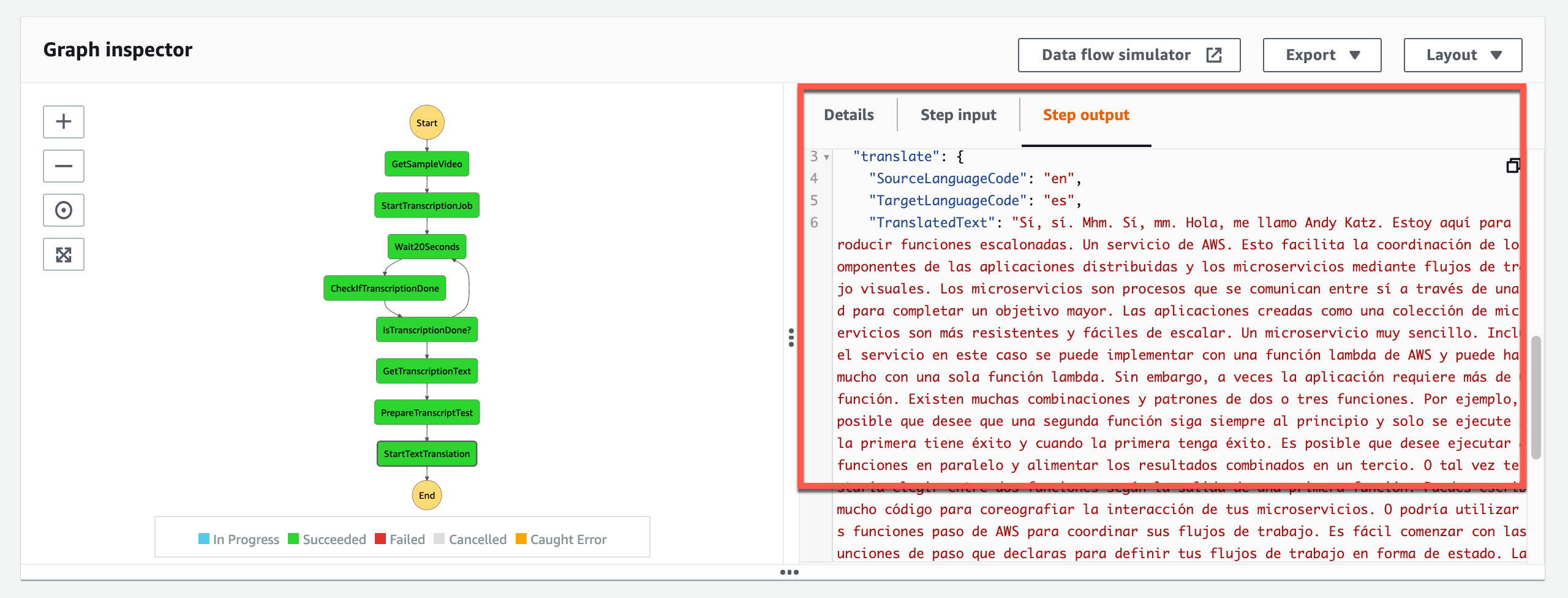
Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/new-amazon-genomics-cli-is-now-open-source-and-generally-available/
Less than 70 years separate us from one of the greatest discoveries of all time: the double helix structure of DNA. We now know that DNA is a sort of a twisted ladder composed of four types of compounds, called bases. These four bases are usually identified by an uppercase letter: adenine (A), guanine (G), cytosine (C), and thymine (T). One of the reasons for the double helix structure is that when these compounds are at the two sides of the ladder, A always bonds with T, and C always bonds with G.
If we unroll the ladder on a table, we’d see two sequences of “letters”, and each of the two sides would carry the same genetic information. For example, here are two series (AGCT and TCGA) bound together:
These series of letters can be very long. For example, the human genome is composed of over 3 billion letters of code and acts as the biological blueprint of every cell in a person. The information in a person’s genome can be used to create highly personalized treatments to improve the health of individuals and even the entire population. Similarly, genomic data can be use to track infectious diseases, improve diagnosis, and even track epidemics, food pathogens and toxins. This is the emerging field of environmental genomics.
Accessing genomic data requires genome sequencing, which with recent advances in technology, can be done for large groups of individuals, quickly and more cost-effectively than ever before. In the next five years, genomics datasets are estimated to grow and contain more than a billion sequenced genomes.
