in the SQL API. These enhancements are designed to provide more flexibility, better performance, and ease of use for developers working with Flink’s SQL API. In this section, we delve into some of the most notable SQL enhancements introduced in this release.
State TTL per operator
Configuring state TTL at the operator level was introduced in Apache Flink 1.18 but wasn’t easily accessible to the end-user. To modify an operator TTL, you had to export the plan at development time, modify it manually, and force Apache Flink to use the edited plan instead of generating a new one when the application starts. The new features added to Flink SQL in 1.19 simplify this process by allowing TTL configurations directly through SQL hints, eliminating the need for JSON plan manipulation.
The following code shows examples of how to use SQL hints to set state TTL:
-- State TTL for Joins
SELECT /*+ STATE_TTL('Orders' = '1d', 'Customers' = '20d') */
*
FROM Orders
LEFT OUTER JOIN Customers
ON Orders.o_custkey = Customers.c_custkey;
-- State TTL for Aggregations
SELECT /*+ STATE_TTL('o' = '1d') */
o_orderkey, SUM(o_totalprice) AS revenue
FROM Orders AS o
GROUP BY o_orderkey;
Session window table-valued functions
Windows are at the heart of processing infinite streams in Apache Flink, splitting the stream into finite buckets for computations. Before 1.19, Apache Flink provided the following types of window table-value functions (TVFs):
Tumble windows – Fixed-size, non-overlapping windows
Hop windows – Fixed-size, overlapping windows with a specified hop interval
Cumulate windows – Increasingly larger windows that start at the same point but grow over time
With the Apache Flink 1.19 release, it has enhanced its SQL capabilities by supporting session window TVFs in streaming mode, allowing for more sophisticated and flexible windowing operations directly within SQL queries. Applications can create dynamic windows that group elements based on session gaps, now supported in streaming mode. The following code shows an example:
-- Session window with partition keys
SELECT
*
FROM TABLE(
SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES));
-- Apply aggregation on the session windowed table with partition keys
SELECT
window_start, window_end, item, SUM(price) AS total_price
FROM TABLE(
SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES))
GROUP BY item, window_start, window_end;
Mini-batch optimization for regular joins
When using the Table API or SQL, regular joins—standard equi-joins like a table SQL join, where time is not a factor—may induce a considerable overhead for the state backend, especially when using RocksDB.
Normally, Apache Flink processes standard joins one record at a time, looking up the state for a matching record in the other side of the join, updating the state with the input record, and emitting the resulting record. This may add considerable pressure on RocksDB, with multiple reads and writes for each record.
Apache Flink 1.19 introduces the ability to use mini-batch processing with equi-joins (FLIP-415). When enabled, Apache Flink will process regular joins not one record at a time, but in small batches, substantially reducing the pressure on the RocksDB state backend. Mini-batching adds some latency, which is controllable by the user. See, for example, the following SQL code (embedded in Java):
TableConfig tableConfig = tableEnv.getConfig();
tableConfig.set("table.exec.mini-batch.enabled", "true");
tableConfig.set("table.exec.mini-batch.allow-latency", "5s");
tableConfig.set("table.exec.mini-batch.size", "5000");
tableEnv.executeSql("CREATE TEMPORARY VIEW ab AS " +
"SELECT a.id as a_id, a.a_content, b.id as b_id, b.b_content " +
"FROM a LEFT JOIN b ON a.id = b.id";
With this configuration, Apache Flink will buffer up to 5,000 records or up to 5 seconds, whichever comes first, before processing the join for the entire mini-batch.
In Apache Flink 1.19, mini-batching only works for regular joins, not windowed or temporal joins. Mini-batching is disabled by default, and you have to explicitly enable it and set the batch size and latency for Flink to use it. Also, mini-batch settings are global, applied to all regular join of your application. At the time of writing, it’s not possible to set mini-batching per join statement.
AsyncScalarFunction
Before version 1.19, an important limitation of SQL and the Table API, compared to the Java DataStream API, was the lack of asynchronous I/O support. Any request to an external system, for example a database or a REST API, or even any AWS API call, using the AWS SDK, is synchronous and blocking. An Apache Flink’s subtask waits for the response before completing the processing of a record and proceeding to the next one. Practically, the roundtrip latency of each request was added to the processing latency for each processed record. Apache Flink’s Async I/O API removes this limitation, but it’s only available for the DataStream API and Java. Until version 1.19, there was no simple efficient workaround in SQL, the Table API, or Python.
Apache Flink 1.19 introduces the new AsyncScalarFunction, a user-defined function (UDF) that can be implemented using non-blocking calls to the external system, to support use cases similar to asynchronous I/O in SQL and the Table API.
This new type of UDF is only available in streaming mode. At the moment, it only supports ordered output. DataStream Async I/O also supports unordered output, which may further reduce latency when strict ordering isn’t required.
Python 3.11 support
Python 3.11 is now supported, and Python 3.7 support has been completely removed (FLINK-33029). Managed Service for Apache Flink currently uses the Python 3.11 runtime to run PyFlink applications. Python 3.11 is a bugfix only version of the runtime. Python 3.11 introduced several performance improvements and bug fixes, but no API breaking changes.
In the latest release of Apache Flink 1.19, significant enhancements have been made to improve checkpoint behavior. With this new release, it gives the application the capability to adjust checkpointing intervals dynamically based on whether the source is processing backlog data (FLIP-309).
In Apache Flink 1.19, you can now specify different checkpointing intervals based on whether a source operator is processing backlog data. This flexibility optimizes job performance by reducing checkpoint frequency during backlog phases, enhancing overall throughput. Extending checkpoint intervals allows Apache Flink to prioritize processing throughput over frequent state snapshots, thereby improving efficiency and performance.
To enable it, you need to define the execution.checkpointing.interval parameter for regular intervals and execution.checkpointing.interval-during-backlog to specify a longer interval when sources report processing backlog.
For example, if you want to run checkpoints every 60 seconds during normal processing, but extend to 10 minutes during the processing of backlogs, you can set the following:
In Amazon Managed Service for Apache Flink, the default checkpointing interval is configured by the application configuration (60 seconds by default). You don’t need to set the configuration parameter. To set a longer checkpointing interval during backlog processing, you can raise a support case to modify execution.checkpointing.interval-during-backlog. See Modifiable Flink configuration properties for further details about modifying Apache Flink configurations.
At the time of writing, dynamic checkpointing intervals are only supported by Apache Kafka source and FileSystem source connectors. If you use any other source connector, intervals during backlog are ignored, and Apache Flink runs a checkpoint at the default interval during backlog processing.
More troubleshooting information: Job initialization and checkpoint traces
With FLIP-384, Apache Flink 1.19 introduces trace reporters, which show checkpointing and job initialization traces. As of 1.19, this trace information can be sent to the logs using Slf4j. In Managed Service for Apache Flink, this is now enabled by default. You can find checkpoint and job initialization details in Amazon CloudWatch Logs, with the other logs from the application.
Checkpoint traces contain valuable information about each checkpoint. You can find similar information on the Apache Flink Dashboard, but only for the latest checkpoints and only while the application is running. Conversely, in the logs, you can find the full history of checkpoints. The following is an example of a checkpoint trace:
Job initialization traces are generated when the job starts and recovers the state from a checkpoint or savepoint. You can find valuable statistics you can’t normally find elsewhere, including the Apache Flink Dashboard. The following is an example of a job initialization trace:
Checkpoint and job initialization traces are logged at INFO level. You can find them in CloudWatch Logs only if you configure a logging level of INFO or DEBUG in your Managed Service for Apache Flink application.
Managed Service for Apache Flink behavior change
As a fully managed service, Managed Service for Apache Flink controls some runtime configuration parameters to guarantee the stability of your application. For details about the Apache Flink settings that can be modified, see Apache Flink settings.
With the 1.19 runtime, if you programmatically modify a configuration parameter that is directly controlled by Managed Service for Apache Flink, you receive an explicit ProgramInvocationException when the application starts, explaining what parameter is causing the problem and preventing the application from starting. With runtime 1.18 or earlier, changes to parameters controlled by the managed service were silently ignored.
In this post, we explored some of the new relevant features and configuration changes introduced with Apache Flink 1.19, now supported by Managed Service for Apache Flink. This latest version brings numerous enhancements aimed at improving performance, flexibility, and usability for developers working with Apache Flink.
With the support of Apache Flink 1.19, Managed Service for Apache Flink now supports the latest released Apache Flink version. We have seen some of the interesting new features available for Flink SQL and PyFlink.
You can find more details about recent releases from the Apache Flink blog and release notes:
If you’re already running an application in Managed Service for Apache Flink, you can safely upgrade it in-place to the new 1.19 runtime.
About the Authors
Francisco Morillo is a Streaming Solutions Architect at AWS, specializing in real-time analytics architectures. With over five years in the streaming data space, Francisco has worked as a data analyst for startups and as a big data engineer for consultancies, building streaming data pipelines. He has deep expertise in Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Francisco collaborates closely with AWS customers to build scalable streaming data solutions and advanced streaming data lakes, ensuring seamless data processing and real-time insights.
Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working in the finance industry both through consultancies and for FinTech product companies. He has leveraged open-source technologies extensively and contributed to several projects, including Apache Flink.
I counted only 21 AWS news since last Monday, most of them being Regional expansions of existing services and capabilities. I hope you enjoyed a relatively quiet week, because this one will be busier.
This week, we’re welcoming our customers and partners at the Jacob Javits Convention Center for the AWS Summit New York on Wednesday, July 10. I can tell you there is a stream of announcements coming, if I judge by the number of AWS News Blog posts ready to be published.
I am writing these lines just before packing my bag to attend the AWS Community Day in Douala, Cameroon next Saturday. I can’t wait to meet our customers and partners, students, and the whole AWS community there.
But for now, let’s look at last week’s new announcements.
Last week’s launches Here are the launches that got my attention.
AWS Lambda introduces new controls to make it easier to search, filter, and aggregate Lambda function logs – You can now capture your Lambda logs in JSON structured format without bringing your own logging libraries. You can also control the log level (for example, ERROR, DEBUG, or INFO) of your Lambda logs without making any code changes. Lastly, you can choose the Amazon CloudWatch log group to which Lambda sends your logs.
Amazon DataZone introduces fine-grained access control – Amazon DataZone has introduced fine-grained access control, providing data owners granular control over their data at row and column levels. You use Amazon DataZone to catalog, discover, analyze, share, and govern data at scale across organizational boundaries with governance and access controls. Data owners can now restrict access to specific records of data instead of granting access to an entire dataset.
AWS Direct Connect proposes native 400 Gbps dedicated connections at select locations – AWS Direct Connect provides private, high-bandwidth connectivity between AWS and your data center, office, or colocation facility. Native 400 Gbps connections provide higher bandwidth without the operational overhead of managing multiple 100 Gbps connections in a link aggregation group. The increased capacity delivered by 400 Gbps connections is particularly beneficial to applications that transfer large-scale datasets, such as for ML and large language model (LLM) training or advanced driver assistance systems for autonomous vehicles.
Other AWS news Here are some additional news items that you might find interesting:
The list of services available at launch in the upcoming AWS Europe Sovereign Cloud Region is available – we shared the list of AWS services that will be initially available at launch in the new AWS European Sovereign Cloud Region. The list has no surprises. Services for security, networking, storage, computing, containers, artificial intelligence (AI), and serverless will be available at launch. We are building the AWS European Sovereign Cloud to offer public sector organizations and customers in highly regulated industries further choice to help them meet their unique digital sovereignty requirements, as well as stringent data residency, operational autonomy, and resiliency requirements. This is an investment of 7.8 billion euros (approximately $8.46 billion). The new Region will be available by the end of 2025.
Upcoming AWS events Check your calendars and sign up for upcoming AWS events:
AWS Summits – Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. To learn more about future AWS Summit events, visit the AWS Summit page. Register in your nearest city: New York (July 10), Bogotá (July 18), and Taipei (July 23–24).
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world. Upcoming AWS Community Days are in Cameroon (July 13), Aotearoa (August 15), and Nigeria (August 24).
Last month, we shared that we are investing €7.8 billion in the AWS European Sovereign Cloud, a new independent cloud for Europe, which is set to launch by the end of 2025. We are building the AWS European Sovereign Cloud designed to offer public sector organizations and customers in highly regulated industries further choice to help them meet their unique digital sovereignty requirements, as well as stringent data residency, operational autonomy, and resiliency requirements. Customers and partners using the AWS European Sovereign Cloud will benefit from the full capacity of AWS including the same familiar architecture, service portfolio, APIs, and security features available in our 33 existing AWS Regions. Today, we are thrilled to reveal an initial roadmap of services that will be available in the AWS European Sovereign Cloud. This announcement highlights the breadth and depth of the AWS European Sovereign Cloud service portfolio, designed to meet customer and partner demand while delivering on our commitment to offer the most advanced set of sovereignty controls and features available in the cloud.
The AWS European Sovereign Cloud is architected to be sovereign-by-design, just as the AWS Cloud has been since day one. We have designed a secure and highly available global infrastructure, built safeguards into our service design and deployment mechanisms, and instilled resilience into our operational culture. Our customers benefit from a cloud built to help them satisfy the requirements of the most security-sensitive organizations. Each Region is comprised of multiple Availability Zones and each Availability Zone is made up of one or more discrete data centers, each with redundant power, connectivity, and networking. The first Region of the AWS European Sovereign Cloud will be located in the State of Brandenburg, Germany, with infrastructure wholly located within the European Union (EU). Like our existing Regions, the AWS European Sovereign Cloud will be powered by the AWS Nitro System. The Nitro System powers all our modern Amazon Elastic Compute Cloud (Amazon EC2) instances and provides a strong physical and logical security boundary to enforce access restrictions so that nobody, including AWS employees, can access customer data running in Amazon EC2.
Service roadmap for the AWS European Sovereign Cloud
AWS is committed to offering our customers the most advanced set of sovereignty controls and features available in the cloud. We have a wide range of offerings to help you meet your unique digital sovereignty requirements, including our eight existing Regions in Europe, AWS Dedicated Local Zones, and AWS Outposts. The AWS European Sovereign Cloud is an additional option to choose from. You can start building in our existing sovereign-by-design Regions and, if needed, migrate to the AWS European Sovereign Cloud. If you have stringent isolation and in-country data residency requirements, you will also be able to use Dedicated Local Zones or Outposts to deploy AWS European Sovereign Cloud infrastructure in locations you select.
Today, you can conduct proof-of-concept exercises and gain hands-on experience that will help you hit the ground running when the AWS European Sovereign Cloud launches in 2025. For example, you can use AWS CloudFormation to create and provision AWS infrastructure deployments predictably and repeatedly in an existing Region to prepare for the AWS European Sovereign Cloud. Using AWS CloudFormation, you can leverage services like Amazon EC2, Amazon Simple Notification Service (Amazon SNS), and Elastic Load Balancing to build highly reliable, highly scalable, cost-effective applications in the cloud in a repeatable, auditable, and automatable manner. You can use Amazon SageMaker to build, train, and deploy your machine learning models (including large language and other foundation models). You can use Amazon S3 to benefit from automatic encryption on all object uploads. If you have a regulatory need to store and use your encryption keys on premises or outside AWS, you can use the AWS KMS External Key Store.
Whether you’re migrating to the cloud for the first time, considering the AWS European Sovereign Cloud, or modernizing your applications to take advantage of cloud services, you can benefit from our experience helping organizations of all sizes move to and thrive in the cloud. We provide a wide range of resources to adopt the cloud effectively and accelerate your cloud migration and modernization journey, including the AWS Cloud Adoption Framework and AWS Migration Acceleration Program. Our global AWS Training and Certification helps learners and organizations build in-demand cloud skills and validate expertise with free and low-cost training and industry-recognized AWS Certification credentials, including more than 100 training resources for AI and machine learning (ML).
