Post Syndicated from Kristian Freeman original https://blog.cloudflare.com/making-static-sites-dynamic-with-cloudflare-d1/

Introduction

There are many ways to store data in your applications. For example, in Cloudflare Workers applications, we have Workers KV for key-value storage and Durable Objects for real-time, coordinated storage without compromising on consistency. Outside the Cloudflare ecosystem, you can also plug in other tools like NoSQL and graph databases.
But sometimes, you want SQL. Indexes allow us to retrieve data quickly. Joins enable us to describe complex relationships between different tables. SQL declaratively describes how our application’s data is validated, created, and performantly queried.
D1 was released today in open alpha, and to celebrate, I want to share my experience building apps with D1: specifically, how to get started, and why I’m excited about D1 joining the long list of tools you can use to build apps on Cloudflare.
D1 is remarkable because it’s an instant value-add to applications without needing new tools or stepping out of the Cloudflare ecosystem. Using wrangler, we can do local development on our Workers applications, and with the addition of D1 in wrangler, we can now develop proper stateful applications locally as well. Then, when it’s time to deploy the application, wrangler allows us to both access and execute commands to your D1 database, as well as your API itself.
What we’re building
In this blog post, I’ll show you how to use D1 to add comments to a static blog site. To do this, we’ll construct a new D1 database and build a simple JSON API that allows the creation and retrieval of comments.
As I mentioned, separating D1 from the app itself – an API and database that remains separate from the static site – allows us to abstract the static and dynamic pieces of our website from each other. It also makes it easier to deploy our application: we will deploy the frontend to Cloudflare Pages, and the D1-powered API to Cloudflare Workers.
Building a new application
First, we’ll add a basic API in Workers. Create a new directory and in it a new wrangler project inside it:
$ mkdir d1-example && d1-example
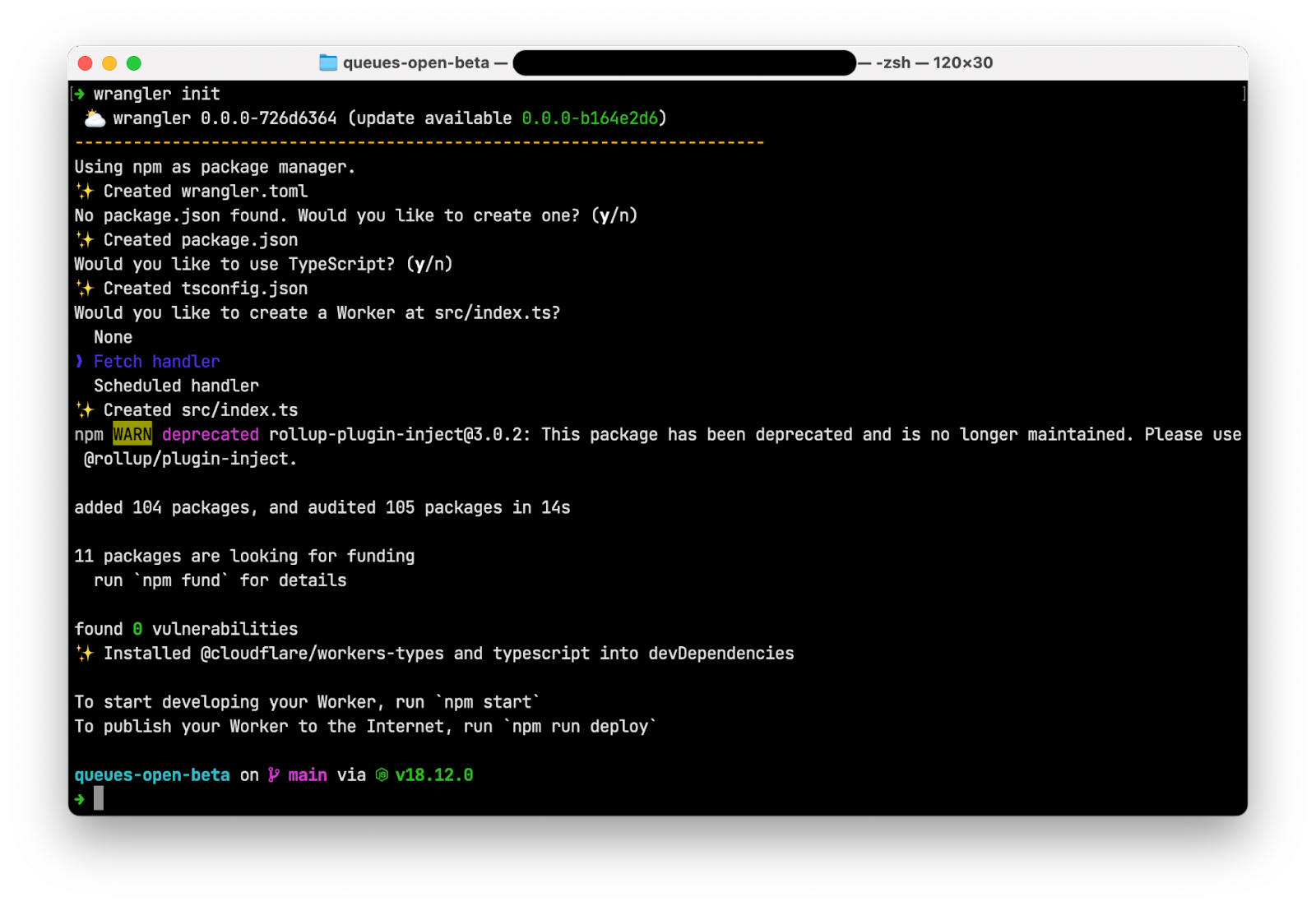
$ wrangler init
In this example, we’ll use Hono, an Express.js-style framework, to rapidly build our API. To use Hono in this project, install it using NPM:
$ npm install hono
Then, in src/index.ts, we’ll initialize a new Hono app, and define a few endpoints – GET /API/posts/:slug/comments, and POST /get/api/:slug/comments.
