Post Syndicated from Anderson dos Santos original https://aws.amazon.com/blogs/big-data/get-started-managing-partitions-for-amazon-s3-tables-backed-by-the-aws-glue-data-catalog/
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of data scanned, long-running queries, and increased cost.
Partitioning is a common technique to lay out your data optimally for distributed analytics engines. By partitioning your data, you can restrict the amount of data scanned by downstream analytics engines, thereby improving performance and reducing the cost for queries.
In this post, we cover the following topics related to Amazon S3 data partitioning:
- Understanding table metadata in the AWS Glue Data Catalog and S3 partitions for better performance
- How to create a table and load partitions in the Data Catalog using Athena
- How partitions are stored in the table
- Different ways to add partitions in a table on the Data Catalog
- Partitioning data stored in Amazon S3 while ingestion and catalog
Understanding table metadata in the Data Catalog and S3 partitions for better performance
A table in the AWS Glue Data Catalog is the metadata definition that organizes the data location, data type, and column schema, which represents the data in a data store. Partitions are data organized hierarchically, defining the location where the data for a particular partition resides. Partitioning your data allows you to limit the amount of data scanned by S3 SELECT, thereby improving performance and reducing cost.
There are a few factors to consider when deciding the columns on which to partition. For example, if you’re using columns as filters, don’t use a column that is partitioning too finely, or don’t choose a column where your data is heavily skewed to one partition value. You can partition your data by any column. Partition columns are usually designed by a common query pattern in your use case. For example, a common practice is to partition the data based on year/month/day because many queries tend to run time series analyses in typical use cases. This often leads to a multi-level partitioning scheme. Data is organized in a hierarchical directory structure based on the distinct values of one or more columns.
Let’s look at an example of how partitioning works.
Files corresponding to a single day’s worth of data are placed under a prefix such as s3://my_bucket/logs/year=2023/month=06/day=01/.
If your data is partitioned per day, every day you have a single file, such as the following:
s3://my_bucket/logs/year=2023/month=06/day=01/file1_example.jsons3://my_bucket/logs/year=2023/month=06/day=02/file2_example.jsons3://my_bucket/logs/year=2023/month=06/day=03/file3_example.json
We can use a WHERE clause to query the data as follows:
The preceding query reads only the data inside the partition folder year=2023/month=06/day=01 instead of scanning through the files under all partitions. Therefore, it only scans the file file1_example.json.
Systems such as Athena, Amazon Redshift Spectrum, and now AWS Glue can use these partitions to filter data by value, eliminating unnecessary (partition) requests to Amazon S3. This capability can improve the performance of applications that specifically need to read a limited number of partitions. For more information about partitioning with Athena and Redshift Spectrum, refer to Partitioning data in Athena and Creating external tables for Redshift Spectrum, respectively.
How to create a table and load partitions in the Data Catalog using Athena
Let’s begin by understanding how to create a table and load partitions using DDL (Data Definition Language) queries in Athena. Note that to demonstrate the various methods of loading partitions into the table, we need to delete and recreate the table multiple times throughout the following steps.
First, we create a database for this demo.
- On the Athena console, choose Query editor.
If this is your first time using the Athena query editor, you need to configure and specify an S3 bucket to store the query results.
- Create a database with the following command:

- In the Data pane, for Database, choose the database
partitions_blog.