Customers and partners welcome the AWS European Sovereign Cloud service roadmap
Adobe is the world leader in creating, managing, and optimizing digital experiences. For over twelve years, Adobe Experience Manager (AEM) Managed Services has leveraged the AWS Cloud to support Adobe customers’ use of AEM Managed Services. “Over the years, AEM Managed Services has focused on the four pillars of security, privacy, regulation, and governance to ensure Adobe customers have best-in-class digital experience management tools at their disposal,” Mitch Nelson, Senior Director, Worldwide Managed Services at Adobe. “We are excited about the launch of the AWS European Sovereign Cloud and the opportunity it presents to align with Adobe’s Single Sovereign Architecture for AEM offering. We look forward to being among the first to provide the AWS European Sovereign Cloud to Adobe customers.”
adesso SE is a leading IT services provider in Germany with a focus on helping customers optimize core business processes with modern IT. adesso SE and AWS have been working together to help organizations drive digital transformations, quickly and efficiently, with tailored solutions. “With the European Sovereign Cloud, AWS is providing another option that can help customers navigate the complexity around changing rules and regulations. Organizations across the public sector and regulated industries are already using the AWS Cloud to help meet their digital sovereignty requirements, and the AWS European Sovereign Cloud will unlock additional opportunities,” said Markus Ostertag, Chief AWS Technologist, adesso SE. “As one of Germany’s largest IT service providers, we see the benefits that the European Sovereign Cloud service portfolio will provide to help customers innovate while getting the reliability, resiliency, and availability they need. AWS and adesso SE share a mutual commitment to meeting the unique needs of our customers, and we look forward to continuing to help organizations across the EU drive advancements.”
Genesys, a global leader in AI-powered experience orchestration, empowers more than 8,000 organizations in over 100 countries to deliver personalized, end-to-end experience at scale. With Genesys Cloud running on AWS, the companies have a longstanding collaboration to deliver scalable, secure, and innovative services to joint global clientele. “Genesys is at the forefront of helping businesses use AI to build loyalty with customers and drive productivity and engagement with employees,” said Glenn Nethercutt, Chief Technology Officer at Genesys. “Delivery of the Genesys Cloud platform on the AWS European Sovereign Cloud will enable even more organizations across Europe to experiment, build, and deploy cutting-edge customer experience applications while adhering to stringent data sovereignty and regulatory requirements. Europe is a key player in the global economy and a champion of data protection standards, and upon its launch, the AWS European Sovereign Cloud will offer a comprehensive suite of services to help businesses meet both data privacy and regulatory requirements. This partnership reinforces our continued investment in the region and Genesys and AWS remain committed to working together to help address the unique challenges faced by European businesses, especially those in highly regulated industries such as finance and healthcare.”
Pega provides a powerful platform that empowers global clients to use AI-powered decisioning and workflow automation solutions to solve their most pressing business challenges – from personalizing engagement to automating service to streamlining operations. Pega’s strategic work with AWS has allowed Pega to transform its as-a-Service business to become a highly scalable, reliable, and agile way for our clients to experience Pega’s platform across the globe. “The collaboration between AWS and Pega will deepen our commitment to our European Union clients to storing and processing their data within region,” said Frank Guerrera, chief technical systems officer at Pegasystems. “Our combined solution, taking advantage of the AWS European Sovereign Cloud, will allow Pega to provide sovereignty assurances at all layers of the service, from Pega’s platform and supporting technologies all the way to the enabling infrastructure. This solution combines Pega Cloud’s already stringent approach to data isolation, people, and process with the new and innovative AWS European Sovereign Cloud to deliver flexibility for our public sector and highly regulated industry clients.”
SVA System Vertrieb Alexander GmbH is one of the leading founder-owned system integrators in Germany with more than 3,200 talented employees at 27 offices across the country that are delivering best-in-class solutions to more than 3,000 customers. The 10-year collaboration between SVA and AWS has helped support customers across all industries and verticals to migrate and modernize workloads from on-premises to AWS or build new solutions from scratch. “The AWS European Sovereign Cloud is addressing specific needs for highly regulated customers, can lower the barriers and unlock huge digitalization potential for these verticals,” said Patrick Glawe, AWS Alliance Lead at SVA System Vertrieb Alexander GmbH. “Given our broad coverage across the public sector and regulated industries, we listen carefully to the discussions regarding cloud adoption and will soon be offering an option to design a highly innovative ecosystem that meets the highest standards of data protection, regulatory compliance, and digital sovereignty requirements. This will have a major impact on the European Union’s digitalization agenda.”
We remain committed to giving our customers more control and more choice to take advantage of the innovation the cloud can offer while helping them meet their unique digital sovereignty needs, without compromising on the full power of AWS. Learn more about the AWS European Sovereign Cloud on our European Digital Sovereignty website and stay tuned for more updates as we continue to drive toward the 2025 launch.
Initial planned services for the AWS European Sovereign Cloud
Analytics
Amazon Athena
Amazon Data Firehose
Amazon EMR
Amazon Kinesis Data Streams
Amazon Managed Service for Apache Flink
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
French version
Annonce des premiers services disponibles dans l’AWS European Sovereign Cloud, basés sur toute la puissance d’AWS
Le mois dernier, nous avons annoncé un investissement de 7,8 milliards d’euros dans l’AWS European Sovereign Cloud, un nouveau cloud indépendant pour l’Europe qui sera lancé d’ici fin 2025. L’AWS European Sovereign Cloud vise à offrir aux organisations du secteur public et aux clients des industries hautement réglementées une nouvelle option pour répondre à leurs exigences spécifiques en matière de souveraineté numérique, de localisation des données, d’autonomie opérationnelle et de résilience. Les clients et partenaires utilisant l’AWS European Sovereign Cloud bénéficieront de toute la puissance d’AWS, mais également de la même architecture à laquelle ils sont habitués, du même portefeuille étendu de services, des mêmes API et des mêmes fonctionnalités de sécurité que dans les 33 Régions AWS déjà en service. Aujourd’hui, nous sommes ravis de dévoiler une première feuille de route des services qui seront disponibles dans l’AWS European Sovereign Cloud. Cette annonce offre un aperçu de la richesse et de la diversité des services de l’AWS European Sovereign Cloud, conçu pour répondre aux besoins de nos clients et partenaires, tout en respectant notre engagement à offrir l’ensemble le plus avancé d’outils et de fonctionnalités de contrôle disponibles dans le cloud au service de la souveraineté.
L’AWS European Sovereign Cloud a été pensé pour être souverain dès sa conception, tout comme l’AWS Cloud depuis l’origine. Nous avons mis en place une infrastructure mondiale sécurisée à haut niveau de disponibilité, intégré des systèmes de protection pour la conception et le déploiement de nos services et développé une culture opérationnelle de la résilience. Nos clients bénéficient ainsi d’un cloud conçu pour les aider à répondre aux exigences de sécurité les plus strictes. Chaque Région est composée de plusieurs zones de disponibilité comprenant chacune un ou plusieurs centres de données distincts avec une alimentation, une connectivité et un réseau redondants. La première Région de l’AWS European Sovereign Cloud sera située dans le land de Brandebourg, en Allemagne, avec une infrastructure entièrement localisée au sein de l’Union Européenne (UE). Comme dans nos Régions existantes, l’AWS European Sovereign Cloud s’appuiera sur AWS Nitro System. Ce système, à la base de nos instances Amazon Elastic Compute Cloud (Amazon EC2) implémente une séparation physique et logique robuste, afin que personne, y compris au sein d’AWS, ne puisse accéder aux données des clients traitées dans Amazon EC2.
Feuille de route des services pour l’AWS European Sovereign Cloud
Lors du lancement d’une nouvelle Région, nous commençons par mettre en place les services de base nécessaires à la gestion des applications critiques, avant d’étendre notre catalogue de services en fonction des demandes de nos clients et partenaires. L’AWS European Sovereign Cloud proposera initialement des services de différentes catégories, notamment pour l’intelligence artificielle avec Amazon SageMaker, Amazon Q et Amazon Bedrock, pour le calcul avec Amazon EC2 et AWS Lambda, pour les conteneurs avec Amazon Elastic Kubernetes Service (Amazon EKS) et Amazon Elastic Container Service (Amazon ECS), pour les bases de données avec Amazon Aurora, Amazon DynamoDB et Amazon Relational Database Service (Amazon RDS), pour la mise en réseau avec Amazon Virtual Private Cloud (Amazon VPC), pour la sécurité avec AWS Key Management Service (AWS KMS) et AWS Private Certificate Authority et pour le stockage avec Amazon Simple Storage Service (Amazon S3) et Amazon Elastic Block Store (Amazon EBS). L’AWS European Sovereign Cloud disposera de ses propres systèmes dédiés de gestion des identités et des accès (IAM), de facturation et de mesure de l’utilisation, fonctionnant de manière indépendante des Régions existantes. Ces systèmes permettront aux clients utilisant l’AWS European Sovereign Cloud de conserver toutes leurs données ainsi que toutes les métadonnées qu’ils créent (comme les rôles, les permissions, les étiquettes de ressources et les configurations utilisées pour exécuter les services) dans l’Union européenne. Les clients d’AWS European Sovereign Cloud pourront également profiter de l’AWS Marketplace, un catalogue numérique organisé qui facilite la recherche, le test, l’achat et le déploiement de logiciels tiers. Afin d’aider les clients et les partenaires à préparer leurs déploiements sur l’AWS European Sovereign Cloud, nous publions la feuille de route des services initiaux à la fin de cet article.
Commencez dès aujourd’hui à développer vos solutions souveraines sur AWS
AWS s’engage à proposer l’ensemble le plus avancé d’outils et de fonctionnalités de contrôle disponibles dans le cloud au service de la souveraineté. Nous disposons d’une large gamme de solutions pour vous aider à répondre à vos exigences uniques en matière de souveraineté numérique, y compris nos huit Régions existantes en Europe, les AWS Dedicated Local Zones et les AWS Outposts. L’AWS European Sovereign Cloud constitue une option supplémentaire. Vous pouvez commencer à développer vos projets dans nos Régions existantes, toutes souveraines dès leur conception, et migrer si nécessaire vers l’AWS European Sovereign Cloud. En cas d’exigences strictes pour l’isolation et la localisation des données dans un pays, vous pourrez également utiliser les Dedicated Local Zones ou les Outposts pour déployer l’infrastructure de l’AWS European Sovereign Cloud là où vous le désirez.
Dès aujourd’hui, vous pouvez construire des démonstrateurs (PoC) et acquérir une expérience pratique qui vous permettra d’être opérationnel dès le lancement de l’AWS European Sovereign Cloud en 2025. Vous pouvez par exemple utiliser AWS CloudFormation pour créer et déployer de manière prévisible et répétée des déploiements d’infrastructure AWS dans une Région existante afin de vous préparer à l’AWS European Sovereign Cloud. Avec AWS CloudFormation, vous pouvez exploiter des services comme Amazon EC2, Amazon Simple Notification Service (Amazon SNS) et Elastic Load Balancing afin de développer des applications cloud hautement fiables et hautement évolutives de manière reproductible, auditable et automatisable. Amazon SageMaker vous permet de créer, d’entraîner et de déployer tous vos modèles d’apprentissage automatique, y compris des grands modèles de langage (LLM). Et avec Amazon S3, vous pouvez bénéficier du chiffrement automatique pour tous les objets importés. Enfin, si vous devez stocker et utiliser vos clés de chiffrement sur site ou en dehors d’AWS en raison de certaines réglementations, vous pouvez utiliser AWS KMS External Key Store.
Que vous vous apprêtiez à migrer vers le cloud pour la première fois, que vous envisagiez de passer à l’AWS European Sovereign Cloud ou que vous ayez pour projet de moderniser vos applications pour profiter des services cloud, notre expérience peut vous être précieuse. Nous aidons des organisations de différentes tailles à réussir leur transition vers le cloud. Nous mettons à votre disposition une large gamme de ressources pour adopter efficacement le cloud, accélérer votre migration ou votre modernisation, à l’image du Framework d’adoption du cloud AWS et du programme d’accélération des migrations AWS. Notre programme de certification AWS permet aux professionnels et aux organisations de développer des compétences cloud très demandées et de valider leur expertise grâce à des formations gratuites ou peu coûteuses ainsi qu’à des certifications AWS reconnues par l’ensemble de l’industrie. Nous proposons ainsi plus de 100 ressources de formation en intelligence artificielle et en apprentissage automatique.
Nos clients et partenaires accueillent favorablement le portefeuille de services de l’AWS European Sovereign Cloud
Adobe est le leader mondial de la création, de la gestion et de l’optimisation des expériences numériques. Depuis plus de douze ans, les services gérés Adobe Experience Manager (AEM) s’appuient sur le cloud Amazon Web Services (AWS) pour accompagner les clients d’Adobe dans leur utilisation d’AEM. « Au fil des années, les services d’AEM se sont concentrés sur les quatre piliers que sont la sécurité, la confidentialité, la réglementation et la gouvernance, afin de garantir aux clients d’Adobe l’accès aux meilleurs outils de gestion d’expérience numérique du marché », a déclaré Mitch Nelson, Senior Director, Worldwide Managed Services, Adobe. « Nous sommes ravis du lancement d’AWS European Sovereign Cloud, qui représente une opportunité unique de s’aligner sur l’architecture souveraine d’Adobe pour l’offre AEM. Nous espérons être parmi les premiers à proposer AWS European Sovereign Cloud aux clients d’Adobe. »
adesso SE est un important fournisseur de services informatiques en Allemagne, spécialisé dans l’optimisation des processus opérationnels essentiels à l’aide de technologies informatiques modernes. En collaboration avec AWS, adesso SE accompagne les organisations dans leurs transformations numériques avec des solutions personnalisées et efficaces. Pour Markus Ostertag, Chief AWS Technologist chez adesso SE, « l’European Sovereign Cloud d’AWS, est une nouvelle option qui va permettre aux clients de se frayer un chemin dans la complexité toujours croissante des réglementations. Les organisations publiques et les industries réglementées utilisent déjà le Cloud AWS pour répondre à leurs exigences en matière de souveraineté numérique, et l’AWS European Sovereign Cloud leur ouvrira de nouvelles perspectives. » Il poursuit : « En tant que l’un des principaux fournisseurs de services informatiques en Allemagne, nous voyons les avantages que le portefeuille de services de l’European Sovereign Cloud apporteront pour stimuler l’innovation tout en garantissant fiabilité, résilience et disponibilité. AWS et adesso SE partagent un engagement commun à répondre aux besoins spécifiques de nos clients, et nous sommes impatients de continuer à accompagner les différentes organisations à travers l’Union européenne dans leurs avancées technologiques. »
Genesys, leader mondial dans l’orchestration des expériences clients alimentées par l’IA, permet à plus de 8 000 organisations réparties dans plus de 100 pays de proposer des expériences personnalisées de bout en bout à grande échelle. En partenariat avec Amazon Web Services (AWS), Genesys Cloud tire parti de cette plateforme depuis longtemps pour fournir des services sécurisés, évolutifs et innovants à une clientèle mondiale commune. Glenn Nethercutt, Chief Technology Officer chez Genesys, commente : « Genesys joue un rôle de premier plan en aidant les entreprises à utiliser l’IA pour fidéliser leurs clients mais aussi améliorer la productivité et l’engagement de leurs employés. Le déploiement de la plateforme Genesys Cloud sur l’AWS European Sovereign Cloud permettra à davantage d’organisations à travers l’Europe d’explorer, développer et déployer des applications avancées d’expérience client, tout en respectant les exigences et les réglementations les plus strictes en matière de souveraineté des données. L’Europe est un acteur clé de l’économie mondiale et un défenseur des normes de protection des données. Avec le lancement prochain de l’AWS European Sovereign Cloud, une gamme complète de services sera proposée pour aider les entreprises à répondre aux exigences réglementaires et de confidentialité des données. Ce partenariat renforce notre investissement continu dans la région. Genesys et AWS restent engagés à collaborer pour relever les défis uniques auxquels les entreprises européennes sont confrontées, en particulier celles des secteurs hautement réglementés comme la finance et la santé. »
Pega propose une plateforme performante qui permet aux clients internationaux de relever leurs défis commerciaux les plus urgents grâce à des solutions d’aide à la prise de décision et d’automatisation des flux basées sur l’IA. Des solutions qui vont de la personnalisation des interactions client à l’automatisation des services en passant par l’optimisation des opérations. Le partenariat stratégique avec AWS a permis à Pega de transformer son activité en mode SaaS (logiciel en tant que service) en une solution hautement évolutive, fiable et agile, offrant à nos clients une expérience optimale de la plateforme Pega, partout dans le monde. Frank Guerrera, Chief Technical Systems Officer chez Pegasystems, précise : « La collaboration entre AWS et Pega renforcera notre engagement envers nos clients de l’Union européenne pour le stockage et le traitement de leurs données dans la région. Notre solution combinée, tirant parti de l’AWS European Sovereign Cloud, permettra à Pega d’offrir des garanties de souveraineté à tous les niveaux du service, de la plateforme Pega et ses technologies jusqu’à l’infrastructure sous-jacente. Cette solution associe l’approche déjà rigoureuse de Pega Cloud en matière d’isolation des données, de ressources humaines et de processus à celle, nouvelle et innovante, de l’AWS European Sovereign Cloud pour offrir une flexibilité accrue à nos clients du secteur public et des industries hautement réglementées. »
SVA System Vertrieb Alexander GmbH est l’un des principaux intégrateurs de systèmes en Allemagne. Fondé et dirigé par ses propriétaires, il emploie plus de 3 200 employés répartis dans 27 bureaux à travers le pays, et fournit des solutions de pointe à plus de 3 000 clients. Les 10 années de collaboration avec AWS ont permis d’aider des clients de tous les secteurs à migrer et à moderniser leurs applications depuis les infrastructures sur site vers AWS, mais aussi à créer de nouvelles solutions à partir de zéro. « L’AWS European Sovereign Cloud répond aux besoins spécifiques des clients issus d’industries hautement réglementées, peut contribuer à réduire les obstacles existants et libérer un formidable potentiel de numérisation », a déclaré Patrick Glawe, AWS Alliance Lead, SVA System Vertrieb Alexander GmbH. « En tant que partenaire privilégié du secteur public et des industries réglementées, nous suivons de près les discussions sur l’adoption du cloud et nous allons bientôt proposer une option permettant de concevoir un écosystème hautement innovant répondant aux normes les plus strictes en matière de protection des données, de conformité réglementaire et de souveraineté numérique. Cela aura un impact majeur sur le programme de numérisation de l’Union européenne. »
Nous réaffirmons notre engagement à offrir à nos clients plus de contrôle et de choix afin qu’ils puissent tirer pleinement parti des innovations offertes par le cloud, tout en les aidant à répondre à leurs besoins spécifiques en matière de souveraineté numérique, sans aucun compromis sur la puissance d’AWS. Découvrez-en davantage sur l’AWS European Sovereign Cloud sur notre site internet dédié à la souveraineté numérique européenne et suivez l’évolution du projet à mesure que nous nous rapprochons de son lancement en 2025.
