Post Syndicated from Steve Roberts original https://aws.amazon.com/blogs/aws/improved-automated-vulnerability-management-for-cloud-workloads-with-a-new-amazon-inspector/
Amazon Inspector is a service used by organizations of all sizes to automate security assessment and management at scale. Amazon Inspector helps organizations meet security and compliance requirements for workloads deployed to AWS, scanning for unintended network exposure, software vulnerabilities, and deviations from application security best practice.
Since the original launch of Amazon Inspector in 2015, vulnerability management for cloud customers has changed considerably. Over the last six years, the team delivered several new customer-requested features, including assessment reporting, support for proxy environments, and integration with Amazon CloudWatch Metrics. However, the team also recognized that there were new requirements to meet – enabling frictionless deployment at scale, support for an expanded set of resource types needing assessment, and a critical need to detect and remediate at speed. Today I’m happy to announce a new Amazon Inspector, able to meet these requirements with the following features:
- Continual, automated assessment scans—replaces periodic, manual scanning.
- Automated resource discovery – once enabled, the new Amazon Inspector automatically discovers all running Amazon Elastic Compute Cloud (Amazon EC2) instances and Amazon Elastic Container Registry repositories.
- New support for container-based workloads—workloads are now assessed on both EC2 and container infrastructure.
- Integration with AWS Organizations—allowing security and compliance teams to enable and take advantage of Amazon Inspector across all accounts in an organization.
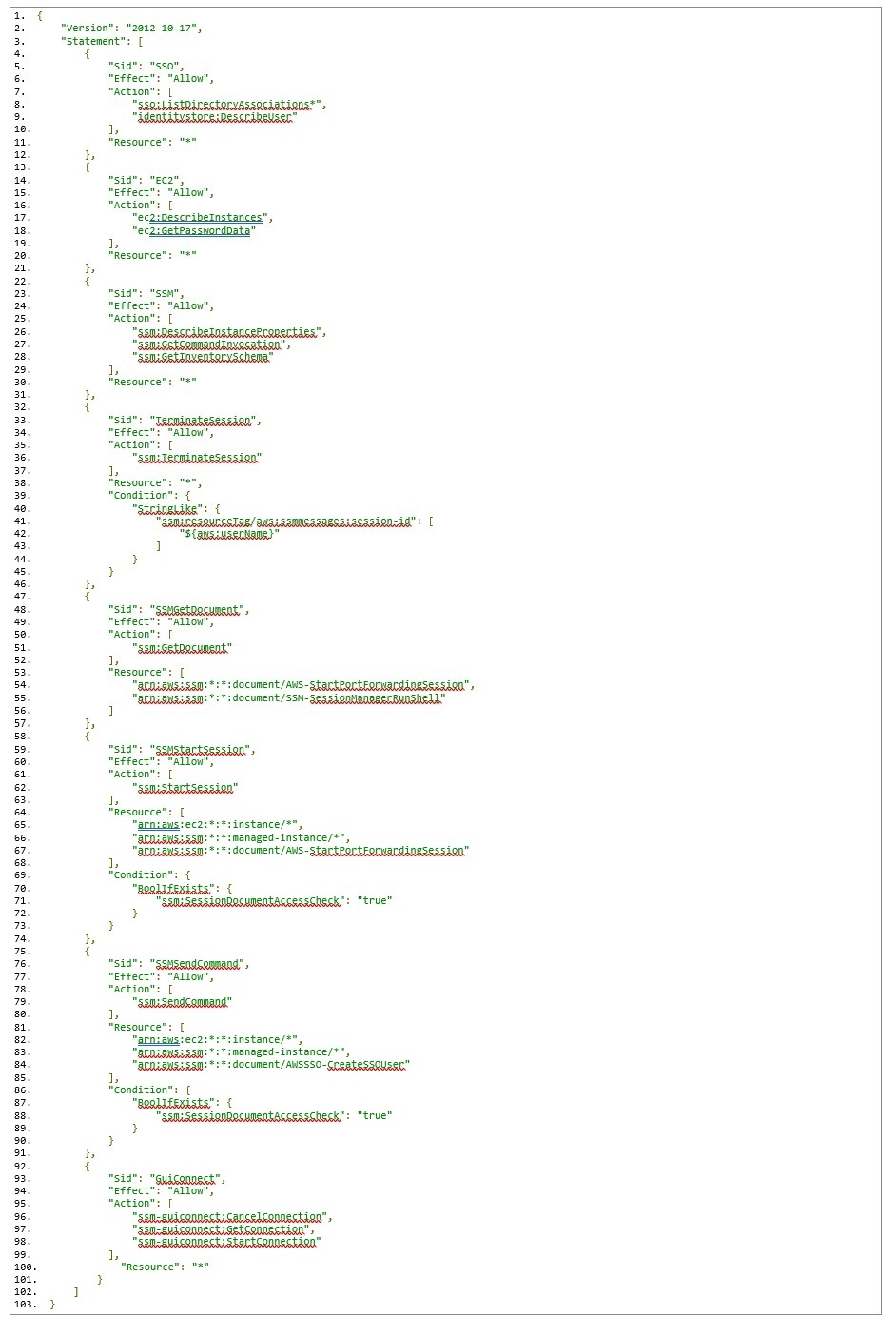
- Removal of the stand-alone Amazon Inspector scanning agent—assessment scanning now uses the widely deployed AWS Systems Manager agent, eliminating the need for a separate agent installation.
- Improved risk scoring—a highly contextualized risk score is now generated for each finding by correlating Common Vulnerability and Exposures (CVE) metadata with environmental factors for resources, such as network accessibility. This makes it easier to identify the most critical vulnerabilities to address as a priority.