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
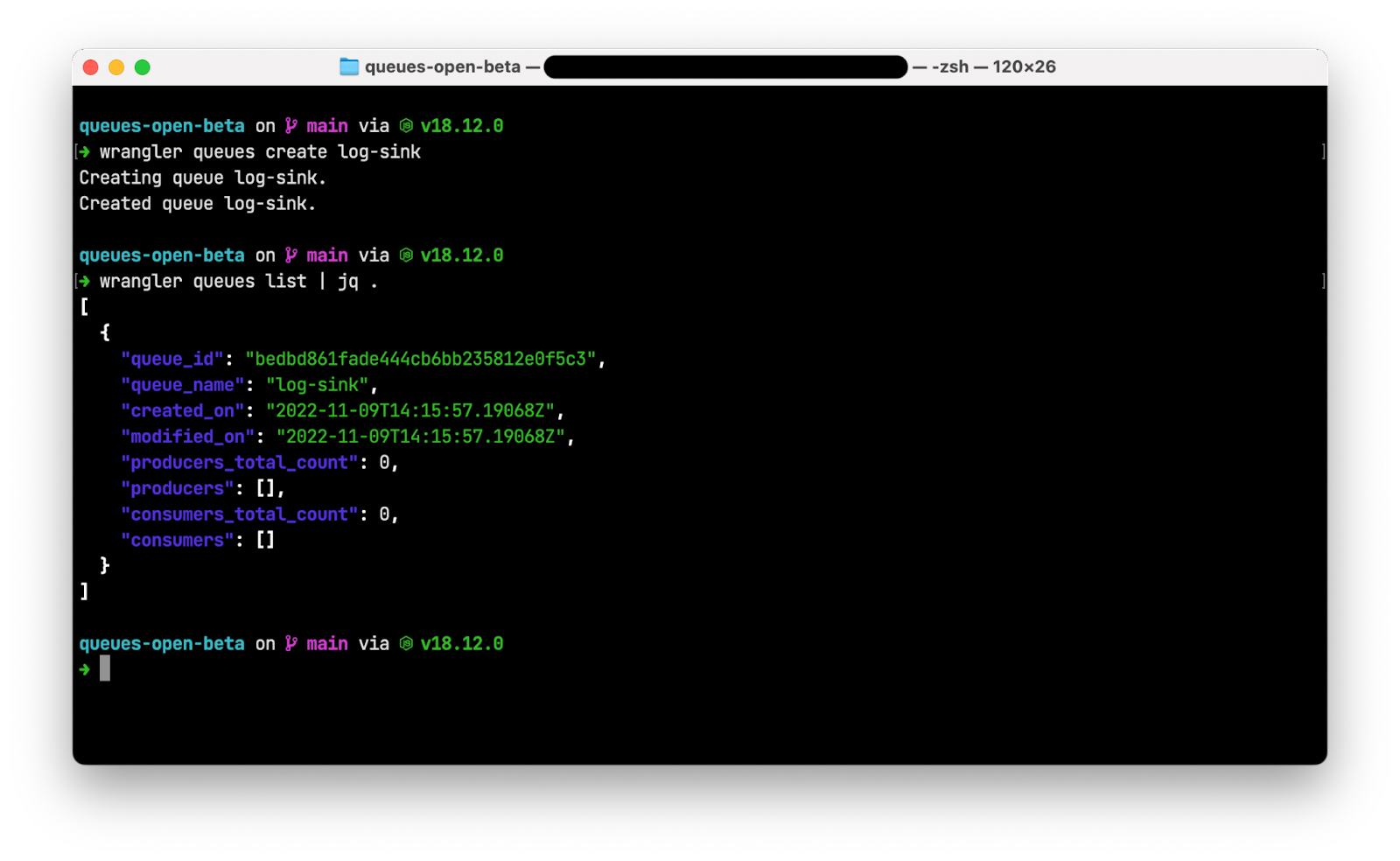
Now we’ll create a D1 database. In Wrangler 2, there is support for the wrangler d1 subcommand, which allows you to create and query your D1 databases directly from the command line. So, for example, we can create a new database with a single command:
$ wrangler d1 create d1-example
With our created database, we can take the database name ID and associate it with a binding inside of wrangler.toml, wrangler’s configuration file. Bindings allow us to access Cloudflare resources, like D1 databases, KV namespaces, and R2 buckets, using a simple variable name in our code. Below, we’ll create the binding DB and use it to represent our new database:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
Note that this directive, the [[d1_databases]] field, currently requires a beta version of wrangler. You can install this for your project using the command npm install -D wrangler/beta.