German version
Bekanntgabe der ersten Services in der AWS European Sovereign Cloud, angetrieben von der vollen Leistungsfähigkeit von AWS
Letzten Monat haben wir bekanntgegeben, dass wir 7,8 Milliarden Euro in die AWS European Sovereign Cloud investieren, eine neue unabhängige Cloud für Europa, die bis Ende 2025 eröffnen soll. Wir bauen die AWS European Sovereign Cloud auf, um Organisationen des öffentlichen Sektors und Kunden in stark regulierten Branchen mehr Wahlmöglichkeiten zu bieten. Wir möchten ihnen dabei helfen, ihre spezifischen Anforderungen an die digitale Souveränität sowie die strengen Vorgaben in Bezug auf den Ort der Datenverarbeitung, die betriebliche Autonomie und die Resilienz zu erfüllen. Kunden und Partner werden von der vollen Leistungsstärke von AWS profitieren, wenn sie die AWS European Sovereign Cloud nutzen. Dazu gehören auch die bekannte Architektur, das Service-Portfolio, die APIs und die Sicherheitsfunktionen, die bereits in unseren 33 bestehenden AWS-Regionen verfügbar sind. Wir freuen uns sehr, heute eine erste Roadmap mit den Services, die in der AWS European Sovereign Cloud verfügbar sein werden, vorzustellen. Diese Bekanntgabe unterstreicht den Umfang des Service-Portfolios der AWS European Sovereign Cloud, das nicht nur die Ansprüche unserer Kunden und Partner erfüllt, sondern auch unser Versprechen, die fortschrittlichsten Souveränitätskontrollen und -funktionen zu bieten, die überhaupt in der Cloud verfügbar sind.
Die AWS European Sovereign Cloud basiert, so wie auch die AWS Cloud seit Tag eins, auf dem „sovereign-by-design“-Ansatz. Wir haben eine sichere und hochverfügbare globale Infrastruktur entwickelt, Schutzmaßnahmen in unser Service-Design und unsere Bereitstellungsmechanismen integriert und Resilienz fest in unserer Betriebskultur verankert. Unsere Kunden profitieren von einer Cloud, die sie dabei unterstützt, selbst die Anforderungen der sicherheitssensibelsten Organisationen zu erfüllen. Jede Region besteht aus mehreren Verfügbarkeitszonen (Availability Zones, AZs) und jede AZ aus einem oder mehreren diskreten Rechenzentren, deren Stromversorgung, Konnektivität und Netzwerk komplett redundant aufgebaut sind. Die erste Region der AWS European Sovereign Cloud ist in Brandenburg geplant, die Infrastruktur wird vollständig in der EU angesiedelt sein. Die AWS European Sovereign Cloud wird wie auch unsere bestehenden Regionen das AWS Nitro System nutzen. Das Nitro System bildet die Grundlage für alle unsere modernen Amazon Elastic Compute Cloud (EC2) Instanzen und basiert auf einer starken physikalischen und logischen Sicherheitsabgrenzung. Damit werden Zugriffsbeschränkungen realisiert, so dass niemand, einschließlich AWS-Mitarbeitern, Zugriff auf Kundendaten, die auf Amazon EC2 laufen, hat.
Service-Roadmap für die AWS European Sovereign Cloud
Beginnen Sie noch heute mit der Umsetzung Ihrer digitalen Souveränität mit AWS
Bei AWS haben wir uns zum Ziel gesetzt, unseren Kunden die fortschrittlichsten Steuerungsmöglichkeiten für Souveränitätsanforderungen und Funktionen anzubieten, die in der Cloud verfügbar sind. Mit unserem breitgefächerten Angebot, darunter z. B. unsere acht bestehenden Regionen in Europa, AWS Dedicated Local Zones und AWS Outposts, helfen wir Ihnen, Ihre individuellen Anforderungen an die digitale Souveränität zu erfüllen. Die AWS European Sovereign Cloud bietet Ihnen eine weitere Wahlmöglichkeit. Sie können in unseren bestehenden „sovereign-by-design“-Regionen anfangen und bei Bedarf in die AWS European Sovereign Cloud migrieren. Wenn Sie weitere Optionen benötigen, um eine Isolierung zu ermöglichen und strenge Anforderungen an den Ort der Datenverarbeitung in einem bestimmten Land zu erfüllen, können Sie auf AWS Dedicated Local Zones oder AWS Outposts zurückgreifen, um die Infrastruktur der AWS European Sovereign Cloud am Ort Ihrer Wahl zu nutzen.
Sie können schon heute Machbarkeitsstudien durchführen und praktische Erfahrung sammeln, sodass Sie sofort loslegen können, wenn die AWS European Sovereign Cloud 2025 eröffnet wird. Beispielsweise können Sie AWS CloudFormation nutzen, um AWS Ressourcen aus einer bestehenden Region automatisiert bereitzustellen und sich damit auf die AWS European Sovereign Cloud vorzubereiten. Mithilfe von AWS CloudFormation können Sie Services wie Amazon EC2, Amazon Simple Notification Service (Amazon SNS) und Elastic Load Balancing nutzen, um sehr zuverlässige, stark skalierbare und kosteneffiziente Anwendungen in der Cloud zu entwickeln – wiederholbar, prüfbar und automatisierbar. Sie können Amazon SageMaker nutzen, um Ihre Modelle für maschinelles Lernen (darunter auch große Sprachmodelle (LLMs) oder andere Grundlagenmodelle) zu entwickeln, zu trainieren und bereitzustellen. Mit Amazon S3 profitieren Sie von der automatischen Verschlüsselung aller Objekt-Uploads. Sollten Sie aufgrund rechtlicher Vorgaben Ihre Verschlüsselungsschlüssel vor Ort oder außerhalb von AWS speichern und nutzen müssen, können Sie den AWS KMS External Key Store nutzen.
Ganz gleich, ob Sie zum ersten Mal in die Cloud migrieren, die AWS European Sovereign Cloud in Erwägung ziehen oder Ihre Anwendungen modernisieren, um Cloud-Services zu Ihrem Vorteil zu nutzen – Sie profitieren in jedem Fall von unserer Erfahrung, denn wir helfen Organisationen jeder Größe, in die Cloud zu migrieren und in der Cloud zu wachsen. Wir bieten eine große Bandbreite an Ressourcen, mit denen Sie die Cloud effektiv nutzen und Ihre Cloud-Migration sowie Ihre Modernisierungsreise beschleunigen können. Dazu gehören das AWS Cloud Adoption Framework und das AWS Migration Acceleration Programm. Unser globales AWS Training and Certification Programm hilft allen Lernenden und Organisationen, benötigte Cloud-Fähigkeiten zu erlangen und die vorhandene Expertise zu validieren – mit kostenlosen und kostengünstigen Schulungen und branchenweit anerkannten AWS-Zertifizierungen, darunter auch mehr als 100 Schulungen für KI und maschinelles Lernen (ML).
Kunden und Partner begrüßen die Service-Roadmap der AWS European Sovereign Cloud
Adobe ist weltweit führend in der Erstellung, Verwaltung und Optimierung digitaler Erlebnisse. Adobe Experience Manager (AEM) Managed Services nutzt seit über 12 Jahren die AWS Cloud, um Adobe-Kunden die Nutzung von AEM Managed Services zu ermöglichen. „Im Laufe der Jahre hat AEM Managed Services sich auf die vier Grundpfeiler Sicherheit, Datenschutz, Regulierung und Governance konzentriert, um sicherzustellen, dass Adobe-Kunden branchenführende Werkzeuge zur Verwaltung ihrer digitalen Erlebnisse zur Verfügung haben“, sagt Mitch Nelson, Senior Director, Worldwide Managed Services bei Adobe. „Wir freuen uns über die Einführung der AWS European Sovereign Cloud und die Möglichkeit, diese an Adobes Single Sovereign Architecture for AEM Angebot auszurichten. Wir freuen uns darauf, zu den Ersten zu gehören, die Adobe-Kunden die AWS European Sovereign Cloud zur Verfügung stellen“.
adesso SE ist ein führender deutscher IT-Service-Provider, der Kunden dabei hilft, zentrale Unternehmensprozesse mithilfe moderner IT zu optimieren. Durch die Zusammenarbeit von adesso SE und AWS können Organisationen ihre digitale Transformation mithilfe maßgeschneiderter Lösungen schnell und effektiv vorantreiben. „Mit der AWS European Sovereign Cloud bietet AWS eine weitere Möglichkeit, die Kunden dabei hilft, den komplexen Herausforderungen der sich ständig ändernden Bestimmungen und Vorschriften zu begegnen. Organisationen aus dem öffentlichen Sektor und aus stark regulierten Branchen nutzen die AWS Cloud bereits, um die Anforderungen an ihre digitale Souveränität erfüllen zu können. Die AWS European Sovereign Cloud wird ihnen zusätzliche Chancen und Möglichkeiten eröffnen“, so Markus Ostertag, Chief AWS Technologist, adesso SE. „Als einer der größten IT-Service-Provider Deutschlands können wir deutlich sehen, welche Vorteile das Service-Portfolio der AWS European Sovereign Cloud bietet und wie es Kunden hilft, Innovationen voranzutreiben und gleichzeitig die benötigte Verlässlichkeit, Resilienz und Verfügbarkeit zu erlangen. AWS und adesso SE haben ein gemeinsames Ziel, denn wir streben beide danach, die individuellen Anforderungen unserer Kunden zu erfüllen. Wir freuen uns darauf, weiterhin EU-weit Unternehmen dabei zu helfen, sich weiterzuentwickeln.“
Genesys, eine weltweit führende KI-gestützte Plattform für die Orchestrierung von Kundenerlebnissen, unterstützt mehr als 8.000 Organisationen in über 100 Ländern dabei, personalisierte End-To-End-Erlebnisse nach Maß bereitzustellen. Genesys Cloud wird auf AWS betrieben und die beiden Unternehmen arbeiten schon lange eng zusammen, um ihrer gemeinsamen globalen Kundenbasis skalierbare, sichere und innovative Services zu bieten. „Genesys ist ein Vorreiter auf ihrem Gebiet. Wir helfen Unternehmen dabei, mithilfe von KI die Kundenloyalität zu verbessern und die Produktivität und das Engagement der Mitarbeitenden zu steigern“, erklärt Glenn Nethercutt, Chief Technology Officer bei Genesys. „Mit der Bereitstellung der Cloud-Plattform von Genesys in der AWS European Sovereign Cloud ermöglichen wir es noch mehr Unternehmen in ganz Europa, hochmoderne Anwendungen für ein besseres Kundenerlebnis zu entwickeln und bereitzustellen, und gleichzeitig strenge gesetzliche Vorgaben sowie Anforderungen an die digitale Souveränität einzuhalten. Europa ist ein wichtiger Akteur in der globalen Wirtschaft und ein Verfechter strenger Datenschutzstandards. Bei ihrer Einführung wird die AWS European Sovereign Cloud eine umfassende Service-Suite bieten, um Unternehmen dabei zu helfen, sowohl datenschutzrechtliche als auch regulatorische Anforderungen zu erfüllen. Die Partnerschaft verstärkt unsere anhaltenden Investitionen in der Region. Genesys und AWS werden weiterhin zusammenarbeiten, um die einzigartigen Herausforderungen anzugehen, denen sich europäische Unternehmen gegenübersehen – vor allem jene in stark regulierten Branchen wie dem Finanz- und Gesundheitswesen.“
Pega bietet globalen Kunden eine starke Plattform für die KI-gestützte Entscheidungsfindung und Workflow-Automatisierung, mit der sie ihre größten Herausforderungen meistern – von der Personalisierung des Engagements über die Automatisierung von Services bis hin zur Optimierung von Betriebsabläufen. Dank der strategischen Zusammenarbeit mit AWS konnte Pega ihr As-a-Service-Geschäft transformieren und Kunden einen stark skalierbaren, verlässlichen und agilen Weg bieten, die Pega-Plattform in aller Welt zu erleben. „Die Zusammenarbeit von AWS und Pega wird unsere Verpflichtung gegenüber unseren Kunden in der EU stärken, ihre Daten in der Region zu speichern und zu verarbeiten“, freut sich Frank Guerrera, Chief Technical Systems Officer bei Pegasystems. „Unsere gemeinsame Lösung, die die Vorteile der AWS European Sovereign Cloud nutzen wird, erlaubt Pega, Souveränitätszusagen auf allen Ebenen des Services zu treffen, von der Pega-Plattform über unterstützende Technologien bis hin zur erforderlichen Infrastruktur. Diese Lösung vereint den bereits vorhandenen strengen Ansatz der Pega Cloud an Datenisolierung, Menschen und Prozesse mit der neuen, innovativen AWS European Sovereign Cloud, um unseren Kunden aus dem öffentlichen Sektor und aus stark regulierten Branchen mehr Flexibilität zu bieten.“
SVA System Vertrieb Alexander GmbH ist einer der führenden inhabergeführten IT-Dienstleister Deutschlands und bietet seinen mehr als 3.000 Kunden mit über 3.200 talentierten Mitarbeitenden an 27 Standorten im Land branchenführende Lösungen. Die bereits zehn Jahre andauernde Zusammenarbeit von SVA und AWS hat dabei geholfen, Kunden aus allen Branchen bei der Migration und Modernisierung ihrer Workloads von eigenen Standorten zu AWS zu unterstützen oder beim Aufbau ganz neuer Lösungen. „Die AWS European Sovereign Cloud ist auf die spezifischen Anforderungen stark regulierter Kunden ausgerichtet. Sie kann die Hürden für diese Branchen mindern und ihnen ein riesiges Digitalisierungspotenzial eröffnen“, sagt Patrick Glawe, AWS Alliance Lead bei SVA System Vertrieb Alexander GmbH. „Angesichts unserer umfassenden Lösungen für den öffentlichen Sektor und regulierte Branchen verfolgen wir aufmerksam die Diskussionen rund um den Einsatz der Cloud und werden bald eine Option anbieten, mit der ein hochinnovatives Ökosystem entwickelt werden kann, das die höchsten Anforderungen an den Datenschutz, an die Einhaltung gesetzlicher Vorschriften und an die digitale Souveränität erfüllt. Das wird enorme Auswirkungen auf die Digitalisierungspläne der Europäischen Union haben.“
Wir sind weiterhin bestrebt, unseren Kunden mehr Kontrolle und weitere Optionen anzubieten, damit sie die Vorteile der Innovationsmöglichkeiten, die ihnen die Cloud bietet, nutzen und gleichzeitig alle individuellen Anforderungen an die digitale Souveränität erfüllen können – ohne auf die volle Leistungsfähigkeit von AWS verzichten zu müssen. Erfahren Sie mehr über die AWS European Sovereign Cloud auf unserer European Digital Sovereignty Website. Wir werden Sie vor dem Start 2025 kontinuierlich auf dem Laufenden halten.