- Integration with Amazon EventBridge—integrate with event management and workflow systems such as Splunk and Jira. And, you can trigger automated remediation, for example, system patching using Systems Manager or virtual machine image rebuilds using EC2 Image Builder.
- Integration with AWS Security Hub—helping your teams to more easily identify those resources with critical vulnerabilities or deviations from security best practices.
Automatically Assessing your Workloads with Amazon Inspector
Tens of thousands of vulnerabilities exist, with new ones being discovered and made public on a regular basis. With this continually growing threat, manual assessment can lead to customers being unaware of an exposure and thus potentially vulnerable between assessments. Additionally, customers with manual processes for managing their inventories of applications resources, the deployment of stand-alone security agents on those resources, and the scheduling of periodic assessments may find the whole process to be a costly and time-consuming exercise. That’s before they have to then sift through the mass of assessment findings to determine the most critical issues to address.
With the new Amazon Inspector, all you need to do is enable the service. It will auto-discover and start continual assessment of your EC2 and your Amazon Elastic Container Registry-based container workloads to evaluate your security posture, even as the underlying resources change.
EC2 instances are discovered and assessed for unintended exposure to external networks and software vulnerabilities using the Systems Manager agent, already included by default in images provided by AWS for instance management, automated patching, and more. Container-based workloads are assessed as the images are pushed to Amazon Elastic Container Registry. Without needing additional software or agents, container images and EC2 instances are assessed in near real time when an event occurs.
Automated assessment is driven by changes in workload configuration and newly published vulnerabilities to ensure resources are only assessed when needed. The new Amazon Inspector collects events from over 50 vulnerability intelligence sources, including CVE, the National Vulnerability Database (NVD), and MITRE. Images that may be affected by a newly identified entry, for example, a new CVE notification, will be automatically rescanned. Image rescanning is enabled for 30 days from the date they are pushed to the registry. You can also enable an option to only scan on image push and not subsequently perform rescans.