With the database configured in our wrangler.toml, we can start interacting with it from the command line and inside our Workers function.
First, you can issue direct SQL commands using wrangler d1 execute:
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
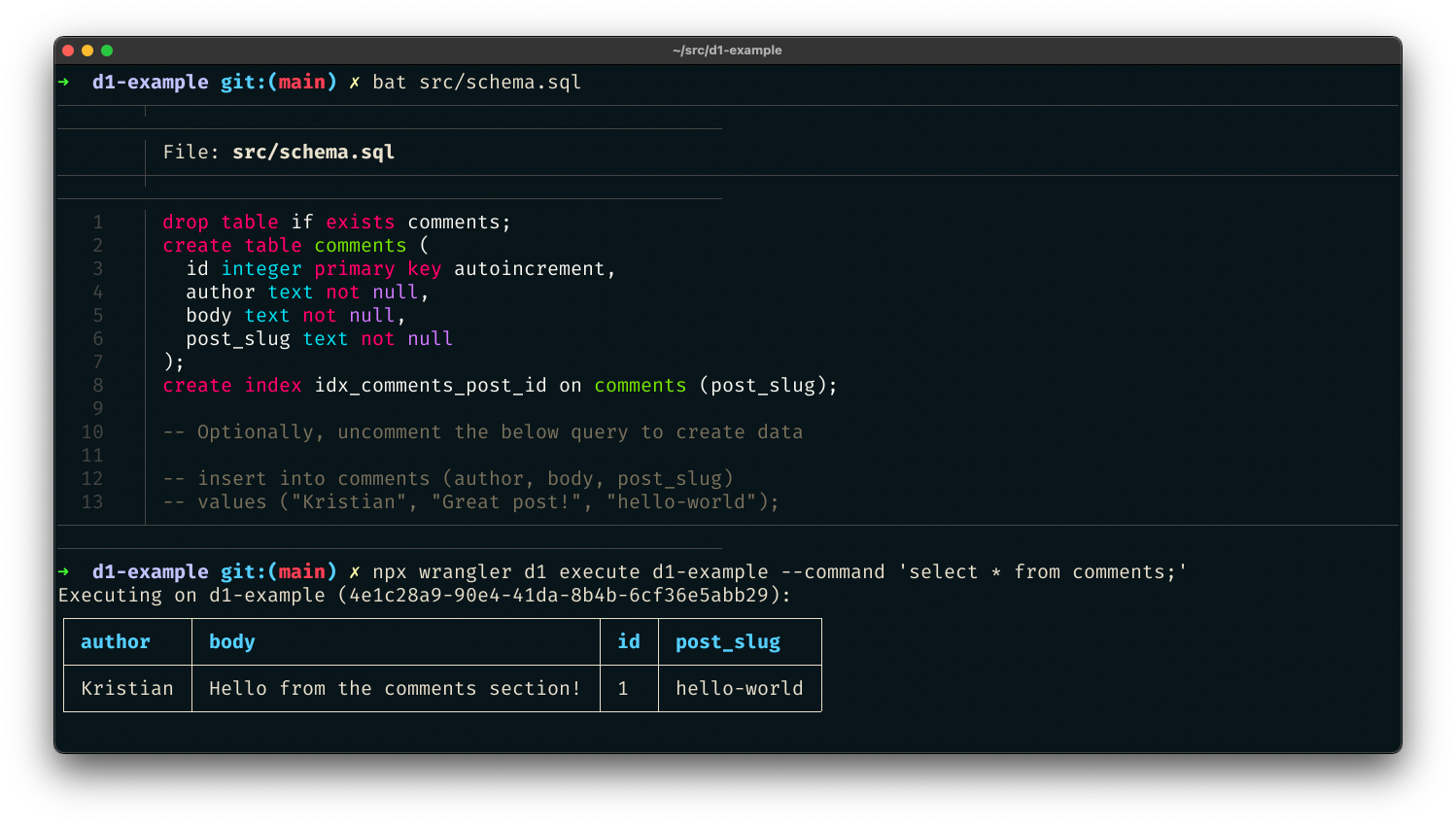
You can also pass a SQL file – perfect for initial data seeding in a single command. Create src/schema.sql, which will create a new comments table for our project:
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
With the file created, execute the schema file against the D1 database by passing it with the flag --file:
$ wrangler d1 execute d1-example --file src/schema.sql
We’ve created a SQL database with just a few commands and seeded it with initial data. Now we can add a route to our Workers function to retrieve data from that database. Based on our wrangler.toml config, the D1 database is now accessible via the DB binding. In our code, we can use the binding to prepare SQL statements and execute them, for instance, to retrieve comments:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
In this function, we accept a slug URL query parameter and set up a new SQL statement where we select all comments with a matching post_slug value to our query parameter. We can then return it as a simple JSON response.