Italian version
Presentiamo l’offerta di servizi base disponibili nell’AWS European Sovereign Cloud, basato sull’eccezionale potenza di calcolo di AWS
Il mese scorso abbiamo annunciato il nostro investimento nell’AWS European Sovereign Cloud pari a 7,8 miliardi di Euro, per sviluppare un nuovo cloud indipendente, dedicato al mercato europeo, che entrerà in servizio per la fine del 2025. Stiamo sviluppando l’AWS European Sovereign Cloud per offrire a una clientela formata da imprese del settore pubblico, e di settori altamente regolamentati, una scelta più ampia di soluzioni che rispondano alle loro specifiche esigenze in fatto di sovranità digitale, e che soddisfino rigorosi requisiti in tema di residenza dei dati, autonomia operativa e resilienza.
I clienti e i partner che sfruttano l’AWS European Sovereign Cloud potranno beneficiare di tutto il potenziale offerto da AWS che include la stessa architettura di sempre, basata su un ventaglio di servizi, API e funzionalità di sicurezza già disponibili nelle 33 Regioni AWS esistenti. Oggi, siamo lieti di annunciare la prima roadmap dei servizi disponibili nell’AWS European Sovereign Cloud. Questo annuncio sottolinea quanto sia ampio e strutturato il portfolio di servizi che saranno disponibili all’interno di questo Cloud, ideati per rispondere alle esigenze di clienti e partner, confermando il nostro impegno a fornire il set più avanzato di controlli sovrani e funzionalità disponibili in un ambiente cloud.
Il AWS European Sovereign Cloud è stato progettato per essere “sovereign-by-design”, proprio come abbiamo ideato il Cloud AWS sin dalle origini. Abbiamo progettato un’infrastruttura globale sicura e altamente accessibile, implementato salvaguardie all’interno dei nostri meccanismi di progettazione e implementazione del servizio e integrato la resilienza nella nostra cultura operativa. I nostri clienti possono beneficiare di un cloud ideato per aiutarli a rispondere alle esigenze di interlocutori che operano in settori critici per la sicurezza. Ogni regione è composta da una serie di Zone di Disponibilità, ognuna composta da uno o più data center riservati, dotati di alimentazione, connettività e rete ridondante. La prima regione del AWS European Sovereign Cloud nel Lander tedesco di Brandeburgo, mentre l’infrastruttura sarà situata interamente all’interno dell’Unione Europea. Al pari delle nostre Regioni già esistenti, l’AWS European Sovereign Cloud sarà basato sul AWS Nitro System. Il Nitro System alla base dei servizi offerti dal nostro avvenieristico Amazon Elastic Compute Cloud (Amazon EC2) garantendo un perimetro di sicurezza fisico e logico di livello assoluto, capace di applicare restrizioni di accesso in modo tale che nessuno, nemmeno i dipendenti AWS, possano accedere ai dati dei clienti in esecuzione su Amazon EC2.
Roadmap dell’implementazione dei servizi offerti nell’AWS European Sovereign Cloud
Quando attiviamo una nuova Regione, partiamo dai servizi di base necessari per supportare carichi di lavoro e applicazioni fondamentali, per poi espandere la nostra offerta di servizi in base alle richieste di clienti e partner. Nella fase iniziale, il AWS European Sovereign Cloud offrirà servizi provenienti da un ampio ventaglio di categorie, come quelli dedicati all’intelligenza artificiale – Amazon SageMaker, Amazon Q, e Amazon Bedrock, al calcolo informatico – Amazon EC2 e AWS Lambda, ai container – Amazon Elastic Kubernetes Service (Amazon EKS) e Amazon Elastic Container Service (Amazon ECS), ai database – Amazon Aurora, Amazon DynamoDB, e Amazon Relational Database Service (Amazon RDS), al networking – Amazon Virtual Private Cloud (Amazon VPC), alla sicurezza – AWS Key Management Service (AWS KMS) e AWS Private Certificate Authority, oltre allo storage – Amazon Simple Storage Service (Amazon S3) e Amazon Elastic Block Store (Amazon EBS). Il AWS European Sovereign Cloud potrà vantare propri sistemi indipendenti di identificazione e accesso (IAM), di fatturazione e di rendicontazione dell’utilizzo, tutti operati in modo autonomo dalle Regioni esistenti. Questi sistemi sono ideati per consentire agli utenti che sfruttano il AWS European Sovereign Cloud di mantenere tutti i dati dei clienti, compresi i metadati creati come ruoli, permessi, etichette di risorse e configurazioni usate per operare in AWS, all’interno dell’Unione Europea. Inoltre, i clienti che usano il AWS European Sovereign Cloud saranno in grado di sfruttare il Marketplace AWS, ovvero, un catalogo digitale che rende più semplice individuare, testare, acquistare e implementare software di terze parti. Per assistere clienti e partner nella loro implementazione del AWS European Sovereign Cloud, abbiamo pubblicato una roadmap dei servizi base consultabile al termine di questo articolo.
Crea da subito la tua sovranità digitale su AWS
AWS si impegna a offrire ai propri clienti il più avanzato set di controlli e funzionalità di sovranità disponibili sul cloud. Mettiamo a disposizione un’ampia gamma di soluzioni dedicate alle tue specifiche esigenze in fatto di sovranità digitale, incluse le nostre otto Regioni esistenti in Europa, AWS Dedicated Local Zones e AWS Outposts, mentre il AWS European Sovereign CloudS è un’ulteriore opzione su cui fare affidamento. Puoi iniziare a lavorare all’interno delle nostre Regioni “sovereign-by-design”, e in caso di necessità, migrare all’interno del AWS European Sovereign Cloud. Se devi ottemperare a rigorose normative in materia di compartimentazione e residenza locale dei dati, possiamo mettere a disposizione anche Dedicated Local Zones o Outposts per usufruire dell’architettura offerta dal Cloud sovrano europeo AWS nella località di tua scelta.
Oggi puoi condurre esercitazioni di “proof-of-concept” per acquisire esperienza pratica capace di apportare un impatto significativo alla tua attività quando l’AWS European Sovereign Cloud sarà attivo nel 2025. Ad esempio, puoi sfruttare la AWS CloudFormation per avviare e impostare l’implementazione dell’infrastruttura AWS in modo puntuale e ripetuto all’interno di una Regione esistente come attività preparatoria all’adozione del AWS European Sovereign Cloud. Grazie alla AWS CloudFormation, puoi sfruttare servizi come Amazon EC2, Amazon Simple Notification Service (Amazon SNS) e il sistema Elastic Load Balancing per creare applicazioni nel cloud che spiccano per affidabilità, scalabilità ed economicità in un modo ripetibile, verificabile e automatizzato. Puoi usare Amazon SageMaker per progettare, addestrare e impegnare i tuoi modelli di machine learning (inclusi i modelli linguistici di grandi dimensioni e i modelli di fondazione). Puoi usare Amazon S3 per sfruttare i vantaggi della crittografia automatica su tutti i caricamenti di oggetti. Se hai esigenze normative che richiedono di archiviare e utilizzare le tue chiavi di crittografia in locale o all’esterno di AWS, puoi usare il AWS KMS External Key Store.
Qualora tu stia effettuando per la prima volta la migrazione verso il cloud, prendendo in considerazione l’utilizzo del AWS European Sovereign Cloud o aggiornando i tuoi applicativi per avvalerti dei servizi cloud, puoi beneficiare dalla nostra esperienza nell’assistere realtà di ogni dimensione che intendono adottare il cloud per sfruttare al meglio il suo potenziale. Offriamo un’ampia gamma di risorse da adottare in modo efficiente nel cloud, così da accelerare il tuo percorso di modernizzazione e migrazione verso il cloud, tra cui spiccano l’AWS Cloud Adoption Framework e l’AWS Migration Acceleration Program. Il nostro programma globale di Formazione e Certificazione AWS è al fianco di personale in formazione e imprese per sviluppare competenze cloud richieste dal mercato e convalidare le proprie conoscenze attraverso percorsi formativi gratuiti e a basso costo, insieme alle credenziali di certificazione AWS riconosciute dal settore che includono oltre 100 risorse didattiche per l’IA e il machine learning (ML).
Clienti e partner danno il benvenuto alla roadmap dell’implementazione dei servizi offerti nell’AWS European Sovereign Cloud
Adobe è il leader mondiale nella creazione, gestione e ottimizzazione delle esperienze digitali. Da oltre dodici anni, Adobe Experience Manager (AEM) Managed Services sfrutta il cloud AWS per supportare l’utilizzo di AEM Managed Services da parte dei clienti Adobe. “Nel corso degli anni, AEM Managed Services si è dimostrato un servizio incentrato su quattro elementi fondamentali come sicurezza, privacy, regolamentazione e governance per garantire che i clienti Adobe possano usare i migliori strumenti di gestione digitale disponibili sul mercato” Ha confermato Mitch Nelson, Senior Director, Workdwide Managed Services di Adobe. “Siamo lieti di presentare l’AWS European Sovereign Cloud e l’opportunità che rappresenta per allinearsi con l’architettura Single Sovereign di Adobe per l’offerta AEM. Non vediamo l’ora di essere tra i primi a fornire il servizio AWS European Sovereign Cloud ai clienti Adobe.”
Adesso SE è un fornitore leader di servizi IT localizzato in Germania, sempre al fianco dei clienti che intendono ottimizzare i principali processi aziendali grazie a una tecnologia digitale all’avanguardia. Adesso SE e AWS lavorano al fianco delle imprese per guidare le trasformazioni digitali in modo rapido ed efficiente grazie a soluzioni su misura. “Con il Cloud sovrano europeo, AWS mette in campo un’ulteriore soluzione ideata per aiutare i clienti a superare agevolmente la complessità di regole e normative in perenne evoluzione. Operatori del settore pubblico e di settori regolamentati stanno già sfruttando AWS Cloud per soddisfare i propri requisiti di sovranità digitale e l’AWS European Sovereign Cloud sbloccherà nuove e interessanti opportunità“, ha affermato Markus Ostertag, Chief AWS Technologist di Adesso SE. “In quanto uno dei principali fornitori tedeschi di servizi IT, siamo consapevoli dei vantaggi che il portfolio di servizi del Cloud sovrano europeo potrà offrire ai clienti che intendono innovare senza rinunciare all’affidabilità, alla resilienza e alla disponibilità di cui hanno bisogno. AWS e Adesso SE sono unite nel soddisfare le specifiche esigenze dei nostri clienti e non vediamo l’ora di continuare a supportare le imprese di tutta l’Unione Europea nel loro percorso di innovazione“.
Genesys, leader globale nell’orchestrazione dell’esperienza basata sull’IA, consente a più di 8.000 imprese dislocate in oltre 100 paesi di offrire esperienze personalizzate e complete su ampia scala. Grazie all’implementazione di Genesys Cloud su AWS, le due aziende firmano una partnership a lungo termine per fornire servizi scalabili, sicuri e innovativi alla loro clientela globale. “Con le sue soluzioni all’avanguardia, Genesys è al fianco delle imprese che intendono sfruttare l’IA per fidelizzare la clientela, aumentando al contempo i livelli di produttività e di coinvolgimento dei dipendenti”, ha affermato Glenn Nethercutt, Chief Technology Officer di Genesys. “L’implementazione della piattaforma Genesys Cloud sul Cloud sovrano europeo AWS potrà consentire a un numero ancora più elevato di imprese in tutta Europa di sperimentare, creare e adottare applicazioni all’avanguardia dedicate alla customer experience, rispettando le normative e i più rigorosi requisiti in fatto di sovranità dei dati. Oltre a essere una potenza mondiale a livello economico, l’Europa si distingue per le sue norme di protezione dei dati e in questo contesto favorevole, l’AWS European Sovereign Cloud sin dalla sua entrata in servizio potrà offrire un ventaglio completo di servizi dedicati alle imprese chiamate a soddisfare sia i requisiti di privacy dei dati che quelli normativi. Questa partnership è il segno tangibile del nostro impegno finanziario a lungo termine nella regione, con Genesys e AWS che confermano e rafforzano il proprio impegno nel rispondere alle sfide che le imprese europee sono chiamate ad affrontare, soprattutto nei settori altamente regolamentati come finanza e sanità”.
Pega fornisce una piattaforma a prestazioni elevate che mette i nostri clienti globali nelle migliori condizioni per sfruttare le nostre soluzioni IA dedicate all’automatizzazione di processi decisionali e flussi di lavoro, ideate per rispondere alle più importanti esigenze aziendali, dalla personalizzazione dell’engagement all’automazione dell’assistenza, fino all’ottimizzazione dell’operatività. La collaborazione strategica tra Pega e AWS ha consentito a Pega di trasformare il proprio modello di “business as-a-Service” in un modello altamente scalabile, affidabile e agile in grado di consentire ai nostri clienti di sperimentare la piattaforma Pega in tutto il mondo. “La collaborazione tra AWS e Pega sarà l’occasione per rafforzare il nostro impegno verso i nostri clienti basati nell’Unione Europea che necessitano di conservare ed elaborare i propri dati all’interno di questa regione”, ha affermato Frank Guerrera, chief technical systems officer di Pegasystems. “Potendo sfruttare l’AWS European Sovereign Cloud, la nostra soluzione integrata consentirà a Pega di garantire sovranità su tutti i livelli di servizio, dalla piattaforma di Pega passando per le tecnologie di supporto, fino all’infrastruttura di implementazione. Questa soluzione abbina il rigoroso approccio verso l’isolamento dei dati, la clientela e le procedure garantito dal Cloud di Pega con il nuovo e innovativo Cloud sovrano europeo firmato AWS per offrire flessibilità ai nostri clienti del settore pubblico e dei settori altamente regolamentati”.
SVA System Vertrieb Alexander GmbH è uno dei più importanti system integrator in Germania, la cui proprietà è ancora detenuta dal fondatore, con una forza lavoro di oltre 3200 talenti distribuiti in 27 uffici su tutto il territorio nazionale, che fornisce soluzioni all’avanguardia a una platea di oltre 3000 clienti. Da 10 anni, la collaborazione tra SVA e AWS si distingue per il continuo sostegno a clienti di ogni settore e ambito operativo che intendono aggiornare e migrare i propri flussi di lavoro da soluzioni in-house verso AWS, oppure, creare soluzioni ex-novo. “l’AWS European Sovereign Cloud risponde a specifiche esigenze dei clienti altamente regolamentati, contribuendo così alla riduzione delle barriere di ingresso per sbloccare il loro immenso potenziale nell’ambito digitale,” ha detto Patrik Glawe, AWS Alliance Lead presso SVA System Vertrieb Alexander GmbH. “ Potendo contare su un’ampia copertura del settore pubblico e dei settori altamente regolamentati, conosciamo alla perfezione le esigenze di chi vuole passare al cloud e stiamo lavorando per offrire a stretto giro una soluzione capace di progettare un ecosistema altamente innovativo in grado di soddisfare i più elevati standard di protezione dei dati, conformità normativa e requisiti di sovranità digitale. Il nostro lavoro avrà un impatto significativo sull’agenda di digitalizzazione dell’Unione Europea.”
Ribadiamo il nostro impegno nel garantire ai nostri clienti livelli ancora più elevati di scelta e di controllo per sfruttare al massimo i vantaggi offerti dal cloud, il tutto fornendo loro assistenza nel rispondere a specifiche esigenze in fatto di sovranità digitale, senza rinunciare a tutta la potenza di AWS. Per saperne di più sul AWS European Sovereign Cloud, consulta il sito web della Sovranità Digitale europea per non perderti gli ultimi aggiornamenti mentre proseguiamo nel nostro lavoro in vista della presentazione nel 2025.
Spanish version
Anuncio de los servicios disponibles inicialmente en la AWS European Sovereign Cloud, respaldada por todo el potencial de AWS
El mes pasado, compartimos nuestra decisión de invertir 7.800 millones de euros en la AWS European Sovereign Cloud, una nueva nube independiente para Europa cuyo lanzamiento está previsto para finales de 2025. Estamos diseñando la AWS European Sovereign Cloud para ofrecer más opciones a organizaciones del sector público y clientes de industrias muy reguladas contribuyendo así a cumplir tanto sus necesidades particulares de soberanía digital como los estrictos requisitos de resiliencia, autonomía operativa y residencia de datos. Los clientes y socios que usen la AWS European Sovereign Cloud se beneficiarán de la plena capacidad de AWS, incluyendo la arquitectura, la cartera de servicios, las API y las características de seguridad ya disponibles en nuestras 33 regiones de AWS. Hoy, anunciamos con entusiasmo una hoja de ruta sobre los servicios iniciales que estarán a disposición en la AWS European Sovereign Cloud. Este comunicado pone de manifiesto el gran alcance de la cartera de servicios de la AWS European Sovereign Cloud, diseñada para satisfacer la demanda de clientes y socios y, al mismo tiempo, ser fieles a nuestro compromiso de proporcionar el conjunto de funciones y controles de soberanía más avanzado que existe en la nube.