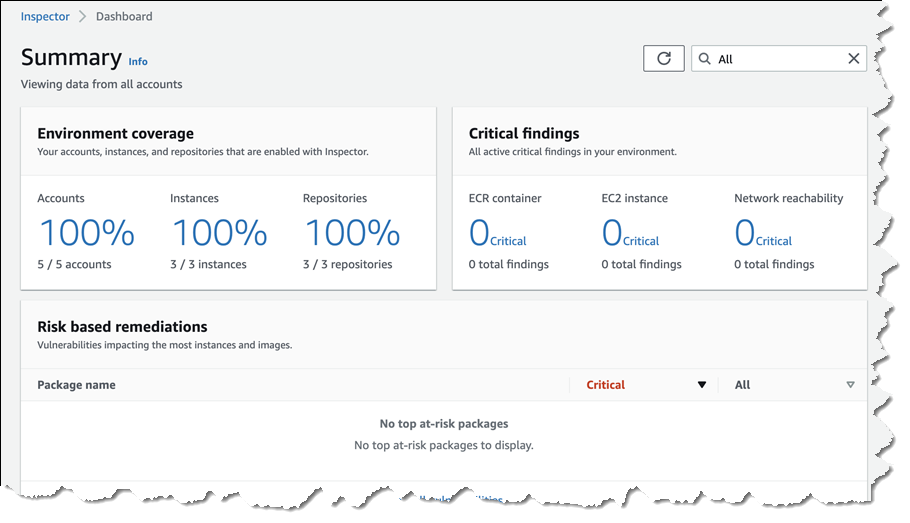
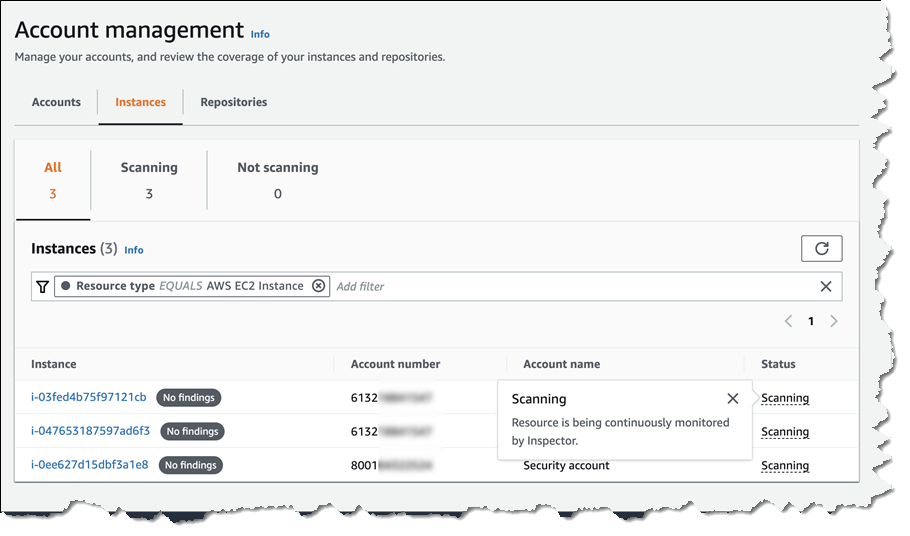
Selecting either Accounts, Instances, or Repositories from your Dashboard page takes you to a detail summary for the selected resource. Below, I’m viewing summary data for EC2 instances across a couple of accounts.
If vulnerabilities are found, you receive actionable assessment findings in a report. Starting today, these findings are summarized with enhanced risk scoring and improved resource detail to help you prioritize the most at-risk resources needing to be addressed. Also new today, the Amazon Inspector console has been redesigned to surface all findings and recommendations for remediation.
Vulnerabilities in container images are also sent to Amazon Elastic Container Registry to be summarized for the owner. And, as I noted earlier, new integrations with AWS Security Hub and Amazon EventBridge allow findings to be sent downstream for additional visibility and remediation by automated workflows. For example, automation can be created to isolate instances, trigger system patching, software image rebuilds, and more. The availability of multiple integration points makes it easier for security and application teams to collaborate to manage remediation. Below, I’m viewing findings from Amazon Inspector in the AWS Security Hub console.