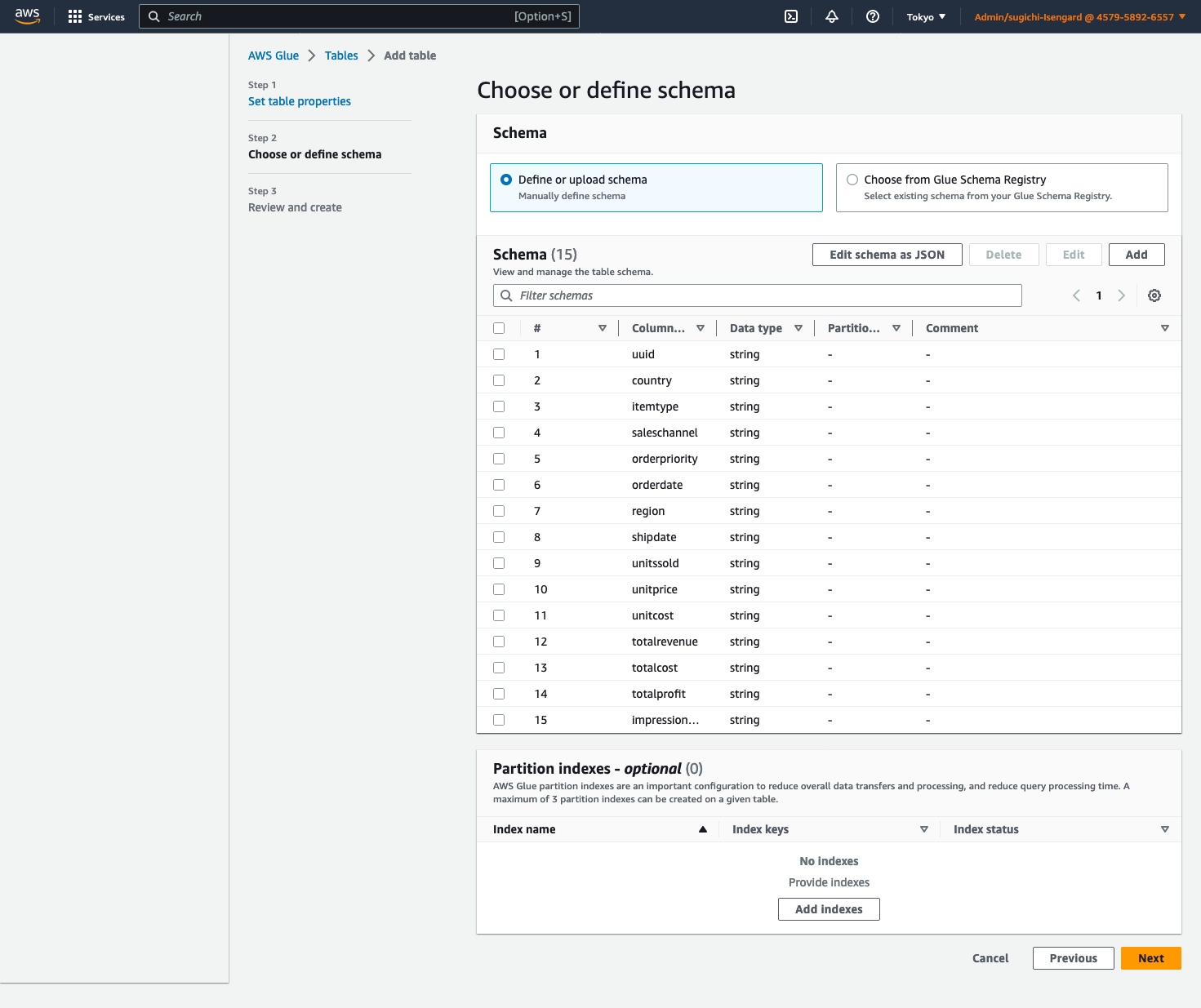
- Create the table
impressionsfollowing the example in Hive JSON SerDe. Replace<myregion>ins3://<myregion>.elasticmapreduce/samples/hive-ads/tables/impressionswith the Region identifier where you run Athena (for example,s3://us-east-1.elasticmapreduce/samples/hive-ads/tables/impressions). - Run the following query to create the table:

The following screenshot shows the query in the query editor.

- Run the following query to review the data:
You can’t see any results because the partitions aren’t loaded yet.

If the partition isn’t loaded into a partitioned table, when the application downloads the partition metadata, the application will not be aware of the S3 path that needs to be queried. For more information, refer to Why do I get zero records when I query my Amazon Athena table.
- Load the partitions using the command
MSCK REPAIR TABLE.