La AWS European Sovereign Cloud es construida soberana por diseño, como lo ha sido la nube de AWS desde el primer día. Hemos creado una infraestructura global segura y altamente disponible, integrado medidas de protección en nuestros mecanismos de diseño e implementación de servicios e infundido resiliencia en nuestra cultura operativa. Nuestros clientes se benefician de una nube ideada para ayudarles a satisfacer los requisitos de organizaciones que dan la máxima importancia a la seguridad. Cada región está compuesta por múltiples zonas de disponibilidad formadas a su vez por uno o más centros de datos, cada uno con potencia, conectividad y redes redundantes. La primera región de la AWS European Sovereign Cloud se ubicará en el estado federado de Brandeburgo (Alemania), con toda su infraestructura emplazada dentro de la Unión Europea (UE). Como las regiones existentes, la AWS European Sovereign Cloud funcionará gracias a la tecnología del AWS Nitro System, que es la base de todas nuestras modernas instancias de Amazon Elastic Compute Cloud (Amazon EC2) y proporciona sólida seguridad física y lógica para hacer cumplir las restricciones de modo que nadie, ni siquiera los empleados de AWS, puedan acceder a los datos de los clientes en Amazon EC2.
Hoja de ruta sobre los servicios de la AWS European Sovereign Cloud
Cómo empezar a construir soberanía hoy mismo con AWS
AWS tiene el compromiso de proporcionar a los clientes el conjunto de funciones y controles de soberanía más avanzado que existe en la nube. Contamos con una amplia oferta para ayudar a cumplir necesidades particulares de soberanía digital, incluyendo nuestras seis regiones en la Unión Europea, AWS Dedicated Local Zones y AWS Outposts. La AWS European Sovereign Cloud es una opción más que se puede elegir. Es posible empezar a trabajar en nuestras regiones soberanas por diseño y, de ser necesario, realizar la migración a la AWS European Sovereign Cloud. Quien deba cumplir estrictos requisitos de aislamiento y residencia de datos a escala nacional también podrá usar Dedicated Local Zones u Outposts para implementar la infraestructura de la AWS European Sovereign Cloud en las ubicaciones seleccionadas.
Actualmente, es posible llevar a cabo pruebas de concepto y adquirir experiencia práctica para empezar con buen pie cuando se lance la AWS European Sovereign Cloud en 2025. Por ejemplo, se puede usar AWS CloudFormation para crear y aprovisionar las implementaciones de la infraestructura de AWS de forma predecible y repetida en una región existente como preparación para la AWS European Sovereign Cloud. AWS CloudFormation permite aprovechar servicios como Amazon EC2, Amazon Simple Notification Service (Amazon SNS) y Elastic Load Balancing para diseñar en la nube aplicaciones de lo más fiables, escalables y rentables de manera reproducible, auditable y automatizable. Asimismo, se puede usar Amazon SageMaker para diseñar, probar e implementar modelos de aprendizaje automático (incluyendo modelos de lenguaje grande y otros modelos fundacionales). También se puede usar Amazon S3 para beneficiarse del cifrado automático en todas las cargas de objetos. Quien tenga necesidad de almacenar y utilizar sus claves de cifrado dentro o fuera de AWS por motivos de regulación puede recurrir a External Key Store de AWS KMS.
Tanto si uno decide realizar la migración a la nube por primera vez, se plantea usar la AWS European Sovereign Cloud o desea modernizar sus aplicaciones para sacar partido de los servicios en la nube, puede beneficiarse de nuestra experiencia en ayudar a organizaciones de todos los tamaños a apostar con éxito por la nube. Ofrecemos una amplia gama de recursos para adoptar la nube de forma efectiva y acelerar el proceso de migración y modernización, incluyendo AWS Cloud Adoption Framework y Migration Acceleration Program de AWS. Nuestro programa global AWS Training and Certification ayuda a quienes están aprendiendo y a organizaciones a obtener capacidades solicitadas en el ámbito de la nube y validar su experiencia con cursos gratuitos o de bajo coste y credenciales de AWS Certification reconocidas por la industria, incluyendo más de 100 recursos de formación en materia de inteligencia artificial y aprendizaje automático.
Clientes y socios reciben con brazos abiertos la hoja de ruta sobre los servicios de la AWS European Sovereign Cloud
Adobe es el líder mundial en la creación, gestión y optimización de experiencias digitales. Durante más de doce años, la nube de AWS ha ayudado a los clientes de Adobe a usar Adobe Experience Manager (AEM) Managed Services. “A lo largo del tiempo, AEM Managed Services se ha centrado en los cuatro pilares de seguridad, privacidad, regulación y gobernanza para garantizar que los clientes de Adobe tengan a su disposición las mejores herramientas de gestión de la experiencia digital”, declaró Mitch Nelson, director senior de Servicios Administrados Mundiales en Adobe. “Nos entusiasma tanto el lanzamiento de la AWS European Sovereign Cloud como la oportunidad que ofrece de alinearse con la Single Sovereign Architecture de Adobe para la oferta de AEM. Deseamos estar entre los primeros en proporcionar la AWS European Sovereign Cloud a los clientes de Adobe.”
adesso SE es un proveedor de servicios informáticos líder en Alemania que se centra en ayudar a los clientes a optimizar los principales procesos empresariales con una infraestructura de TI moderna. adesso SE y AWS vienen colaborando para impulsar la transformación digital de las organizaciones de forma rápida y eficiente mediante soluciones personalizadas. “Con la nube soberana europea, AWS ofrece otra opción que puede ayudar a los clientes a lidiar con la complejidad de los cambios en normas y reglamentos. Varias organizaciones del sector público e industrias reguladas ya usan la nube de AWS para cumplir sus requisitos de soberanía digital, y la AWS European Sovereign Cloud proporcionará oportunidades adicionales”, afirmó Markus Ostertag, responsable de tecnología de AWS en adesso SE. “Como uno de los proveedores de servicios informáticos más importantes de Alemania, somos conscientes de los beneficios que aportará la cartera de servicios de la Nube Soberana Europea a la hora de ayudar a los clientes a innovar y, al mismo tiempo, obtener la fiabilidad, resiliencia y disponibilidad que necesitan. AWS y adesso SE comparten el compromiso mutuo de satisfacer las necesidades particulares de los clientes y deseamos seguir ayudando a avanzar a organizaciones de toda la UE”.
Genesys, líder mundial en orquestación de experiencias impulsadas por la inteligencia artificial, ayuda a más de 8000 organizaciones en más de 100 países a proporcionar una experiencia end-to-end personalizada a escala. Al combinar Genesys Cloud con AWS, las compañías mantienen su larga colaboración para ofrecer servicios escalables, seguros e innovadores a una clientela global común. “Genesys está a la vanguardia cuando se trata de ayudar a las empresas a usar la inteligencia artificial para fidelizar a los clientes y fomentar la productividad y el compromiso de los empleados”, declaró Glenn Nethercutt, director tecnológico en Genesys. “Integrar la plataforma Genesys Cloud en la AWS European Sovereign Cloud permitirá que aún más organizaciones europeas diseñen, prueben e implementen aplicaciones de experiencia del cliente punteras y, al mismo tiempo, cumplan los estrictos requisitos de regulación y soberanía de datos. Europa desempeña un papel clave en la economía global y da ejemplo en materia de estándares de protección de datos; en el momento de su lanzamiento, la AWS European Sovereign Cloud ofrecerá un completo paquete de servicios para ayudar a las empresas a cumplir los requisitos de regulación y privacidad de datos. Esta colaboración reafirma nuestra continua inversión en la región, y Genesys y AWS mantienen el compromiso de trabajar juntos para abordar los desafíos únicos que afrontan las empresas europeas, especialmente aquellas que operan en industrias muy reguladas, como la financiera y la sanitaria”.
Pega proporciona una potente plataforma que permite que los clientes internacionales usen nuestras soluciones de automatización de flujos de trabajo y toma de decisiones basadas en la inteligencia artificial para resolver sus retos empresariales más urgentes, desde la personalización del compromiso hasta la automatización del servicio y la optimización de las operaciones. El estratégico trabajo de Pega con AWS ha favorecido la transformación de su modelo de negocio como servicio para que constituya una forma extremadamente escalable, fiable y ágil de poner la plataforma de Pega a disposición de nuestros clientes a escala global. “La colaboración entre AWS y Pega reforzará nuestro compromiso con los clientes de la Unión Europea de almacenar y procesar sus datos dentro de la región”, aseguró Frank Guerrera, director técnico de sistemas en Pegasystems. “Nuestra solución combinada, aprovechando la AWS European Sovereign Cloud, permitirá que Pega ofrezca garantías de soberanía en todos los niveles del servicio, desde la plataforma y las tecnologías de soporte hasta la infraestructura básica. Esta solución aúna el estricto enfoque de Pega Cloud sobre los procesos, las personas y el aislamiento de datos con la nueva e innovadora Nube Soberana Europea de AWS para ofrecer flexibilidad a nuestros clientes del sector público e industrias muy reguladas”.
SVA System Vertrieb Alexander GmbH, propiedad del fundador, es un integrador de sistemas líder en Alemania, con más de 3200 empleados y 27 oficinas distribuidas por el país, que ofrece soluciones sin parangón a más de 3000 clientes. La colaboración entre SVA y AWS, iniciada hace 10 años, ha permitido ayudar a clientes de diferentes industrias y verticales a modernizar las cargas de trabajo y realizar su migración a AWS o a diseñar nuevas soluciones desde cero. “La AWS European Sovereign Cloud aborda necesidades específicas de clientes sometidos a una elevada regulación, puede eliminar barreras y liberar un enorme potencial de digitalización para estas verticales”, comentó Patrick Glawe, responsable de AWS Alliance en SVA System Vertrieb Alexander GmbH. Debido a nuestro amplio alcance en el sector público e industrias reguladas, seguimos atentamente los debates sobre la adopción de la nube y pronto ofreceremos la opción de diseñar un ecosistema extremadamente innovador que se ajuste a los estándares más altos en materia de protección de datos, cumplimiento normativo y soberanía digital. Esto ejercerá un gran impacto en la agenda de digitalización de la Unión Europea”.
Reafirmamos nuestro compromiso de ofrecer a los clientes más control y opciones para sacar provecho de la innovación que ofrece la nube y, al mismo tiempo, ayudarlos a cumplir sus necesidades particulares de soberanía digital sin poner en riesgo todo el potencial de AWS. En nuestro sitio web de soberanía digital en Europa ofrecemos más información sobre la AWS European Sovereign Cloud. Asimismo, invitamos a todos los interesados a seguir atentamente nuestras próximas noticias de cara al lanzamiento de 2025.
To make sure OSI can connect and read data successfully, the following conditions should be met:
Network connectivity to data sources – OSI is generally deployed in a public network, such as the internet, or in a virtual private cloud (VPC). OSI deployed in a customer VPC is able to access data sources in the same or different VPC and on the internet with an attached internet gateway. If your data sources are in another VPC, common methods for network connectivity include direct VPC peering, using a transit gateway, or using customer managed VPC endpoints powered by AWS PrivateLink. If your data sources are on your corporate data center or other on-premises environment, common methods for network connectivity include AWS Direct Connect and using a network hub like a transit gateway. The following diagram shows a sample configuration of OSI running in a VPC and using Amazon OpenSearch Service as a sink. OSI runs in a service VPC and creates an Elastic Network interface (ENI) in the customer VPC. For self-managed data source these ENIs are used for reading data from on-premises environment. OSI creates an VPC endpoint in the service VPC to send data to the sink.
Name resolution for data sources – OSI uses an Amazon Route 53resolver. This resolver automatically answers queries to names local to a VPC, public domain names on the internet, and records hosted in private hosted zones. If you’re are using a private hosted zone, make sure you have a DHCP option set enabled, attached to the VPC using AmazonProvidedDNS as domain name server. For more information, see Work with DHCP option sets. Additionally, you can use resolver inbound and outbound endpoints if you need a complex resolution schemes with conditions that are beyond a simple private hosted zone.
Certificate verification for data source names – OSI supports only SASL_SSL for transport for Apache Kafka source. Within SASL, Amazon OpenSearch Service supports most authentication mechanisms like PLAIN, SCRAM, IAM, GSAPI and others. When using SASL_SSL, make sure you have access to certificates needed for OSI to authenticate. For self-managed OpenSearch data sources, make sure verifiable certificates are installed on the clusters. Amazon OpenSearch Service doesn’t support insecure communication between OSI and OpenSearch. Certificate verification cannot be turned off. In particular, the “insecure” configuration option is not supported.
Create a pipeline with self-managed Kafka as a source
After you complete the prerequisites, you’re ready to create a pipeline for your data source. Complete the following steps:
On the OpenSearch Service console, choose Pipelines under Ingestion in the navigation pane.
Choose Create pipeline.
Choose Streaming under Use case in the navigation pane.
Select Self managed Apache Kafka under Ingestion pipeline blueprints and choose Select blueprint.
This will populate a sample configuration for this pipeline.
Provide a name for this pipeline and choose the appropriate pipeline capacity.
Under Pipeline configuration, provide your pipeline configuration in YAML format. The following code snippet shows sample configuration in YAML for SASL_SSL authentication:
Choose Validate pipeline and confirm there are no errors.
Under Network configuration, choose Public access or VPC access. (For this post, we choose VPC access).
If you chose VPC access, specify your VPC, subnets, and an appropriate security group so OSI can reach the outgoing ports for the data source.
Under VPC attachment options, select Attach to VPC and choose an appropriate CIDR range.
OSI resources are created in a service VPC managed by AWS that is separate from the VPC you chose in the last step. This selection allows you to configure what CIDR ranges OSI should use inside this service VPC. The choice exists so you can make sure there is no address collision between CIDR ranges in your VPC that is attached to your on-premises network and this service VPC. Many pipelines in your account can share same CIDR ranges for this service VPC.
Specify any optional tags and log publishing options, then choose Next.
Review the configuration and choose Create pipeline.
You can monitor the pipeline creation and any log messages in the Amazon CloudWatch Logs log group you specified. Your pipeline should now be successfully created. For more information about how to provision capacity for the performance of this pipeline, see the section Recommended Compute Units (OCUs) for the MSK pipeline in Introducing Amazon MSK as a source for Amazon OpenSearch Ingestion.
Create a pipeline with self-managed OpenSearch as a source
The steps for creating a pipeline for self-managed OpenSearch are similar to the steps for creating one for Kafka. During the blueprint selection, choose Data Migration under Use case and select Self managed OpenSearch/Elasticsearch. OpenSearch Ingestion can source data from all versions of OpenSearch and Elasticsearch from version 7.0 to version 7.10.
The following blueprint shows a sample configuration YAML for this data source:
Considerations for self-managed OpenSearch data source
Certificates installed on the OpenSearch cluster need to be verifiable for OSI to connect to this data source before reading data. Insecure connections are currently not supported.
After you’re connected, make sure the cluster has sufficient read bandwidth to allow for OSI to read data. Use the Min and Max OCU setting to limit OSI read bandwidth consumption. Your read bandwidth will vary depending upon data volume, number of indexes, and provisioned OCU capacity. Start small and increase the number of OCUs to balance between available bandwidth and acceptable migration time.
This source is typically meant for one-time migration of data and not as continuous ingestion to keep data in sync between data sources and sinks.
OpenSearch Service domains support remote reindexing, but that consumes resources in your domains. Using OSI will move this compute out of the domain, and OSI can achieve significantly higher bandwidth than remote reindexing, thereby resulting in faster migration times.
In this post, we introduced self-managed sources for OpenSearch Ingestion that enable you to ingest data from corporate data centers or other on-premises environments. OSI also supports various other data sources and integrations. Refer to Working with Amazon OpenSearch Ingestion pipeline integrations to learn about these other data sources.
About the Authors
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.
AWS Summit New York is 10 days away, and I am very excited about the new announcements and more than 170 sessions. There will be A Night Out with AWS event after the summit for professionals from the media and entertainment, gaming, and sports industries who are existing Amazon Web Services (AWS) customers or have a keen interest in using AWS Cloud services for their business. You’ll have the opportunity to relax, collaborate, and build new connections with AWS leaders and industry peers.
Let’s look at the last week’s new announcements.
Last week’s launches Here are the launches that got my attention.
