Post Syndicated from Joaquin Gimenez original http://blog.cloudflare.com/cloudflare-workers-database-integration-with-upstash/


During Developer Week we announced Database Integrations on Workers a new and seamless way to connect with some of the most popular databases. You select the provider, authorize through an OAuth2 flow and automatically get the right configuration stored as encrypted environment variables to your Worker.
Today we are thrilled to announce that we have been working with Upstash to expand our integrations catalog. We are now offering three new integrations: Upstash Redis, Upstash Kafka and Upstash QStash. These integrations allow our customers to unlock new capabilities on Workers. Providing them with a broader range of options to meet their specific requirements.
Add the integration
We are going to show the setup process using the Upstash Redis integration.
Select your Worker, go to the Settings tab, select the Integrations tab to see all the available integrations.
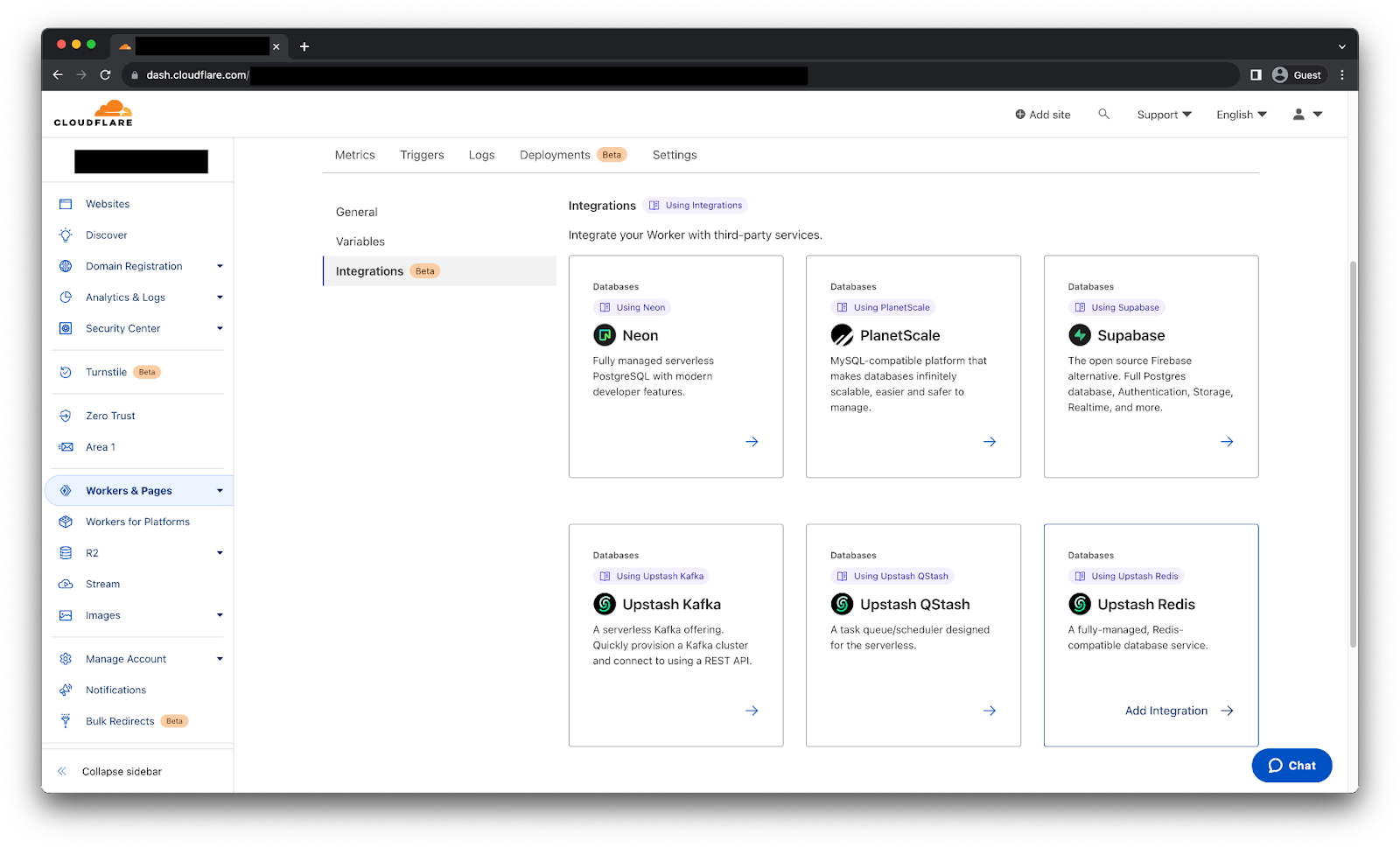
After selecting the Upstash Redis integration we will get the following page.