The MSCK REPAIR TABLE command was designed to manually add partitions that are added to or removed from the file system, such as HDFS or Amazon S3, but are not present in the metastore.
- Query the table again to see the results.
After the MSCK REPAIR TABLE command scans Amazon S3 and adds partitions to AWS Glue for Hive-compatible partitions, the records under the registered partitions are now returned.

How partitions are stored in the table metadata
We can list the table partitions in Athena by running the SHOW PARTITIONS command, as shown in the following screenshot.

We also can see the partition metadata on the AWS Glue console. Complete the following steps:
- On the AWS Glue console, choose Tables in the navigation pane under Data Catalog.
- Choose the
impressionstable in thepartitions_blogdatabase.

- On the Partitions tab, choose View Properties next to a partition to view its details.



The following screenshot shows an example of the partition properties.

We can also get the partitions using the AWS Command Line Interface (AWS CLI) command get-partitions, as shown in the following screenshot.

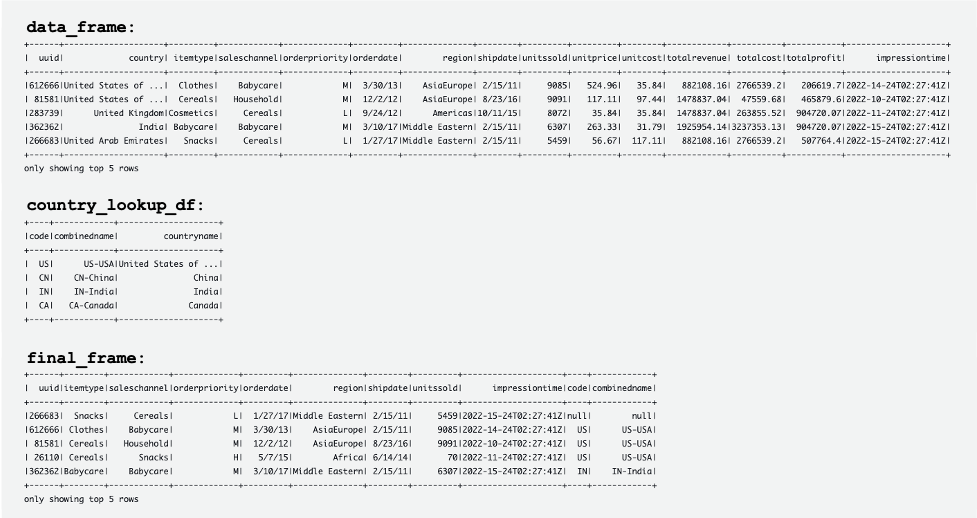
From the get-partitions, the element “Values” defines the partition value and “Location” defines the S3 path to be queried by the application:
When querying the data from the partition dt="2009-04-12-19-05", the application lists and reads only the files in the S3 path s3://us-east-1.elasticmapreduce/samples/hive-ads/tables/impressions/dt="2009-04-12-19-05".
Different ways to add partitions in a table on the Data Catalog
There are multiple ways to load partitions into the table. You can create tables and partitions directly using the AWS Glue API, SDKs, AWS CLI, DDL queries on Athena, using AWS Glue crawlers, or using AWS Glue ETL jobs.
For the next examples, we need to drop and recreate the table. Run the following command in the Athena query editor:

After that, recreate the table:

Creating partitions individually
If the data arrives in an S3 bucket at a scheduled time, for example every hour or once a day, you can individually add partitions. One way of doing so is by running an ALTER TABLE ADD PARTITION DDL query on Athena.
We use Athena for this query as an example. You can do the same from Hive on Amazon EMR, Spark on Amazon EMR, AWS Glue for Apache Spark jobs, and more.
To load partitions using Athena, we need to use the ALTER TABLE ADD PARTITION command, which can create one or more partitions in the table. ALTER TABLE ADD PARTITION supports partitions created on Amazon S3 with camel case (s3://bucket/table/dayOfTheYear=20), Hive format (s3://bucket/table/dayoftheyear=20), and non-Hive style partitioning schemes used by AWS CloudTrail logs, which use separate path components for date parts, such as s3://bucket/data/2021/01/26/us/6fc7845e.json.
To load partitions into a table, you can run the following query in the Athena query editor:

Refer to ALTER TABLE ADD PARTITION for more information.
Another option is using AWS Glue APIs. AWS Glue provides two APIs to load partitions into table create_partition() and batch_create_partition(). For the API parameters, refer to CreatePartition.
The following example uses the AWS CLI:
Both commands (ALTER TABLE in Athena and the AWS Glue API create-partition) will create partition enhancing from the table definition.
Load multiple partitions using MSCK REPAIR TABLE
You can load multiple partitions in Athena. MSCK REPAIR TABLE is a DDL statement that scans the entire S3 path defined in the table’s Location property. Athena lists the S3 path searching for Hive-compatible partitions, then loads the existing partitions into the AWS Glue table’s metadata. A table needs to be created in the Data Catalog, and the data source must be from Amazon S3 before it can run. You can create a table with AWS Glue APIs or by running a CREATE TABLE statement in Athena. After the table creation, run MSCK REPAIR TABLE to load the partitions.

The parameter DDL query timeout in the service quotas defines how long a DDL statement can run. The runtime increases accordingly to the number of folders or partitions in the S3 path.
The MSCK REPAIR TABLE command is best used when creating a table for the first time or when there is uncertainty about parity between data and partition metadata. It supports folders created in lowercase and using Hive-style partitions format (for example, year=2023/month=6/day=01). Because MSCK REPAIR TABLE scans both the folder and its subfolders to find a matching partition scheme, you should keep data for separate tables in separate folder hierarchies.
Every MSCK REPAIR TABLE command lists the entire folder specified in the table location. If you add new partitions frequently (for example, every 5 minutes or every hour), consider scheduling an ALTER TABLE ADD PARTITION statement to load only the partitions defined in the statement instead of scanning the entire S3 path.
The partitions created in the Data Catalog by MSCK REPAIR TABLE enhance the schema from the table definition. Note that Athena doesn’t charge for DDL statements, making MSCK REPAIR TABLE a more straightforward and affordable way to load partitions.
Add multiple partitions using an AWS Glue crawler
An AWS Glue crawler offers more features when loading partitions into the table. A crawler automatically identifies partitions in Amazon S3, extracts metadata, and creates table definitions in the Data Catalog. Crawlers can crawl the following file-based and table-based data stores.
Crawlers can help automate table creation and loading partitions into tables. They are charged per hour, and bill per second. You can optimize the crawler’s performance by altering parameters like the sample size or by specifying it to crawl new folders only.
If the schema of the data changes, the crawler will update the table and partition schemas accordingly. The crawler configuration options have parameters such as update the table definition in the Data Catalog, add new columns only, and ignore the change and don’t update the table in the Data Catalog, which tell the crawler how to update the table when needed and evolve the table schema.
Crawlers can create and update multiple tables from the same data source. When an AWS Glue crawler scans Amazon S3 and detects multiple directories, it uses a heuristic to determine where the root for a table is in the directory structure and which directories are partitions for the table.
To create an AWS Glue crawler, complete the following steps:
- On the AWS Glue console, choose Crawlers in the navigation pane under Data Catalog.
- Choose Create crawler.

- Provide a name and optional description, then choose Next.

- Under Data source configuration, select Not yet and choose Add a data source.

- For Data source, choose S3.
- For S3 path, enter the path of the impression data (
s3://us-east-1.elasticmapreduce/samples/hive-ads/tables/impressions). - Select a preference for subsequent crawler runs.
- Choose Add an S3 data source.

- Select your data source and choose Next.

- Under IAM role, either choose an existing AWS Identity and Access Management (IAM) role or choose Create new IAM role.
- Choose Next.