How Genomics Data Analysis Works
Genomics data analysis uses a variety of tools that need to be orchestrated as a specific sequence of steps, or a workflow. To facilitate developing, sharing, and running workflows, the genomics and bioinformatics communities have developed specialized workflow definition languages like WDL, Nextflow, CWL, and Snakemake.
However, this process generates petabytes of raw genomic data and experts in genomics and life science struggle to scale compute and storage resources to handle data at such massive scale.
To process data and provide answers quickly, cloud resources like compute, storage, and networking need to be configured to work together with analysis tools. As a result, scientists and researchers often have to spend valuable time deploying infrastructure and modifying open-source genomics analysis tools instead of making contributions to genomics innovations.
Introducing Amazon Genomics CLI
A couple of months ago, we shared the preview of Amazon Genomics CLI, a tool that makes it easier to process genomics data at petabyte scale on AWS. I am excited to share that the Amazon Genomics CLI is now an open source project and is generally available today. You can use it with publicly available workflows as a starting point and develop your analysis on top of these.
Amazon Genomics CLI simplifies and automates the deployment of cloud infrastructure, providing you with an easy-to-use command line interface to quickly setup and run genomics workflows on AWS. By removing the heavy lifting from setting up and running genomics workflows in the cloud, software developers and researchers can automatically provision, configure and scale cloud resources to enable faster and more cost-effective population-level genetics studies, drug discovery cycles, and more.
Amazon Genomics CLI lets you run your workflows on an optimized cloud infrastructure. More specifically, the CLI:
- Includes improvements to genomics workflow engines to make them integrate better with AWS, removing the burden to manually modify open-source tools and tune them to run efficiently at scale. These tools work seamlessly across Amazon Elastic Container Service (Amazon ECS), Amazon DynamoDB, Amazon Elastic File System (Amazon EFS), and Amazon Simple Storage Service (Amazon S3), helping you to scale compute and storage and at the same time optimize your costs using features like EC2 Spot Instances.
- Eliminates the most time-consuming tasks like provisioning storage and compute capacities, deploying the genomics workflow engines, and tuning the clusters used to execute workflows.
- Automatically increases or decreases cloud resources based on your workloads, which eliminates the risk of buying too much or too little capacity.
- Tags resources so that you can use tools like AWS Cost & Usage Report to understand the costs related to your genomics data analysis across multiple AWS services.
The use of Amazon Genomics CLI is based on these three main concepts:
Workflow – These are bioinformatics workflows written in languages like WDL or Nextflow. They can be either single script files or packages of multiple files. These workflow script files are workflow definitions and combined with additional metadata, like the workflow language the definition is written in, form a workflow specification that is used by the CLI to execute workflows on appropriate compute resources.
Context – A context encapsulates and automates time-consuming tasks to configure and deploy workflow engines, create data access policies, and tune compute clusters (managed using AWS Batch) for operation at scale.
Project – A project links together workflows, datasets, and the contexts used to process them. From a user perspective, it handles resources related to the same problem or used by the same team.
Let’s see how this works in practice.