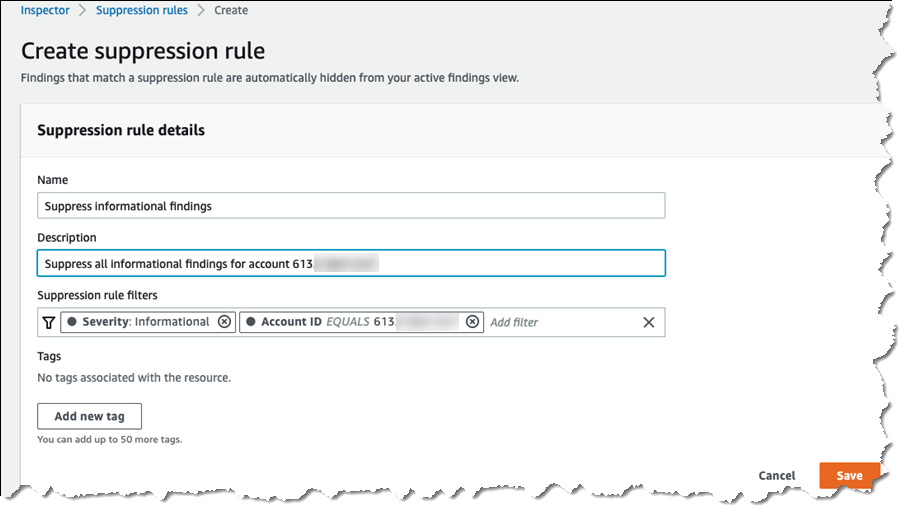
Assessments can result in hundreds of thousands, or more, findings that need to be filtered and sifted to determine the most critical to action. Also available today, organizations can determine which of the findings they consider to be acceptable and mark those findings for temporary or permanent suppression. This helps reduce the volume of alerts, further assisting with prioritization and automated remediation. Suppression filters can be set from several screens. Rules specify one or more filters, such as Severity, that will cause findings that match the filters to be removed from display. When defining rules, a list is shown of the findings that will be suppressed, helping you fine-tune the filter values to match your specific needs.
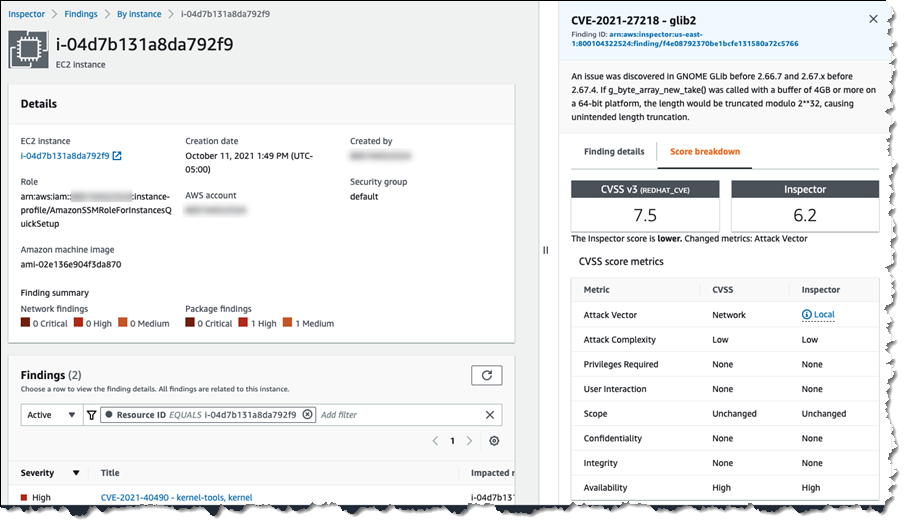
I mentioned earlier that the new Amazon Inspector implements a contextualized risk assessment score for findings. The screenshot below shows an example of Amazon Inspector‘s risk assessment score, compared to a generic Common Vulnerability Scoring System (CVSS) score. Contextual risk assessment takes into account additional factors such as accessibility to the internet and ease of exploitability to make the score more meaningful. In the image below, Amazon Inspector‘s risk assessment score is lower than the CVSS score because the attack vector requires network access. Amazon Inspector knows that the vulnerability identified in the GNOME Glib will be difficult to exploit because in this resource, there is no network access, and therefore it lowered the risk score.
Start a Free Trial with Amazon Inspector Today
The new Amazon Inspector is available now in the US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Milan), Europe (Paris), Europe (Stockholm), Middle East (Bahrain), and South America (São Paulo) Regions.
Amazon Inspector offers a free 15-day trial, so you can put it to work to see how Amazon Inspector can help your security and compliance teams reduce operational complexity and cost associated with managing resource inventories, stand-alone security agents, and repetitive manual assessments.