- For Target database, choose
partitions_blog. - For Table name prefix, enter
crawler_.






We use the table prefix to add a custom prefix in front of the table name. For example, if you leave the prefix field empty and start the crawler on s3://my-bucket/some-table-backup, it creates a table with the name some-table-backup. If you add crawler_ as a prefix, it a creates table called crawler_some-table-backup.
- Choose your crawler schedule, then choose Next.

- Review your settings and create the crawler.
- Select your crawler and choose Run.



Wait for the crawler to finish running.

You can go to Athena and check the table was created:

Partitioning data stored in Amazon S3 while ingestion and cataloging
The previous examples work with data that already exists in Amazon S3. If you’re using AWS Glue jobs to write data on Amazon S3, you have the option to create partitions with DynamicFrames by enabling the “enableUpdateCatalog=True” parameter. Refer to Creating tables, updating the schema, and adding new partitions in the Data Catalog from AWS Glue ETL jobs for more information.
DynamicFrame supports native partitioning using a sequence of keys, using the partitionKeys option when you create a sink. For example, the following Python code writes out a dataset to Amazon S3 in Parquet format into directories partitioned by the ‘year’ field. After ingesting the data and registering partitions from the AWS Glue job, you can utilize these partitions from queries running on other analytics engines such as Athena.
Conclusion
This post showed multiple methods for partitioning your Amazon S3 data, which helps reduce costs by avoiding unnecessary data scanning and also improves the overall performance of your processes. We further described how AWS Glue makes effective metadata management for partitions possible, allowing you to optimize your storage and query operations in AWS Glue and Athena. These partitioning methods can help optimize scanning high volumes of data or long-running queries, as well as reduce the cost of scanning.
We hope you try out these options!
About the authors
 Anderson Santos is a Senior Solutions Architect at Amazon Web Services. He works with AWS Enterprise customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS.
Anderson Santos is a Senior Solutions Architect at Amazon Web Services. He works with AWS Enterprise customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS.
 Arun Pradeep Selvaraj is a Senior Solutions Architect and is part of Analytics TFC at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build and reinvent. He is creative, fast-paced, deeply customer-obsessed and leverages the working backwards process to build modern architectures to help customers solve their unique challenges.
Arun Pradeep Selvaraj is a Senior Solutions Architect and is part of Analytics TFC at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build and reinvent. He is creative, fast-paced, deeply customer-obsessed and leverages the working backwards process to build modern architectures to help customers solve their unique challenges.
 Patrick Muller is a Senior Solutions Architect and a valued member of the Datalab. With over 20 years of expertise in analytics, data warehousing, and distributed systems, he brings extensive knowledge to the table. Patrick’s passion lies in evaluating new technologies and assisting customers with innovative solutions. During his free time, he enjoys watching soccer.
Patrick Muller is a Senior Solutions Architect and a valued member of the Datalab. With over 20 years of expertise in analytics, data warehousing, and distributed systems, he brings extensive knowledge to the table. Patrick’s passion lies in evaluating new technologies and assisting customers with innovative solutions. During his free time, he enjoys watching soccer.













 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community. Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.