Using Amazon Genomics CLI
I follow the instructions to install Amazon Genomics CLI on my laptop. Now, I can use the agc command to manage genomic workloads. I see the available options with:
The first time I use it, I activate my AWS account:
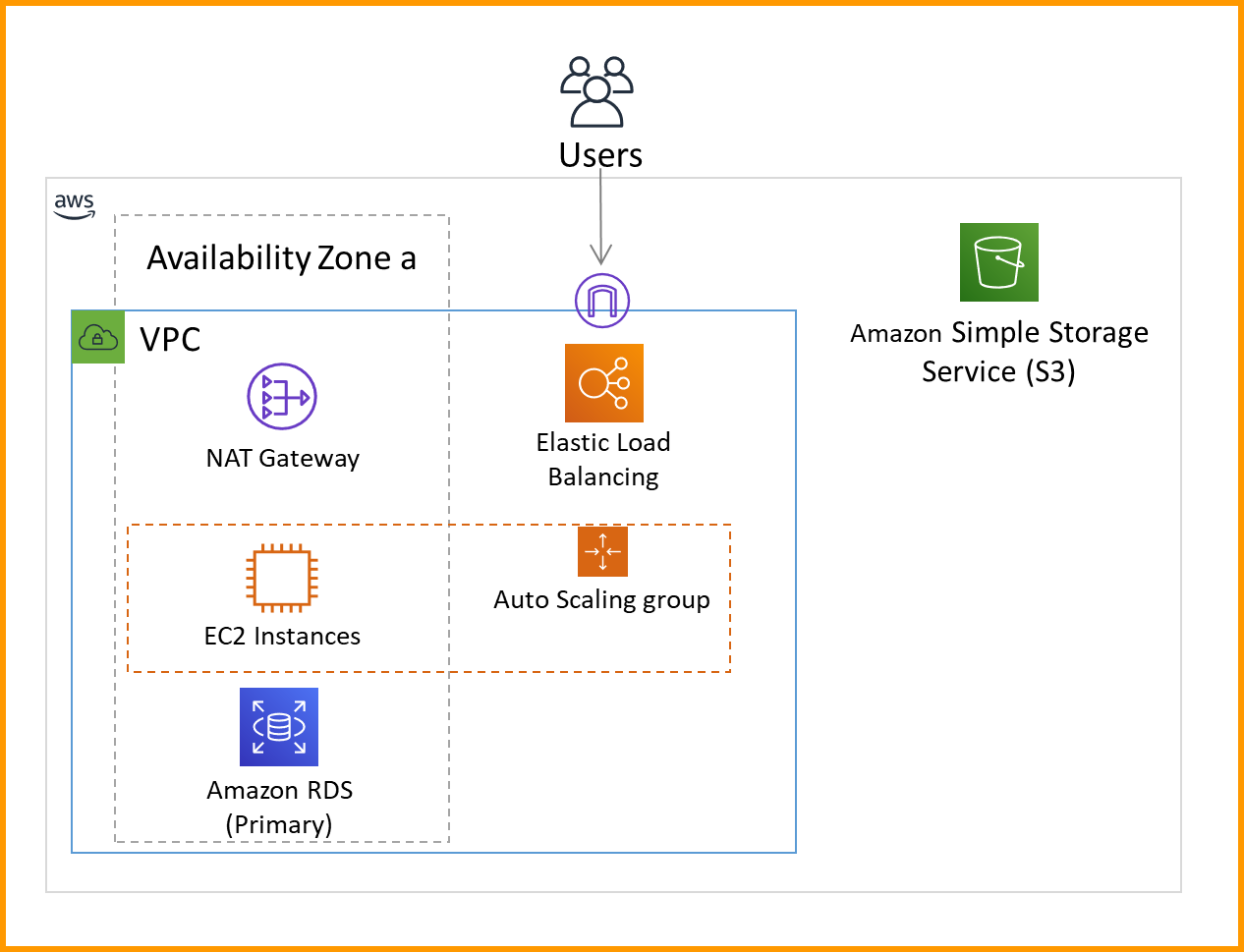
This creates the core infrastructure that Amazon Genomics CLI needs to operate, which includes an S3 bucket, a virtual private cloud (VPC), and a DynamoDB table. The S3 bucket is used for durable metadata, and the VPC is used to isolate compute resources.
Optionally, I can bring my own VPC. I can also use one of my named profiles for the AWS Command Line Interface (CLI). In this way, I can customize the AWS Region and the AWS account used by the Amazon Genomics CLI.
I configure my email address in the local settings. This wil be used to tag resources created by the CLI:
There are a few demo projects in the examples folder included by the Amazon Genomics CLI installation. These projects use different engines, such as Cromwell or Nextflow. In the demo-wdl-project folder, the agc-project.yaml file describes the workflows, the data, and the contexts for the Demo project:
---
name: Demo
schemaVersion: 1
workflows:
hello:
type:
language: wdl
version: 1.0
sourceURL: workflows/hello
read:
type:
language: wdl
version: 1.0
sourceURL: workflows/read
haplotype:
type:
language: wdl
version: 1.0
sourceURL: workflows/haplotype
words-with-vowels:
type:
language: wdl
version: 1.0
sourceURL: workflows/words
data:
- location: s3://gatk-test-data
readOnly: true
- location: s3://broad-references
readOnly: true
contexts:
myContext:
engines:
- type: wdl
engine: cromwell
spotCtx:
requestSpotInstances: true
engines:
- type: wdl
engine: cromwell
For this project, there are four workflows (hello, read, words-with-vowels, and haplotype). The project has read-only access to two S3 buckets and can run workflows using two contexts. Both contexts use the Cromwell engine. One context (spotCtx) uses Amazon EC2 Spot Instances to optimize costs.