So far, we’ve built read-only access to our data. But “inserting” values to SQL is, of course, possible as well. So let’s define another function that allows POST-ing to an endpoint to create a new comment:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
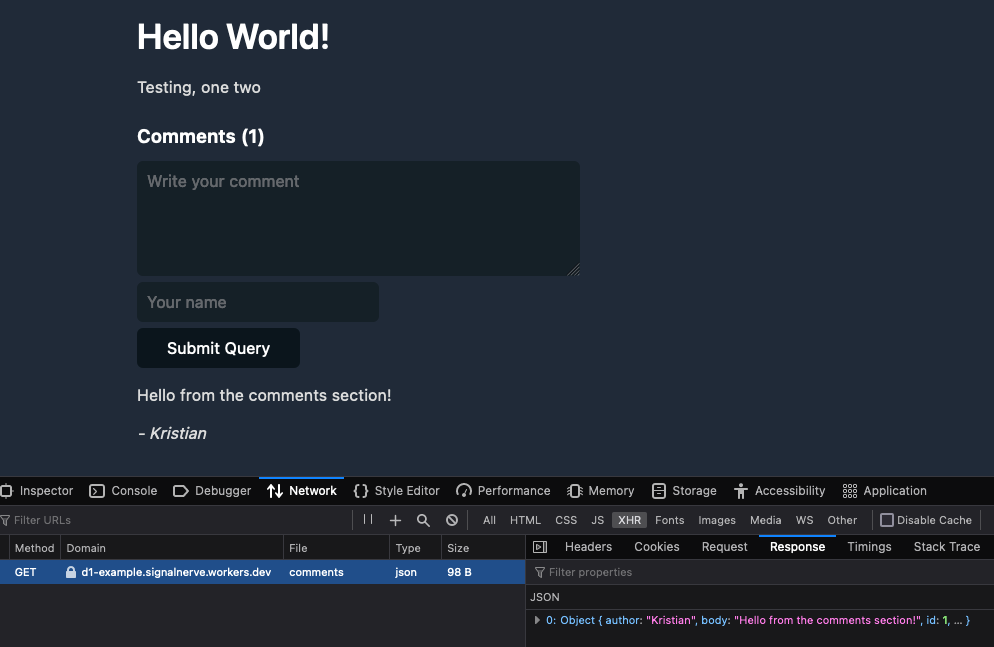
In this example, we built a comments API for powering a blog. To see the source for this D1-powered comments API, you can visit cloudflare/templates/worker-d1-api.
Conclusion
One of the things most exciting about D1 is the opportunity to augment existing applications or websites with dynamic, relational data. As a former Ruby on Rails developer, one of the things I miss most about that framework in the world of JavaScript and serverless development tools is the ability to rapidly spin up full data-driven applications without needing to be an expert in managing database infrastructure. With D1 and its easy onramp to SQL-based data, we can build true data-driven applications without compromising on performance or developer experience.
This shift corresponds nicely with the advent of static sites in the last few years, using tools like Hugo or Gatsby. A blog built with a static site generator like Hugo is incredibly performant – it will build in seconds with small asset sizes.
But by trading a tool like WordPress for a static site generator, you lose the opportunity to add dynamic information to your site. Many developers have patched over this problem by adding more complexity to their build processes: fetching and retrieving data and generating pages using that data as part of the build.
This addition of complexity in the build process attempts to fix the lack of dynamism in applications, but it still isn’t genuinely dynamic. Instead of being able to retrieve and display new data as it’s created, the application rebuilds and redeploys whenever data changes so that it appears to be a live, dynamic representation of data. Your application can remain static, and the dynamic data will live geographically close to the users of your site, accessible via a queryable and expressive API.