 Sumesh M R is a Full Stack Machine Learning Architect at Cargotec. He has several years of software engineering and ML background. Sumesh is an expert in Sagemaker and other AWS ML/Analytics services. He is passionate about data science and loves to explore the latest ML libraries and techniques. Before joining Cargotec, he worked as a Solution Architect at TCS. In his spare time, he loves to play cricket and badminton.
Sumesh M R is a Full Stack Machine Learning Architect at Cargotec. He has several years of software engineering and ML background. Sumesh is an expert in Sagemaker and other AWS ML/Analytics services. He is passionate about data science and loves to explore the latest ML libraries and techniques. Before joining Cargotec, he worked as a Solution Architect at TCS. In his spare time, he loves to play cricket and badminton. Tero Karttunen is a Senior Cloud Architect at Knowit Finland. He advises clients on architecting and adopting Data Architectures that best serve their Data Analytics and Machine Learning needs. He has helped Cargotec in their data journey for more than two years. Outside of work, he enjoys running, winter sports, and role-playing games.
Tero Karttunen is a Senior Cloud Architect at Knowit Finland. He advises clients on architecting and adopting Data Architectures that best serve their Data Analytics and Machine Learning needs. He has helped Cargotec in their data journey for more than two years. Outside of work, he enjoys running, winter sports, and role-playing games. Arun A K is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on AWS Glue, AWS Lake Formation, Amazon Athena, and Amazon EMR. In his free time, he likes to spend time with his friends and family.
Arun A K is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on AWS Glue, AWS Lake Formation, Amazon Athena, and Amazon EMR. In his free time, he likes to spend time with his friends and family.
 Tome Tanasovski is a Technical Manager at AWS, for a team that manages capabilities into Amazon’s big data platforms via AWS Glue. Prior to working at AWS, Tome was an executive for a market-leading global financial services firm in New York City where he helped run the Firm’s Artificial Intelligence & Machine Learning Center of Excellence. Prior to this role he spent nine years in the Firm focusing on automation, cloud, and distributed computing. Tome has a quarter-of-a-century worth of experience in technology in the Tri-state area across a wide variety of industries including big tech, finance, insurance, and media.
Tome Tanasovski is a Technical Manager at AWS, for a team that manages capabilities into Amazon’s big data platforms via AWS Glue. Prior to working at AWS, Tome was an executive for a market-leading global financial services firm in New York City where he helped run the Firm’s Artificial Intelligence & Machine Learning Center of Excellence. Prior to this role he spent nine years in the Firm focusing on automation, cloud, and distributed computing. Tome has a quarter-of-a-century worth of experience in technology in the Tri-state area across a wide variety of industries including big tech, finance, insurance, and media. Brian Ross is a Senior Software Development Manager at AWS. He has spent 24 years building software at scale and currently focuses on serverless data integration with AWS Glue. In his spare time, he studies ancient texts, cooks modern dishes and tries to get his kids to do both.
Brian Ross is a Senior Software Development Manager at AWS. He has spent 24 years building software at scale and currently focuses on serverless data integration with AWS Glue. In his spare time, he studies ancient texts, cooks modern dishes and tries to get his kids to do both.













 Zack Zhou is a Software Development Engineer on the AWS Glue team.
Zack Zhou is a Software Development Engineer on the AWS Glue team.
 Avik Bhattacharjee is a Senior Partner Solutions Architect at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible, focusing on big data and analytics and AI/ML.
Avik Bhattacharjee is a Senior Partner Solutions Architect at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible, focusing on big data and analytics and AI/ML. Amit Kumar Panda is a Data Architect at AWS Professional Services who is passionate about helping customers build scalable data analytics solutions to enable making critical business decisions.
Amit Kumar Panda is a Data Architect at AWS Professional Services who is passionate about helping customers build scalable data analytics solutions to enable making critical business decisions.










 Neel Patel is a software engineer working within GlueML. He has contributed to the AWS Glue Data Quality feature and hopes it will expand the repertoire for all AWS CloudFormation users along with displaying the power and usability of AWS Glue as a whole.
Neel Patel is a software engineer working within GlueML. He has contributed to the AWS Glue Data Quality feature and hopes it will expand the repertoire for all AWS CloudFormation users along with displaying the power and usability of AWS Glue as a whole. Edward Cho is a Software Development Engineer at AWS Glue. He has contributed to the AWS Glue Data Quality feature as well as the underlying open-source project Deequ.
Edward Cho is a Software Development Engineer at AWS Glue. He has contributed to the AWS Glue Data Quality feature as well as the underlying open-source project Deequ.
