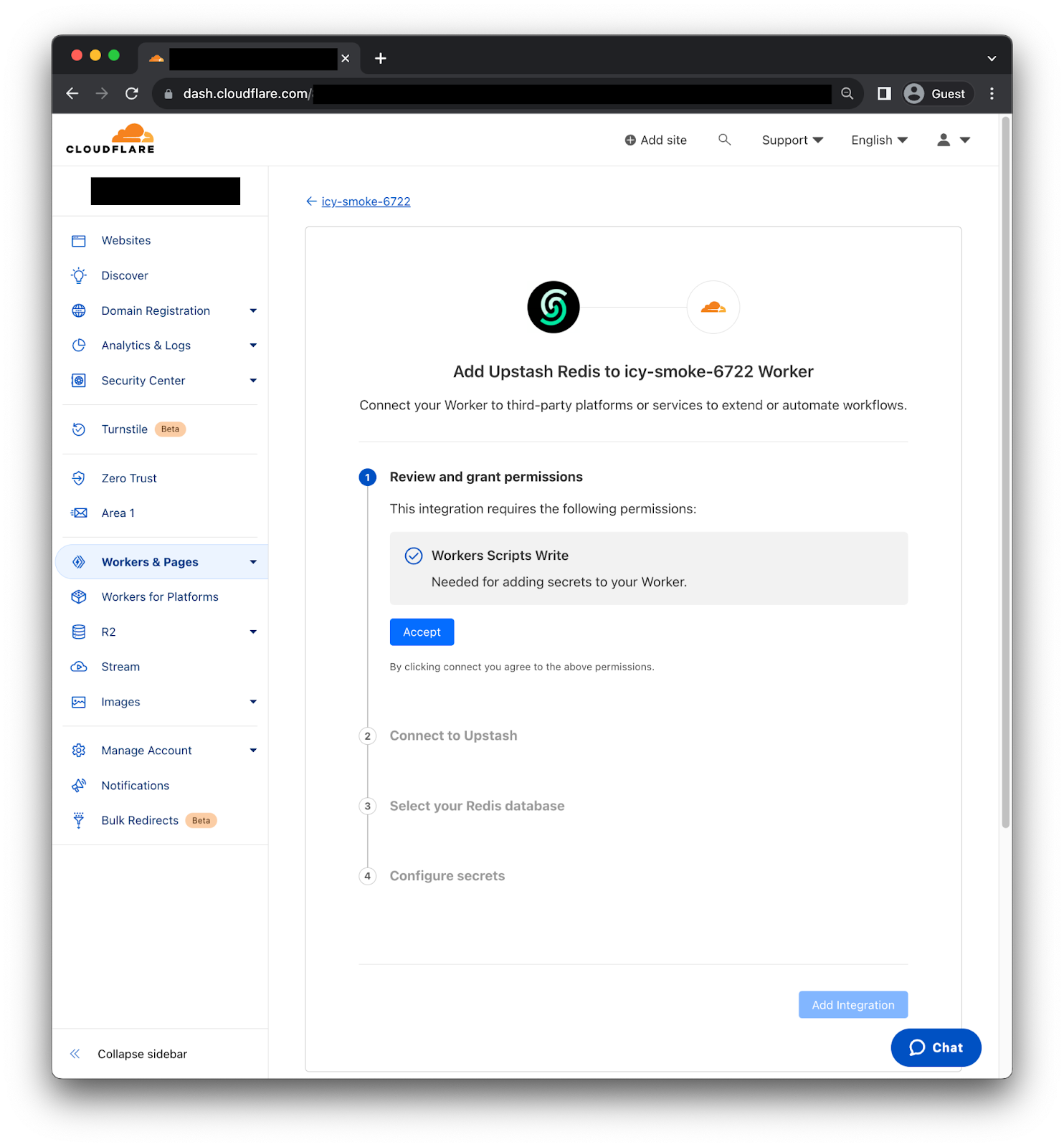
First, you need to review and grant permissions, so the Integration can add secrets to your Worker. Second, we need to connect to Upstash using the OAuth2 flow. Third, select the Redis database we want to use. Then, the Integration will fetch the right information to generate the credentials. Finally, click “Add Integration” and it's done! We can now use the credentials as environment variables on our Worker.
Implementation example
On this occasion we are going to use the CF-IPCountry header to conditionally return a custom greeting message to visitors from Paraguay, United States, Great Britain and Netherlands. While returning a generic message to visitors from other countries.
To begin we are going to load the custom greeting messages using Upstash’s online CLI tool.
➜ set PY "Mba'ẽichapa 🇵🇾"
OK
➜ set US "How are you? 🇺🇸"
OK
➜ set GB "How do you do? 🇬🇧"
OK
➜ set NL "Hoe gaat het met u? 🇳🇱"
OKWe also need to install @upstash/redis package on our Worker before we upload the following code.
import { Redis } from '@upstash/redis/cloudflare'
export default {
async fetch(request, env, ctx) {
const country = request.headers.get("cf-ipcountry");
const redis = Redis.fromEnv(env);
if (country) {
const localizedMessage = await redis.get(country);
if (localizedMessage) {
return new Response(localizedMessage);
}
}
return new Response("👋👋 Hello there! 👋👋");
},
};
Just like that we are returning a localized message from the Redis instance depending on the country which the request originated from. Furthermore, we have a couple ways to improve performance, for write heavy use cases we can use Smart Placement with no replicas, so the Worker code will be executed near the Redis instance provided by Upstash. Otherwise, creating a Global Database on Upstash to have multiple read replicas across regions will help.
Try it now
Upstash Redis, Kafka and QStash are now available for all users! Stay tuned for more updates as we continue to expand our Database Integrations catalog.