AI21 Labs’ Jamba-Instruct now available in Amazon Bedrock – AI21 Labs’ Jamba-Instruct is an instruction-following large language model (LLM) for reliable commercial use, with the ability to understand context and subtext, complete tasks from natural language instructions, and ingest information from long documents or financial filings. With strong reasoning capabilities, Jamba-Instruct can break down complex problems, gather relevant information, and provide structured outputs to enable uses like Q&A on calls, summarizing documents, building chatbots, and more. For more information, visit AI21 Labs in Amazon Bedrock and the Amazon Bedrock User Guide.
Amazon WorkSpaces Pools, a new feature of Amazon WorkSpaces – You can now create a pool of non-persistent virtual desktops using Amazon WorkSpaces and save costs by sharing them across users who receive a fresh desktop each time they sign in. WorkSpaces Pools provides the flexibility to support shared environments like training labs and contact centers, and some user settings like bookmarks and files stored in a central storage repository such as Amazon Simple Storage Service (Amazon S3) or Amazon FSx can be saved for improved personalization. You can use AWS Auto Scaling to automatically scale the pool of virtual desktops based on usage metrics or schedules. For pricing information, refer to the Amazon WorkSpaces Pricing page.
API-driven, OpenLineage-compatible data lineage visualization in Amazon DataZone (preview) – Amazon DataZone introduces a new data lineage feature that allows you to visualize how data moves from source to consumption across organizations. The service captures lineage events from OpenLineage-enabled systems or through API to trace data transformations. Data consumers can gain confidence in an asset’s origin, and producers can assess the impact of changes by understanding its consumption through the comprehensive lineage view. Additionally, Amazon DataZone versions lineage with each event to enable visualizing lineage at any point in time or comparing transformations across an asset or job’s history. To learn more, visit Amazon DataZone, read my News Blog post, and get started with data lineage documentation.
Knowledge Bases for Amazon Bedrock now offers observability logs– You can now monitor knowledge ingestion logs through Amazon CloudWatch, S3 buckets, or Amazon Data Firehose streams. This provides enhanced visibility into whether documents were successfully processed or encountered failures during ingestion. Having these comprehensive insights promptly ensures that you can efficiently determine when your documents are ready for use. For more details on these new capabilities, refer to the Knowledge Bases for Amazon Bedrock documentation.
Updates and expansion to the AWS Well-Architected Framework and Lens Catalog – We announced updates to the AWS Well-Architected Framework and Lens Catalog to provide expanded guidance and recommendations on architectural best practices for building secure and resilient cloud workloads. The updates reduce redundancies and enhance consistency in resources and framework structure. The Lens Catalog now includes the new Financial Services Industry Lens and updates to the Mergers and Acquisitions Lens. We also made important updates to the Change Enablement in the Cloud whitepaper. You can use the updated Well-Architected Framework and Lens Catalog to design cloud architectures optimized for your unique requirements by following current best practices.
Amazon Redshift Serverless with lower base capacity is now available in the Asia Pacific (Mumbai), Europe (Stockholm), and US West (N. California) Regions. Amazon Redshift Serverless now has a lower minimum base capacity of 8 RPUs, down from 32 RPUs, providing more flexibility to support a diverse range of small to large workloads based on price-performance requirements by measuring capacity in RPUs paid per second.
Other AWS news Here are some additional news items that you might find interesting:
Top reasons to build and scale generative AI applications on Amazon Bedrock – Check out Jeff Barr’s video, where he discusses why our customers are choosing Amazon Bedrock to build and scale generative artificial intelligence (generative AI) applications that deliver fast value and business growth. Amazon Bedrock is becoming a preferred platform for building and scaling generative AI due to its features, innovation, availability, and security. Leading organizations across diverse sectors use Amazon Bedrock to speed their generative AI work, like creating intelligent virtual assistants, creative design solutions, document processing systems, and a lot more.
Four ways AWS is engineering infrastructure to power generative AI – We continue to optimize our infrastructure to support generative AI at scale through innovations like delivering low-latency, large-scale networking to enable faster model training, continuously improving data center energy efficiency, prioritizing security throughout our infrastructure design, and developing custom AI chips like AWS Trainium to increase computing performance while lowering costs and energy usage. Read the new blog post about how AWS is engineering infrastructure for generative AI.
AWS re:Inforce 2024 re:Cap – It’s been 2 weeks since AWS re:Inforce 2024, our annual cloud-security learning event. Check out the summary of the event prepared by Wojtek.
Upcoming AWS events Check your calendars and sign up for upcoming AWS events:
AWS Summits – Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. To learn more about future AWS Summit events, visit the AWS Summit page. Register in your nearest city: New York (July 10), Bogotá (July 18), and Taipei (July 23–24).
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world. Upcoming AWS Community Days are in Cameroon (July 13), Aotearoa (August 15), and Nigeria (August 24).
You can now create a pool of non-persistent virtual desktops using Amazon WorkSpaces and share them across a group of users. As the desktop administrator you can manage your entire portfolio of persistent and non-persistent virtual desktops using one GUI, command line, or set of API-powered tools. Your users can log in to these desktops using a browser, a client application (Windows, Mac, or Linux), or a thin client device.
Amazon WorkSpaces Pools (non-persistent desktops) WorkSpaces Pools ensures that each user gets the same applications and the same experience. When the user logs in, they always get access to a fresh WorkSpace that’s based on the latest configuration for the pool, centrally managed by their administrator. If the administrator enables application settings persistence for the pool, users can configure certain application settings, such as browser favorites, plugins, and UI customizations. Users can also access persistent file or object storage external to the desktop.
These desktops are a great fit for many types of users and use cases including remote workers, task workers (shared service centers, finance, procurement, HR, and so forth), contact center workers, and students.
As the administrator for the pool, you have full control over the compute resources (bundle type) and the initial configuration of the desktops in the pool, including the set of applications that are available to the users. You can use an existing custom WorkSpaces image, create a new one, or use one of the standard ones. You can also include Microsoft 365 Apps for Enterprise on the image. You can configure the pool to accommodate the size and working hours of your user base, and you can optionally join the pool to your organization’s domain and active directory.
Getting started Let’s walk through the process of setting up a pool and inviting some users. I open the WorkSpaces console and choose Pools to get started:
I have no pools, so I choose Create WorkSpace on the Pools tab to begin the process of creating a pool:
The console can recommend workspace options for me, or I can choose what I want. I leave Recommend workspace options… selected, and choose No – non-persistent to create a pool of non-persistent desktops. Then I select my use cases from the menu and pick the operating system and choose Next to proceed:
The use case menu has lots of options:
On the next page I start by reviewing the WorkSpace options and assigning a name to my pool:
Next, I scroll down and choose a bundle. I can pick a public bundle or a custom one of my own. Bundles must use the WSP 2.0 protocol. I can create a custom bundle to provide my users with access to applications or to alter any desired system settings.
Moving right along, I can customize the settings for each user session. I can also enable application settings persistence to save application customizations and Windows settings on a per-user basis between sessions:
Next, I set the capacity of my pool, and optionally establish one or more schedules based on date or time. The schedules give me the power to match the size of my pool (and hence my costs) to the rhythms and needs of my users:
If the amount of concurrent usage is more dynamic and not aligned to a schedule, then I can use manual scale out and scale in policies to control the size of my pool:
I tag my pool, and then choose Next to proceed:
The final step is to select a WorkSpaces pool directory or create a new one following these steps. Then, I choose Create WorkSpace pool.
After the pool has been created and started, I can send registration codes to users, and they can log in to a WorkSpace:
I can monitor the status of the pool from the console:
Things to know Here are a couple of things that you should know about WorkSpaces Pools:
Programmatic access – You can automate the setup process that I showed above by using functions like CreateWorkSpacePool, DescribeWorkSpacePool, UpdateWorkSpacePool, or the equivalent AWS command line interface (CLI) commands.
Regions – WorkSpaces Pools is available in all commercial AWS Regions where WorkSpaces Personal is available, except Israel (Tel Aviv), Africa (Cape Town), and China (Ningxia). Check the full Region list for future updates.
Amazon DataZone is a data management service to catalog, discover, analyze, share, and govern data between data producers and consumers in your organization. Engineers, data scientists, product managers, analysts, and business users can easily access data throughout your organization using a unified data portal so that they can discover, use, and collaborate to derive data-driven insights.
Now, I am excited to announce in preview a new API-driven and OpenLineage compatible data lineage capability in Amazon DataZone, which provides an end-to-end view of data movement over time. Data lineage is a new feature within Amazon DataZone that helps users visualize and understand data provenance, trace change management, conduct root cause analysis when a data error is reported, and be prepared for questions on data movement from source to target. This feature provides a comprehensive view of lineage events, captured automatically from Amazon DataZone’s catalog along with other events captured programmatically outside of Amazon DataZone by stitching them together for an asset.
When you need to validate how the data of interest originated in the organization, you may rely on manual documentation or human connections. This manual process is time-consuming and can result in inconsistency, which directly reduces your trust in the data. Data lineage in Amazon DataZone can raise trust by helping you understand where the data originated, how it has changed, and its consumption in time. For example, data lineage can be programmatically setup to show the data from the time it was captured as raw files in Amazon Simple Storage Service (Amazon S3), through its ETL transformations using AWS Glue, to the time it was consumed in tools such as Amazon QuickSight.
With Amazon DataZone’s data lineage, you can reduce the time spent mapping a data asset and its relationships, troubleshooting and developing pipelines, and asserting data governance practices. Data lineage helps you gather all lineage information in one place using API, and then provide a graphical view with which data users can be more productive, make better data-driven decisions, and also identify the root cause of data issues.
Let me tell you how to get started with data lineage in Amazon DataZone. Then, I will show you how data lineage enhances the Amazon DataZone data catalog experience by visually displaying connections about how a data asset came to be so you can make informed decisions when searching or using the data asset.
Getting started with data lineage in Amazon DataZone In preview, I can get started by hydrating lineage information into Amazon DataZone programmatically by either directly creating lineage nodes using Amazon DataZone APIs or by sending OpenLineage compatible events from existing pipeline components to capture data movement or transformations that happens outside of Amazon DataZone. For information about assets in the catalog, Amazon DataZone automatically captures lineage of its states (i.e., inventory or published states), and its subscriptions for producers, such as data engineers, to trace who is consuming the data they produced or for data consumers, such as data analyst or data engineers, to understand if they are using the right data for their analysis.
With the information being sent, Amazon DataZone will start populating the lineage model and will be able to map the identifier sent through the APIs with the assets already cataloged. As new lineage information is being sent, the model starts creating versions to start the visualization of the asset at a given time, but it also allows me to navigate to previous versions.
I use a preconfigured Amazon DataZone domain for this use case. I use Amazon DataZone domains to organize my data assets, users, and projects. I go to the Amazon DataZone console and choose View domains. I choose my domain Sales_Domain and choose Open data portal.
I enter “Market Sales Table” in the Search Assets bar and then go to the detail page for the Market Sales Table asset. I choose the LINEAGE tab to visualize lineage with upstream and downstream nodes.
I can now dive into asset details, processes, or jobs that lead to or from those assets and drill into column-level lineage.
Interactive visualization with data lineage I will show you the graphical interface using various personas who regularly interact with Amazon DataZone and will benefit from the data lineage feature.
First, let’s say I am a marketing analyst, who needs to confirm the origin of a data asset to confidently use in my analysis. I go to the MarketingTestProject page and choose the LINEAGE tab. I notice the lineage includes information about the asset as it occurs inside and out of Amazon DataZone. The labels Cataloged, Published, and Access requested represent actions inside the catalog. I expand the market_sales dataset item to see where the data came from.
I now feel assured of the origin of the data asset and trust that it aligns with my business purpose ahead of starting my analysis.
Second, let’s say I am a data engineer. I need to understand the impact of my work on dependent objects to avoid unintended changes. As a data engineer, any changes made to the system should not break any downstream processes. By browsing lineage, I can clearly see who has subscribed and has access to the asset. With this information, I can inform the project teams about an impending change that can affect their pipeline. When a data issue is reported, I can investigate each node and traverse between its versions to dive into what has changed over time to identify the root cause of the issue and fix it in a timely manner.
Finally, as an administrator or steward, I am responsible for securing data, standardizing business taxonomies, enacting data management processes, and for general catalog management. I need to collect details about the source of data and understand the transformations that have happened along the way.
For example, as an administrator looking to respond to questions from an auditor, I traverse the graph upstream to see where the data is coming from and notice that the data is from two different sources: online sale and in-store sale. These sources have their own pipelines until the flow reaches a point where the pipelines merge.
While navigating through the lineage graph, I can expand the columns to ensure sensitive columns are dropped during the transformation processes and respond to the auditors with details in a timely manner.
Join the preview Data lineage capability is available in preview in all Regions where Amazon DataZone is generally available. For a list of Regions where Amazon DataZone domains can be provisioned, visit AWS Services by Region.
Data lineage costs are dependent on storage usage and API requests, which are already included in Amazon DataZone’s pricing model. For more details, visit Amazon DataZone pricing.
In this release, we updated the implementation guidance for the new and existing best practices to be more prescriptive. This includes enhanced recommendations and steps on reusable architecture patterns focused on specific business outcomes.
A brief history
The Well-Architected Framework is a collection of best practices that allow customers to evaluate and improve the design, implementation, and operations of their workloads in the cloud.
In 2020, we released the new version of the Well-Architected Framework guidance, more lenses, and an API integration with the AWS Well-Architected Tool. We added the sixth pillar, Sustainability, in 2021. In 2022, dedicated HTML pages were introduced for each consolidated best practice across all six pillars, with several best practices updated with improved prescriptive guidance. By December 2023, we improved more than 75% of the Framework’s best practices. As of June 2024, more than 95% of the Framework’s best practices have been refreshed at least once.
What’s new
The Well-Architected Framework supports customers as they mature in their cloud journey by providing guidance to help achieve accurate business, environment, and workload solutions. Well-Architected is committed to providing such information to customers by continually evolving and updating our guidance.
In the Operational Excellence Pillar, we updated 30 best practices across six questions. This includes OPS01, OPS02, OPS03, OPS07, OPS10, and OPS11. This update includes a refreshed structure and improved prescriptive guidance with updates on observability, generative AI capabilities, operating models, and the evolution of operational practices.
As part of this update, we consolidated four best practices into two (OPS01-BP07 merged into OPS01-BP06, OPS03-BP08 merged into OPS03-BP04) and changed the titles of seven best practices. Additionally, we added one new design principal to highlight the importance of aligning operating models to business outcomes and reordered design principles according to their priority from foundational to specialized. We updated three design principles and changed the title of one design principle. We’ve also updated the operating model guidance section of the pillar to be more prescriptive, showcasing pathways to evolving operating models.
The implementation guidance in best practices includes guidance on implementing generative AI capabilities with Amazon Q (Q Developer, Q Business, Q in QuickSight), the latest capabilities from Amazon CloudWatch Network Monitor, Amazon CloudWatch Internet Monitor, Amazon CloudWatch Logs, Amazon CloudWatch best practice alarms, cross-account observability, log-based alarms, log data protection, and AWS Health.
Security
In the Security Pillar, we updated 28 best practices across 10 questions. This includes SEC01, SEC02, SEC03, SEC04, SEC05, SEC06, SEC07, SEC08, SEC09, and SEC10. Best practice updates include removing duplication, clarifying desired outcomes, and providing robust prescriptive implementation guidance. As part of this update, we merged SEC01-BP05 into SEC01-BP04. We deleted two practices, SEC08-BP05 and SEC09-BP03, to remove the duplication of guidance covered across other existing practices. We updated the titles for 14 practices and changed the order of nine practices to improve clarity and flow.
Reliability
In the Reliability Pillar, we updated 11 best practices across six questions. This includes REL02, REL04, REL05, REL06, REL07, and REL08, with three best practices changing titles including REL04-BP01, REL05-BP06, and REL06-BP05. We improved resources available in best practices to include more recent blog posts, technical talks, and presentations. We also improved the prescriptive guidance by expanding on implementation steps. New services and service features added to the best practices guidance for AWS Resilience Hub, Amazon Route 53, Amazon Route53 Application Recovery Controller, AWS Fault Injection Service, and Amazon CloudWatch Synthetics.
Performance Efficiency
In the Performance Efficiency Pillar, we updated nine best practices across three questions. This includes PERF01, PERF03, and PERF05. We improved the prescriptive guidance on these best practices and added pillar-specific guidance on services including Amazon Devops Guru and Amazon ElastiCache Serverless. We’ve updated the resources section of all best practices with new and relevant resources.