In the demo-wdl-project folder, I use the Amazon Genomics CLI to deploy the spotCtx context:
$ agc context deploy -c spotCtx
After a few minutes, the context is ready, and I can execute the workflows. Once started, a context incurs about $0.40 per hour of baseline costs. These costs don’t include the resources created to execute workflows. Those resources depend on your specific use case. Contexts have the option to use spot instances by adding the requestSpotInstances flag to their configuration.
I use the CLI to see the status of the contexts of the project:
$ agc context status
INSTANCE spotCtx STARTED true
Now, let’s look at the workflows included in this project:
$ agc workflow list
2021-09-24T11:15:29+01:00 𝒊 Listing workflows.
WORKFLOWNAME haplotype
WORKFLOWNAME hello
WORKFLOWNAME read
WORKFLOWNAME words-with-vowels
The simplest workflow is hello. The content of the hello.wdl file is quite understandable if you know any programming language:
version 1.0
workflow hello_agc {
call hello {}
}
task hello {
command { echo "Hello Amazon Genomics CLI!" }
runtime {
docker: "ubuntu:latest"
}
output { String out = read_string( stdout() ) }
}
The hello workflow defines a single task (hello) that prints the output of a command. The task is executed on a specific container image (ubuntu:latest). The output is taken from standard output (stdout), the default file descriptor where a process can write output.
Running workflows is an asynchronous process. After submitting a workflow from the CLI, it is handled entirely in the cloud. I can run multiple workflows at a time. The underlying compute resources will automatically scale and I will be charged only for what I use.
Using the CLI, I start the hello workflow:
$ agc workflow run hello -c spotCtx
2021-09-24T13:03:47+01:00 𝒊 Running workflow. Workflow name: 'hello', Arguments: '', Context: 'spotCtx'
fcf72b78-f725-493e-b633-7dbe67878e91
The workflow was successfully submitted, and the last line is the workflow execution ID. I can use this ID to reference a specific workflow execution. Now, I check the status of the workflow:
$ agc workflow status
2021-09-24T13:04:21+01:00 𝒊 Showing workflow run(s). Max Runs: 20
WORKFLOWINSTANCE spotCtx fcf72b78-f725-493e-b633-7dbe67878e91 true RUNNING 2021-09-24T12:03:53Z hello
The hello workflow is still running. After a few minutes, I check again:
$ agc workflow status
2021-09-24T13:12:23+01:00 𝒊 Showing workflow run(s). Max Runs: 20
WORKFLOWINSTANCE spotCtx fcf72b78-f725-493e-b633-7dbe67878e91 true COMPLETE 2021-09-24T12:03:53Z hello
The workflow has terminated and is now complete. I look at the workflow logs:
$ agc logs workflow hello
2021-09-24T13:13:08+01:00 𝒊 Showing the logs for 'hello'
2021-09-24T13:13:12+01:00 𝒊 Showing logs for the latest run of the workflow. Run id: 'fcf72b78-f725-493e-b633-7dbe67878e91'
Fri, 24 Sep 2021 13:07:22 +0100 download: s3://agc-123412341234-eu-west-1/scripts/1a82f9a96e387d78ae3786c967f97cc0 to tmp/tmp.498XAhEOy/batch-file-temp
Fri, 24 Sep 2021 13:07:22 +0100 *** LOCALIZING INPUTS ***
Fri, 24 Sep 2021 13:07:23 +0100 download: s3://agc-123412341234-eu-west-1/project/Demo/userid/danilop20tbvT/context/spotCtx/cromwell-execution/hello_agc/fcf72b78-f725-493e-b633-7dbe67878e91/call-hello/script to agc-024700040865-eu-west-1/project/Demo/userid/danilop20tbvT/context/spotCtx/cromwell-execution/hello_agc/fcf72b78-f725-493e-b633-7dbe67878e91/call-hello/script
Fri, 24 Sep 2021 13:07:23 +0100 *** COMPLETED LOCALIZATION ***
Fri, 24 Sep 2021 13:07:23 +0100 Hello Amazon Genomics CLI!