 Navnit Shukla is AWS Specialist Solutions Architect in Analytics. He is passionate about helping customers uncover insights from their data. He builds solutions to help organizations make data-driven decisions.
Navnit Shukla is AWS Specialist Solutions Architect in Analytics. He is passionate about helping customers uncover insights from their data. He builds solutions to help organizations make data-driven decisions. Rahul Sharma is a Software Development Engineer at AWS Glue. He focuses on building distributed systems to support features in AWS Glue. He has a passion for helping customers build data management solutions on the AWS Cloud.
Rahul Sharma is a Software Development Engineer at AWS Glue. He focuses on building distributed systems to support features in AWS Glue. He has a passion for helping customers build data management solutions on the AWS Cloud. Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.
Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.














 Stuti Deshpande is an Analytics Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in Big Data, ETL, and Analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
Stuti Deshpande is an Analytics Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in Big Data, ETL, and Analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends. Aniket Jiddigoudar is a Big Data Architect on the AWS Glue team. He works with customers to help improve their big data workloads. In his spare time, he enjoys trying out new food, playing video games, and kickboxing.
Aniket Jiddigoudar is a Big Data Architect on the AWS Glue team. He works with customers to help improve their big data workloads. In his spare time, he enjoys trying out new food, playing video games, and kickboxing. Joseph Barlan is a Frontend Engineer at AWS Glue. He has over 5 years of experience helping teams build reusable UI components and is passionate about frontend design systems. In his spare time, he enjoys pencil drawing and binge watching tv shows.
Joseph Barlan is a Frontend Engineer at AWS Glue. He has over 5 years of experience helping teams build reusable UI components and is passionate about frontend design systems. In his spare time, he enjoys pencil drawing and binge watching tv shows. Jesus Max Hernandez is a Software Development Engineer at AWS Glue. He joined the team in August after graduating from The University of Texas at El Paso. Outside of work, you can find him practicing guitar or playing softball in Central Park.
Jesus Max Hernandez is a Software Development Engineer at AWS Glue. He joined the team in August after graduating from The University of Texas at El Paso. Outside of work, you can find him practicing guitar or playing softball in Central Park. Divya Gaitonde
Divya Gaitonde
 Mira Daniels (Data Engineer in Data Platform team), recently moved from Data Analytics to Data Engineering to make quality data more easily accessible for data consumers. She has been focusing on Digital Analytics and marketing data in the past.
Mira Daniels (Data Engineer in Data Platform team), recently moved from Data Analytics to Data Engineering to make quality data more easily accessible for data consumers. She has been focusing on Digital Analytics and marketing data in the past. Sean Whitfield (Senior Data Engineer in Data Platform team), a data enthusiast with a life science background who pursued his passion for data analysis into the realm of IT. His expertise lies in building robust data engineering and self-service tools. He also has a fervor for sharing his knowledge with others and mentoring aspiring data professionals.
Sean Whitfield (Senior Data Engineer in Data Platform team), a data enthusiast with a life science background who pursued his passion for data analysis into the realm of IT. His expertise lies in building robust data engineering and self-service tools. He also has a fervor for sharing his knowledge with others and mentoring aspiring data professionals.




 Abdel Jaidi is a Senior Cloud Engineer for AWS Professional Services. He works on open-source projects focused on AWS Data & Analytics services. In his spare time, he enjoys playing tennis and hiking.
Abdel Jaidi is a Senior Cloud Engineer for AWS Professional Services. He works on open-source projects focused on AWS Data & Analytics services. In his spare time, he enjoys playing tennis and hiking. Anton Kukushkin is a Data Engineer for AWS Professional Services based in London, UK. In his spare time, he enjoys playing musical instruments.
Anton Kukushkin is a Data Engineer for AWS Professional Services based in London, UK. In his spare time, he enjoys playing musical instruments. Leon Luttenberger is a Data Engineer for AWS Professional Services based in Austin, Texas. He works on AWS open-source solutions that help our customers analyze their data at scale. In his spare time, he enjoys reading and traveling.
Leon Luttenberger is a Data Engineer for AWS Professional Services based in Austin, Texas. He works on AWS open-source solutions that help our customers analyze their data at scale. In his spare time, he enjoys reading and traveling.



 Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 13 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 13 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking. Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga. Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada.
Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada. Manjula Nagineni is a Senior Solutions Architect with AWS based in New York. She works with major financial service institutions, architecting and modernizing their large-scale applications while adopting AWS Cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in software development, analytics, and architecture across multiple domains such as finance, retail, and telecom.
Manjula Nagineni is a Senior Solutions Architect with AWS based in New York. She works with major financial service institutions, architecting and modernizing their large-scale applications while adopting AWS Cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in software development, analytics, and architecture across multiple domains such as finance, retail, and telecom. Sohaib Katariwala is an Analytics Specialist Solutions Architect at AWS. He has over 12 years of experience helping organizations derive insights from their data.
Sohaib Katariwala is an Analytics Specialist Solutions Architect at AWS. He has over 12 years of experience helping organizations derive insights from their data.














 Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their data analytics and AI needs. He partners with customers on their AWS journey to solve their business problems and build scalable prototypes. Before joining AWS, Manish’s experience includes helping customers implement data warehouse, BI, data integration, and data lake projects.
Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their data analytics and AI needs. He partners with customers on their AWS journey to solve their business problems and build scalable prototypes. Before joining AWS, Manish’s experience includes helping customers implement data warehouse, BI, data integration, and data lake projects. Santosh Kotagiri is a Solutions Architect at AWS with experience in data analytics and cloud solutions leading to tangible business results. His expertise lies in designing and implementing scalable data analytics solutions for clients across industries, with a focus on cloud-native and open-source services. He is passionate about leveraging technology to drive business growth and solve complex problems.
Santosh Kotagiri is a Solutions Architect at AWS with experience in data analytics and cloud solutions leading to tangible business results. His expertise lies in designing and implementing scalable data analytics solutions for clients across industries, with a focus on cloud-native and open-source services. He is passionate about leveraging technology to drive business growth and solve complex problems. Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends.
Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.

 Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers in the south east modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working.
Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers in the south east modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working. Angus Ferguson is a Solutions Architect at AWS who is passionate about meeting customers across the world, helping them solve their technical challenges. Angus specializes in Data & Analytics with a focus on customers in the financial services industry.
Angus Ferguson is a Solutions Architect at AWS who is passionate about meeting customers across the world, helping them solve their technical challenges. Angus specializes in Data & Analytics with a focus on customers in the financial services industry.









 Rushabh Lokhande is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, and analytics solutions. Outside of work, he enjoys spending time with family, reading, running, and golf.
Rushabh Lokhande is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, and analytics solutions. Outside of work, he enjoys spending time with family, reading, running, and golf. Ryan Gomes is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He is passionate about helping customers achieve better outcomes through analytics and machine learning solutions in the cloud. Outside of work, he enjoys fitness, cooking, and spending quality time with friends and family.
Ryan Gomes is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He is passionate about helping customers achieve better outcomes through analytics and machine learning solutions in the cloud. Outside of work, he enjoys fitness, cooking, and spending quality time with friends and family. Vishwa Gupta is a Senior Data Architect with the AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.
Vishwa Gupta is a Senior Data Architect with the AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.


 Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team. He’s been an Apache Spark enthusiast since version 0.8. In his spare time, he likes playing board games.
Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team. He’s been an Apache Spark enthusiast since version 0.8. In his spare time, he likes playing board games. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies.
Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies. Rajendra Gujja is a Senior Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about the data.
Rajendra Gujja is a Senior Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about the data. Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on solving challenging distributed systems problems for data integration on Glue platform for customers using Apache Spark.
Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on solving challenging distributed systems problems for data integration on Glue platform for customers using Apache Spark. Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team works on distributed systems for building data lakes on AWS and simplifying integration with data warehouses for customers using Apache Spark.
Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team works on distributed systems for building data lakes on AWS and simplifying integration with data warehouses for customers using Apache Spark.