Cost Optimization
In the Cost Optimization Pillar, we updated eight best practices across five questions. This includes COST01, COST02, COST03, COST05, and COST11. One new best practice added in COST06 highlights the benefits of using shared resources for organizational cost optimization. The improved best practices include guidance on AWS services and features including the AWS Cost Optimization Hub, AWS Billing and Cost Management features, and AWS Data Exports. These updates also cover sample key performance indicators (KPIs) for tracking optimization efforts, elaborate on the use of cost allocation tags, and discuss the split cost allocation for Amazon EKS and Amazon ECS to separate costs of containerized workloads. Additionally, the updates offer improved prescriptive and clear guidance on budgeting and forecasting. Finally, you’ll find guidance on using automations to reduce costs.
Sustainability
In the Sustainability Pillar, we updated 18 best practices across five questions. This includes SUS01, SUS02, SUS03, SUS04, SUS05, and SUS06. We improved the prescriptive guidance on these best practices, and added Pillar-specific guidance on services, including AWS Local Zones, AWS Outposts, Amazon Chime, AWS Wickr, Amazon CodeWhisperer, and AWS Customer Carbon Footprint Tool. We’ve expanded lists of resources across all best practices with new and relevant resources.
Conclusion
This release includes updates and improvements to the Framework guidance totaling 105 best practices. As of this release, we’ve updated 95% of the existing Framework best practices at least once since October 2022. With this release, we have refreshed 100% of the Operational Excellence, Security, Performance Efficiency, Cost Optimization, and Sustainability Pillars, as well as 79% of Reliability Pillar best practices. Best practice updates in this release across Operational Excellence, Security, and Reliability (a total of 66) are first-time updates since major Framework improvements started in 2022.
The content is available in 11 languages: English, Spanish, French, German, Italian, Japanese, Korean, Indonesian, Brazilian Portuguese, Simplified Chinese, and Traditional Chinese.
Updates in this release are also available in the AWS Well-Architected Tool, which you can use to review your workloads, address important design considerations, and help you follow the AWS Well-Architected Framework guidance.
AWS Certificate Manager (ACM) is a managed service that you can use to provision, manage, and deploy public and private TLS certificates for use with Elastic Load Balancing (ELB), Amazon CloudFront, Amazon API Gateway, and other integrated AWS services. Starting August 2024, public certificates issued from ACM will terminate at the Starfield Services G2 (G2) root with subject C=US, ST=Arizona, L=Scottsdale, O=Starfield Technologies, Inc., CN=Starfield Services Root Certificate Authority – G2 as the trust anchor. We will no longer cross sign ACM public certificates with the GoDaddy operated root Starfield Class 2 (C2) with subject C=US, O=Starfield Technologies, Inc., OU=Starfield Class 2 Certification Authority.
Background
Public certificates that you request through ACM are obtained from Amazon Trust Services. Like other public CAs, Amazon Trust Services CAs have a structured trust hierarchy. A public certificate issued to you, also known as the leaf certificate, chains to one or more intermediate CAs and then to the Amazon Trust Services root CA.
The Amazon Trust Services root CAs 1 to 4 are cross signed by the Amazon Trust Services root Starfield Services G2 (G2) and further by the GoDaddy operated Starfield Class 2 root (C2). The cross signing was done to provide broader trust because Starfield Class 2 was widely trusted when ACM was launched in 2016.
What is changing?
Starting August 2024, the last certificate in an AWS issued certificate chain will be one of Amazon Root CAs 1 to 4 where the trust anchor is Starfield Services G2. Currently, the last certificate in the chain that is returned by ACM is the cross-signed Starfield Services G2 root where the trust anchor could be Starfield Class 2, as shown in Figure 1 that follows.
Current chain
Figure 1: Certificate chain for ACM prior to August 2024
New chain
Figure 2 shows the new chain, where the last certificate in an AWS issued certificate’s chain is one of the Amazon Root CAs (1 to 4), and the trust anchor is Starfield Services G2.
Figure 2: New certificate chain for ACM starting on August 2024
Why are we making this change?
Starfield Class 2 is operated by GoDaddy, and GoDaddy intends to deprecate C2 in the future. To align with this, ACM is removing the trust anchor dependency on the C2 root.
How will this change impact my use of ACM?
We don’t expect this change to impact most customers. Amazon owned trust anchors have been established for over a decade across many devices and browsers. The Amazon owned Starfield Services G2 is trusted on Android devices starting with later versions of Gingerbread, and by iOS starting at version 4.1. Amazon Root CAs 1 to 4 are trusted by iOS starting at version 11. A browser, application, or OS that includes the Amazon or Starfield G2 roots will trust public certificates obtained from ACM.
What should you do to prepare?
We expect the impact of removing Starfield Services C2 as a trust anchor to be limited to the following types of customers:
To resolve this, you can add the Amazon CAs to your trust store.
Customers who pin to the cross-signed certificate or the certificate hash of Starfield Services G2 rather than the public key of the certificate.
Certificate pinning guidance can be found in the Amazon Trust repository.
Customers who have taken a dependency on the chain length. The chain length for ACM issued public certificates will reduce from 3 to 2 as part of this change.
Customers who have a dependency on chain length will need to update their processes and checks to account for the new length.
Customers can test that their clients are able to open the Valid test certificates from the Amazon Trust Repository.
FAQs
What should I do if the Amazon Trust Services CAs aren’t in my trust store?
If your application is using a custom trust store, you must add the Amazon Trust Services root CAs to your application’s trust store. The instructions for doing this vary based on the application or service. Refer to the documentation for the application or service that you’re using.
If your tests of any of the test URLs failed, you must update your trust store. The simplest way to update your trust store is to upgrade the operating system or browser that you’re using.
The following operating systems use the Amazon Trust Services CAs:
Amazon Linux (all versions)
Microsoft Windows versions, with updates installed, from January 2005, Windows Vista, Windows 7, Windows Server 2008, and later versions
Mac OS X 10.4 with Java for Mac OS X 10.4 Release 5, Mac OS X 10.5, and later versions
Red Hat Enterprise Linux 5 (March 2007 release), Linux 6, and Linux 7 and CentOS 5, CentOS 6, and CentOS 7
Ubuntu 8.10
Debian 5.0
Java 1.4.2_12, Java 5 update 2 and all later versions, including Java 6, Java 7, and Java 8
Modern browsers trust Amazon Trust Services CAs. To update the certificate bundle in your browser, update your browser. For instructions on how to update your browser, see the update page for your browser:
The Windows operating system manages certificate bundles for Internet Explorer and Microsoft Edge, so to update your browser, you must update Windows.
Why does ACM have to change the trust anchor? Why can’t ACM continue to vend certificates cross signed with C2?
There are some rare clients who check for the validity of all the certificates in the certificate chain returned by an endpoint even when they have a shorter-path trust anchor. If ACM continues to return the chain with the G2 root cross signed by C2, such clients might check the CRL and OCSP issued by Starfield Class 2. These clients will see failures on CRL and OCSP lookup chain after the expiry of the CRLs or OCSP responses issued by Starfield Class 2.
When will GoDaddy deprecate the Starfield Class 2 root?
GoDaddy has not announced specific dates for deprecation of the Starfield Class 2 root. We are working with GoDaddy to minimize customer impact.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Certificate Manager re:Post or contact AWS Support.
Amazon CodeCatalyst is a unified software development and delivery service. It enables software development teams to quickly and easily plan, develop, collaborate on, build, and deliver applications on Amazon Web Services (AWS), reducing friction throughout the development lifecycle.
The GitHub, GitLab.com, and Bitbucket Cloud repositories extension for CodeCatalyst simplifies managing your development workflow. The extension allows you to view and manage external repositories directly within CodeCatalyst. Additionally, you can store and manage workflow definition files alongside your code in external repositories while also creating, reading, updating, and deleting files in linked repositories from CodeCatalyst dev environments. The extension also triggers CodeCatalyst workflow runs automatically upon code pushes and when pull requests are opened, merged, or closed. Furthermore, it allows you to directly utilize source files from linked repositories and execute actions within CodeCatalyst workflows, eliminating the need to switch platforms and maximizing efficiency.
But there’s more: starting today, you can create a CodeCatalyst project in a GitHub, GitLab.com, or Bitbucket Cloud repository from a blueprint, you can add a blueprint to an existing code base in a repository on any of those three systems, and you can also create custom blueprints stored in your external repositories hosted on GitHub, GitLab.com, or Bitbucket Cloud.
CodeCatalyst blueprints help to speed up your developments. These pre-built templates provide a source repository, sample code, continuous integration and delivery (CI/CD) workflows, and integrated issue tracking to get you started quickly. Blueprints automatically update with best practices, keeping your code modern. IT leaders can create custom blueprints to standardize development for your team, specifying technology, access controls, deployment, and testing methods. And now, you can use blueprints even if your code resides in GitHub, GitLab.com, or Bitbucket Cloud.
Link your CodeCatalyst space with a git repository hosting service Getting started using any of these three source code repository providers is easy. As a CodeCatalyst space administrator, I select the space where I want to configure the extensions. Then, I select Settings, and in the Installed extensions section, I select Configure to link my CodeCatalyst space with my GitHub, GitLab.com, or Bitbucket Cloud account.
This is a one-time operation for each CodeCatalyst space, but you might want to connect your space to multiple source providers’ accounts.
When using GitHub, I also have to link my personal CodeCatalyst user to my GitHub user. Under my personal menu on the top right side of the screen, I select My settings. Then, I navigate down to the Personal connections section. I select Create and follow the instructions to authenticate on GitHub and link my two identities.
This is a one-time operation for each user in the CodeCatalyst space. This is only required when you’re using GitHub with blueprints.
Create a project from a blueprint and host it on GitHub, GitLab.com, and Bitbucket Cloud Let’s show you how to create a project in an external repository from a blueprint and later add other blueprints to this project. You can use any of the three git hosting providers supported by CodeCatalyst. In this demo, I chose to use GitHub.
Let’s imagine I want to create a new project to implement an API. I start from a blueprint that implements an API with Python and the AWS Serverless Application Model (AWS SAM). The blueprint also creates a CI workflow and an issue management system. I want my project code to be hosted on GitHub. It allows me to directly use source files from my repository in GitHub and execute actions within CodeCatalyst workflows, eliminating the need to switch platforms.
I start by selecting Create project on my CodeCatalyst space page. I select Start with a blueprint and select the CodeCatalyst blueprint or Space blueprint I want to use. Then, I select Next.
I enter a name for my project. I open the Advanced section, and I select GitHub as Repository provider and my GitHub account. You can configure additional connections to GitHub by selecting Connect a GitHub account.
The rest of the configuration depends on the selected blueprint. In this case, I chose the language version, the AWS account to deploy the project to, the name of the AWS Lambda function, and the name of the AWS CloudFormation stack.
After the project is created, I navigate to my GitHub account, and I can see that a new repository has been created. It contains the code and resources from the blueprint.
I can now add a blueprint to an existing project in an external source code repository. Now that my backend API project has been created, I want to add a web application to my project.
I navigate to the Blueprints section in the left-side menu, and I select the orange Add blueprint button on the top-right part of the screen.
I select the Single-page application blueprint and select Next.
On the next screen, I make sure to select my GitHub connection, as I did when I created the project. I also fill in the required information for this specific template. On the right side of the screen, I review the proposed changes.
When CodeCatalyst finishes installing the new blueprint, I can see a second repository on GitHub.
Single or multiple repository strategies When organizing code, you can choose between a single large repository, like a toolbox overflowing with everything, or splitting it into smaller, specialized ones for better organization. Single repositories simplify dependency management for tightly linked projects but can become messy at scale. Multiple repositories offer cleaner organization and improved security but require planning to manage dependencies between separate projects.
In the example I showed before, the blueprint I selected proposed to apply the second blueprint as a separate repository in GitHub. Depending on the blueprint you selected, the blueprint may propose that you create a separate repository or merge the new code in an existing repository. In the latter case, the blueprint will submit a pull request for you to merge into your repository.
Region and availability This new GitHub integration is available at no additional cost in the two AWS Regions where Amazon CodeCatalyst is available, US West (Oregon) and Europe (Ireland) at the time of publication.
Last week, we announced the general availability of custom AWS service blueprints, a new feature in Amazon DataZone allowing you to customize your Amazon DataZone project environments to use existing AWS Identity and Access Management (IAM) roles and AWS services to embed the service into your existing processes. In this post, we share how this new feature can help you in federating to your existing AWS resources using your own IAM role. We also delve into details on how to configure data sources and subscription targets for a project using a custom AWS service blueprint.
New feature: Custom AWS service blueprints
Previously, Amazon DataZone provided default blueprints that created AWS resources required for data lake, data warehouse, and machine learning use cases. However, you may have existing AWS resources such as Amazon Redshift databases, Amazon Simple Storage Service (Amazon S3) buckets, AWS Glue Data Catalog tables, AWS Glue ETL jobs, Amazon EMR clusters, and many more for your data lake, data warehouse, and other use cases. With Amazon DataZone default blueprints, you were limited to only using preconfigured AWS resources that Amazon DataZone created. Customers needed a way to integrate these existing AWS service resources with Amazon DataZone, using a customized IAM role so that Amazon DataZone users can get federated access to those AWS service resources and use the publication and subscription features of Amazon DataZone to share and govern them.
Now, with custom AWS service blueprints, you can use your existing resources using your preconfigured IAM role. Administrators can customize Amazon DataZone to use existing AWS resources, enabling Amazon DataZone portal users to have federated access to those AWS services to catalog, share, and subscribe to data, thereby establishing data governance across the platform.
Benefits of custom AWS service blueprints
Custom AWS service blueprints don’t provision any resources for you, unlike other blueprints. Instead, you can configure your IAM role (bring your own role) to integrate your existing AWS resources with Amazon DataZone. Additionally, you can configure action links, which provide federated access to any AWS resources like S3 buckets, AWS Glue ETL jobs, and so on, using your IAM role.
You can also configure custom AWS service blueprints to bring your own resources, namely AWS databases, as data sources and subscription targets to enhance governance across those assets. With this release, administrators can configure data sources and subscription targets on the Amazon DataZone console and not be restricted to do those actions in the data portal.
Custom blueprints and environments can only be set up by administrators to manage access to configured AWS resources. As custom environments are created in specific projects, the right to grant access to custom resources is delegated to the project owners who can manage project membership by adding or removing members. This restricts the ability of portal users to create custom environments without the right permissions in AWS Console for Amazon DataZone or access custom AWS resources configured in a project that they are not a member of.
Solution overview
To get started, administrators need to enable the custom AWS service blueprints feature on the Amazon DataZone console. Then administrators can customize configurations by defining which project and IAM role to use when federating to the AWS services that are set up as action links for end-users. After the customized set up is complete, when a data producer or consumer logs in to the Amazon DataZone portal and if they’re part of those customized projects, they can federate to any of the configured AWS services such as Amazon S3 to upload or download files or seamlessly go to existing AWS Glue ETL jobs using their own IAM roles and continue their work with data with the customized tool of choice. With this feature, you can how include Amazon DataZone in your existing data pipeline processes to catalog, share, and govern data.
The following diagram shows an administrator’s workflow to set up a custom blueprint.
In the following sections, we discuss common use cases for custom blueprints, and walk through the setup step by step. If you’re new to Amazon DataZone, refer to Getting started.
Use case 1: Bring your own role and resources
Customers manage data platforms that consist of AWS managed services such as AWS Lake Formation, Amazon S3 for data lakes, AWS Glue for ETL, and so on. With those processes already set up, you may want to bring your own roles and resources to Amazon DataZone to continue with an existing process without any disruption. In such cases, you may not want Amazon DataZone to create new resources because it disrupts existing processes in data pipelines and to also curtail AWS resource usage and costs.
In the current setup, you can create an Amazon DataZone domain associated with different accounts. There could be a dedicated account that acts like a producer to share data, and a few other consumer accounts to subscribe to published assets in the catalog. The consumer account has IAM permissions set up for the AWS Glue ETL job to use for the subscription environment of a project. By doing so, the role has access to the newly subscribed data as well as permissions from previous setups to access data from other AWS resources. After you configure the AWS Glue job IAM role in the environment using the custom AWS service blueprint, the authorized users of that role can use the subscribed assets in the AWS Glue ETL job and extend that data for downstream activities to store them in Amazon S3 and other databases to be queried and analyzed using the Amazon Athena SQL editor or Amazon QuickSight.
Use case 2: Amazon S3 multi-file downloads
Customers and users of the Amazon DataZone portal often need the ability to download files after searching and filtering through the catalog in an Amazon DataZone project. This requirement arises because the data and analytics associated with a particular use case can sometimes involve hundreds of files. Downloading these files individually would be a tedious and time-consuming process for Amazon DataZone users. To address this need, the Amazon DataZone portal can take advantage of the capabilities provided by custom AWS service blueprints. These custom blueprints allow you to configure action links to S3 bucket folders associated with specified Amazon DataZone projects.