Fri, 24 Sep 2021 13:07:23 +0100 *** DELOCALIZING OUTPUTS ***
Fri, 24 Sep 2021 13:07:24 +0100 upload: ./hello-rc.txt to s3://agc-123412341234-eu-west-1/project/Demo/userid/danilop20tbvT/context/spotCtx/cromwell-execution/hello_agc/fcf72b78-f725-493e-b633-7dbe67878e91/call-hello/hello-rc.txt
Fri, 24 Sep 2021 13:07:25 +0100 upload: ./hello-stderr.log to s3://agc-123412341234-eu-west-1/project/Demo/userid/danilop20tbvT/context/spotCtx/cromwell-execution/hello_agc/fcf72b78-f725-493e-b633-7dbe67878e91/call-hello/hello-stderr.log
Fri, 24 Sep 2021 13:07:25 +0100 upload: ./hello-stdout.log to s3://agc-123412341234-eu-west-1/project/Demo/userid/danilop20tbvT/context/spotCtx/cromwell-execution/hello_agc/fcf72b78-f725-493e-b633-7dbe67878e91/call-hello/hello-stdout.log
Fri, 24 Sep 2021 13:07:25 +0100 *** COMPLETED DELOCALIZATION ***
Fri, 24 Sep 2021 13:07:25 +0100 *** EXITING WITH RETURN CODE ***
Fri, 24 Sep 2021 13:07:25 +0100 0
In the logs, I find as expected the Hello Amazon Genomics CLI! message printed by workflow.
I can also look at the content of hello-stdout.log on S3 using the information in the log above:
aws s3 cp s3://agc-123412341234-eu-west-1/project/Demo/userid/danilop20tbvT/context/spotCtx/cromwell-execution/hello_agc/fcf72b78-f725-493e-b633-7dbe67878e91/call-hello/hello-stdout.log -
Hello Amazon Genomics CLI!
It worked! Now, let’s look for at more complex workflows. Before I change project, I destroy the context for the Demo project:
$ agc context destroy -c spotCtx
In the gatk-best-practices-project folder, I list the available workflows for the project:
$ agc workflow list
2021-09-24T11:41:14+01:00 𝒊 Listing workflows.
WORKFLOWNAME bam-to-unmapped-bams
WORKFLOWNAME cram-to-bam
WORKFLOWNAME gatk4-basic-joint-genotyping
WORKFLOWNAME gatk4-data-processing
WORKFLOWNAME gatk4-germline-snps-indels
WORKFLOWNAME gatk4-rnaseq-germline-snps-indels
WORKFLOWNAME interleaved-fastq-to-paired-fastq
WORKFLOWNAME paired-fastq-to-unmapped-bam
WORKFLOWNAME seq-format-validation
In the agc-project.yaml file, the gatk4-data-processing workflow points to a local directory with the same name. This is the content of that directory:
$ ls gatk4-data-processing
MANIFEST.json
processing-for-variant-discovery-gatk4.hg38.wgs.inputs.json
processing-for-variant-discovery-gatk4.wdl
This workflow processes high-throughput sequencing data with GATK4, a genomic analysis toolkit focused on variant discovery.
The directory contains a MANIFEST.json file. The manifest file describes which file contains the main workflow to execute (there can be more than one WDL file in the directory) and where to find input parameters and options. Here’s the content of the manifest file:
{
"mainWorkflowURL": "processing-for-variant-discovery-gatk4.wdl",
"inputFileURLs": [
"processing-for-variant-discovery-gatk4.hg38.wgs.inputs.json"
],
"optionFileURL": "options.json"
}
In the gatk-best-practices-project folder, I create a context to run the workflows:
$ agc context deploy -c spotCtx
Then, I start the gatk4-data-processing workflow:
$ agc workflow run gatk4-data-processing -c spotCtx
2021-09-24T12:08:22+01:00 𝒊 Running workflow. Workflow name: 'gatk4-data-processing', Arguments: '', Context: 'spotCtx'
630e2d53-0c28-4f35-873e-65363529c3de
After a couple of hours, the workflow has terminated:
$ agc workflow status
2021-09-24T14:06:40+01:00 𝒊 Showing workflow run(s). Max Runs: 20
WORKFLOWINSTANCE spotCtx 630e2d53-0c28-4f35-873e-65363529c3de true COMPLETE 2021-09-24T11:08:28Z gatk4-data-processing
I look at the logs:
$ agc logs workflow gatk4-data-processing
...