You can build projects and subscribe to both unstructured and structured data assets within the Amazon DataZone portal. For structured datasets, you can use Amazon DataZone blueprint-based environments like data lakes (Athena) and data warehouses (Amazon Redshift). For unstructured data assets, you can use the custom blueprint-based Amazon S3 environment, which provides a familiar Amazon S3 browser interface with access to specific buckets and folders, using an IAM role owned and provided by the customer. This functionality streamlines the process of finding and accessing unstructured data and allows you to download multiple files at once, enabling you to build and enhance your analytics more efficiently.
Use case 3: Amazon S3 file uploads
In addition to the download functionality, users often need to retain and attach metadata to new versions of files. For example, when you download a file, you can perform data changes, enrichment, or analysis on the file, and then upload the updated version back to the Amazon DataZone portal. For uploading files, Amazon DataZone users can use the same custom blueprint-based Amazon S3 environment action links to upload files.
Use case 4: Extend existing environments to custom blueprint environments
You may have existing Amazon DataZone project environments created using default data lake and data warehouse blueprints. With other AWS services set up in the data platform, you may want to extend the configured project environments to include those additional services to provide a seamless experience for your data producers or consumers while switching between tools.
Now that you understand the capabilities of the new feature, let’s look at how administrators can set up a custom role and resources on the Amazon DataZone console.
Create a domain
First, you need an Amazon DataZone domain. If you already have one, you can skip to enabling your custom blueprints. Otherwise, refer to Create domains for instructions to set up a domain. Optionally, you can associate accounts if you want to set up Amazon DataZone across multiple accounts.
Associate accounts for cross-account scenarios
You can optionally associate accounts. For instructions, refer to Request association with other AWS accounts. Make sure to use the latest AWS Resource Access Manager (AWS RAM) DataZonePortalReadWrite policy when requesting account association. If your account is already associated, request access again with the new policy.
Add associated account users in the Amazon DataZon domain account
With this launch, you can set up associated account owners to access the Amazon DataZone data portal from their account. To enable this, they need to be registered as users in the domain account. As a domain admin, you can create Amazon DataZone user profiles to allow Amazon DataZone access to users and roles from the associated account. Complete the following steps:
On the Amazon DataZone console, navigate to your domain.
On the User management tab, choose Add IAM Users from the Add dropdown menu.
Enter the ARNs of your associated account IAM users or roles. For this post, we add arn:aws:iam::123456789101:role/serviceBlueprintRole and arn:aws:iam::123456789101:user/Jacob.
Choose Add users(s).
Back on the User management tab, you should see the new user state with Assigned status. This means that the domain owner has assigned associated account users to access Amazon DataZone. This status will change to Active when the identity starts using Amazon DataZone from the associated account.
As of writing this post, there is a maximum limit of adding six identities (users or roles) per associated account.
Enable the custom AWS service blueprint feature
You can enable custom AWS service blueprints in the domain account or the associated account, according to your requirements. Complete the following steps:
On the Account associations tab, choose the associated domain.
Choose the AWS service blueprint.
Choose Enable.
Create an environment using the custom blueprint
If an associated account is being used to create this environment, use the same associated account IAM identity assigned by the domain owner in the previous step. Your identity needs to be explicitly assigned a user profile in order for you to create this environment. Complete the following steps:
Choose the custom blueprint.
In the Created environments section, choose Create environment.
Select Create and use a new project or use an existing project if you already have one.
For Environment role, choose a role. For this post, we curated a cross-account role called AmazonDataZoneAdmin and gave it AdministratorAccess This is the bring your own role feature. You should curate your role according to your requirements. Here are some guidelines on how to set up custom role as we have used a more permissible policy for this blog:
You can use AWS Policy Generator to build a policy that fits your requirements and attach it to the custom IAM role you want to use.
Make sure the role begins with AmazonDataZone* to follow conventions. This is not mandatory, but recommended. If the IAM admin is using an AmazonDataZoneFullAccess policy, you need to follow this convention because there is a pass role check validation.
When you create the CustomRole (AWSDataZone*) make sure it trusts amazonaws.com in its trust policy:
Although you could use the same IAM role for multiple environments in a project, the recommendation is to not use a same IAM role for multiple environments across projects. Subscription grants are fulfilled at the project construct and therefore we don’t allow the same environment role to be used across different projects.
Configure custom action links
After you create the AWS service environment, you can configure any AWS Management Console links to your environment. Amazon DataZone will assume the custom role to help federate environment users to the configured action links. Complete the following steps:
In your environment, choose Customize AWS links.
Configure any S3 buckets, Athena workgroups, AWS Glue jobs, or other custom resources.
Select Custom AWS links and enter any AWS service console custom resources. For this post, we link to the Amazon Relational Database Service (Amazon RDS) console.
You should now see the console links set up for your environment.
Access resources using a custom role through the Amazon DataZone portal from an associated account
Associate account users who have been added to Amazon DataZone can access the data portal from their associated account directly. Complete the following steps:
In your environment, in the Summary section, choose the My Environment link.
You should see all your configured resources (role and action links) for your environment.
Choose any action link to navigate to the appropriate console resources.
Choose any action link for a custom resource (for this post, Amazon RDS).
You’re directed to the appropriate service console.
With this setup, you have now configured a custom AWS service blueprint to use your own role for the environment to use for data access as well. You have also set up action links for configured AWS resources to be shown to data producers and consumers in the Amazon DataZone data portal. With these links, you can federate to those services in a single click and take the project context along while working with the data.
Configure data sources and subscription targets
Additionally, administrators can now configure data sources and subscription targets on the Amazon DataZone console using custom AWS service blueprint environments. This needs to be configured to set up the database role ManagedAccessRole to the data source and subscription target, which you can’t do through the Amazon DataZone portal.
Configure data sources in the custom AWS service blueprint environment for publishing
Complete the following steps to configure your data source:
On the Amazon DataZone console, navigate to the custom AWS service blueprint environment you just created.
On the Data sources tab, choose Add
Select AWS Glue or Amazon Redshift.
For AWS Glue, complete the following steps:
Enter your AWS Glue database. If you don’t already have an existing AWS Glue database setup, refer to Create a database.
Enter the manageAccessRole role that is added as a Lake Formation admin. Make sure the role provided has aws.internal in its trust policy. The role starts with AmazonDataZone*.
Choose Add.
For Amazon Redshift, complete the following steps:
Choose Create new AWS Secret or use a preexisting one.
If you’re creating a new secret, enter a secret name, user name, and password.
Choose the cluster or workgroup you want to connect to.
Enter the database and schema names.
Enter the role ARN for manageAccessRole.
Choose Add.
Configure a subscription target in the AWS service environment for subscribing
Complete the following steps to add your subscription target
On the Amazon DataZone console, navigate the custom AWS service blueprint environment you just created.
On the Subscription targets tab, choose Add.
Follow the same steps as you did to set up a data source.
For Redshift subscription targets, you also need to add a database role that will be granted access to the given schema. You can enter a specific Redshift user role or, if you’re a Redshift admin, enter sys:superuser.
Create a new tag on the environment role (BYOR) with RedshiftDbRoles as key and the database name used for configuring the Redshift subscription target as value.
Extend existing data lake and data warehouse blueprints
Finally, if you want to extend existing data lake or data warehouse project environments to create to use existing AWS services in the platform, complete the following steps:
Create a copy of the environment role of an existing Amazon DataZone project environment.
Extend this role by adding additional required policies to allow this custom role to access additional resources.
Create a custom AWS service environment in the same Amazon DataZone project using this new custom role.
Configure the subscription target and data source using the database name of the existing Amazon DataZone environment (<env_name>_pub_db, <env_name>_sub_db).
Use the same managedAccessRole role from the existing Amazon DataZone environment.
Request subscription to the required data assets or add subscribed assets from the project to this new AWS service environment.
Clean up
To clean up your resources, complete the following steps:
If you used sample code for AWS Glue and Redshift databases, make sure to clean up all those resources to avoid incurring additional charges. Delete any S3 buckets you created as well.
On the Amazon DataZone console, delete the projects used in this post. This will delete most project-related objects like data assets and environments.
On the Lake Formation console, delete the Lake Formation admins registered by Amazon DataZone.
On the Lake Formation console, delete any tables and databases created by Amazon DataZone.
Conclusion
In this post, we discussed how the custom AWS service blueprint simplifies the process to start using existing IAM roles and AWS services in Amazon DataZone for end-to-end governance of your data in AWS. This integration helps you circumvent the prescriptive default data lake and data warehouse blueprints.
To learn more about Amazon DataZone and how to get started, refer to the Getting started guide. Check out the YouTube playlist for some of the latest demos of Amazon DataZone and more information about the capabilities available.
About the Authors
Anish Anturkar is a Software Engineer and Designer and part of Amazon DataZone with an expertise in distributed software solutions. He is passionate about building robust, scalable, and sustainable software solutions for his customers.
Navneet Srivastava is a Principal Specialist and Analytics Strategy Leader, and develops strategic plans for building an end-to-end analytical strategy for large biopharma, healthcare, and life sciences organizations. Navneet is responsible for helping life sciences organizations and healthcare companies deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications, while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies.
Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
Subrat Das is a Senior Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.










































 Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.
Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems.
Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems. Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes.
Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes. Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.











 Hernan Garcia is a Senior Solutions Architect at AWS, based out of Amsterdam, working with enterprises in the Financial Services Industry. He specializes in application modernization and supports customers in the adoption of serverless technologies.
Hernan Garcia is a Senior Solutions Architect at AWS, based out of Amsterdam, working with enterprises in the Financial Services Industry. He specializes in application modernization and supports customers in the adoption of serverless technologies. Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
 Francisco Morillo is a Streaming Solutions Architect at AWS, specializing in real-time analytics architectures. With over five years in the streaming data space, Francisco has worked as a data analyst for startups and as a big data engineer for consultancies, building streaming data pipelines. He has deep expertise in Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Francisco collaborates closely with AWS customers to build scalable streaming data solutions and advanced streaming data lakes, ensuring seamless data processing and real-time insights.
Francisco Morillo is a Streaming Solutions Architect at AWS, specializing in real-time analytics architectures. With over five years in the streaming data space, Francisco has worked as a data analyst for startups and as a big data engineer for consultancies, building streaming data pipelines. He has deep expertise in Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Francisco collaborates closely with AWS customers to build scalable streaming data solutions and advanced streaming data lakes, ensuring seamless data processing and real-time insights. Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working in the finance industry both through consultancies and for FinTech product companies. He has leveraged open-source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working in the finance industry both through consultancies and for FinTech product companies. He has leveraged open-source technologies extensively and contributed to several projects, including Apache Flink.





 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas. Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.
Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.
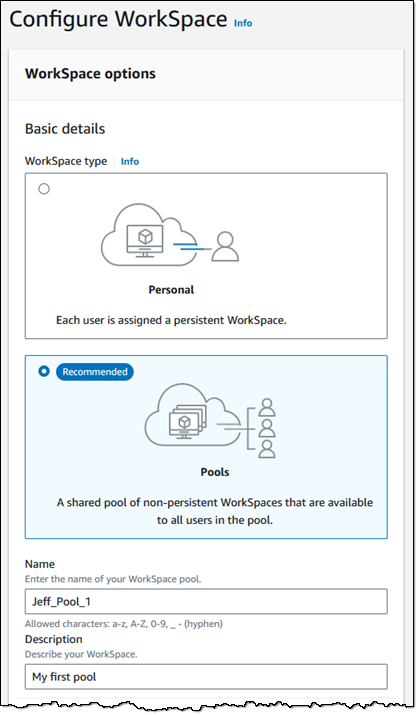
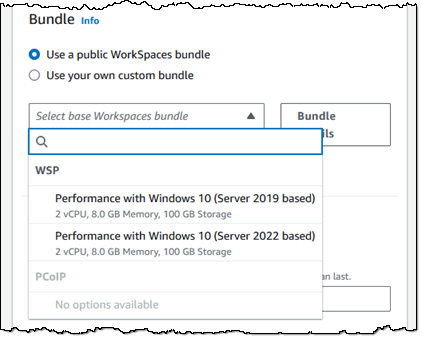
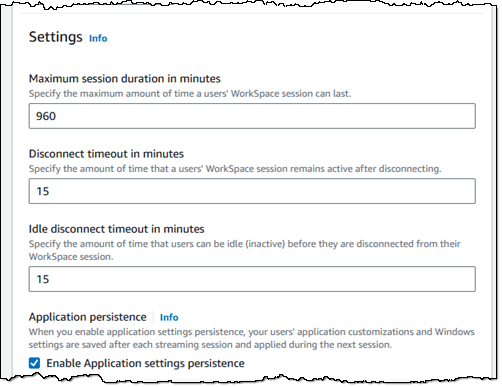
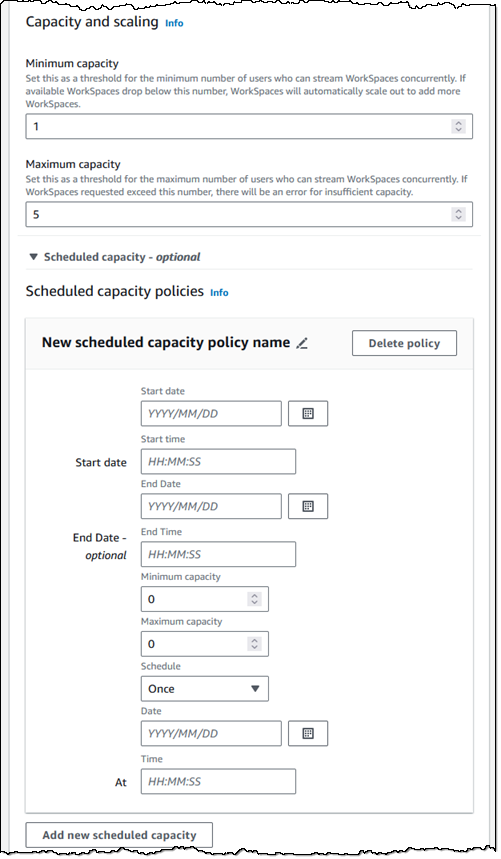
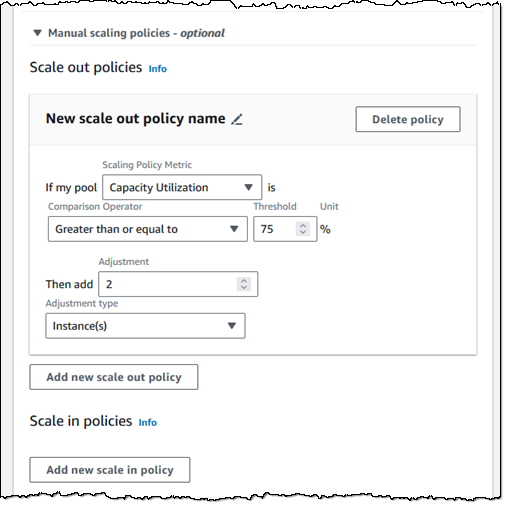











































 Anish Anturkar is a Software Engineer and Designer and part of Amazon DataZone with an expertise in distributed software solutions. He is passionate about building robust, scalable, and sustainable software solutions for his customers.
Anish Anturkar is a Software Engineer and Designer and part of Amazon DataZone with an expertise in distributed software solutions. He is passionate about building robust, scalable, and sustainable software solutions for his customers. Navneet Srivastava is a Principal Specialist and Analytics Strategy Leader, and develops strategic plans for building an end-to-end analytical strategy for large biopharma, healthcare, and life sciences organizations. Navneet is responsible for helping life sciences organizations and healthcare companies deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications, while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies.
Navneet Srivastava is a Principal Specialist and Analytics Strategy Leader, and develops strategic plans for building an end-to-end analytical strategy for large biopharma, healthcare, and life sciences organizations. Navneet is responsible for helping life sciences organizations and healthcare companies deploy data governance and analytical applications, electronic medical records, devices, and AI/ML-based applications, while educating customers about how to build secure, scalable, and cost-effective AWS solutions. His expertise spans across data analytics, data governance, AI, ML, big data, and healthcare-related technologies. Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball. Subrat Das is a Senior Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.
Subrat Das is a Senior Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.