Fri, 24 Sep 2021 14:02:32 +0100 *** DELOCALIZING OUTPUTS ***
Fri, 24 Sep 2021 14:03:45 +0100 upload: ./NA12878.hg38.bam to s3://agc-123412341234-eu-west-1/project/GATK/userid/danilop20tbvT/context/spotCtx/cromwell-execution/PreProcessingForVariantDiscovery_GATK4/630e2d53-0c28-4f35-873e-65363529c3de/call-GatherBamFiles/NA12878.hg38.bam
Fri, 24 Sep 2021 14:03:46 +0100 upload: ./NA12878.hg38.bam.md5 to s3://agc-123412341234-eu-west-1/project/GATK/userid/danilop20tbvT/context/spotCtx/cromwell-execution/PreProcessingForVariantDiscovery_GATK4/630e2d53-0c28-4f35-873e-65363529c3de/call-GatherBamFiles/NA12878.hg38.bam.md5
Fri, 24 Sep 2021 14:03:47 +0100 upload: ./NA12878.hg38.bai to s3://agc-123412341234-eu-west-1/project/GATK/userid/danilop20tbvT/context/spotCtx/cromwell-execution/PreProcessingForVariantDiscovery_GATK4/630e2d53-0c28-4f35-873e-65363529c3de/call-GatherBamFiles/NA12878.hg38.bai
Fri, 24 Sep 2021 14:03:48 +0100 upload: ./GatherBamFiles-rc.txt to s3://agc-123412341234-eu-west-1/project/GATK/userid/danilop20tbvT/context/spotCtx/cromwell-execution/PreProcessingForVariantDiscovery_GATK4/630e2d53-0c28-4f35-873e-65363529c3de/call-GatherBamFiles/GatherBamFiles-rc.txt
Fri, 24 Sep 2021 14:03:49 +0100 upload: ./GatherBamFiles-stderr.log to s3://agc-123412341234-eu-west-1/project/GATK/userid/danilop20tbvT/context/spotCtx/cromwell-execution/PreProcessingForVariantDiscovery_GATK4/630e2d53-0c28-4f35-873e-65363529c3de/call-GatherBamFiles/GatherBamFiles-stderr.log
Fri, 24 Sep 2021 14:03:50 +0100 upload: ./GatherBamFiles-stdout.log to s3://agc-123412341234-eu-west-1/project/GATK/userid/danilop20tbvT/context/spotCtx/cromwell-execution/PreProcessingForVariantDiscovery_GATK4/630e2d53-0c28-4f35-873e-65363529c3de/call-GatherBamFiles/GatherBamFiles-stdout.log
Fri, 24 Sep 2021 14:03:50 +0100 *** COMPLETED DELOCALIZATION ***
Fri, 24 Sep 2021 14:03:50 +0100 *** EXITING WITH RETURN CODE ***
Fri, 24 Sep 2021 14:03:50 +0100 0
Results have been written to the S3 bucket created during the account activation. The name of the bucket is in the logs but I can also find it stored as a parameter by AWS Systems Manager. I can save it in an environment variable with the following command:
$ export AGC_BUCKET=$(aws ssm get-parameter \
--name /agc/_common/bucket \
--query 'Parameter.Value' \
--output text)
Using the AWS Command Line Interface (CLI), I can now explore the results on the S3 bucket and get the outputs of the workflow.
Before looking at the results, I remove the resources that I don’t need by stopping the context. This will destroy all compute resources, but retain data in S3.
$ agc context destroy -c spotCtx
Additional examples on configuring different contexts and running additional workflows are provided in the documentation on GitHub.
Availability and Pricing
Amazon Genomics CLI is an open source tool, and you can use it today in all AWS Regions with the exception of AWS GovCloud (US) and Regions located in China. There is no cost for using the AWS Genomics CLI. You pay for the AWS resources created by the CLI.
With the Amazon Genomics CLI, you can focus on science instead of architecting infrastructure. This gets you up and running faster, enabling research, development, and testing workloads. For production workloads that scale to several thousand parallel workflows, we can provide recommended ways to leverage additional Amazon services, like AWS Step Functions, just reach out to our account teams for more information.
— Danilo